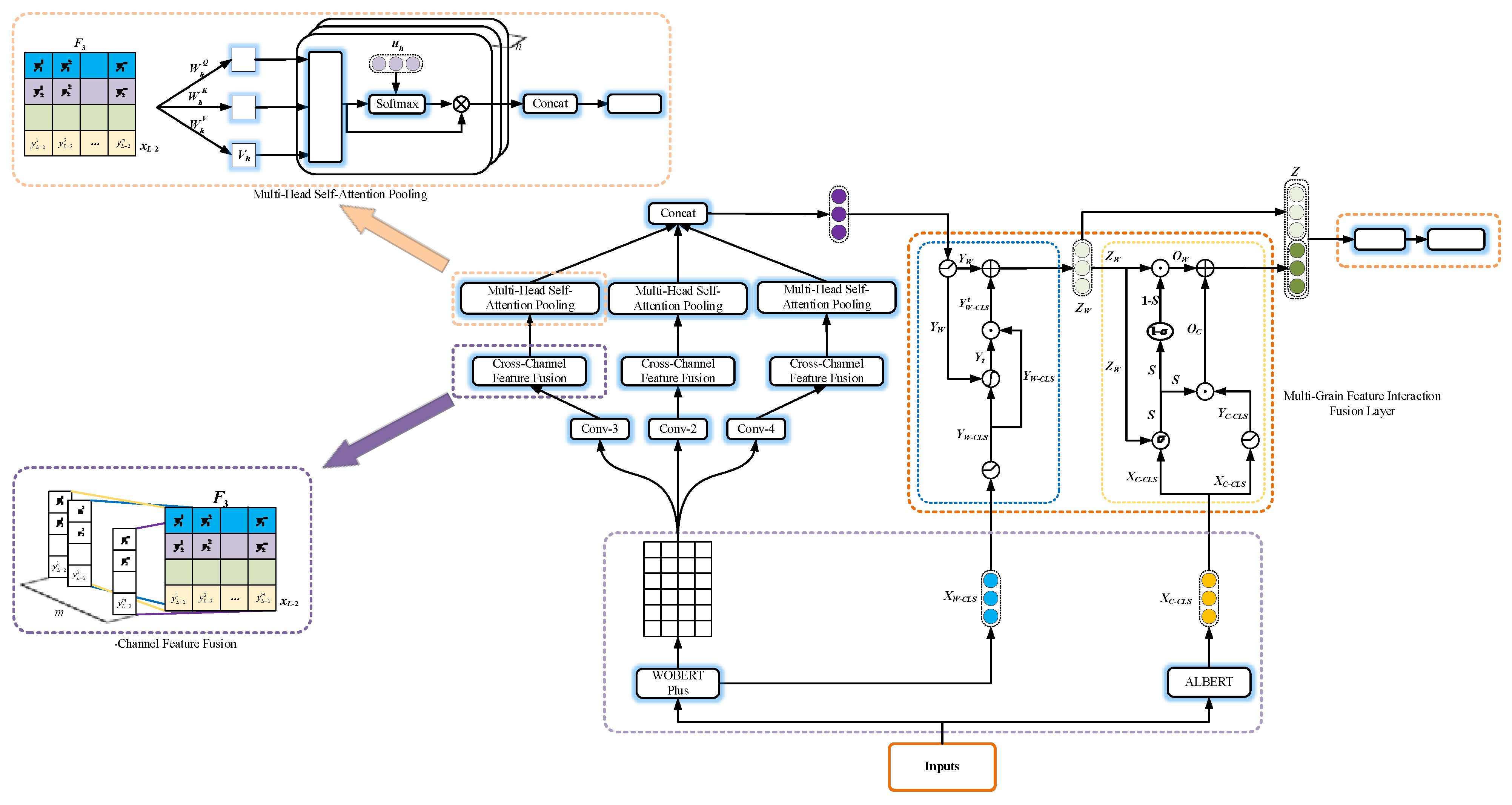
3.1. Dual-Stream Dynamic Coding Layer
Chinese characters and words both contain important semantic information, and there are differences in the information they contain. Therefore, it is necessary to extract both character-level and word-level information when performing microblog sentiment analysis, to achieve complementarity between them and improve model performance. The character-based pre-trained language model does not rely on word separation tools, thus avoiding the problem of inaccurate word boundary delineation, does not include semantic noise caused by improper word separation, and does not need to consider the impact of unregistered words on downstream tasks; the word-based model can make the processing sequence shorter and speed up the model’s operation. In addition, the semantic uncertainty of word meaning is lower than that of character meaning, and its semantic information is richer, which helps improve the accuracy of the text classification task. Therefore, we combine the advantages of character and word pre-training models, and propose a dual-stream dynamic encoding mechanism that uses WOBERT Plus and ALBERT to complete text dynamic word-level encoding and character-level encoding, respectively. Both the WOBERT Plus and ALBERT models need to add a CLS vector when encoding text. CLS does not represent the information of a single character or word, but contains the semantics of the entire sentence.
- (1)
WOBERT Plus word-level dynamic encoding
The WOBERT Plus model is used to train word vectors on the input text, and its output contains two parts: the CLS vector and the word vector matrix.
Here is the word vector matrix , , , where is the number of words in the input text, is the word vector dimension (), and each row of the word vector matrix represents a vector of individual word maps.
- (2)
ALBERT character-level dynamic encoding
The ALBERT model is used to train character vectors on the input text, and the CLS vectors imply the semantics of the whole sentence. To reduce the model parameters and complexity, only the encoded CLS vectors are output.
The CLS vector , d is the word vector dimension.
3.3. Cross-Channel Feature Fusion Layer
The information fusion operation is performed on the high-level features located in multiple channels after the convolution operation, and then the high-level semantic feature matrix
Fk is obtained.
where
Concat represents the vector stitching operation,
k represents the number of the matrix, and
m is the convolution kernel number.
Taking the semantic feature matrix obtained by a convolution kernel with a size of 3 as an example, the cross-channel feature fusion layer is further explained, as shown in the model diagram in
Figure 1:
According to the convolution formula, feature values ~ are obtained by convolving different convolution kernels of the same size (in this case, the convolution kernel size is 3) with the local text word vectors. Since the convolutional kernel weight matrices are different from one another, the semantic feature values ~ represent high-level features of the same region of text captured from different perspectives, i.e., the textual information contained in the same three words. Therefore, the row vectors of matrix F3 cover the high-level information of the same region of text extracted from different angles by convolutional operations. The same is true for the remaining semantic feature matrices F2 and F4, except that they have different degrees of information granularity. The cross-channel feature fusion mechanism can differentiate the original word vector matrix into three high-level semantic information matrices with different granularities of semantic information, and the three matrices cover the local key information extracted from different angles with different granularities, enhancing the local text feature representation, and thus enabling the multi-head attention pooling layer to learn more word-level text information and ensure the extraction of more accurate global dependent information.
3.4. Multi-Head Self-Attention Pooling Layer
Convolution and cross-channel feature fusion operations only mine and integrate local information and do not employ contextual semantic information. Global semantic information is essential in the face of microblogging speech, which requires a high level of semantic understanding in the model. In addition, the semantic information matrix contains some redundant information and noisy data, so it is necessary to optimize the features, filter out the key features, and reduce the number of parameters.
However, the commonly used pooling approach suffers from information loss, which is not conducive to the operation of a model for sentiment analysis of microblog speech. To address these problems, we propose a multi-head self-attention pooling mechanism based on the multi-head self-attention mechanism. The multi-head self-attention pooling mechanism can establish connections between the isolated rows of the matrix and pass information among them to obtain the long-range dependencies of text, enabling the model to extract key text features from multiple subspaces separately by adjusting the weight parameters.
The multi-head self-attention pooling mechanism can be divided into two steps: multi-head self-attention operations and multi-head pooling operations. An example of the multi-head self-attention pooling mechanism is illustrated by the operation performed in the h-th subspace.
First, the multi-head self-attention algorithm is executed. Initialize the parameter matrices
,
,
, and perform the self-attention operation on the semantic information matrix
, so that each of the row vectors of the matrix
F passes information to one another and establishes the connection, and thus the global semantic information is included in each row vector, and the matrix
is obtained. Then, the multi-head pooling algorithm we proposed on top of the multi-head self-attention mechanism is executed. Initialize the parameter vector
, perform matrix multiplication operation between
and
to obtain the joint vector
of the two, calculate the probability distribution vector
between each row vector using the Softmax function, and finally multiply
with the matrix
to increase the weight of key information by adjusting the weights to achieve feature optimization and parameter reduction in order to obtain the vector
. For the model to learn information from different representation subspaces, different information is obtained from each subspace by repeating the operations several times in parallel to extract richer data features. Finally, the information captured in each subspace is stitched together to obtain the result of multi-head self-attention pooling
M.
where
,
, and
are the linear mapping weight matrices of the
h-th subspace of matrix
,
headh is the feature matrix generated by the
h-th subspace through the self-attentive mechanism,
is the dynamically updated parameter vector within the subspace,
is the joint vector generated by the joint action of
headh and
,
is the weight vector, and
is the vector obtained from the feature matrix
headh after the condensation of key features.
represents the number of subspaces in the multi-head self-attention pooling mechanism.
denotes the dimensionality of each high-level semantic vector, and
M is the feature resulting from the information collocation of
subspaces.
From the model diagram in
Figure 1, it can be seen that three multi-head self-attention layer channels are operating in parallel. The vectors generated by the three channels are named
M2,
M3, and
M4 according to the different sizes of the convolutional kernels, and the vectors generated by the three channels are stitched together to obtain the word-level semantic information
XW.
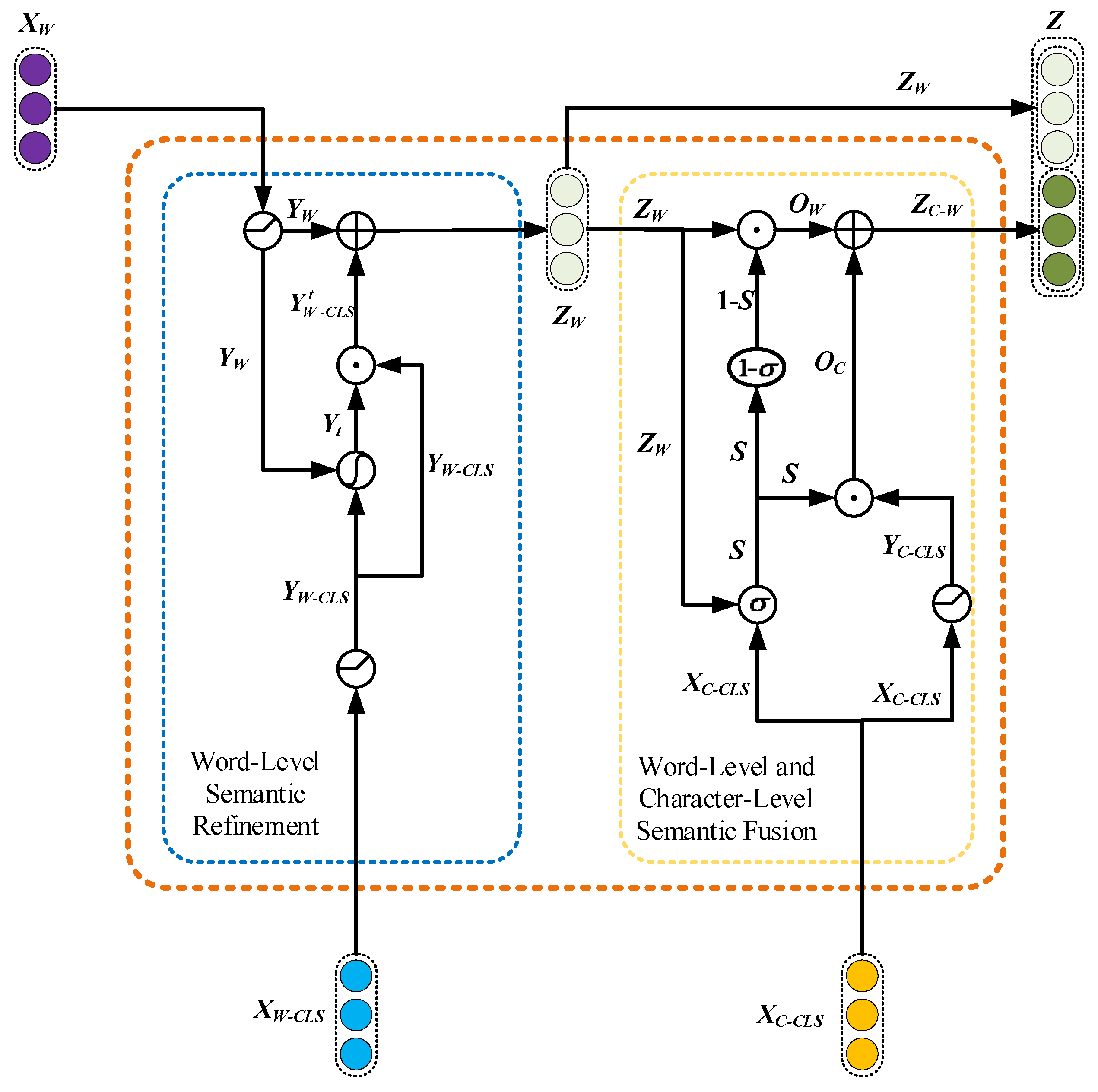
3.5. Multi-Granularity Feature Interaction Fusion Layer
The information granularity of the CLS tag vector
XW−CLS output by WOBERT Plus, the CLS tag vector
XC−CLS output by ALBERT, and the multi-head self-attention pooling layer output vector
XW are not the same;
XW−CLS and
XW belong to the word-level semantic information and
XC−CLS belongs to the character-level semantic information. Different information granularities have different levels of importance in different contexts and produce different effects in the classification results. In addition, factors such as improper word separation may introduce noise into the word-level text information, and the character-level semantic information may present the problem of containing insufficient semantic information, necessitating further processing of the information. Therefore, it is not reasonable to process character-level and word-level semantic information by means of direct splicing or simple summation. To enhance the interactivity between character- and word-level information, realize the complementarity between character-level and word-level information, and strengthen the weight of important information while filtering out noise, thus resulting in the output of more effective joint character and word feature information, we propose a multi-granularity feature interaction fusion mechanism in this paper. The multi-granularity feature interaction fusion mechanism is shown in
Figure 2. The multi-granularity feature interaction fusion mechanism mainly consists of two parts: word-level semantic refinement and word-level and character-level semantic fusion.
- (1)
Word-Level Semantic Refinement
Word-level semantic feature refinement is used to correct and remove noise from the information to achieve an effective fusion of word-level granularity information
and
XW.
where
,
are weight matrices,
,
,
are bias terms, and
YW−CLS and
YW are word-level semantic vectors obtained after feature condensation and noise filtering for
XW−CLS and
XW, respectively.
Yt is the weight vector generated by combining
YW−CLS and
.
is the vector of moderation factors generated using
YW−CLS and
Yt. Sign
denotes Hadamard product.
ZW is the vector after implementing key feature correction for
YW, which effectively incorporates word-level semantic information.
Since the ReLU function can map negative values to zero, Equation (15) uses the ReLU function to generate the vector YW by initially filtering the noisy regions in the word-level vector XW.
Similarly, Equation (16) uses the ReLU function to filter the noisy region in XW−CLS to generate YW−CLS so that the modulation factor vector does not contain invalid and disruptive information that could lead to noisy information in the vector ZW.
Since the tanh function maps the eigenvalues to the interval (−1,1), the range it can regulate is broader and more flexible compared to that available to the Sigmoid function. Equation (17) generates the weight vector using the tanh function for YW−CLS and YW.
Equation (18) performs the Hadamard product operation on Yt and the filtered feature vector YW−CLS. The features contained in YW−CLS are assigned positive and negative weights according to their roles in generating the modulation factor vector . If the element value in is 0, this means that the feature values in YW do not need to be corrected. If it is positive, it plays an enhancing and complementary role to the feature values in YW, and if it is negative, it plays an attenuating role to the feature values in YW.
Equation (19) adds the moderation factor vector to the feature values contained in the word-level semantic information vector YW bit by bit, eliminates the noisy features in YW, and corrects the feature values in the key regions. Using this approach causes ZW effectively to fuse the word-level information contained in and XW in order to achieve word-level semantic feature refinement.
- (2)
Word-Level and Character-Level Semantic Fusion
Although character-level semantic information does not involve noise caused by improper word separation or poor word list quality, its semantic information is not as rich as word-level information and may present the problem of there being insufficient semantic information; therefore, it is necessary to further process its information. In addition, when performing multi-granularity information fusion, the information with different granularities will have different importance for the sentiment analysis results. Therefore, when using multi-granularity information for sentiment analysis, it is necessary to distinguish the importance of word-level information from that of character-level information for the sentiment analysis of the target sequence and enhance the weight of important information to obtain more effective joint sentiment features across granularities.
ZW is the word-level granularity information after refinement, and
XC−CLS is the character-level granularity information; the two have different information granularity, so the character-level and word-level semantic fusion operation should be adopted differently from the word-level semantic feature refinement to obtain the interaction vector containing both character-level and word-level information. Character-level and word-level semantic fusion is shown in Equations (20)–(24).
where
,
, and
are weight matrices,
and
are bias terms,
S is the weight vector generated jointly by character-level semantic information
XC−CLS and word-level semantic information
ZW,
YC−CLS is the character-level semantic vector generated by
XC−CLS after adaptive fine-tuning and feature condensation,
is the Hadamard product,
OW is the word-level significant feature,
OC is the character-level significant feature, and
ZC−W is the interaction vector output by the dynamic fusion mechanism of character-level and word-level semantics.
Equation (20) is the weight vector S generated by YC−CLS and ZW under the action of the Sigmoid function. S can adaptively adjust the output ratio of the two according to the different importance of character-level and word-level information, and conditionally calculate the interaction vector between different granularity information.
Equation (21) is the character-level semantic information vector XC−CLS subjected to feature condensation and adaptive fine-tuning to obtain the character-level semantic vector YC−CLS.
Equation (22) is the Hadamard product operation of ZW and the weight vector S to obtain the word-level conditional vector OW.
Equation (23) is the Hadamard product operation of YC−CLS and the weight vector 1−S to obtain the character-level conditional vector OC.
Equation (24) adds the word-level conditional vector OW with the character-level conditional vector OC to achieve a fusion between different granularity features, and generates an interaction vector ZC−W that contains both character- and word-level semantic information.
Finally, the multi-grain feature interaction fusion layer stitches the word-level semantic information
ZW together with the character-level and word-level semantic feature interaction information
ZC−W.
The final classification results are obtained by feeding vector Z, which combines character-level and word-level information, into the Softmax classifier.





{kind=link}
{kind=link}