In this paper, we consider only convergecast data collection in mobile scenarios. In these scenarios all or part of the nodes are free to move except the sink node. Every node sends periodic data at a constant rate to the sink node, which is the only destination. Before sending packets, each node will select a best next-hop from its neighbours based on the rank mechanism and metric values. According to RPL, nodes can only select the nodes with lower ranks as the next-hop. However, in mobility, topology changes frequently and positions of nodes will not stay the same. If rank values cannot be updated timely according to the movement of nodes, loops may appear. In [
13], an enhancement mechanism, called RSSI and level (RL), is proposed. RL is based on a combination of received signal strength indicator (RSSI) monitoring and level updating. This mechanism makes faster decisions for updating next-hop neighbours but suffers from high overhead. In [
14], an enhancement mechanism for RPL, called RSSI, rank, and dynamic (RRD), is proposed. RRD is based on a combination of received signal strength indicator (RSSI) monitoring, rank updating, and dynamic control message management. Compared to RL, RRD not only makes faster decisions for updating next-hop neighbours, but also reduces the network overhead. When applied to RPL, RRD enhances the ability of RPL to cope with mobility scenarios, and thus, enhances the overall performance of the network. Rank updating is an important mechanism in our proposal. However, in reality, according to multipath propagation effects (known as fading effects), the received power at a certain distance follows a random behaviour [
15]. Nodes that are close to the edge of transmission range will suffer from frequent rank updating, which may cause parent node loss in the parents set. Therefore, in this paper we proposed RRD+, which is an improvement over RRD that takes into account hysteresis of the coverage zone of the transmission range of nodes. In what follows we will describe in details how RRD+ operates.
4.1. Link Existence and Movement Direction Monitoring
It is important to be able to estimate if a link is about the break in order to anticipate and find a new next-hop. In order to do so, we monitor the existence of links and try to anticipate if the link is about the break or not based on the variation of RSSI values.
In RRD+ every node monitors links between itself and nodes in the parents set in order to avoid packet loss when link does not exist. The parents set contains neighbour nodes that have lower rank values. We use the RSSI values to estimate link quality. RSSI values are obtained from acknowledgement messages (ACK) and DIO messages. At the initial stage, network topology is constructed using DIO messages and RSSI values are obtained from these messages. After topology construction, for each successfully received data packet, receivers will send an ACK. This way senders will continuously get RSSI values from these ACK. A node may store two RSSI values for each node in its parents set, the old RSSI value and the new RSSI value. The old RSSI comes from the previous ACK or DIO and the new RSSI value is obtained from the current ACK or DIO. We use these two RSSI values to estimate the direction of movement. When the new RSSI is smaller than the old RSSI, we suppose the node is moving away from its parent node. When the new RSSI is bigger than old RSSI, we suppose the node is moving closer to its parent node.
RSSI values might vary even when both nodes are not moving. Indeed, cover zones of transmitting nodes are very unstable especially in confined and complex environments. In order to take into account this phenomenon, we use two RSSI thresholds that we call
and
, where
as shown in
Figure 1. These two thresholds will help better estimate the link quality between two nodes as follows. When a new RSSI is smaller than or equal to
, the node considers that it has a good link quality with its parent node. If new RSSI is within the interval [
,
], the node needs to detect movement direction first and then to consider whether to stop using the link or not. In order to reduce the influence of variable coverage zone, we add a hysteresis value on the old RSSI when comparing new RSSI to old RSSI values. When the new RSSI is smaller than
, only new RSSI and old RSSI will be used to estimate direction without using hysteresis. If the node is getting closer to its parent, we consider that this parent node can still be used as a next-hop. Otherwise, the parent node should be replaced.
At the initial stage, each time a node receives a DIO and adds a new node into its parents set, a timer is set for this parent. We call this timer the lifetime of a parent. A parent is kept in the parents set for the duration of its lifetime timer and can be selected as the next-hops. A parent is deleted from the parents set when the timer expires. However, before the timer expires, if a new control message is received from this parent, the timer will be reset and lifetime is renewed. According to the RRD+ mechanism, we set two sorts of lifetimes: long lifetime and short lifetime.
A long lifetime is given to the parent node in the case that the new RSSI is bigger than . In the case the new RSSI is smaller than , movement direction will be estimated first and a short lifetime is given to parent node when the movement direction is towards parent node, otherwise the rank value will be updated. When the rank value is updated, the current parent is removed from the parents set. Indeed, when the parent node is in a zone where the radio link is about to fail, a short lifetime will help avoid using this parent node for a long period in case we no longer receive its control messages.
4.2. Loop Avoidance and Rank Update
Routing loop avoidance is a challenging task in mobility scenarios. In order to avoid this, RPL uses the rank value. The rank of a node must be greater than the rank of all nodes in its potential parents set and nodes cannot forward data packets to nodes with higher or equal ranks. However, RPL does not support rank update. A current next-hop may become a descendant due to untimely update of the rank value, and loops will occur. We propose monitoring link existence and movement direction to allow nodes to update their ranks in a timely manner. The goal is to update the rank of a node when it is about to lose its link with its current parent based on the link monitoring mechanism. Algorithm 1 depicts the rank update process. stands for the rank of the receiver of the control message and stands for the rank of the sender of the control message. stands for the long lifetime and represents the short lifetime. stands for the value of MinHopRankIncrease.
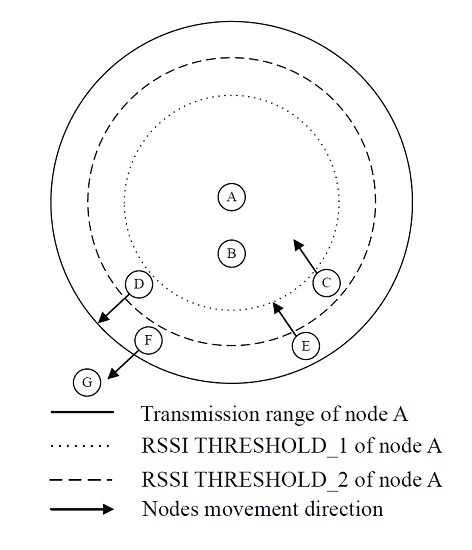
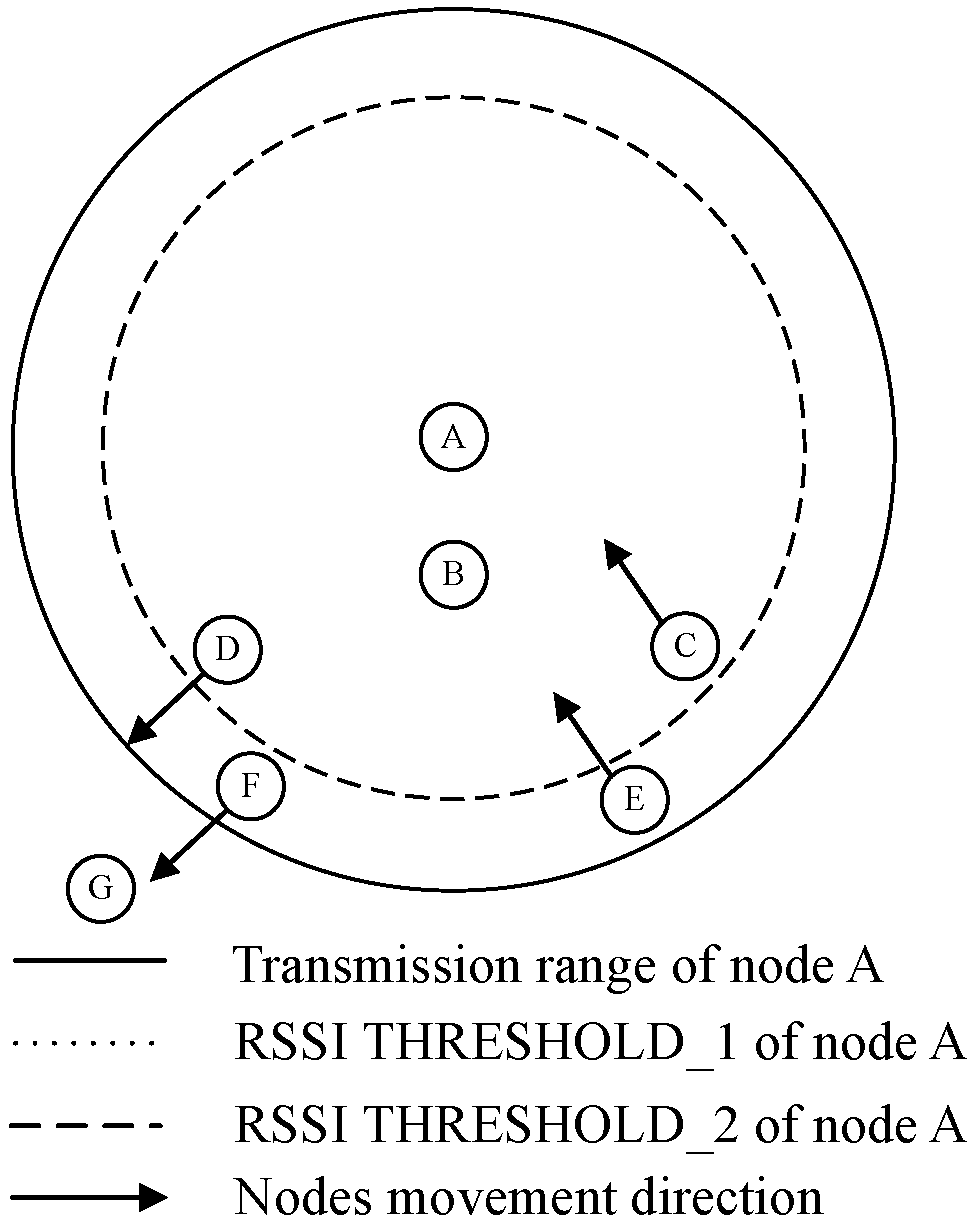
Figure 1 shows a scenario with four nodes A, B, C, D, E, F and G. A is neighbour of nodes B, C, D, E and F. D and F are neighbours of G. We use a dotted circle to represent RSSI
of node A and dashed circle to represent RSSI
of node A. Note that due to the nature of wireless signal propagation, in reality both RSSI thresholds and transmission range are most likely to look like a cloud that changes from one transmission to another. Indeed, in our simulation model we used a probabilistic propagation model to take into account coverage zone instability. B, C, D, E and F will execute Algorithm 1 whenever they receive a DIO message from A. G will execute Algorithm 1 whenever it receives a DIO message from D and F.
Algorithm 1 is explained in what follows and the scenario of
Figure 1 is used as an example. When a control message is received, if the rank of receiver node (
) is bigger than the rank of sender nodes (
), as in the case of node B, C, D, E and F, they need to check the new RSSI value (
) of the control message. If the new RSSI is bigger than
, as in the case of node B, the receiver node sets a long lifetime for this parent and updates its rank
.
| Algorithm 1: Rank Update |
![Futureinternet 09 00086 i001]() |
If the new RSSI is within the interval (, ), as in the case of nodes C and D, in order to avoid the influence of signal fading we set a hysteresis when estimating movement direction with the new and old RSSI. If , as is the case of node D, this means the receiver and the sender are getting away from each other. In this case, the receiver updates its own rank according to . When the rank value is updated, the children nodes of the receiver node will no longer choose it as a parent. This is the case of node G, in it that will no longer consider node D as a parent node once node D has updated its rank. Indeed, this will help avoid using a node that might lose its current link with its parent. In case receiver node moves back towards sender node, it will receive a new DIO message from the sender node and will update its rank according to the algorithm.
Otherwise, in the case , the receiver node gives a short lifetime for the sender node and updates its own rank according to . By this way the receiver node is only one level below the sender node. This is the case of node C. The receiver node set the parent with a short lifetime in order to avoid keeping the sender node as a parent in case the receiver node moves away from the sender node.
If the new RSSI is smaller than or equal to , as in the case of node E and F, the receiver checks the difference between the new RSSI and the old RSSI to estimate movement direction without using hysteresis. In this case the receiver node is at the edge of transmission range of the sender, thus, updating information fast is imperative, therefore the receiver ignores the hysteresis test. In this situation, if the new RSSI value is bigger than the old one, as in the case of node E, this means that the receiver is at the edge of transmission range but is moving forwards node A. In this case , node E gives a short lifetime for node A and updates its own rank according to . Otherwise, if the new RSSI value is smaller than the old one, as in the case of node F, this means that receiver node is getting away from the sender. In this case, node F increments its own rank by .
Finally, in case is smaller than we ignore the control messages.
4.3. Ripple Control Message Management
The trickle algorithm is used by RPL in order to reduce overhead in static networks. The trickle algorithm starts with a short interval between two DIOs in order to construct the network fast. Each time, the interval will be increased until it reaches . However, when the interval increases, the trickle algorithm cannot cope with information update in a timely manner, which is important in mobility. Therefore, we propose a new DIO interval management called ripple control message management, which copes with topology changes and reduces overhead. This algorithm dynamically modifies the sending interval of DIOs according to rank updates as described in what follows.
DIO messages are broadcast by the sink node and propagated by other nodes until they reach leaf nodes. The main function of DIO messages is to help children nodes find parent nodes. If we consider the rank as a virtual range, based on the sink, the rank in the network will be like ripples in the water and the sink is the center of the ripples. We think a DIO message that comes from a lower rank is more important than a DIO message that comes from a higher rank due to the fact that lower rank DIO messages will help more nodes find parent nodes. Thus, nodes that are closer to the sink should send DIO messages more frequently and the frequency of DIO messages may be reduced for nodes with higher ranks. Hence, we designed a dynamic DIO interval management according to rank updates to reduce overhead. The DIO interval calculation is shown in Equation (
3).
where
dynamically changes due to the change of rank of nodes in mobility. The
is the smallest
.
stands for the current rank value of a node. The
is the incremental step in the DIO frequency.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}