
An Obstacle Detection Algorithm Suitable for Complex Traffic Environment


Abstract
:1. Introduction
2. Road-Free Space Extraction and Obstacle Detection
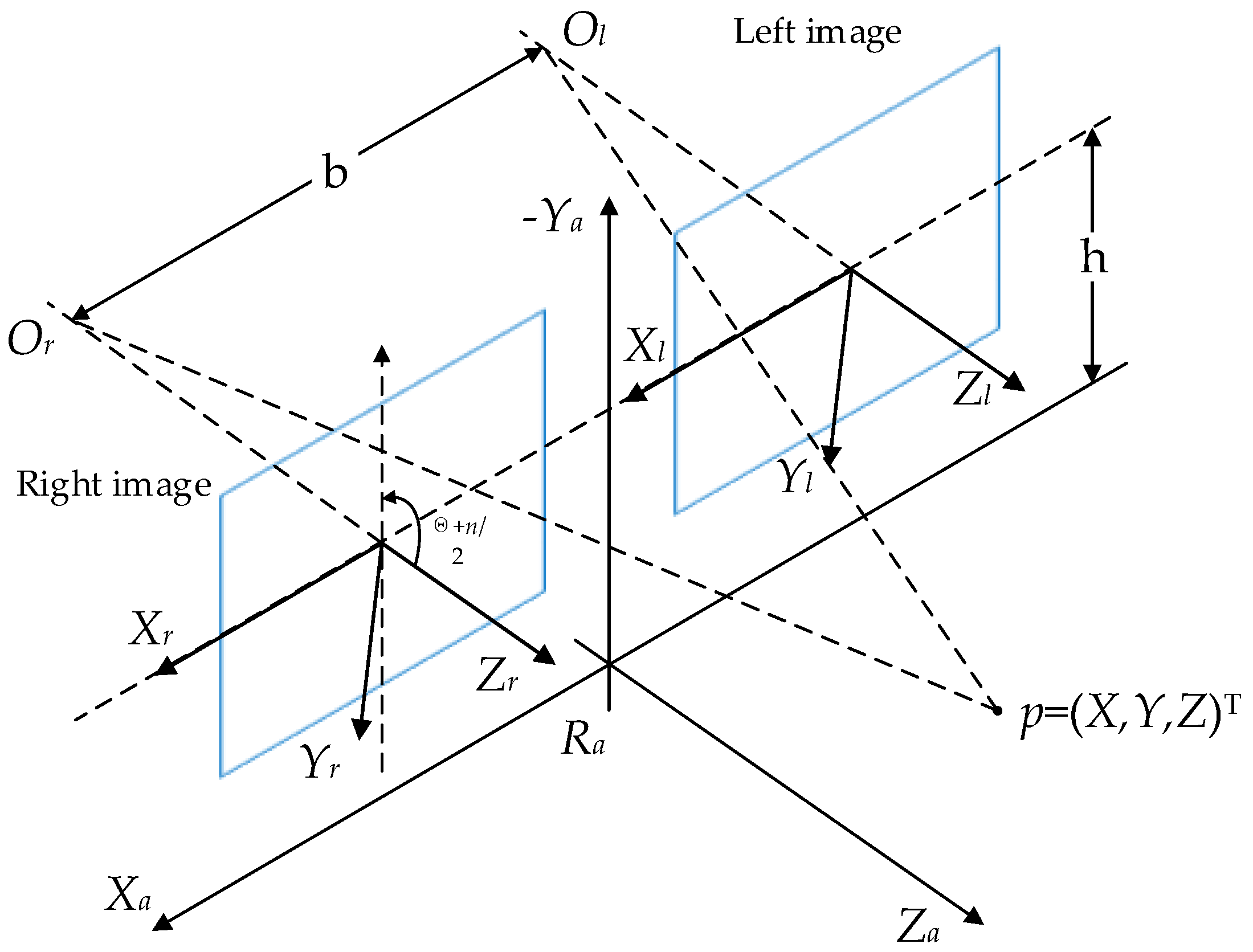
2.1. Stereo Geometry
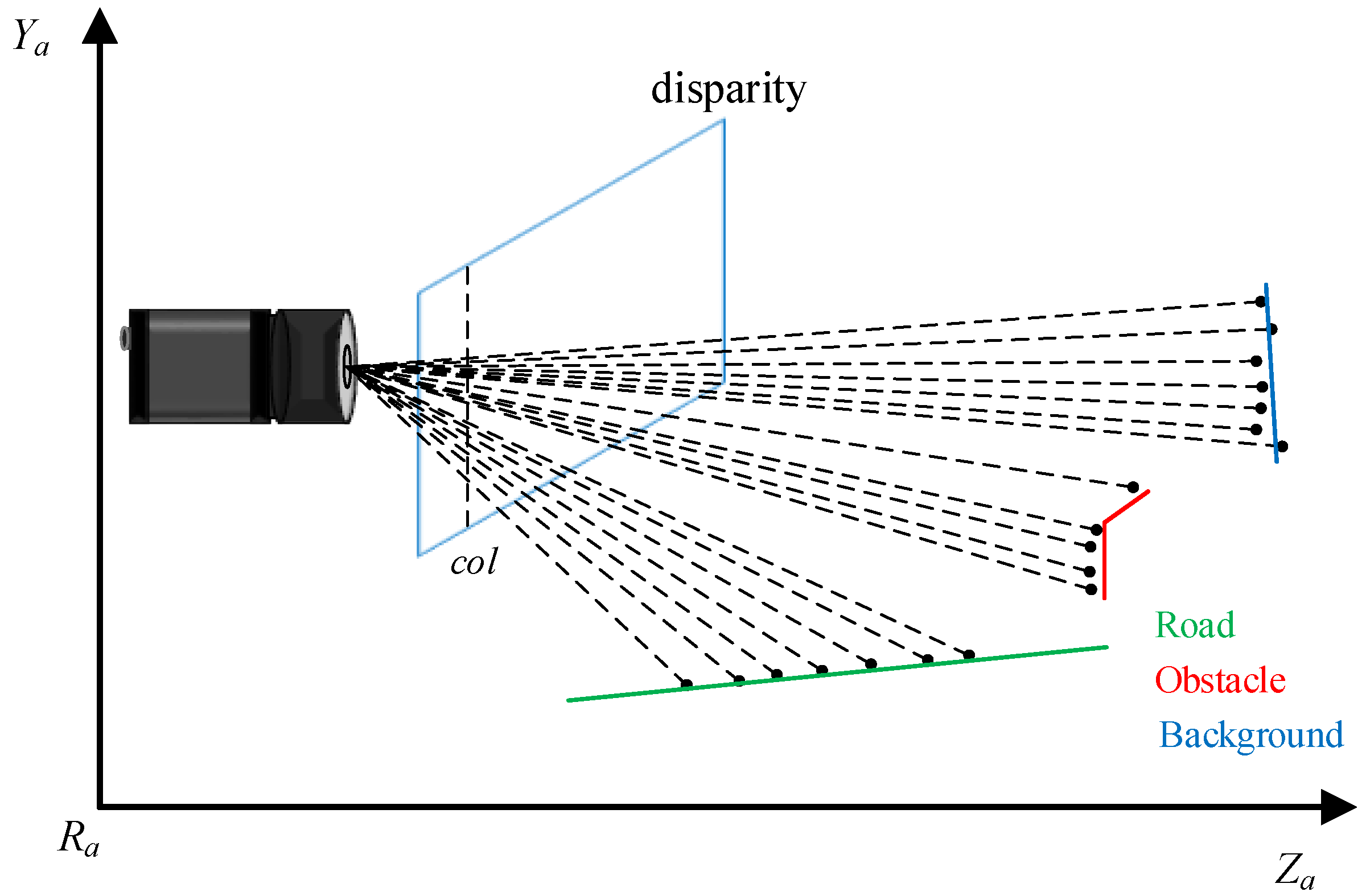
2.2. Extraction of Free Space
2.3. Height Information
2.4. Obstacle Detection
3. Experiment
3.1. Datasets and Evaluation Index
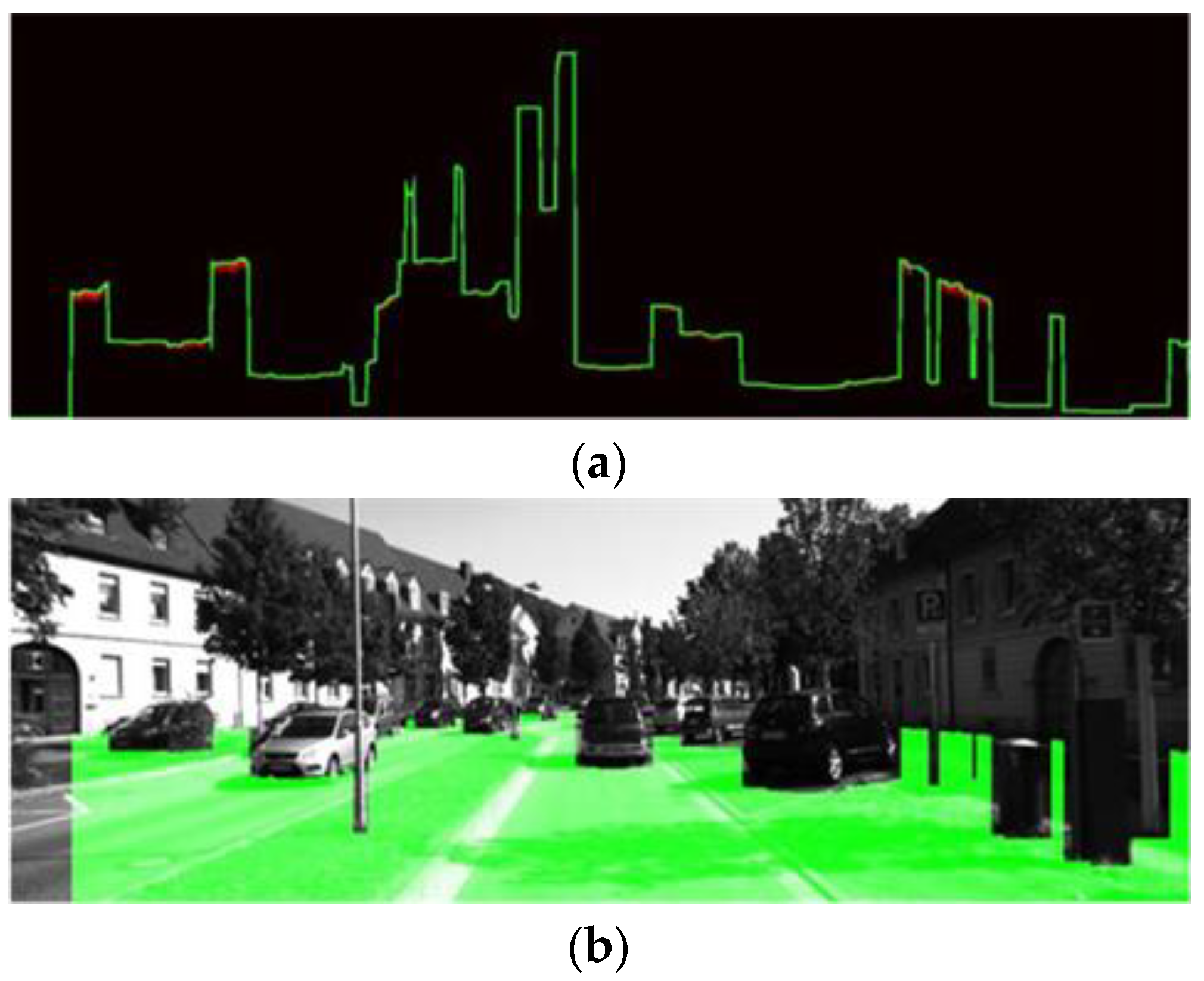
3.2. Calculate the Free Space
3.3. Estimate Height Information
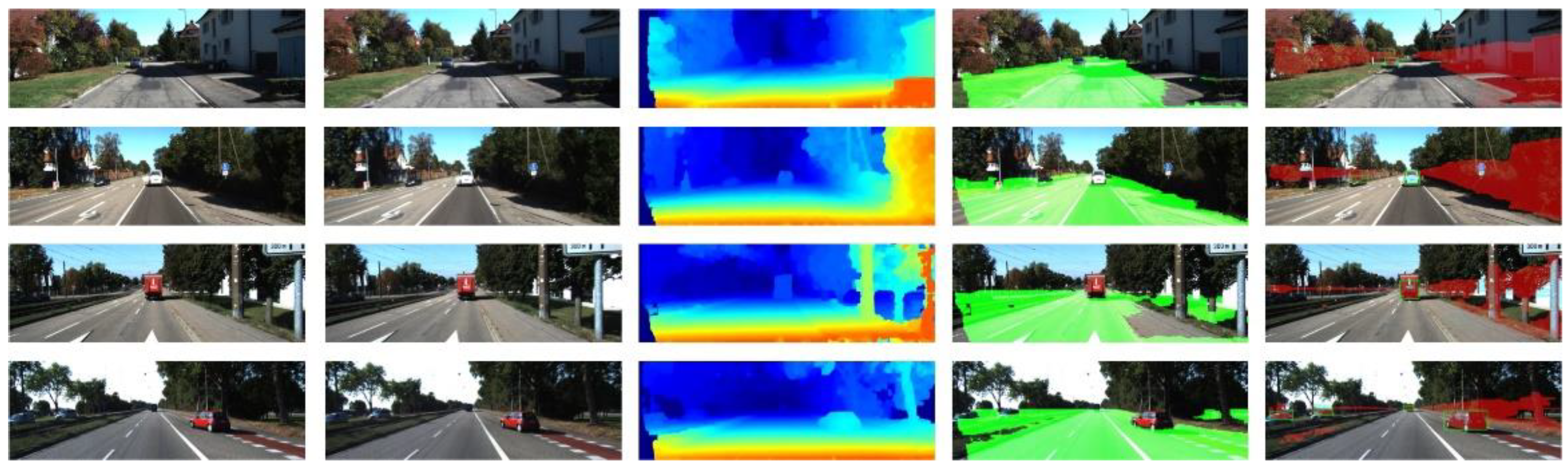
3.4. Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Song, W.J.; Yang, Y.Y.; Fu, M.Y.; Li, Y.J.; Wang, M.L. Lane detection and classification for forward collision warning system based on stereo vision. IEEE Sens. J. 2018, 18, 5151–5163. [Google Scholar] [CrossRef]
- Juarez, D.H.; Schneider, L.; Cebrian, P.; Espinosa, A.; Vazquez, D.; López, A.M.; Franke, U.; Pollefeys, M.; Moure, J.C. Slanted stixels: A way to represent steep streets. Int. J. Comput. Vis. 2019, 127, 1643–1658. [Google Scholar] [CrossRef] [Green Version]
- Leng, J.X.; Liu, Y.; Du, D.; Zhang, T.L.; Quan, P. Robust obstacle detection and recognition for driver assistance systems. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1560–1571. [Google Scholar] [CrossRef]
- Bichsel, R.; Borges, P.V.K. Discrete-continuous clustering for obstacle detection using stereo vision. In Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 538–545. [Google Scholar]
- Pantilie, C.D.; Nedevschi, S. SORT-SGM: Subpixel optimized real-time semiglobal matching for intelligent vehicles. IEEE Trans. Veh. Technol. 2012, 61, 1032–1042. [Google Scholar] [CrossRef]
- Hu, Z.; Uchimura, K. UV-disparity: An efficient algorithm for stereovision-based scene analysis. In Proceedings of the Intelligent Vehicles Symposium, Las Vegas, NV, USA, 6–8 June 2005; pp. 48–54. [Google Scholar]
- Sahdev, R. Free space estimation using occupancy grids and dynamic object detection. arXiv 2017, arXiv:1708.04989. [Google Scholar]
- Labayrade, R.; Aubert, D.; Tarel, J.P. Real time obstacle detection in stereovision on non-flat road geometry through “v-disparity” representation. In Proceedings of the Intelligent Vehicle Symposium, Versailles, France, 17–21 June 2002; pp. 646–651. [Google Scholar]
- Zhang, M.; Liu, P.Z.; Zhao, X.C.; Zhao, X.X.; Zhang, Y. An obstacle detection algorithm based on UV disparity map analysis. In Proceedings of the 2010 IEEE International Conference on Information Theory and Information Security, Beijing, China, 17–19 December 2010; pp. 763–766. [Google Scholar]
- Badino, H.; Franke, U.; Pfeiffer, D. The stixel world-a compact medium level representation of the 3d-world. In Proceedings of the Joint Pattern Recognition Symposium, Berlin, Germany, 9–11 September 2009; pp. 51–60. [Google Scholar]
- Hirschmuller, H. Stereo processing by semiglobal matching and mutual information. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 30, 328–341. [Google Scholar] [CrossRef] [PubMed]
- Wu, M.Q.; Lam, S.K.; Srikanthan, T. Nonparametric technique based high-speed road surface detection. IEEE Trans. Intell. Transp. Syst. 2014, 16, 874–884. [Google Scholar] [CrossRef]
- Chen, H.; Gao, T.; Qian, G.D.; Chen, W.; Zhang, Y. Tensored generalized hough transform for object detection in remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 3503–3520. [Google Scholar] [CrossRef]
- Oniga, F.; Nedevschi, S. Processing dense stereo data using elevation maps: Road surface, traffic isle, and obstacle detection. IEEE Trans. Veh. Technol. 2009, 59, 1172–1182. [Google Scholar] [CrossRef]
- Pfeiffer, D.; Franke, U. Efficient representation of traffic scenes by means of dynamic stixels. In Proceedings of the Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 217–224. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The kitti vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Alvarez, J.M.; Gevers, T.; Lopez, A.M. 3D scene priors for road detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 57–64. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Road | Non-Road | |
|---|---|---|
| Detected road | TN | FN |
| Detected non-road | FP | TP |
| Pixel-Wise Metric | Definition |
|---|---|
| Quality | |
| Detection rate | |
| Detection accuracy | |
| Effectiveness |
| Method | Q | DR | DA | E | T (ms) |
|---|---|---|---|---|---|
| Stixel-origin | 0.792 | 0.849 | 0.923 | 0.884 | 5.673 |
| V-disparity-based method | 0.781 | 0.921 | 0.831 | 0.874 | 6.345 |
| Our method | 0.820 | 0.863 | 0.941 | 0.900 | 5.145 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, G.; Chen, X.; Lin, W.; Dai, J.; Liang, P.; Zhang, C. An Obstacle Detection Algorithm Suitable for Complex Traffic Environment. World Electr. Veh. J. 2022, 13, 69. https://doi.org/10.3390/wevj13040069
Luo G, Chen X, Lin W, Dai J, Liang P, Zhang C. An Obstacle Detection Algorithm Suitable for Complex Traffic Environment. World Electric Vehicle Journal. 2022; 13(4):69. https://doi.org/10.3390/wevj13040069
Chicago/Turabian StyleLuo, Guantai, Xinwei Chen, Wenwei Lin, Jie Dai, Peidong Liang, and Chentao Zhang. 2022. "An Obstacle Detection Algorithm Suitable for Complex Traffic Environment" World Electric Vehicle Journal 13, no. 4: 69. https://doi.org/10.3390/wevj13040069
APA StyleLuo, G., Chen, X., Lin, W., Dai, J., Liang, P., & Zhang, C. (2022). An Obstacle Detection Algorithm Suitable for Complex Traffic Environment. World Electric Vehicle Journal, 13(4), 69. https://doi.org/10.3390/wevj13040069