
Domain Adaptation Speech-to-Text for Low-Resource European Portuguese Using Deep Learning

 ,
,  ,
,  ,
,  and
and
Abstract
:1. Introduction
2. Literature Review
2.1. Deep Learning in ASR
2.2. ASR in the Portuguese Language
3. Data
3.1. LibriSpeech and Multilingual LibriSpeech
3.2. SpeechDat
- OK—clean audio and ready to be used;
- NOISE—audio with some background noise;
- GARBAGE—empty audio, missing transcriptions, only background noise, noise produced by others;
- OTHER—audio containing disfluencies, hesitations, stuttering, or unintelligible speech;
- NO_PTO—audio files without label file.
4. Proposed System
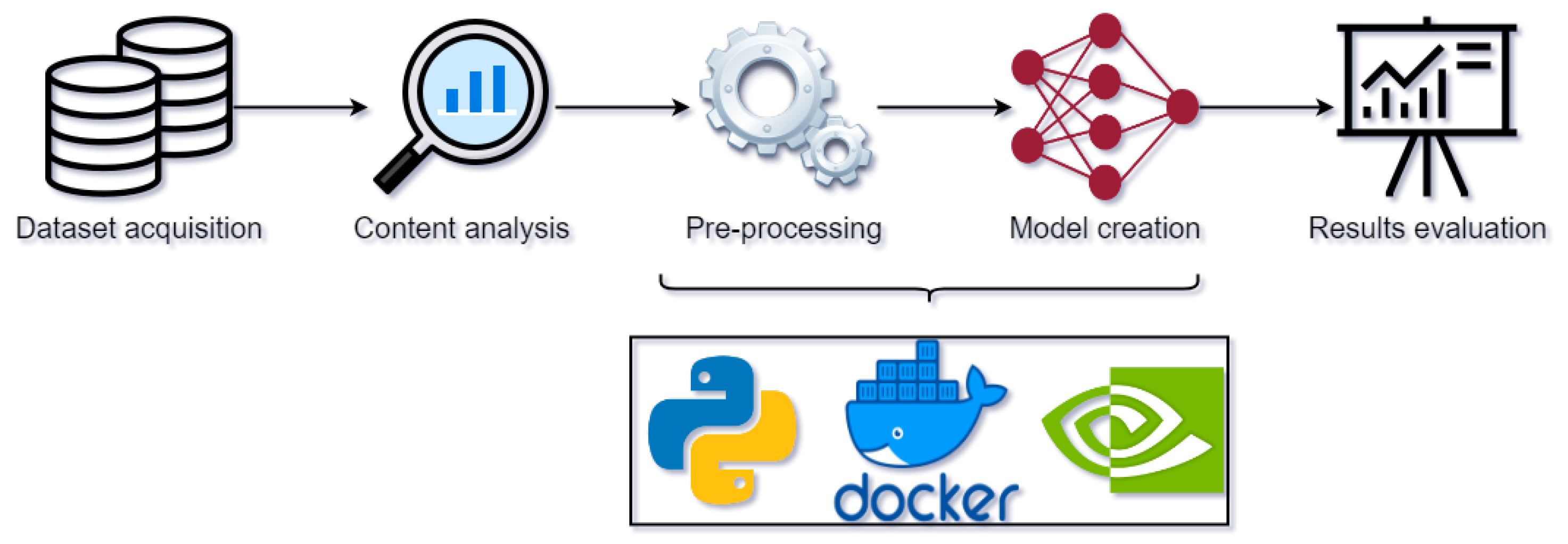
4.1. Architecture
- Dataset Acquisition—explore and acquire new speech datasets in Portuguese (audio recording files and respective transcriptions);
- Content Analysis—dataset analysis, assessment of the dataset’s initial structure, documentation, content quantity and quality, and audio file encodings;
- Pre-Processing—dataset restructuring, data pre-processing, and manifest creation;
- Model Creation—model creation with the pre-processed data;
- Results Evaluation—testing and evaluation of the created model.
4.2. NVIDIA NeMo
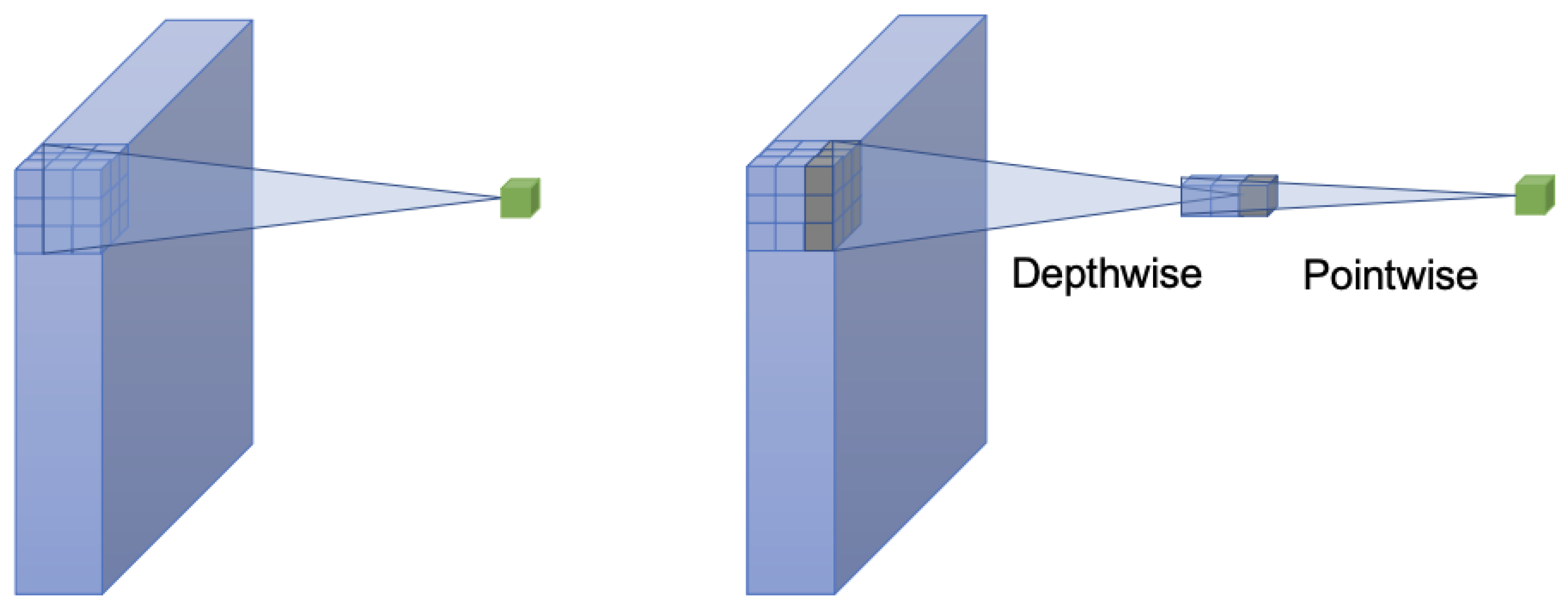
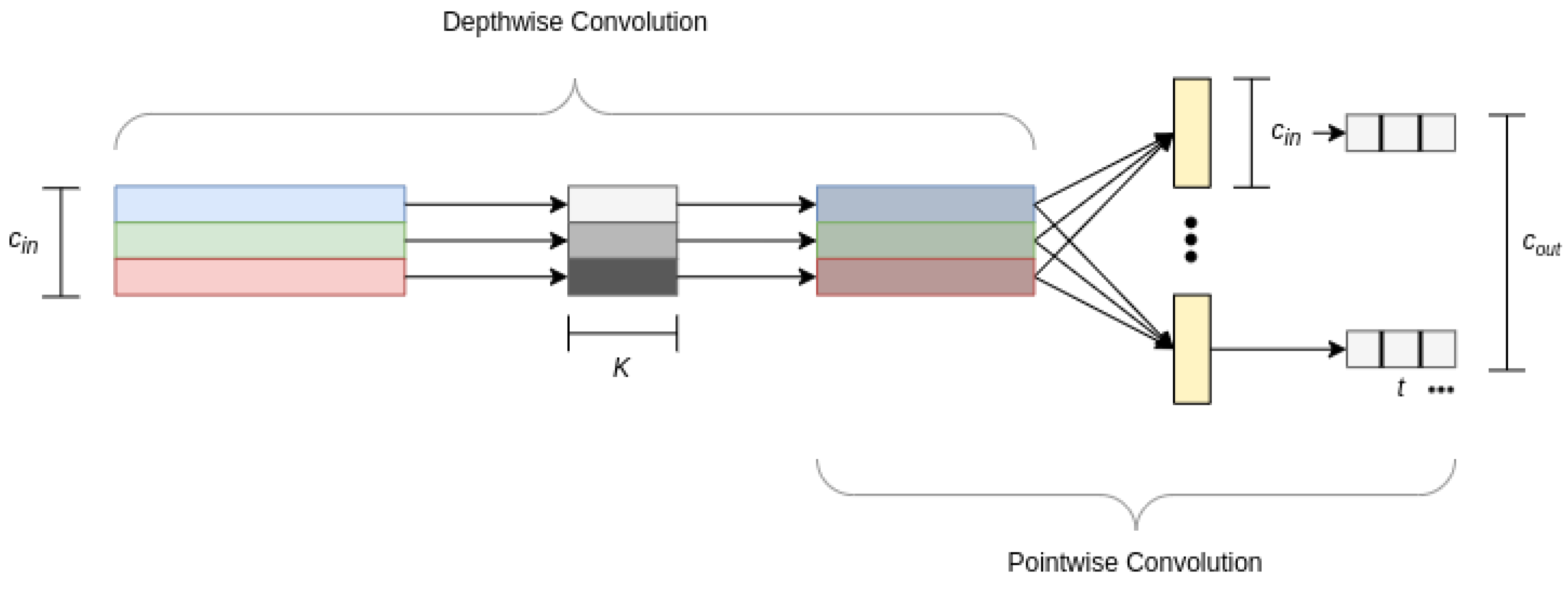
4.3. Model Architecture
4.4. Data Pre-Processing
5. Experiments and Results
5.1. Hardware Infrastructure
- GPUS: 8×NVIDIA A100 40 GB Tensor Core GPUs;
- GPU Memory: 320 GB total;
- CPU: Dual AMD Rome 7742, 128 cores total;
- Networking (clustering): 8 × Single-Port NVIDIA ConnectX-6 VPI 200 Gb/s InfiniBand;
- Networking (storage): 1 × Dual-Port NVIDIA ConnectX-6 VPI 200 Gb/s InfiniBand.
5.2. Performance Metric
5.3. Experiments and Results
5.3.1. Models from Scratch
5.3.2. Transfer Learning
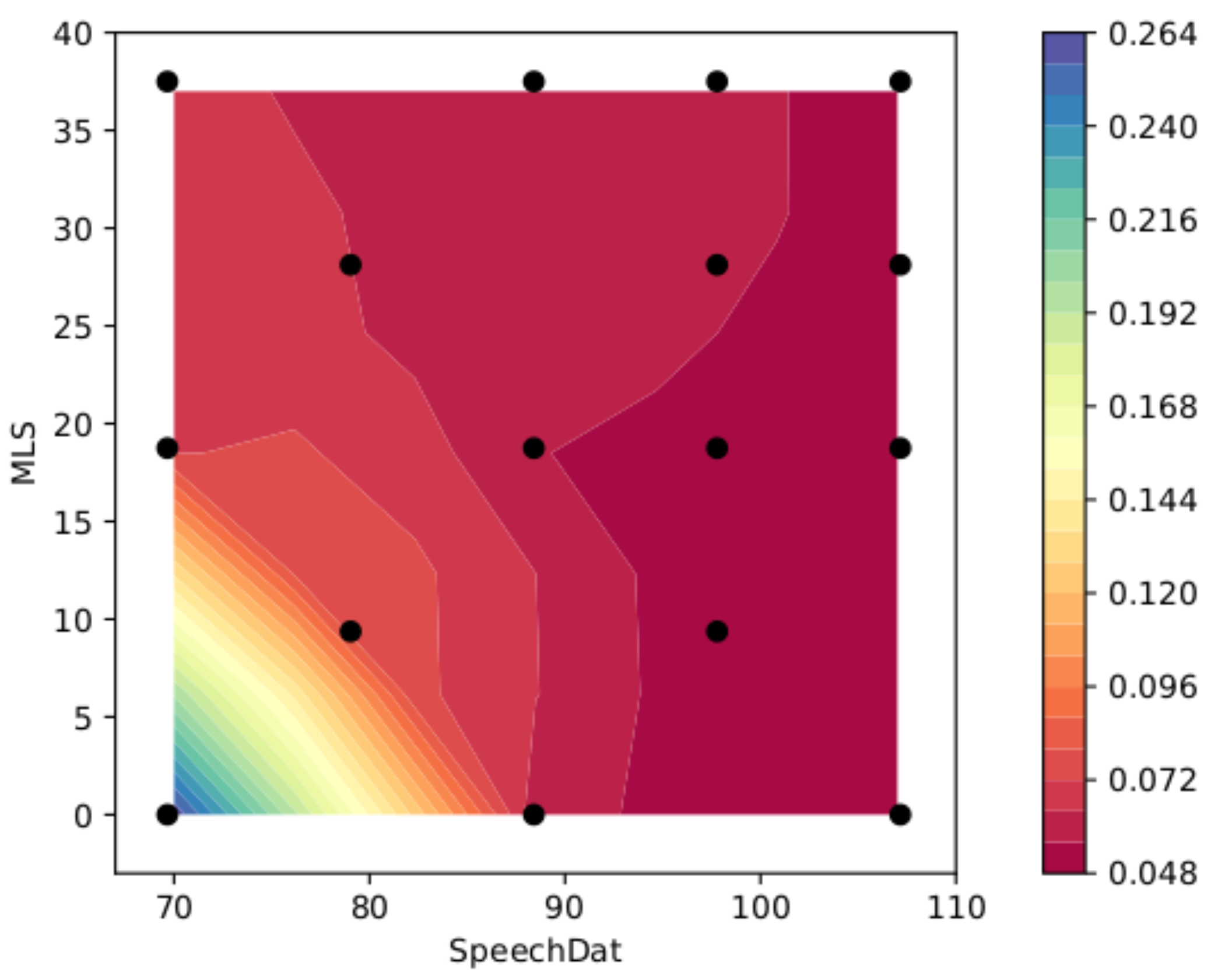
5.4. Domain Adaptation
6. Discussion
- The amount of data used during the training phase strongly impacts the model’s performance; transfer learning improves the WER performance from 0.1945 to 0.0557.
- It has been found that pre-trained models successfully adapt to new data by moving away from the data they were originally trained on.
- Using smaller subsets, i.e., MLS subsets, the best results were achieved when using combinations with the largest subset (“BR”).
- Models yielded the best results when developed with the largest subsets available, i.e., SpeechDat subsets.
7. Conclusions
- Data quantity is essential for building deep neural models, either from scratch or using transfer learning.
- The larger the amount of data from a domain used in the training or transfer process, the better the performance over the test set from the same domain.
- Data quality also plays an important role in the model’s performance, since the dataset with better data quality (the SpeechDat dataset, as defined in Definition 2) yields the best performance.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ruan, S.; Wobbrock, J.O.; Liou, K.; Ng, A.; Landay, J. Speech Is 3x Faster than Typing for English and Mandarin Text Entry on Mobile Devices. arXiv 2016, arXiv:1608.07323. [Google Scholar]
- Amigo, J.M. Data Mining, Machine Learning, Deep Learning, Chemometrics Definitions, Common Points and Trends (Spoiler Alert: VALIDATE your models!). Braz. J. Anal. Chem. 2021, 8, 45–61. [Google Scholar] [CrossRef]
- Eberhard, D.M.; Simons, G.F.; Fennig, C.D. Ethnologue: Languages of the World, 26th ed.; SIL International: Dallas, TX, USA, 2023. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Kuchaiev, O.; Li, J.; Nguyen, H.; Hrinchuk, O.; Leary, R.; Ginsburg, B.; Kriman, S.; Beliaev, S.; Lavrukhin, V.; Cook, J.; et al. NeMo: A toolkit for building AI applications using Neural Modules. arXiv 2019, arXiv:1909.09577. [Google Scholar] [CrossRef]
- Kriman, S.; Beliaev, S.; Ginsburg, B.; Huang, J.; Kuchaiev, O.; Lavrukhin, V.; Leary, R.; Li, J.; Zhang, Y. Quartznet: Deep Automatic Speech Recognition with 1D Time-Channel Separable Convolutions. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6124–6128. [Google Scholar] [CrossRef]
- Li, J. Recent Advances in End-to-End Automatic Speech Recognition. 2022. Available online: http://xxx.lanl.gov/abs/2111.01690 (accessed on 16 April 2023).
- Zhang, Y.; Pezeshki, M.; Brakel, P.; Zhang, S.; Bengio, C.L.Y.; Courville, A. Towards End-to-End Speech Recognition with Deep Convolutional Neural Networks. 2017. Available online: http://xxx.lanl.gov/abs/1701.02720 (accessed on 16 April 2023).
- Graves, A.; Jaitly, N. Towards End-To-End Speech Recognition with Recurrent Neural Networks. In Proceedings of Machine Learning Research, Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Xing, E.P., Jebara, T., Eds.; PMLR: Bejing, China, 2014; Volume 32, pp. 1764–1772. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3214–3218. [Google Scholar] [CrossRef]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. 2022. Available online: http://xxx.lanl.gov/abs/2212.04356 (accessed on 16 April 2023).
- Li, J.; Lavrukhin, V.; Ginsburg, B.; Leary, R.; Kuchaiev, O.; Cohen, J.M.; Nguyen, H.; Gadde, R.T. Jasper: An End-to-End Convolutional Neural Acoustic Model. arXiv 2019, arXiv:1904.03288. [Google Scholar] [CrossRef]
- Buijs, R.; Koch, T.; Dugundji, E. Applying transfer learning and various ANN architectures to predict transportation mode choice in Amsterdam. Procedia Comput. Sci. 2021, 184, 532–540. [Google Scholar] [CrossRef]
- Xavier Sampaio, M.; Pires Magalhães, R.; Linhares Coelho da Silva, T.; Almada Cruz, L.; Romero de Vasconcelos, D.; Antônio Fernandes de Macêdo, J.; Gonçalves Fontenele Ferreira, M. Evaluation of Automatic Speech Recognition Systems. In Anais do XXXVI Simpósio Brasileiro de Bancos de Dados; Technical Report; SBC: Porto Alegre, Brazil, 2021. [Google Scholar]
- Dalmia, S.; Sanabria, R.; Metze, F.; Black, A.W. Sequence-based Multi-lingual Low Resource Speech Recognition. 2018. Available online: http://xxx.lanl.gov/abs/1802.07420 (accessed on 16 April 2023).
- Cho, J.; Baskar, M.K.; Li, R.; Wiesner, M.; Mallidi, S.; Yalta, N.; Karafiát, M.; Watanabe, S.; Hori, T. Multilingual Sequence-to-Sequence Speech Recognition: Architecture, Transfer Learning, and Language Modeling. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 521–527. [Google Scholar] [CrossRef]
- Pellegrini, T.; Hämäläinen, A.; de Mareüil, P.B.; Tjalve, M.; Trancoso, I.; Candeias, S.; Dias, M.S.; Braga, D. A corpus-based study of elderly and young speakers of European Portuguese: Acoustic correlates and their impact on speech recognition performance. In Proceedings of the Proc. Interspeech 2013, Lyon, France, 25–29 August 2013; pp. 852–856. [Google Scholar] [CrossRef]
- Hämäläinen, A.; Cho, H.; Candeias, S.; Pellegrini, T.; Abad, A.; Tjalve, M.; Trancoso, I.; Dias, M.S. Automatically Recognising European Portuguese Children’s Speech. In Computational Processing of the Portuguese Language. PROPOR 2014. Lecture Notes in Computer Science; Baptista, J., Mamede, N., Candeias, S., Paraboni, I., Pardo, T.A.S., Volpe Nunes, M.d.G., Eds.; Springer: Cham, Switzerland, 2014; pp. 1–11. [Google Scholar] [CrossRef]
- Meinedo, H.; Caseiro, D.; Neto, J.; Trancoso, I. AUDIMUS.MEDIA: A Broadcast News Speech Recognition System for the European Portuguese Language. In Proceedings of the Computational Processing of the Portuguese Language; Mamede, N.J., Trancoso, I., Baptista, J., das Graças Volpe Nunes, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 9–17. [Google Scholar] [CrossRef]
- Meinedo, H.; Abad, A.; Pellegrini, T.; Neto, J.; Trancoso, I. The L2F Broadcast News Speech Recognition System. In Proceedings of the Fala 2010 Conference, Vigo, Spain, 10–12 November 2010. [Google Scholar]
- Aguiar de Lima, T.; Da Costa-Abreu, M. A survey on automatic speech recognition systems for Portuguese language and its variations. Comput. Speech Lang. 2020, 62, 101055. [Google Scholar] [CrossRef]
- Gris, L.R.S.; Casanova, E.; Oliveira, F.S.d.; Soares, A.d.S.; Candido-Junior, A. Desenvolvimento de um modelo de reconhecimento de voz para o Português Brasileiro com poucos dados utilizando o Wav2vec 2.0. In Anais do Brazilian e-Science Workshop (BreSci); SBC: Porto Alegre, Brazil, 2021; pp. 129–136. [Google Scholar] [CrossRef]
- Stefanel Gris, L.R.; Casanova, E.; de Oliveira, F.S.; da Silva Soares, A.; Candido Junior, A. Brazilian Portuguese Speech Recognition Using Wav2vec 2.0. In Proceedings of the Computational Processing of the Portuguese Language; Pinheiro, V., Gamallo, P., Amaro, R., Scarton, C., Batista, F., Silva, D., Magro, C., Pinto, H., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 333–343. [Google Scholar] [CrossRef]
- Macedo Quintanilha, I. End-to-End Speech Recognition Applied to Brazilian Portuguese Using Deep Learning. Master’s Thesis, Universidade Federal do Rio de Janeiro, Rio de Janeiro, Brazil, 2017. [Google Scholar] [CrossRef]
- Quintanilha, I.M.; Netto, S.L.; Biscainho, L.W.P. An open-source end-to-end ASR system for Brazilian Portuguese using DNNs built from newly assembled corpora. J. Commun. Inf. Syst. 2020, 35, 230–242. [Google Scholar] [CrossRef]
- Amodei, D.; Anubhai, R.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Chen, J.; Chrzanowski, M.; Coates, A.; Diamos, G.; et al. Deep Speech 2: End-to-End Speech Recognition in English and Mandarin. In International Conference on Machine Learning; PMLR: London, UK, 2015; pp. 173–182. [Google Scholar] [CrossRef]
- Tejedor-García, C.; Escudero-Mancebo, D.; González-Ferreras, C.; Cámara-Arenas, E.; Cardeñoso-Payo, V. TipTopTalk! Mobile Application for Speech Training Using Minimal Pairs and Gamification. 2016. Available online: https://uvadoc.uva.es/handle/10324/27857 (accessed on 13 March 2023).
- Saon, G.; Kurata, G.; Sercu, T.; Audhkhasi, K.; Thomas, S.; Dimitriadis, D.; Cui, X.; Ramabhadran, B.; Picheny, M.; Lim, L.L.; et al. English Conversational Telephone Speech Recognition by Humans and Machines. arXiv 2017, arXiv:1703.02136. [Google Scholar] [CrossRef]
- Panayotov, V.; Chen, G.; Povey, D.; Khudanpur, S. Librispeech: An ASR corpus based on public domain audio books. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; pp. 5206–5210. [Google Scholar] [CrossRef]
- Pratap, V.; Xu, Q.; Sriram, A.; Synnaeve, G.; Collobert, R. MLS: A Large-Scale Multilingual Dataset for Speech Research. In Proceedings of the Interspeech 2020, Shanghai, China, 25–29 October 2020. [Google Scholar] [CrossRef]
- G.711 Standard; Pulse Code Modulation (PCM) of Voice Frequencies. International Telecommunication Union: Geneva, Switzerland, 1988.
- Mordido, G.; Van Keirsbilck, M.; Keller, A. Compressing 1D Time-Channel Separable Convolutions using Sparse Random Ternary Matrices. arXiv 2021, arXiv:2103.17142. [Google Scholar] [CrossRef]
- Guo, Y.; Li, Y.; Feris, R.; Wang, L.; Rosing, T. Depthwise Convolution is All You Need for Learning Multiple Visual Domains. arXiv 2019, arXiv:1902.00927. [Google Scholar] [CrossRef]
- Yoo, A.B.; Jette, M.A.; Grondona, M. SLURM: Simple Linux Utility for Resource Management. In Proceedings of the Job Scheduling Strategies for Parallel Processing; Feitelson, D., Rudolph, L., Schwiegelshohn, U., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 44–60. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Architecture | Train Hours |
|---|---|
| Facebook wav2vec 2.0 | 1041 |
| Google LAS | 2025 |
| Microsoft ASR System | 12,500 |
| Architecture | MCV WER | Voxfoge WER |
|---|---|---|
| Facebook wav2vec 2.0 | 12.29% | 11.44% |
| Google LAS | 12.58% | 10.49% |
| Microsoft ASR System | 9.56% | 7.25% |
| Region | Number of Speakers | Number of Speakers (%) |
|---|---|---|
| Entre-Douro-e-Minho | 1048 | 26 |
| Transmontano | 202 | 5 |
| Beira-Litoral | 537 | 13 |
| Beira-Alta | 227 | 6 |
| Beira-Baixa | 97 | 2 |
| Estremadura | 858 | 21 |
| Ribatejo | 151 | 4 |
| Alentejo | 325 | 8 |
| Algarve | 148 | 4 |
| Azores | 163 | 4 |
| Madeira | 95 | 2 |
| Portuguese-speaking countries | 116 | 3 |
| Other countries | 29 | 1 |
| Empty field | 31 | 1 |
| Age Groups | Male Speakers | Female Speakers | Percentage of Total |
|---|---|---|---|
| <16 | 93 | 148 | 6.0 |
| 16-30 | 581 | 823 | 34.9 |
| 31-45 | 742 | 790 | 38.0 |
| 46-60 | 376 | 335 | 17.7 |
| >60 | 69 | 70 | 3.4 |
| Quality Label | Hours |
|---|---|
| OK | 152.99 |
| NOISE | 30.82 |
| GARBAGE | 1.04 |
| OTHER | 0.34 |
| NO_PTO | 0.90 |
| TOTAL | 186.09 |
| Subset | MLS | SpeechDat |
|---|---|---|
| Train | 37,498 | 107,158 |
| Validation | 826 | 22,960 |
| Test | 906 | 22,961 |
| Train | Validation | Test | WER |
|---|---|---|---|
| PT | PT | PT | 0.9952 |
| BR | BR | BR | 0.8156 |
| BR | BR | PT | 0.8842 |
| PT + BR | PT + BR | PT | 0.8900 |
| PT + BR | PT + BR | BR | 0.8065 |
| Train | Validation | Test | WER |
|---|---|---|---|
| SpeechDat | SpeechDat | SpeechDat | 0.3035 |
| ENG | 0.9962 | ||
| PT + BR | 0.9173 |
| Train | Validation | Test | WER |
|---|---|---|---|
| SpeechDat | SpeechDat | SpeechDat | 0.1945 |
| ENG | 0.9924 | ||
| PT + BR | 0.9055 |
| Train/Validation | Transfer | Test | WER |
|---|---|---|---|
| Pre-trained ENG | PT | PT | 1.0164 |
| PT | BR | 0.9722 | |
| BR | PT | 0.7075 | |
| BR | BR | 0.5139 | |
| PT + BR | BR | 0.5025 | |
| PT + BR | PT + BR | 0.5083 | |
| SpeechDat 1 | SpeechDat | 0.1603 | |
| ENG | 1.0186 | ||
| PT + BR | 0.7912 | ||
| SpeechDat 2 | SpeechDat | 0.0557 | |
| ENG | 1.006 | ||
| PT + BR | 0.7680 |
| MIX ID | Transfer | Validation | ||
|---|---|---|---|---|
| MLS | SpeechDat | MLS | SpeechDat | |
| 0.00 | 0 | 107,158 | 0 | 22,960 |
| 0.25 | 9374 | 97,784 | 206 | 22,754 |
| 0.50 | 18,749 | 88,409 | 413 | 22,547 |
| 0.75 | 28,123 | 79,035 | 619 | 22,341 |
| 1.00 | 37,498 | 69,660 | 826 | 22,134 |
| MIX ID | Test Set | |||
|---|---|---|---|---|
| SpeechDat | ENG | MLS | SpeechDat + MLS | |
| 0.00 | 0.0513 | 1.0014 | 0.7682 | 0.1912 |
| 0.25 | 0.0586 | 0.9969 | 0.5665 | 0.2155 |
| 0.50 | 0.0581 | 1.0013 | 0.3918 | 0.1221 |
| 0.75 | 0.0667 | 0.9943 | 0.3574 | 0.1225 |
| 1.00 | 0.0735 | 0.9949 | 0.3306 | 0.1231 |
| Test Set | Instances |
|---|---|
| SpeechDat | 22,961 |
| ENG | 28,539 |
| MLS | 906 |
| SpeechDat + MLS | 23,867 |
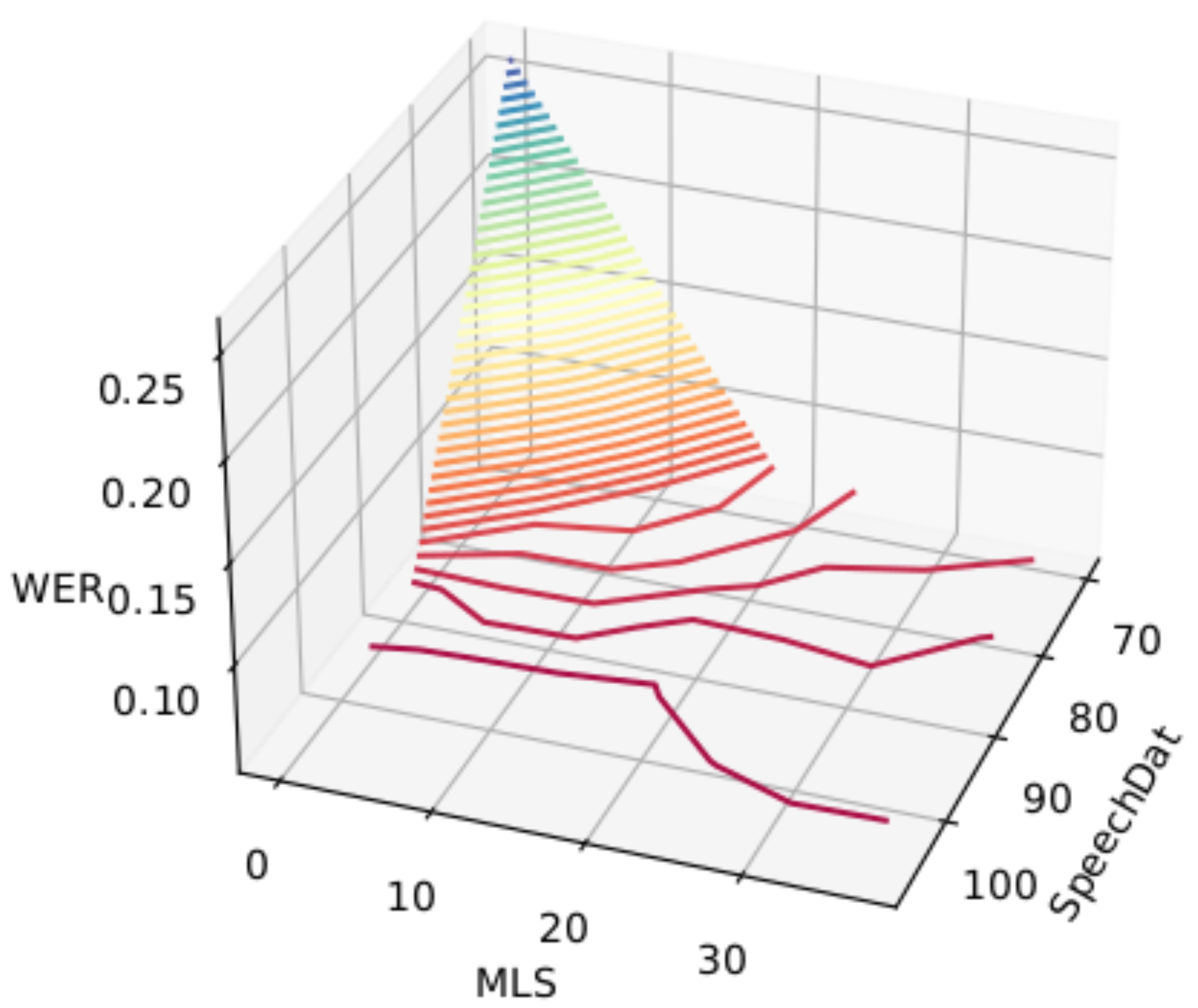
| MLS Instances | SpeechDat Instances | WER |
|---|---|---|
| 0 | 69,660 | 0.26626 |
| 88,409 | 0.05776 | |
| 107,158 | 0.05032 | |
| 9374 | 79,035 | 0.08266 |
| 97,784 | 0.05320 | |
| 18,749 | 69,660 | 0.07130 |
| 88,409 | 0.05602 | |
| 97,784 | 0.05408 | |
| 107,158 | 0.05398 | |
| 28,123 | 79,035 | 0.06460 |
| 97,784 | 0.05802 | |
| 107,158 | 0.05274 | |
| 37,498 | 69,660 | 0.06687 |
| 88,409 | 0.05607 | |
| 97,784 | 0.05828 | |
| 107,158 | 0.05233 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Medeiros, E.; Corado, L.; Rato, L.; Quaresma, P.; Salgueiro, P. Domain Adaptation Speech-to-Text for Low-Resource European Portuguese Using Deep Learning. Future Internet 2023, 15, 159. https://doi.org/10.3390/fi15050159
Medeiros E, Corado L, Rato L, Quaresma P, Salgueiro P. Domain Adaptation Speech-to-Text for Low-Resource European Portuguese Using Deep Learning. Future Internet. 2023; 15(5):159. https://doi.org/10.3390/fi15050159
Chicago/Turabian StyleMedeiros, Eduardo, Leonel Corado, Luís Rato, Paulo Quaresma, and Pedro Salgueiro. 2023. "Domain Adaptation Speech-to-Text for Low-Resource European Portuguese Using Deep Learning" Future Internet 15, no. 5: 159. https://doi.org/10.3390/fi15050159
APA StyleMedeiros, E., Corado, L., Rato, L., Quaresma, P., & Salgueiro, P. (2023). Domain Adaptation Speech-to-Text for Low-Resource European Portuguese Using Deep Learning. Future Internet, 15(5), 159. https://doi.org/10.3390/fi15050159