
ReSQoV: A Scalable Resource Allocation Model for QoS-Satisfied Cloud Services


Abstract
:1. Introduction
- A QoS remediation model (ReSQoV) using response time and throughput parameters.
- Cloud Service capacity model generation using Universal Scalability Law.
- Demonstrate the better performance of the model through simulation and comparison with other policy-based resource allocations.
- Validation of the Significance difference through the statistical test ANOVA.
2. Related Work

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Technique Used | Evaluation Metrics | Workload Dataset | Virtualization | Environment | Auto-Scaling Strategy |
|---|---|---|---|---|---|---|
| M. Etemadi [18] | Bayesian learning | CPU utilization, cost | rea world IoT workload trace | VM | Fog | Proactive |
| M. Ghobaei [19] | ANFIS | Response Time, Cost | synthetic workloads | VMs | Cloud | Proactive |
| M.S. Aslanpour [20] | Radial basis function neural network (RBFNN) | Response Time, SLA Violations Cost | Web server workload HP | VM | Cloud | Reactive |
| N. Chauhan [21] | Naive bayes | CPU utilization, response time, and memory utilization | real-time workload | VM | Cloud | Reactive |
| M. Ghobaei [22] | biogeography-based optimization (BBO), K-means, Bayesian learning | SLA violation ratio, cost, energy consumption | Clustering workload | VM | Cloud | Proactive |
| S. Agarwal [25] | Naïve Bayes (NB) and Random Forest (RF) | Memory, CPU usage | Google’s cluster trace dataset | VM | SOA | Reactive |
| M. Hani [26] | Support Vector Regression model | Availability, response time, and throughput | Private Cloud dataset | VM | Cloud | Reactive |
| R. Hemmet [27] | Naive Bayes and Random Forest Models | availability, throughput, response time | Google cluster | VM | Cloud | Reactive |
3. Proposed Approach
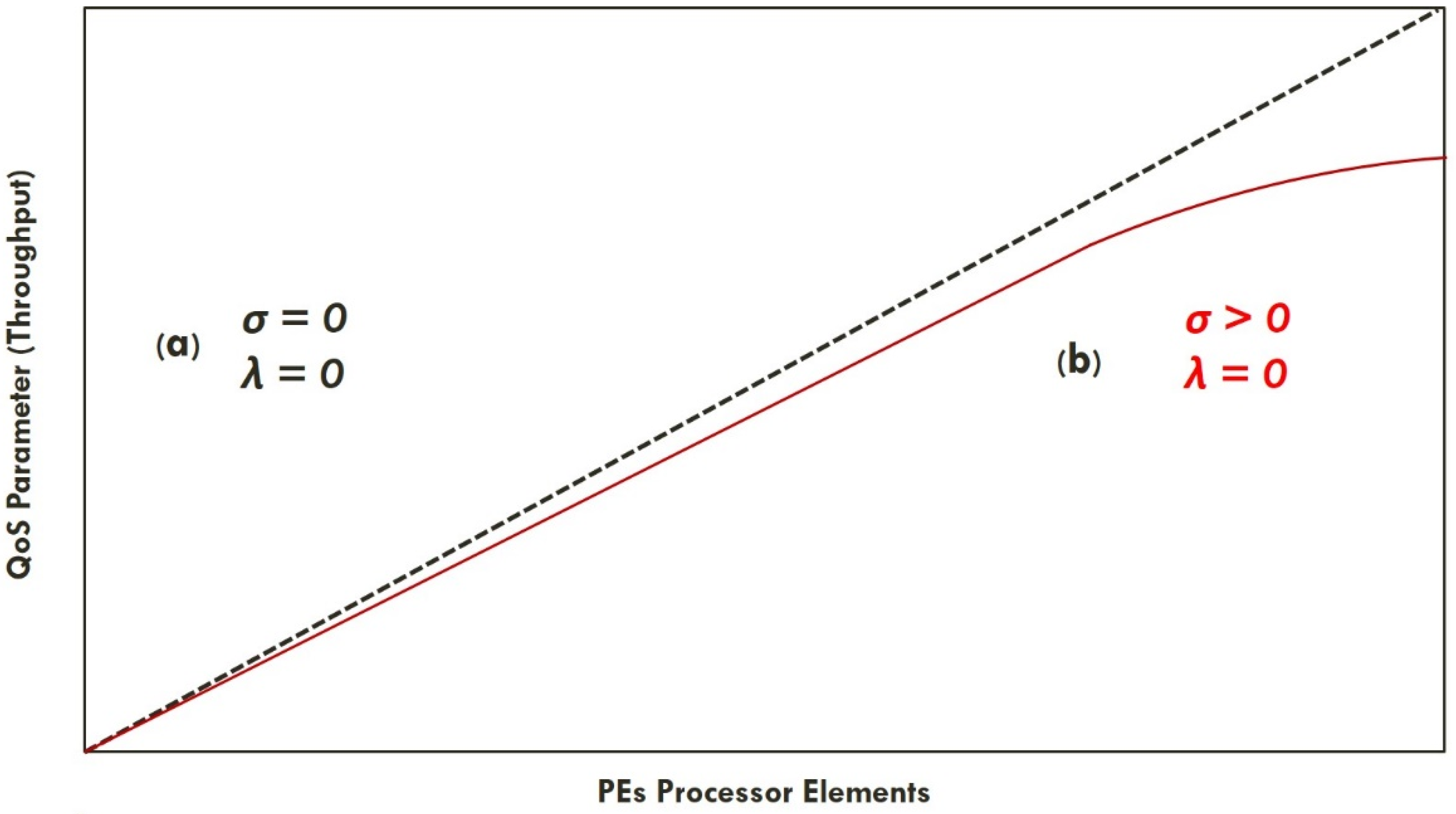
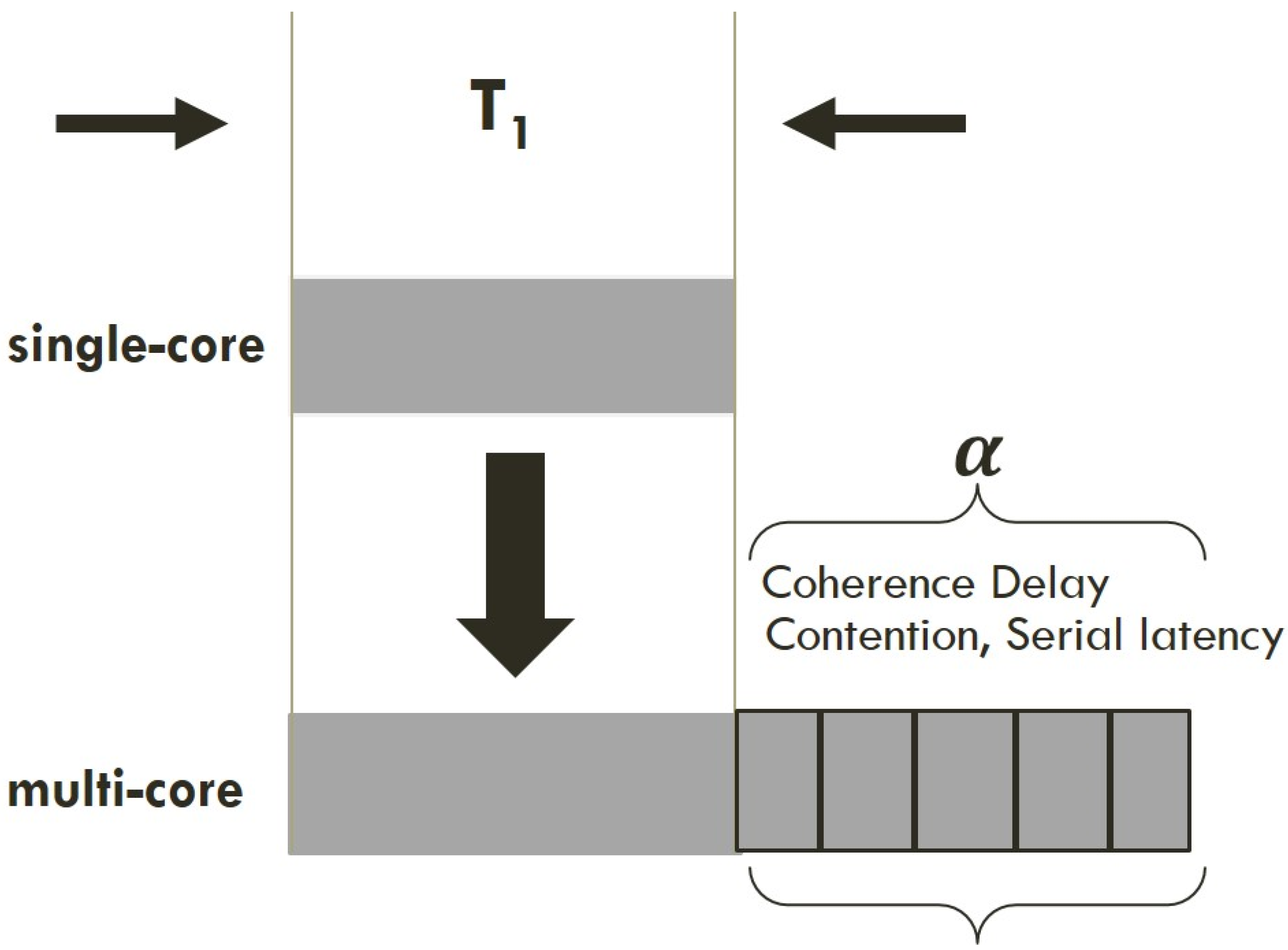
3.1. Scalable Resource Allocation
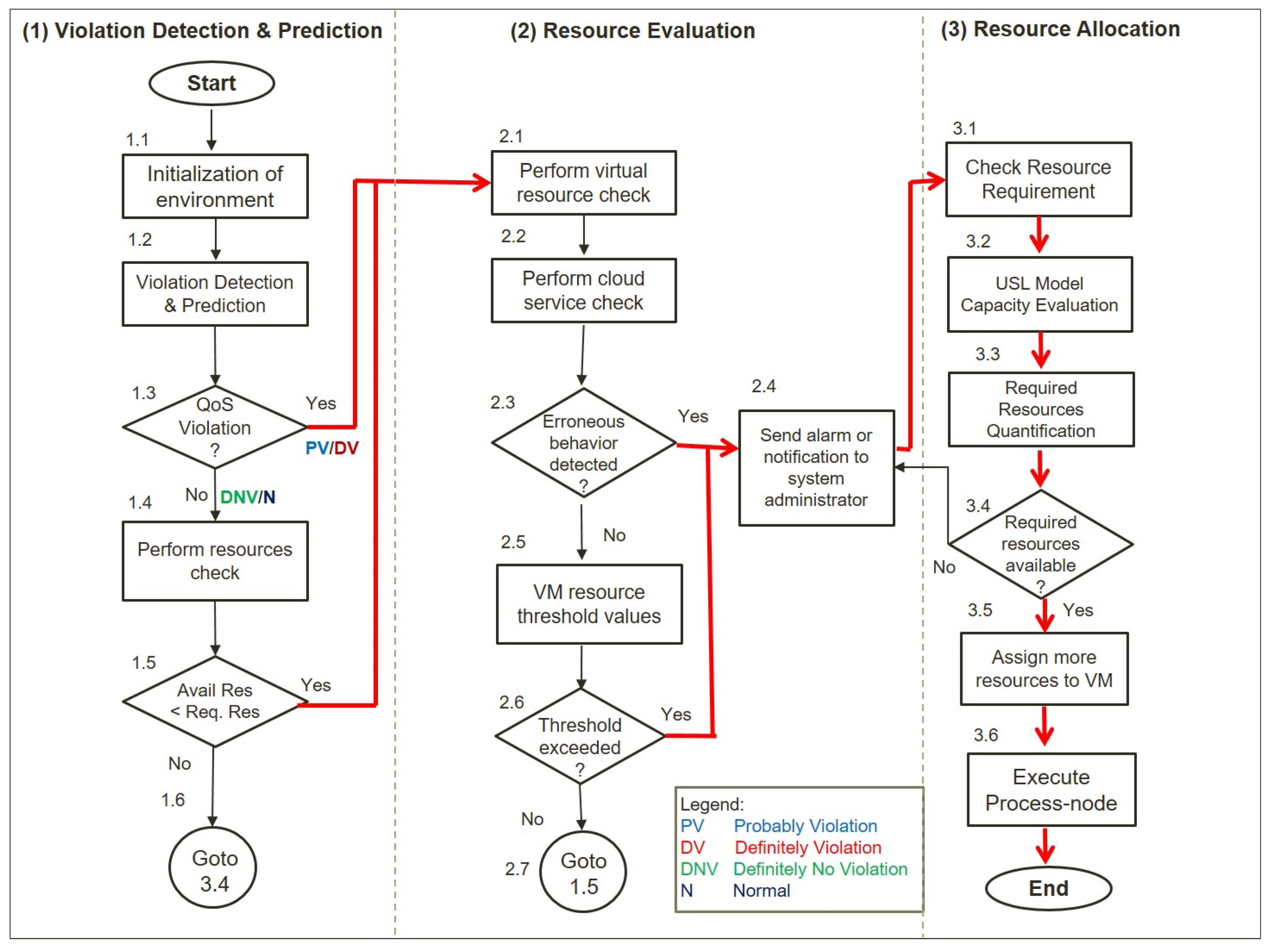
3.2. Elaboration and Flow of Proposed Approach
- Violation Detection and Prediction: the initialization of the environment, which includes keeping a log of the present status of the available resources. QoS monitored values of each process node are then compared to the fuzzy-if-then rules. If there is definitely no violation (DNV) or if the state is normal (N), then normally perform execute; otherwise, if there is a probably violation (PV) or a definitely violation (DV), then perform resource evaluation.
- Resource Evaluation: to find the corresponding defects, a resource evaluation is conducted. It searches for newly added cloud resource nodes and any other changes. A resource check is necessary to avoid performance deterioration, maximize resource use, and eliminate defects. To find flaws in the application, it runs software checks. It looks through the logs for any application-related events. The type of event (error, critical), the event id, and the time stamp are all stored. Check the following settings for resource thresholds: The program tracks memory and CPU consumption. The system generates notifications when the memory and CPU consumption values exceed the threshold.
| Algorithm 1. Resource Allocation after modelling Universal Scalability Law |
| (1) USL_Model_Generation with current Resources |
| (2) For (All Process_ node) |
| (3) Resource_Repository == USL_model_desired_resource |
| (4) if Violation_Decision != Normal && Definitely_No_Violation |
| (5) { if process_nodecurrent != Active Then |
| (6) process_nodecurrent == dead, log_data} |
| (7) elseif (process_nodecurrent == Active) |
| (8) { process_nodecurrent = assign_resources |
| (9) End if |
| (10) End If |
| (11) End for |
4. Experimental Setup and Scenario-Based Simulation
4.1. Dataset Generation
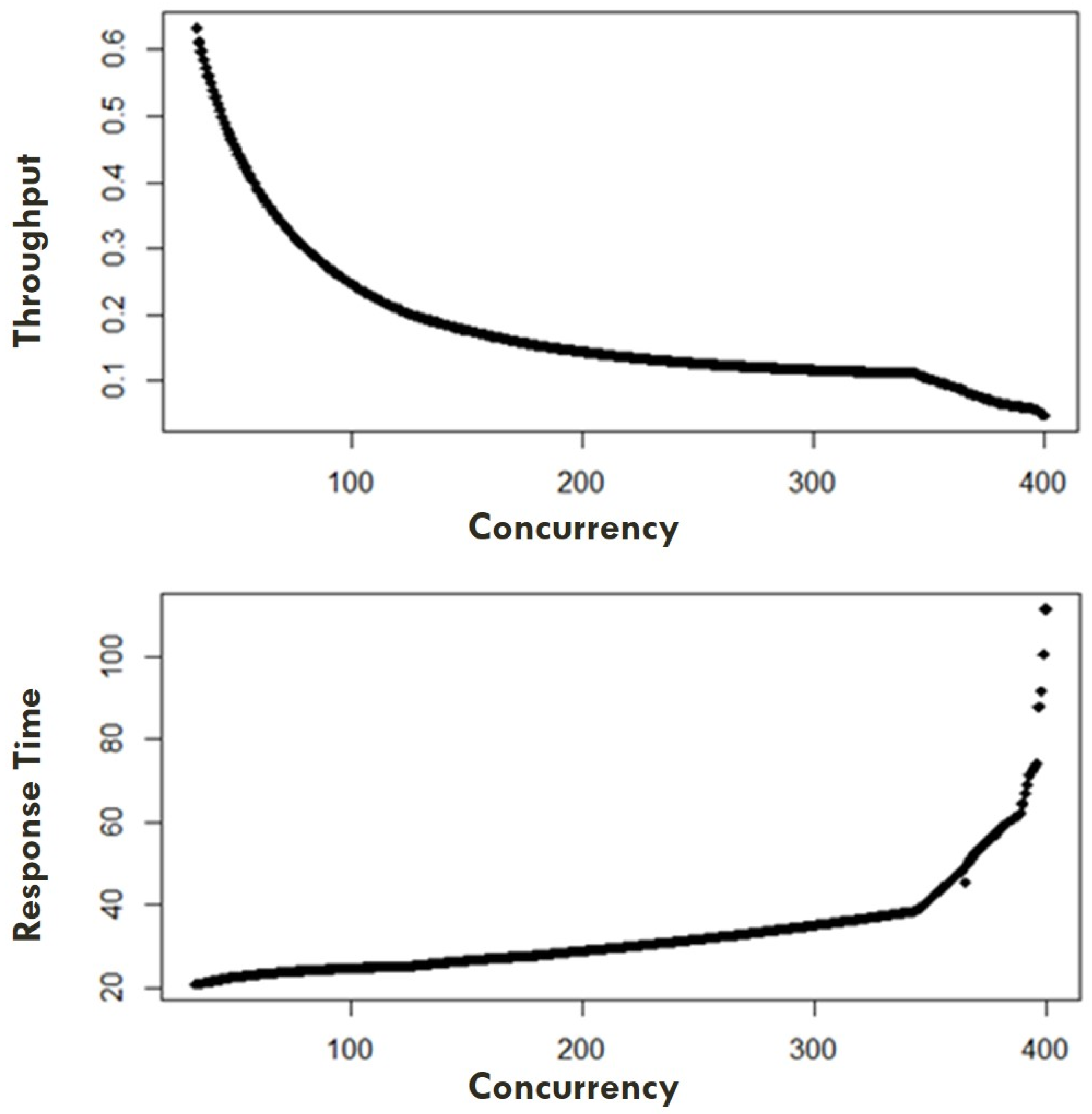
4.2. USL Model Generation Based on Concurrency and Throughput/Response Time
4.3. Scenario-Based Simulation
4.4. USL Model Generation
4.5. Experiment Scenarios
5. Experiment Results
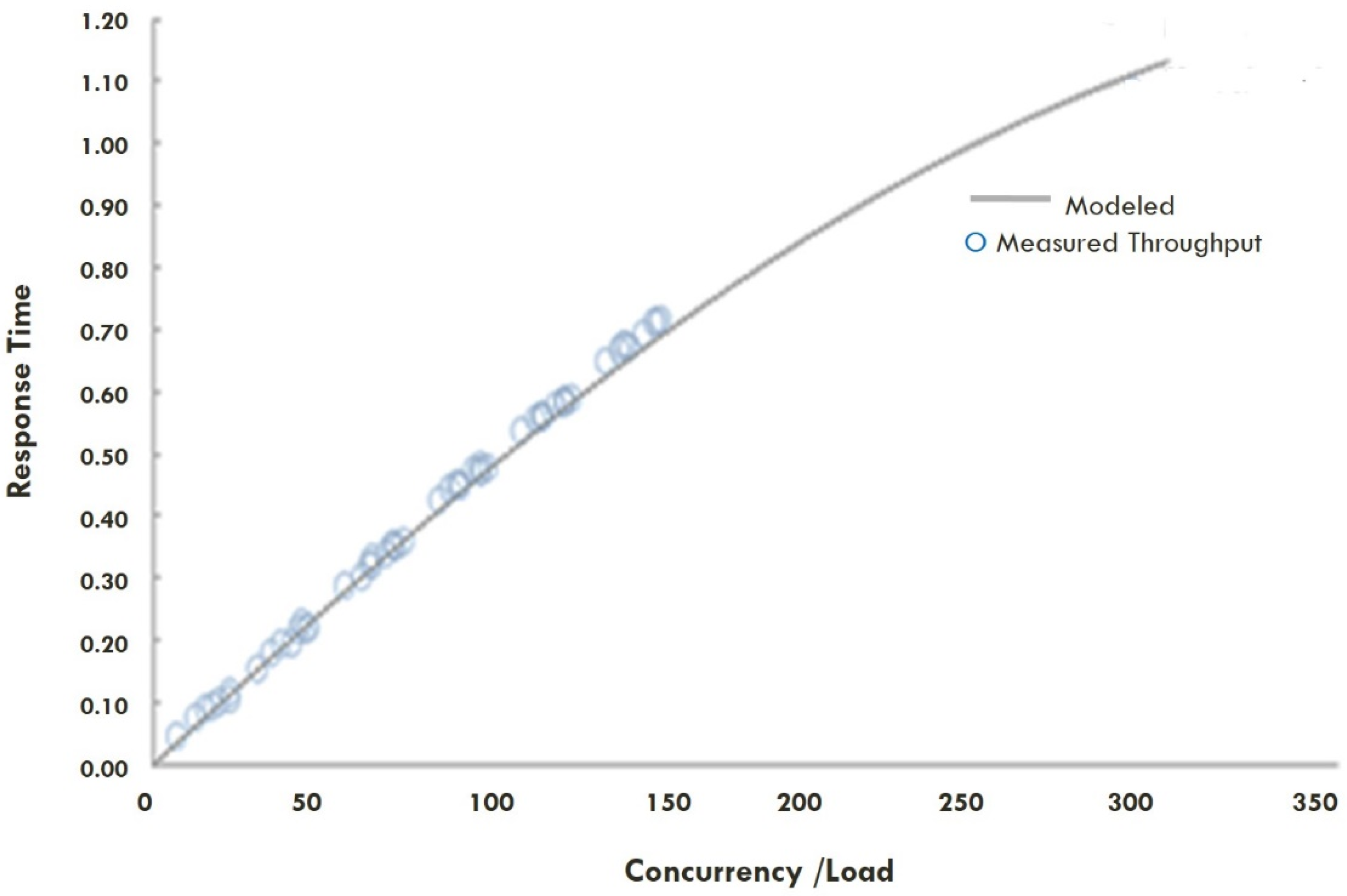
5.1. USL Model Efficiency
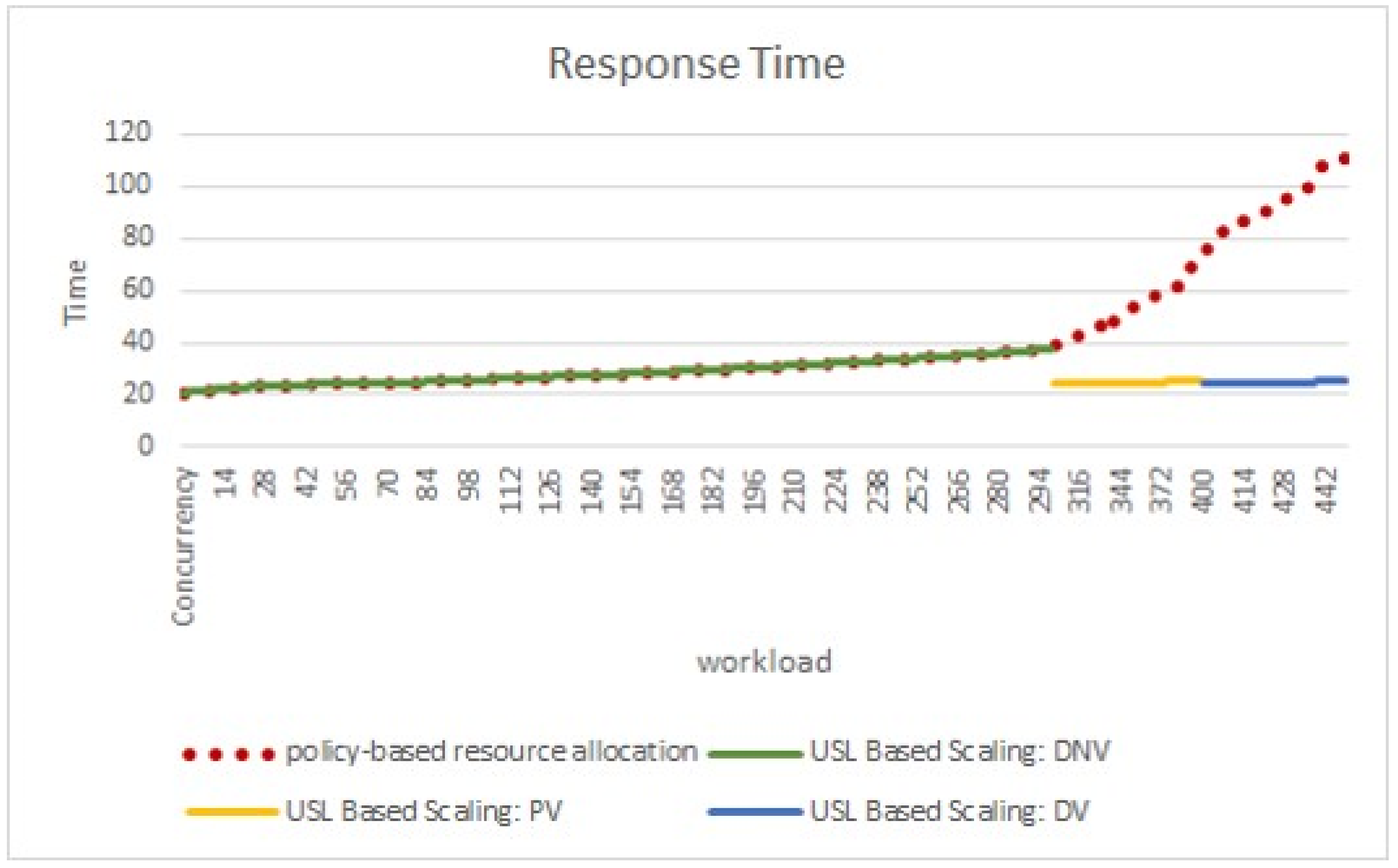
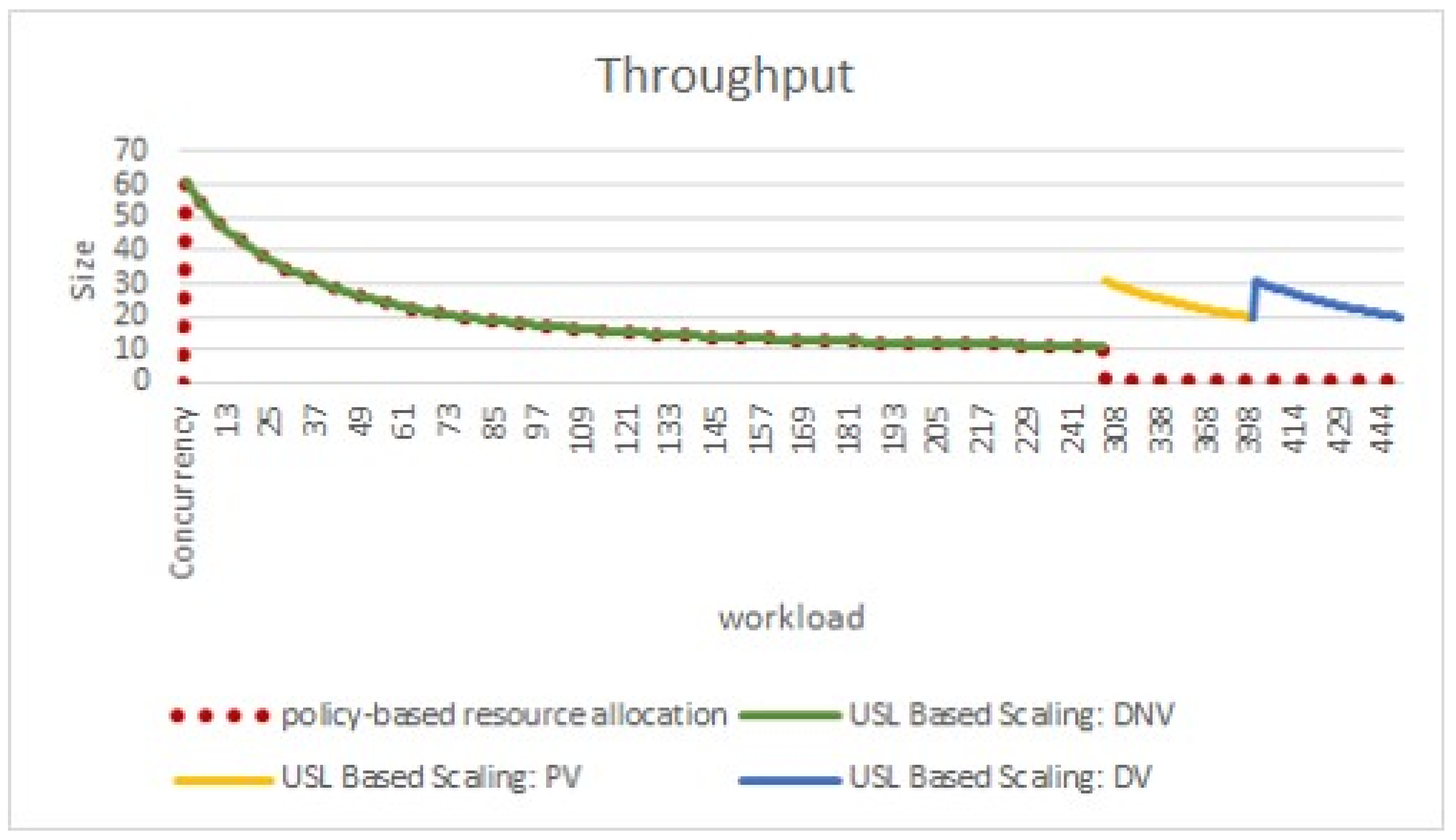
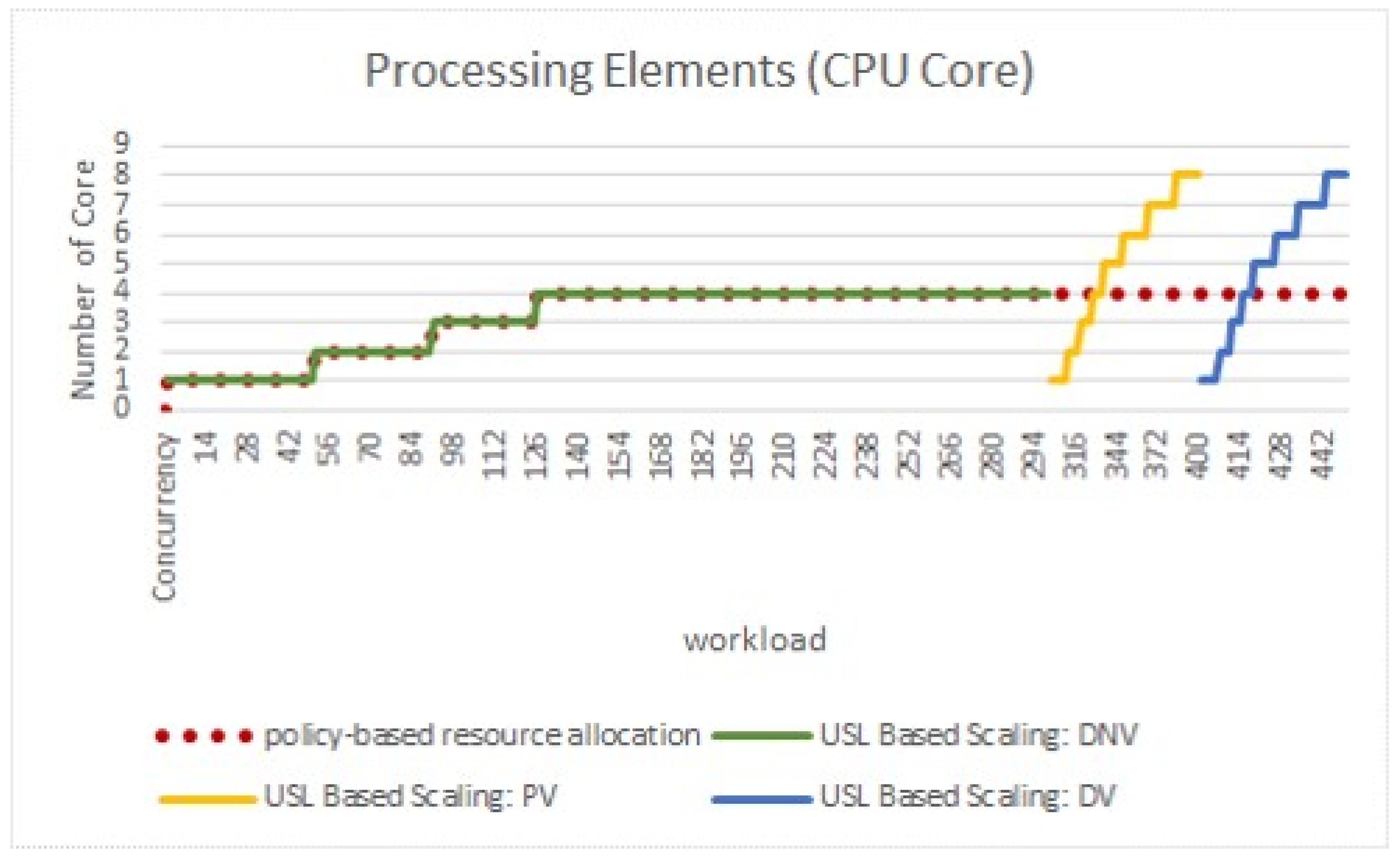
5.2. Scenarios Experiment Results
5.3. Analysis of Variance (ANOVA)
5.4. Threats to Validity
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kan, Y. A Cloud Computing Resource Optimal Allocation Scheme Based on Data Correlation Analysis. In Proceedings of the 4th International Conference on Electronics, Communications and Control Engineering, Seoul, Korea, 9–11 April 2021; ACM: New York, NY, USA; pp. 26–31. [Google Scholar] [CrossRef]
- Adnan Khan, M.; Kanwal, A.; Abbas, S.; Khan, F.; Whangbo, T. Intelligent Model for Predicting the Quality of Services Violation. Comput. Mater. Contin. 2022, 71, 3607–3619. [Google Scholar] [CrossRef]
- Khalil, M.I.K.; Ahmad, I.; Shah, S.A.A.; Jan, S.; Khan, F.Q. Energy Cost Minimization for Sustainable Cloud Computing Using Option Pricing. Sustain. Cities Soc. 2020, 63, 102440. [Google Scholar] [CrossRef]
- Gill, S.S.; Chana, I.; Singh, M.; Buyya, R. CHOPPER: An Intelligent QoS-Aware Autonomic Resource Management Approach for Cloud Computing. Cluster Comput. 2018, 21, 1203–1241. [Google Scholar] [CrossRef]
- Psychas, K.; Ghaderi, J. A Theory of Auto-Scaling for Resource Reservation in Cloud Services. ACM SIGMETRICS Perform. Eval. Rev. 2021, 48, 27–32. [Google Scholar] [CrossRef]
- Qu, C.; Calheiros, R.N.; Buyya, R. Auto-Scaling Web Applications in Clouds. ACM Comput. Surv. 2019, 51, 1–33. [Google Scholar] [CrossRef]
- Fuerst, A.; Ali-Eldin, A.; Shenoy, P.; Sharma, P. Cloud-Scale VM-Deflation for Running Interactive Applications On Transient Servers. In Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing, Stockholm, Sweden, 23–26 June 2020; ACM: New York, NY, USA, 2020; pp. 53–64. [Google Scholar]
- Santos, G.; Paulino, H.; Vardasca, T. QoE-Aware Auto-Scaling of Heterogeneous Containerized Services (and Its Application to Health Services). In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Brno, Czech Republic, 30 March–3 April 2020; pp. 242–249. [Google Scholar]
- Lehrig, S.; Eikerling, H.; Becker, S. Scalability, Elasticity, and Efficiency in Cloud Computing. In Proceedings of the 11th International ACM SIGSOFT Conference on Quality of Software Architectures, Montréal, QC, Canada, 4–8 May 2015; pp. 83–92. [Google Scholar]
- Dabbagh, M.; Hamdaoui, B.; Guizani, M.; Rayes, A. Energy-Efficient Resource Allocation and Provisioning Framework for Cloud Data Centers. IEEE Trans. Netw. Serv. Manag. 2015, 12, 377–391. [Google Scholar] [CrossRef]
- Vasu, R.; Nehru, E.I.; Ramakrishnan, G. Load Forecasting for Optimal Resource Allocation in Cloud Computing Using Neural Method Senior Technical Director, National Informatics Centre, Chennai, India. Middle East J. Sci. Res. 2016, 24, 1995–2002. [Google Scholar] [CrossRef]
- Mashayekhy, L.; Nejad, M.M.; Grosu, D.; Vasilakos, A.V. An Online Mechanism for Resource Allocation and Pricing in Clouds. IEEE Trans. Comput. 2016, 65, 1172–1184. [Google Scholar] [CrossRef]
- Goutam, S.; Yadav, A.K. Preemptable Priority based Dynamic Resource Allocation in Cloud Computing with Fault Tolerance. In Proceedings of the 2015 International Conference on Communication Networks (ICCN), Gwalior, India, 19–21 November 2015; pp. 278–285. [Google Scholar]
- Abdelmaboud, A.; Jawawi, D.N.A.; Ghani, I.; Elsafi, A.; Kitchenham, B. Quality of service approaches in cloud computing: A systematic mapping study. J. Syst. Softw. 2015, 101, 159–179. [Google Scholar] [CrossRef]
- Ardagna, D.; Casale, G.; Ciavotta, M.; Pérez, J.F.; Wang, W. Quality-of-service in cloud computing: Modeling techniques and their applications. J. Internet Serv. Appl. 2014, 5, 11. [Google Scholar] [CrossRef] [Green Version]
- Katyal, M.; Mishra, A. Application of Selective Algorithm for Effective Resource Provisioning in Cloud Computing Environment. Int. J. Cloud Comput. Serv. Arch. 2014, 4, 1–10. [Google Scholar] [CrossRef]
- Calheiros, R.; Ranjan, R.; Beloglazov, A.; De Rose, C.A.F.; Buyya, R. CloudSim: A toolkit for modeling and simulation of cloud computing environments and evaluation of resource provisioning algorithms. Softw. Pr. Exp. 2011, 41, 23–50. [Google Scholar] [CrossRef]
- Etemadi, M.; Ghobaei-Arani, M.; Shahidinejad, A. Resource provisioning for IoT services in the fog computing environment: An autonomic approach. Comput. Commun. 2020, 161, 109–131. [Google Scholar] [CrossRef]
- Ghobaei-Arani, M.; Khorsand, R.; Ramezanpour, M. An autonomous resource provisioning framework for massively multiplayer online games in cloud environment. J. Netw. Comput. Appl. 2019, 142, 76–97. [Google Scholar] [CrossRef]
- Aslanpour, M.S.; Dashti, S.E.; Ghobaei-Arani, M.; Rahmanian, A.A. Resource Provisioning for Cloud Applications: A 3-D, Provident and Flexible Approach; Springer: Manhattan, NY, USA, 2018; Volume 74. [Google Scholar]
- Chauhan, N.; Agrawal, R. Probabilistic Optimized Kernel Naive Bayesian Cloud Resource Allocation System. Wirel. Pers. Commun. 2022, 1–20. [Google Scholar] [CrossRef]
- Ghobaei-Arani, M. A workload clustering based resource provisioning mechanism using Biogeography based optimization technique in the cloud based systems. Soft Comput. 2021, 25, 3813–3830. [Google Scholar] [CrossRef]
- Shyam, G.K.; Manvi, S.S. Resource allocation in cloud computing using agents. In Proceedings of the 2015 IEEE International Advance Computing Conference (IACC), Banglore, India, 12–13 June 2015; pp. 458–463. [Google Scholar]
- Radhakrishnan, A.; Kavitha, V. Trusted Virtual Machine Allocation in Cloud Computing IaaS Service. Res. J. Appl. Sci. Eng. Technol. 2014, 7, 2921–2928. [Google Scholar] [CrossRef]
- Agarwal, S. An Approach of SLA Violation Prediction and QoS Optimization using Regression Machine Learning Techniques. Electron. Theses Diss. 2020, 1–93. [Google Scholar]
- Hani, A.F.M.; Paputungan, I.V.; Fadzil, M.H.; Vijanth, S.A. Manifold Learning in SLA Violation Detection and Prediction for Cloud-Based System. In Proceedings of the ICC ’17 Second International Conference on Internet of things, Data and Cloud Computing, Cambridge, UK, 22–23 March 2017; ACM: Cambridge, UK; pp. 1–5. [Google Scholar] [CrossRef]
- Hemmat, R.A.; Hafid, A. SLA Violation Prediction in Cloud Computing: A Machine Learning Perspective. 2016. Available online: https://www.researchgate.net/publication/311222705_SLA_Violation_Prediction_In_Cloud_Computing_A_Machine_Learning_Perspective (accessed on 10 March 2022).
- Chan, G.Y.; Khan, H.M.; Chua, F.F. Resource Scalability as Preventive and Remedial Measures for Cloud Service Violation. In Proceedings of the 2018 IEEE 6th International Conference on Future Internet of Things and Cloud (FiCloud), Barcelona, Spain, 6–8 August 2018; pp. 428–435. [Google Scholar]
- Khan, H.M.; Chan, G.Y.; Chua, F.-F. A Fuzzy Model for Detecting and Predicting Cloud Quality of Service Violation. J. Eng. Sci. Technol. 2018, 13, 58–77. [Google Scholar]
- Gunther, N.J. A General Theory of Computational Scalability Based on Rational Functions. arXiv 2008, arXiv:0808.1431. [Google Scholar]
- Gunther, N.J. Guerrilla Capacity Planning: A Tactical Approach to Planning for Highly Scalable Applications and Services. 2007. Available online: https://www.researchgate.net/publication/220689673_Guerrilla_capacity_planning_A_tactical_approach_to_planning_for_highly_scalable_applications_and_services (accessed on 10 March 2022).
- Filho, M.C.S.; Oliveira, R.L.; Monteiro, C.C.; Inacio, P.R.; Freire, M.M. CloudSim Plus: A Cloud Computing Simulation Framework Pursuing Software Engineering Principles for Improved Modularity, Extensibility and Correctness. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 400–406. [Google Scholar]
- Amazon Web Services, Inc. Amazon EC2 Instance Types—Amazon Web Services. 2019. Available online: https://aws.amazon.com/ec2/instance-types/ (accessed on 10 March 2022).
- Geekbench. Available online: https://browser.geekbench.com/v5/cpu (accessed on 10 March 2022).
- Cohen, E.A.; Moravec, H.P. Robot: Mere Machine to Transcendent Mind. Foreign Aff. 1999, 78, 131. [Google Scholar] [CrossRef]
- Möding, S. Using the Usl Package, Analyze System Scalability in R with the Universal Scalability Law. 2020. Available online: https://cran.r-project.org/web/packages/usl/vignettes/usl.pdf (accessed on 10 March 2022).
- Muller, K.E.; Fetterman, B.A. Regression and ANOVA: An Integrated Approach Using SAS Software; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2003. [Google Scholar]








| 1. Serial # | 2. Workload length (MIPS) | 3. Response Time (sec) | 4. Throughput (kbps) | 5. Workload Distribution (%age) | 6. ANFIS Decision Rules | 7. Decision Rule Distribution Percentile (%age) |
|---|---|---|---|---|---|---|
| 1 | 28,000 | 0.209 | 61.261 | 15% | Definitely No Violation (DNV) | 5% |
| 2 | 32,000 | 0.216 | 55.278 | 40% | ||
| 3 | 35,200 | 0.220 | 51.136 | 35% | ||
| 4 | 36,000 | 0.221 | 50.227 | 10% | ||
| 5 | 64,800 | 0.240 | 31.612 | 20% | Normal (N) | 80% |
| 6 | 123,600 | 0.267 | 18.043 | 30% | ||
| 7 | 205,600 | 0.322 | 12.960 | 40% | ||
| 8 | 264,000 | 0.374 | 11.607 | 10% | ||
| 9 | 278,800 | 0.407 | 10.843 | 15% | Probably Violation (PV) | 14% |
| 10 | 296,800 | 0.534 | 7.962 | 35% | ||
| 11 | 302,400 | 0.571 | 7.166 | 30% | ||
| 12 | 312,400 | 0.663 | 6.235 | 20% | ||
| 13 | 317,200 | 0.782 | 5.808 | 15% | Definitely Violation (DV) | 1% |
| 14 | 318,400 | 0.916 | 5.412 | 30% | ||
| 15 | 319,200 | 1.004 | 5.185 | 35% | ||
| 16 | 320,000 | 1.115 | 4.958 | 20% |
| Virtual Machine Configuration | |
|---|---|
| CPU | 1 Unit, Scalable Processor up to 56 Core |
| CPU Processing Power | 93,000 MI |
| RAM | 8 GB |
| Network Bandwidth | 100 Mbps |
| Min | 1Q | Median | 3Q | Max |
|---|---|---|---|---|
| −5.8866 | −1.1396 | 0.1346 | 2.0116 | 4.3765 |
| Estimate | Std. Error | t-Value | Pr (>|t|) | ||
|---|---|---|---|---|---|
| Contention σ | 1 | 0.053249 | 18.78 | <2 × 10−16 | *** |
| Coherence λ | 0.025887 | 0.001111 | 23.29 | <2 × 10−16 | *** |
| coefficient γ | 61.159017 | 2.588041 | 23.63 | <2 × 10−16 | *** |
| S # | Df | Sum Sq | Mean Sq | F value | Pr (>F) | ||
|---|---|---|---|---|---|---|---|
| 1 | System | 1 | 61.6 | 61.6 | 1236.281 | <2 × 10−16 | *** |
| 2 | Response Time | 1 | 0.1 | 0.1 | 2.396 | 0.123 | |
| 3 | Throughput | 1 | 515.5 | 515.5 | 10,345.388 | <2 × 10−16 | *** |
| 4 | System:Response Time | 1 | 0 | 0 | 0.076 | 0.783 | |
| 5 | System:Throughput | 1 | 1.7 | 1.7 | 34.05 | 2.252 × 10−8 | *** |
| 6 | Response Time:Thtoughput | 1 | 0.1 | 0.1 | 1.135 | 0.288 | |
| 7 | System:Res_Time:Throughput | 1 | 0.8 | 0.8 | 16.572 | 6.84 × 10−5 | *** |
| Residuals | 192 | 9.6 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, H.M.; Chua, F.-F.; Yap, T.T.V. ReSQoV: A Scalable Resource Allocation Model for QoS-Satisfied Cloud Services. Future Internet 2022, 14, 131. https://doi.org/10.3390/fi14050131
Khan HM, Chua F-F, Yap TTV. ReSQoV: A Scalable Resource Allocation Model for QoS-Satisfied Cloud Services. Future Internet. 2022; 14(5):131. https://doi.org/10.3390/fi14050131
Chicago/Turabian StyleKhan, Hassan Mahmood, Fang-Fang Chua, and Timothy Tzen Vun Yap. 2022. "ReSQoV: A Scalable Resource Allocation Model for QoS-Satisfied Cloud Services" Future Internet 14, no. 5: 131. https://doi.org/10.3390/fi14050131
APA StyleKhan, H. M., Chua, F. -F., & Yap, T. T. V. (2022). ReSQoV: A Scalable Resource Allocation Model for QoS-Satisfied Cloud Services. Future Internet, 14(5), 131. https://doi.org/10.3390/fi14050131