
BERT4Loc: BERT for Location—POI Recommender System


Abstract
:1. Introduction
2. Related Work
3. Methodology
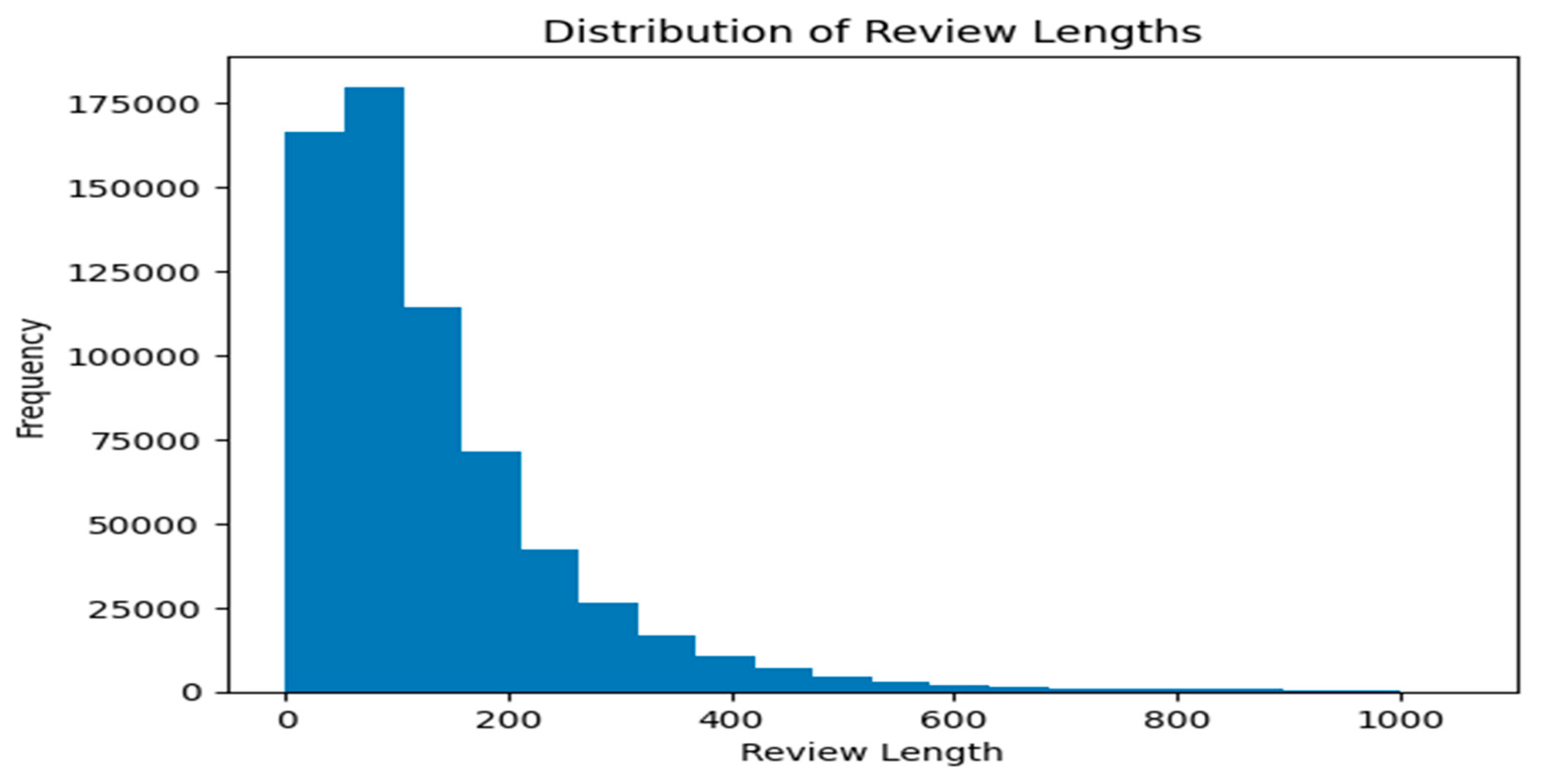
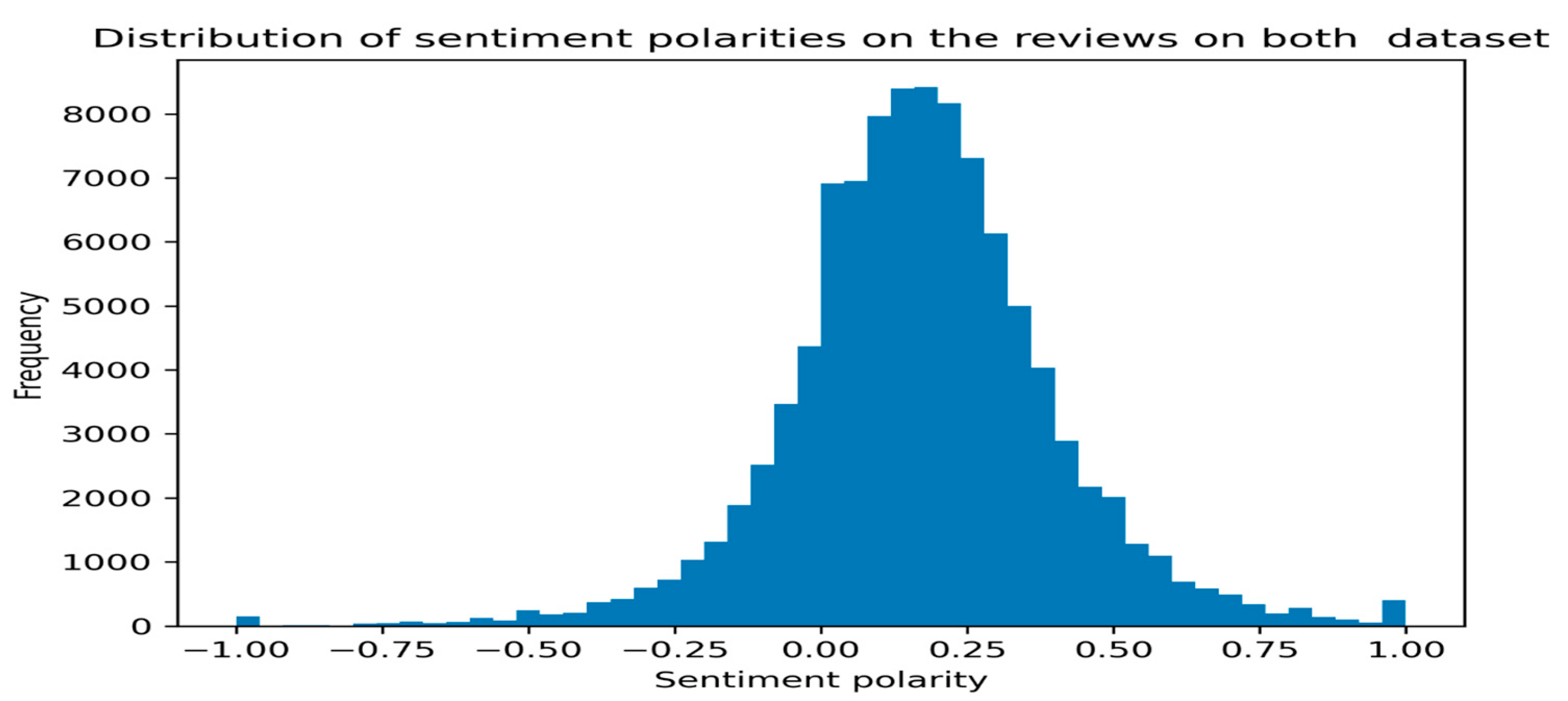
3.1. Data Collection
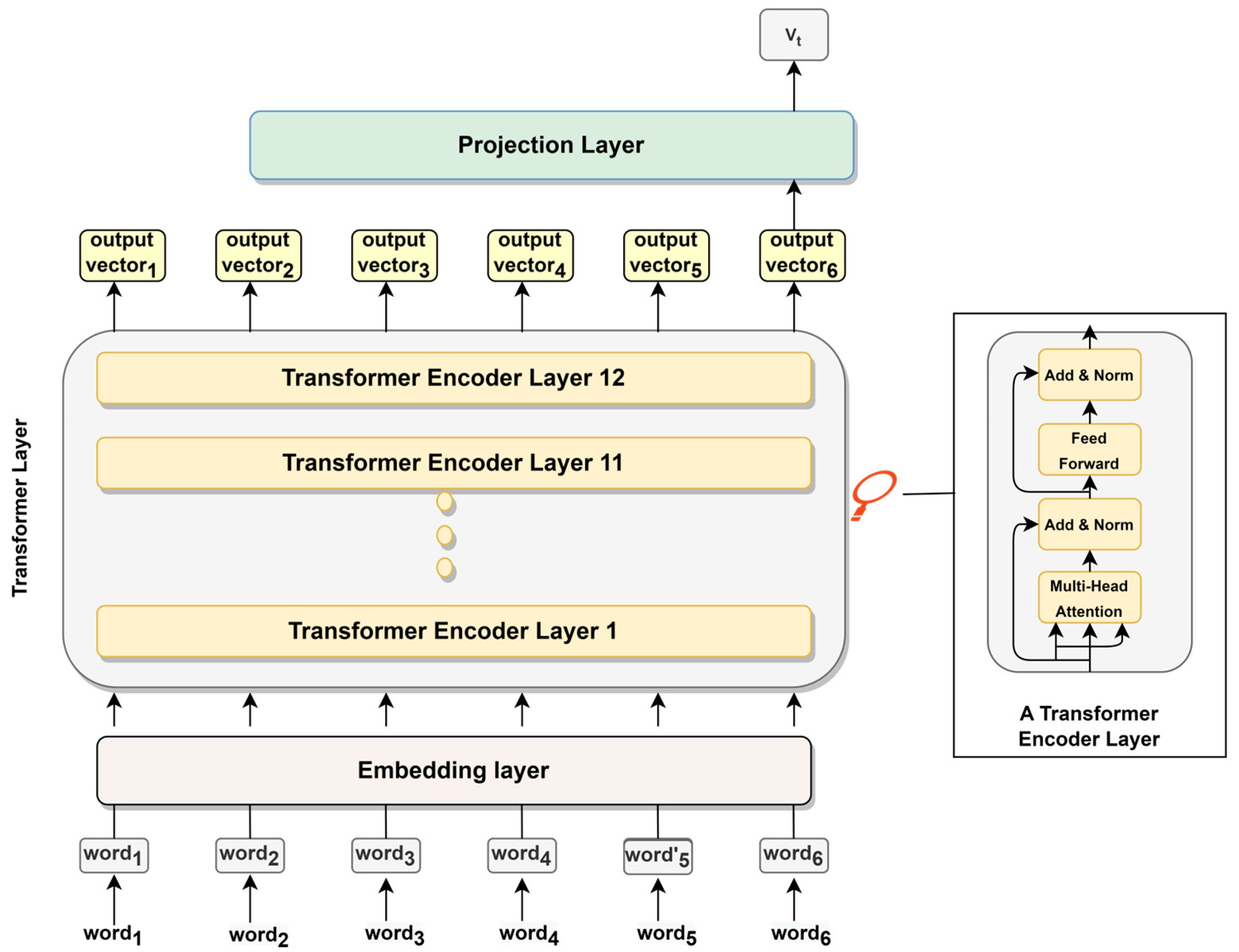
3.2. POI Recommendation Model
- Embedding layer: This layer learns a representation of the inputs, including the POI (business) ID and the associated metadata (e.g., business category), and transforms this representation into continuous vectors or “embeddings”. These embeddings capture the semantic meaning and characteristics of the inputs, providing dense information for the upcoming layers. The resulting embeddings are then passed to the Transformer Layer for further processing.
- Transformer layer: This layer consists of a stack of 12 Transformer blocks, each with 12 self-attention heads. The mechanism of self-attention allows the model to weigh the importance of each item in a sequence relative to the others. Each layer takes in a list of token embeddings and produces the same number of embeddings on the output (with transformed feature values). The output of the final Transformer block is passed to the projection layer.
- Projection layer: This layer takes the refined embeddings from the Transformer Layer and maps them into the item space. It uses a SoftMax layer to probabilistically rank all potential recommendations. We employ the Cloze task [36] as our training method. This method randomly masks certain items in the interaction sequence, prompting the model to predict these “hidden” (POI) items. The model learns to anticipate user behavior, preparing it to make future recommendations.
3.3. Training
3.4. Prediction and Recommendation
4. Experimental Setup
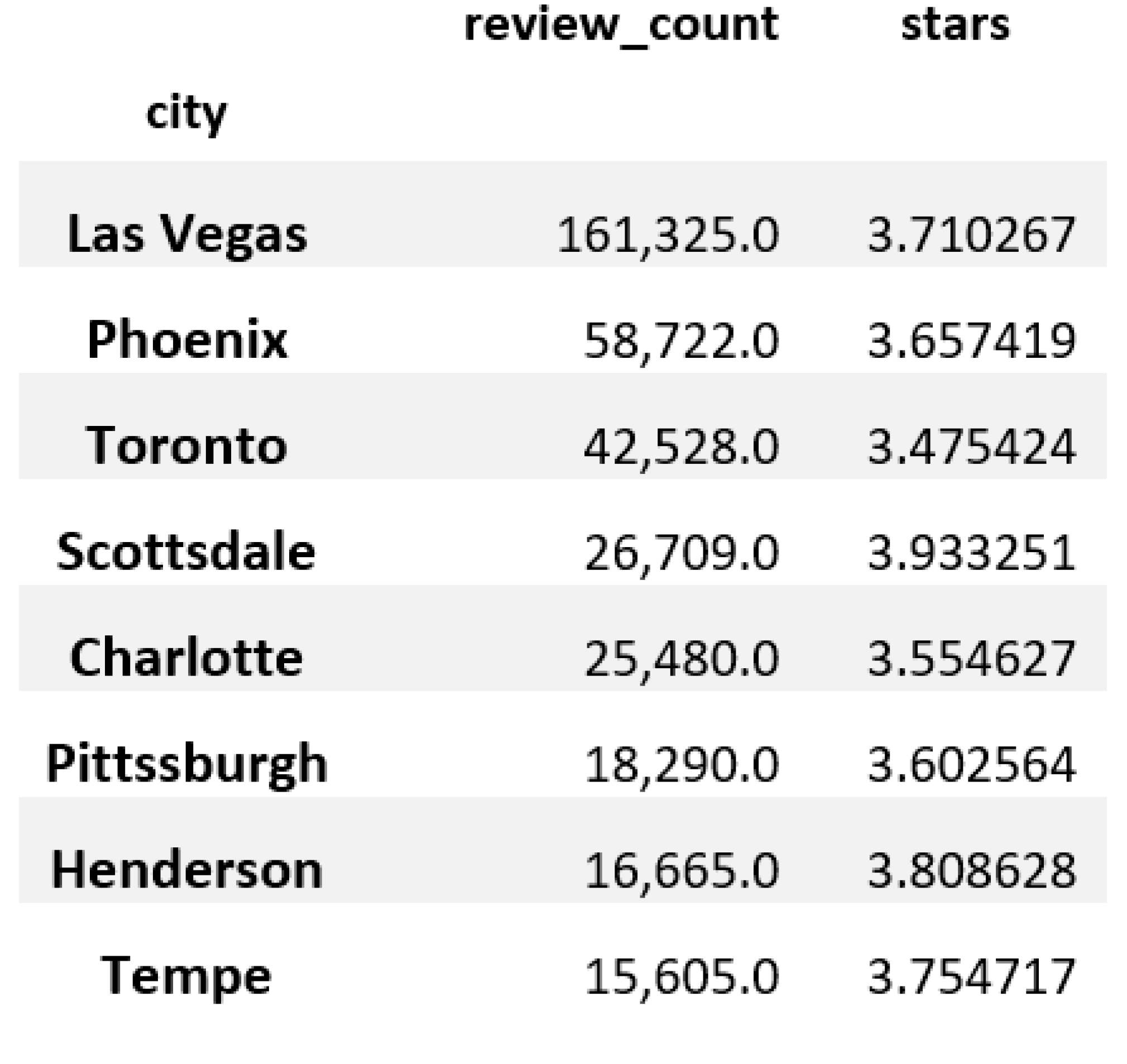
4.1. Data Set
4.2. Evaluation Methodology
4.3. Baselines
4.4. Hyperparameters Setting
5. Results and Analysis
5.1. Overall Results
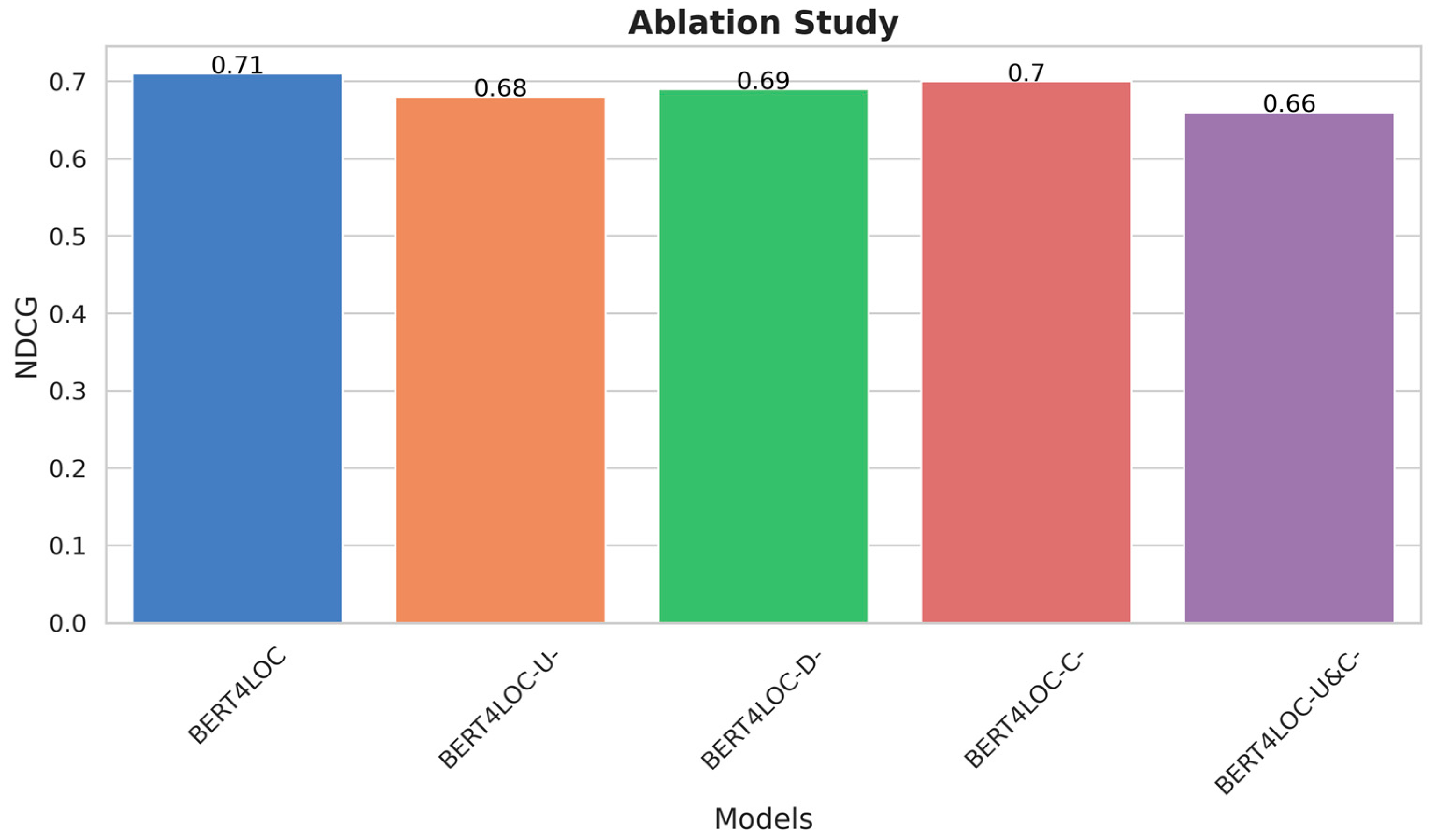
5.2. Ablations
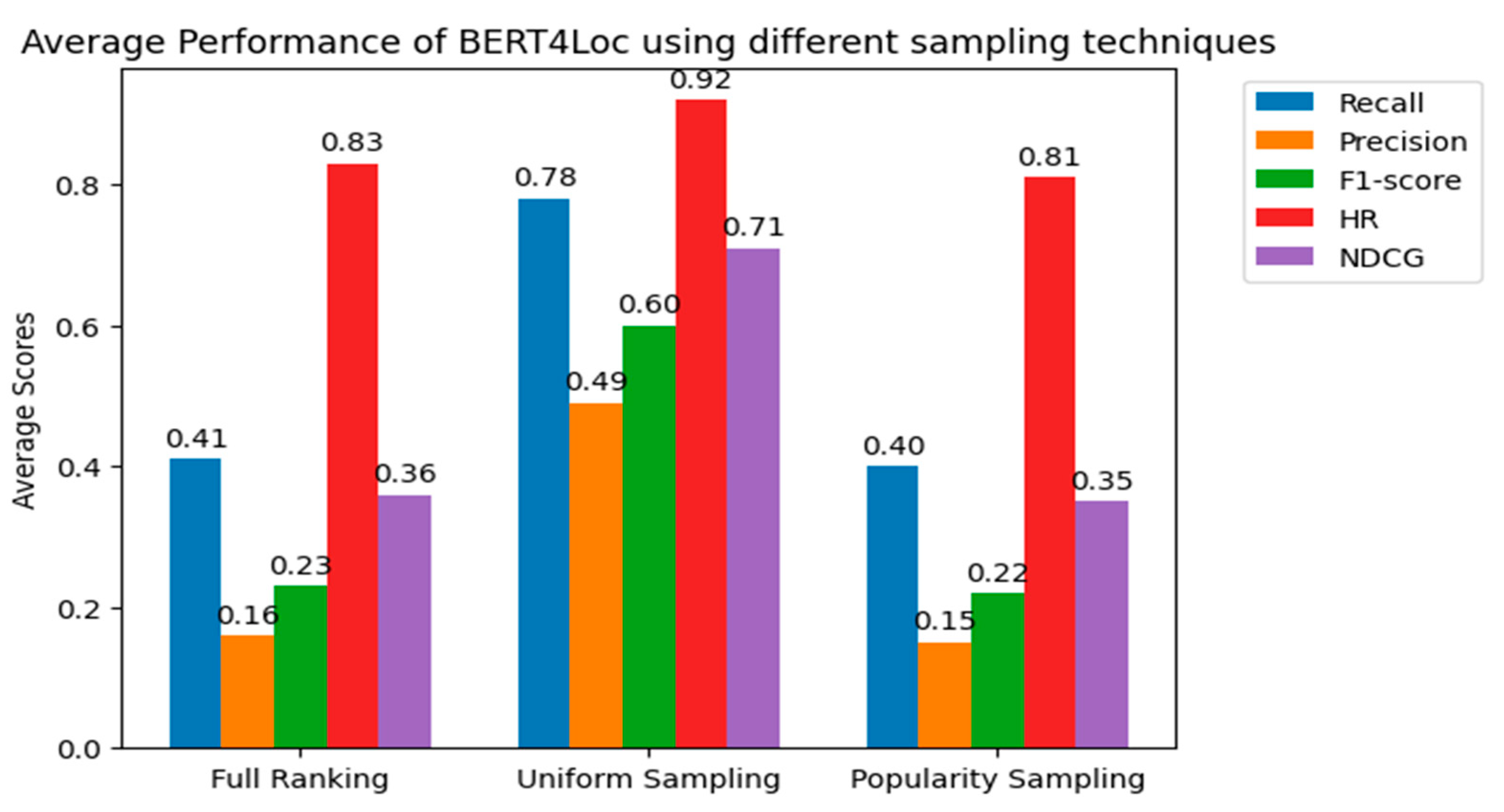
5.3. Effectiveness of Different Sampling Techniques
- Full ranking: evaluating the model on all sets of items.
- Uniform X (uni-X): uniformly sample X negative items for each positive item in the testing set, and evaluate the model’s performance for these positive items with their sampled negative items.
- Popularity X (pop-X): sample X negative items for each positive item in the testing set based on item popularity, and evaluate the model’s performance for these positive items with their sampled negative items.
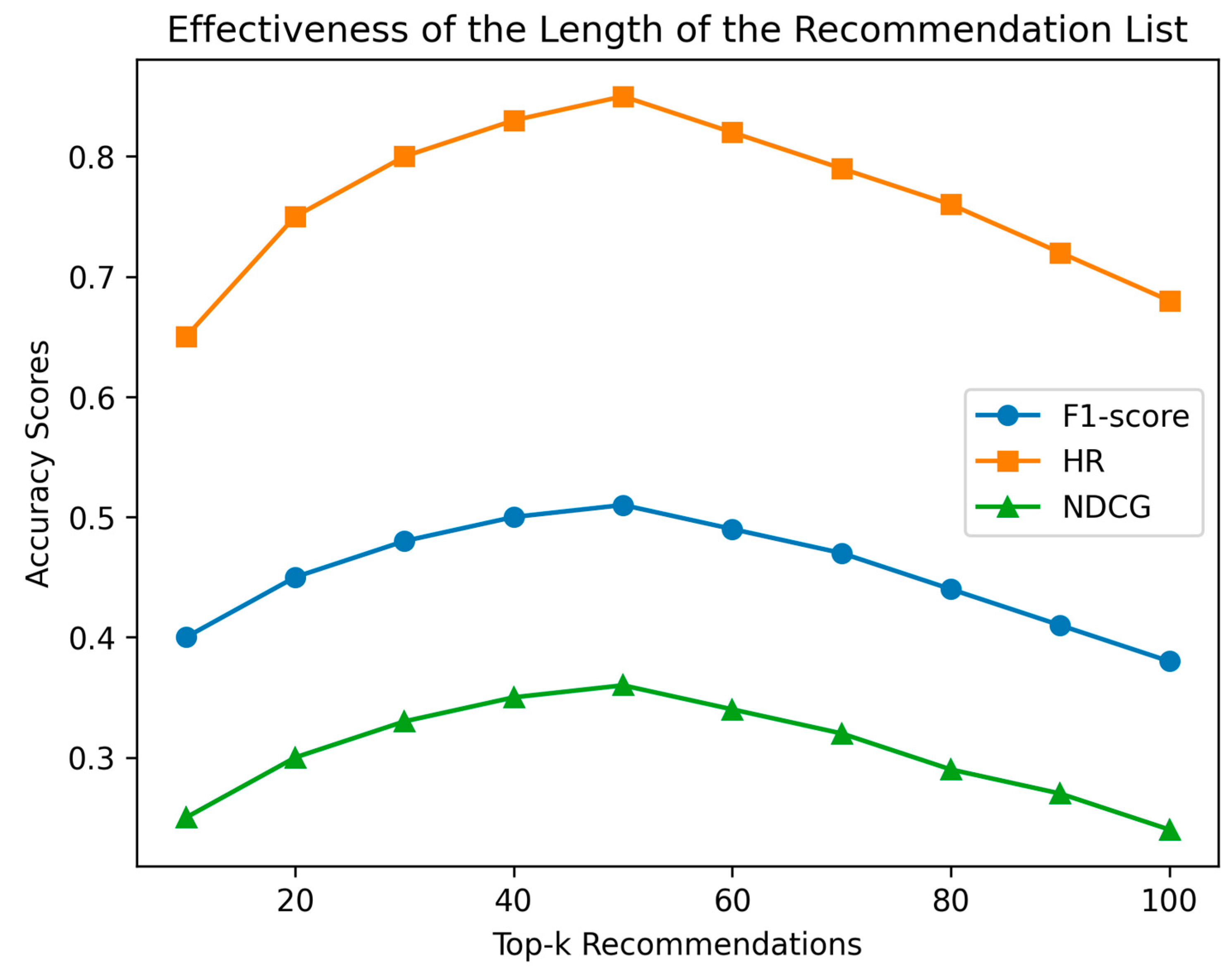
5.4. Effectiveness of the Length of the Recommendation List
5.5. Comparison of Cold-Start Approaches
5.6. Example of BERT4LOC
6. Discussion
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dingqi YANG Foursquare Dataset. Dingqi YANG’s Homepage; China. 2019. Available online: https://sites.google.com/site/yangdingqi/home (accessed on 1 May 2023).
- Cho, E.K.; Myers, S.A.; Leskovec, J. The Social Network of a Mobile Society: Combining Geographic and Social Network Analysis with Participatory Sensing. In Proceedings of the 2011 IEEE Third International Conference on Privacy, Security, Risk and Trust and 2011 IEEE Third International Conference on Social Computing, Boston, MA, USA, 9–11 October 2011; pp. 278–285. [Google Scholar]
- Raza, S.; Ding, C. Progress in Context-Aware Recommender Systems—An Overview. Comput. Sci. Rev. 2019, 31, 84–97. [Google Scholar] [CrossRef]
- Raza, S.; Ding, C. News Recommender System Considering Temporal Dynamics and News Taxonomy. In Proceedings of the—2019 IEEE International Conference on Big Data, Big Data 2019, Los Angeles, CA, USA, 9–12 December 2019; pp. 920–929. [Google Scholar]
- Karatzoglou, A.; Hidasi, B. Deep Learning for Recommender Systems. In Proceedings of the RecSys 2017—11th ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 396–397. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies—Proceedings of the Conference, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in {BERT}ology: What We Know About How {BERT} Works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Rendle, S. Factorization Machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Sun, F.; Liu, J.; Wu, J.; Pei, C.; Lin, X.; Ou, W.; Jiang, P. BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1441–1450. [Google Scholar]
- Lian, D.; Zhao, C.; Xie, X.; Sun, G.; Chen, E.; Rui, Y. GeoMF: Joint Geographical Modeling and Matrix Factorization for Point-of-Interest Recommendation. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 831–840. [Google Scholar] [CrossRef]
- Al-Molegi, A.; Jabreel, M.; Ghaleb, B. STF-RNN: Space Time Features-Based Recurrent Neural Network for Predicting People next Location. In Proceedings of the 2016 IEEE Symposium Series on Computational Intelligence (SSCI), Athens, Greece, 6–9 December 2016; pp. 1–7. [Google Scholar]
- Liu, W.; Wang, Z.J.; Yao, B.; Yin, J. Geo-ALM: POI Recommendation by Fusing Geographical Information and Adversarial Learning Mechanism. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 1807–1813. [Google Scholar]
- Jiao, X.; Xiao, Y.; Zheng, W.; Wang, H.; Hsu, C.H. A Novel next New Point-of-Interest Recommendation System Based on Simulated User Travel Decision-Making Process. Futur. Gener. Comput. Syst. 2019, 100, 982–993. [Google Scholar] [CrossRef]
- Nguyen, L.V.; Nguyen, T.H.; Jung, J.J. Tourism Recommender System Based on Cognitive Similarity between Cross-Cultural Users. In Proceedings of the Intelligent Environments 2021: Workshop Proceedings of the 17th International Conference on Intelligent Environments, Dubai, United Arab Emirates, 21–24 June 2021; Volume 29, pp. 225–232. [Google Scholar]
- Nguyen, L.V.; Jung, J.J.; Hwang, M. Ourplaces: Cross-Cultural Crowdsourcing Platform for Location Recommendation Services. ISPRS Int. J. Geo-Inf. 2020, 9, 711. [Google Scholar] [CrossRef]
- Li, Z.; Xiong, F.; Wang, X.; Chen, H.; Xiong, X. Topological Influence-Aware Recommendation on Social Networks. Complexity 2019, 2019, 6325654. [Google Scholar] [CrossRef]
- Guy, I. Social Recommender Systems. In Recommender Systems Handbook, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2015; pp. 511–543. ISBN 9781489976376. [Google Scholar]
- Jamali, M.; Ester, M. A Matrix Factorization Technique with Trust Propagation for Recommendation in Social Networks. In Proceedings of the Fourth ACM Conference on Recommender Systems, Barcelona, Spain, 26–30 September 2010; Association for Computing Machinery: New York, NY, USA, 2010; pp. 135–142. [Google Scholar]
- Ma, H.; Zhou, D.; Liu, C.; Lyu, M.R.; King, I. Recommender Systems with Social Regularization. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, Hong Kong, China, 9–12 February 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 287–296. [Google Scholar]
- Guo, G.; Zhang, J.; Yorke-Smith, N. TrustSVD: Collaborative Filtering with Both the Explicit and Implicit Influence of User Trust and of Item Ratings. Proc. Natl. Conf. Artif. Intell. 2015, 1, 123–129. [Google Scholar] [CrossRef]
- Guo, H.; Tang, R.; Ye, Y.; Li, Z.; He, X. DeepFM: A Factorization-Machine Based Neural Network for Ctr Prediction. arXiv 2017, arXiv:1703.04247. [Google Scholar]
- Wang, R.; Fu, B.; Fu, G.; Wang, M. Deep & Cross Network for Ad Click Predictions. arXiv 2017, arXiv:1708.05123. [Google Scholar]
- He, X.; Chua, T.-S. Neural Factorization Machines for Sparse Predictive Analytics. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017. [Google Scholar] [CrossRef] [Green Version]
- Xiao, J.; Ye, H.; He, X.; Zhang, H.; Wu, F.; Chua, T.-S. Attentional Factorization Machines: Learning the Weight of Feature Interactions via Attention Networks. arXiv 2017, arXiv:1708.04617. [Google Scholar]
- Feng, Y.; Lv, F.; Shen, W.; Wang, M.; Sun, F.; Zhu, Y.; Yang, K. Deep Interest Network for Click-through Rate Prediction. IJCAI Int. Jt. Conf. Artif. Intell. 2019, 2019, 2301–2307. [Google Scholar] [CrossRef] [Green Version]
- Quadrana, M.; Cremonesi, P.; Jannach, D. Sequence-Aware Recommender Systems. ACM Comput. Surv. 2018, 51, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Hidasi, B.; Karatzoglou, A.; Baltrunas, L.; Tikk, D. Session-Based Recommendations with Recurrent Neural Networks. arXiv 2015, arXiv:1511.06939. [Google Scholar]
- Kang, W.C.; McAuley, J. Self-Attentive Sequential Recommendation. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 197–206. [Google Scholar] [CrossRef] [Green Version]
- Pugoy, R.A.; Kao, H.-Y. {BERT}-Based Neural Collaborative Filtering and Fixed-Length Contiguous Tokens Explanation. In Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing 2020, Suzhou, China, 4–7 December 2020; pp. 143–153. [Google Scholar]
- Channarong, C.; Paosirikul, C.; Maneeroj, S.; Takasu, A. HybridBERT4Rec: A Hybrid (Content-Based Filtering and Collaborative Filtering) Recommender System Based on BERT. IEEE Access 2022, 10, 56193–56206. [Google Scholar] [CrossRef]
- Seol, J.J.; Ko, Y.; Lee, S.G. Exploiting Session Information in BERT-Based Session-Aware Sequential Recommendation. In Proceedings of the SIGIR 2022—Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval, Madrid, Spain, 11–15 July 2022; pp. 2639–2644. [Google Scholar]
- Wan, L.; Wang, H.; Hong, Y.; Li, R.; Chen, W.; Huang, Z. ITourSPOT: A Context-Aware Framework for next POI Recommendation in Location-Based Social Networks. Int. J. Digit. Earth 2022, 15, 1614–1636. [Google Scholar] [CrossRef]
- Zhong, C.; Xiong, F.; Pan, S.; Wang, L.; Xiong, X. Hierarchical Attention Neural Network for Information Cascade Prediction. Inf. Sci. 2023, 622, 1109–1127. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z.; Schmidt-Thieme, L. BPR: Bayesian Personalized Ranking from Implicit Feedback. arXiv 2012, arXiv:1205.2618. [Google Scholar]
- Wu, X.; Zhang, T.; Zang, L.; Han, J.; Hu, S. Mask and Infill: Applying Masked Language Model to Sentiment Transfer. IJCAI Int. Jt. Conf. Artif. Intell. 2019, 2019, 5271–5277. [Google Scholar] [CrossRef] [Green Version]
- Asghar, N. Yelp Dataset Challenge: Review Rating Prediction. 2016. Available online: https://arxiv.org/abs/1605.05362 (accessed on 1 May 2023).
- Hutto, C.J.; Gilbert, E. VADER: A Parsimonious Rule-Based Model for Sentiment Analysis of Social Media Text. In Proceedings of the 8th International Conference on Weblogs and Social Media, ICWSM 2014, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8, pp. 216–225. [Google Scholar]
- Liang, D.; Krishnan, R.G.; Hoffman, M.D.; Jebara, T. Variational Autoencoders for Collaborative Filtering. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 689–698. [Google Scholar]
- Chen, C.; Zhang, M.; Zhang, Y.; Liu, Y.; Ma, S. Efficient Neural Matrix Factorization without Sampling for Recommendation. ACM Trans. Inf. Syst. 2020, 38, 1–28. [Google Scholar] [CrossRef] [Green Version]
- Zhang, T.; Zhao, P.; Liu, Y.; Sheng, V.S.; Xu, J.; Wang, D.; Liu, G.; Zhou, X. Feature-Level Deeper Self-Attention Network for Sequential Recommendation. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Macao, China, 10–16 August 2019; pp. 4320–4326. [Google Scholar]
- Ren, P.; Chen, Z.; Li, J.; Ren, Z.; Ma, J.; De Rijke, M. Repeatnet: A Repeat Aware Neural Recommendation Machine for Session-Based Recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 4806–4813. [Google Scholar]
- Ning, X.; Karypis, G. Slim: Sparse Linear Methods for Top-n Recommender Systems. In Proceedings of the 2011 IEEE 11th International Conference on Data Mining, Vancouver, BC, Canada, 11–14 December 2011; pp. 497–506. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural Collaborative Filtering. In Proceedings of the 26th International World Wide Web Conference, WWW 2017, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Rendle, S.; Freudenthaler, C.; Schmidt-Thieme, L. Factorizing Personalized Markov Chains for Next-Basket Recommendation. In Proceedings of the 19th International Conference on World Wide Web, Raleigh, NC, USA, 26–30 April 2010; pp. 811–820. [Google Scholar]
- Krichene, W.; Rendle, S. On Sampled Metrics for Item Recommendation. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual Event, 23–27 August 2020; pp. 1748–1757. [Google Scholar] [CrossRef]
- Raza, S.; Ding, C. Deep Neural Network to Tradeoff between Accuracy and Diversity in a News Recommender System. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 5246–5256. [Google Scholar]
- Raza, S.; Ding, C. News Recommender System: A Review of Recent Progress, Challenges, and Opportunities. Artif. Intell. Rev. 2021, 55, 749–800. [Google Scholar] [CrossRef]
- Raza, S.; Schwartz, B. Entity and Relation Extraction from Clinical Case Reports of COVID-19: A Natural Language Processing Approach. BMC Med. Inform. Decis. Mak. 2023, 23, 20. [Google Scholar] [CrossRef]
- Raza, S.; Schwartz, B.; Rosella, L.C. CoQUAD: A COVID-19 Question Answering Dataset System, Facilitating Research, Benchmarking, and Practice. BMC Bioinform. 2022, 23, 210. [Google Scholar] [CrossRef] [PubMed]
- Collins, E. LaMDA: Our Breakthrough Conversation Technology. Google AI Blog 2021. OpenAI. Available online: https://blog.google/technology/ai/lamda/ (accessed on 1 May 2023).
- Roy, A.; Saffar, M.; Vaswani, A.; Grangier, D. Efficient Content-Based Sparse Attention with Routing Transformers. Trans. Assoc. Comput. Linguist. 2021, 9, 53–68. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Set of users | |
| Set of items (POI) | |
| List of interactions of user u with items | |
| Number of interactions of user u | |
| Item at the relative time step t for user u | |
| Set of keywords describing item v | |
| Set of side (metadata) information related to the items | |
| Set of all possible keyword combinations | |
| Embedding of the POI (item) identifier | |
| Embedding for the position of items in the sequence | |
| Input sequence length | |
| Sum of item embedding et and the positional embedding pt | |
| Embedding of the keywords Kvt of item vt | |
| Number of Transformer layers | |
| Last hidden state of the Lth Transformer layer | |
| Bayesian Personalized Ranking | |
| Number of sampled negative items in uniform distribution |
| Dataset | Unique Locations | Users | Check-Ins | Minimum Check-Ins per User | Features (User) | Features (Locations) |
|---|---|---|---|---|---|---|
| Yelp | 61,184 | 366,715 | 1,569,264 | N/A | User ID, User Reviews, Ratings, Timestamps | Location ID, Business Name, Category |
| Foursquare | 43,108 | 18,107 | 2,073,740 | 10 | User ID, User Reviews, Ratings, Timestamps | Location ID, Location Name, Category |
| Model | Top-k | Precision (Mean ± SD) | Recall (Mean ± SD) | F1-Score (Mean ± SD) | HR (Mean ± SD) | NDCG (Mean ± SD) |
|---|---|---|---|---|---|---|
| Yelp Dataset | ||||||
| BERT4Loc | 10 | 0.56 ± 0.04 | 0.45 ± 0.05 | 0.50 ± 0.05 | 0.82 ± 0.06 | 0.42 ± 0.03 |
| 20 | 0.52 ± 0.03 | 0.60 ± 0.07 | 0.56 ± 0.05 | 0.91 ± 0.04 | 0.51 ± 0.03 | |
| 50 | 0.49 ± 0.02 | 0.78 ± 0.09 | 0.60 ± 0.06 | 0.92 ± 0.03 | 0.71 ± 0.03 | |
| BERT4Rec | 10 | 0.61 ± 0.04 | 0.43 ± 0.05 | 0.50 ± 0.05 | 0.65 ± 0.05 | 0.52 ± 0.01 |
| 20 | 0.57 ± 0.03 | 0.49 ± 0.06 | 0.54 ± 0.06 | 0.72 ± 0.04 | 0.67 ± 0.03 | |
| 50 | 0.43 ± 0.03 | 0.72 ± 0.08 | 0.54 ± 0.06 | 0.86 ± 0.05 | 0.70 ± 0.03 | |
| MultiVAE | 10 | 0.28 ± 0.03 | 0.27 ± 0.04 | 0.27 ± 0.03 | 0.63 ± 0.05 | 0.33 ± 0.02 |
| 20 | 0.23 ± 0.02 | 0.39 ± 0.05 | 0.29 ± 0.03 | 0.78 ± 0.06 | 0.32 ± 0.03 | |
| 50 | 0.18 ± 0.02 | 0.48 ± 0.07 | 0.26 ± 0.03 | 0.87 ± 0.05 | 0.33 ± 0.03 | |
| RepeatNet | 10 | 0.26 ± 0.02 | 0.13 ± 0.03 | 0.17 ± 0.02 | 0.20 ± 0.03 | 0.18 ± 0.02 |
| 20 | 0.21 ± 0.01 | 0.24 ± 0.04 | 0.22 ± 0.03 | 0.23 ± 0.03 | 0.20 ± 0.02 | |
| 50 | 0.18 ± 0.01 | 0.41 ± 0.06 | 0.25 ± 0.03 | 0.34 ± 0.04 | 0.24 ± 0.03 | |
| SASRecF | 10 | 0.22 ± 0.02 | 0.14 ± 0.03 | 0.17 ± 0.02 | 0.12 ± 0.02 | 0.12 ± 0.01 |
| 20 | 0.20 ± 0.02 | 0.18 ± 0.04 | 0.19 ± 0.03 | 0.16 ± 0.03 | 0.15 ± 0.02 | |
| 50 | 0.19 ± 0.01 | 0.22 ± 0.04 | 0.20 ± 0.02 | 0.22 ± 0.03 | 0.16 ± 0.02 | |
| ENMF | 10 | 0.12 ± 0.01 | 0.14 ± 0.03 | 0.13 ± 0.02 | 0.20 ± 0.0 | 0.17 ± 0.02 |
| 20 | 0.11 ± 0.01 | 0.19 ± 0.03 | 0.14 ± 0.02 | 0.19 ± 0.03 | 0.18 ± 0.02 | |
| 50 | 0.10 ± 0.01 | 0.20 ± 0.04 | 0.13 ± 0.02 | 0.24 ± 0.03 | 0.20 ± 0.02 | |
| SLIM | 10 | 0.33 ± 0.03 | 0.32 ± 0.04 | 0.32 ± 0.03 | 0.55 ± 0.05 | 0.29 ± 0.02 |
| 20 | 0.28 ± 0.02 | 0.40 ± 0.05 | 0.33 ± 0.03 | 0.68 ± 0.06 | 0.31 ± 0.03 | |
| 50 | 0.23 ± 0.02 | 0.55 ± 0.07 | 0.32 ± 0.03 | 0.80 ± 0.05 | 0.35 ± 0.03 | |
| NCF | 10 | 0.41 ± 0.04 | 0.35 ± 0.05 | 0.38 ± 0.04 | 0.64 ± 0.06 | 0.25 ± 0.02 |
| 20 | 0.35 ± 0.03 | 0.45 ± 0.06 | 0.39 ± 0.04 | 0.76 ± 0.05 | 0.30 ± 0.03 | |
| 50 | 0.29 ± 0.02 | 0.65 ± 0.08 | 0.40 ± 0.05 | 0.86 ± 0.04 | 0.38 ± 0.03 | |
| GRU4Rec | 10 | 0.39 ± 0.03 | 0.27 ± 0.04 | 0.32 ± 0.03 | 0.61 ± 0.05 | 0.28 ± 0.02 |
| 20 | 0.34 ± 0.02 | 0.38 ± 0.05 | 0.36 ± 0.03 | 0.74 ± 0.05 | 0.33 ± 0.03 | |
| 50 | 0.27 ± 0.02 | 0.54 ± 0.07 | 0.36 ± 0.04 | 0.82 ± 0.05 | 0.37 ± 0.03 | |
| FPMC | 10 | 0.30 ± 0.03 | 0.21 ± 0.03 | 0.25 ± 0.02 | 0.47 ± 0.04 | 0.22 ± 0.02 |
| 20 | 0.25 ± 0.02 | 0.29 ± 0.04 | 0.27 ± 0.03 | 0.58 ± 0.05 | 0.24 ± 0.02 | |
| 50 | 0.20 ± 0.01 | 0.37 ± 0.05 | 0.26 ± 0.03 | 0.68 ± 0.06 | 0.27 ± 0.04 | |
| Foursquare Dataset | ||||||
| BERT4Loc | 10 | 0.54 ± 0.03 | 0.42 ± 0.04 | 0.48 ± 0.04 | 0.81 ± 0.05 | 0.40 ± 0.03 |
| 20 | 0.50 ± 0.03 | 0.58 ± 0.06 | 0.54 ± 0.04 | 0.89 ± 0.04 | 0.49 ± 0.03 | |
| 50 | 0.47 ± 0.02 | 0.76 ± 0.08 | 0.58 ± 0.05 | 0.91 ± 0.03 | 0.69 ± 0.03 | |
| BERT4REC | 10 | 0.59 ± 0.03 | 0.40 ± 0.04 | 0.48 ± 0.04 | 0.63 ± 0.05 | 0.50 ± 0.01 |
| 20 | 0.55 ± 0.03 | 0.47 ± 0.05 | 0.51 ± 0.03 | 0.70 ± 0.04 | 0.65 ± 0.02 | |
| 50 | 0.41 ± 0.02 | 0.70 ± 0.07 | 0.52 ± 0.05 | 0.84 ± 0.05 | 0.68 ± 0.03 | |
| MultiVAE | 10 | 0.27 ± 0.03 | 0.25 ± 0.03 | 0.26 ± 0.02 | 0.61 ± 0.05 | 0.32 ± 0.02 |
| 20 | 0.22 ± 0.02 | 0.37 ± 0.04 | 0.28 ± 0.02 | 0.76 ± 0.05 | 0.31 ± 0.03 | |
| 50 | 0.17 ± 0.02 | 0.46 ± 0.06 | 0.25 ± 0.02 | 0.85 ± 0.04 | 0.32 ± 0.03 | |
| RepeatNet | 10 | 0.25 ± 0.02 | 0.12 ± 0.02 | 0.16 ± 0.02 | 0.19 ± 0.03 | 0.17 ± 0.02 |
| 20 | 0.20 ± 0.01 | 0.23 ± 0.03 | 0.21 ± 0.02 | 0.22 ± 0.03 | 0.19 ± 0.02 | |
| 50 | 0.17 ± 0.01 | 0.39 ± 0.05 | 0.24 ± 0.02 | 0.33 ± 0.04 | 0.23 ± 0.03 | |
| SASRecF | 10 | 0.21 ± 0.02 | 0.13 ± 0.02 | 0.16 ± 0.02 | 0.11 ± 0.02 | 0.11 ± 0.01 |
| 20 | 0.19 ± 0.02 | 0.17 ± 0.03 | 0.18 ± 0.02 | 0.15 ± 0.03 | 0.14 ± 0.02 | |
| 50 | 0.18 ± 0.01 | 0.21 ± 0.03 | 0.19 ± 0.02 | 0.21 ± 0.03 | 0.15 ± 0.02 | |
| ENMF | 10 | 0.11 ± 0.01 | 0.13 ± 0.02 | 0.12 ± 0.02 | 0.19 ± 0.03 | 0.16 ± 0.02 |
| 20 | 0.10 ± 0.01 | 0.18 ± 0.03 | 0.13 ± 0.02 | 0.18 ± 0.03 | 0.17 ± 0.02 | |
| 50 | 0.09 ± 0.01 | 0.19 ± 0.03 | 0.12 ± 0.02 | 0.23 ± 0.03 | 0.19 ± 0.02 | |
| SLIM | 10 | 0.32 ± 0.03 | 0.30 ± 0.03 | 0.31 ± 0.02 | 0.54 ± 0.05 | 0.28 ± 0.02 |
| 20 | 0.27 ± 0.02 | 0.38 ± 0.04 | 0.32 ± 0.02 | 0.67 ± 0.05 | 0.30 ± 0.03 | |
| 50 | 0.22 ± 0.02 | 0.53 ± 0.06 | 0.31 ± 0.02 | 0.79 ± 0.04 | 0.34 ± 0.03 | |
| NCF | 10 | 0.39 ± 0.03 | 0.33 ± 0.04 | 0.36 ± 0.03 | 0.63 ± 0.05 | 0.24 ± 0.02 |
| 20 | 0.34 ± 0.03 | 0.43 ± 0.05 | 0.38 ± 0.03 | 0.75 ± 0.04 | 0.29 ± 0.03 | |
| 50 | 0.28 ± 0.02 | 0.63 ± 0.07 | 0.39 ± 0.04 | 0.85 ± 0.03 | 0.37 ± 0.03 | |
| GRU4Rec | 10 | 0.38 ± 0.03 | 0.26 ± 0.03 | 0.31 ± 0.02 | 0.60 ± 0.04 | 0.27 ± 0.02 |
| 20 | 0.33 ± 0.02 | 0.36 ± 0.04 | 0.34 ± 0.02 | 0.73 ± 0.04 | 0.32 ± 0.03 | |
| 50 | 0.26 ± 0.02 | 0.52 ± 0.06 | 0.35 ± 0.03 | 0.81 ± 0.04 | 0.36 ± 0.03 | |
| FPMC | 10 | 0.29 ± 0.02 | 0.20 ± 0.03 | 0.24 ± 0.02 | 0.46 ± 0.03 | 0.21 ± 0.02 |
| 20 | 0.24 ± 0.02 | 0.28 ± 0.03 | 0.26 ± 0.02 | 0.57 ± 0.04 | 0.23 ± 0.02 | |
| 50 | 0.19 ± 0.01 | 0.36 ± 0.04 | 0.25 ± 0.02 | 0.67 ± 0.03 | 0.26 ± 0.03 | |
| Model | Precision | Recall | F1-Score | HR | NDCG |
|---|---|---|---|---|---|
| Collaborative filtering | 0.38 | 0.45 | 0.41 | 0.79 | 0.35 |
| Content-based filtering | 0.29 | 0.34 | 0.31 | 0.72 | 0.27 |
| Hybrid approach | 0.47 | 0.53 | 0.49 | 0.86 | 0.42 |
| BERT4LOC | 0.78 | 0.49 | 0.60 | 0.92 | 0.71 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bashir, S.R.; Raza, S.; Misic, V.B. BERT4Loc: BERT for Location—POI Recommender System. Future Internet 2023, 15, 213. https://doi.org/10.3390/fi15060213
Bashir SR, Raza S, Misic VB. BERT4Loc: BERT for Location—POI Recommender System. Future Internet. 2023; 15(6):213. https://doi.org/10.3390/fi15060213
Chicago/Turabian StyleBashir, Syed Raza, Shaina Raza, and Vojislav B. Misic. 2023. "BERT4Loc: BERT for Location—POI Recommender System" Future Internet 15, no. 6: 213. https://doi.org/10.3390/fi15060213
APA StyleBashir, S. R., Raza, S., & Misic, V. B. (2023). BERT4Loc: BERT for Location—POI Recommender System. Future Internet, 15(6), 213. https://doi.org/10.3390/fi15060213