
Intelligent Reflecting Surface-Aided Device-to-Device Communication: A Deep Reinforcement Learning Approach



Abstract
:1. Introduction
1.1. Related Works
1.2. Contributions
- The objective of this paper is to maximize the network’s SE, i.e., sum rate of both the CUs and the D2D pairs, by jointly optimizing the transmit power for both the CUs and the D2D pairs, the resource reuse indicators, and the IRS reflection coefficients. The optimization problem is subjected to the signal-to-interference-plus-noise ratio (SINR) constraints to meet the minimum data rate requirements to ensure the QoS for both the CUs and the D2D radio links. Since the constructed problem in this paper is a mixed integer non-linear optimization problem and poses challenges to being solved optimally, RL-based approaches are utilized.
- The IRS-assisted D2D underlay cellular network is structured by a Markov Decision Process (MDP) in the RL framework. At first, a Q-learning-based solution scheme is utilized. Then, to make a scalable solution in the large dimensional state and action spaces, a deep Q-learning-based solution scheme using experience replay is adopted. Lastly, an actor-critic framework based on the deep deterministic policy gradient (DDPG) scheme is proposed to learn the optimal policy of the constructed optimization problem with the consideration of the continuous-valued state and action spaces.
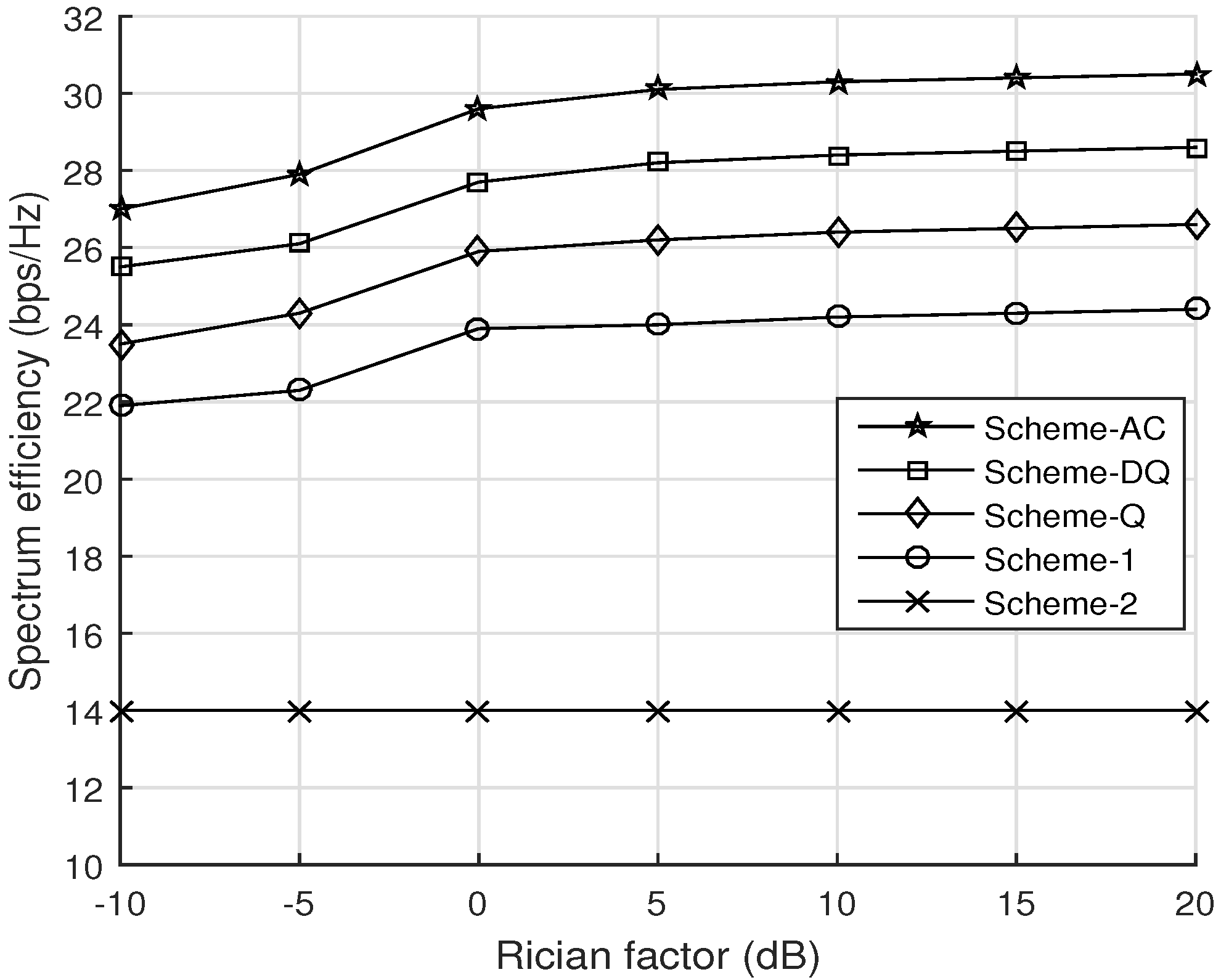
- Simulation outcomes under various representative parameters are provided to prove the effectiveness of the proposed RL-based solution schemes, and an analysis of the impact of different parameters on the system performance is also provided. It is certainly observed that the proposed RL-based solution schemes can provide significantly higher SE compared to the traditional underlay D2D network without IRS and without RL under different network parameters.
1.3. Organization
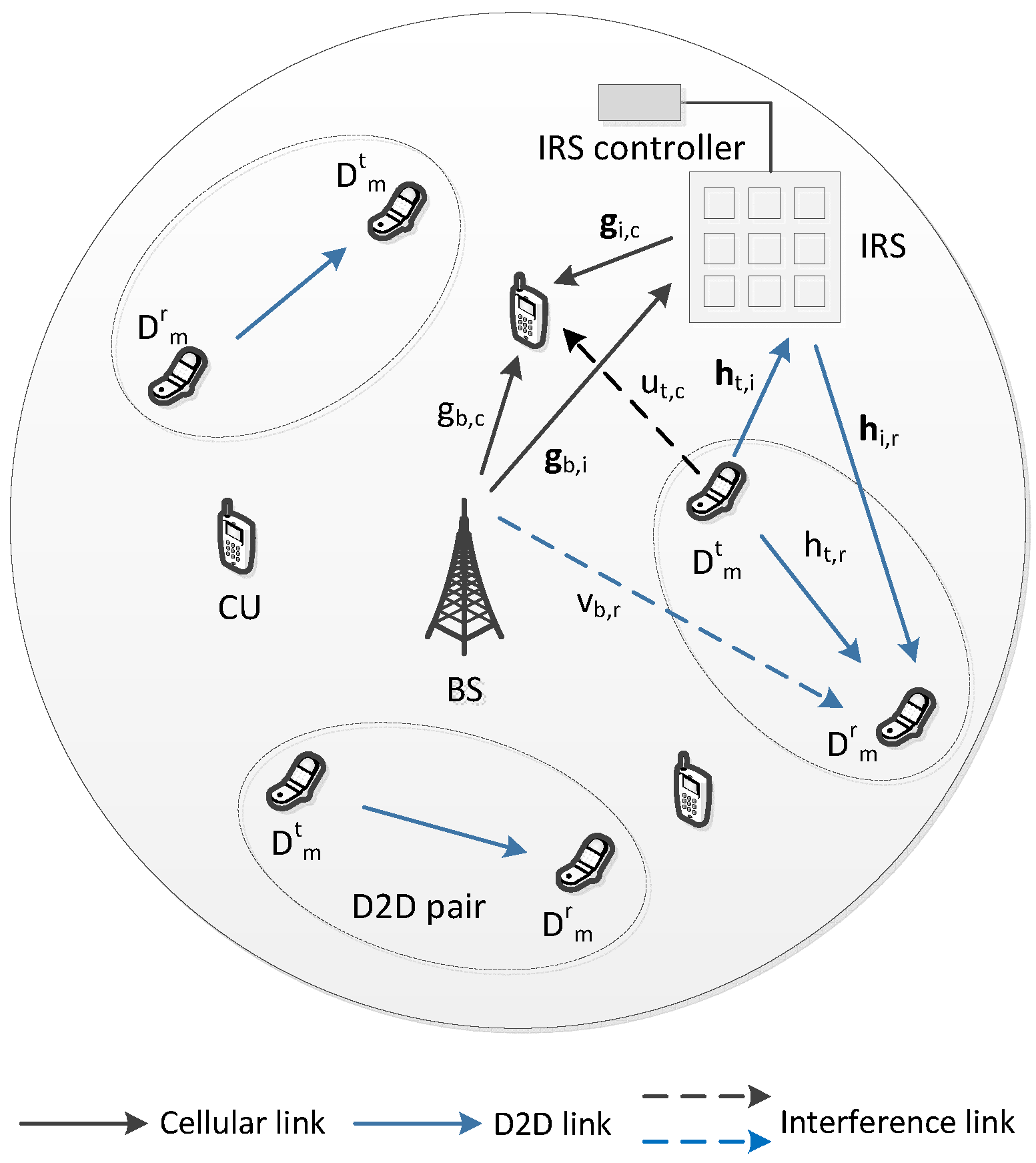
2. System Model and Problem Formulation
2.1. System Model
2.2. Problem Formulation
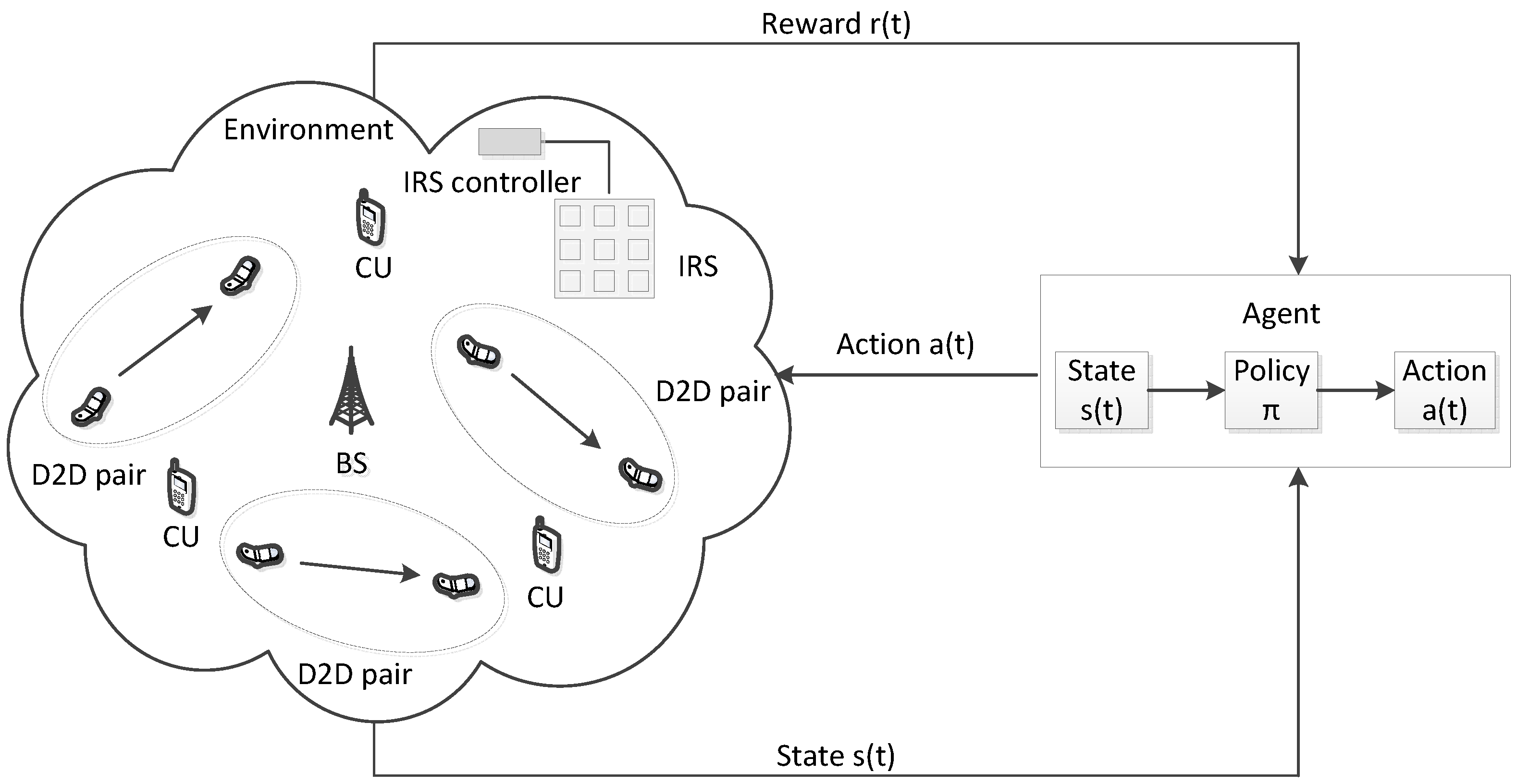
3. Reinforcement Learning-Based Solution
3.1. Reinforcement Learning (RL)
- Agent: A pair of every D2D transmitter and receiver.
- State: The observed information in the environment constitutes the system state , which characterizes the environment at current time t. It includes the channel information and all D2D agents’ behaviors (e.g., SINR requirement). Therefore, the system state can be defined by the following expression:where denotes the instantaneous channel information of the cellular communication link that includes , , and . represents the instant channel information of the D2D communication link that includes , , and .
- Action: The learning agent (D2D pair) does the appropriate action at time t during the learning process following the current state, , based on the policy . Hence, the action is defined by constraints C3 and C4 (a D2D pair shares at most one CU’s spectrum and the spectrum of a CU can be shared by at most one D2D pair, respectively), constraints C5 and C6 (maximum transmission power constraints for the CUs and the D2D pairs, respectively), and constraint C7 (practical reflecting coefficients of the IRS). Based on the constraints in the formulated optimization problem, the action in this reinforcement learning framework depends on the transmit power, the resource reuse indicator, and the IRS reflection coefficients. Thus, the action can be defined as follows:
- Transition probability: is the probability of transitioning from a current state to a new state after executing an action .
- Policy: The D2D agent’s behavior is defined by a policy , which maps states to a probability distribution over the actions , e.g., . Note that the policy function needs to satisfy .
- Reward: The reward r is the immediate return to the D2D agent after taking the action given the state . It is also a performance indicator that indicates how good the action is in a given state at time instant t. Hence, considering the interactions with the environment, each D2D agent takes its decision to maximize its reward. Now, the reward function for the D2D pair can be written as
3.2. Q-Learning-Based Solution Scheme
| Algorithm 1: Q-learning Based Solution Scheme |
Initialization: Initialize the Q-value function with random weights Parameter Setting and Updating: foreach episodedo Initial states observed by all D2D agents for each time slot do Actions are selected using the -greedy scheme (17) and then executed by all D2D agents; Perform observation of the rewards and the new state ; Update using (16); Update ; |
3.3. Deep Q-Learning-Based Solution Scheme
| Algorithm 2: Deep Q-learning Based Solution Scheme using Experience Replay |
Initialization: Initialize the Q-network and the target Q-network with the parameterized function and the experience replay buffer . Parameter Setting and Updating: foreach episodedo Initial states observed by all D2D agents for each time slot do Actions with the parameterized function is selected and executed by all D2D agents; Perform observation of the rewards and the new state ; if the transition number then Save the transition in the experience replay buffer; else Restore the first stored transition with in the experience replay buffer; A mini-batch of B transitions is selected from the experience replay buffer; Update the gradient of the loss function with respect to the parameterized function using (22) |
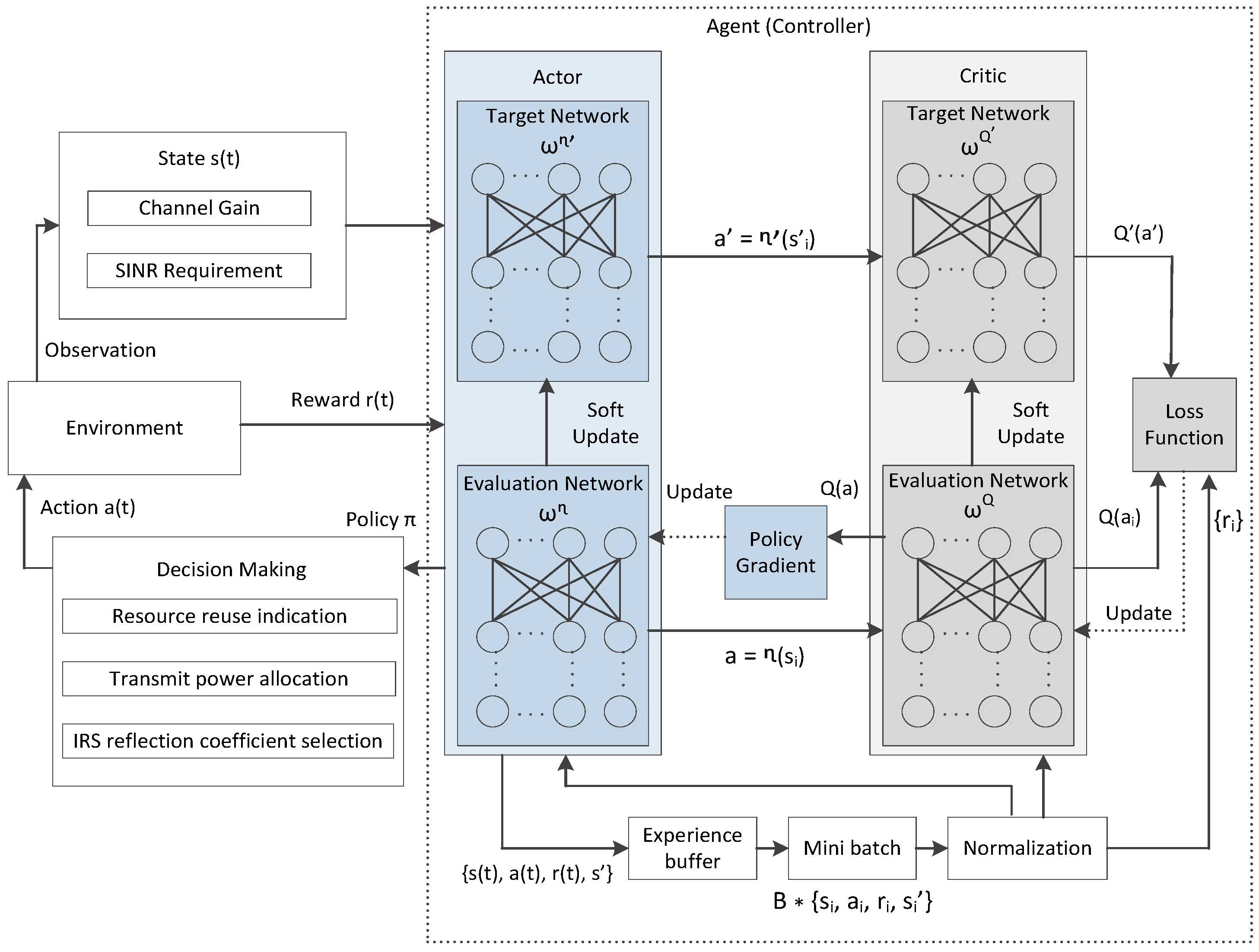
3.4. Actor-Critic-Based Solution Scheme
| Algorithm 3: DDPG-based Actor-Critic Solution Scheme |
Initialization: Initialize the parameterized functions , , , and of the evaluation and target networks of the actor-critic structure and the experience replay buffer . Parameter Setting and Updating: foreach episodedo Initial states observed by all D2D agents for each time slot do Actions with the parameterized function is selected and executed by all D2D agents; Perform observation of the rewards and the new state ; if the transition number then Save the transition in the experience replay buffer; else Restore the first stored transition with in the experience replay buffer; A mini-batch of B transitions is selected from the experience replay buffer; Update the parameterized functions of the critic structure: ; ; Update the parameterized functions of the actor structure: ; ; |
4. Performance Analysis and Simulation Outcomes
4.1. Simulation Setup
- Underlaying D2D without RL (scheme-1): An IRS-empowered underlay D2D communication network is considered scheme-1 [28]. Here, a user-pairing scheme determines the resource reuse indicator, and then, the transmit power and the passive beamforming are jointly optimized by iterative algorithms.
- Underlaying D2D without IRS without RL (scheme-2): A traditional cellular system underlaying the D2D network without IRS is considered scheme-2, where a two-stage approach is proposed to solve the optimization problem instead of RL [6].
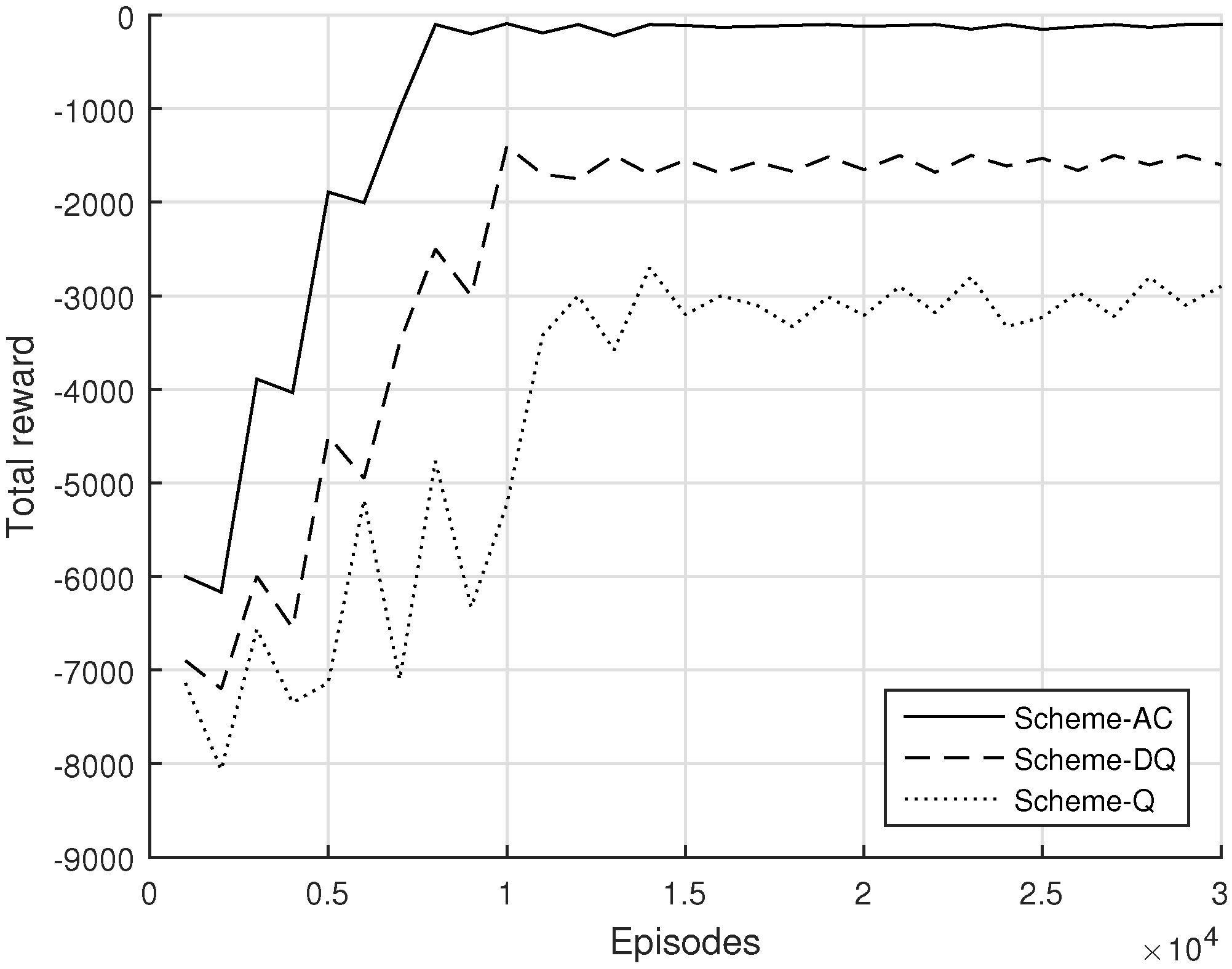
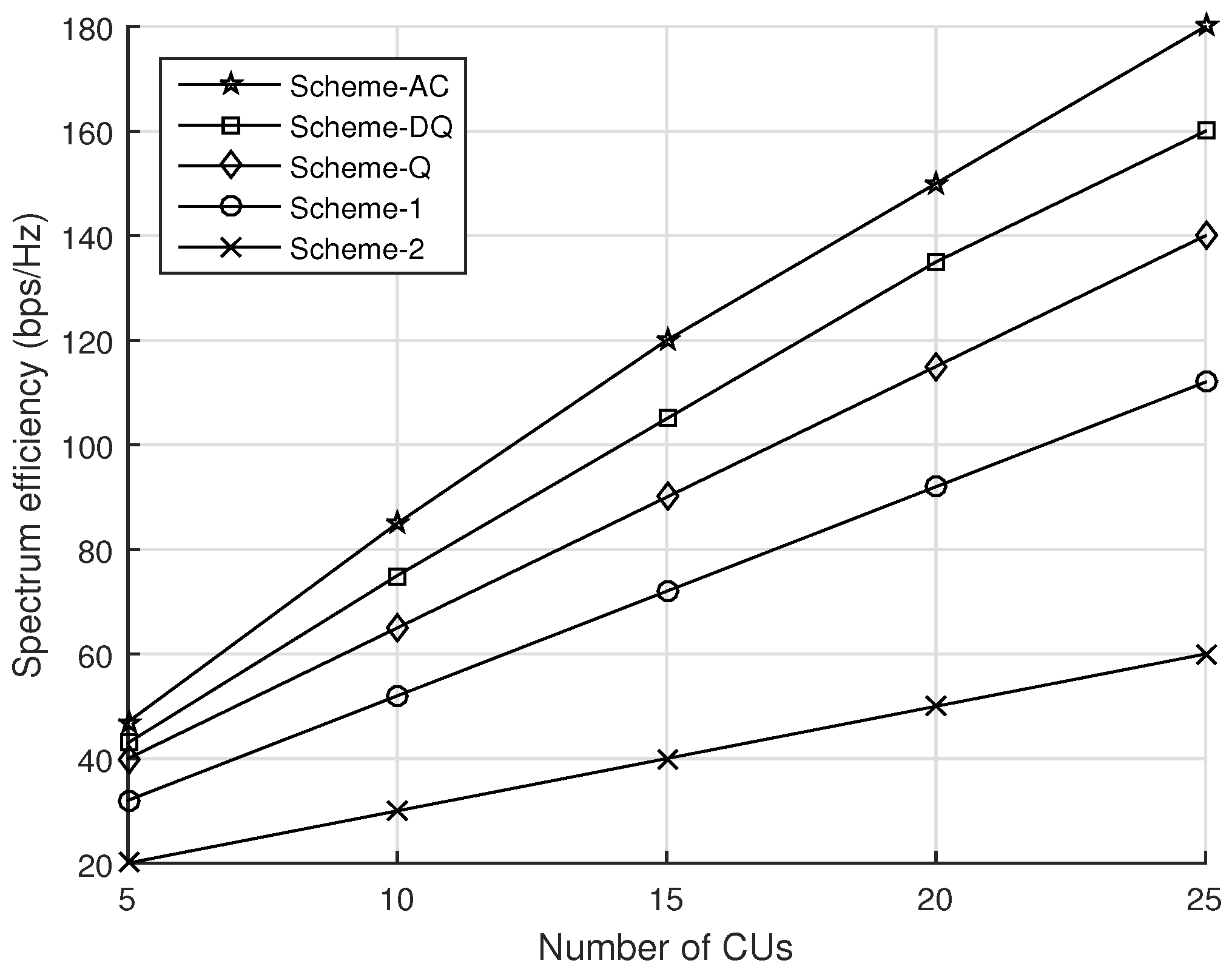
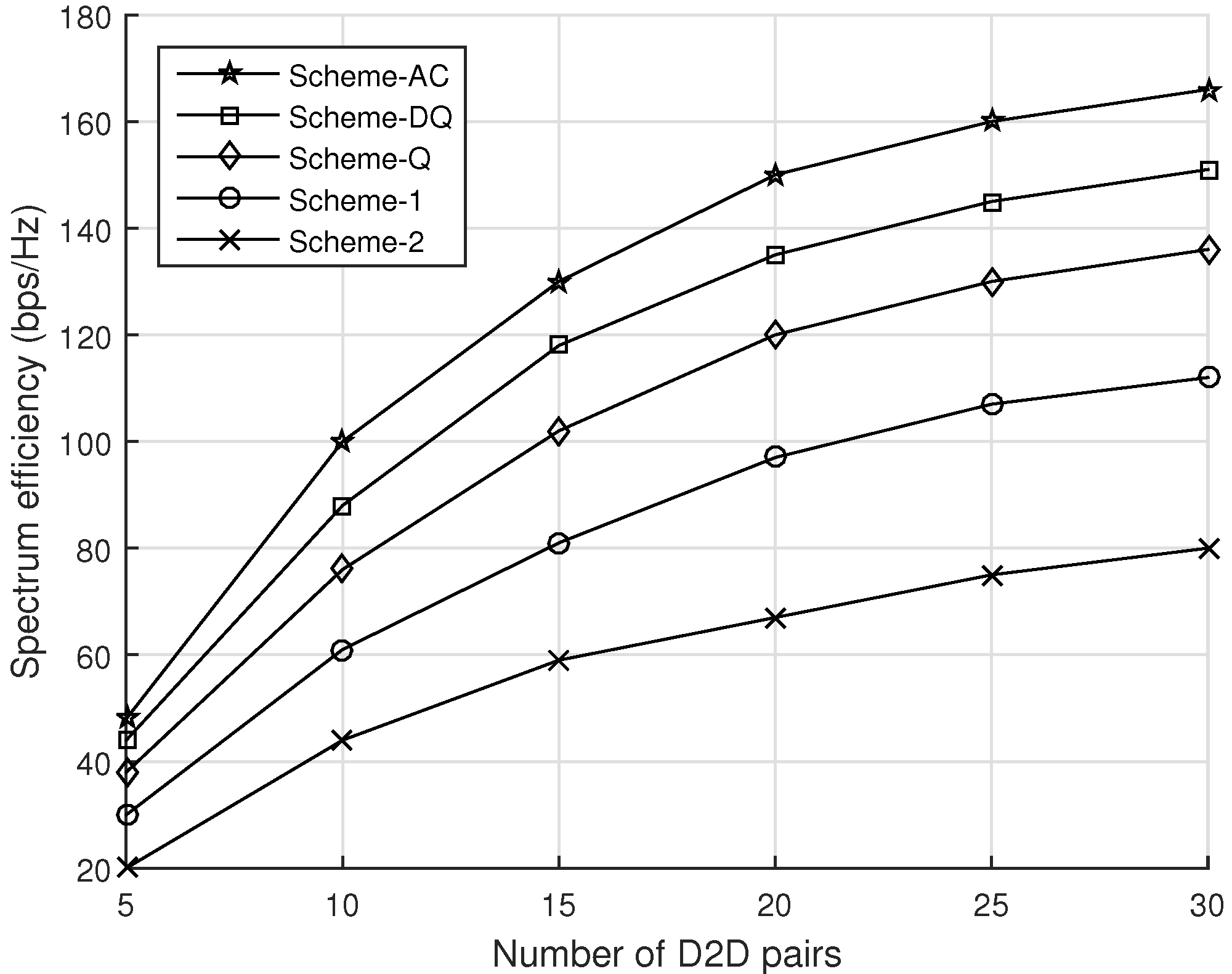
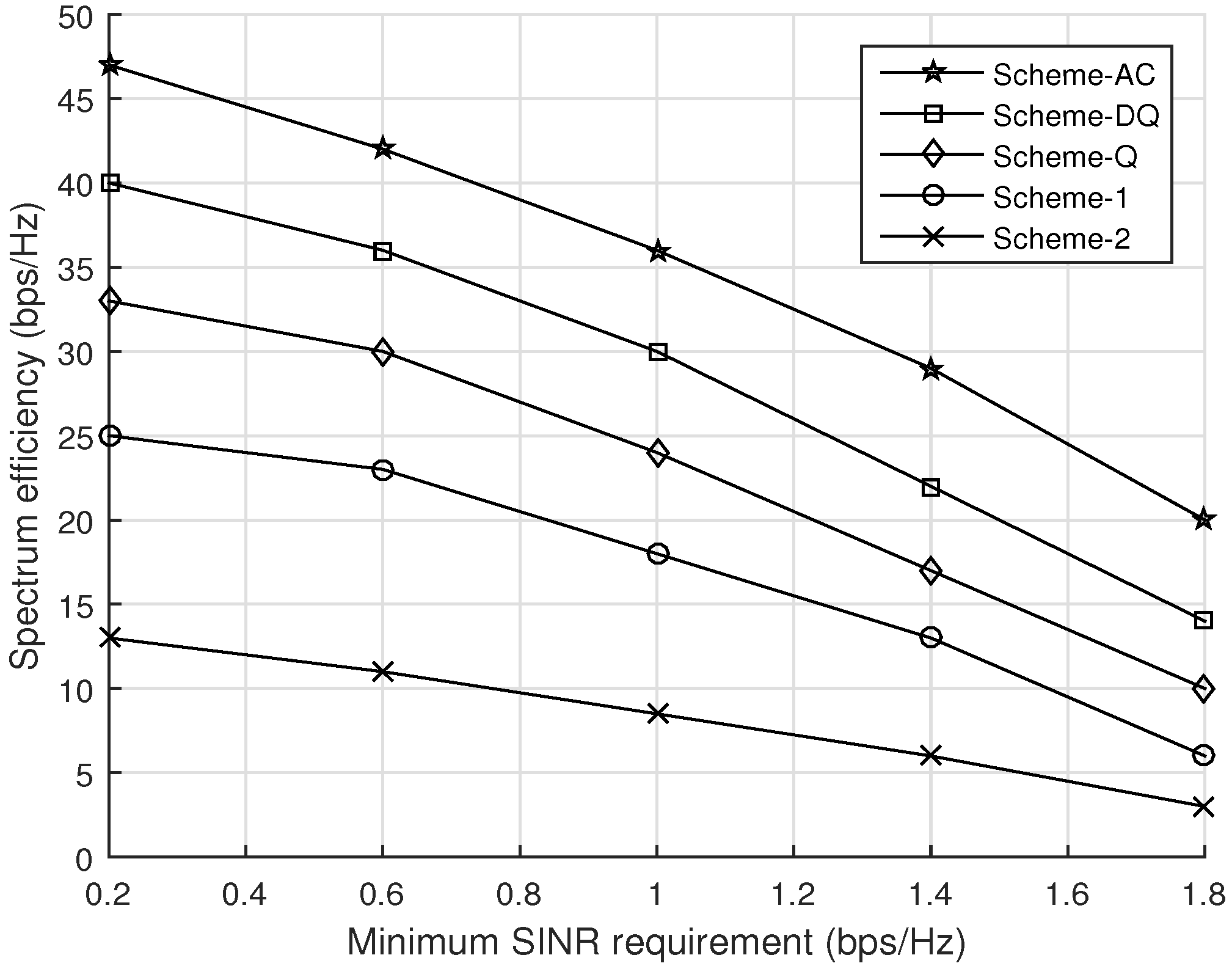
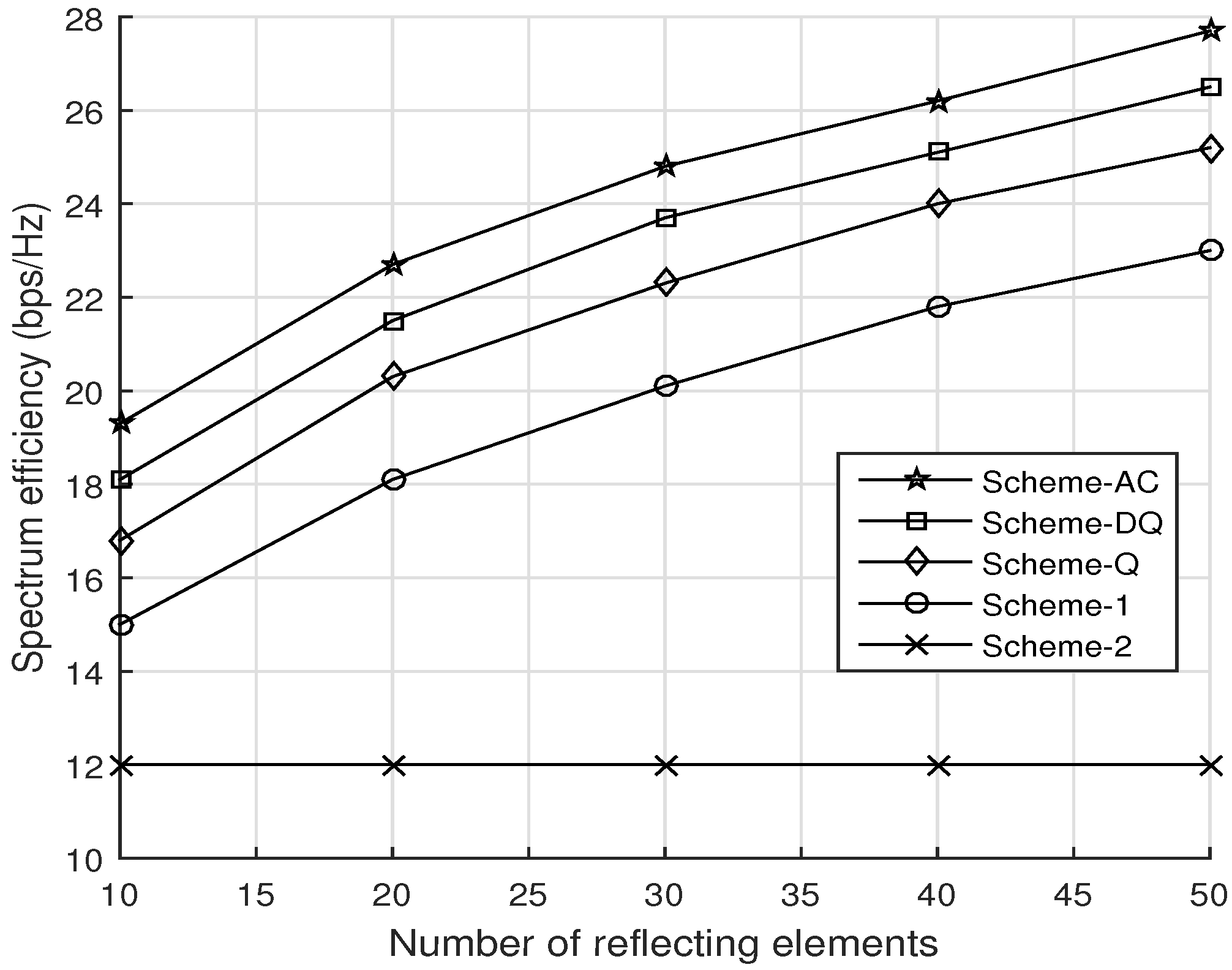
4.2. Evaluation of the Proposed Solution Schemes
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Guo, F.; Yu, F.R.; Zhang, H.; Li, X.; Ji, H.; Leung, V.C.M. Enabling massive IoT Toward 6G: A comprehensive survey. IEEE Internet Things 2021, 8, 11891–11915. [Google Scholar] [CrossRef]
- Worldwide Global Datasphere IoT Device and Data Forecast, 2021–2025, IDC: US48087621. Available online: https://www.idc.com/getdoc.jsp?containerId=US48087621 (accessed on 24 August 2022).
- Qi, Q.; Chen, X.; Zhong, C.; Zhang, Z. Integration of energy, computation and communication in 6G cellular internet of things. IEEE Commun. Lett. 2020, 24, 1333–1337. [Google Scholar] [CrossRef]
- Zhang, S.; Liu, J.; Guo, H.; Qi, M.; Kato, N. Envisioning Device-to-Device communications in 6G. IEEE Netw. 2020, 34, 86–98. [Google Scholar] [CrossRef]
- Jameel, F.; Hamid, Z.; Jabeen, F.; Zeadally, S.; Javed, M.A. A survey of device-to-device communications: Research issues and challenges. IEEE Commun. Surv. Tutor. 2018, 20, 2133–2168. [Google Scholar] [CrossRef]
- Sultana, A.; Zhao, L.; Fernando, X. Efficient resource allocation in device-to-device communication using cognitive radio technology. IEEE Trans. Veh. Technol. 2017, 66, 10024–10034. [Google Scholar] [CrossRef]
- Xu, W.; Liang, L.; Zhang, H.; Jin, S.; Li, J.C.; Lei, M. Performance enhanced transmission in device-to-device communications: Beamforming or interference cancellation? In Proceedings of the IEEE GLOBECOM, Anaheim, CA, USA, 3–7 December 2012; pp. 4296–4301. [Google Scholar]
- Wu, Q.; Zhang, R. Towards smart and reconfigurable environment: Intelligent reflecting surface aided wireless network. IEEE Commun. Mag. 2020, 58, 106–112. [Google Scholar] [CrossRef]
- Gong, S.; Lu, X.; Hoang, D.T.; Niyato, D.; Shu, L.; Kim, D.I.; Liang, Y.C. Toward Smart Wireless Communications via Intelligent Reflecting Surfaces: A Contemporary Survey. IEEE Commun. Surv. Tutor. 2020, 22, 2283–2314. [Google Scholar] [CrossRef]
- Yang, G.; Liao, Y.; Liang, Y.C.; Tirkkonen, O.; Wang, G.; Zhu, X. Reconfigurable intelligent surface empowered Device-to-Device communication underlaying cellular networks. IEEE Trans. Commun. 2021, 69, 7790–7805. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Zappone, A.; Renzo, M.D.; Debbah, M. Wireless networks design in the era of deep learning: Model-based, AI-based, or both? IEEE Trans. Commun. 2019, 67, 7331–7376. [Google Scholar] [CrossRef] [Green Version]
- Kumar, A.S.; Zhao, L.; Fernando, X. Multi-Agent deep reinforcement learning-empowered channel allocation in vehicular networks. IEEE Trans. Veh. Technol. 2022, 71, 1726–1736. [Google Scholar] [CrossRef]
- Shah, S.A.A.; Illanko, K.; Fernando, X. Deep learning based traffic flow prediction for autonomous vehicular mobile networks. In Proceedings of the IEEE VTC2021-Fall, Norman, OK, USA, 27–30 September 2021; pp. 1–5. [Google Scholar]
- Mao, S.; Chu, X.; Wu, Q.; Liu, L.; Feng, J. Intelligent reflecting surface enhanced D2D cooperative computing. IEEE Wirel. Commun. Lett. 2021, 10, 1419–1423. [Google Scholar] [CrossRef]
- Liu, Y.; Hu, Q.; Cai, Y.; Juntti, M. Latency minimization in intelligent reflecting surface assisted D2D offloading systems. IEEE Wirel. Commun. Lett. 2021, 9, 3046–3050. [Google Scholar] [CrossRef]
- Khalid, W.; Yu, H.; Do, D.T.; Kaleem, Z.; Noh, S. RIS-aided physical layer security with full-duplex jamming in underlay D2D networks. J. Commun. Inf. Netw. 2021, 9, 99667–99679. [Google Scholar] [CrossRef]
- Ji, Z.; Qin, Z.; Parini, C.G. Reconfigurable intelligent surface assisted Device-to-Device communications. arXiv 2021, arXiv:2107.02155v1. [Google Scholar]
- Chen, Y.; Ai, B.; Zhang, H.; Niu, Y.; Song, L.; Han, Z.; Poor, H.V. Reconfigurable intelligent surface assisted Device-to-Device communications. IEEE Trans. Wirel. Commun. 2021, 20, 2792–2804. [Google Scholar] [CrossRef]
- Zhang, C.; Chen, W.; He, C.; Li, X. Throughput maximization for intelligent reflecting surface-aided Device-to-Device communications system. J. Commun. Inf. Netw. 2020, 5, 403–410. [Google Scholar] [CrossRef]
- Cai, C.; Yang, H.; Yuan, X.; Liang, Y.C. Two-timescale optimization for intelligent reflecting surface aided D2D underlay communication. In Proceedings of the IEEE GLOBCOM, Taipei, Taiwan, 7–11 December 2020; pp. 1–6. [Google Scholar]
- Plaisted, D.A. Some polynomial and integer divisibility problems are NP-HARD. In Proceedings of the Symposium on Foundations of Computer Science SFCS, Houston, TX, USA, 25–27 October 1976; pp. 264–267. [Google Scholar]
- Wiering, M.; Otterlo, M. Reinforcement Learning: State-of-the-Art; Springer Publishing Company, Incorporated: Berlin, Germany, 2014. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2019, arXiv:1509.02971v6. [Google Scholar]
- Grondman, I.; Busoniu, L.; Lopes, G.A.; Babuska, R. A survey of actorcritic reinforcement learning: Standard and natural policy gradients. IEEE Trans. Syst. Man Cybern. C Appl. Rev. 2012, 42, 1291–1307. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Sutton, R.S.; Ghavamzadeh, M.; Lee, M. Natural actorcritic algorithms. Automatica 1976, 45, 2471–2482. [Google Scholar] [CrossRef] [Green Version]
- Yang, G.; Liao, Y.; Liang, Y.C.; Tirkkonen, O. Reconfigurable intelligent surface empowered underlying Device-to-Device communication. In Proceedings of the IEEE WCNC, Nanjing, China, 29 March–1 April 2021. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | Values |
|---|---|
| Cellular cell radius | 500 m |
| D2D link distance | 10–50 m |
| Number of CUs | 5–25 |
| Number of D2D users | 5–35 |
| Number of reflecting elements | 50 |
| CUs’ maximum transmit power | 24 dBm |
| D2D transmitters’ maximum transmit power | 24 dBm |
| CUs’ minimum SINR requirement | 0.3 bps/Hz |
| D2D receivers’ minimum SINR requirement | 0.3 bps/Hz |
| Resource block bandwidth | 180 kHz |
| Pathloss exponent | 4 |
| Pathloss constant | |
| Shadowing | 8 dB |
| Multi-path fading | 1 |
| Noise spectral density | −144 dBm/Hz |
| Parameters | Values |
|---|---|
| Learning rates of the actor/critic | 0.0001/0.001 |
| Discount factor | 0.99 |
| Greedy rate | 0.1 |
| Soft target update parameter | 0.001 |
| Replay buffer size | 10,000 |
| Mini-batch size | 62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sultana, A.; Fernando, X. Intelligent Reflecting Surface-Aided Device-to-Device Communication: A Deep Reinforcement Learning Approach. Future Internet 2022, 14, 256. https://doi.org/10.3390/fi14090256
Sultana A, Fernando X. Intelligent Reflecting Surface-Aided Device-to-Device Communication: A Deep Reinforcement Learning Approach. Future Internet. 2022; 14(9):256. https://doi.org/10.3390/fi14090256
Chicago/Turabian StyleSultana, Ajmery, and Xavier Fernando. 2022. "Intelligent Reflecting Surface-Aided Device-to-Device Communication: A Deep Reinforcement Learning Approach" Future Internet 14, no. 9: 256. https://doi.org/10.3390/fi14090256
APA StyleSultana, A., & Fernando, X. (2022). Intelligent Reflecting Surface-Aided Device-to-Device Communication: A Deep Reinforcement Learning Approach. Future Internet, 14(9), 256. https://doi.org/10.3390/fi14090256