3.1. Model Prediction Process and Framework
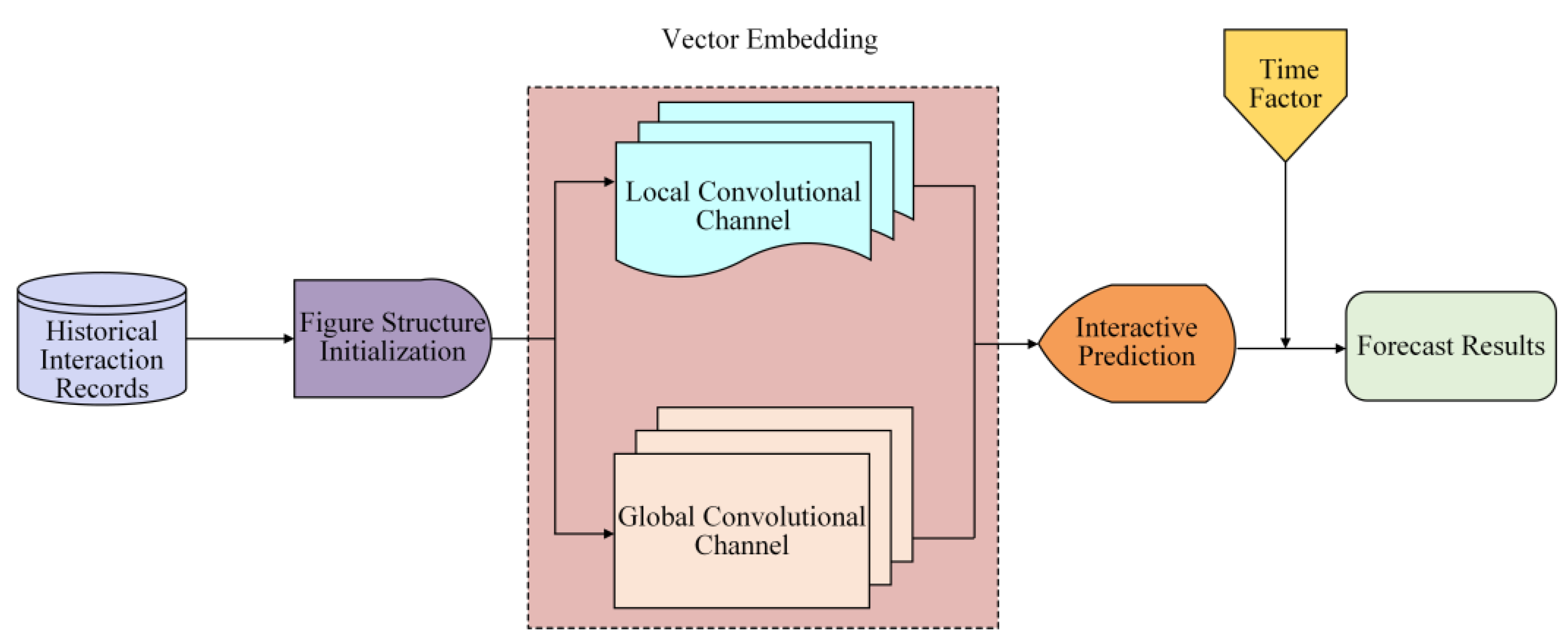
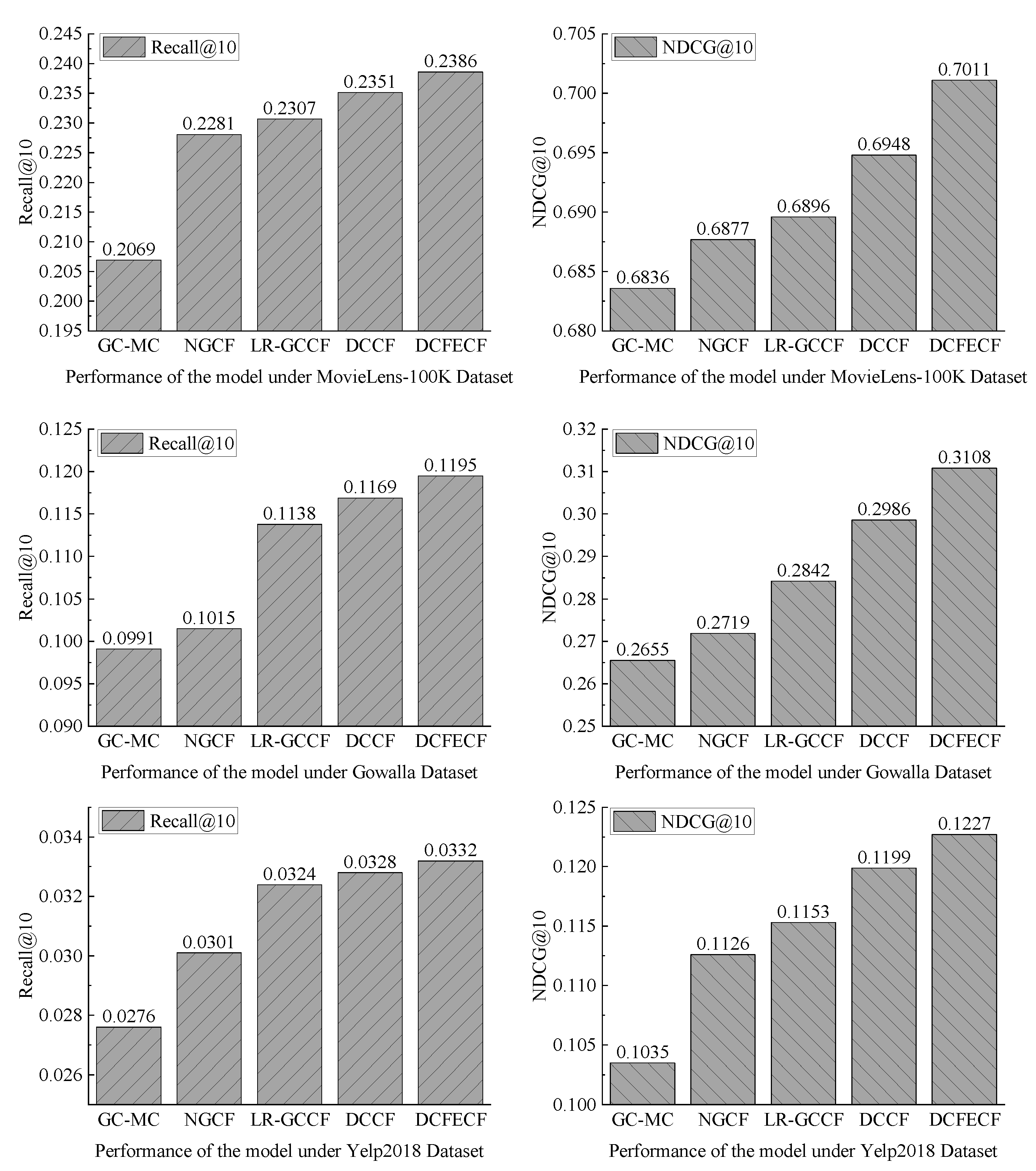
Compared with the DCCF model, the DCFECF model adds the introduction of the time factor. Its prediction process is shown in
Figure 1. Firstly, the initial graph structure is exported from the historical interaction record, including the bipartite interactive graph between users and items, and the initialization vector expression of nodes in the graph. Secondly, local and global convolutional channels are used to express the interaction relationship between higher-order nodes. Then, in the form of vector inner product, interactions that were not observed in historical interaction records are predicted. Finally, the time factor is added to the interactive prediction to further improve the prediction results.
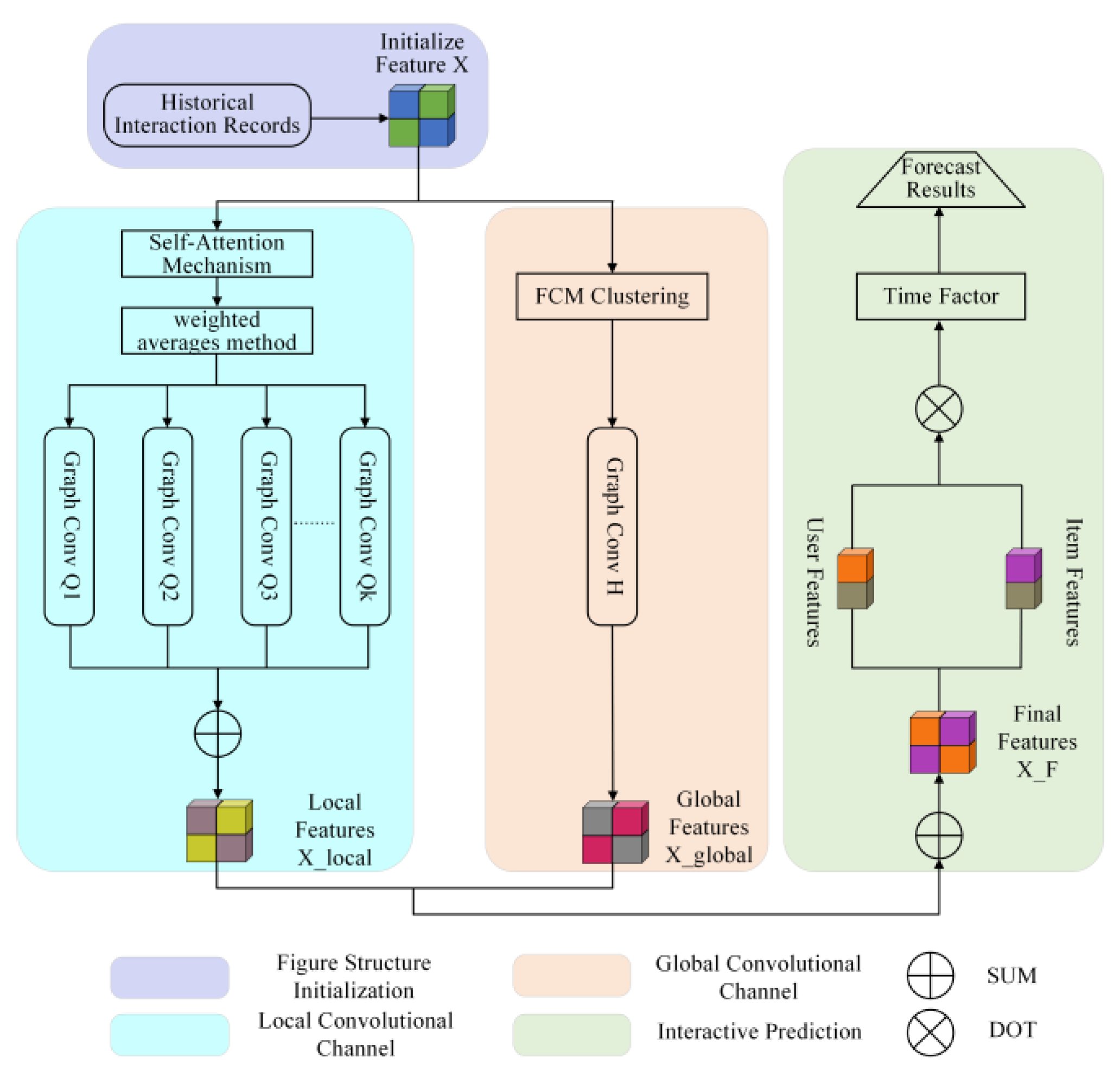
Based on the above analysis, the structure of the DCFECF model is shown in
Figure 2, which is mainly divided into three parts: the local convolutional channel, the global convolutional channel, and the interactive prediction module.
Where the local convolutional channel aggregates the feature information in the local neighborhood structure, it uses a state transition matrix to determine the high-order neighborhood range of nodes. By using the self-attention mechanism and the weighted average method, the threshold of the neighborhood transition probability of each order is obtained. Then, a single-layer graph convolutional network is used to aggregate local information between user nodes and item nodes, thereby suppressing the over-smoothing problem. In the global convolution channel, the fuzzy C-means clustering algorithm optimized by K-means++ clustering is used for clustering, and a global interaction graph is constructed. According to the feature similarity between nodes, neighbor nodes with similar features are selected for user and item nodes from the global perspective to supplement global information and overcome the problem that interaction information is limited to the local neighborhood. In the interaction prediction stage, local and global information are integrated, and the inner product of the vector representations of user nodes and item nodes is used to predict unknown interactions. Finally, the time factor is added to the interactive prediction to further improve the prediction results.
3.2. Local Convolutional Channel
Like the setting of DCCF, DCFECF introduces the transition matrix [
14] into the process of graph convolution operation, and the transition matrix is defined as Equation (5).
is the adjacency matrix of bipartite interactive graph, and is the degree matrix of the adjacency matrix. Each component in the first-order transition matrix represents the transition probability of node taking one step to reach node . For the higher-order transition matrix , each component of the matrix represents the probability of node taking steps to reach node .
In the local convolution channel, when determining the neighborhood range of user nodes and item nodes in the graph, the first-order neighborhood is determined by the adjacency matrix . For high-order neighborhoods with order greater than or equal to 2, the transition probability threshold for each order is set based on the corresponding transition matrix to determine the range of neighborhoods for each order of the node.
The transition probability threshold in DCCF is set to a fixed value of 0.5, and the neighborhood information filtered for different sample data is different. In fact, the process of determining the range of neighborhoods of different orders is progressive step by step. For example, when calculating the range of second-order neighborhoods, it is performed on the basis of first-order neighborhoods. The filtered second-order neighborhoods have strong correlation with the first-order neighborhoods, and nodes with high transfer probabilities are selected into the second-order neighborhoods. It can be considered that first-order neighborhood nodes play a certain role in determining the nodes of the second-order neighborhoods, and the weight values of the connecting edges of the two nodes become the basis for determining the strength of the correlation between the two nodes. By introducing the self-attention mechanism, the weight value of each edge can be obtained. By combining the weight value with the transfer probability, the weighted average value is obtained, which is the transfer probability threshold within the neighborhood of that order.
Based on the above analysis, the next step is to determine the transition probability threshold
for each order. Firstly, the self-attention mechanism [
15] is used to obtain the weight values of each edge. The self-attention mechanism can independently calculate attention weights at each position, which has advantages over traditional attention mechanisms. Assuming there are a total of
items, taking user
’s interaction with items
as an example to calculate the weight value, where
represents different items and
represents the user’s rating on the items. The specific process is as follows.
Step 1: Input source information. Enter the rating information for items.
Step 2: Calculate attention weight distribution. In the basic attention mechanism,
, calculate the attention distribution using Equation (6).
where
is the distribution of attention weights, representing the importance of information.
is the attention scoring mechanism, and we use the scaled dot product model as the scoring mechanism. The calculation formula is shown in Equation (7), and
represents that
has been normalized:
Step 3: Weighted summation of information. From
, we can obtain the degree of attention to
-th information when querying
q and then weigh and sum each value of
according to Equation (8).
Therefore, the weight value of user u‘s evaluation of items is expressed as .
Furthermore, if the weights of
are
, respectively, the formula for calculating the weighted average
of these
numbers is shown in Equation (9):
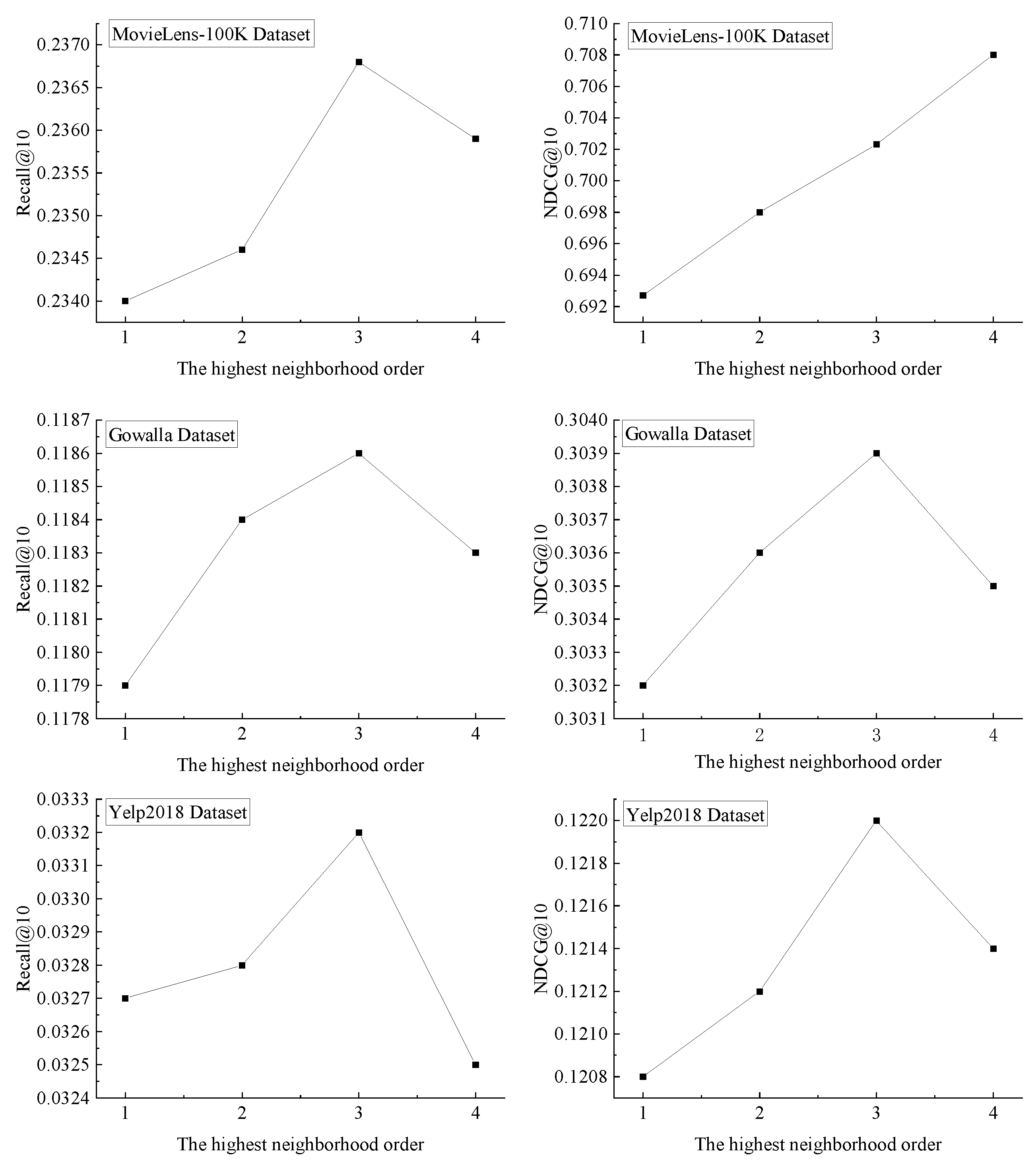
Assuming that the upper limit of the neighborhood order of user node
is
, the process of determining the transition probability threshold
for each order is listed in Algorithm 1:
| Algorithm 1: Calculation of transition probability threshold for the of user node in each order |
| Input: User-Item initialization bipartite interaction graph |
| Output: Transition probability threshold for each order |
| 1. Calculate the transfer matrix of each order, obtain the weight value of each connecting edge through the self-attention mechanism, and determine the first-order neighborhood range of user node . |
| 2. for from 2 to do |
| 3. Identify all -order nodes in the bipartite interaction graph, that is, all nodes that can reach user node through connecting edges. |
| 4. For each -order node, identify the nodes connected to it in the order neighborhood, and obtain the weight value of the connecting edges between the two nodes. |
| 5. Combine the weight value with the transfer probability of -order nodes to obtain the weighted average value, which is the -order transition probability threshold . |
| 6. end for |
| 7. return |
The following content continues the setting of neighborhood information aggregation methods in DCCF. If the component
in the transfer matrix exists, then there is a reachable path between node
and node
in the corresponding
-order neighborhood. Taking user node
and item node
as examples, the aggregation method of their corresponding neighborhood information is shown in Equations (10) and (11).
where
is the order of the neighborhood,
is the
k-th order neighborhood of the node, and
is the number of neighboring nodes within the
-th neighborhood of the node. In each order of neighborhood, the feature information of neighboring nodes is weighted and accumulated.
and
are attenuation coefficients, which play a normalization role. By integrating neighborhood information of each order through mean aggregation, local neighborhood features of nodes are obtained.
Finally, the output of the local convolutional channel is shown in Equations (14) and (15).
where
and
represent the characteristics of user node
u and item node
, respectively. In addition,
represents local neighborhood features. Combining node features and local neighborhood information of nodes, the calculation results of local convolutional channels are obtained.
3.3. Global Convolutional Channel
The fuzzy C-means clustering algorithm has strong scalability and can handle large-scale data. Compared to the K-means clustering algorithm, this algorithm integrates the essence of fuzzy theory and can provide more flexible clustering results. However, the fuzzy C-means clustering algorithm randomly selects the initial clustering centers, and different clustering centers will affect the convergence of the membership function and still fall into local optima. The K-means++ clustering algorithm is improved on the basis of the K-means clustering algorithm to ensure the uniformity of the clustering centers. If the K-means++ clustering algorithm is used to determine the initial clustering center of the fuzzy C-means clustering algorithm, and then the fuzzy C-means clustering algorithm is used for clustering, it not only solves the problem of easily falling into local optima but also improves the clustering effect, thereby constructing a more comprehensive global interaction graph.
In this section, we continue the setting of the global interaction graph and the information aggregation method within the global neighborhood in DCCF. In the global convolutional channel, a global interaction graph is constructed using clustering based on the vector features of user nodes and item nodes. By using a fuzzy C-means clustering algorithm optimized based on K-means++ for clustering, if two nodes are filtered into the same category, a connecting edge is added between the two nodes to obtain a global interaction graph .
In the local convolutional channel, the neighborhood feature information of each node is obtained. In order to reflect the structure of the nodes, the features of the nodes themselves are concatenated with the first-order neighborhood features:
where
is the Laplacian matrix of adjacency matrix
. Based on this, a node feature matrix
with first-order neighborhood information is obtained, and during the clustering process, user nodes and item nodes are treated as nodes of the same type for further classification. When using the fuzzy C-means clustering algorithm, the fuzzy index
is set to 2, and the iteration limit index
is set to 0.0005. The process of constructing the global interaction graph
is listed in Algorithm 2:
| Algorithm 2: Construction of global interaction graph |
| Input: with first-order neighborhood feature information |
| Output: Global interaction graph |
| 1. Randomly select one node from all nodes as the first clustering center, and use the K-means++ clustering algorithm to obtain clustering centers. |
| 2. Based on with first-order neighborhood feature information, calculate the distance between each node and cluster centers, calculate the membership degree according to Equation (3), obtain the initial membership matrix of the fuzzy C-means clustering algorithm, and calculate the objective function value according to Equation (1). |
| 3. Obtain the final membership matrix using the fuzzy C-means clustering algorithm. |
| 4. for each node in do |
| 5. Based on the feature vector of the current node , the final membership matrix is used to obtain the membership degree of each cluster node belonging to each cluster center. |
| 6. Sort according to the degree of membership, and classify the current node into the category with the highest degree of membership. |
| 7. Add all other nodes belonging to the category as neighboring nodes in the global neighborhood of current node . |
| 8. end for |
| 9. return |
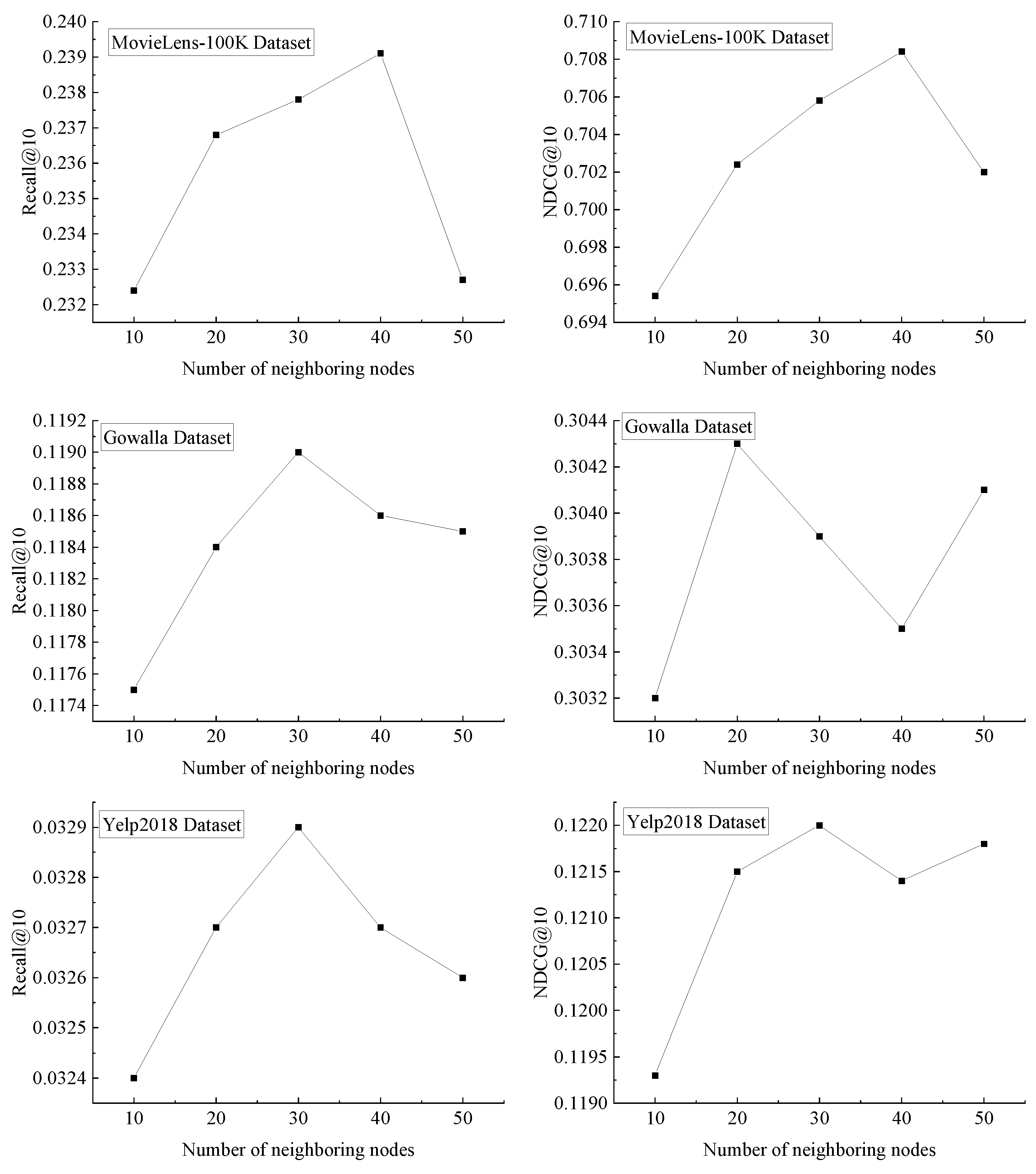
The clustering results obtained from the algorithm process also require secondary filtering, that is, for the neighborhoods of all nodes, a fixed number of neighboring nodes with the closest feature performance are selected for each node within its category. Taking user node
and item node
as examples, their information aggregation in the global neighborhood is shown in Equations (17) and (18):
where
and
represent the global neighborhood characteristics of user node
and item node
, respectively.
represents the global neighborhood of the node,
represents the number of neighboring nodes in the global neighborhood, and
is the attenuation coefficient, which plays a normalization role. Then, the original features of the nodes and the global neighborhood features are added to obtain the output of the global convolutional channel:
3.4. Time Factor Weighting
In the traditional collaborative filtering model, the similarity between users and the real score of users are usually taken into account when predicting the score, while the time factor is often ignored. In practical applications, users may no longer be interested in items they were previously interested in, especially as the impact on predictions gradually decreases over time. Therefore, a time factor is introduced to weight the score in order to more accurately predict the user’s next visit.
Among commonly used weighting functions, the Ebbinghaus forgetting curve and logistic function are widely used in research. Wang Y.G. et al. [
16] introduce the time factor
, as shown in Equation (21), to improve the recommendation effect by considering possible changes in user interest during different time periods. Yan H.G. et al. [
17] combine the Ebbinghaus forgetting curve with
to address the issue of long user history intervals, balance the scoring time difference, simulate changes in human interest, and optimize the time factor
to
, as shown in Equation (22).
where
is the time corresponding to the user’s rating of item
,
is the time corresponding to the user’s first item rating, and
is the total time the user has used the recommendation system.
In time factor
, the consideration is to homogenize the time interval for each user’s rating, assuming that the time interval for each user to rate the item is uniform. However, in practical application scenarios, the time interval for user rating is not uniform because user rating time exists in dense and non-dense areas [
18]. That is to say, the level of user memory for evaluation items over a period of time is not only related to the length of the interval but also to the number of items evaluated by the user during that period. If the number of item ratings accounts for a large proportion of the total number of item ratings from the first time that user rated an item to the time that user rated item
, it is considered that the user has a high level of memory during this period, and the time weight of the scoring intensive area should be appropriately increased.
Therefore, this paper modifies the time factor
and obtains the time factor
, denoted as function
, as shown in Equation (23):
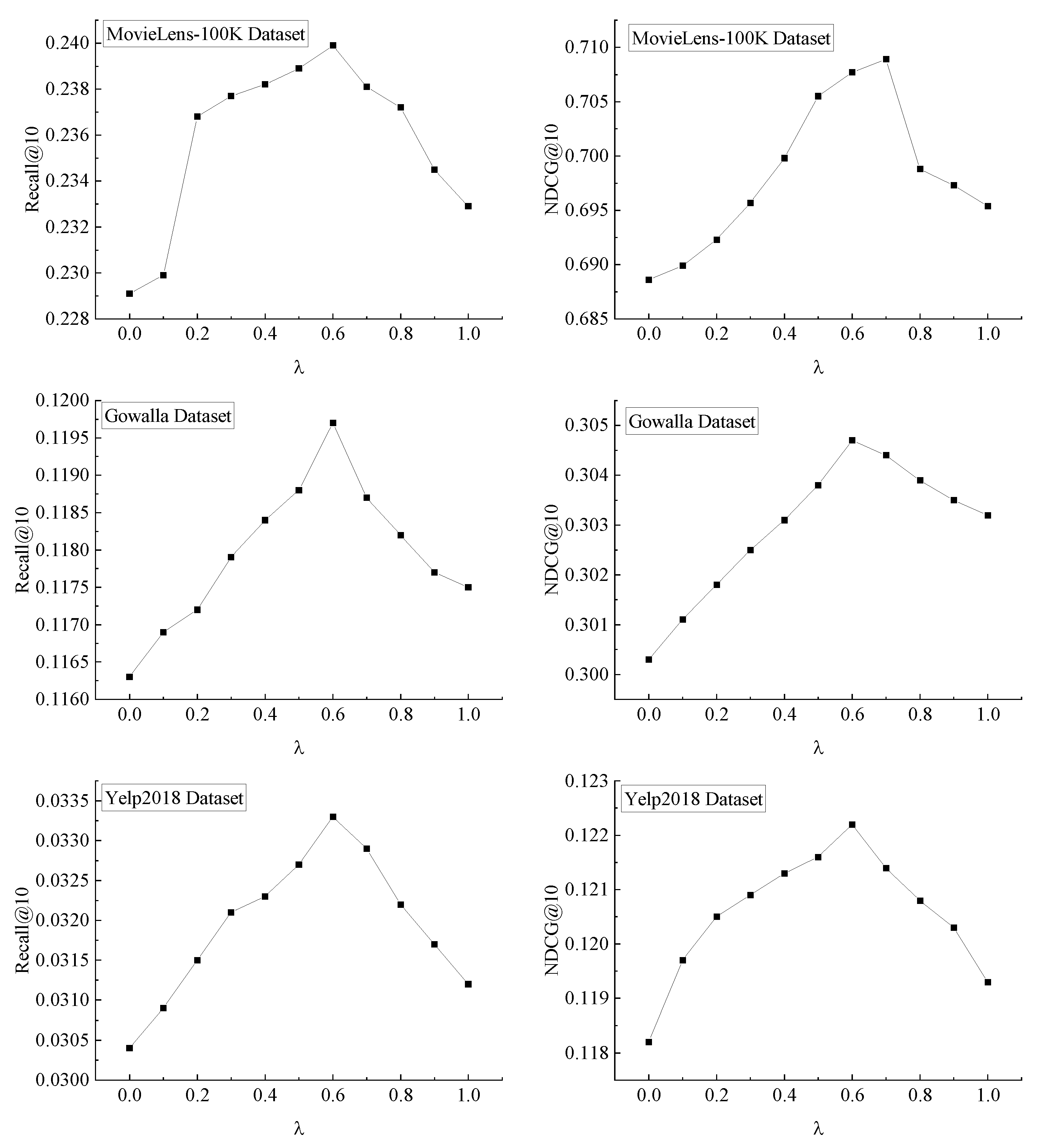
where
is a hyperparameter, which is used to balance the coefficient proportion of the time interval factor and item scoring density factor.
represents the time corresponding to the user’s last item rating,
represents the number of item ratings given by the user received during the time period from
to
, and
represents the total number of item ratings the user received during the use of the recommendation system.
We add a density factor of the item score in to make the time factor expression more reasonable and record function as function .











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}