
Analysis of Digital Information in Storage Devices Using Supervised and Unsupervised Natural Language Processing Techniques



Abstract
:1. Introduction
2. Computer Forensics
- Identification: Identifying digital evidence is the first step in the digital forensic process. This step involves identifying one or more storage sources such as hard drives, USB sticks, SD memory sticks, mobile phones, remote storage services, IoT devices, and virtualised equipment. Typically, these devices are derived from a legal process and must be properly seized, following the chain of custody, and isolated to prevent any tampering with potential evidence. When the investigation is conducted on commonly used equipment in an organisation, such as servers, network equipment, or cloud-hosted services, the investigation team and the organisation must ensure that no one other than the investigation team’s analysts have access to them.
- Evidence examination: This step is performed using forensic tools and methodologies for the extraction of data that may be useful in an investigation in a legal process, storing all evidence securely. The evidence must be securely stored in various storage devices to leave the original information, also called the “forensic image”, intact until they are needed for further research.
- Analysis: In the process of analysing the extracted data, the analyst thoroughly investigates the extracted information in order to identify, interpret, classify, and convert it into useful research information, using specialised tools and techniques. This process is perhaps the most complex and can take the most time to analyse. To be successful, the analyst must be experienced in looking for patterns of information that can add value to the research.
- Documentation: Once the digital evidence has been obtained, the relevant documentation of the findings is carried out, providing a summary and conclusion of the research carried out [6].
- Presentation: Data obtained through proper forensic methodology, using the scientific method, may be admitted by a judge as evidence in litigation cases.
3. Natural Language Processing
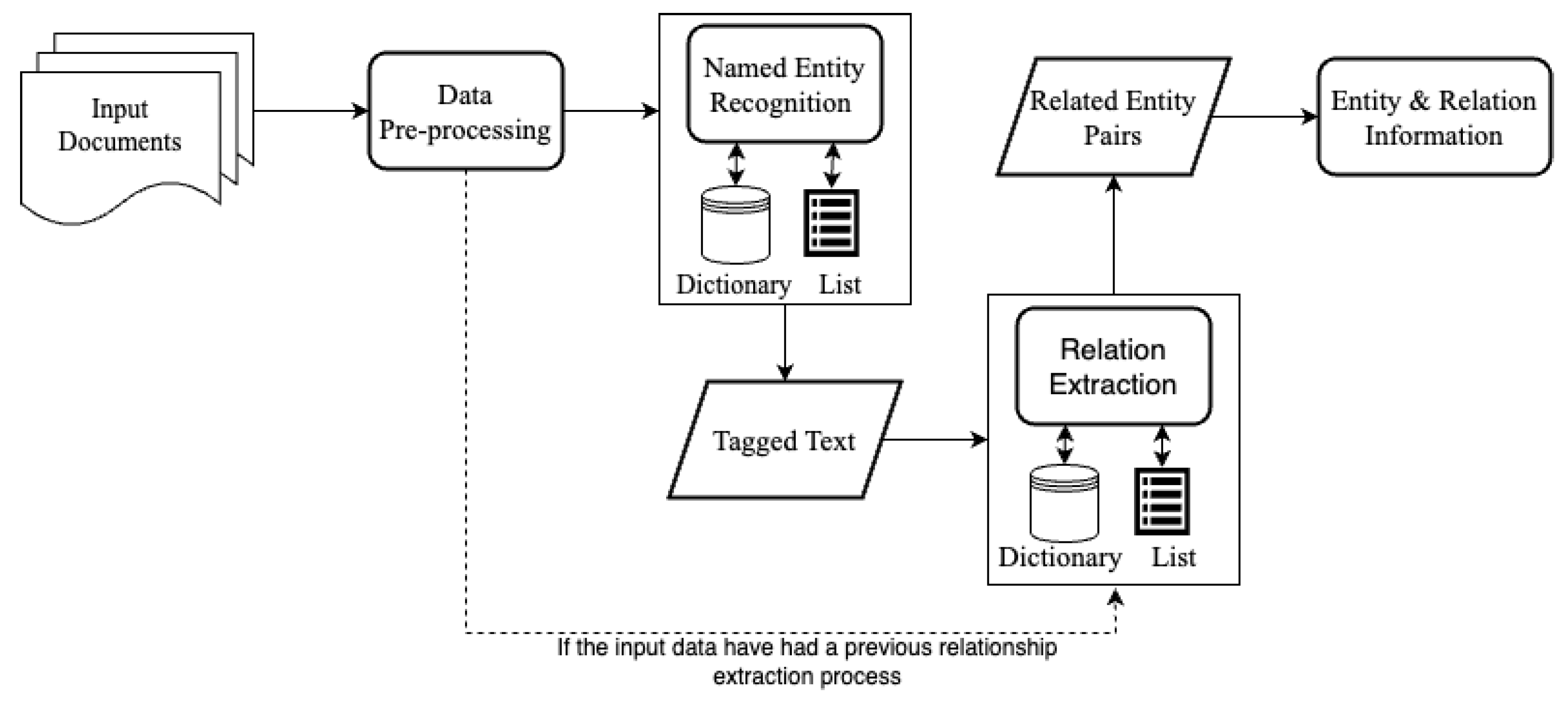
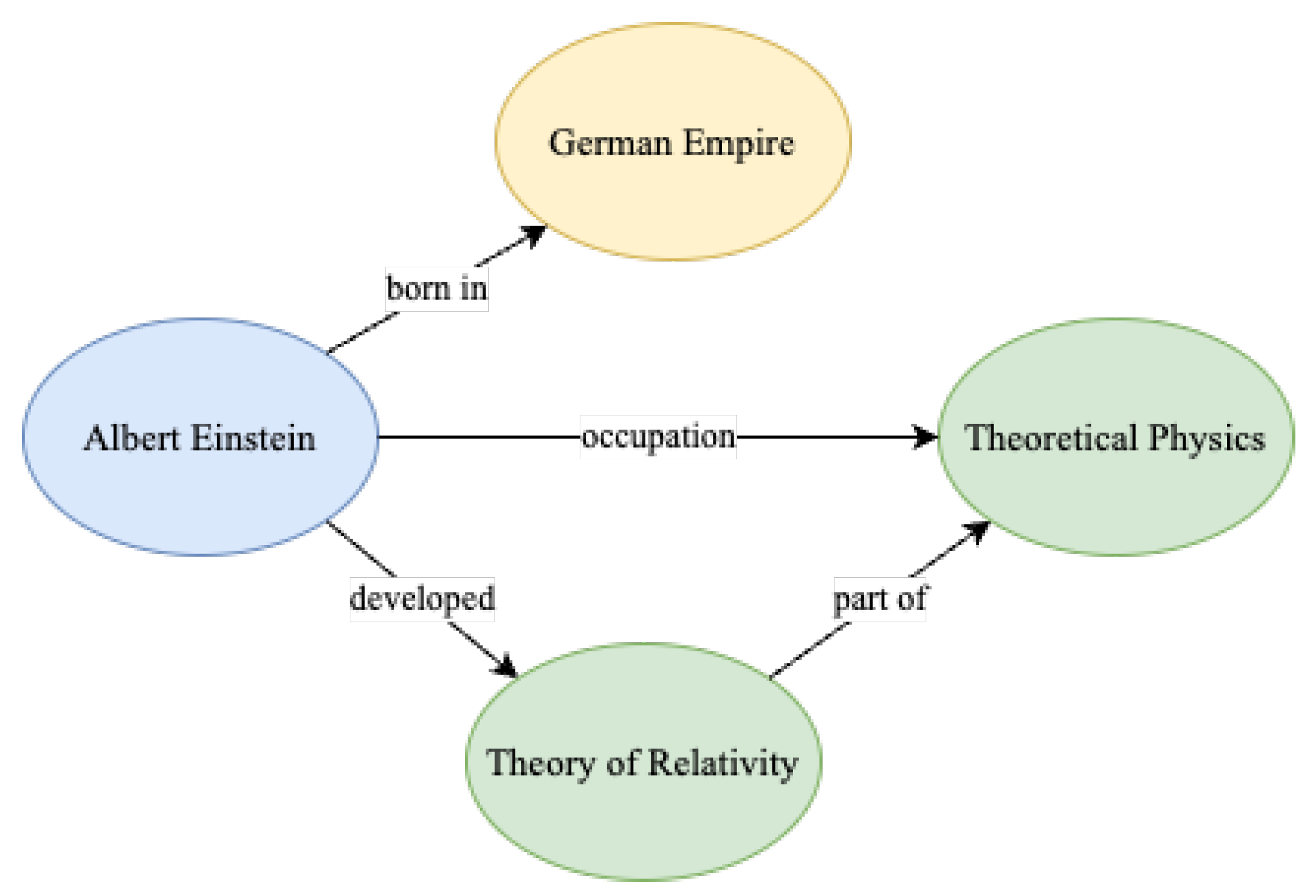
3.1. Named-Entity Recognition
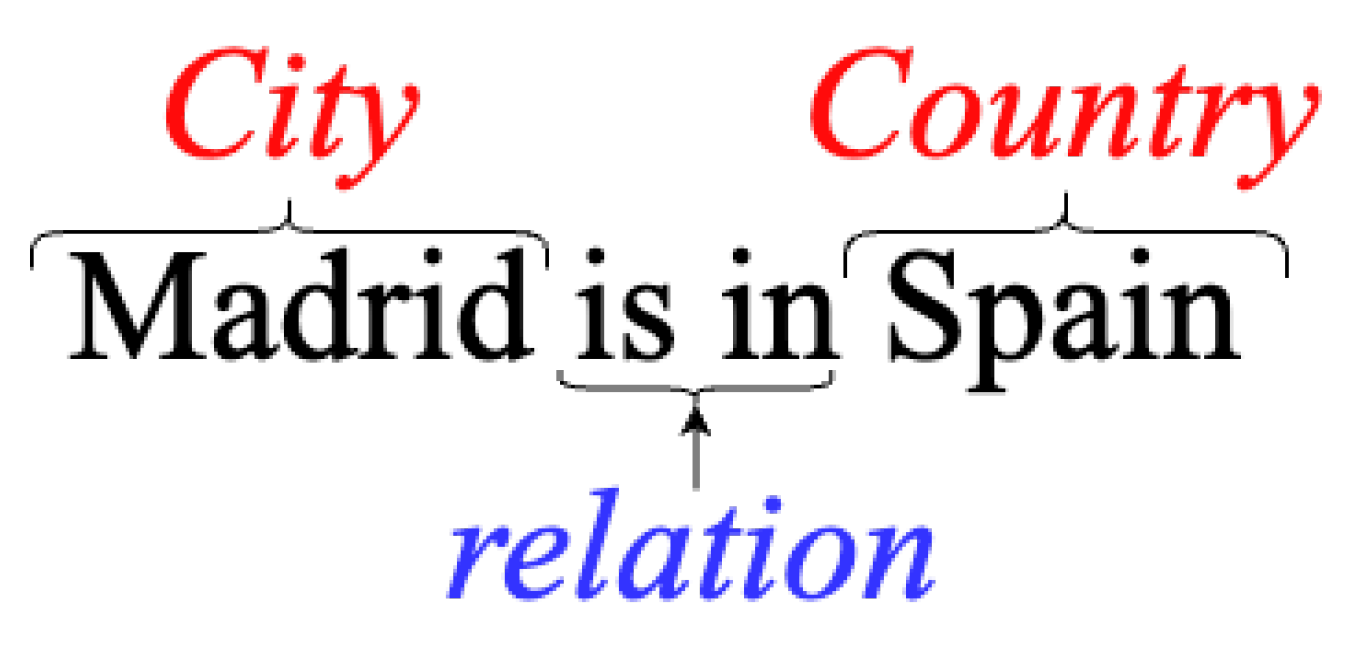
3.2. Relationship Extraction
- RE rule-based: In rule-based methods, a manual analysis of a set of sentences is carried out in order to identify what sentences that include a relation look like [34]. This method seeks to identify patterns of the type 1, where X_1 and Y_1 are identified entities and alpha () is intermediate words. These types of patterns are called word sequence patterns, because they follow a coherent syntactic and semantic order in the text, however, the implemented rules are inefficient for sequences of larger scope and variety, e.g., ”John and Mary got married”. In this example, the rule specifies a pattern that follows the sequence of the text, which defines easily identifiable patterns in word sequences.
- Weakly supervised RE: This method starts with a set of manually created rules and, based on these, finds new ones from the unmarked text data. One way to start is to create a set of “seed tuples” that describe specific relationships between entities [35]. For example, seed = seed = {(PER: Bob, LOC: USA), (PER: Joe, LOC: Spain)} these seeds establish entities that have a relationship based on the “is in” relationship PER is in LOC), from this pattern new ones are generated from the text recursively, (PER: Alice, LOC: Germany). This method is increasingly error-prone and new seeds will be needed when new types of relations are needed.
- Supervised RE: The most common way to extract existing relationships is to train a binary classifier that determines whether a relationship exists between two entities [36,37]. These binary classifiers take as input semantic and syntactic features of the text, which requires the text to be previously marked by other NLP methods.
- Distantly supervised RE: This method combines the techniques of using a classifier and seed data, with the difference that instead of using a set of tuples [38], all knowledge is taken from an existing knowledge base such as Freebase, DBpedia, Ontonotes, Wikipedia, WNUT, Yago. It allows for reduced manual effort, as well as the scalability to use a large number and variety of tags and relations. This method is limited to the knowledge base used and, in case it is needed for the research in question, an adjustment of the trained data will be necessary.
- Unsupervised RE: This method, unlike the previous ones, is based on a very general and heuristic set of constraints, so there is no need to use labelled data, seed sets or rules are used to capture the different relationships in the text [39]. In this method, more general rules of thumb are used to find the tuples. For some cases, even taking advantage of small labelled text datasets to design and modify systems. In general, these methods tend to require less supervision overall.
3.3. Supervised RE
3.4. Unsupervised RE
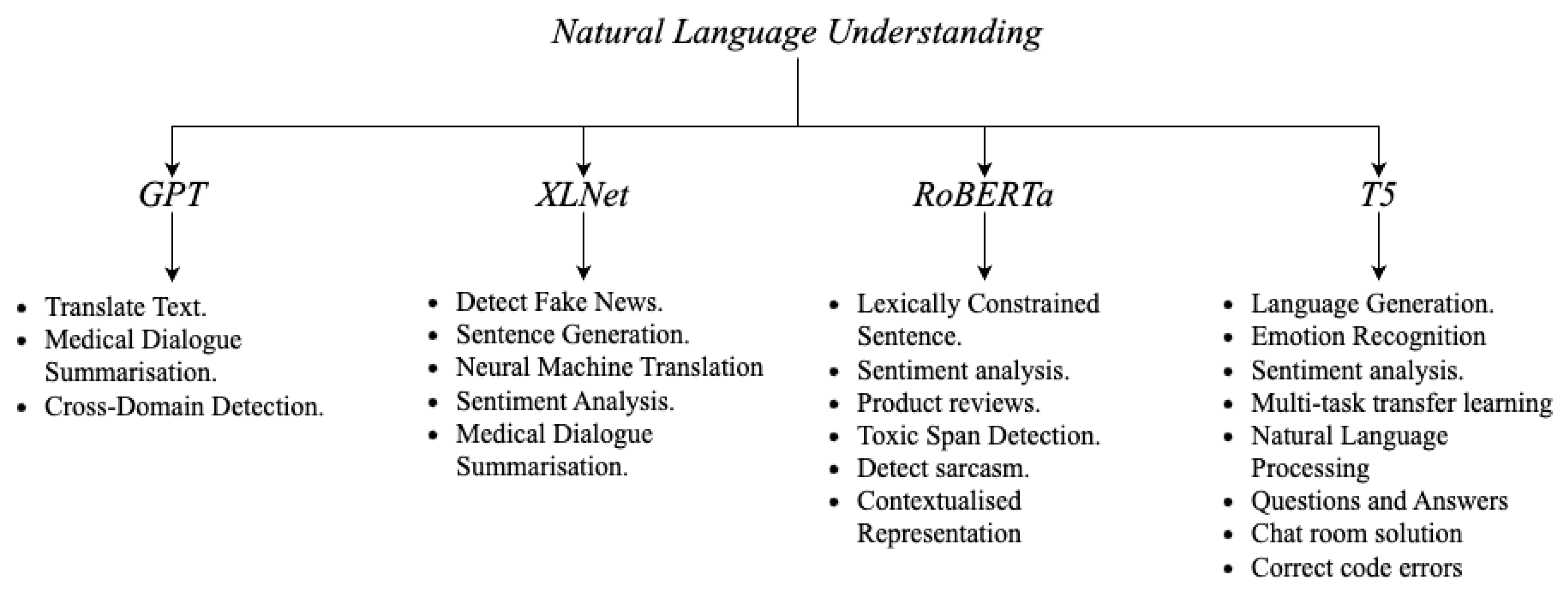
4. Natural Language Understanding
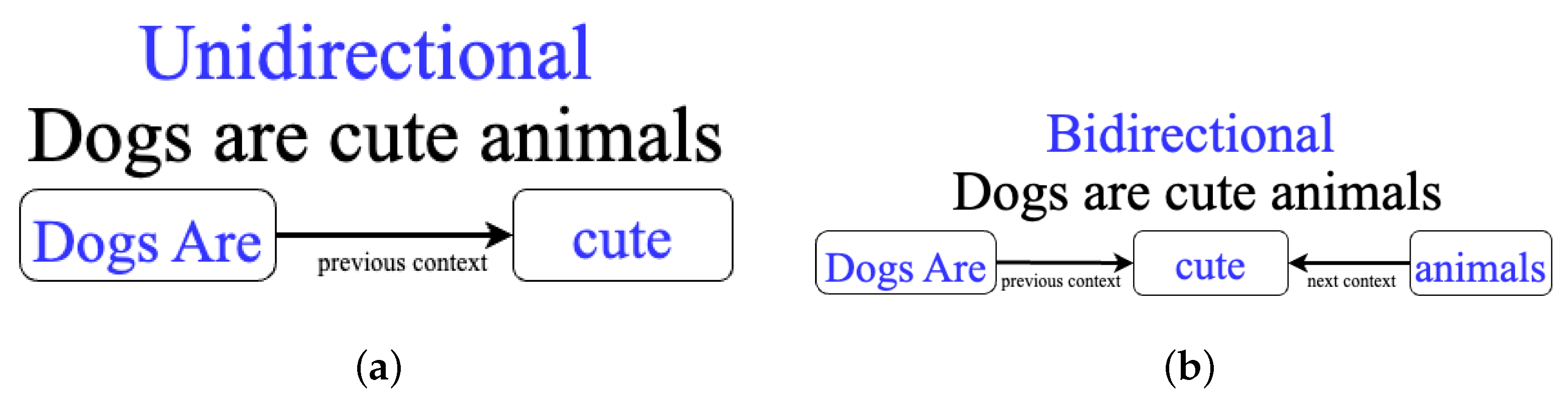
4.1. Bidirectional Encoder Representations from Transformers
4.2. Generative Pretrained Transformer
- GPT-2: This version contains 1.5 billion parameters [66]. The model is initially trained using data collected from web pages and subsequently the model is fitted with a custom dataset that is oriented to a particular task. This technique is called two-step training: pretraining and tuning.
- GPT-3: This model uses a different learning strategy to its predecessor, using prompts which learn from examples of NLP or NLG tasks. This model is trained with 400 billion tokens and has a maximum of 175 billion parameters [67].
4.3. XLNet
4.4. DistilBERT
- Distillation loss: The model was trained to return the same training rate as the baseline BERT.
- Masked language modelling (MLM): It bases its learning on a bidirectional analysis of the sentence.
- Loss of cosine embedding: The training of the model generates hidden states as close as possible to the base BERT model.
4.5. Text-to-Text Transfer Transformer
4.6. ALBERT
4.7. RoBERTa
5. Challenges
- Abbreviations: One of the most important challenges faced when analysing a document, regardless of language, is recognising words that may have multiple meanings or words that may be part of different sentences, and classifying similar words. Several words or sentences can be written in different ways, these can be abbreviated to facilitate writing, reading, and understanding. The same words can be written in long forms, e.g., BTW means By the way, and in many cases abbreviations may coincide with an organisation, a place, a position, or a position title.
- Errors related to speed and text: Models that rely on semantics cannot be trained if the speech and text data are wrong. This problem is analogous to the implication of misused or even misspelled words, which allow the model to learn over time. Although evolved grammar correction tools are good enough to remove sentence-specific errors, the training data must be error-free to facilitate accurate development in the first place.
- Spelling Variation: The vowels in the English language are very important. These letters do not make a big difference when heard, but they do make a big difference in spelling. Everybody makes spelling mistakes, but for the majority of us, we can gauge what the word was actually meant to be. However, this is a major challenge for computers, as they do not have the same ability to infer what the word was actually meant to be.
- Foreign Words: Words that are currently not used or heard very often are an area of interest in this field. Such words include names of people, place names, or ancient organisations.
- Different types of text: Sometimes, when analysing a document, it is difficult to relate two texts of different subject matter, for example, it is difficult to relate a judicial text to a common text, given that the words used to refer to the same thing may vary.
- Synonyms: Some phrases or words can have exactly the same meanings at different grammatical levels and with the same grammatical category. In any language, people often use synonyms to denote slightly different meanings within their vocabulary without changing the meaning of the sentence. Small and little can be synonyms when automatically parsing a sentence to denote the same meaning, but they are not interchangeable in all contexts, as one could denote only size and the other could denote both size and emotion. For example, buy a small cup of coffee for the office and even the small change can make a difference, in this example the words are not interchangeable.
- Colloquialisms: In every culture, phrases, expressions, and idiomatic jargon are used that have specific meanings, posing a problem for NLP developments. These expressions may exist in more than one culture, yet have different meanings in different geographical regions or simply have no coherent meaning. Even if NLP services try to scale beyond ambiguities, errors, and homonyms, it is not easy to include specific words that have different connotations from one culture to another. There are words that lack a definition in the language, but may still be relevant to a specific audience. It is important to include relevant references so that the resource is sufficiently perceptive.
- Sarcasm: Generally used words and phrases that can be positive or negative, but in reality connote the opposite. When expressing a sentence, the intention with which it is intended to be transmitted, the emotions that were present when creating it, and the personality of the author or speaker can influence it. Some of them, such as irony and sarcasm, can make a sentence be taken as positive, however, the emotions of the author can go in an opposite sense to the literal one. Although sentiment analysis has now made advances, the correct extraction of context when confronted with sarcastic sentences remains a research challenge.
- Disambiguation of the meaning of words: To perform a correct sentence disambiguation process, it is necessary to understand the context in which it was written. For this, it is necessary to extract the meaning of the word by taking into account the adjacent words, because they have related meanings.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Statista. Annual Number of Suspected and Arrested Individuals for Cybercrimes in Spain from 2011 to 2019. Available online: https://www.statista.com/statistics/1173433/cybercrime-number-of-detained-and-investigated-spain/ (accessed on 6 January 2023).
- Noblett, M.; Pollitt, M.; Presley, L. Recovering and Examining Computer Forensic Evidence. Available online: https://archives.fbi.gov/archives/about-us/lab/forensic-science-communications/fsc/oct2000/computer.htm (accessed on 6 January 2023).
- Raghavan, S. Digital forensic research: Current state of the art. CSI Trans. ICT 2013, 1, 91–114. [Google Scholar] [CrossRef]
- Patel, J. Forensic Investigation Life Cycle (FILC) using 6‘R’ Policy for Digital Evidence Collection and Legal Prosecution. Int. J. Emerg. Trends Technol. Comput. Sci. 2013, 1, 129–132. [Google Scholar]
- Ćosić, J.; Cosic, J.; Cosic, Z. Chain of Custody and Life Cycle of Digital Evidence. Comput. Technol. Appl. 2012, 3, 126–129. [Google Scholar]
- Agarwal, A.; Agarwal, A.; Gupta, S.; Gupta, S.C. Systematic Digital Forensic Investigation Model. Int. J. Comput. Sci. Secur. 2011, 5, 118–131. [Google Scholar]
- Amato, F.; Cozzolino, G.; Giacalone, M.; Moscato, F.; Romeo, F.; Xhafa, F. A Hybrid Approach for Document Analysis in Digital Forensic Domain. In Proceedings of the International Conference on Emerging Internetworking, Data & Web Technologies, EIDWT 2019, Fujairah Campus, United Arab Emirates, 26–28 February 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 170–179. [Google Scholar]
- Chowdhary, K.R. Natural Language Processing. In Fundamentals of Artificial Intelligence; Springer: New Delhi, India, 2020; pp. 603–649. [Google Scholar] [CrossRef]
- Meurers, D. Natural language processing and language learning. Encycl. Appl. Linguist. 2012, 9, 4193–4205. [Google Scholar]
- Li, J.; Sun, A.; Han, J.; Li, C. A Survey on Deep Learning for Named Entity Recognition. IEEE Trans. Knowl. Data Eng. 2022, 34, 50–70. [Google Scholar] [CrossRef]
- Wu, C.; Wu, F.; Qi, T.; Huang, Y. Named Entity Recognition with Context-Aware Dictionary Knowledge. In Proceedings of the Chinese Computational Linguistics: 19th China National Conference, CCL 2020, Hainan, China, 30 October 30–1 November 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 129–143. [Google Scholar]
- Mollá, D.; Van Zaanen, M.; Smith, D. Named entity recognition for question answering. Proc. Australas. Lang. Technol. Workshop 2006, 2006, 51–58. [Google Scholar]
- Modrzejewski, M.; Exel, M.; Buschbeck, B.; Ha, T.L.; Waibel, A. Incorporating external annotation to improve named entity translation in NMT. In Proceedings of the 22nd Annual Conference of the European Association for Machine Translation, Lisboa, Portugal, 3–5 November 2020; pp. 45–51. [Google Scholar]
- Dill, S.; Eiron, N.; Gibson, D.; Gruhl, D.; Guha, R.; Jhingran, A.; Kanungo, T.; Rajagopalan, S.; Tomkins, A.; Tomlin, J.A.; et al. SemTag and Seeker: Bootstrapping the Semantic Web via Automated Semantic Annotation. In Proceedings of the 12th International Conference on World Wide Web (WWW ’03); Association for Computing Machinery: New York, NY, USA, 2003; pp. 178–186. [Google Scholar] [CrossRef]
- Sang, E.F.; De Meulder, F. Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition. arXiv 2003, arXiv:cs/0306050. [Google Scholar]
- Weischedel, R.; Palmer, M.; Marcus, M.; Hovy, E.; Pradhan, S.; Ramshaw, L.; Xue, N.; Taylor, A.; Kaufman, J.; Franchini, M.; et al. OntoNotes Release 5.0. Available online: https://catalog.ldc.upenn.edu/LDC2013T19 (accessed on 6 January 2023).
- Doğan, R.I.; Leaman, R.; Lu, Z. The NCBI Disease Corpus. Available online: https://www.ncbi.nlm.nih.gov/CBBresearch/Dogan/DISEASE/ (accessed on 6 January 2023).
- Derczynski, L.; Nichols, E.; van Erp, M.; Limsopatham, N. Results of the WNUT2017 shared task on novel and emerging entity recognition. In Proceedings of the 3rd Workshop on Noisy User-generated Text, Copenhagen, Denmark, 7 September 2017; pp. 140–147. [Google Scholar]
- Tsujii, J. GENIA Corpus. Available online: http://www.geniaproject.org/home (accessed on 6 January 2023).
- Reddy, S.; Biswal, P. IIITBH at WNUT-2020 Task 2: Exploiting the best of both worlds. In Proceedings of the Sixth Workshop on Noisy User-generated Text (W-NUT 2020); Association for Computational Linguistics: Online, 2020; pp. 342–346. [Google Scholar] [CrossRef]
- Luz de Araujo, P.H.; de Campos, T.E.; de Oliveira, R.R.R.; Stauffer, M.; Couto, S.; Bermejo, P. LeNER-Br: A Dataset for Named Entity Recognition in Brazilian Legal Text. In International Conference on the Computational Processing of Portuguese (PROPOR); Lecture Notes on Computer Science (LNCS); Springer: Canela, Brazil, 2018; pp. 313–323. [Google Scholar] [CrossRef]
- Ling, X.; Weld, D.S. Fine-grained entity recognition. In Proceedings of the Twenty-Sixth AAAI Conference on Artificial Intelligence, Toronto, ON, Canada, 22–26 July 2012. [Google Scholar]
- Tedeschi, S.; Maiorca, V.; Campolungo, N.; Cecconi, F.; Navigli, R. WikiNEuRal: Combined Neural and Knowledge-based Silver Data Creation for Multilingual NER. In Findings of the Association for Computational Linguistics: EMNLP 2021; Association for Computational Linguistics: Punta Cana, Dominican Republic, 2021; pp. 2521–2533. [Google Scholar]
- Derczynski, L.; Bontcheva, K.; Roberts, I. Broad Twitter Corpus: A Diverse Named Entity Recognition Resource. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 1169–1179. [Google Scholar]
- Project, G. Gate. Available online: https://gate.ac.uk/ (accessed on 6 January 2023).
- NLTK. Natural Language Toolkit. Available online: https://www.nltk.org/ (accessed on 6 January 2023).
- Group, T.S.N.L.P. Stanford Named Entity Recognizer (NER). Available online: https://nlp.stanford.edu/software/CRF-NER.shtml (accessed on 6 January 2023).
- Spacy. Entity Recognizer. Available online: https://spacy.io/api/entityrecognizer (accessed on 6 January 2023).
- Poliglot. Named Entity Extraction. Available online: https://polyglot.readthedocs.io/en/latest/NamedEntityRecognition.html (accessed on 6 January 2023).
- flairNLP. Flair. Available online: https://github.com/flairNLP/flair (accessed on 6 January 2023).
- DeepPavlov. Named Entity Recognition (NER). Available online: https://docs.deeppavlov.ai/en/0.0.8/components/ner.html (accessed on 6 January 2023).
- AllenNLP. Named Entity Recognition (NER). Available online: https://allenai.org/allennlp (accessed on 6 January 2023).
- Project, G. ANNIE: A Nearly-New Information Extraction System. Available online: https://gate.ac.uk/sale/tao/splitch6.html#x9-1200006.1 (accessed on 6 January 2023).
- Claro, D.B.; Souza, M.; Castellã Xavier, C.; Oliveira, L. Multilingual Open Information Extraction: Challenges and Opportunities. Information 2019, 10, 228. [Google Scholar] [CrossRef]
- Huang, H.; Wong, R.K.; Du, B.; Han, H.J. Weakly-Supervised Relation Extraction in Legal Knowledge Bases. In Digital Libraries at the Crossroads of Digital Information for the Future; Jatowt, A., Maeda, A., Syn, S.Y., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 263–270. [Google Scholar]
- Gao, T.; Han, X.; Qiu, K.; Bai, Y.; Xie, Z.; Lin, Y.; Liu, Z.; Li, P.; Sun, M.; Zhou, J. Manual Evaluation Matters: Reviewing Test Protocols of Distantly Supervised Relation Extraction. arXiv 2021, arXiv:2105.09543. [Google Scholar]
- Shao, C.; Li, M.; Li, G.; Zhou, M.; Han, D. CRSAtt: By Capturing Relational Span and Using Attention for Relation Classification. Appl. Sci. 2022, 12, 1068. [Google Scholar] [CrossRef]
- Chen, X.; Huang, X. EANT: Distant Supervision for Relation Extraction with Entity Attributes via Negative Training. Appl. Sci. 2022, 12, 8821. [Google Scholar] [CrossRef]
- Lange Di Cesare, K.; Zouaq, A.; Gagnon, M.; Jean-Louis, L. A Machine Learning Filter for the Slot Filling Task. Information 2018, 9, 133. [Google Scholar] [CrossRef]
- Wang, W.; Hu, W. Improving Relation Extraction by Multi-Task Learning. In Proceedings of the 2020 4th High Performance Computing and Cluster Technologies Conference & 2020 3rd International Conference on Big Data and Artificial Intelligence (HPCCT & BDAI ’20); Association for Computing Machinery: New York, NY, USA, 2020; pp. 152–157. [Google Scholar] [CrossRef]
- Sahu, S.K.; Anand, A.; Oruganty, K.; Gattu, M. Relation extraction from clinical texts using domain invariant convolutional neural network. arXiv 2016, arXiv:1606.09370. [Google Scholar] [CrossRef]
- Genest, P.Y.; Portier, P.E.; Egyed-Zsigmond, E.; Goix, L.W. PromptORE—A Novel Approach Towards Fully Unsupervised Relation Extraction. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management (CIKM ’22); Association for Computing Machinery: New York, NY, USA, 2022; pp. 561–571. [Google Scholar] [CrossRef]
- Ali, M.; Saleem, M.; Ngomo, A.C.N. Unsupervised Relation Extraction Using Sentence Encoding. In The Semantic Web: ESWC 2021 Satellite Events; Verborgh, R., Dimou, A., Hogan, A., d’Amato, C., Tiddi, I., Bröring, A., Mayer, S., Ongenae, F., Tommasini, R., Alam, M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 136–140. [Google Scholar]
- De Lacalle, O.L.; Lapata, M. Unsupervised relation extraction with general domain knowledge. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing: Seattle, Washington, DC, USA, 18–21 October 2013; pp. 415–425. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. GraphRel: Modeling Text as Relational Graphs for Joint Entity and Relation Extraction. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics; Association for Computational Linguistics: Florence, Italy, 2019; pp. 1409–1418. [Google Scholar] [CrossRef]
- Shi, P.; Lin, J. Simple BERT Models for Relation Extraction and Semantic Role Labeling. arXiv 2019, arXiv:1904.05255. [Google Scholar]
- Christopoulou, F.; Miwa, M.; Ananiadou, S. Connecting the Dots: Document-level Neural Relation Extraction with Edge-oriented Graphs. arXiv 2019, arXiv:1909.00228. [Google Scholar]
- Yao, Y.; Ye, D.; Li, P.; Han, X.; Lin, Y.; Liu, Z.; Liu, Z.; Huang, L.; Zhou, J.; Sun, M. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. arXiv 2019, arXiv:1906.06127. [Google Scholar]
- Semaan, P. Natural language generation: An overview. J. Comput. Sci. Res. 2012, 1, 50–57. [Google Scholar]
- Petrović, D.; Stankovic, M. Use of linguistic forms mining in the link analysis of legal documents. Comput. Sci. Inf. Syst. 2018, 15, 5. [Google Scholar] [CrossRef]
- Zhu, J.; Xia, Y.; Wu, L.; He, D.; Qin, T.; Zhou, W.; Li, H.; Liu, T. Incorporating BERT into Neural Machine Translation. arXiv 2020, arXiv:2002.06823. [Google Scholar]
- Kudande, D.; Dolai, P.; Hole, A. Fake News Detection & Sentiment Analysis on Twitter Data Using NLP. Int. Res. J. Eng. Technol. (IRJET) 2021, 8, 1571–1574. [Google Scholar]
- Tan, K.L.; Lee, C.P.; Anbananthen, K.S.M.; Lim, K.M. RoBERTa-LSTM: A Hybrid Model for Sentiment Analysis With Transformer and Recurrent Neural Network. IEEE Access 2022, 10, 21517–21525. [Google Scholar] [CrossRef]
- Mishakova, A.; Portet, F.; Desot, T.; Vacher, M. Learning Natural Language Understanding Systems from Unaligned Labels for Voice Command in Smart Homes. In Proceedings of the 2019 IEEE International Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), Kyoto, Japan, 11–15 March 2019; pp. 832–837. [Google Scholar] [CrossRef]
- Zhao, H.; Cao, J.; Xu, M.; Lu, J. Variational neural decoder for abstractive text summarization. Comput. Sci. Inf. Syst. 2020, 17, 537–552. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Otter, D.W.; Medina, J.R.; Kalita, J.K. A Survey of the Usages of Deep Learning for Natural Language Processing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 604–624. [Google Scholar] [CrossRef] [PubMed]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. Xlnet: Generalized autoregressive pretraining for language understanding. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. 2018. Available online: https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf (accessed on 6 January 2023).
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Soricut, R.; Lan, Z. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. Available online: https://ai.googleblog.com/2019/12/albert-lite-bert-for-self-supervised.html (accessed on 6 January 2023).
- Roberts, A.; Raffel, C.; Lee, K.; Matena, M.; Shazeer, N.; Liu, P.J.; Narang, S.; Li, W.; Zhou, Y. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Technical Report; Google. 2019. Available online: https://research.google/pubs/pub48643/ (accessed on 18 January 2023).
- Jwa, H.; Oh, D.; Park, K.; Kang, J.M.; Lim, H. exBAKE: Automatic Fake News Detection Model Based on Bidirectional Encoder Representations from Transformers (BERT). Appl. Sci. 2019, 9, 4062. [Google Scholar] [CrossRef]
- Solaiman, I.; Clark, J.; Brundage, M. GPT-2: 1.5B Release. Available online: https://openai.com/blog/gpt-2-1-5b-release/ (accessed on 6 January 2023).
- OPENAI. Models: Overview. Available online: https://beta.openai.com/docs/models/overview (accessed on 6 January 2023).
- Trummer, I. CodexDB: Synthesizing Code for Query Processing from Natural Language Instructions Using GPT-3 Codex. Proc. VLDB Endow. 2022, 15, 2921–2928. [Google Scholar] [CrossRef]
- MacNeil, S.; Tran, A.; Mogil, D.; Bernstein, S.; Ross, E.; Huang, Z. Generating Diverse Code Explanations Using the GPT-3 Large Language Model. In Proceedings of the 2022 ACM Conference on International Computing Education Research—Volume 2 (ICER ’22); Association for Computing Machinery: New York, NY, USA, 2022; pp. 37–39. [Google Scholar] [CrossRef]
- Chintagunta, B.; Katariya, N.; Amatriain, X.; Kannan, A. Medically aware gpt-3 as a data generator for medical dialogue summarization. In Proceedings of the Machine Learning for Healthcare Conference (PMLR), Online, 6–7 August 2021; pp. 354–372. [Google Scholar]
- Rodriguez, J.; Hay, T.; Gros, D.; Shamsi, Z.; Srinivasan, R. Cross-Domain Detection of GPT-2-Generated Technical Text. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics. Seattle, WD, USA, 10–15 July 2022; pp. 1213–1233. [Google Scholar] [CrossRef]
- Kumar J, A.; Esther Trueman, T.; Cambria, E. Fake News Detection Using XLNet Fine-Tuning Model. In Proceedings of the 2021 International Conference on Computational Intelligence and Computing Applications (ICCICA), Nagpur, India, 18–19 June 2021; pp. 1–4. [Google Scholar] [CrossRef]
- He, X.; Li, V.O. Show Me How To Revise: Improving Lexically Constrained Sentence Generation with XLNet. Proc. AAAI Conf. Artif. Intell. 2021, 35, 12989–12997. [Google Scholar] [CrossRef]
- Wu, N.; Hou, H.; Guo, Z.; Zheng, W. Low-Resource Neural Machine Translation Using XLNet Pre-training Model. In Artificial Neural Networks and Machine Learning—ICANN 2021; Farkaš, I., Masulli, P., Otte, S., Wermter, S., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 503–514. [Google Scholar]
- Mohamad Zamani, N.A.; Liew, J.S.Y.; Yusof, A.M. XLNET-GRU Sentiment Regression Model for Cryptocurrency News in English and Malay. In Proceedings of the 4th Financial Narrative Processing Workshop @LREC2022; European Language Resources Association: Marseille, France, 2022; pp. 36–42. [Google Scholar]
- Bansal, A.; Susan, S.; Choudhry, A.; Sharma, A. Covid-19 Vaccine Sentiment Analysis During Second Wave in India by Transfer Learning Using XLNet. In Pattern Recognition and Artificial Intelligence; El Yacoubi, M., Granger, E., Yuen, P.C., Pal, U., Vincent, N., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 443–454. [Google Scholar]
- Ardimento, P. Predicting Bug-Fixing Time: DistilBERT Versus Google BERT. In Product-Focused Software Process Improvement; Taibi, D., Kuhrmann, M., Mikkonen, T., Klünder, J., Abrahamsson, P., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 610–620. [Google Scholar]
- Saha, U.; Mahmud, M.S.; Keya, M.; Lucky, E.A.E.; Khushbu, S.A.; Noori, S.R.H.; Syed, M.M. Exploring Public Attitude Towards Children by Leveraging Emoji to Track Out Sentiment Using Distil-BERT a Fine-Tuned Model. In Third International Conference on Image Processing and Capsule Networks; Chen, J.I.Z., Tavares, J.M.R.S., Shi, F., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 332–346. [Google Scholar]
- Palliser-Sans, R.; Rial-Farràs, A. HLE-UPC at SemEval-2021 Task 5: Multi-Depth DistilBERT for Toxic Spans Detection. arXiv 2021, arXiv:2104.00639. [Google Scholar]
- Jojoa, M.; Eftekhar, P.; Nowrouzi-Kia, B.; Garcia-Zapirain, B. Natural language processing analysis applied to COVID-19 open-text opinions using a distilBERT model for sentiment categorization. AI Soc. 2022, 1–8. [Google Scholar] [CrossRef]
- Dogra, V.; Singh, A.; Verma, S.; Kavita; Jhanjhi, N.Z.; Talib, M.N. Analyzing DistilBERT for Sentiment Classification of Banking Financial News. In Intelligent Computing and Innovation on Data Science; Peng, S.L., Hsieh, S.Y., Gopalakrishnan, S., Duraisamy, B., Eds.; Springer Nature Singapore: Singapore, 2021; pp. 501–510. [Google Scholar]
- Chaudhary, Y.; Gupta, P.; Saxena, K.; Kulkarni, V.; Runkler, T.A.; Schütze, H. TopicBERT for Energy Efficient Document Classification. arXiv 2020, arXiv:2010.16407. [Google Scholar]
- Nie, P.; Zhang, Y.; Geng, X.; Ramamurthy, A.; Song, L.; Jiang, D. DC-BERT: Decoupling Question and Document for Efficient Contextual Encoding. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’20); Association for Computing Machinery: New York, NY, USA, 2020; pp. 1829–1832. [Google Scholar] [CrossRef]
- Bambroo, P.; Awasthi, A. LegalDB: Long DistilBERT for Legal Document Classification. In Proceedings of the 2021 International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 19–20 February 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Dogra, V. Banking news-events representation and classification with a novel hybrid model using DistilBERT and rule-based features. Turk. J. Comput. Math. Educ. 2021, 12, 3039–3054. [Google Scholar]
- Caballero, E.Q.; Rahman, M.S.; Cerny, T.; Rivas, P.; Bejarano, G. Study of Question Answering on Legal Software Document using BERT based models. Latinx Nat. Lang. Process. Res. Work. 2022. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Elmadany, A.; Abdul-Mageed, M. AraT5: Text-to-Text Transformers for Arabic Language Generation. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Dublin, Ireland, 22–27 May 2022; pp. 628–647. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A massively multilingual pre-trained text-to-text transformer. arXiv 2020, arXiv:2010.11934. [Google Scholar]
- Deng, J.J.; Leung, C.H.C.; Li, Y. Multimodal Emotion Recognition Using Transfer Learning on Audio and Text Data. In Computational Science and Its Applications—ICCSA 2021; Gervasi, O., Murgante, B., Misra, S., Garau, C., Blečić, I., Taniar, D., Apduhan, B.O., Rocha, A.M.A.C., Tarantino, E., Torre, C.M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 552–563. [Google Scholar]
- Oshingbesan, A.; Ekoh, C.; Atakpa, G.; Byaruagaba, Y. Extreme Multi-Domain, Multi-Task Learning With Unified Text-to-Text Transfer Transformers. arXiv 2022, arXiv:2209.10106. [Google Scholar]
- Nagoudi, E.M.B.; Chen, W.R.; Abdul-Mageed, M.; Cavusogl, H. Indt5: A text-to-text transformer for 10 indigenous languages. arXiv 2021, arXiv:2104.07483. [Google Scholar]
- Mastropaolo, A.; Scalabrino, S.; Cooper, N.; Nader Palacio, D.; Poshyvanyk, D.; Oliveto, R.; Bavota, G. Studying the Usage of Text-To-Text Transfer Transformer to Support Code-Related Tasks. In Proceedings of the 2021 IEEE/ACM 43rd International Conference on Software Engineering (ICSE), Madrid, Spain, 22–30 May 2021; pp. 336–347. [Google Scholar] [CrossRef]
- Hwang, M.H.; Shin, J.; Seo, H.; Im, J.S.; Cho, H.; Lee, C.K. Ensemble-NQG-T5: Ensemble Neural Question Generation Model Based on Text-to-Text Transfer Transformer. Appl. Sci. 2023, 13, 903. [Google Scholar] [CrossRef]
- Phakmongkol, P.; Vateekul, P. Enhance Text-to-Text Transfer Transformer with Generated Questions for Thai Question Answering. Appl. Sci. 2021, 11, 267. [Google Scholar] [CrossRef]
- Katayama, S.; Aoki, S.; Yonezawa, T.; Okoshi, T.; Nakazawa, J.; Kawaguchi, N. ER-Chat: A Text-to-Text Open-Domain Dialogue Framework for Emotion Regulation. IEEE Trans. Affect. Comput. 2022, 13, 2229–2237. [Google Scholar] [CrossRef]
- AI, M. RoBERTa: An Optimized Method for Pretraining Self-Supervised NLP Systems. Available online: https://ai.facebook.com/blog/roberta-an-optimized-method-for-pretraining-self-supervised-nlp-systems/ (accessed on 6 January 2023).
- Lee, L.H.; Hung, M.C.; Lu, C.H.; Chen, C.H.; Lee, P.L.; Shyu, K.K. Classification of Tweets Self-reporting Adverse Pregnancy Outcomes and Potential COVID-19 Cases Using RoBERTa Transformers. In Proceedings of the Sixth Social Media Mining for Health (#SMM4H) Workshop and Shared Task; Association for Computational Linguistics: Mexico City, Mexico, 2021; pp. 98–101. [Google Scholar] [CrossRef]
- You, L.; Han, F.; Peng, J.; Jin, H.; Claramunt, C. ASK-RoBERTa: A pretraining model for aspect-based sentiment classification via sentiment knowledge mining. Knowl.-Based Syst. 2022, 253, 109511. [Google Scholar] [CrossRef]
- Dai, J.; Pan, F.; Shou, Z.; Zhang, H. RoBERTa-IAN for aspect-level sentiment analysis of product reviews. J. Phys. Conf. Ser. 2021, 1827, 012079. [Google Scholar] [CrossRef]
- Suman, T.A.; Jain, A. AStarTwice at SemEval-2021 Task 5: Toxic Span Detection Using RoBERTa-CRF, Domain Specific Pre-Training and Self-Training. In Proceedings of the 15th International Workshop on Semantic Evaluation (SemEval-2021), Association for Computational Linguistics. Online, Bangkok, Thailand, 5–6 August 2021; pp. 875–880. [Google Scholar] [CrossRef]
- Hercog, M.; Jaroński, P.; Kolanowski, J.; Mieczyński, P.; Wiśniewski, D.; Potoniec, J. Sarcastic RoBERTa: A RoBERTa-Based Deep Neural Network Detecting Sarcasm on Twitter. In Big Data Analytics and Knowledge Discovery; Wrembel, R., Gamper, J., Kotsis, G., Tjoa, A.M., Khalil, I., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2022; pp. 46–52. [Google Scholar]
- Straka, M.; Náplava, J.; Straková, J.; Samuel, D. RobeCzech: Czech RoBERTa, a Monolingual Contextualized Language Representation Model. In Text, Speech, and Dialogue; Ekštein, K., Pártl, F., Konopík, M., Eds.; Springer International Publishing: Berlin/Heidelberg, Germany, 2021; pp. 197–209. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised cross-lingual representation learning at scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]
- Arkhipov, M.; Trofimova, M.; Kuratov, Y.; Sorokin, A. Tuning multilingual transformers for language-specific named entity recognition. In Proceedings of the 7th Workshop on Balto-Slavic Natural Language Processing, Florence, Italy, 2 August 2019; pp. 89–93. [Google Scholar]
- Ling, Y.; Guan, W.; Ruan, Q.; Song, H.; Lai, Y. Variational Learning for the Inverted Beta-Liouville Mixture Model and Its Application to Text Categorization. arXiv 2021, arXiv:2112.14375. [Google Scholar] [CrossRef]
- Oh, K.; Kang, M.; Oh, S.; Kim, D.H.; Kang, S.H.; Lee, Y. AB-XLNet: Named Entity Recognition Tool for Health Information Technology Standardization. In Proceedings of the 2022 13th International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 19–21 October 2022; pp. 742–744. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Language | Text Source | #Tags |
|---|---|---|---|
| CoNLL 2003 [15] | English, German, Dutch | Reuters news | 4 |
| Ontonotes V5 [16] | English, Chinese, Arabic | Mobile conversations, religious texts, newsgroups, broadcast news and conversation weblogs, newscast | 18 |
| NCBI disease [17] | English | PubMed | 14 |
| WNUT 2017 [18] | English | Emerging discussions | 6 |
| GENIA [19] | English | PubMed | 36 |
| WNUT 2020 [20] | English | 2 | |
| LeNER-Br [21] | Portuguese | Legal text | 6 |
| WikiFiger [22] | English | Wikipedia | 112 |
| WikiNEuRal [23] | English, Italian, German, Dutch, French, Portuguese, Russian, Polish | PubMed | 5 |
| Broad Twitter corpus [24] | English | 3 |
| Tool | Platform | Source URL |
|---|---|---|
| GATE | Java | [25] |
| NLTK | Python | [26] |
| Stanford | Java | [27] |
| Spacy | Python | [28] |
| Poliglot | Python | [29] |
| Flair | Python | [30] |
| DeepPavlov | Python | [31] |
| Allen | Python | [32] |
| Annie | Python | [33] |
| Proposal | Technique | Approach | Scope |
|---|---|---|---|
| Wang et al. [40] | Extraction-Based Relationships | Supervised | Phrase |
| Genest et al. [42] | Instruction-Based Relationship Extraction | Unsupervised | Phrase |
| Ali et al. [43] | Phrase Supervision | Unsupervised | Phrase |
| De Lacalle et al. [44] | General Domain Knowledge | Unsupervised | Phrase |
| Fu et al. [45] | Convolutional Graph Networks | Unsupervised | Phrase |
| Sahu et al. [41] | Convolutional Neural Networks | Supervised | Phrase |
| Shi et al. [46] | BERT | Unsupervised | Phrase |
| Yao et al. [48] | Dataset from Wikipedia and Wikidata | Supervised/Unsupervised | Dataset |
| Christopoulou et al. [47] | Multi-Instance Learning Graphs | Unsupervised | Document |
| Model | #Parameters | Features Layer/Hidden/Heads | Method |
|---|---|---|---|
| BERT [58] | Base: 110M Large: 340M | 12/768/12 24/1024/16 | Bidirectional transformer MLM, NSP |
| RoBERTa [59] | Base: 123M Large: 355M | 12/768/12 24/1024/16 | BERT without NSP using dynamic masking |
| XLNet [60] | Base: 110M Large: 340M | 12/768/12 24/1024/16 | Bidirectional transformer |
| GPT [61] | 110M | 12/768/12 | Transformers |
| DistilBERT [62] | 134M | 6/768/12 | BERT distillation |
| ALBERT [63] | Base: 11M Large: 17M | 12/768/12 24/1024/16 | BERT with reduced para- meters, SOP (not NSP) |
| T5 [64] | Base: 220M Large: 770M | 12/768/12 24/1024/16 | Text-to-text |
| Model | Parameters (Billions) | Decoder Layers | Context Token Size | Hidden Layer | Batch Size | Training Data |
|---|---|---|---|---|---|---|
| GPT | 0.117 | 12 | 512 | 768 | 64 | BookCrawl |
| GPT-2 | 1.5 | 48 | 1024 | 1600 | 512 | WebText |
| GPT-3 | 175 | 96 | 2048 | 12,288 | 3.2M | CommonCrawl |
| Proposal | Extraction Approach | Model Scope | Datasets | Results F1 Score |
|---|---|---|---|---|
| Adverse Pregnancy Outcomes and Potential COVID-19 [98] | Lexically constrained sentence generation | Medical | Medication Abuse in Tweets | 0.9305 |
| ASK-RoBERTa [99] | Sentiment analysis | Lexical | Restaurant-14-16, Laptop-14 | 0.779, 0.821, 0.71, 0.792 |
| RoBERTa-IAN [100] | Product reviews | Marketing | SEMVAL | 0.90 |
| RoBERTa-CRF [101] | Toxic span detection | Sentiment analysis | Civil Comments | 0.66 |
| Sarcastic RoBERTa [102] | Detect sarcasm in tweets | Sentiment analysis | iSarcasm | 0.526 |
| RobeCzech [103] | Contextualised representation | Lexical | Czech Facebook dataset | 0.801 |
| Proposal | Extraction Approach | Model Scope | Model | Datasets |
|---|---|---|---|---|
| CodexDB [68] | Translate text | SQL query processing | GPT-3 | WikiSQL, SPIDER |
| GPT-3-ENS [70] | Medical dialogue summarisation | Medical | GPT-3 | Human labeled, GPT-3-ENS |
| Cross-Domain Detection [71] | Cross-domain detection | Technical text | GPT-3 | SME-labeled, Proxy data |
| Fake News Detection [72] | Detect fake news | News | XLNet | LIAR |
| Show Me How To Revise [73] | Sentence generation | Lexical | XLNet | One-Billion-Word |
| Low-resource neural machine translation [74] | Neural machine translation | Translation | XLNet | CCMT2019 |
| XLNet-GRU [75] | Detect fake news | News | XLNet-GRU | Cryptocurrency news |
| Sentiment Analysis [76] | Tweet-based sentiment analysis | Medical | XLNet | COCO val |
| AB-XLNet [107] | Drugs in discharge summaries | Medical | XLNet | |
| AraT5 [88] | Language generation | Lexical | T5 | Arabic MT datasets |
| mT5 [89] | Language generation | Lexical | T5 | |
| Multimodal Emotion Recognition [90] | Emotion recognition | Sentiment analysis | T5 | IEMOCAP |
| Extreme Multi-Domain [91] | Multi-task transfer learning | Lexical | T5 | |
| Indt5 [92] | Natural language processing for indigenous languages | Lexical | T5 | IndCorpus |
| Ensemble-NQG-T5 [94] | Neural generation of questions | Questions and answers | T5 | SQuAD 2.0 |
| Generated Questions for Thai [95] | Answer questions | Questions and answers | T5 | Wiki QA and iApp Wiki QA |
| ER-Chat [96] | Chat room | Chat | T5 | |
| Code-Related Tasks [93] | Correct code errors | Code-related | T5 | Bug-Fix Pairs |
| Adverse Pregnancy Outcomes and Potential COVID-19 [98] | Lexical constrained sentence generation | Medical | RoBERTa | Medication Abuse in Tweets |
| ASK-RoBERTa [99] | Sentiment analysis | Lexical | RoBERTa | Restaurant-14, Restaurant-16, Laptop-14 |
| RoBERTa-IAN [100] | Product reviews | Marketing | RoBERTa | SEMVAL |
| RoBERTa-CRF [101] | Toxic span detection | Sentiment analysis | RoBERTa | Civil Comments |
| Sarcastic RoBERTa [102] | Detect sarcasm in tweets | Sentiment analysis | RoBERTa | iSarcasm |
| RobeCzech [103] | Contextualised representation | Lexical | RoBERTa | Czech Facebook dataset |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martínez Hernández, L.A.; Sandoval Orozco, A.L.; García Villalba, L.J. Analysis of Digital Information in Storage Devices Using Supervised and Unsupervised Natural Language Processing Techniques. Future Internet 2023, 15, 155. https://doi.org/10.3390/fi15050155
Martínez Hernández LA, Sandoval Orozco AL, García Villalba LJ. Analysis of Digital Information in Storage Devices Using Supervised and Unsupervised Natural Language Processing Techniques. Future Internet. 2023; 15(5):155. https://doi.org/10.3390/fi15050155
Chicago/Turabian StyleMartínez Hernández, Luis Alberto, Ana Lucila Sandoval Orozco, and Luis Javier García Villalba. 2023. "Analysis of Digital Information in Storage Devices Using Supervised and Unsupervised Natural Language Processing Techniques" Future Internet 15, no. 5: 155. https://doi.org/10.3390/fi15050155
APA StyleMartínez Hernández, L. A., Sandoval Orozco, A. L., & García Villalba, L. J. (2023). Analysis of Digital Information in Storage Devices Using Supervised and Unsupervised Natural Language Processing Techniques. Future Internet, 15(5), 155. https://doi.org/10.3390/fi15050155