Incorporating Power Transmission Bottlenecks into Aggregated Energy System Models


Abstract
:1. Introduction
1.1. Motivation
1.2. Objective
- The approach must enable the identification of transmission links that show frequent congestions in operation.
- Real-world electricity transmission grids are networks that cover large geographical scales and consist of several thousands of nodes. To manage the appropriate amount of data, an automatized process is preferable.
- A reproducible method is required that is adjustable to changes in generation and consumption patterns. This becomes important to identify intra-regional bottlenecks over a long-term time horizon by myopically adjusting the spatial aggregation.
- It can be assumed that with an increasing number of modeled regions, the accuracy of an ESM can be improved and that there is probably an optimal spatial resolution regarding the trade-off between computing time and model accuracy. However, for our study, the spatial resolution should remain on a level that is comparable to the state of the art [15,16,17], which allows the comparison to typical ESM resolutions.
- To still be able to derive results for regions of interest, e.g., administrative regions, the definition of static overlay-borders should be possible (even if the spatial aggregation is myopically adjusted).
- Aggregation methods that are able to simplify the whole network representation of the model instead of focusing on specific areas are preferred.
1.3. Literature Review: Spatial Aggregation
1.3.1. Network Partitioning
1.3.2. Network Equivalents
2. Materials and Methods
2.1. Overview
- Setup of a reference model: This ESM is parameterized and used for conducting an optimal power flow. Its spatial resolution corresponds to the topology of the power transmission grid and thus represents the original network used for the subsequent spatial aggregation.
- Network partitioning: This step contains the analysis of the operational data, using the differences in nodal marginal costs for the total power supply (in the following, referred to as nodal price differences) as indicators for the connectivity of regions in the original network as proposed in [24]. In other words, the weaker the connectivity of two regions (indicated by the magnitude of nodal price differences) is, the more likely it is that these regions belong to different clusters. The novelty of the presented approach is the application of this particular attribute to a spectral clustering algorithm which can be executed automatically. In contrast to approaches that use spectral clustering for ESMs [32], the topological information of the original network given by its incidence matrix is extended by the operational data. Furthermore, compared to existing studies that use this data in form of nodal prices [25], the purpose of evaluating their differences is rather the determination of relevant congestions in the transmission network than the identification of price zones.
- Network equivalent: After getting the results from the clustering algorithm, the spatial data of the reference model are aggregated. Therefore, we use the simple approach of creating aggregated areas (in the following, referred to as clusters or zones), which means that power generation capacities and power consumption profiles are summed over all regions within a cluster as well as grid transfer capacities of links that connect regions belonging to different clusters. In a further step, network equivalencing introduced by [26] is applied for assessing the accuracy of the aggregated ESM instances.
2.2. Model Setup
2.3. Data Pre-Processing
2.3.1. Disaggregation of Cross-Border Flows
2.3.2. Assignment of Power Generation and Consumption to Network Nodes
2.3.3. Disaggregation of National Scenario Data
- Central power plants with less total installed capacity compared to the validation dataset: Based on the commissioning year, the sites of the oldest power plants are decommissioned as long as the total installed capacity reaches the same order of magnitude as in the given scenario data.
- Central and biomass power plants with more installed capacity compared to the validation dataset: The installed capacity of existing power plants is equally scaled until the total installed capacity of the scenario data is reached.
- Photovoltaic and onshore wind farms: One-half of the installed capacity of the scenario data is distributed equally to the spatial distribution of the validation dataset. The other half is distributed equally to a technologically specific distribution of capacity factors that are derived from a potential analysis [39].
- Offshore wind farms and pumped storage: Sites of planned power plants [47] are added to the validation dataset.
2.4. Clustering
- : hour of the year for which the maximum of the sum of the generated power from wind onshore and the load can be observed; this point in time can be identified by purely analyzing the input time series of the reference model.
- : hour of the year for which the maximum of the nodal price differences can be observed.
- : hour of the year for which the maximum of the relative grid transfer capacity usage can be observed.
2.5. Derivation of Spatially Aggregated Energy System Models
3. Results and Discussion
3.1. Validation of the Reference Model
- The strategic behavior of market actors, which is not captured by modeling the fundamental interdependencies of the electricity market.
- Assuming static costs for fuels and emission allowances as well as the classification of power plants by fuel type also results in equalizing specific production costs of large power generation units and, thus, a smaller diversity of marginal costs.
- The chosen economic dispatch model overestimates the flexibility capabilities of certain power plants, e.g., must-run capacities, such as combined heat and power plants.
3.2. Clustering of Regions
3.2.1. Preservation of Critical Transmission Links
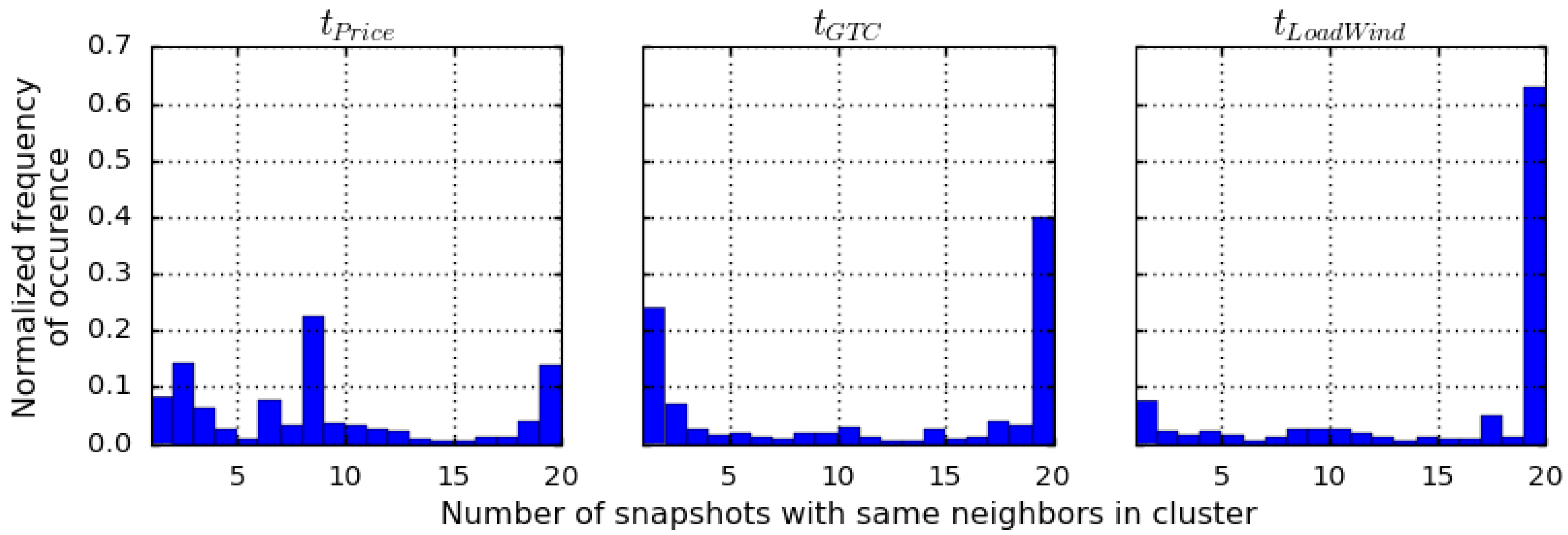
3.2.2. Stability of Aggregated Regions over Selected Critical States
3.3. Comparison of Aggregated Models
3.3.1. Redispatch
3.3.2. Capacity Factors
3.4. Case Study
3.5. Comment on Computing Times
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| CCGT | Combined Cycle Gas Turbines |
| ENTSO-E | European Network of Transmission System Operators for Electricity |
| ESMs | Energy system models |
| HVDC | High-Voltage Direct Current |
| NUTS | Nomenclature des unités territoriales statistiques |
| PTDF | Power Transfer Distribution Factors |
| REI | Radial Equivalent Independent |
| SP | Spatially differentiated |
| TC | Technologically differentiated |
| TM | Temporally differentiated |
| vRES | variable renewable energy sources |
| Symbols | |
| Grid transfer capacity of a link in the original network | |
| Grid transfer capacity of a link in the aggregated network | |
| Incidence matrix | |
| k | Number of clusters |
| Unnormalized Laplacian matrix of the original network | |
| Set of links in the original network (transmission lines in an ESM) | |
| Set of links in the aggregated network | |
| Element of the links set in the original network | |
| Element of the links set in the aggregated network | |
| Set of nodes in the original network (modeled regions of an ESM) | |
| Subset of containing only active nodes (nodes with power generation or consumption) | |
| Subset of containing the three closest substations to the geographical center of a NUTS3 region | |
| Set of nodes in the aggregated network | |
| Set of NUTS3 regions considered in the reference model | |
| Element of the nodes set in the original network | |
| Element of the subset | |
| Element of the subset | |
| Element of the set of NUTS3 regions considered in the reference model | |
| Element of the nodes set in the aggregated network | |
| Installed power generation capacity in the original network | |
| Installed power generation capacity in the aggregated network | |
| T | Set of hourly time steps |
| t | Element of the set of hourly time steps |
| Selected time step within the set of time steps where a high utilization of transmission lines can be detected in the reference model | |
| Selected time step within the set of time steps where a high magnitude of power demand and power feed-in from wind turbines can be observed in the input data | |
| Selected time step within the set of time steps where high nodal price differences can be observed in the solution of the reference model | |
| Nodal price difference | |
| Number of nearest neighbors to be used | |
| Mapping matrix between links of the original and the aggregated network | |
| Mapping matrix between nodes of the original and the aggregated network | |
| Nodal marginal system costs for total power supply (nodal prices) | |
| Diagonal matrix of nodal price differences | |
| Set of technologies | |
| Subset of containing decentral power generation technologies | |
| Element of the set of technologies | |
| Element of the subset | |
Appendix A. Essential Equations of REMix for Performing a DC Optimal Power Flow
Appendix A.1. Objective Function
- : Element of the set of all considered technologies.
- Element of the set of years (either set to y = 2012 for the validation data set or y = 2030 for the scenario data set).
- Element of the subset of link dependent technologies
- Element of the subset of node dependent technologies
- : Element of the set of links
- Scaling factor for sub-annual analyses
Appendix A.2. Essential Constraints
- Element of the subset of power generation technologies
- Element of the subset of storage technologies
- Element of the subset of power transmission technologies
- Element of the subset of transmission technologies realized as AC grids
- : Nodal susceptance matrix of the considered AC transmission network
- Voltage angle at node n in time step t and year y
- Transposed incidence matrix of the considered AC transmission network
- Diagonal matrix of the link susceptances of the considered AC transmission network
- Losses factor
- : Length of the link l
Appendix B. Assignment of Power Generation and Consumption

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Parameter | Approach |
|---|---|
Installed capacity of central power plants:
| Nearest neighbor |
Installed capacity of decentral power plants:
| 3-nearest neighbor |
| Annual electricity demand | 3-nearest neighbor |
Appendix C. Estimation of the Transmission Capacities from Thermal Limits
- : nominated voltage of a transmission system
- thermal limit for 243-A1/39-St1A conductors
- number of conductors per line
- number of circuits per trace
- (n-1) security margin
Appendix D. Determination of Snapshots
- 0.95-quantile
- Spatially aggregated time series of power generation by wind turbines and power consumption
- Time series of power generation of wind turbines in each region n
- Time series of power consumption in each region n
- 0.05-quantile
- Spatially aggregated time series of relative power flows
- Time series of relative power flows over each transmission line l
Appendix E. Calculation of Annual Redispatch for the Reference Model
Appendix F. Clustering Maps


Appendix G. Concurrency of Redispatch Measures

- As it could be expected, in case of the copper plate model no curtailment can be observed since no power transmission limits are considered in this aggregated ESM instance.
- The reference model (black curve) shows the highest magnitudes while the aggregated ESM instances (colored curves) underestimate these effects. However, the ESM instances determined with the spectral clustering of nodal price differences (blue curves) are closer to the reference than it is the case for the aggregated benchmark models (red curves). This corresponds to the findings deduced from Figure 7.
- The frequency of the occurrence of non-zero values in Figure A2 gives an indication for the points in time when redispatch takes place. If the colored curves show this behavior, the black curve indicates non-zero values as well. On other words, the aggregated models are able to detect curtailment or redispatch events like the reference model. This is more often the case for the blue curves than for the red ones (e.g., in hour 8132). We therefore conclude once again, that Clustered , Clustered , and Clustered perform better than the benchmark cases. However, it must be noted that they are not able to capture all relevant curtailment events of the reference model (e.g., between hours 8408 and 8456).
Appendix H. Expansion Planning in the Case Study
- Specific investment costs for AC grid expansion
- Annuity factor
| Technology | Specific Investment Costs | Life Time (Years) |
|---|---|---|
| Lithium-ion batteries | 225 €/kWh | 22 |
| GTCAC | 346 €/(km∙MW) | 40 |
| GTCDC | 544 €/(km∙MW) | 40 |
| Converter station DC | 102,000 €/MW | 20 |
References
- Paltsev, S. Energy scenarios: The value and limits of scenario analysis. Wiley Interdiscip. Rev. Energy Environ. 2017, 6. [Google Scholar] [CrossRef]
- Grunwald, A. Energy futures: Diversity and the need for assessment. Futures 2011, 43, 820–830. [Google Scholar] [CrossRef]
- Herbst, A.; Toro, F.; Reitze, F.; Jochem, E. Introduction to energy systems modelling. Swiss J. Econ. Stat. 2012, 148, 111–135. [Google Scholar] [CrossRef]
- Connolly, D.; Lund, H.; Mathiesen, B.V.; Leahy, M. A review of computer tools for analysing the integration of renewable energy into various energy systems. Appl. Energy 2010, 87, 1059–1082. [Google Scholar] [CrossRef]
- Schlachtberger, D.P.; Brown, T.; Schramm, S.; Greiner, M. The benefits of cooperation in a highly renewable European electricity network. Energy 2017, 134, 469–481. [Google Scholar] [CrossRef] [Green Version]
- Gils, H.C.; Scholz, Y.; Pregger, T.; de Tena, D.L.; Heide, D. Integrated modelling of variable renewable energy-based power supply in Europe. Energy 2017, 123, 173–188. [Google Scholar] [CrossRef]
- Pfenninger, S.; Hawkes, A.; Keirstead, J. Energy systems modeling for twenty-first century energy challenges. Renew. Sustain. Energy Rev. 2014, 33, 74–86. [Google Scholar] [CrossRef]
- Kondziella, H.; Bruckner, T. Flexibility requirements of renewable energy based electricity systems—A review of research results and methodologies. Renew. Sustain. Energy Rev. 2016, 53, 10–22. [Google Scholar] [CrossRef]
- Krishnan, V.; Ho, J.; Hobbs, B.F.; Liu, A.L.; McCalley, J.D.; Shahidehpour, M.; Zheng, Q.P. Co-optimization of electricity transmission and generation resources for planning and policy analysis: Review of concepts and modeling approaches. Energy Syst. 2015. [Google Scholar] [CrossRef]
- Haas, J.; Cebulla, F.; Cao, K.; Nowak, W.; Palma-Behnke, R.; Rahmann, C.; Mancarella, P. Challenges and trends of energy storage expansion planning for flexibility provision in low-carbon power systems—A review. Renew. Sustain. Energy Rev. 2017, 80, 603–619. [Google Scholar] [CrossRef]
- Schmid, E.; Knopf, B. Quantifying the long-term economic benefits of European electricity system integration. Energy Policy 2015, 87, 260–269. [Google Scholar] [CrossRef] [Green Version]
- Spiecker, S.; Weber, C. The future of the European electricity system and the impact of fluctuating renewable energy—A scenario analysis. Energy Policy 2014, 65, 185–197. [Google Scholar] [CrossRef]
- Lumbreras, S.; Ramos, A. The new challenges to transmission expansion planning. Survey of recent practice and literature review. Electr. Power Syst. Res. 2016, 134, 19–29. [Google Scholar] [CrossRef]
- Wang, S.J.; Shahidehpour, S.M.; Kirschen, D.S.; Mokhtari, S.; Irisarri, G.D. Short-term generation scheduling with transmission and environmental constraints using an augmented Lagrangian relaxation. IEEE Trans. Power Syst. 1995, 10, 1294–1301. [Google Scholar] [CrossRef] [Green Version]
- Zerrahn, A.; Schill, W.-P. Long-run power storage requirements for high shares of renewables: Review and a new model. Renew. Sustain. Energy Rev. 2017, 79, 1518–1534. [Google Scholar] [CrossRef]
- Göransson, L.; Johnsson, F. Cost-optimized allocation of wind power investments: A Nordic-German perspective. Wind Energy 2012, 16, 587–604. [Google Scholar] [CrossRef]
- Bucksteeg, M.; Trepper, K.; Weber, C. Impacts of renewables generation and demand patterns on net transfer capacity: Implications for effectiveness of market splitting in Germany. IET Gener. Transm. Distrib. 2015, 9, 1510–1518. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Moeller, C.; Meiss, J.; Mueller, B.; Hlusiak, M.; Breyer, C.; Kastner, M.; Twele, J. Transforming the electricity generation of the Berlin–Brandenburg region, Germany. Renew. Energy 2014, 72, 39–50. [Google Scholar] [CrossRef]
- Kurzidem, M.J. Analysis of Flow-Based Market Coupling in Oligopolistic Power Markets; ETH Zurich: Zürich, Switzerland, 2010. [Google Scholar]
- Anderski, T.; Surmann, Y.; Stemmer, S.; Grisey, N.; Momo, E.; Leger, A.-C.; Betraoui, B.; Roy, P.V. Modular Development Plan of the Pan-European Transmission System 2050—European Cluster Model of the Pan-European Transmission Grid; e-Highway2050: Brussels, Belgium, 2014. [Google Scholar]
- German Transmission System Operators. Übersicht über die Voraussichtliche Entwicklung der Installierten Kraftwerksleistung und der Leistungsflüsse in den Netzgebieten der Deutschen Übertragungsnetzbetreiber (Regionenmodell Stromtransport 2013); EnBW Transportnetze AG: Karlsruhe, Germany; RWE Transportnetz Strom GmbH: Dortmund, Deutschland; Transpower Stromübertragungs GmbH: Bayreuth, Deutschland; Vattenfall Europe Transmission GmbH: Berlin, Germany, 2013. [Google Scholar]
- Shayesteh, E.; Hamon, C.; Amelin, M.; Söder, L. REI method for multi-area modeling of power systems. Int. J. Electr. Power Energy Syst. 2014, 60, 283–292. [Google Scholar] [CrossRef]
- Lumbreras, S.; Banez-Chicharro, F.; Pache, C. Modular Development Plan of the Pan-European Transmission System 2050—Enhanced Methodology to Define Optimal Grid Architectures for 2050; e-Highway2050: Brussels, Belgium, 2015. [Google Scholar]
- Singh, H.K.; Srivastava, S.C. A reduced network representation suitable for fast nodal price calculations in electricity markets. In Proceedings of the IEEE Power Engineering Society General Meeting, San Francisco, CA, USA, 16 June 2005. [Google Scholar]
- Shi, D.; Tylavsky, D.J. A Novel Bus-Aggregation-Based Structure-Preserving Power System Equivalent. IEEE Trans. Power Syst. 2015, 30, 1977–1986. [Google Scholar] [CrossRef]
- Gang, L.; Dongyuan, S.; Jinfu, C.; Xianzhong, D. Automatic identification of transmission sections based on complex network theory. IET Gener. Transm. Distrib. 2014, 8, 1203–1210. [Google Scholar] [CrossRef]
- Papaemmanouil, A.; Andersson, G. On the reduction of large power system models for power market simulations. In Proceedings of the 17th Power Systems Computation Conference (PSCC), Stockholm, Sweden, 22–26 August 2011; pp. 1308–1313. [Google Scholar]
- Akhavein, A.; Firuzabad, M.F.; Billinton, R.; Farokhzad, D. Review of reduction techniques in the determination of composite system adequacy equivalents. Electr. Power Syst. Res. 2010, 80, 1385–1393. [Google Scholar] [CrossRef]
- Dorfler, F.; Bullo, F. Kron Reduction of Graphs with Applications to Electrical Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2013, 60, 150–163. [Google Scholar] [CrossRef]
- Cheng, X.; Overbye, T.J. PTDF-based power system equivalents. IEEE Trans. Power Syst. 2005, 20, 1868–1876. [Google Scholar] [CrossRef]
- Hamon, C.; Shayesteh, E.; Amelin, M.; Söder, L. Two partitioning methods for multi-area studies in large power systems. Int. Trans. Electr. Energy Syst. 2015, 25, 648–660. [Google Scholar] [CrossRef]
- Wiegmans, B. GridKit Extract of ENTSO-E Interactive Map; Zenodo: Oldenburg, Germany, 2016. [Google Scholar] [CrossRef]
- Scholz, Y.; Gils, H.C.; Pietzcker, R.C. Application of a high-detail energy system model to derive power sector characteristics at high wind and solar shares. Energy Econ. 2017, 64, 568–582. [Google Scholar] [CrossRef]
- Gils, H.C.; Simon, S. Carbon neutral archipelago—100% renewable energy supply for the Canary Islands. Appl. Energy 2017, 188, 342–355. [Google Scholar] [CrossRef]
- Gils, H.; Simon, S.; Soria, R. 100% Renewable Energy Supply for Brazil—The Role of Sector Coupling and Regional Development. Energies 2017, 10, 1859. [Google Scholar] [CrossRef]
- Gils, H.C.; Bothor, S.; Genoese, M.; Cao, K.-K. Future security of power supply in Germany—The role of stochastic power plant outages and intermittent generation. Int. J. Energy Res. 2018. accepted for publication. [Google Scholar] [CrossRef]
- Cebulla, F.; Naegler, T.; Pohl, M. Electrical energy storage in highly renewable European energy systems: Capacity requirements, spatial distribution, and storage dispatch. J. Energy Storage 2017, 14, 211–223. [Google Scholar] [CrossRef]
- Scholz, Y. Renewable Energy Based Electricity Supply at Low Costs: Development of the REMix Model and Application for Europe. Ph.D. Thesis, Universität Stuttgart, Stuttgart, Germany, 2012. [Google Scholar]
- Rippel, K.M.; Preuß, A.; Meinecke, M.; König, R. Netzentwicklungsplan 2030 Zahlen Daten Fakten; German Transmission System Operators: Brussels, Belgium, 2017. [Google Scholar]
- Teruel, A.G. Perspestective of the Energy Transition: Technology Development and Investments under Uncertainty; Technical University of Munich: Munich, Germany, 2015. [Google Scholar]
- Egerer, J.; Gerbaulet, C.; Ihlenburg, R.; Kunz, F.; Reinhard, B.; von Hirschhausen, C.; Weber, A.; Weibezahn, J. Electricity Sector Data for Policy-Relevant Modeling: Data Documentation and Applications to the German and European Electricity Markets; Data Documentation; DIW: Berlin, Germany, 2014. [Google Scholar]
- Open Power System Data Data Package Time Series. (Primary Data from Various Sources, for a Complete List See URL), Version 2017-07-09. Available online: https://data.open-power-system-data.org/time_series/2017-07-09 (accessed on 21 July 2017).
- Hörsch, J.; Brown, T. The role of spatial scale in joint optimisations of generation and transmission for European highly renewable scenarios. In Proceedings of the 2017 14th International Conference on the European Energy Market (EEM), Dresden, Germany, 6–9 June 2017; pp. 1–7. [Google Scholar]
- ENTSO-E Transparency Platform Cross-Border Commercial Schedule and Cross-Border Physical Flow. Available online: https://transparency.entsoe.eu/content/static_content/Static%20content/legacy%20data/legacy%20data2012.html (accessed on 29 June 2017).
- Eurostat European Commission Eurostat. NUTS—Nomenclature of Territorial Units for Statistics; European Commission: Brussels, Belgium, 2017. [Google Scholar]
- Bundesnetzagentur Kraftwerksliste zu der Genehmigung des Szenariorahmens für die Netzentwicklungspläne Strom 2017–2030; Bundesnetzagentur: Bonn, Germany, 2017.
- von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef] [Green Version]
- Metzdorf, J. Development and Implementation of a Spatial Clustering Approach Using a Transmission Grid Energy System Model. Ph.D. Thesis, University of Stuttgart, Stuttgart, Germany, 2016. [Google Scholar]
- Pape, C.; Hagemann, S.; Weber, C. Are fundamentals enough? Explaining price variations in the German day-ahead and intraday power market. Energy Econ. 2016, 54, 376–387. [Google Scholar] [CrossRef] [Green Version]
- Grote, F.; Maaz, A.; Drees, T.; Moser, A. Modeling of electricity pricing in European market simulations. In Proceedings of the 2015 12th International Conference on the European Energy Market (EEM), Lisbon, Portugal, 20–22 May 2015; pp. 1–5. [Google Scholar]
- Bundesnetzagentur. Monitoringbericht 2013; Bundesnetzagentur: Bonn, Germany, 2014. [Google Scholar]
- Zhu, J. Optimization of Power System Operation; John Wiley & Sons: Hoboken, NJ, USA, 2015; Volume 47. [Google Scholar]
- ENTSO-E. Memo 2012, Provisional Values as of 30 April 2013; ENTSO-E: Brussels, Belgium, 2013. [Google Scholar]
- Zelnik-Manor, L.; Perona, P. Self-tuning spectral clustering. In Advances in Neural Information Processing Systems; The MIT Press: Cambridge, MA, USA, 2005; pp. 1601–1608. [Google Scholar]
- Breuer, C.; Moser, A. Optimized bidding area delimitations and their impact on electricity markets and congestion management. In Proceedings of the 11th International Conference on the European Energy Market (EEM14), Kraków, Poland, 28–30 May 2014; pp. 1–5. [Google Scholar]
- Mohapatra, S.; Jang, W.; Overbye, T.J. Equivalent Line Limit Calculation for Power System Equivalent Networks. IEEE Trans. Power Syst. 2014, 29, 2338–2346. [Google Scholar] [CrossRef]
- Pfenninger, S. Dealing with multiple decades of hourly wind and PV time series in energy models: A comparison of methods to reduce time resolution and the planning implications of inter-annual variability. Appl. Energy 2017, 197, 1–13. [Google Scholar] [CrossRef]
- Cao, K.-K.; Gleixner, A.; Miltenberger, M. Methoden zur Reduktion der Rechenzeit linearer Optimierungsmodelle in der Energiewirtschaft? Eine Performance-Analyse. In Proceedings of the 14th Symposium Energieinnovation, Graz, Austria, 10–12 February 2016. [Google Scholar]
- Oeding, D.; Oswald, B.R. Elektrische Kraftwerke und Netze; Springer: Berlin, Germany, 2011; ISBN 9783642192456. [Google Scholar]










| Model Name | REMix | |||
|---|---|---|---|---|
| Author (Institution) | German Aerospace Center (DLR), Institute of Engineering Thermodynamics | |||
| Model type | Linear programing Minimization of total costs for system operation Economic dispatch Optimal direct current (DC) power flow (Appendix A) | |||
| Sectoral focus | Electricity | |||
| Geographical focus | Germany | |||
| Spatial resolution | >450 nodes (reference model) | |||
| Analyzed year (scenario) | 2012 (2030) | |||
| Temporal resolution | 8760 time steps (hourly) | |||
| Input-parameters: | TM | TC | SP | |
| Conversion efficiencies [41] | √ | |||
| Operational costs [41] | √ | |||
| Fuel prices and emission allowances [42] | √ | |||
| Electricity load profiles [43] | √ | √ | ||
| Capacities of power generation, storage and grid transfer capacities and annual electricity demand [33,40,44] | √ | √ | ||
| Renewable energy resources feed-in profiles | √ | √ | √ | |
| Import and export time series for cross-border power flows [45] | √ | √ | ||
| Evaluated output parameters for clustering | Marginal costs of total power supply | √ | ||
| (Nodal balance of total power generation and consumption) | √ | |||
| Observed | Modeled | |
|---|---|---|
| Grid Losses [TWh] [52] | 6.2 | 5.1 |
| Redispatched energy [TWh] [52] | 2.6 | 6.65 |
| Congestion events [52] | 7160 | 17,662 |
| Annual power generation share from vRES [54] | 23% | 29% |
| Model Instance | Objective Value (Total System Costs) | Total Computing Time |
|---|---|---|
| Cluster & PTDF tPrice | 100.0% | 2.8% |
| Cluster & PTDF tGTC | 99.3% | 4.8% |
| Clustered tLoadWind | 98.4% | 3.9% |
| Clustered tGTC | 98.0% | 4.4% |
| Clustered tPrice | 97.6% | 3.2% |
| Simple Aggregation | 94.8% | 4.8% |
| Classical | 93.2% | 3.8% |
| Cluster & PTDF tLoadWind | 92.6% | 4.3% |
| Copper Plate | 89.8% | 0.7% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, K.-K.; Metzdorf, J.; Birbalta, S. Incorporating Power Transmission Bottlenecks into Aggregated Energy System Models. Sustainability 2018, 10, 1916. https://doi.org/10.3390/su10061916
Cao K-K, Metzdorf J, Birbalta S. Incorporating Power Transmission Bottlenecks into Aggregated Energy System Models. Sustainability. 2018; 10(6):1916. https://doi.org/10.3390/su10061916
Chicago/Turabian StyleCao, Karl-Kiên, Johannes Metzdorf, and Sinan Birbalta. 2018. "Incorporating Power Transmission Bottlenecks into Aggregated Energy System Models" Sustainability 10, no. 6: 1916. https://doi.org/10.3390/su10061916
APA StyleCao, K. -K., Metzdorf, J., & Birbalta, S. (2018). Incorporating Power Transmission Bottlenecks into Aggregated Energy System Models. Sustainability, 10(6), 1916. https://doi.org/10.3390/su10061916