
A Review on Deep-Learning-Based Cyberbullying Detection

 ,
, 
 ,
,  and
and
Abstract
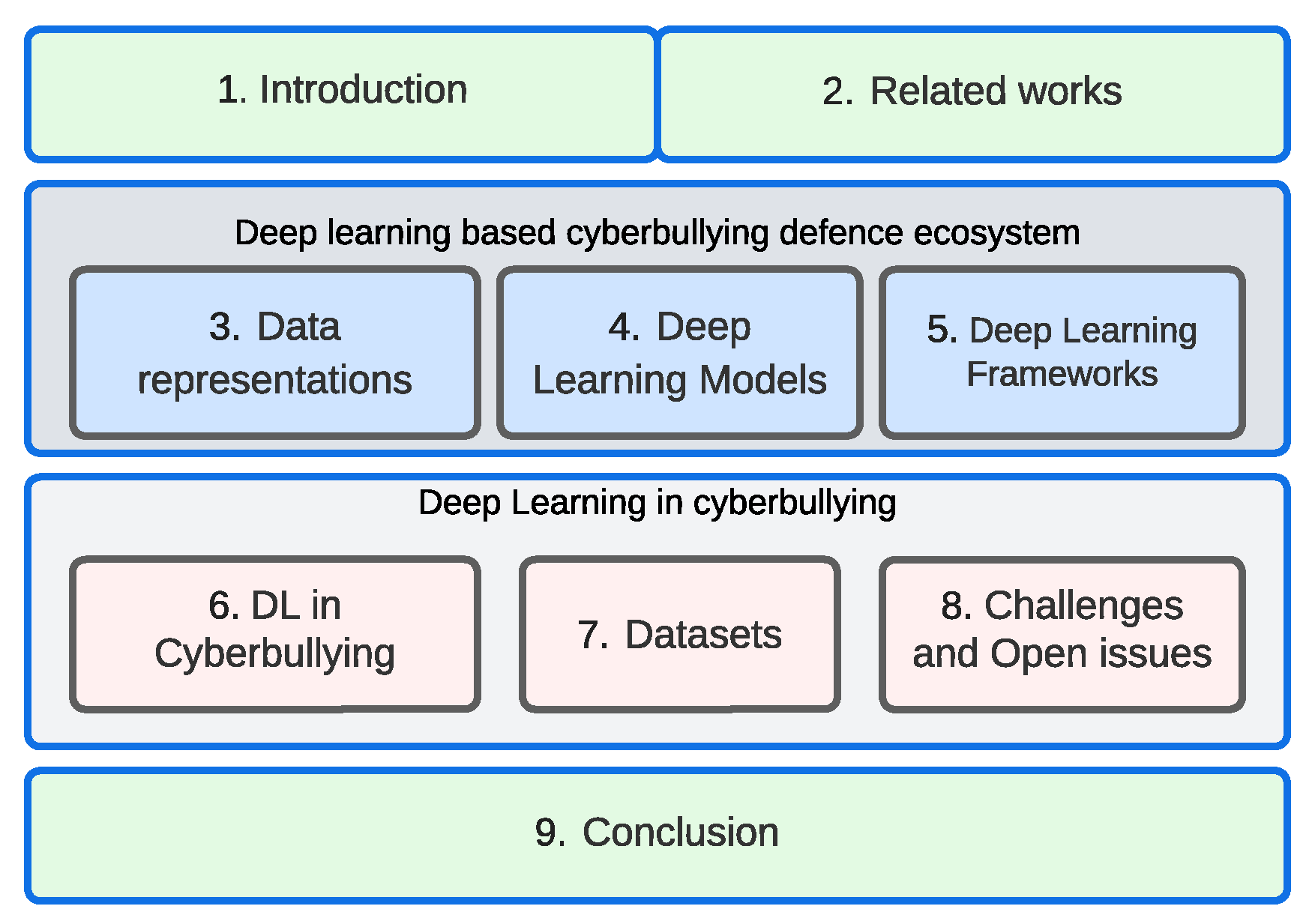
:1. Introduction
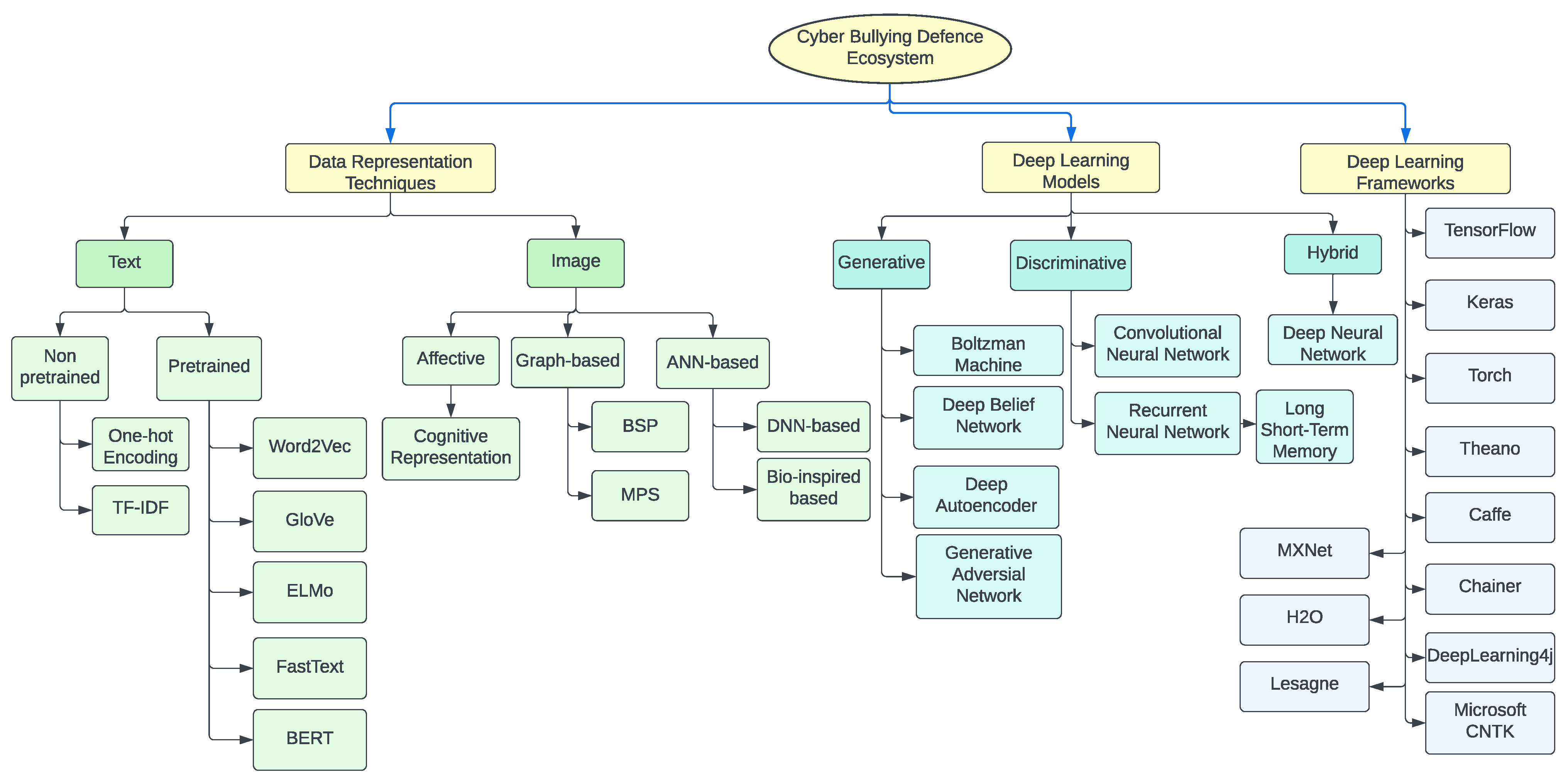
- We present a DL-based cyberbullying defense ecosystem with the help of a taxonomy. We also discuss data representation, models and frameworks for DL techniques.
- We compare several RNN, CNN, attention, and their fusion-based cyberbullying detection studies in the existing literature.
- We analyze several text and image datasets extracted from social media and virtual platforms related to cyberbullying detection.
- We identify the challenges and open issues related to cyberbullying.
2. Related Works
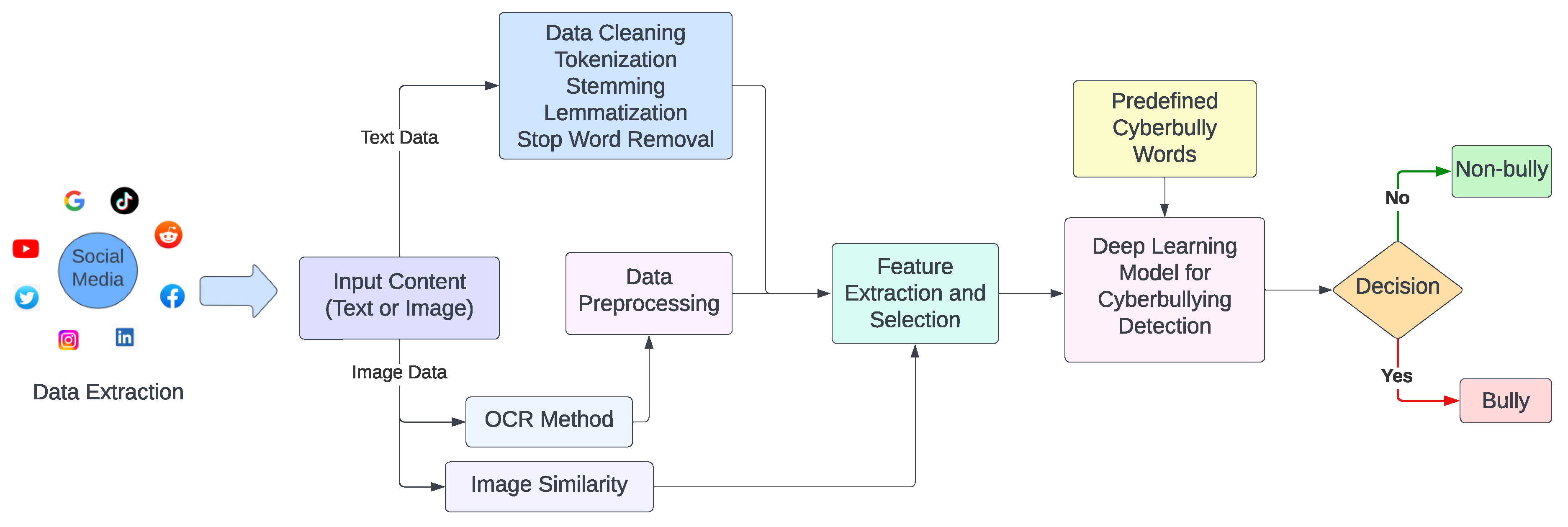
3. Methodology
4. Data Representation Techniques
4.1. Text Data Representation
4.1.1. One-Hot Encoding
4.1.2. TF-IDF
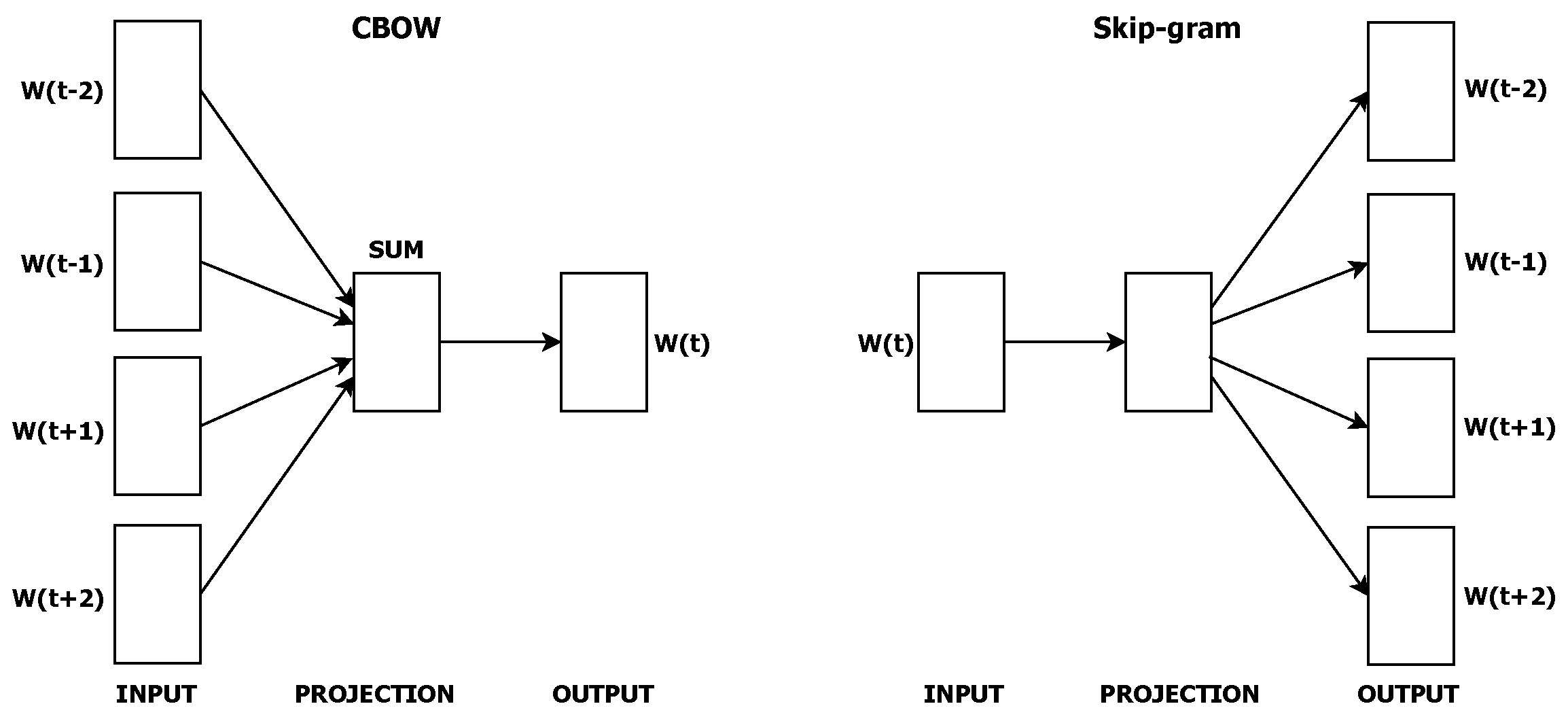
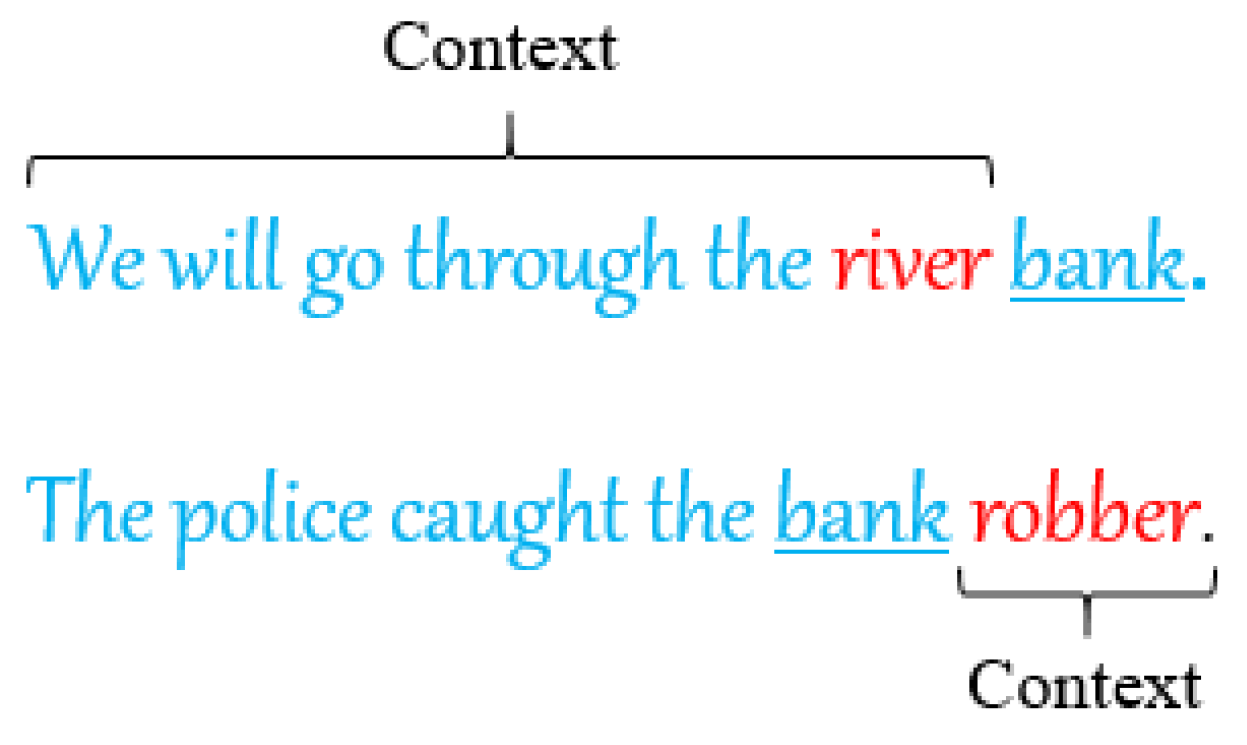
4.1.3. Word2Vec
4.1.4. GloVe
4.1.5. ELMo
4.1.6. FastText
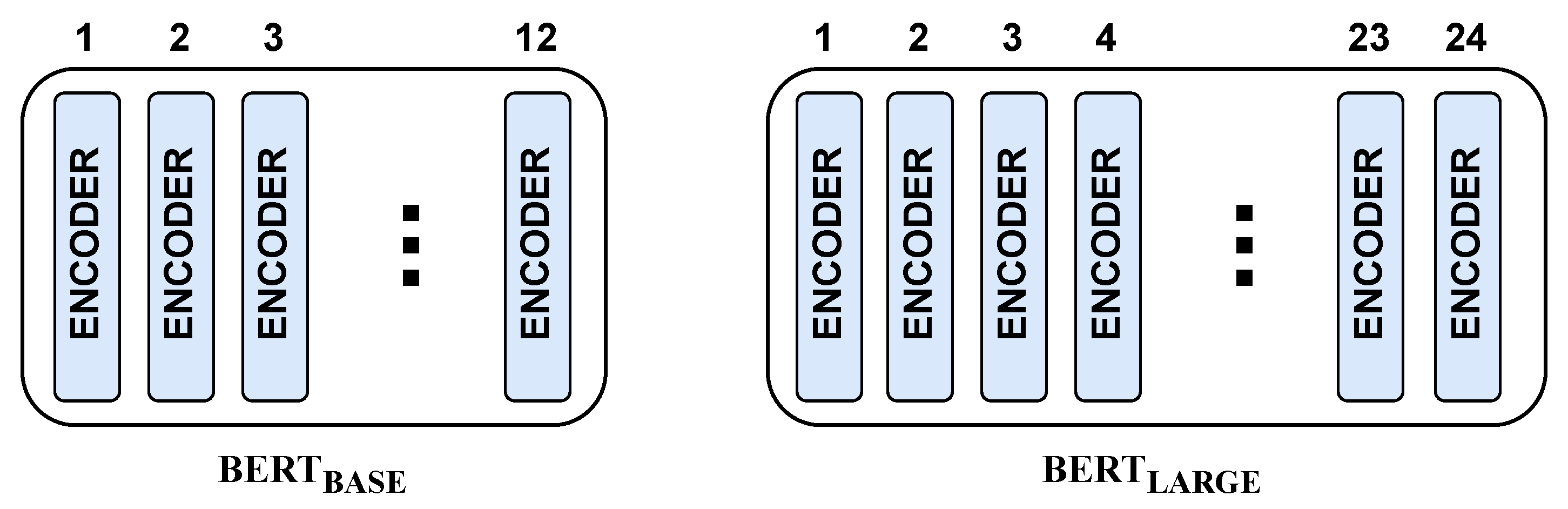
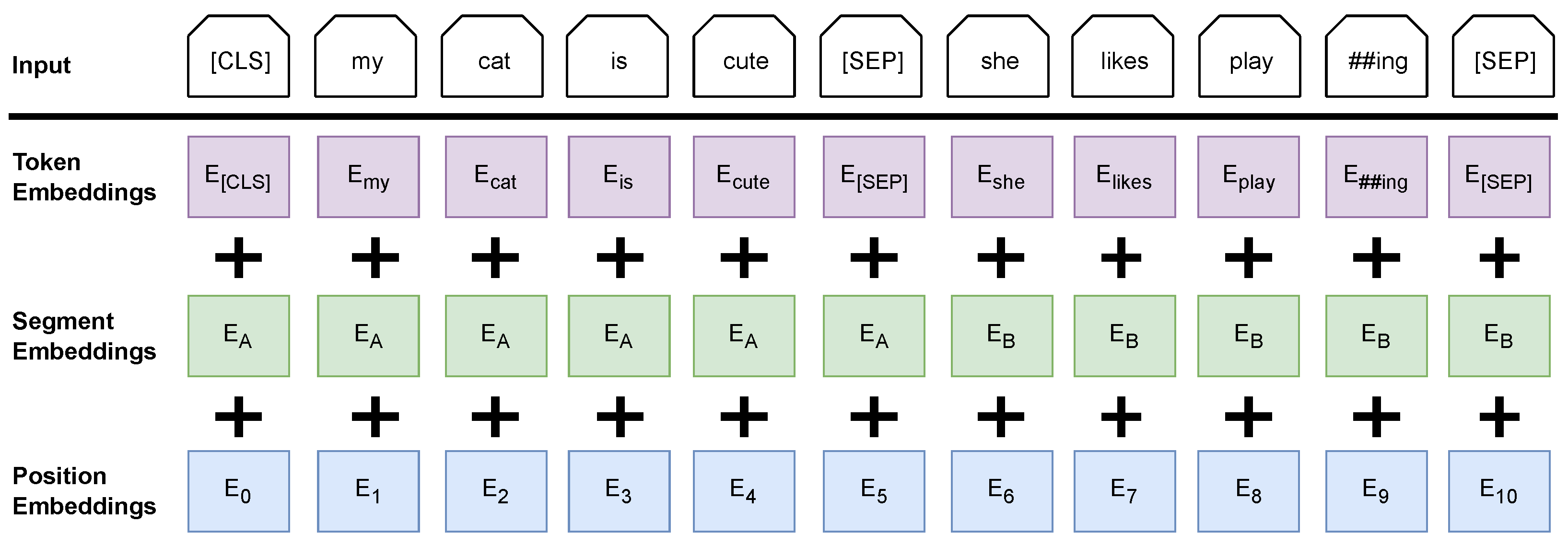
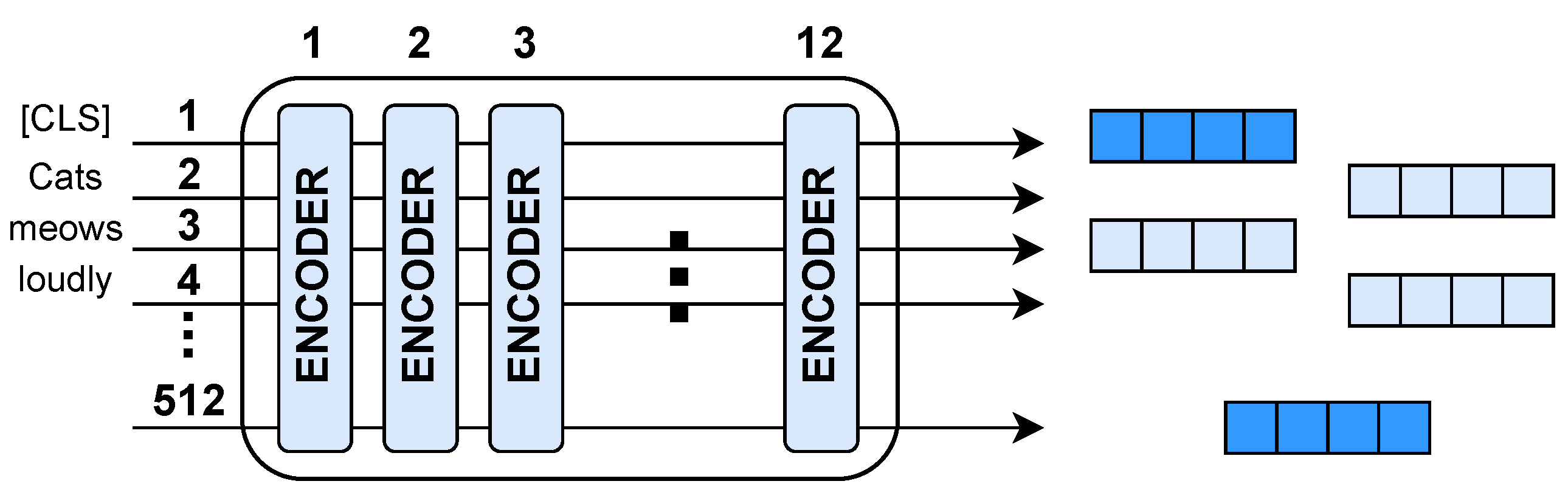
4.1.7. BERT
4.1.8. Efficacy of Various Embeddings for Detecting Cyberbullying
4.2. Image Data Representation
4.2.1. Cognitive Image Representation
4.2.2. BSP Representation
4.2.3. Bio-Inspired Model Representation
4.2.4. MPS Representation
4.2.5. Deep Neural Networks-based Image Representation [83]
4.2.6. Optical Character Recognition (OCR)
5. Deep-Learning-Based Models
5.1. Deep Neural Network (DNN)
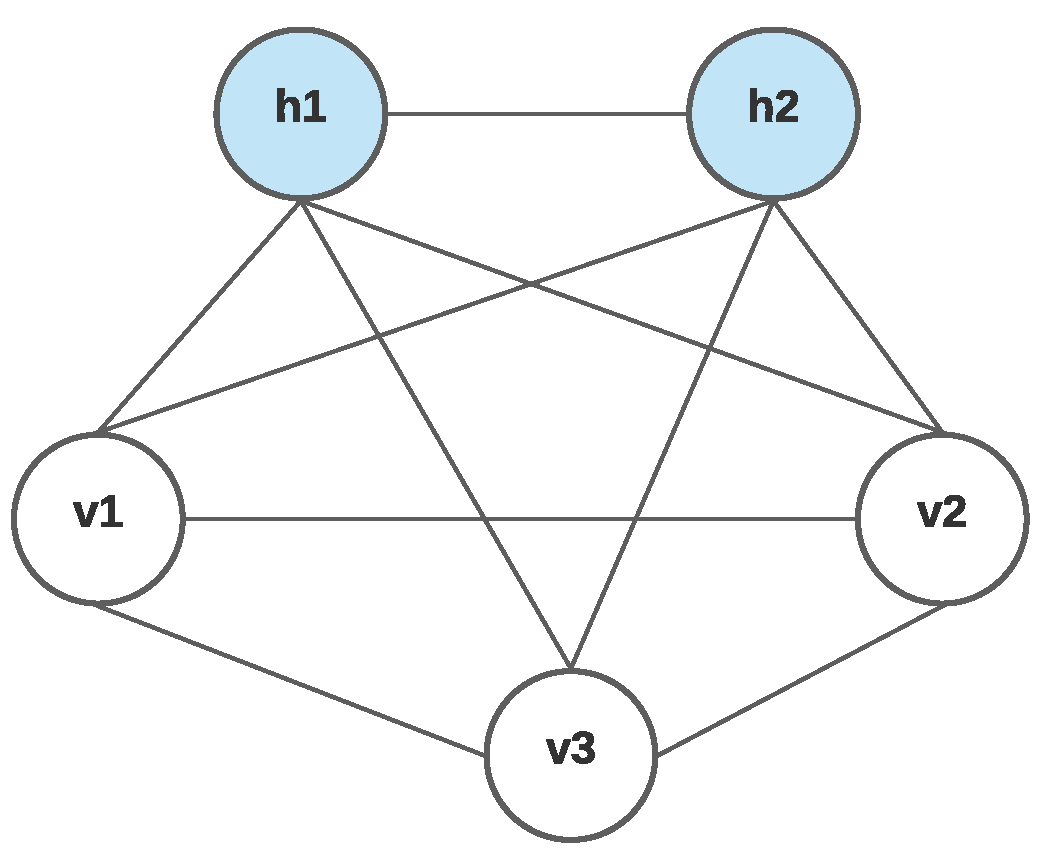
5.2. Boltzmann Machines (BMs)
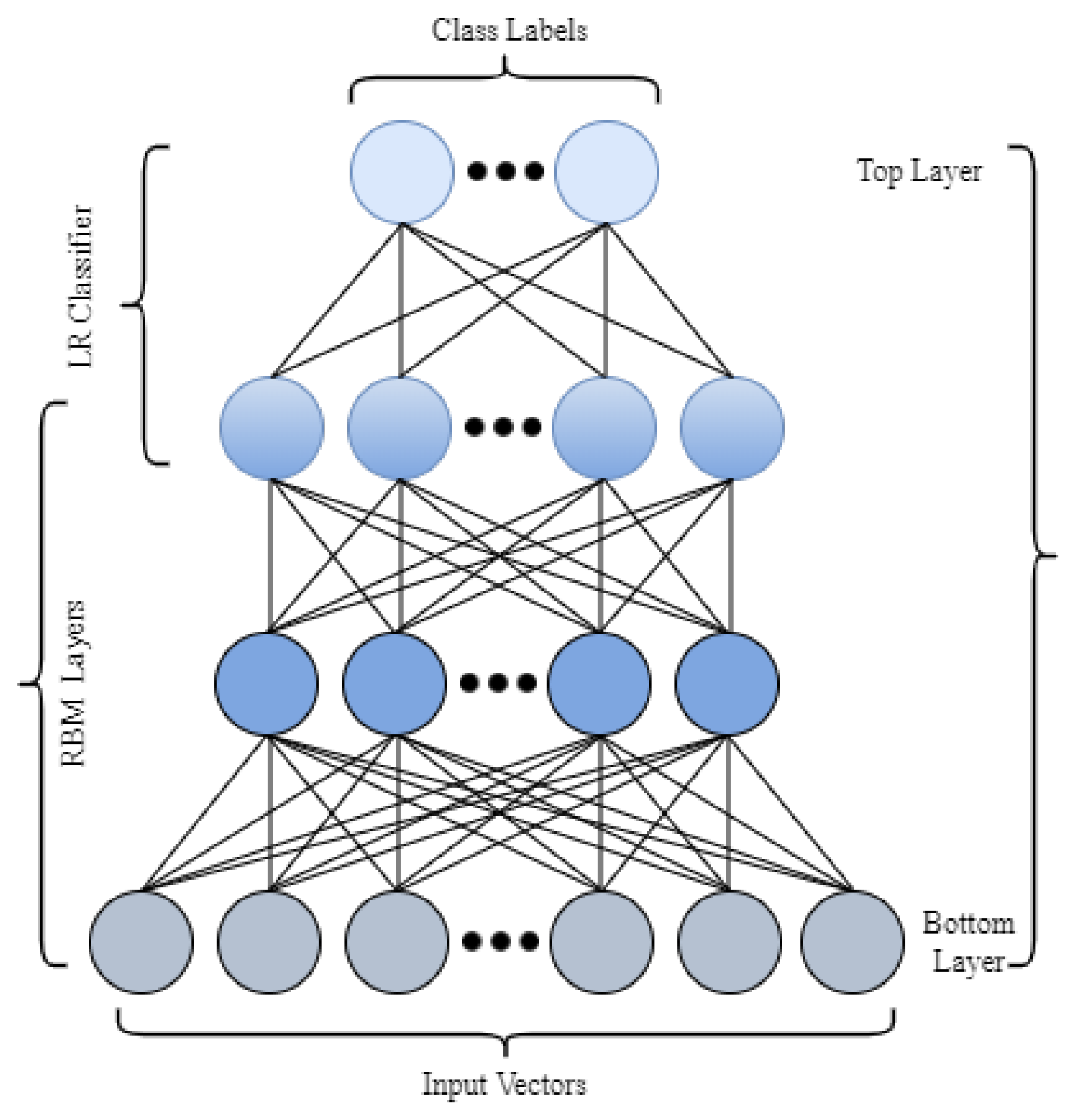
5.3. Deep Belief Network (DBN)
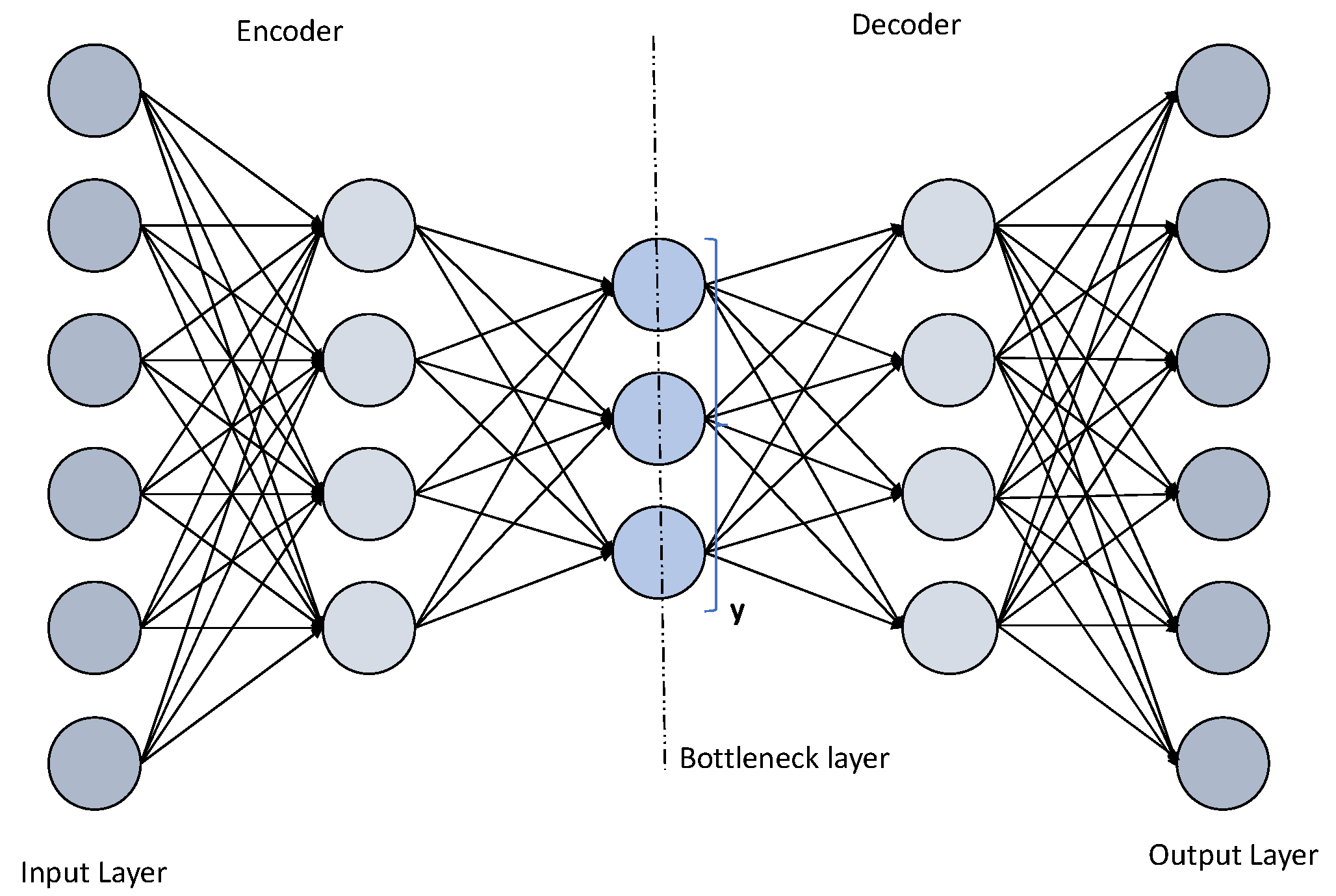
5.4. Deep Autoencoder (DAE)
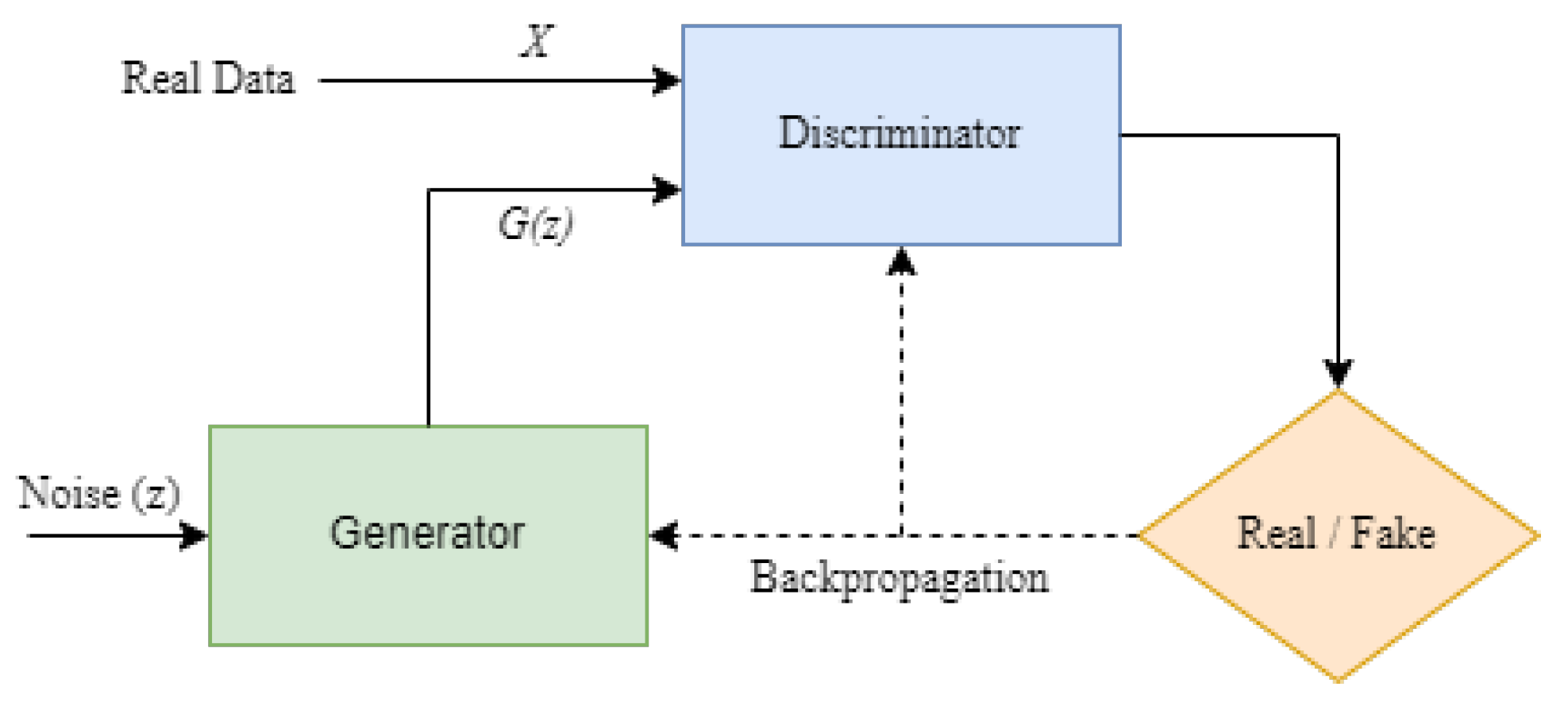
5.5. Generative Adversarial Network (GAN)
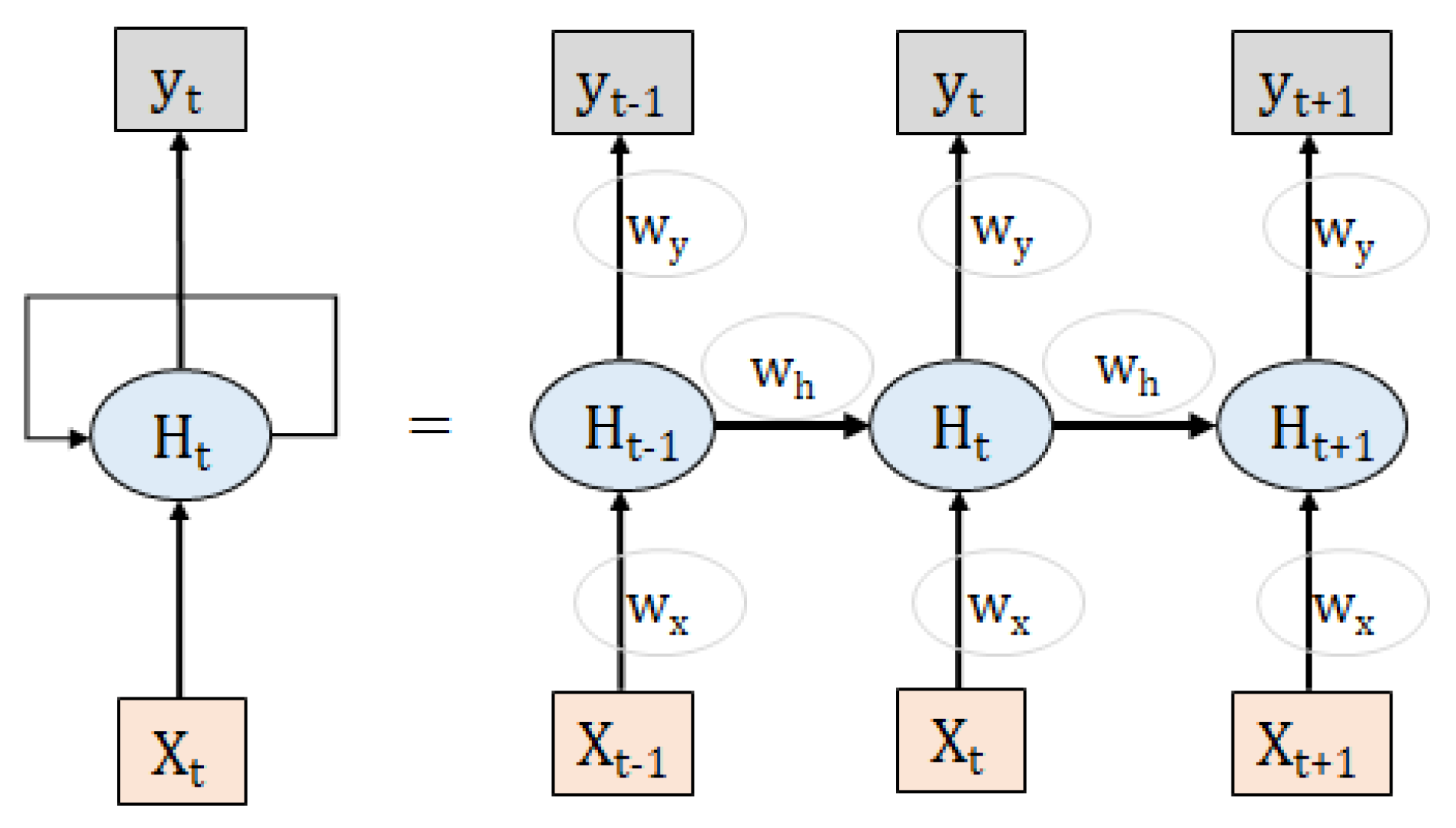
5.6. Recurrent Neural Network (RNN)
- 1.
- The training of an RNN is very difficult.
- 2.
- It cannot process with a very long sequence of sentences.
- 3.
- RNN does not support long-term memory storage.
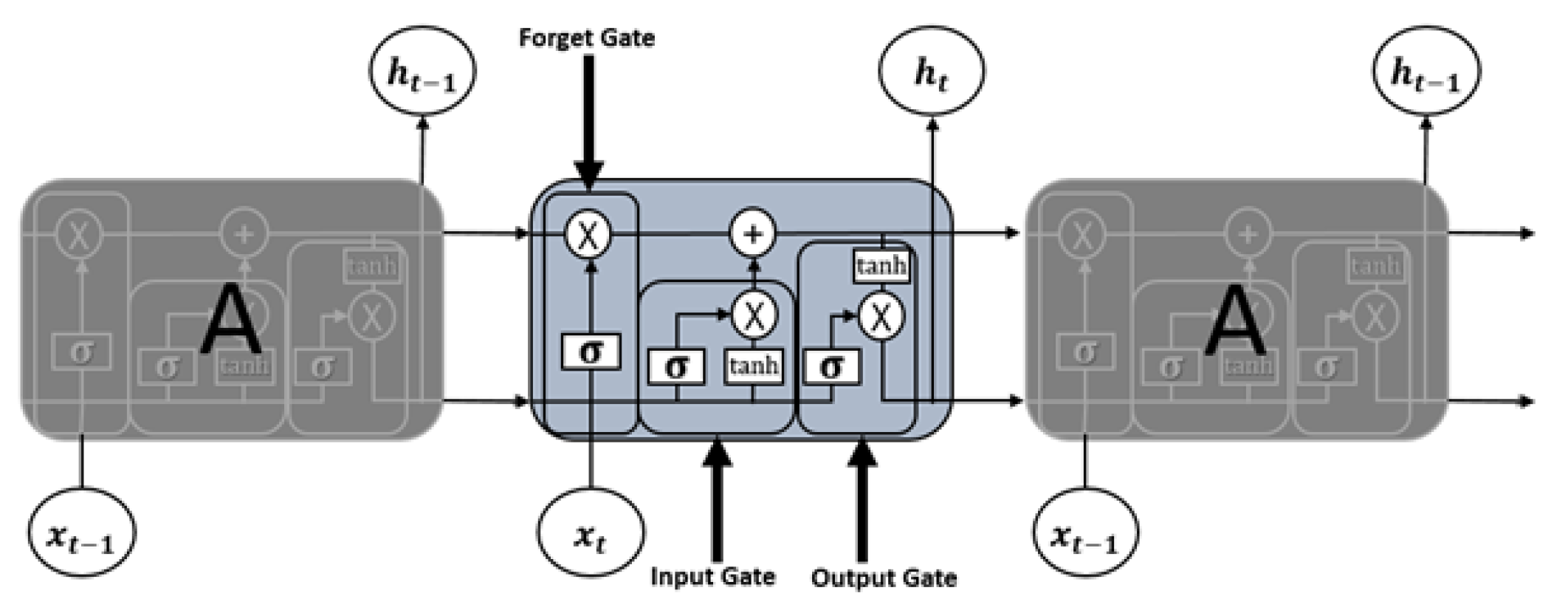
5.7. Long Short-Term Memory
- 1.
- Forget Gate “f”;
- 2.
- Cell State “C”;
- 3.
- Input Gate “i”;
- 4.
- Output Gate “o”;
- 5.
- Hidden state “h”;
- 6.
- Memory state “C”.
- —element wise multiplication;
- —element wise addition;
5.8. Convolutional Neural Network (CNN)
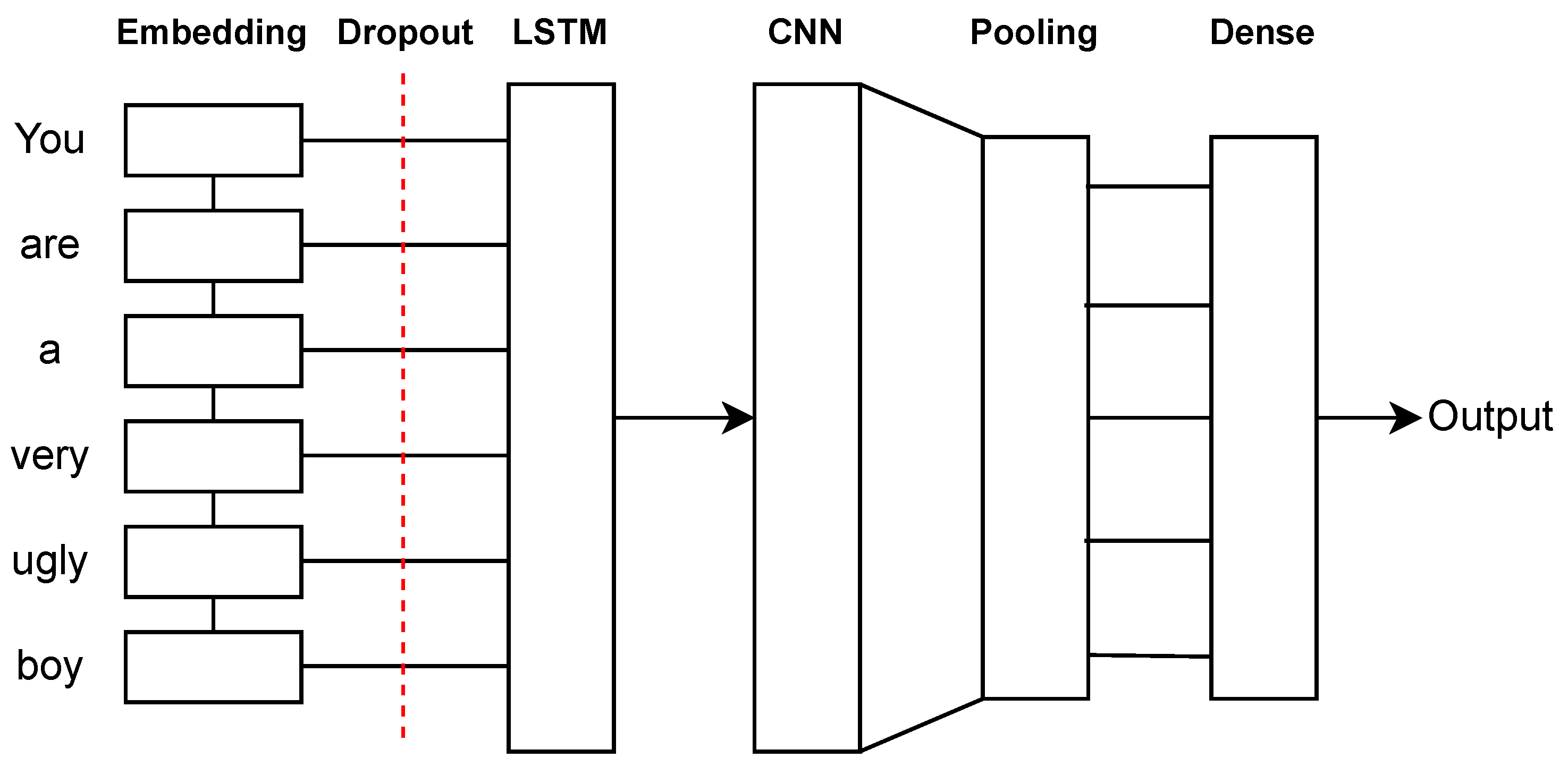
5.9. Hybrid Models (LSTM-CNN, CNN-LSTM)
5.10. Attention-Based Model
5.10.1. Transformers
5.10.2. BERT (Bidirectional Encoder Representations from Transformers)
5.10.3. Hierarchical Attention Networks (HAN)
5.10.4. Convolutional Neural Networks with Attention (CNN-Att)
5.10.5. Long Short-Term Memory Networks with Attention (LSTM-Att)
5.10.6. Gated Recurrent Units with Attention (GRU-Att)

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DL Models | Used in Cyberbullying Applications | Area of Applications | Limitations |
|---|---|---|---|
| Deep Neural Network (DNN) [92] | Chats and Tweets [14], Social networks’ text and image [128] | Speech Recognition, Image recognition and the natural language processing | Requires large amount of data, expensive to train, and issues of overfitting |
| Boltzmann Machines (BMs) [39] | Offline content [129], Image content [130], Arabic content [74] | Emotion recognition from thermal images, estimation of music similarity, extracting the structure of explored data | Training is challenging, and weight adjustment is hard |
| Deep Belief Networks (DBN) [40] | Arabic content [74], Social media text [131], Social media image [132] | Image classification, natural language understanding, speech recognition to audio classification | Expensive to train because of the complex data models, huge data is required, and needs classifiers to grasp the output |
| Deep Autoencoder (DAE) [41] | Chats and Tweets [14], Social media content [73] | Image search and data compression, dimensionality reduction, image denoising | The bottleneck layer is too narrow, lossy, and requires large amount of data |
| Generative Adversarial Networks (GAN) [42] | Web-application for detecting cyberbullying [133] | Improve astronomical images, gravitational lens simulation for dark matter exploration, excellent low resolution, generate realistic images and cartoon characters | Non-convergence, mode collapse, and diminished gradient |
| Recurrent Neural Networks (RNN) [44] | Social Commentary [21], Cyberbert: Bert for cyber- bullying identification [22], Identification and classification from social media [134] | Image captioning, time-series analysis, natural language processing, handwriting recognition, and machine translation | The gradation disappears and the problem explodes, difficult to train, and unable to handle very long sequences when tanh or ReLU is used as the activation function |
| Long Short-Term Memory (LSTM) [109] | Social media content [7,21,68], Wikipedia, Twitter, Formspring and YouTube [25], CyberBERT [22], Bangla text [18], Indonesian language [64], Twitter [2,63] | Time-series prediction, speech recognition, music composition, and pharmaceutical development | Training takes time, training requires more memory, easy to overfit, and Dropouts are much more difficult to implement in LSTMs |
| Bidirectional LSTM (Bi-LSTM) | Social media content [6,7,21,68,134], Visual contents [6], Wikipedia, Twitter, Formspring and YouTube [25], CyberBERT [22], Bangla text [18], Indonesian language [64], Text and emoji data [135], Facebook [136], Twitter[2,136] | Text classification, speech recognition, and forecasting models | Costly as double LSTM cells are used, takes longer to train, and easy to overfit |
| Convolutional Neural Networks (CNN) [43] | Social media content [5,6,7,21,68,115,134], Visual contents [6], Twitter [2,14,25,63,67,136,137], Formspring.me [25,137], Facebook [136], Chats [14], YouTube and Wikipedia [25] | Image processing, and object detection | Significantly slower due to an operation such as maxpooling, large datasets are required to process, and train neural networks [138] |
| Radial Basis Function Networks (RBFNs) [139] | Youtube content [140], Formspring.me, MySpace, and YouTube content [141] | Classification, regression and time-series prediction | Classification is slow because every node in the hidden layer needs to compute the RBF function |
| Multilayer Perceptrons (MLPs) | Text and emoji data [135] | Speech recognition, image-recognition, and machine translation | As it is fully connected, there are too many parameters, each node is connected to another node in a very dense network, which creates redundancy and inefficiency |
| Self-Organizing Maps (SOMs) [142] | Social media content [143] | Data visualization for high dimensional data | Requires sufficient neuron weight to cluster inputs [144] |
| Restricted Boltzmann Machines (RBMs) [96] | Turkish social media contents [145], Arabic content [74] | Dimensionality reduction, classification, regression, feature learning, topic modeling, and collaborative filtering | Training is more difficult because it is difficult to calculate the energy gradient function, the CD-k algorithm used in RBM is not as well known as the backpropagation algorithm, weight adjustment |
| Gated Recurrent Units (GRU) [146] | Social Commentary [21], Facebook and Twitter aggressive speech [115], Bangla text [18], Formspring.me, MySpace and YouTube content [135] | Sequence learning, Solved Vanishing–Exploding gradients problem | Slow convergence and low learning efficiency |
| Attention-based model [147] | Twitter bullied text identification [78], social media text analysis [112], online textual harassment detection [71], contextual textual bullies [148], Instagram bullied text identification [118], Abusive Bangla Comment detection [121], Trait-based bullying detection [114] | The method provides a simple and efficient architecture with a fixed length vector to pay attention of a sentence’s high-level meaning | The model requires more weight parameters, which results in a longer training time |
5.11. Performance Comparison of DL Models in Cyberbullying Detection
6. DL in Cyberbullying Detection
7. Deep Learning Frameworks
Applicability of Different DL Frameworks
8. Datasets for Experiments
9. Challenges, Open Issues, and Future Trends
9.1. Issues in DL
- Require a large amount of dataset: Large volumes of labeled data are required for DL. For example, the creation of self-driving cars involves millions of photos and hundreds of hours of video [198]. It is commonly known that data preparation consumes 80–90% of the time spent on ML development. Furthermore, even the strongest DL algorithms will struggle to function without good data and present weak performance to handle biased and unclean data during model training [199].
- High computational power: DL takes a lot of computational power. The parallel design of high-performance GPUs is ideal for DL. When used in conjunction with clusters or cloud computing, this allows development teams to cut DL network time for training from weeks to hours or less [198].
- Reasoning of prediction unexplainable: DL result prediction follows the Black-Box testing approach. Thus, it is not capable of making any explainable predictions. Since DL’s hidden weight and activation are non-interpretable, its predictions are considered as non-explainable [200].
- Security issue: Preventing the DL models from security attacks is the biggest challenge nowadays. Based on the occurring time, there are two types of security attacks. One is poisoning attack, which occurs during the training period, and another one is evasion attack, which occurs during interference (after training). By corrupting the data with malicious examples, poisoning attacks compromise the training process. On the other hand, evasion attacks use adversarial examples to confuse the entire classification process [201].
- Models are not adaptive: In the present world, data are very dynamic. Data are changing due to various factors, which may be constantly changing, such as location, time, and many other factors. However, DL models are built using a defined set, which is called the training dataset. Later, the performance of the model is measured by the data, which also comes from the same distribution of the training data, and eventually, the model performs well. Later, the same model may start performing poorly due to the changing the characteristics of the data, which are not entirely different, but have some variations from the training data. This is difficult to manage in DL to retrain the old models.
9.2. Challenges in Cyberbullying detection
- Cultural diversity for cyberbullying: Language is one of the important parts of the culture of a nation. Since cyberbullying has become a common problem among different nations, we may not expect a good prediction model by using a dataset of one nation and testing over the dataset of another culturally varied nation.
- Language challenge: Capturing context and analyzing the sentiment from different types of sentences is a difficult task and challenging work for cyberbullying detection. For example, “The image that you have sent so irritated me and I would rather not contact with you any longer!” is not easy to detect as cyberbullying without investigating from a rationale factor, albeit that model shows negative sentiment [26].
- Dataset challenge: Retrieving data from social media is not an easy task, as it relates to private information. Moreover, social media sites do not share user data publicly. Due to these issues, it is hard to gather quality data from social sites, which causes the lack of quality data to improve learning. Another challenging task is to annotate or label the data because they require a domain expert to label the corpus [202].
- Data representation challenge: Setting up an effective cyberbullying-detection system is difficult due to the need for human interaction and the nature of cyberbullying. Furthermore, the nature of cyberbullying is challenging to identify in the cyberbullying detection problem. The vast majority of the exploratory works directly identified bullying words in social media. However, separating content-based features have their own difficulties. For the absence of appropriate information, the performance of the model might decay [203].
- Natural Language Processing (NLP) challenges: The biggest challenge in natural language processing is understanding the meaning of the text. The relevant task is to build the right vocabulary, link the various components of the vocabulary, establish context, and extract semantic meaning from the data [204]. Misspelling and ambiguous expressions are other challenges that are very difficult to solve for the machine.
- Reusability of pre-trained model for sentiment analysis and cyberbullying: Although cyberbullying detection and sentiment analysis are related tasks, these two tasks have significant differences from each other; therefore, the pre-trained model of one task is likely to be difficult to use to predict another task. Sentiment analysis involves determining the overall emotional tone of a text, where the sentence is positive, negative, or neutral. On the contrary, cyberbullying detection involves identifying specific patterns of harmful words.Yet, there are some sentiment analysis approaches that can be used to identify cyberbullying. Atoum et al. [205] proposed an approach for detecting cyberbullying using sentiment analysis techniques. Nahar et al. [206] presented a novel method for identifying online bullying on social media sites from sentiment analysis. Dani et al. [207] presented a novel framework for supervised learning that uses sentiment analysis to identify cyberbullying.Overall, while sentiment analysis models may be helpful for cyberbullying detection, they cannot be directly reused without significant modifications and additional training. Cyberbullying detection (i.e., yes/no classes) largely needs to identify negative words, which are used to harass a person, while sentiment analysis has three different classes (i.e., negative, positive, and neutral) where negative patterns are part of the problem. In this case, positive and neutral categories are also dominant class labels. Since the nature of the outputs is different in two different problems, we cannot completely reuse one pre-trained model for other cases.
9.3. Future Trends
- Multilingual and multimedia content: In current times, social media and other virtual platforms are widely used among different levels of users in terms of age group, culture, language, taste, education, etc. Since social media is a vital platform for propagating cyber harassment, users may use multilingual and multimedia content; therefore, we may put more attention on building efficient cyberbullying detection systems for multilingual and multimedia content.
- Cyberbullying detection-specific word embedding: In recent times, researchers are introducing different domain specific word-embedding techniques, because these platforms produce accurate results for relevant sets of vocabularies. For example, Med-BERT is used for health-domain-based BERT-aware embedding systems. In this connection, researchers may propose a specialized word-embedding system for cyberbullying detection problems.
- Cyberbullying detection in SMS and email: Users are concerned with combating cyberbullying problems, which largely propagate through social media platforms. However, future researchers may put more attention on investigating Short Message Service (SMS)- and email-based cyberbullying detection methods.
- Cyberbullying impact on mental health: Cyberbullying may leave a long-term impact on the mental status of an individual. Some may take a life-threatening step or commit self-injury to curb the severity of the harassment and take death for granted. Therefore, mental health researchers can consider this issue as a timely topic and introduce different methods to fight against cyber harassment.
- Use of cutting-edge deep learning: With the advancement of deep-learning-based methods, we may introduce more subtle and delicate techniques to detect cyberbullying problems. For example, stacked and multi-channel CNN or Bi-LSTM-based cyberbullying-based frameworks or their advanced version or hybridization of these models may produce more sophisticated solutions to counter the problems.
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Feinberg, T.; Robey, N. Cyberbullying. Educ. Dig. 2009, 74, 26. [Google Scholar]
- Marwa, T.; Salima, O.; Souham, M. Deep learning for online harassment detection in tweets. In Proceedings of the 2018 3rd International Conference on Pattern Analysis and Intelligent Systems (PAIS), Tebessa, Algeria, 24–25 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Nikolaou, D. Does cyberbullying impact youth suicidal behaviors? J. Health Econ. 2017, 56, 30–46. [Google Scholar] [CrossRef] [PubMed]
- Brailovskaia, J.; Teismann, T.; Margraf, J. Cyberbullying, positive mental health and suicide ideation/behavior. Psychiatry Res. 2018, 267, 240–242. [Google Scholar] [CrossRef] [PubMed]
- Lu, N.; Wu, G.; Zhang, Z.; Zheng, Y.; Ren, Y.; Choo, K.K.R. Cyberbullying detection in social media text based on character-level convolutional neural network with shortcuts. Concurr. Comput. Pract. Exp. 2020, 32, e5627. [Google Scholar] [CrossRef]
- Paul, S.; Saha, S.; Hasanuzzaman, M. Identification of cyberbullying: A deep learning based multimodal approach. Multimed. Tools Appl. 2020, 81, 26989–27008. [Google Scholar] [CrossRef]
- Buan, T.A.; Ramachandra, R. Automated cyberbullying detection in social media using an svm activated stacked convolution lstm network. In Proceedings of the 2020 the 4th International Conference on Compute and Data Analysis, Silicon Valley, CA, USA, 9–12 March 2020; pp. 170–174. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Caroppo, A.; Leone, A.; Siciliano, P. Comparison between deep learning models and traditional machine learning approaches for facial expression recognition in ageing adults. J. Comput. Sci. Technol. 2020, 35, 1127–1146. [Google Scholar] [CrossRef]
- Yilmaz, A.; Demircali, A.A.; Kocaman, S.; Uvet, H. Comparison of Deep Learning and Traditional Machine Learning Techniques for Classification of Pap Smear Images. arXiv 2020, arXiv:2009.06366. [Google Scholar]
- Finizola, J.S.; Targino, J.M.; Teodoro, F.G.S.; Moraes Lima, C.A.d. A comparative study between deep learning and traditional machine learning techniques for facial biometric recognition. In Proceedings of the Ibero-American Conference on Artificial Intelligence, Trujillo, Peru, 13–16 November 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 217–228. [Google Scholar]
- Banerjee, V.; Telavane, J.; Gaikwad, P.; Vartak, P. Detection of cyberbullying using Deep Neural Network. In Proceedings of the 2019 5th International Conference on Advanced Computing & Communication Systems (ICACCS), Coimbatore, India, 15–16 March 2019; IEEE: PIscataway, NJ, USA, 2019; pp. 604–607. [Google Scholar]
- Kamath, C.N.; Bukhari, S.S.; Dengel, A. Comparative study between traditional machine learning and deep learning approaches for text classification. In Proceedings of the ACM Symposium on Document Engineering 2018, Halifax, NS, Canada, 28–31 August 2018; pp. 1–11. [Google Scholar]
- Wang, P.; Fan, E.; Wang, P. Comparative analysis of image classification algorithms based on traditional machine learning and deep learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Naufal, M.F.; Kusuma, S.F.; Prayuska, Z.A.; Yoshua, A.A.; Lauwoto, Y.A.; Dinata, N.S.; Sugiarto, D. Comparative Analysis of Image Classification Algorithms for Face Mask Detection. J. Inf. Syst. Eng. Bus. Intell. 2021, 7, 56–66. [Google Scholar] [CrossRef]
- Ahmed, M.T.; Rahman, M.; Nur, S.; Islam, A.; Das, D. Deployment of machine learning and deep learning algorithms in detecting cyberbullying in bangla and romanized bangla text: A comparative study. In Proceedings of the 2021 International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 19–20 February 2021; IEEE: PIscataway, NJ, USA, 2021; pp. 1–10. [Google Scholar]
- Rezvani, N.; Beheshti, A.; Tabebordbar, A. Linking textual and contextual features for intelligent cyberbullying detection in social media. In Proceedings of the 18th International Conference on Advances in Mobile Computing & Multimedia, Chiang Mai, Thailand, 30 November–2 December 2020; pp. 3–10. [Google Scholar]
- Al-Ajlan, M.A.; Ykhlef, M. Deep learning algorithm for cyberbullying detection. Int. J. Adv. Comput. Sci. Appl 2018, 9, 199–205. [Google Scholar] [CrossRef]
- Iwendi, C.; Srivastava, G.; Khan, S.; Maddikunta, P.K.R. Cyberbullying detection solutions based on deep learning architectures. Multimed. Syst. 2020, 1–14. [Google Scholar] [CrossRef]
- Paul, S.; Saha, S. CyberBERT: BERT for cyberbullying identification. Multimed. Syst. 2022, 28, 1897–1904. [Google Scholar] [CrossRef]
- Akhter, M.P.; Jiangbin, Z.; Naqvi, I.R.; AbdelMajeed, M.; Zia, T. Abusive language detection from social media comments using conventional machine learning and deep learning approaches. Multimed. Syst. 2022, 28, 1925–1940. [Google Scholar] [CrossRef]
- Picon, A.; Alvarez-Gila, A.; Irusta, U.; Echazarra, J. Why deep learning performs better than classical machine learning? Dyna Ing. Ind. 2020, 95, 119–122. [Google Scholar] [CrossRef]
- Dadvar, M.; Eckert, K. Cyberbullying detection in social networks using deep learning based models; a reproducibility study. arXiv 2018, arXiv:1812.08046. [Google Scholar]
- Salawu, S.; He, Y.; Lumsden, J. Approaches to automated detection of cyberbullying: A survey. IEEE Trans. Affect. Comput. 2017, 11, 3–24. [Google Scholar] [CrossRef]
- Rosa, H.; Pereira, N.; Ribeiro, R.; Ferreira, P.C.; Carvalho, J.P.; Oliveira, S.; Coheur, L.; Paulino, P.; Simão, A.V.; Trancoso, I. Automatic cyberbullying detection: A systematic review. Comput. Hum. Behav. 2019, 93, 333–345. [Google Scholar] [CrossRef]
- Kim, S.; Razi, A.; Stringhini, G.; Wisniewski, P.J.; De Choudhury, M. A Human-Centered Systematic Literature Review of Cyberbullying Detection Algorithms. Proc. ACM Hum.-Comput. Interact. 2021, 5, 1–34. [Google Scholar] [CrossRef]
- Elsafoury, F.; Katsigiannis, S.; Pervez, Z.; Ramzan, N. When the Timeline Meets the Pipeline: A Survey on Automated Cyberbullying Detection. IEEE Access 2021, 9, 103541–103563. [Google Scholar] [CrossRef]
- Haidar, B.; Chamoun, M.; Yamout, F. Cyberbullying detection: A survey on multilingual techniques. In Proceedings of the 2016 European Modelling Symposium (EMS), Pisa, Italy, 28–30 November 2016; pp. 165–171. [Google Scholar]
- Al-Garadi, M.A.; Hussain, M.R.; Khan, N.; Murtaza, G.; Nweke, H.F.; Ali, I.; Mujtaba, G.; Chiroma, H.; Khattak, H.A.; Gani, A. Predicting Cyberbullying on Social Media in the Big Data Era Using Machine Learning Algorithms: Review of Literature and Open Challenges. IEEE Access 2019, 7, 70701–70718. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. Glove: Global vectors for word representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ramos, J. Using tf-idf to determine word relevance in document queries. In Proceedings of the First Instructional Conference on Machine Learning; Rutgers University: Piscataway, NJ, USA, 2003; Volume 242, pp. 29–48. [Google Scholar]
- Ackley, D.H.; Hinton, G.E.; Sejnowski, T.J. A learning algorithm for Boltzmann machines. Cogn. Sci. 1985, 9, 147–169. [Google Scholar] [CrossRef]
- Hinton, G.E. Deep belief networks. Scholarpedia 2009, 4, 5947. [Google Scholar] [CrossRef]
- Baldi, P. Autoencoders, unsupervised learning, and deep architectures. In Proceedings of the ICML Workshop on Unsupervised and Transfer Learning, Bellevue, WA, USA, 2 July 2011; pp. 37–49. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernockỳ, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Interspeech, Makuhari, Japan, 26–30 September 2010; Volume 2, pp. 1045–1048. [Google Scholar]
- Al-Harigy, L.M.; Al-Nuaim, H.A.; Moradpoor, N.; Tan, Z. Building toward Automated Cyberbullying Detection: A Comparative Analysis. Comput. Intell. Neurosci. 2022, 2022, 4794227. [Google Scholar] [CrossRef] [PubMed]
- Riadi, I.; Widiandana, P. Mobile Forensics for Cyberbullying Detection using Term Frequency-Inverse Document Frequency (TF-IDF). J. Eng. Sci. Technol. 2019, 5, 68–76. [Google Scholar] [CrossRef]
- Rahman, S.; Talukder, K.H.; Mithila, S.K. An Empirical Study to Detect Cyberbullying with TF-IDF and Machine Learning Algorithms. In Proceedings of the 2021 International Conference on Electronics, Communications and Information Technology (ICECIT), Khulna, Bangladesh, 14–16 September 2021; pp. 1–4. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Yani, M.A.A.; Maharani, W. Analyzing Cyberbullying Negative Content on Twitter Social Media with the RoBERTa Method. JINAV J. Inf. Vis. 2023, 4. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv 2019, arXiv:1909.11942. [Google Scholar]
- Tripathy, J.K.; Chakkaravarthy, S.S.; Satapathy, S.C.; Sahoo, M.; Vaidehi, V. ALBERT-based fine-tuning model for cyberbullying analysis. Multimed. Syst. 2022, 28, 1941–1949. [Google Scholar] [CrossRef]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. Electra: Pre-training text encoders as discriminators rather than generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Harbaoui, A.; Benaissa, A.R. Cost-Sensitive PLM-based Approach for Arabic and English Cyberbullying Classification. Available at Research Square. 2023. Available online: https://www.researchsquare.com/article/rs-2524732/v1 (accessed on 6 April 2023).
- Sokolová, Z.; Staš, J.; Juhár, J. Review of Recent Trends in the Detection of Hate Speech and Offensive Language on Social Media. Acta Electrotech. Inform. 2022, 22, 18–24. [Google Scholar]
- Warke, O.; Jose, J.M.; Breitsohl, J. Utilising Twitter Metadata for Hate Classification. In Proceedings of the Advances in Information Retrieval: 45th European Conference on Information Retrieval, ECIR 2023, Dublin, Ireland, 2–6 April 2023; Proceedings, Part II. Springer: Berlin/Heidelberg, Germany, 2023; pp. 676–684. [Google Scholar]
- Sun, Z.; Yu, H.; Song, X.; Liu, R.; Yang, Y.; Zhou, D. Mobilebert: A compact task-agnostic bert for resource-limited devices. arXiv 2020, arXiv:2004.02984. [Google Scholar]
- Mazari, A.C.; Boudoukhani, N.; Djeffal, A. BERT-based ensemble learning for multi-aspect hate speech detection. Clust. Comput. 2023, 1–15. [Google Scholar] [CrossRef]
- Coban, O.; Ozel, S.A.; Inan, A. Detection and cross-domain evaluation of cyberbullying in Facebook activity contents for Turkish. In ACM Transactions on Asian and Low-Resource Language Information Processing; Association for Computing Machinery: New York, NY, USA, 2023; Volume 22. [Google Scholar]
- Mozafari, M.; Farahbakhsh, R.; Crespi, N. A BERT-based transfer learning approach for hate speech detection in online social media. In Proceedings of the Complex Networks and Their Applications VIII: Volume 1 Proceedings of the Eighth International Conference on Complex Networks and Their Applications COMPLEX NETWORKS 2019, Lisbon, Portugal, 10–12 December 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 928–940. [Google Scholar]
- Feng, Z.; Su, J.; Cao, J. BHF: BERT-based Hierarchical Attention Fusion Network for Cyberbullying Remarks Detection. In Proceedings of the 2022 5th International Conference on Machine Learning and Natural Language Processing, Hangzhou, China, 23–25 September 2022; pp. 1–7. [Google Scholar]
- Ishaq, A.; Malik, K.M.; Zafar, A. Hatespeechbert: Retraining Bert for Automatic Hate Speechdetection. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4329716 (accessed on 5 April 2023).
- Gada, M.; Damania, K.; Sankhe, S. Cyberbullying Detection using LSTM-CNN architecture and its applications. In Proceedings of the 2021 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 27–29 January 2021; pp. 1–6. [Google Scholar]
- Anindyati, L.; Purwarianti, A.; Nursanti, A. Optimizing deep learning for detection cyberbullying text in indonesian language. In Proceedings of the 2019 International Conference of Advanced Informatics: Concepts, Theory and Applications (ICAICTA), Yogyakarta, Indonesia, 20–21 September 2019; pp. 1–5. [Google Scholar]
- Al-Hashedi, M.; Soon, L.K.; Goh, H.N. Cyberbullying detection using deep learning and word embeddings: An empirical study. In Proceedings of the 2019 2nd International Conference on Computational Intelligence and Intelligent Systems, Bangkok Thailand, 23–25 November 2019; pp. 17–21. [Google Scholar]
- Bu, S.J.; Cho, S.B. A hybrid deep learning system of CNN and LRCN to detect cyberbullying from SNS comments. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Oviedo, Spain, 20–22 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 561–572. [Google Scholar]
- Al-Ajlan, M.A.; Ykhlef, M. Optimized twitter cyberbullying detection based on deep learning. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–5. [Google Scholar]
- Agrawal, S.; Awekar, A. Deep learning for detecting cyberbullying across multiple social media platforms. In Proceedings of the European Conference on Information Retrieval, Grenoble, France, 26–29 March 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 141–153. [Google Scholar]
- Azumah, S.W.; Elsayed, N.; ElSayed, Z.; Ozer, M. Cyberbullying in Text Content Detection: An Analytical Review. Available online: https://arxiv.org/pdf/2303.10502.pdf (accessed on 5 April 2023).
- Bhatt, J. Using Hybrid Deep Learning and Word Embedding Based Approach for Advance Cyberbullying Detection. Ph.D Thesis, National College of Ireland, Dublin, Ireland, 2020. [Google Scholar]
- Kumar, A.; Sachdeva, N. A Bi-GRU with attention and CapsNet hybrid model for cyberbullying detection on social media. World Wide Web 2022, 25, 1537–1550. [Google Scholar] [CrossRef]
- Wang, K.; Cui, Y.; Hu, J.; Zhang, Y.; Zhao, W.; Feng, L. Cyberbullying detection, based on the fasttext and word similarity schemes. ACM Trans. Asian Low-Resour. Lang. Inf. Process. (TALLIP) 2020, 20, 1–15. [Google Scholar] [CrossRef]
- Yadav, J.; Kumar, D.; Chauhan, D. Cyberbullying detection using pre-trained BERT model. In Proceedings of the 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), Coimbatore, India, 2–4 July 2020; pp. 1096–1100. [Google Scholar]
- Haidar, B.; Chamoun, M.; Serhrouchni, A. Arabic cyberbullying detection: Using deep learning. In Proceedings of the 2018 7th International Conference on Computer and Communication Engineering (ICCCE), Kuala Lumpur, Malaysia, 19–20 September 2018; pp. 284–289. [Google Scholar]
- Aldhyani, T.H.; Al-Adhaileh, M.H.; Alsubari, S.N. Cyberbullying identification system based deep learning algorithms. Electronics 2022, 11, 3273. [Google Scholar] [CrossRef]
- Pericherla, S.; Ilavarasan, E. Performance analysis of word embeddings for cyberbullying detection. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Sanya, China, 12–14 November 2021; IOP Publishing: Bristol, UK, 2021; Volume 1085, p. 012008. [Google Scholar]
- Eronen, J.; Ptaszynski, M.; Masui, F. Comparing Performance of Different Linguistically Backed Word Embeddings for Cyberbullying Detection. arXiv 2022, arXiv:2206.01950. [Google Scholar]
- Alhloul, A.; Alam, A. Bullying Tweets Detection Using CNN-Attention. Int. J. Cybern. Inform. (IJCI) 2023, 12, 65–78. [Google Scholar] [CrossRef]
- Kountchev, R.; Rubin, S.; Milanova, M.; Todorov, V.; Kountcheva, R. Cognitive image representation based on spectrum pyramid decomposition. In Proceedings of the WSEAS International Conference on Mathematical Methods and Computational Techniques in Electrical Engineering (MMACTEE), Athens, Greece, 29–31 December 2008; pp. 230–235. [Google Scholar]
- Sudirman, S.; Qiu, G. Colour image representation using BSP Tree. Proc. CGIP 2000, 1–4. Available online: http://www.cs.nott.ac.uk/~pszqiu/Online/CGIP2000.pdf (accessed on 5 April 2023).
- Wei, H.; Zuo, Q.; Lang, B. A bio-inspired model for image representation and image analysis. In Proceedings of the 2011 IEEE 23rd International Conference on Tools with Artificial Intelligence, Boca Raton, FL, USA, 7–9 November 2011; pp. 409–413. [Google Scholar]
- Xue, X.; Wu, X. Directly operable image representation of multiscale primal sketch. IEEE Trans. Multimed. 2005, 7, 805–816. [Google Scholar]
- Gao, S.; Duan, L.; Tsang, I.W. DEFEATnet—A deep conventional image representation for image classification. IEEE Trans. Circuits Syst. Video Technol. 2015, 26, 494–505. [Google Scholar] [CrossRef]
- Mori, S.; Suen, C.Y.; Yamamoto, K. Historical review of OCR research and development. Proc. IEEE 1992, 80, 1029–1058. [Google Scholar] [CrossRef]
- Pradheep, T.; Sheeba, J.; Yogeshwaran, T.; Pradeep Devaneyan, S. Automatic Multi Model Cyber Bullying Detection from Social Networks. In Proceedings of the International Conference on Intelligent Computing Systems (ICICS 2017), Irbid, Jordan, 15–16 September 2017; Sona College of Technology: Tamil Nadu, Idia, 2017. [Google Scholar]
- Sheeba, J.; Devaneyan, S.P. Impulsive intermodal cyber bullying recognition from public nets. Int. J. Adv. Res. Comput. Sci. 2018, 9. [Google Scholar]
- Kumari, K.; Singh, J.P.; Dwivedi, Y.K.; Rana, N.P. toward Cyberbullying-free social media in smart cities: A unified multi-modal approach. Soft Comput. 2020, 24, 11059–11070. [Google Scholar] [CrossRef]
- Verge, T. Instagram’s Bullying Comment Filter Hides Mean Comments. 2018. Available online: https://www.theverge.com/2018/5/1/17307980/instagram-bullying-comment-filter-machine-learning (accessed on 8 March 2023).
- Facebook. Inside Feed: Fighting Abuse. 2018. Available online: https://about.fb.com/news/2018/05/inside-feed-fighting-abuse/ (accessed on 8 March 2023).
- Gao, X.; Han, Y.; Tang, Q.; Liu, Z.; Ma, J. Chinese cyberbullying detection with OCR and deep learning. J. Intell. Fuzzy Syst. 2021, 40, 4731–4743. [Google Scholar]
- Borah, N.; Borah, P. Detecting cyberbullying on social media using OCR and machine learning. In Proceedings of the 4th International Conference on Intelligent Computing and Control Systems (ICICCS 2020), Madurai, India, 13–15 May 2020; pp. 300–305. [Google Scholar]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Prechelt, L. Early stopping-but when? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Das, H.S.; Roy, P. A deep dive into deep learning techniques for solving spoken language identification problems. In Intelligent Speech Signal Processing; Elsevier: Amsterdam, The Netherlands, 2019; pp. 81–100. [Google Scholar]
- Hinton, G.E. A practical guide to training restricted Boltzmann machines. In Neural networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 599–619. [Google Scholar]
- Salakhutdinov, R.; Hinton, G. Deep Boltzmann Machines. In Proceedings of the Twelth International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; van Dyk, D., Welling, M., Eds.; Proceedings of Machine Learning Research. PMLR, Hilton Clearwater Beach Resort: Clearwater, FL, USA, 2009; Volume 5, pp. 448–455. [Google Scholar]
- Courville, A.; Bergstra, J.; Bengio, Y. A spike and slab restricted Boltzmann machine. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 11–13 April 2011; JMLR Workshop and Conference Proceedings. pp. 233–241. [Google Scholar]
- Hinton, G.E. Boltzmann machine. Scholarpedia 2007, 2, 1668. [Google Scholar] [CrossRef]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. Adv. Neural Inf. Process. Syst. 2006, 19. [Google Scholar]
- Li, C.; Wang, Y.; Zhang, X.; Gao, H.; Yang, Y.; Wang, J. Deep belief network for spectral–spatial classification of hyperspectral remote sensor data. Sensors 2019, 19, 204. [Google Scholar] [CrossRef]
- Salakhutdinov, R.; Hinton, G. Semantic hashing. Int. J. Approx. Reason. 2009, 50, 969–978. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef]
- Vachhani, B.; Bhat, C.; Das, B.; Kopparapu, S.K. Deep Autoencoder Based Speech Features for Improved Dysarthric Speech Recognition. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 1854–1858. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Makhzani, A.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, arXiv:1511.05644. [Google Scholar]
- Feng, J.; Feng, X.; Chen, J.; Cao, X.; Zhang, X.; Jiao, L.; Yu, T. Generative adversarial networks based on collaborative learning and attention mechanism for hyperspectral image classification. Remote Sens. 2020, 12, 1149. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Hopfield, J.J. Hopfield network. Scholarpedia 2007, 2, 1977. [Google Scholar] [CrossRef]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Rezvani, N.; Beheshti, A. toward Attention-Based Context-Boosted Cyberbullying Detection in social media. J. Data Intell. 2021, 2, 418–433. [Google Scholar] [CrossRef]
- Pericherla, S.; Ilavarasan, E. Transformer network-based word embeddings approach for autonomous cyberbullying detection. Int. J. Intell. Unmanned Syst. 2021; ahead-of-print. [Google Scholar]
- Ahmed, T.; Ivan, S.; Kabir, M.; Mahmud, H.; Hasan, K. Performance analysis of transformer-based architectures and their ensembles to detect trait-based cyberbullying. Soc. Netw. Anal. Min. 2022, 12, 99. [Google Scholar] [CrossRef]
- Alotaibi, M.; Alotaibi, B.; Razaque, A. A multichannel deep learning framework for cyberbullying detection on social media. Electronics 2021, 10, 2664. [Google Scholar] [CrossRef]
- Yafooz, W.M.; Al-Dhaqm, A.; Alsaeedi, A. Detecting Kids Cyberbullying Using Transfer Learning Approach: Transformer Fine-Tuning Models. In Kids Cybersecurity Using Computational Intelligence Techniques; Springer International Publishing: Berlin, Germany, 2023. [Google Scholar]
- Guo, X.; Anjum, U.; Zhan, J. Cyberbully Detection Using BERT with Augmented Texts. In Proceedings of the 2022 IEEE International Conference on Big Data (Big Data), Osaka, Japan, 17–20 December 2022; pp. 1246–1253. [Google Scholar]
- Cheng, L.; Guo, R.; Silva, Y.; Hall, D.; Liu, H. Hierarchical attention networks for cyberbullying detection on the instagram social network. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; pp. 235–243. [Google Scholar]
- Cheng, L.; Guo, R.; Silva, Y.N.; Hall, D.; Liu, H. Modeling temporal patterns of cyberbullying detection with hierarchical attention networks. ACM/IMS Trans. Data Sci. 2021, 2, 1–23. [Google Scholar] [CrossRef]
- Sreelakshmi, K.; Premjith, B.; Soman, K.P. Detection of Hate Speech Text in Hindi-English Code-mixed Data. Procedia Comput. Sci. 2020, 171, 737–744. [Google Scholar] [CrossRef]
- Aurpa, T.T.; Sadik, R.; Ahmed, M.S. Abusive Bangla comments detection on Facebook using transformer-based deep learning models. Soc. Netw. Anal. Min. 2022, 12, 24. [Google Scholar] [CrossRef]
- Khan, S.; Fazil, M.; Sejwal, V.K.; Alshara, M.A.; Alotaibi, R.M.; Kamal, A.; Baig, A.R. BiCHAT: BiLSTM with deep CNN and hierarchical attention for hate speech detection. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 4335–4344. [Google Scholar] [CrossRef]
- Fang, Y.; Yang, S.; Zhao, B.; Huang, C. Cyberbullying detection in social networks using Bi-gru with self-attention mechanism. Information 2021, 12, 171. [Google Scholar] [CrossRef]
- Maity, K.; Kumar, A.; Saha, S. A Multitask Multimodal Framework for Sentiment and Emotion-Aided Cyberbullying Detection. IEEE Internet Comput. 2022, 26, 68–78. [Google Scholar] [CrossRef]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.u.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Jiang, M.; Liang, Y.; Feng, X.; Fan, X.; Pei, Z.; Xue, Y.; Guan, R. Text classification based on deep belief network and softmax regression. Neural Comput. Appl. 2018, 29, 61–70. [Google Scholar] [CrossRef]
- Goroshin, R.; LeCun, Y. Saturating auto-encoders. arXiv 2013, arXiv:1301.3577. [Google Scholar]
- Dadvar, M.; Eckert, K. Cyberbullying detection in social networks using deep learning based models. In Proceedings of the International Conference on Big Data Analytics and Knowledge Discovery, Bratislava, Slovakia, 14–17 September 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 245–255. [Google Scholar]
- Chandra, N.; Khatri, S.K.; Som, S. Cyberbullying detection using recursive neural network through offline repository. In Proceedings of the 2018 7th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Nordia, India, 29–31 August 2018; pp. 748–754. [Google Scholar]
- Elmezain, M.; Malki, A.; Ibrahim, G.; El-Sayed, A. Hybrid Deep Learning Model–Based Prediction of Images Related to Cyberbullying. Int. J. Appl. Math. Comput. Sci. 2022, 32, 323–334. [Google Scholar]
- Chandrasekaran, S.; Singh Pundir, A.K.; Lingaiah, T.B. Deep Learning Approaches for Cyberbullying Detection and Classification on Social Media. Comput. Intell. Neurosci. 2022, 2022, 2163458. [Google Scholar]
- Kumar, A.; Sachdeva, N. Cyberbullying detection on social multimedia using soft computing techniques: A meta-analysis. Multimed. Tools Appl. 2019, 78, 23973–24010. [Google Scholar] [CrossRef]
- Sripada, N.K.; Sirikonda, S.; Areefa; Leena, G.; Sriabhinay, K. Web-application for detecting cyber bullying using machine learning approach. Proc. AIP Conf. Proc. 2022, 2418, 020082. [Google Scholar]
- Agarwal, A.; Chivukula, A.S.; Bhuyan, M.H.; Jan, T.; Narayan, B.; Prasad, M. Identification and classification of cyberbullying posts: A recurrent neural network approach using under-sampling and class weighting. In Proceedings of the International Conference on Neural Information Processing, New Delhi, India, 22–26 November 2021; Springer: Berlin/Heidelberg, Germany, 2020; pp. 113–120. [Google Scholar]
- Luo, Y.; Zhang, X.; Hua, J.; Shen, W. Multi-featured Cyberbullying Detection Based on Deep Learning. In Proceedings of the 2021 16th International Conference on Computer Science & Education (ICCSE), Lancaster, UK, 17–21 August 2021; pp. 746–751. [Google Scholar]
- Golem, V.; Karan, M.; Šnajder, J. Combining shallow and deep learning for aggressive text detection. In Proceedings of the First Workshop on Trolling, Aggression and Cyberbullying (TRAC-2018), Santa Fe, NM, USA, 25 August 2018; pp. 188–198. [Google Scholar]
- Zhang, X.; Tong, J.; Vishwamitra, N.; Whittaker, E.; Mazer, J.P.; Kowalski, R.; Hu, H.; Luo, F.; Macbeth, J.; Dillon, E. Cyberbullying detection with a pronunciation based convolutional neural network. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 740–745. [Google Scholar]
- O’Shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Orr, M.J. Introduction to Radial Basis Function Networks; Technical Report; Center for Cognitive Science, University of Edinburgh: Edinburgh, UK, 1996. [Google Scholar]
- Çürük, E.; Acı, Ç.; Eşsiz, E.S. The effects of attribute selection in artificial neural network based classifiers on cyberbullying detection. In Proceedings of the 2018 3rd International Conference on Computer Science and Engineering (UBMK), Sarajevo, Bosnia and Herzegovina, 20–23 September 2018; pp. 6–11. [Google Scholar]
- Çiğdem, A.; Çürük, E.; Eşsiz, E.S. Automatic detection of cyberbullying in formspring. me, Myspace and YouTube social networks. Turk. J. Eng. 2019, 3, 168–178. [Google Scholar]
- Ritter, H.; Martinetz, T.; Schulten, K. Neural Computation and Self-Organizing Maps: An Introduction; Addison-Wesley Reading: Boston, MA, USA, 1992. [Google Scholar]
- Desai, A.; Kalaskar, S.; Kumbhar, O.; Dhumal, R. Cyber Bullying Detection on Social Media using Machine Learning. In Proceedings of the ITM Web of Conferences, Navi Mumbai, India, 14–15 July 2021; EDP Sciences: Ulis, France, 2021; Volume 40, p. 03038. [Google Scholar]
- Miljković, D. Brief review of self-organizing maps. In Proceedings of the 2017 40th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 22–26 May 2017; pp. 1061–1066. [Google Scholar]
- Bozyiğit, A.; Utku, S.; Nasiboğlu, E. Cyberbullying detection by using artificial neural network models. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; pp. 520–524. [Google Scholar]
- Cho, K.; Van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the properties of neural machine translation: Encoder-decoder approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- de Santana Correia, A.; Colombini, E.L. Attention, please! A survey of neural attention models in deep learning. Artif. Intell. Rev. 2022, 55, 6037–6124. [Google Scholar] [CrossRef]
- Zhang, A.; Li, B.; Wan, S.; Wang, K. Cyberbullying detection with birnn and attention mechanism. In Proceedings of the Machine Learning and Intelligent Communications: 4th International Conference, MLICOM 2019, Nanjing, China, 24–25 August 2019; Springer: Berlin/Heidelberg, Germany, 2019; pp. 623–635. [Google Scholar]
- Raj, C.; Agarwal, A.; Bharathy, G.; Narayan, B.; Prasad, M. Cyberbullying detection: Hybrid models based on machine learning and natural language processing techniques. Electronics 2021, 10, 2810. [Google Scholar] [CrossRef]
- Bharti, S.; Yadav, A.K.; Kumar, M.; Yadav, D. Cyberbullying detection from tweets using deep learning. Kybernetes 2021, 51, 2695–2711. [Google Scholar] [CrossRef]
- Murshed, B.A.H.; Abawajy, J.; Mallappa, S.; Saif, M.A.N.; Al-Ariki, H.D.E. DEA-RNN: A hybrid deep learning approach for cyberbullying detection in Twitter social media platform. IEEE Access 2022, 10, 25857–25871. [Google Scholar] [CrossRef]
- Raj, M.; Singh, S.; Solanki, K.; Selvanambi, R. An application to detect cyberbullying using machine learning and deep learning techniques. SN Comput. Sci. 2022, 3, 401. [Google Scholar] [CrossRef] [PubMed]
- Beniwal, R.; Maurya, A. Toxic comment classification using hybrid deep learning model. In Proceedings of the Sustainable Communication Networks and Application: Proceedings of ICSCN 2020, Erode, India, 6–7 August 2020; Springer: Berlin/Heidelberg, Germany, 2021; pp. 461–473. [Google Scholar]
- Singh, N.K.; Singh, P.; Chand, S. Deep Learning based Methods for Cyberbullying Detection on Social Media. In Proceedings of the 2022 International Conference on Computing, Communication, and Intelligent Systems (ICCCIS), Greater Noida, India, 4–5 November 2022; pp. 521–525. [Google Scholar]
- Pang, B.; Nijkamp, E.; Wu, Y.N. Deep learning with tensorflow: A review. J. Educ. Behav. Stat. 2020, 45, 227–248. [Google Scholar] [CrossRef]
- Borkan, D.; Dixon, L.; Sorensen, J.; Thain, N.; Vasserman, L. Nuanced metrics for measuring unintended bias with real data for text classification. In Proceedings of the Companion Proceedings of the 2019 World Wide Web Conference, San Francisco, CA, USA, 13–17 May 2019; pp. 491–500. [Google Scholar]
- Huang, X.; Xing, L.; Dernoncourt, F.; Paul, M.J. Multilingual twitter corpus and baselines for evaluating demographic bias in hate speech recognition. arXiv 2020, arXiv:2002.10361. [Google Scholar]
- Wulczyn, E.; Thain, N.; Dixon, L. Ex machina: Personal attacks seen at scale. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 1391–1399. [Google Scholar]
- Kennedy, B.; Atari, M.; Davani, A.M.; Yeh, L.; Omrani, A.; Kim, Y.; Coombs, K.; Havaldar, S.; Portillo-Wightman, G.; Gonzalez, E.; et al. Introducing the Gab Hate Corpus: Defining and applying hate-based rhetoric to social media posts at scale. Lang. Resour. Eval. 2022, 56, 79–108. [Google Scholar] [CrossRef]
- Gencoglu, O. Cyberbullying detection with fairness constraints. IEEE Internet Comput. 2020, 25, 20–29. [Google Scholar] [CrossRef]
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Kargutkar, S.; Chitre, V. Implementation of Cyberbullying Detection Using Machine Learning Techniques. Int. J. Res. Appl. Sci. Eng. Technol. 2021, 9, 290–294. [Google Scholar] [CrossRef]
- Roy, P.K.; Mali, F.U. Cyberbullying detection using deep transfer learning. Complex Intell. Syst. 2022, 8, 5449–5467. [Google Scholar] [CrossRef]
- Jain, V.; Kumar, V.; Pal, V.; Vishwakarma, D.K. Detection of cyberbullying on social media using machine learning. In Proceedings of the 2021 5th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 8–10 April 2021; pp. 1091–1096. [Google Scholar]
- Stevens, E.; Antiga, L.; Viehmann, T. Deep Learning with PyTorch; Manning Publications: Shelter Island, NY, USA, 2020. [Google Scholar]
- Pramanick, S.; Sharma, S.; Dimitrov, D.; Akhtar, M.S.; Nakov, P.; Chakraborty, T. MOMENTA: A multimodal framework for detecting harmful memes and their targets. arXiv 2021, arXiv:2109.05184. [Google Scholar]
- Sharma, S.; Akhtar, M.; Nakov, P.; Chakraborty, T. DISARM: Detecting the victims targeted by harmful memes. arXiv 2022, arXiv:2205.05738. [Google Scholar]
- Vishwamitra, N.; Hu, H.; Luo, F.; Cheng, L. toward understanding and detecting cyberbullying in real-world images. In Proceedings of the 2020 19th IEEE International Conference on Machine Learning and Applications (ICMLA), Online, 14–17 December 2020. [Google Scholar]
- Brownlee, J. Deep Learning with Python: Develop Deep Learning Models on Theano and 1678 Tensor Flow Using Keras; Machine Learning Mastery: Vermont, VIC, Australia, 2016. [Google Scholar]
- Sintaha, M.; Satter, S.B.; Zawad, N.; Swarnaker, C.; Hassan, A. Cyberbullying Detection Using Sentiment Analysis in Social Media. Ph.D Thesis, BRAC University, Dhaka, Bangladesh, 2016. [Google Scholar]
- Kumar, A.; Sachdeva, N. Multimodal cyberbullying detection using capsule network with dynamic routing and deep convolutional neural network. Multimed. Syst. 2021, 28, 2043–2052. [Google Scholar] [CrossRef]
- Kumar, A.; Sachdeva, N. Multi-input integrative learning using Deep Neural Networks and 1684 transfer learning for cyberbullying detection in real-time code-mix data. Multimed. Syst. 2022, 28, 2027–2041. [Google Scholar] [CrossRef]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Tokui, S.; Okuta, R.; Akiba, T.; Niitani, Y.; Ogawa, T.; Saito, S.; Suzuki, S.; Uenishi, K.; Vogel, B.; Yamazaki Vincent, H. Chainer: A Deep Learning Framework for Accelerating the Research Cycle. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: NewYork, NY, USA, 2019; pp. 2002–2011. [Google Scholar]
- Parvat, A.; Chavan, J.; Kadam, S.; Dev, S.; Pathak, V. A survey of deep-learning frameworks. In Proceedings of the 2017 International Conference on Inventive Systems and Control (ICISC), Coimbatore, India, 19–20 January 2017; pp. 1–7. [Google Scholar]
- Neubig, G.; Dyer, C.; Goldberg, Y.; Matthews, A.; Ammar, W.; Anastasopoulos, A.; Ballesteros, M.; Chiang, D.; Clothiaux, D.; Cohn, T.; et al. Dynet: The dynamic neural network toolkit. arXiv 2017, arXiv:1701.03980. [Google Scholar]
- Hodnett, M.; Wiley, J.F. R Deep Learning Essentials: A Step-by-Step Guide to Building Deep Learning Models Using TensorFlow, Keras, and MXNet; Packt Publishing Ltd.: Birmingham, UK, 2018. [Google Scholar]
- Zaheri, S.; Leath, J.; Stroud, D. Toxic comment classification. SMU Data Sci. Rev. 2020, 3, 13. [Google Scholar]
- Dieleman, S.; Schlüter, J.; Raffel, C.; Olson, E.; Sønderby, S.K.; Nouri, D. Lasagne: First Release; Zenodo: Geneva, Switzerland, 2015. [Google Scholar]
- Candel, A.; Parmar, V.; LeDell, E.; Arora, A. Deep learning with H2O; H2O ai Inc.: Mountain View, CA, USA, 2016; pp. 1–21. [Google Scholar]
- Tong, Z.; Du, N.; Song, X.; Wang, X. Study on MindSpore Deep Learning Framework. In Proceedings of the 2021 17th International Conference on Computational Intelligence and Security (CIS), Chengdu, China, 19–22 November 2020; pp. 183–186. [Google Scholar]
- Zhao, Z.; Gao, M.; Luo, F.; Zhang, Y.; Xiong, Q. LSHWE: Improving similarity-based word embedding with locality sensitive hashing for cyberbullying detection. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Ahmed, M.F.; Mahmud, Z.; Biash, Z.T.; Ryen, A.A.N.; Hossain, A.; Ashraf, F.B. Cyberbullying detection using Deep Neural Network from social media comments in bangla language. arXiv 2021, arXiv:2106.04506. [Google Scholar]
- Dewani, A.; Memon, M.A.; Bhatti, S. Cyberbullying detection: Advanced preprocessing techniques & deep learning architecture for Roman Urdu data. J. Big Data 2021, 8, 160. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Collobert, R.; Bengio, S.; Mariéthoz, J. Torch: A modular Machine Learning Software Library; Technical Report; Idiap: Maldini, Switzerland, 2002. [Google Scholar]
- Patange, T.; Singh, J.; Thorve, A.; Somaraj, Y.; Vyawahare, M. Detection of Cyberhectoring on Instagram. In Proceedings of the Proceedings 2019: Conference on Technologies for Future Cities (CTFC), Pillai College of Engineering, New Panvel, India, 8–9 February 2019. [Google Scholar]
- Shahane, P.; Gore, D. Detection of Fake Profiles on Twitter using Random Forest & Deep Convolutional Neural Network. Int. J. Manag. Technol. Eng. 2019, 9, 3663–3667. [Google Scholar]
- Bhaskaran, J.; Kamath, A.; Paul, S. DISCo: Detecting Insults in Social Commentary. 2017. Available online: http://cs229.stanford.edu/proj2017/final-reports/5242067.pdf (accessed on 5 April 2023).
- Waseem, Z.; Hovy, D. Hateful symbols or hateful people? predictive features for hate speech detection on twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 13–15 June 2016; pp. 88–93. [Google Scholar]
- Kasture, A.S. A predictive Model to Detect Online Cyberbullying. Ph.D Thesis, Auckland University of Technology, Auckland, New Zealand, 2015. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the International AAAI Conference on Web and Social Media, Montreal, QC, Canada, 15–18 May 2017; Volume 11, pp. 512–515. [Google Scholar]
- Dadvar, M.; Trieschnigg, D.; Jong, F.d. Experts and machines against bullies: A hybrid approach to detect cyberbullies. In Proceedings of the Canadian conference on artificial intelligence, Montreal, QC, USA, 6–9 May 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 275–281. [Google Scholar]
- Toxic Comment Classification Challenge. Available online: https://www.kaggle.com/competitions/jigsaw-toxic-comment-classification-challenge/data (accessed on 5 April 2023).
- Data and Code for the Study of Bullying. Available online: https://research.cs.wisc.edu/bullying/data.html (accessed on 5 April 2023).
- Rafiq, R.I.; Hosseinmardi, H.; Han, R.; Lv, Q.; Mishra, S.; Mattson, S.A. Careful what you share in six seconds: Detecting cyberbullying instances in Vine. In Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, France, 25–28 August 2015; pp. 617–622. [Google Scholar]
- Rafiq, R.I.; Hosseinmardi, H.; Mattson, S.A.; Han, R.; Lv, Q.; Mishra, S. Analysis and detection of labeled cyberbullying instances in Vine, a video-based social network. Soc. Netw. Anal. Min. 2016, 6, 88. [Google Scholar] [CrossRef]
- Zohuri, B.; Moghaddam, M. Deep learning limitations and flaws. Mod. Approaches Mater. Sci 2020, 2, 241–250. [Google Scholar] [CrossRef]
- Whang, S.; Lee, J.G. Data Collection and Quality Challenges for Deep Learning. In Proceedings of the VLDB Endowment, Online, 31 August–4 September 2020; VLDB Endowment: Los Angeles, CA, USA, 2020; Volume 13. [Google Scholar]
- Pramod, A.; Naicker, H.S.; Tyagi, A.K. Machine learning and deep learning: Open issues and future research directions for the next 10 years. Computational Analysis and Deep Learning for Medical Care: Principles, Methods, and Applications; John Wiley & Sons, Ltd.: Chichester, UK, 2021; pp. 463–490. [Google Scholar]
- Bae, H.; Jang, J.; Jung, D.; Jang, H.; Ha, H.; Lee, H.; Yoon, S. Security and privacy issues in deep learning. arXiv 2018, arXiv:1807.11655. [Google Scholar]
- Raisi, E.; Huang, B. Cyberbullying identification using participant-vocabulary consistency. arXiv 2016, arXiv:1606.08084. [Google Scholar]
- Ali, W.N.H.W.; Mohd, M.; Fauzi, F. Cyberbullying detection: An overview. In Proceedings of the 2018 Cyber Resilience Conference (CRC), Putrajaya, Malaysia, 13–15 November 2018; pp. 1–3. [Google Scholar]
- Weischedel, R.M.; Bates, M. Challenges in Natural Language Processing; Cambridge University Press: Cambridge, UK, 2006. [Google Scholar]
- Atoum, J.O. Cyberbullying Detection Through Sentiment Analysis. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; pp. 292–297. [Google Scholar]
- Nahar, V.; Unankard, S.; Li, X.; Pang, C. Sentiment analysis for effective detection of cyber bullying. In Proceedings of the Web Technologies and Applications: 14th Asia-Pacific Web Conference, APWeb 2012, Kunming, China, 11–13 April 2012; Proceedings 14. Springer: Berlin/Heidelberg, Germany, 2012; pp. 767–774. [Google Scholar]
- Dani, H.; Li, J.; Liu, H. Sentiment informed cyberbullying detection in social media. In Proceedings of the Machine Learning and Knowledge Discovery in Databases: European Conference, ECML PKDD 2017, Skopje, Macedonia, 18–22 September 2017; Proceedings, Part I 10. Springer: Berlin/Heidelberg, Germany, 2017; pp. 52–67. [Google Scholar]



















| Reference | Deep Learning Models | Method. | Taxnom. | Data Represent. Tech. | Framewrk. | Dataset (Pub. Avail.) | Discussion in Challenges and Future Trends | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Application in Cyberbullying | Strength and Limitation | Text | Img. | Cultural Diversity | Data Represent. | Multimedia and Multilingual Content | Impact on Mental Health | |||||
| [30] | ✘ | ✘ | ✘ | ✘ | ✓ | ✘ | N/A | ✘ | ✘ | ✘ | ✘ | ✘ |
| [26] | ✓ | ✓ | ✓ | ✘ | ✓ | ✘ | ✘ | ✓ | ✘ | ✘ | ✘ | ✓ |
| [27] | ✘ | ✘ | ✓ | ✘ | ✓ | ✓ | N/A | ✓ | ✘ | ✘ | ✘ | ✘ |
| [31] | ✘ | ✘ | ✓ | ✘ | ✓ | ✘ | N/A | ✓ | ✓ | ✓ | ✓ | ✘ |
| [29] | ✓ | ✘ | ✓ | ✘ | ✓ | ✘ | ✘ | ✓ | ✘ | ✓ | ✓ | ✘ |
| [28] | ✓ | ✘ | ✓ | ✘ | ✓ | ✓ | ✘ | ✘ | ✘ | ✘ | ✘ | ✘ |
| [45] | ✓ | ✘ | ✓ | ✘ | ✓ | ✓ | ✘ | ✘ | ✘ | ✘ | ✘ | ✓ |
| Ours | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Reference | Collection Sources | Keywords | Timeline | Initial Paper Count | Final Paper Count |
|---|---|---|---|---|---|
| [30] | - | - | - | - | - |
| [26] | Scopus, the ACM Digital Library, and the IEEE Xplore digital library | Cyberbully or cyberbullying detection, detecting cyberbully or cyberbullying, electronic or online bullying detection, detecting electronic or online bullying, cyberbullying prevention tool, cyberbullying prevention software, cyberbullying software, anti cyberbu- llying detecting electronic or online harassment | 2008–2016 | 89 | 46 |
| [27] | Google Scholar, Research Gate, ACM Digital Library, Arxiv, Scopus, Mendeley | - | 2011–2018 | 71 | 22 |
| [31] | Scopus, Clarivate Analytics’ Web of Science, DBLP Computer Science Bibliography, ACM Digital Library, ScienceDirect, SpringerLink, and IEEE Xplore, Qatar University’s digital library | Cyberbullying, aggressive behavior, big data, and cyberbullying models | - | - | - |
| [29] | Google Scholar, IEEE Xplore, Science Direct, ACM Digital Library and Wiley online databases | Cyberbullying detection | 2008–2020 | 106 | 65 |
| [28] | The ACM Digital Library, IEEE Xplore Digital Library, and Springer Link databases | Cyberbullying detection, Cyberbullying detection algorithm | 2010–2020 | 118 | 56 |
| [45] | Google Scholar, IEEE, Springer, ACM, and others | Abuse, offensive or hate speech, sarcasm, and irony | 2012–2020 | 70 | 45 |
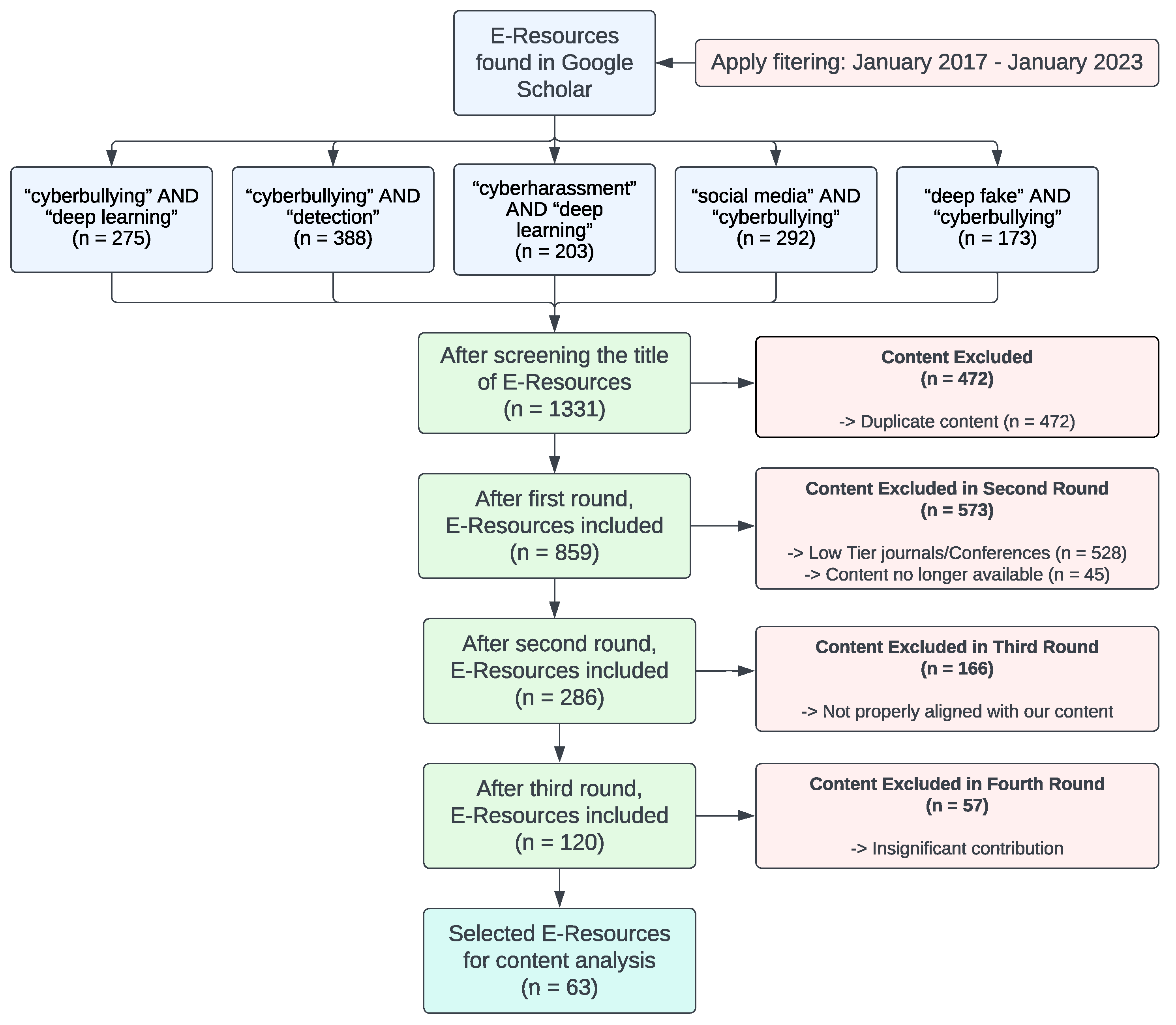
| Ours | IEEE Xplore, ScienceDirect, ACM Digital Library, Wiley, Springer Link, Taylor & Francis, MDPI, etc. | Cyberbullying and deep learning, cyberbullying detection, cyberharassment and deep learning, social media and cyberbullying, deep fake and cyberbullying | 2017–Jan 2023 | 1331 | 63 |
| Word-Embedding Technique | Context Sensitive Embedding | ML Based | RNN Based | Transformer Based | Pretrained | Used in Cyberbullying Application |
|---|---|---|---|---|---|---|
| One-hot Embedding | No | No | No | No | No | YouTube Bengali text [18] |
| TF-IDF | No | No | No | No | No | Chinese Weibo dataset and English tweets [5], Twitter English text [63], YouTube Bengali text [18] |
| Word2Vec | No | Yes | No | No | Yes | Twitter Indonesian text [64], Twitter English text [2,63], Social media text [65,66] |
| GloVe | No | Yes | No | No | Yes | Twitter English text [2,7,67], Formspring, Twitter, and Wikipedia posts [25,68], YouTube English text [25], Social media text [65] |
| ELMo | Yes | Yes | Yes | No | Yes | Social media text [65], Formspring English text [69,70,71], MySpace English text [69,71] |
| fastText | No | Yes | No | No | Yes | Formspring English text [70], Social media text [72] |
| BERT | Yes | Yes | No | Yes | Yes | Arabic Social media text [73], Formspring, Twitter, Wikipedia English posts [22] |
| Study | Dataset | Hybrid Model | Experimental Models | Best Performing Model | Performance Metrics |
|---|---|---|---|---|---|
| Raj et al. [149] | Wikipedia Attack Dataset | No | LSTM, Bi-LSTM, GRU, Bi-GRU | Bi-GRU | Accuracy: 96.98%, F1 Score: 98.56% |
| Raj et al. [149] | Wikipedia Web Toxicity Dataset | No | LSTM, Bi-LSTM, GRU, Bi-GRU | Bi-LSTM | Accuracy: 96.5%, F1 Score: 98.69% |
| Bharti et al. [150] | Tweets | No | Bi-LSTM | Bi-LSTM | Accuracy: 92.60%, Precision: 96.60%, F1 Score: 94.20% |
| Iwendi et al. [21] | DISCo dataset | No | Bi-LSTM, GRU, LSTM, RNN | Bi-LSTM | Accuracy: 82.18% |
| Agarwal et al. [134] | Wikipedia dataset | No | Bi-LSTM with attention layers | Bi-LSTM with attention layers | Precision: 89%, Recall: 86%, F1 Score: 88% |
| Singh et al. [154] | Twitter dataset | No | LSTM, GRU, traditional ML algorithms | GRU | F1 Score: 92% |
| Alotaibi et al. [115] | Twitter comments | Yes | Transformer block, Bi-GRU, CNN | Proposed model | Accuracy: 88% |
| Bu et al. [66] | SNS comments | Yes | CNN, LRCN | Proposed model | AUC-ROC score: 88.54%, Accuracy: 87.22% |
| Murshed et al. [151] | Twitter dataset | Yes | Bi-LSTM, RNN, DEA-RNN (proposed model) | DEA-RNN | Accuracy: 90.45%, Precision: 89.52%, Recall: 88.98%, F1 Score: 89.25% |
| Raj et al. [152] | Real-time posts on Twitter | Yes | CNN + Bi-GRU, Bi-LSTM + Bi-GRU, CNN + Bi-LSTM (proposed model) | Proposed model | Accuracy: 95% |
| Beniwal et al. [153] | Toxic Comment Classification Challenge | Yes | CNN + Bi-GRU | Proposed model | Accuracy: 98.39%, F1 Score: 79.91% |
| References | Theme | Major Contributions | Future Research Directions |
|---|---|---|---|
| [7,64,137] | Improvement of DL models | These studies show improvement of cyberbullying detection by using CNN, LSTM, and BiGRUA-CNN models. These models show enhancement of the classification problem by adjusting activation function, weight regularization, and dropout configuration. |
|
| [5,115,135] | Performance optimization of the models | Studies applied char-CNN, BiGRU, and transformer models. They largely optimize weights, number of layers, combination of models during cyberbullying detection in social media discourse. |
|
| [18,63,134] | Improving data capability | LSTM-CNN and RNN-based models have been applied in text, randomized and wikipedia datasets. The authors proposed several techniques to improve the capacity of the dataset. |
|
| Frameworks | Strengths | Limitations | Supported DL Algorithms | Used in Cyberbullying |
|---|---|---|---|---|
| TensorFlow |
|
| Wide range of models including CNN, RNN, GAN, Transformer, etc. [155] | Chats and Tweets [14], Bangla Text [18], Offline Content [129], Social Media text analysis [112], Comments and Toxicity [156], Multilingual Tweets and Hate speech [157], Wikipedia talk page [158], Post of Social Network platform Gab [159,160] |
| Keras |
|
| Wide range of models including CNN, RNN, GAN, Transformer, etc. [161] | Twitter [2,75,115,162], Bully, Sentiment, Emotion and Sarcasm from Twitter and Reddit [124], Social media content[68,115,163], Twitter and Wikipedia [164], Chats and Tweets [14], Wikipedia, Twitter, Formspring and YouTube [25], Social networks’ text and image [25], online textual harassment [71] |
| Torch/ PyTorch |
|
| Majority of the DL Models including CNN, RNN, GAN, Transformer, etc. [165] | Social Network platform Gab [159], Twitter, Wikipedia, Formspring [22], Harmful meme of COVID-19 [166], Memes of US politics [167], Image from online [168], Cyberbert: BERT for cyberbullying identification [22], Social media content [73] |
| Theano |
|
| Majority of the DL Models [169] | Twitter and Formspring.me [137], Twitter [137,170], Comments and posts from YouTube, Instagram and Twitter [171], Twitter and Facebook [172], Social media image [132], Online textual harassment [71] |
| Caffe |
|
| Initially designed for CNNs [173] | No Works Found |
| Chainer |
|
| For CNNs, Dynamic Computational Graph [174] | No Works Found |
| Deep- Learning4j |
|
| DL models that are used in NLP tasks [175] | No Works Found |
| DyNet |
|
| RNNs [176] | No Works Found |
| MXNet |
|
| CNNs, RNNs, GANs [177] | Wikipedia talk pages [178] |
| Lasagne |
|
| Feed-Forward Networs such as CNNs, Recurrent Networks including LSTM, and any combination thereof [179]. | No Works Found |
| HO |
|
| Variety of DL models including CNNs RNNs [180]. | No Works Found |
| Google JAX |
|
| Variety of DL models including CNNs and autoaggressive models. | No Works Found |
| Mind- Spore |
|
| CNNs and RNNs with a focus on distributed training and image processing [181]. | No Works Found |
| Dataset | DL Architectures | Major Tasks |
|---|---|---|
| Textual Content | ||
| Impermium [189] | Bi-LSTM, GRU, LSTM, and RNN | Intimidation detection on social media platforms [21] |
| Formspring (a Q&A forum) | Single Linear Neural Network Layer and Transformer | Cyberbullying detection [73] |
| CNN, LSTM, Bi-LSTM, Bi-LSTM with Attention | Systematically analyzes cyberbullying detection [68] | |
| PCNN | Handle the difficulty of noise and distortion in social media postings and messages in detecting cyberbullying [137] | |
| Wikipedia | Single Linear NN, Transformer [73], MLP [158] | Cyberbullying detection [68,73,158] |
| CNN, LSTM, Bi-LSTM, Bi-LSTM with Attention [68] | Systematically analyzes cyberbullying detection | |
| Twitter [190] | CNN, LSTM, Bi-LSTM, Bi-LSTM with Attention [68] | Systematically analyzes cyberbullying detection [68] |
| Char-CNNS | Cyberbullying detection [5] | |
| Text | ||
| Twitter [191] | PCNN | Handling the difficulty of noise and distortion in social media postings and messages in detecting cyberbullying [137] |
| Twitter (combination of 3 datasets) [115,190,192] | Bi-GRU, Transformer Block, and CNN | Detecting Aggressive Behavior |
| Twitter (Indonesian Language) [64] | LSTM, Bi-LSTM, and CNN | Cyberbullying Detection |
| YouTube [193] | Bi-LSTM with attention | Cyberbullying Detection [25] |
| Bangla and Romanized Bangla [18] | CNN, LSTM, Bi-LSTM, and GRU | Comparative analysis [18] |
| Toxic Comment Classification challenge [194] | LSTM-CNN [63] | Cyberbullying Detection [63] |
| The bullying traces dataset [195] | SVM activated stacked convolution LSTM network [7] | |
| Textual and Visual | ||
| Vine [196,197] | ResidualBiLSTM-RCNN | Cyberbullying Detection [6] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hasan, M.T.; Hossain, M.A.E.; Mukta, M.S.H.; Akter, A.; Ahmed, M.; Islam, S. A Review on Deep-Learning-Based Cyberbullying Detection. Future Internet 2023, 15, 179. https://doi.org/10.3390/fi15050179
Hasan MT, Hossain MAE, Mukta MSH, Akter A, Ahmed M, Islam S. A Review on Deep-Learning-Based Cyberbullying Detection. Future Internet. 2023; 15(5):179. https://doi.org/10.3390/fi15050179
Chicago/Turabian StyleHasan, Md. Tarek, Md. Al Emran Hossain, Md. Saddam Hossain Mukta, Arifa Akter, Mohiuddin Ahmed, and Salekul Islam. 2023. "A Review on Deep-Learning-Based Cyberbullying Detection" Future Internet 15, no. 5: 179. https://doi.org/10.3390/fi15050179
APA StyleHasan, M. T., Hossain, M. A. E., Mukta, M. S. H., Akter, A., Ahmed, M., & Islam, S. (2023). A Review on Deep-Learning-Based Cyberbullying Detection. Future Internet, 15(5), 179. https://doi.org/10.3390/fi15050179