
BERT- and BiLSTM-Based Sentiment Analysis of Online Chinese Buzzwords


Abstract
:1. Introduction
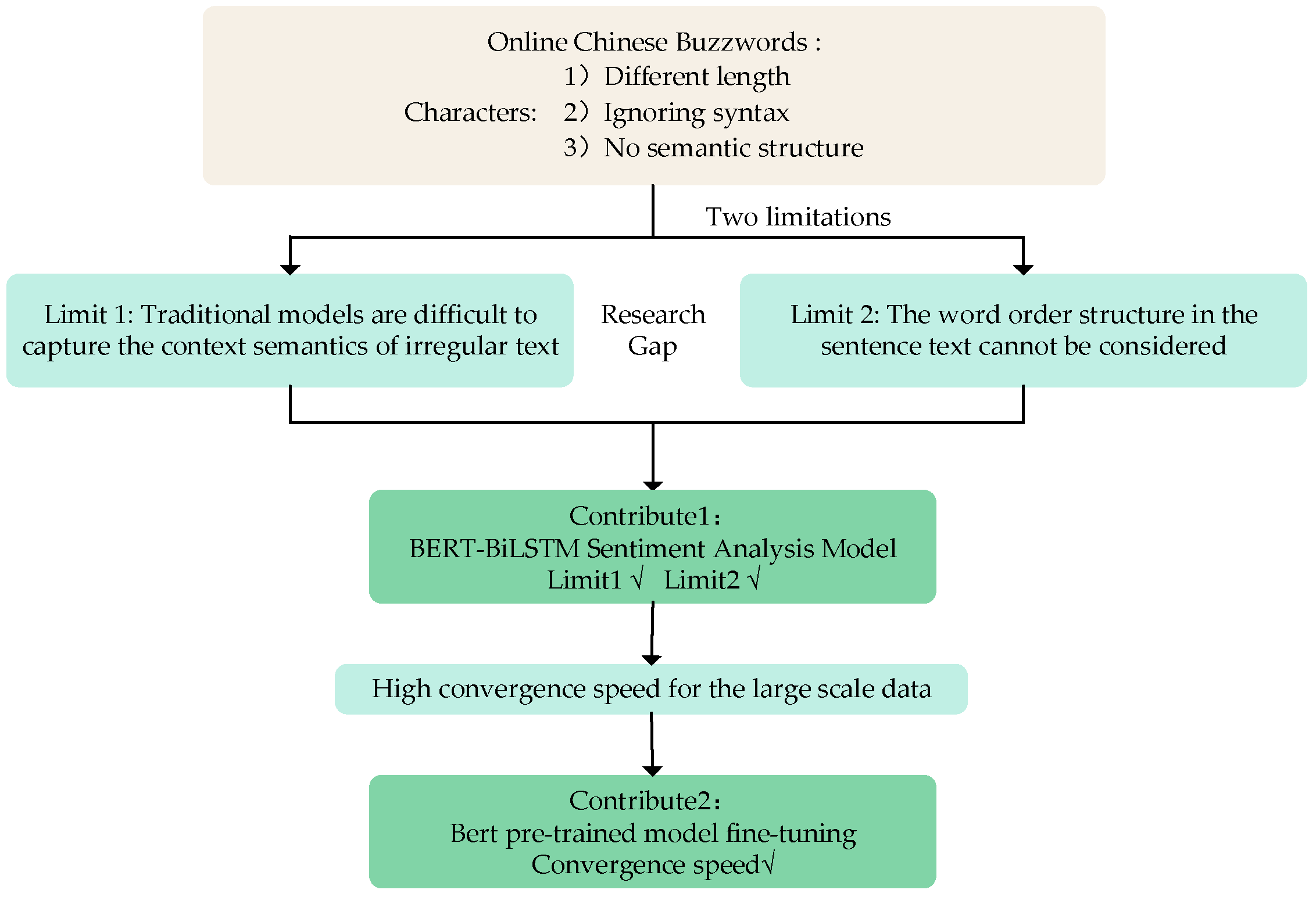
- The BERT–BiLSTM model is proposed. The model does not require word separation during sentiment analysis and is able to capture deep contextual information from the word order structure. The superiority of BERT–BiLSTM is illustrated in Section 3.
- A fine-tuned sentiment analysis of OCBs is proposed to accelerate the model convergence speed. First, the fine-tuning process directly employs the parameters obtained from the pre-training as the initial values of the proposed model. Then, the manually labeled dataset is transferred according to the downstream tasks to balance the relationship between the data and the model.
- From the extensive experimental results on the OCBs dataset, we can conclude that BERT–BiLSTM outperforms seven state-of-the-art models in terms of recall and F1-score. In addition, the ablation experiments demonstrate the superiority of the proposed model combining BERT and BiLSTM. The proposed model has significant implications for sentiment analysis of OCBs.
- The proposed model is trained on datasets with small data volume (60,000 online Chinese buzzwords texts) in this paper. We will study its application on large-scale datasets in the future.
- The proposed model is applied to static data in this paper. However, emotional analysis of dynamic data is also of great significance. For example, DTSCM tracks the change trend of theme emotion in different time segments by capturing the theme of microblog messages in different time segments [6].
- This model divides the emotions of online Chinese buzzwords into two categories (i.e., positive and negative), but the classification of multiple categories of emotions needs further research (e.g., sadness, anger, tension, happiness).
2. Related Work
3. Proposed Model
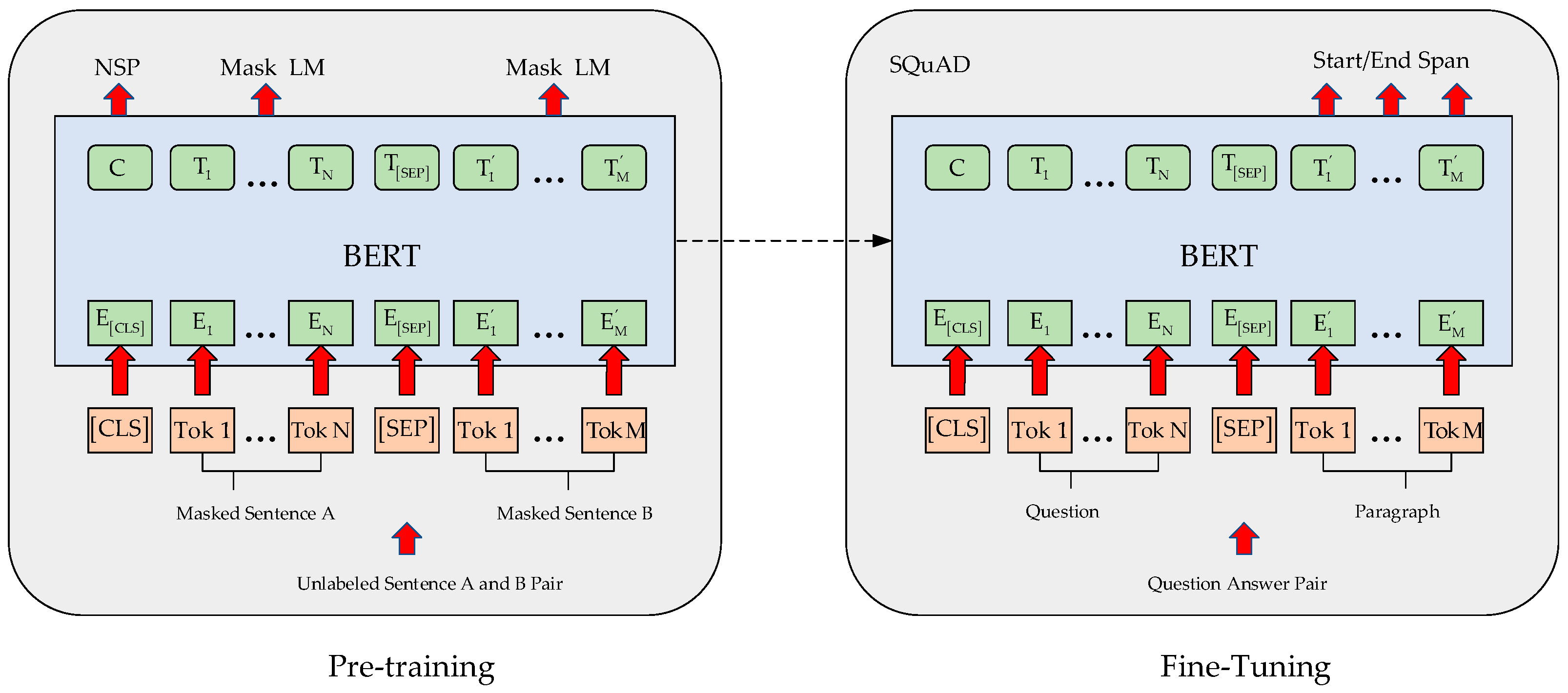
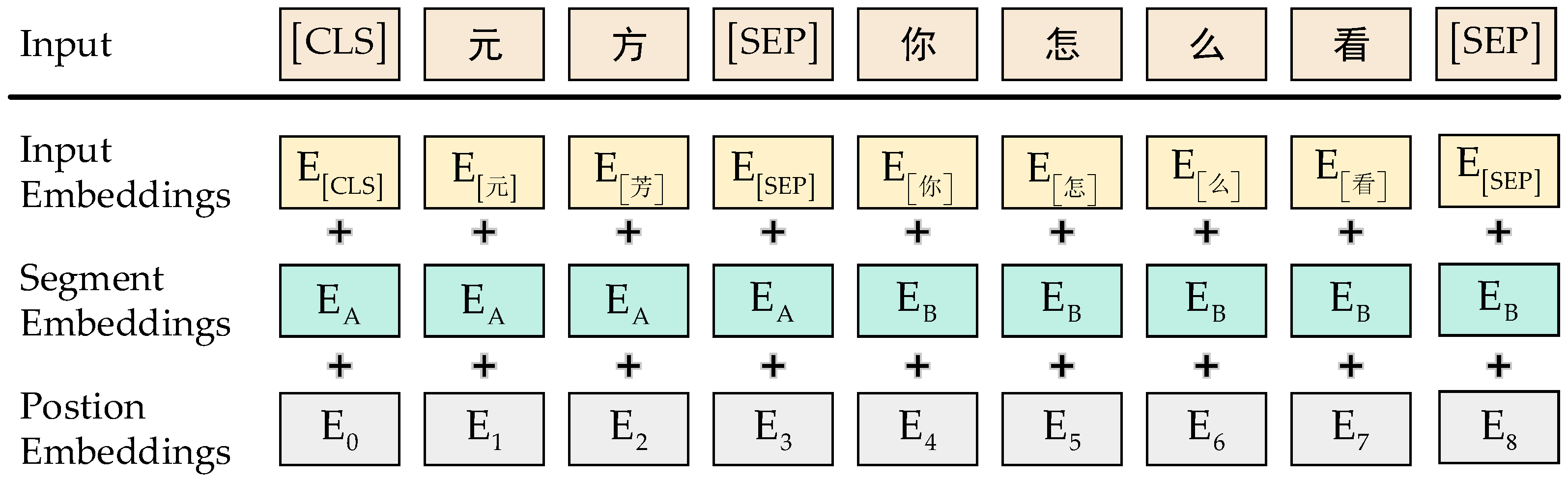
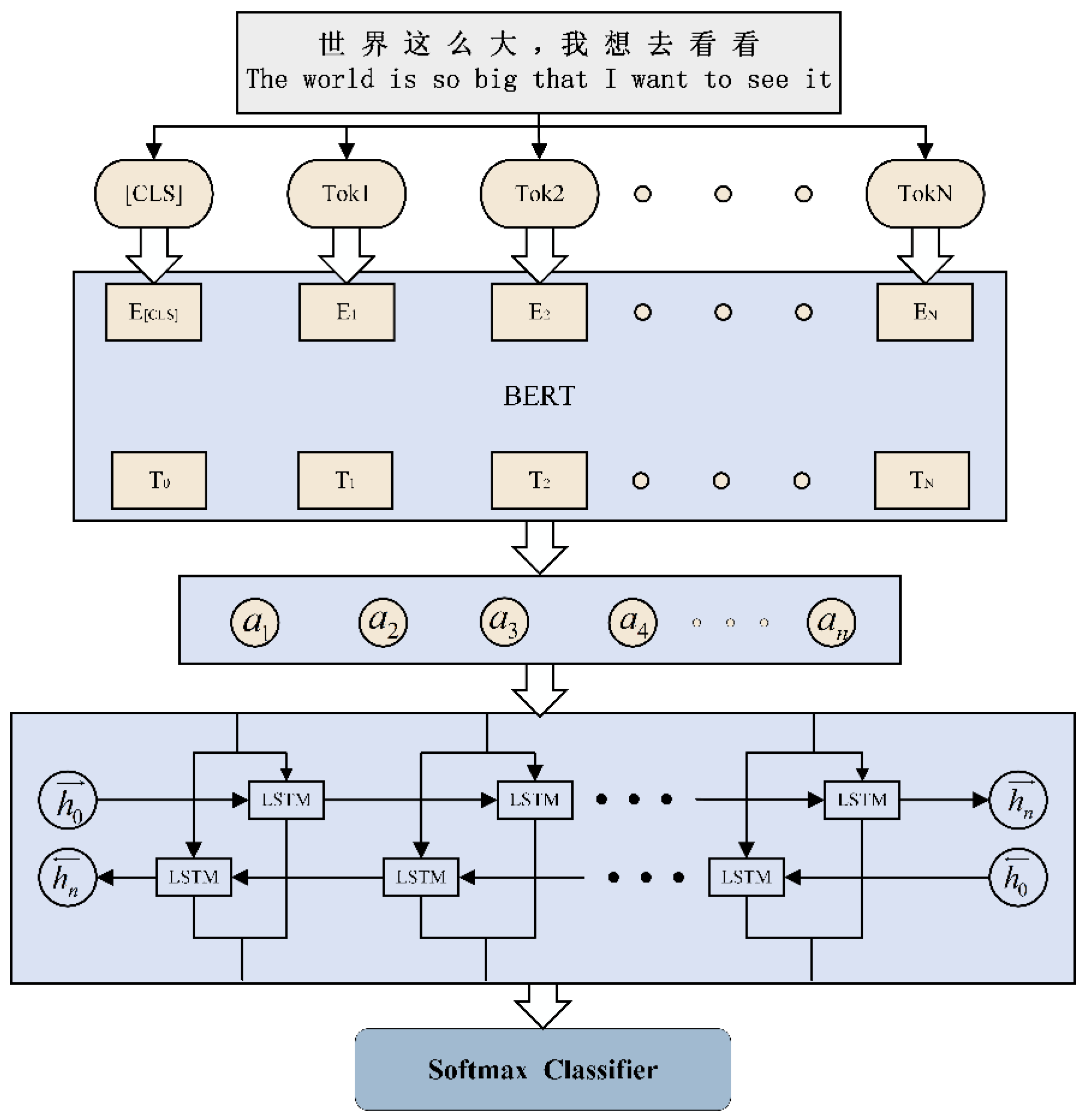
3.1. BERT Pretraining Language Model
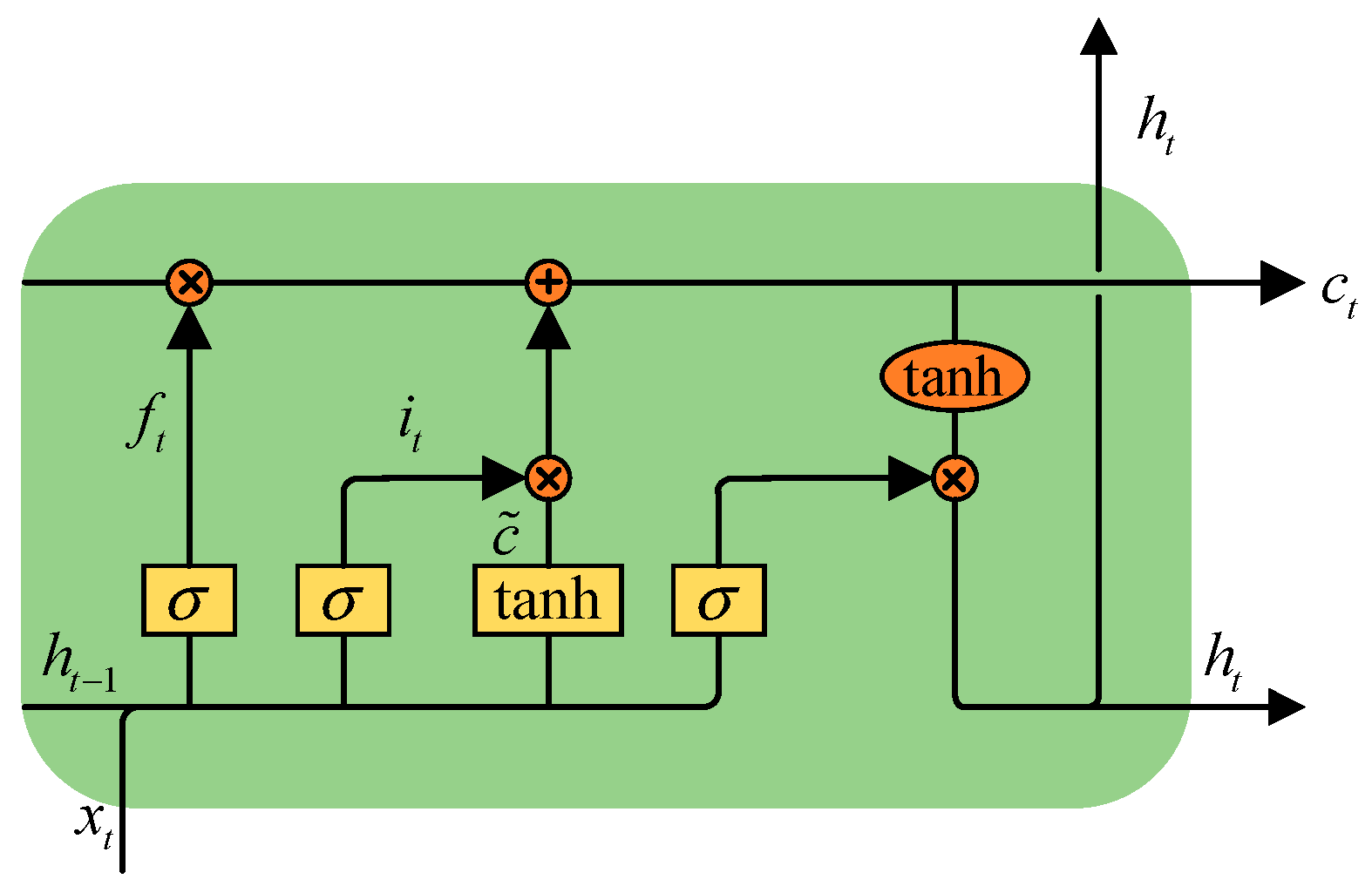
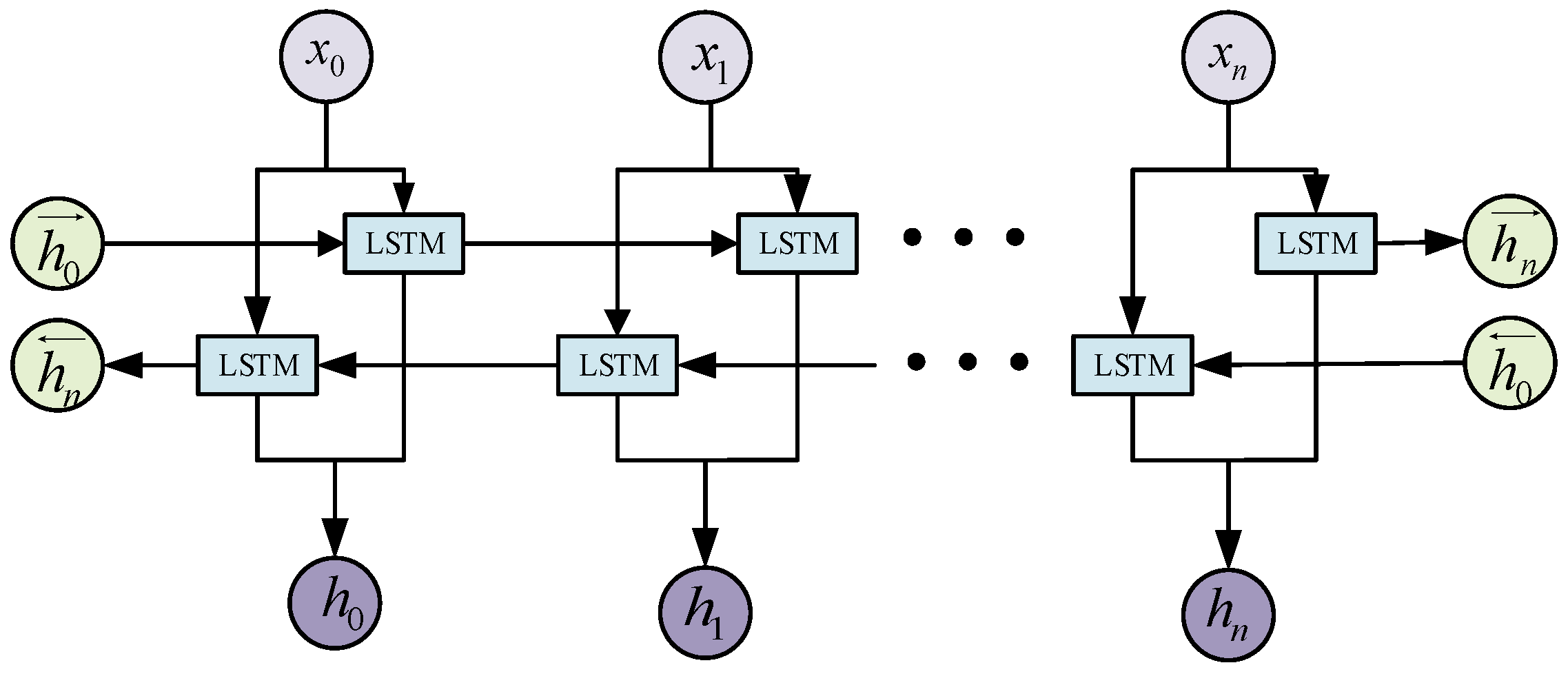
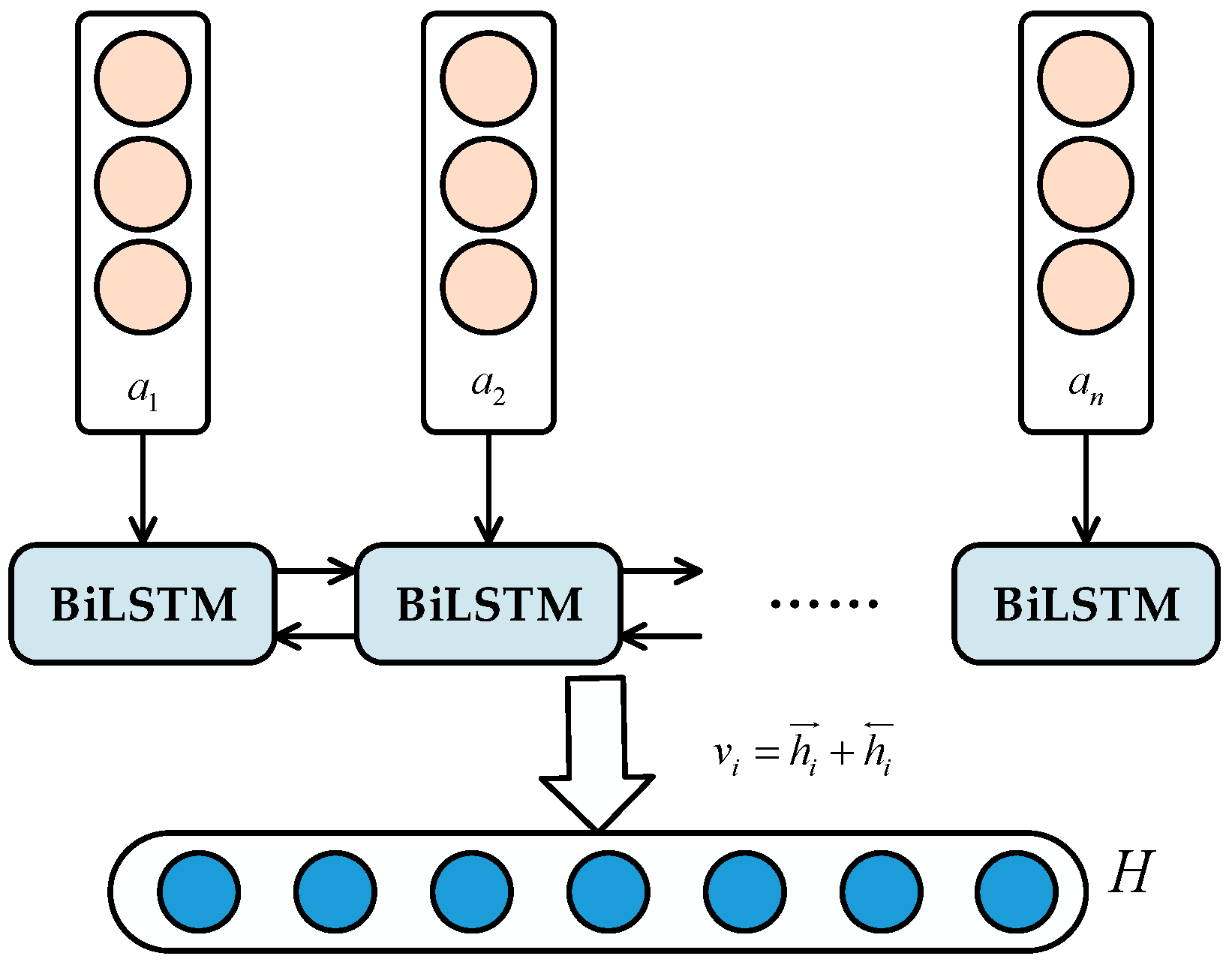
3.2. BiLSTM Network
- Forget gate mechanism:
- 2.
- Input gate mechanism:
- 3.
- Current unit status:
- 4.
- Update unit status:
- 5.
- Output gate mechanism:
- 6.
- The current state of the hidden layer:
3.3. Network Buzzwords Sentiment Analysis Model
4. Experiments and Analysis
4.1. Datasets
4.2. Parameters
4.3. Metrics
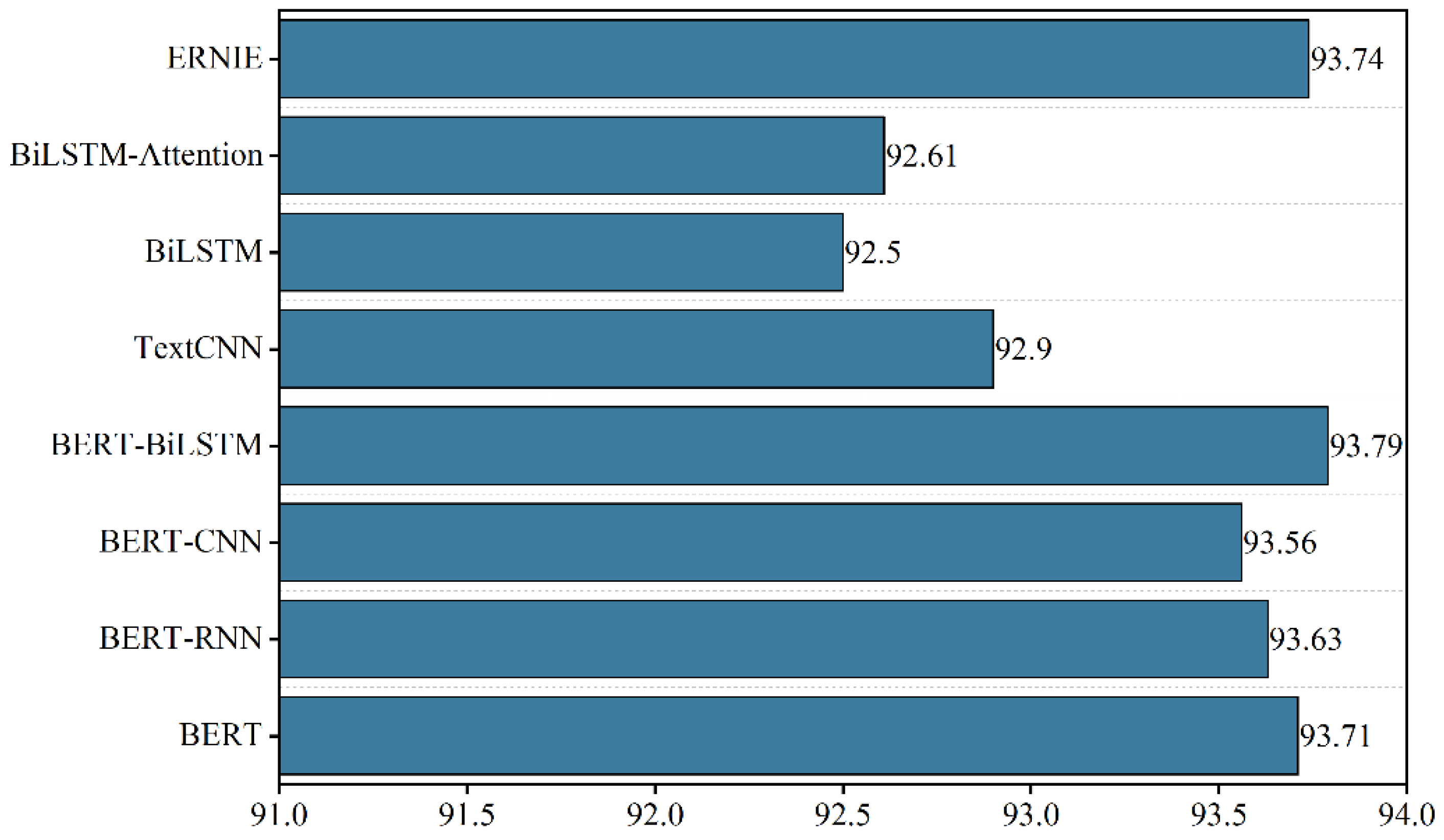
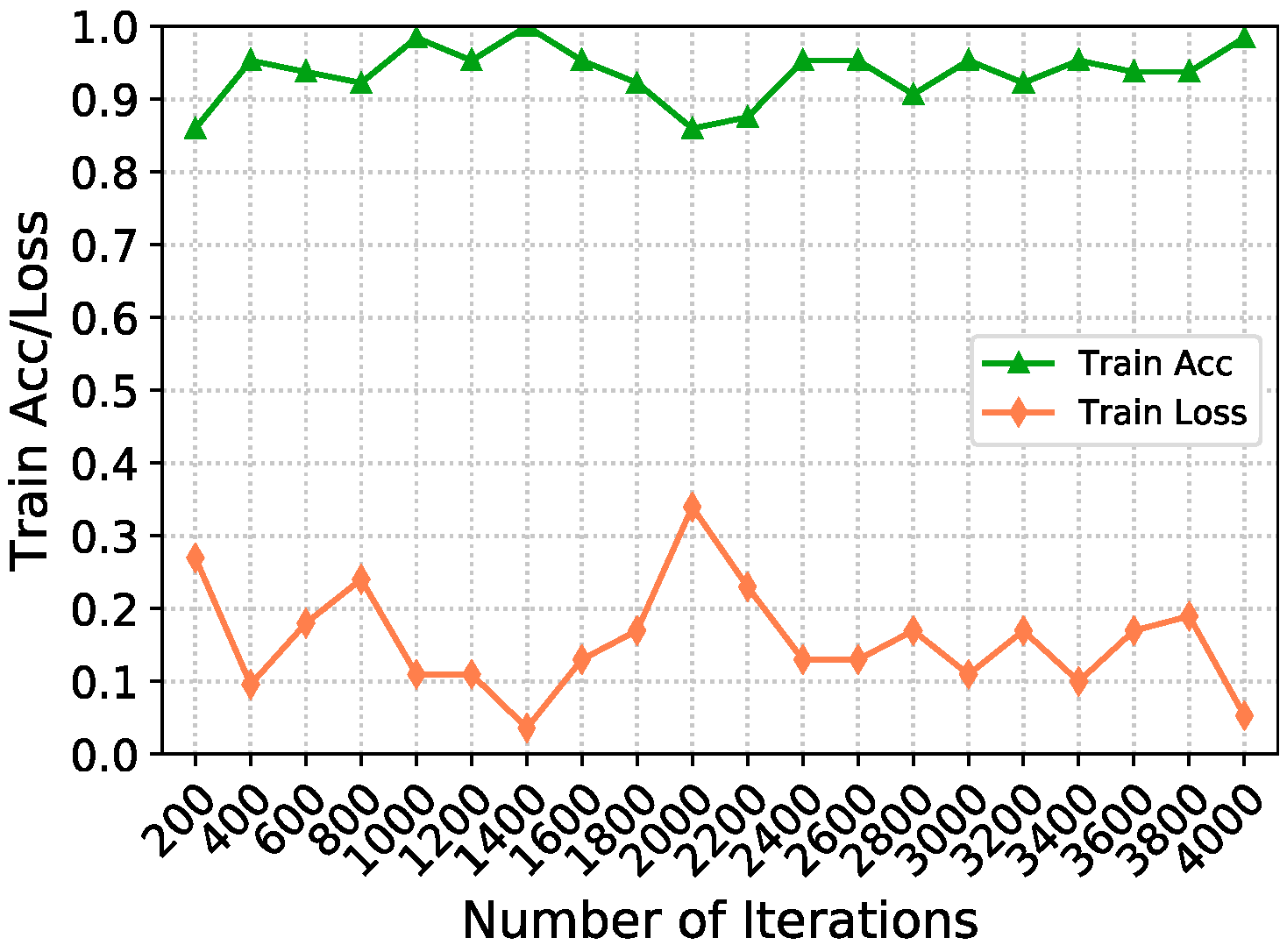
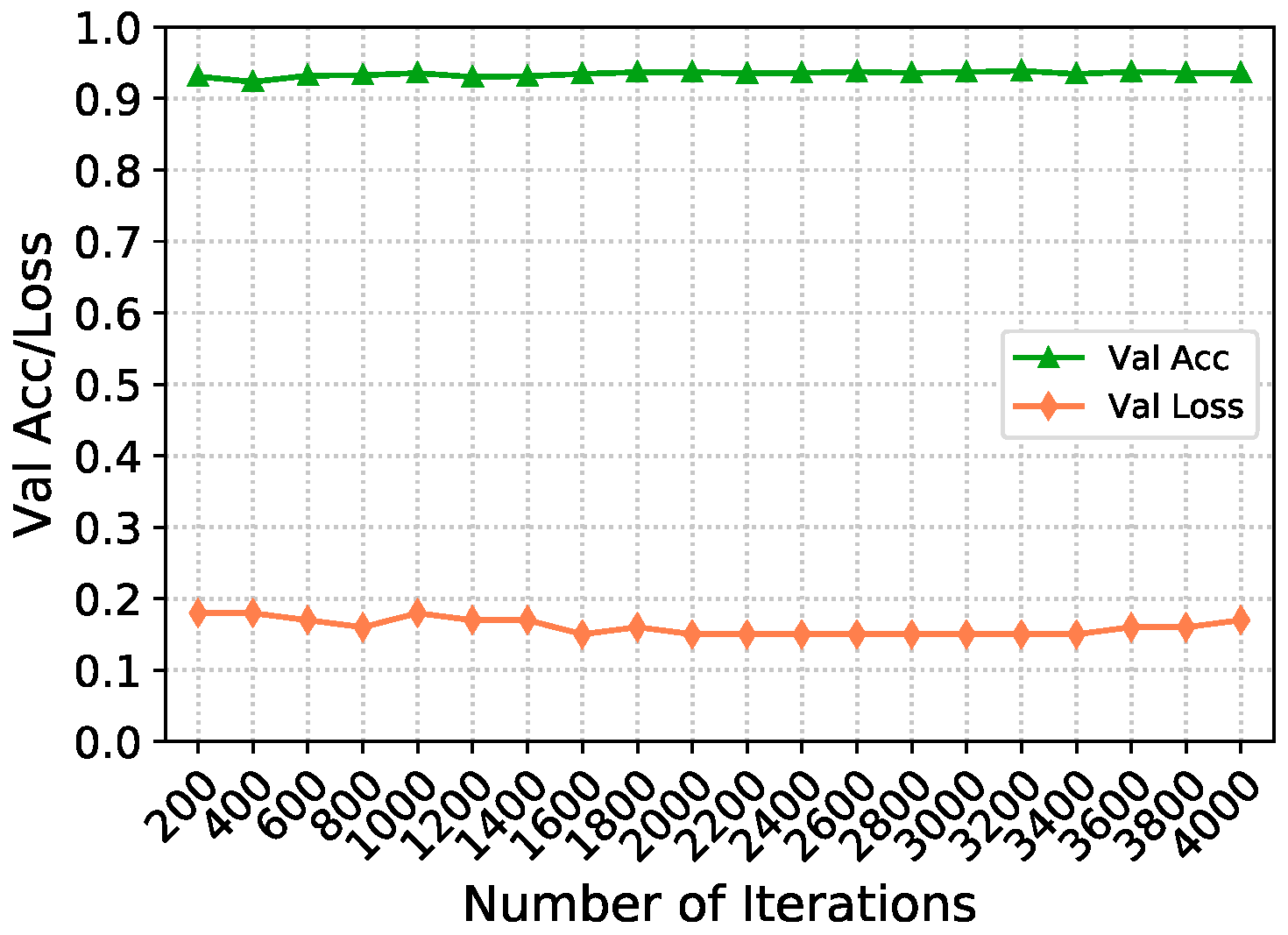
4.4. Experiment Analysis
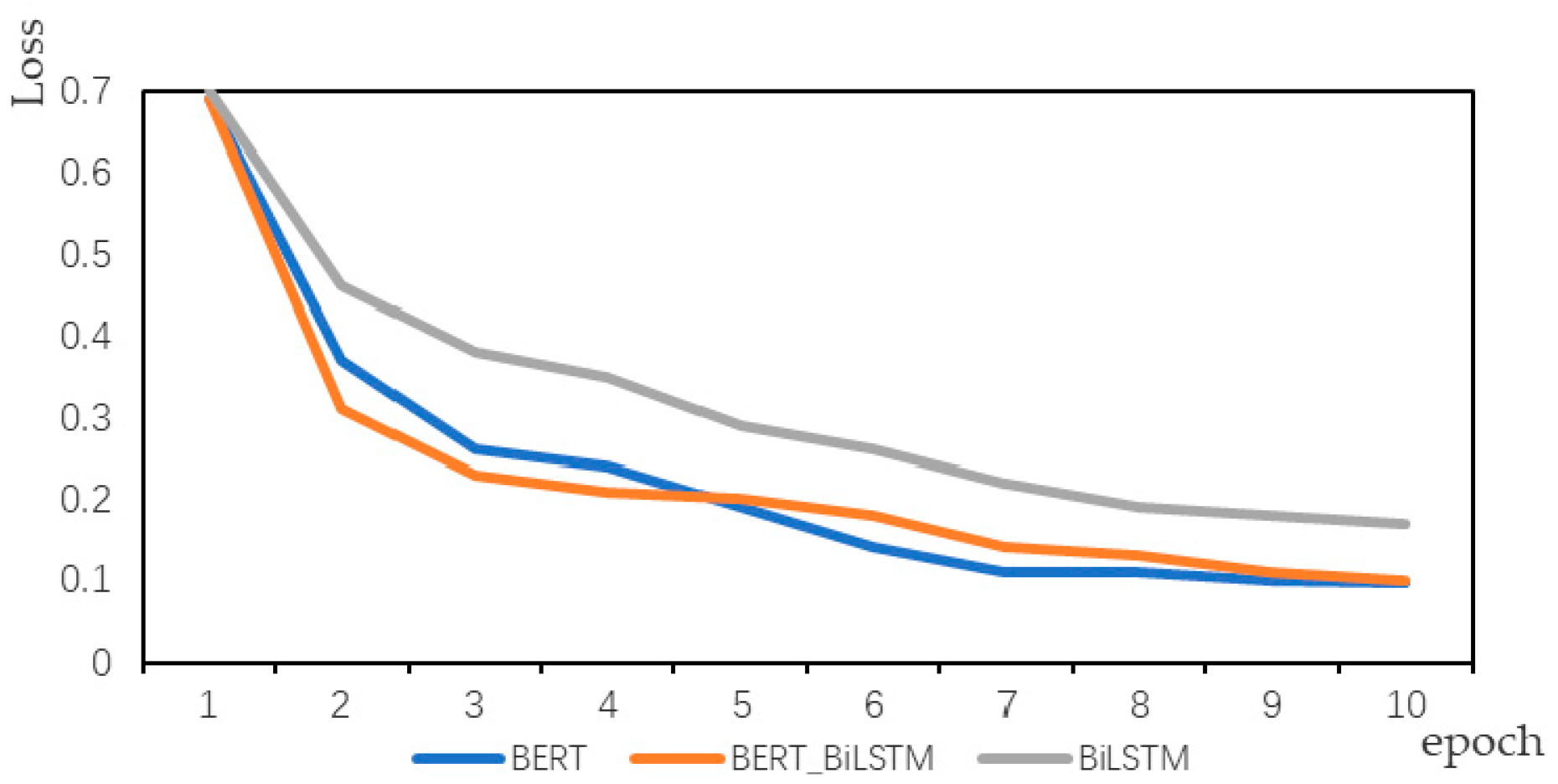
Ablation Experiment
- BERT: The word vector output from BERT pre-training model is used to calculate the emotional polarity through Softmax (a traditional classifier).
- BiLSTM: The OCBs vector is generated through word2vec (a typical method of word embedding), then the generated word vector is input into the BiLSTM model for feature extraction, and then emotional classification is conducted through Softmax (a traditional classifier).
- BERT–BiLSTM: By fine-tuning the BERT model, the dynamic representation of the OCBs vector is generated in the downstream task, then the generated word vector is input to the BiLSTM model for feature extraction, and then the emotional classification is conducted through Softmax (a traditional classifier).
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zan, H.Y.; Xu, H.F.; Zhang, K.L. The construction of Internet slang dictionary and Its analysis. J. Chin. Inf. Process. 2016, 30, 133–139. [Google Scholar]
- Cheng, Y. A study on the standardization of modern Chinese from the perspective of Network language Niche. This Anc. Invasive 2022, 12, 126–128. [Google Scholar]
- Tang, L. A study on the dissemination influence of contemporary Chinese internet buzzwords—Taking 15 internet buzzwords in the first half of 2015 as an example. J. Hubei Univ. Natl. (Soc. Sci. Ed.) 2016, 34, 139–144. [Google Scholar]
- Ji, W. An analysis of the youth mentality behind internet buzzwords. People’s Trib. 2022, 4, 28–31. [Google Scholar]
- Liu, W.; Li, Y.; Luo, J. Sentiment analysis of Chinese short text based on BERT and BiLSTM. J. Taiyuan Norm. Univ. Nat. Sci. Ed. 2020, 19, 52–58. [Google Scholar]
- Li, C.; Huang, F.; Wen, X.; Li, X.; Yuan, C.A. Evolution analysis method of microblog topic-sentiment based on dynamic topic sentiment combining model. J. Comput. Appl. 2015, 35, 2905–2910. [Google Scholar]
- Zhang, S.; Wei, Z.; Wang, Y.; Liao, T. Sentiment analysis of Chinese micro-blog text based on extended sentiment dictionary. Future Gener. Comput. Syst. 2018, 81, 395–403. [Google Scholar] [CrossRef]
- Gang, Z.; Zan, X. Research on the sentiment analysis model of product reviews based on machine learning. Comput. Eng. Appl. 2017, 3, 166–170. [Google Scholar]
- Tang, L.; Xiong, C.; Wang, Y.; Zhou, Y.; Zhao, Z. Review of deep learning for short text sentiment tendency analysis. J. Front. Comput. Sci. Technol. 2021, 15, 794–811. [Google Scholar]
- Wang, T.; Yang, W. Review of text sentiment analysis methods. Comput. Eng. Appl. 2021, 57, 11–24. [Google Scholar]
- Madani, Y.; Erritali, M.; Bengourram, J.; Sailhan, F. A Hybrid Multilingual Fuzzy-Based Approach to the Sentiment Analysis Problem Using SentiWordNet. Int. J. Uncertain. Fuzziness Knowl.-Based Syst. 2020, 28, 361–390. [Google Scholar] [CrossRef]
- Ku, L.; Chen, H.-H. Mining opinions from the Web: Beyond relevance retrieval. J. Am. Soc. Inf. Sci. Technol. 2007, 58, 1838–1850. [Google Scholar] [CrossRef]
- Wang, H.; Marius, P.; Pan, J. Research on improved algorithm of word semantic similarity based on HowNet. Comput. Digit. Eng. 2022, 50, 225–228. [Google Scholar]
- Hao, M.; Chen, L. Chinese Microblog polarity classification based on Hownet and PMI. J. Electron. Sci. Technol. 2021, 34, 50–55. [Google Scholar]
- Ye, X.; Cao, J.; Xu, F. Sentiment dictionary adaptive learning method in Chinese domain. Comput. Eng. Des. 2020, 41, 2231–2237. [Google Scholar]
- Yang, Z. Sentiment Analysis of Movie Reviews based on Machine Learning. In Proceedings of the 2th International Workshop on Artificial Intelligence and Education, Montreal, QC, Canada, 6–8 November 2020; pp. 1–4. [Google Scholar]
- Tiwari, P.; Mishra, B.K.; Kumar, S.; Kumar, V. Implementation of n-gram Methodology for Rotten Tomatoes Review Dataset Sentiment Analysis. Int. J. Knowl. Discov. Bioinform. 2017, 7, 689–701. [Google Scholar] [CrossRef]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of sentiment reviews using n-gram machine learning approach. Expert Syst. Appl. 2016, 57, 117–126. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv preprint 2014, arXiv:1408.5882. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv preprint 2014, arXiv:1409.1259. [Google Scholar]
- Qu, Z.; Yuan, W.; Wang, X. A Transfer Learning Based Hierarchical Attention Neural Network for Sentiment Classification. In Proceedings of the International Conference on Data Mining & Big Data, Belgrade, Serbia, 14–20 July 2020; Springer: Cham, Switzerland, 2018; pp. 383–392. [Google Scholar]
- Abid, F.; Alam, M.; Yasir, M.; Li, C. Sentiment analysis through recurrent variants latterly on convolutional neural network of Twitter. Future Gener. Comput. Syst. 2019, 95, 292–308. [Google Scholar] [CrossRef]
- Arkhipenko, K.; Kozlov, I.; Trofimovich, J. Comparison of neural network architectures for sentiment analysis of Russian tweets. Comput. Linguist. Intellect. Technol. Proc. Int. Conf. Dialogue 2016, 15, 50–59. [Google Scholar]
- Qian, Q.; Huang, M.; Lei, J. Linguistically regularized lstms for sentiment classification. arXiv preprint 2016, arXiv:1611.03949. [Google Scholar]
- Nio, L.; Murakami, K. Japanese sentiment classification using bidirectional long short-term memory recurrent neural network. In Proceedings of the Japanese Sentiment Classification Using Bidirectional Long Short-Term Memory Recurrent Neural Network, Okayama, Japan, 13–15 March 2018; pp. 1119–1122. [Google Scholar]
- Zhang, M.; Zhou, Z. A Review on Multi-Label Learning Algorithms. IEEE Trans. Knowl. Data Eng. 2014, 26, 1819–1837. [Google Scholar] [CrossRef]
- Thakur, N.; Han, C.Y. An Exploratory Study of Tweets about the SARS-CoV-2 Omicron Variant: Insights from Sentiment Analysis, Language Interpretation, Source Tracking, Type Classification, and Embedded URL Detection. COVID 2022, 2, 1026–1049. [Google Scholar] [CrossRef]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharyad, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Palomino, M.A.; Aider, F. Evaluating the Effectiveness of Text Pre-Processing in Sentiment Analysis. Appl. Sci. 2022, 12, 8765–8786. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint 2018, arXiv:181004805. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Doha, Qatar; 2014; pp. 1532–1543. [Google Scholar]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment analysis of comment texts based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Internet Corpus of Sogou Labs. Available online: https://pinyin.sogou.com/dict/search/search_list/%CD%F8%C2%E7%C1%F7%D0%D0%D3%EF/normal (accessed on 27 September 2022).
- Weibo Popular Events. Available online: https://weibo.com/a/hot/realtime (accessed on 27 September 2022).
- Alhaj, Y.A.; Dahou, A.; Al-qaness, M.A.; Abualigah, L.; Abbasi, A.A.; Almaweri, N.A.O.; Elaziz, M.A.; Damaševičius, R. A Novel Text Classification Technique Using Improved Particle Swarm Optimization: A Case Study of Arabic Language. Future Internet 2022, 14, 194. [Google Scholar] [CrossRef]
- Wang, H.; Sun, M. Chinese short text classification based on ERNIE-RCNN model. Comput. Technol. Dev. 2022, 32, 28–33. [Google Scholar]
- Ge, H.; Zheng, S.; Wang, Q. Based BERT-BiLSTM-ATT Model of Commodity Commentary on The Emotional Tendency Analysis. In Proceedings of the 2021 IEEE 4th International Conference on Big Data and Artificial Intelligence (BDAI), Qingdao, China, 2–4 July 2021; pp. 130–133. [Google Scholar]
- Ce, P.; Tie, B. An analysis method for interpretability of CNN text classification model. Future Internet 2020, 12, 228. [Google Scholar] [CrossRef]
- Meyes, R.; Lu, M.; de Puiseau, C.W. Ablation studies in artificial neural networks. arXiv preprint 2019, arXiv:1901.08644. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text of Online Chinese Buzzwords | Label |
|---|---|
| 坐沙发,赏灯会。 Sit on the couch, enjoy the lights. | 1 |
| 这是什么神仙操作。 What kind of celestial manipulation is this. | 1 |
| 悲催!隐形眼镜配戴时间过长,眼睛又发炎了。 Grief! Time of contacting lenses is too long. The eyes are inflamed. again. | 0 |
| 亲爱滴,有点像手表广告,不过脸很美。 Dear drip, it’s a bit like a watch advertisement, but the face is beautiful. | 1 |
| 我的hotmail邮箱被黑了,莫名其妙自动给所有人发了个链接。 My hotmail email was hacked and somehow automatically sent a link. to everyone | 0 |
| 头晕晕,眼花花,早上醒不来,各种状态不佳,我不能再这样下去了。 Dizziness, dizziness, not waking up in the morning, all kinds of poor state, I can′t go on like this. | 0 |
| Parameters | Values |
|---|---|
| Num_epochs | 9 |
| Batch_size | 128 |
| Pad_size | 64 |
| Hidden_size | 768 |
| Learning_rate | 5 × 10−5 |
| Filter_sizes | (2, 3, 4) |
| Result | Positive | Negative |
|---|---|---|
| Guessed pos | TP | FP |
| Guessed neg | FN | TN |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Lei, Y.; Ji, S. BERT- and BiLSTM-Based Sentiment Analysis of Online Chinese Buzzwords. Future Internet 2022, 14, 332. https://doi.org/10.3390/fi14110332
Li X, Lei Y, Ji S. BERT- and BiLSTM-Based Sentiment Analysis of Online Chinese Buzzwords. Future Internet. 2022; 14(11):332. https://doi.org/10.3390/fi14110332
Chicago/Turabian StyleLi, Xinlu, Yuanyuan Lei, and Shengwei Ji. 2022. "BERT- and BiLSTM-Based Sentiment Analysis of Online Chinese Buzzwords" Future Internet 14, no. 11: 332. https://doi.org/10.3390/fi14110332
APA StyleLi, X., Lei, Y., & Ji, S. (2022). BERT- and BiLSTM-Based Sentiment Analysis of Online Chinese Buzzwords. Future Internet, 14(11), 332. https://doi.org/10.3390/fi14110332