
Fraud Detection Using Neural Networks: A Case Study of Income Tax

 ,
,  ,
,
Abstract
:
1. Introduction
2. Related Work
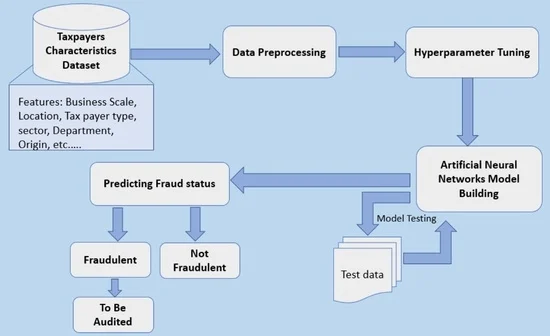
3. Methodology
3.1. Structure of Artificial Neural Networks
3.2. Model Architecture
3.3. Model Evaluation
3.4. Confusion Matrix
- True Positives (TP) are cases in which the taxpayer is predicted to be a fraudster and is, in fact, a fraudster.
- False Positives (FP) are cases in which the taxpayer is predicted to be a fraudster and is actually not a fraudster. This is also known as Type I error.
- True Negatives (TN) are cases in which the taxpayer is predicted not to be a fraudster and is not a fraudster.
- False Negatives (FN) are cases in which the taxpayer is predicted not to be a fraudster and is actually a fraudster. This case is most known as the Type II error, and it is a very risky error especially in tax fraud detection.
3.5. Feature Importance Evaluation
4. Results and Discussion
4.1. Data Description and Pre-Processing
4.2. Results
4.3. Test Result
4.4. Important Features
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features and values | Frequency | Non Fraudulent | Fraudulent |
|---|---|---|---|
| Province | |||
| KIGALI CITY | 5715 | 4550 | 1165 |
| EAST | 580 | 515 | 65 |
| WEST | 580 | 400 | 180 |
| SOUTH | 525 | 345 | 180 |
| NORTH | 440 | 375 | 65 |
| Scale | |||
| SMALL | 6300 | 5015 | 1285 |
| MEDIUM | 680 | 490 | 190 |
| MICRO | 475 | 445 | 30 |
| LARGE | 385 | 235 | 150 |
| Tax Payer Type Desc | |||
| NON INDIVIDUAL | 4295 | 3250 | 1045 |
| INDIVIDUAL | 3545 | 2935 | 610 |
| Registration Status | |||
| Yes | 7835 | 6185 | 1650 |
| NO | 5 | 0 | 5 |
| Sector | |||
| Services | 6585 | 5145 | 1440 |
| Industry | 1155 | 950 | 205 |
| Agriculture | 95 | 85 | 10 |
| OTHERS | 5 | 5 | 0 |
| Department | |||
| Customs | 5335 | 4550 | 1165 |
| Domestic | 580 | 515 | 65 |
| Filing Status | |||
| ONTIME | 7360 | 5800 | 1560 |
| LATE | 480 | 385 | 95 |
| Time of Business (years) | |||
| 0–5 | 7360 | 5800 | 1560 |
| 6–10 | 480 | 385 | 95 |
| 11–15 | 480 | 385 | 95 |
| 16–Above | 480 | 385 | 95 |
| Business origin | |||
| National | 7835 | 6185 | 1650 |
| International | 5 | 0 | 5 |
References
- Smelser, N.J.; Baltes, P.B. International Encyclopedia of the Social & Behavioral Sciences, 11th ed.; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- de la Feria, R. Tax Fraud and the Rule of Law; Oxford University Centre for Business Taxation: Oxford, UK, 2018. [Google Scholar]
- Tax Evasion Most Prevalent Financial Crime in Rwanda. Available online: https://www.newtimes.co.rw/news/tax-evasion-most-prevalent-financial-crime-rwanda (accessed on 25 August 2021).
- Using Analytics Successfully to Detect Fraud. Available online: https://assets.kpmg/content/dam/kpmg/pdf/2016/07/using-analytics-sucessfully-to-detect-fraud.pdf (accessed on 16 August 2021).
- Kültür, Y.; Çağlayan, M.U. Tax fraud and the rule of law. Expert Syst. 2017, 34, 12191. [Google Scholar] [CrossRef]
- González, P.C.; Velásquez, J.D. Characterization and detection of taxpayers with false invoices using data mining techniques. Expert Syst. Appl. 2013, 40, 1427–1436. [Google Scholar] [CrossRef]
- Dias, A.; Pinto, C.; Batista, J.; Neves, E. Signaling tax evasion, financial ratios and cluster analysis. BIS Q. Rev. 2016. [Google Scholar]
- Wu, R.S.; Ou, C.S.; Lin, H.; Chang, S.I.; Yen, D.C. Using data mining technique to enhance tax evasion detection performance. Expert Syst. Appl. 2012, 10, 8769–8777. [Google Scholar] [CrossRef]
- Asha, R.B.; Suresh Kumar, K.R. Credit card fraud detection using Artificial Neural Networks. Glob. Transitions Proc. 2021, 2, 35–41. [Google Scholar]
- Ghosh, S.; Douglas, L.R. Credit card fraud detection with a neural-network. In Proceedings of the Twenty-Seventh Hawaii International Conference, Wailea, HI, USA, 4–7 January 1994. [Google Scholar]
- Mubarek, A.M.; Eşref, A. CMultilayer perceptron neural network technique for fraud detection. In Proceedings of the S2017 International Conference on Computer Science and Engineering (UBMK), Antalya, Turkey, 5–8 October 2017. [Google Scholar]
- Fawcett, T.; Provost, F. Adaptive fraud detection. Data Min. Knowl. Discov. 1997, 1, 291–316. [Google Scholar] [CrossRef]
- Bonchi, F.; Giannotti, F.; Mainetto, G.; Pedreschi, D. Using data mining techniques in fiscal fraud detection. In Proceedings of the International Conference on Data Warehousing and Knowledge Discovery, Berlin/Heidelberg, Germany, 30 August 1999; pp. 369–376.
- de Roux, D.; Perez, B.; Moreno, A.; Villamil, M.D.P.; Figueroa, C. Tax fraud detection for under-reporting declarations using an unsupervised machine learning approach. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 215–222. [Google Scholar]
- Pérez López, C.; Delgado Rodríguez, M.; de Lucas Santos, S. Tax fraud detection through neural networks: An application using a sample of personal income taxpayers. Future Internet 2019, 11, 86. [Google Scholar] [CrossRef] [Green Version]
- Savić, M.; Atanasijević, J.; Jakovetić, D.; Krejić, N. Tax Evasion Risk Management Using a Hybrid Unsupervised Outlier Detection Method. arXiv 2021, arXiv:2103.01033. [Google Scholar] [CrossRef]
- Neagoe, V.-E.; Ciotec, A.-D.; Cucu, G.-S. Deep convolutional neural networks versus multilayer perceptron for financial prediction. In Proceedings of the 2018 International Conference on Communications (COMM), Bucharest, Romania, 14–16 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- McCulloch, W.S.; Pitts, W. A Logical Calculus of the Ideas Immanent in Nervous Activity; Springer: Berlin/Heidelberg, Germany, 1943. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Newton, MA, USA, 2019. [Google Scholar]
- Abraham, A. Artificial Neural Networks; John Wiley & Sons, Ltd.: Chichester, UK, 2005. [Google Scholar]
- Math behind Artificial Neural Networks. Available online: https://medium.com/analytics-vidhya/math-behind-artificial-neural-networks-42f260fc1b25 (accessed on 31 July 2020).
- Mohamed, H.; Negm, A.; Zahran, M.; Saavedra, O.C. Assessment of Artificial Neural Networks for Bathymetry Estimation Using High Resolution Satellite Imagery in Shallow Lakes: Case Study El Burullus Lake. In Proceedings of the Eighteenth International Water Technology Conference, IWTC18 Sharm, ElSheikh, Egypt, 12–14 March 2015; pp. 12–14. [Google Scholar]
- Sharma, S.; Sharma, S.; Athaiya, A. Activation Functions in Neural Networks; Towards Data Science: UK, 2017; Volume 12, pp. 310–316. Available online: http://ijeast.com/papers/310-316,Tesma412,IJEAST.pdf (accessed on 31 July 2020).
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Agostinelli, F.; Hoffman, M.; Sadowski, P.; Baldi, P. Learning Activation Functions to Improve Deep Neural Networks. arXiv 2014, arXiv:1412.6830. [Google Scholar]
- Dangeti, P. Statistics for Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Lin, G.; Shen, W. Research on Convolutional Neural Network Based on Improved Relu Piecewise Activation Function; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Anthadupula, S.P.; Gyanchandani, M. A Review and Performance Analysis of Non-Linear Activation Functions in Deep Neural Networks. Int. Res. J. Mod. Eng. Technol. Sci. 2021. [Google Scholar]
- Zheng, H.; Yang, Z.; Liu, W.; Liang, J.; Li, Y. Improving Deep Neural Networks Using Softplus Units; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Difference between a Batch and an Epoch in a Neural Network. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/ (accessed on 13 July 2018).
- Goutte, C.; Gaussier, E. A Probabilistic Interpretation of Precision, Recall and F-Score, With Implication for Evaluation; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Kull, M.; Silva, F.; Telmo, M.; Flach, P. Beyond Sigmoids: How to Obtain Well-Calibrated Probabilities from Binary Classifiers with Beta Calibration. Electron. J. Stat. 2017, 11, 5052–5080. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Heaton, J.; McElwee, S.; Fraley, J.; Cannady, J. Early Stabilizing Feature Importance for TensorFlow Deep Neural Networks; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- de Sá, C.R. Variance-based feature importance in neural networks. In Proceedings of the 22nd International Conference, DS 2019, Split, Croatia, 28–30 October 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 306–315. [Google Scholar]
- Zhou, Z.; Zheng, W.-S.; Hu, J.-F.; Xu, Y.; You, J. One-Pass Online Learning: A Local Approach; Elsevier: Amsterdam, The Netherlands, 2016. [Google Scholar]
- Garavaglia, S.; Sharma, A. A smart guide to dummy variables: Four applications and a macro. In Proceedings of the Northeast SAS Users Group Conference, Pittsburgh, PA, USA, 4–6 October 1998; Volume 43. [Google Scholar]
- Kaur, P.; Gosain, A. Comparing the behavior of oversampling and undersampling approach of class imbalance learning by combining class imbalance problem with noise. In ICT Based Innovations; Springer: Berlin/Heidelberg, Germany, 2018; pp. 23–30. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Murorunkwere, B.F.; Dominique, H.; Nzabanita, J.; Kipkogei, F. Predicting Tax Fraud Using Supervised Machine Learning Approach. Afr. J. Sci. Technol. Innov. Dev. 2022, submitted. [Google Scholar]




| Activation | Batch | Epochs | Layers and Neurons | Train Acc | Val Acc | Test Acc |
|---|---|---|---|---|---|---|
| sigmoid | 40 | 30 | [50] | 0.8672 | 0.8643 | 0.8703 |
| sigmoid | 40 | 50 | [50, 40, 30, 20, 10] | 0.7918 | 0.7769 | 0.7891 |
| relu | 40 | 30 | [50] | 0.8948 | 0.8871 | 0.8929 |
| relu | 128 | 50 | [50, 20] | 0.8989 | 0.8889 | 0.8954 |
| softsign | 80 | 100 | [50, 40, 30, 20, 10] | 0.7918 | 0.7769 | 0.7891 |
| softsign | 40 | 100 | [20] | 0.9069 | 0.8889 | 0.8954 |
| softsign | 40 | 100 | [50] | 0.8979 | 0.8889 | 0.8954 |
| linear | 80 | 100 | [60, 45, 30, 15] | 0.9002 | 0.8862 | 0.8920 |
| linear | 128 | 100 | [50, 40, 30, 20, 10] | 0.8982 | 0.8889 | 0.8954 |
| hard_sigmoid | 100 | 100 | [50] | 0.8756 | 0.8670 | 0.8780 |
| hard_sigmoid | 40 | 100 | [60, 45, 30, 15] | 0.7918 | 0.7769 | 0.7891 |
| softplus | 80 | 100 | [50] | 0.8968 | 0.8889 | 0.8954 |
| softmax | 128 | 50 | [50,20] | 0.7918 | 0.7769 | 0.7891 |
| softmax | 40 | 30 | [50, 40, 30, 20, 10] | 0.7918 | 0.7769 | 0.7891 |
| Metric | Original Data | Re-Sampled Data |
|---|---|---|
| Accuracy | 0.90 | 0.92 |
| Precision | 0.68 | 0.85 |
| Recall | 0.99 | 0.99 |
| F1 score | 0.79 | 0.92 |
| AUC-ROC | 0.94 | 0.95 |
| Features | Importance |
|---|---|
| Department_Customs | 0.5447 |
| Department_Domestic | 0.3496 |
| Time of Business | 0.2799 |
| Scale_SMALL | 0.2636 |
| Tax Payer Type Desc_NON INDIVIDUAL | 0.1553 |
| Tax Payer Type Desc_INDIVIDUAL | 0.1341 |
| District Name_KICUKIRO | 0.0838 |
| Scale_LARGE | 0.0830 |
| District Name_NYARUGENGE | 0.0796 |
| Scale_MICRO | 0.0777 |
| District Name_GASABO | 0.0761 |
| Sector_Services | 0.0697 |
| Scale_MEDIUM | 0.0625 |
| Sector_Industry | 0.0624 |
| Province_KIGALI CITY | 0.0517 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Murorunkwere, B.F.; Tuyishimire, O.; Haughton, D.; Nzabanita, J. Fraud Detection Using Neural Networks: A Case Study of Income Tax. Future Internet 2022, 14, 168. https://doi.org/10.3390/fi14060168
Murorunkwere BF, Tuyishimire O, Haughton D, Nzabanita J. Fraud Detection Using Neural Networks: A Case Study of Income Tax. Future Internet. 2022; 14(6):168. https://doi.org/10.3390/fi14060168
Chicago/Turabian StyleMurorunkwere, Belle Fille, Origene Tuyishimire, Dominique Haughton, and Joseph Nzabanita. 2022. "Fraud Detection Using Neural Networks: A Case Study of Income Tax" Future Internet 14, no. 6: 168. https://doi.org/10.3390/fi14060168
APA StyleMurorunkwere, B. F., Tuyishimire, O., Haughton, D., & Nzabanita, J. (2022). Fraud Detection Using Neural Networks: A Case Study of Income Tax. Future Internet, 14(6), 168. https://doi.org/10.3390/fi14060168