1. Introduction
The evolution of 5G technology has ushered in a new era of connectivity, offering enhanced capabilities that extend beyond traditional communication paradigms. Advanced 5G networks facilitate a diverse range of applications, characterized by their complexity, computational demand, and low-latency requirements. These applications, designed to leverage the capabilities of advanced 5G, exhibit a hybrid profile, relying on resources spanning the spectrum from data centers to the cloud to the edge.
In particular, the deployment of edge infrastructure in 5G environments is crucial to addressing the unique challenges posed by latency-sensitive and data-intensive applications [
1,
2]. The next generation of applications, encompassing smart IoT applications, real-time analytics, machine learning applications, and more, require intelligent orchestration of resources in the edge domain, where computational tasks are strategically placed closer to data sources to minimize latency and enhance overall system performance.
Orchestrating edge infrastructure in 5G environments is not without its complexities. The heterogeneous nature of edge devices, coupled with the dynamic and resource-constrained characteristics of these environments, presents challenges for effective resource management. Unlike traditional cloud-centric models, the edge requires a nuanced approach that considers factors such as reliability, security, data protection, and energy efficiency. In light of these challenges, the need for intelligent orchestration becomes paramount. An orchestration system driven by artificial intelligence (AI) and machine learning (ML) techniques can dynamically allocate and coordinate resources across a distributed edge infrastructure.
In the current cloud market, various vendors and tools claim to employ intelligent techniques for resource management and monitoring. For instance, VMware implements a predictive distributed resource scheduler (DRS) [
3] for cloud platforms, which forecasts future demand and preemptively addresses potential hot spots, by reallocating workloads well in advance of any contention. OPNI [
4], an open source project from SUSE, is another noteworthy example aimed at enhancing observability, monitoring, and logging in Kubernetes-based clusters. It offers a range of AIOps tools for detecting log anomalies, identifying root causes, and spotting metric irregularities. Google Active Assist [
5] is another tool that aims to provide intelligent solutions for improving cloud operations, by offering recommendations for cost reduction, performance enhancement, security improvement, and sustainability. Generally, these prediction and optimization techniques deployed by cloud stakeholders are tailored for centralized cloud platforms and often comprise simple, proprietary solutions that may not be adaptable to highly distributed 5G edge environments. On the other hand, recent initiatives like OpenNebula OneEdge [
6] enable the deployment and management of geo-distributed edge/cloud infrastructures, leveraging resources from various public cloud and edge infrastructure providers. However, these tools are still nascent and primarily offer basic management functionalities rather than advanced, intelligent orchestration capabilities for optimizing the deployment of large scale edge infrastructures.
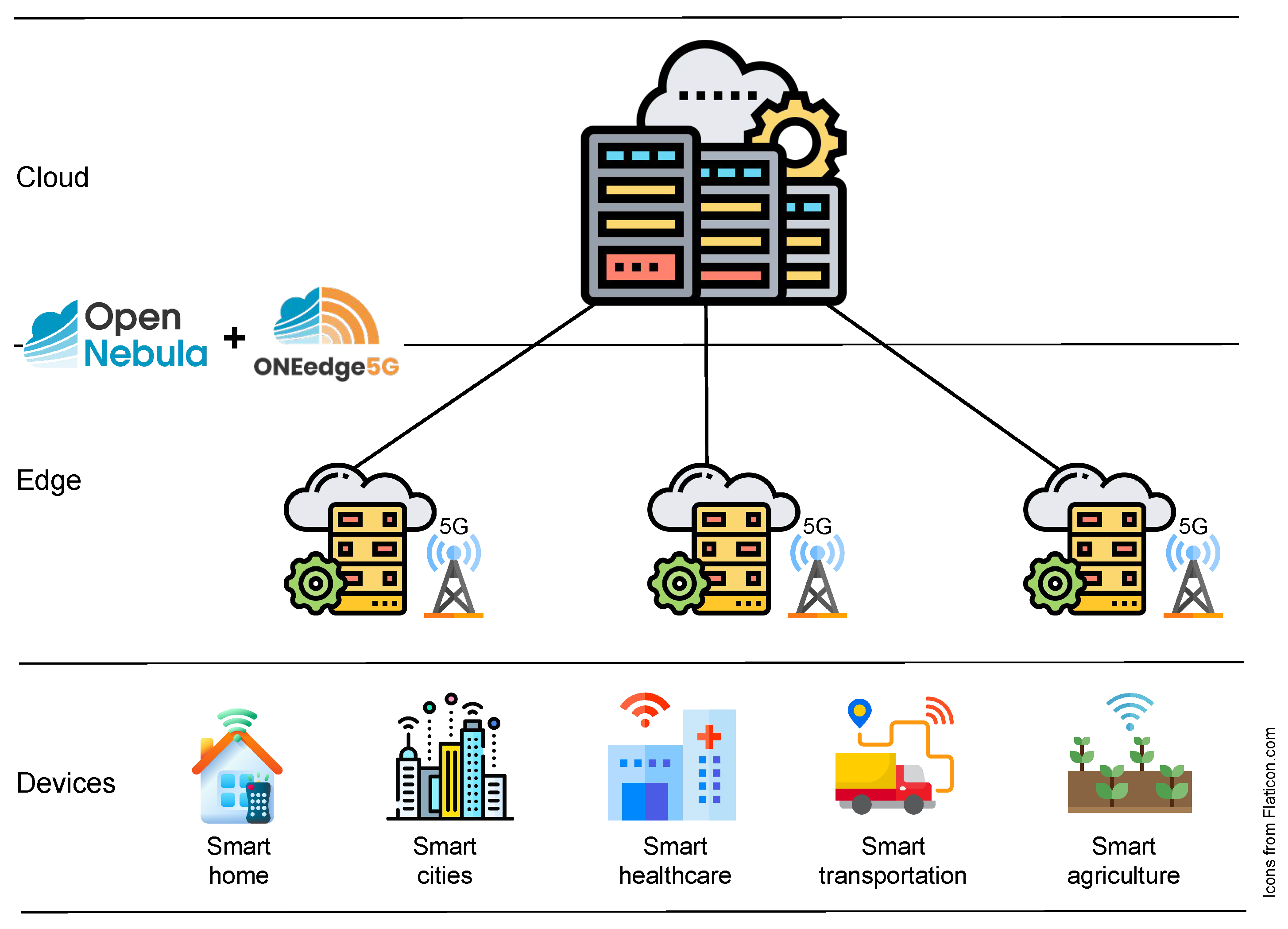
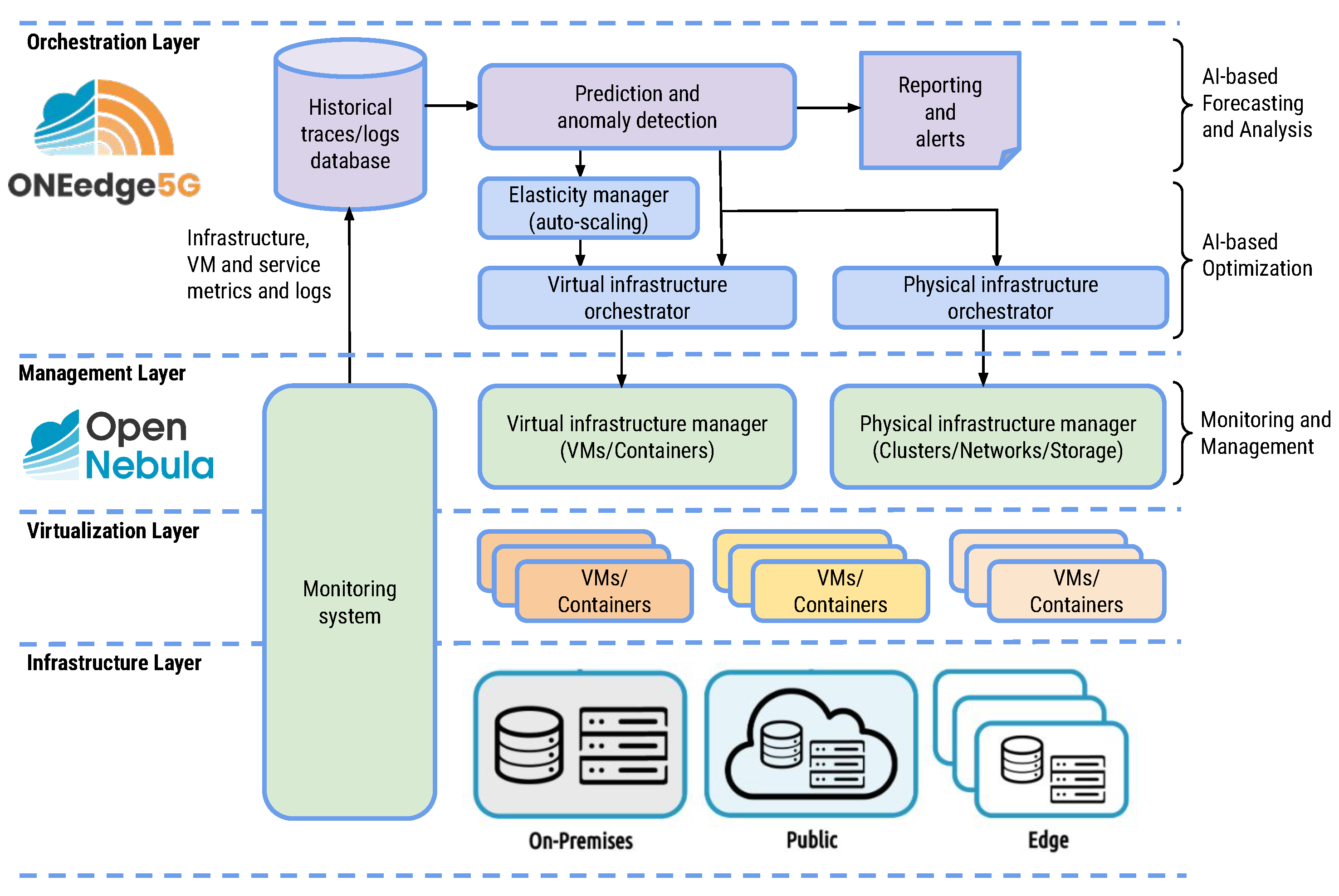
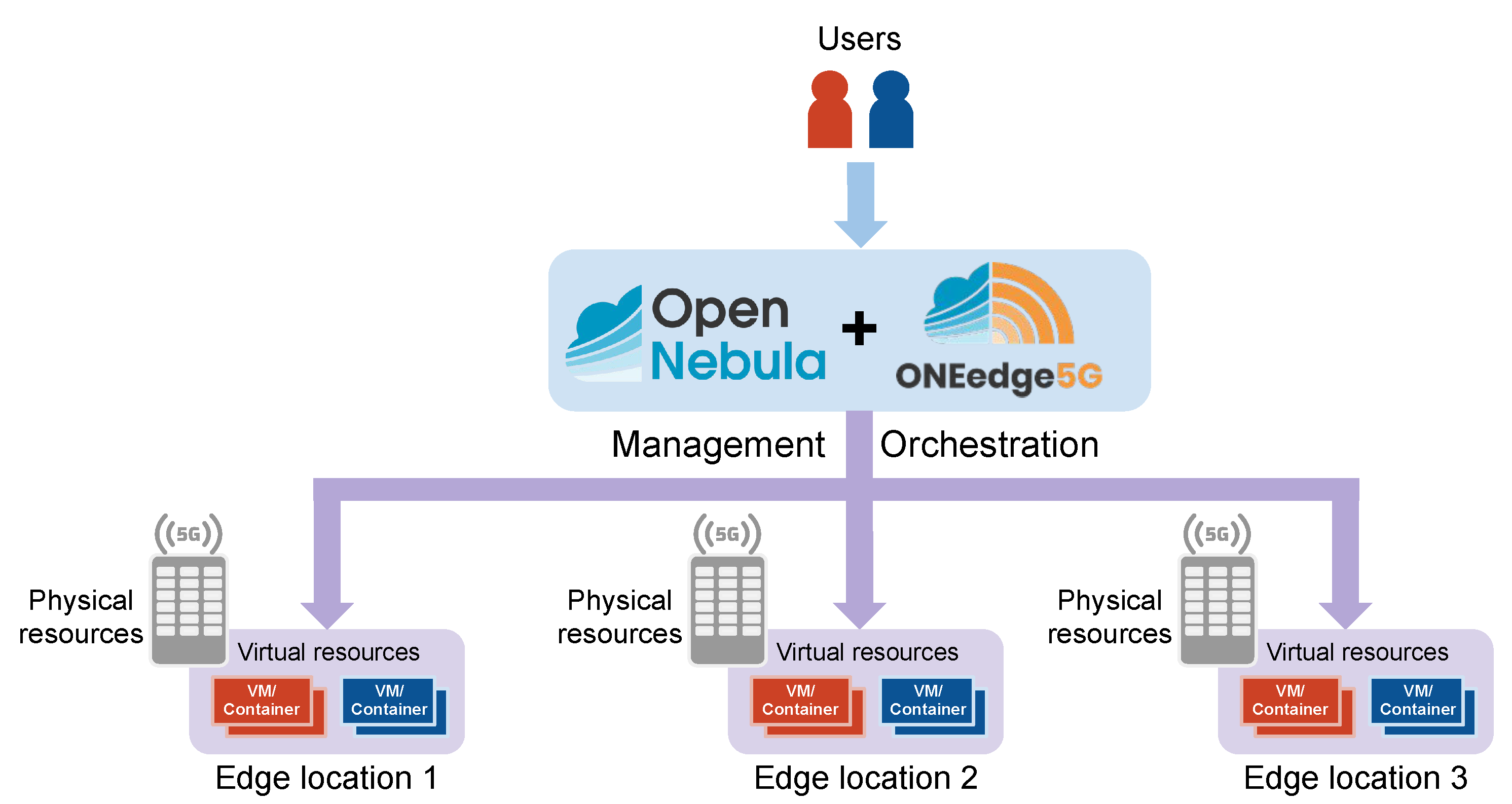
In this work, we propose a pioneering Smart 5G Edge-Cloud Management Architecture, which seeks to expand the existing edge management platforms by integrating intelligent orchestration capabilities. This integration aims to automate and optimize the provisioning and deployment of geographically distributed 5G edge infrastructures. This architecture, built upon the foundation of OpenNebula [
7,
8], will integrate cutting-edge experimental components under development in the ONEedge5G project, as shown in
Figure 1. ONEedge5G aims to enable efficient capacity planning, provisioning, and risk prevention in geographically distributed edge infrastructures and applications within the context of advanced 5G networks. This is achieved through the characterization and monitoring of edge infrastructures and virtual applications, prediction of the state of the data center–cloud–edge continuum, and programmatic intervention based on these predictions.
In its current developmental phase, ONEedge5G integrates diverse predictive intelligence mechanisms for workload forecasting. It also embeds various optimization algorithms to ensure optimal resource allocation across multiple edge locations. This paper introduces and assesses these intelligent techniques, demonstrating their effectiveness for improving the management and performance of distributed edge infrastructures.
To evaluate the efficacy of our Smart 5G Edge-Cloud Management Architecture, we conducted comprehensive tests and experiments. Through rigorous analysis, we assessed the capabilities of a ONEedge5G prototype in accurate workload forecasting and optimization. By presenting the results of these experiments, we demonstrate the benefits and efficiency gains achieved by leveraging intelligent prediction and optimization techniques in 5G edge management.
The remainder of this paper is structured as follows:
Section 2 analyzes the advantages and challenges of edge computing on 5G networks.
Section 3 discusses related works.
Section 4 presents the design and main components of the Smart 5G Edge-Cloud Management Architecture.
Section 5 summarizes the time-series forecasting models employed for workload prediction.
Section 6 introduces the mathematical models utilized in the integer linear programming (ILP) formulation for edge resource optimization.
Section 7 demonstrates the virtual resource CPU usage forecasting results for the different datasets and the resource optimization outcomes for the various objective functions and constraints. Finally,
Section 8 summarizes the conclusions of this study and suggests potential directions for future research.
2. Edge Computing and Advanced 5G Networks
Advanced 5G networks bring a multitude of advantages [
9], including significantly faster data speeds, through enhanced mobile broadband (eMBB), ultra-reliable and low-latency communication (URLLC), and support for a large number of connected devices with massive machine-type communication (mMTC). The implementation of network slicing allows customizable network services, tailoring offerings to specific requirements, while technologies like beamforming and MIMO contribute to improved network coverage and efficiency. Deploying edge computing infrastructures on advanced 5G networks offers several key benefits. First, it significantly reduces latency by processing data closer to the source, ensuring quicker response times for applications. This is particularly crucial for real-time applications like augmented reality and autonomous vehicles. Second, edge computing enhances energy efficiency by minimizing data transmission between central clouds and end devices, contributing to a more sustainable network. Third, the proximity of computational resources at the edge ensures improved application performance, particularly for latency-sensitive tasks. The combination of these technologies, along with the growth of the Internet of Things (IoT), has given rise to the emergence of new computing paradigms, such as multi-access edge computing (MEC) [
10], which is aimed at extending cloud computing capabilities to the edge of the radio access network, hence providing real-time, high-bandwidth, and low-latency access to radio network resources.
According to [
11], the main objectives of edge computing in 5G environments are the following: (1) improving data management, in order to handle the large amounts of real-time delay-sensitive data generated by user equipments (UEs); (2) improving quality of service (QoS) to meet diverse QoS requirements, thereby improving the quality of experience (QoE) for applications that demand low latency and high bandwidth; (3) predicting network demand, which involves estimating the network resources required to cater to local proximity network (or user) demand, and subsequently providing optimal resource allocation; (4) managing location awareness, to enable geographically distributed edge servers to infer their own locations and track the location of UEs to support location-based services; and (5) improving resource management, in order to optimize network resource utilization for network performance enhancement in the edge cloud, acknowledging the challenges of catering to diverse applications, user requirements, and varying demands with limited resources compared to the central cloud.
Focusing on the last objective, efficient resource management and orchestration in 5G edge computing [
12,
13] are crucial as they not only contribute to latency reduction by strategically deploying computing resources, minimizing the time for data processing and enhancing application responsiveness, but also play a pivotal role in optimizing energy consumption through dynamic allocation based on demand, thereby reducing the environmental footprint. Furthermore, proper resource management is essential for performance optimization, preventing bottlenecks, ensuring balanced workload distribution, and maintaining consistent application performance, all of which collectively enhance the overall user experience in these advanced network environments. In this context, AI and ML techniques prove instrumental in addressing these challenges [
14,
15,
16,
17,
18]. For example, through predictive analytics and forecasting, ML algorithms can anticipate future demands, enabling proactive resource allocation and strategic deployment for minimized data processing times and reduced latency. AI-driven dynamic allocation can optimize resource utilization and, consequently, energy consumption by adapting to real-time demand patterns. Additionally, ML models, employing clustering and anomaly detection, can ensure consistent application performance by preventing bottlenecks and optimizing workload distribution.
In this article, we specifically address the issue of intelligent resource orchestration in distributed edge computing infrastructures by integrating forecasting techniques for predicting resource utilization [
19,
20] and optimization techniques for optimal resource allocation [
21,
22]. Resource utilization forecasting leverages historical and real-time data to predict future resource demands accurately. By employing both traditional statistical techniques and AI-based ML techniques [
23,
24], these forecasts enable proactive resource allocation, mitigating the risk of resource shortages or over-provisioning. Furthermore, forecasting techniques facilitate capacity planning, allowing organizations to scale their resources dynamically based on anticipated demands. Optimization techniques also play a vital role in orchestrating resources across multiple edge locations. These techniques employ mathematical models such as ILP and heuristic algorithms [
25,
26] to determine the optimal mapping of virtual resources (VMs or containers) onto physical servers. By considering various factors including proximity, resource availability, and application requirements, these techniques ensure efficient utilization of resources and minimize resource fragmentation.
3. Related Work
The literature has extensively explored the application of artificial intelligence (AI) techniques, including evolutionary algorithms and machine learning (ML) algorithms, to address diverse prediction and optimization challenges in both cloud and edge environments. A recent study [
27] offered a comprehensive review of machine-learning-based solutions for resource management in cloud computing. This review encompassed areas such as workload estimation, task scheduling, virtual machine (VM) consolidation, resource optimization, and energy efficiency techniques. Additionally, a recent book [
28] compiled various research works that considered optimal resource allocation, energy efficiency, and predictive models in cloud computing. These works leveraged a range of ML techniques, including deep learning and neural networks. For edge computing platforms, surveys such as [
29] have analyzed different machine and deep learning techniques for resource allocation in multi-access edge computing. Similarly, ref. [
30] provided a review of task allocation and optimization techniques in edge computing, covering centralized, decentralized, hybrid, and machine learning algorithms.
If we focus on workload prediction, we see this is an essential technique in cloud computing environments, as it enables providers to effectively manage and allocate cloud resources, save on infrastructure costs, implement auto-scaling policies, and ensure compliance with service-level agreements (SLAs) with users. Workload prediction can be performed at application or infrastructure level. Application-level techniques [
31,
32] involve predicting a metric related to the application demand (e.g., requests per second or task arrival rate) to anticipate the optimal amount of resources needed to meet that demand. On the other hand, infrastructure-level techniques [
33,
34] are based on predicting one or more resource usage metrics (such as CPU, memory, disk, or network) and making advanced decisions about the optimal amount and size of virtual or physical resources to provision to avoid overload or over-sizing situations. Another interesting piece of research in this area is [
35], which presented a taxonomy of the various real-world metrics used to evaluate the performance of cloud, fog, and edge computing environments.
The most common workload prediction techniques used in cloud computing are based on time-series prediction methods [
19,
24], which involve collecting historical data of the target metric (e.g., the historical CPU usage of a VM or group of VMs) and forecasting future values of that metric for a certain time horizon. There are many different methods for modeling and predicting the time-series used in cloud computing, many of them based on classical techniques such as linear regression [
36], Bayesian models [
37], or ARIMA statistical methods [
38]. The main advantage of these models is their flexibility and simplicity in representing different types of time-series, making them quick and easy to use. However, they have a significant limitation in their linear behavior, making them inadequate in some practical situations.
More recently, different methods have been proposed for time-series prediction based on machine learning and deep learning models [
34,
39,
40] using artificial neural networks that have inherent non-linear modeling capabilities. One of the most common ML models applied to time-series is the long short-term memory (LSTM) neural network [
23,
41,
42], which overcomes the problem of vanishing gradients associated with other neural networks. However, these methods also have several drawbacks. The first is that the training and prediction times of the neural network can be quite high (several minutes, or even hours), making them unfeasible in certain situations. The second problem is that the quality of predictions of neural-network-based methods depends heavily on correct selection of the model’s hyperparameters, which can vary depending on the input data, meaning that adjusting these hyperparameters poses a serious challenge, even for expert analysts.
In absolute terms, it is not possible to claim that one prediction method is better than another, as their behavior will depend on the specific use case, the profile of the input data, the correct tuning of each model’s hyperparameters, and the use or non-use of co-variables that may correlate with the variable being predicted. In this context, research in this field involves exploring and comparing different prediction methods for each case, improving existing methods, and combining different techniques by proposing new hybrid or adaptive methods that allow for the most accurate forecasts possible. Likewise, applying these prediction techniques to other emerging environments such as highly geo-distributed edge/cloud environments, IoT environments, and server-less environments also represents a significant challenge.
On the other hand, the optimal allocation of resources in cloud computing is an important problem that must be addressed to ensure efficient use of resources and to meet SLAs agreed with users. The goal is to allocate resources (e.g., VMs to physical hosts) in a way that maximizes infrastructure utilization, subject to certain performance or application response time requirements.
There are different optimization techniques used to solve this problem. One of the most commonly used techniques is linear programming, which finds the optimal solution to a linear function subject to a set of linear constraints. This technique is very useful for problems involving a large number of variables and constraints. For example, ref. [
43] was a pioneering work in cloud brokering that used ILP to optimize the cost of a virtual infrastructure deployed on a set of cloud providers. Subsequently, this research was expanded upon in [
44], which addressed dynamic cloud scenarios and incorporated diverse optimization criteria such as cost or performance. The authors in [
45,
46] presented MALLOOVIA, a multi-application load-level-based optimization for virtual machine allocation. MALLOOVIA formulates an optimization problem based on ILP and takes the levels of performance to must be reached by a set of applications as input, and generates a VM allocation to support the performance requirements of all applications as output.The authors in [
47,
48] provided an approach for supporting the deployment of microservices in multi-cloud environments, focusing on the quality of monitoring and adopting a multi-objective mixed integer linear optimization problem, in order to find the optimal deployment satisfying all the constraints and maximizing the quality of monitored data, while minimizing costs. Some recent works have also used ILP optimization for resource allocation in edge computing infrastructures. For example, ref. [
49] formulated an ILP model to minimize the access delay of mobile users’ requests, in order to improve the efficiency of edge server and service entity placement. The authors in [
50] focused on the joint optimization problem of edge sever placement and virtual machine placement. The optimization models proposed, which take into account the network load and the edge server load, are based on ILP and mixed integer programming.
Other optimization approaches that we can find in the literature are heuristic techniques based on bio-inspired algorithms [
26,
51,
52,
53,
54], such as genetic algorithms, particle swarm optimization), and ant colony optimization, among others. These algorithms allow users to find suboptimal solutions for optimization problems that are too complex to solve exactly. Genetic algorithms, for example, are inspired by natural selection and biological evolution to find optimal solutions. Reinforcement learning is another technique that has been successfully used in resource management and allocation in cloud computing [
55,
56,
57]. This technique is based on a learning model in which an agent interacts with an environment and receives a reward or punishment based on its actions. Through experience, the agent learns to make the optimal decisions that maximize the expected reward.
Each technique has its advantages and disadvantages, and the choice of the most appropriate technique will depend on the specific characteristics of the problem to be solved. In general, linear programming is more suitable for well-structured problems with a limited number of variables and constraints. Metaheuristic algorithms are more suitable for more complex problems with a large number of variables and constraints. Reinforcement learning, on the other hand, is more suitable for problems involving uncertain dynamic environments. Sometimes it will also be necessary to address multi-objective problems where it is necessary to optimize more than one objective function subject to certain constraints. Research in this field involves exploring, analyzing, and comparing different optimization techniques adapted to each problem and use case, including the treatment of both single and multi-objective problems, and the possibility of combining different techniques through the proposal of new hybrid optimization techniques. Furthermore, the application of these optimization techniques to other emerging environments such as highly geo-distributed edge/cloud environments, IoT environments, and serverless environments also represents an important challenge.
In the above research review, we found many studies focusing on predicting loads and optimizing resources in centralized clouds or simple edge infrastructures, using various machine learning techniques. However, there has been limited exploration or implementation of these techniques in highly distributed 5G edge environments within actual cloud/edge infrastructure managers. The Smart 5G Edge-Cloud Management Architecture proposed in this study aims to address this gap. It intends to analyze, enhance, and expand AI-based prediction and optimization methods for large-scale 5G edge infrastructures. Additionally, it plans to integrate these methods with existing edge management platforms like OpenNebula. This integration will enable automated and optimized provisioning and deployment of geo-distributed 5G edge infrastructures.
8. Conclusions and Future Work
This work introduced a novel Smart 5G Edge-Cloud Management Architecture based on OpenNebula. The proposed architecture incorporates experimental components from the ONEedge5G project which, in its current developmental phase, will incorporate predictive intelligence mechanisms for CPU utilization forecasting and optimization algorithms for the optimal allocation of virtual resources (VMs or containers) on geographically distributed 5G edge infrastructures.
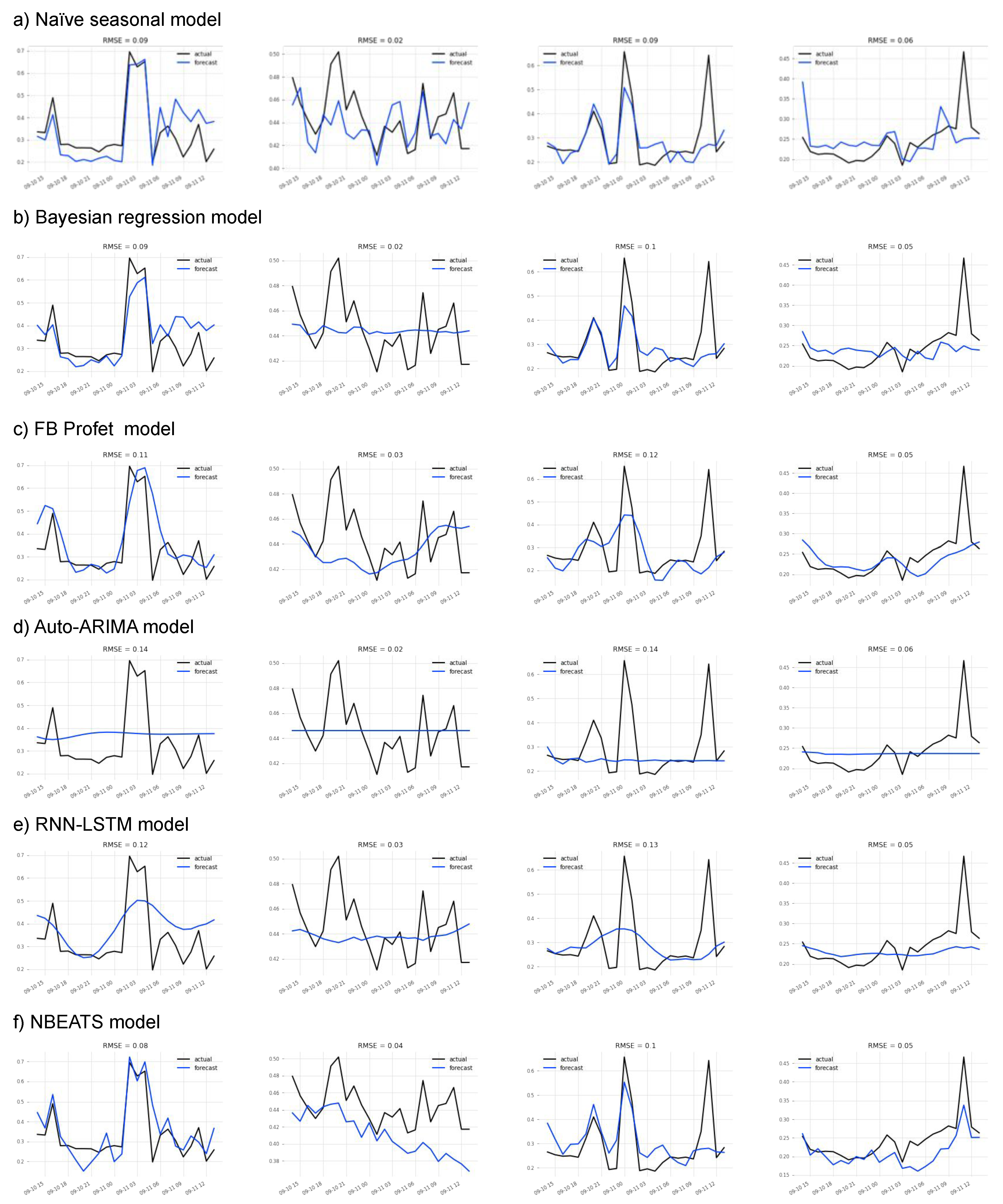
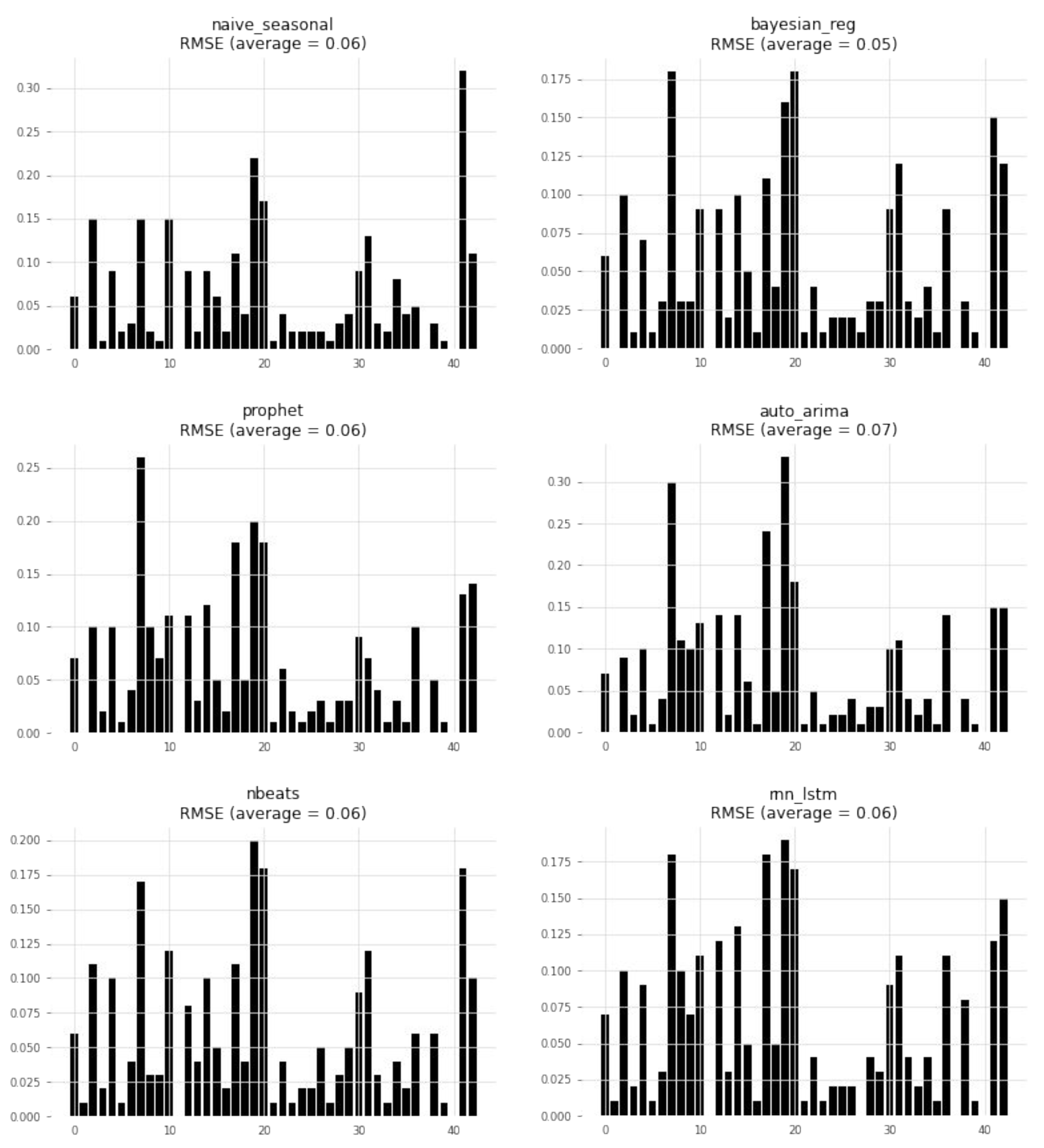
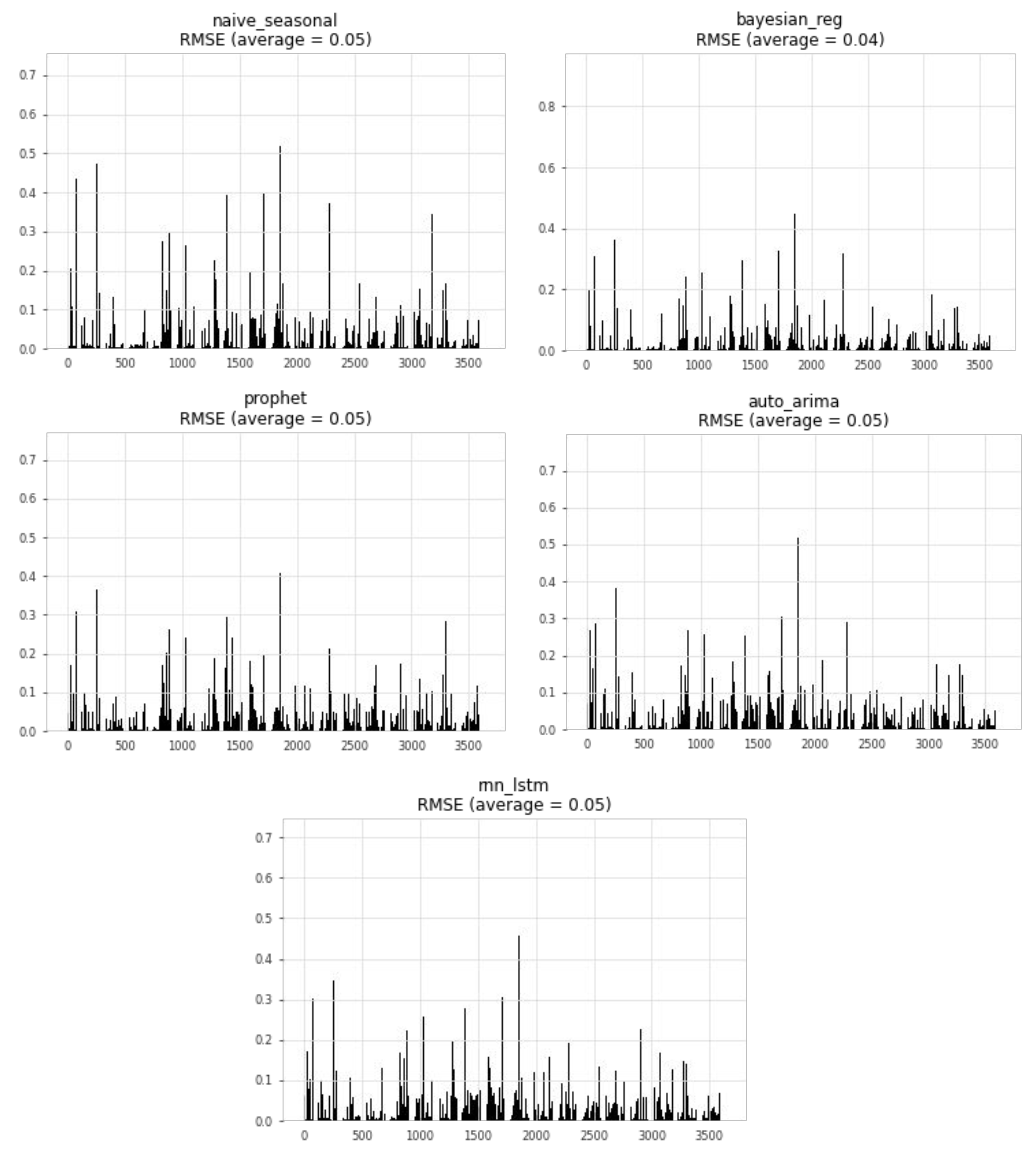
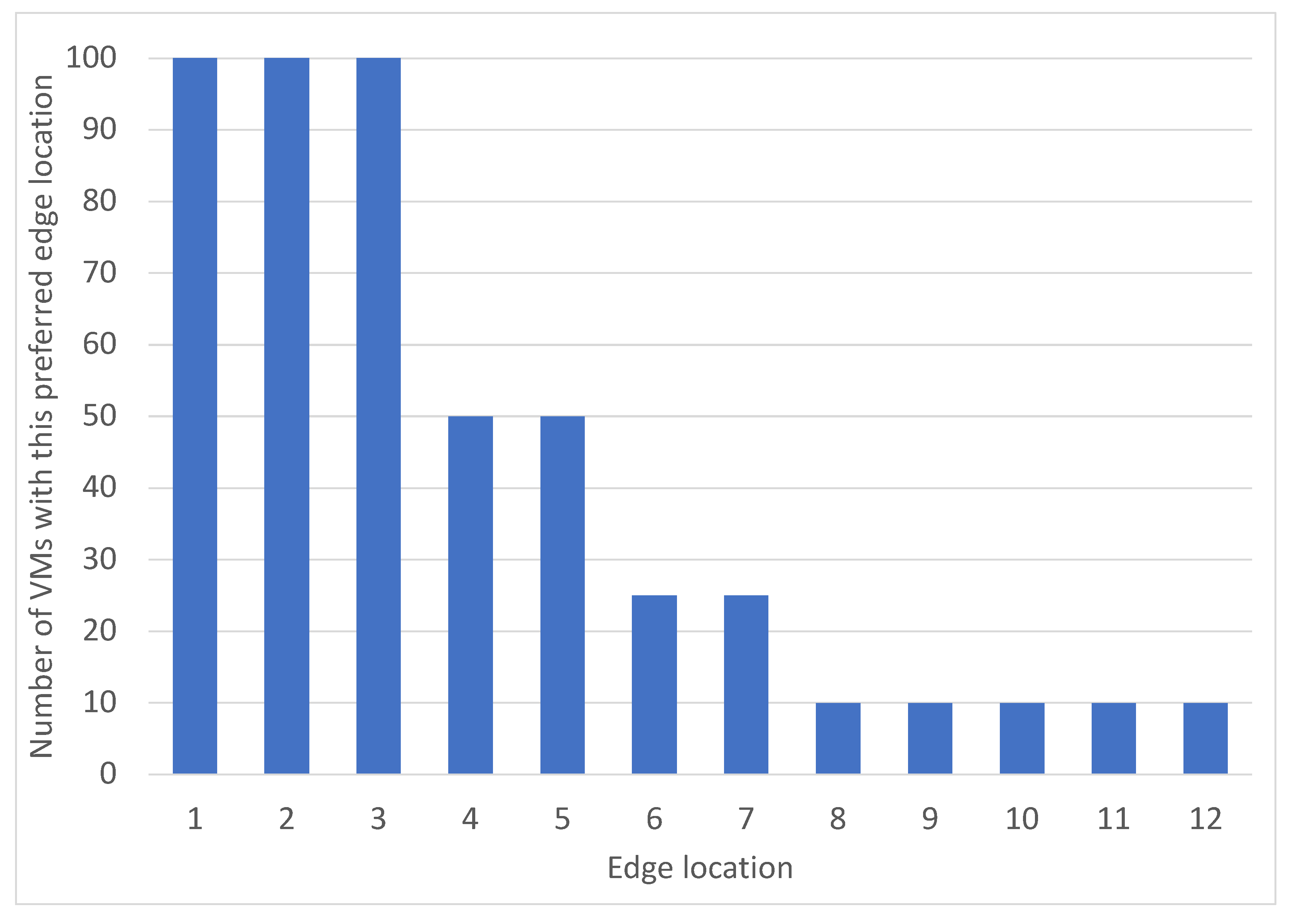
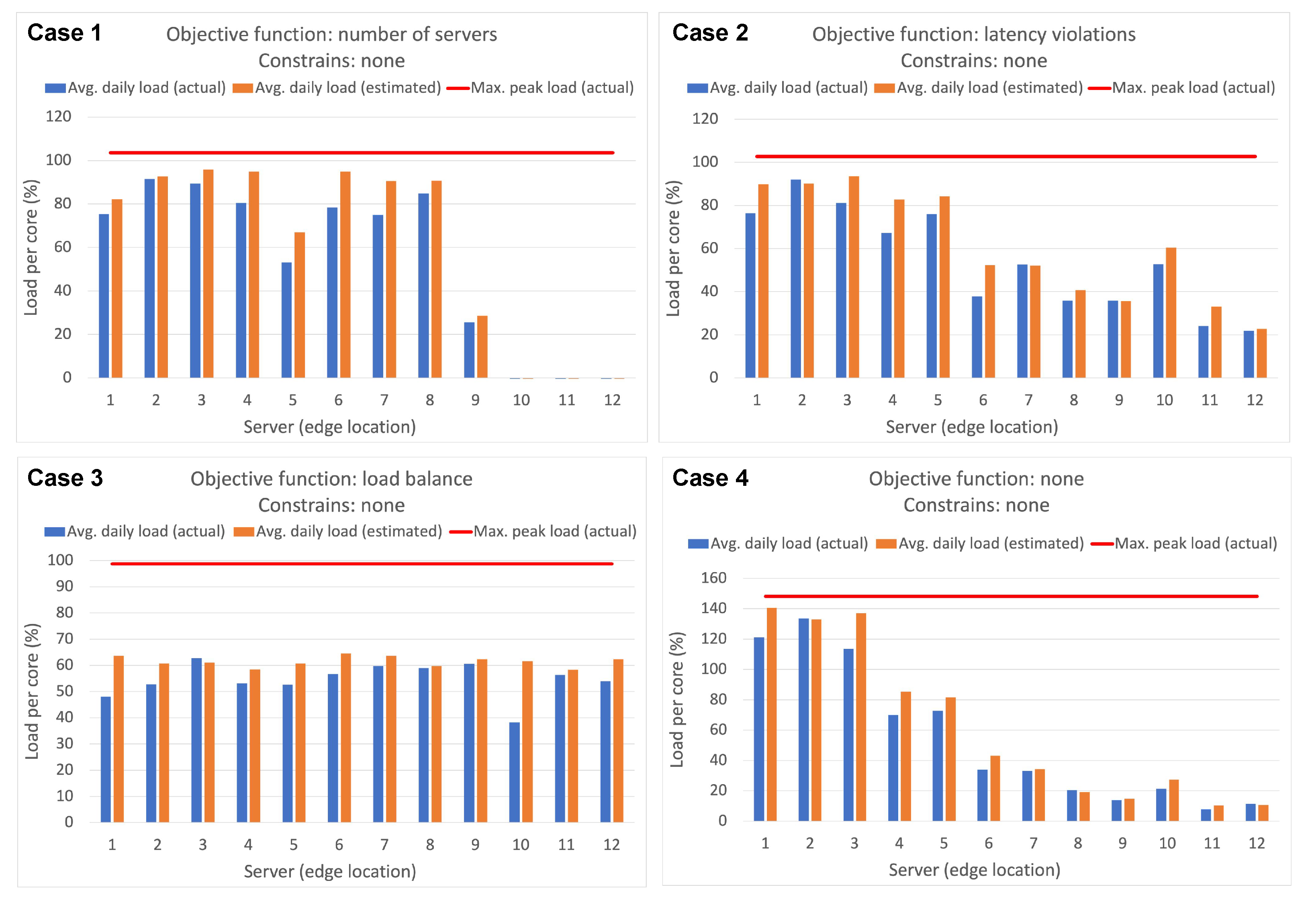
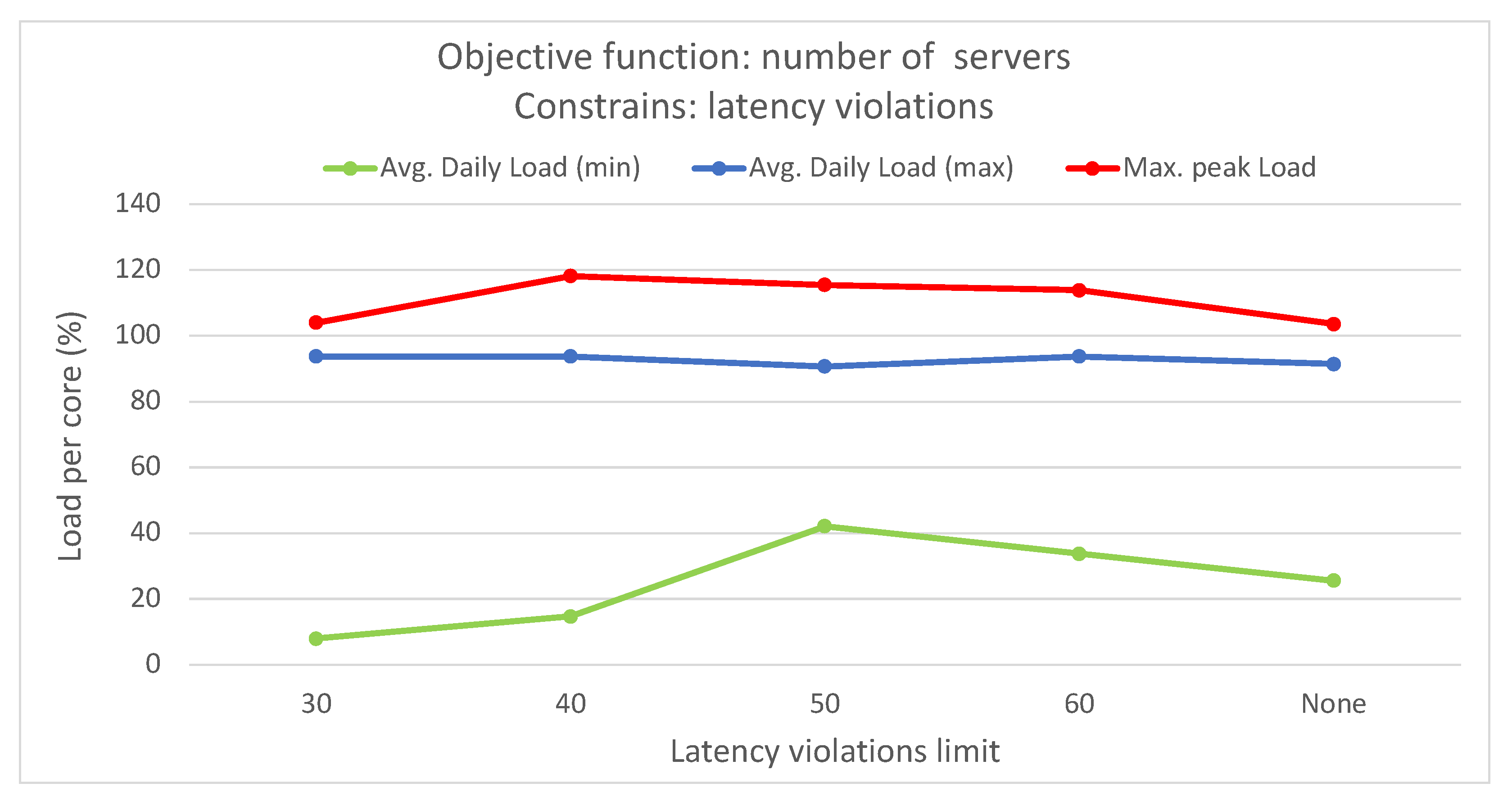
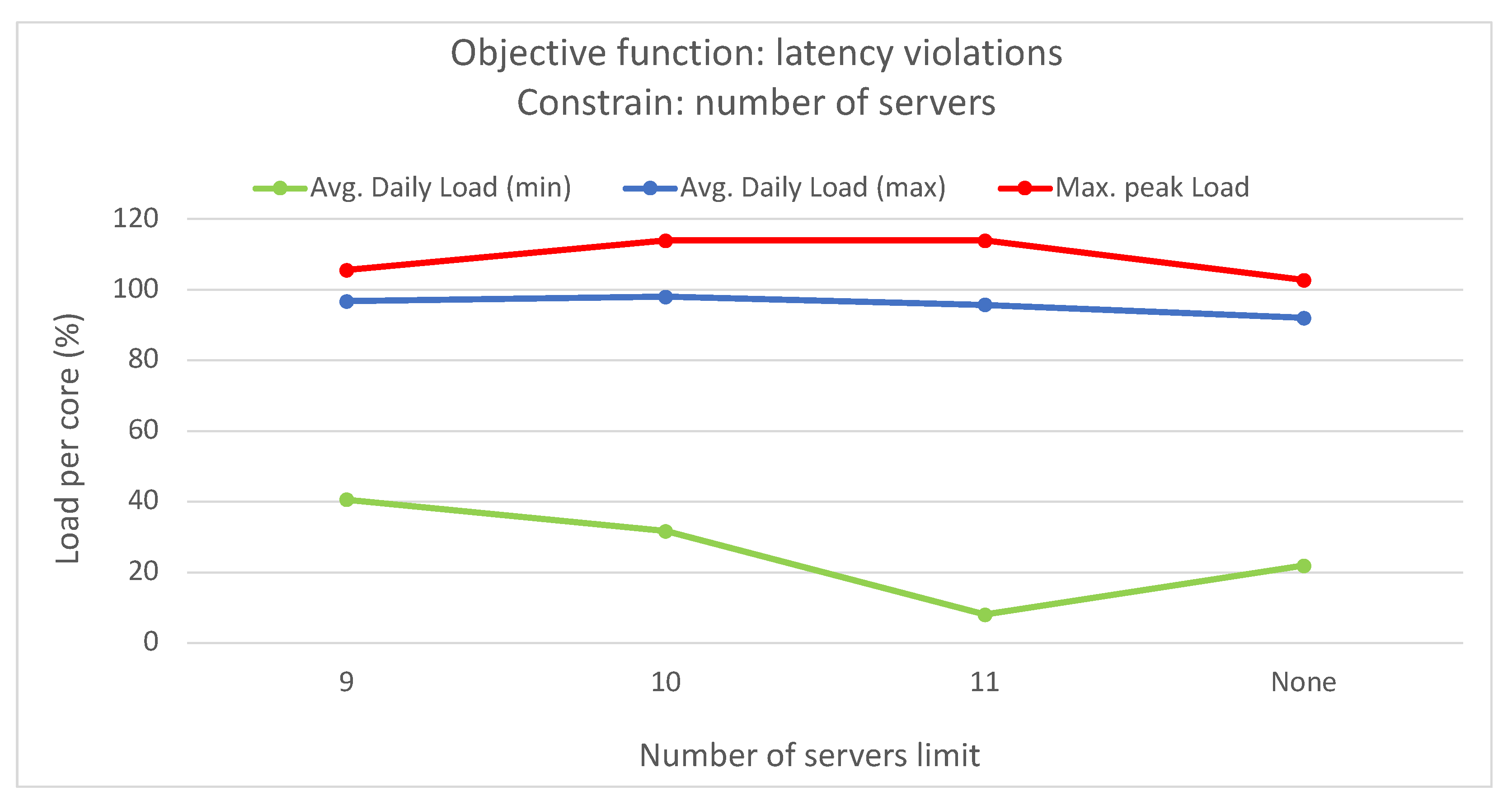
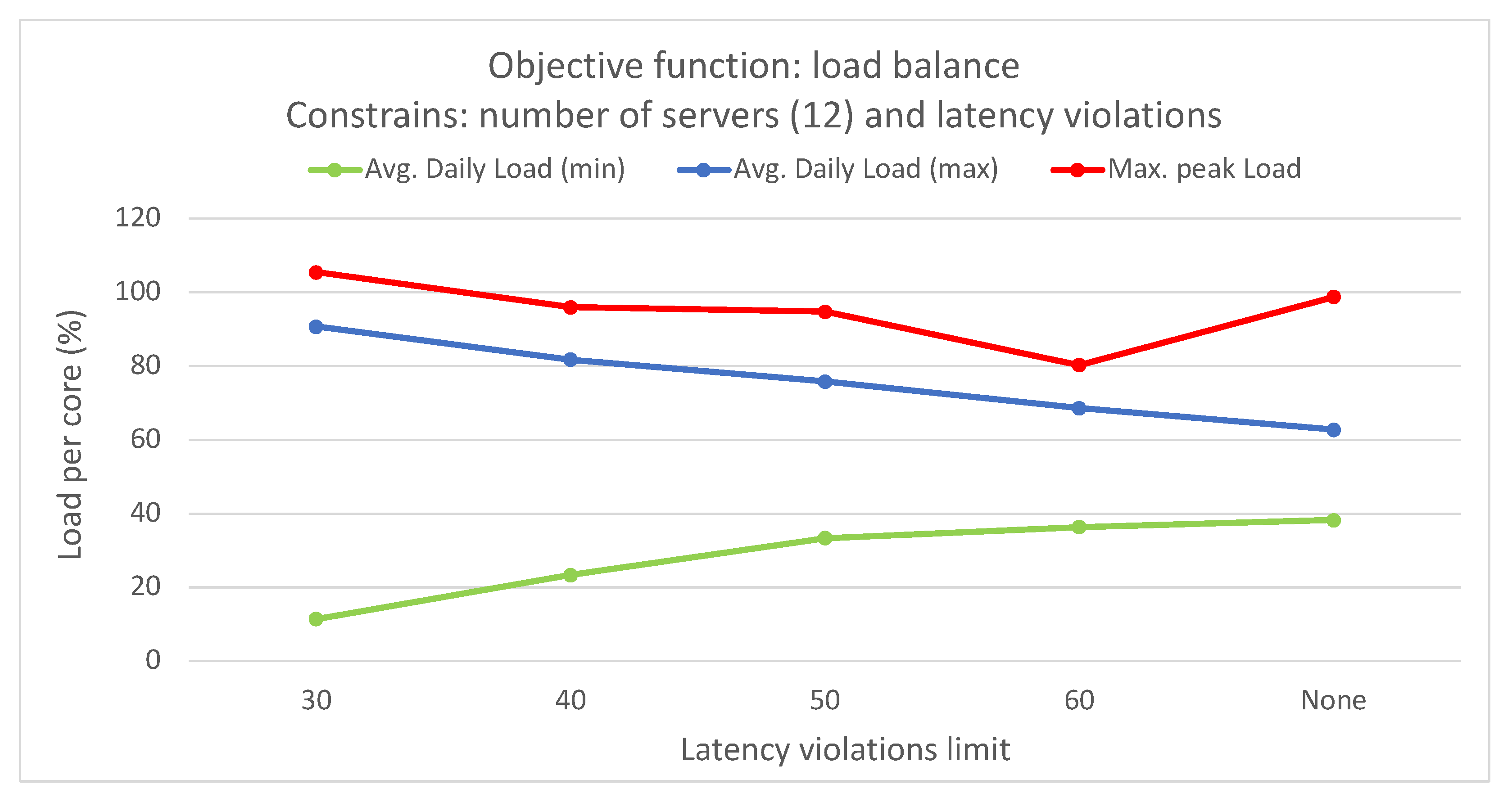
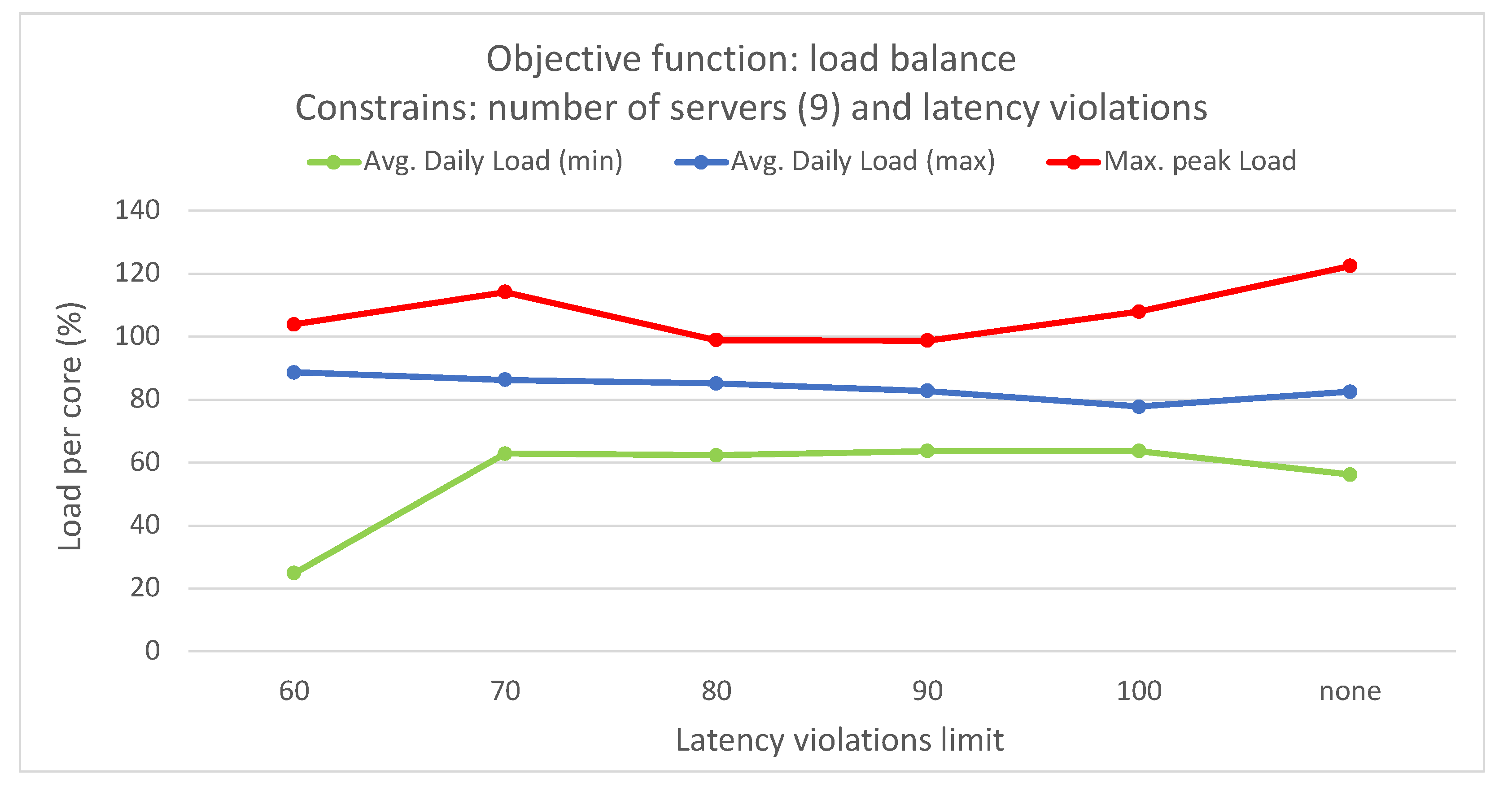
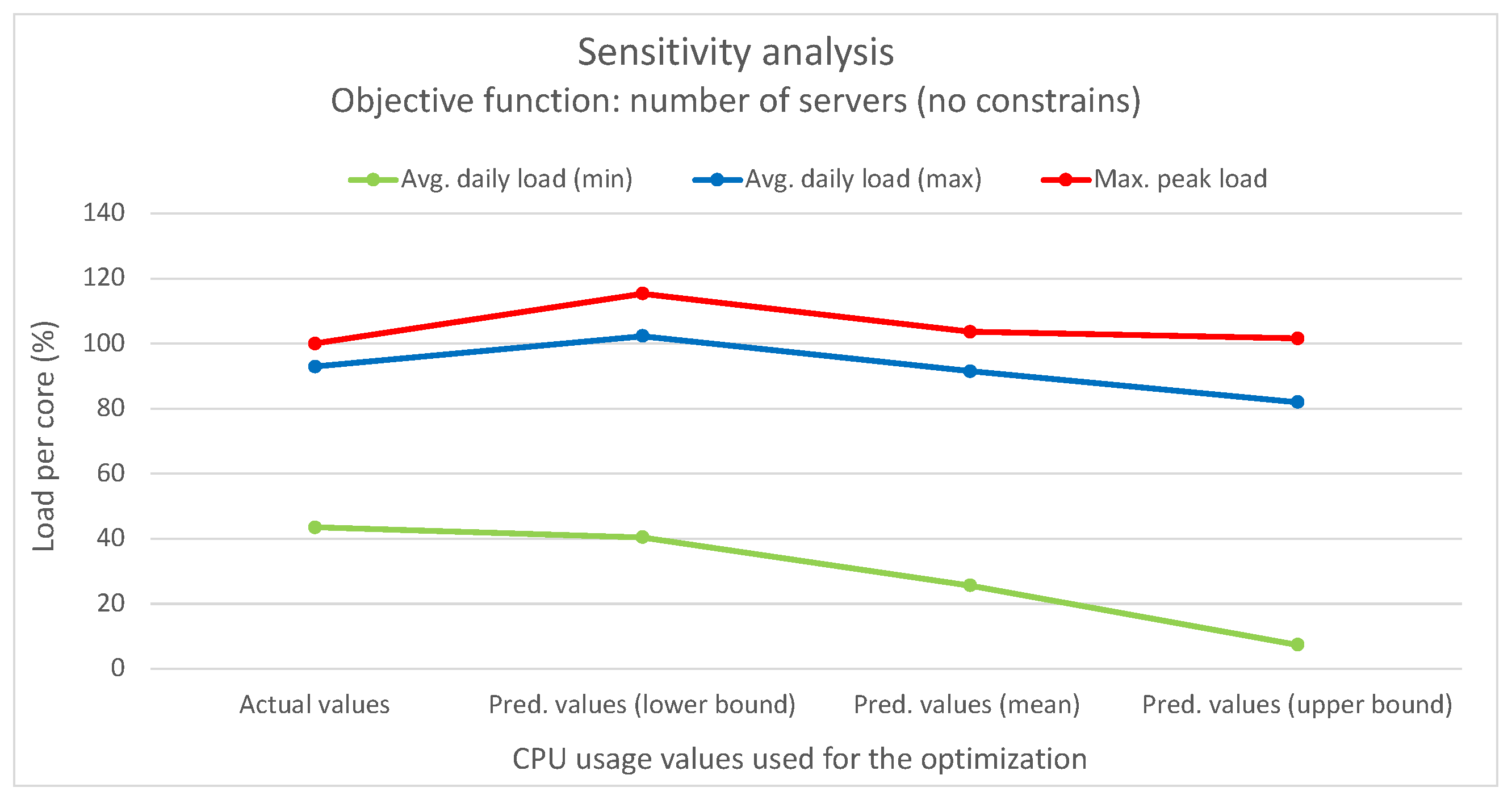
This study emphasized infrastructure-level techniques for CPU usage forecasting, employing different statistical and ML time-series forecasting methods. Bayesian regression demonstrated the highest accuracy among the methods evaluated. The optimization problem addressed involved finding the optimal mapping of virtual resources to edge servers using different criteria and constraints. An ILP formulation was proposed for solving this problem. The scenario included a distributed edge infrastructure with physical servers, each with specific computing and memory capacities. Virtual resources with their computing requirements, as well as preferred edge locations based on proximity criteria, were deployed in the infrastructure. The results showed that optimizing different objective functions, such as minimizing the number of servers, reducing latency violations, or balancing server loads, led to improved management of the infrastructure. Allocating virtual resources based on their preferred edge locations without optimization resulted in no latency violations but severe server overloading. However, optimization algorithms successfully prevented overloading, while maintaining an average daily load per server below 100%.
By merging various optimization criteria and constraints, such as the number of servers in use and the number of latency violations, different optimized solutions can be obtained. For instance, one approach is to minimize latency violations to a minimum of 29 by utilizing all available servers, while another option is to reduce the number of servers to nine with only 59 latency violations. However, these solutions introduce significant imbalances in load distribution among servers and may result in overloading on certain servers and time slots. To address this issue, incorporating the load balancing objective function proves effective, as it can achieve solutions with a limited number of latency violations, while improving load distribution and preventing overloading.
In our future work, we have various plans to enhance the prediction and optimization models. First, we aim to incorporate additional hardware metrics, including memory, bandwidth, and disk usage, to explore their potential correlation and integrate them into the mathematical models for optimization. Additionally, we plan to propose new optimization criteria based on the previous metrics, as well as integrating different objective functions using various multi-objective approaches. We also intend to investigate alternative optimization techniques, such as bio-inspired algorithms or reinforcement learning algorithms, to further improve the efficiency of the system. Another aspect not addressed in this study but worthy of consideration in future research is the potential utilization of nested virtualization, where containers are not run directly on bare-metal servers but within VMs. In such scenarios, two levels of allocation should be addressed: containers to VMs, and VMs to physical servers. Finally, expanding the capabilities of the ONEedge5G modules is on our agenda, encompassing functionality for capacity planning, prediction, and anomaly detection, as well as proactive auto-scaling mechanisms to facilitate elasticity management. These advancements will contribute to the comprehensive development of our Smart 5G Edge-Cloud Management Architecture and enable more robust and adaptive management of distributed 5G edge infrastructures.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}