
How Can We Achieve Query Keyword Frequency Analysis in Privacy-Preserving Situations?


Abstract
:1. Introduction
1.1. Our Contribution
- We propose a novel KFA-PEKS scheme that combines searchable encryption with keyword frequency analysis, while maintaining high levels of security and scalability. Our solution allows the server to periodically analyze the frequency of queried keywords without linking this information to the user’s identity, thereby preserving user privacy.
- We conduct a comprehensive functional comparison of our KFA-PEKS scheme with existing SE schemes. The comparison results demonstrate that our scheme is unique in achieving multi-keyword search, resistance to KGA, and frequency analysis of query keywords within a multi-writer/multi-reader model. Furthermore, the complexity analysis of our scheme indicates that it is highly practical and applicable.
- We implement our KFA-PEKS scheme using Python, and perform extensive security evaluations, including computational and communication overhead analysis, to demonstrate its feasibility and effectiveness. Our experimental results highlight the advantages of our KFA-PEKS scheme compared to other PEKS schemes, showcasing its superior performance and suitability for real-world applications.
1.2. Paper Organization
2. Related Work
3. Preliminaries
3.1. Pseudorandom Function
3.2. Subset Decision Mechanism (SDM)
| Algorithm 1 Subset Decision Mechanism Source: [22], Algorithm 1 Subset Decision |
| Input: A universal set , two subsets . Output: Whether .
|
| Algorithm 2 Subset Decision Mechanism With Modification. Source: [22], Algorithm 1 Subset Decision with Modification |
| Input: A universal set , two subsets . Output: Whether .
|
3.3. Secure Bit-Decomposition (SBD)
3.4. DT-PKC
3.4.1. Basic Structure
- : Given the security parameter , KGC finds two large primes p, q such that = = , where refers to the length of the parameter x, then computes N = , = , = , of which and are two strong primes. Simultaneously, KGC also chooses a generator of the order , and chooses a random number such that . Finally, KGC obtains the public key and the private key for user i, and computes the master key , where refers to finding the least common multiple of a and b.
- : Enter the plaintext m and the public key and choose a random number r () to generate the ciphertext , where ;
- Decryption With User’s Private Key (UDec): Enter the ciphertext and the private key to generate the corresponding plaintext m as follows:
- Decryption With Master Key (MDec): Enter the ciphertext and the master key to generate the corresponding plaintext m by first calculating:Then, since , we are able to obtain m by the following expression:
- Master Key Splitting (MkeyS): Enter the master key to generate two partial master keys and such that and .
- Partial Decryption With Partial Master Key Step One (PMDec1): Enter the ciphertext and the partial master key to generate the partial ciphertext as follows:
- Partial Decryption With Partial Master Key Step Two (PMDec2): Enter the partial ciphertext , the ciphertext and the partial master key to generate the corresponding plaintext m by first calculating:Then, we can obtain the plaintext m by computing:
- Ciphertext Refresh (CR): Enter the ciphertext and a random number to generate another ciphertext , where
3.4.2. Sub-Protocols
- Secure Addition Protocol across Domains (SAD): Enter the two ciphertexts and , the partial master keys and , and the public keys , and to generate the addition of two ciphertexts in different encryption domains.
- Secure Multiplication Protocol across Domains (SMD): Enter the same inputs as the SAD to generate the multiplication of two ciphertexts in different encryption domains.
4. KFA-PEKS
4.1. System Model
- KGC: The role of the KGC is to generate public parameters and distribute the corresponding keys to the various entities involved in the scheme.
- MS: The MS mainly provides secure file storage services for the DOs and secure file search services for the DUs.
- KFS: The KFS collaborates with the MS in processing the DUs’ file query requests, and conducts keyword frequency analysis on the DUs’ queries, while ensuring the privacy of the DUs, in order to provide enhanced file storage and lookup services to both the DOs and DUs.
- TS: The TS periodically sends time tokens embedded with the current timestamp to the MS, which are then used to recover keyword information from the DUs’ queries in order to conduct keyword frequency analysis.
- DO: Each DO generates their own public–private key pair based on the public parameters. They then extract keywords from a file to generate searchable ciphertext, which is sent to the MS along with the file for secure storage and search services.
- DU: Each DU generates their own public–private key pair based on the public parameters and generates a query trapdoor for a set of keywords of interest. Only the DU has the ability to decrypt the queried results received from the MS in order to obtain the corresponding file index, thereby ensuring privacy and security.
4.2. Threat Model
4.3. Security Goals
- Keyword privacy of DUs Before TSO: The DUs’ query operations will not leak keyword information until the current time reaches the specified by the DU.
- Indistinguishability of DO’s searchable ciphertext: The searchable ciphertext uploaded by the DO does not reveal any information related to the file.
- Keyword privacy for DUs after TSO: After reaching the specified by the DU, only the KFS can recover the queried keywords, and for others, the trapdoor still retains its previous security.
- Unlinkability of recovered keywords and DUs’ identities: The KFS is unable to locate the relevant DU through recovering the keyword.
- Resist KGA: The focus of this paper is on offline keyword-guessing attacks by internal attackers, that is, on preventing internal attackers, such as untrusted cloud servers, from performing exhaustive attacks on keyword information in encrypted searchable ciphertext or trapdoors.
4.4. Syntax
- () →: Given the security parameter , the KGC generates the public parameter , a value shared by the KFS and DUs, and a key , shared by the TS and DUs.
- () → (,): Given the public parameter , the KGC generates two keys for the MS and KFS, and .
- () →,: Given the public parameter , the KGC generates the public–private key pair , for the DOs.
- () → (, ): Given the public parameter , the KGC generates the public–private key pair , for the DUs.
- () → (, ): Given the public parameter , the KGC generates the public–private key pair , for the TS.
- (W, , ) →: Given the universal keyword set W, a keyword subset , and the DO’s public key, the DO computes the searchable ciphertext .
- (W, r, , , , ) →: Given the universal keyword set W, the value r, the key , the DU’s secret key , the TS’s public key , and a timestamp, the DU computes an encryption key and the trapdoor .
- (, , , , , ) → or : Given the searchable ciphertext , trapdoor , the MS’s secret key , the KFS’s secret key , the DO’s public key , and the encryption key , the MS and the KFS compute a test result. The DU can compute the test result and outputs 1 if , or otherwise, 0.
- (, , , ) →: Given the TS’s secret key , the DU’s public key , the key , and a timestamp, the TS generates a time token .
- (, r, ) → t: Given the encryption key , the value r, and a time token , the KFS can recover to obtain t.
4.5. Correctness
- Correctness of search results:
- -
- (, , , , , ) → 1 if, and only if, .
- -
- (, , , , , ) → 0 if, and only if, .
- Correctness of keyword frequency analysis:
- -
- (, r, ) → t if, and only if, .
- -
- (, r, ) →. if, and only if, .
5. Construction
5.1. The Concrete Construction
- () →: Given the security parameter , the KGC finds two large primes p, q such that = = , where refers to the length of the parameter x, then computes N = , = , = , of which and are two strong primes. Simultaneously, the KGC also chooses a generator of the order and initializes a set of keywords W, the total number of which is . Later the KGC sends a secret value r to the KFS and the DUs, and sends = (W, , N, g) to others.
- () → (,): The KGC first executes in DT-PKC to obtain the master key , and then executes in DT-PKC to generate two partial master keys = , = . Finally, the KGC sends = = to the MS, the partial master key = = to the KFS, and keeps = secret.
- () → (,: Each DO chooses a random number and calculates . They then publish as their public key, and keep as their private key.
- () → (, ): Each DU chooses a random number and calculates . They then publish as their public key, and keep as their private key.
- () → (, ): Each TS chooses a random number and calculates . They then publish as their public key, and keep as their private key.
- (W, , ) →: Firstly, DO chooses a random number , and generates based on W such that ⊆W and computes the corresponding decimal number T according to its binary representation; then, encrypts T with their public key to obtain the encrypted searchable ciphertext = (, ), which specifically is as follows:Finally, the DO sends to the MS.
- (W, r, , , , ) →: the DU uses their own private key and TS’s public key to generate an encryption key = . They then generate the keyword set of interest based on T such that and compute the corresponding decimal number t according to its binary representation. At the same time, the DU runs a PRF F for the specified point in order to obtain a timestamp, and shares the key with the TS. Subsequently, the DU encrypts t with , a secret value r (shared with the KFS) and their specified timestamp, and obtains the trapdoor = , , which specifically is as follows:Finally, the DU sends to the MS.
- (, , , , , ) → or : After receiving and , the MS can perform the following four steps with the KFS to obtain an encrypted query result and send it to the DU.
- -
- step 1: After the MS receives and , it will execute the protocol with the KFS to calculate the ciphertext of each bit of and t, i.e., and for i∈.
- -
- step 2: After obtaining and , the MS can calculate the ciphertext of each and mentioned in the SDM, i.e., and together with the KFS, and finally the MS sends the randomized matching result to the DU.
- -
- step 3: After obtaining , the MS and KFS together calculate the matching result and the randomized value, i.e., and .
- -
- step 4: After receiving , the DU decrypts the final matching result. A result of 0 means that the file does not match. Any other result means that the current file does match, in which case the DU will request this file from the MS.
- (, , , ) →: The TS uses and to deal with the current timestamp and obtain a time token = , this is sent periodically to the KFS.
- (, r, ) → t: The KFS receives the , and when the timestamp in the is consistent with the timestamp specified by the DU, then, the KFS can recover the keyword information in the trapdoor with r and , so as to analyze the frequency of the queried keywords later. The recovery process is as follows:
5.2. Process of KFA-PEKS
5.3. Security Proof
- Setup: First, chooses a point in time at which to make the attack. Then, executes algorithms , , , , and to obtain , , , , and . Furthermore, it sends to .
- Phase 1: interacts with , which executes the algorithm in an imitation of the TS, and sends the resulting time token to .
- Challenge: picks two different keyword sets , ⊆W, and sends and , representing the two sets, to . Then, picks , runs (W, r, , , ) →, and sends to .
- Phase 2: can continue with the first phase of queries while also executing the algorithm in an imitation of the MS interacting with the KFS.
- Guess: starts guessing b. If the given guess satisfies , then wins this game.
- : Input a keyword set and the DU’s public key , because simulator has the TS’s private key , so it can obtain the encryption key ; then, simulator runs the algorithm to generate the query trapdoor corresponding to keyword set , and then, simulator sends this query trapdoor to adversary .
- : The current timestamp is input, and since the simulator has the secret value r shared by the KFS and the DU and the secret value shared by the TS and the DU, it can obtain the processed timestamp and give this value to the adversary .
- : In this stage of interrogation, adversary has the partial master key of the MS, and simulator uses the partial master key of the KFS to cooperate with adversary to execute the algorithm and send the matching result to adversary . For trapdoor , it satisfies:
- Setup: First, chooses a point in time at which to make the attack. Then, executes algorithms , , , , and to obtain , , , , and . Furthermore, it sends to .
- Challenge: picks two different keyword sets , ⊆W, and sends , , representing and , to . Then, picks , runs (W, , ) →, and sends to .
- Guess: starts guessing b. If the given guess satisfies = b, then wins this game.
- Input the keyword set and the DO’s public key , and simulator runs the algorithm to generate the searchable ciphertext corresponding to the keyword set , where the ciphertext structure is as follows:Then, simulator sends this searchable ciphertext to adversary .
- Setup: First, chooses a point in time at which to make the attack. Then, executes algorithms , , , , and to obtain , , , , and . Furthermore, it sends to .
- Phase 1: interacts with , which executes the algorithm in an imitation of the TS, and sends the resulting time token to .
- Challenge: picks two different keyword sets , ⊆W, and sends and , representing the two sets, to . Then, picks , runs (W, r, , , ) →, and sends to .
- Phase 2: can continue with the first phase of queries while also executing the algorithm in an imitation of the MS interacting with the KFS.
- Guess: starts guessing b. If the given guess satisfies , then wins this game.
- Input a keyword set and DU’s public key , because simulator has the TS’s private key , so it can obtain the encryption key ; then simulator runs algorithm to generate the query trapdoor corresponding to keyword set , and then simulator sends this query trapdoor to adversary .
- The current timestamp is input, and since the simulator has the secret value r shared by the KFS and the DU and the secret value shared by the TS and the DU, it can obtain the processed timestamp and give this value to the adversary .
- In this stage of interrogation, adversary has the partial master key of the MS, and simulator uses the partial master key of the KFS to cooperate with adversary to execute the algorithm and send the matching result to adversary . For trapdoor , it satisfies:
6. Performance Evalution
6.1. Experimental Results
6.2. Theoretical Analysis
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lv, Z.; Singh, A.K. Big Data Analysis of Internet of Things System. ACM Trans. Internet Technol. 2021, 21, 28:1–28:15. [Google Scholar] [CrossRef]
- Li, X.; Liu, H.; Wang, W.; Zheng, Y.; Lv, H.; Lv, Z. Big data analysis of the Internet of Things in the digital twins of smart city based on deep learning. Future Gener. Comput. Syst. 2022, 128, 167–177. [Google Scholar] [CrossRef]
- Kamara, S.; Lauter, K.E. Cryptographic Cloud Storage. In Proceedings of the Financial Cryptography and Data Security, FC 2010 Workshops, RLCPS, WECSR, and WLC 2010, Tenerife, Canary Islands, Spain, 25–28 January 2010; Revised Selected Papers. Sion, R., Curtmola, R., Dietrich, S., Kiayias, A., Miret, J.M., Sako, K., Sebé, F., Eds.; Springer: Cham, Switzerland, 2010; Volume 6054, pp. 136–149. [Google Scholar] [CrossRef]
- Boneh, D.; Crescenzo, G.D.; Ostrovsky, R.; Persiano, G. Public Key Encryption with Keyword Search. In Proceedings of the Advances in Cryptology-EUROCRYPT 2004, International Conference on the Theory and Applications of Cryptographic Techniques, Interlaken, Switzerland, 2–6 May 2004; Springer: Cham, Switzerland, 2004; Volume 3027, pp. 506–522. [Google Scholar] [CrossRef]
- Liu, J.; Wu, M.; Sun, R.; Du, X.; Guizani, M. BMDS: A Blockchain-based Medical Data Sharing Scheme with Attribute-Based Searchable Encryption. In Proceedings of the ICC 2021-IEEE International Conference on Communications, Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Li, H.; Yang, Y.; Dai, Y.; Yu, S.; Xiang, Y. Achieving Secure and Efficient Dynamic Searchable Symmetric Encryption over Medical Cloud Data. IEEE Trans. Cloud Comput. 2020, 8, 484–494. [Google Scholar] [CrossRef]
- Liu, P.; Liu, K.; Fu, T.; Zhang, Y.; Hu, J. A privacy-preserving resource trading scheme for Cloud Manufacturing with edge-PLCs in IIoT. J. Syst. Archit. 2021, 117, 102104. [Google Scholar] [CrossRef]
- Song, D.X.; Wagner, D.; Perrig, A. Practical techniques for searches on encrypted data. In Proceedings of the Proceeding 2000 IEEE Symposium on Security and Privacy, S&P 2000, IEEE, Berkeley, CA, USA, 14–17 May 2000; pp. 44–55. [Google Scholar]
- Curtmola, R.; Garay, J.A.; Kamara, S.; Ostrovsky, R. Searchable symmetric encryption: Improved definitions and efficient constructions. In Proceedings of the 13th ACM Conference on Computer and Communications Security, CCS 2006, Alexandria, VA, USA, 30 October–3 November 2006; Juels, A., Wright, R.N., di Vimercati, S.D.C., Eds.; ACM: New York, NY, USA, 2006; pp. 79–88. [Google Scholar] [CrossRef]
- Moataz, T.; Shikfa, A. Boolean symmetric searchable encryption. In Proceedings of the 8th ACM Symposium on Information, Computer and Communications Security, ASIA CCS ’13, Hangzhou, China, 8–10 May 2013; Chen, K., Xie, Q., Qiu, W., Li, N., Tzeng, W., Eds.; ACM: New York, NY, USA, 2013; pp. 265–276. [Google Scholar] [CrossRef]
- Cash, D.; Jarecki, S.; Jutla, C.; Krawczyk, H.; Roşu, M.C.; Steiner, M. Highly-scalable searchable symmetric encryption with support for boolean queries. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 18–22 August 2013; Springer: Cham, Switzerland, 2013; pp. 353–373. [Google Scholar]
- Rhee, H.S.; Park, J.H.; Susilo, W.; Lee, D.H. Improved searchable public key encryption with designated tester. In Proceedings of the 2009 ACM Symposium on Information, Computer and Communications Security, ASIACCS 2009, Sydney, Australia, 10–12 March 2009; Li, W., Susilo, W., Tupakula, U.K., Safavi-Naini, R., Varadharajan, V., Eds.; ACM: New York, NY, USA, 2009; pp. 376–379. [Google Scholar] [CrossRef]
- Lu, Y.; Li, J. Efficient searchable public key encryption against keyword guessing attacks for cloud-based EMR systems. Clust. Comput. 2019, 22, 285–299. [Google Scholar] [CrossRef]
- Senouci, M.R.; Benkhaddra, I.; Senouci, A.; Li, F. An efficient and secure certificateless searchable encryption scheme against keyword guessing attacks. J. Syst. Archit. 2021, 119, 102271. [Google Scholar] [CrossRef]
- Gu, X.; Wang, Z.; Fu, M.; Ren, P. A Certificateless Searchable Public Key Encryption Scheme for Multiple Receivers. In Proceedings of the 2021 IEEE International Conference on Web Services, ICWS 2021, Chicago, IL, USA, 5–10 September 2021; Chang, C.K., Daminai, E., Fan, J., Ghodous, P., Maximilien, M., Wang, Z., Ward, R., Zhang, J., Eds.; IEEE: Piscataway, NJ, USA, 2021; pp. 635–641. [Google Scholar] [CrossRef]
- Wang, P.; Wang, H.; Pieprzyk, J. Keyword field-free conjunctive keyword searches on encrypted data and extension for dynamic groups. In Proceedings of the International Conference on Cryptology and Network Security, Hong Kong, China, 2–4 December 2008; Springer: Cham, Switzerland, 2008; pp. 178–195. [Google Scholar]
- Zhang, B.; Zhang, F. An efficient public key encryption with conjunctive-subset keywords search. J. Netw. Comput. Appl. 2011, 34, 262–267. [Google Scholar] [CrossRef]
- Sun, S.; Liu, J.K.; Sakzad, A.; Steinfeld, R.; Yuen, T.H. An Efficient Non-interactive Multi-client Searchable Encryption with Support for Boolean Queries. In Proceedings of the Computer Security-ESORICS 2016 - 21st European Symposium on Research in Computer Security, Heraklion, Greece, 26–30 September 2016; Proceedings, Part I. Askoxylakis, I.G., Ioannidis, S., Katsikas, S.K., Meadows, C.A., Eds.; Springer: Cham, Switzerland, 2016; Volume 9878, pp. 154–172. [Google Scholar] [CrossRef]
- Bethencourt, J.; Sahai, A.; Waters, B. Ciphertext-policy attribute-based encryption. In Proceedings of the 2007 IEEE Symposium on Security and Privacy (SP’07), IEEE, Berkeley, CA, USA, 20–23 May 2007; pp. 321–334. [Google Scholar]
- Xu, L.; Yuan, X.; Steinfeld, R.; Wang, C.; Xu, C. Multi-writer searchable encryption: An LWE-based realization and implementation. In Proceedings of the 2019 ACM Asia Conference on Computer and Communications Security, Auckland, New Zealand, 9–12 July 2019; pp. 122–133. [Google Scholar]
- Camenisch, J.; Kohlweiss, M.; Rial, A.; Sheedy, C. Blind and anonymous identity-based encryption and authorised private searches on public key encrypted data. In Proceedings of the International Workshop on Public Key Cryptography, Irvine, CA, USA, 18–20 March 2009; pp. 196–214. [Google Scholar]
- Liu, X.; Yang, G.; Susilo, W.; Tonien, J.; Liu, X.; Shen, J. Privacy-preserving multi-keyword searchable encryption for distributed systems. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 561–574. [Google Scholar] [CrossRef]
- Liu, X.; Deng, R.H.; Choo, K.K.R.; Weng, J. An efficient privacy-preserving outsourced calculation toolkit with multiple keys. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2401–2414. [Google Scholar] [CrossRef]
- Xu, L.; Li, W.; Zhang, F.; Cheng, R.; Tang, S. Authorized keyword searches on public key encrypted data with time controlled keyword privacy. IEEE Trans. Inf. Forensics Secur. 2019, 15, 2096–2109. [Google Scholar] [CrossRef]
- Byun, J.W.; Rhee, H.S.; Park, H.A.; Lee, D.H. Off-line keyword guessing attacks on recent keyword search schemes over encrypted data. In Proceedings of the Workshop on Secure Data Management, Seoul, Korea, 10–11 September 2006; pp. 75–83. [Google Scholar]
- Yau, W.C.; Heng, S.H.; Goi, B.M. Off-line keyword guessing attacks on recent public key encryption with keyword search schemes. In Proceedings of the International Conference on Autonomic and Trusted Computing, Oslo, Norway, 23–25 June 2008; pp. 100–105. [Google Scholar]
- Huang, Q.; Li, H. An efficient public-key searchable encryption scheme secure against inside keyword guessing attacks. Inf. Sci. 2017, 403, 1–14. [Google Scholar] [CrossRef]
- Qin, B.; Chen, Y.; Huang, Q.; Liu, X.; Zheng, D. Public-key authenticated encryption with keyword search revisited: Security model and constructions. Inf. Sci. 2020, 516, 515–528. [Google Scholar] [CrossRef]
- He, D.; Ma, M.; Zeadally, S.; Kumar, N.; Liang, K. Certificateless Public Key Authenticated Encryption With Keyword Search for Industrial Internet of Things. IEEE Trans. Ind. Inf. 2018, 14, 3618–3627. [Google Scholar] [CrossRef]
- Xu, P.; Jin, H.; Wu, Q.; Wang, W. Public-key encryption with fuzzy keyword search: A provably secure scheme under keyword guessing attack. IEEE Trans. Comput. 2012, 62, 2266–2277. [Google Scholar] [CrossRef]
- Ghareh Chamani, J.; Papadopoulos, D.; Papamanthou, C.; Jalili, R. New constructions for forward and backward private symmetric searchable encryption. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1038–1055. [Google Scholar]
- Samanthula, B.K.; Chun, H.; Jiang, W. An efficient and probabilistic secure bit-decomposition. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 541–546. [Google Scholar]
- Kamara, S.; Mohassel, P.; Raykova, M. Outsourcing Multi-Party Computation. Available online: https://eprint.iacr.org/2011/272 (accessed on 25 May 2023).
- Bresson, E.; Catalano, D.; Pointcheval, D. A simple public-key cryptosystem with a double trapdoor decryption mechanism and its applications. In Proceedings of the Advances in Cryptology-ASIACRYPT 2003: 9th International Conference on the Theory and Application of Cryptology and Information Security, Taipei, Taiwan, 30 November–4 December 2003; Proceedings 9. Springer: Cham, Switzerland, 2003; pp. 37–54. [Google Scholar]
- Akinyele, J.; Green, M.; Rubin, A. Charm-Crypto Framework. Available online: https://eprint.iacr.org/2011/617 (accessed on 25 May 2023).
- Zheng, Y.; Xu, P.; Wang, W.; Chen, T.; Susilo, W.; Liang, K.; Jin, H. DEKS: A Secure Cloud-Based Searchable Service Can Make Attackers Pay. In Proceedings of the Computer Security-ESORICS 2022-27th European Symposium on Research in Computer Security, Copenhagen, Denmark, 26–30 September 2022; Proceedings, Part II. Atluri, V., Pietro, R.D., Jensen, C.D., Meng, W., Eds.; Springer: Cham, Switzerland, 2022; Volume 13555, pp. 86–104. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
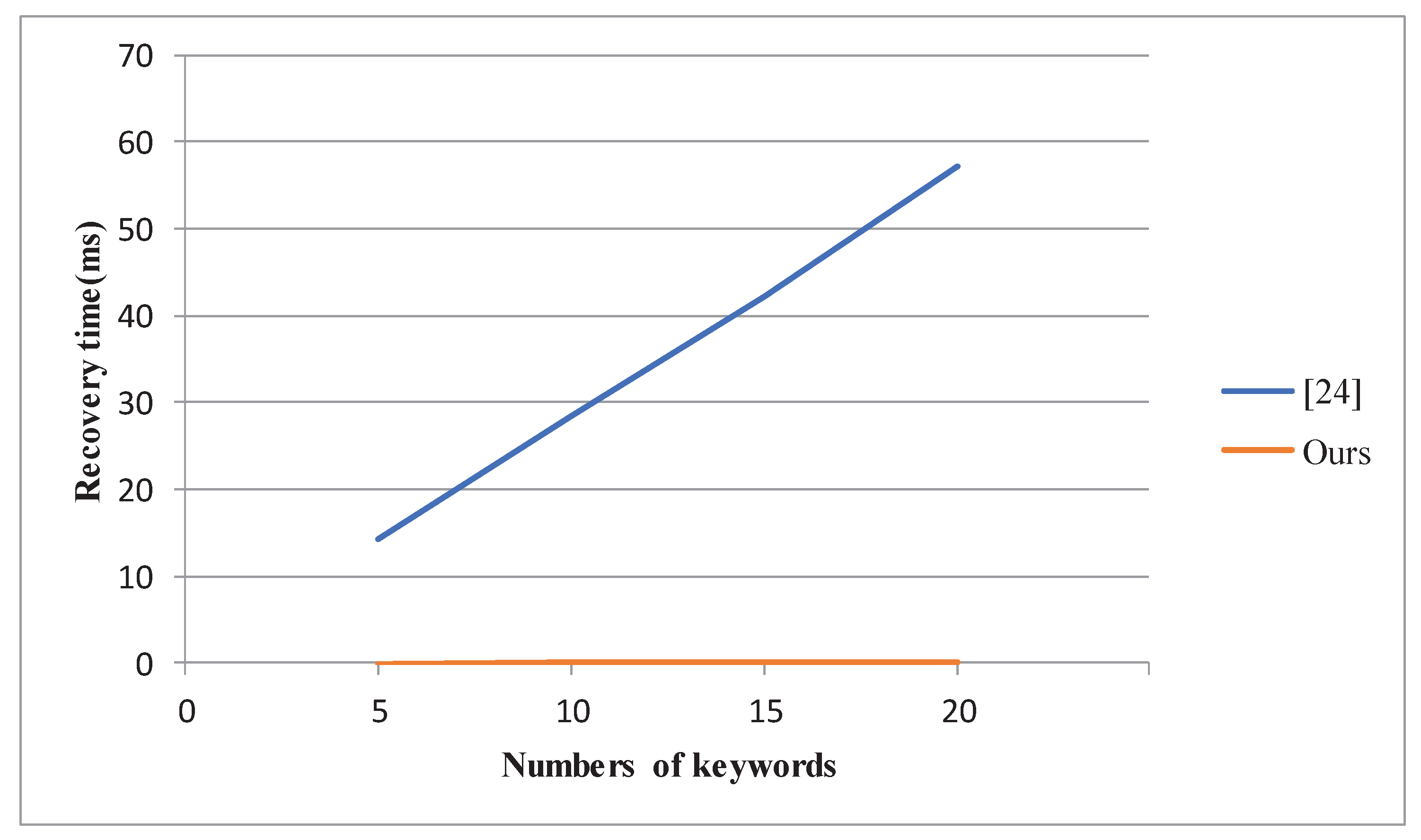{kind=link}
| Notations | Descriptions |
|---|---|
| W | The universal keyword set |
| D | A document |
| All documents stored on the server | |
| All documents that contain the keyword | |
| Keywords included in a query | |
| All keywords contained in document with identifier | |
| The keyword set represented by c | |
| A keyword | |
| The unsigned binary representation of a positive decimal c | |
| The highest bit | |
| The least bit | |
| The bit length of c, the number of keywords in W | |
| The complement of c | |
| T | A positive decimal integer is used as the plaintext representation of searchable ciphertext, and its binary representation can represent the relationship between the set and the universal set W |
| t | A positive decimal integer is used as the plaintext representation of searchable ciphertext, and its binary representation can represent the relationship between the set and the universal set W |
| Secret key of participant i | |
| Public key of participant i | |
| Partial master key of participant i | |
| Timestamp specified by DUs | |
| Timestamp generated periodically by the time server | |
| The encryption of · under the public key | |
| The decimal integer | |
| The bit length of · |
| Multi-User | KGA Resilience | Keyword Recovery | CipNum | TrapNum | CipSize | TrapSize | |
|---|---|---|---|---|---|---|---|
| [4] | × | × | × | ||||
| [22] | √ | √ | × | 1 | |||
| [24] | × | × | √ | ||||
| [36] | × | √ | × | ||||
| [16] | × | √ | × | 1 | |||
| [18] | × | √ | × | ||||
| ours | √ | √ | √ | 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Y.; Zhou, D.; Li, Y.; Song, B.; Wang, C. How Can We Achieve Query Keyword Frequency Analysis in Privacy-Preserving Situations? Future Internet 2023, 15, 197. https://doi.org/10.3390/fi15060197
Zhu Y, Zhou D, Li Y, Song B, Wang C. How Can We Achieve Query Keyword Frequency Analysis in Privacy-Preserving Situations? Future Internet. 2023; 15(6):197. https://doi.org/10.3390/fi15060197
Chicago/Turabian StyleZhu, Yiming, Dehua Zhou, Yuan Li, Beibei Song, and Chuansheng Wang. 2023. "How Can We Achieve Query Keyword Frequency Analysis in Privacy-Preserving Situations?" Future Internet 15, no. 6: 197. https://doi.org/10.3390/fi15060197
APA StyleZhu, Y., Zhou, D., Li, Y., Song, B., & Wang, C. (2023). How Can We Achieve Query Keyword Frequency Analysis in Privacy-Preserving Situations? Future Internet, 15(6), 197. https://doi.org/10.3390/fi15060197