

Multi-Level Split Federated Learning for Large-Scale AIoT System Based on Smart Cities




Abstract
:1. Introduction
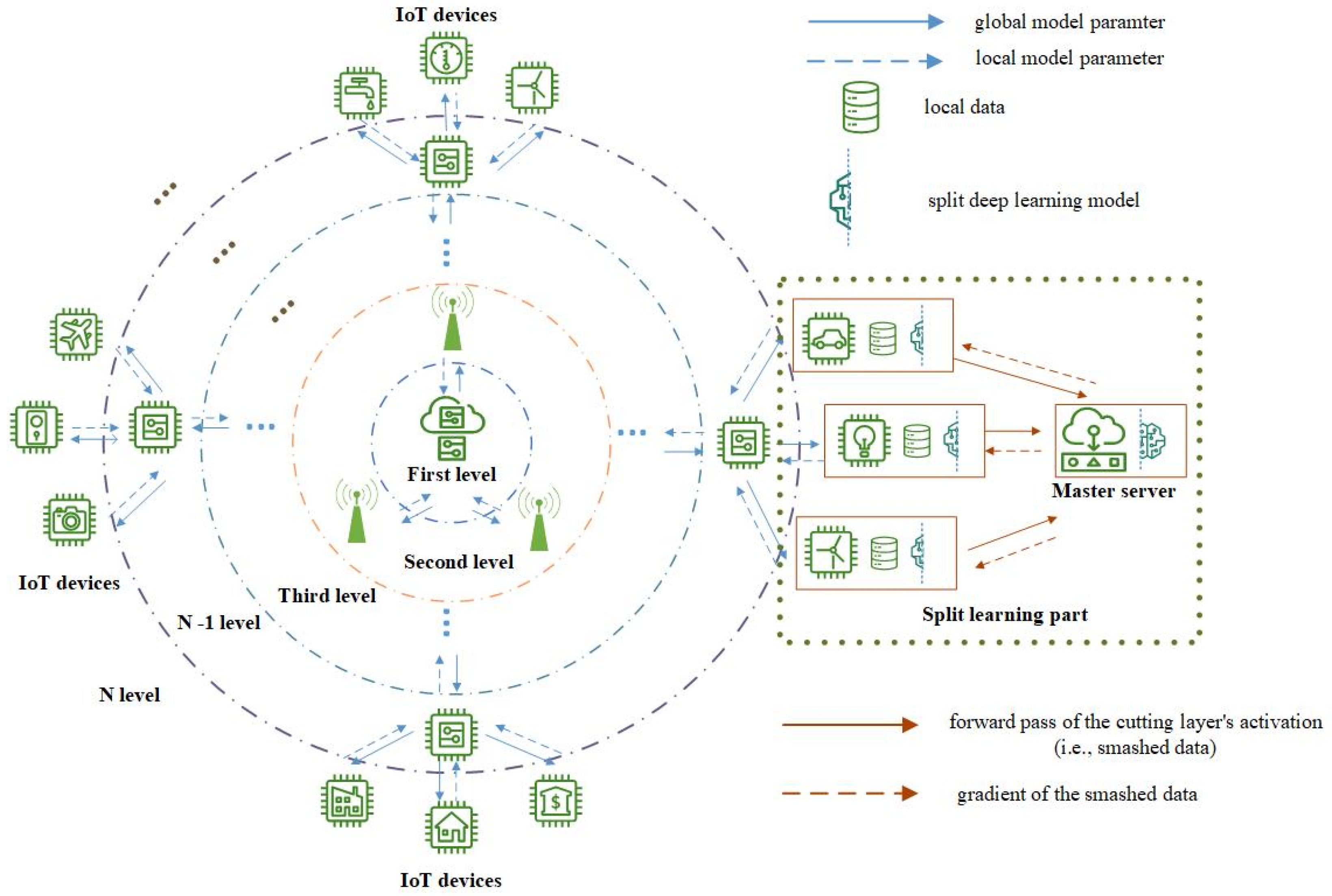
- This paper proposes a multi-level split federated learning architecture based on IoT device location model information aggregation. The architecture reduces the communication delay between the client and the cloud server. Compared to hierarchical FL, multi-level SFL improves the scalability of the AIoT system through initial aggregation in multi-level edge nodes before the cloud server’s aggregation.
- The split learning algorithm is added to multi-level federated learning, which reduces the impact of system heterogeneity on client collaborative learning and the possibility of abandonment due to limited client computing resources.
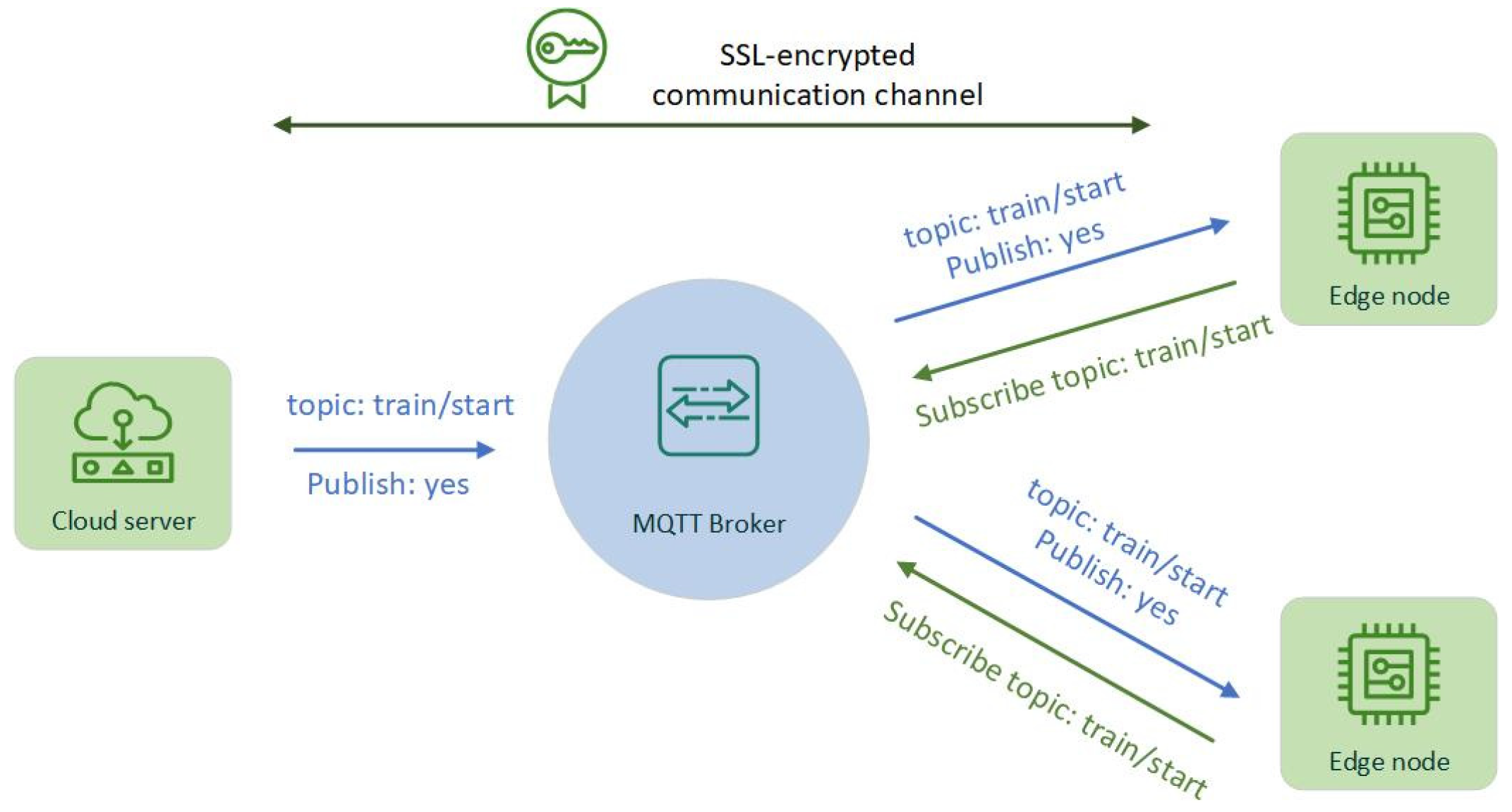
- We utilize the Message Queuing Telemetry Transport (MQTT) protocol to aggregate geographically located IoT devices by sending topics and assigning the nearest master server for split learning training. The client groups in each region communicate with the primary server through their respective local networks.
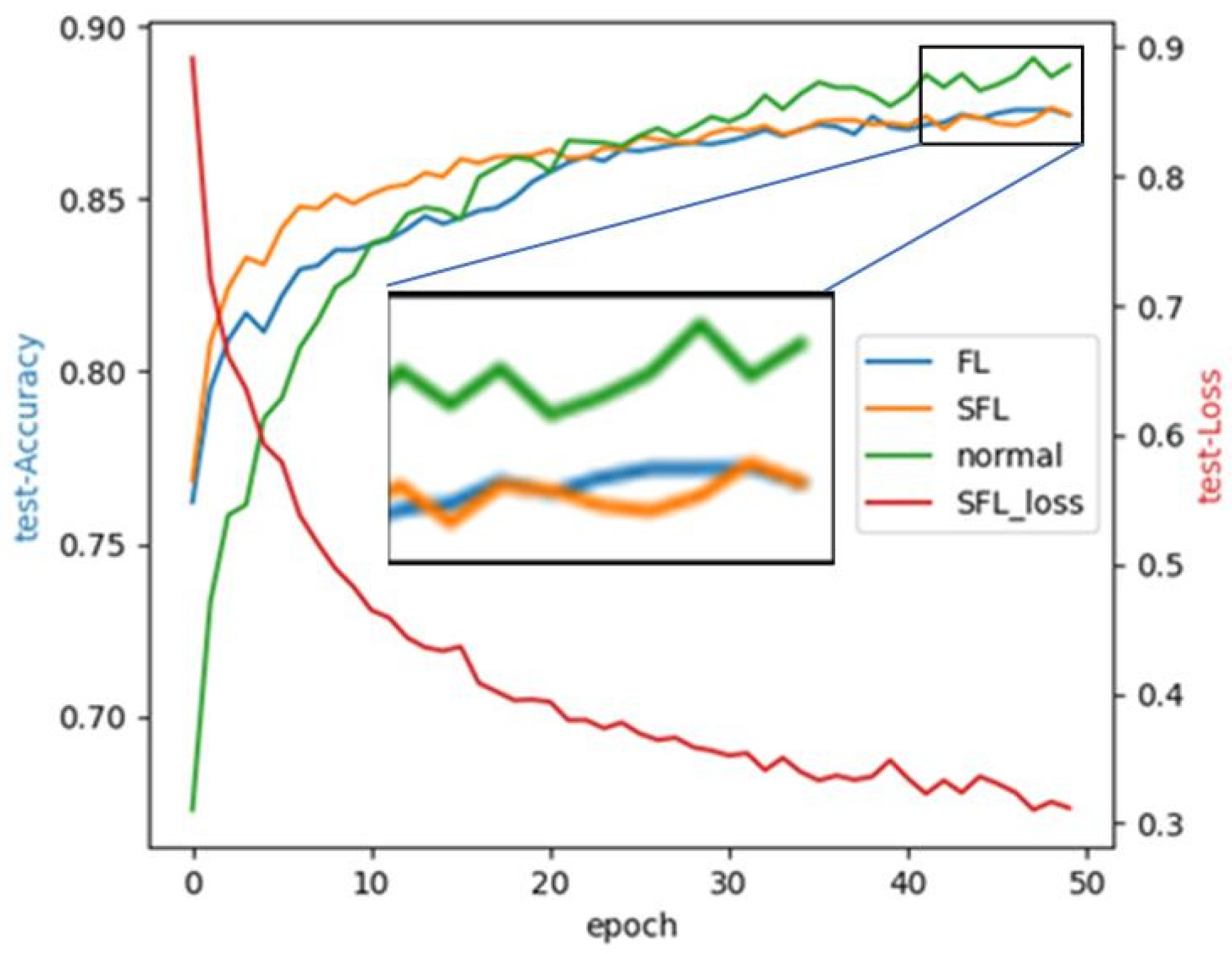
- Simulation experiments on multi-level split federated learning using Docker verify that our proposed framework can effectively improve the model accuracy of collaborative training under large-scale clients. In addition, compared with traditional SFL, multi-level SFL in non-IID scenarios can converge faster and reduce the influence of non-IID data on model accuracy.
2. Related Works
3. Proposed Framework
3.1. MQTT Protocol-Based Message Exchange
3.2. Split Learning Side
| Algorithm 1 Split learning part in multi-level split federated learning |
| Notations: is the size of total samples; is time period; is the smashed data of IoT device at ; is the gradient of the loss for IoT device ; is the true label from IoT device . |
| Initialize: for each IoT device in parallel do , initialize weight using end for In master server: , initialize weight using |
|
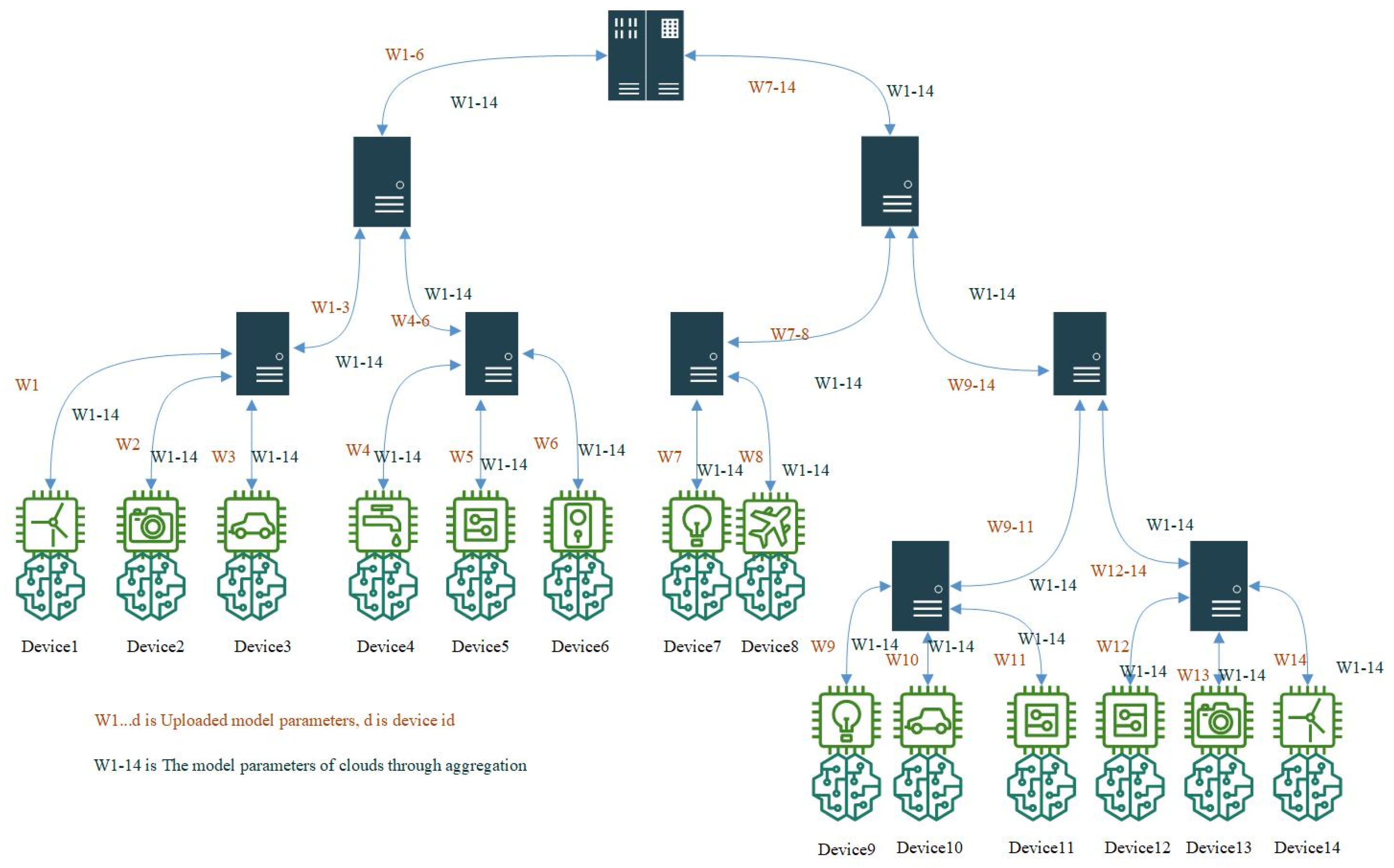
3.3. Multi-Level Federated Learning Workflow
| Algorithm 2 Multi-level SFL algorithm and multi-level FL workflow |
| Notations: is the size of total samples; is time period; is the number of edge servers in each level. |
| Initialize: ; global model in cloud server ; |
|
4. Experiment
4.1. Experiment Setting
4.2. Experiment Dataset and Simulation
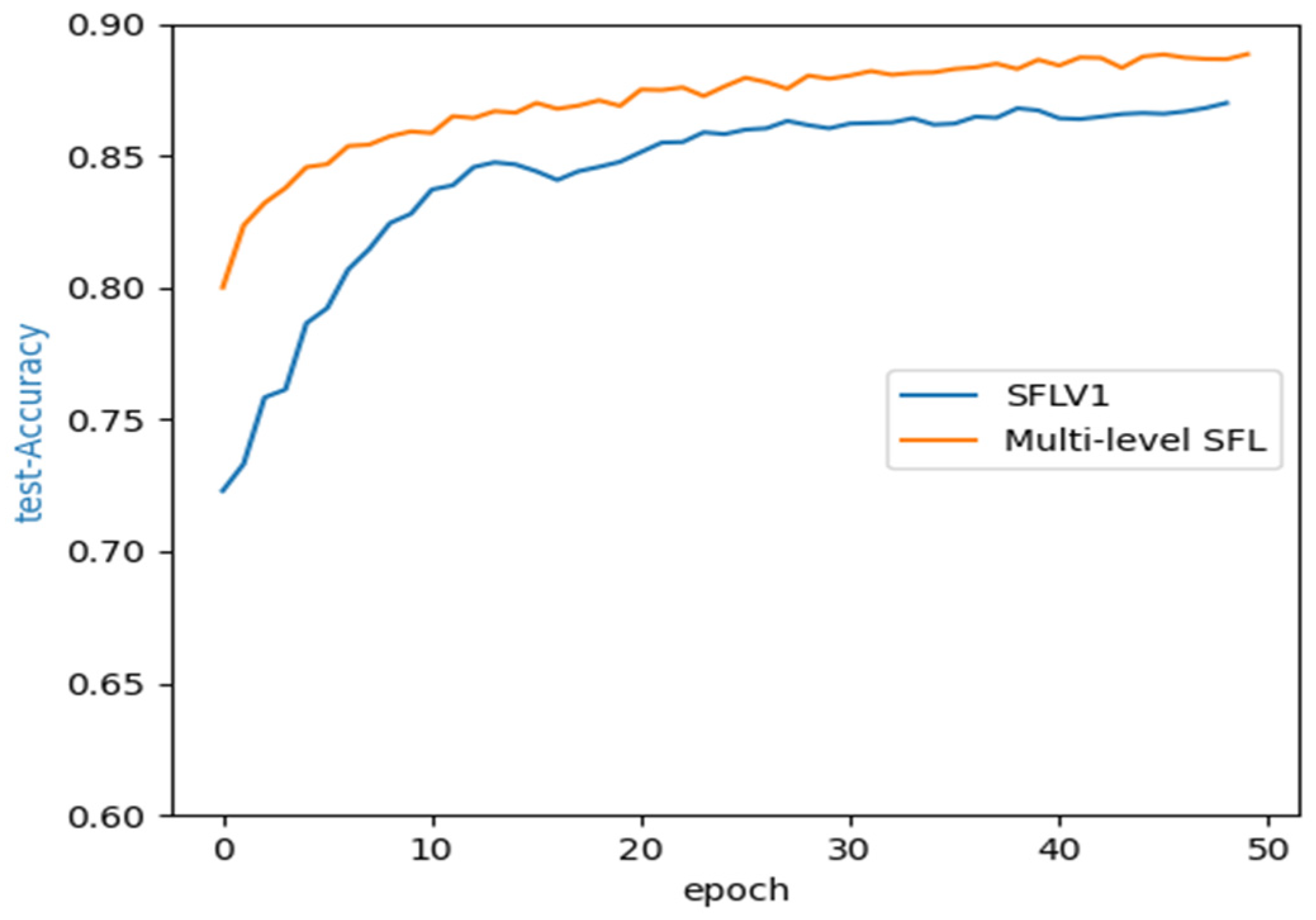
4.3. Performance of Multi-Level SFL, FL, and Centralized Learning
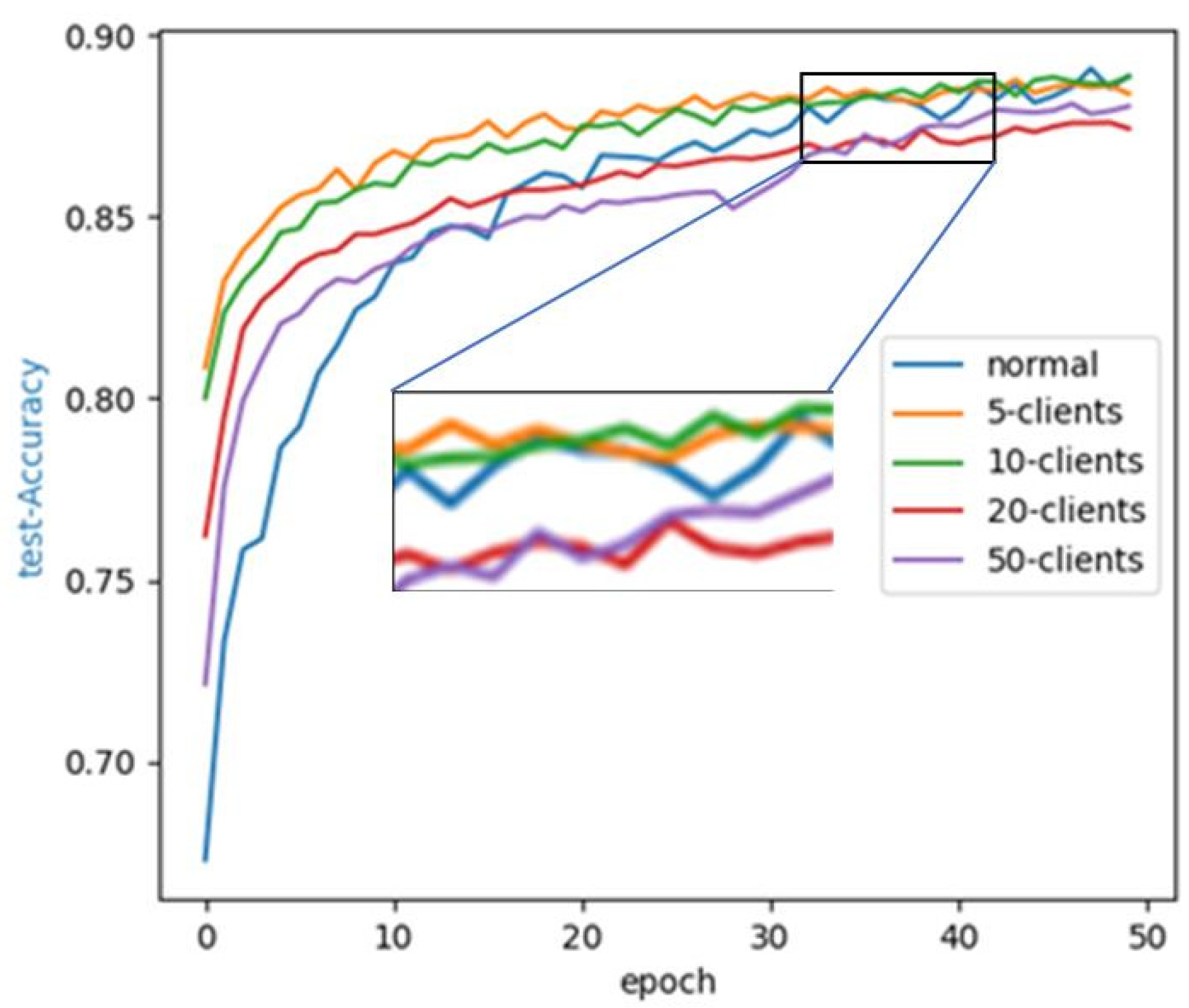
4.4. Effect of Different Clients on Performance
4.5. Impact of Different Level Layer on the SFL Model Training
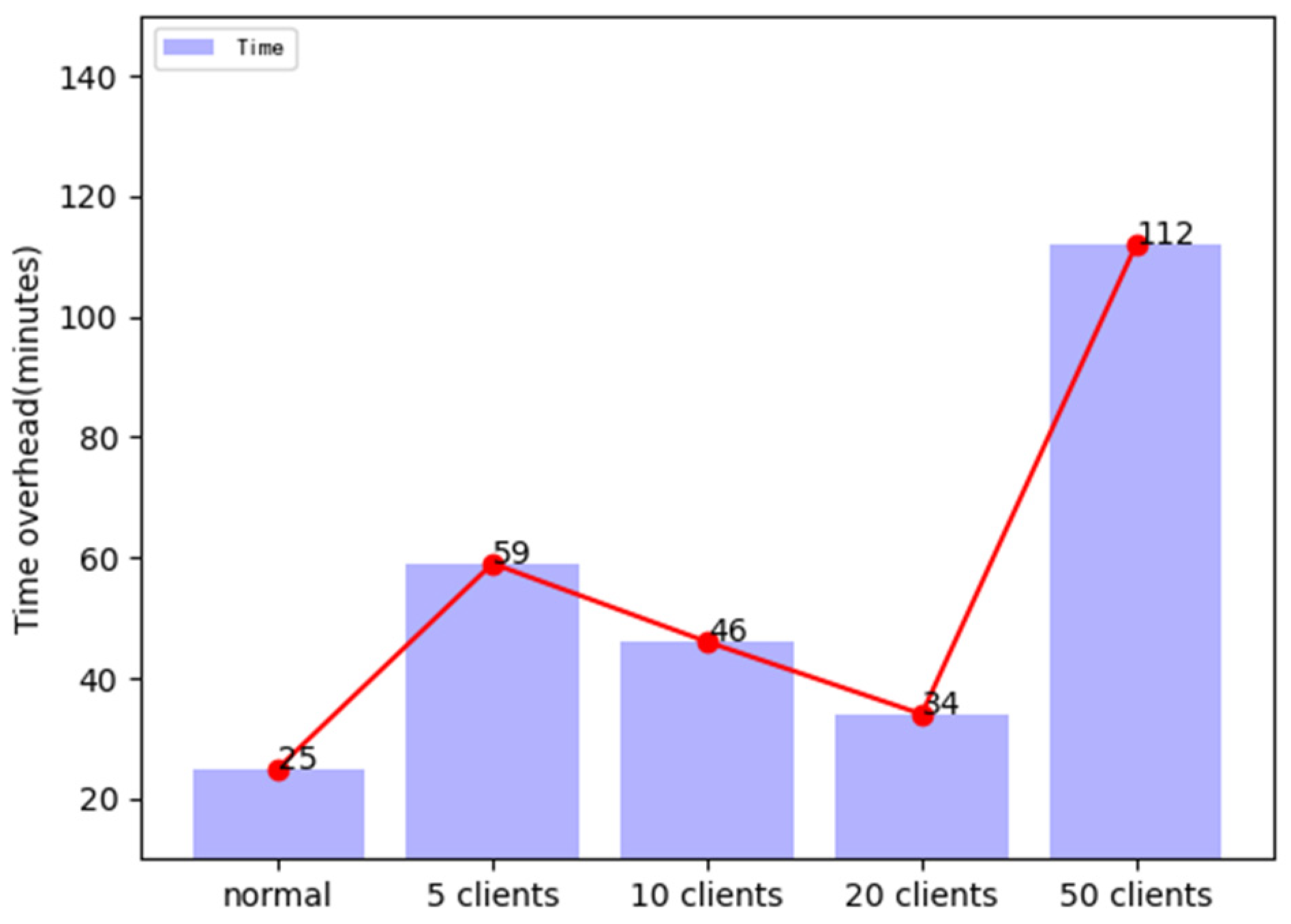
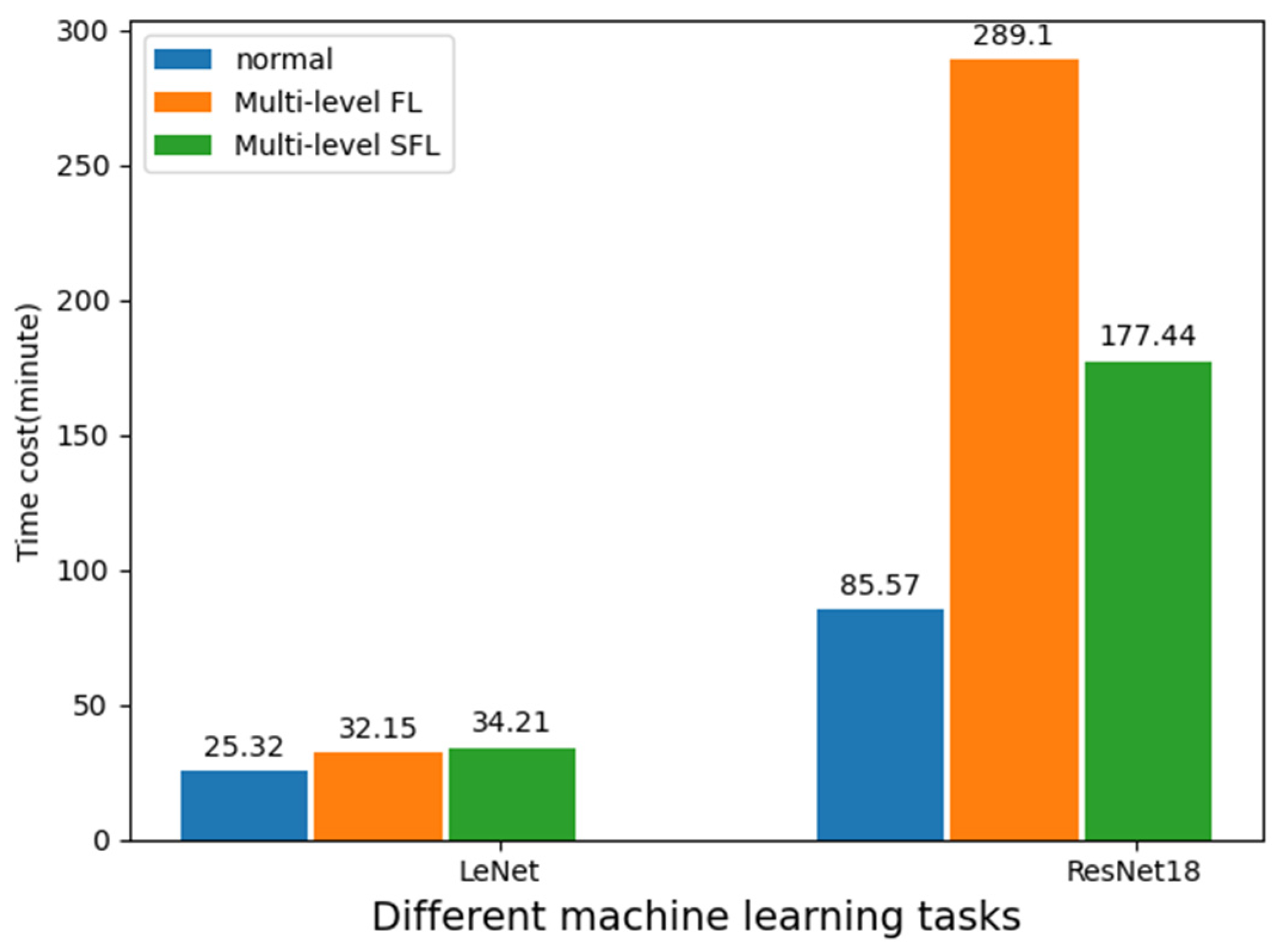
4.6. Comparison of Multi-Level SFL and FL Time Cost
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Su, Z.; Wang, Y.; Luan, T.H.; Zhang, N.; Li, F.; Chen, T.; Cao, H. Secure and Efficient Federated Learning for Smart Grid With Edge-Cloud Collaboration. IEEE Trans. Ind. Inform. 2022, 18, 1333–1344. [Google Scholar] [CrossRef]
- Xu, C.; Qu, Y.; Luan, T.H.; Eklund, P.W.; Xiang, Y.; Gao, L. An Efficient and Reliable Asynchronous Federated Learning Scheme for Smart Public Transportation. IEEE Trans. Veh. Technol. 2023, 72, 6584–6598. [Google Scholar] [CrossRef]
- Lian, Z.; Yang, Q.; Wang, W.; Zeng, Q.; Alazab, M.; Zhao, H.; Su, C. DEEP-FEL: Decentralized, Efficient and Privacy-Enhanced Federated Edge Learning for Healthcare Cyber Physical Systems. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3558–3569. [Google Scholar] [CrossRef]
- Taïk, A.; Mlika, Z.; Cherkaoui, S. Clustered Vehicular Federated Learning: Process and Optimization. IEEE Trans. Intell. Transp. Syst. 2022, 23, 25371–25383. [Google Scholar] [CrossRef]
- Bebortta, S.; Tripathy, S.S.; Basheer, S.; Chowdhary, C.L. FedEHR: A Federated Learning Approach towards the Prediction of Heart Diseases in IoT-Based Electronic Health Records. Diagnostics 2023, 13, 3166. [Google Scholar] [CrossRef]
- Hsu, R.-H.; Wang, Y.-C.; Fan, C.-I.; Sun, B.; Ban, T.; Takahashi, T.; Wu, T.-W.; Kao, S.-W. A Privacy-Preserving Federated Learning System for Android Malware Detection Based on Edge Computing. In Proceedings of the 2020 15th Asia Joint Conference on Information Security (AsiaJCIS), Taipei, Taiwan, 20–21 August 2020; pp. 128–136. [Google Scholar]
- Yamamoto, F.; Ozawa, S.; Wang, L. eFL-Boost: Efficient Federated Learning for Gradient Boosting Decision Trees. IEEE Access 2022, 10, 43954–43963. [Google Scholar] [CrossRef]
- Jiang, L.; Wang, Y.; Zheng, W.; Jin, C.; Li, Z.; Teo, S.G. LSTMSPLIT: Effective SPLIT Learning Based LSTM on Sequential Time-Series Data. In Proceedings of the 36th AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 28 February–1 March 2022. [Google Scholar]
- Hsieh, C.-Y.; Chuang, Y.-C.; Wu, A.-Y. C3-SL: Circular Convolution-Based Batch-Wise Compression for Communication-Efficient Split Learning. In Proceedings of the 2022 IEEE 32nd International Workshop on Machine Learning for Signal Processing (MLSP), Xi’an, China, 22–25 August 2022. [Google Scholar]
- Chen, X.; Li, J.; Chakrabarti, C. Communication and Computation Reduction for Split Learning Using Asynchronous Training. In Proceedings of the 2021 IEEE Workshop on Signal Processing Systems (SiPS), Coimbra, Portugal, 19–21 October 2021; pp. 76–81. [Google Scholar]
- Abedi, A.; Khan, S.S. FedSL: Federated Split Learning on Distributed Sequential Data in Recurrent Neural Networks. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Wu, Y.; Kang, Y.; Luo, J.; He, Y.; Yang, Q. FedCG: Leverage Conditional GAN for Protecting Privacy and Maintaining Competitive Performance in Federated Learning. arXiv 2022, arXiv:2111.08211. [Google Scholar]
- Zhang, Z.; Pinto, A.; Turina, V.; Esposito, F.; Matta, I. Privacy and Efficiency of Communications in Federated Split Learning. IEEE Trans. Big Data 2023, 9, 1380–1391. [Google Scholar] [CrossRef]
- Deng, Y.; Lyu, F.; Ren, J.; Zhang, Y.; Zhou, Y.; Zhang, Y.; Yang, Y. SHARE: Shaping Data Distribution at Edge for Communication-Efficient Hierarchical Federated Learning. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; pp. 24–34. [Google Scholar]
- Liu, L.; Zhang, J.; Song, S.H.; Letaief, K.B. Client-Edge-Cloud Hierarchical Federated Learning. In Proceedings of the ICC 2020—2020 IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Mansour, Y.; Mohri, M.; Ro, J.; Suresh, A.T. Three Approaches for Personalization with Applications to Federated Learning. arXiv 2020, arXiv:2002.10619. [Google Scholar]
- Hao, M.; Li, H.; Luo, X.; Xu, G.; Yang, H.; Liu, S. Efficient and Privacy-Enhanced Federated Learning for Industrial Artificial Intelligence. IEEE Trans. Ind. Inform. 2020, 16, 6532–6542. [Google Scholar] [CrossRef]
- Wang, H.; Kaplan, Z.; Niu, D.; Li, B. Optimizing Federated Learning on Non-IID Data with Reinforcement Learning. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; pp. 1698–1707. [Google Scholar]
- Guo, J.; Ho, I.W.-H.; Hou, Y.; Li, Z. FedPos: A Federated Transfer Learning Framework for CSI-Based Wi-Fi Indoor Posi-tioning. IEEE Syst. J. 2023, 17, 4579–4590. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; Kale, S.; Mohri, M.; Reddi, S.J.; Stich, S.U.; Suresh, A.T. SCAFFOLD: Stochastic Controlled Averaging for Federated Learning. In Proceedings of the 37th International Conference on Machine Learning, PMLR, Online, 13–18 July 2020; Volume 119, pp. 5132–5143. [Google Scholar]
- Tan, A.Z.; Yu, H.; Cui, L.; Yang, Q. Towards Personalized Federated Learning. IEEE Trans. Neural Netw. Learn. Syst. 2023, 34, 9587–9603. [Google Scholar] [CrossRef]
- Xu, Y.; Fan, H. FedDK: Improving Cyclic Knowledge Distillation for Personalized Healthcare Federated Learning. IEEE Access 2023, 11, 72409–72417. [Google Scholar] [CrossRef]
- Guo, S.; Xiang, B.; Chen, L.; Yang, H.; Yu, D. Multi-Level Federated Learning Mechanism with Reinforcement Learning Optimizing in Smart City. In Proceedings of the Artificial Intelligence and Security; Sun, X., Zhang, X., Xia, Z., Bertino, E., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 441–454. [Google Scholar]
- Campolo, C.; Genovese, G.; Singh, G.; Molinaro, A. Scalable and Interoperable Edge-Based Federated Learning in IoT Contexts. Comput. Netw. 2023, 223, 109576. [Google Scholar] [CrossRef]
- Liu, L.; Tian, Y.; Chakraborty, C.; Feng, J.; Pei, Q.; Zhen, L.; Yu, K. Multilevel Federated Learning-Based Intelligent Traffic Flow Forecasting for Transportation Network Management. IEEE Trans. Netw. Serv. Manag. 2023, 20, 1446–1458. [Google Scholar] [CrossRef]
- Wu, Z.; Wu, X.; Long, Y. Multi-Level Federated Graph Learning and Self-Attention Based Personalized Wi-Fi Indoor Fingerprint Localization. IEEE Commun. Lett. 2022, 26, 1794–1798. [Google Scholar] [CrossRef]
- Thapa, C.; Chamikara, M.A.P.; Camtepe, S.A. Advancements of Federated Learning Towards Privacy Preservation: From Federated Learning to Split Learning. In Federated Learning Systems: Towards Next-Generation; Rehman, M.H.U., Gaber, M.M., Eds.; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2021; pp. 79–109. ISBN 978-3-030-70604-3. [Google Scholar]
- Ayad, A.; Renner, M.; Schmeink, A. Improving the Communication and Computation Efficiency of Split Learning for IoT Applications. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021; pp. 01–06. [Google Scholar]
- Thapa, C.; Chamikara, M.A.P.; Camtepe, S.; Sun, L. SplitFed: When Federated Learning Meets Split Learning. Proc. AAAI Conf. Artif. Intell. 2022, 36, 8485–8493. [Google Scholar] [CrossRef]
- Tian, Y.; Wan, Y.; Lyu, L.; Yao, D.; Jin, H.; Sun, L. FedBERT: When Federated Learning Meets Pre-Training. ACM Trans. Intell. Syst. Technol. 2022, 13, 66:1–66:26. [Google Scholar] [CrossRef]
- Jiang, H.; Liu, M.; Sun, S.; Wang, Y.; Guo, X. FedSyL: Computation-Efficient Federated Synergy Learning on Heterogeneous IoT Devices. In Proceedings of the 2022 IEEE/ACM 30th International Symposium on Quality of Service (IWQoS), Oslo, Norway, 10–12 June 2022; pp. 1–10. [Google Scholar]
- Deng, R.; Du, X.; Lu, Z.; Duan, Q.; Huang, S.-C.; Wu, J. HSFL: Efficient and Privacy-Preserving Offloading for Split and Federated Learning in IoT Services. In Proceedings of the 2023 IEEE International Conference on Web Services (ICWS), Chicago, IL, USA, 2–8 July 2023; pp. 658–668. [Google Scholar]
- Samikwa, E.; Maio, A.D.; Braun, T. ARES: Adaptive Resource-Aware Split Learning for Internet of Things. Comput. Netw. 2022, 218, 109380. [Google Scholar] [CrossRef]
- Gao, Y.; Kim, M.; Abuadbba, S.; Kim, Y.; Thapa, C.; Kim, K.; Camtep, S.A.; Kim, H.; Nepal, S. End-to-End Evaluation of Federated Learning and Split Learning for Internet of Things. In Proceedings of the 2020 International Symposium on Reliable Distributed Systems (SRDS), Shanghai, China, 21–24 September 2020; pp. 91–100. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Shahri, E.; Pedreiras, P.; Almeida, L. Extending MQTT with Real-Time Communication Services Based on SDN. Sensors 2022, 22, 3162. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-Based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Tschandl, P.; Rosendahl, C.; Kittler, H. The HAM10000 Dataset, a Large Collection of Multi-Source Dermatoscopic Images of Common Pigmented Skin Lesions. Sci. Data 2018, 5, 180161. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Message Exchange. | Topic | Details |
|---|---|---|
| Device–Edge | client/group | IoT devices are grouped according to the public socket IP they provide, and the corresponding master server is assigned. |
| train/start | The grouped IoT devices receive the signal from the edge server to start the model training. | |
| train/update | When the server needs to receive the local model weight of the IoT device, the IoT device receives the signal from the edge server. | |
| Edge–Edge Edge–Cloud | train/start | The edge server receives the signal from the upper-level server and starts to trigger the model training. |
| train/update | At the beginning of each communication turn, the selected clients are notified that their weights will be aggregated. | |
| client/join | Receive messages when a new IoT device joins a group. The message includes contextual information about the newly joining IoT device, including its status (whether it can participate in training) and its public socket IP. |
| Method | Comms. per IoT Devices | Total Comms. |
|---|---|---|
| FL | 2 | |
| SL | ||
| Multi-level SFL |
| Dataset | Training Samples | Testing Samples | Image Size |
|---|---|---|---|
| Fashion MNIST [37] | 60,000 | 10,000 | |
| HAM10000 [38] | 9013 | 1002 |
| Dataset | Architecture | Centralized Learning | Multi-Level FL | Multi-Level SFL | |||
|---|---|---|---|---|---|---|---|
| Train | Test | Train | Test | Train | Test | ||
| HAM10000 | ResNet18 | 74.4% | 79.6% | 76.9% | 77.3% | 78.6% | 79.4% |
| Fashion MNIST | LeNet | 88.7% | 90.2% | 86.1% | 87.6% | 87.9% | 88.9% |
| The number of clients | 5 | 10 | 20 | 50 |
| The number of edge nodes in edge level | 2 | 2 | 2 | 4 |
| The number of fog nodes in fog level | 1 | 1 | 2 | 2 |
| The number of cloud servers | 1 | 1 | 1 | 1 |
| The number of master servers | 2 | 2 | 2 | 4 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, H.; Seng, K.P.; Smith, J.; Ang, L.M. Multi-Level Split Federated Learning for Large-Scale AIoT System Based on Smart Cities. Future Internet 2024, 16, 82. https://doi.org/10.3390/fi16030082
Xu H, Seng KP, Smith J, Ang LM. Multi-Level Split Federated Learning for Large-Scale AIoT System Based on Smart Cities. Future Internet. 2024; 16(3):82. https://doi.org/10.3390/fi16030082
Chicago/Turabian StyleXu, Hanyue, Kah Phooi Seng, Jeremy Smith, and Li Minn Ang. 2024. "Multi-Level Split Federated Learning for Large-Scale AIoT System Based on Smart Cities" Future Internet 16, no. 3: 82. https://doi.org/10.3390/fi16030082
APA StyleXu, H., Seng, K. P., Smith, J., & Ang, L. M. (2024). Multi-Level Split Federated Learning for Large-Scale AIoT System Based on Smart Cities. Future Internet, 16(3), 82. https://doi.org/10.3390/fi16030082