
Relational Action Bank with Semantic–Visual Attention for Few-Shot Action Recognition


Abstract
:1. Introduction
- To the best of our knowledge, we are the first to propose a relational action bank to assist the few-shot action recognition.
- The proposed relational action bank can both enhance the representation ability of clips in each video and learn the feature vector representations for each class adaptively.
- We propose a semantic–visual attention mechanism, which can utilize the relational action bank both in semantic categories and visual similarities.
- Our proposed method obtains state-of-the-art performance in few-shot action recognition on Kinetics dataset, notably achieving an average improvement of 6.2%. Furthermore, we achieve the improved performance on the HMDB dataset compared to the original model.
2. Related Works
2.1. Video Action Recognition
2.2. Attention Mechanism
2.3. Few-Shot Learning
3. Method
3.1. The Framework
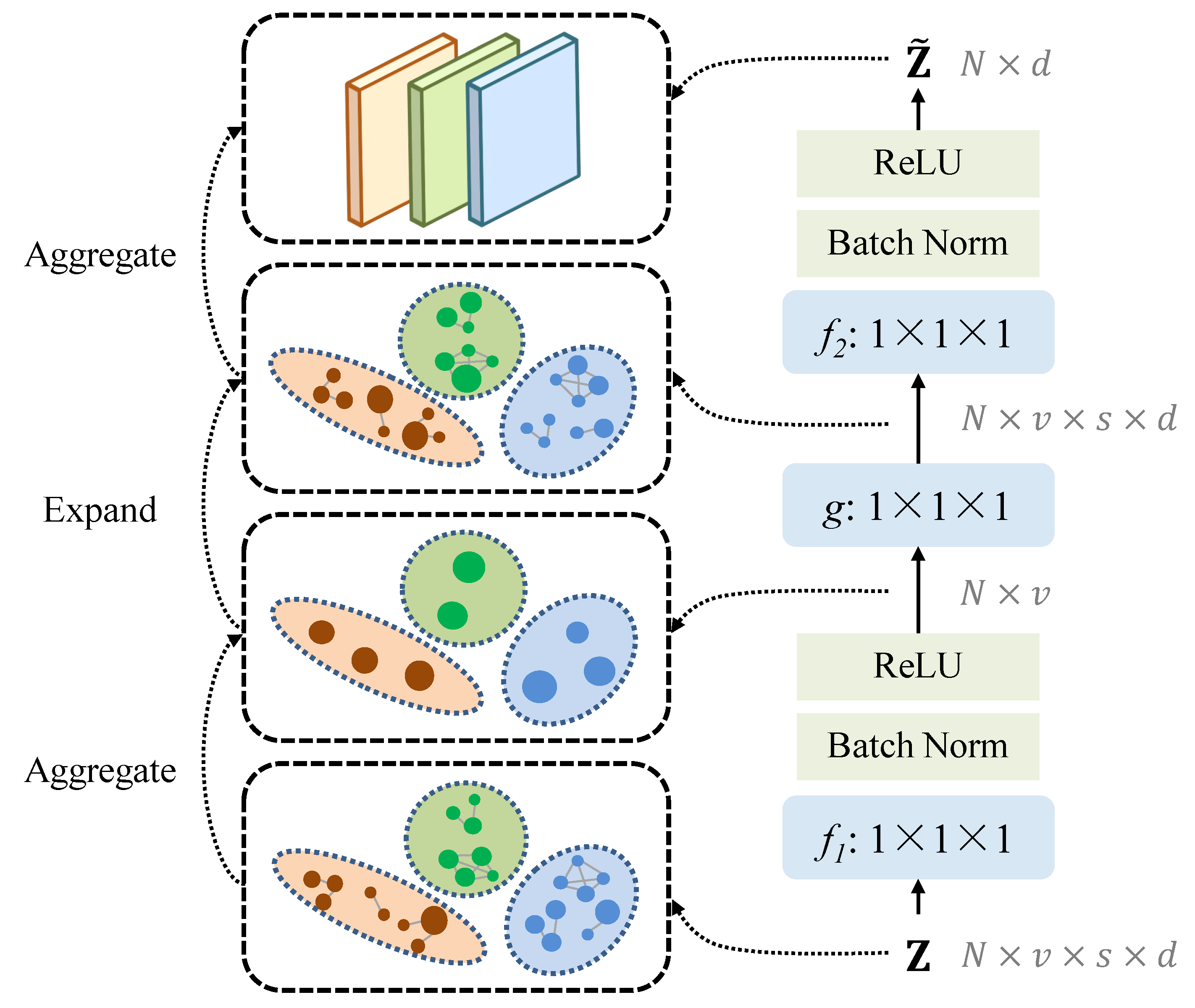
3.2. Relational Action Bank
3.3. Semantic–Visual Attention Mechanism
3.3.1. Semantic Attention
3.3.2. Visual Attention
3.3.3. Fusion
4. Experiments
4.1. Datasets
4.1.1. HMDB-51
4.1.2. Kinetics
4.2. Implementation Details
4.3. Ablation Analysis
4.3.1. Naive Aggregation, K-Means Aggregation and Relational Action Bank
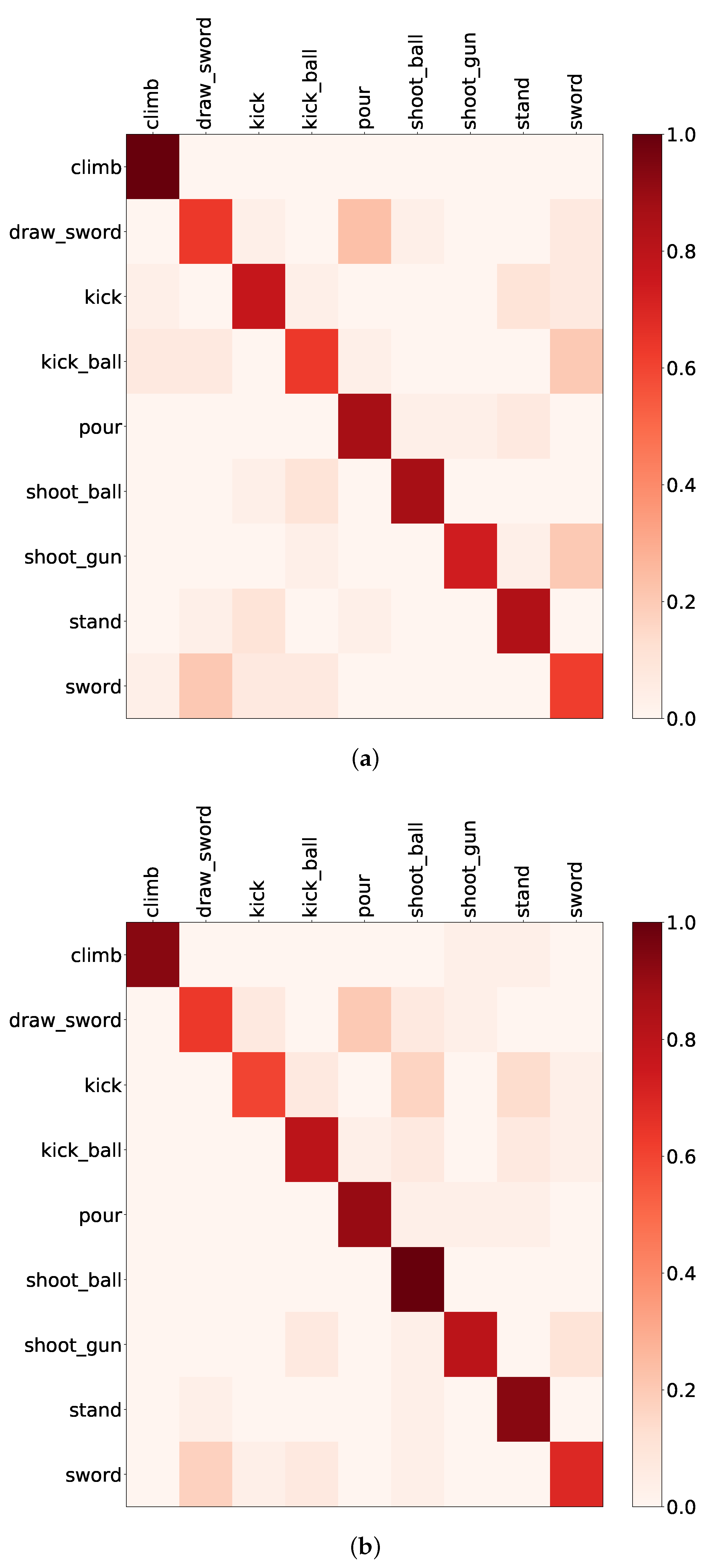
4.3.2. Semantic Attention, Visual Attention and Semantic–Visual Attention
4.3.3. With and without the RABSVA Module
4.4. Comparison with State-of-the-Art Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Karpathy, A.; Toderici, G.; Shetty, S.; Leung, T.; Sukthankar, R.; Fei-Fei, L. Large-scale Video Classification with Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Carreira, J.; Noland, E.; Hillier, C.; Zisserman, A. A short note on the kinetics-700 human action dataset. arXiv 2019, arXiv:1907.06987. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 3630–3638. [Google Scholar]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4077–4087. [Google Scholar]
- Zhu, L.; Yang, Y. Compound memory networks for few-shot video classification. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 751–766. [Google Scholar]
- Xu, B.; Ye, H.; Zheng, Y.; Wang, H.; Luwang, T.; Jiang, Y. Dense dilated network for few shot action recognition. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 379–387. [Google Scholar]
- Bishay, M.; Zoumpourlis, G.; Patras, I. TARN: Temporal Attentive Relation Network for Few-Shot and Zero-Shot Action Recognition. arXiv 2019, arXiv:1907.09021. [Google Scholar]
- Wang, L.; Qiao, Y.; Tang, X. Latent hierarchical model of temporal structure for complex activity classification. IEEE Trans. Image Process. 2013, 23, 810–822. [Google Scholar] [CrossRef] [PubMed]
- Niebles, J.C.; Chen, C.W.; Fei-Fei, L. Modeling temporal structure of decomposable motion segments for activity classification. In Proceedings of the European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 392–405. [Google Scholar]
- Liu, F.; Xu, X.; Zhang, T.; Guo, K.; Wang, L. Exploring privileged information from simple actions for complex action recognition. Neurocomputing 2020, 380, 236–245. [Google Scholar] [CrossRef]
- Thatipelli, A.; Narayan, S.; Khan, S.; Anwer, R.M.; Khan, F.S.; Ghanem, B. Spatio-temporal relation modeling for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 19958–19967. [Google Scholar]
- Wu, J.; Zhang, T.; Zhang, Z.; Wu, F.; Zhang, Y. Motion-Modulated Temporal Fragment Alignment Network for Few-Shot Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 9151–9160. [Google Scholar]
- Yang, L.; Huang, Y.; Sugano, Y.; Sato, Y. Interact Before Align: Leveraging Cross-Modal Knowledge for Domain Adaptive Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 14722–14732. [Google Scholar]
- Yang, J.; Dong, X.; Liu, L.; Zhang, C.; Shen, J.; Yu, D. Recurring the Transformer for Video Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 14063–14073. [Google Scholar]
- Truong, T.D.; Bui, Q.H.; Duong, C.N.; Seo, H.S.; Phung, S.L.; Li, X.; Luu, K. Direcformer: A directed attention in transformer approach to robust action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 20030–20040. [Google Scholar]
- Wang, H.; Klser, A.; Schmid, C.; Liu, C.L. Action recognition by dense trajectories. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2019. [Google Scholar]
- Wang, H.; Schmid, C. Action recognition with improved trajectories. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2019. [Google Scholar]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. 2012. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=3c86dfdbdf37060d5adcff6c4d7d453ea5a8b08f (accessed on 4 February 2023).
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning spatiotemporal features with 3d convolutional networks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Stroud, J.C.; Ross, D.A.; Sun, C.; Deng, J.; Sukthankar, R. D3D: Distilled 3D Networks for Video Action Recognition. In Proceedings of the 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass Village, CO, USA, 1–5 March 2020. [Google Scholar]
- Carreira, J.; Zisserman, A. Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Diba, A.; Fayyaz, M.; Sharma, V.; Arzani, M.M.; Yousefzadeh, R.; Gall, J.; Van Gool, L. Spatio-temporal channel correlation networks for action classification. In Proceedings of the the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 284–299. [Google Scholar]
- Duan, H.; Zhao, Y.; Chen, K.; Lin, D.; Dai, B. Revisiting skeleton-based action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2969–2978. [Google Scholar]
- Xu, Y.; Wei, F.; Sun, X.; Yang, C.; Shen, Y.; Dai, B.; Zhou, B.; Lin, S. Cross-model pseudo-labeling for semi-supervised action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2959–2968. [Google Scholar]
- Guo, H.; Wang, H.; Ji, Q. Uncertainty-Guided Probabilistic Transformer for Complex Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 20052–20061. [Google Scholar]
- Plizzari, C.; Cannici, M.; Matteucci, M. Skeleton-based action recognition via spatial and temporal transformer networks. Comput. Vis. Image Underst. 2021, 208, 103219. [Google Scholar] [CrossRef]
- Patrick, M.; Campbell, D.; Asano, Y.; Misra, I.; Metze, F.; Feichtenhofer, C.; Vedaldi, A.; Henriques, J.F. Keeping your eye on the ball: Trajectory attention in video transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12493–12506. [Google Scholar]
- Arnab, A.; Dehghani, M.; Heigold, G.; Sun, C.; Lučić, M.; Schmid, C. Vivit: A video vision transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6836–6846. [Google Scholar]
- Herzig, R.; Ben-Avraham, E.; Mangalam, K.; Bar, A.; Chechik, G.; Rohrbach, A.; Darrell, T.; Globerson, A. Object-region video transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 3148–3159. [Google Scholar]
- Qiu, H.; Hou, B.; Ren, B.; Zhang, X. Spatio-Temporal Tuples Transformer for Skeleton-Based Action Recognition. arXiv 2022, arXiv:2201.02849. [Google Scholar]
- Huang, Z.; Qing, Z.; Wang, X.; Feng, Y.; Zhang, S.; Jiang, J.; Xia, Z.; Tang, M.; Sang, N.; Ang Jr, M.H. Towards training stronger video vision transformers for epic-kitchens-100 action recognition. arXiv 2021, arXiv:2106.05058. [Google Scholar]
- Shi, F.; Lee, C.; Qiu, L.; Zhao, Y.; Shen, T.; Muralidhar, S.; Han, T.; Zhu, S.C.; Narayanan, V. Star: Sparse transformer-based action recognition. arXiv 2021, arXiv:2107.07089. [Google Scholar]
- Bertasius, G.; Wang, H.; Torresani, L. Is space-time attention all you need for video understanding? In Proceedings of the International Conference on Machine Learning, Online, 19–20 July 2021; Volume 2, p. 4. [Google Scholar]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A self-attention model for short-time pose-based human action recognition. Pattern Recognit. 2022, 124, 108487. [Google Scholar] [CrossRef]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 3202–3211. [Google Scholar]
- Tong, Z.; Song, Y.; Wang, J.; Wang, L. Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training. arXiv 2022, arXiv:2203.12602. [Google Scholar]
- Qing, Z.; Zhang, S.; Huang, Z.; Wang, X.; Wang, Y.; Lv, Y.; Gao, C.; Sang, N. MAR: Masked Autoencoders for Efficient Action Recognition. arXiv 2022, arXiv:2207.11660. [Google Scholar]
- Yan, S.; Xiong, X.; Arnab, A.; Lu, Z.; Zhang, M.; Sun, C.; Schmid, C. Multiview transformers for video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 3333–3343. [Google Scholar]
- Wei, C.; Fan, H.; Xie, S.; Wu, C.Y.; Yuille, A.; Feichtenhofer, C. Masked feature prediction for self-supervised visual pre-training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 14668–14678. [Google Scholar]
- Wu, C.Y.; Li, Y.; Mangalam, K.; Fan, H.; Xiong, B.; Malik, J.; Feichtenhofer, C. Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 13587–13597. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2048–2057. [Google Scholar]
- Lu, J.; Yang, J.; Batra, D.; Parikh, D. Hierarchical question-image co-attention for visual question answering. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective approaches to attention-based neural machine translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Daniluk, M.; Rocktäschel, T.; Welbl, J.; Riedel, S. Frustratingly short attention spans in neural language modeling. arXiv 2017, arXiv:1702.04521. [Google Scholar]
- Zhao, S.; Zhang, Z. Attention-via-attention neural machine translation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Zhu, X.; Cheng, D.; Zhang, Z.; Lin, S.; Dai, J. An empirical study of spatial attention mechanisms in deep networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6688–6697. [Google Scholar]
- Gregor, K.; Danihelka, I.; Graves, A.; Rezende, D.; Wierstra, D. Draw: A recurrent neural network for image generation. In Proceedings of the International Conference on Machine Learning, Miami, FL, USA, 9–11 December 2015; pp. 1462–1471. [Google Scholar]
- Wang, F.; Jiang, M.; Qian, C.; Yang, S.; Li, C.; Zhang, H.; Wang, X.; Tang, X. Residual attention network for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3156–3164. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Li, K.; Wu, Z.; Peng, K.C.; Ernst, J.; Fu, Y. Tell me where to look: Guided attention inference network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 9215–9223. [Google Scholar]
- Li, W.; Zhu, X.; Gong, S. Harmonious attention network for person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2285–2294. [Google Scholar]
- Wang, C.; Zhang, Q.; Huang, C.; Liu, W.; Wang, X. Mancs: A multi-task attentional network with curriculum sampling for person re-identification. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 365–381. [Google Scholar]
- Jetley, S.; Lord, N.A.; Lee, N.; Torr, P.H. Learn to pay attention. arXiv 2018, arXiv:1804.02391. [Google Scholar]
- Yuan, Y.; Huang, L.; Guo, J.; Zhang, C.; Chen, X.; Wang, J. Ocnet: Object context network for scene parsing. arXiv 2018, arXiv:1809.00916. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Zhang, H.; Dana, K.; Shi, J.; Zhang, Z.; Wang, X.; Tyagi, A.; Agrawal, A. Context encoding for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7151–7160. [Google Scholar]
- Chen, L.; Zhang, H.; Xiao, J.; Nie, L.; Shao, J.; Liu, W.; Chua, T.S. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5659–5667. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Huang, Q.; Ren, H.; Leskovec, J. Few-shot Relational Reasoning via Connection Subgraph Pretraining. arXiv 2022, arXiv:2210.06722. [Google Scholar]
- Wang, S.; Chen, C.; Li, J. Graph few-shot learning with task-specific structures. arXiv 2022, arXiv:2210.12130. [Google Scholar]
- Jiang, Z.; Dai, Y.; Xin, J.; Li, M.; Lin, J. Few-shot non-parametric learning with deep latent variable model. arXiv 2022, arXiv:2206.11573. [Google Scholar]
- Hermann, M.; Saha, S.; Zhu, X.X. Filtering Specialized Change in a Few-Shot Setting. IEEE J. Sel. Top. Appl. Earth Obs. Remote. Sens. 2023, 16, 1185–1196. [Google Scholar] [CrossRef]
- Vanschoren, J. Meta-learning: A survey. arXiv 2018, arXiv:1810.03548. [Google Scholar]
- Santoro, A.; Bartunov, S.; Botvinick, M.; Wierstra, D.; Lillicrap, T. One-shot learning with memory-augmented neural networks. arXiv 2016, arXiv:1605.06065. [Google Scholar]
- Ravi, S.; Larochelle, H. Optimization as a Model for Few-Shot Learning. 2016. Available online: https://openreview.net/pdf?id=rJY0-Kcll (accessed on 4 February 2023).
- Zhang, H.; Zhang, J.; Koniusz, P. Few-shot Learning via Saliency-guided Hallucination of Samples. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 2770–2779. [Google Scholar]
- Alfassy, A.; Karlinsky, L.; Aides, A.; Shtok, J.; Harary, S.; Feris, R.; Giryes, R.; Bronstein, A. LaSO: Label-Set Operations Networks for Multi-Label Few-Shot Learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Dwivedi, S.; Gupta, V.; Mitra, R.; Ahmed, S.; Jain, A. ProtoGAN: Towards Few Shot Learning for Action Recognition. arXiv 2019, arXiv:1909.07945. [Google Scholar]
- Zhu, X.; Toisoul, A.; Perez-Rua, J.M.; Zhang, L.; Martinez, B.; Xiang, T. Few-shot action recognition with prototype-centered attentive learning. arXiv 2021, arXiv:2101.08085. [Google Scholar]
- Peng, K.; Roitberg, A.; Yang, K.; Zhang, J.; Stiefelhagen, R. Delving Deep into One-Shot Skeleton-based Action Recognition with Diverse Occlusions. IEEE Trans. Multimed. 2023. [Google Scholar] [CrossRef]
- Cao, K.; Ji, J.; Cao, Z.; Chang, C.; Niebles, J. Few-shot video classification via temporal alignment. arXiv 2019, arXiv:1906.11415. [Google Scholar]
- Careaga, C.; Hutchinson, B.; Hodas, N.; Phillips, L. Metric-Based Few-Shot Learning for Video Action Recognition. arXiv 2019, arXiv:1909.09602. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hamilton, W.L.; Ying, R.; Leskovec, J. Representation learning on graphs: Methods and applications. arXiv 2017, arXiv:1709.05584. [Google Scholar]
- Morris, C.; Ritzert, M.; Fey, M.; Hamilton, W.L.; Lenssen, J.E.; Rattan, G.; Grohe, M. Weisfeiler and leman go neural: Higher-order graph neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4602–4609. [Google Scholar]
- Hara, K.; Kataoka, H.; Satoh, Y. Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 6546–6555. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 1126–1135. [Google Scholar]
- Cao, K.; Ji, J.; Cao, Z.; Chang, C.Y.; Niebles, J.C. Few-shot video classification via temporal alignment. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10618–10627. [Google Scholar]
- Perrett, T.; Masullo, A.; Burghardt, T.; Mirmehdi, M.; Damen, D. Temporal-relational crosstransformers for few-shot action recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 475–484. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | 1st Run | 2nd Run | 3rd Run | AVG |
|---|---|---|---|---|
| Baseline | 77.4 | 77.0 | 71.9 | 75.4 |
| RABSA | 78.9 | 78.9 | 72.6 | 76.8 |
| RABVA | 79.3 | 79.3 | 72.2 | 76.9 |
| Naive-RABSVA | 80.7 | 77.0 | 71.5 | 76.4 |
| Kmeans-RABSVA | 80.7 | 77.0 | 75.2 | 77.6 |
| RABSVA | 80.7 | 80.7 | 75.2 | 78.9 |
| Method | 1-Shot | 2-Shot | 3-Shot | 4-Shot | 5-Shot |
|---|---|---|---|---|---|
| Baseline | 54.3 | 64.0 | 67.9 | 73.8 | 75.4 |
| RABSVA | 54.8 | 68.4 | 68.4 | 74.7 | 78.9 |
| Method | 1-Shot | 2-Shot | 3-Shot | 4-Shot | 5-Shot | AVG |
|---|---|---|---|---|---|---|
| Matching Net [4] | 53.3 | 64.3 | 69.2 | 71.8 | 74.6 | 66.6 |
| MAML [85] | 54.2 | 65.5 | 70.0 | 72.1 | 75.3 | 67.4 |
| CMN [6] | 60.5 | 70.0 | 75.6 | 77.3 | 78.9 | 72.5 |
| TARN [8] | 66.6 | 74.6 | 77.3 | 78.9 | 80.7 | 75.6 |
| OTAM [86] | 73.0 | - | - | - | 85.8 | - |
| TRX [87] | - | - | - | - | 85.9 | - |
| RABSVA-C3D (Ours) | 71.0 | 79.0 | 85.8 | 85.4 | 87.8 | 81.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liang, H.; Du, J.; Zhang, H.; Han, B.; Ma, Y. Relational Action Bank with Semantic–Visual Attention for Few-Shot Action Recognition. Future Internet 2023, 15, 101. https://doi.org/10.3390/fi15030101
Liang H, Du J, Zhang H, Han B, Ma Y. Relational Action Bank with Semantic–Visual Attention for Few-Shot Action Recognition. Future Internet. 2023; 15(3):101. https://doi.org/10.3390/fi15030101
Chicago/Turabian StyleLiang, Haoming, Jinze Du, Hongchen Zhang, Bing Han, and Yan Ma. 2023. "Relational Action Bank with Semantic–Visual Attention for Few-Shot Action Recognition" Future Internet 15, no. 3: 101. https://doi.org/10.3390/fi15030101
APA StyleLiang, H., Du, J., Zhang, H., Han, B., & Ma, Y. (2023). Relational Action Bank with Semantic–Visual Attention for Few-Shot Action Recognition. Future Internet, 15(3), 101. https://doi.org/10.3390/fi15030101