1. Introduction
In general terms, a Composite Indicator (CI) represents a measure that encompasses the collective character of simultaneous and different dimensions of a certain aspect of reality. The Joint Research Center defines composite indicators as “an aggregate index comprising individual indicators and weights that commonly represent the relative importance of each indicator” [
1]. Tarantola and Saltelli (after Hammond, 2008) [
2] define an indicator as a measure of some characteristics of reality that are not immediately detectable. In other words, a composite indicator is the result of the mathematical combination of individual indicators that represents different dimensions of a concept, the description of which is the objective of the analysis [
3]. Saltelli [
4] indicates sensu lato a composite indicator as a manipulation of different indicators to produce an aggregate ordinal or cardinal measure of the performance of administrative units most commonly at the national level.
To date, CIs have mainly been used to assess the level of socio-economic performance of countries, and to support evidence-based policy making. Nowadays, the use of composite indicators is facing an increasing interest that may be attributed to different advantages [
1], including:
Capacity of CI to summarize complex and multidimensional issues;
Capacity to provide a big picture about a certain phenomenon and to facilitate the construction of a rank for spatial units, usually countries or other administrative units, on complex issues;
Capability to attract public interest;
Effectiveness in reducing the size of a list of indicators.
Despite their several potential advantages, CIs are still subject to debate in the scientific community, specifically regarding existing discordances about their use. The first issue of concern regards the fact that CIs are models which represent a certain aspect of the reality; hence, CIs may represent different legitimate and contrasting perspectives by different stakeholders. This highlights the fact that, in the use of CIs, negotiation among stakeholders has to be reached in order to clearly define the structure and the intended semantic of the indicator; therefore, CIs cannot be considered only as an aggregation of numbers [
1]. This point is crucial to send the correct political message by means of CIs. The second point of debate concerns the fact that, as a model, CIs are subjected to uncertainty [
5]. The third point of discordance concerns the different scientific positions between aggregators and non-aggregators. Aggregators support the use of CIs because of their capability to capture and summarize the complexity of the reality; usually the CIs are driven by the need of advocacy, whose rationale can be mainly identified in the generation of narratives supporting the subject of the advocacy.
Non-aggregators conversely support the hypothesis that a set of individual indicators is sufficient to support information in policy and decision making [
6]. In addition, they criticize the use of weights to combine the variables, because of the arbitrary nature of weighting procedure [
4].
Notwithstanding the debate on the opportunity to use CIs in policy and decision-making, with the due precautions to address the issues outlined above, in several domains the advantages on using CIs are evident [
7,
8,
9,
10,
11,
12].
There is not a standard methodology to build CIs. Nevertheless, the Organization for Economic Co-operation and Development (OECD) and the Joint Research Centre of the European Commission (JRC), two institutions which have been making large use of CIs, supply guidelines for their construction. As a mathematical model, the construction of CIs follows a sequence of steps; each step can be developed in various ways, although methodological coherence should be ensured in the overall process.
According to the guidelines provided by the OECD and the JRC [
13] the construction of the step involved in the construction of CIs are:
Formalization of the theoretical framework;
Data selection;
Imputation of missing data;
Multivariate analysis;
Weighting and aggregation;
Uncertainty and sensitivity analysis;
Back to the original data;
Link to other indicators;
Visualization of the result.
Most of these steps are developed by the use of statistical techniques, as in case of the imputation of missing data, of the multivariate analysis, of the weighting, and of the uncertainty and sensitivity analysis. Usually, the construction of composite indicators involves the use of socio-economic dataset, but the spatial dimension of data is considered neither with regards to data nor for analysis. However, recent development in spatial statistics techniques makes actual the possibility to expand the methodology in order to incorporate the study of the spatial dimension into the CIs’ building process. This opportunity is made further urgent by the potential for exploiting the growing availability of interoperable spatial data made available, thanks to recent developments in Spatial Data Infrastructures (SDI), such as in the case of the European INSPIRE SDI [
14] to support environmental protection policies and spatial governance and decision-making [
15].
Towards Spatial Composite Indicators
The literature review reveals that little attention has been paid to the study of the spatial dimension of CIs and of the constituting variables involved in the building process. In building CIs, the input variables are commonly considered as average attribute values of geo-referenced administrative spatial unit. However, seldom environmental, economic and social phenomena unfold uniformly within given conventional boundaries. Therefore, the actual unprecedented availability of large scale spatial data representing real-world objects and phenomena offers the opportunity to make value of the spatial dimension of input variables enriching the modeling and analytical power for CIs to become spatial.
The analysis of the spatial dimension of data is becoming a crucial point for both spatial and socio-economic data [
16] thanks to the rapid changes in perceived space, to the improvements in technologies, and to the change in political landscapes [
17]. Currently, the development in the provision and quality of digital data create new opportunities for spatial and temporal measures at a finer level of detail than in the past, including large intra-urban scales [
18]. Recent studies on Spatial Decision Support Systems [
19,
20] have demonstrated how spatial multi-criteria indicators can be used to represent complex phenomena in order to help stake-holders’ complex decisions in physical planning. However, in the study of the spatial dimension, the location where data were collected is very important, because it creates a link among the value of the data, their position, and their values in the nearest location. This aspect brings to two important spatial effects: spatial heterogeneity and spatial dependence [
16,
21]. Spatial heterogeneity and spatial dependence invalidate the basic statistics assumption of the independence of data and of the random distribution of data across space [
16,
22,
23,
24,
25]. The effect of the data location makes it necessary to treat spatial data by means of particular spatial statistical methods, which are able to capture the special nature of spatial data, to discover spatial patterns, and to identify various spatial regimes and other forms of spatial non-stationary [
23].
Various empirical studies proved the importance of the spatial dimension to better understand the reality. Mainly, the focus of these studies is the finding of spatial relations among various social characteristics, often social disadvantage, in order to achieve deeper spatial information on the spatial behavior of social indicators and their mutual spatial relationship [
18,
26,
27,
28].
In the specific case of CIs, spatial analysis has been barely applied. However, spatial information may enable policy makers to make more robust and more effective decisions [
29]. Two case studies appear particularly interesting: (i) the application of spatial autocorrelation for the Regional Competitiveness Index (RCI) [
30]; and (ii) the study of social vulnerability to malaria in East Africa [
31]. In the first case, the analysis of the spatial dimension was carried out after the calculation of the overall CI. The aim was to discover clusters with similar behavior among the EU regions (i.e., the chosen administrative spatial units) and the presence of spillover regions. Additionally, the study focused on the detection of the spatial relationships between CI and its sub-dimension.
In the case study on social vulnerability to malaria, the aim was to distinguish areas on the basis of the risk of malaria. The use of the concept of geoms [
32] allowed for the identifying of homogenous spatial units of analysis. Geoms are homogeneous spatial objects defined in terms of spatial variation of phenomena under the influence of policy interventions, generated by scale specific spatial regionalization of a complex and multidimensional geographical reality, and incorporating expert knowledge [
26]. With this attempt, the malaria vulnerability study represents an early proposal to introduce the study of spatial dimension in the construction process of the CIs.
A common point of the studies presented above, is the fact that the assignment of the weights is not local. It means that the spatial variation of the importance of the variables that compose the final indicator is not detected; once weights are assigned, they are kept constant in each location. In the RCI case study, the weighting procedure adopted equal weights based on a previous Principal Component Analysis (PCA), while in the case of Malaria Vulnerability, the weights were set by experts. The case studies offer two examples of the two alternative weighting procedures: the data-driven methods, as in the case of RCI, and the knowledge-driven methods, as in the case of the Malaria study [
33].
To the first group belong to those methods based on data mining techniques, which seek to identify trends in the hierarchy of variables according to what happens in reality, measured by samples chosen to investigate the territory [
34]. Conversely, in the knowledge driven approach, the goal is to receive feedback by experts on the investigated phenomenon [
35].
In light of the above premise, it appears urgent to investigate the possibility to improve the methodology for the construction of CIs. Such a methodology should be able to take into account both the spatial effects due to the use of spatial data, and their consequences in the assignment of weights, in order to have a set of local weights based on the spatial variability of data. To achieve this goal, an extension of the OECD/JRC methodology is proposed and tested on the case study of the landscape in Sardinia.
2. Methods
2.1. The Integration of Spatial Statistics to Account for the Spatial Dimension in SCIs
The special nature of spatial data and its effects (spatial dependence and spatial heterogeneity) invalidate the hypothesis of random distribution of variables across the space, creating a spatial non-stationary condition. This condition may affect also the local importance of variables, invalidating the use of constant weights. In addition to this, spatial relations among the spatial units have to be studied in a spatial way in order to understand where the effect of spatial non-stationary creates a spatial cluster. Indeed, there is a need to treat spatial data with specific techniques which are able to consider the mentioned spatial effects. Recent development in spatial statistics offers new methods that may contribute to the achievement of this goal. Replacing some steps in the original OECD/JRC methodology with these novel spatial statistical methods, it is expected to improve the capability of CIs to provide a richer “spatial” picture of certain phenomena by means of more detailed spatial information.
Table 1 shows the comparison between the OECD/JRC, and the spatially-enabled version of the methodology. The main conceptual difference between the two is the introduction of spatial data as input datasets and the application of the Geographically-Weighted Principal Component Analysis (GWPCA) in replacement of the traditional multivariate analysis. GWPCA is a quite recent technique that represents the local form of PCA [
36]. It assumes that there may be various regions in which it is needed to apply different and distinct PCA in order to take into account local variation (non-stationary spatial condition) on the set of data. This way it is also possible to explore the internal structure of spatial data. Indeed, GWPCA provides a locally-derived set of principal components at all data locations [
37]. In addition, GWPCA returns, for each component the so called variable loading, which has been used to obtain local weights, as will be shown later in the case study section.
In order to be applied, the GWPCA needs a preliminary calibration in order to minimize the distance between the original data and the obtained components. The calibration is carried out by the research of the so-called bandwidth, which can be defined as a fixed quantity (in terms of spatial units) that reflects local sample size [
38].
A further difference between the two methodologies is that in the spatial case, some steps are carried out in different sequence order than in the traditional non-spatial case.
The different order in the implementation of some steps is specifically required by the use of spatial data. A relevant example is data normalization: in the spatial case it is recommended to perform the normalization before carrying on the spatial multivariate analysis, because the effect of the use of non-normalized data in GWPCA is still subjected to further research [
38].
Finally, spatial autocorrelation is used to detect spatial clusters with similar behavior of the indicator’s value [
30]. Local spatial autocorrelation, both univariate and bivariate, is then used to take into account also the spatial relation between the value of the indicator and the data used for the CI construction, and in order to identify locations in which spatial autocorrelation is significant [
39].
2.2. Case Study: Landscape
The methodology proposed has been tested on the case of the landscape in Sardinia. Landscape has been chosen as the case study because it can be considered both a spatial and a complex phenomenon. In addition, landscape preservation is currently a priority informing the development of spatial development policies in the region.
According to the methodology proposed by OECD/JRC, the first important step in the construction of a composite indicator (be it spatial or not) is to build a robust theoretical framework for the indicator. The construction of the theoretical framework starts from a clear definition of the phenomena that the indicator is intended to describe, in order to identify the various dimensions that compose it.
Defining landscape is not an easy task, because it is the result of an ongoing interaction of several aspects, involving natural, anthropogenic and perceptive dimensions [
40,
41]. Landscape is a holistic, dynamic and abstract concept. It has no defined borders despite the fact that it is possible to recognize various types of landscape in a topological sense [
40]. The intrinsic complexity of the landscape is proven by the large number of approaches used in landscape studies. Most of the approaches focus only on one or a few (if compared with the large number of aspects involved) particular aspects of the landscape: different approaches which consider landscape from either an ecological, or a cultural or a perceptive perspective are found. However, the various approaches are barely integrated together, despite the fact that the integration among them appears to be essentially relevant in order to try to consider all the landscape dimensions at the same time [
42].The need to have a holistic representation of the landscape, which may be able to consider simultaneously the physical, cultural and perceptive aspects, is suggested also by the European Landscape Convention, which states: “Landscape means an area, as perceived by people, whose character is the result of the actions and interaction of natural and/or human factors [
43].
The European Landscape Convention puts more emphasis on the fact that landscape is a resource in which local communities have formed their own culture, creating and modifying the various places that compose the overall European landscape. Hence, great attention should be paid to landscape protection. However, landscape is a dynamic process that changes continuously and inevitably due to both natural and human factors. Often, human modifications are responsible for the fastest landscape changes. Mankind modifies landscape to satisfy the need for food, housing and services. In some cases, these changes may be undesirable in terms of their consequences on environmental or on cultural features.
According to Steiner (2000) [
44], indicators are the best tools to understand and to measure the alterations of landscapes and their consequences. Unfortunately, the complexity of landscape does not make its description easy by means of indicators. The main difficulty is to understand exactly which indicators should be measured. In general terms, the objective is to obtain indices able to provide information about the state of the environment and about the consequences in landscape structure and landscape functions [
41]. Another difficulty in landscape measures comes from the dynamic nature of landscape: for the calculation of indicators it is necessary to specify both the spatial and the temporal scale [
45,
46]. The spatial scale refers both to the extension of the study area and to the choice of the basic spatial units of analysis. The spatial scale strongly influences the relevance of the landscape factors and also their behavior across space [
46,
47,
48]. The temporal scale determines how landscape patterns change overtime, in order to discover the causes of the landscape evolution and also its causes and consequences on the landscape [
49]. In addition, it is difficult to assess the significance of a pattern measured at one point, without considering the historical variability of the pattern [
45].
Landscape indicators can be divided in two main groups [
41,
50]: the indicators about the physical and the ecological characteristics and the indicators about the visual, the social and the cultural aspects. The first group focuses on the objective components of the landscape such as the landscape structure, and the physical/ecological landscape functions. The landscape functions aim to describe how landscape changes affect the species and the communities; furthermore, a prerequisite to understanding landscape functions is the comprehension of the landscape structure [
51,
52].
The landscape structure concerns two important aspects: composition and configuration [
50]. Composition refers to the non-spatially-explicit characteristics of landscape (richness, evenness, diversity), while configuration is related to the spatially-explicit characteristics of the land cover type in a given area; the latter are associated with patch geometry or with the spatial distribution of patches. Landscape metrics are the most used indicators for the physical/ecological characteristics of a landscape. Landscape metrics are a selection of indicators mainly developed in Landscape Ecology [
52,
53] with the aim of evaluating the state of the landscape from an ecological point of view, that is, to understand the effect of changes on the landscape structure and on the landscape functions.
Landscape metrics should be not interpreted individually, but in combination with each other, in order to achieve more complete information. The optimal sub-set of landscape metrics should be chosen in order to provide the largest information set possible, but at the same time, the redundancy among metrics must be avoided. Therefore, it is necessary to choose carefully the set of indicators to use, in order to ensure the independence among them.
The second main group of landscape indicators focuses mainly on the perceived aspects of landscape. Quantifying the perceived aspects of the landscape is not an easy task. The main difficulty relies on the fact that perception is inevitably subjective, because people see and appreciate the landscape in different ways. Therefore, the appreciation of the landscape might vary on the basis on the involved observers. Indeed, the most commonly used way to collect data about landscape appreciation is through questionnaire-surveys. This is one of the main limits responsible for the shortage of indicators measuring landscape perception [
54,
55]. The perceived landscape encompasses also the so-called cultural landscape, which can be defined as a portion of land in which human activities created a particular system of patterns [
56]. The main threats for cultural landscape are the changes caused by socio-economic factors, such as modifications in agricultural and forestry practice or human disturbances such as urban sprawl. These changes might bring to the loss of cultural landscape [
57].
The European Landscape Convention brings the social and cultural dimensions of landscape to the forefront for the landscape definition, and highlights the need to develop indicators able to carefully take into account both the physical factors and the human perceptions [
42]. Moreover, according to Rossler (2006) [
58] cultural places cannot be considered isolated but they are part of a broadest system with the ecological aspects, creating links in space and time. Thus, on the basis of these considerations, and on the basis of the need to combine together the various indicators of landscape, the creation of a spatial composite indicator of landscape appears to be an urgent challenge.
The methodology presented in the previous section has been applied in the Oristano Province in Sardinia, Italy. The Sardinian Regional Government adopted in 2006 the first Regional Landscape Plan (RLP). In Sardinia, the planning system follows a top-down hierarchical approach, according to which any physical or sector plan should comply with the RLP in order to ensure landscape protection measures are implemented locally.
During the RLP plan-making process the Regional Government collected a large amount of spatial data setting up a regional Spatial Data Infrastructure, in compliancy with the principles and technology standards of the INSPIRE Directive (2007/2/EC). Therefore, the opportunity to build a complex landscape SCI became feasible; at the same time, it would represent a mean to demonstrate the value of having a regional SDI.
2.3. Building a Spatial Composite Indicator of Landscape
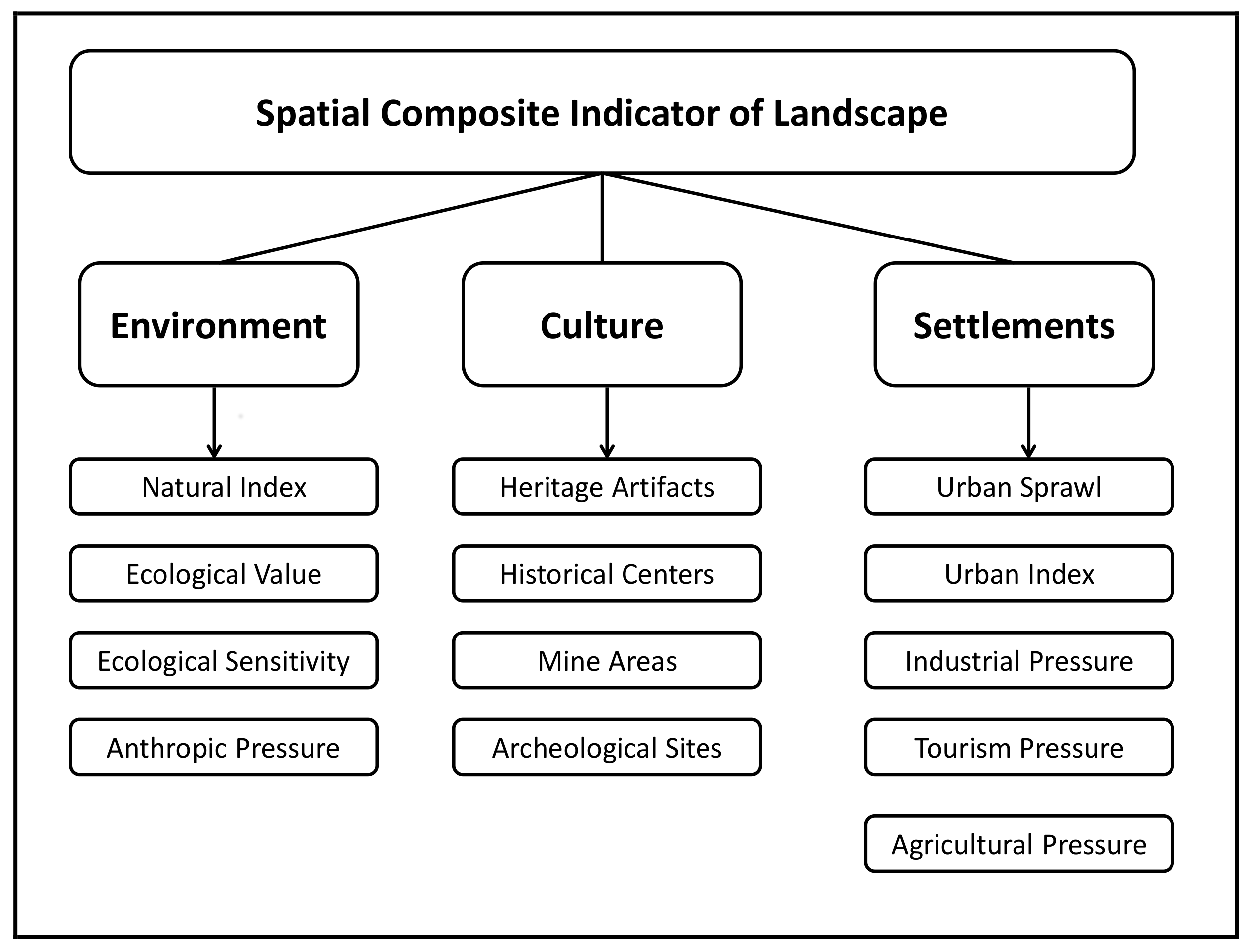
On the basis of the literature review the structure of the Spatial Composite Indicator of Landscape (SCIL) was designed relying on three main macro-dimensions: environment, culture and settlements. In turns, each macro-dimension was described by means of a selection of sub-indicators. The set of indicators to be included in each macro-dimension was driven by their relevance in the description of each macro-dimension and by the data availability (
Figure 1). The main data source for the calculation of the indicators was the regional SDI of Sardinia, with the exception of the environmental macro-dimension (
Table 2).
In fact, the ecological indicators (e.g., landscape metrics) strongly depends on the ecosystems or species under investigation [
51], hence describing in a detailed way the ecological macro-dimension of landscape detailed data about how different species perceive the landscape are needed. Indeed, this description requires a large amount of different data in order to identify the various ecosystems for each species [
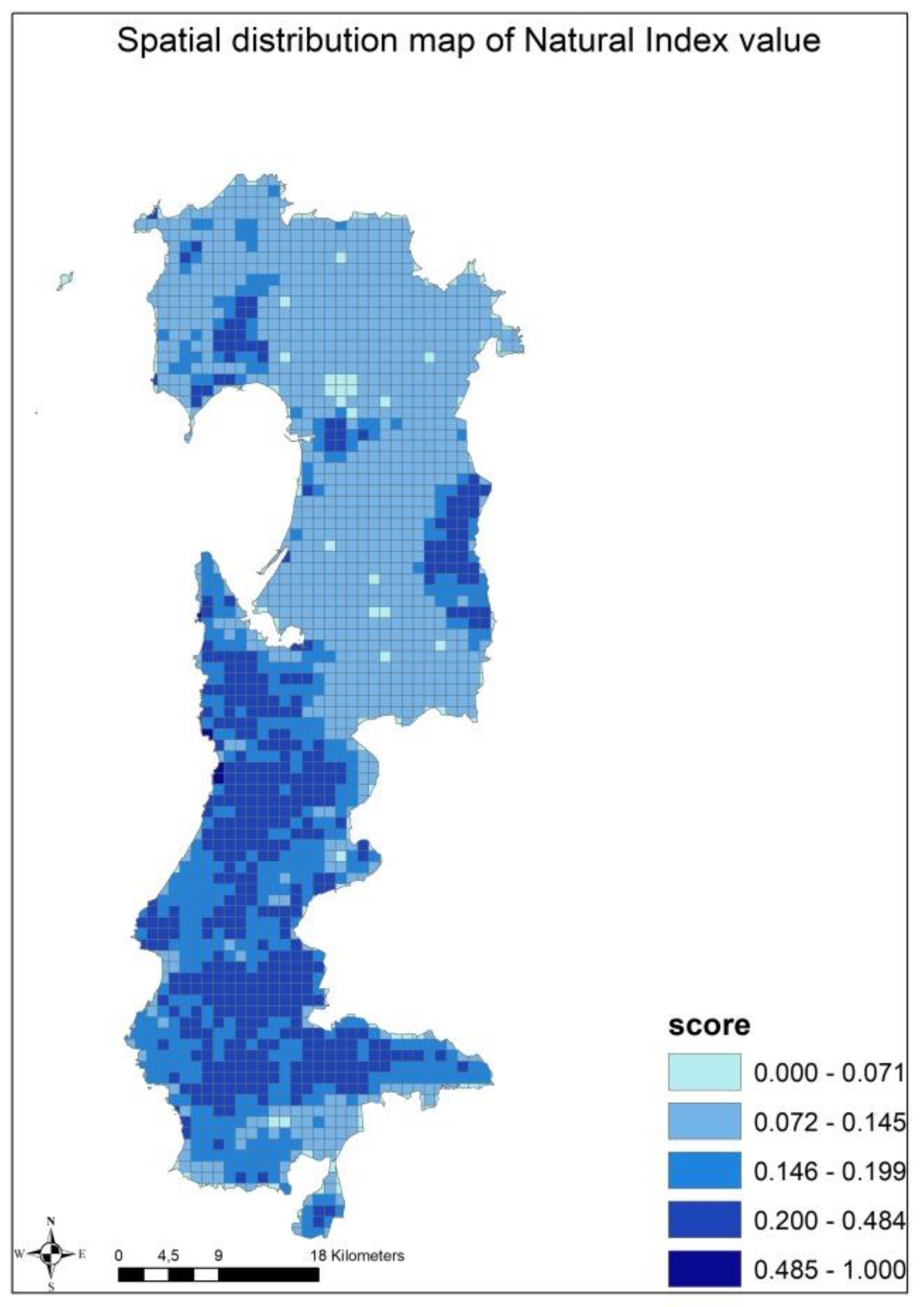
51]. Despite the large amount of spatial data layers provided, the regional SDI does not supply all the data necessary for this kind of detailed analysis. To overcome this issue and to describe the environmental macro-dimension in a proper manner we used three indicators from a study called “Carta della Natura” (i.e., Nature Map) carried on by the Italian Superior Institute for the Environmental Protection and Research (ISPRA) [
59]. The Nature Map identifies the main biotopes in Sardinia assessing three environmental indicators: ecological value, ecological sensitivity and anthropic pressure (
Table 3).
The cultural macro-dimension quantifies those aspects of the landscape that are relevant from a historical point of view, or that created a strong link between local communities and the territory. Data used to quantify the cultural macro-dimension allow for knowing the location and size of cultural heritage or archeological sites; in seldom cases data reports and also information about the state of conservation and/or the importance of the artifacts, although this information is available only for a sub-set of records. In addition, it is not possible to achieve their level of appreciation by spatial data. Therefore, we quantify the cultural aspects on the basis of their quantity and size.
The settlement macro-dimension encompasses those aspects that, according to the literature review, create landscape disturbances. Landscape disturbances are considered all the human action able to create landscape loss in terms of landscape identity and biodiversity. The literature review mainly identified as causes of landscape disturbance the uncontrolled urban growth and the anthropic pressure in term of industrial, tourism and intensive agricultural activities.
The study area which is located in the west coast of Sardinia was divided by means of a regular 1 km-size vector grid, or
fishnet. Using a geoprocessing workflow, the value of each sub-indicator was calculated in each cell of the grid. In total the spatial domain is composed by 2043 cells (
Figure 2). Considering that landscape “has no borders”, the use of the grid model enabled the study of the landscape without the use artificial spatial constraints, as in the case of the use administrative units, which are commonly used in CI studies.
Despite the fact that the selection of indicators may have limits in describing the overall landscape complexity, it offered the possibility to test the spatial methodology for CIs, in order to demonstrate the possibility to study the spatial dimension of the involved variables.
3. Results
Once data were collected and indicators were calculated, the creation of a composite indicator required the assessment of weights to assign to each indicator. The weights express a measure of the relative importance of the involved variable in each macro-dimension. In this particular case study, weights were assessed with a data-driven approach and locally, by the GWPCA in order to take into account the spatial effects. In addition, the use of GWPCA returns a group of variables (components) that are each other independent, enabling to avoid problems of double counting in the aggregation stage [
60]. The variable loading, returned by the GWPCA for each component, reflects the local importance of the variables; hence it can be used to calculate spatial weights. At the same time the use of GWPCA allows finding out the local variance as explained by each individual component. Finally, the significance test is performed to confirm the presence of spatial heterogeneity. It is based on the assessment of the variance which comes from the randomization of the local eigenvalues; if the significance analysis returns
p-values less than 0.05 it is possible to reject the null hypothesis about the random distribution of the eigenvalues. In this case it is possible to conclude that the spatial effects are relevant and the use of the GWPCA is validated [
38]. Before the application of GWPCA, indicators have been standardized by using the Min-Max method, in order to make them comparable.
Both GWPCA and PCA were applied to each macro-dimension, in order to highlight the differences between the two methods and to put in evidence how the spatial effects influence the results of the analysis.
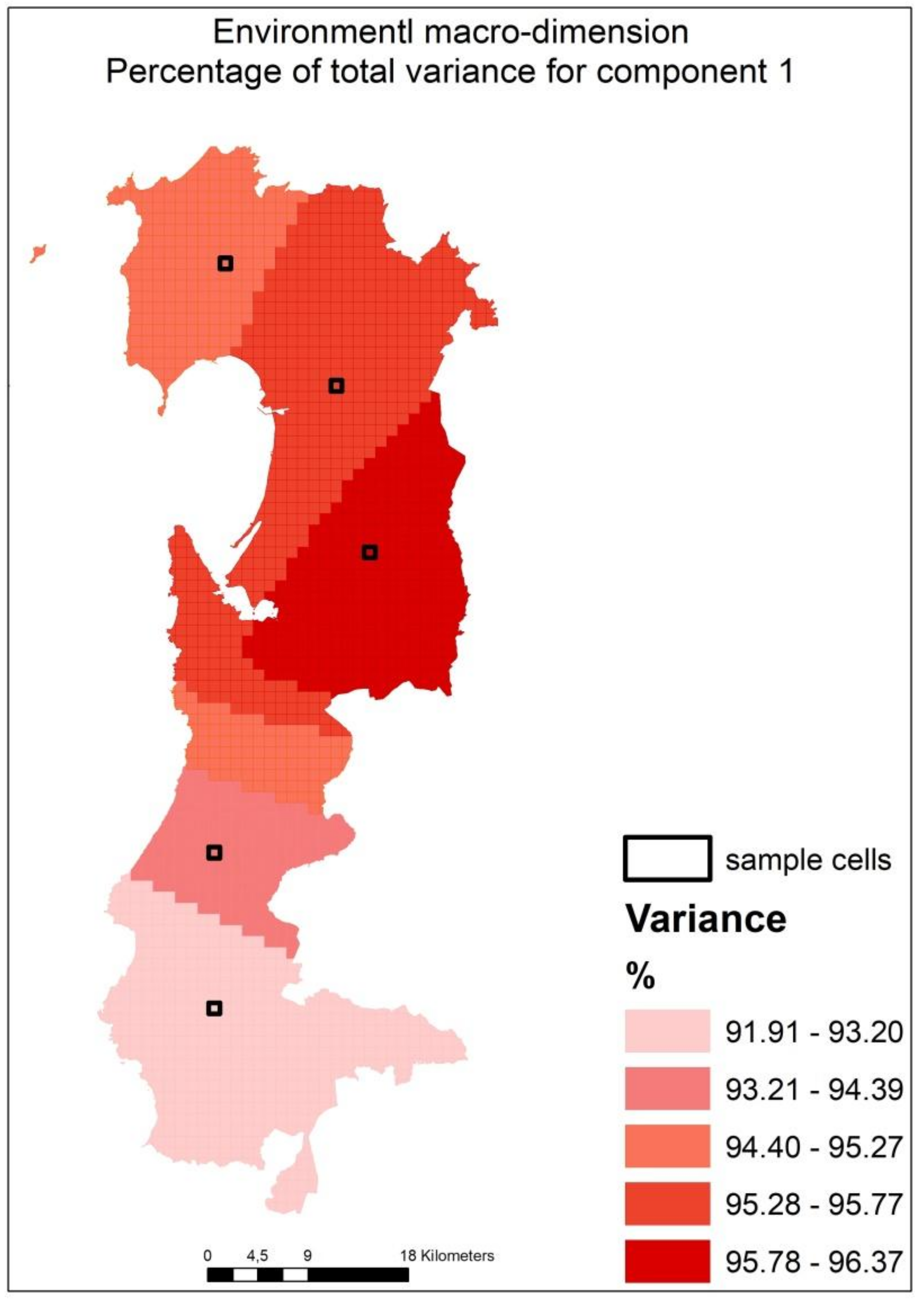
Table 4a,b reports the comparison between the results of the GWPCA and of the PCA for the environmental macro-dimension. As it is possible to see in the example in
Table 4b, with reference to the sample cells in
Figure 3, in the case of the GWPCA the percentage of the total variance is returned for each spatial unit, thanks to the spatial (local) nature of this method.
According to Gollini et al. [
38], the bandwidth resulting from the previous model calibration supplies the first information set about the presence of spatial heterogeneity. If the bandwidth is very small with respect to the total amount of spatial units, then it is possible to say that the effect of spatial heterogeneity is very relevant for the set of variables.
Table 5 shows the resulting bandwidth for each of the three macro-dimensions. The significance analysis confirms the presence of spatial heterogeneity and the
p-value it returned is less than 0.05 for each macro-dimension (
Table 5). Hence it is possible to reject the null hypothesis about the spatial random distribution of the eigenvalues [
38].
For all the three macro-dimensions the first extracted component explains the highest share of variation of data (
Table 6), hence the variable loading of the indicator in this component has been used to assess the weights.
The value of the variable loading has been considered in absolute value and it has been rescaled so that its sum is equal to 1 in each spatial unit (
Table 7). The use of the GWPCA, allowed obtaining a different set of weights for each spatial unit, which is in total 2043 sets of weights for each macro-dimension. Conversely, with the application of PCA it is possible to obtain only one set of weight across the overall spatial domain: weights are not different among spatial units, hence only a global importance of the various variables can be considered, thereby introducing uncertainty. In this sense, the use of the GWPCA can be seen as a local data-driven assessment for weights.
Once weights were obtained, the overall value of the macro-dimensions was obtained as the weighted sum (linear combination) of the variables, location by location (Equation (1)).
where MC
j is the resulting value of the macro-dimension, ω
ij is the weights associate to i indicator in the j-spatial units, and I is the indicator in the j-spatial unit (
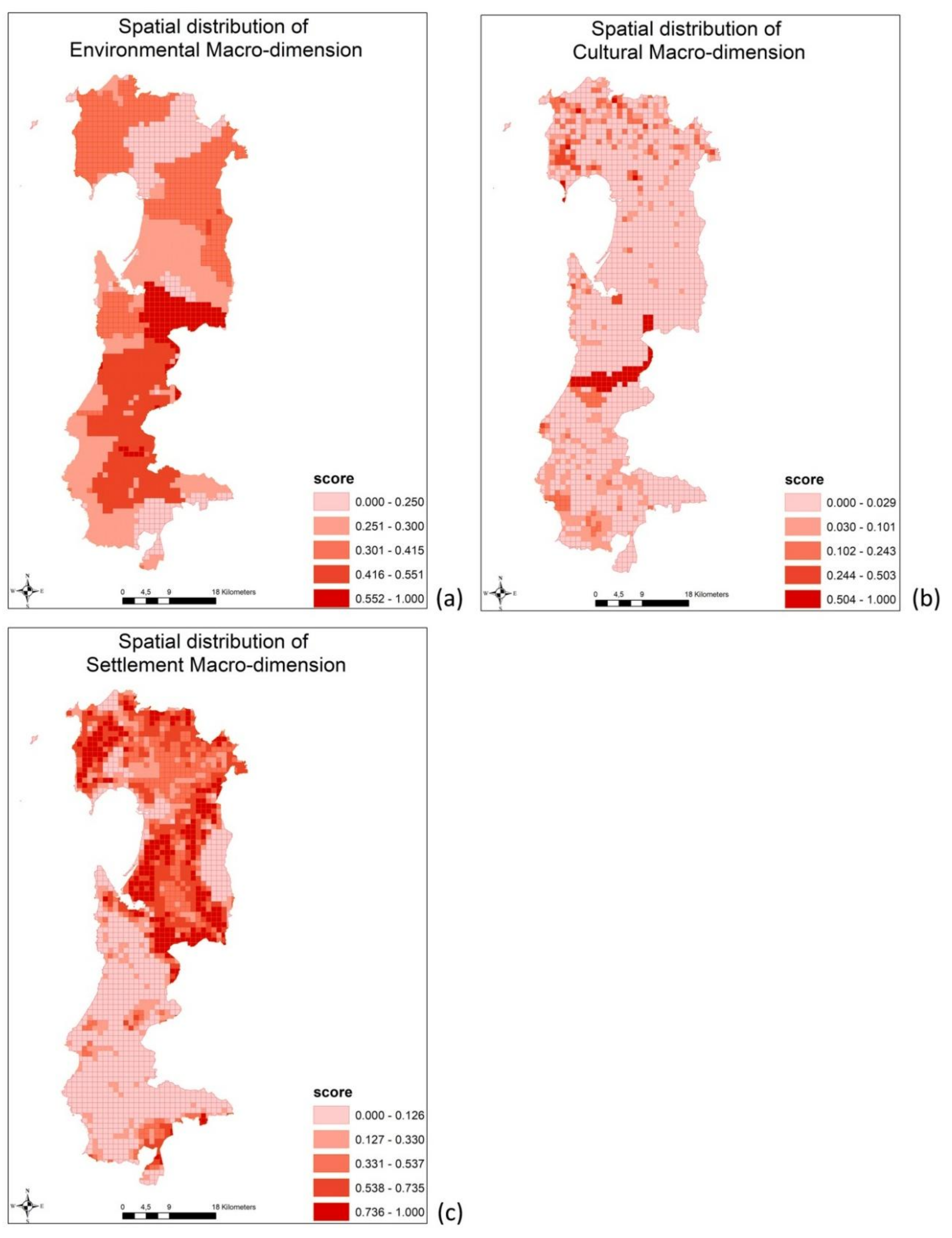
Figure 4a–c). The final score of the macro-dimension has been rescaled from 0 to 1, in order to make them comparable.
The overall landscape value was assessed as linear combination of the three macro-dimensions: environment, cultural heritage and settlements.
In the Equation (2), the settlements macro-dimension have been considered as negative terms, according to the fact that in the indicator’s framework it contains the landscape disturbance [
57]. The macro-dimensions have not been weighted in this case because they are considered equally important on the basis of the landscape literature review. The final result has been rescaled from 0 to 1;
Figure 5 shows the spatial distribution of the final indicators of landscape, where higher values correspond to high landscape quality.
The following spatial autocorrelation analysis has been performed for the overall landscape indicator, in a univariate way, and for the indicators and their macro-dimensions, in a bivariate way, to highlight the presence of spatial dependence between the spatial units and to gain additional information about the spatial structure of the indicators. The application of local spatial autocorrelation analysis allowed detecting spatial cluster in which the presence of spatial dependence among spatial units is very significant. The evaluation of the spatial autocorrelation has been calculated using rook contiguity [
61] at level 1 because it provided the highest value of the coefficient of the Moran‘s Indicator of spatial autocorrelation “I”. The results (
Table 8) confirm the presence of high spatial autocorrelation in the univariate case; in the bivariate case autocorrelation was found between the SCIL and the settlement macro-dimension. In the latter case, the spatial autocorrelation is strong and negative. Conversely, in the cases of bivariate analysis between the SCIL and the environmental and cultural macro-dimensions, spatial autocorrelation is smaller than in the previous cases. Spatial clusters resulting for the local spatial autocorrelation analysis enabled to identify different types of landscape areas.
In the case of univariate analysis, it is possible to distinguish mainly two cluster types: the cluster in red represents the spatial units with high score of SCIL surrounded by spatial units with similar values of SCIL, while the blue cluster are spatial units in which the score of SCIL is low, surrounded by spatial units with low values of SCIL.
4. Discussion
The aim of the proposed methodology was to make spatial the OCED/JRC methodology for the construction of CI, in order to introduce the analysis of the spatial dimension in the description of complex territorial phenomena. The results confirm the new opportunities offered by the applications of this methodology applied in the case of landscape in Sardinia. In general, the value of this approach consists on the possibility to assign a spatial weight to each variable and to mark homogeneous areas based on the mutual spatial relation among spatial units. The methodology allowed for describing the landscape phenomenon in a spatial way. In particular, the use of spatial data from the SDI and the application of the recent spatial statistical techniques enabled to consider spatial variation of the importance of data and to understand the spatial relations among the different variables and dimensions used for the landscape description.
Landscape is a spatial phenomenon created by the continuous interactions of different aspects, which may be different depending on the spatial position and on the mutual spatial position of the variables. These variations have been confirmed by the results, which indicated a strong spatial heterogeneity on the data distribution, because of the small
p-value and the small bandwidth (
Table 5). The environmental macro-dimension exhibits a large bandwidth, if compared with the others two macro-dimensions. Actually, the indicators used in the description of the environmental aspect of landscape are arranged across the space in a more homogeneous manner, because they have a value in each cell of the spatial domain. Conversely the indicators of the cultural and settlement macro-dimension are allocated in a non-continuous way, because they represent punctual characteristics of the landscape or landscape aspects which themselves merge in small areas. As a matter of fact, some cells contain all indicators of the cultural or settlement macro-dimension, while in other cells only part of the set of indicators are present. The differences in the distribution of indicators in the cells produce different spatial relations among indicators depending on their local distribution; therefore, different spatial regimes are generated with the consequently spatial variation on the local importance of indicators, as it has been proven by the results (
Table 6 and
Table 7).
The spatial distribution of the value of the macro-dimensions substantially confirms what it was explained above. Although spatial variation is present, the environmental macro-dimension score has a more homogeneous spatial distribution (quite homogeneous mosaic) if compared with the settlement and cultural macro-dimension (
Figure 5). Areas with high environmental value, in dark red, appear to be large (
Figure 4a) hence it is possible to conclude that the overall study area is characterized by a high environmental quality. In case of cultural and settlement macro-dimension the mosaic of the score distribution is more heterogeneous. The spatial distribution of cultural macro-dimension score allows for identifying a high cultural level area (in dark red
Figure 4b), corresponding in reality to the main mining area. In the upper part of the map, it is shown a concentration of cells with significant cultural score; these cells correspond to location where it is relevant the presence of archaeological sites, heritage buildings, and the ancient part of the towns.
The distribution of the settlement macro-dimension score clearly indicates where the anthropic disturbances on the landscape are located (in dark red in
Figure 4c). These areas represent the locations in which there is a large concentration of settlements and intensive agricultural practice. Although present, the touristic and industrial disturbances are less relevant because they occupy small areas. The rest of the map indicates scarce human activities. The final indicators score summarizes the simultaneous effect of the three macro dimensions in each cell. The map of the spatial distribution of landscape quality shows that the southern part of the study area is the most remarkable, on the basis of the final score of the SCIL. Indeed, this area is characterized by scarce human presence and rich uncontaminated forest land.
The spatial autocorrelation analysis allows highlighting the spatial relation, in terms of spatial dependence among the cells, on the basis of the score of the final indicator and on the macro-dimensions and the final indicator. The purpose of the application of this technique was to identify the homogeneous areas of landscape based on the score of the indicator, in order to compare these areas with the homogenous ones identified by the RLP (
Figure 6). In this sense the methodology offers a quantitative method which gave the possibility to supply further information in the process of landscape knowledge, and it may be considered complementary to the qualitative information provided by the RLP.
The main result of the spatial autocorrelation analysis is the identification of the two main kind of homogeneous areas, as shown in
Figure 7a. As it is possible to see from the figure, the identified homogeneous areas by the spatial autocorrelation analysis provide a further partition of the RLP’s homogenous areas. The meaning of the spatial autocorrelation in these clusters is that there may be a contagious effect among cells. In other words, cells with high or low landscape level tend to be close together.
This tendency is exhibited also in case of bivariate analysis with the environmental macro-dimension. Substantially, cells with high environmental level are close to cells with high landscape level and vice versa (
Figure 7b). In the case of the cultural macro-dimension, there are some relevant considerations that are worth to explain. Bivariate spatial autocorrelation analysis reveals the presence of a large cluster (in blue in
Figure 7c), in which cultural macro-dimension indicator and the SCIL have both a low score. This behavior may be due to the fact that in this area of the study region is low on cultural aspects (
Figure 4b), and at the same time, it is rich in landscape disturbances. In the upper part of the
Figure 7c, the bivariate analysis highlights a situation of competition between cells. In fact, the results return cluster types with high cultural level (in pink), surrounded by cell with low landscape level; this is most likely due to the existing high human activities in these areas (
Figure 4c and
Figure 5). From a landscape protection point of view, this analysis suggests to pay particular attention on these areas. Indeed, the high presence of landscape disturbance may cause cultural landscape loss, if not regulated with specific planning actions. Finally, the result of bivariate analysis between the settlement macro-dimension and the SCIL, substantially confirms the theoretical framework for the Spatial Composite Indicators, in which settlement macro-dimension encompass the landscape disturbances. According to this fact, the clusters resulting from the spatial autocorrelation analysis highlight the competition between the human activities and the landscape quality, and allows identifying were this competition is relevant. Despite the fact that, in general terms, cluster types were expected, is interesting to note that there are few small red clusters. They represent portions of land in which, despite the high presence of human disturbance (settlement macro-dimension) the landscape value is high. In fact, as it is possible to note from the
Figure 4a–c, these locations exhibit high scores in all the three macro-dimensions. Therefore, as suggested in the previous case of the cultural macro-dimension, particular attention has to be paid on these areas in order to propose correct policy action to preserve the landscape quality.
The combination of spatial data from Sardinian SDI with the spatial statistical techniques offered a new approach in landscape studies. The novelty of this method is the use of spatial data in a different manner than in the past, where different factors individually described spatial characteristics of the landscape without considering the mutual spatial relations among them. In this sense, the construction of a spatial composite indicator of landscape may be considered as a quantitative method that is complementary to the existing qualitative landscape assessment done by the RLP. This represents the main advantage in the construction of the spatial composite.
Despite the fact that the introduction of the spatial dimension represents an advantage for an integrated spatial description of the landscape, some controversial point still remains. The first one concerns the data issue. In general terms, composite indicators, spatial or not, are data hungry and the SDIs offer a novel and complementary data source which can be very valuable. In addition, they offer the possibility to expand the range of complex aspects of the reality to be described by means of CI. Nevertheless, in the specific case study of the landscape in Sardinia, data provided by regional’s SDI are still insufficient. The complexity of landscape, in particular the complexity of its environmental macro-dimension, requires specific data able to take into account the different landscape perception with regard to the different species. These kinds of data require sampling depending on the focus species; these datasets are not available yet in the SDI of Sardinia, which is rich of topographic data but still poor of environmental data. Another issue of concern with regards to Sardinian SDI data is that in some cases the thematic attributes are incomplete; hence it was not possible to discern many thematic characteristics. For instance, the data set of the heritage building is incomplete regarding the age of buildings or their conservation, despite the fact that the attribute table has these specific fields. For those reasons the selection of the used indicators may be considered not optimal for a deeper landscape description; still it allowed considering the main landscape aspects.
The limitation in the set of indicators leads to another criticism of the methodology, in this particular case study: the possibility to perform a good sensitivity analysis. Generally, sensitivity analysis is performed by replacing some variables or by considering one variable at time, in order to explore the behavior of the overall indicator [
1]. In some cases, sensitivity analysis is carried out by discarding one of the indicators at time, while keeping all the others [
31]. In other cases, sensibility is performed by application methods on spatial models in which the model is decomposed in sub groups of variables to analyze the variability of data, usually the variance of the input [
62]. The scarcity of variables makes this kind of analysis (the one in which one indicator is discarded) unfeasible, while in the second kind of methods a spatial model is needed. Therefore, the question about how perform sensitivity analysis in a case where the weights are local still remains opened. In part, this lack is partially overcome by the significance analysis encompassed in the GWPCA methods. The method here presented uses only the first component extracted because it explains the most part of the variance of data, despite the fact this is not true for all the spatial units; therefore, the method needs to be improved so as to discriminate the spatial units on the basis of the winning component.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}