1. Introduction
Critical infrastructure systems, such as water supply, power supply, transportation, telecommunications, etc., play a significant role in the sustainable development of modern societies. Modern infrastructure systems are highly interconnected and consist of geographically extensive networks. Continuous communication and data exchange between these systems leads to interdependencies that are essential for their proper functioning and the functioning of the overall system they belong to. Due to the large-scale networking of infrastructure systems, there can be economic, social, health, and environmental problems in case of their failure. The failure of these systems can arise from extreme natural phenomena (hurricanes, floods) or technological disasters and cyber-attacks. As a result, systems of this type must be regularly monitored, upgraded, and maintained [
1].
Ensuring the healthy and continuous operation of systems such as aircraft engines, cars, computer servers, and even satellites, is an imperative need, given their contribution to critical services, beyond urban infrastructure. The accurate prediction of their malfunctions and, by extension, their operational interruptions, can contribute to improvements in the design of proactive fault-tolerant systems, as well as significant cost reduction through prompt fault reporting. Previous research has used various techniques to create predictions in scenarios such as the autoregressive model [
2], principal component analysis [
3], and opposite degree algorithm [
4].
Furthermore, a significant amount of research has been carried out in the anomaly detection field, which has a closely correlated relation to machine failure. The research involves a variety of proposed models mostly making use of different machine learning techniques such as ANN [
5,
6], RF and SVM [
7], and convolutional neural networks (CNNs) and long short-term memory (LSTM) [
8].
To accurately predict machine failure and prevent costly downtime, it is essential to utilize a reliable and flexible approach that can account for a wide range of factors influencing machine degradation. While traditional statistical models have been widely used in failure prediction [
9], they often rely on strict assumptions about machine degradation patterns that may not accurately reflect the real-world complexity of the problem. In contrast, survival analysis has emerged as a promising approach, offering several advantages that can help improve the accuracy and efficiency of predictions. By incorporating time-to-failure information, handling right-censored data, accounting for covariate effects, and providing flexibility in application, survival analysis represents a superior alternative to traditional models in the context of machine failure prediction.
This research aims to address a gap in the literature by exploring the use of survival analysis in combination with various feature selection/analysis and machine learning methods to predict machine failure. While some studies have utilized survival analysis to predict failure, few have examined the effectiveness of different feature selection/analysis methods in conjunction with this technique. Most of the existing research focuses primarily on different machine learning models, such as LSTM networks [
10,
11], moving away from the survival analysis approach. While machine learning models are undoubtedly useful in predicting machine failure, survival analysis may be more appropriate when the goal is to predict failure times and identify key factors in failure prediction. In this proposed model, a machine learning survival analysis technique is used, along with feature analysis and selection methods. The machine learning model used is random survival forest (RSF), which is well-suited to time-to-event data, such as machine failure times, and has several advantages over other machine learning methods in the context of survival analysis. Examples include the ability to handle time-dependent covariates, non-linear relationships between covariates and survival, and interactions between covariates [
12].
Unlike survival analysis models, standard machine learning algorithms are not equipped to handle the right-censored data that are prevalent in machine failure datasets. RSF is a great way to incorporate machine learning and simultaneously overcome this problem, due to its ability to handle high-dimensional, complex data [
13]. RSF can handle both continuous and categorical predictors, as well as complex interactions, nonlinear relationships, and time-varying effects. This makes it particularly useful in survival analysis settings where there may be many potential predictors that interact in complex ways [
14]. One of the key benefits of using RSF is its ability to handle missing data, which is common in many real-world datasets [
13,
14,
15]. RSF uses a tree-based approach to impute missing values by splitting the data at each node based on the available data, and then using the available data to make a prediction for the missing value [
13]. This imputation process is repeated multiple times, resulting in a distribution of imputed datasets that can be used to estimate uncertainty. Overall, the flexibility and versatility of RSF make it a powerful tool for survival analysis, particularly in situations where there are many potential predictors and complex interactions among variables [
13].
Our research makes the following contributions:
We propose a new machine failure prediction model aimed at increasing prediction accuracy using machine learning mechanisms and the method of survival analysis;
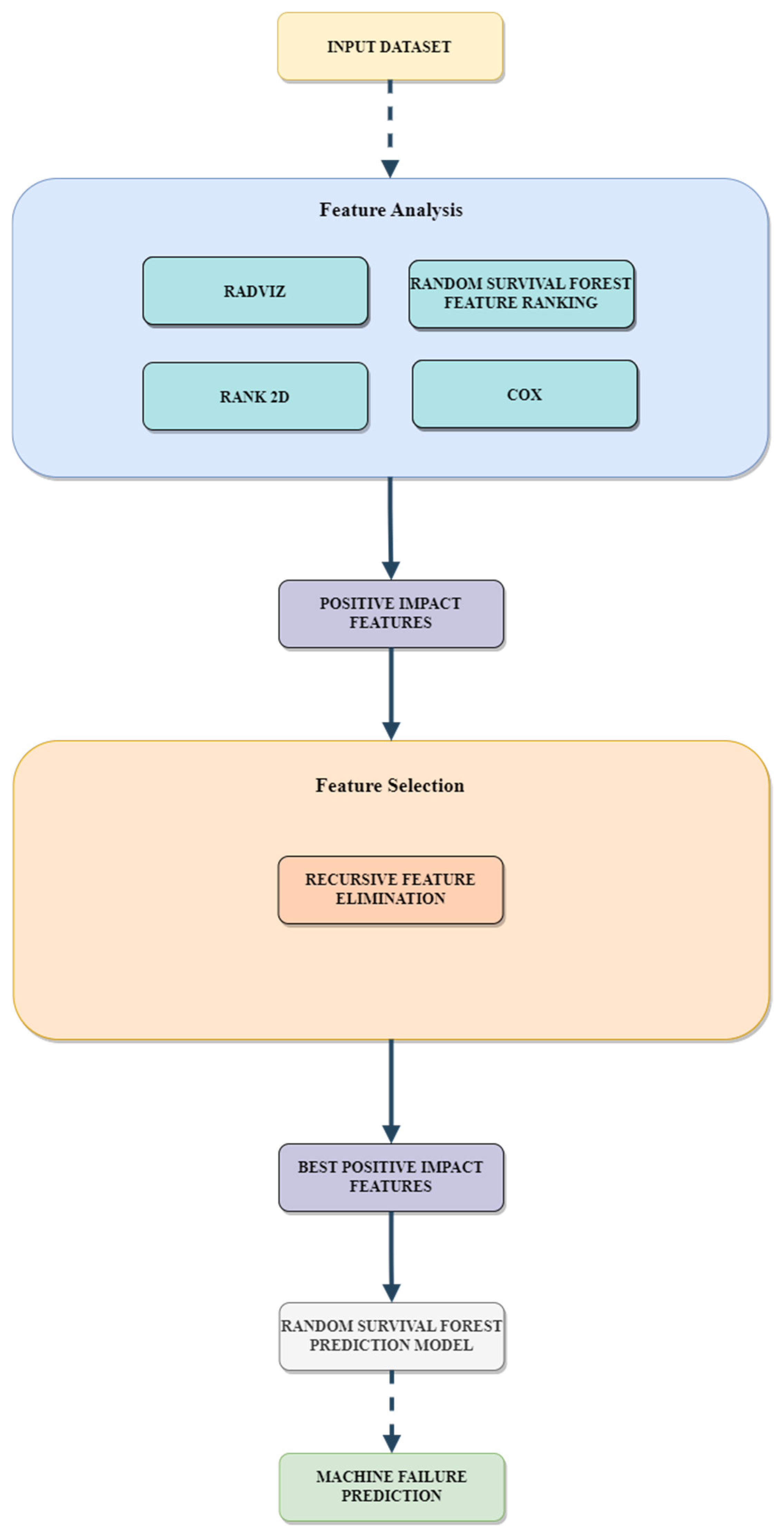
The proposed model includes a data filtering/selection layer that is designed to choose the most suitable features for training the machine learning model. This is achieved by implementing various feature analysis/selection techniques. Each of the techniques employed targets a distinct aspect of comprehending the data;
A random survival forest model is used to combine machine learning and statistical analysis, overcoming their limitations, that affect the prediction [
12];
We objectively examine the model on a collection of 10,000 machine instances, with experiments showing promising statistical accuracy;
Our work contributes to the existing literature on the use of RSF for machine failure prediction, as well as the need for a strong feature extraction level for model training.
The innovation presented in this paper centers around a novel approach to predict machine failure in large-scale systems, by incorporating a technique that prioritizes the suitability of the data. The proposed method utilizes the RSF model and an efficient feature filtering mechanism, incorporating a range of feature importance ranking techniques to eliminate irrelevant data and retain only pertinent information. This process effectively eliminates “noise” from the data, ultimately leading to increased accuracy and consistency in the prediction outcomes.
The overall organization of the paper is as follows.
Section 2 provides an overview of the related work that was reviewed for this research, including a comparison of our proposed approach to other proposals in the literature. In
Section 3, we present the mathematical and theoretical background of the techniques utilized in this study. In
Section 4, we describe the model created in our study as well as the dataset used for training and testing the model. Additionally, we discuss the different failure modes of the machines in the dataset. In
Section 5, we present the results and findings of our study, which are later discussed in
Section 6. Finally,
Section 7 concludes and closes the paper.
2. Related Work
Despite the abundance of statistical methods that can be used, survival analysis is conceptually largely aligned with the study of predicting the failure of a machine [
16].
Kaplan–Meier curves and the COX regression model have been employed in similar research to determine the relationship between the survival time of a subject and one or more prognostic variables. In [
17], the SMED (single-minute exchange of die) philosophy and survival analysis are used to reduce transition times. In this research, the COX model is also used to identify the significance of causes of time loss. The proposed methodology predicts activity times, considering only the characteristics that were identified as significant toward transition times, which is defined as a limitation by the authors.
Similarly, the model proposed in [
18] follows a gradual Bayesian approach to model failure using the tree-like accident theory and the Bayesian survival analysis model to predict the probability of survival for welded pipes. Using Bayesian, Kaplan–Meier, and Weibull curves, the authors construct staged Bayesian distribution, which is then used to make predictions about the time-to-failure of the pipes. Weibull distribution is also used in [
19] to predict the life of battery cells, combined with the exponential, log-normal, and log-logistic distributions to create an accelerated failure time (AFT) parametric survival model. In this research, the authors concluded that low values of prediction error could be achieved by only using a small number of variables on the proposed model. The authors assert that this discovery holds significant value in their research, as their model yielded a total decrease of 40% in the root mean square error (RMSE). A limitation of this study is that the authors relied on only two datasets to support their findings, without exploring the use of other datasets.
In [
10], an LSTM approach is presented for the remaining life prediction of machines. The proposed approach leverages the advantages of LSTMs in capturing temporal dependencies in sensor data while also effectively handling missing data. The authors conducted experiments on a real-world dataset of a milling machine and evaluated the performance of their novel approach in comparison to various baseline methods. The results indicate that the LSTM-based approach surpasses the other methods in accurately predicting the machine’s health status and effectively capturing its dynamic behavior. Out of the variety of models tested, the bidirectional-LSTM model had a total RMSE value of 15.42 cycles, outperforming all other models, such as deep convolutional neural network (DCNN) (18.44 cycles); support vector regressor (SVR) (20.96 cycles); multilayer perceptron (MLP) (20.84 cycles); bidirectional recurrent neural network (BD-RNN) (20.04 cycles); and a classic LSTM (18.07 cycles). Similarly, the authors of [
11] proposed a semi-supervised deep architecture for predicting the remaining useful life (RUL) of turbofan engines. The model uses both labeled and unlabeled data to enhance its performance and reduce the need for extensive labeled data. It involves a combination of a convolutional neural network (CNN) and a LSTM network that work in tandem to extract features and capture the temporal dependencies of the input data. The model was evaluated on the C-MAPSS dataset and compared against several state-of-the-art methods, achieving superior performance in terms of both RUL prediction accuracy and mean absolute error. Specifically, the model proposed by the authors yielded superior RMSE results for most of the subsets that it tested, with the value of 12.10 on the FD003 subset being the lowest, while also providing the best prediction result on all of them (FD001: 231, FD002: 3366, FD003: 251, FD004: 2840). A limitation of the study, as stated by the authors, is the use of a piece-wise linear degradation model, which does not account for the individual degradation patterns of each engine in each subset. The authors plan to address this limitation in future work by exploring the use of an unsupervised fault detector based on a variational autoencoder to optimize performance.
Introduced in [
20] is a method based on DCNNs to diagnose faults in induction motors using multiple signals. The proposed method leverages the advantages of DCNNs in automatic feature extraction and achieves improved diagnostic performance by combining information from multiple sensor signals. The authors conducted experiments on a dataset containing multiple types of faults in induction motors and evaluated the performance between two different architectures of their proposed method. The first architecture utilized a multichannel model that merged two separate time–frequency images from vibration signals and current signals, forming a two-channel image. This image was then fed into a deep model that consisted of three 2D convolutional layers and a fully connected layer with ReLU activation functions. The output layer had six units that correlated with six distinct labels. The second architecture used two convolutional networks were utilized to analyze different sensor signals separately, and then merged in fully connected layers to contribute to the output of label prediction. One network was trained on vibration signals, while the other was trained on current signals. The learned fault signatures from each network were combined by flattening them into a fully connected layer with 1024 ReLUs. The output layer used for predicting the state label was the same as the one used in architecture 1. The confidence interval analysis showed that the proposed multi-signal DCNN model had stable performance and the merged model outperformed the multi-channel model, with a 95% likelihood of covering fault classification skill between 99.89% and 99.93%. To address the issue of limited training data for deep architectures, the authors suggest the use of data augmentation techniques to expand the dataset and exploring pre-existing models for fault diagnosis as fields of improvement for their future work.
The paper [
21] proposes a method for equipment failure diagnosis that addresses the challenge of limited data and imbalanced data distribution. Specifically, the proposed method combines the synthetic minority oversampling technique (SMOTE) with a conditional tabular generative adversarial network (CTGAN) to predict equipment failures with a mixture of numerical and categorical data. The experimental results show that the proposed method outperforms other similar methods in five-category failure classification, even when failure data account for less than 1% of the total data. The proposed model showed a high recall rate of 0.9068, an accuracy of 0.8712, and a balanced accuracy of 0.8883. The recall rate and balanced accuracy were the highest across all methods tested by the authors which, apart from the crated model, were a CatBoost (non-oversampling) model, a combination of SmoteNC and CatBoost, and finally, another combination of the ctGAN and CatBoost models. It is noteworthy that the highest accuracy was obtained using the CatBoost algorithm without oversampling. Moreover, the paper highlights the importance of false positives in equipment failure prediction, as the cost of sudden machine downtime far exceeds that of system misdiagnosis. Therefore, the proposed method aims to increase the possibility of false positives to reduce the possibility of false negatives. The authors also note that the interpretability of the equipment failure prediction results is crucial, and they incorporated a tree-based model for failure prediction to analyze the causes of failures and implement preventive measures accordingly.
In [
22], the authors make a comparative study to evaluate a plethora of machine learning techniques for the task of fault detection and classification. The models used in this study are SVM classifier, KNN classifier, random forest, logistic regression, and decision tree. All models were tested on five datasets, and their accuracy and AUC-ROC scores were measured. The authors concluded that the best performing machine learning method was random forest, with an average accuracy of 0.964 and an average AUC_ROC score of 0.948 across all datasets. The other notable methods were the decision tree model, with an average accuracy of 0.959 and AUC_ROC score of 0.944, and KNC, with an average accuracy and AUC_ROC score of 0.942 and 0.930, respectively.
In the proposal of [
12], the authors suggest a new approach for predicting the remaining service life of water mains by combining machine learning and survival statistics. The authors developed a machine learning algorithm that uses a combination of historical failure data and pipe-specific characteristics to predict the probability of failure at any given time. They then applied survival statistics to estimate the remaining service life of the water main based on the predicted failure probability. The study utilized two distinct machine learning models—specifically, a random forest model and a random survival forest model—and additionally incorporated the Weibull proportional hazard survival model to assess and compare their respective abilities, in order to accurately predict the remaining useful life of water mains. The results showed that the RSF model achieved superior performance (C-index = 0.880) compared to the Weibull proportional hazard survival model (C-index = 0.734) and the random forest machine learning model (C-index = 0.807), indicating the potential of machine learning in predicting the remaining service life of water mains.
The literature reviewed in this study indicates that many of the methods for predicting remaining useful life either solely employ survival analysis [
16,
18,
23] or only use machine learning techniques [
10,
11,
20]. However, combining both approaches can be beneficial, as demonstrated by the papers [
12,
19], which use a combination of survival analysis and machine learning to make their predictions. Furthermore, most of the papers using survival analysis rely on the use of the COX model for their feature evaluation [
18,
19,
23,
24]. By relying solely on the COX model for feature selection, important non-linear or time-dependent relationships between predictor variables and survival time may be missed or obscured, leading to a potentially incomplete or inaccurate understanding of the underlying data. Similarly, in the case of [
12], only using feature ranking from a RSF model may not provide information about the direction or magnitude of the relationship between predictor variables and survival time. That is where the combination of different feature ranking/selection techniques can prove to be an advantage in our model. By not only using the standard COX and RSF feature ranking/selection methods, we can achieve a more comprehensive and accurate understanding of the data, as well as increased confidence and validation of the results, while mitigating some of the limitations and biases of each individual method.
5. Results
The model was tested for its accuracy performance in the machine failure prediction, while also in the prediction of the type of machine failure. This means that the feature ranking/selection layer was also used to measure the best features to calculate each machine failure mode.
5.1. Model Evaluation Criteria
5.1.1. C-Index
Assessing the accuracy of machine failure prediction models can be challenging due to the presence of right-censored failure events in the testing dataset. This means that some machines may have been operational for the entire duration of the testing period, making it impossible to observe when they would have failed. To address this challenge, a common metric used to evaluate the performance of machine failure prediction models is the concordance index (C-index).
The C-index considers both the observed failure times and the predicted failure times, including those that are censored. This is achieved by creating pairs of machines, where the machine with an observed failure time is ranked higher than the machine with a censored failure time. The C-index ranges from 0.5 to 1, with a value of 1 indicating perfect prediction performance, where the observed failure times follow the same order as the predicted failure times, and a value of 0.5, indicating that the prediction model performs no better than random chance. Therefore, the C-index provides a reliable way to assess the accuracy of machine failure prediction models, even in the presence of censored data [
22].
Calculate the total C-index by summing all values and dividing by the total number of possible pairs:
where
represents the C-index;
= number of all comparable pairs;
and
represent the observed and predicted time to fail, respectively; and
is the indicator function. Therefore, this metric includes censored data, creating ranked pairs where the observed, uncensored events occur before the observed censored event.
5.1.2. Percentage Change
Percentage change is a mathematical calculation that shows the difference between two values as a percentage of the original value. To calculate the percentage increase, the difference between the new and old values must be found and divided by the original value. This difference is then multiplied by 100 to obtain the percentage increase. The formula used to make this calculation is presented in Equation (12).
In Equation (11), is the number before the increase, is the number after the increase, and is the increase between the two values. In Equation (12), is the increase between the values and is the original number.
5.2. COX and RSF Feature Analysis
For the selection of the most important features, a set of feature selection and feature analysis techniques were used. These results were then compared and the features that prevailed were applied to the RSF model for training. The features were also ranked for each of the machine failure types mentioned in
Section 4.3.
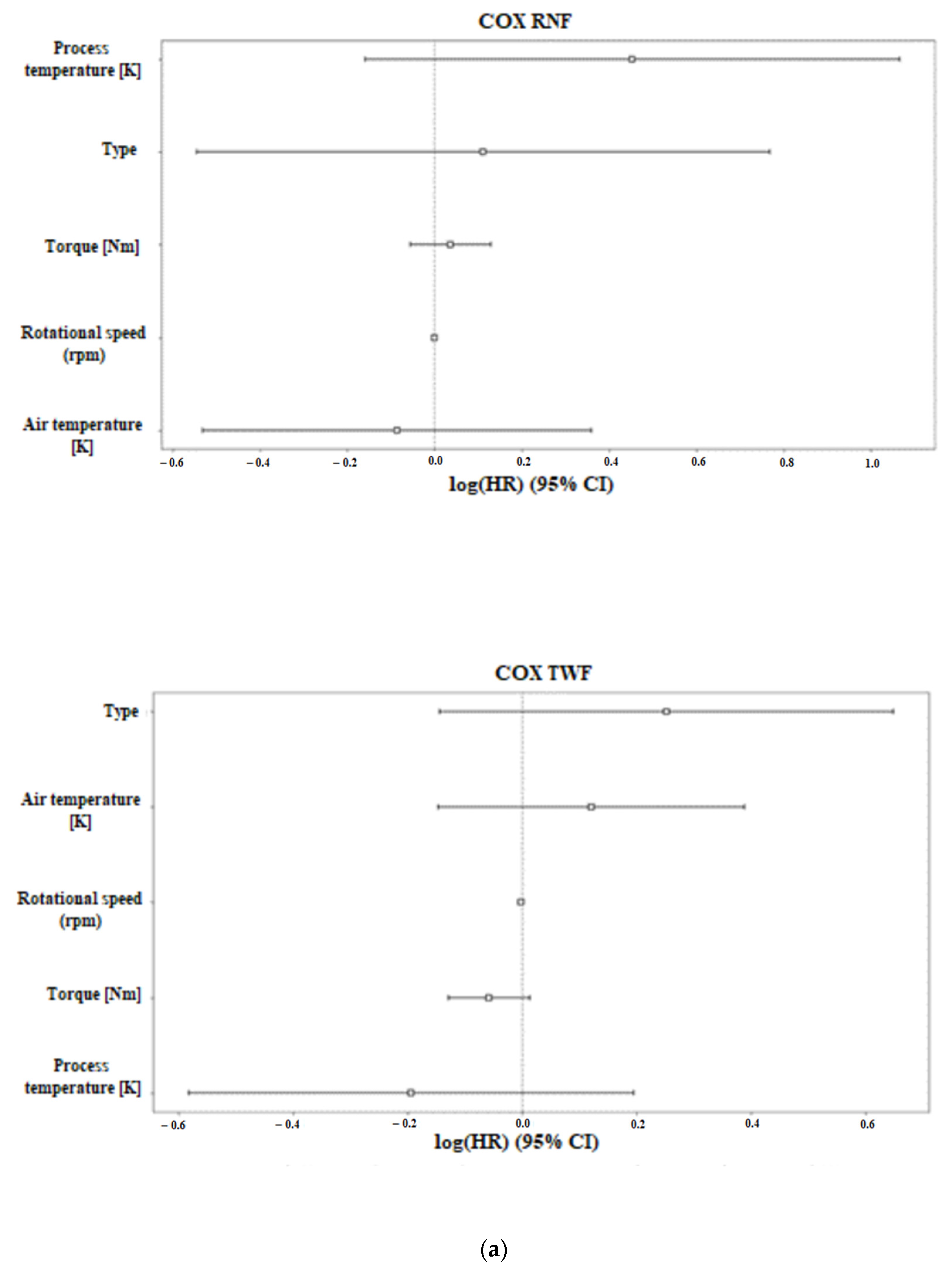
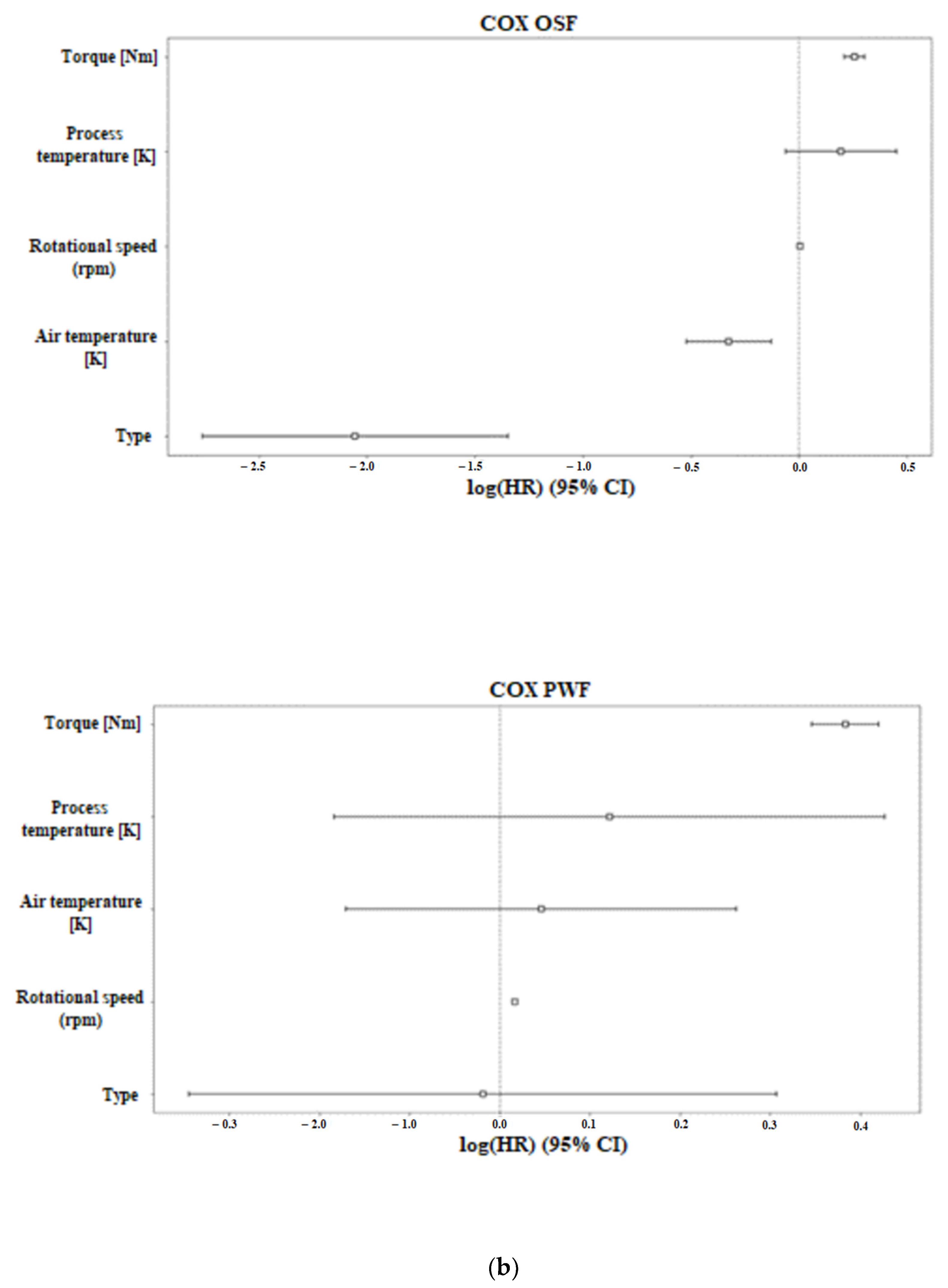
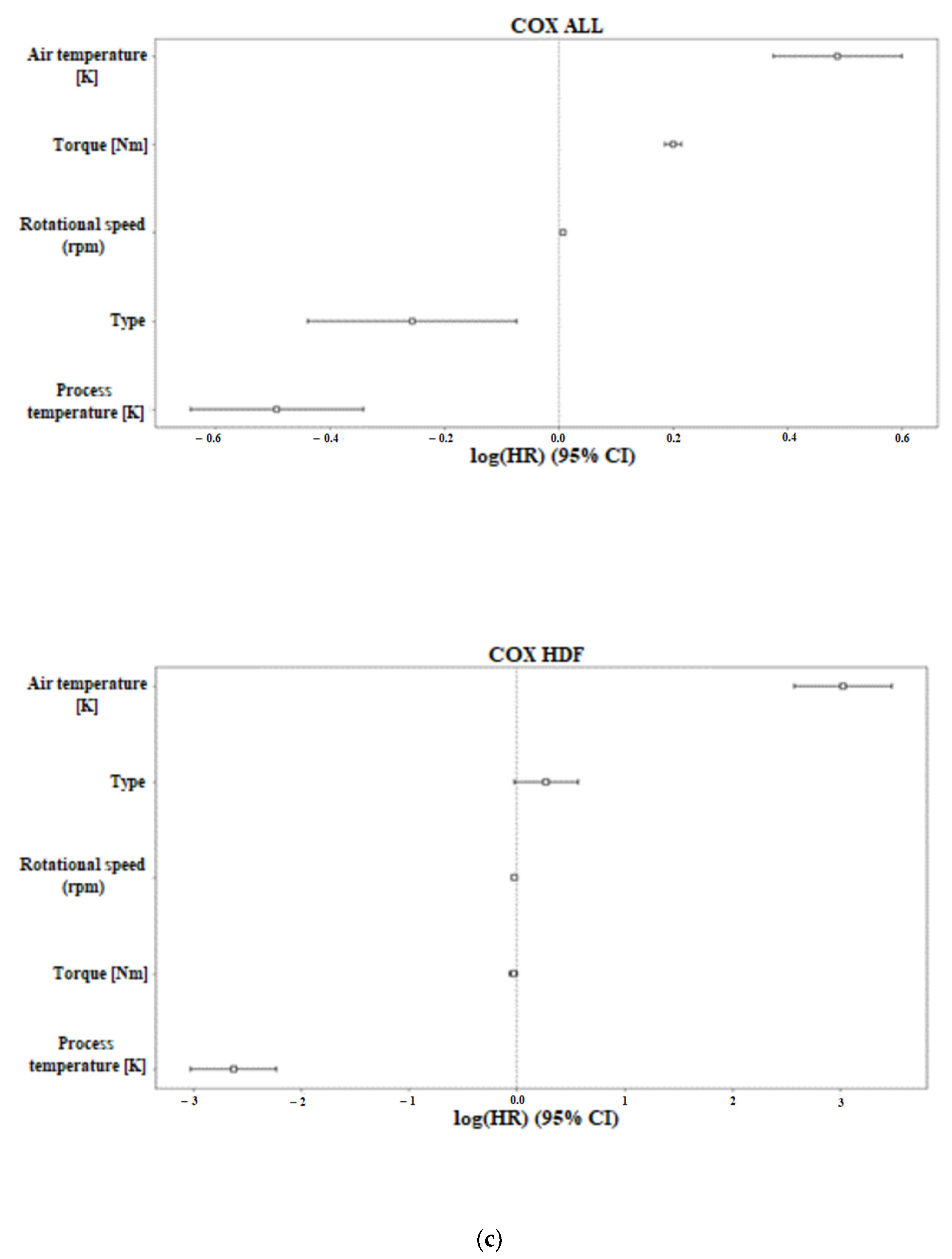
The COX and RSF methods in the feature ranking section showed that the most important features in terms of machine failure were torque, rpm, and air temperature, as shown in
Figure 2 and
Table 2. Specifically, in the figure and table, the ranking of the characteristics is shown for the type of machine failure. In the COX results, the values that have a negative value indicate low correlation with machine failure, while positive values indicate an increased probability of machine failure. In contrast, in the RSF results, negative values indicate that the characteristic reduces the predictive ability of the model, i.e., in this specific case, the correlation of the characteristic with a low risk of machine failure. In the case of RNF prediction, all characteristics have negative values, indicating that they are all related to a low risk of machine failure. Although this complicates the model prediction, including the context of machine failure, i.e., a random factor, it is somewhat logical.
The ranking of the features in the various techniques differed slightly, but the characteristics were consistently among the top-ranked features. Specifically, the features of torque and rpm were consistently ranked among the top three features.
For the COX results shown in
Figure 2, we can observe that in the case of all the failed machines, the COX diagram showed a strong correlation between the machine failure risk and the increase in the air temperature. Moreover, the torque feature seems to have a correlation with the failure of the machine but to a smaller degree. The rest of the features in the diagram seem to have either no impact (rotational speed) or are associated with a lowered risk of the failure of the machine. Similar results are shown in the HDF failure type on the COX diagram where the air temperature seems to have the highest correlation to the risk of machine failure, while the increase values in other features seem to have a lower risk. For the OSF, RNF, PWF, and TWF failure types, all the features seem to have a small correlation with the event we aimed to capture, so using the other metrics in combination with the COX diagram is needed to better evaluate the features. The small correlation is noticed because of the small values of the positive and negative rankings, which means that most of the features are closer to 0.
5.3. RadViz and Rank2D Depiction of Feature Relations
For a better understanding of the features, feature analysis techniques such as the RadViz and Rank2D technique were used. Through them, the relationships of the characteristics between them can be analyzed and better understood, which provides better results in their sorting.
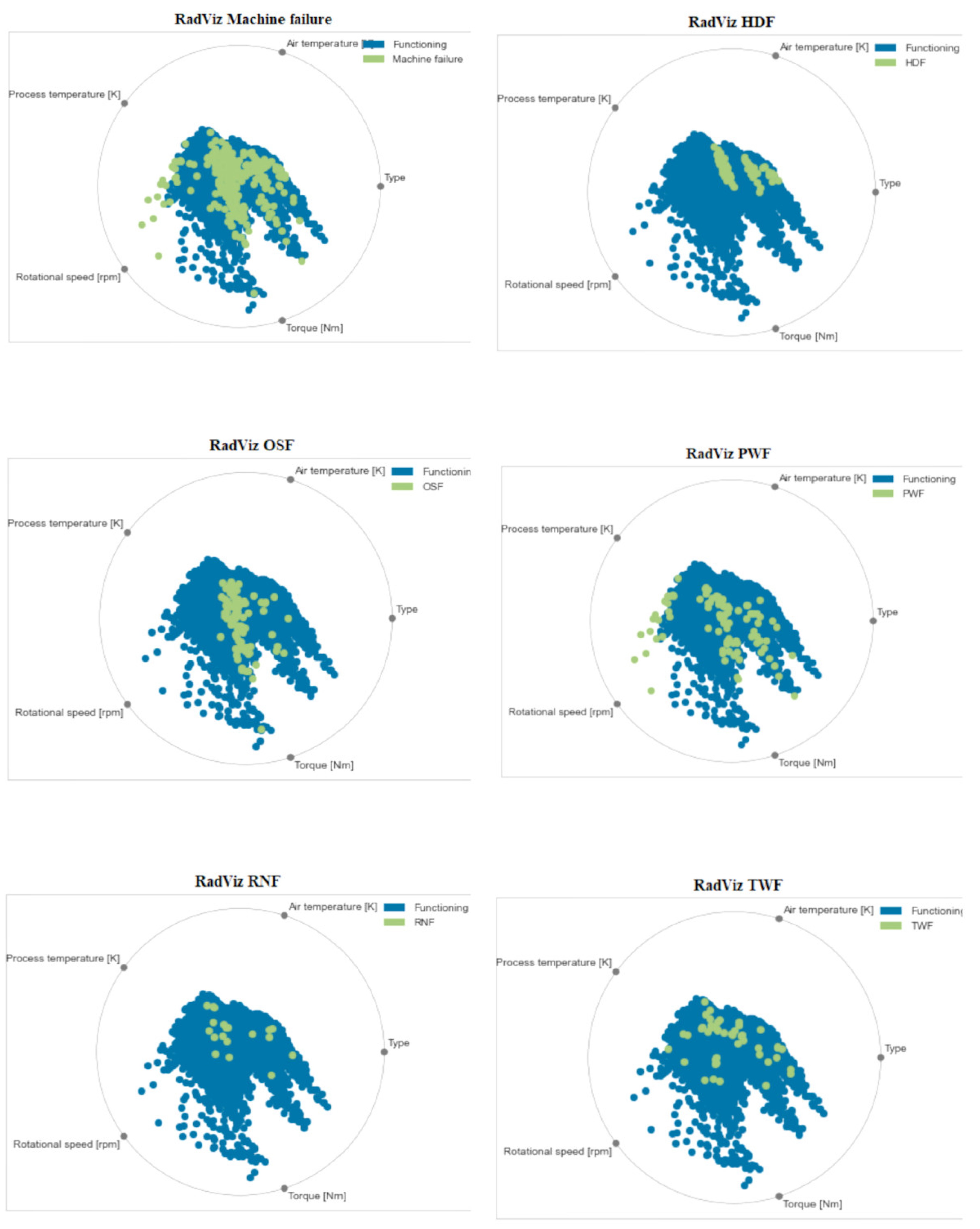
In case of machine failure, the RadViz analysis, depicted in
Figure 3, showed that a high rotational speed combined with a high process temperature is a possible factor contributing to the failure. This is evident as only failed machines are pulled towards the rpm feature, with some being close to the middle of rpm and the process temperature. The same results can be observed in the PWF case, where most of the failed machines in the machine failure category that were pulled towards the rpm feature seem to belong in PWF. So, we can assume that increased rpm is correlated with a PWF type of machine failure. Apart from that, we can see that most of the machines, working or otherwise, are closer to the torque feature and the area between the torque and the type of machine. The strong pull towards the torque feature indicates that torque is critical for the proper functioning of the machines. The fact that many of the machines are also located in the area between torque and type suggests that there may be a relationship between the type of machine and its torque output. Finally, the light pull towards the process temperature for both working and failed machines indicates the importance of this feature, especially in the failure categories of PWF, TWF, and RNF, where some of the failed machines can be seen moving towards that area of the diagram.
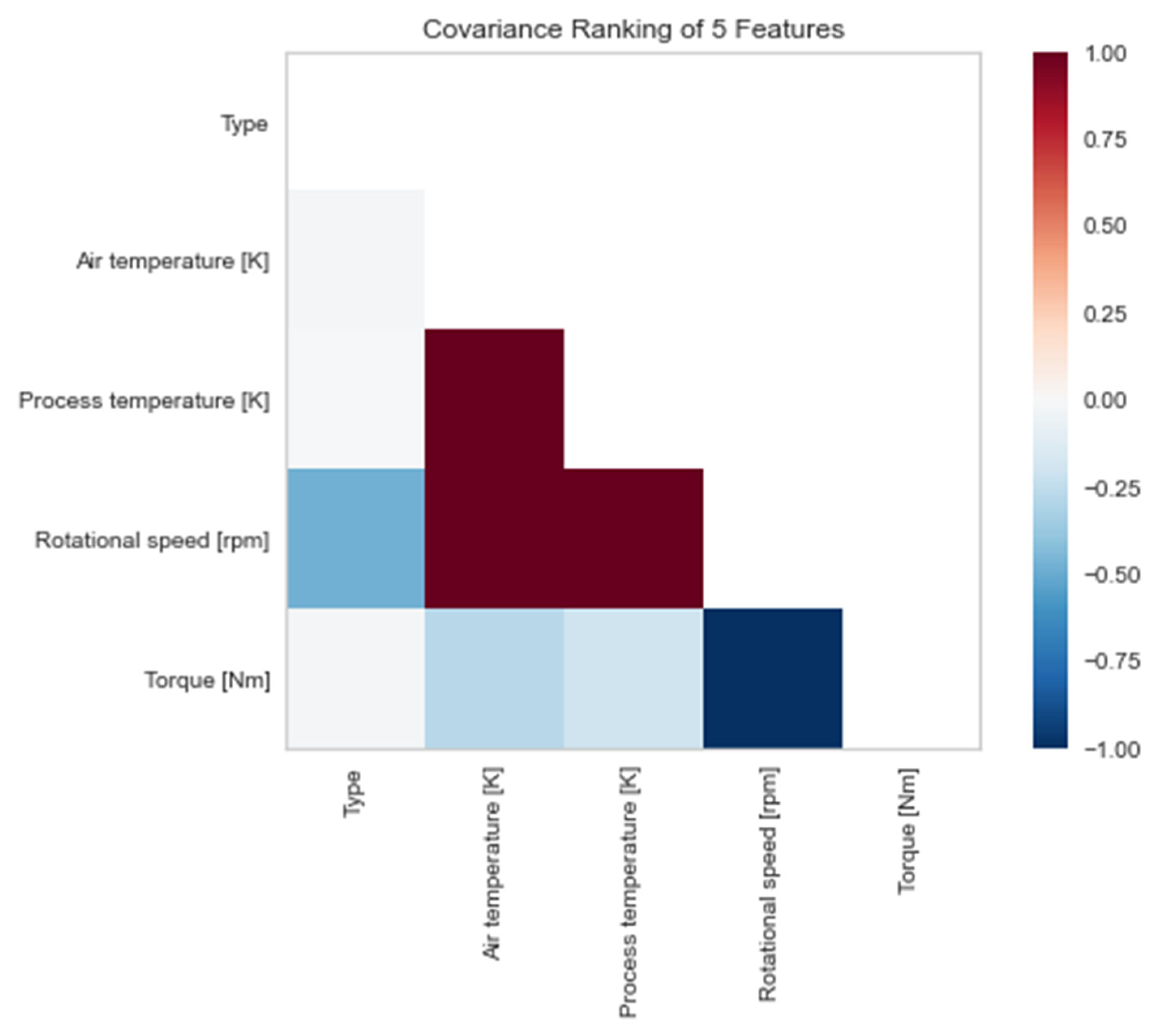
Through the analysis of 2D ranking, a strong correlation between the process and air temperature features with the rpm of the machine is observed, which is logical in the mechanical context. Additionally, increasing the rpm of the machine results in a corresponding decrease in its torque, as shown in
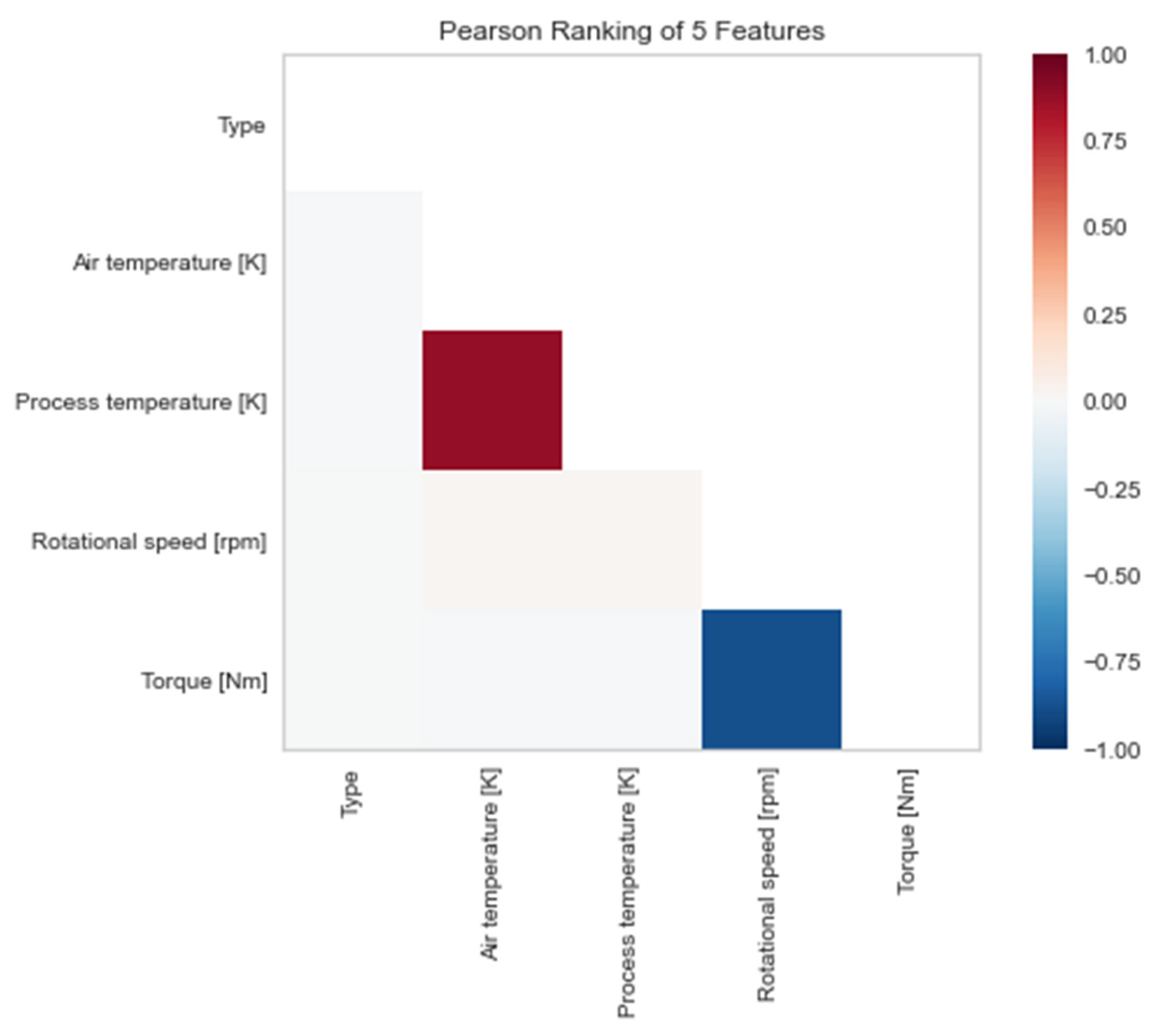
Figure 4. Moreover, using the Pearson ranking 2D model, as shown in
Figure 5, we observe an almost perfect positive correlation between the air temperature and process temperature features. This leads us to the conclusion that an increase in one of these two variables may lead to the destruction of the machine. Similarly, the almost complete negative correlation between the rotational speed and torque variables is also evident from the same diagram. This negative correlation may indicate that an increase in one of the two variables results in a decrease in the probability of machine failure. These observations highlight the importance of considering these variables in machine failure prediction models.
5.4. Number of Selected Features
The recursive feature elimination technique was used to select the number of characteristics to be used in the final prediction model. Based on this, as well as the results of the negative influence of features obtained from RSF and COX, we can formulate the characteristics that will give us the best possible prediction results.
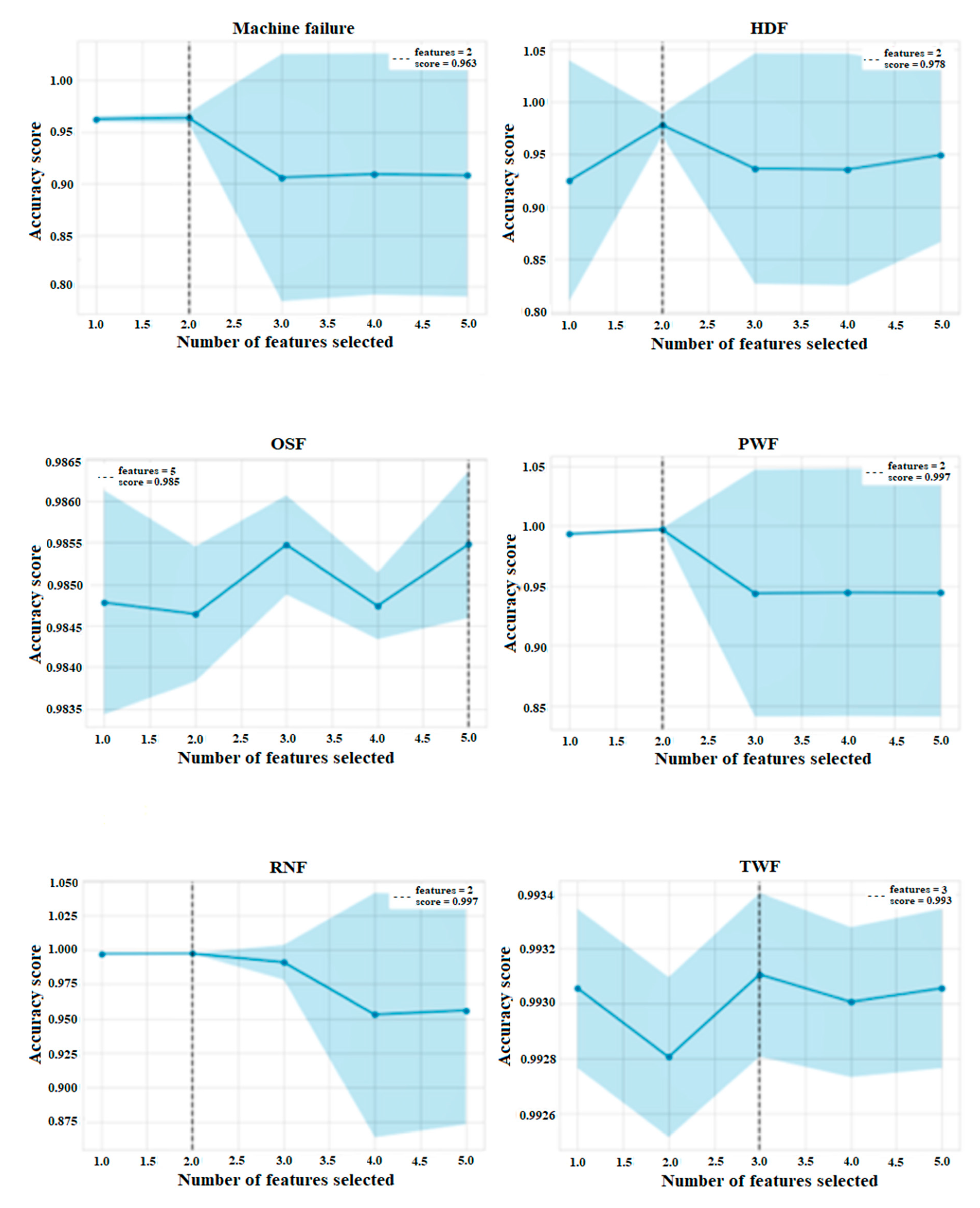
According to the results for the general prediction of machine failure, RFE used two features to achieve the best prediction, as shown in
Figure 6. The addition of more features reduced the prediction accuracy, which is normal considering the previous feature ranking evaluation. However, if we also consider the results of the RSF and COX, we can be more generous with the number of features that will be used, by adjusting their quantity to a number quite close to the original number given by RFE. The same methodology can be used for predicting the type of machine failure.
Furthermore, in
Figure 6, it was observed that in most cases, the best prediction accuracy was achieved with only two features. The only exceptions were the TWF case, which required three features, and the OSF case, which required all five features to achieve the best possible prediction. The decrease in the precision with the addition of more features could be an indicator that the most relevant information for the prediction was contained within a small subset of the available features.
5.5. Survival and Cumulative Hazard Curves
From the analysis of the survival and cumulative hazard curves, it is observed that the safe operation of the machines ranges from 0 to ~200 min of operation. From this point onwards, the risk of machine failure increases rapidly. The same pattern is confirmed by the failure of machines after this time point, as shown in
Figure 7. Furthermore, an examination was carried out on the machines in the only categorical variable contained in the dataset, which was the type of machine shown in
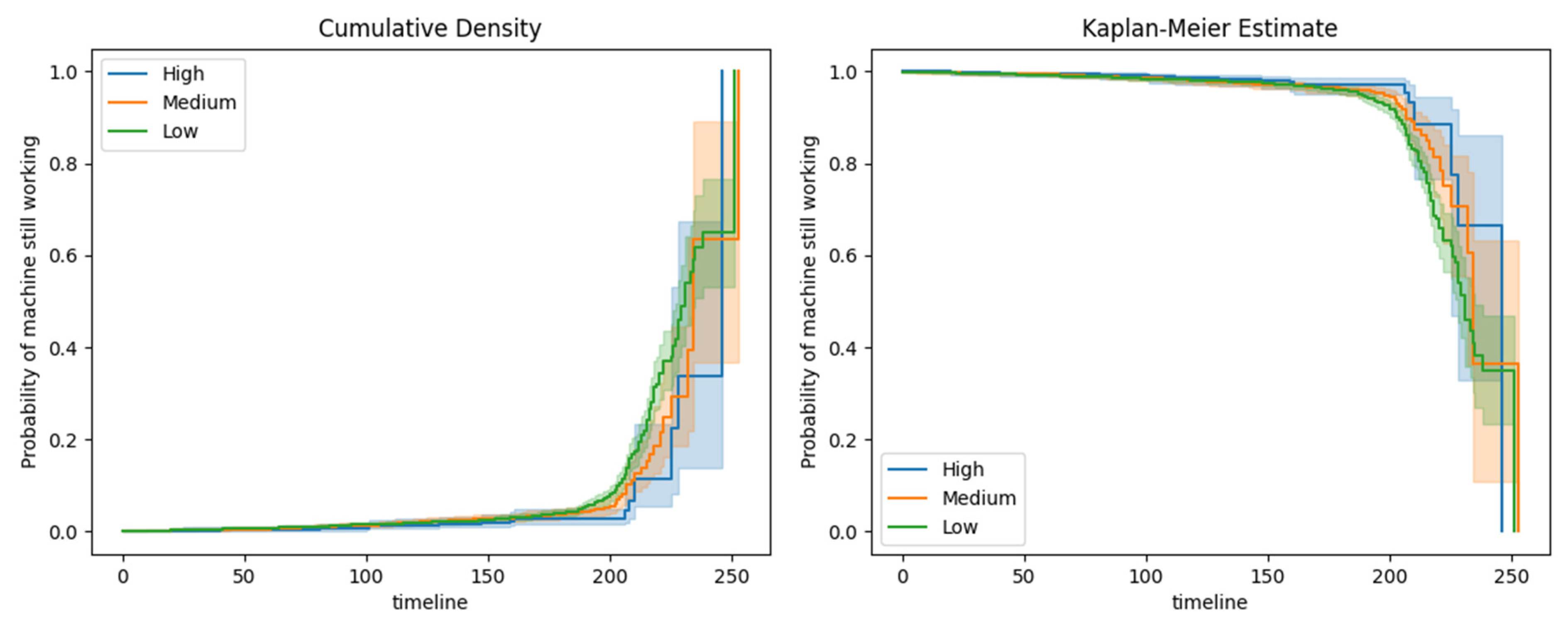
Figure 8. This variable took on the values of high, medium, and low. From this examination, it appears that high-quality machines perform better than low- and medium-quality machines, although to a small extent, in the time range of 200–240 min. This may also be due to their relatively smaller population, as high-quality machines accounted for 20% of the total dataset. In addition, a noticeable superiority of medium-quality machines over low-quality machines is observed in the time range of 200–230 min, which evens out in the later time frames.
5.6. Model Training and Results
For our evaluation, we measured the predictions of the RSF model against a normal random forest model, which was trained with the exact same dataset and configuration as the RSF but with the downside of ignoring the right-censored data, unlike in RSF. We used the models one time to make the prediction using the whole dataset (
Table 3) and its features and another time with the feature selecting layer (
Table 4). In both, we used the metric of the C-index to calculate the accuracy of each model. It is important to note that both models were trained using identical hyperparameters for the calculation of the C-index.
The data were divided into a 75% training and 25% testing set to evaluate the performance of our model. For the RSF, we selected the splitting criterion based on the log-rank test, which compares survival curves between two or more groups. The data were applied to the RSF model consisting of 1000 trees. To make a prediction, a sample descends tree by tree down to a terminal node in the forest. The data in each terminal node are used for non-parametric estimation of the survival function and cumulative hazard using the Kaplan–Meier and Nelson–Aalen estimators, respectively. Additionally, the risk score representing the expected number of events for a particular terminal node can also be computed. The overall prediction is the average of all the predictions of the trees in the forest. The model produced very accurate prediction results for machine failure, about 97%, as well as when the machine failed due to heat dissipation failure (HDF~99%), overload (OSF~97%), and lack of power supply (PWF~99%). In cases of random failure (RNF) and tool wear failure (TWF), the model did not predict the outcome as efficiently, achieving a C-index of ~54% for RNF and ~0.67% for TWF. This fact is likely due to the lack of sufficient machines that have stopped working due to these causes, as well as the more difficult nature of predicting them.
The results show that the RSF model has the upper hand in the main prediction of the machine failure out of all the models tested but lacks in the prediction of some types of failure. In the failure prediction and without using the data analysis/selection layer, the model that kept up with the RSF in terms of C-index score was random forest with a score of 0.9558, only 0.0166 less than the C-index of RSF. Both COX PH and ST scored below 90%. As for the types of failure, the results showed an imbalance among the predictions of the models, where no model excelled in the prediction of all the types. For the HDF and RNF failure types, the best prediction was achieved by the RSF with a percentage of approximately 99% and 67%, respectively, while for the failure types of OSF and TWF, the COX PH model displayed the best C-index score among all the other models, achieving scores of 99.57% and 96%, respectively. Finally, the RF model produced the best C-index score for the PWF failure type with 99.86%. The numbers discussed are presented in
Table 3.
With the insertion of the feature selection layer, all models increased their predictions in most cases. It is noteworthy that the optimal set of selected features used by the models differed across the various modes of failure. The features used by each model to achieve its best C-index score can be seen in
Table 5. All models used on average four features, with the decimal values rounded up to the closest integer because the features cannot be split. One outlier to this was the prediction of TWF, where three out of the four models used two features to achieve their best prediction, while the RF model used all five.
The RSF model showed significant improvements in the prediction of TWF (from ~54% to ~68%) and RNF (from ~67% to ~76%) types, while also making slightly better predictions on the PWF, OSF, and HDF types. The RF model also improved its results both in the machine failure prediction (increase by ~1.1%) and in the prediction of the failure types of RNF, PWF, and OSF. In the case of RNF, the increase was significant as the RF model was almost 10% more accurate using the feature selection. In contrast, the prediction of the TWF and HDF showed a small decrease in accuracy. The COX PH model exhibited improvements in most performance categories, with the exception of PWF, where its performance remained stable, and HDF, where the C-index decreased by 0.0272. The most significant increase was the RNF prediction where the C-index score improved from 39% to 86%, showing a high 119.9% increase. Finally, ST also made major improvements in the prediction of the machine failure, as well as the OSF, PWF, and TWF failure types. It was also the model with the most significant decrease in the C-index score after the feature analysis/selection layer, with the score of HDF decreasing by approximately 31%. Another drop-off was also present in the RNF failure type, although this was less significant. The percentages of increase and decrease in the C-index scores of each model are presented in
Table 6.
Considering all models, the RSF, despite feature selection, did not manage to surpass the results of the RF in the predictions of OSF and PWF, and in the predictions of the COX PH model on the RNF and TWF failure types. Especially in the case of TWF, the difference remained significant despite the improved accuracy. However, RSF performed better in the overall prediction of failure but also stayed close or performed better than the other models in all cases except TWF.
6. Discussion
The results show that the RSF model performs better than the other models selected for this study in predicting the main cause of machine failure, achieving a C-index of 0.9724. In general, the feature selection layer had a mostly positive impact on the C-index score in all the models, as depicted in
Table 6. The table was calculated using the method described in
Section 5.1.2. The most impressive increase was seen in the COX PH model, which more than doubled its C-index score. Furthermore, the model that seemed to be favored the most by the addition of the feature selection layer was RSF, which is the only one that either increased or kept the same C-index score. In contrast, the addition of the feature selection layer exhibited a negative impact on the prediction of the HDF failure type in three out of the four models that were tested. The most significant decrease of this failure type was noted in the ST model, whose C-index score decreased by approximately 31%. This shows that further research may be needed to address this issue in this specific type of failure, as it seems to be more susceptible to changes in the data.
One notable finding from our study is that most models demonstrated improved accuracy in predicting failure types that were previously challenging to evaluate, suggesting a substantial enhancement in their predictive capabilities. This improvement is attributed to the incorporation of a feature analysis and selection layer, which effectively identified and leveraged the most relevant features for predicting these challenging failure types. This was mainly in the RNF and TWF failure types, where the models demonstrated lower C-index scores. For RNF, all models showed increases of over 14%—apart from the ST model, which had a slight decrease of 0.1%. Regarding TWF, the models that had the worst performance, namely the RSF and ST, had an increase of 25.65% and 8.9%, respectively. These increases in C-index score in the models show that the feature selection layer critically improves the overall prediction, helping it reach a more consistent prediction accuracy among all the failure types. It must be noted that the limited number of features provided in the dataset used may be a restricting element of the overall increase that the feature selection layer can provide to the model. Moreover, as emphasized in the Results section, the decrease in the C-index score of the HDF failure type is of major importance, and further research is needed to address this issue.
One limitation of this study is the exclusive use of a single dataset. While the dataset was selected based on its suitability for addressing the research questions and objectives, the findings may not be generalizable to other populations or contexts. Additionally, the dataset contained a high number of right-censored data, with 96.61% (
Table 1) of the instances being censored. This could impact the accuracy and reliability of the results, as well as limit the methods that were used. It is important for future research to consider using multiple datasets and exploring alternative methods for addressing censored data to improve the validity and generalizability of the findings.
7. Conclusions
The breakdown of machines is a major issue in today’s technology-dependent societies. To better manage this problem, we propose a machine failure prediction model based on survival analysis techniques. The developed model filters the main features that contribute to machine failure through RSF, COX regression, Rank2D, and RFE techniques. Then, the selected data are fed into the RSF model, which is used to perform the prediction. Using RSF in this scenario provides better management of censored data, as machines failure datasets are often heavily right-censored.
The model was subjected to a comparative analysis against a conventional random forest model, survival trees model, and COX PH survival analysis model. It exhibited superior performance in two out of the six categories, while consistently producing reliable predictions, and demonstrating comparable C-index scores with the top-performing models, on the rest of the categories. Additionally, the use of this model enables support for high-dimensional data, which is a common occurrence in machine breakdown. The model showed promising prediction results with a success rate of approximately 97%, while also demonstrating a high ability to predict the cause of the failure of the machine.
The high level of accuracy achieved by the proposed approach makes it an especially valuable tool for the development of fault-tolerant systems in large-scale environments, including those within the Internet of Things (IoT). The ability to accurately predict machine failure can help to prevent costly downtime and minimize the risk of catastrophic system failures, thus enhancing the overall reliability and stability of these complex systems. The proposed approach provides a promising solution for the performance optimization and security enhancement of large-scale systems, with potential benefits spanning a wide range of industries and applications.
While our study provides valuable insights into the performance of the predictive models in the specific dataset used, there are limitations that warrant further research. Future work could involve the evaluation of our proposed approach on a variety of different datasets to assess its generalizability and robustness. Additionally, further optimization of the feature analysis and selection layer could be considered. These efforts could lead to the development of an even more accurate and reliable predictive model.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}