
TinyML for Ultra-Low Power AI and Large Scale IoT Deployments: A Systematic Review





Abstract
:1. Introduction
- ▪
- Presentation of major performance measures for the TinyML framework, as well as its definition and overview; examination of important technologies.
- ▪
- Review of research on TinyML conducted by various research groups and creation of an academic map.
- ▪
- Identify important obstacles and give a future direction for TinyML research in which we cover numerous concerns.
- ▪
- To assemble a list of existing TinyML-based toolkits for training and model construction at the edge, where hardware platforms, software programs, and libraries are available.
- ▪
- Present and analyze TinyML application areas, as well as illustrate various TinyML use cases.
2. TinyML
2.1. Overview
2.2. Challenges
2.2.1. Low Power
2.2.2. Limited Memory
2.2.3. Processor Power
2.2.4. The Machine Learning Is Extensive and Requires Resources
2.2.5. Heterogeneous Hardware
2.2.6. An Absence of Suitable Datasets
2.2.7. Network and Data Administration
2.2.8. New Machine Learning Models Are Required
2.2.9. Benchmarking
2.3. Academic Map
- For the first search cycle, the term “TinyML” is utilized.
- The term “Tiny ML” is applied to the second search cycle.
- The term “Tiny-ML” is utilized for the third search cycle.
- The term “Tiny Machine Learning” is used in the fourth cycle of searches.
- The fifth search cycle use the term “Tiny Deep Learning”.
- For the sixth search cycle, the term “Tiny-DL” is utilized.
- The seventh search cycle used the term “TinyDL”.
- For the eighth search cycle, the term “Tiny DL” is utilized.
- MDPI (https://www.mdpi.com/)
- Wiley-Blackwell (https://onlinelibrary.wiley.com/)
- Emerald (https://www.emeraldinsight.com/)
- Elsevier (https://www.sciencedirect.com/)
- Taylor and Francis (https://www.tandfonline.com/)
- Springer (https://www.springer.com/)
2.4. Tools of TinyML
2.4.1. Hardware
2.4.2. Software and Libraries
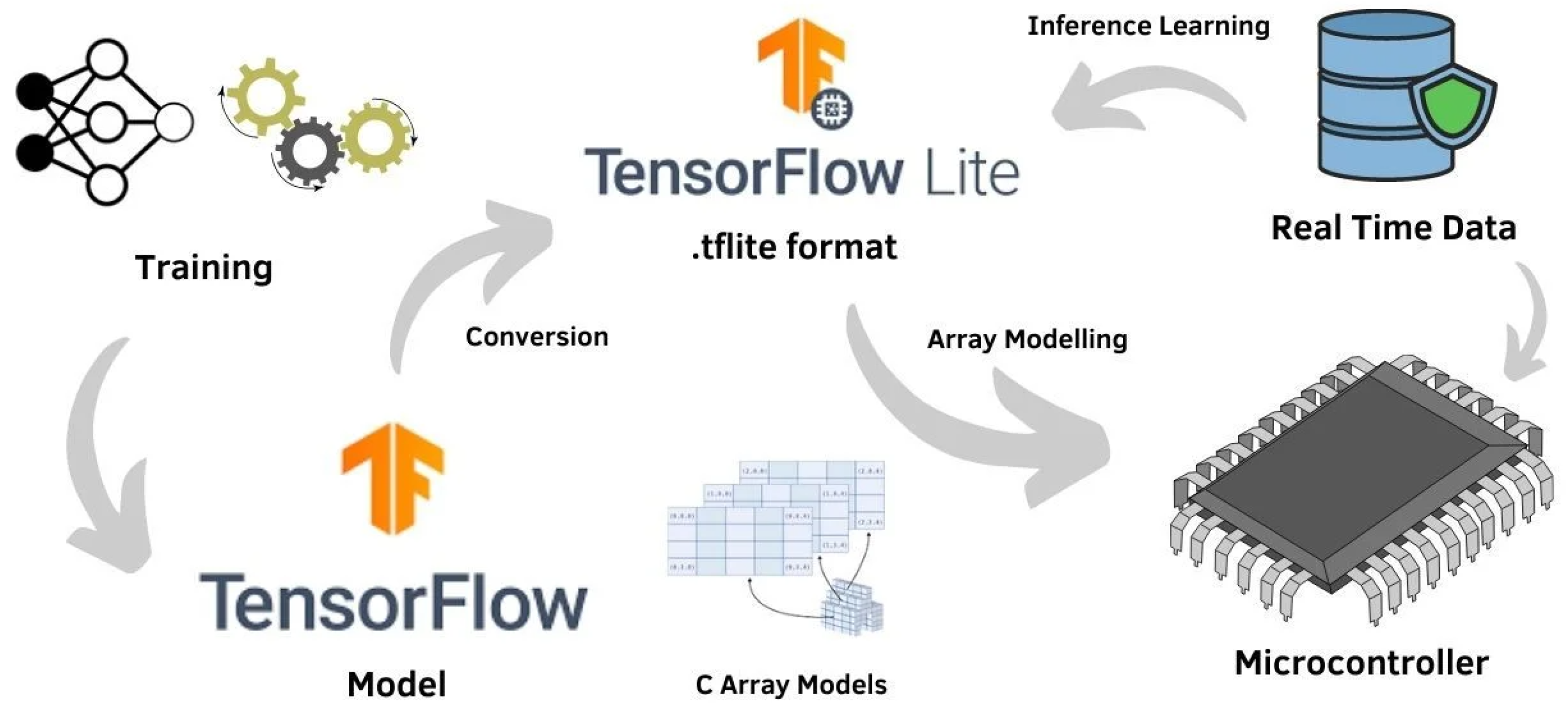
- TensorFlow Lite (TFL): It is a deep learning framework that is open source and supports edge-aware learning inference. This framework may approach edge-aware machine learning at the device by using five important restrictions (e.g., size, latency, connectivity, power consumption and privacy). It is compatible with iOS, embedded Linux, Android, and a range of microcontrollers [82]. Swift, Java, C++, Objective-C, and Python are just a few of the programming languages that are supported for machine learning on edge devices. TFL enables hardware-accelerated model optimization. A wide range of AI applications, including photo and text categorization, question response, object identification, and pose estimation, may be easily handled. Because all operators are coupled to 32-bit ARM builds, the binary size is 1 MB. When particular image classification techniques are used, it can generate a binary file as little as 300 KB. The TFL working process is completed by quantizing the 32-bit floating point values to 8-bit integers, which completes the TF model transformation into a compressed flat buffer (.tflite) and loading into an embedded edge device. A TFL plugin called TensorFlow Lite Micro (TSFM) was created to enable machine learning on ARM Cortex processors with KB memory. TFLM runs on a 32-bit platform and was created in C++ 11. However, it does not offer on-device training.
- NanoEdge AI Studio: Previously known as cartesiam.ai, the software today tests library performance using an emulator before final deployment to the edge and allows for the selection of the best library [83]. It contains various useful features, such as (i) frequency filtering, (ii) restricting the maximum necessary flash memory when creating a project, (iii) flash memory optimization, (iv) real-time search, (v) graphical representation of serial data, and (vi) library selection after comparison. It may be used to discover and classify abnormalities in data sets. It is compatible with the Arduino Nano 33 IoT board as well as the STM32 Nucleo-32 board.
- PyTorch Mobile: Belongs to the PyTorch ecosystem, which aims to make it possible for all stages of machine learning model generation, starting with training (for example, Android, iOS), can be done on smartphones and tablets [84]. Machine learning may be pre-processed in mobile apps using a variety of APIs. Both TorchScript IR detection and scripting are supported. Additionally, the 8-bit quantized XNNPACK kernel is supported for ARM CPUs. Additionally supported are neural processing units, digital signal processors and GPUs. The mobile interpreter enables mobile development optimization. Now supported are question answering, speech recognition, object identification, video processing, and image segmentation.
- uTensor: It is an open-source embedded learning environment that facilitates rapid development and prototyping on IoT edge devices [85]. It includes a future data collection architecture, a graph processing tool and an inference engine. For training, a Keras-made neural network model is required. After that, the learnt model is translated into C++. The model is modified for usage on ST, K64, and Mbed boards with the aid of uTensor. With just 2 KB of storage needed, the uTensor is a tiny device. The use of a Python SDK is required for full configuration of uTensor; it depends on the Jupyter, Python, ST-link toolkits (for ST boards)—uTensor-CLI and Mbed-CLI. A model is built initially, and then the quantization outcome is produced. Writing code for the proper edge devices is the next stage.
- STM32Cube.AI: This is optimization software and code creation for STM32 ARM Cortex Mb-based boards [86], trying to make machine learning and AI-related jobs simpler. The STM32Cube may be used directly to implement neural networks on the STM32 board. AI will be used to turn neural networks into efficient code for better-suited MCUs. It is capable of employing any trained model produced using conventional tools like MATLAB, ONNX, TFL, and PyTorch. The STM32CubeMX framework that supports STM32Cube originally gave birth to this utility. AI in parameter estimation middleware and code development for the STM32 edge device.
- Edge Impulse: For edge computing systems, it is a cloud service that develops TinyML machine learning models. For edge platforms, it can support AutoML [87]. The building of learning models is also supported across a number of platforms, including smartphones. The learning is done in the cloud, and using a data-forwarding-capable connection, the learned model may be exported to an edge device. Using the integrated Python, Node.js, C++, and Go SDKs, it may be executed locally on a workstation. A WebAssembly library for Impulses is also available.
- Embedded Learning Library (ELL): Microsoft released ELL to enable the TinyML ecosystem for embedded learning [88]. It works with the micro:bit platforms, Raspberry Pi and Arduino. Models built on such devices are internet-independent, therefore no connectivity to the cloud is necessary. Image and audio categorization are presently supported.
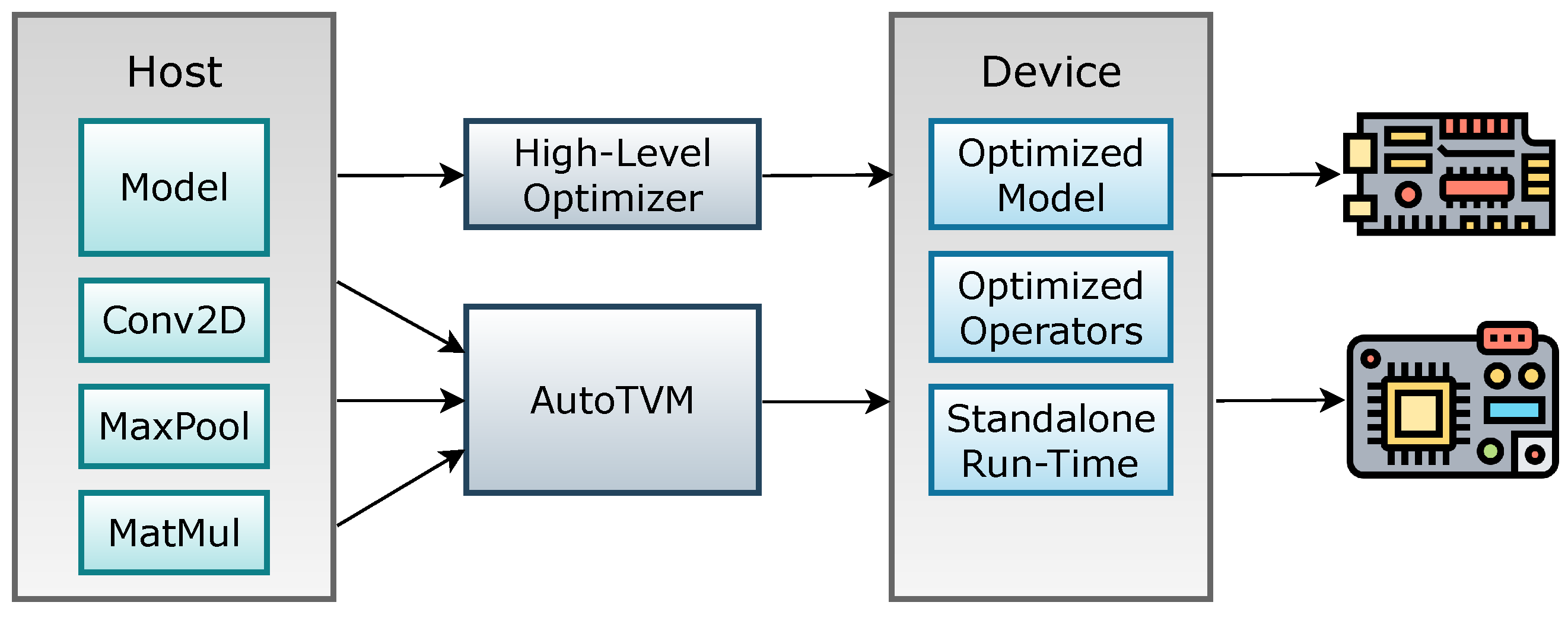
- μTVM: Tensor programming can be conducted on microcontroller devices thanks to the microTVM extension of virtual tensor machines (TVM) as it is currently. The AutoTVM platform, which supports the optimization of tensor programs, makes it possible to optimize these programs [89]. In fact, a USB-JTAG interface links a microcontroller to a computer or high-end device that is simultaneously running the TVM. The PC runs OpenOCD, which connects the microcontroller to the computer. By applying device identification to the TCP port, OpenOCD allows mTVM to operate the microcontroller. The user must submit specifics (such as a method for reading, writing, and executing to the memory of the device, a C cross-compiler toolchain for a microcontroller, a description of the architectural layout of the device, and a section of code to set the device up for operation) in order to receive support from TVM. The MicroSession must connect to the device using the provided way in order for the TVM to function (e.g., OpenOCD). The previously mentioned cross-compiler is then used to cross-compile the TVM runtime. The binary of the produced code is then transferred to the device. The relationship between the TVM and TinyML may be discussed from several angles, including tensor loading, unit loading function calling, and slow execution. In Figure 4, the system model based on TinyML [90] is shown for building the best models on microcontrollers, sometimes referred to as edge devices.
2.5. TinyML Benefits
- Transition from basic to smart IoT devicesThe capacity of the sensor system to generate massive volumes of raw data has also hindered the ability of cloud computing to process these data. Due to the lack of transmission to the cloud, the abundance of data is wasted at the edge. TinyML enables data analysis in a resource-constrained setting, where every IoT device becomes smart by embedding ML algorithms. A smart car, for instance, creates 1 GB of data per second [92], whereas the Boeing 787 generates 5 GB per second [93]. Therefore, it would be better to do a preliminary analysis of raw data using ML algorithms on each IoT device in order to gather necessary information and eliminate useless data rather than uploading all raw data to the cloud.
- Network BandwidthIn order to input data, evaluate information, and execute ML algorithms, the “traditional” IoT uses gateways, a network of sensors to gateway networks, cloud services and gateways to the internet network [94]. In contrast, novel techniques of the TinyML have the ability to redefine these criteria in resource-constrained settings by lessening the pervasiveness of cloud services and making other IoT layer services optional.TinyML offers greater independence than standard IoT services thanks to its low transmission and maybe constrained bandwidth capabilities. Furthermore, in a setting with a high density of IoT devices, the bandwidth needed for providing raw data is rather significant. Therefore, analyzing raw data at the edge and only transmitting the information that is essential would significantly minimize the needed bandwidth.
- Security and privacyAs enormous amounts of private data are transferred to the cloud, data security is one of the variables impacting IoT adoption [95]. When third-party suppliers are employed for IoT services, the end user has no idea who owns the data or where their personal information is maintained. Additionally, data transfer makes it simpler for shady individuals to eavesdrop. Therefore, by avoiding data leakage and keeping data confined within the device, privacy and security are strengthened. Since TinyML data is rarely (or never) delivered, it is less vulnerable to attacks. Because of this, TinyML by default has built-in data security and privacy protections.
- LatencyOnce the sensor data is sent from IoT devices to cloud servers, the decision (prediction) generated in the cloud by the IoT devices comes to an end in an IoT ecosystem. This series of events clearly shows that detailed observation of the device is required because to the high latency of the strategy. TinyML is a good way to deal with this issue. Additionally, on safety-critical systems like healthcare (such as microsurgery) and driverless cars, waiting for the cloud to decide might have disastrous consequences. As there is less reliance on external connectivity in such cases, TinyML will act as an infrastructure to enable decreased (near-zero) latency for ML service delivery. Local real-time data processing on the devices enables quicker reaction and analysis in emergency situations. Furthermore, the strain on the cloud is minimized [96,97,98].
- Energy efficiencyAnother major and popular TinyML indicator in MCUs is this one. The majority of IoT devices operate on batteries and are constantly on in an IoT ecosystem. Coin batteries, like the CR2032, are frequently used to power IoT devices, and they should allow them to operate for several months or perhaps several years. To enable the MCU to review the data and power on when necessary, it is usually crucial that the device remain predominantly in a suspended state. Data transport may occasionally use more energy than local ML service provision, too. TinyML would be a very useful tool for resolving these problems [99].
- ReliabilityThe capacity to do data-driven calculations within the sensor network is the main feature that is much wanted for IoT. TinyML has been recognized as a resolution for executing work in situations where mobile connectivity/internet is extremely restricted, such as offshore and rural areas. IoT services become more dependable as a result.
- Low costFirst off, by limiting data flow, bandwidth requirements are lowered, which results in cost savings. To achieve this, we believe that TinyML solutions paired with cloud technology can enhance the aforementioned performance metrics by adding new data management channels, expanding the capability of current cloud services, or delegating tasks to MCUs. TinyML is therefore the upcoming big thing, and many are touting it as the technology that will fuel the digitization of industries or the Industry 4.0 revolution [100].
- Data FiltrationThe intelligence of the IoT device enables the designer to examine the data and remove residuals. When deployed in use cases with high traffic volumes, the intelligent support system at the edge can significantly outperform traditional systems. A surveillance system that focuses on anomaly detection, for instance, consists of a number of cameras, and the vast majority of the data that the cameras collect is redundant. In these cases, it makes more sense to filter the extra photographs locally rather than uploading them all to the cloud.
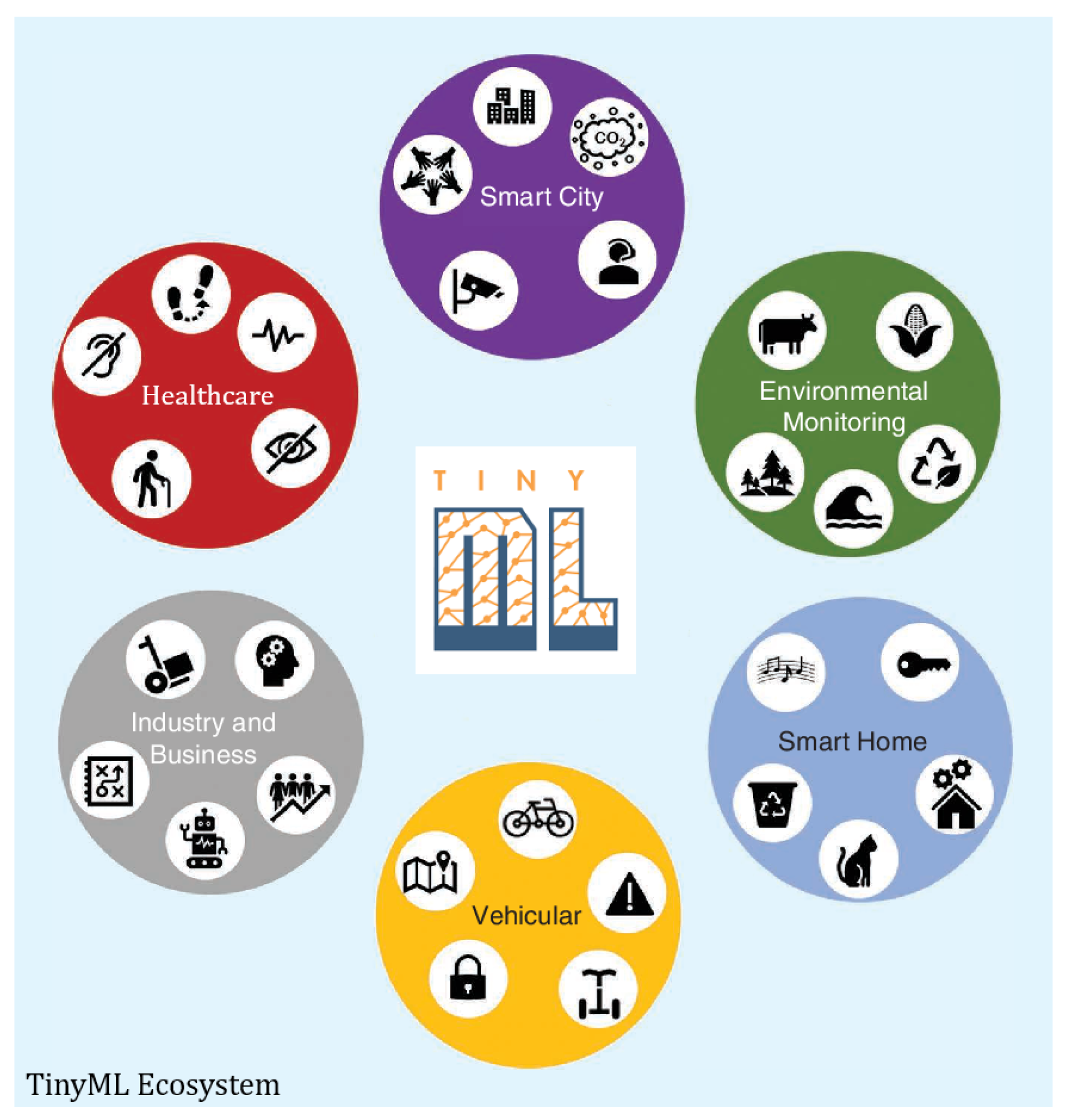
2.6. Applications Areas of TinyML
- Intelligent Objects (IoT):
- Monitoring and Control of the Industry:TinyML has considerable potential influence on the industrial and manufacturing sectors, which are undergoing digitization as part of the Industry 4.0 revolution [100]. MCUs are unable to consistently carry out some operations because of the highly changing compute and memory requirements of the processing activities in these sectors. The incorporation of ML-based decision support systems (DSS) into MCUs, on the other hand, enables them to choose whether to take on a given computational task or offload it to higher processing layers, such the edge or cloud. Furthermore, intelligence along the production chain may be used to improve production processes, decision making, asset monitoring, production and assembly line quality assurance, real-time diagnostics of assembly machines, and so on [107].
- TinyML in Healthcare:Wearable devices, such as smartwatch, are loaded with a variety of biological sensors that monitor vital functions like as heart rate, blood oxygen concentration, exercise, and even obesity [108,109], and deliver accurate real-time visualization of the current health status of the user in a confidential, safe, and dependable manner. Smart camera sensors capable of monitoring patients in their own environments and swiftly assisting with nurse notification, real-time diagnosis and aid, personalized and translational medicine, and so on [110,111,111]. Additionally, smart microprocessors that utilize TinyML, can effectively predict the likelihood of an accident [112].
- TinyML in Security and Surveillance:Camera sensors with hardware capable of conducting relatively rapid and accurate visual processing are used in a variety of industries, including tele-health [113], security and surveillance, services, surveillance, navigation devices, and so on.
- TinyML in Smart Agriculture [114]:TinyML offers a lot of potential in Africa, where embedded systems and artificial intelligence are still underutilized [115,116]. Cassava farming is one of these chances, as it provides a key source of food for hundreds of millions of people each year. However, it is always under threat from many illnesses. To combat it, PlantVillage [117], an open-source project managed by Penn State University, has created Nuru, an artificial intelligence-based program that can function on mobile phones without internet connectivity—a valuable asset for distant African farmers. By evaluating sensory data in the field, the Nuru app has been successful in minimizing hazards to cassava farming. PlantVillage intends to employ TinyML more widely in the development of Nuru, sending microcontroller sensors to remote farms to offer better monitoring information for analysis. TinyML is also discovering new applications in the agricultural commodities chain, such as coffee beans [118]. For example, two Norwegian businesses, Roest and Soundsensing, have devised a method to automatically recognize the “first crack” of coffee beans during the roasting process. It is critical to identify the first crack since the time spent roasting after the first crack has a major impact on the quality and flavor of the processed beans. To accomplish this task, companies have added a microcontroller with TinyML in their bean roasting equipment, which has increased the efficiency, precision, and scalability of the coffee roasting process. Also, a farmer could with the right equipment as well as with appropriate forecasting models running for weather forecasting, know locally for that particular field its daily weather and its characteristics.
- TinyML in Vehicular Services and Autonomous Vehicles:As more environmentally friendly and healthful vehicles, such as shared bicycles, electric mopeds, scooters, and so on, come into existence, current patterns in urban transportation are changing. However, due to the high energy requirements of their linked on-board units (OBUs), modern vehicle networks largely take into account conventional forms of road transportation including cars, buses, and trucks. Although various attempts to connect bicycles to C-ITS systems have been made [119], personal autos have not been taken into consideration due to their novelty and inherent limitations. The ability to integrate these devices into C-ITS and smart city ecosystems, on the other hand, is made possible by connecting them with MCU-based OBUs [120]. Thus, basic vehicle services like route planning, device status monitoring, and driving safety and so on [120] will be accessible to light cars.Autonomous driving has made giant strides since the advent of deep learning (DL). Small vehicles driving choices have historically been off-loaded to remote computers, requiring energy-intensive, time-consuming, and unreliable transfers of raw data. By processing data on-board and immediately controlling the motor controllers, off-system transfers may be avoided. However, because the system is battery-powered, only a tiny portion of the electricity can be sent toward the processing unit, which is the autonomous vehicle’s “brain”. TinyML approaches are therefore required to solve these issues and deal with on-device sensor data processing at the hardware, algorithmic, and software levels.
- TinyML in Smart and Secure Societies:Water systems, a safe food supply chain [121], intelligent transportation systems, disaster relief [122], smart energy grids [123], and emergency response technologies [124], and so on [125]. Also, efficient defect detection in modern production lines, such as logistics, in numerous stages of the manufacturing process [126].
- TinyML in Intelligent New Spaces:The collaborative intelligence that now exists in scenarios like smart cities and cognitive buildings, to name a few, will be strengthened by simple objects with ML capabilities. Current IoT-based surveillance and monitoring systems, such as those used for traffic, pollution [96], and crowd identification, will grow into autonomous and intelligent entities [127] capable of making quick and decentralized choices. Because of independence from the power grid and the simplicity of installation, items may be installed in isolated and rural locations, creating smart spaces [128] with smooth mobility between them. Furthermore, lower end-device costs will stimulate their adoption in underserved areas, which may assist revitalize local economies and commercial activity.
2.7. Use Cases of the TinyML
2.7.1. Image Recognition
2.7.2. Hand Gesture Recognition
2.7.3. Face Detection
2.7.4. Anomaly Detection
2.7.5. Phenomenal and Ecological Maintenance
2.7.6. Autonomous Vehicle and Traffic Management
2.7.7. Body Pose Evaluation
2.7.8. Detection of Respiratory Symptoms Associated with Coughing
2.7.9. Speech-Voice Recognition
2.7.10. Oral Tongue Lesions Pre-Screening
3. TensorFlow Lite—TensorFlow Lite for Micro
3.1. Overview
- Inability to install models in many embedded architectures easily and portably;
- There is an absence of optimizations that make use of the hardware in question without needing the construction of frameworks to execute platform-specific efforts;
- Lack of productivity tools that link training with platforms and development tools;
- Infrastructure for model calling, quantization, compression, and execution is insufficient;
- Minimum support features for debugging, organization, performance profiling, etc;
- No benchmarks exist that enable manufacturers to precisely and repeatedly measure the performance of their semiconductor;
- There is a lack of testing in real-world applications.
- The compiler-based solution is versatile, portable, and simple to include new applications and features.
- To achieve hardware independence, decrease the use of library requests and external dependencies.
- It allows hardware suppliers to provide kernel-specific optimization platforms without the need to develop hardware-specific compilers.
- Benchmarks adopted by leading benchmarking organizations such as MLPerf are provided.
- The framework is compatible with popular, well-maintained Google apps under development.
- It allows hardware suppliers to easily incorporate optimizations into their kernel to guarantee production performance and hardware benchmarking.
- The TensorFlow Lite model transformation and optimization infrastructure is one of many machine learning ecosystems that the model architecture framework is compatible with.
- Adafruit Circuit Playground Bluefruit
- Kit Discovery STM32F746
- Adafruit EdgeBadge
- Espressif ESP32-DevKitC
- Himax WE-I Plus EVB Endpoint AI Development Board
- Wio Terminal: ATSAMD51
- Kit Adafruit TensorFlow Lite for microcontrollers
- Espressif ESP-EYE
- SparkFun Edge
- Arduino Nano 33 BLE Sense
3.2. Technical Challenges
- Missing features:
- A decentralized market and environment:
- Resources are limited:
3.3. Implementation of TensorFlow Lite—TensorFlow Lite Micro
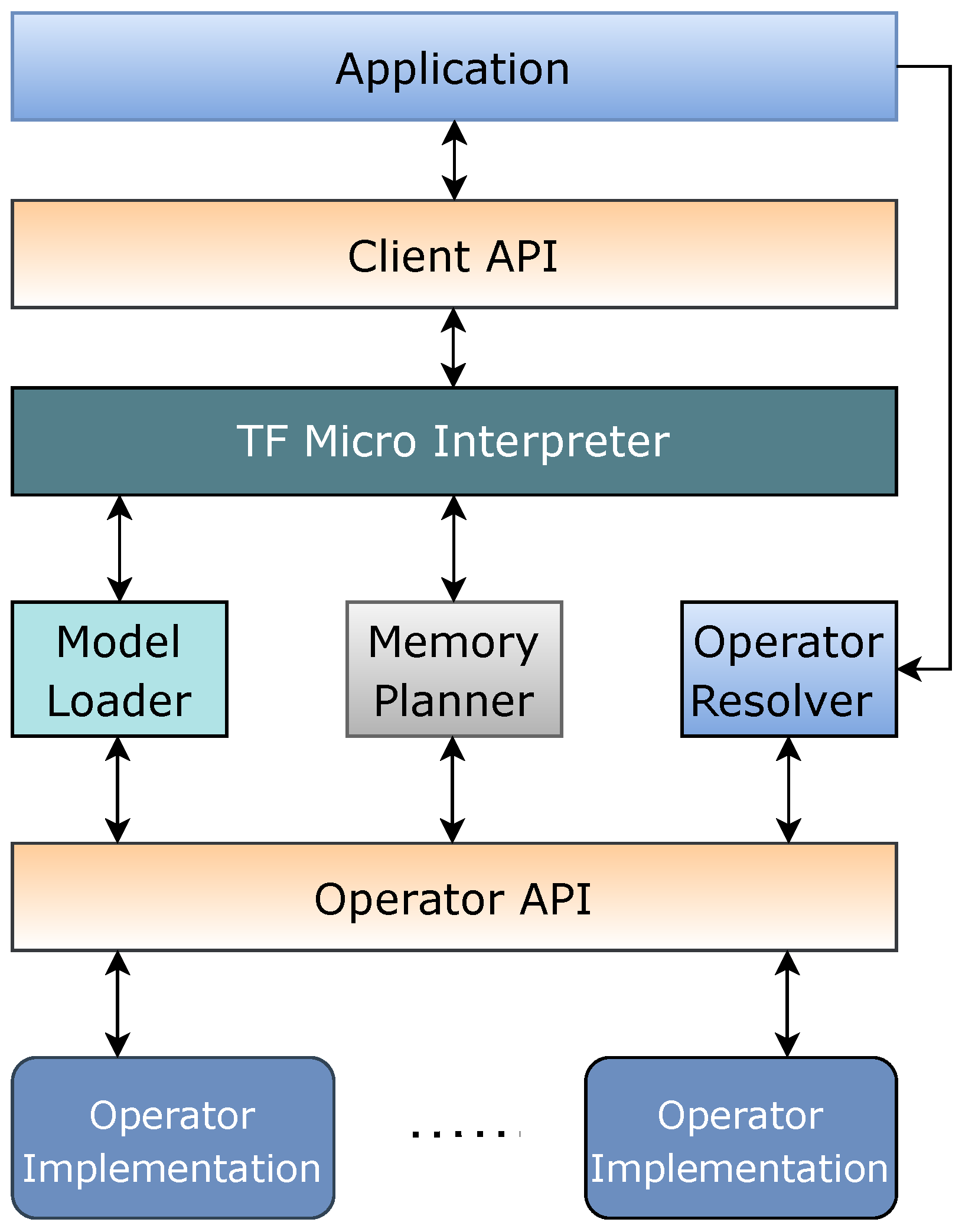
- System overview
- TFLM Interpreter
- Loading of the model
- -
- Model serialization
- -
- Model representation
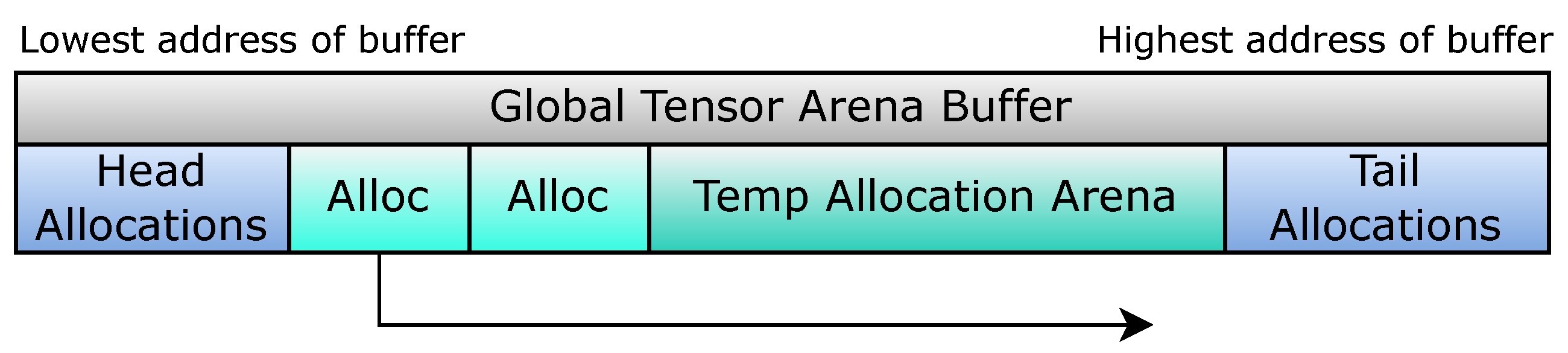
- Memory management
- -
- Persistent Memory and Scratchpads
- Multi-tenancy
- Multithreading
- Operator Support
- Build all-in-one System
3.4. Summary of TensorFlow Lite
4. Integrating TinyML with Network Technologies
4.1. 5G and TinyML
- A significant number of devices are linked together [152].
- The goal is to minimize energy use by about 90% [147].
- It offers massive bandwidth, cheap cost, and extended battery life.
- Unsupervised learning: Unsupervised learning is achievable due to the efficiency of deep learning in processing semi-labeled or unlabeled input. This is essential for dealing with the enormous amounts of unlabeled data that mobile systems frequently deal with.
- In contrast to conventional ML methods, deep learning performance usually increases rapidly as the size of the training data increases. As a result, it can exploit the enormous amounts of mobile data created at high rates of speed.
- Geometric mobile data learning: Geometric mobile data analysis has been transformed by specific deep learning architectures for modeling geometric mobile data.
- Extraction of features: Through layers of varied depths, deep neural networks can automatically retrieve high-level information. This makes it possible to analyze heterogeneous and noisy mobile big data with lower cost human feature engineering.
- Multitask learning: Using transfer learning, features gained from neural networks via hidden layers may be applied to other tasks. This minimizes the processing and memory needs for doing multitask learning in mobile devices.
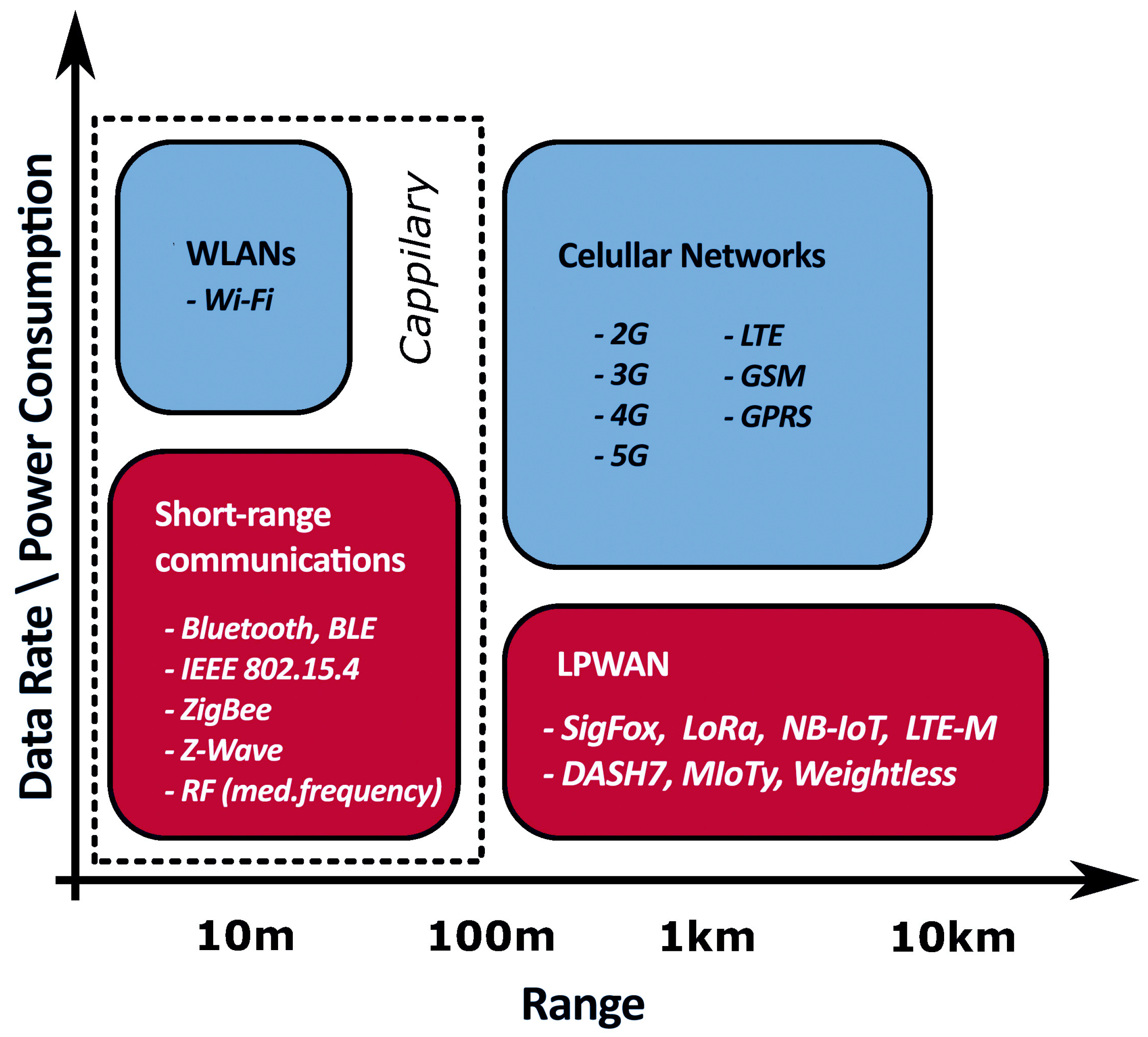
4.2. LPWAN and TinyML on Embedded Devices
5. Discussion and Future Directions
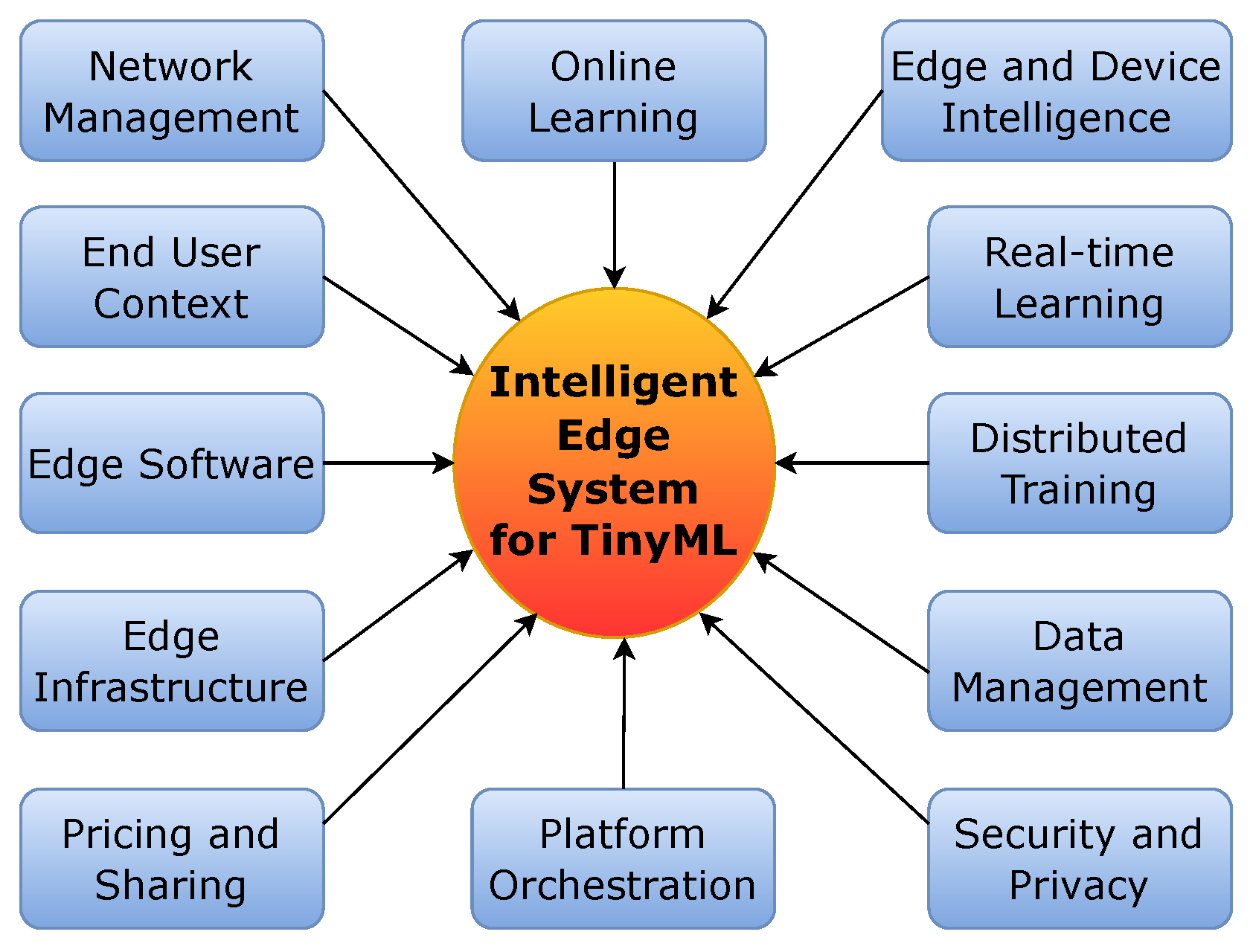
- New dimension: A variety of variables are claimed to influence the development and acceptance of the TinyML standard in the future. An intelligent edge system, for example, necessitates edge software that integrates sophistication, edge-device intelligence consistency, real-time learning, distributed learning, online learning, and data-network management. This partnership should be expanded to strengthen local security and privacy by allowing end-user context to be stored on edge devices. Additionally, it should give priority to improving edge device infrastructure, low-cost knowledge sharing capabilities in edge device systems and edge device platform orchestration. Figure 18 emphasizes the contributions of these factors to the evolution of the TinyML paradigm.
- Support for portability: Another issue that may be overcome by establishing improved compute data delivery methods on Edge platforms is portability support. Location-aware optimization can conserve network capacity and boost network spectrum coverage for edge devices, allowing them to collaborate with neighboring devices. It can therefore contribute to the progressive transfer of know-how and models for others to utilize. Furthermore, the quality of service may be altered to forecast how edge devices would behave when interacting with neighboring nodes. These data may be exchanged across nodes or clouds in the immediate vicinity to forecast the intelligent orientation of edge devices.
- Edge Intelligence Framework: The following should be the foundation of a standard edge intelligence framework: (i) energy-efficient management, (ii) dynamic task distribution, (iii) data intelligence, (iv) wireless networking, (v) collaborative intelligence, (vi) predictive service quality, (vii) communication service implementation, (viii) real-time inference, (ix) liquid software propagation between edge nodes, and (x) machine learning as a service. From a future-proof learning perspective, take into account implementing such TinyML arrangements to make them compatible with 5G and 6G technologies. Therefore, mmWave xhaul systems have to be included to TinyML systems to enhance ML models optimization. Hypercooperation between the cloud and the edge may thus be implemented in an effective manner [168,169,170].
- Offloading operations: The activation/deactivation of processing tasks can actually be exploited during machine learning scenarios triggered by the edge. These loading methods ought to be included to the dynamic configuration of edge-aware features that is already accessible. Thus, TinyML will enhance the transmission of resource-intensive processes from edge devices with low resources. Interoperability between the edge and the cloud could become more focused as a result. It is necessary to undertake investigations to determine the underlying processes that support these resource allocations (e.g., machine learning, channel bandwidth, memory chunks, data recruitment, sensing capabilities, CPU cycles).
- Future Perspective: TinyML is progressively becoming a must and a reality for making educated decisions in everyday life. Especially for low-power embedded devices used in a variety of applications. To provide consumers with an upgraded user experience, mobile platforms must adjust their orientation to TinyML. TinyML-aware approaches for next age intelligent and wearable devices are recommended for technical developers and enterprises. There is a great requirement to reduce CPU-GPU-TPU interaction, which costs resources, in order to provide smart decision support. Microcontroller makers should prioritize integrated TinyML design standards so that customers do not have to deal with external alignments linked to artificial intelligence. TinyML integration in the realm of IoT-edge analysis should be explored in order to make the application more user-friendly and trustworthy. To assist developers in implementing the market-ready development scenario, a uniform flow methodology should be designed. It is necessary to provide appropriate dataset repositories and lightweight benchmarking tools. TinyML adaptation should target X.0 industrial applications in the future days. Furthermore, such low-memory libraries should be used with 8-bit microcontroller devices. TinyML should be used to resolve latency mitigation in edge-level effects. TinyML is used in low-cost and portable digital devices to deliver immediate input to consumers. TinyML frameworks may be used to reduce needless utilization and reliance on GPUs, TPUs, and cloud platforms.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Correction Statement
References
- Kuo, Y.H.; Kusiak, A. From data to big data in production research: The past and future trends. Int. J. Prod. Res. 2019, 57, 4828–4853. [Google Scholar] [CrossRef]
- Ma, S.; Zhang, X.; Jia, C.; Zhao, Z.; Wang, S.; Wang, S. Image and video compression with neural networks: A review. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 1683–1698. [Google Scholar] [CrossRef]
- Estrebou, C.A.; Fleming, M.; Saavedra, M.D.; Adra, F.; De Giusti, A.E. Lightweight Convolutional Neural Networks Framework for Really Small TinyML Devices. In Proceedings of the International Conference on Smart Technologies, Systems and Applications, Quito, Ecuador, 1–3 December 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 3–16. [Google Scholar]
- Carvalho, G.; Cabral, B.; Pereira, V.; Bernardino, J. Edge computing: Current trends, research challenges and future directions. Computing 2021, 103, 993–1023. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. arXiv 2017, arXiv:1707.01083. [Google Scholar]
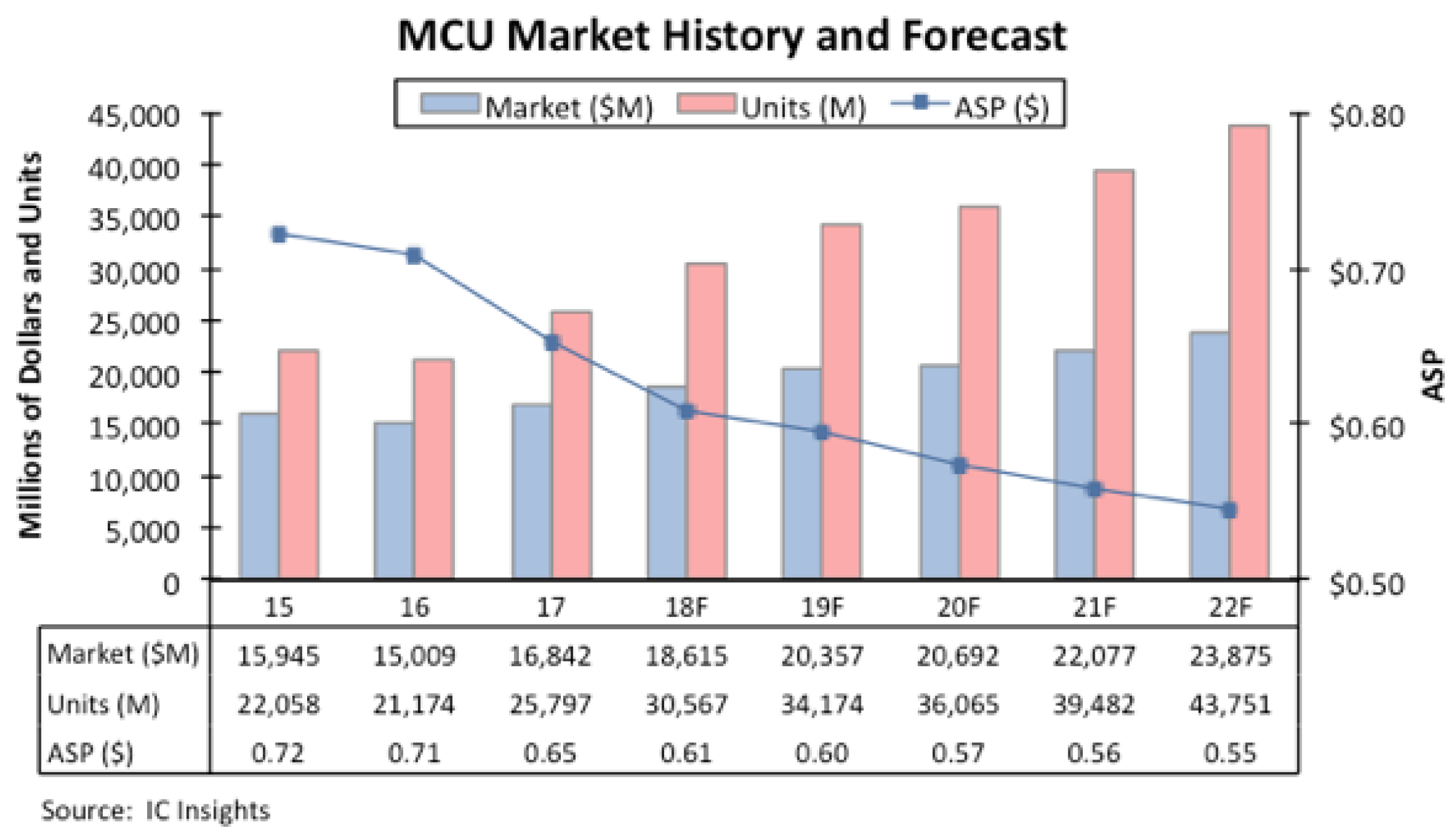
- MCUs-Sales-To-Reach-RecordHigh-Annual-Revenues-Through-2022. Available online: https://www.icinsights.com/news/bulletins/MCUs-Sales-To-Reach-RecordHigh-Annual-Revenues-Through-2022/ (accessed on 15 October 2022).
- Cornetta, G.; Touhafi, A. Design and evaluation of a new machine learning framework for iot and embedded devices. Electronics 2021, 10, 600. [Google Scholar] [CrossRef]
- Budjac, R.; Barton, M.; Schreiber, P.; Skovajsa, M. Analyzing Embedded AIoT Devices for Deep Learning Purposes. In Proceedings of the Computer Science On-Line Conference, 26 April 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 434–448. [Google Scholar]
- Fedorov, I.; Adams, R.P.; Mattina, M.; Whatmough, P.N. SpArSe: Sparse Architecture Search for CNNs on Resource-Constrained Microcontrollers. arXiv 2019, arXiv:1905.12107. [Google Scholar]
- Zhang, Y.; Suda, N.; Lai, L.; Chandra, V. Hello Edge: Keyword Spotting on Microcontrollers. arXiv 2017, arXiv:1711.07128. [Google Scholar]
- Sakr, F.; Bellotti, F.; Berta, R.; De Gloria, A. Machine learning on mainstream microcontrollers. Sensors 2020, 20, 2638. [Google Scholar] [CrossRef]
- Flamand, E.; Rossi, D.; Conti, F.; Loi, I.; Pullini, A.; Rotenberg, F.; Benini, L. GAP-8: A RISC-V SoC for AI at the Edge of the IoT. In Proceedings of the 2018 IEEE 29th International Conference on Application-Specific Systems, Architectures and Processors (ASAP), Milano, Italy, 10–12 July 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Warden, P. Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition. arXiv 2018, arXiv:1804.03209. [Google Scholar]
- TinyML Foundation. Available online: https://www.tinyml.org/ (accessed on 15 October 2022).
- Warden, P. Why the Future of Machine Learning Is Tiny, 2018b. Available online: https://petewarden.com/2018/06/11/why-the-future-of-machine-learning-is-tiny/ (accessed on 15 October 2022).
- Lin, J.; Chen, W.M.; Lin, Y.; Gan, C.; Han, S. Mcunet: Tiny deep learning on iot devices. Adv. Neural Inf. Process. Syst. 2020, 33, 11711–11722. [Google Scholar]
- Sanchez-Iborra, R.; Skarmeta, A.F. TinyML-Enabled Frugal Smart Objects: Challenges and Opportunities. IEEE Circuits Syst. Mag. 2020, 20, 4–18. [Google Scholar] [CrossRef]
- Doyu, H.; Morabito, R.; Höller, J. Bringing machine learning to the deepest IoT edge with TinyML as-a-service. IEEE IoT Newsl. 2020, 11. [Google Scholar]
- Kumar, A.; Goyal, S.; Varma, M. Resource-efficient Machine Learning in 2 KB RAM for the Internet of Things. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Precup, D., Teh, Y.W., Eds.; Volume 70, pp. 1935–1944. [Google Scholar]
- Lai, L.; Suda, N.; Chandra, V. CMSIS-NN: Efficient Neural Network Kernels for Arm Cortex-M CPUs. arXiv 2018, arXiv:1801.06601. [Google Scholar]
- Garofalo, A.; Tagliavini, G.; Conti, F.; Rossi, D.; Benini, L. XpulpNN: Accelerating Quantized Neural Networks on RISC-V Processors through ISA Extensions. In Proceedings of the 23rd Conference on Design, Automation and Test in Europe, DATE’20, Grenoble, France, 9–13 March 2020; EDA Consortium: San Jose, CA, USA, 2020; pp. 186–191. [Google Scholar]
- Wang, K.; Liu, Z.; Lin, Y.; Lin, J.; Han, S. HAQ: Hardware-Aware Automated Quantization. arXiv 2018, arXiv:1811.08886. [Google Scholar]
- Moons, B.; Bankman, D.; Yang, L.; Murmann, B.; Verhelst, M. BinarEye: An Always-On Energy-Accuracy-Scalable Binary CNN Processor With All Memory On Chip in 28 nm CMOS. arXiv 2018, arXiv:1804.05554. [Google Scholar]
- Sudharsan, B.; Yadav, P.; Breslin, J.G.; Ali, M.I. An sram optimized approach for constant memory consumption and ultra-fast execution of ml classifiers on tinyml hardware. In Proceedings of the 2021 IEEE International Conference on Services Computing (SCC), Virtual, 5–11 September 2021; pp. 319–328. [Google Scholar]
- MacGillivray, C.; Torchia, M. Internet of Things: Spending Trends and Outlook. 2019. Available online: https://www.idc.com/getdoc.jsp?containerId=US45161419 (accessed on 15 October 2022).
- Gomez, J.; Patel, S.; Sarwar, S.S.; Li, Z.; Capoccia, R.; Wang, Z.; Pinkham, R.; Berkovich, A.; Tsai, T.H.; De Salvo, B.; et al. Distributed On-Sensor Compute System for AR/VR Devices: A Semi-Analytical Simulation Framework for Power Estimation. arXiv 2022, arXiv:2203.07474. [Google Scholar]
- Global Shipments of TinyML Devices to Reach 2.5 Billion by 2030. Available online: https://www.prnewswire.com/news-releases/global-shipments-of-tinyml-devices-to-reach-2-5-billion-by-2030–301123076.html (accessed on 15 October 2022).
- Vuppalapati, C. Democratization of Artificial Intelligence for the Future of Humanity; CRC Press: Boca Raton, FL, USA, 2021. [Google Scholar]
- Ray, P.P. A review on TinyML: State-of-the-art and prospects. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 1595–1623. [Google Scholar] [CrossRef]
- Dutta, D.L.; Bharali, S. TinyML Meets IoT: A Comprehensive Survey. Internet Things 2021, 16, 100461. [Google Scholar] [CrossRef]
- Wu, Z.; Jiang, M.; Li, H.; Zhang, X. Mapping the knowledge domain of smart city development to urban sustainability: A scientometric study. J. Urban Technol. 2021, 28, 29–53. [Google Scholar] [CrossRef]
- Kim, H.; Chen, Q.; Yoo, T.; Kim, T.T.H.; Kim, B. A 1-16b Precision Reconfigurable Digital In-Memory Computing Macro Featuring Column-MAC Architecture and Bit-Serial Computation. In Proceedings of the ESSCIRC 2019-IEEE 45th European Solid State Circuits Conference (ESSCIRC), Cracow, Poland, 23–26 September 2019; pp. 345–348. [Google Scholar] [CrossRef]
- Mahdavinejad, M.S.; Rezvan, M.; Barekatain, M.; Adibi, P.; Barnaghi, P.; Sheth, A.P. Machine learning for Internet of Things data analysis: A survey. Digit. Commun. Netw. 2018, 4, 161–175. [Google Scholar] [CrossRef]
- Banbury, C.R.; Reddi, V.J.; Lam, M.; Fu, W.; Fazel, A.; Holleman, J.; Huang, X.; Hurtado, R.; Kanter, D.; Lokhmotov, A. Benchmarking TinyML Systems: Challenges and Direction. arXiv 2020, arXiv:2003.04821. [Google Scholar]
- Osman, A.; Abid, U.; Gemma, L.; Perotto, M.; Brunelli, D. TinyML Platforms Benchmarking. In Proceedings of the International Conference on Applications in Electronics Pervading Industry, Environment and Society, Genova, Italy, 26–27 September 2022; pp. 139–148. [Google Scholar]
- Shafique, M.; Theocharides, T.; Reddy, V.J.; Murmann, B. TinyML: Current Progress, Research Challenges, and Future Roadmap. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 1303–1306. [Google Scholar]
- Alongi, F.; Ghielmetti, N.; Pau, D.; Terraneo, F.; Fornaciari, W. Tiny Neural Networks for Environmental Predictions: An Integrated Approach with Miosix. In Proceedings of the 2020 IEEE International Conference on Smart Computing (SMARTCOMP), Bologna, Italy, 14–17 September 2020; pp. 350–355. [Google Scholar] [CrossRef]
- Lootus, M.; Thakore, K.; Leroux, S.; Trooskens, G.; Sharma, A.; Ly, H. A VM/Containerized Approach for Scaling TinyML Applications. arXiv 2022, arXiv:2202.05057. [Google Scholar] [CrossRef]
- Banbury, C.R.; Reddi, V.J.; Torelli, P.; Holleman, J.; Jeffries, N.; Király, C.; Montino, P.; Kanter, D.; Ahmed, S.; Pau, D.; et al. MLPerf Tiny Benchmark. arXiv 2021, arXiv:2106.07597. [Google Scholar]
- Ghamari, S.; Ozcan, K.; Dinh, T.; Melnikov, A.; Carvajal, J.; Ernst, J.; Chai, S. Quantization-Guided Training for Compact TinyML Models. arXiv 2021, arXiv:2103.06231. [Google Scholar]
- Coffen, B.; Mahmud, M. TinyDL: Edge Computing and Deep Learning Based Real-time Hand Gesture Recognition Using Wearable Sensor. In Proceedings of the 2020 IEEE International Conference on E-Health Networking, Application Services (HEALTHCOM), Virtual, 1–2 March 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Crocioni, G.; Gruosso, G.; Pau, D.; Denaro, D.; Zambrano, L.; di Giore, G. Characterization of Neural Networks Automatically Mapped on Automotive-grade Microcontrollers. arXiv 2021, arXiv:2103.00201. [Google Scholar]
- Disabato, S.; Roveri, M. Incremental On-Device Tiny Machine Learning. In Proceedings of the Proceedings of the 2nd International Workshop on Challenges in Artificial Intelligence and Machine Learning for Internet of Things, AIChallengeIoT’20, Virtual, 16–19 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 7–13. [Google Scholar] [CrossRef]
- Doyu, H.; Morabito, R.; Brachmann, M. A TinyMLaaS Ecosystem for Machine Learning in IoT: Overview and Research Challenges. In Proceedings of the 2021 International Symposium on VLSI Design, Automation and Test (VLSI-DAT), Hsinchu, Taiwan, 19–22 April 2021; pp. 1–5. [Google Scholar] [CrossRef]
- Banbury, C.R.; Zhou, C.; Fedorov, I.; Navarro, R.M.; Thakker, U.; Gope, D.; Reddi, V.J.; Mattina, M.; Whatmough, P.N. MicroNets: Neural Network Architectures for Deploying TinyML Applications on Commodity Microcontrollers. arXiv 2020, arXiv:2010.11267. [Google Scholar]
- Fahim, F.; Hawks, B.; Herwig, C.; Hirschauer, J.; Jindariani, S.; Tran, N.; Carloni, L.P.; Guglielmo, G.D.; Harris, P.C.; Krupa, J.D.; et al. hls4ml: An Open-Source Codesign Workflow to Empower Scientific Low-Power Machine Learning Devices. arXiv 2021, arXiv:2103.05579. [Google Scholar]
- Giordano, M.; Mayer, P.; Magno, M. A Battery-Free Long-Range Wireless Smart Camera for Face Detection. In Proceedings of the 8th International Workshop on Energy Harvesting and Energy-Neutral Sensing Systems, ENSsys ’20, Virtual, 16–19 November 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 29–35. [Google Scholar] [CrossRef]
- Kwon, J.; Park, D. Toward Data-Adaptable TinyML Using Model Partial Replacement for Resource Frugal Edge Device. In Proceedings of the The International Conference on High Performance Computing in Asia-Pacific Region, HPC Asia 2021, Virtual, 20–22 January 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 133–135. [Google Scholar] [CrossRef]
- Langroudi, H.F.; Karia, V.; Pandit, T.; Kudithipudi, D. TENT: Efficient Quantization of Neural Networks on the tiny Edge with Tapered FixEd PoiNT. arXiv 2021, arXiv:2104.02233. [Google Scholar]
- Lin, J.; Chen, W.; Lin, Y.; Cohn, J.; Gan, C.; Han, S. MCUNet: Tiny Deep Learning on IoT Devices. arXiv 2020, arXiv:2007.10319. [Google Scholar]
- Roshan, A.N.; Gokulapriyan, B.; Siddarth, C.; Kokil, P. Adaptive Traffic Control With TinyML. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021; pp. 451–455. [Google Scholar] [CrossRef]
- Paul, A.J.; Mohan, P.; Sehgal, S. Rethinking Generalization in American Sign Language Prediction for Edge Devices with Extremely Low Memory Footprint. arXiv 2020, arXiv:2011.13741. [Google Scholar]
- Ren, H.; Anicic, D.; Runkler, T.A. The Synergy of Complex Event Processing and Tiny Machine Learning in Industrial IoT. arXiv 2021, arXiv:2105.03371. [Google Scholar]
- Sudharsan, B.; Salerno, S.; Nguyen, D.D.; Yahya, M.; Wahid, A.; Yadav, P.; Breslin, J.G.; Ali, M.I. TinyML Benchmark: Executing Fully Connected Neural Networks on Commodity Microcontrollers. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 883–884. [Google Scholar] [CrossRef]
- Svoboda, F.; Nunes, D.; Alizadeh, M.; Daries, R.; Luo, R.; Mathur, A.; Bhattacharya, S.; Silva, J.S.; Lane, N.D. Resource Efficient Deep Reinforcement Learning for Acutely Constrained TinyML Devices. Available online: https://openreview.net/forum?id=_vo8DFo9iuB (accessed on 15 October 2022).
- Toma, C.; Popa, M.; Doinea, M. AI neural networks inference into the IoT embedded devices using tinyml for pattern detection within a security system. In Proceedings of the International Conference on Informatics in Economy Education, Research and Business Technologies, Timisoara, Romania, 21–24 May 2020; pp. 14–22. [Google Scholar]
- Vuppalapati, C.; Ilapakurti, A.; Chillara, K.; Kedari, S.; Mamidi, V. Automating Tiny ML Intelligent Sensors DevOPS Using Microsoft Azure. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2375–2384. [Google Scholar] [CrossRef]
- Vuppalapati, C.; Ilapakurti, A.; Kedari, S.; Vuppalapati, J.; Kedari, S.; Vuppalapati, R. Democratization of AI, Albeit Constrained IoT Devices amp; Tiny ML, for Creating a Sustainable Food Future. In Proceedings of the 2020 3rd International Conference on Information and Computer Technologies (ICICT), San Jose, CA, USA, 9–12 March 2020; pp. 525–530. [Google Scholar] [CrossRef]
- Siddiqui, S.; Kyrkou, C.; Theocharides, T. Mini-NAS: A Neural Architecture Search Framework for Small Scale Image Classification Applications. 2021. Available online: https://openreview.net/forum?id=ERhIA5Y7IaT (accessed on 15 October 2022).
- Jiao, B.; Zhang, J.; Xie, Y.; Wang, S.; Zhu, H.; Kang, X.; Dong, Z.; Zhang, L.; Chen, C. A 0.57-GOPS/DSP Object Detection PIM Accelerator on FPGA. In Proceedings of the 26th Asia and South Pacific Design Automation Conference, ASPDAC’21, Tokyo, Japan, 18–21 January 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 13–14. [Google Scholar] [CrossRef]
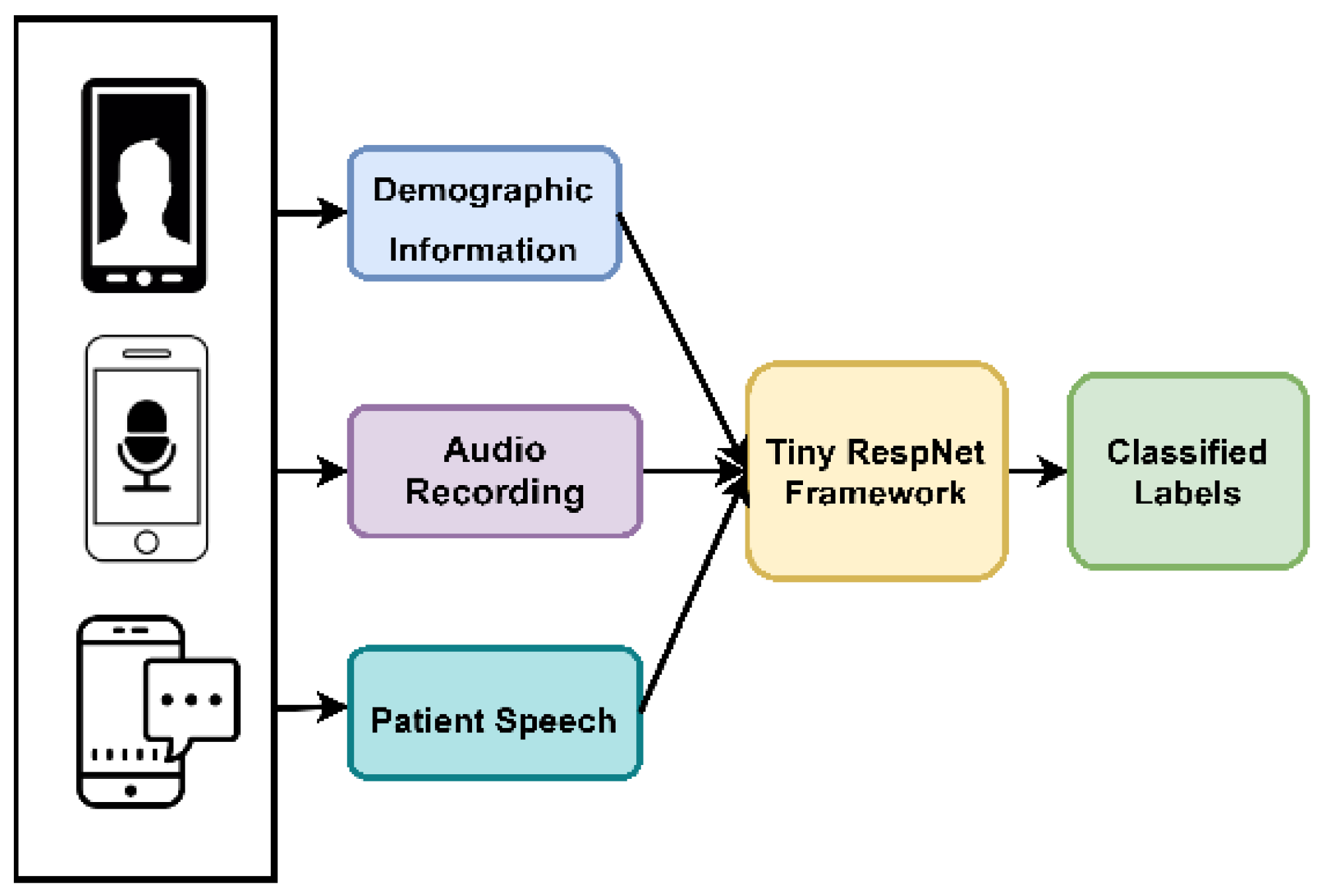
- Tiny RespNet: A Scalable Multimodal TinyCNN Processor for Automatic Detection of Respiratory Symptoms. 2020. Available online: https://www.semanticscholar.org/paper/Tiny-RespNet%3A-A-Scalable-Multimodal-TinyCNN-for-of/2720facfbfed71d40a57dfb93b2845430b98cf67 (accessed on 15 October 2022).
- Wen, X.; Famouri, M.; Hryniowski, A.; Wong, A. AttendSeg: A Tiny Attention Condenser Neural Network for Semantic Segmentation on the Edge. arXiv 2021, arXiv:2104.14623. [Google Scholar]
- Signoretti, G.; Silva, M.; Andrade, P.; Silva, I.; Sisinni, E.; Ferrari, P. An Evolving TinyML Compression Algorithm for IoT Environments Based on Data Eccentricity. Sensors 2021, 21, 4153. [Google Scholar] [CrossRef] [PubMed]
- Capotondi, A.; Rusci, M.; Fariselli, M.; Benini, L. CMix-NN: Mixed Low-Precision CNN Library for Memory-Constrained Edge Devices. IEEE Trans. Circuits Syst. II Express Briefs 2020, 67, 871–875. [Google Scholar] [CrossRef]
- David, R.; Duke, J.; Jain, A.; Reddi, V.J.; Jeffries, N.; Li, J.; Kreeger, N.; Nappier, I.; Natraj, M.; Regev, S.; et al. TensorFlow Lite Micro: Embedded Machine Learning on TinyML Systems. arXiv 2020, arXiv:2010.08678. [Google Scholar]
- de Prado, M.; Donze, R.; Capotondi, A.; Rusci, M.; Monnerat, S.; Benini, L.; Pazos, N. Robust navigation with TinyML for autonomous mini-vehicles. arXiv 2020, arXiv:2007.00302. [Google Scholar]
- Heim, L.; Biri, A.; Qu, Z.; Thiele, L. Measuring what Really Matters: Optimizing Neural Networks for TinyML. arXiv 2021, arXiv:2104.10645. [Google Scholar]
- Ren, H.; Anicic, D.; Runkler, T.A. TinyOL: TinyML with Online-Learning on Microcontrollers. arXiv 2021, arXiv:2103.08295. [Google Scholar]
- Wong, A.; Famouri, M.; Shafiee, M.J. AttendNets: Tiny Deep Image Recognition Neural Networks for the Edge via Visual Attention Condensers. arXiv 2020, arXiv:2009.14385. [Google Scholar]
- Zim, M.Z.H. TinyML: Analysis of Xtensa LX6 microprocessor for Neural Network Applications by ESP32 SoC. arXiv 2021, arXiv:2106.10652. [Google Scholar]
- Campolo, C.; Genovese, G.; Iera, A.; Molinaro, A. Virtualizing AI at the Distributed Edge towards Intelligent IoT Applications. J. Sens. Actuator Netw. 2021, 10, 13. [Google Scholar] [CrossRef]
- Miao, H.; Lin, F.X. Enabling Large NNs on Tiny MCUs with Swapping. arXiv 2021, arXiv:2101.08744. [Google Scholar]
- Wong, A.; Famouri, M.; Pavlova, M.; Surana, S. TinySpeech: Attention Condensers for Deep Speech Recognition Neural Networks on Edge Devices. arXiv 2020, arXiv:2008.04245. [Google Scholar] [CrossRef]
- Ajani, T.; Imoize, A.; Atayero, P.A. An Overview of Machine Learning within Embedded and Mobile Devices-Optimizations and Applications. Sensors 2021, 21, 4412. [Google Scholar] [CrossRef] [PubMed]
- Mohan, P.; Paul, A.J.; Chirania, A. A Tiny CNN Architecture for Medical Face Mask Detection for Resource-Constrained Endpoints. arXiv 2020, arXiv:2011.14858. [Google Scholar]
- Warden, P.; Situnayake, D. TinyML: Machine Learning with TensorFlow Lite on Arduino and Ultra-Low-Power Microcontrollers; O’Reilly: Sebastopol, CA, USA, 2020. [Google Scholar]
- Rusci, M.; Fariselli, M.; Capotondi, A.; Benini, L. Leveraging Automated Mixed-Low-Precision Quantization for tiny edge microcontrollers. arXiv 2020, arXiv:2008.05124. [Google Scholar]
- Soro, S. TinyML for Ubiquitous Edge AI. arXiv 2021, arXiv:2102.01255. [Google Scholar]
- Reddi, V.J.; Plancher, B.; Kennedy, S.; Moroney, L.; Warden, P.; Agarwal, A.; Banbury, C.R.; Banzi, M.; Bennett, M.; Brown, B.; et al. Widening Access to Applied Machine Learning with TinyML. arXiv 2021, arXiv:2106.04008. [Google Scholar]
- Han, H.; Siebert, J. TinyML: A Systematic Review and Synthesis of Existing Research. In Proceedings of the 2022 International Conference on Artificial Intelligence in Information and Communication (ICAIIC), Jeju Island, Republic of Korea, 21–24 February 2022; pp. 269–274. [Google Scholar] [CrossRef]
- TensorFlow Lite (TFL). Available online: https://www.tensorflow.org/lite (accessed on 15 October 2022).
- NanoEdge AI Studio. Available online: https://cartesiam-neai-docs.readthedocs-hosted.com/ (accessed on 15 October 2022).
- PyTorch. Available online: https://pytorch.org/ (accessed on 15 October 2022).
- uTensor. Available online: http://utensor.ai (accessed on 15 October 2022).
- STM32Cube.AI. Available online: https://www.st.com/content/st_com/en/ecosystems/stm32-ann.html (accessed on 15 October 2022).
- Edge Impulse. Available online: https://www.edgeimpulse.com/ (accessed on 15 October 2022).
- ELL. Available online: https://microsoft.github.io/ELL/ (accessed on 15 October 2022).
- uTVM. Available online: https://octoml.ai/blog/tinyml-tvm-taming-the-final-ml-frontier (accessed on 15 October 2022).
- uTVM System. Available online: https://tvm.apache.org/2020/06/04/tinyml-how-tvm-is-taming-tiny (accessed on 15 October 2022).
- Wang, X.; Magno, M.; Cavigelli, L.; Benini, L. FANN-on-MCU: An open-source toolkit for energy-efficient neural network inference at the edge of the Internet of Things. IEEE Internet Things J. 2020, 7, 4403–4417. [Google Scholar] [CrossRef]
- Create, S.D.C.W. Petabytes of Data, What Are the Big Data Opportunities for the Car Industry. Available online: http://www.computerworlduk.com/news/data/boeing-787screate-half-terabyte-of-dataper-flight-says-virgin-atlantic-3433595/ (accessed on 7 December 2016).
- Wang, S. Edge Computing: Applications, State-of-the-Art and Challenges. Adv. Netw. 2019, 7, 8–15. [Google Scholar] [CrossRef]
- Mishra, P.; Puthal, D.; Tiwary, M.; Mohanty, S.P. Software defined IoT systems: Properties, state of the art, and future research. IEEE Wirel. Commun. 2019, 26, 64–71. [Google Scholar] [CrossRef]
- Barani Sundaram, B.; Pandey, A.; Abiko, A.T.; Vijaykumar, J.; Rastogi, U.; Genale, A.H.; Karthika, P. Analysis of Machine Learning Data Security in the Internet of Things (IoT) Circumstance. In Expert Clouds and Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 227–236. [Google Scholar]
- Puthal, D.; Mohanty, S.P.; Wilson, S.; Choppali, U. Collaborative edge computing for smart villages [energy and security]. IEEE Consum. Electron. Mag. 2021, 10, 68–71. [Google Scholar] [CrossRef]
- Merenda, M.; Porcaro, C.; Iero, D. Edge machine learning for ai-enabled iot devices: A review. Sensors 2020, 20, 2533. [Google Scholar] [CrossRef] [PubMed]
- Niu, W.; Ma, X.; Lin, S.; Wang, S.; Qian, X.; Lin, X.; Wang, Y.; Ren, B. Patdnn: Achieving real-time dnn execution on mobile devices with pattern-based weight pruning. In Proceedings of the Twenty-Fifth International Conference on Architectural Support for Programming Languages and Operating Systems, Lausanne, Switzerland, 16–20 March 2020; pp. 907–922. [Google Scholar]
- Costa, R. The Internet of moving things [industry view]. IEEE Technol. Soc. Mag. 2018, 37, 13–14. [Google Scholar] [CrossRef]
- Wollschlaeger, M.; Sauter, T.; Jasperneite, J. The Future of Industrial Communication: Automation Networks in the Era of the Internet of Things and Industry 4.0. IEEE Ind. Electron. Mag. 2017, 11, 17–27. [Google Scholar] [CrossRef]
- Fedorov, I.; Stamenovic, M.; Jensen, C.; Yang, L.C.; Mandell, A.; Gan, Y.; Mattina, M.; Whatmough, P.N. TinyLSTMs: Efficient Neural Speech Enhancement for Hearing Aids. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020. [Google Scholar] [CrossRef]
- Rossi, D.; Conti, F.; Marongiu, A.; Pullini, A.; Loi, I.; Gautschi, M.; Tagliavini, G.; Capotondi, A.; Flatresse, P.; Benini, L. PULP: A parallel ultra low power platform for next generation IoT applications. In Proceedings of the 2015 IEEE Hot Chips 27 Symposium (HCS), Cupertino, CA, USA, 22–25 August 2015; pp. 1–39. [Google Scholar] [CrossRef]
- Monfort Grau, M. TinyML: From Basic to Advanced Applications. Bachelor’s Thesis, Universitat Politècnica de Catalunya, Barcelona, Spain, 2021. [Google Scholar]
- Shanthamallu, U.S.; Spanias, A. Machine and Deep Learning Applications. In Machine and Deep Learning Algorithms and Applications; Springer: Berlin/Heidelberg, Germany, 2022; pp. 59–72. [Google Scholar]
- Bian, S.; Lukowicz, P. Capacitive sensing based on-board hand gesture recognition with TinyML. In Proceedings of the Adjunct Proceedings of the 2021 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2021 ACM International Symposium on Wearable Computers, Virtual, 21–26 September 2021; pp. 4–5. [Google Scholar]
- Koufos, K.; EI Haloui, K.; Dianati, M.; Higgins, M.; Elmirghani, J.; Imran, M.A.; Tafazolli, R. Trends in Intelligent Communication Systems: Review of Standards, Major Research Projects, and Identification of Research Gaps. J. Sens. Actuator Netw. 2021, 10, 60. [Google Scholar] [CrossRef]
- Antonini, M.; Pincheira, M.; Vecchio, M.; Antonelli, F. A TinyML approach to non-repudiable anomaly detection in extreme industrial environments. In Proceedings of the 2022 IEEE International Workshop on Metrology for Industry 4.0 & IoT (MetroInd4. 0&IoT), Trento, Italy, 7–9 June 2022; pp. 397–402. [Google Scholar]
- Venzke, M.; Klisch, D.; Kubik, P.; Ali, A.; Missier, J.D.; Turau, V. Artificial Neural Networks for Sensor Data Classification on Small Embedded Systems. arXiv 2020, arXiv:2012.08403. [Google Scholar]
- Pinge, A.; Bandyopadhyay, S.; Ghosh, S.; Sen, S. A Comparative Study between ECG-based and PPG-based Heart Rate Monitors for Stress Detection. In Proceedings of the 2022 14th International Conference on COMmunication Systems & NETworkS (COMSNETS), Bangalore, India, 4–8 January 2022; pp. 84–89. [Google Scholar] [CrossRef]
- Tsoukas, V.; Boumpa, E.; Giannakas, G.; Kakarountas, A. A Review of Machine Learning and TinyML in Healthcare. In Proceedings of the 25th Pan-Hellenic Conference on Informatics, PCI 2021, Volos, Greece, 26–28 November 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 69–73. [Google Scholar] [CrossRef]
- Boumpa, E.; Tsoukas, V.; Gkogkidis, A.; Spathoulas, G.; Kakarountas, A. Security and Privacy Concerns for Healthcare Wearable Devices and Emerging Alternative Approaches. In Proceedings of the International Conference on Wireless Mobile Communication and Healthcare, Virtual, 13–14 November 2021; Springer: Berlin/Heidelberg, Germany, 2022; pp. 19–38. [Google Scholar]
- Zacharia, A.; Zacharia, D.; Karras, A.; Karras, C.; Giannoukou, I.; Giotopoulos, K.C.; Sioutas, S. An Intelligent Microprocessor Integrating TinyML in Smart Hotels for Rapid Accident Prevention. In Proceedings of the 2022 7th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Ioannina, Greece, 23–25 September 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Santiago, P.R. Tinyml Monitoring Techniques for A-Vent: An Iot Edge for Tracking Clinical Risk Outcomes and Automatic Detection of Patient-Ventilator Asynchrony. Ph.D. Thesis, Ateneo de Manila University, Metro Manila, Philippines, 2021. [Google Scholar]
- Nicolas, C.; Naila, B.; Amar, R.C. TinyML Smart Sensor for Energy Saving in Internet of Things Precision Agriculture platform. In Proceedings of the 2022 Thirteenth International Conference on Ubiquitous and Future Networks (ICUFN), Barcelona, Spain, 5–8 July 2022; pp. 256–259. [Google Scholar]
- Ooko, S.O.; Ogore, M.M.; Nsenga, J.; Zennaro, M. TinyML in Africa: Opportunities and Challenges. In Proceedings of the 2021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 7–11 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Ogore, M.M.; Nkurikiyeyezu, K.; Nsenga, J. Offline Prediction of Cholera in Rural Communal Tap Waters Using Edge AI inference. In Proceedings of the 2021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 7–11 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- PlantVillage. Available online: https://plantvillage.psu.edu/ (accessed on 15 October 2022).
- Roasting Coffee To Perfection Using AI. Available online: https://highdemandskills.com/coffee-roasting-ai/ (accessed on 15 October 2022).
- Santa, J.; Fernández, P.J. Seamless IPv6 connectivity for two-wheelers. Pervasive Mob. Comput. 2017, 42, 526–541. [Google Scholar] [CrossRef]
- Andrade, P.; Silva, I.; Silva, M.; Flores, T.; Cassiano, J.; Costa, D.G. A TinyML Soft-Sensor Approach for Low-Cost Detection and Monitoring of Vehicular Emissions. Sensors 2022, 22, 3838. [Google Scholar] [CrossRef]
- Tsoukas, V.; Gkogkidis, A.; Kampa, A.; Spathoulas, G.; Kakarountas, A. Enhancing Food Supply Chain Security through the Use of Blockchain and TinyML. Information 2022, 13, 213. [Google Scholar] [CrossRef]
- Costa, D.G.; Peixoto, J.P.J.; Jesus, T.C.; Portugal, P.; Vasques, F.; Rangel, E.; Peixoto, M. A Survey of Emergencies Management Systems in Smart Cities. IEEE Access 2022. [Google Scholar] [CrossRef]
- Zhao, L.; Li, J.; Li, Q.; Li, F. A federated learning framework for detecting false data injection attacks in solar farms. IEEE Trans. Power Electron. 2021, 37, 2496–2501. [Google Scholar] [CrossRef]
- Gkogkidis, A.; Tsoukas, V.; Papafotikas, S.; Boumpa, E.; Kakarountas, A. A TinyML-based system for gas leakage detection. In Proceedings of the 2022 11th International Conference on Modern Circuits and Systems Technologies (MOCAST), Samos, Greece, 3–7 July 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Alajlan, N.N.; Ibrahim, D.M. TinyML: Enabling of Inference Deep Learning Models on Ultra-Low-Power IoT Edge Devices for AI Applications. Micromachines 2022, 13, 851. [Google Scholar] [CrossRef]
- Papageorgiou, E.I.; Theodosiou, T.; Margetis, G.; Dimitriou, N.; Charalampous, P.; Tzovaras, D.; Samakovlis, I. Short Survey of Artificial Intelligent Technologies for Defect Detection in Manufacturing. In Proceedings of the 2021 12th International Conference on Information, Intelligence, Systems & Applications (IISA), Chania Crete, Greece, 12–14 July 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Delnevo, G.; Prandi, C.; Mirri, S.; Manzoni, P. Evaluating the practical limitations of TinyML: An experimental approach. In Proceedings of the 2021 IEEE Globecom Workshops (GC Wkshps), Madrid, Spain, 7–11 December; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Miksikova, S.; Kuda, F.; Steinova, I. Intelligent and efficient parking solutions. IOP Conf. Ser. Earth Environ. Sci. 2021, 900, 012025. [Google Scholar] [CrossRef]
- Zhou, A.; Muller, R.; Rabaey, J. Memory-Efficient, Limb Position-Aware Hand Gesture Recognition using Hyperdimensional Computing. arXiv 2021, arXiv:2103.05267. [Google Scholar]
- Mohan, P.; Paul, A.J.; Chirania, A. A tiny CNN architecture for medical face mask detection for resource-constrained endpoints. In Innovations in Electrical and Electronic Engineering; Springer: Berlin/Heidelberg, Germany, 2021; pp. 657–670. [Google Scholar]
- Häkkilä, J.; Lopes, P.; Kosch, T.; Nishida, J.; Strohmeier, P.; Abdelrahman, Y. Proceedings of the Augmented Humans Conference 2021: AHs 2021. Available online: https://research.ulapland.fi/en/publications/proceedings-augmented-humans-conference-2021-ahs-2021 (accessed on 15 October 2022).
- Lord, M.; Kaplan, A. Mechanical Anomaly Detection on an Embedded Microcontroller. In Proceedings of the 2021 International Conference on Computational Science and Computational Intelligence (CSCI), Beijing, China, 4–6 December 2021; pp. 562–568. [Google Scholar] [CrossRef]
- Nakhle, F.; Harfouche, A.L. Ready, Steady, Go AI: A practical tutorial on fundamentals of artificial intelligence and its applications in phenomics image analysis. Patterns 2021, 2, 100323. [Google Scholar] [CrossRef]
- Curnick, D.J.; Davies, A.J.; Duncan, C.; Freeman, R.; Jacoby, D.M.; Shelley, H.T.; Rossi, C.; Wearn, O.R.; Williamson, M.J.; Pettorelli, N. SmallSats: A new technological frontier in ecology and conservation? Remote Sens. Ecol. Conserv. 2022, 8, 139–150. [Google Scholar] [CrossRef]
- de Prado, M.; Rusci, M.; Capotondi, A.; Donze, R.; Benini, L.; Pazos, N. Robustifying the Deployment of TinyML Models for Autonomous Mini-Vehicles. Sensors 2021, 21, 1339. [Google Scholar] [CrossRef]
- Vuletic, M.; Mujagic, V.; Milojevic, N.; Biswas, D. Edge AI Framework for Healthcare Applications. In Proceedings of the 30th International Joint Conference on Artificial Intelligence, Virtual, 19–26 August 2021. [Google Scholar]
- Rana, A.; Dhiman, Y.; Anand, R. Cough Detection System using TinyML. In Proceedings of the 2022 International Conference on Computing, Communication and Power Technology (IC3P), Visakhapatnam, India, 7–8 January 2022; pp. 119–122. [Google Scholar]
- Kwon, J.; Park, D. Hardware/Software Co-Design for TinyML Voice-Recognition Application on Resource Frugal Edge Devices. Appl. Sci. 2021, 11, 11073. [Google Scholar] [CrossRef]
- Shamim, M.Z.M. Hardware Deployable Edge-AI Solution for Pre-screening of Oral Tongue Lesions using TinyML on Embedded Devices. IEEE Embed. Syst. Lett. 2022, 14, 183–186. [Google Scholar] [CrossRef]
- TensorFlow Lite for Microcontrollers. Available online: https://www.tensorflow.org/lite/microcontrollers (accessed on 15 October 2022).
- Intel. Intel-64 and ia-32 Architectures Software Developer’s Manual; Volume 3A: System Programming Guide, Part 1 (64); Intel: Santa Clara, CA, USA, 2013. [Google Scholar]
- Waterman, A.; Asanovi, K. The RISC-V Instruction Set Manual Volume I: Unprivileged ISA, Document Version 20191213; RISC-V Foundation, 2019. [Google Scholar]
- Wu, X.; Lee, I.; Dong, Q.; Yang, K.; Kim, D.; Wang, J.; Peng, Y.; Zhang, Y.; Saligane, M.; Yasuda, M.; et al. A 0.04MM316NW Wireless and Batteryless Sensor System with Integrated Cortex-M0+ Processor and Optical Communication for Cellular Temperature Measurement. In Proceedings of the 2018 IEEE Symposium on VLSI Circuits, Honolulu, HI, USA, 18–22 June 2018; pp. 191–192. [Google Scholar] [CrossRef]
- IC Insights Inc. MCUs Expected to Make Modest Comeback After 2020 Drop; IC Insights Inc.: Scottsdale, AZ, USA, 2020. [Google Scholar]
- TensorFlow. TensorFlow Lite Guide, 2020b. Available online: https://www.tensorflow.org/lite/guide?hl=zh-cn (accessed on 15 October 2022).
- Khandelwal, R. A Basic Introduction to TensorFlow Lite. Available online: https://towardsdatascience.com/a-basic-introduction-to-tensorflow-lite-59e480c57292 (accessed on 15 October 2022).
- Chettri, L.; Bera, R. A comprehensive survey on Internet of Things (IoT) toward 5G wireless systems. IEEE Internet Things J. 2019, 7, 16–32. [Google Scholar] [CrossRef]
- Liu, H.; Wei, Z.; Zhang, H.; Li, B.; Zhao, C. Tiny Machine Learning (Tiny-ML) for Efficient Channel Estimation and Signal Detection. IEEE Trans. Veh. Technol. 2022, 71, 6795–6800. [Google Scholar]
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A survey on internet of things: Architecture, enabling technologies, security and privacy, and applications. IEEE Internet Things J. 2017, 4, 1125–1142. [Google Scholar] [CrossRef]
- Agiwal, M.; Roy, A.; Saxena, N. Next generation 5G wireless networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]
- Bockelmann, C.; Pratas, N.; Nikopour, H.; Au, K.; Svensson, T.; Stefanovic, C.; Popovski, P.; Dekorsy, A. Massive machine-type communications in 5G: Physical and MAC-layer solutions. IEEE Commun. Mag. 2016, 54, 59–65. [Google Scholar] [CrossRef]
- Palattella, M.R.; Dohler, M.; Grieco, A.; Rizzo, G.; Torsner, J.; Engel, T.; Ladid, L. Internet of things in the 5G era: Enablers, architecture, and business models. IEEE J. Sel. Areas Commun. 2016, 34, 510–527. [Google Scholar] [CrossRef]
- Kaloxylos, A.; Gavras, A.; Camps Mur, D.; Ghoraishi, M.; Hrasnica, H. AI and ML—Enablers for Beyond 5G Networks. 2020. Available online: https://www.recercat.cat/handle/2072/522533 (accessed on 15 October 2022).
- Cayamcela, M.E.M.; Lim, W. Artificial intelligence in 5G technology: A survey. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 17–19 October 2018; pp. 860–865. [Google Scholar]
- Karatzas, A.; Karras, A.; Karras, C.; Giotopoulos, K.C.; Oikonomou, K.; Sioutas, S. On Autonomous Drone Navigation Using Deep Learning and an Intelligent Rainbow DQN Agent. In Proceedings of the Intelligent Data Engineering and Automated Learning—IDEAL 2022, Manchester, UK, 24–26 November 2022; Yin, H., Camacho, D., Tino, P., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 134–145. [Google Scholar]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Mao, Q.; Hu, F.; Hao, Q. Deep learning for intelligent wireless networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2018, 20, 2595–2621. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Sanchez-Iborra, R. LPWAN and embedded machine learning as enablers for the next generation of wearable devices. Sensors 2021, 21, 5218. [Google Scholar] [CrossRef]
- Karras, A.; Karras, C.; Giotopoulos, K.C.; Tsolis, D.; Oikonomou, K.; Sioutas, S. Peer to Peer Federated Learning: Towards Decentralized Machine Learning on Edge Devices. In Proceedings of the 2022 7th South-East Europe Design Automation, Computer Engineering, Computer Networks and Social Media Conference (SEEDA-CECNSM), Ioannina, Greece, 23–25 September 2022; pp. 1–9. [Google Scholar] [CrossRef]
- Singh Bali, M.; Gupta, K.; Kour Bali, K.; Singh, P.K. Towards energy efficient NB-IoT: A survey on evaluating its suitability for smart applications. Mater. Today Proc. 2022, 49, 3227–3234. [Google Scholar] [CrossRef]
- Hossain, M.I.; Markendahl, J.I. Comparison of LPWAN Technologies: Cost Structure and Scalability. Wirel. Pers. Commun. 2021, 121, 887–903. [Google Scholar] [CrossRef]
- Qin, J.; Li, Z.; Wang, R.; Li, L.; Yu, Z.; He, X.; Liu, Y. Industrial Internet of Learning (IIoL): IIoT based pervasive knowledge network for LPWAN—concept, framework and case studies. CCF Trans. Pervasive Comput. Interact. 2021, 3, 25–39. [Google Scholar] [CrossRef]
- Khalifeh, A.; Aldahdouh, K.A.; Darabkh, K.A.; Al-Sit, W. A Survey of 5G Emerging Wireless Technologies Featuring LoRaWAN, Sigfox, NB-IoT and LTE-M. In Proceedings of the 2019 International Conference on Wireless Communications Signal Processing and Networking (WiSPNET), Chennai, India, 21–23 March 2019; pp. 561–566. [Google Scholar] [CrossRef]
- Ayoub, W.; Samhat, A.E.; Nouvel, F.; Mroue, M.; Prévotet, J.C. Internet of mobile things: Overview of lorawan, dash7, and nb-iot in lpwans standards and supported mobility. IEEE Commun. Surv. Tutor. 2018, 21, 1561–1581. [Google Scholar]
- Oliveira, L.; Rodrigues, J.J.; Kozlov, S.A.; Rabêlo, R.A.; Albuquerque, V.H.C.d. MAC layer protocols for Internet of Things: A survey. Future Internet 2019, 11, 16. [Google Scholar]
- Shilpa, B.; Radha, R.; Movva, P. Comparative Analysis of Wireless Communication Technologies for IoT Applications. In Proceedings of the Artificial Intelligence and Technologies; Springer: Berlin/Heidelberg, Germany, 2022; pp. 383–394. [Google Scholar]
- Lim, W.Y.B.; Ng, J.S.; Xiong, Z.; Jin, J.; Zhang, Y.; Niyato, D.; Leung, C.; Miao, C. Decentralized edge intelligence: A dynamic resource allocation framework for hierarchical federated learning. IEEE Trans. Parallel Distrib. Syst. 2021, 33, 536–550. [Google Scholar] [CrossRef]
- Zhang, X.; Wang, Y.; Lu, S.; Liu, L.; Shi, W.; et al. OpenEI: An open framework for edge intelligence. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Richardson, TX, USA, 7–9 July 2019; pp. 1840–1851. [Google Scholar]
- Zhang, Y.; Jiang, C.; Yue, B.; Wan, J.; Guizani, M. Information fusion for edge intelligence: A survey. Inf. Fusion 2022, 81, 171–186. [Google Scholar] [CrossRef]
- Kamruzzaman, M.; Alrashdi, I.; Alqazzaz, A. New opportunities, challenges, and applications of edge-AI for connected healthcare in internet of medical things for smart cities. J. Healthc. Eng. 2022, 2022, 2950699. [Google Scholar] [CrossRef]
- Ray, P.P.; Dash, D.; De, D. Edge computing for Internet of Things: A survey, e-healthcare case study and future direction. J. Netw. Comput. Appl. 2019, 140, 1–22. [Google Scholar] [CrossRef]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Types of Publication | References |
|---|---|
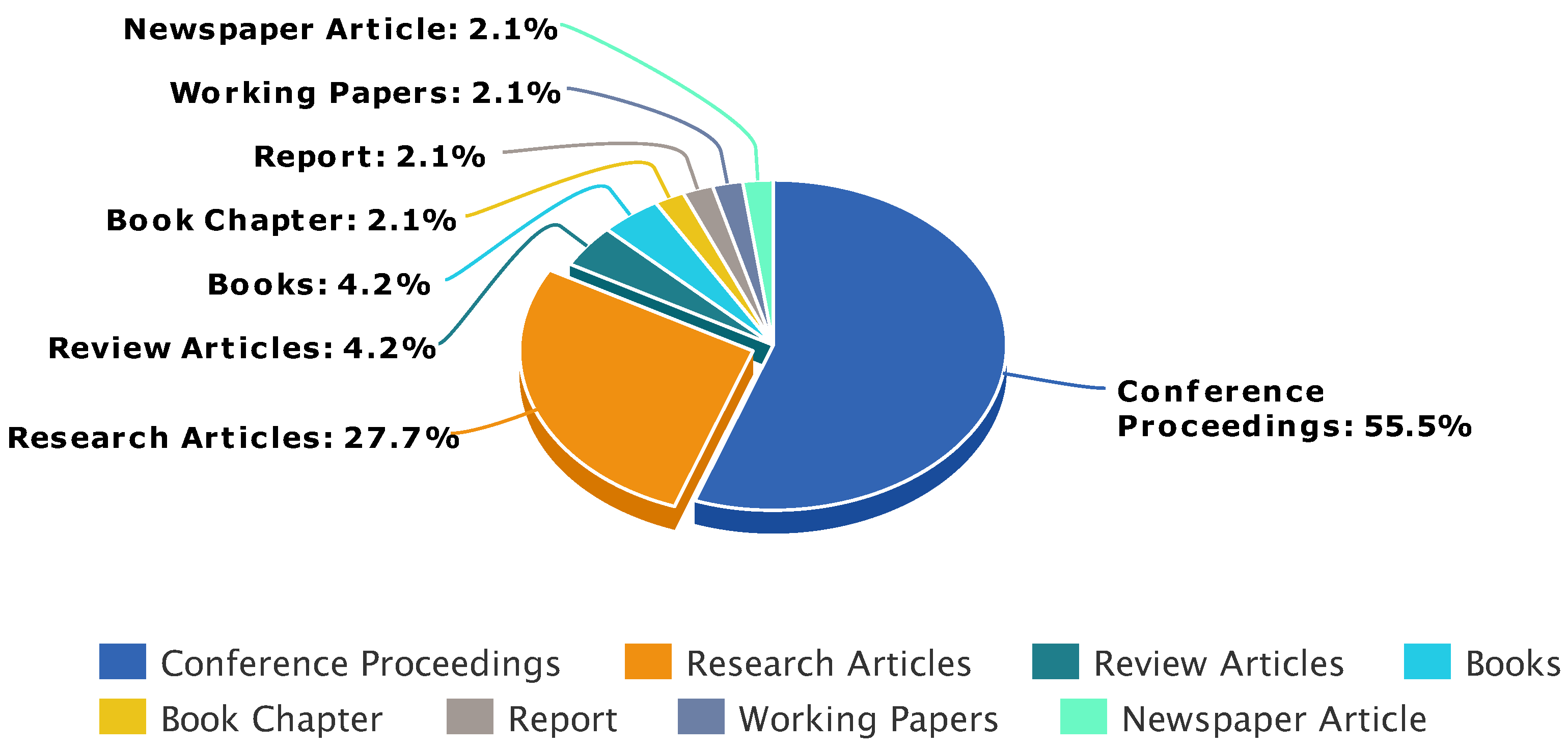
| Conference Proceedings | [38,39,40,41,42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63] |
| Research Articles | [18,63,64,65,66,67,68,69,70,71,72,73,74] |
| Review Articles | [35,75] |
| Book Chapter | [76] |
| Books | [77,78] |
| Report | [79] |
| Working Papers | [80] |
| Newspaper Article | [19] |
| Board/Platform | Micro-Processor | CPU Clock Speed | Flash Memory | SRAM Size | Voltage and Power | Connectivity Availability | Connectors and Sensors | Company |
|---|---|---|---|---|---|---|---|---|
| Thunderboard Sense 2 Sensor-to-Cloud Advanced IoT Kit | EFR32™ Mighty Gecko Wireless SoC | 38.4 MHz | 1 KB | 256 KB | 3.3–5 V, Coin cell, ULP | SPI, 2.4 GHz, USB | Pressure, air quality, microphone, temperature, humidity, ambient light, hall-effect, UV | Silicon Labs |
| Syntiant Tiny ML Board | Syntiant® NDP101 NDP, 32-bit ARM Cortex-M0 | 48 MHz | 256 KB | 32 KB | 3.7–5 V, LiPo battery | I2C, UART | Microphone, motion | Sytiant |
| TI CC1352P LaunchPad | CC1352R Wireless MCU LaunchPad™ | 48 MHz | 352 KB | 8 KB | 60 μA/MHz, 1.8–3.8 V | 868/915/433 MHz, UART, ZigBee, SSI, I2C, Thread, I2S, BLE, 802.15.4, Sub-1 Ghz | Temperature | TI |
| MKR Video 4000 | Intel® Cyclone® 10CL016 FPGA, 32-bit ARM Cortex M0 | 48–200 MHz | 2 MB, 256 KB | 32 KB, 8 MB SDRAM | 3.7 V Li-Po, 1024 mAh | USB, MIPI, u-blox NINA-W102, SPI, UART, I2C | – | Arduino |
| Apollo3 | 32-bit Arm® Cortex®-M4F | 48 MHz, 96 MHz with TurboSPOTTM | 1 MB | 384 KB | 6 μA/MHz Battery option, | FTDI SPI, USB, BLE5 | MEMS microphone, accelerometer, HM01B0 camera | SparkFun |
| STM32F Discovery | 32-bit Arm® Cortex®-M4 FPU Core | 48 MHz | 1 MB | 192 KB | 3–5 V | USB, LQFP100 I/O | Microphone, accelerometer | STMicroelectronics |
| ST IoTDiscovery | Arm® Cortex®-M4 | 48 MHz | 1 MB,64 Mbit Quad-SPI | 128 KB | Battery option | 868/915 MHz, BLE 4.1, NFC, USB, 8.211b/g/n | Accelerometer, microphone, gesture detection, gyroscope, temperature, barometer, humidity | STMicroelectronics |
| Nordic Semi nRF52840 DK | Arm® Cortex®-M4 | 64 MHz | 192 KB | 24 KB | 1.7–5 V Li-Po | Zigbee, BLE5, NFC, Thread, UART, 802.15.4, ANT, 2.4 GHz, Bluetooth mesh | – | Nordic |
| Arduino Nicla Sense ME | Arm® Cortex®-M4 | 64 MHz | 512 KB | 64 KB | 3.7 V Li-Po | USB, BLE4.2, I2C, SPI | Geomagnetic, accelerometer, gyroscope, humidity, pressure, geomagnetic, gas, temperature | Arduino |
| Nordic Semiconductor Thingy:91™ Multisensor Prototyping Kit | Arm® Cortex®-M33, nRF9160 SiP | 64 MHz | 1 MB | 256 KB | 1440 mAh Li-Po | I2S, SPI, LTE-M, NB-IoT, UART, | Humidity, pressure, color, air quality, temperature, light | Nordic |
| Arduino Nano 33 BLE Sense | nRF52840 | 64 MHz | 1 MB | 256 KB | 3.3 V, 15 mA/pin | USB, UART, SPI, I2C, BLE, SPI | Barometer, IMU, gesture, temperature, light, proximity, humidity, microphone | Arduino |
| Board/Platform | Micro-Processor | CPU Clock Speed | Flash Memory | SRAM Size | Voltage and Power | Connectivity Availability | Connectors and Sensors | Company |
|---|---|---|---|---|---|---|---|---|
| ECM3532 AI Vision Board | Arm® Cortex®-M3, NXP CoolFlux 16-bit DSP | 100 MHz | 512 KB | 256 KB | 5 μA/MHz, Battery option | USB, RF, BLE 4.2 | Temperature, pressure, microphone, gyroscope, accelerometer | Eta Compute |
| Freedom-K64F | Arm® Cortex®-M4 | 120 Mhz | 1 MB | 256 KB | 1.7–3.6 V, Coin cell | CAN, I2S, SPI, I2C, UART, Ethernet | Magnetometer, accelerometer | Mbed |
| Arducam Pico4ML-BLE | Raspberry Pi RP2040 DSP dual core | 133 MHz | 4 MB | 264 KB | 1.7–3.6 V, battery | I2C, USB, BLE | IMU, camera QVGA 60 FPS, microphone | ArduoCam |
| Sony’s Spresense | Arm® Cortex®-M4F 6 Core | 156 MHz | 8 MB | 1.5 MB | 3.3–5 V | GNSS antenna, UART, I2C, SPI, I2S | Camera, microphone | Sony |
| AI-deck 1.1 | GAP8, ESP32 | 168 MHz | 1 MB | 192 KB | 3–5 V | URT, SPI, WiFi | Monochrome camera | Bitcraze |
| ESP-EYE | 32-bit ESP32 | 240 MHz | 4 MB | 8 MB PSRAM | 3.3 V | UART, USB, BLE, SPI, I2C, WiFi | 2MP camera | Espressif |
| GAP8 | RISC-V, hardware convolution engine | 250 MHz (FC), 175 MHz (C), 22.65GOPs | 512 KB | 80 KB, 8 MB SDRAM | 1.8–3.3 V, 4.24 mW/GOP | I2S, SPI, UART, I2C, CPI, Hyperbus, Serial | Extension camera | Green Wave Technologies |
| Himax EW-I Plus | 32-bit ARC EM9D DSP with FPU Core | 400 MHz | 2 MB | 2 MB | 1.2–3.3 V, Battery | USB, SPI2, UART, I2C | Accelerometer, VGA Camera 60 FPS, microphone | SparkFun |
| GAP9 | RISC-V, hardware convolution engine | 400 MHz, 150.8GOPs | 1.5 MB | 128 KB, 2 MB External | 1.8–3.3 V, 0.33 mW/GOP | CPI, SPI, I2C, UART, I2S, Hyperbus, Serial | Extension camera | Green Wave Technologies |
| Arduino Portenta H7 | Arm® Cortex®-M7, Arm® Cortex®-M4 GPU | 480 MHz, 240 MHz | 16 MB | 8 MB SDRAM | 3.7–5 V, Li-Po cell, 700 mAh | MIPI DSI, BLE, 10/100 Ethernet Phy, USB, MPI D-PHY, WiFi | Camera extension, temperature | Arduino |
| OpenMV Cam H7 Plus | Arm® Cortex®-M7 | 480 MHz | 2 MB (Internal) | 1 MB, 32 MB SDRAM | 3.7 V Li-Ion | UART, USB, I2C, CAN | 5MP Camera at 50 FPS | OpenMV |
| XCore.ai | Convolution and dense neural network FPU 16 core | 3200MIPS, 1 M 512 FFTs/s | – | 1 MB | 1.8–3.3 V, 500 mW | USB, MIPI, I2C, UART, SPI, I2S | – | XMOS |
| Raspberry Pi 4 Model B | 64-bit Arm® Cortex®-A72 quad core, Broadcom BCM2711 | 1.5 GHz | – | 256 KB | 3.8–4 W, 3.3–5 V | Ethernet, USB, HDMI, WiFo, BLE, DSI, CSI | Temperature | Raspberry Pi |
| Framework | Algorithms | Compatible Platforms | Publicly Available | Main Developer |
|---|---|---|---|---|
| emlearn | Random forestDecision treeNaive GaussianBayesNeuralnetworks | AVR AtmegaESP8266Linux | Yes | Specificdeveloper |
| EmbML | SVMDecision treeNeuralnetworks | ArduinoTeensy | No | Research group |
| weka-porter | Decision tree | Nonconstrainedplatforms & multipleconstrained | Yes | Specificdeveloper |
| TinyMLgen | Neuralnetworks | ARM Cortex-MESP32 | Yes | Specificdeveloper |
| uTensor | Neuralnetworks | mBed boards | Yes | Specificdeveloper |
| FANN-on-MCU | Neuralnetworks | ARM Cortex-MPULP | Yes | Research group |
| CMix-NN | Neuralnetworks | ARM Cortex-M | Yes | Research group |
| Framework | Algorithms | Compatible Platforms | Publicly Available | Main Developer |
|---|---|---|---|---|
| MicroMLGen | SVMRVM | ArduinoESP32ESP8266 | Yes | Particulardeveloper |
| MicroMLGen | SVMRVM | ArduinoESP32ESP8266 | Yes | Particulardeveloper |
| m2cgen | LGBMClassifier LogisticregressionLinearregressionSVMNeuralnetworksDecision treeRandom Forest | Multipleconstrained &nonconstrainedplatforms | Yes | Particulardeveloper |
| AIfES | Neuralnetworks | ARM Cortex-M4Windows (DLL)STM32 F4SeriesArduinoATMega32U4Raspberry Pi | No | Fraunhofer IMS |
| CMSIS-NN | Neuralnetworks | ARM Cortex-M | Yes | ARM |
| ELL | Neuralnetworks | ARM Cortex-MARM Cortex-AArduinomicro:bit | Yes | Microsoft |
| TensorFlowLite | Neuralnetworks | ARM Cortex-M | Yes | |
| ARM-NN | Neuralnetworks | ARM EthosProcessorARM MaliGraphicsProcessorsARM Cortex-A | Yes | ARM |
| STM 32Cube.AI | Neuralnetworks | STM32 | Yes | STMicroelectronics |
| sklearnporter | NeuralnetworksSVMRandom ForestAda BoostClassifierk-NNDecision treeNaive Bayes | Multipleconstrained &nonconstrainedplatforms | Yes | Particulardeveloper |
| NanoEdgeAI Studio | Unsupervisedlearning | ARM Cortex-M | No | Cartesian |
| Learning Classes | Learning Models | 5G Application Illustration |
|---|---|---|
| Support Vector Machines (SVM) | Model for predicting path loss in urban contexts | |
| Approaches for machine learning and statistical logistic regression | In deployments of self-organized LTE dense small cells, dynamic frequency and bandwidth allocation is used. | |
| Supervised learning | Neural-Network-based approximation | Channel learning is used to infer unobservable channel state information (CSI) from an observable channel. |
| Frameworks for Supervised Machine Learning | Adjustment of the TDD Uplink-Downlink configuration in XG-PON-LTE Systems to enhance network performance in the hybrid optical-wireless network based on current traffic circumstances | |
| Multi-Layer Perceptrons (MLPs) and Artificial Neural Networks (ANN) | In next-generation wireless networks, objective function modeling and estimates for link budget and propagation loss are used | |
| Reinforcement Learning algorithm based on long short-term memory (RL-LSTM) cells. | Based on long-term WLAN activity in the channels and LTE-U traffic loads, proactive resource allocation in LTE-U networks, implemented as a non-cooperative game, enables SBSs to determine which unlicensed channel to utilize. | |
| Reinforcement Learning | the modified Roth-Erev (MRE), Gradient follower (GF), and the modified Bush and Mosteller (MBM). | Allow Femto-Cells (FCs) to monitor the radio environment autonomously and opportunistically and alter their settings in HetNets to eliminate intra/inter-tier interference |
| Reinforcement Learning with Network assisted feedback. | Selection of Heterogeneous Radio Access Technologies (RATs) | |
| Clustering using Affinity Propagation. | Data-Driven Resource Management for Ultra-Dense Small Cells | |
| Hierarchical Clustering. | Detection of anomalies, faults, and intrusions in mobile wireless networks | |
| Unsupervised Learning | ML Framework for Unsupervised Soft-Clustering. | In heterogeneous cellular networks, latency is reduced by grouping fog nodes to automatically identify which low power node (LPN) gets converted to a high power node (HPN) |
| Expectation Maximization (EM), K-means clustering and Gaussian Mixture Model (GMM). | Relay node selection and cooperative spectrum sensing in vehicle networks |
| Parameter | LoRa | SigFox | NB-IoT | LTE-M | DASH7 |
|---|---|---|---|---|---|
| Standard | LoRa Alliance | SigFox/ETSI LTN | 3 GPP Release 13, 14 | 3 GPP | Dash Alliance |
| Bandwidth | 250 kHz | 100 Hz | 200 kHz | 1.4–20 MHz | 433/868/915 MHz |
| Modulation | FSS/CSS | D-BPSK | QPSK | DL: OFDMA, 16 QAM | GFSK |
| Spectrum | 1175 kHz | 200 kHz | 200 kHz | Licensed LTE bands | Licensed |
| Frequency band | EU: 868 MHz | EU: 868 MHz | 7–900 MHz | Cellular Band | Cellular Band |
| Transmission | FHSS (Aloha) | UNB | FDD | FDD/TDD | BLAST |
| Topology | Star-of-stars | Star | Star | Star | Half |
| Security | AES 128b | Optional encryption | NSA AES 256 | AES 256 | AES 128 |
| Range (Urban) | 2–5 km | 3–10 km | 1–5 km | 1–5 km | 1 km |
| Range (Rural) | 20 km | 50 km | 10–15 km | 10–15 km | 2 km |
| Data Rate (Min) | 250 bps | 100 bps | 100 kbps | 1 Mbps | 27.8 kbps |
| Data Rate (Max) | 50 kbps | 600 bps | 200 kbps | 4 Mbps | 200 kbps |
| Throughput | 50 kbps | - | 127 Kbit | 1 Mbit | 167 Kbit |
| Energy Consumption | Very Low | Low | Medium Low | Medium | Low |
| Battery Life | ∼10 years | ∼12 years | ∼10 years | ∼2 years | ∼10 years |
| Deployment Cost | Moderate | Moderate | High | High | Moderate |
| TinyML Availability | Yes | Not applicable | Not applicable | Yes | Yes |
| Parameter | TinyML | Machine Learning |
|---|---|---|
| Battery Life | ✓ | |
| Cost efficiency | ✓ | |
| Scalability | ✓ | |
| Robustness | ✓ | |
| Deployment | ✓ | |
| Performance | ✓ | |
| Security | ✓ |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Schizas, N.; Karras, A.; Karras, C.; Sioutas, S. TinyML for Ultra-Low Power AI and Large Scale IoT Deployments: A Systematic Review. Future Internet 2022, 14, 363. https://doi.org/10.3390/fi14120363
Schizas N, Karras A, Karras C, Sioutas S. TinyML for Ultra-Low Power AI and Large Scale IoT Deployments: A Systematic Review. Future Internet. 2022; 14(12):363. https://doi.org/10.3390/fi14120363
Chicago/Turabian StyleSchizas, Nikolaos, Aristeidis Karras, Christos Karras, and Spyros Sioutas. 2022. "TinyML for Ultra-Low Power AI and Large Scale IoT Deployments: A Systematic Review" Future Internet 14, no. 12: 363. https://doi.org/10.3390/fi14120363
APA StyleSchizas, N., Karras, A., Karras, C., & Sioutas, S. (2022). TinyML for Ultra-Low Power AI and Large Scale IoT Deployments: A Systematic Review. Future Internet, 14(12), 363. https://doi.org/10.3390/fi14120363