
Utilizing Half Convolutional Autoencoder to Generate User and Item Vectors for Initialization in Matrix Factorization

 ,
,  ,
,  ,
, 
Abstract
:1. Introduction
- Designing a CNN-based autoencoder named Half Convolutional Autoencoder (HCAE) where convolutional layers are used as a feature extractor to generate a lower dimensional descriptor for each movie regardless of the arrangement or the semantic relationships of original features, which helps to increase the accuracy of RSs.
- Utilizing the content-based information produced by HCAE and available ratings to parameterize user preferences for resolving the initialization problem of model-based method, which considerably improves the performance of the traditional matrix factorization models.
2. Preliminaries
2.1. Memory-Based CF
2.2. Model-Based CF
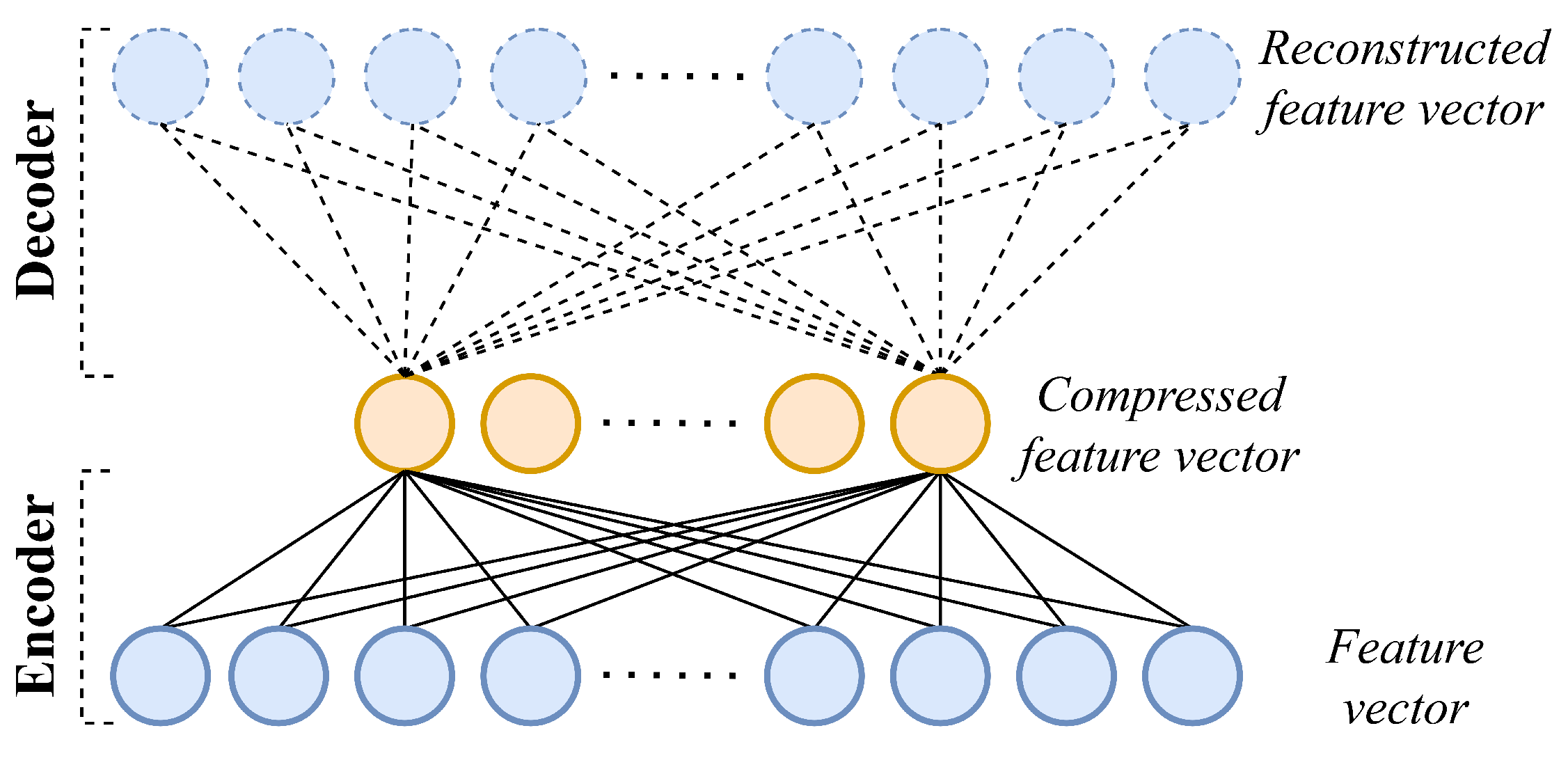
2.3. Autoencoder
- An encoder that maps the input features into the code.
- A decoder that reconstructs the original features from the code.
3. Previous Work
4. Experimental Setup
4.1. Dataset
4.2. Evaluation Scheme
- RMSE (Root Mean Squared Error) for rating prediction task: evaluate the errors of the predicted ratings where smaller values provide more accurate recommendations:where is the size of the testing set, denotes the predicted rating of user u to item i estimated by the model, and the corresponding observed rating in the testing set is denoted by .
- Precision@k (P@k) and Recall@k (R@k) for the ranking (top-k recommendation) task: Precision@k is defined as a fraction of relevant items among the top k recommended items, and Recall@k is defined as a fraction of relevant items in the top k recommended items among all relevant items. Higher P@k and R@k indicate that more relevant items are recommended to users.
- Time [s] for timing evaluation: the total duration of the model’s learning process on the training set and predicting all samples in the testing set.
4.3. Baselines and Experimental Settings
- ii-CF [24]: the similarity score between movies is measured using PCCBaseline with the number of neighbors is set at 40.
- NMF: optimization procedure is a regularized SGD based on Euclidean distance error function [41] with regularization strength of 0.02 and 40 hidden factors.
- kNN-Content [38]: PCCgenome is used as the similarity measure.
- kNN-ContentAE-SVD and kNN-ContentAE-SVD++ [39]: 600-feature vectors for movies are learned from 1044 NLP-preprocessed genome tags using a 3-layer AE.
- FMgenome [14]: each feature vector is composed of one-hot encoded user and movie ID, movie genres and genome scores associated with each movie; the model is trained with degree and 50 iterations.
- I-AutoRec [35]: a 3-layer AE is trained using 600 hidden neurons, and the combination of activation functions is .
5. Half Convolutional Autoencoder
5.1. Learning New Representation of Structured Data with an HCAE
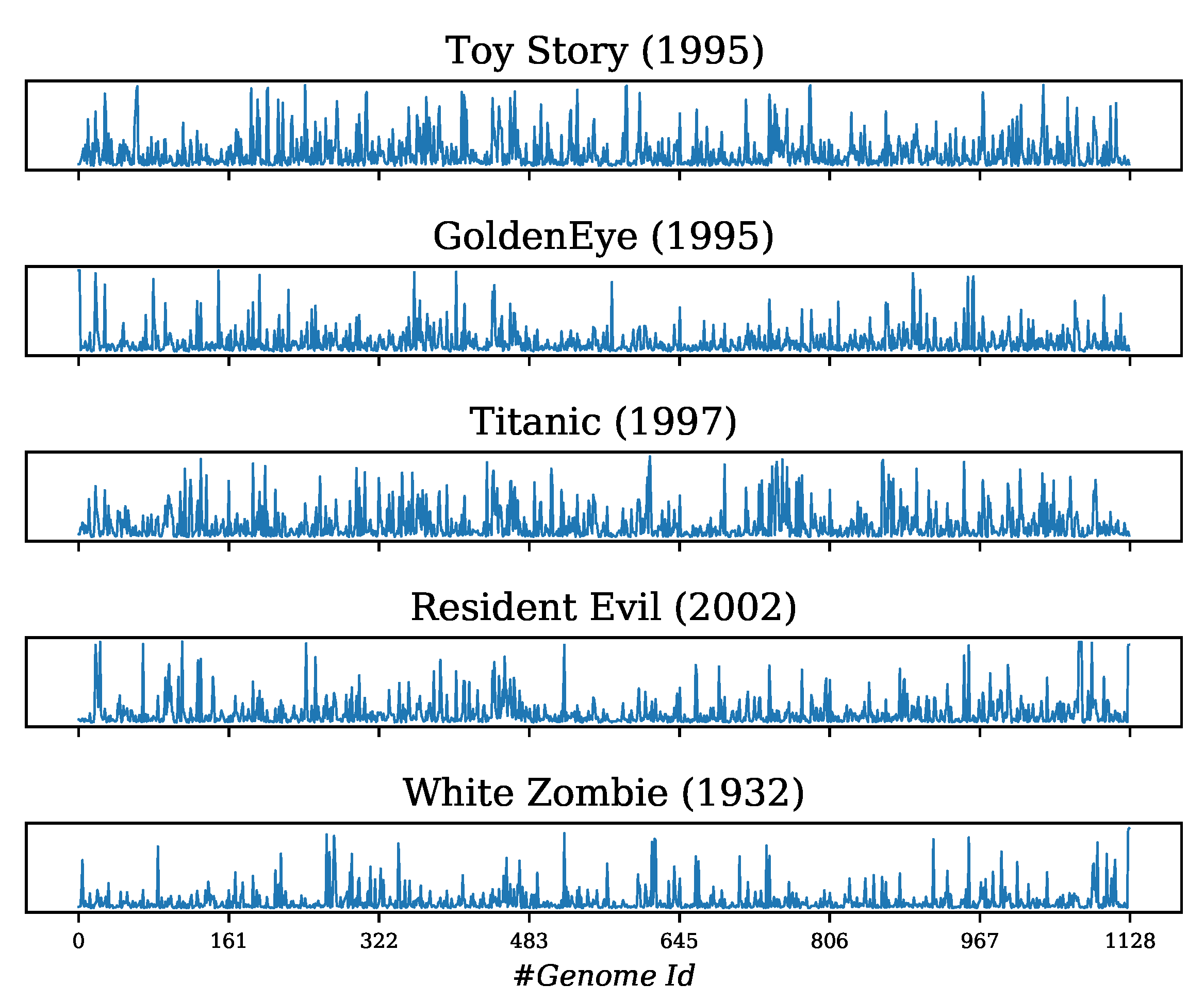
- Firstly, we reorganize Tag Genome data into a table so that each movie is represented as a row and its genome scores are stored in the columns (as in Table 2). It can be seen that each row has fully numerical values in the range of which indicate the strength of the relevance between a movie and its corresponding genome tags (i.e., attributes). If each row is assumed to be a discrete-time signal where the attributes’ positions are treated as “timestamps” and their values as the displacements, each movie will be characterized by a signal bringing its information. Moreover, the attributes are generally independent of each other, so this signal resembles a random vibration illustrated in Figure 2 that we could apply a 1D-CNN to extract its features [44].
- Secondly, if the order of the columns is shuffled simultaneously for all movies, the physical shapes of the signals will change in a consistent way (i.e., the correlation between a random pair of signals remains unchanged) and still deliver the knowledge about the movies. In other words, the above assumption holds true regardless of the positioning of the movie attributes into the table. Consequently, a 1D-CNN still has the potential to perform feature extraction on the new signals.
- 1.
- A feature vector representing a random vibration signal is fed to the input layer of the HCAE;
- 2.
- Each neuron of the 1D-Convolution layer performs a linear convolution between the signal and corresponding filter to generate the input feature map of the neuron;
- 3.
- The input feature map of each neuron is passed through the activation function to generate the output feature map of the neuron of the convolution neuron;
- 4.
- In the 1D-Pooling layer, each neuron’s feature map is created by decimating the output feature map of the previous neuron of the 1D-Convolution layer to reduce the dimensions of the final feature maps;
- 5.
- In the Flatten layer, the output feature maps are flattened into a single feature vector, which is forward-propagated through the following fully-connected Compression layer to encode the feature map into lower dimensional space;
- 6.
- The decoder structure remains fully connected like a vanilla AE, where the output code are forward-propagated through a fully connected decoder to reconstruct the original feature vector, or the 1D-signal.
5.2. Utilizing HCAE in Recommendation Systems
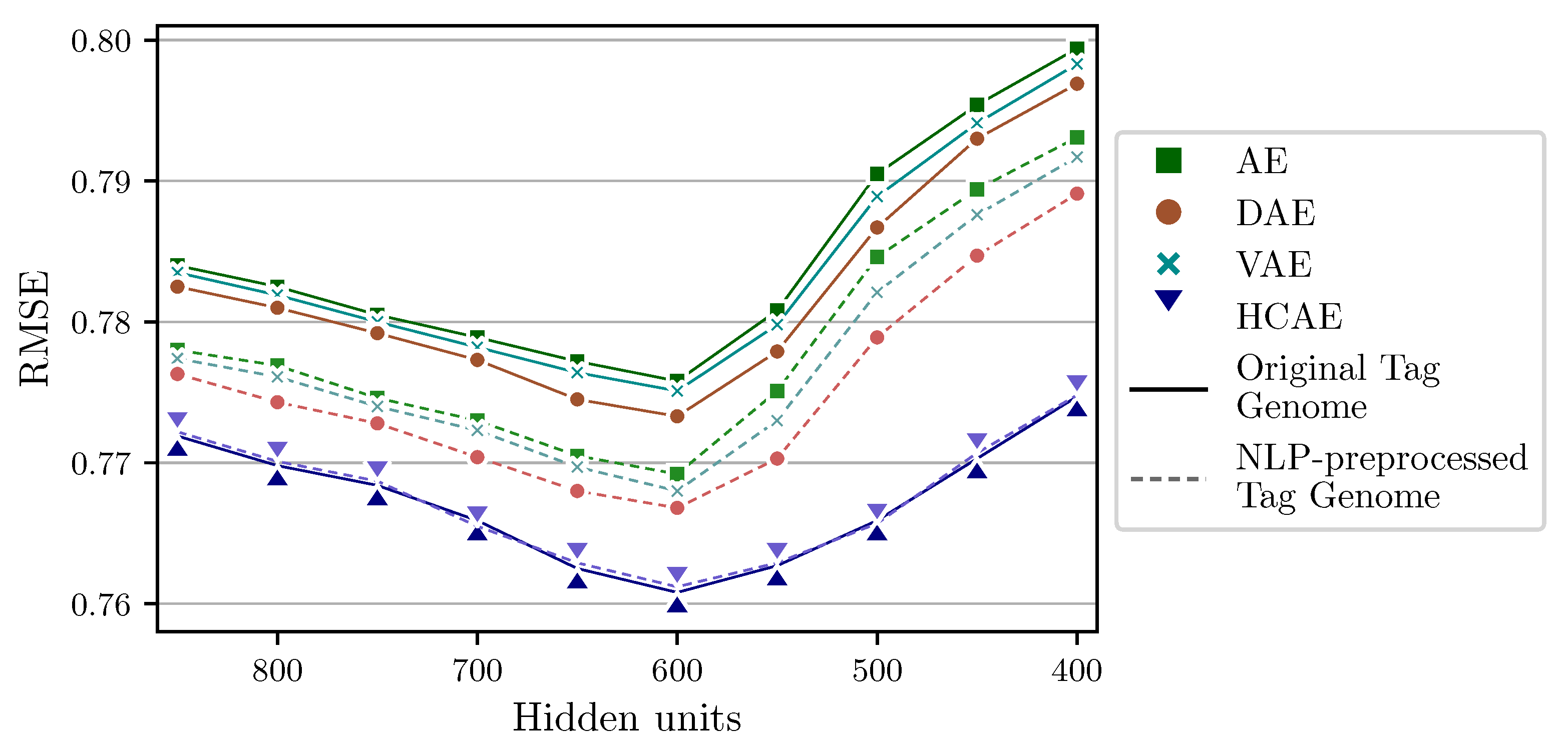
- AE: a 3-hidden layer AE that uses activation function at all hidden layers and activation function at the output layer; the number of units at hidden layers and is fixed at 900;
- DAE: a 1-hidden layer DAE with that uses activation function at the hidden layer and activation function at the output layer;
- VAE: a 4-hidden layer VAE is configured as follows: 900-unit hidden layers and use activation function; Compression layer constructed from layer and layer use activation function; activation function is used for output layer.
6. Novel Initialization Method Using Content-Based Information for Matrix Factorization Techniques
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Lops, P.; De Gemmis, M.; Semeraro, G. Content-based recommender systems: State of the art and trends. In Recommender Systems Handbook; Springer: Cham, Switzerland, 2011; pp. 73–105. [Google Scholar]
- Narducci, F.; Basile, P.; Musto, C.; Lops, P.; Caputo, A.; de Gemmis, M.; Iaquinta, L.; Semeraro, G. Concept-based item representations for a cross-lingual content-based recommendation process. Inf. Sci. 2016, 374, 15–31. [Google Scholar] [CrossRef]
- Su, X.; Khoshgoftaar, T.M. A Survey of Collaborative Filtering Techniques. Available online: https://downloads.hindawi.com/archive/2009/421425.pdf (accessed on 2 November 2021).
- Ricci, F.; Rokach, L.; Shapira, B. Recommender systems: Introduction and challenges. In Recommender Systems Handbook; Springer: Cham, Switzerland, 2015; pp. 1–34. [Google Scholar]
- Funk, S. Netflix Update: Try This at Home. 2006. Available online: https://sifter.org/simon/journal/20061211.html (accessed on 2 November 2021).
- Koren, Y. Factorization meets the neighborhood: A multifaceted collaborative filtering model. In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Las Vegas, NV, USA, 24–27 August 2008; pp. 426–434. [Google Scholar]
- Koren, Y. Collaborative filtering with temporal dynamics. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 447–456. [Google Scholar]
- Wild, S.; Curry, J.; Dougherty, A. Improving non-negative matrix factorizations through structured initialization. Pattern Recognit. 2004, 37, 2217–2232. [Google Scholar] [CrossRef]
- Boutsidis, C.; Gallopoulos, E. SVD based initialization: A head start for nonnegative matrix factorization. Pattern Recognit. 2008, 41, 1350–1362. [Google Scholar] [CrossRef] [Green Version]
- Albright, R.; Cox, J.; Duling, D.; Langville, A.N.; Meyer, C. Algorithms, Initializations, and Convergence for the Nonnegative Matrix Factorization. Available online: https://www.ime.usp.br/~jmstern/wp-content/uploads/2020/04/Albright1.pdf (accessed on 2 November 2021).
- Agarwal, D.; Chen, B.C. Regression-based latent factor models. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris France, 28 June–1 July 2009; pp. 19–28. [Google Scholar]
- Barragáns-Martínez, A.B.; Costa-Montenegro, E.; Burguillo, J.C.; Rey-López, M.; Mikic-Fonte, F.A.; Peleteiro, A. A hybrid content-based and item-based collaborative filtering approach to recommend TV programs enhanced with singular value decomposition. Inf. Sci. 2010, 180, 4290–4311. [Google Scholar] [CrossRef]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Hidasi, B.; Tikk, D. Initializing Matrix Factorization Methods on Implicit Feedback Databases. J. UCS 2013, 19, 1834–1853. [Google Scholar]
- Zhao, J.; Geng, X.; Zhou, J.; Sun, Q.; Xiao, Y.; Zhang, Z.; Fu, Z. Attribute mapping and autoencoder neural network based matrix factorization initialization for recommendation systems. Knowl. Based Syst. 2019, 166, 132–139. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web, International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, Geneva, Switzerland, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Martins, G.B.; Papa, J.P.; Adeli, H. Deep learning techniques for recommender systems based on collaborative filtering. Expert Syst. 2020, 37, e12647. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time Series. Available online: www.iro.umontreal.ca/lisa/pointeurs/handbook-convo.pdf (accessed on 2 November 2021).
- Abdul, A.; Chen, J.; Liao, H.Y.; Chang, S.H. An emotion-aware personalized music recommendation system using a convolutional neural networks approach. Appl. Sci. 2018, 8, 1103. [Google Scholar] [CrossRef] [Green Version]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Harper, F.M.; Konstan, J.A. The movielens datasets: History and context. ACM Trans. Interact. Intell. Syst. (TIIS) 2016, 5, 19. [Google Scholar] [CrossRef]
- Herlocker, J.L.; Konstan, J.A.; Borchers, A.; Riedl, J. An algorithmic framework for performing collaborative filtering. In Proceedings of the 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR 1999, Berkeley, CA, USA, 15–19 August 1999. [Google Scholar]
- Sarwar, B.M.; Karypis, G.; Konstan, J.A.; Riedl, J. Item-Based Collaborative Filtering Recommendation Algorithms. Available online: https://dl.acm.org/doi/pdf/10.1145/371920.372071?casa_token=r5ThY9p5rlIAAAAA:RWJZHgJl4YQsoHgKGGJvFWuQe8vU9-deU5lKUxCQaxykLNW1nmAvqcX1l_SVKtwPSJYhTaXV47ujrA (accessed on 2 November 2021).
- Koren, Y. Factor in the neighbors: Scalable and accurate collaborative filtering. ACM Trans. Knowl. Discov. Data (TKDD) 2010, 4, 1. [Google Scholar] [CrossRef]
- Duong, T.N.; Than, V.D.; Tran, T.H.; Dang, Q.H.; Nguyen, D.M.; Pham, H.M. An Effective Similarity Measure for Neighborhood-based Collaborative Filtering. In Proceedings of the 2018 5th NAFOSTED Conference on Information and Computer Science (NICS), Ho Chi Minh City, Vietnam, 23–24 November 2018; pp. 250–254. [Google Scholar]
- Zhang, S.; Wang, W.; Ford, J.; Makedon, F. Learning from incomplete ratings using non-negative matrix factorization. In Proceedings of the 2006 SIAM International Conference on Data Mining, Bethesda, MD, USA, 20–22 April 2006; pp. 549–553. [Google Scholar]
- Gemulla, R.; Nijkamp, E.; Haas, P.J.; Sismanis, Y. Large-scale matrix factorization with distributed stochastic gradient descent. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 69–77. [Google Scholar]
- Bao, Y.; Fang, H.; Zhang, J. Topicmf: Simultaneously exploiting ratings and reviews for recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, 2014, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Zhang, Y.; Chen, X. Explainable recommendation: A survey and new perspectives. arXiv 2018, arXiv:1804.11192. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A.; Bottou, L. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. Available online: https://www.jmlr.org/papers/volume11/vincent10a/vincent10a.pdf?source=post_page (accessed on 2 November 2021).
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar]
- Wang, H.; Wang, N.; Yeung, D.Y. Collaborative deep learning for recommender systems. In Proceedings of the 21th ACM SIGKDD International Conference on knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1235–1244. [Google Scholar]
- Sedhain, S.; Menon, A.K.; Sanner, S.; Xie, L. Autorec: Autoencoders meet collaborative filtering. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 8–22 May 2015; pp. 111–112. [Google Scholar]
- Jhamb, Y.; Ebesu, T.; Fang, Y. Attentive contextual denoising autoencoder for recommendation. In Proceedings of the 2018 ACM SIGIR International Conference on Theory of Information Retrieval, Tianjin, China, 14–17 September 2018; pp. 27–34. [Google Scholar]
- Wang, R.; Jiang, Y.; Lou, J. TDR: Two-stage deep recommendation model based on mSDA and DNN. Expert Syst. Appl. 2020, 145, 113116. [Google Scholar] [CrossRef]
- Duong, T.N.; Than, V.D.; Vuong, T.A.; Tran, T.H.; Dang, Q.H.; Nguyen, D.M.; Pham, H.M. A Novel Hybrid Recommendation System Integrating Content-Based and Rating Information. In Proceedings of the International Conference on Network-Based Information Systems 2019, Oita, Japan, 5–7 September 2019; pp. 325–337. [Google Scholar]
- Duong, T.N.; Vuong, T.A.; Nguyen, D.M.; Dang, Q.H. Utilizing an Autoencoder-Generated Item Representation in Hybrid Recommendation System. IEEE Access 2020, 8, 75094–75104. [Google Scholar] [CrossRef]
- Bennett, J.; Lanning, S. The netflix prize. In Proceedings of the KDD Cup and Workshop, New York, NY, USA, 12 August 2007; Volume 2007, p. 35. [Google Scholar]
- Takahashi, N.; Katayama, J.; Takeuchi, J. A generalized sufficient condition for global convergence of modified multiplicative updates for NMF. In Proceedings of the 2014 International Symposium on Nonlinear Theory and Its Applications, Luzern, Switzerland, 14–18 September 2014; pp. 44–47. [Google Scholar]
- Lam, S.K.; Pitrou, A.; Seibert, S. Numba: A llvm-based python jit compiler. In Proceedings of the Second Workshop on the LLVM Compiler Infrastructure in HPC, Austin, TX, USA, 15 November 2015; pp. 1–6. [Google Scholar]
- Ivan, C. Convolutional Neural Networks on Randomized Data. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–20 June 2019; pp. 1–8. [Google Scholar]
- Kiranyaz, S.; Avci, O.; Abdeljaber, O.; Ince, T.; Gabbouj, M.; Inman, D.J. 1D convolutional neural networks and applications: A survey. Mech. Syst. Signal Process. 2021, 151, 107398. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C. Bearings fault diagnosis based on convolutional neural networks with 2-D representation of vibration signals as input. In Proceedings of the MATEC Web of Conferences, EDP Sciences, Sibiu, Romania, 7–9 June 2017; Volume 95, p. 13001. [Google Scholar]
- Hoang, D.T.; Kang, H.J. Convolutional neural network based bearing fault diagnosis. In Proceedings of the International Conference on Intelligent Computing, Madurai, India, 15–16 June 2017; pp. 105–111. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Wild, S.; Wild, W.S.; Curry, J.; Dougherty, A.; Betterton, M. Seeding Non-Negative Matrix Factorizations with the Spherical K-Means Clustering. Ph.D. Thesis, University of Colorado, Boulder, CO, USA, 2003. [Google Scholar]
- Rendle, S. Scaling factorization machines to relational data. Proc. VLDB Endow. 2013, 6, 337–348. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # Ratings | # Users | # Movies | Sparsity | |
|---|---|---|---|---|
| Original dataset | 20,000,263 | 138,493 | 27,278 | 99.47% |
| Preprocessed dataset | 19,793,342 | 138,185 | 10,239 | 98.97% |
| Tag #1 | Tag #2 | Tag #3 | ⋯ | Tag #1127 | Tag #1128 | |
|---|---|---|---|---|---|---|
| Toy Story (1995) | 0.0250 | 0.0250 | 0.0578 | ⋯ | 0.0778 | 0.0230 |
| GoldenEye (1995) | 0.9998 | 0.9998 | 0.0195 | ⋯ | 0.0730 | 0.0183 |
| Titanic (1997) | 0.0380 | 0.0345 | 0.1190 | ⋯ | 0.0693 | 0.0210 |
| Resident Evil (2002) | 0.0403 | 0.0350 | 0.0195 | ⋯ | 0.9588 | 0.9598 |
| White Zombie (1932) | 0.0188 | 0.0203 | 0.0270 | ⋯ | 0.9670 | 0.9840 |
| ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ | ⋯ |
| Activation Function | RMSE | Time [s] | |
|---|---|---|---|
| Convolution Layer | Compression Layer | ||
| Identity | Identity | 0.7856 | 295 |
| Identity | ReLU | 0.7608 | 297 |
| Identity | Sigmoid | 0.7638 | 298 |
| ReLU | Identity | 0.7854 | 296 |
| ReLU | ReLU | 0.7739 | 297 |
| ReLU | Sigmoid | 0.7641 | 300 |
| Sigmoid | Identity | 0.7976 | 298 |
| Sigmoid | ReLU | 0.7932 | 299 |
| Sigmoid | Sigmoid | 0.7678 | 302 |
| Model | Auto Encoder | RMSE | P@5 | P@10 | R@5 | R@10 | Time [s] |
|---|---|---|---|---|---|---|---|
| kNN- Content | AE | 0.7692 | 0.8142 | 0.7906 | 0.4352 | 0.5587 | 289 |
| (−1.09%) | (+0.68%) | (+0.79%) | (+0.55%) | (+0.68%) | |||
| VAE | 0.7680 | 0.8137 | 0.7914 | 0.4358 | 0.5592 | 316 | |
| (−0.94%) | (+0.74%) | (+0.69%) | (+0.41%) | (+0.59%) | |||
| DAE | 0.7668 | 0.8147 | 0.7925 | 0.4355 | 0.5588 | 291 | |
| (−0.78%) | (+0.62%) | (+0.55%) | (+0.48%) | (+0.66%) | |||
| HCAE | 0.7608 | 0.8198 | 0.7969 | 0.4376 | 0.5625 | 297 | |
| FMgenome | AE | 0.7702 | 0.8052 | 0.7836 | 0.4300 | 0.5571 | 23,412 |
| (−0.87%) | (+0.62%) | (+0.72%) | (+0.78%) | (+0.71%) | |||
| VAE | 0.7688 | 0.8057 | 0.7841 | 0.4295 | 0.5578 | 23,535 | |
| (−0.69%) | (+0.56%) | (+0.66%) | (+0.90%) | (+0.59%) | |||
| DAE | 0.7681 | 0.8063 | 0.7852 | 0.4310 | 0.5587 | 23,447 | |
| (−0.60%) | (+0.48%) | (+0.52%) | (+0.55%) | (+0.43%) | |||
| HCAE | 0.7635 | 0.8102 | 0.7893 | 0.4334 | 0.5611 | 23,503 | |
| kNN- Content- SVD | AE | 0.7634 | 0.8162 | 0.7946 | 0.4356 | 0.5575 | 596 |
| (−0.98%) | (+0.78%) | (+0.76%) | (+0.53%) | (+0.78%) | |||
| VAE | 0.7623 | 0.8166 | 0.7941 | 0.4349 | 0.5580 | 653 | |
| (−0.84%) | (+0.73%) | (+0.82%) | (+0.68%) | (+0.69%) | |||
| DAE | 0.7612 | 0.8177 | 0.7954 | 0.4355 | 0.5594 | 603 | |
| (−0.70%) | (+0.60%) | (+0.66%) | (+0.55%) | (+0.44%) | |||
| HCAE | 0.7559 | 0.8226 | 0.8007 | 0.4379 | 0.5619 | 612 | |
| kNN- Content- SVD++ | AE | 0.7584 | 0.8186 | 0.7959 | 0.4368 | 0.5609 | 27,687 |
| (−0.90%) | (+0.78%) | (+0.90%) | (+0.66%) | (+0.69%) | |||
| VAE | 0.7569 | 0.8191 | 0.7962 | 0.4363 | 0.5610 | 27,761 | |
| (−0.70%) | (+0.72%) | (+0.86%) | (+0.77%) | (+0.67%) | |||
| DAE | 0.7560 | 0.8198 | 0.7972 | 0.4374 | 0.5617 | 27,698 | |
| (−0.58%) | (+0.63%) | (+0.73%) | (+0.52%) | (+0.55%) | |||
| HCAE | 0.7516 | 0.8250 | 0.8031 | 0.4397 | 0.5648 | 27,737 |
| Model | RMSE | Epochs | Time [s] |
|---|---|---|---|
| NMF () | 0.7993 | 305 | 32,115 |
| NMF-genome | 0.7797 | 200 | 21,220 |
| (1128 original scores) | (−2.45%) | (−34.43%) | (−33.92%) |
| NMF () | 0.7987 | 290 | 18,802 |
| NMF-genome | 0.7792 | 165 | 10,843 |
| (1044 NLP-preprocessed scores) | (−2.44%) | (−43.10%) | (−42.33%) |
| NMF () | 0.7984 | 265 | 9,937 |
| NMF-genome | 0.7718 | 125 | 4695 |
| (600 scores of DAE) | (−3.33%) | (−52.83%) | (−52.75%) |
| NMF-genome | 0.7688 | 97 | 3729 |
| (600 scores of HCAE) | (−3.71%) | (−63.40%) | (−62.47%) |
| SVD () | 0.7930 | 230 | 11,201 |
| SVD-genome | 0.7582 | 55 | 2713 |
| (1128 original scores) | (−4.39%) | (−76.09%) | (−75.78%) |
| SVD () | 0.7927 | 150 | 5895 |
| SVD-genome | 0.7547 | 45 | 1787 |
| (1044 NLP-preprocessed scores) | (−4.79%) | (−70.00%) | (−69.69%) |
| SVD () | 0.7925 | 140 | 3018 |
| SVD-genome | 0.7536 | 35 | 905 |
| (600 scores of DAE) | (−4.91%) | (−75.00%) | (−70.01%) |
| SVD-genome | 0.7472 | 30 | 814 |
| (600 scores of HCAE) | (−5.72%) | (−78.57%) | (−73.03%) |
| Model | RMSE | P@5 | P@10 | R@5 | R@10 |
|---|---|---|---|---|---|
| ii-CF | 0.8046 | 0.7967 | 0.7721 | 0.4261 | 0.5541 |
| (−7.13%) | (+4.06%) | (+4.45%) | (+3.79%) | (+3.20%) | |
| I-AutoRec | 0.7808 | 0.7778 | 0.7559 | 0.3972 | 0.5228 |
| (−4.30%) | (+6.33%) | (+6.46%) | (+10.32%) | (+8.67%) | |
| NMF | 0.7981 | 0.7951 | 0.7743 | 0.4296 | 0.5583 |
| (−6.38%) | (+4.25%) | (+4.18%) | (+3.00%) | (+2.46%) | |
| SVD | 0.7922 | 0.8005 | 0.7786 | 0.4322 | 0.5628 |
| (−5.68%) | (+3.60%) | (+3.65%) | (+2.42%) | (+1.68%) | |
| SVD++ | 0.7894 | 0.8030 | 0.7817 | 0.4339 | 0.5639 |
| (−5.35%) | (+3.30%) | (+3.27%) | (+2.03%) | (+1.48%) | |
| kNN-ContentHCAE-SVD | 0.7559 | 0.8226 | 0.8007 | 0.4379 | 0.5619 |
| (−1.15%) | (+0.94%) | (+0.92%) | (+1.13%) | (+1.83%) | |
| kNN-ContentHCAE-SVD++ | 0.7516 | 0.8250 | 0.8031 | 0.4397 | 0.5648 |
| (−0.59%) | (+0.65%) | (+0.62%) | (+0.72%) | (+1.33%) | |
| NMF-genome | 0.7688 | 0.8174 | 0.7941 | 0.4389 | 0.5689 |
| (−2.81%) | (+1.57%) | (+1.73%) | (+0.90%) | (+0.61%) | |
| SVD-genome | 0.7472 | 0.8304 | 0.8081 | 0.4429 | 0.5724 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Duong, T.N.; Doan, N.N.; Do, T.G.; Tran, M.H.; Nguyen, D.M.; Dang, Q.H. Utilizing Half Convolutional Autoencoder to Generate User and Item Vectors for Initialization in Matrix Factorization. Future Internet 2022, 14, 20. https://doi.org/10.3390/fi14010020
Duong TN, Doan NN, Do TG, Tran MH, Nguyen DM, Dang QH. Utilizing Half Convolutional Autoencoder to Generate User and Item Vectors for Initialization in Matrix Factorization. Future Internet. 2022; 14(1):20. https://doi.org/10.3390/fi14010020
Chicago/Turabian StyleDuong, Tan Nghia, Nguyen Nam Doan, Truong Giang Do, Manh Hoang Tran, Duc Minh Nguyen, and Quang Hieu Dang. 2022. "Utilizing Half Convolutional Autoencoder to Generate User and Item Vectors for Initialization in Matrix Factorization" Future Internet 14, no. 1: 20. https://doi.org/10.3390/fi14010020
APA StyleDuong, T. N., Doan, N. N., Do, T. G., Tran, M. H., Nguyen, D. M., & Dang, Q. H. (2022). Utilizing Half Convolutional Autoencoder to Generate User and Item Vectors for Initialization in Matrix Factorization. Future Internet, 14(1), 20. https://doi.org/10.3390/fi14010020