

Task Scheduling for Federated Learning in Edge Cloud Computing Environments by Using Adaptive-Greedy Dingo Optimization Algorithm and Binary Salp Swarm Algorithm

Abstract
:1. Introduction
- We propose an adaptive dingo optimization algorithm (DOA) based on greedy strategies to search for the optimal solution to the PA problem, called AGDOA. The DOA incorporates a greedy algorithm, to optimize the initial value of the DOA, which improves the convergence speed. It also makes its parameters adaptively adjusted according to the convergence speed of the algorithm, to prevent it from falling into a local optimum;
- We advocate utilizing a binary salp swarm algorithm (SSA) method, known as BSSA, for the JRORS problem. We can use our approach for federated learning tasks in edge cloud computing environments;
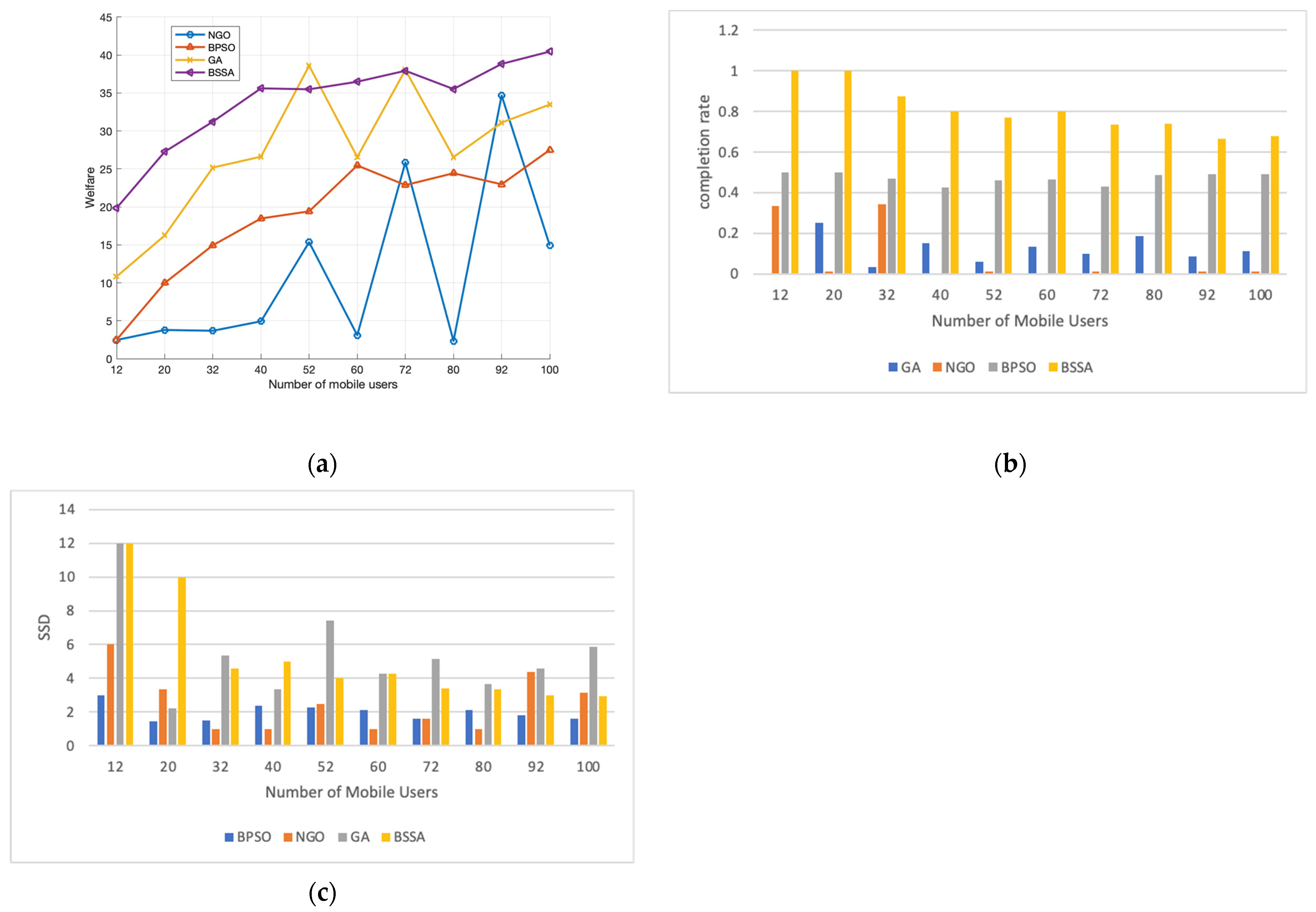
- Simulations showed that the individual improvements of AGDOA significantly improved on the original algorithm, in terms of optimization results and convergence speed, while the search results outperformed the traditional algorithm. BSSA had a superior performance compared to the conventional algorithm for different numbers of mobile users, different workloads, and different configurations.
2. Related Work
3. Preliminaries and Definitions
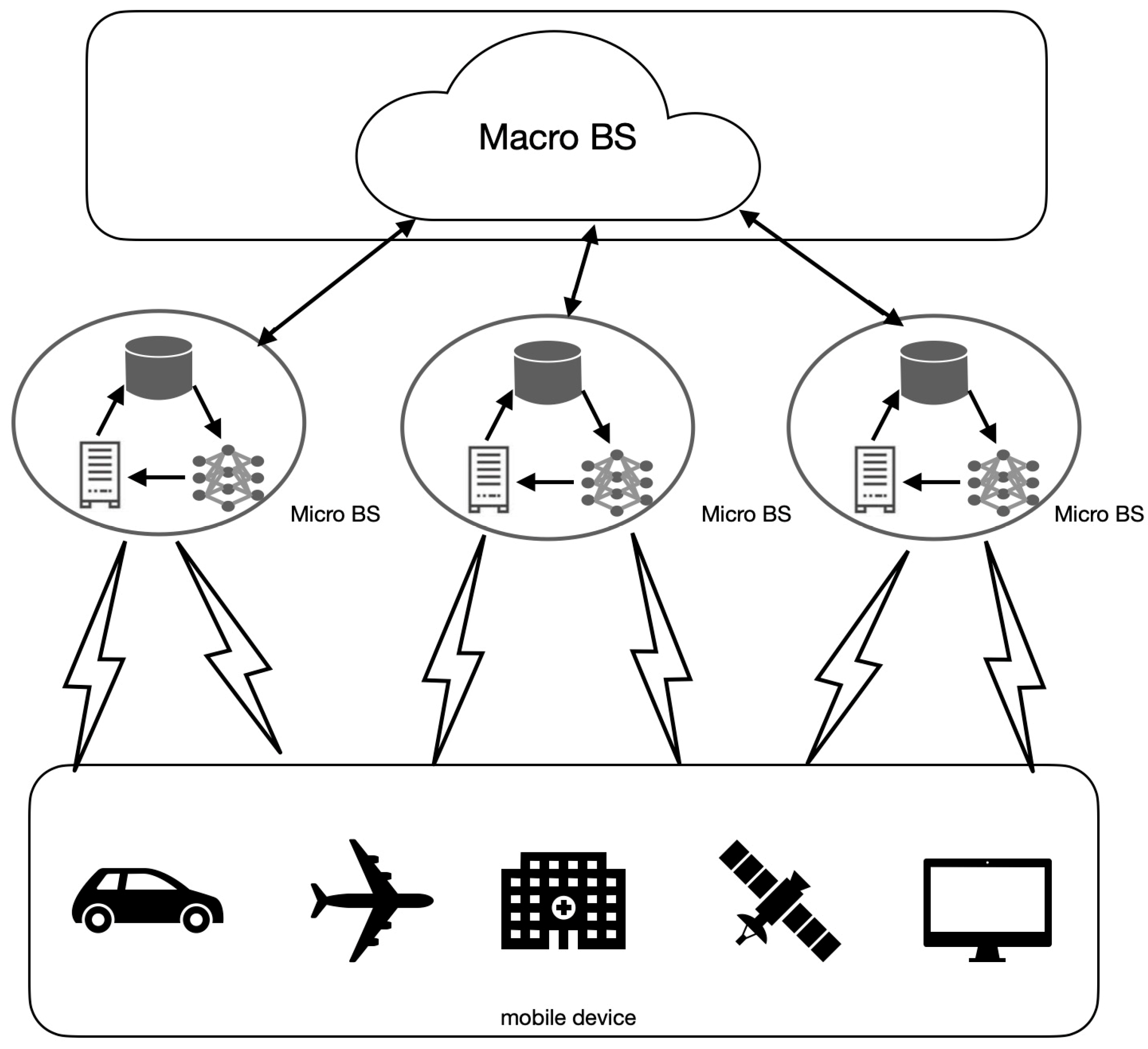
3.1. Network Architecture
3.2. Definition of JRORS
3.3. Definition of PA
4. Proposed Approach
4.1. BSSA Algorithm
4.1.1. SSA Model
| Algorithm 1: Salp Swarm Algorithm (SSA) |
| Input: ub, lb Output: fitness |
| 1: xi ←initial salp population considering ub and lb 2: function SSA() 3: while end condition is not satisfied do 4: Calculate the fitness of each search agent (salp) 5: Set F as the food source 6: for each salp () do 7: if The salp population is in the top half then 8: Update the position of the leading salp using Equation (7) 9: else 10: Update the position of the follower salp using Equation (8) 11: end if 12: end for 13: end while 14: return F 15: end function |
4.1.2. Proposed BSSA Algorithm
| Algorithm 2: BSSA |
| Input: user_profile , na_min, na_max, max_lter, N Output: fval_BSSA Initialize parameters |
| 1: lb ← 0 2: ub ← 1 3: thres ← 0.5 4: max_lter ← 600 5: convlter ← 0 6: dim ← length(user_profile) 7: Q ← 0.7 8: beta1 ← −2 + 4 × rand() 9: beta2 ← −1 + 2 × rand() 10: nalni ← 2 11: na ← round(na_min + (na_max − na_min) × rand()) 12: while t <= max_lter do 13: for i ← 1 to N do 14: Calculate fitness fit(i) using JRORS function 15: Negate fit(i) 16: if fit(i) > fitF then 17: Set Xf = X(i,:) and fitF = fit(i) 18: End if 19: End for 20: Update X as Leader Salp or Follower Salp 21: Set curve(t) ← fitF 22: Increment t 23:End while 24: Convert binary positions to feature subsets 25: Determine Sf, Nf based on Xf 26: Calculate sFeat from user_profile and Sf 27: return fval_BSSA ← fitF |
- Initialize the population. Within the upper bound 1 and lower bound 0 of the search space, a salp swarm of size N × D whose position is binary is randomly initialized;
- Calculate the initial fitness. According to Equation (1), the fitness values of N salps in the JRORS problem are calculated;
- Choose food. The salp swarm is sorted according to the fitness value, and the position of the salp swarm with the best fitness in the first place is set as the current food position;
- Choose leaders and followers. After the food location is selected, there are N − 1 remaining salps in the group, and according to the ranking of the salp groups, the salps in the first half are regarded as leaders and the rest as followers;
- Location update. First, the position of the leader is updated according to Equation (7), and then the position of the follower is updated according to Equation (8);
- Calculate the fitness. Compute the fitness of the updated population. The updated fitness value of each individual salp sheath is compared with the fitness value of the current food. If the fitness value of the updated salp sheath is higher than that of the food, the salp sheath position with the higher fitness value is taken as the new food position;
- Repeat steps 4–6 until a certain number of iterations is reached, and the current food position is output as the estimated position of the target.
4.2. AGDOA Algorithm
4.2.1. DOA Model
4.2.2. DOA Considering Greedy Strategies
| Algorithm 3: Greedy Initialization |
| Input: alloted_bs, U, punt Output: initial_profile Initialize parameters: |
| 1: initial_profile ← Create a matrix of size (|U| × |n|) with initial values as pmax 2: function greedy_initialization(alloted_bs, U, punt) 3: for each user u in U do 4: Get the current allocated base station index n for user u 5: Set initial_profile[u,n] to punt[u,n] 6: end for 7: return initial_profile 8: end function |
4.2.3. Proposed AGDOA Algorithm
| Algorithm 4: Adjust Parameters Adaptively |
| Input: Max_iter, Curve, tol, max_counter, vMin Output: Adjusted value of na based on adaptive mechanism |
| 1: tol_counter ← 0 2: for t ← 1 to Max_iter do 3: Calculate vMin for current iteration 4: if t > 1 then 5: Calculate diff_vMin = abs(Curve(t) − Curve(t + 1)) 6: if diff_vMin < tol then 7: Increase tol_counter by 1 8: else 9: Reset tol_counter to 0 10: if tol_counter >= max_counter then 11: Decrease na 12: else 13: Increase na 14: end for 15: return na |
| Algorithm 5: AGDOA |
| Input: Max_iter, Curve, conver_tol, conver_counter, na_min, na_max Output: vMin Initialize parameters |
| 1: threshold ← 0.005 2: converged ← false 3: consecutive_iterations ← 10 4: iteration_count ← 0 5: convlter ← 0 6: P ← 0.5 7: Q ← 0.7 8: beta1 ← −2 + 4 × rand() 9: beta2 ← −1 + 2 × rand() 10: nalni ← 2 11: na ← round(na_min + (na_max − na_min) × rand()) 12: Positions ← initialize from Algorithm 3 13: for each position i in Positions do 14: Calculate Fitness(i) 15: end for 16: for each iteration t from 1 to Max_iter do 17: for each agent r from 1 to SearchAgent_no do 18: sumatory ← 0 19: if random number() < P then 20: Calculate sumatory using Attack function 21: if random number() < Q then 22: Update Agent position using strategy for group attack by Equation (9) 23: else 24: Update agent position using strategy for persecution by Equation (10) 25: end if 26: else 27: Update agent position using strategy for scavenging by Equation (11) 28: end if 29: if survival rate is below 0.3 then 30: Execute survival process to update agent position by Equation (12) 31: end if 32: Calculate Fnew 33: if Fnew <= Fitness(r) then 34: Update agent position and fitness value 35: end if 36: if Fnew <= vMin then 37: Count and update convlter 38: Update theBestVct and vMin 39: end if 40: end for 41: Update na by Algorithm 4 42: end for 43: return vMin |
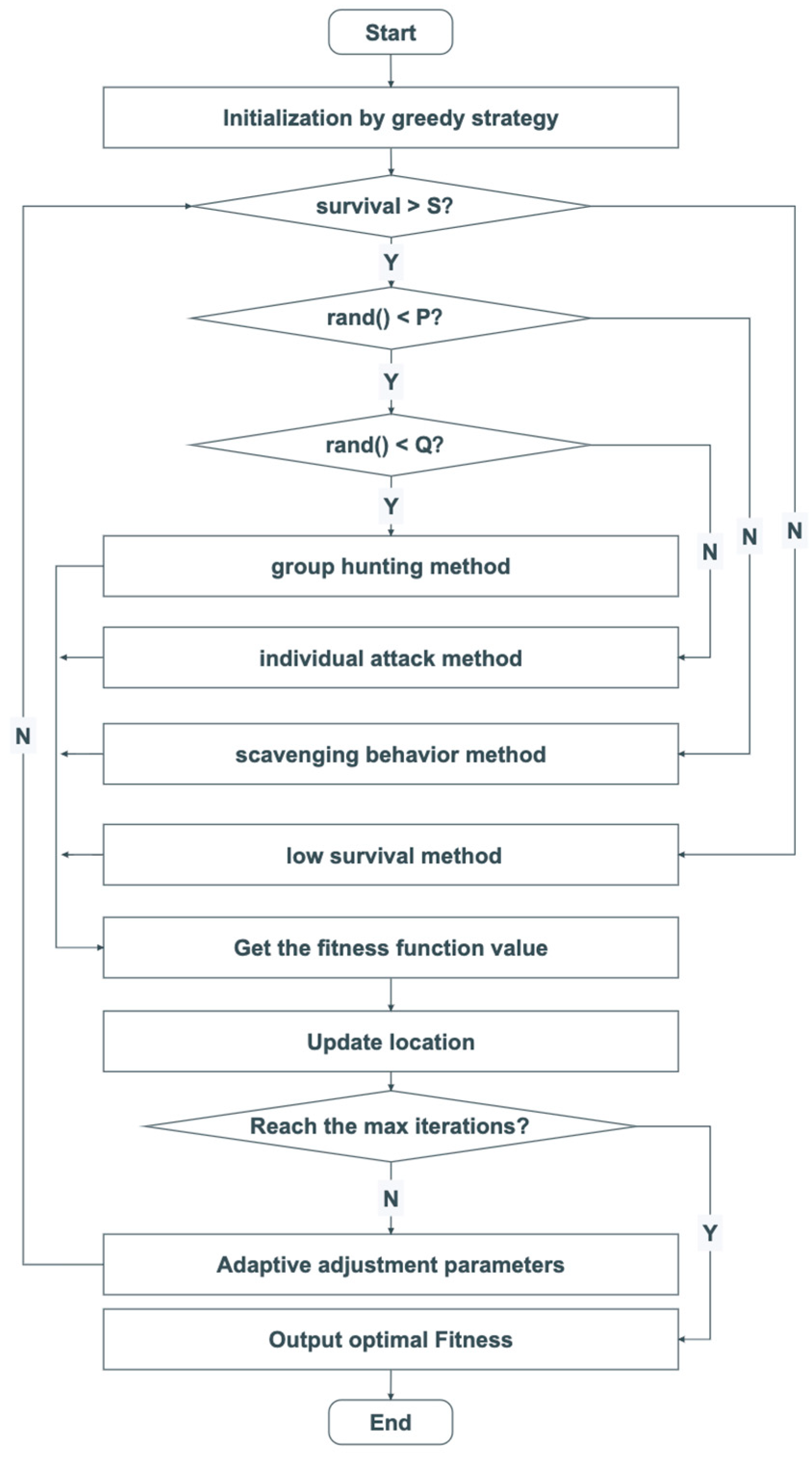
- Use Algorithm 3 to initialize the dingo population position through the greedy strategy;
- Calculate the survival probability;
- If the survival probability is greater than the set point, jump to step 4, otherwise jump to step 9;
- If the random value is less than P, jump to step 5, otherwise jump to step 8;
- If the random value is less than Q, jump to step 6, otherwise jump to step 7;
- Perform a group attack according to Equation (9) to update the agent location;
- Perform individual persecution according to Equation (10) to update the agent location;
- Perform the clearance strategy according to Equation (11) to update the agent location;
- Update the position of the group with low survival rate according to Equation (12);
- Update the fitness value and the agent location;
- If the maximum number of iterations is not reached, update the adaptive parameters according to Algorithm 4 and repeat steps 2–10, otherwise output the optimal fitness;
5. Experimental Setup
5.1. Simulation Settings
5.2. Comparative Experiments
5.2.1. Comparative Experiments of BSSA
- Northern Goshawk Algorithm (NGO): NGO is a relatively new algorithm that has the advantage of diverse search strategies that may help to better explore the solution space [13];
- Genetic Algorithm (GA): The GA performs well in dealing with discrete problems and can effectively represent and manipulate discrete decision variables through the use of binary or integer coding [38].
- Binary Particle Swarm Optimization Algorithm (BPSO): BPSO is suitable for discrete optimization problems and it can represent the decision variables of the problem in binary [39].
5.2.2. Comparative Experiments with AGDOA
- Greedy Particle Swarm Optimization (GPSO): The PSO application has advantages for multivariate problems and is suitable for solving PA problems involving power allocation decisions among multiple mobile users and multiple base stations. Meanwhile, the initialization of the particle swarm was optimized using a greedy strategy to obtain GPSO [40];
- Simulated Annealing PA: Simulated annealing (SA) is suitable for complex problems and can effectively solve discrete NP-hard problems [41];
- Subgradient-based non-cooperative game model (NCGG): the NCGG algorithm is usually used to solve the problem of optimal decision making for multiple participants in a game, and is suitable for optimizing the multi-user PA problem [42].
5.3. Performance Metrics
5.3.1. Convergence Speed
5.3.2. System Response Rate
5.3.3. Scheduling Dominance Degree (SDD)
6. Performance Evaluation and Analysis
6.1. Performance of BSSA
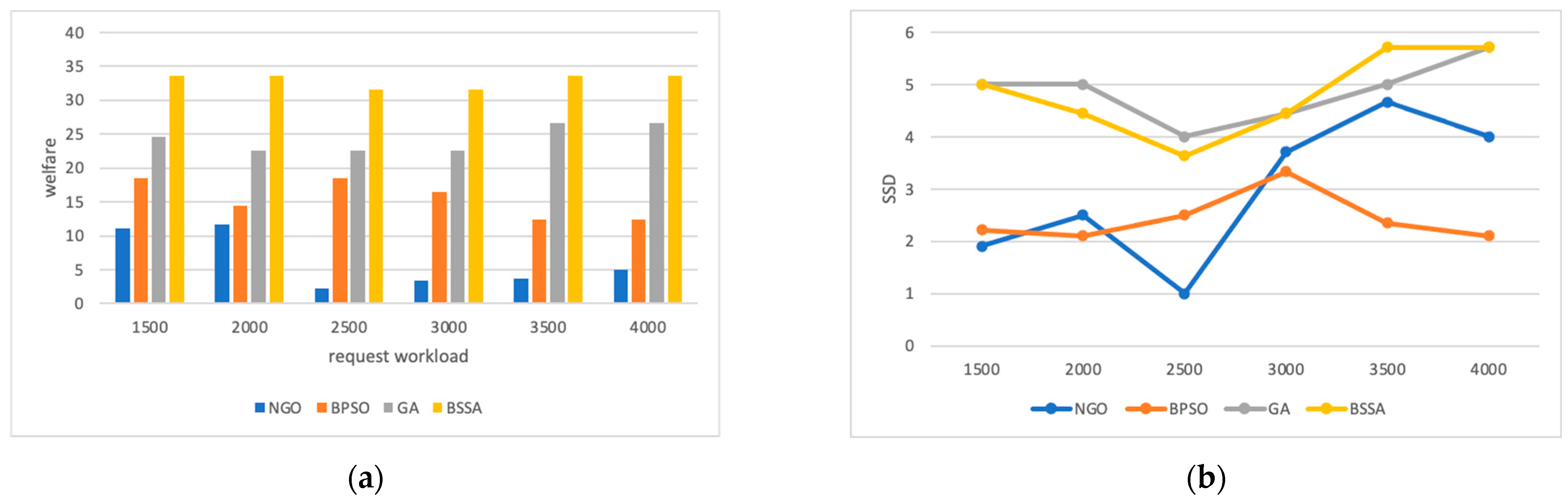
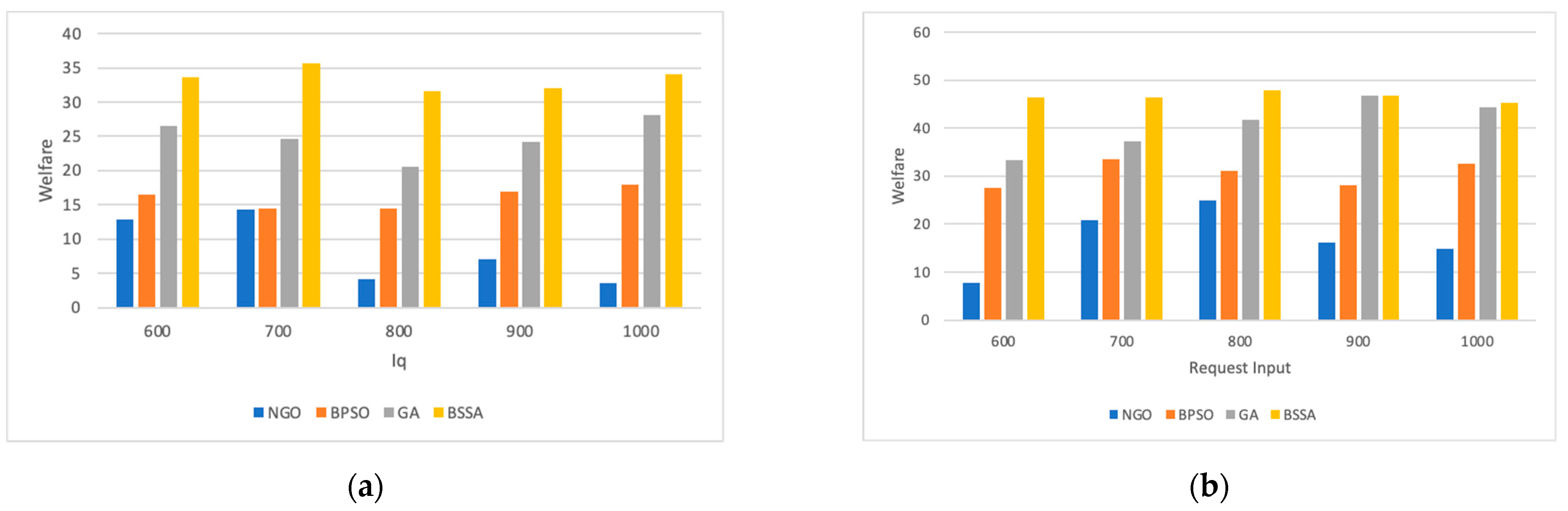
6.1.1. Impact of the Number of Mobile Users
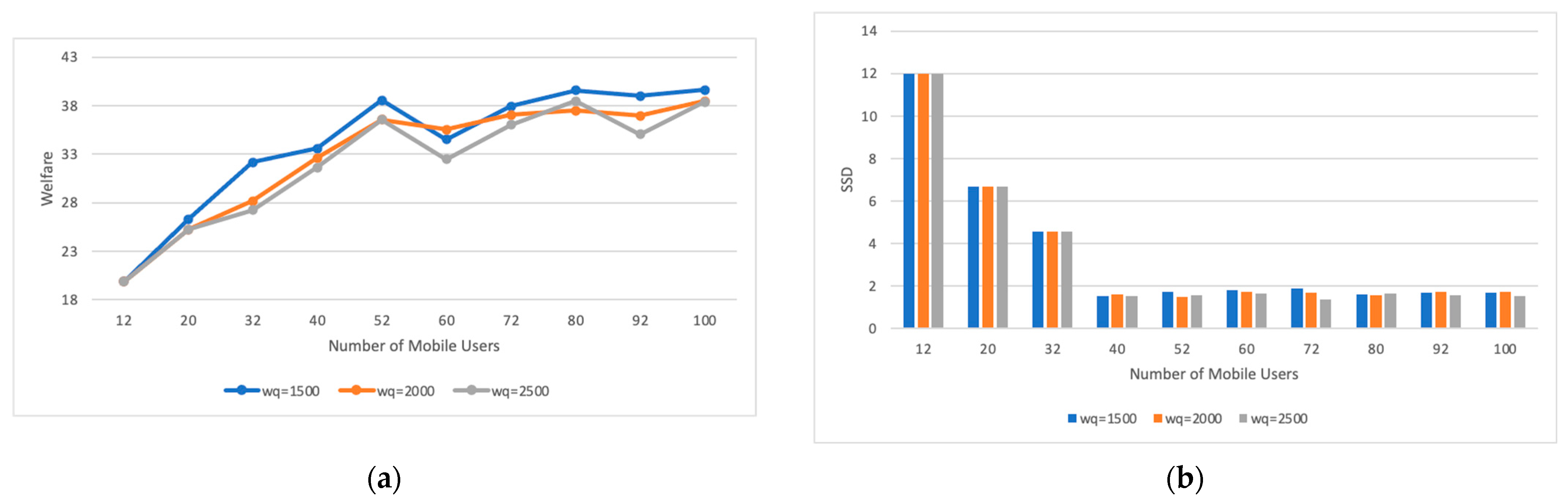
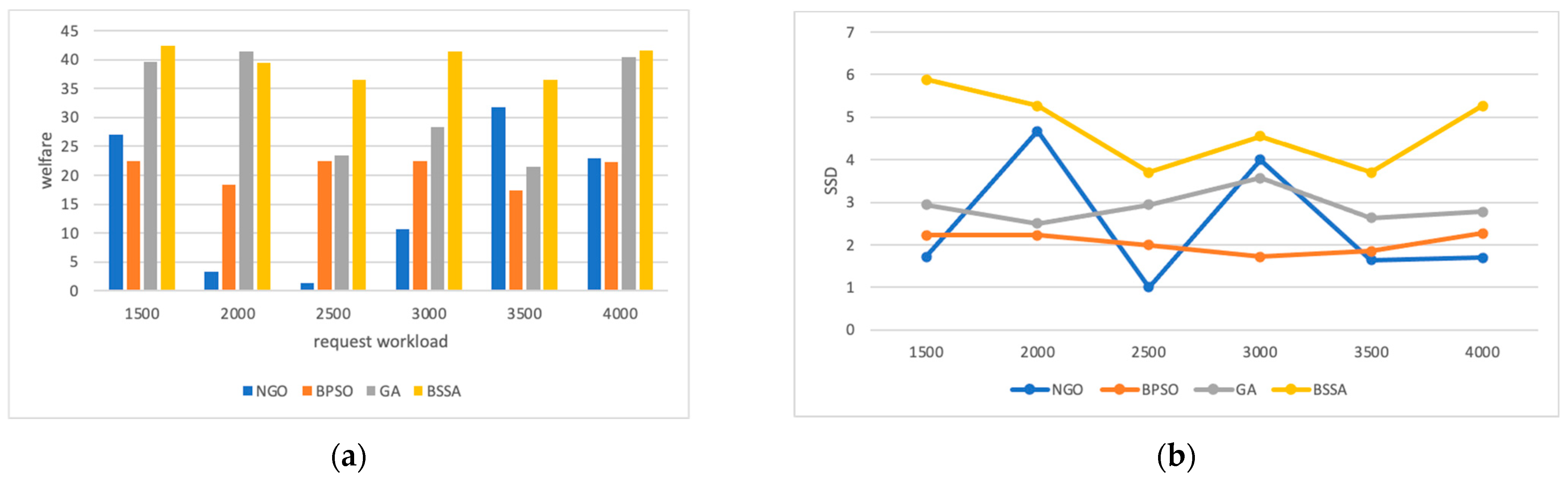
6.1.2. Impact of Request Workloads
6.1.3. Impact of Request Workload Configuration
6.2. Performance of AGDOA
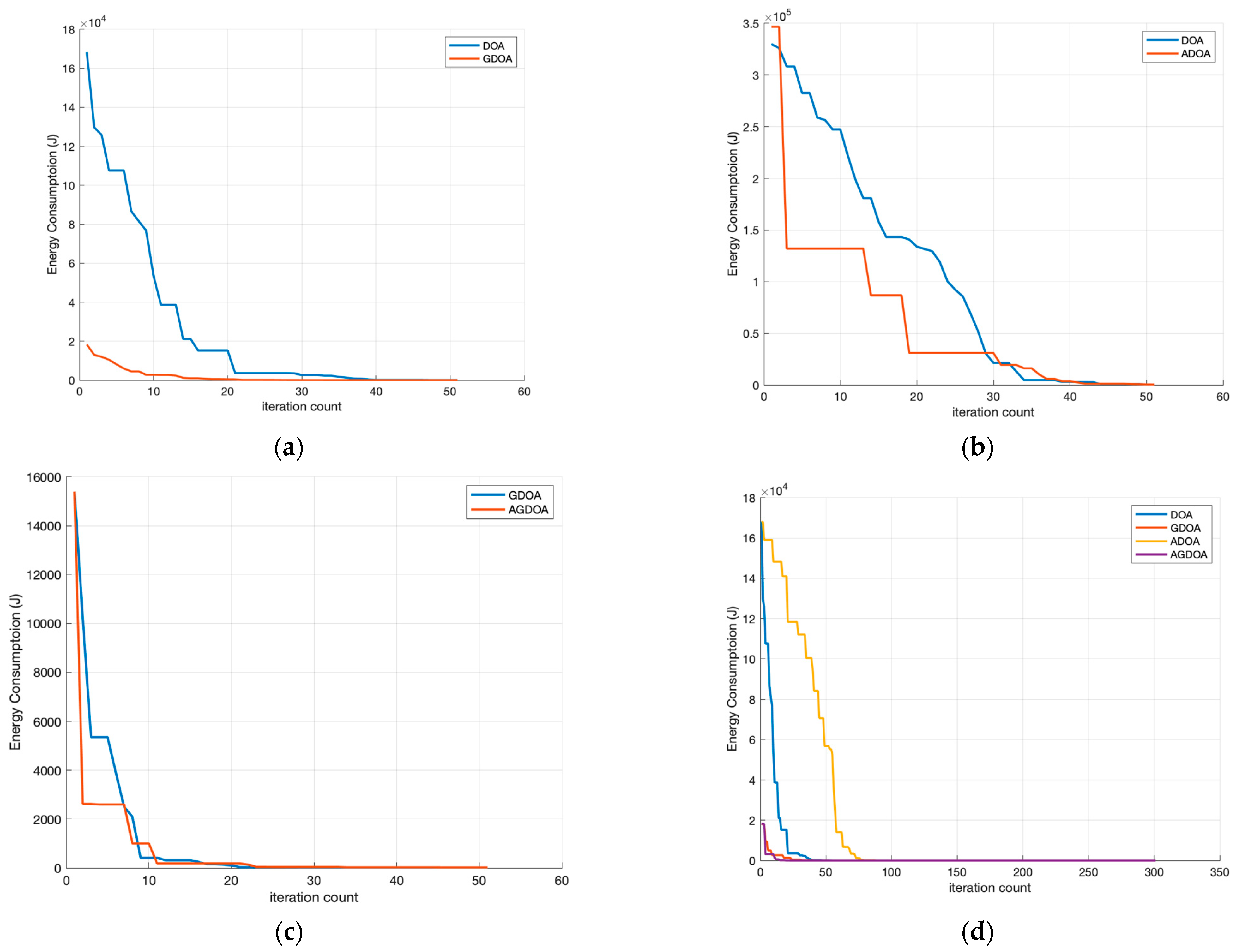
6.2.1. Ablation Experiments
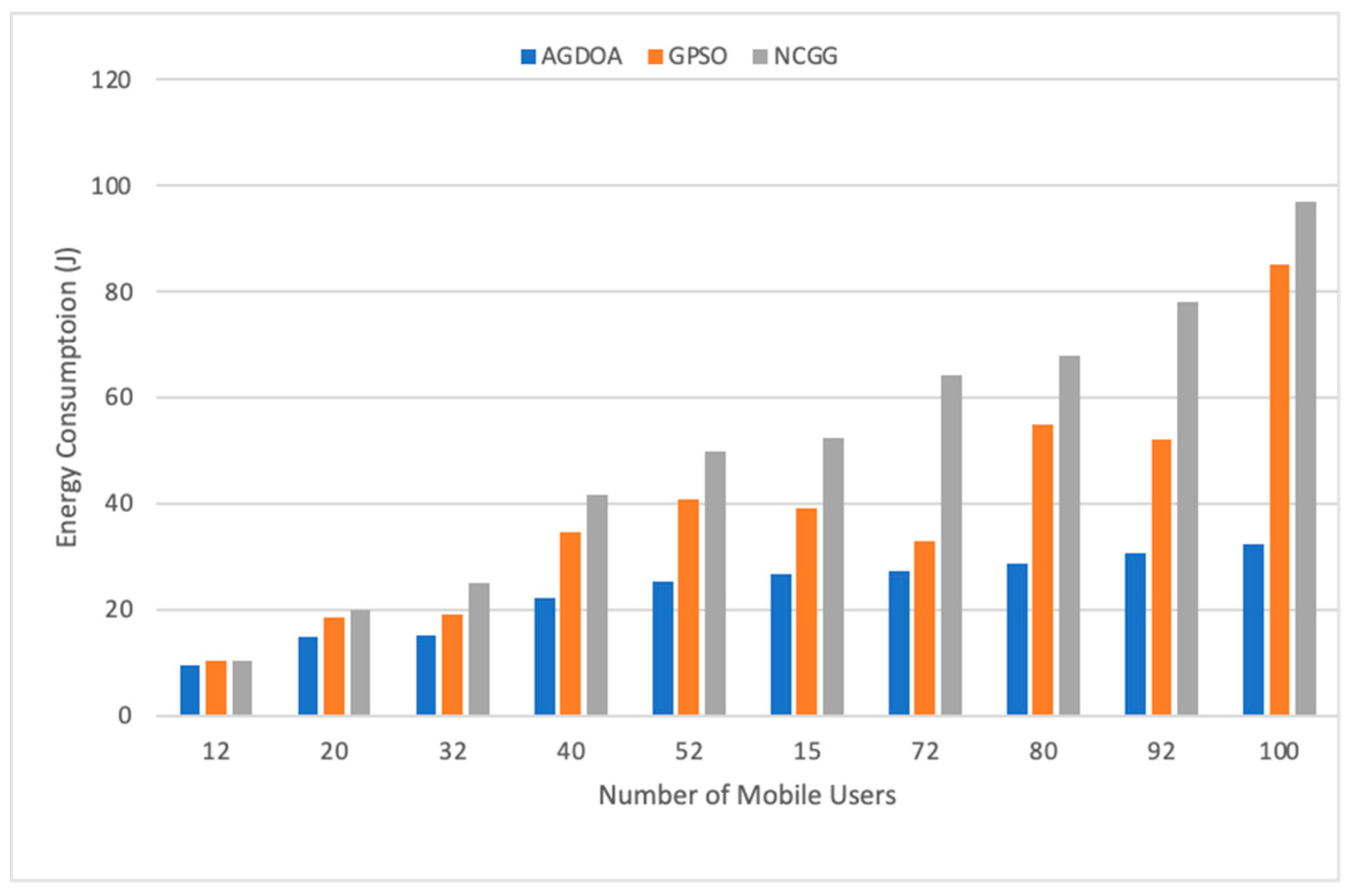
6.2.2. Energy Consumption vs. Number of Mobile Devices
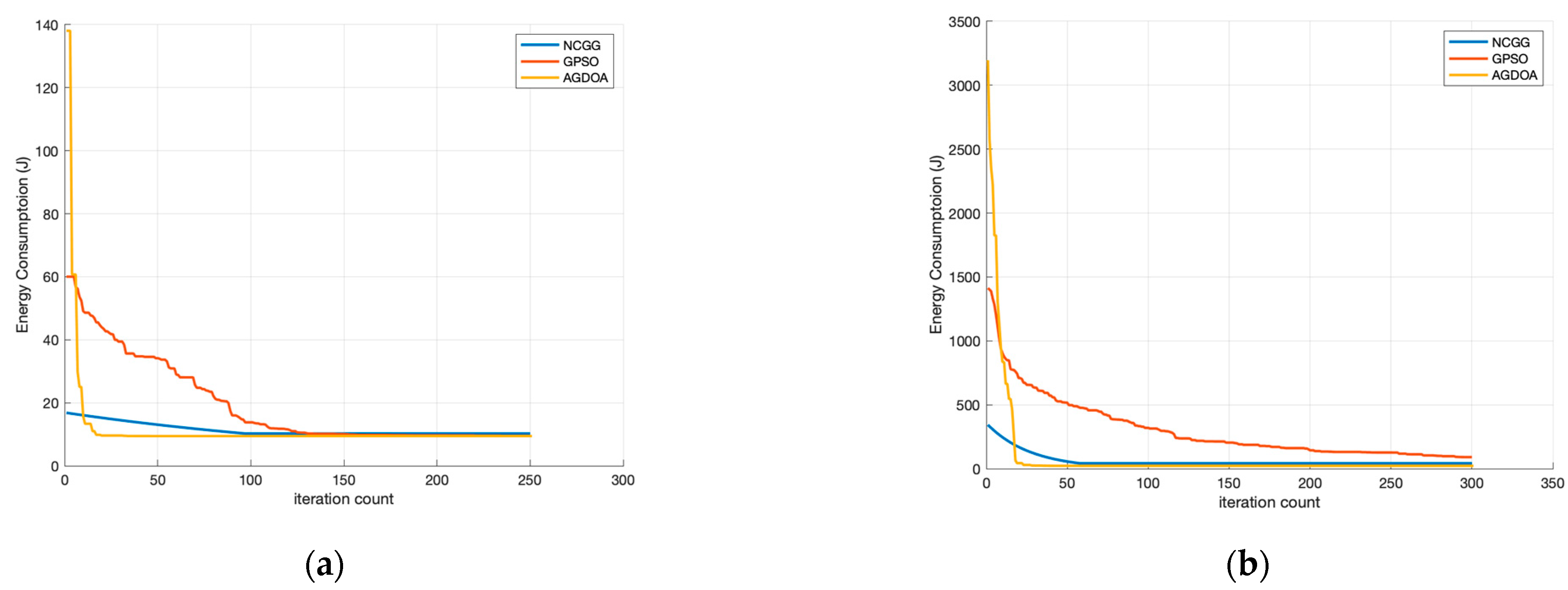
6.2.3. Convergence Properties of AGDOA
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Du, X.; Chen, X.; Lu, Z.; Duan, Q.; Wang, Y.; Wu, J.; Hung, P.C. A Blockchain-Assisted Intelligent Edge Cooperation System for IoT Environments with Multi-Infrastructure Providers. IEEE Internet Things J. 2023, 1. [Google Scholar] [CrossRef]
- Cao, X.W.; Wang, F.; Xu, J.; Zhang, R.; Cui, S. Joint computation and communication cooperation for energy-efficient mobile edge computing. IEEE Internet Things J. 2019, 6, 4188–4200. [Google Scholar] [CrossRef]
- Kishor, A.; Chakarbarty, C. Task Offloading in Fog Computing for Using Smart Ant Colony Optimization. Wirel. Pers. Commun. 2022, 127, 1683–1704. [Google Scholar] [CrossRef]
- Thapa, C.; Chamikara, M.A.P.; Camtepe, S.A. Advancements of federated learning towards privacy preservation: From federated learning to split learning. In Federated Learning Systems: Towards Next-Generation AI; Springer: Berlin/Heidelberg, Germany, 2021; pp. 79–109. [Google Scholar]
- Ma, X.; Zhu, J.; Lin, Z.; Chen, S.; Qin, Y. A state-of-the-art survey on solving non-IID data in Federated Learning. Future Gener. Comput. Syst. 2022, 135, 244–258. [Google Scholar] [CrossRef]
- Nadembega, A.; Taleb, T.; Hafid, A. A destination prediction model based on historical data contextual knowledge and spatial conceptual maps. In Proceedings of the 2012 IEEE International Conference on Communications (ICC), Ottawa, ON, Canada, 10–15 June 2012; pp. 1416–1420. [Google Scholar]
- Hou, X.; Li, Y.; Chen, M.; Wu, D.; Jin, D.; Chen, S. Vehicular Fog Computing: A Viewpoint of Vehicles as the Infrastructures. IEEE Trans. Veh. Technol. 2016, 65, 3860–3873. [Google Scholar] [CrossRef]
- Duan, S.; Wang, D.; Ren, J.; Lyu, F.; Zhang, Y.; Wu, H.; Shen, X. Distributed Artificial Intelligence Empowered by End-Edge-Cloud Computing: A Survey. IEEE Commun. Surv. Tutorials 2022, 25, 591–624. [Google Scholar] [CrossRef]
- Du, X.; Tang, S.; Lu, Z.; Wet, J.; Gai, K.; Hung, P.C.K. A Novel Data Placement Strategy for Data-Sharing Scientific Workflows in Heterogeneous Edge-Cloud Computing Environments. In Proceedings of the 2020 IEEE International Conference on Web Services (ICWS), Beijing, China, 19–23 October 2020; pp. 498–507. [Google Scholar]
- Chen, M.; Hao, Y.; Li, Y.; Lai, C.F.; Wu, D. On the Computation Offloading at Ad Hoc Cloudlet: Architecture and Service Modeo. IEEE Commun. Mag. 2015, 53, 18–24. [Google Scholar] [CrossRef]
- Du, X.; Chen, X.; Lu, Z.; Duan, Q.; Wang, Y.; Wu, J. BIECS: A Blockchain-based Intelligent Edge Cooperation System for Latency-Sensitive Services. In Proceedings of the 2022 IEEE International Conference on Web Services (ICWS), Barcelona, Spain, 10–16 July 2022; pp. 367–372. [Google Scholar]
- Krishnan, M.; Yun, S.; Jung, Y.M. Enhanced clustering and ACO-based multiple mobile sinks for efficiency improvement of wireless sensor networks. Comput. Netw. 2019, 160, 33–40. [Google Scholar] [CrossRef]
- Hu, S.; Li, G. Dynamic Request Scheduling Optimization in Mobile Edge Computing for IoT Applications. IEEE Internet Things J. 2020, 7, 1426–1437. [Google Scholar] [CrossRef]
- Market Research Report by International Data Corporation. Available online: https://www.idc.com/getdoc.jsp?containerId=prUS50936423 (accessed on 20 June 2023).
- Yin, L.; Feng, J.; Xun, H.; Sun, Z.; Cheng, X. A Privacy-Preserving Federated Learning for Multiparty Data Sharing in Social IoTs. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2706–2718. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint task offloading and resource allocation for multi-server mobile-edge computing networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef]
- Du, X.; Tang, S.; Lu, Z.; Gai, K.; Wu, J.; Hung, P.C. Scientific workflows in iot environments: A data placement strategy based on heterogeneous edge-cloud computing. ACM Trans. Manag. Inf. Syst. (TMIS) 2022, 13, 1–26. [Google Scholar] [CrossRef]
- Ra, M.R.; Sheth, A.; Mummert, L.; Pillai, P.; Wetherall, D.; Govindan, R. Odessa: Enabling Interactive Perception Applications on Mobile Devices. In Proceedings of the 9th International Conference on Mobile Systems, Applications, and Services, Bethesda, MD, USA, 28 June–1 July 2011. [Google Scholar]
- Chen, C.; Chang, Y.-C.; Chen, C.-H.; Lin, Y.-S.; Chen, J.-L.; Chang, Y.-Y. Cloud-fog computing for information-centric Internet-of-Things applications. In Proceedings of the 2017 International Conference on Applied System Innovation (ICASI), Sapporo, Japan, 13–17 May 2017; pp. 637–640. [Google Scholar]
- Chang, Z.; Zhou, Z.; Ristaniemi, T.; Niu, Z. Energy efficient optimization for computation offloading in fog computing system. In Proceedings of the GLOBECOM 2017–2017 IEEE Global Communications Conference, Singapore, 4–8 December 2017; pp. 1–6. [Google Scholar]
- Alazab, A.; Venkatraman, S.; Abawajy, J.; Alazab, M. An optimal transportation routing approach using GIS-based dynamic traffic flows. In Proceedings of the ICMTA 2010, Proceedings of the International Conference on Management Technology and Applications, Singapore, 10 September 2010; Research Publishing Services: Singapore, 2011; pp. 172–178. [Google Scholar]
- Pham, Q.V.; Mirjalili, S.; Kumar, N.; Alazab, M.; Hwang, W.J. Whale optimization algorithm with applications to resource allocation in wireless networks. IEEE Trans. Veh. Technol. 2020, 69, 4285–4297. [Google Scholar] [CrossRef]
- Abdi, S.; Motamedi, S.A.; Sharifian, S. Task scheduling using modified PSO algorithm in cloud computing environment. In Proceedings of the International Conference on Machine Learning, Electrical and Mechanical Engineering, Dubai, United Arab Emirates, 8–9 January 2014; Volume 4, pp. 8–12. [Google Scholar]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic computation offloading for mobile-edge computing with energy harvesting devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Shojafar, M.; Cordeschi, N.; Baccarelli, E. Energy-efficient adaptive resource management for real-time vehicular cloud services. IEEE Trans. Cloud Comput. 2019, 7, 196–209. [Google Scholar] [CrossRef]
- Haxhibeqiri, J.; Van den Abeele, F.; Moerman, I.; Hoebeke, J. LoRa scalability: A simulation model based on interference measurements. Sensors 2017, 17, 1193. [Google Scholar] [CrossRef]
- Mikhaylov, K.; Petäjäjärvi, J.; Janhunen, J. On LoRaWAN scalability: Empirical evaluation of susceptibility to inter-network interference. In Proceedings of the 2017 European Conference on Networks and Communications (EuCNC), Oulu, Finland, 12–15 June 2017; pp. 1–6. [Google Scholar]
- Tang, S.; Du, X.; Lu, Z.; Gai, K.; Wu, J.; Hung, P.C.; Choo, K.K.R. Coordinate-based efficient indexing mechanism for intelligent IoT systems in heterogeneous edge computing. J. Parallel Distrib. Comput. 2022, 166, 45–56. [Google Scholar] [CrossRef]
- Rajab, H.; Cinkler, T.; Bouguera, T. IoT scheduling for higher throughput and lower transmission power. Wirel. Netw. 2021, 27, 1701–1714. [Google Scholar] [CrossRef]
- Rodrigues, T.K.; Suto, K.; Kato, N. Edge cloud server deployment with transmission power control through machine learning for 6G Internet of Things. IEEE Trans. Emerg. Top. Comput. 2019, 9, 2099–2108. [Google Scholar] [CrossRef]
- Vispute, S.D.; Vashisht, P. Energy-Efficient Task Scheduling in Fog Computing Based on Particle Swarm Optimization. SN Comput. Sci. 2023, 4, 391. [Google Scholar] [CrossRef]
- Xia, W.; Shen, L. Joint Resource Allocation at Edge Cloud Based on Ant Colony Optimization and Genetic Algorithm. Wirel. Pers. Commun. 2021, 117, 355–386. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Peraza-Vázquez, H.; Peña-Delgado, A.F.; Echavarría-Castillo, G.; Morales-Cepeda, A.B.; Velasco-Álvarez, J.; Ruiz-Perez, F. A bio-inspired method for engineering design optimization inspired by dingoes hunting strategies. Math. Probl. Eng. 2021, 2021, 9107547. [Google Scholar] [CrossRef]
- Pan, G.; Li, K.; Ouyang, A.; Li, K. Hybrid immune algorithm based on greedy algorithm and delete-cross operator for solving TSP. Soft Comput. 2016, 20, 555–566. [Google Scholar] [CrossRef]
- de Perthuis de Laillevault, A.; Doerr, B.; Doerr, C. Money for nothing: Speeding up evolutionary algorithms through better initialization. In Proceedings of the 2015 Annual Conference on Genetic and Evolutionary Computation, Yangon, Myanmar, 26–28 August 2015; pp. 815–822. [Google Scholar]
- Guo, M.; Xin, B.; Chen, J.; Wang, Y. Multi-agent coalition formation by an efficient genetic algorithm with heuristic initialization and repair strategy. Swarm Evol. Comput. 2020, 55, 100686. [Google Scholar] [CrossRef]
- Das, S.; Idicula, S.M. Greedy search-binary PSO hybrid for biclustering gene expression data. Int. J. Comput. Appl. 2010, 2, 1–5. [Google Scholar] [CrossRef]
- Alrefaei, M.H.; Andradóttir, S. A simulated annealing algorithm with constant temperature for discrete stochastic optimization. Manag. Sci. 1999, 45, 748–764. [Google Scholar] [CrossRef]
- Dehghani, M.; Hubálovský, Š.; Trojovský, P. Northern goshawk optimization: A new swarm-based algorithm for solving optimization problems. IEEE Access 2021, 9, 162059–162080. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks: Theory and Applications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–55. [Google Scholar]
- El-Maleh, A.H.; Sheikh, A.T.; Sait, S.M. Binary particle swarm optimization (BPSO) based state assignment for area minimization of sequential circuits. Appl. Soft Comput. 2013, 13, 4832–4840. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| New location for dingoes | |
| Subset of search agents | |
| Current search agent, i.e., subset of wild dogs being attacked | |
| Iteration of the best subset of dingoes so far | |
| Randomly selected , search agent, i.e., subset of dingoes, where | |
| Total size of the dingo population | |
| Randomly generated binary numbers, | |
| Randomly generated scale factor | |
| Random numbers generated from [1, maximum search agent size] with ; |
| Parameter | Value |
|---|---|
| Number of Mobile Users u | {12,20,32,40,52,60,72,80,92,100} |
| Number of Micro-BSs n | {3,5,8,10,13,15,18,20,23,25} |
| The fixed bandwidth B | 20 (MHz) |
| The fixed height of BSs H | 10 (m) |
| Workload of request wq | 600–1000 (MHz) |
| Input data of request lq | 300–1500 (KB) |
| Ideal delay of request q Tgq | 0.5 ± 0.1 (s) |
| Tolerable delay of request q Tbq | Tgq + [0.1,0.15] (s) |
| Maximum transmission power for mobile users Pmax | 5 (w) |
| Background Gaussian noise power Sig | −100 (dBm) |
| Average power consumption of microbase station Pmi | 7500 (w) |
| Average power consumption of macrobase station Pma | 15,000 (w) |
| The computing power of edge servers Rmi | 70 (GHz) |
| Computing power of the cloud server Rma | 140 (GHz) |
| Algorithm | Number of Mobile Users | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 12 | 20 | 32 | 40 | 52 | 60 | 72 | 80 | 92 | 100 | |
| DOA | 166 | 75 | 62 | 91 | 94 | 119 | 95 | 159 | 165 | 127 |
| ADOA | 125 | 69 | 97 | 69 | 76 | 111 | 90 | 110 | 142 | 142 |
| GDOA | 71 | 66 | 78 | 77 | 82 | 80 | 125 | 99 | 102 | 146 |
| AGDOA | 57 | 53 | 51 | 66 | 34 | 66 | 71 | 89 | 80 | 74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, W.; Duan, F. Task Scheduling for Federated Learning in Edge Cloud Computing Environments by Using Adaptive-Greedy Dingo Optimization Algorithm and Binary Salp Swarm Algorithm. Future Internet 2023, 15, 357. https://doi.org/10.3390/fi15110357
Cai W, Duan F. Task Scheduling for Federated Learning in Edge Cloud Computing Environments by Using Adaptive-Greedy Dingo Optimization Algorithm and Binary Salp Swarm Algorithm. Future Internet. 2023; 15(11):357. https://doi.org/10.3390/fi15110357
Chicago/Turabian StyleCai, Weihong, and Fengxi Duan. 2023. "Task Scheduling for Federated Learning in Edge Cloud Computing Environments by Using Adaptive-Greedy Dingo Optimization Algorithm and Binary Salp Swarm Algorithm" Future Internet 15, no. 11: 357. https://doi.org/10.3390/fi15110357
APA StyleCai, W., & Duan, F. (2023). Task Scheduling for Federated Learning in Edge Cloud Computing Environments by Using Adaptive-Greedy Dingo Optimization Algorithm and Binary Salp Swarm Algorithm. Future Internet, 15(11), 357. https://doi.org/10.3390/fi15110357