
Turning Video Resource Management into Cloud Computing

Abstract
:
1. Introduction
2. Related Work
3. The Video Resource Management System in HDFS-Based Cloud Computing
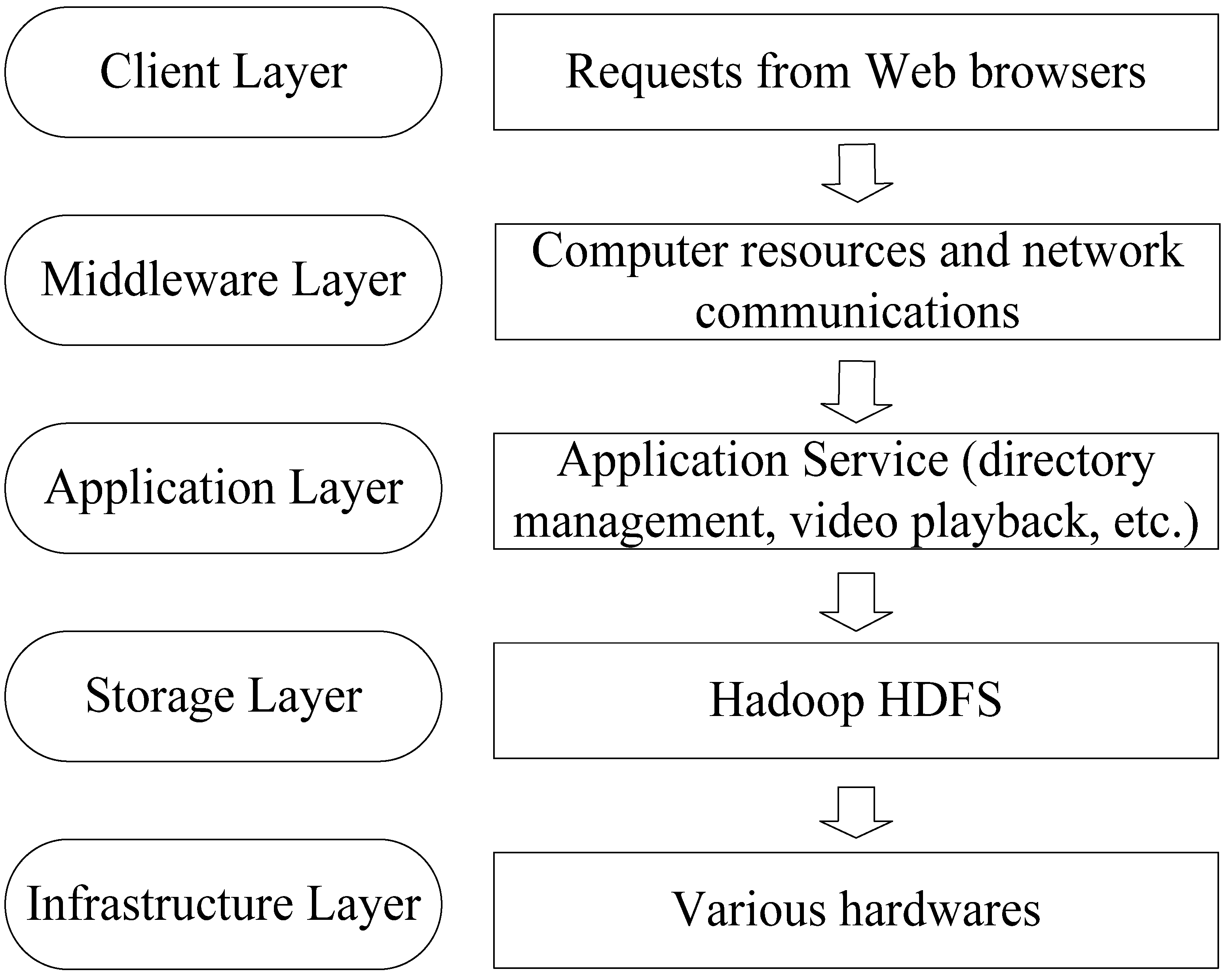
3.1. System Layers
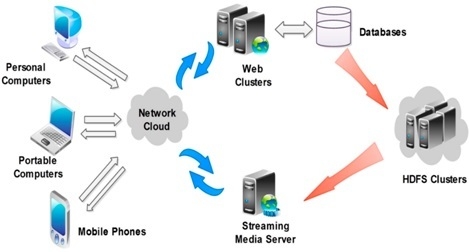
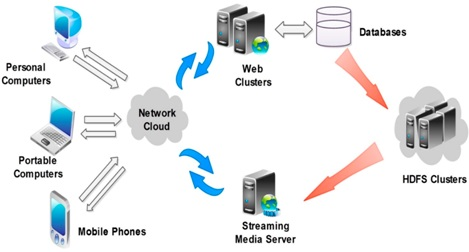
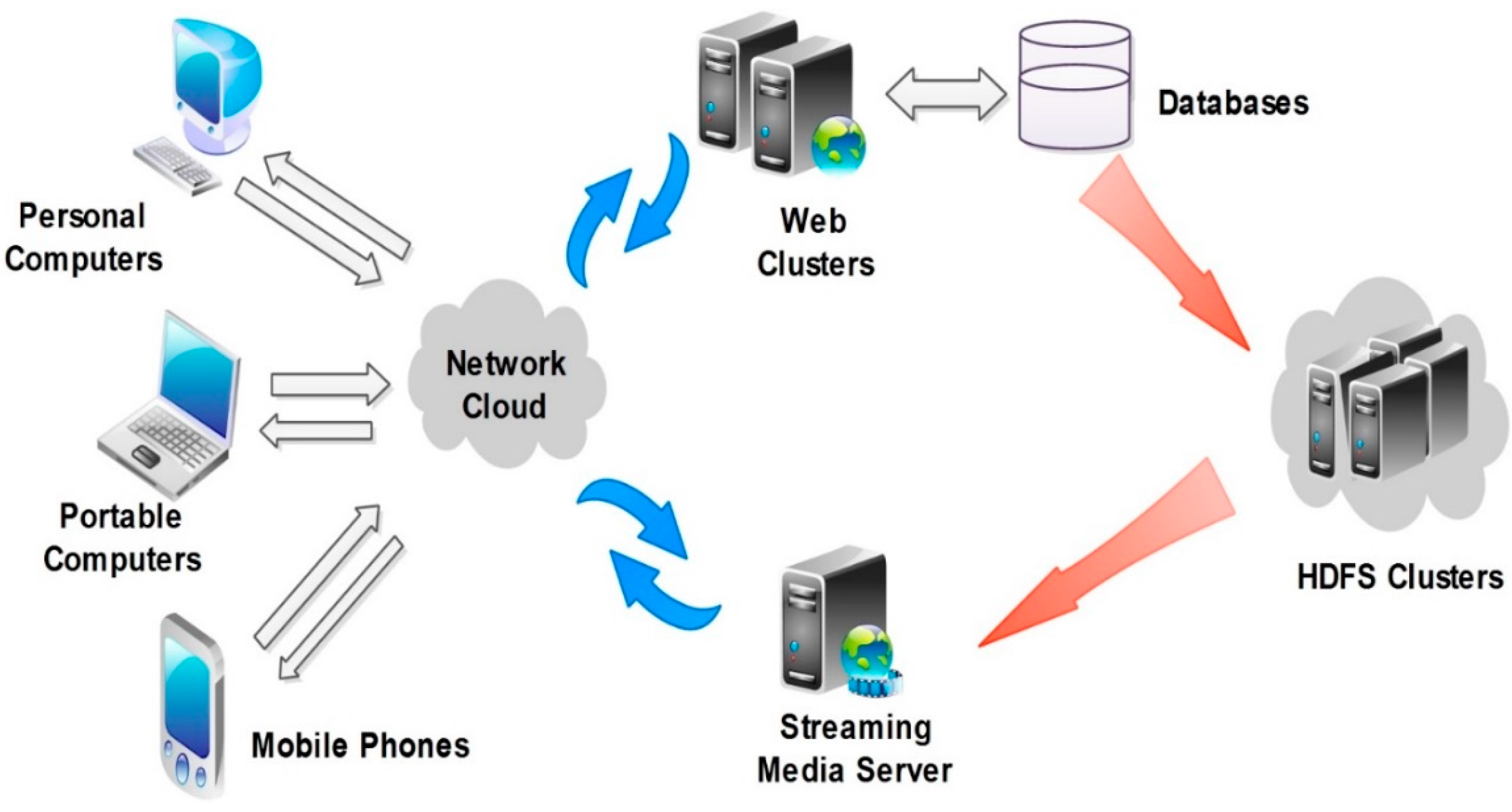
3.2. HDFS-Based Architecture of Video Resource Management
3.2.1. The Clients
3.2.2. The Web Service Clusters
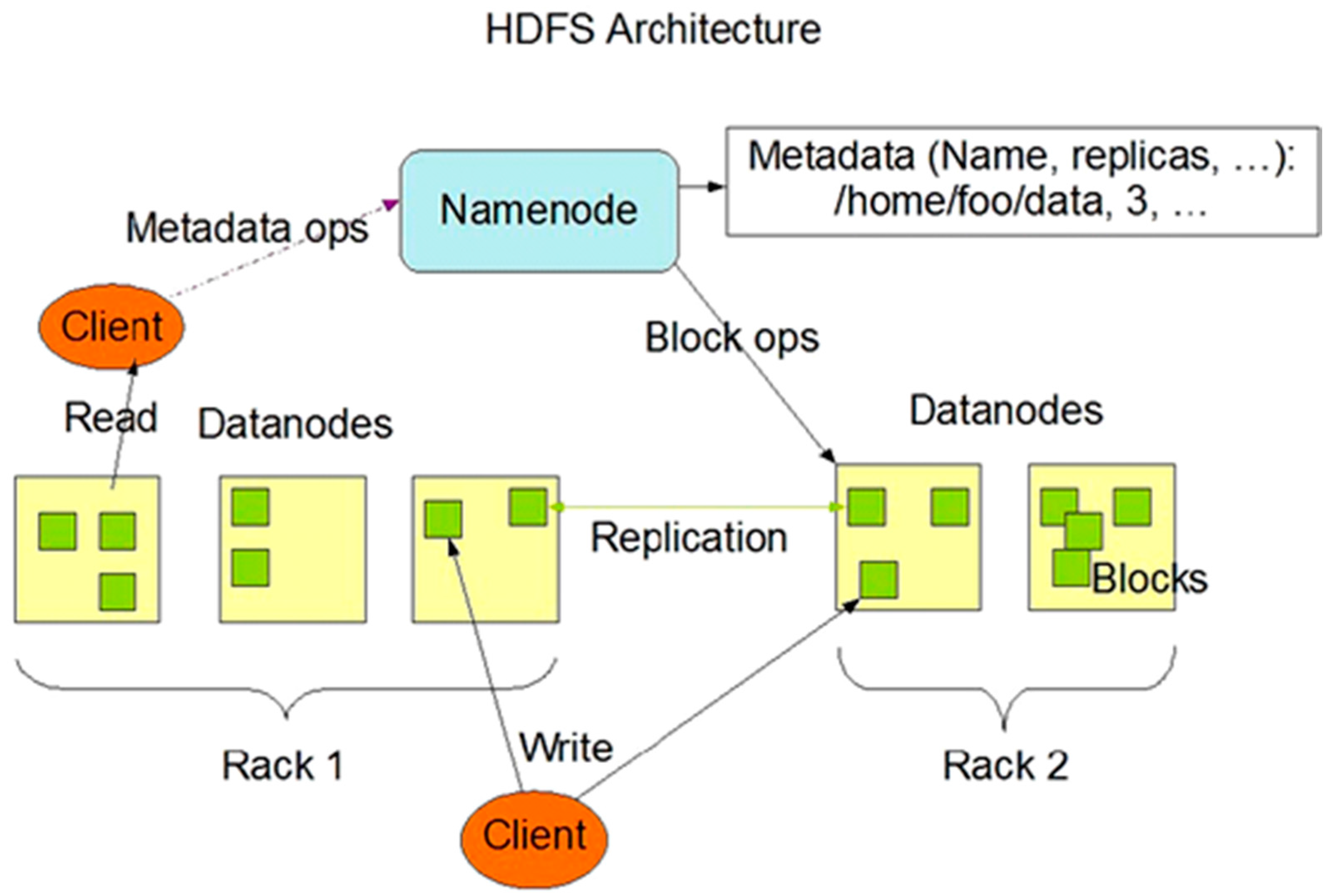
3.2.3. HDFS-Based Video Resource Clusters
3.2.4. Streaming Media Servers
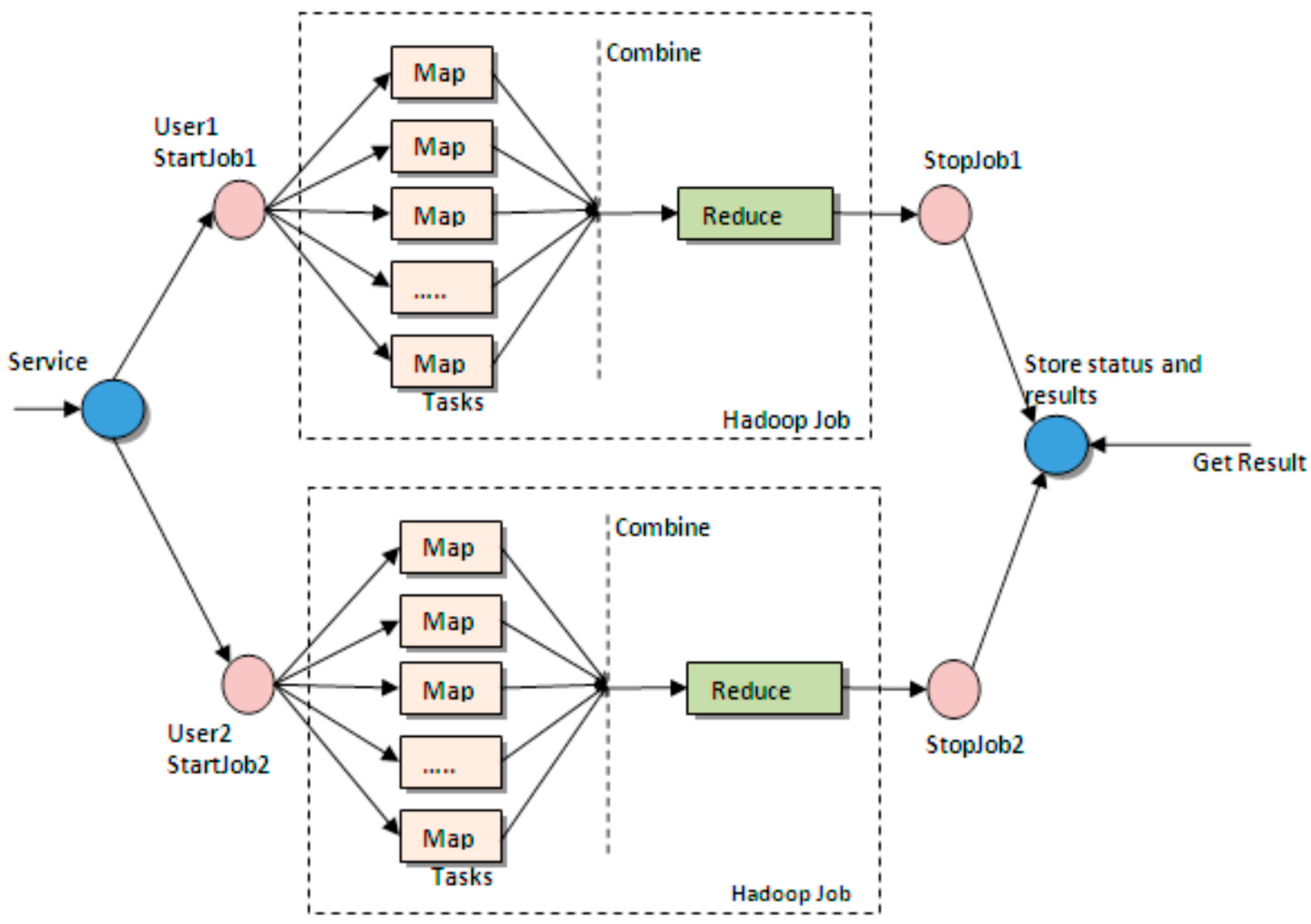
3.3. Key Algorithms
3.3.1. Pseudo Codes for Uploading Video Files from Local Servers to HDFS Clusters
public void copytoHDFS()
{
//Create configuration property object
Configuration conf = new Configuration();
//Fetch Hadoop configuration information
conf.addResource(new Path(str_conf));
//Create file sysytem object
FileSystem hdfs = FileSystem.get(conf);
//Get absolute path of local files
Path src = new Path(src_conf);
//Upload files to specified HDFS directories
Path dst = new Path(dst_conf);
//Upload files
hdfs.copyFromLocalFile(src, dst);
}3.3.2. Pseudo Codes for Reading Video Information from HDFS Clusters by Streaming Media Servers
public void readFromHDFS
{
//Create configuration property object
Configuration conf = new Configuration();
//Create file system object
FileSystem hdfs = FileSystem.get(conf);
//Call FSDataInputStream function
FSDataInputStream hdfsInStream = fs.open();
//Declare a array
byte[] ioBuffer = new byte[10240];
//Read the length of the array
int readLen = hdfsInStream.read(ioBuffer);
// Start an array for writing data
while(readLen!=-1)
{
System.out.write(ioBuffer, 0, readLen);
readLen = hdfsInStream.read(ioBuffer);
}
//Close data stream
hdfsInStream.close();
//Close HDFS
fs.close();
}4. Experiments and Results
4.1. Facilities and Configurations
4.2. The Experimental Results
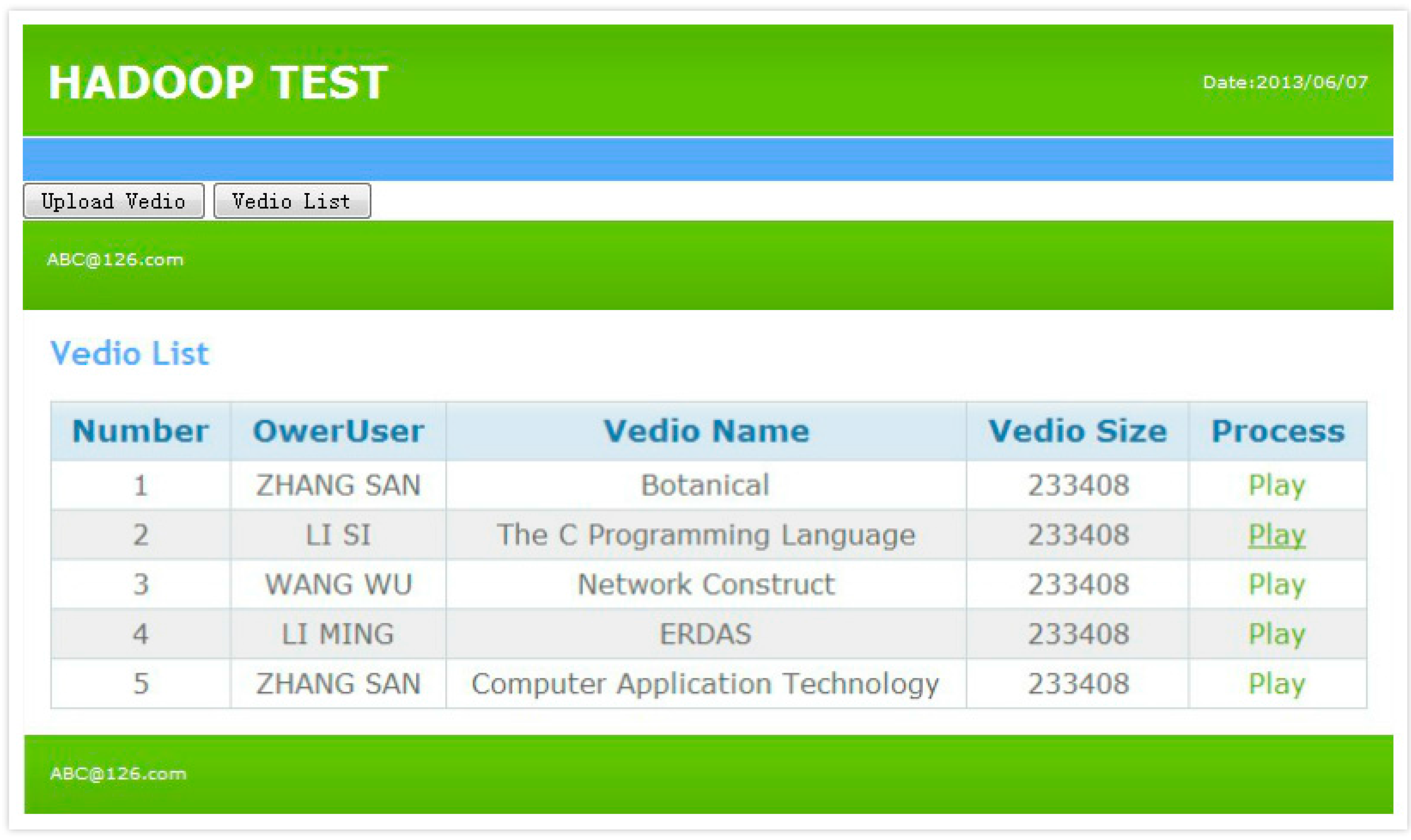
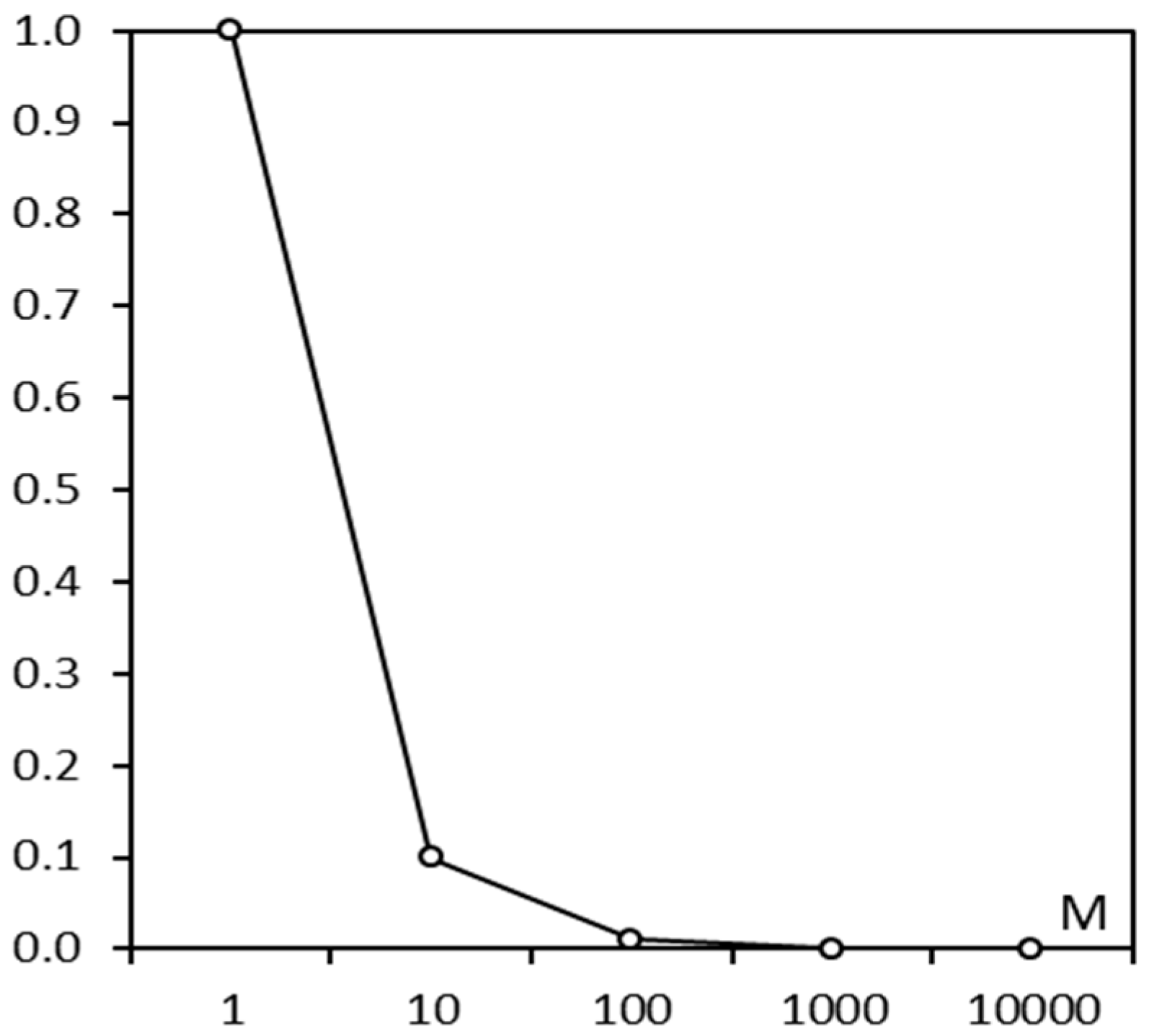
4.2.1. Functional Testing
4.2.2. Performance Testing
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Yang, C.-T.; Huang, K.-L.; Liu, J.-C.; Chen, W.-S. Construction of Cloud IaaS Using KVM and Open Nebula for Video Services. In Proceedings of the 41st International Conference on Parallel Processing Workshops (ICPPW), Pittsburgh, PA, USA, 10–13 September 2012; pp. 212–221.
- Pereira, R.; Azambuja, M.; Breitman, K; Endler, M. An Architecture for Distributed High Performance Video Processing in the Cloud. In Proceedings of the 3rd IEEE International Conference on Computer Science and Information Technology (ICCSIT), Chengdu, China, 9–11 July 2010; pp. 482–489.
- Wu, Y.-S.; Chang, Y.-S.; Juang, T.-Y.; Yen, J.-S. An Architecture for Video Surveillance Service based on P2P and Cloud Computing. In Proceedings of the 9th IEEE International Conference on Ubiquitous Intelligence and Computing (UIC 2012), Fukuoka, Japan, 4–7 September 2012; pp. 661–666.
- Garcia, A.; Kalva, H.; Furht, B. A study of transcoding on cloud environments for video content delivery. In Proceedings of the 2010 ACM Multimedia Workshop on Mobile Cloud Media Computing, New York, NY, USA, 25–29 October 2010; pp. 13–18.
- Sun, B.-J.; Wu, K.-J. Research on Cloud Computing Application in the Peer-to-Peer Based Video-on-Demand Systems. In Proceedings of the 3rd International Workshop on Intelligent Systems and Applications (ISA), Wuhan, China, 28–29 May 2011; pp. 1–4.
- Li, J.; Guo, R.; Zhang, X. Study on Service-Oriented Cloud Conferencing. In Proceedings of the 3rd IEEE International Conference on Computer Science and Information Technology (ICCSIT), Chengdu, China, 9–11 July 2010; pp. 21–25.
- Ghemawat, S.; Gobioff, H.; Leung, S.-T. The Google file system. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, Bolton Landing, NY, USA, 19–22 October 2003.
- Srirama, S.N.; Jakovits, P.; Vainikko, E. Adapting scientific computing problems to clouds using MapReduce. J. Future Gener. Comput. Syst. 2012, 28, 184–192. [Google Scholar] [CrossRef]
- Kim, M.; Cui, Y.; Han, S.; Lee, H. Towards Efficient Design and Implementation of a Hadoop-based Distributed Video Transcoding System in Cloud Computing Environment. Int. J. Multimed. Ubiquitous Eng. 2013, 8, 213. [Google Scholar]
- Web Technologies—Distributed Computing/Big Data 2016. Available online: http://www.bogotobogo.com/WebTechnologies/distributedcomputing.php (accessed on 14 July 2016).
- Pereira, R.; Azambuja, M.; Breitman, K.; Endler, M. An Architecture for Distributed High Performance Video. In Proceedings of the 2010 IEEE 3rd International Conference on Cloud Computing (CLOUD), Miami, FL, USA, 5–10 July 2010; pp. 482–489.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | CPU | Memory | Hard Disk | Node Type | Roles |
|---|---|---|---|---|---|
| 1 | Intel(R) Pentium(R)4 CPU 3.06 GHz | 2G | 80GB | Namenode master | Web server for streaming medias |
| 2 | Datanode slave | Web server | |||
| 3 | / | ||||
| 4 | / |
| Node Type | IP Address | Host Name |
|---|---|---|
| Namenode, master | 172.16.10.11/24 | Hadoop1.com |
| Datanode, slave | 172.16.10.12/24 | Hadoop2.com |
| Datanode, slave | 172.16.10.13/24 | Hadoop3.com |
| Datanode, slave | 172.16.10.14/24 | Hadoop4.com |
| Host name | IP address | Software | Version |
|---|---|---|---|
| Hadoop1.com | 172.16.10.11/24 | apache-tomcat-7.0.39.tar.gz | 7.0.39 |
| httpd-2.2.24.tar.gz | 2.2.24 | ||
| tomcat-connectors-1.2.37-src.tar.gz | 1.2.37 | ||
| jdk-6u35-linux-i586-rpm | 6u35 | ||
| Hadoop2.com | 172.16.10.12/24 | apache-tomcat-7.0.39.tar.gz | 7.0.39 |
| tomcat-connectors-1.2.37-src.tar.gz | 1.2.37 | ||
| jdk-6u35-linux-i586-rpm | 6u35 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kou, W.; Li, H.; Zhou, K. Turning Video Resource Management into Cloud Computing. Future Internet 2016, 8, 35. https://doi.org/10.3390/fi8030035
Kou W, Li H, Zhou K. Turning Video Resource Management into Cloud Computing. Future Internet. 2016; 8(3):35. https://doi.org/10.3390/fi8030035
Chicago/Turabian StyleKou, Weili, Hui Li, and Kailai Zhou. 2016. "Turning Video Resource Management into Cloud Computing" Future Internet 8, no. 3: 35. https://doi.org/10.3390/fi8030035
APA StyleKou, W., Li, H., & Zhou, K. (2016). Turning Video Resource Management into Cloud Computing. Future Internet, 8(3), 35. https://doi.org/10.3390/fi8030035