Low-Cost Implementation of a Named Entity Recognition System for Voice-Activated Human-Appliance Interfaces in a Smart Home

Abstract
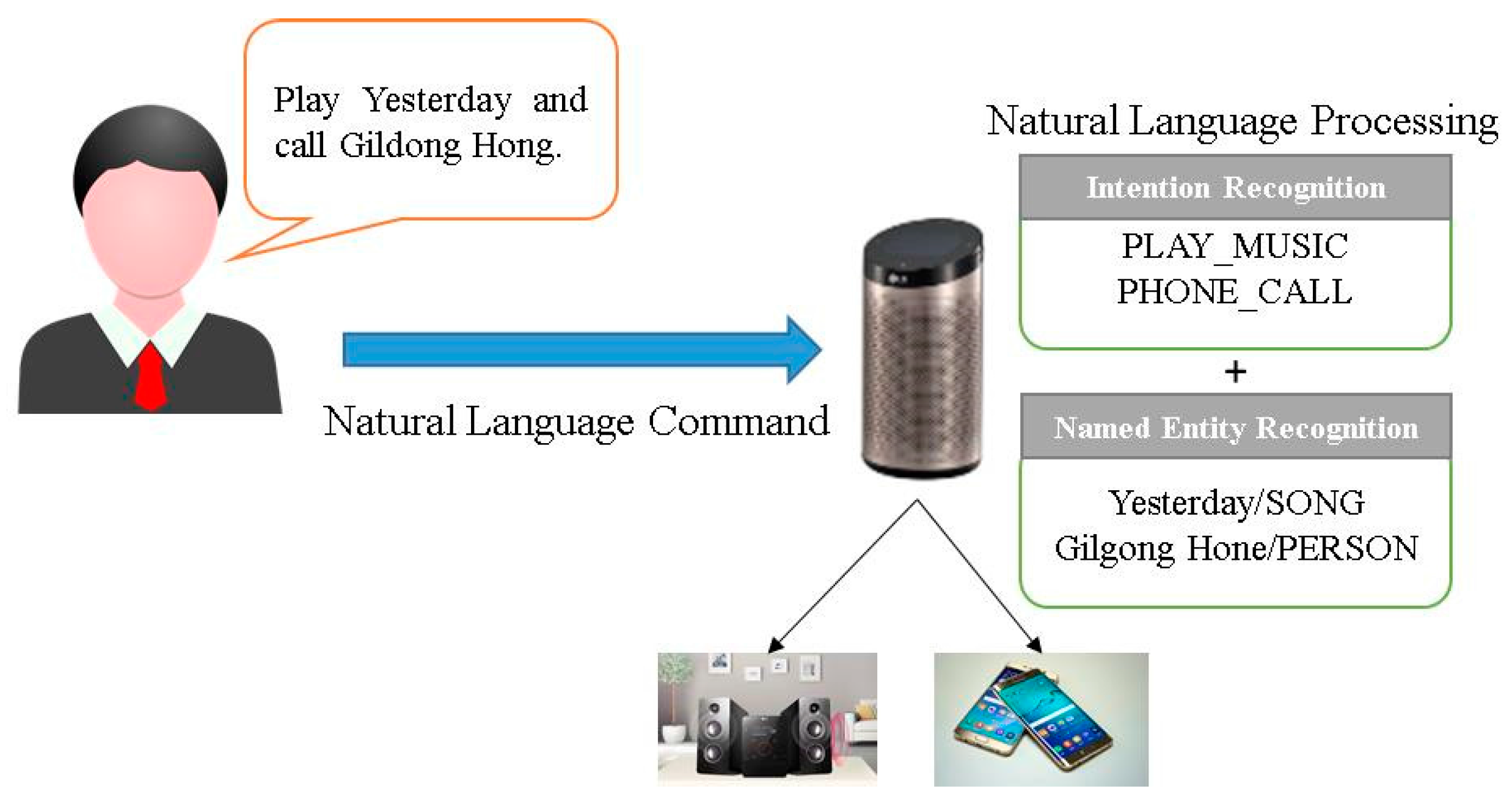
:1. Introduction
2. Previous Works
3. Named Entity Recognition Using Two-Phase Bagging-Based Active Learning
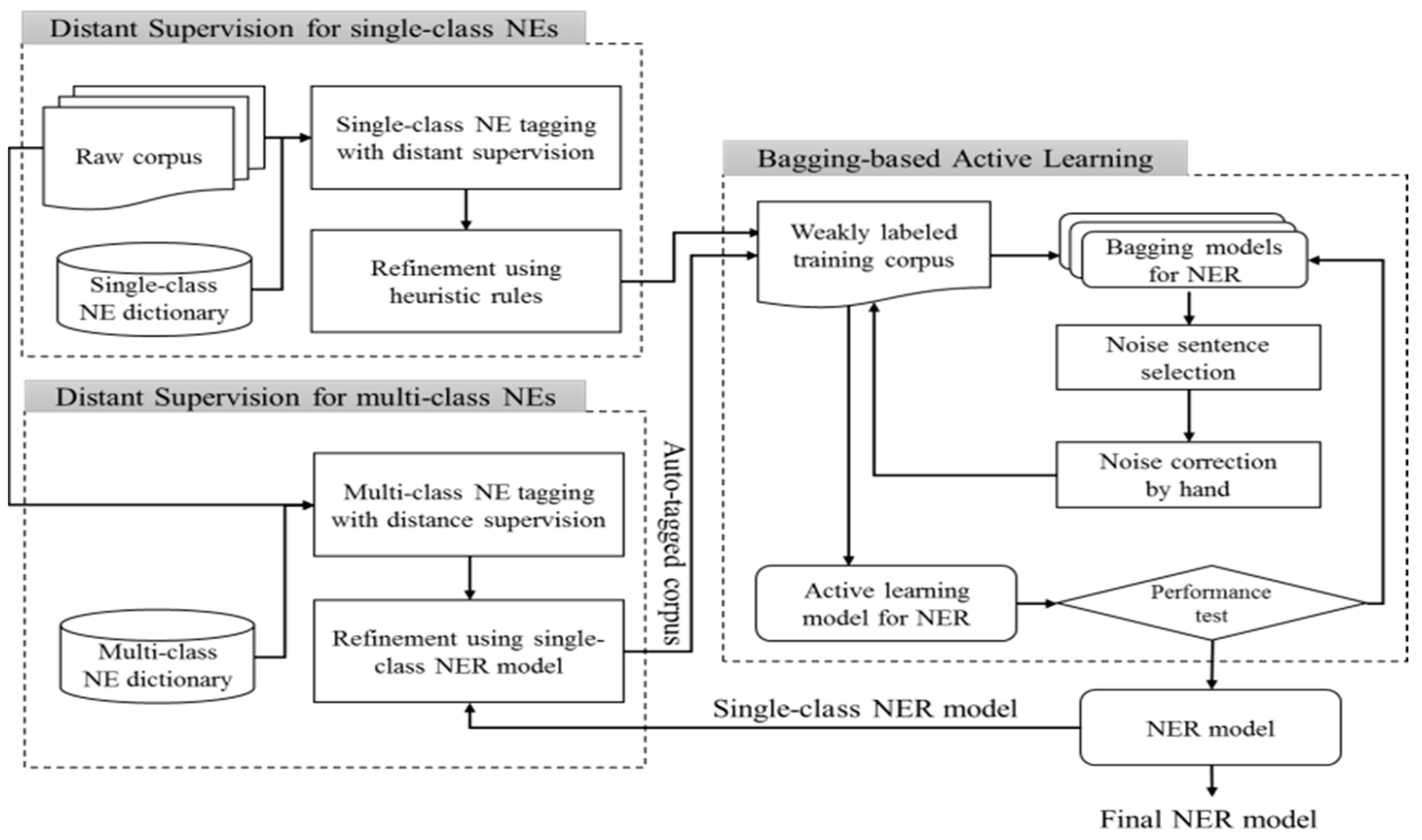
3.1. System Architecture
3.2. Constructing Weakly Labeled Corpus Using Distant Supervision
- Remove labels of words with declined or conjugated endings because endings of NEs are generally nouns.
- Remove labels of high-frequency words in the weakly labeled training corpus because NEs are not common words (Zipf’s law) [20].
| Algorithm 1. Bagging-Based Active Learning |
|
| Check accuracy of the NER model by using gold-labeled validation corpus. If accuracy improvement is converged, terminate the learning process. Otherwise, go to step (1). |
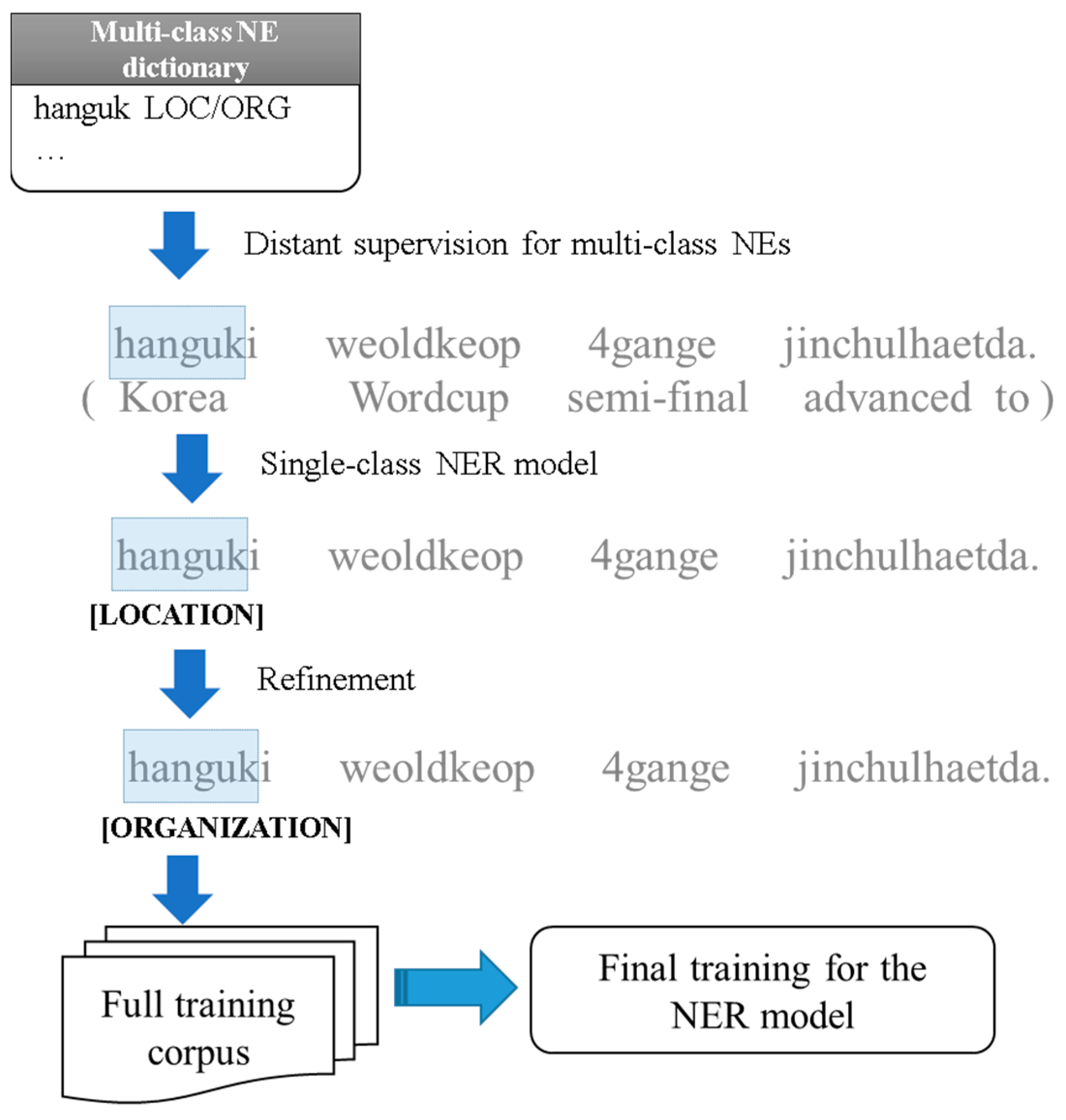
3.3. Multi-Class NE Learning Phase: Constructing a Final NER System from Single-Class NE Tagged Corpus
4. Evaluation
4.1. Data Sets and Experimental Settings
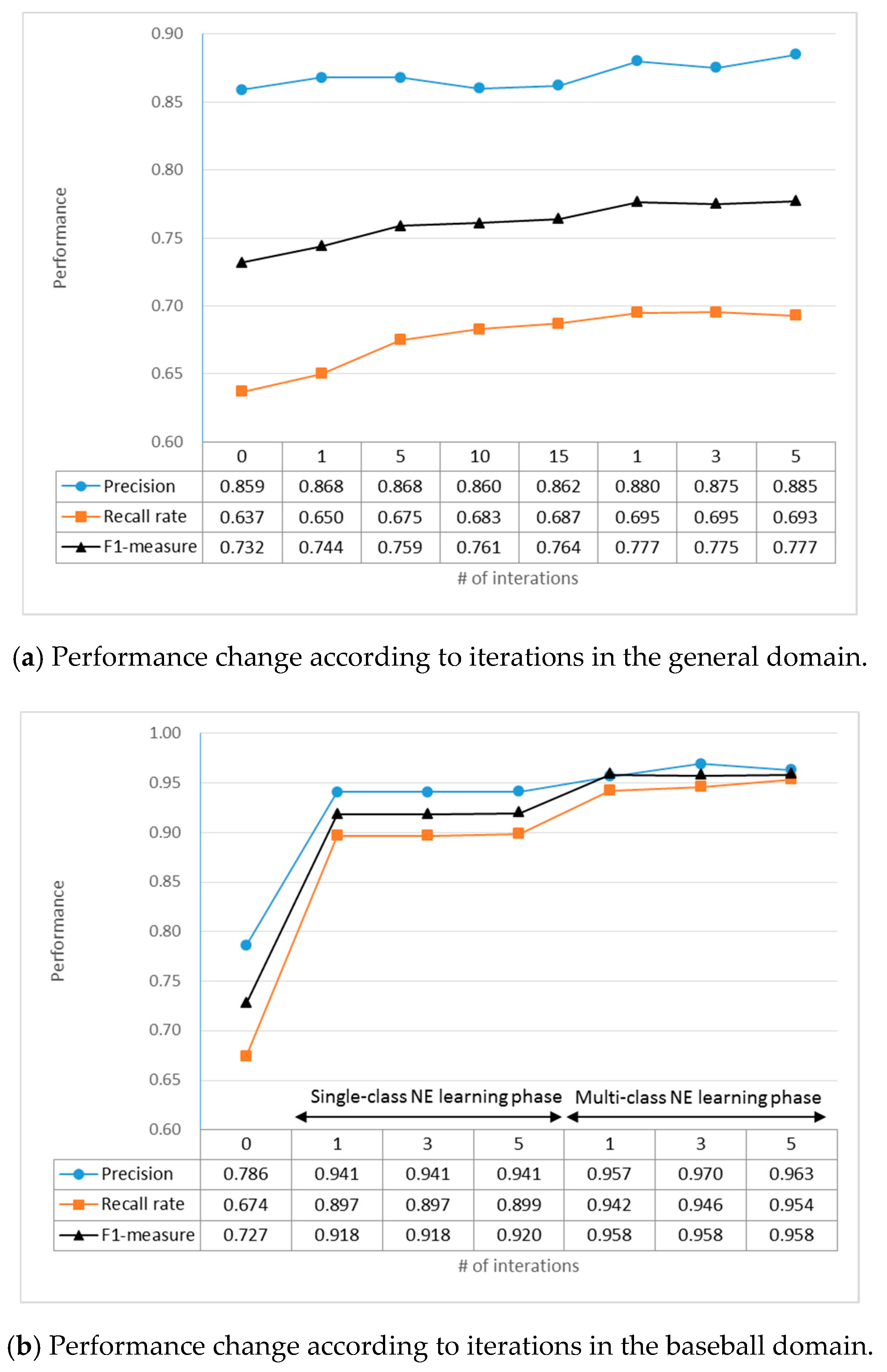
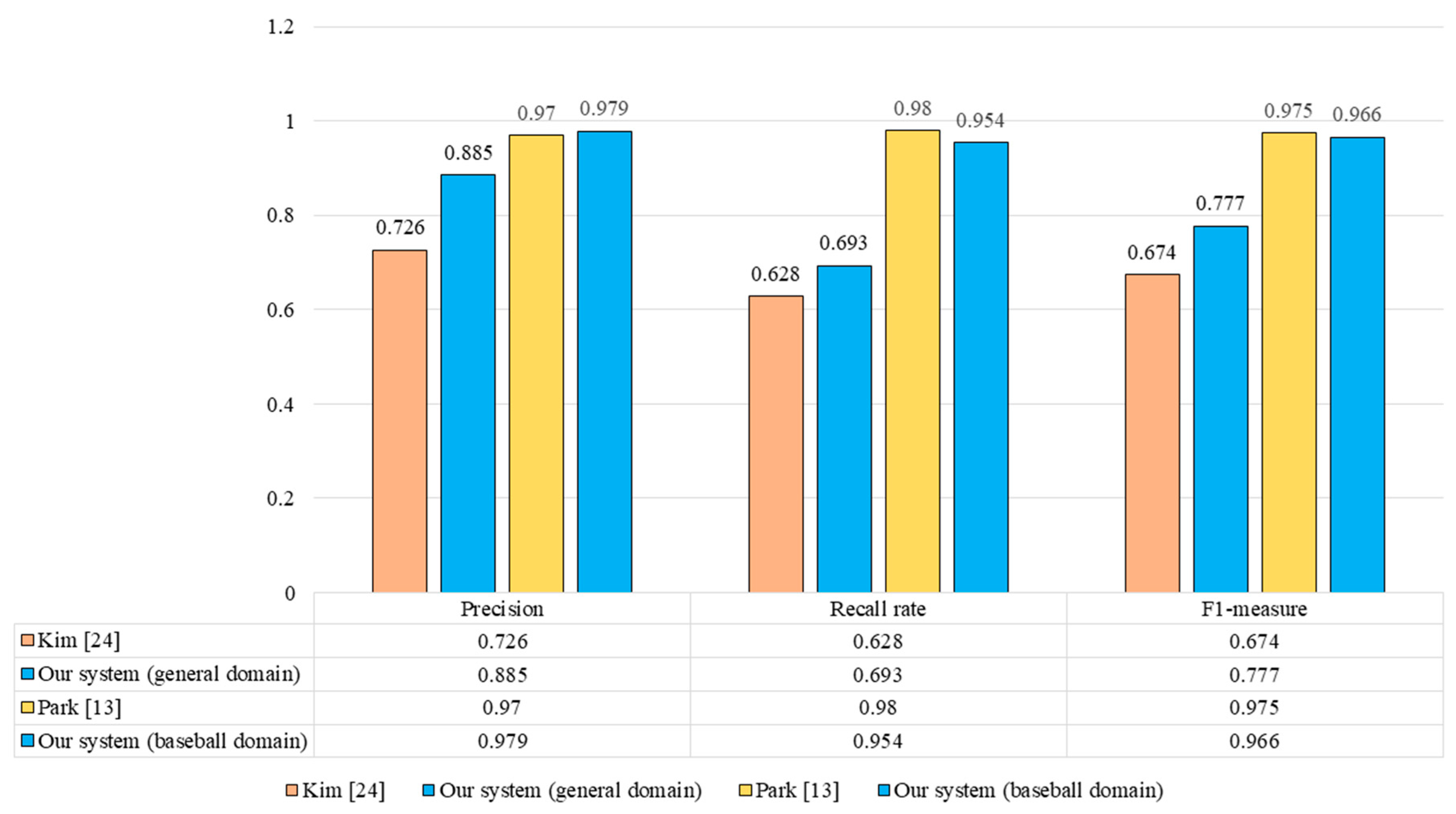
4.2. Experimental Results
4.3. Limitations
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Noh, T.; Lee, S. Extraction and Classification of Proper Nous by Rule-based Machine Learnin. In Proceedings of the KIISE Korea Computer Congress, Gyeongju, Korea, 29 June–1 July 2000. (In Korean). [Google Scholar]
- Seon, C.; Kim, H.; Seo, J. Translation Assistance System Based on Selective Weighting and Cluster-Based Searching Methods. Int. J. Artif. Intell. Tools 2012, 21. [Google Scholar] [CrossRef]
- Hwang, Y.; Lee, H.; Chung, E.; Yun, B.; Park, S. Korean Named Entity Recognition Based on Supervised Learning Using Named Entity Construction Principle. In Proceedings of the HCLT, Choengju, Korea, 11–12 October 2002. (In Korean). [Google Scholar]
- Sekine, S.; Grishman, R.; Shinnou, H. A Decision Tree Method for Finding and Classifying Names in Japanese Texts. In Proceedings of the 6th Workshop on Very Large Corpora, Montreal, QC, Canada, 15–16 August 1998. [Google Scholar]
- Brothwick, A.; Sterling, J.; Agichtein, E.; Grishman, R. NYU: Description of the MENE Named Entity System as Used in MUC-7. In Proceedings of the Seventh Message Understanding Conference, Fairfax, VA, USA, 29 April–1 May 1997. [Google Scholar]
- Cohen, W.W.; Sarawagi, S. Exploiting Dictionaries in Named Entity Extraction: Combining Semi-Markov Extraction Processes and Data Integration Methods. In Proceedings of the Tenth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Seattle, WA, USA, 22–25 August 2004. [Google Scholar]
- Lee, C.; Hwang, Y.G.; Oh, H.J.; Lim, S.; Heo, J.; Lee, C.; Kim, H.; Wang, J.; Jang, M. Fine-Grained Named Entity Recognition Using Conditional Random Fields for Question Answering. In Proceedings of the HCLT, Pohang, Korea, 13–14 October 2006. (In Korean). [Google Scholar]
- Lee, C.; Jang, M. Named Entity Recognition with Structural SVMs and Pegasos Algorithm. Korean J. Cogn. Sci. 2010, 21, 655–667. (In Korean) [Google Scholar]
- Seon, C.; Kim, H.; Seo, J. Efficient Appointment Information Extraction from Short Messages in Mobile Devices with Limited Hardware Resources. Pattern Recognit. Lett. 2011, 32, 127–133. [Google Scholar] [CrossRef]
- Seon, C.; Yoo, J.; Kim, H.; Kim, J.; Seo, J. Lightweight Named Entity Extraction for Korean Short Message Service Text. KSII Trans. Internet Inf. Syst. 2011, 5, 560–574. [Google Scholar] [CrossRef]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the NAACL-HLT, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Kwon, S.; Ko, Y.; Seo, J. A Robust Named-Entity Recognition System Using Syllable Bigram Embedding with Eojeol Prefix Information. In Proceedings of the CIKM, Singapore, 6–10 November 2017. [Google Scholar]
- Park, G.; Lee, H.; Kim, H. Named Entity Recognition Model Based on Neural Networks Using Parts of Speech Probability and Gazetteer Features. Adv. Sci. Lett. 2017, 23, 9530–9533. [Google Scholar] [CrossRef]
- Shen, D.; Zhang, J.; Su, J.; Zhou, G.; Tan, C.L. Multi-Criteria-based Active Learning for Named Entity Recognition. In Proceedings of the ACL, Barcelona, Spain, 21–26 July 2004. [Google Scholar]
- Law, F.; Schutze, H. Stopping Criteria for Active Learning of Named Entity Recognition. In Proceedings of the COLING, Manchester, UK, 18–22 August 2008. [Google Scholar]
- Cohn, D.A.; Ghahramani, Z.; Jordan, M.I. Active Learning with Statistical Models. J. Artif. Intell. Res. 1996, 4, 705–712. [Google Scholar]
- Ha, K.; Cho, S.; MacLachlan, D. Response Models based on Bagging Neural Networks. J. Interact. Mark. 2005, 19, 17–30. [Google Scholar] [CrossRef]
- Mintz, M.; Bills, S.; Snow, R.; Jurafsky, D. Distant Supervision for Relation Extraction without Labeled Data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Suntec, Singapore, 2–7 August 2009. [Google Scholar]
- Lee, S.; Song, Y.; Choi, M.; Kim, H. Bagging-Based Active Learning Model for Named Entity Recognition with Distant Supervision. In Proceedings of the BigComp, HongKong, China, 18–20 January 2016. [Google Scholar]
- Zipf, G.K. The Psychobiology of Language; The MIT Press: Cambridge, MA, USA, 1935. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the ICML, Williamstown, MA, USA, 28 June–1 July 2001. [Google Scholar]
- Song, Y.; Kim, H. Semi-automatic Construction of a Named Entity Dictionary Based on Active Learning. Comput. Sci. Appl. 2015, 330, 65–70. [Google Scholar]
- Song, Y.; Jeong, S.; Kim, H. Semi-automatic Construction of a Named Entity Dictionary for Entity-Based Sentiment Analysis in Social Media. Multimed. Tools Appl. 2017, 76, 11319–11329. [Google Scholar] [CrossRef]
- Kim, Y. Automatic Training Corpus Generation Method of Named Entity Recognition Using Big Data. Master’s Thesis, Sogang University, Seoul, Korea, 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Name | Explanation |
|---|---|
| LEX | The current eojeol (Korean spacing unit) |
| FW_2_Lex, BW_2_Lex | First two eomjeols (Korean syllable) and last two eomjeols in the preceding, current, and next eojeols |
| FW_2_Tags, BW_2_Tags | NE categories matching against FW_2_Lex and BW_2_Lex in the preceding, current, and next eojeols |
| FW_3_Lex, BW_3_Lex | First three eomjeols and last three eomjeols in the preceding, current, and next eojeols |
| FW_3_Tags, BW_3_Tags | NE categories matching against FW_3_Lex and BW_3_Lex in the preceding, current, and next eojeols |
| BIEF (BE, BF, IE, IF) | BE: a tag meaning “the current eojeol is exactly matched against an entry in an NE dictionary” BF: a tag meaning “the current eojeol is partially matched against first few eomjeols in an entry in an NE dictionary” IE: a tag meaning “the current eojeol is included in an entry in an NE dictionary” IF: a tag meaning “the current eojeol is partially matched against last few eomjeols in an entry in an NE dictionary” |
| POS_Bigram | POS (part-of-speech) bi-grams of the preceding, current, and next eojeols |
| LEX-POS_Unigram | “Morpheme/POS” uni-grams of the preceding, current, and next eojeols |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, G.; Kim, H. Low-Cost Implementation of a Named Entity Recognition System for Voice-Activated Human-Appliance Interfaces in a Smart Home. Sustainability 2018, 10, 488. https://doi.org/10.3390/su10020488
Park G, Kim H. Low-Cost Implementation of a Named Entity Recognition System for Voice-Activated Human-Appliance Interfaces in a Smart Home. Sustainability. 2018; 10(2):488. https://doi.org/10.3390/su10020488
Chicago/Turabian StylePark, Geonwoo, and Harksoo Kim. 2018. "Low-Cost Implementation of a Named Entity Recognition System for Voice-Activated Human-Appliance Interfaces in a Smart Home" Sustainability 10, no. 2: 488. https://doi.org/10.3390/su10020488
APA StylePark, G., & Kim, H. (2018). Low-Cost Implementation of a Named Entity Recognition System for Voice-Activated Human-Appliance Interfaces in a Smart Home. Sustainability, 10(2), 488. https://doi.org/10.3390/su10020488