
Forecasting Students Dropout: A UTAD University Study

 , , ,
, , ,  and
and
Abstract
:1. Introduction
2. Background Theory and Literature Review
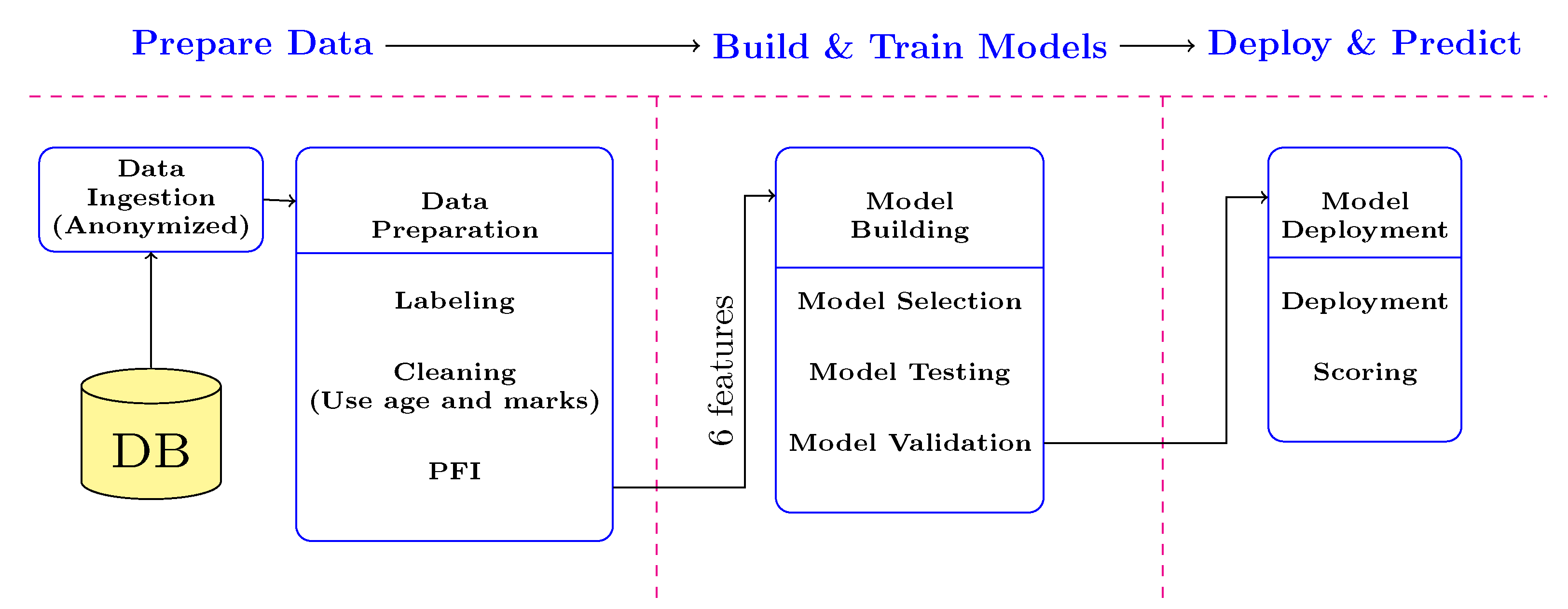
3. Data and Methods
3.1. Data Collection
3.2. Artificial Neural Networks
3.3. Ensemble Methods
3.3.1. Random Forests
3.3.2. Gradient Boosting
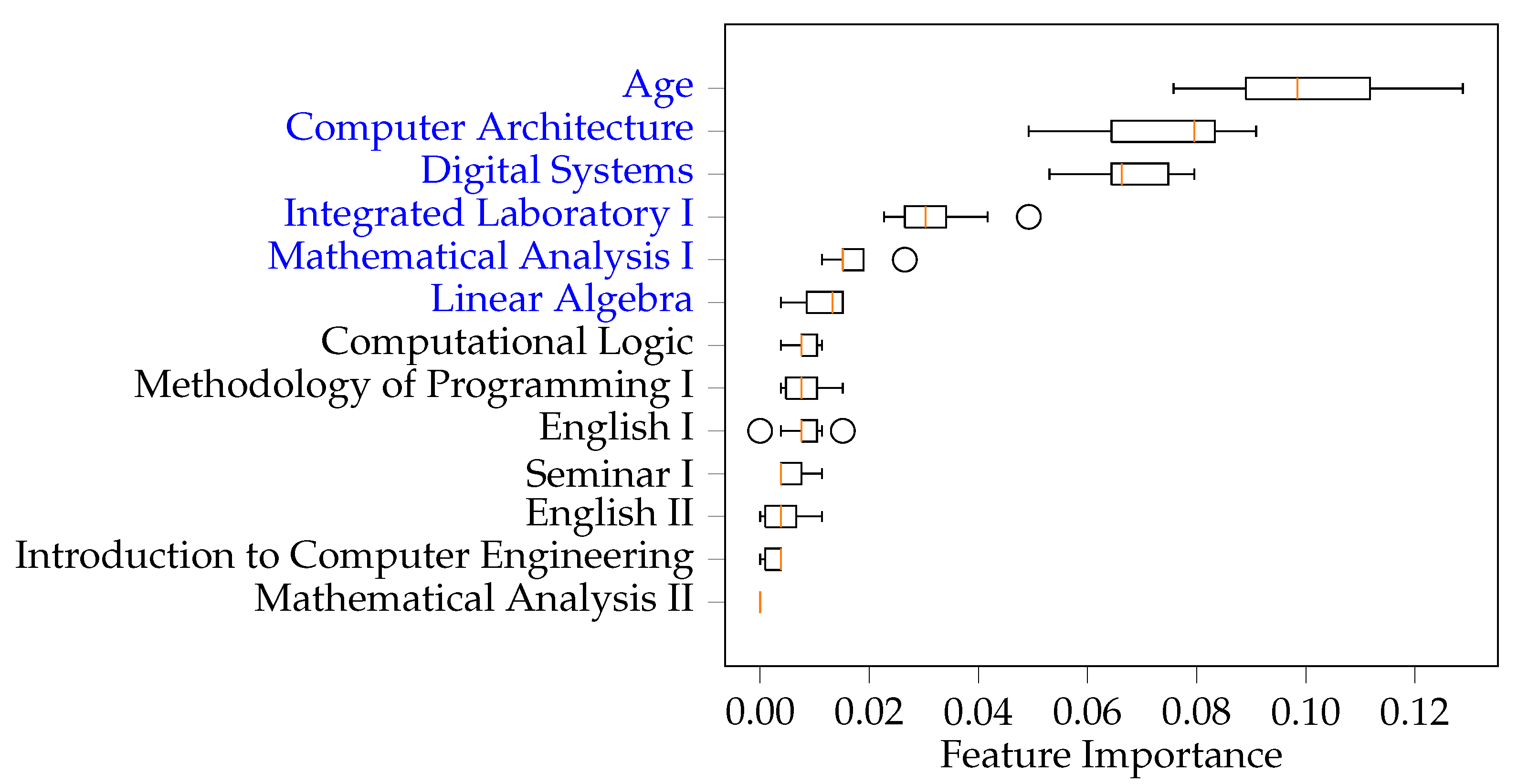
3.4. Permutation Feature Importance
3.5. Random Over-Sampling
3.6. Data Pre-Processing
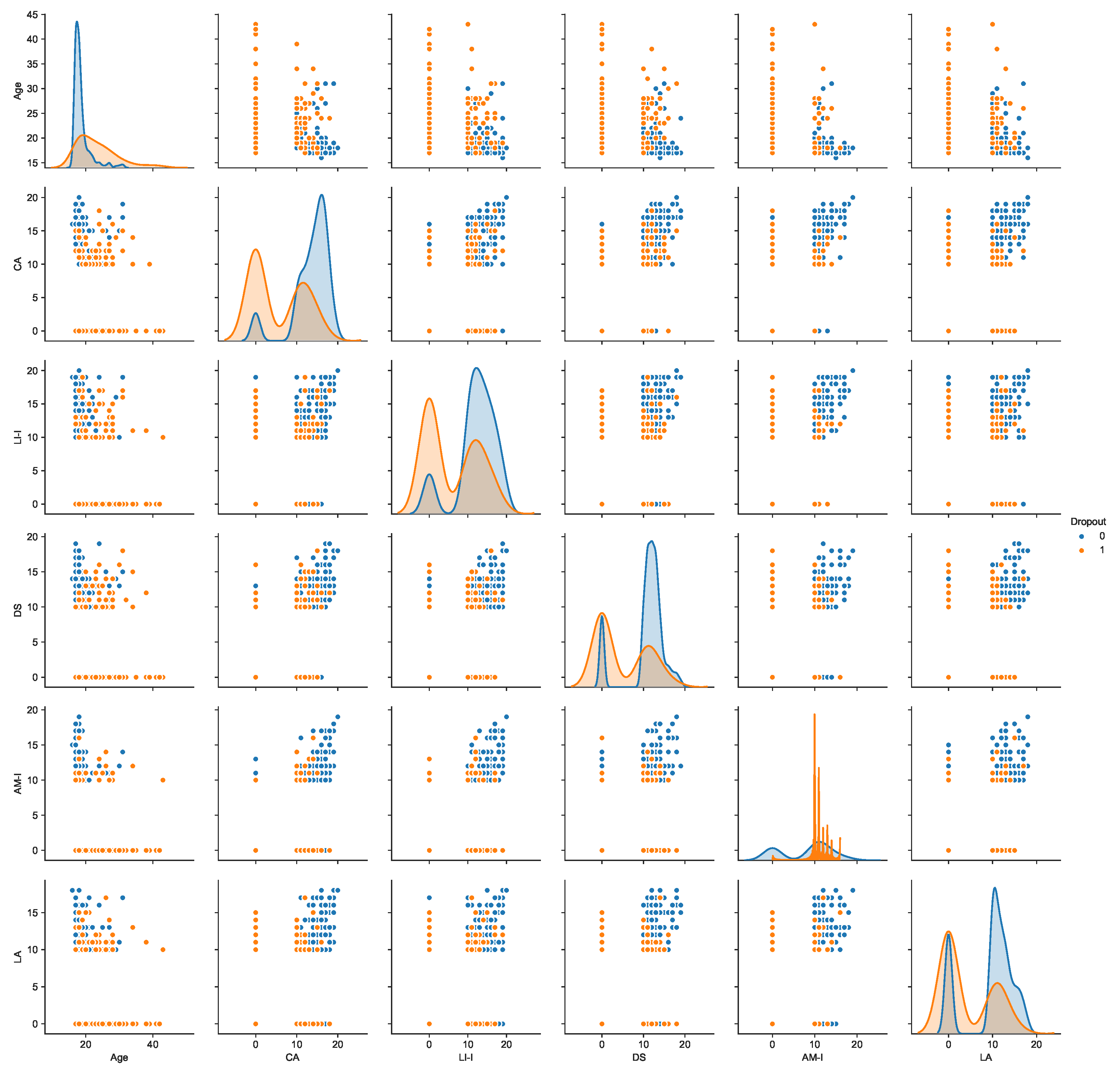
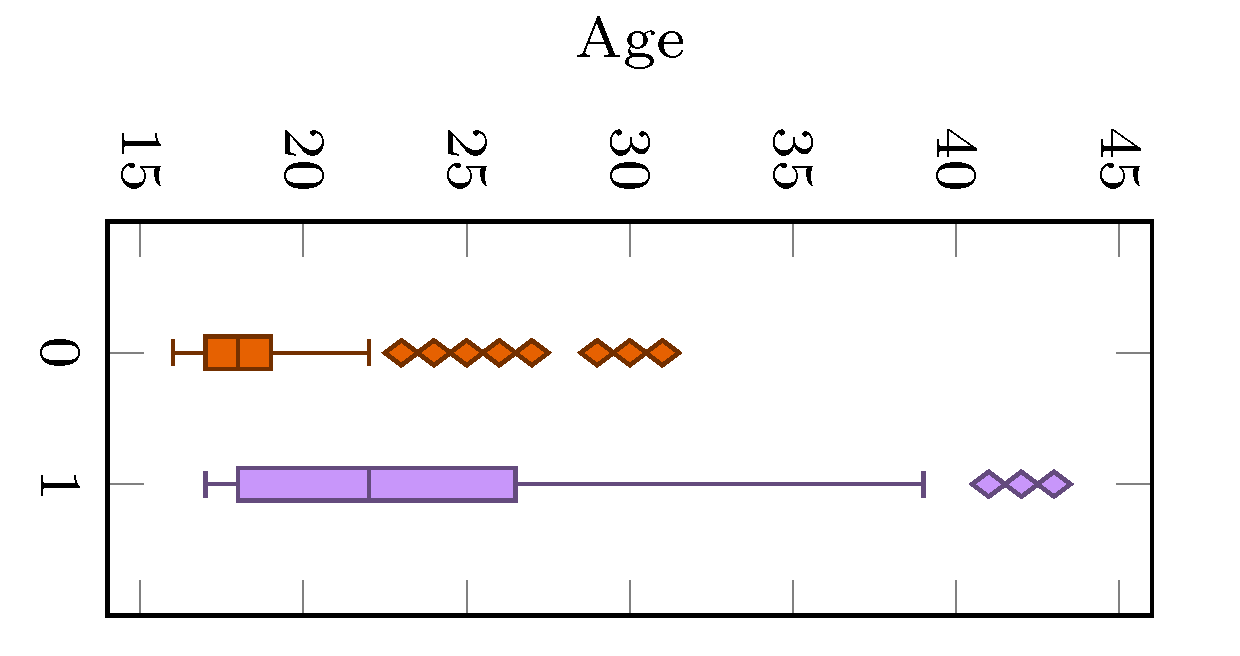
4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| ACC | Accuracy |
| ADA | ADABoost |
| Age | Age |
| ANN | Artificial Neural Network |
| AUC | Area Under the Curve |
| CA | Computer Architecture (CU) |
| CL | Computational Logic (CU) |
| CNN | Convolutional Neural Networks |
| CU | Curricular Unit |
| DGEEC | Direção Geral de Estatística a Educação e Ciência |
| DS | Digital Systems (CU) |
| DT | Decision Tree |
| E-I | English I (CU) |
| E-II | English II (CU) |
| GA | Genetic Algorithm |
| GB | Gradient Boosted Tree |
| ICE | Introduction to Computer Engineering (CU) |
| IL-I | Integrated Laboratory I (CU) |
| KNN | K-Nearest Neighbor |
| LA | Linear Algebra (CU) |
| LG | logistic regression |
| LSTM | Long Short-Time Memory |
| MA-I | Mathematical Analysis I (CU) |
| MA-II | Mathematical Analysis II (CU) |
| ML | Machine Learning |
| MLP | MultiLayer Percepton |
| MP-I | Methodology of Programming I (CU) |
| NB | Naïve Bayes |
| RF | Random Forest |
| ROC | Operating Characteristic Curve |
| S-I | Seminar I (CU) |
| SVM | Suppor Vector Machine |
| UTAD | Universidade de Trás-os-Montes e Alto Douro |
| XGB | Extra Boosted Tree |
References
- Engrácia, P.; Oliveira, J.; DGEEC. Percursos no Ensino Superior 2018. Available online: https://www.dgeec.mec.pt/np4/292/%7B$clientServletPath%7D/?newsId=516&fileName=DGEEC_SituacaoApos4AnosLicenciaturas.pdf (accessed on 17 January 2022).
- Siri, A. Predicting Students’ Dropout at University Using Artificial Neural Networks. Ital. J. Sociol. Educ. 2015, 7, 225–247. [Google Scholar]
- Queiroga, E.M.; Lopes, J.L.; Kappel, K.; Aguiar, M.; Araújo, R.M.; Munoz, R.; Villarroel, R.; Cechinel, C. A Learning Analytics Approach to Identify Students at Risk of Dropout: A Case Study with a Technical Distance Education Course. Appl. Sci. 2020, 10, 3998. [Google Scholar] [CrossRef]
- Mubarak, A.A.; Cao, H.; Hezam, I.M. Deep analytic model for student dropout prediction in massive open online courses. Comput. Electr. Eng. 2021, 93, 107271. [Google Scholar] [CrossRef]
- Dass, S.; Gary, K.; Cunningham, J. Predicting Student Dropout in Self-Paced MOOC Course Using Random Forest Model. Information 2021, 12, 476. [Google Scholar] [CrossRef]
- Alban, M.; Mauricio, D. Neural networks to predict dropout at the universities. Int. J. Mach. Learn. Comput. 2019, 9, 149–153. [Google Scholar] [CrossRef] [Green Version]
- Plagge, M. Using Artificial Neural Networks to predict first-year traditional students second year retention rates. In Proceedings of the Annual Southeast Conference, Savannah, GA, USA, 4–6 April 2013; ACM Press: New York, NY, USA, 2013; p. 1. [Google Scholar] [CrossRef]
- Chung, J.Y.; Lee, S. Dropout early warning systems for high school students using machine learning. Child. Youth Serv. Rev. 2019, 96, 346–353. [Google Scholar] [CrossRef]
- Pereira, R.T.; Zambrano, J.C. Application of decision trees for detection of student dropout profiles. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 528–531. [Google Scholar]
- Fernández-García, A.J.; Preciado, J.C.; Melchor, F.; Rodriguez-Echeverria, R.; Conejero, J.M.; Sánchez-Figueroa, F. A real-life machine learning experience for predicting university dropout at different stages using academic data. IEEE Access 2021, 9, 133076–133090. [Google Scholar] [CrossRef]
- Hutagaol, N.; Suharjito, S. Predictive modelling of student dropout using ensemble classifier method in higher education. Adv. Sci. Technol. Eng. Syst. J. 2019, 4, 206–211. [Google Scholar] [CrossRef] [Green Version]
- Kiss, B.; Nagy, M.; Molontay, R.; Csabay, B. Predicting dropout using high school and first-semester academic achievement measures. In Proceedings of the 2019 17th International Conference on Emerging eLearning Technologies and Applications (ICETA), Starý Smokovec, Slovakia, 21–22 November 2019; pp. 383–389. [Google Scholar]
- Dharmawan, T.; Ginardi, H.; Munif, A. Dropout detection using non-academic data. In Proceedings of the 2018 4th International Conference on Science and Technology (ICST), Yogyakarta, Indonesia, 7–8 August 2018; pp. 1–4. [Google Scholar]
- Hasbun, T.; Araya, A.; Villalon, J. Extracurricular activities as dropout prediction factors in higher education using decision trees. In Proceedings of the 2016 IEEE 16th International Conference on Advanced Learning Technologies (ICALT), Yogyakarta, Indonesia, 7–8 August 2016; pp. 242–244. [Google Scholar]
- Mduma, N.; Kalegele, K.; Machuve, D. A survey of Machine Learning Approaches and Techniques for Student Dropout Prediction 2019. Available online: https://dspace.nm-aist.ac.tz/handle/20.500.12479/71 (accessed on 17 January 2022).
- de Oliveira, C.F.; Sobral, S.R.; Ferreira, M.J.; Moreira, F. How Does Learning Analytics Contribute to Prevent Students’ Dropout in Higher Education: A Systematic Literature Review. Big Data Cogn. Comput. 2021, 5, 64. [Google Scholar] [CrossRef]
- Kriesel, D. Neural Networks. 2007. Available online: https://www.dkriesel.com/_media/science/neuronalenetze-en-zeta2-2col-dkrieselcom.pdf (accessed on 17 January 2022).
- Zhou, Z.H. Ensemble Learning. In Encyclopedia of Biometrics; Springer: Boston, MA, USA, 2009; pp. 270–273. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2000; Volume 1857, pp. 1–15. [Google Scholar] [CrossRef] [Green Version]
- Brodley, C.E.; Friedl, M.A. Decision tree classification of land cover from remotely sensed data. Remote Sens. Environ. 1997, 61, 399–409. [Google Scholar] [CrossRef]
- Trainor, P.J.; Yampolskiy, R.V.; DeFilippis, A.P. Wisdom of artificial crowds feature selection in untargeted metabolomics: An application to the development of a blood-based diagnostic test for thrombotic myocardial infarction. J. Biomed. Inform. 2018, 81, 53–60. [Google Scholar] [CrossRef] [PubMed]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobot. 2013, 7, 21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. Association for Computing Machinery, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef] [Green Version]
- Dorogush, A.V.; Ershov, V.; Gulin, A. CatBoost: Gradient boosting with categorical features support. arXiv 2018, arXiv:1810.11363. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Vishwakarma, G.; Sonpal, A.; Hachmann, J. Metrics for Benchmarking and Uncertainty Quantification: Quality, Applicability, and Best Practices for Machine Learning in Chemistry. Trends Chem. 2021, 3, 146–156. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Work | Features | Methods | Metrics | Result |
|---|---|---|---|---|
| Alban and Mauricio [6] | Personal | ANN | ACC | 0.963 |
| Knowledge | RNN | ACC | 0.968 | |
| Chung and Lee [8] | Personal | RF | ACC | 0.95 |
| Test marks | AUC | 0.97 | ||
| Attendance | Sensitivity | 0.85 | ||
| Volunteer | Specificity | 0.95 | ||
| Dass et al. [5] | Activity | RF | F1-score | 0.875 |
| AUC | 0.945 | |||
| ACC | 0.875 | |||
| Recall | 0.875 | |||
| Precision | 0.88 | |||
| Dharmawan et al. [13] | Demography | DT | ACC | 0.660 |
| Economic | SVM | ACC | 0.660 | |
| Social iteraction | KNN | ACC | 0.564 | |
| Motivation | ||||
| Personal | ||||
| Fernádez-García et al. [10] | Marks | GB | ACC | 0.682 |
| Personal | RF | ACC | 0.686 | |
| SVM | ACC | 0.686 | ||
| Ensemble | ACC | 0.670 | ||
| Hasbun et al. [14] | Academic | DT | ACC | 0.793 |
| Personal | ACC | 0.939 | ||
| Sports | ||||
| High School data | ||||
| Hutagaol et al. [11] | Academic | KNN | ACC | 0.753 |
| Demography | Naïve Bayes | ACC | 0.629 | |
| DT | ACC | 0.649 | ||
| GB | ACC | 0.791 | ||
| Kiss et al. [12] | Academic | GB | ACC | 0.680-0.858 |
| Personal | XGB | Precision | 0.670–0.863 | |
| High School data | MLP | Recall | 0.735–0.818 | |
| AUC | 0.729–0.920 | |||
| Mubarak et al. [4] | Activity | CNN-LSTM | AUC | 0.76–0.86 |
| Deep Neural Network | F1-score | 0.86–0.89 | ||
| SVM | Precision | 0.90–0.97 | ||
| Linear Regression | Recall | 0.79–0.88 | ||
| Pereira and Zambrano [9] | Marks | DT | Confidence | 0.800 |
| SocioEonomic | ||||
| Personal | ||||
| Institutional | ||||
| Plagge [7] | Academic | ANN | ACC | 0.750 |
| Queiroga et al. [3] | Activity | GA (ADA, DT, RF, MLP, LG) | AUC | 0.845 |
| Feature Name | Acronym | Curricular Unit (CU) | Scale |
|---|---|---|---|
| Age | Age | Ordinal | |
| City | Nominal | ||
| Father Employment Status | Nominal | ||
| Father Education | Nominal | ||
| Father Profession | Nominal | ||
| Mother Employment Status | Nominal | ||
| Mother Education | Nominal | ||
| Mother Profession | Nominal | ||
| Final Grade | Ordinal | ||
| Graduation Year | Ordinal | ||
| Registration Status | Nominal | ||
| Computational Logic | CL | Yes | Ordinal |
| Computer Architecture | CA | Yes | Ordinal |
| Digital Systems | DS | Yes | Ordinal |
| English I | E-I | Yes | Ordinal |
| English II | E-II | Yes | Ordinal |
| Integrated Laboratory I | IL-I | Yes | Ordinal |
| Introduction to Computer Engineering | ICE | Yes | Ordinal |
| Linear Algebra | LA | Yes | Ordinal |
| Mathematical Analysis I | MA-I | Yes | Ordinal |
| Mathematical Analysis II | MA-II | Yes | Ordinal |
| Methodology of Programming I | MP-I | Yes | Ordinal |
| Seminar I | S-I | Yes | Ordinal |
| Model | Hyperparameters |
|---|---|
| CatBoost | iterations = 50 |
| learning_rate = 0.9 | |
| l2_leaf_reg = 11 | |
| class_weights = [1, 1.67] | |
| eval_metric = AUC | |
| max_depth = 1 | |
| Random Forest | class_weight = [1, 1.67] |
| max_depth = 7 | |
| min_samples_leaf = 2 | |
| min_samples_split = 10 | |
| XGBoost | learning_rate = 0.15 |
| scale_pos_weight = 1.67 | |
| colsample_bytree = 0.7 | |
| n_estimators = 100 | |
| min_child_weight = 7 | |
| max_depth = 5 | |
| gamma = 0.4 | |
| ANN | activation = logistic |
| alpha = 0.001 | |
| early_stopping = True | |
| hidden_layer_sizes = 12 | |
| learning_rate_init = 0.6 |
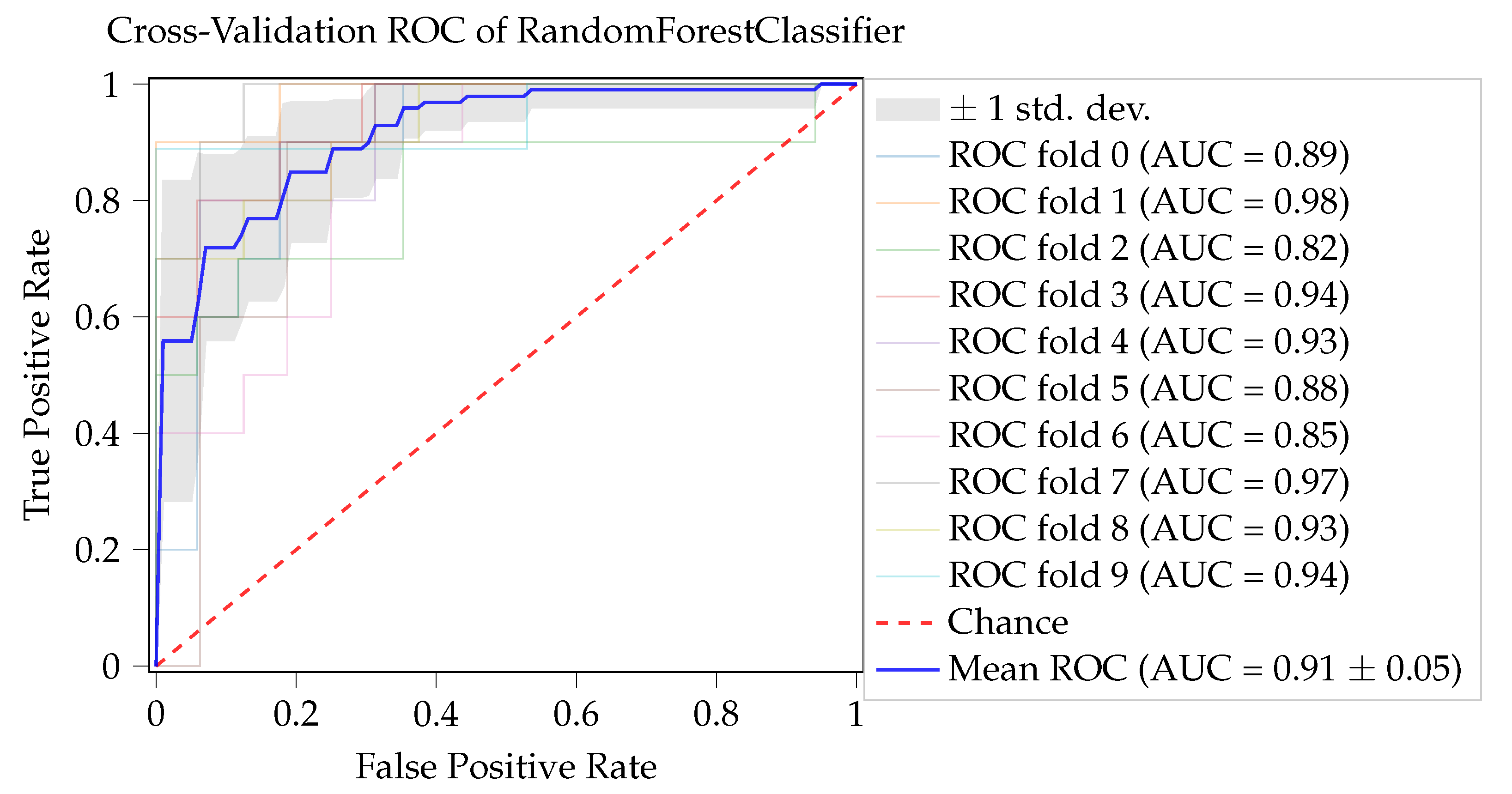
| Precision 1 | Recall 1 | F1-Score 1 | AUROC 1 | Accuracy 1 | |
|---|---|---|---|---|---|
| CatBoost | |||||
| Random Forest | |||||
| XGBoost | |||||
| ANN |
| Precision | Recall | F1-Score | AUROC | Accuracy | |
|---|---|---|---|---|---|
| CatBoost | 0.84 | 0.84 | 0.84 | 0.95 | 0.88 |
| Random Forest | 0.81 | 0.88 | 0.85 | 0.96 | 0.88 |
| XGBoost | 0.82 | 0.92 | 0.87 | 0.95 | 0.90 |
| ANN | 0.77 | 0.80 | 0.78 | 0.94 | 0.84 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moreira da Silva, D.E.; Solteiro Pires, E.J.; Reis, A.; de Moura Oliveira, P.B.; Barroso, J. Forecasting Students Dropout: A UTAD University Study. Future Internet 2022, 14, 76. https://doi.org/10.3390/fi14030076
Moreira da Silva DE, Solteiro Pires EJ, Reis A, de Moura Oliveira PB, Barroso J. Forecasting Students Dropout: A UTAD University Study. Future Internet. 2022; 14(3):76. https://doi.org/10.3390/fi14030076
Chicago/Turabian StyleMoreira da Silva, Diogo E., Eduardo J. Solteiro Pires, Arsénio Reis, Paulo B. de Moura Oliveira, and João Barroso. 2022. "Forecasting Students Dropout: A UTAD University Study" Future Internet 14, no. 3: 76. https://doi.org/10.3390/fi14030076
APA StyleMoreira da Silva, D. E., Solteiro Pires, E. J., Reis, A., de Moura Oliveira, P. B., & Barroso, J. (2022). Forecasting Students Dropout: A UTAD University Study. Future Internet, 14(3), 76. https://doi.org/10.3390/fi14030076