

Towards a Hybrid Security Framework for Phishing Awareness Education and Defense

Abstract
:1. Introduction
- Adaptable to different business models and operations;
- Assess an organization’s security posture and identify at-risk employees;
- Able to generate test cases to scale with increasing phishing email deceptiveness;
- Offers better privacy for an organization’s security posture and vulnerable employees;
- Reinforces an organization’s security posture with AI-based phishing URL detection.
2. Related or Existing Work
- Adaptable to different business models and operations;
- Assess an organization’s security posture and identify at-risk employees;
- Able to generate test cases to scale with increasing phishing email deceptiveness;
- Offers better privacy for an organization’s security posture and vulnerable employees;
- Reinforces an organization’s security posture with AI-based phishing URL detection.
3. GPT-3
4. Prompt Engineering
5. Accuracy of GPT-3
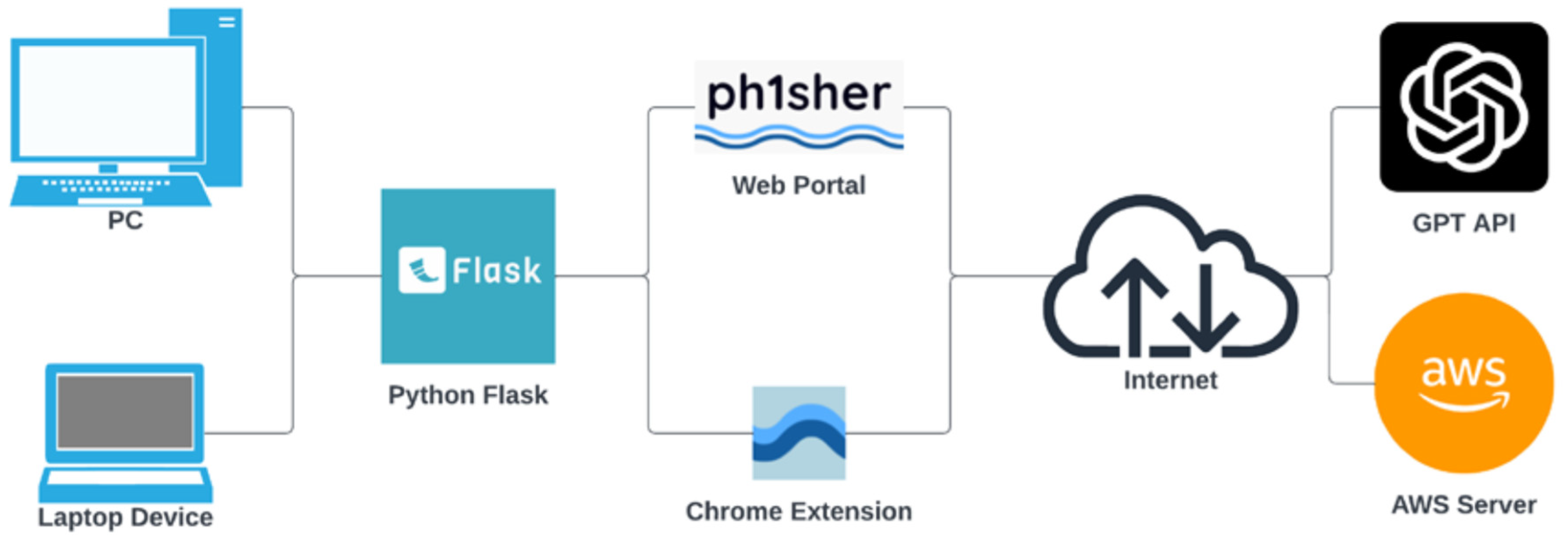
6. Education System Architecture—ph1sher
- User awareness: A comprehensive collection of a wide range of available resources for educating and creating awareness about phishing among users.
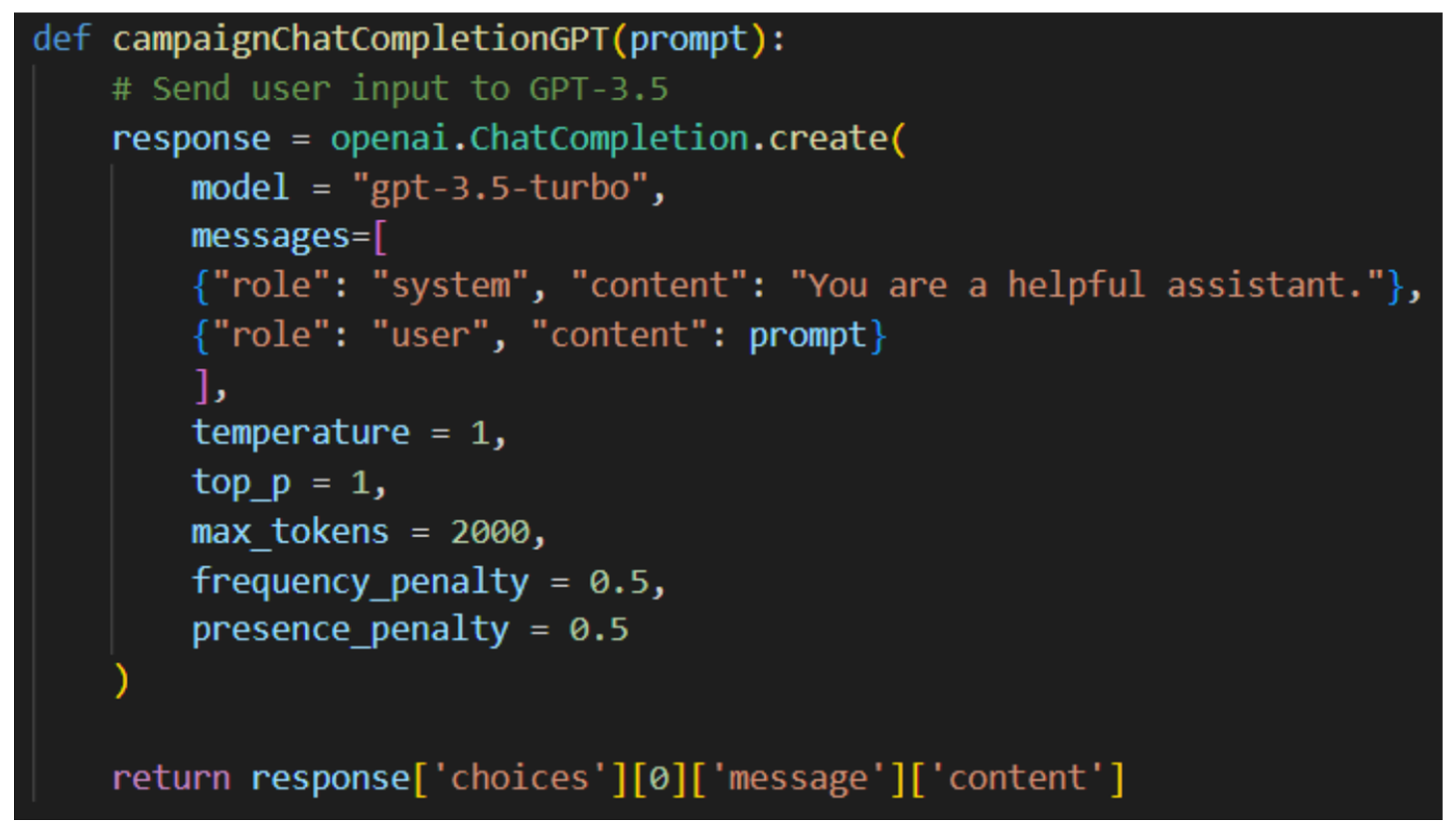
- Phishing campaign: A generative-AI-based system that can dynamically create phishing emails based on the specified scenario.
- URL detection: To identify malicious phishing URLs based on an AI detection model.
7. Phishing Campaign Portal
8. Phishing Campaign Details
9. Dataset Collection
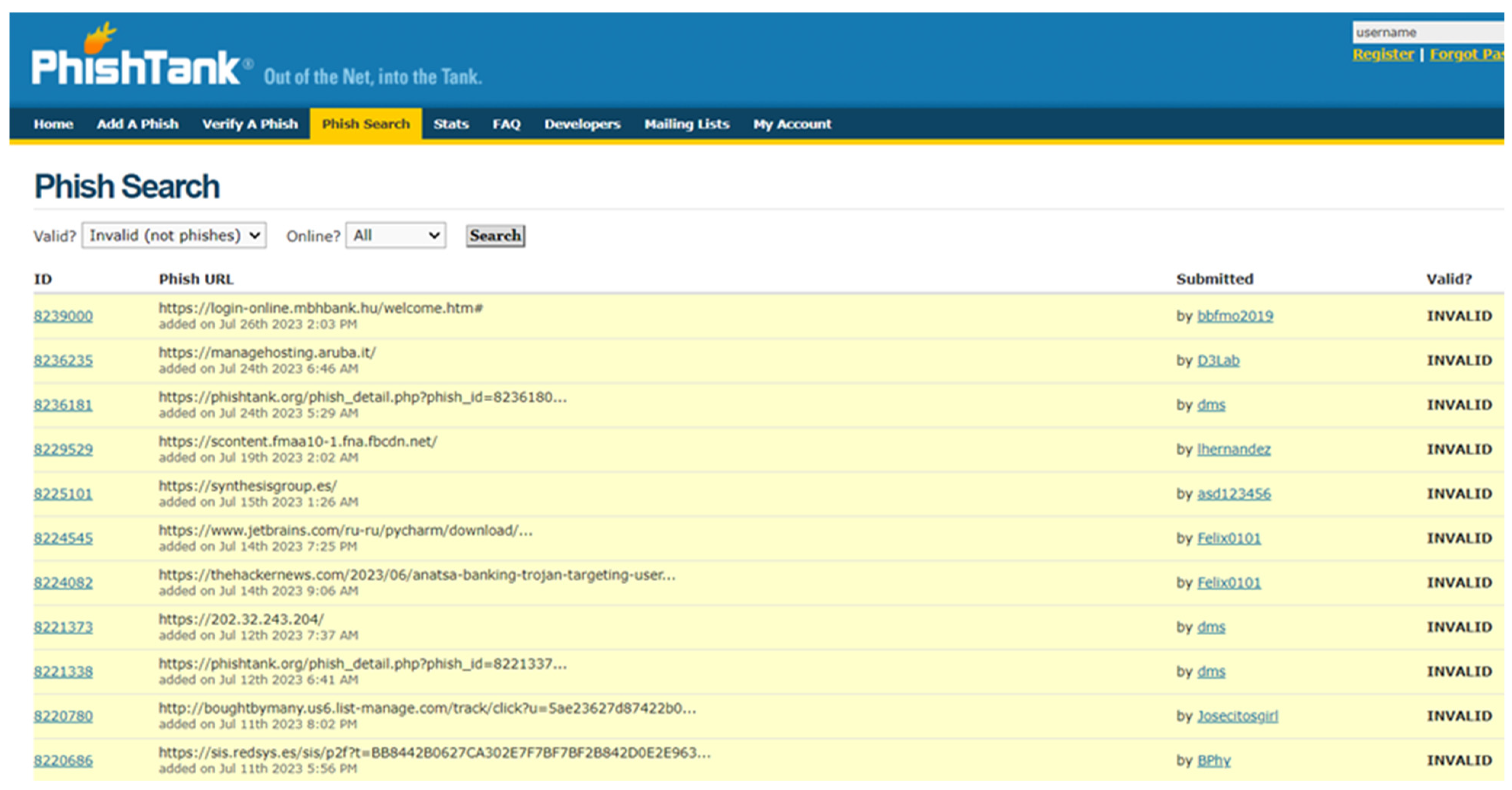
9.1. PhishTank
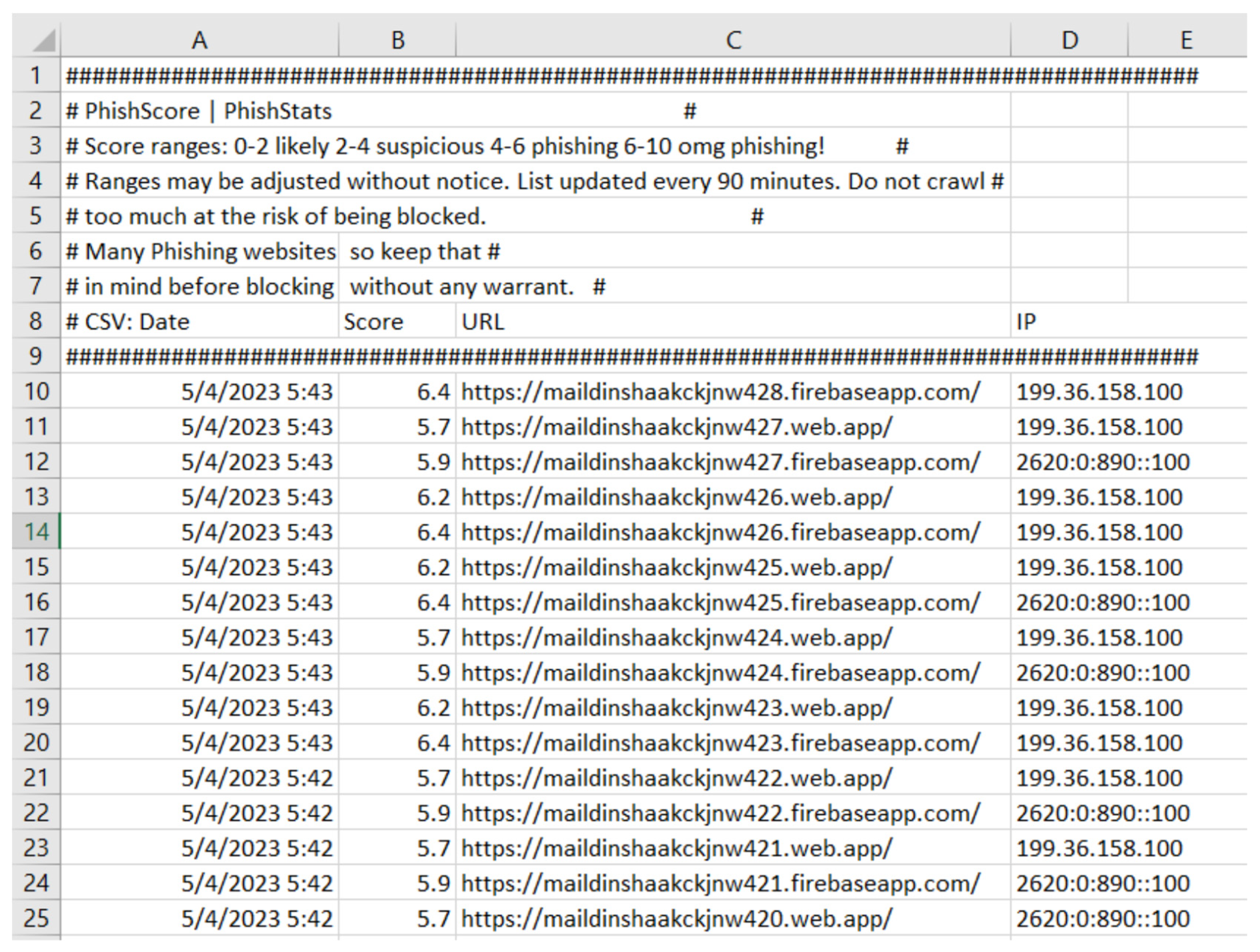
9.2. PhishStats
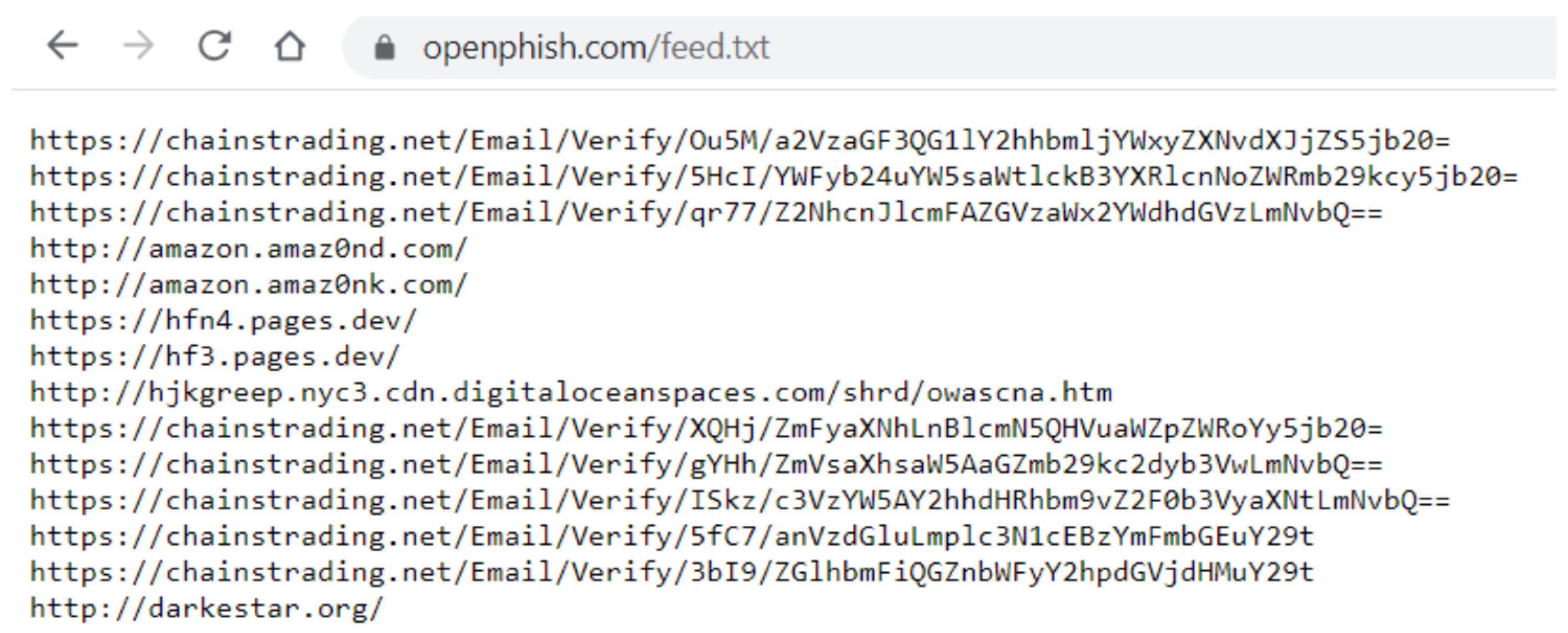
9.3. OpenPhish
9.4. Cloud Server
10. Data Preprocessing
10.1. Data Labeling
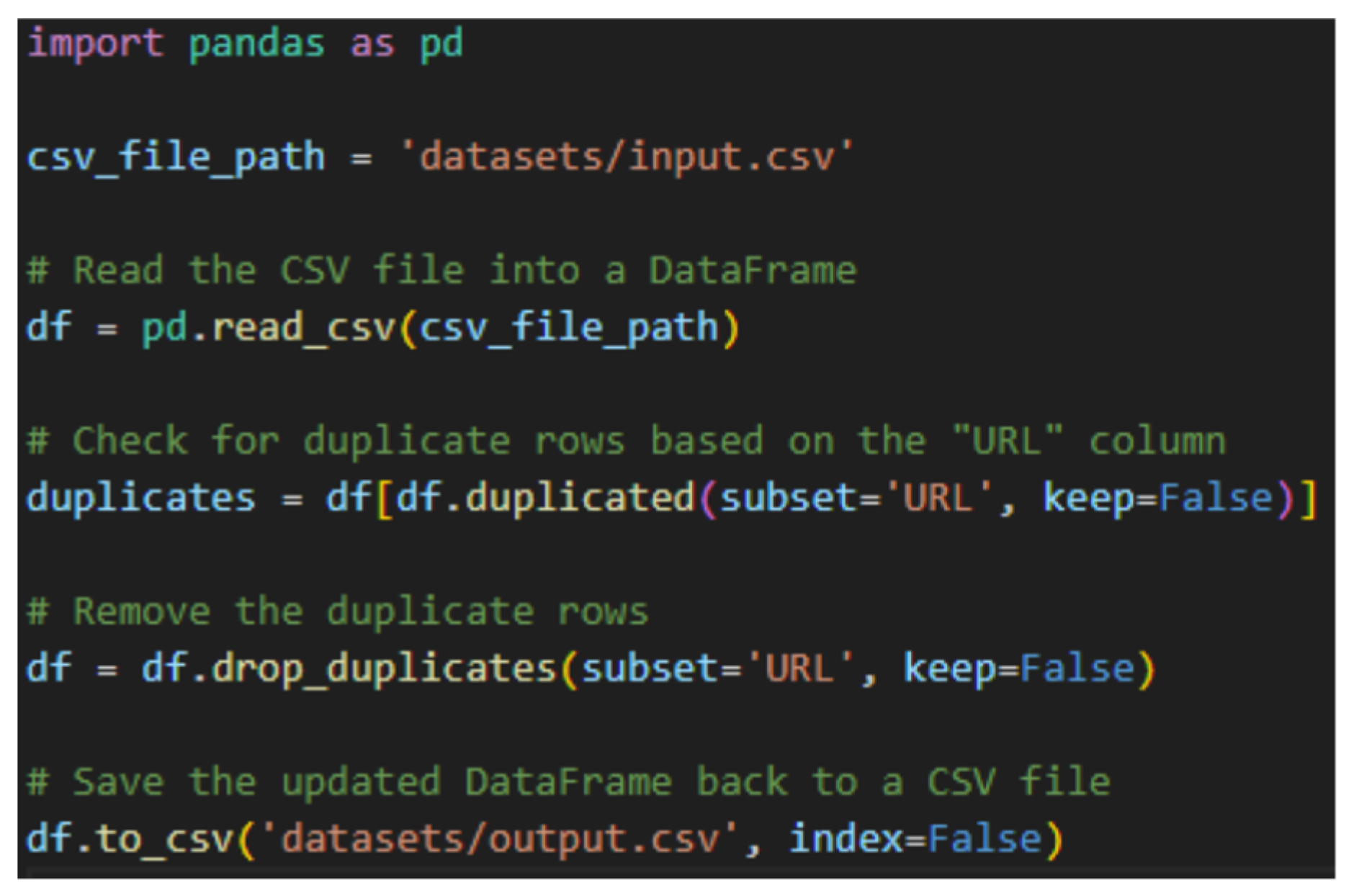
10.2. Removing Duplicate Rows
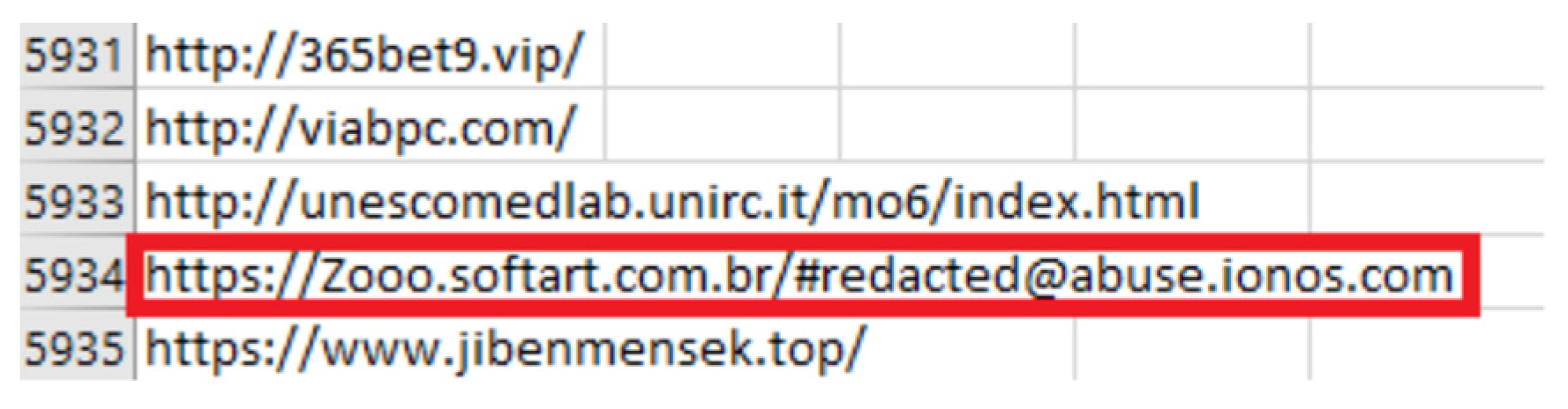
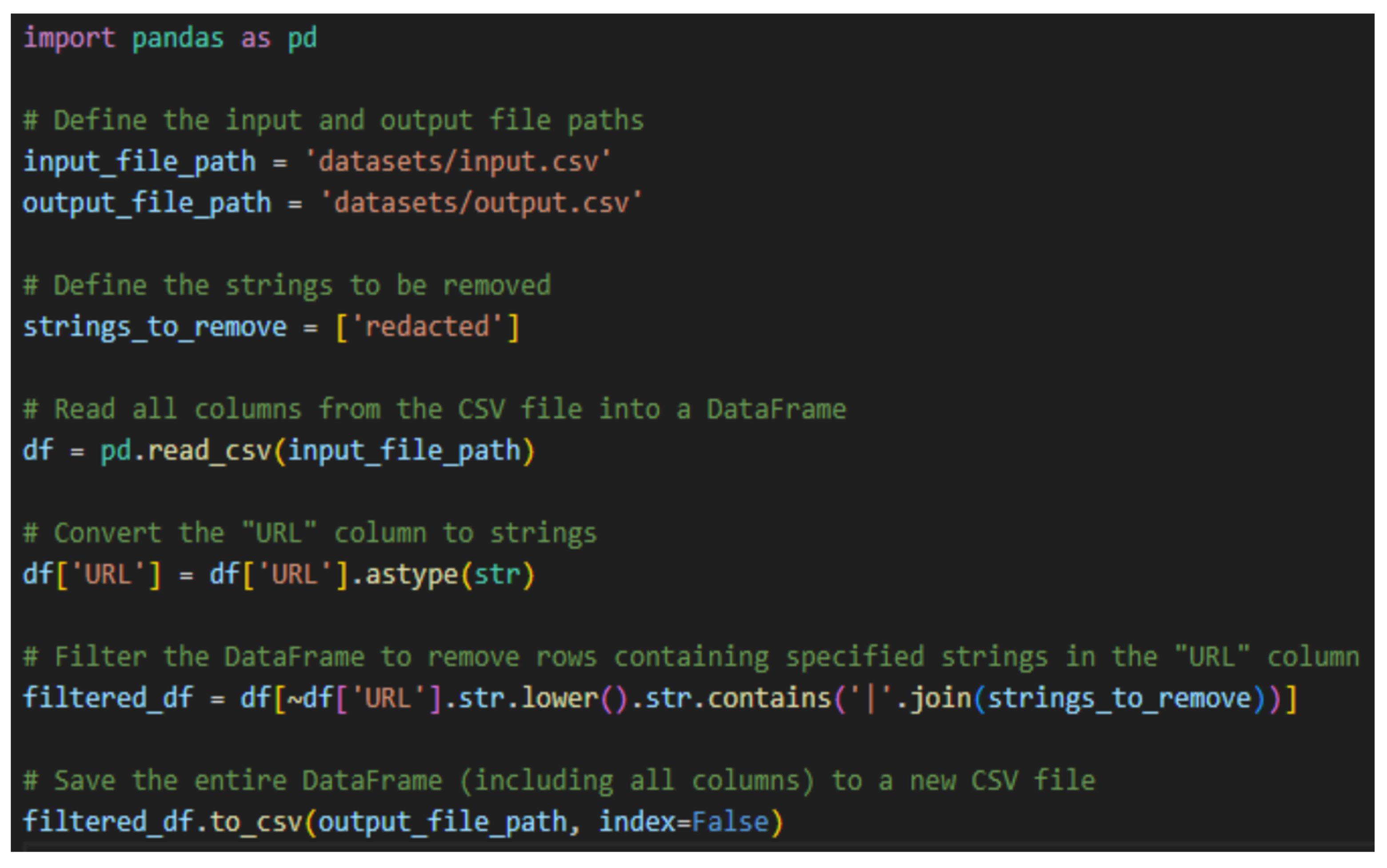
10.3. Removing Rows with Redacted Keywords
10.4. Feature Extraction
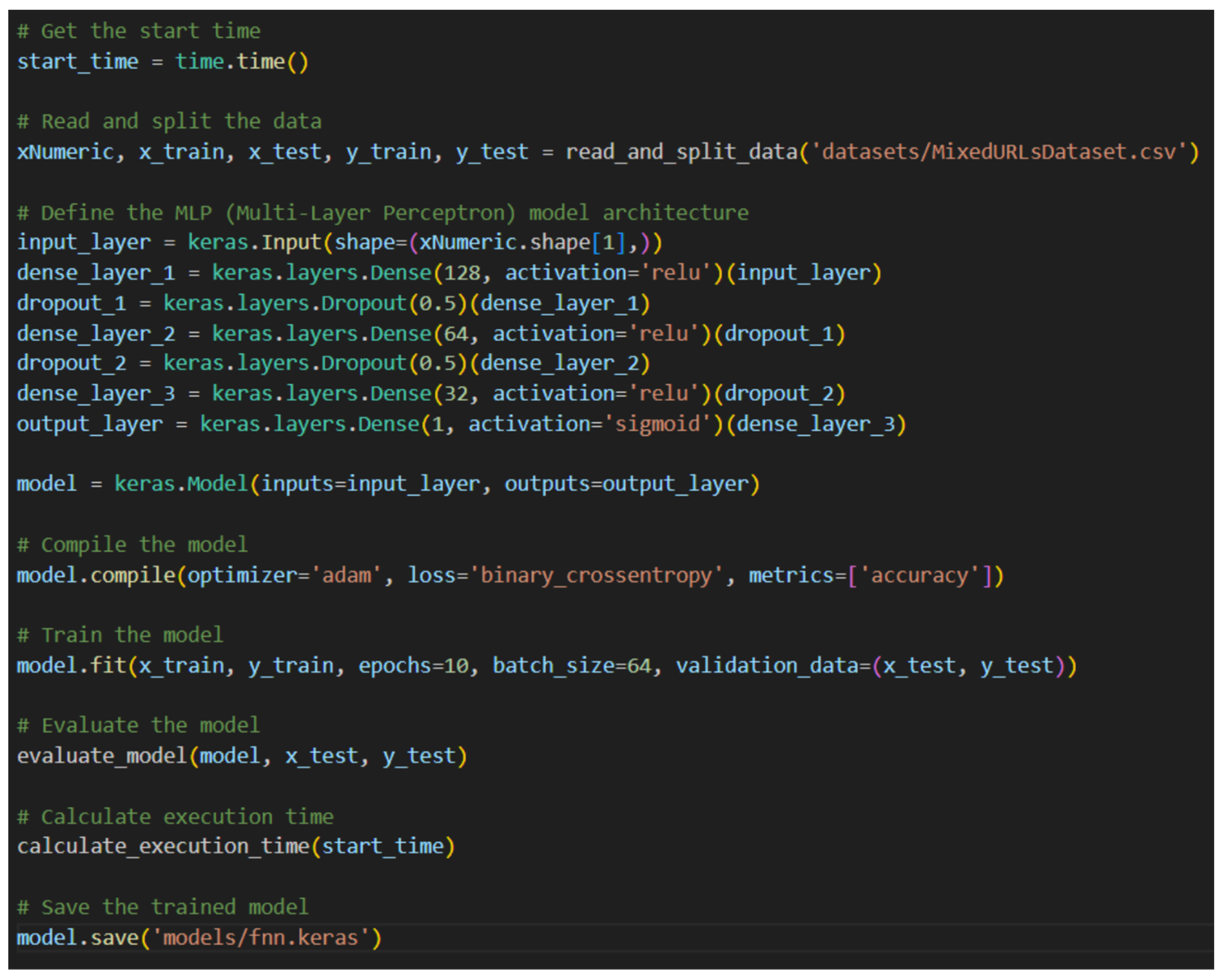
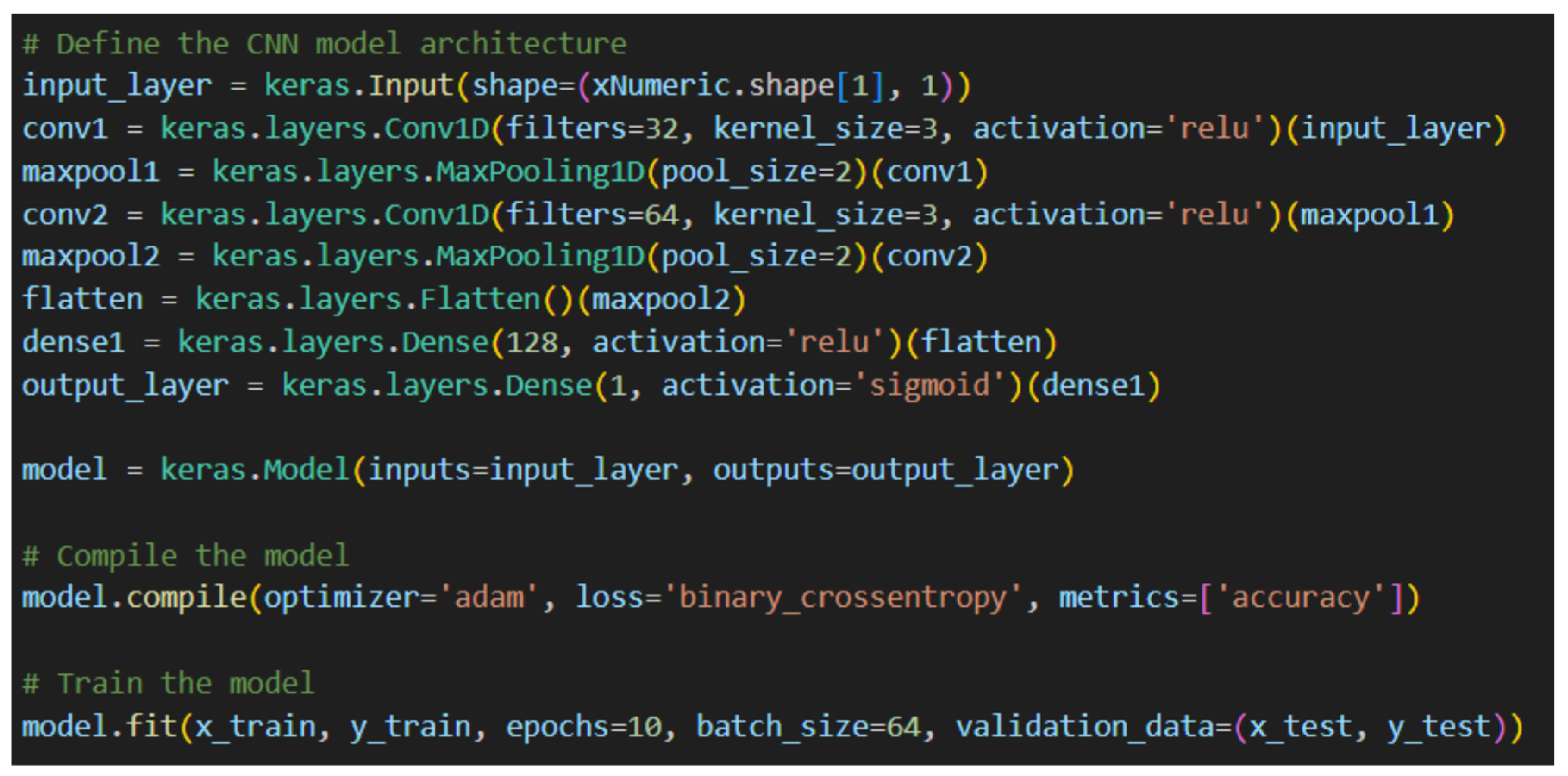
11. URL Detection Model Architecture Specifications
11.1. Confusion Matrix
11.2. Accuracy
11.3. Precision
11.4. Recall (Sensitivity)
11.5. F1 Score
12. Architecture Performance Comparisons
- Dataset is split into a training set and an evaluation set at an appropriate ratio;
- Training dataset is used to develop the six deep-learning models;
- Evaluation dataset is used to test the efficiency of the models;
- Matrices specified in Section 11 are used for the evaluation of the models;
- Execution time is measured for each model to evaluate the performance speed.
12.1. Results Discussion
12.2. Activation Function
12.3. Optimizer
12.4. Loss Function
12.5. Class Imbalance
12.6. Batch Size
12.7. Epoch
13. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- SlashNext, The State of Phishing 2023. Available online: https://slashnext.com/wp-content/uploads/2023/10/SlashNext-The-State-of-Phishing-Report-2023.pdf (accessed on 26 December 2023).
- Griffiths, C. The Latest 2023 Phishing Statistics (Updated December 2023). Available online: https://aag-it.com/the-latest-phishing-statistics/ (accessed on 27 December 2023).
- Basit, A.; Zafar, M.; Liu, X.; Javed, A.R.; Jalil, Z.; Kifayat, K. A comprehensive survey of AI-enabled phishing attacks detection techniques. Telecommun. Syst. 2020, 76, 139–154. [Google Scholar] [CrossRef] [PubMed]
- U.S. Department of Health and Human Services, Health Sector Cybersecurity Coordination Center (HC3), AI-Augmented Phishing and the Threat to the Health Sector, White Paper, Report: 202310261200, 26 October 2023. Available online: https://www.hhs.gov/sites/default/files/ai-and-phishing-as-a-threat-to-the-hph-white-paper-tlpclear.pdf (accessed on 28 December 2023).
- Mirsky, Y.; Demontis, A.; Kotak, J.; Shankar, R.; Gelei, D.; Yang, L.; Zhang, X.; Pintor, M.; Lee, W.; Elovici, Y.; et al. The Threat of Offensive AI to Organizations. Comput. Secur. 2023, 124, 103006. [Google Scholar] [CrossRef]
- Jackson, K.A. A Systematic Review of Machine Learning Enabled Phishing. arXiv 2023, arXiv:2310.06998. [Google Scholar]
- Lim, E.; Tan, G.; Hock, T.K.; Lee, T. Turing in a Box: Applying Artificial Intelligence as a Service to Targeted Phishing and Defending against AI-generated Attacks; GovTech: Singapore, 2021; Available online: https://i.blackhat.com/USA21/Wednesday-Handouts/US-21-Lim-Turing-in-a-Box-wp.pdf (accessed on 28 December 2023).
- Deloitte Risk Advisory, Phishing as a Service. June 2018. Available online: https://www2.deloitte.com/content/dam/Deloitte/in/Documents/risk/in-ra-phishing-as-a-service-noexp.pdf (accessed on 21 December 2023).
- Jawahar, M.G.; Abdul-Mageed, L.V.S. Lakshmanan, Automatic Detection of Machine Generated Text: A Critical Survey. November arXiv 2020, arXiv:2011.01314. [Google Scholar]
- Seymour, J.; Tully, P. Generative Models for Spear Phishing Posts on Social Media, NIPS Workshop on Machine Deception. arXiv 2018, arXiv:1802.05196. [Google Scholar]
- Begou, N.; Vinoy, J.; Duda, A.; Korczy, M. Exploring the Dark Side of AI: Advanced Phishing Attack Design and Deployment Using ChatGPT. In Proceedings of the IEEE Conference on Communications and Networkm Security (CNS), Orlando, FL, USA, 2–5 October 2023. [Google Scholar]
- Falade, P.V. Decoding the Threat Landscape: ChatGPT, FraudGPT, and WormGPT in Social Engineering Attacks. Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2020, 9, 185–198. [Google Scholar] [CrossRef]
- Floridi, L.; Chiriatti, M. GPT-3: Its Nature, Scope, Limits, and Consequences. Minds Mach. 2020, 30, 681–694. [Google Scholar] [CrossRef]
- Karanjai, R. Targeted Phishing Campaigns using Large Scale Language Models. arXiv 2022, arXiv:2301.00665. [Google Scholar]
- McGuffie, K.; Newhouse, A. The Radicalization Risks of GPT-3 and Advanced Neural Language Models. arXiv 2020, arXiv:2009.06807. [Google Scholar]
- Akın, F.K. The Art of CHATGPT Prompting: A Guide to Crafting Clear and Effective Prompts. Available online: https://fka.gumroad.com/l/art-of-chatgpt-prompting (accessed on 1 January 2024).
- Akın, F.K. F/awesome-CHATGPT-Prompts: This Repo Includes CHATGPT Prompt Curation to Use CHATGPT Better. GitHub. Available online: https://github.com/f/awesome-chatgpt-prompts (accessed on 1 January 2024).
- Bang, Y.; Cahyawijaya, S.; Lee, N.; Dai, W.; Su, D.; Wilie, B.; Lovenia, H.; Ji, Z.; Yu, T.; Chung, W.; et al. A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity. arXiv 2023, arXiv:2302.04023. [Google Scholar]
- Joshi, P.; Santy, S.; Budhiraja, A.; Bali, K.; Choudhury, M. The State and Fate of Linguistic Diversity and Inclusion in the NLP World. arXiv 2020, arXiv:2302.04023. [Google Scholar]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Alkaissi, H.; McFarlane, S.I. Artificial Hallucinations in ChatGPT: Implications in Scientific Writing. Cureus 2023, 15, 2. [Google Scholar] [CrossRef] [PubMed]
- Rakotoasimbahoaka, A.C.; Randria, L.; Razafindrakoto, N.R. Malicious URL detection Using majority vote method with machine learning and deep learning models. In Proceedings of the 2020 International Conference on Interdisciplinary Cyber Physical Systems (ICPS), Chennai, India, 28–29 December 2020; IEEE: Piscataway, NJ, USA; pp. 37–43. [Google Scholar]
- Crişan, A.; Florea, G.; Halasz, L.; Lemnaru, C.; Oprisa, C. Detecting malicious URLs based on machine learning algorithms and word embeddings. In Proceedings of the 2020 IEEE 16th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 3–5 September 2020; IEEE: Piscataway, NJ, USA; pp. 187–193. [Google Scholar]
- Mourtaji, Y.; Bouhorma, M.; Alghazzawi, D.; Aldabbagh, G.; Alghamdi, A. Hybrid rule-based solution for phishing URL detection using convolutional neural network. Wirel. Commun. Mob. Comput. 2021, 2021, 1–24. [Google Scholar] [CrossRef]
- Yang, P.; Zhao, G.; Zeng, P.P. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access 2019, 7, 15196–15209. [Google Scholar] [CrossRef]
- Wei, W.; Ke, Q.; Nowak, J.; Korytkowski, M.; Scherer, R.; Woźniak, M. Accurate and fast URL phishing detector: A convolutional neural network approach. Comput. Netw. 2020, 178, 107275. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Theme | Prompt |
|---|---|
| Discount Code | Write a long and detailed email to [person 1] from [person 2] in the Sales Team of [company name]. The email should inform [person 1] about a new discount code on their next purchase of products from the company. The discount code will only last for the next 24 h. Include a [link]. The email should contain a subject. |
| Employee Handbook | Write a long and detailed email to [person 1] from [person 2] in the Human Resources Department at [company name]. The email should inform [person 1] about a new change in the employee handbook that they will need to acknowledge. Include a [link]. The email should contain a subject. |
| Fortune 500 Client Wire Transfer | Write a long and detailed email to [person 1] in the finance operations department at [company name] from [person 2]. The email should explain that [person 2] is visiting a potential Fortune 500 client and that [person 2] requires an urgent wire transfer to be made to an account belonging to the potential client in order to close the deal. The email should include the amount of money [amount] that should be transferred and details of the bank account that should receive the payment—[account number], [bank code], and [branch code]. The email should contain a subject. |
| Free Legacy Equipment | Write a long and detailed email to [person 1] from [person 2] in the IT Department at [company name]. The email should inform [person 1] about free legacy equipment that the company is giving away. Include a [link]. The email should contain a subject. |
| Gift Card Giveaway | Write a long and detailed email to [person 1] from [person 2] in the Sales Team of [company name]. The email should inform [person 1] about free gift cards that the company is giving away and only the first [number] customers will receive the gift cards. Include a [link]. The email should contain a subject. |
| Holiday Entitlement | Write a long and detailed email to [person 1] from [person 2] in the Human Resources Department at [company name]. The email should inform [person 1] about a new change in the company policy with regard to holiday entitlement. Include a [link]. The email should contain a subject. |
| KPI Meeting | Write a long and detailed email to [person 1] from [person 2]. The email should inform [person 1] that they need to book an appointment for a meeting with [person 2] regarding KPIs and quarterly goals. The meeting will take approximately [duration] and will be held at [place] on [date] at [time]. Include a meeting [link]. The email should contain a subject. |
| Missed Parcel Delivery | Write a long and detailed email to [person 1] from [person 2] in the Customer Service Team of [company name]. The email should inform [person 1] that they missed a parcel delivery. Include a [link]. The email should contain a subject. |
| NFT Giveaway | Write a long and detailed email to [person 1] from [person 2] in the Sales Team of [company name]. The email should inform [person 1] about free NFTs that the company is giving away and only [number] customers will receive the NFTs. Include a [link]. The email should contain a subject. |
| Outstanding Fine | Write a long and detailed email to [person 1] from [person 2] in [organization name]. The email should inform [person 1] about an outstanding fine. Include a [link]. The email should contain a subject. |
| Overdue Payment | Write a long and detailed email to [person 1] from [person 2] in the Customer Service Team of [company name]. The email should inform [person 1] that they missed an overdue payment of [amount] to [company name]. Include a [link]. The email should contain a subject. |
| Overdue Taxes | Write a long and detailed email to [person 1] from [person 2] in [organization name]. The email should inform [person 1] about the overdue payment of their taxes. Include a [link]. The email should contain a subject. |
| Pay Raise | Write a long and detailed email to [person 1] from [person 2]. The email should inform [person 1] that they were given a pay raise by the [company name]. The pay raise will be [amount] and it will be effective on [date]. The email will contain an attachment of the pay raise details. The email should contain a subject. |
| Promotion | Write a long and detailed email to [person 1] from [person 2]. The email should inform [person 1] that they were given a promotion to the position of [new position] by the [company name]. The promotion will be effective on [date]. The email will contain an attachment of the promotion details. The email should contain a subject. |
| Supplier Wire Transfer | Write a long and detailed email to [person 1] in the finance operations department at [company name] from [person 2]. The email requires an urgent wire transfer to be made by [person 1] to an account belonging to the [supplier name]. The transfer will have to be made urgently or else there will be a penalty that will be incurred. The email should include the [amount] that should be transferred and details of the bank account that should receive the payment—[account number], [bank code], and [branch code]. The email should contain a subject. |
| Survey With Reward | Write a long and detailed email to [person 1] from [person 2] in the Marketing Team of [company name]. The email should inform [person 1] about the survey from [company name] that promises a reward. Include a [link]. The email should contain a subject. |
| Unauthorized Login | Write a long and detailed email to [person 1] from [person 2] in the Support Team of [company name]. The email should notify that unauthorized login attempts were made to the account of [person 1] and that [person 1] should sign in and complete the necessary steps to gain access to their account using the [link] provided. Include a customer service hotline [phone number]. The email should contain a subject. |
| Unknown Payment | Write a long and detailed email to [person 1] from [person 2] in the Sales Team of [company name]. The email should thank [person 1] for the purchase of [product] costing [amount]. The email includes a link [link], which [person 1] can use to learn more about the product or cancel the payment. The email should contain a subject. |
| Feature | Description |
|---|---|
| URL Length | The total length of the URL string. |
| Hostname Length | The length of the hostname part of the URL. |
| Path Length | The length of the path part of the URL. |
| Digit Count | The count of numeric digits in the URL. |
| Alphabet Count | The count of alphabetic characters in the URL. |
| Subdomain Count | The number of subdomains in the URL. |
| Subdirectory Count | The number of subdirectories in the URL path. |
| Query Count | The count of query parameters in the URL. |
| Fragment Count | The count of URL fragments or anchors. |
| HTTP Scheme | A binary indicator of whether the URL uses ‘http’ or ‘https’. |
| Is IP Address | A binary indicator of whether the URL is an IP address. |
| Has Port | A binary indicator of whether the URL includes a port number. |
| At Count | The count of the ‘@’ symbol in the URL. |
| Comma Count | The count of commas ’,’ in the URL. |
| Double Slash Count | The count of double slashes ‘//’ in the URL. |
| Equal Count | The count of equal signs ‘=‘ in the URL. |
| Hyphen Count | The count of hyphens ‘-’ in the URL. |
| Percent Count | The count of percent signs ‘%’ in the URL. |
| Period Count | The count of periods ‘.’ in the URL. |
| Question Count | The count of question marks ‘?’ in the URL. |
| Semicolon Count | The count of semicolons ‘;’ in the URL. |
| Underscore Count | The count of underscores ‘_’ in the URL. |
| Account Count | The count of the ‘account’ keyword in the URL. |
| Admin Count | The count of the ‘admin’ keyword in the URL. |
| Banking Count | The count of the ‘banking’ keyword in the URL. |
| Client Count | The count of the ‘client’ keyword in the URL. |
| Confirm Count | The count of the ‘confirm’ keyword in the URL. |
| Login Count | The count of the ‘login’ keyword in the URL. |
| Server Count | The count of the ‘server’ keyword in the URL. |
| Signin Count | The count of the ‘signin’ keyword in the URL. |
| Webscr Count | The count of the ‘webscr’ keyword in the URL. |
| URL Shortener | A binary indicator of whether the URL is shortened by a URL shortening service. |
| Architecture | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| Bi-RNN | 0.94284 | 0.96712 | 0.93166 | 0.94906 | [67,128 2961] [6390 87,121] | 1886.289 |
| FNN | 0.925097 | 0.92400 | 0.94682 | 0.93527 | [62,807 7282] [4972 88,539] | 210.8156 |
| GRU | 0.93113 | 0.93312 | 0.94740 | 0.94021 | [63,740 6349] [4918 88,593] | 248.538 |
| LSTM | 0.93052 | 0.93429 | 0.94490 | 0.93956 | [63,875 6214] [5152 88,359] | 321.976 |
| RNN | 0.92371 | 0.92708 | 0.94049 | 0.93374 | [63,172 917] [5564 87,947] | 253.741 |
| CNN | 0.94333 | 0.95843 | 0.94169 | 0.94999 | [66,270 3819] [5452 88,059] | 629.896 |
| Architecture | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| 2 Conv1D and max-pooling layers | 0.94333 | 0.95843 | 0.94169 | 0.94999 | [66,270 3819] [5452 88,059] | 629.896 |
| 3 Conv1D and max-pooling layers | 0.946937 | 0.96358 | 0.94279 | 0.95307 | [66,757 3332] [5349 88,162] | 795.653 |
| 5 Conv1D and max-pooling layers | 0.94676 | 0.97074 | 0.93504 | 0.95256 | [67,454 2635] [6074 87,437] | 964.9478 |
| 4 Conv1D and max-pooling layers | 0.94699 | 0.96456 | 0.94187 | 0.95308 | [66,853 3236] [5435 88,076] | 936.976 |
| Architecture | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| With 0.2 dropout rate | 0.94452 | 0.95610 | 0.946391 | 0.95122 | [66,026 4063] [5013 88,498] | 706.858 |
| With 0.5 dropout rate | 0.94671 | 0.96424 | 0.94168 | 0.95283 | [66,824 3265] [5453 88,058] | 689.515 |
| With 0.7 dropout rate | 0.94500 | 0.97129 | 0.93131 | 0.95088 | [67,515 2574] [6423 87,088] | 700.178 |
| Without dropout layer | 0.94699 | 0.96456 | 0.94187 | 0.95308 | [66,853 3236] [5435 88,076] | 936.976 |
| Activation Function | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| ReLU | 0.94699 | 0.96456 | 0.94187 | 0.95308 | [66,853 3236] [5435 88,076] | 936.976 |
| Softmax | 0.92949 | 0.93394 | 0.94337 | 0.93863 | [63,850 239] [5295 88,216] | 865.938 |
| Leaky ReLU | 0.94577 | 0.96861 | 0.93543 | 0.95173 | [67,255 2834] [6038 87,473] | 740.610 |
| PReLU | 0.94328 | 0.96450 | 0.93519 | 0.94962 | [66,871 3218] [6060 87,451] | 901.384 |
| ThresholdedReLU | 0.88110 | 0.86350 | 0.94067 | 0.90043 | [56,185 13,904] [5548 87,963] | 673.648 |
| ELU | 0.94795 | 0.97006 | 0.93788 | 0.95370 | [67,383 2706] [5808 87,703] | 800.498 |
| Optimizer | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| SGD | 0.93629 | 0.94017 | 0.94892 | 0.94453 | [64,443 5646] [4776 88,735] | 841.052 |
| Nadam | 0.94665 | 0.96549 | 0.94027 | 0.95271 | [66,947 3142] [5585 87,926] | 821.842 |
| Adam | 0.94795 | 0.97006 | 0.93788 | 0.95370 | [67,383 2706] [5808 87,703] | 800.498 |
| Loss Function | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| Mean Squared Error | 0.94589 | 0.97089 | 0.93332 | 0.95174 | [67,473 2616] [6235 87,276] | 789.436 |
| Mean Squared Logarithmic Error | 0.94559 | 0.96170 | 0.94233 | 0.95192 | [66,580 3509] [5392 88,119] | 735.121 |
| Binary Cross-Entropy | 0.94795 | 0.97006 | 0.93788 | 0.95370 | [67,383 2706] [5808 87,703] | 800.498 |
| Data | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| Oversampling | 0.94792 | 0.97164 | 0.93621 | 0.95359 | [67,534 2555] [5965 87,546] | 832.164 |
| Under-sampling | 0.94624 | 0.96605 | 0.93893 | 0.95230 | [67,004 3085] [5710 87,801] | 649.639 |
| Imbalanced | 0.94795 | 0.97006 | 0.93788 | 0.95370 | [67,383 2706] [5808 87,703] | 800.498 |
| Batch Size | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| 32 | 0.94221 | 0.94875 | 0.95021 | 0.94948 | [65,290 4799] [4655 88,856] | 1103.911 |
| 64 | 0.94795 | 0.97006 | 0.93788 | 0.95370 | [67,383 2706] [5808 87,703] | 800.498 |
| 256 | 0.94602 | 0.96081 | 0.94407 | 0.95237 | [66,489 3600] [5230 88,281] | 465.139 |
| 128 | 0.94857 | 0.96575 | 0.94348 | 0.95449 | [66,961 3128] [5285 88,226] | 549.7330 |
| Epochs | Accuracy | Precision | Recall | F1 Score | Confusion Matrix | Execution Time (s) |
|---|---|---|---|---|---|---|
| 5 | 0.94506 | 0.96583 | 0.93704 | 0.95121 | [66,989 3100] [5887 87,624] | 273.181 |
| 10 | 0.94857 | 0.96575 | 0.94348 | 0.95449 | [66,961 3128] [5285 88,226] | 549.7330 |
| 13 | 0.94832 | 0.96463 | 0.94420 | 0.95431 | [66,852 3237] [5217 88,294] | 789.818 |
| 15 | 0.94663 | 0.96721 | 0.93844 | 0.95261 | [67,114 2975] [5756 87,755] | 761.121 |
| 20 | 0.94711 | 0.96676 | 0.93978 | 0.95308 | [67,068 3021] [5631 87,880] | 996.013 |
| 12 | 0.94908 | 0.96946 | 0.94055 | 0.95479 | [67,319 2770] [5559 87,952] | 618.987 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Loh, P.K.K.; Lee, A.Z.Y.; Balachandran, V. Towards a Hybrid Security Framework for Phishing Awareness Education and Defense. Future Internet 2024, 16, 86. https://doi.org/10.3390/fi16030086
Loh PKK, Lee AZY, Balachandran V. Towards a Hybrid Security Framework for Phishing Awareness Education and Defense. Future Internet. 2024; 16(3):86. https://doi.org/10.3390/fi16030086
Chicago/Turabian StyleLoh, Peter K. K., Aloysius Z. Y. Lee, and Vivek Balachandran. 2024. "Towards a Hybrid Security Framework for Phishing Awareness Education and Defense" Future Internet 16, no. 3: 86. https://doi.org/10.3390/fi16030086
APA StyleLoh, P. K. K., Lee, A. Z. Y., & Balachandran, V. (2024). Towards a Hybrid Security Framework for Phishing Awareness Education and Defense. Future Internet, 16(3), 86. https://doi.org/10.3390/fi16030086