1. Introduction
Recently, with the development of networks and the spread of smart devices, people are living in an age of flood of information [
1]. In addition, Internet of Things (IoT) technology has enabled all objects to be connected to the Internet to support mutual exchange of information [
2]. The production of information has been transferred from person to thing, and it can utilize and collect necessary information anytime and anywhere to overcome temporal and spatial constraints.
As the time and space limitations of information have been overcome, many researchers and developers have become interested in context aware communication and computing [
3]. In addition, real-time information from mobile and social networking platforms is expanding the use of situational awareness around us [
4]. By using smartphone, users can trace world-related information and their physical activities are aggregated and used for related situation-aware services. In addition, with the advent of Web 2.0 paradigm, people are participating more in user-created contents (UCC) and social involvement. Seamless convergence of the worlds of Internet, broadcasting, social networking, and mobile communication is expected to enhance the interactions between users and to improve the experience by collecting information that supports the identification of the user’s current situation in terms of situation-awareness.
On the other hand, due to the rapid urbanization of society, various problems have arisen. People face urban transportation, health and environmental issues because of people’s lifestyles and environmental changes [
5]. To improve quality of life, sustainable life services based on information technology should be provided as well as physical infrastructure expansion. Furthermore, the amount of information requires effective monitoring and decision support [
3]. For example, people could avoid diverse disasters such as floods and earthquakes as well as improve wellness with intelligent decision support for healthcare and wellness. Then, it is necessary to provide various types of information according to the contextual condition, which provides the sustainability and convenience [
6].
What is still missing is the knowledge support capability which can truly enrich the whole intelligent service cycle considering user situations. However, the problem is non-trivial because each service has its own characteristics and the context of a person is defined by various factors, such as location, preference, social environment, etc. Nevertheless, we believe the potentials of collective intelligence because it aggregate huge amounts of people’s experiences and opinions about various types of objects and services. This existing research on utilizing collective intelligence is quite diverse, ranging from simple query expansions or image tagging in information retrieval area [
1] to situation-aware service mashup in semantic service creation area [
1,
7].
One of the key requirements in situation-aware service system is to maximize possible unobtrusiveness and transparency to the users, which demands easy and efficient use of relevant context information for users’ decisions [
8]. Even when the context information cannot be accessed in a direct way, available pieces of context and easily understandable analysis results that are processed with an appropriate inference mechanism should be presented to users. In terms of people related information, the analysis can go back in time by exploring available archives. In this line of context, constructing a situation-awareness supporting framework by fully exploiting the power of the collective intelligence obtained from the Web is necessary to best meet user’s needs; it aggregates raw data from the Web, extracts relevant information, converts them as a reusable format, and analyzes them according to user requests.
In this paper, we propose a text-mining based situation-aware decision-making framework that can be an effective and sustainable knowledge management. As an effort to realize the situation-awareness supporting framework, we are focusing on how to utilize collective intelligence existing in online communities in aspects of service-specific domain knowledge. To this end, we first adopt Service Quality Model for Hospitals (SQM-H), which is used for knowledge extraction, analysis, and retrieval. Previously, service quality factors for hospitals was used for analyzing online health communities [
9], but we devised it in aspects of hospital related knowledge processing. Based on the SQM-H, we built a set of text-mining techniques to extract hospital name, six service quality categories (i.e., “services”, “professionalism”, “process”, “environment”, “impression”, and “popularity”), and three user intention types (i.e., recommendation, neutral, and non-recommendation). The text-mining techniques aggregate SQM-H based service-specific knowledge from online health communities. The collective intelligence can be utilized by situation-aware recommendation services through our service quality analysis and Open Application Programming Interfaces (Open APIs) provided. The services would relieve the burden of users to explicitly define what information is currently relevant to them and could offer enriched information that are specifically tailored to the user’s situation. Furthermore, the situation-aware service system can move on the social level and contact colleagues, friends and group of the people of same interests. It may allow user to share his/her own experiential knowledge and to infer more useful information based on that.
This article is structured as follows. We shortly overview background and state-of-the-art related work. Then, we introduce overall architecture and its core components related to text-mining techniques and service quality analysis model along with a domain-specific SQM-H. Finally, we present a prototype implementation for hospital recommendations that are based on the data model and the constructed knowledge, and discuss lessons learned from the implementation, while directions of our current research conclude the article.
2. Background and State of the Art
The recent drastic increase of smartphone users is highly correlated with social networking services including Facebook and Twitter. The widespread use of smartphones opened new opportunities for personal situation-awareness by utilizing heterogeneous sensors (e.g., GPS receiver, accelerometers, compasses, microphones and camera) in smartphone. It is possible to use GPS and base station to estimate user position, microphone to analyze the social situation (user chatting with people, stuck in traffic, in an office, etc.) and accelerometer to discriminate physical activity (running, walking, driving, etc.). The current state-of-the-art systems already recognize several activities with good precision.
Collective intelligence has provided the foundation for an innovative knowledge management platform that utilizes human resources, and this has been realized through a user participation in web environments [
4]. Although the Web is not a learning methodology by itself, it promotes a cultural learning platform by various efforts of contributors [
10]. Using the Internet, people can easily acquire, analyze and apply knowledge with other people’s experiences in various fields (encyclopedias, process management, recommendation services, etc.) [
11]. Furthermore, context means all the information that can be used in the interaction process between individuals and services [
12]. Context-Awareness is the context in which a service is provided for a specific purpose. Many researchers are interested in recommendation services which could be divided into contents based on a collaborative filtering approach according to the purposes [
13]. Mobility management represents one of the most important properties for context-awareness [
14,
15]. Meanwhile, opinion mining is also one of the important factors in personalized recommendation services [
16].
In addition, the analysis on social context of users permits inferring the users’ interests via information provided spontaneously by users, and analyzing behaviors and habits of his/her friend networks. However, it is prone to errors and imprecisions due to innate ambiguities of social networks [
17]. As a user-driven, but more pragmatic solution, Twitter and Google+ are using the hash tag as a tool for crowdsourcing to categorize content by users. For example, keywords are marked by the # symbol (e.g., #sustainability). They are used for content classification and recommendation by improving the accuracy of searches on past messages. In addition, it is possible to classify the category by user.
In natural language processing area, on the other hand, there are numerous approaches to catch reusable knowledge and explicit intentions from formal/information texts. Reference [
18] is an automated system for processing a large text corpus distilling a knowledge base about persons, organizations and location which can produce a comprehensive set of <Subject, Predicate, Object> triples that encode relationships between and attributes of the named-entities that are mentioned in news articles or Wikipedia articles. For example, the sentence—“He is an employee of Subway”—can be <He, employee of, subway>. Extracted triple sentences, actually fact statements, themselves are knowledge. Based on the extracted triples, users can get answers about a question, for example, “List the employers of people living in Nebraska or Kansas who are older than 40”. Situation Ontology [
19] built a large situation knowledge base of human activities by utilizing text mining techniques from how-tos descriptions. It covers activities of daily living as shopping, driving, wedding, etc., but the use of activity knowledge has not been extended to handling more detailed context variables of a specific service domain (e.g., sentiment, service quality, and preferences). More recently, Chen et al. [
20] studied intent identification which aims to detect discussion posts expressing certain user intentions that can be exploited by businesses or other interested parties.
State-of-the-art approaches are mostly focused on identifying user posts with explicit intentions or extracting scrappy facts of high accuracy. However, to enable more intensive user-friendly services, a fruitful domain-specific knowledge base, which can respond users’ service needs, should be prepared in advance. To our best knowledge, there are few attempts to construct an intent-aware knowledge based on collective intelligence in any situation-aware recommendation services. Research on how to construct domain-specific service knowledge considering user intention types and how to utilize the constructed knowledge by accommodating immediate user requirements are in high demand.
3. Situation-Awareness Supporting Platform
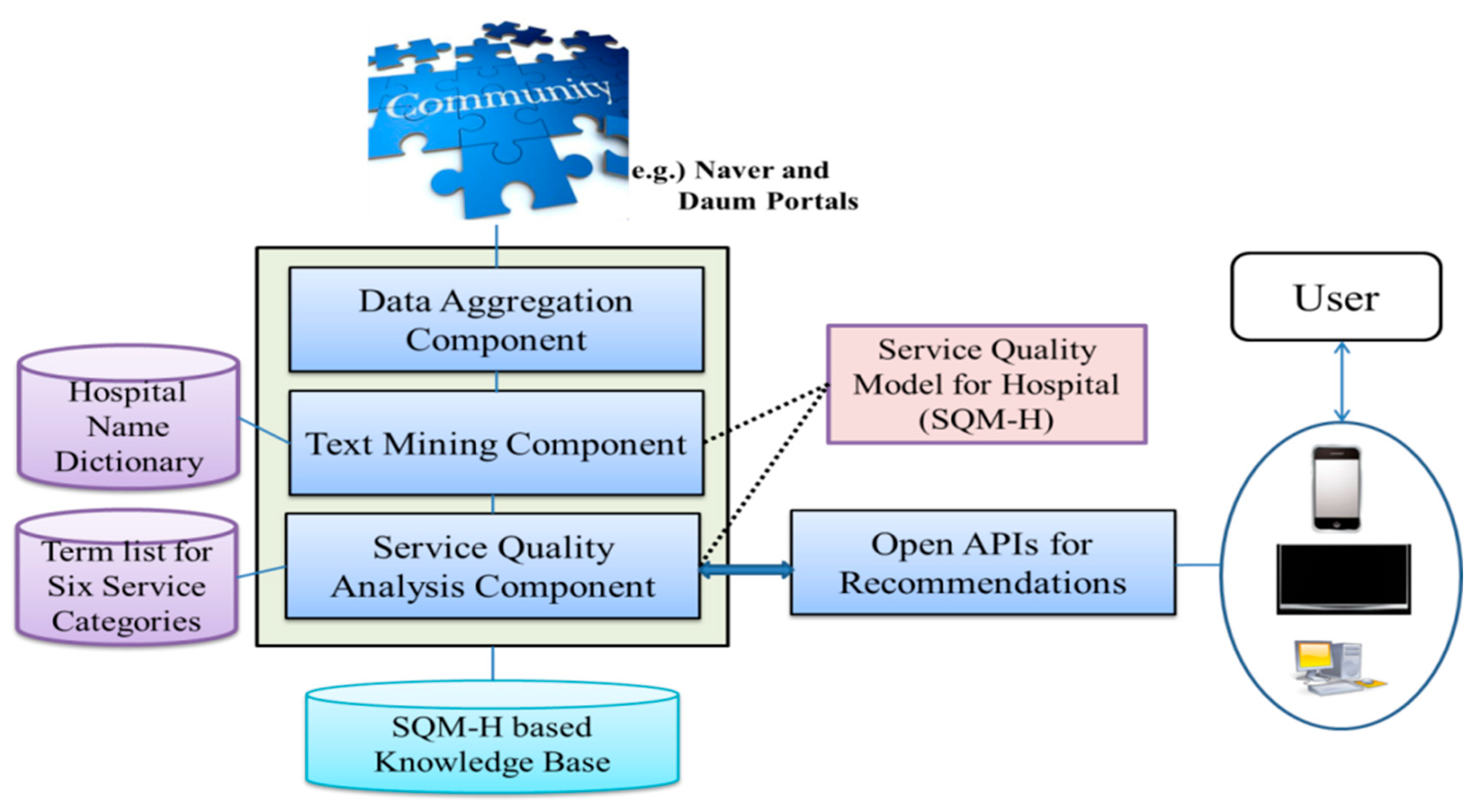
Our proposed architecture consists of three major components according to the complexity starting from aggregating raw data to high-level information analysis (
Figure 1). The high-level architecture is to process collective intelligence for situation-aware recommendation services. Although we choose hospital recommendation service to show our approach’s feasibility, the architecture and subordinating components can be adapted to other service domains if appropriate knowledge model and service-related terms are constructed.
3.1. Data Aggregation Component
It automatically crawls healthcare/hospital-related mentions from online health communities served on two biggest web portals, Naver [
21] and Daum [
22], in South Korea. We select the most promising communities in the health domain which have outstanding members, popularity, and vigorous activity among members compared to others. Those online communities give opinions about hospital service qualities of both small scale clinics and hospitals. We opted for those local online communities as our text mining information sources. Each online community provides search function that help us find particular webpages having “pediatric” and “recommendation” keywords. The webpages from selected online communities were crawled and stored in HTML format. Before storing the data, HTML tags and non-textual information such as images, JavaScript codes, and advertisements were deleted from the extracted files. For effective handling of HTML content, we used the Beautiful Soup library [
23], designed in the Python programming language. Using the data aggregation component, we aggregated approximately 173,000 messages that were written between April 2007 and May 2013.
3.2. Service Quality Model for Hospitals (SQM-H)
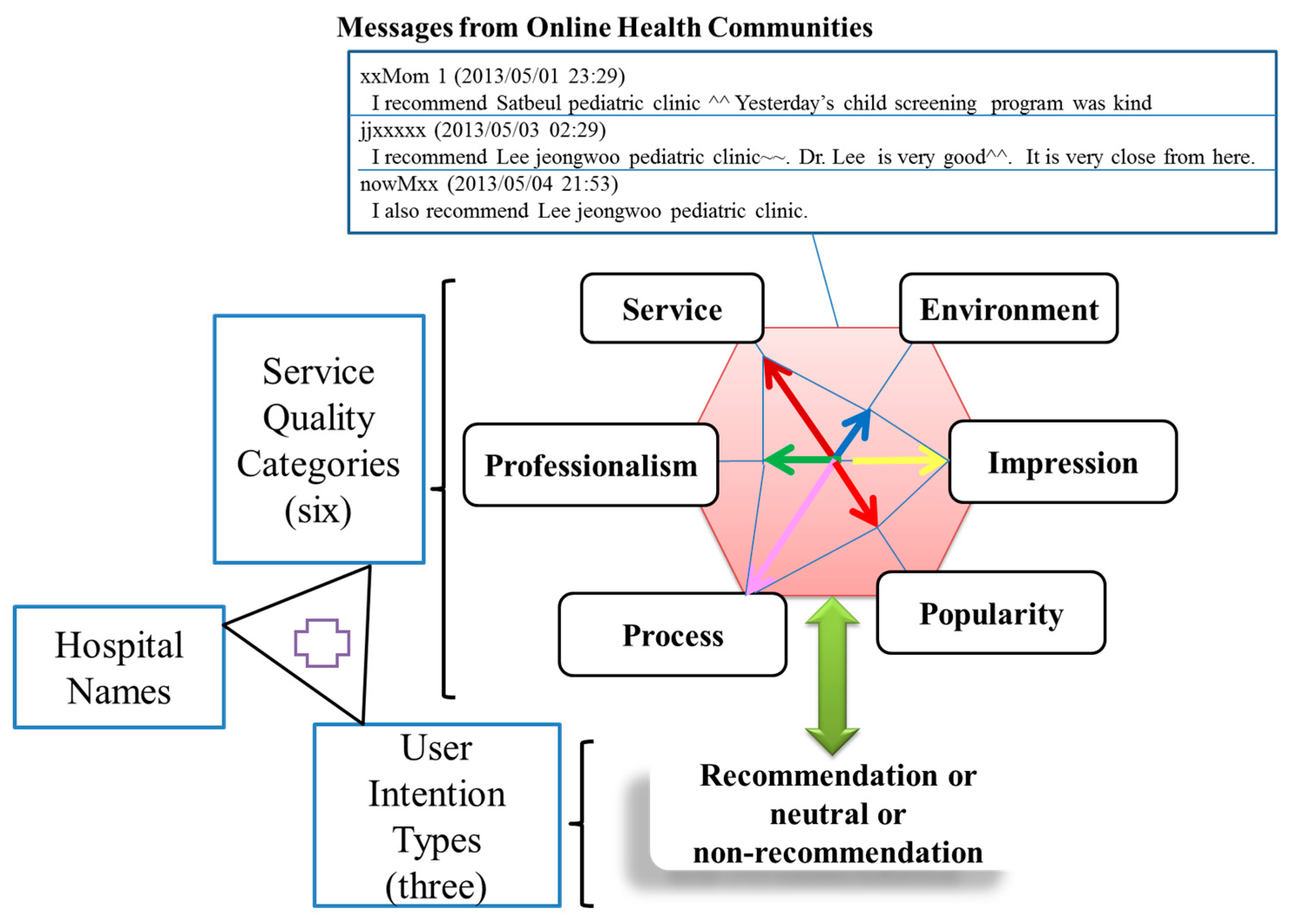
To facilitate efficient management of service-specific knowledge, we devised a SQM-H by referring to social media-based key quality factors for hospitals [
9]. Our SQM-H consists of six service quality categories (i.e., “services”, “professionalism”, “process”, “environment”, “impression”, and “popularity”), three user intention types (i.e., recommendation, neutral, and non-recommendation), and hospital name (
Figure 2). Each service quality category has on average 1000 keywords as features which can be used for analyzing the content of user written messages. In the case of user intention types, they have mostly sentiment keywords as features that may fall into one of positive or negative polarity. The SQM-H is mainly used for storing/discovering service-related knowledge of hospitals, but those term features in each service quality category and each recommendation type are used in the next text mining component.
3.3. Text Mining Component
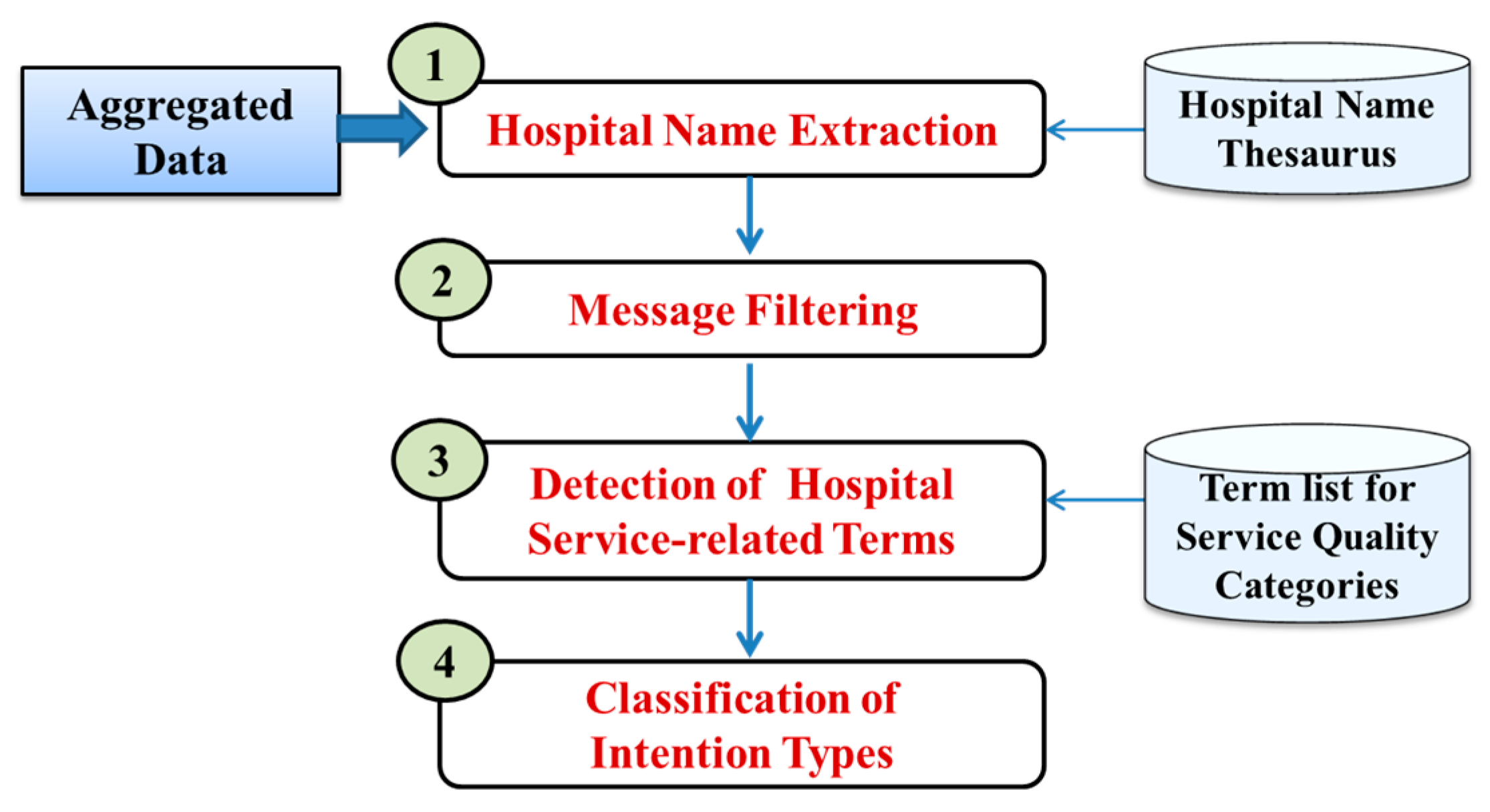
We implemented a set of text mining modules to handle healthcare/hospital-related messages that mention hospital/clinic names explicitly and to extract service-specific knowledge from the identified messages (
Figure 3). First, hospital names expressed in each message are identified. To consider hospital-related information, messages which do not contain hospital/clinic names are filtered out. For the construction of reusable service-specific knowledge from the filtered messages, we additionally extract service-specific knowledge which tells about service qualities and user intentions by following the SQM-H. After tokening each sentence into terms, dictionary look-up tasks are performed iteratively to find out the relevant service quality category for the given terms. Finally, intention type classification is done based on the extracted service-related terms and associated sentiment keywords. In addition, it tracks the changes of sentiments if the given message has multiple sentences. For every filtered message, the four text mining steps are applied to detect service quality related keywords used for describing hospitals’ service quality and to classify intent type of each message for the designated hospitals. The extracted knowledge is stored and maintained as the following six tuples: (Region, Date, Hospital Name, [Service Quality Category]*, User Intention Type).
Currently, F1-measure (the harmonic mean of precision and recall) of hospital name extraction’s performance is 77.7%, and that score of hospital service-related terms detection amounts to 90.8%. In terms of intention type classification, our manually checked accuracy is on average 77.8%, despite careful sentiment term selection during implementation. The term selection includes manual inter-agreement evaluations upon candidate terms which may fall into one of the polarities (positive or neutral or negative); the term selection gives effects of the sentiment analysis results. The checked accuracy signifies that the hospital name identification and sentiment analysis in Korean language have still rooms for further improvements. The region and date information can be extracted almost perfectly by using regular-expression based rules. Among 173,000+ messages analyzed, we could identify at least one service quality factor from 32,000+ messages (18%). Only messages containing service quality factors were used to construct the service quality analysis component and service prototype “Hospital for Me”.
3.4. Service Quality Analysis Component
3.4.1. Characteristics of Service Quality Model for Hospitals based Service-Specific Knowledge
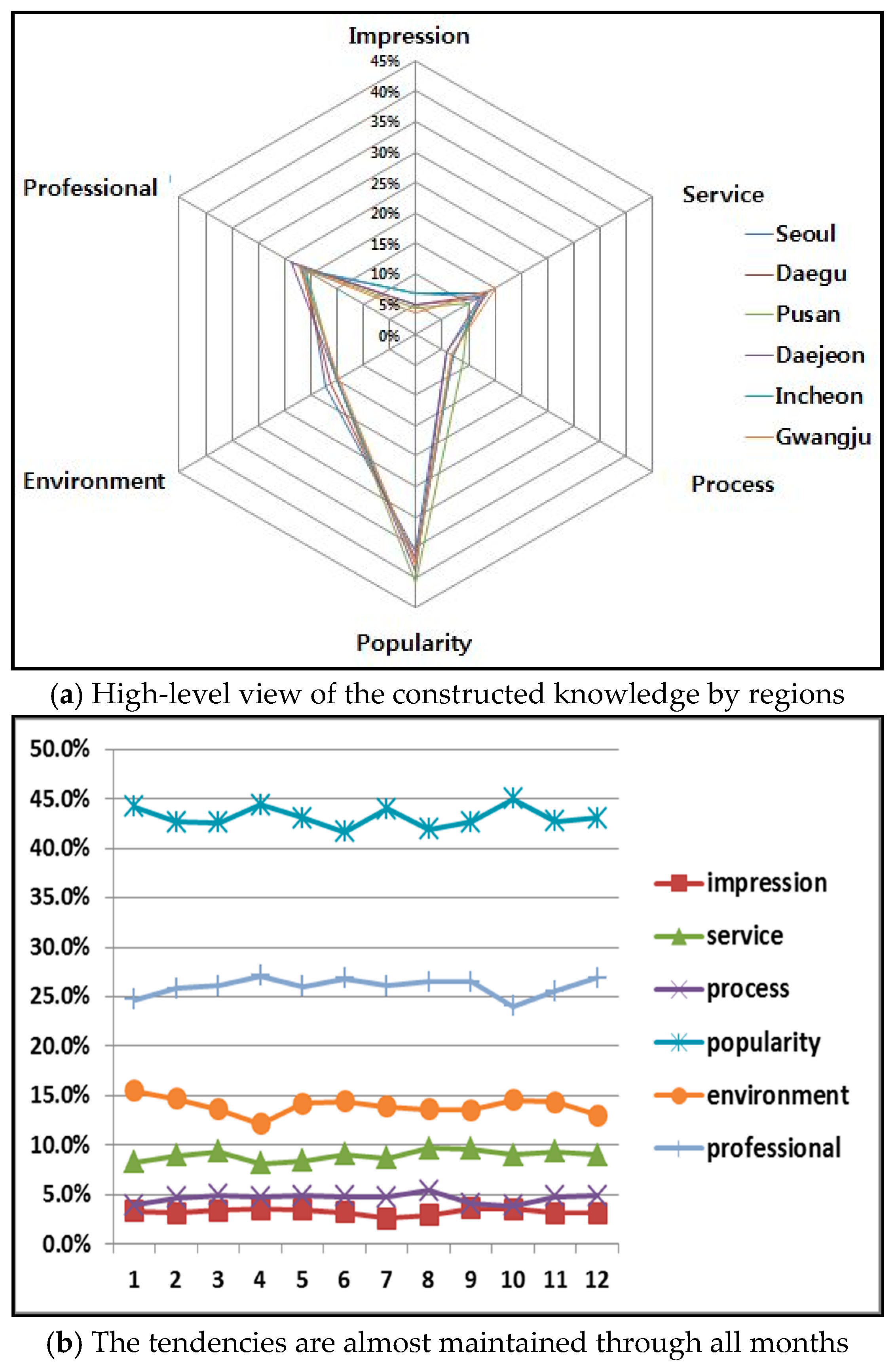
Our SQM-H based knowledge base includes service-specific knowledge of six big cities (e.g., Seoul, Pusan, Daegu, Daejeon, Inchon, and Gwangju in South Korea) during April 2007–May 2013. Basically, the knowledge can be analyzed by date (month or year), region, service quality category, and intention type. For example,
Figure 4a shows a high-level view of the constructed knowledge by regions. Although there are small ups and downs in different service quality categories, one possible explanation is that most of them highly respond to popularity of hospital, and then professionalism. The tendencies are almost maintained through all months (
Figure 4b) when we rescaled them into mean relative frequency ratio. The relative frequency ratio is normalized (representing the portion of the given category divided by the total frequencies of each month) and presented on a scale of 0–100%.
Assuming that the frequencies of each service quality category for the given hospital represent caregivers’ beliefs as a measure of collective intelligence (CI), they can be used as background knowledge when users want to choose hospitals/clinics that satisfy user’s selective preferences on different service quality categories. Moreover, the knowledge base enables in-depth analyses of the observed hospitals according to service quality categories and intention types together with time (i.e., date, month, and year) and location (i.e., nearest distance, same region, and domestic) factors.
3.4.2. Search Technique based Analysis Engine
To immediately deal with user requests and adjustable requirements, we implemented a service quality analysis engine with a built-in search technique which is different from casual SPARQL-based [
24] inference systems. SPARQL allows users to query information from data sources that can be mapped to RDF. Our analysis engine is optimized for the following six tuples because aggregated knowledge is not in RDF format. The analysis module returns a list of hospital candidates which satisfying users’ inquiry or intent. The six tuples, (Region, Date, Hospital Name, [Service Quality Category]*, User Intention Type), are the basic internal query template for the knowledge discovery when user’s natural language input is given. Depending on the users’ input, more than one factors are combined to make a new query. For the utilization of the analysis engine, we implemented several prototypical RE presentational State Transfer (REST) APIs to provide more convenient connectivity across different smart devices and applications. The APIs can handle diverse user requests ranging from querying simple status or direction toward hospital to recommending the hospitals with certain aspect that users care about. We discuss them in
Section 4 in detail.
4. A Prototype for Hospital Recommendation: “Hospital for Me”
As a proof of concept for the situation-aware recommendation service based on collective intelligence, a simplified version of the recommendation services has been implemented in the form of REST API. The REST API can be accessed through devices connected to the network, such as desktop, mobile phone, and smart TV. Connection is based on HTTP/REST protocol which is used in common, synchronous/asynchronous communication. In this case, 3rd party services can pull the information to make another hospital related service. Regarding applications, the REST-style API allows developers to implement situation-aware hospital services to end-users.
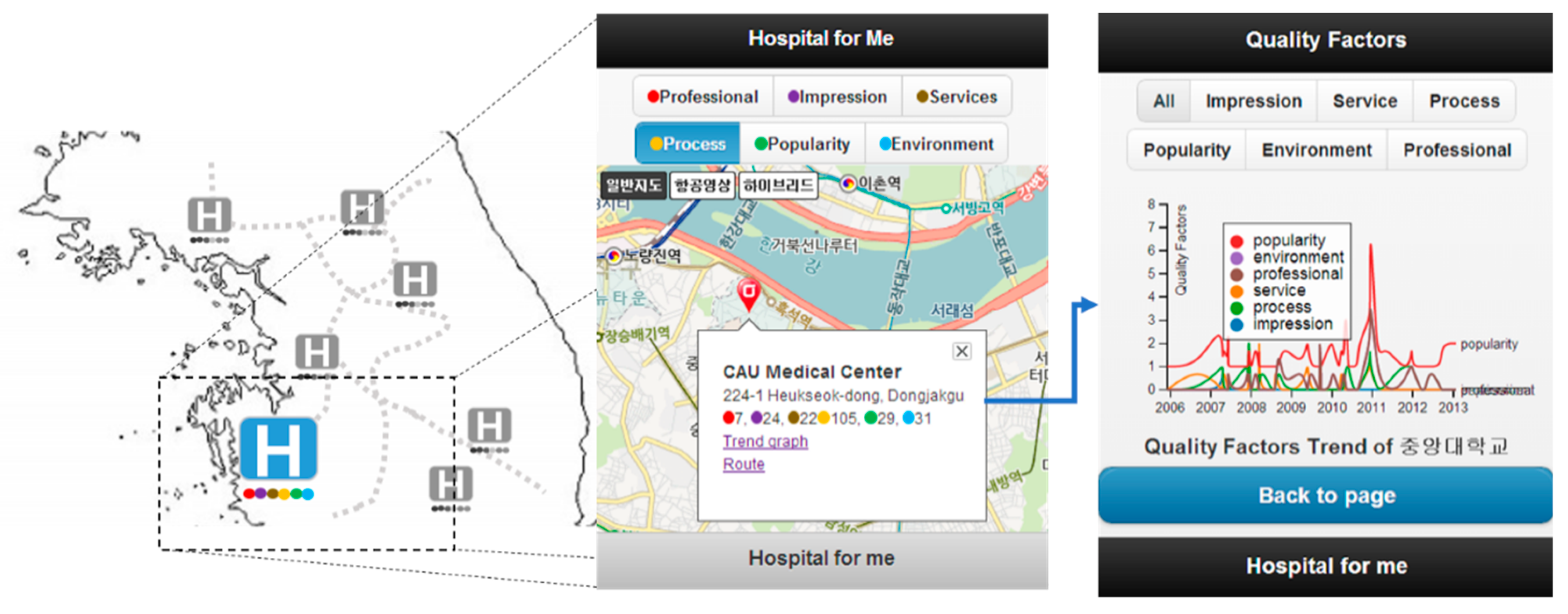
As our prototype implementation, we designed a web application type mash up (
Figure 5). Users can navigate around the hospital where they are. Users can see the location of the hospital on the map at a glance, and get a brief look at the name and service quality of each hospital. This prototype also provides a chart showing the trends in detailed service quality, allowing the users to recognize how the quality of service varies with time. For example, if hospital facilities are important to users, the users prefer hospitals with high environmental quality. On the other hand, for users who need quick prescriptions, a hospital with a high process quality would be appropriate. To demonstrate these scenarios, we implemented hospital recommendation APIs and geocode APIs using 3rd party web service provider. The detailed explanations of APIs are as follow. Detailed information of those APIs, including request data type and result type, is summarized in
Table 1.
Get Hospital by Geo Code: Recommends hospitals based on user location. HTML 5 Geolocation API [
25] is used to extract user’s current geocode. It provides nearby location of hospitals.
Get Hospital by SQM-H Category: Recommends hospitals based on user selected service quality category.
Get Trend of Hospital SQM-H: Provides trend data of SQM-H for the selected hospital. Users can see overall graph of six kinds of SQM-H through client-side user interface.
Get Route: Provides driving route and distance from user’s current location to hospital.
In our prototype implementation, we divided required functions into three main parts: client, API server, and back-end server. The client contains User Interface (UI) in HTML, Cascading Style Sheets (CSS) and communication and event handling functions in JavaScript. We tested on various devices with modern browsers such as mobile phone, notebook, desktop, and Smart TV. Since HTML 5 Geolocation API is available in almost all browsers, we can easily get location information of client. The API server providing multiple REST APIs is based on Node JS [
26] and Express [
27] web application framework. It has two main roles: (i) to provide static files required to render UI on the devices; and (ii) receives client requests on behalf of back-end server. The back-end server is our situation-aware knowledge supporting framework which aggregates data, performs text-mining, and SQM-H based analysis. Those three players (i.e., client, API Server, and back-end server) communicate by Wi-Fi and cellular connection upon TCP/IP protocols.
More specifically, users can see SQM-H trends for the selected hospital in the form of graph through client-side user interface as line graph in
Figure 5. The user interface interconnects with context-ware knowledge supporting framework through Open APIs. With buttons on the user interface, users can browse overall SQM-H trends and detailed changes of selected SQM-H categories, such as impression, service, process, etc. For example, in 2011, the popularity was the strongest category among others.
5. Discussion
Even though not thoroughly tested in terms of user satisfaction, decision and performance, several lessons learned could be derived from our prototype implementation.
Our proposed approach supports the situation-aware recommendation services with a service quality model (i.e., SQM-H) based on the obtained healthcare-related collective intelligence. The model is particularly feasible for health-information seeking users since the reasoning capability combined with the service quality model actively responds to frequently asked hospital related questions. Additionally, the service quality analysis component, which is followed by data aggregation and text mining components, practically deals with the lack of domain-specific knowledge, which is already known as a bottleneck of existing situation-aware systems.
With the help of high-speed Internet connection in Korea and lightweight server modules, users do not feel disturbing delays in viewing visualized analysis results when browsing the prototype application. However, at present, our prototype implementation has no options to communicate with neighborhoods or friend who have same healthcare related interests due to some privacy and security issues. If the problems are resolved, our open APIs can be used by existing mobile messenger applications, such as KakaoTalk of KAKAO Inc. (Jeju City, Korea) and WhatApp of WhatApp Inc. (Menlo Park, CA, USA) By understanding user-written short query, our APIs will be called interactively to share other users’ experiential knowledge regardless of knowing each other previously and to get inferred analysis based on the knowledge.
In terms of the accuracy of text-mining component, there is much room for enhancements. It should be noted that the context of an Internet forum is disorganized and the language used tends to follow the idiosyncratic nature of human beings rather than grammatical standards and rules. We are upgrading of the text-mining component with more robust anaphora resolution of hospital names and user intention type classification by considering textual relationship between service quality expressions that influence people’s choice of hospitals.
Aside from the accuracy of the text-mining component, fabricated messages on online health communities is another bottleneck in constructing robust ground truth data for hospital service quality measurements. It may cause a great deal of confusion about the reputations of hospitals. It is already a known fact that some persons concerned with hospitals pay online writers to fabricate messages which talks about reputations of specific hospitals or they sometimes request to delete messages that harshly criticize their hospitals. There are few good ways to avoid the intended fabrications except ignoring messages of potentially disguising participants because our proposed SQM-H model is highly depending on users’ participations.
6. Concluding Remarks
With the spread of IoT devices and the development of network technology, people’s lifestyle and environment have changed. The acquisition of context-aware information from amounts of data has become an important factor in adapting to rapidly changing environments. In addition, distributing trustworthy information through sustainable knowledge management could enhance decision support.
We proposed a text-mining based situation-awareness supporting framework which can be applicable to domain-specific recommendation services. To check the workability and feasibility of the proposed framework, we selected health domain, especially service quality of hospitals as our application domain. In addition, SQM-H is designed for knowledge storage, discovery, and analysis. The SQM-H based text-mining component and service quality analysis component play key roles in extracting and analyzing service-specific knowledge. Moreover, our prototype implementation shows new potentials when applied to healthcare domain in terms of supporting decision-making.
Have you turned on a computer or smart phone and asked for a good hospital nearby? Give it a shot and see which hospitals are recommended by other users according to your medical problems. Perhaps you are choosing between more than two different hospitals; in this situation, our proposed framework can provide invaluable information and meaningful clues for users’ decision-making. Good hospitals are not always popular on social media, but the recommended hospitals are more likely to provide better care and facilities, and have better qualified doctors.
Our future work will cover diverse user inputs/requirements through designing new intuitive user interface and to improve the accuracy of the text-mining component. We believe that the proposed situation-awareness supporting framework can be employed to other service domains such as product recommendation, tourist recommendation and restaurant recommendation if appropriate service quality model is redesigned. It could provide a foundation for individuals to easily acquire information appropriate to their situation in the information explosion in the Big Data era. As a result, we expect to improve knowledge availability and the availability of infrastructure and improve people’s sustainable quality of life.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}