
Holistic Utility Satisfaction in Cloud Data Centre Network Using Reinforcement Learning



Abstract
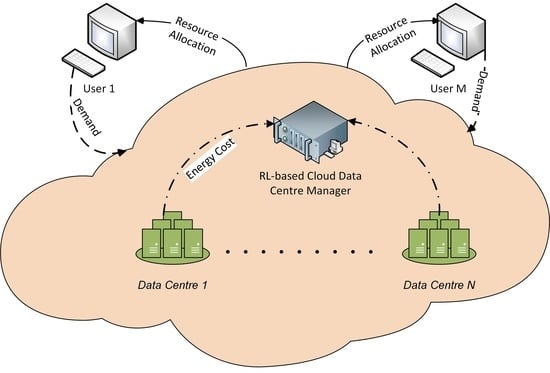
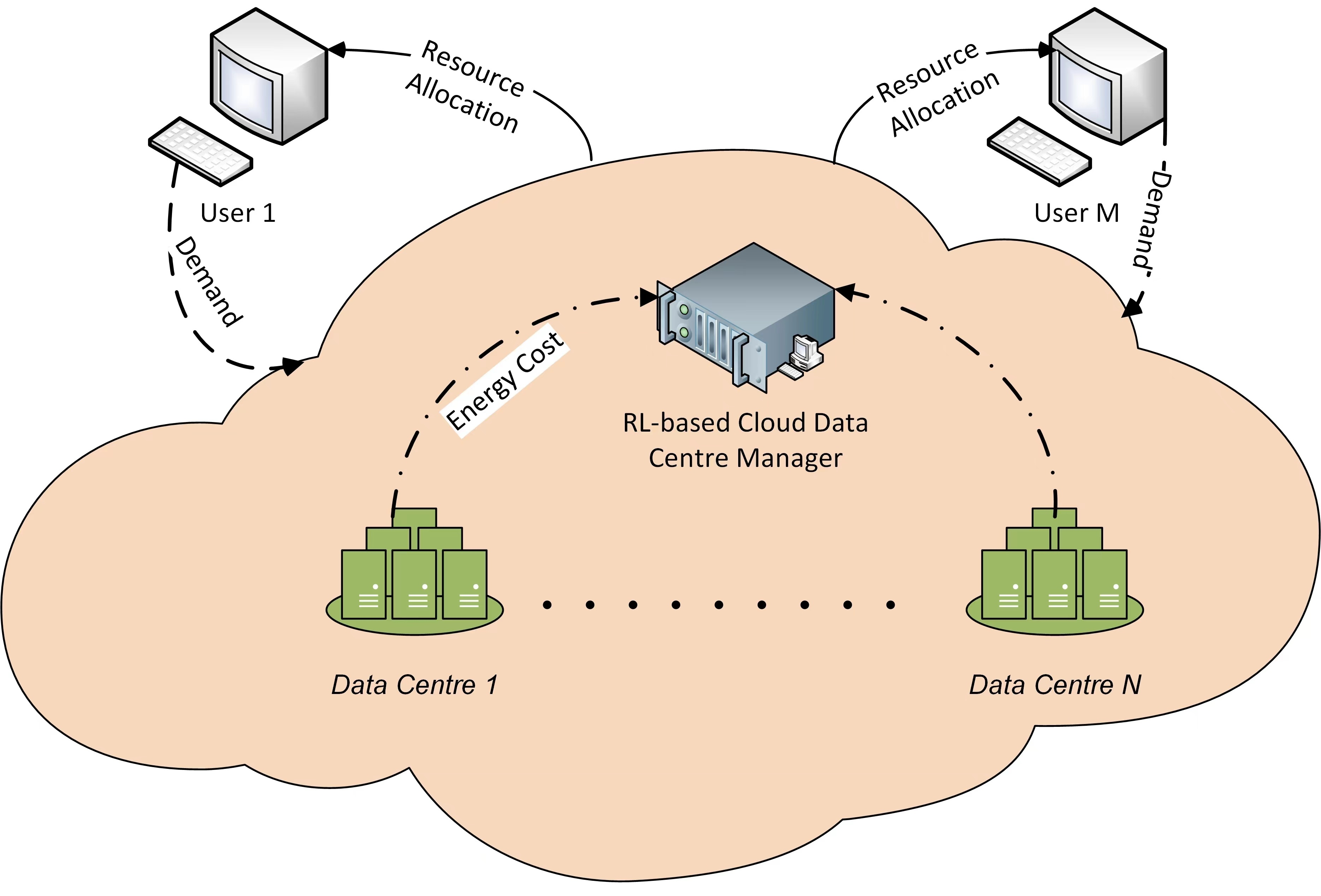
:
1. Introduction
- Utility modelling was adopted for the overall CDCN system, in terms of virtualising the networking resources, which are: CPU, RAM, storage, and access/connection bandwidth.
- The energy consumption model of the cloud data centres is described and used in the utility modelling of the cloud manager.
- After modelling the utility/satisfaction functions associated with the cloud users/provider, a reinforcement learning sub-type (which is Q-learning) was adopted for optimised resource assignment to different cloud users, which also simultaneously satisfies the requirements of the CDCN manager/provider in terms of energy efficiency in a holistic manner.
- Finally, the online and model-free property of the Q-learning algorithm results in converging to optimal utility levels for both the cloud users and cloud provider in different cloud user population scenarios in a fast and low-complexity manner.
2. Related Work
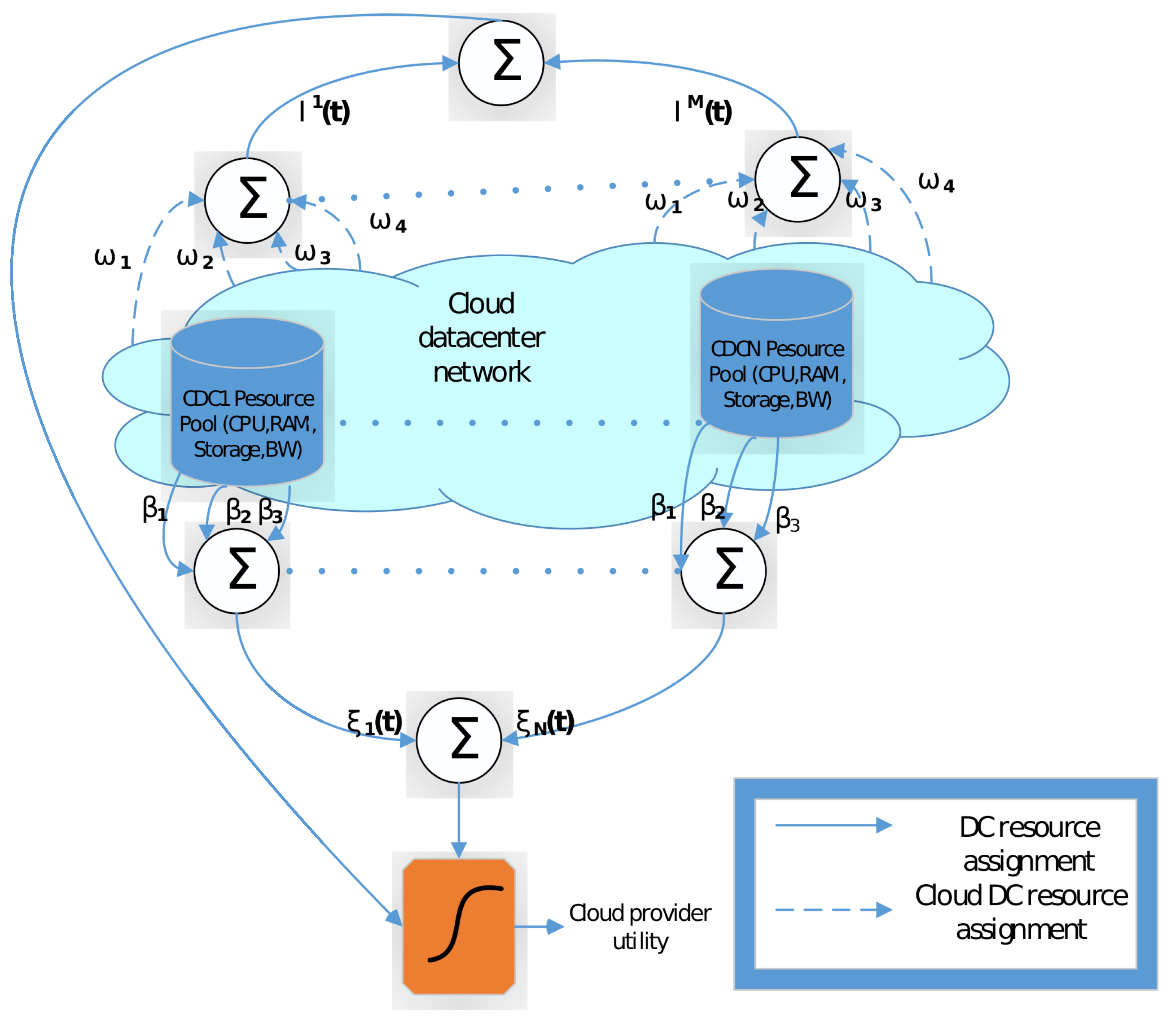
3. Modelling of the CDCN
3.1. The Utility Function Model for Cloud Users
3.2. The Utility Modelling for Cloud Data Centre Provider
4. Reinforcement-Learning-Based Cloud Resource Allocation
4.1. Q-Learning Model
4.2. The Proposed QLRA algorithm
| Algorithm 1 Proposed QLRA algorithm. |
| 1 Initialise Q-score and time slot, Q = 0, t = 0 |
| 2 |
| 3 Generate state set |
| 4 for do: |
| 5 Generate action set and according to [64]: |
| 6 |
| 7 Choose an action according to: |
| 8
|
| 9 |
| 10 |
| 11 Update Q according to: |
| 12 |
| 13 |
| 14 If |
| 15 ( is a small positive constant) |
| 16 Go to 3 |
| 17 Obtain the final Q-score. |
4.3. Remark
5. Simulation Results
5.1. Numerical Analysis Parameter Description
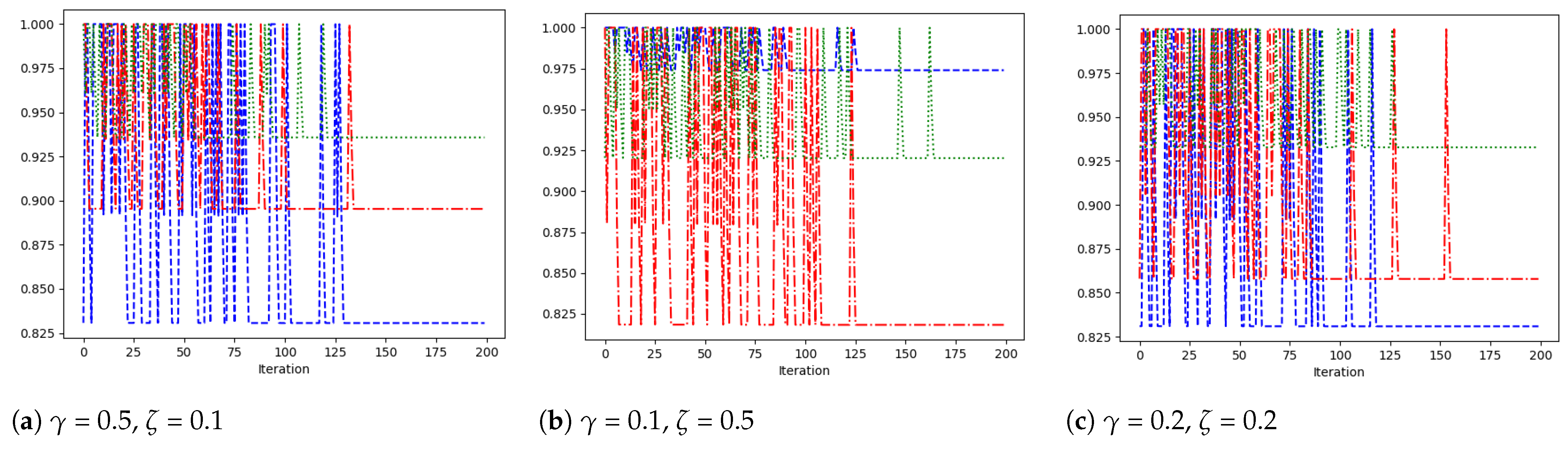
5.2. QLRA Algorithm Results and Comparative Analysis
5.3. Performance Comparison with Similar Approaches
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| CDC | Cloud data centre |
| CDCN | Cloud data centre network |
| CP | Cloud provider |
| DC | Data centre |
| DCN | Data centre network |
| ML | Machine learning |
| QoE | Quality of experience |
| QoS | Quality of service |
| RL | Reinforcement learning |
| RTT | Round-trip time |
| SLA | Service-level agreement |
| VM | Virtual machine |
References
- Wang, B.; Qi, Z.; Ma, R.; Guan, H.; Vasilakos, A.V. A survey on data centre networking for cloud computing. Comput. Netw. 2015, 91, 528–547. [Google Scholar] [CrossRef]
- Stergiou, C.L.; Psannis, K.E.; Gupta, B.B. InFeMo: Flexible Big Data Management Through a Federated Cloud System. ACM Trans. Internet Technol. 2022, 22, 1–22. [Google Scholar] [CrossRef]
- Goudarzi, P.; Hosseinpour, M.; Ahmadi, M.R. Joint customer/provider evolutionary multi-objective utility maximization in cloud data centre networks. Iran. J. Sci. Technol. Trans. Electr. Eng. 2021, 45, 479–492. [Google Scholar] [CrossRef]
- Samuel, A.L. Some studies in machine learning using the game of checkers. IBM J. Res. Develop. 1959, 3, 210–229. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach. In Prentice-Hall, 3rd ed.; Pearson Education, Inc.: Upper Saddle River, NJ, USA, 2009. [Google Scholar]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef] [Green Version]
- Barlow, B.H. Unsupervised learning. Neural Comput. 1989, 1, 295–311. [Google Scholar] [CrossRef]
- Ghahramani, Z. Unsupervised learning. In Summer School on Machine Learning; Springer: Berlin/Heidelberg, Germany, 2003; pp. 72–112. [Google Scholar]
- Zhu, X. Semi-supervised learning literature survey. In Tech. Rep.; Dept. Comput. Sci., Univ. Wisconsin-Madison: Madison, WI, USA, 1530; Available online: https://pages.cs.wisc.edu/~jerryzhu/pub/ssl_survey.pdf (accessed on 15 November 2022).
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef] [Green Version]
- Tryon, R.C. Cluster Analysis: Correlation Profile and Orthometric (Factor) Analysis for the Isolation of Unities in Mind and Personality; Edwards brother, Inc.: Lillington, NC, USA, 1939. [Google Scholar]
- Estivill-Castro, V. Why so many clustering algorithms: A position paper. ACM SIGKDD Explor. Newslett. 2002, 4, 65–75. [Google Scholar] [CrossRef]
- Roweis, S.T.; Saul, L.K. Nonlinear dimensionality reduction by locally linear embedding. Science 2000, 290, 2323–2327. [Google Scholar] [CrossRef] [Green Version]
- Ahmad, I.; Shahabuddin, S.; Malik, H.; Harjula, E.; Leppänen, T.; Loven, L.; Anttonen, A.; Sodhro, A.H.; Alam, M.M.; Juntti, M.; et al. Machine Learning Meets Communication Networks: Current Trends and Future Challenges. IEEE Access 2020, 8, 223418–223460. [Google Scholar] [CrossRef]
- Buda, T.S.; Assem, H.; Xu, L.; Raz, D.; Margolin, U.; Rosensweig, E.; Lopez, D.R.; Corici, M.-I.; Smirnov, M.; Mullins, R.; et al. Can machine learning aid in delivering new use cases and scenarios in 5G? In Proceedings of the NOMS 2016-2016 IEEE/IFIP Network Operations and Management Symposium, Istanbul, Turkey, 25–29 April 2016; pp. 1279–1284. [Google Scholar]
- Ahmad, I.; Shahabuddin, S.; Kumar, T.; Harjula, E.; Meisel, M.; Juntti, M.; Sauter, T.; Ylianttila, M. Challenges of AI in wireless networks for IoT. IEEE Ind. Electron. Mag. 2020, 15, 1–16. [Google Scholar]
- Jain, N.; Choudhary, S. Overview of virtualization in cloud computing. In Proceedings of the 2016Symposium on Colossal Data Analysis and Networking (CDAN), Indore, India, 18–19 March 2016. [Google Scholar]
- Razaque, A.; Vennapusa, N.R.; Soni, N.; Janapati, G.S.; Vangala, K.R. Task scheduling in Cloud computing. In Proceedings of the IEEE Long Island Systems, Applications and Technology Conference (LISAT), Farmingdale, NY, USA, 9 April 2016. [Google Scholar]
- Zhu, F.; Li, H.; Lu, J. A service level agreement framework of cloud computing based on the Cloud Bank model. In Proceedings of the 2012 IEEE International Conference on Computer Science and Automation Engineering (CSAE), Zhangjiajie, China, 25–27 May 2012. [Google Scholar]
- Wu, L.; Garg, S.K.; Buyya, R. SLA-based admission control for a Software-as-a-Service provider in Cloud computing environments. J. Comput. Syst. Sci. 2012, 78, 1280–1299. [Google Scholar] [CrossRef] [Green Version]
- Rebai, S. Resource allocation in Cloud federation. These de Doctorat Conjoint Telecom SudParis et L’Universite Pierre et Marie Curie. 2017. Available online: https://theses.hal.science/tel-01534528/document (accessed on 15 November 2022).
- Goudarzi, P. Multi-Source Video Transmission with Minimized Total Distortion Over Wireless Ad Hoc Networks. Wirel. Pers. Commun. 2009, 50, 329–349. [Google Scholar] [CrossRef]
- Zheng, K.; Meng, H.; Chatzimisios, P.; Lei, L.; Shen, X. An SMDP-based resource allocation in vehicular cloud computing systems. IEEE Trans. Ind. Electron. 2015, 62, 7920–7928. [Google Scholar] [CrossRef]
- Zhou, Z.; Bambos, N. A general model for resource allocation in utility computing. In Proceedings of the 2015 American Control Conference (ACC), Chicago, IL, USA, 1–3 July 2015. [Google Scholar]
- Khasnabish, J.N.; Mitani, M.F.; Rao, S. Generalized nash equilibria for the service provisioning problem in cloud systems. IEEE Trans. Serv. Comput. 2013, 6, 429–442. [Google Scholar]
- Johari, R.; Mannor, S.; Tsitsiklis, J.N. Efficiency loss in a network resource allocation game: The case of elastic supply. IEEE Trans. Autom. Control 2005, 50, 1712–1724. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Tang, X.; Cai, W. Dynamic bin packing for on-demand cloud resource allocation. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 157–170. [Google Scholar] [CrossRef]
- Liang, H.; Cai, L.; Huang, D.; Shen, X.; Peng, D. An SMDP-based service model for interdomain resource allocation in mobile cloud networks. IEEE Trans. Veh. Technol. 2012, 61, 157–170. [Google Scholar]
- Zu, D.; Liu, X.; Niu, Z. Joint Resource Provisioning for Internet Datacentres with Diverse and Dynamic Traffic. IEEE Trans. Cloud Comput. 2017, 5, 71–84. [Google Scholar]
- Goudarzi, P.; Sheikholeslam, F. A fast fuzzy-based (Ω, α)-fair rate allocation algorithm. In Proceedings of the 19th IEEE International Parallel and Distributed Processing Symposium, Denver, CO, USA, 4–8 April 2005. [Google Scholar]
- Pilla, P.S.; Rao, S. Resource Allocation in Cloud Computing Using the Uncertainty Principle of Game Theory. IEEE Syst. J. 2016, 10, 637–648. [Google Scholar] [CrossRef]
- Li, B.; Li, J.; Tang, K.; Yao, X. Many-Objective Evolutionary Algorithms: A Survey. ACM Comput. Surv. 2015, 48, 1–35. [Google Scholar] [CrossRef] [Green Version]
- Deb, K. Multi-objective evolutionary algorithms. In Springer Handbook of Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2015; pp. 995–1015. [Google Scholar]
- Chang, R.; Li, M.; Li, K.; Yao, X. Evolutionary Multiobjective Optimization Based Multimodal Optimization: Fitness Landscape Approximation and Peak Detection. IEEE Trans. Evol. Comput. 2017, 22, 692–706. [Google Scholar] [CrossRef]
- Li, X.; Garraghan, P.; Jiang, X.; Wu, Z.; Xu, J. Holistic Virtual Machine Scheduling in Cloud Datacentres towards Minimizing Total Energy. IEEE Trans. Parallel Distrib. Syst. 2018, 29, 1317–1331. [Google Scholar] [CrossRef] [Green Version]
- Sayadnavard, M.H.; Haghighat, A.T.; Rahmani, A.M. A multi-objective approach for energy-efficient and reliable dynamic VM consolidation in cloud data centres. Eng. Sci. Technol. Int. J. 2021, 6, 100995. [Google Scholar]
- Zhang, C.; Wang, Y.; Lv, Y.; Wu, H.; Guo, H. An Energy and SLA-Aware Resource Management Strategy in Cloud Data Centers. Sci. Program. 2019, 2019, 3204346. [Google Scholar] [CrossRef]
- Ilager, S. Machine Learning-based Energy and Thermal Efficient Resource Management Algorithms for Cloud Data Centres. Ph.D. Dissertation, University of Melbourne, Melbourne, Australia, 2021. [Google Scholar]
- Gill, S.S.; Garraghan, P.; Stankovski, V.; Casale, G.; Thulasiram, R.K.; Ghosh, S.K.; Ramamohanarao, K.; Buyya, R. Holistic Resource Management for Sustainable and Reliable Cloud Computing: An Innovative Solution to Global Challenge. J. Syst. Software 2019, 155, 104–129. [Google Scholar] [CrossRef]
- Heimerson, A.; Brännvall, R.; Sjölund, J.; Eker, J.; Gustafsson, J. Towards a Holistic Controller: Reinforcement Learning for Data Center Control. e-Energy 2021, 424–429. Available online: https://dl.acm.org/doi/10.1145/3447555.3466581 (accessed on 15 November 2022).
- Baek, J.Y.; Kaddoum, G.; Garg, S.; Kaur, K.; Gravel, V. Managing Fog Networks Using Reinforcement Learning Based Load Balancing Algorithm. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019. [Google Scholar]
- Garcia, J.L.B. Improved Self-management of DataCenter Systems Applying Machine Learning. Ph.D. Dissertation, Universitat Politecnica de Catalunya, Barcelona, Spain, 2013. [Google Scholar]
- Li, D.; Chen, C.; Guan, J.; Zhang, Y.; Zhu, J.; Yu, R. DCloud: Deadline-Aware Resource Allocation for Cloud Computing Jobs. IEEE Trans. Parallel Distrib. Syst. 2016, 27, 2248–2260. [Google Scholar] [CrossRef]
- Parikh, S.M. A survey on cloud computing resource allocation techniques. In Proceedings of the 2013 Engineering (NUiCONE), Ahmedabad, India, 28–30 November 2013. [Google Scholar]
- Khasnabish, J.N.; Mitani, M.F.; Rao, S. Tier-Centric Resource Allocation in Multi-Tier Cloud Systems. IEEE Trans. Cloud Comput. 2017, 5, 576–589. [Google Scholar] [CrossRef]
- Liu, X.F.; Zhan, Z.H.; Deng, J.D.; Li, Y.; Gu, T.; Zhang, J. An Energy Efficient Ant Colony System for Virtual Machine Placement in Cloud Computing. IEEE Trans. Evol. Comput. 2017, 22, 113–128. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Yu, H. A Game Theory Approach to Fair and Efficient Resource Allocation in Cloud Computing. Math. Probl. Eng. 2014, 2014, 915878. [Google Scholar] [CrossRef] [Green Version]
- Ashraf, A.; Porres, I. Multi-objective dynamic virtualmachine consolidation in the cloud using ant colony system. Int. J. Parallel, Emergent Distrib. Syst. 2017, 33, 103–120. [Google Scholar] [CrossRef] [Green Version]
- Md Feraus, H.; Murshed, M.; Calheiros, R.N.; Buyya, R. Multi-objective, Decentralized Dynamic Virtual Machine Consolidation using ACO Metaheuristic in Computing Clouds. In Concurrency and Computation: Practice and Experience. 2016. Available online: https://ui.adsabs.harvard.edu/abs/2017arXiv170606646H/abstract (accessed on 15 November 2022).
- Shaw, R.; Howley, E.; Barrett, E. Applying Reinforcement Learning towards automating energy efficient virtual machine consolidation in cloud data centres. Inf. Syst. 2022, 107, 101722. [Google Scholar] [CrossRef]
- Lin, B.; Zhu, F.; Zhang, J.; Chen, J.; Chen, X.; Xiong, N.N.; Lloret, J. A time-driven data placement strategy for a scientific workflow combining edge computing and cloud computing. IEEE Trans. Ind. Inform. 2019, 15, 4254–4265. [Google Scholar] [CrossRef] [Green Version]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Shallow neural network with kernel approximation for prediction problems in highly demanding data networks. Expert Syst. Appl. 2019, 124, 196–208. [Google Scholar] [CrossRef]
- Mao, H.; Schwarzkopf, M.; Venkatakrishnan, S.B.; Meng, Z.; Alizadeh, M. Learning scheduling algorithms for data processing clusters. In Proceedings of the ACM Special Interest Group on Data Communication, Beijing, China, 19–23 August 2019; pp. 270–288. [Google Scholar]
- Ghafouri, S.; Saleh-Bigdeli, A.A.; Doyle, J. Consolidation of Services in Mobile Edge Clouds using a Learning-based Framework. In Proceedings of the IEEE World Congress on Services (SERVICES), Beijing, China, 18–23 October 2020; pp. 116–121. [Google Scholar]
- Guo, W.; Tian, W.; Ye, Y.; Xu, L.; Wu, K. Cloud resource scheduling with deep reinforcement learning and imitation learning. IEEE Internet Things J. 2020, 8, 3576–3586. [Google Scholar] [CrossRef]
- Buyya, R.; Beloglazov, A.; Abawajy, J. Energy-efficient management of data centre resources for cloud computing: A vision architectural elements and open challenges. In Proceedings of the Conference on Parallel and Distributed Processing Techniques and Applications, Las Vegas, NV, USA, 12–15 July 2010. [Google Scholar]
- Das, R.; Kephart, J.O.; Lenchner, J.; Hamann, H. Utility-Function-Driven Energy-Efficient Cooling in Data Centers. In Proceedings of the 7th International Conference on Autonomic Computing (ICAC), Washington, DC, USA, 7–11 June 2010. [Google Scholar]
- Ranaldo, N.; Zimeo, E. Capacity-Aware Utility Function for SLA Negotiation of Cloud Services. In Proceedings of the IEEE/ACM 6th International Conference on Utility and Cloud Computing (UCC), Dresden, Germany, 9–12 December 2013. [Google Scholar]
- ITU-T. Vocabulary for Performance and Quality of Service. 2006. Available online: https://www.itu.int/rec/T-REC-P.10 (accessed on 15 November 2022).
- Wei, D.X.; Cao, P.; Low, S.H. Packet Loss Burstiness: Measurements and Implications for Distributed Applications. In Proceedings of the IEEE International Parallel and Distributed Processing Symposium, IPDPS, Long Beach, CA, USA, 26–30 March 2007. [Google Scholar]
- Elteto, T.; Molnar, S. On the distribution of round-trip delays in TCP/IP networks. In Proceedings of the 24th Conference on Local Computer Networks. LCN, Lowell, MA, USA, 18–20 October 1999. [Google Scholar]
- Yu, L.; Zhang, C.; Jiang, J.; Yang, H.; Shang, H. Reinforcement learning approach for resource allocation in humanitarian logistics. Expert Syst. Appl. 2021, 173, 114663. [Google Scholar] [CrossRef]
- Semrov, D.; Marsetic, R.; Zura, M.; Todorovski, L.; Srdic, A. Reinforcement learning approach for train rescheduling on a single-track railway. Transp. Res. Part B Methodol. 2016, 86, 250–267. [Google Scholar] [CrossRef]
- Russel, S.J.; Norvig, P. Artificial Intelligence, a Random Approach, 3rd ed.; Pearson Education: New York, NY, USA, 2003. [Google Scholar]
- Regehr, M.T.; Ayoub, A. An Elementary Proof that Q-learning Converges Almost Surely. arXiv 2021, arXiv:2108.02827. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Strategy | |
|---|---|
| Multi-disciplinary | [2,19,20,21,22,24,28,29,30] |
| [36,38,40,44,46,52,57] | |
| ML-based | [39,41,42,43,51,53,54,55,56] |
| Game-theory-based | [26,32,48] |
| Evolutionary/multi-objective-based | [3,37,47,49,50] |
| Sets and Indices | |
|---|---|
| and | State and action spaces for time slot t and iteration |
| i, j | Indices of cloud users and cloud data centres |
| ℓ, L | Iteration number and number of training episodes in Q-learning |
| System Parameters | |
| t and | time slot/frame parameter and time frame period |
| , , , , k, | Some positive constants |
| Variables | |
| , | Number of CDCs and cloud users for time t |
| ,, , | Total assigned CDCN resources to user i at t |
| ,, , | assigned CDC j resources assigned to user i at t |
| ,, , | Relative resource prices at time t |
| , | Unit time per unit resource price of each storage and bandwidth unit at time t |
| Energy dissipation price for CDC j at time t | |
| ,, | Positive cloud energy consumption parameters at time slot t |
| Cloud user/customer utility function | |
| Utility of cloud provider at slot t | |
| ,, , | Existing CP resource pool at time t |
| Parameter | Value |
|---|---|
| Number of users (M) | 5 (small), 20 (medium), 50 (large) |
| Number of data centres (N) | 6 |
| Minimum user bandwidth () | 100 Mbps |
| Minimum user CPU cores () | 1 Core |
| Minimum user RAM () | 1 Gigabyte |
| Minimum user storage () | 100 Megabytes |
| Minimum data centre racks | 10 |
| Total cloud provider racks | 500 |
| Maximum cloud provider utility | 20 |
| Maximum achievable user utility | 5 |
| 0.8 | |
| 0.1, 0.2, 0.5 | |
| 0.1, 0.2, 0.5 | |
| , i = 1, …,4 | 5 |
| (, , , , , , ) | (0.01, 0.1, 0.0001, 0.001, 0.1, 0.1, 0.1) |
| , i = 1, …,7 | 5 |
| 0.05 | |
| 0.5 | |
| 0.0005 | |
| 0.5 | |
| 0.001 | |
| L | 10,000 |
| Algorithm | |||
|---|---|---|---|
| CCEA | 2.93 | 28.03 | 35.993 |
| QLRA | 1.54 | 27.7 | 35.931 |
| Xu et al. | 3.44 | 26.12 | 29.241 |
| Li et al. | 7.45 | 27.23 | 33.031 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Goudarzi, P.; Hosseinpour, M.; Goudarzi, R.; Lloret, J. Holistic Utility Satisfaction in Cloud Data Centre Network Using Reinforcement Learning. Future Internet 2022, 14, 368. https://doi.org/10.3390/fi14120368
Goudarzi P, Hosseinpour M, Goudarzi R, Lloret J. Holistic Utility Satisfaction in Cloud Data Centre Network Using Reinforcement Learning. Future Internet. 2022; 14(12):368. https://doi.org/10.3390/fi14120368
Chicago/Turabian StyleGoudarzi, Pejman, Mehdi Hosseinpour, Roham Goudarzi, and Jaime Lloret. 2022. "Holistic Utility Satisfaction in Cloud Data Centre Network Using Reinforcement Learning" Future Internet 14, no. 12: 368. https://doi.org/10.3390/fi14120368
APA StyleGoudarzi, P., Hosseinpour, M., Goudarzi, R., & Lloret, J. (2022). Holistic Utility Satisfaction in Cloud Data Centre Network Using Reinforcement Learning. Future Internet, 14(12), 368. https://doi.org/10.3390/fi14120368