Impact of Spatial Aggregation Level of Climate Indicators on a National-Level Selection for Representative Climate Change Scenarios



Abstract
:1. Introduction
2. Methods
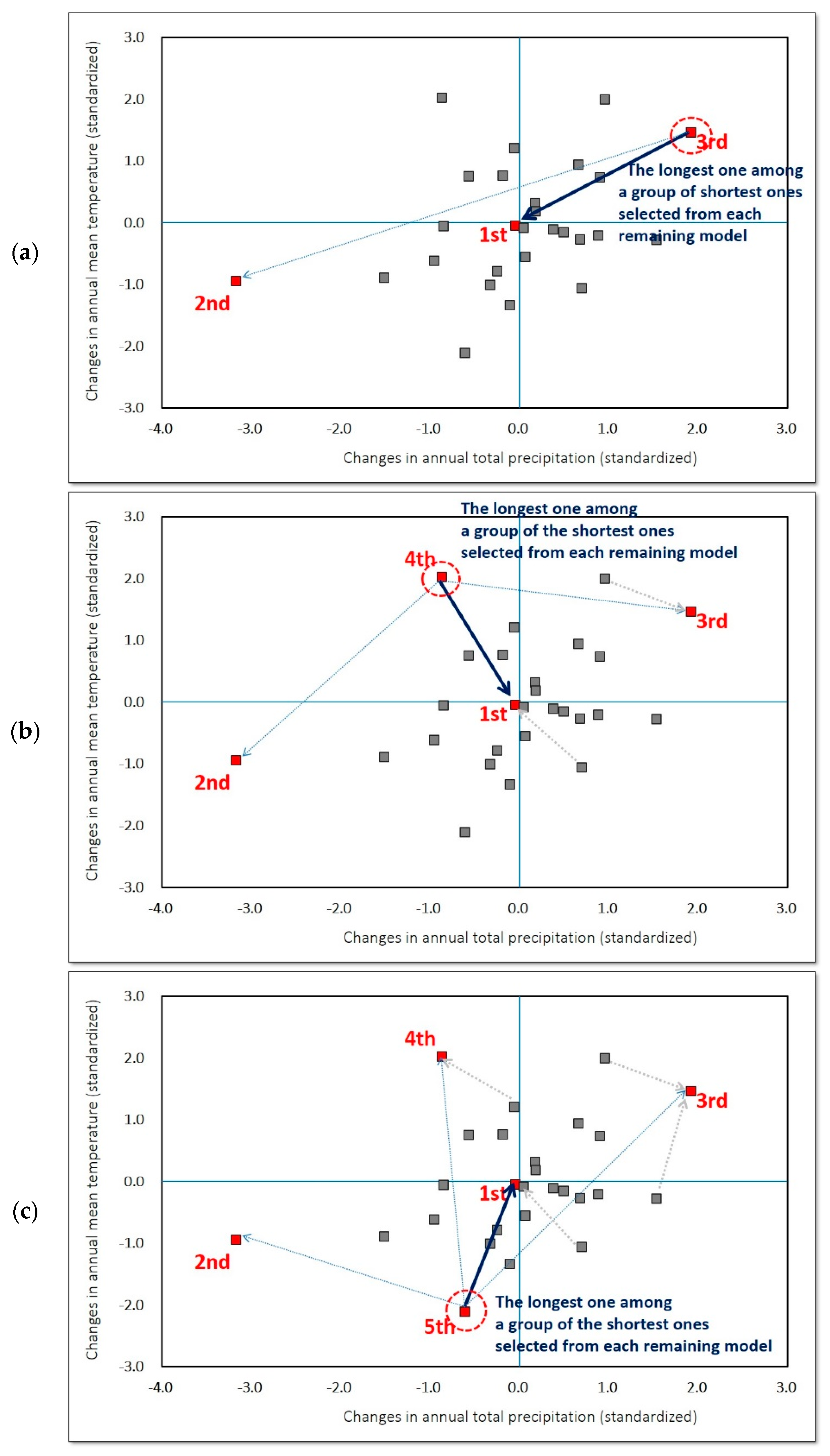
2.1. Scenario Selection: KKZ Algorithm
- (1)
- For the first GCM selection, the model that lies closest to the ensemble centroid, i.e., the GCM with the lowest sum of squared errors (SSE) to the centroid across all the climate variables is selected, as illustrated in Equation (1).where represents the value of the pth climate variable for the ith GCM, and forms the centroid value of the pth climate variable across all GCMs.
- (2)
- For the second GCM selection, the GCM that lies farthest from the first GCM is selected. The Euclidean (P-space) distance is applied to calculate the distance, d(i,j), between two GCMs (the ith and jth GCMs).
- (3)
- For the selection of the following GCMs (from the 3rd till the last selection),
- (i)
- the distances from each remaining GCM to the previously selected GCMs are calculated (“each remaining GCM” becomes from the 3rd till the last selection sequentially);
- (ii)
- only the lowest distance among those calculated in step 3(i) for each remaining GCM is retained;
- (iii)
- the GCM with the maximum distance among those determined in step 3(ii) is selected as the next GCM.
- (4)
- Step 3 is repeated until all GCMs have been placed in order.
2.2. Climate Indices
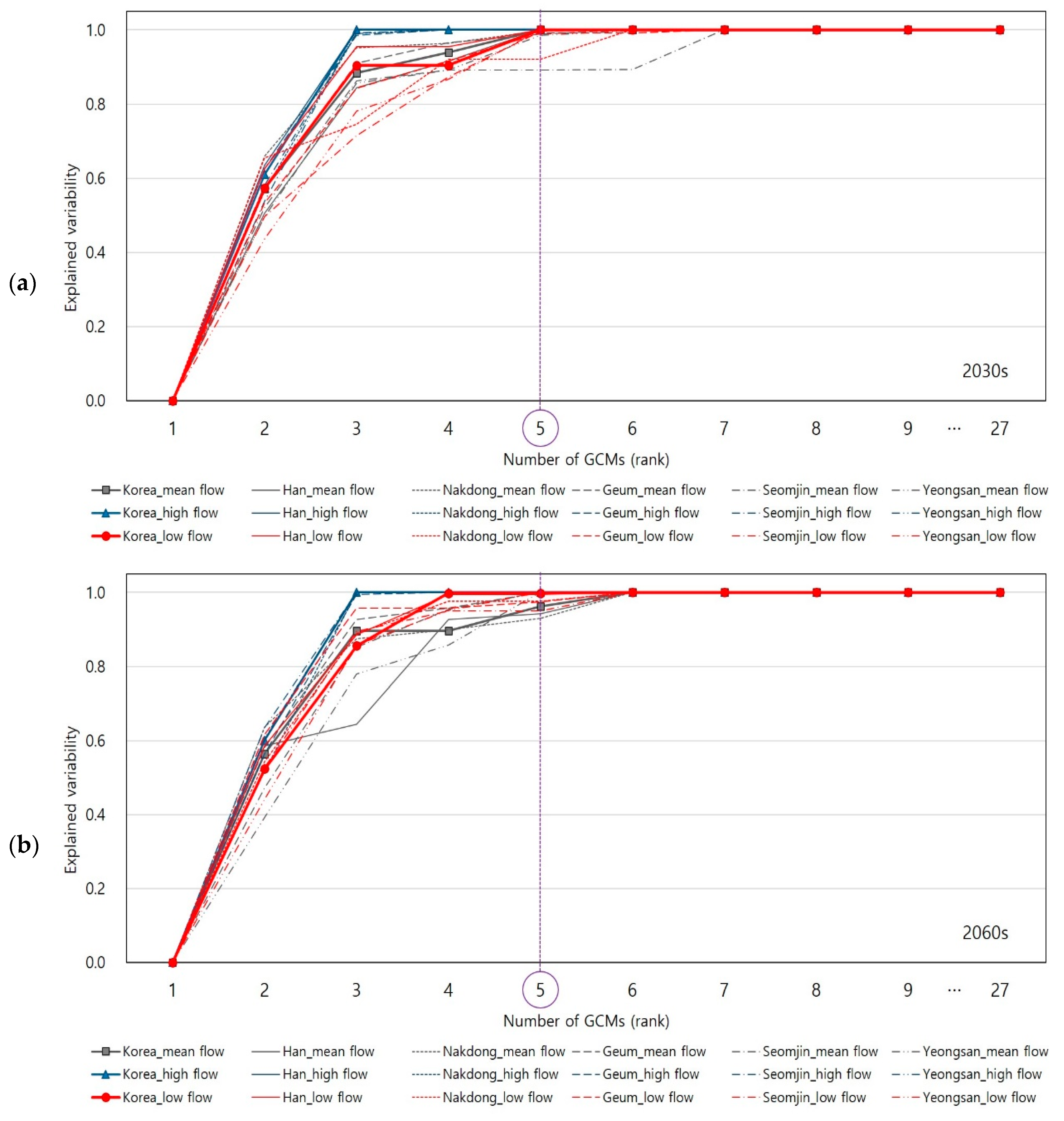
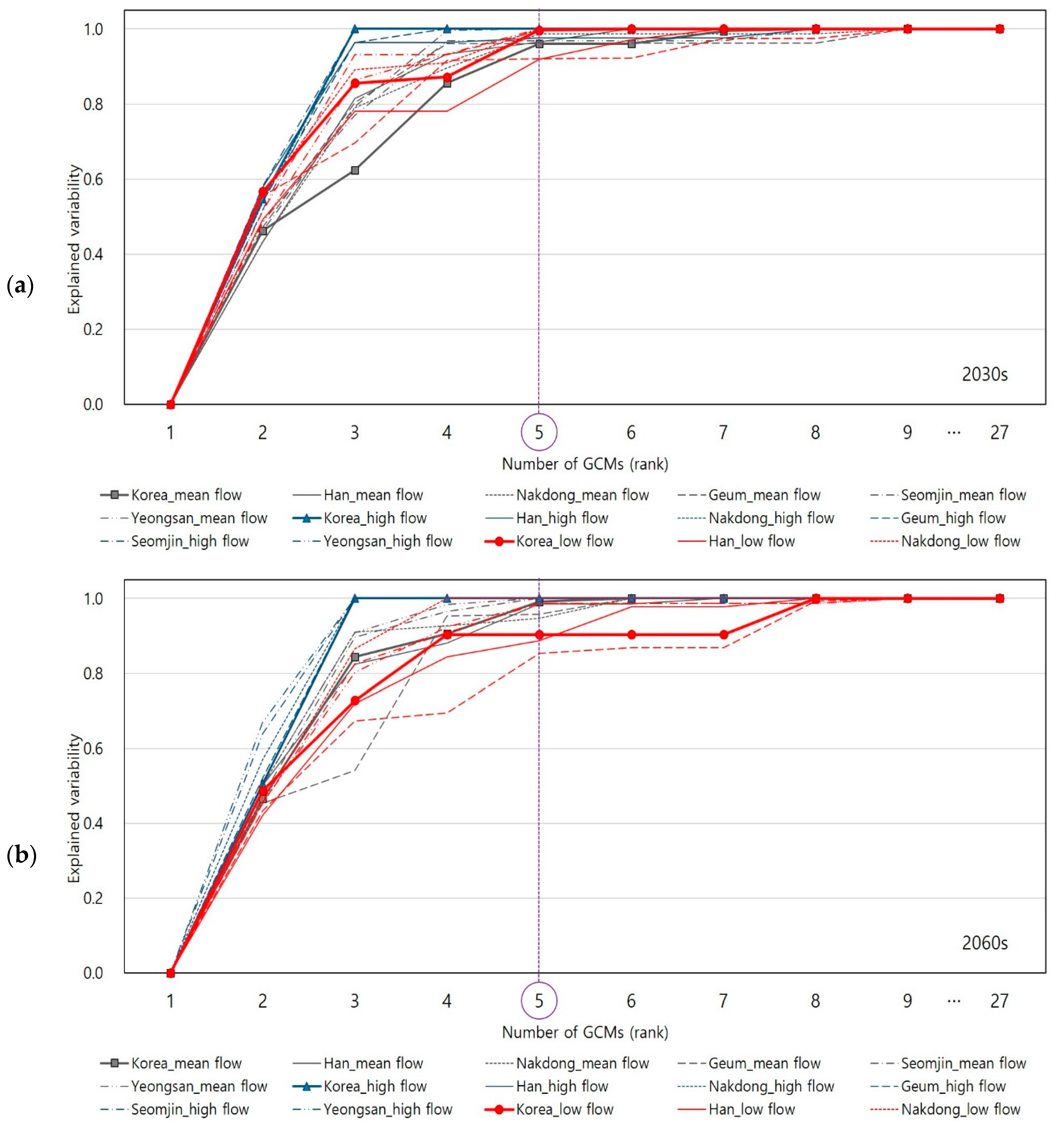
2.3. Explained Variability
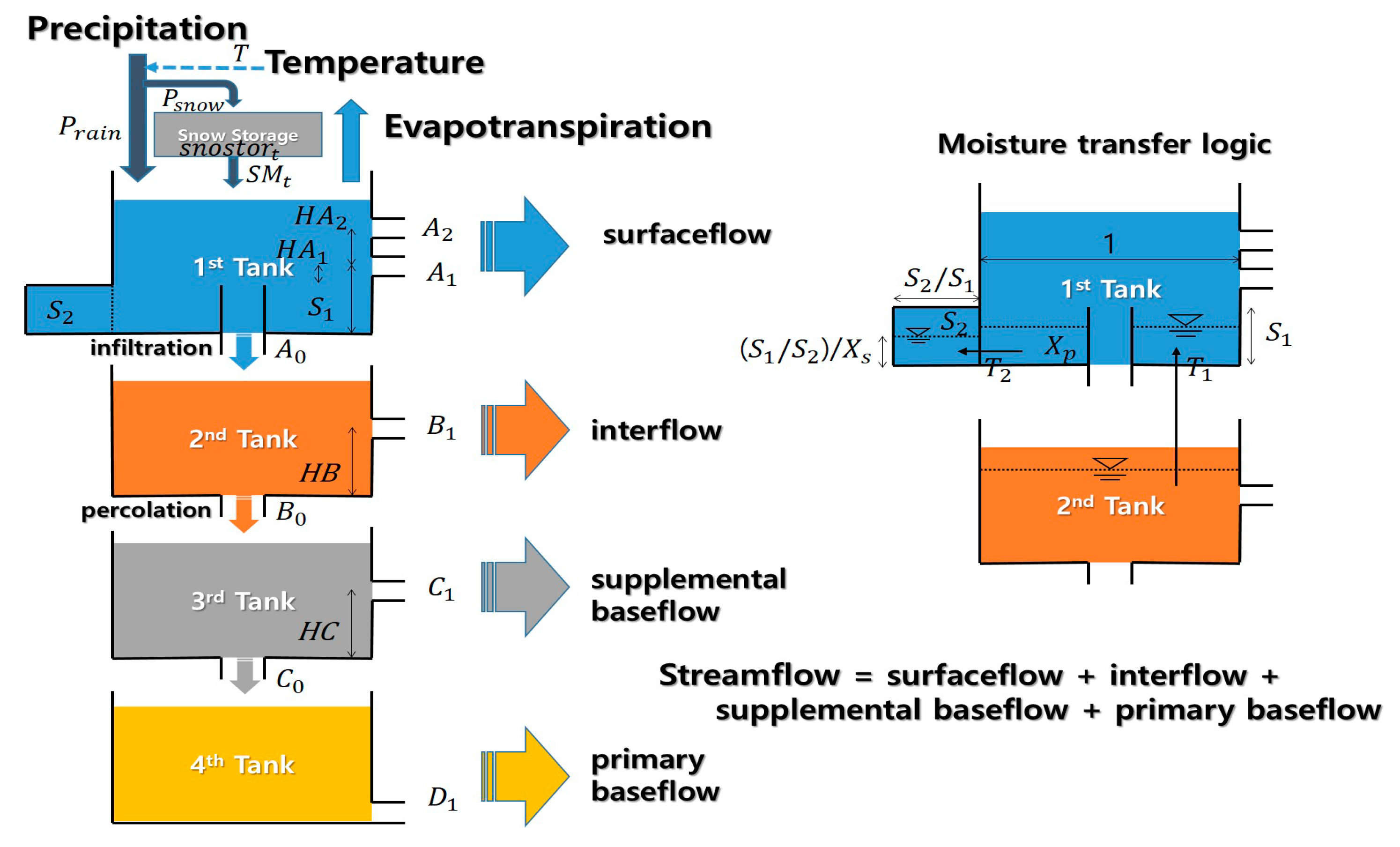
2.4. Rainfall-Runoff Model: Tank Model
3. Application
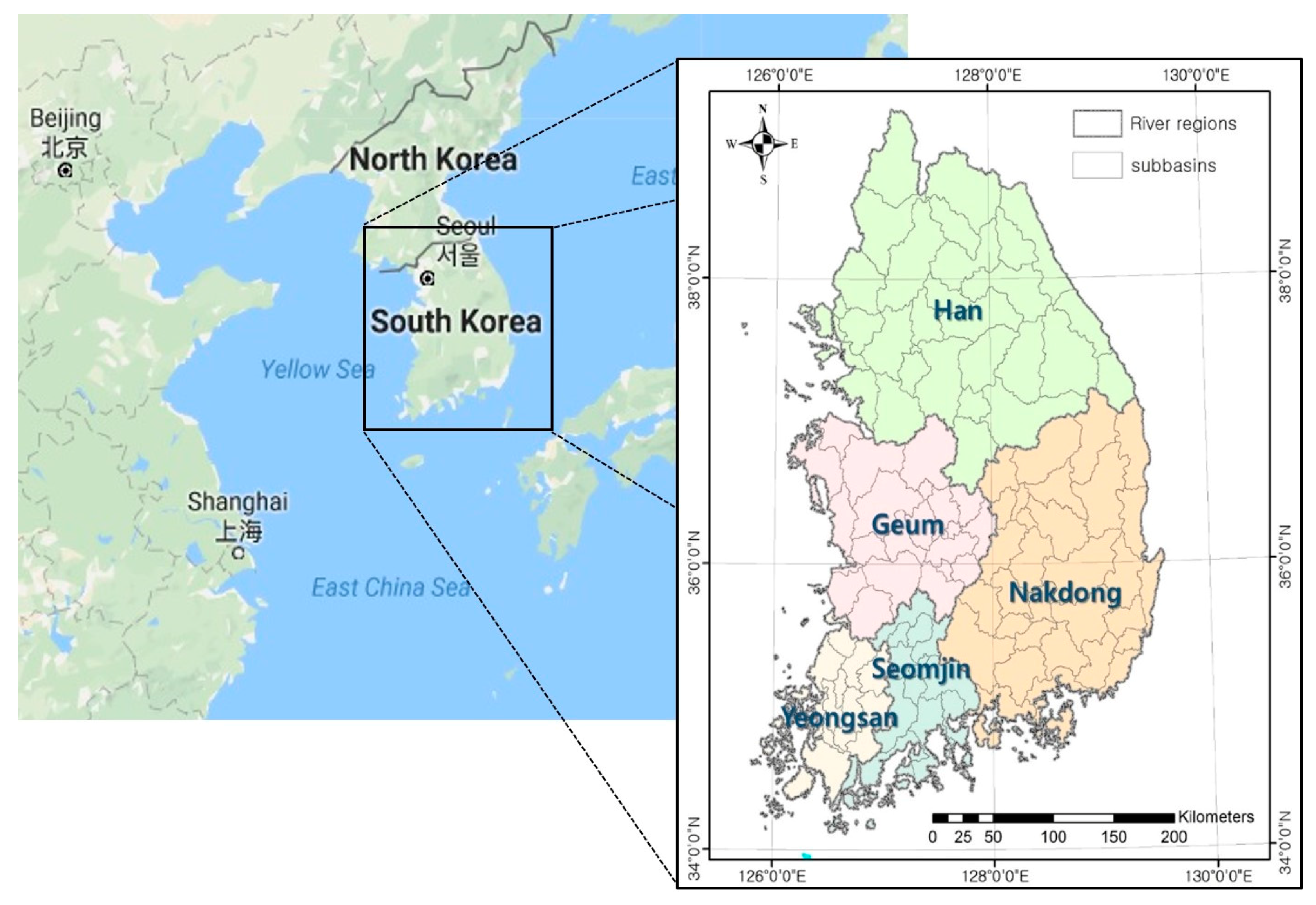
3.1. Study Area: South Korea
3.2. Data Sets
3.2.1. Observed Meteorological Data Sets
3.2.2. GCM Data Sets
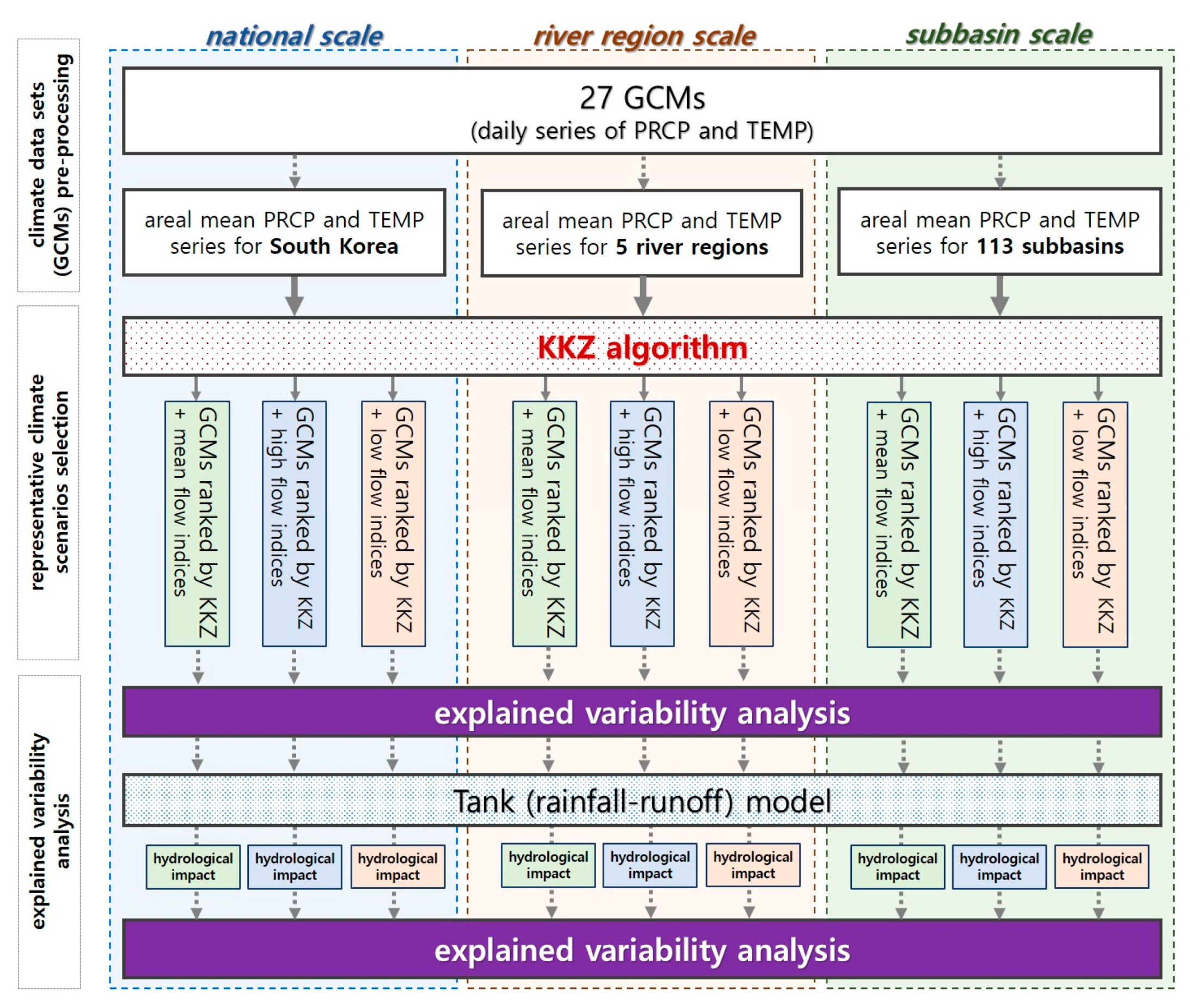
3.3. Modelling Framework
4. Results
4.1. Tank Model Parameter Estimation
4.2. Selection of Representative Scenarios
4.3. Explained Variability on Climate Indices
4.4. Explained Variability on Hydrologic Variables
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Seo, S.B.; Kim, Y.-O.; Kim, Y.; Eum, H.-I. Selecting climate change scenarios for regional hydrologic impact studies based on climate extreme indices. Clim. Dyn. 2018. [Google Scholar] [CrossRef]
- Dubrovsky, M.; Trnka, M.; Holman, I.P.; Svobodova, E.; Harrison, P.A. Developing a reduced-form ensemble of climate change scenarios for Europe and its application to selected impact indicators. Clim. Chang. 2015, 128, 169–186. [Google Scholar] [CrossRef]
- Lee, J.-K.; Kim, Y.-O. Selecting climate change scenarios reflecting uncertainties. Atmosphere 2012, 22, 149–161. [Google Scholar] [CrossRef]
- Knutti, R.; Masson, D.; Gettelman, A. Climate model genealogy: Generation CMIP5 and how we got there. Geophys. Res. Lett. 2013, 40, 1194–1199. [Google Scholar] [CrossRef] [Green Version]
- McSweeney, C.F.; Jones, R.G.; Booth, B.B.B. Selecting ensemble members to provide regional climate change information. J. Clim. 2012, 25, 7100–7121. [Google Scholar] [CrossRef]
- Masson, D.; Knutti, R. Climate model genealogy. Geophys. Res. Lett. 2011, 38, L08703. [Google Scholar] [CrossRef]
- Mendlik, T.; Gobiet, A. Selecting climate simulations for impact studies based on multivariate patterns of climate change. Clim. Chang. 2016, 135, 381–393. [Google Scholar] [CrossRef] [PubMed]
- Wilcke, R.A.I.; Bärring, L. Selecting regional climate scenarios for impact modelling studies. Environ. Model. Softw. 2016, 78, 191–201. [Google Scholar] [CrossRef]
- Mote, P.W.; Salathé, E.P. Future climate in the Pacific Northwest. Clim. Chang. 2010, 102, 29–50. [Google Scholar] [CrossRef] [Green Version]
- Rupp, D.E.; Abatzoglou, J.T.; Hegewisch, K.C.; Mote, P.W. Evaluation of CMIP5 20th century climate simulations for the Pacific Northwest USA. J. Geophys. Res. Atmos. 2013, 118, 10884–10906. [Google Scholar] [CrossRef]
- Vano, J.A.; Kim, J.B.; Rupp, D.E.; Mote, P.W. Selecting climate change scenarios using impact-relevant sensitivities. Geophys. Res. Lett. 2015, 42, 5516–5525. [Google Scholar] [CrossRef] [Green Version]
- Cannon, A.J. Selecting GCM scenarios that span the range of changes in a multimodel ensemble: Application to CMIP5 climate extremes indices. J. Clim. 2015, 28, 1260–1267. [Google Scholar] [CrossRef]
- Houle, D.; Bouffard, A.; Duchesne, L.; Logan, T.; Harvey, R. Projections of future soil temperature and water content for three southern quebec forested sites. J. Clim. 2012, 25, 7690–7701. [Google Scholar] [CrossRef]
- Katsavounidis, I.; Kuo, C.C.J.; Zhang, Z. A new initialization technique for generalized Lloyd iteration. IEEE Signal Process. Lett. 1994, 1, 144–146. [Google Scholar] [CrossRef]
- Chen, J.; Brissette, F.P.; Lucas-Picher, P. Transferability of optimally-selected climate models in the quantification of climate change impacts on hydrology. Clim. Dyn. 2016, 47, 3359–3372. [Google Scholar] [CrossRef]
- Zhang, X.; Alexander, L.; Hegerl, G.C.; Jones, P.; Tank, A.K.; Peterson, T.C.; Trewin, B.; Zwiers, F.W. Indices for monitoring changes in extremes based on daily temperature and precipitation data. WIREs Clim. Chang. 2011, 2, 851–870. [Google Scholar] [CrossRef]
- Kustu, M.D.; Fan, Y.; Robock, A. Large-scale water cycle perturbation due to irrigation pumping in the US High Plains: A synthesis of observed streamflow changes. J. Hydrol. 2010, 390, 222–244. [Google Scholar] [CrossRef]
- Wang, H.; Brill, E.D.; Ranjithan, R.S.; Sankarasubramanian, A. A framework for incorporating ecological releases in single reservoir operation. Adv. Water Resour. 2015, 78, 9–21. [Google Scholar] [CrossRef]
- Woolfenden, R.; Nishikawa, T. Simulation of Groundwater and Surface-Water Resources of the Santa Rosa Plain Watershed, Sonoma County, California; Scientific Investigations Report; US Geological Survey: Reston, VA, USA, 2014.
- Sugawara, M. Tank model. In Computer Models of Watershed Hydrology; Water Resources Publications: Littleton, CO, USA, 1995. [Google Scholar]
- Cai, J.; Liu, Y.; Lei, T.; Pereira, L.S. Estimating reference evapotranspiration with the FAO Penman–Monteith equation using daily weather forecast messages. Agric. For. Meteorol. 2007, 145, 22–35. [Google Scholar] [CrossRef]
- McCabe, G.J.; Markstrom, S.L. A Monthly Water-Balance Model Driven by a Graphical User Interface (No. 2007-1088); Geological Survey (US): Reston, VA, USA, 2007.
- Duan, Q.; Sorooshian, S.; Gupta, V. Effective and efficient global optimization for conceptual rainfall-runoff models. Water Resour. Res. 1992, 28, 1015–1031. [Google Scholar] [CrossRef]
- Thiessen, A. Precipitations averages for large areas. Mon. Weather Rev. 1911, 39, 1082–1089. [Google Scholar] [CrossRef]
- Wu, T. A mass-flux cumulus parameterization scheme for large-scale models: Description and test with observations. Clim. Dyn. 2012, 38, 725–744. [Google Scholar] [CrossRef]
- Chylek, P.; Li, J.; Dubey, M.K.; Wang, M.; Lesins, G. Observed and model simulated 20th century Arctic temperature variability: Canadian Earth System Model CanESM2. Atmos. Chem. Phys. Discuss. 2011, 11, 22893–22907. [Google Scholar] [CrossRef]
- Gent, P.R.; Danabasoglu, G.; Donner, L.J.; Holland, M.M.; Hunke, E.C.; Jayne, S.R.; Lawrence, D.M.; Neale, R.B.; Rasch, P.J.; Vertenstein, M.; et al. The Community Climate System Model Version 4. J. Clim. 2011, 24, 4973–4991. [Google Scholar] [CrossRef] [Green Version]
- Moore, J.K.; Lindsay, K.; Doney, S.C.; Long, M.C.; Misumi, K. Marine ecosystem dynamics and biogeochemical cycling in the Community Earth System Model [CESM1(BGC)]: Comparison of the 1990s with the 2090s under the RCP4.5 and RCP8.5 Scenarios. J. Clim. 2013, 26, 9291–9312. [Google Scholar] [CrossRef]
- Meehl, G.A.; Washington, W.M.; Arblaster, J.M.; Hu, A.; Teng, H.; Kay, J.E.; Gettelman, A.; Lawrence, D.M.; Sanderson, B.M.; Strand, W.G. Climate change projections in CESM1(CAM5) compared to CCSM4. J. Clim. 2013, 26, 6287–6308. [Google Scholar] [CrossRef]
- Scoccimarro, E.; Gualdi, S.; Bellucci, A.; Sanna, A.; Giuseppe Fogli, P.; Manzini, E.; Vichi, M.; Oddo, P.; Navarra, A. Effects of tropical cyclones on ocean heat transport in a high-resolution coupled general circulation model. J. Clim. 2011, 24, 4368–4384. [Google Scholar] [CrossRef]
- Davini, P.; Cagnazzo, C.; Fogli, P.G.; Manzini, E.; Gualdi, S.; Navarra, A. European blocking and Atlantic jet stream variability in the NCEP/NCAR reanalysis and the CMCC-CMS climate model. Clim. Dyn. 2014, 43, 71–85. [Google Scholar] [CrossRef]
- Voldoire, A.; Sanchez-Gomez, E.; Salas y Mélia, D.; Decharme, B.; Cassou, C.; Sénési, S.; Valcke, S.; Beau, I.; Alias, A.; Chevallier, M.; et al. The CNRM-CM5.1 global climate model: Description and basic evaluation. Clim. Dyn. 2013, 40, 2091–2121. [Google Scholar] [CrossRef] [Green Version]
- Bao, Q.; Lin, P.; Zhou, T.; Liu, Y.; Yu, Y.; Wu, G.; He, B.; He, J.; Li, L.; Li, J.; et al. The Flexible Global Ocean-Atmosphere-Land system model, Spectral Version 2: FGOALS-s2. Adv. Atmos. Sci. 2013, 30, 561–576. [Google Scholar] [CrossRef]
- Dunne, J.P.; John, J.G.; Adcroft, A.J.; Griffies, S.M.; Hallberg, R.W.; Shevliakova, E.; Stouffer, R.J.; Cooke, W.; Dunne, K.A.; Harrison, M.J.; et al. GFDL’s ESM2 Global Coupled Climate–Carbon Earth System Models. Part I: Physical formulation and baseline simulation characteristics. J. Clim. 2012, 25, 6646–6665. [Google Scholar] [CrossRef]
- Schmidt, G.A.; Kelley, M.; Nazarenko, L.; Ruedy, R.; Russell, G.L.; Aleinov, I.; Bauer, M.; Bauer, S.E.; Bhat, M.K.; Bleck, R.; et al. Configuration and assessment of the GISS ModelE2 contributions to the CMIP5 archive. J. Adv. Model Earth Syst. 2014, 6, 141–184. [Google Scholar] [CrossRef] [Green Version]
- Collins, W.J.; Bellouin, N.; Doutriaux-Boucher, M.; Gedney, N.; Halloran, P.; Hinton, T.; Hughes, J.; Jones, C.D.; Joshi, M.; Liddicoat, S.; et al. Development and evaluation of an Earth-System model—HadGEM2. Geosci. Model Dev. 2011, 4, 1051–1075. [Google Scholar] [CrossRef]
- Volodin, E.M.; Dianskii, N.A.; Gusev, A.V. Simulating present-day climate with the INMCM4.0 coupled model of the atmospheric and oceanic general circulations. Izv. Atmos. Ocean Phys. 2010, 46, 414–431. [Google Scholar] [CrossRef]
- Dufresne, J.-L.; Foujols, M.-A.; Denvil, S.; Caubel, A.; Marti, O.; Aumont, O.; Balkanski, Y.; Bekki, S.; Bellenger, H.; Benshila, R.; et al. Climate change projections using the IPSL-CM5 Earth System Model: From CMIP3 to CMIP5. Clim. Dyn. 2013, 40, 2123–2165. [Google Scholar] [CrossRef] [Green Version]
- Tatebe, H.; Ishii, M.; Mochizuki, T.; Chikamoto, Y.; Sakamoto, T.T.; Komuro, Y.; Mori, M.; Yasunaka, S.; Watanabe, M.; Ogochi, K.; et al. The initialization of the MIROC climate models with hydrographic data assimilation for decadal prediction. J. Meteorol. Soc. Jpn. 2012, 90A, 275–294. [Google Scholar] [CrossRef]
- Watanabe, S.; Hajima, T.; Sudo, K.; Nagashima, T.; Takemura, T.; Okajima, H.; Nozawa, T.; Kawase, H.; Abe, M.; Yokohata, T.; et al. MIROC-ESM 2010: Model description and basic results of CMIP5-20c3m experiments. Geosci. Model Dev. 2011, 4, 845–872. [Google Scholar] [CrossRef]
- Giorgetta, M.A.; Jungclaus, J.; Reick, C.H.; Legutke, S.; Bader, J.; Böttinger, M.; Brovkin, V.; Crueger, T.; Esch, M.; Fieg, K.; et al. Climate and carbon cycle changes from 1850 to 2100 in MPI-ESM simulations for the Coupled Model Intercomparison Project phase 5. J. Adv. Model Earth Syst. 2013, 5, 572–597. [Google Scholar] [CrossRef] [Green Version]
- Yukimoto, S.; Adachi, Y.; Hosaka, M.; Sakami, T.; Yoshimura, H.; Hirabara, M.; TANAKA, T.Y.; Shindo, E.; Tsujino, H.; Deushi, M.; et al. A new global climate model of the Meteorological Research Institute: MRI-CGCM3—Model description and basic performance. J. Meteorol. Soc. Jpn. 2012, 90A, 23–64. [Google Scholar] [CrossRef]
- Bentsen, M.; Bethke, I.; Debernard, J.B.; Iversen, T.; Kirkevåg, A.; Seland, Ø.; Drange, H.; Roelandt, C.; Seierstad, I.A.; Hoose, C.; et al. The Norwegian Earth System Model, NorESM1-M—Part 1: Description and basic evaluation of the physical climate. Geosci. Model Dev. 2013, 6, 687–720. [Google Scholar] [CrossRef]
- Cannon, A.J.; Sobie, S.R.; Murdock, T.Q. Bias correction of GCM precipitation by quantile mapping: How well do methods preserve changes in quantiles and extremes? J. Clim. 2015, 28, 6938–6959. [Google Scholar] [CrossRef]
- Eum, H.-I.; Cannon, A.J. Intercomparison of projected changes in climate extremes for South Korea: Application of trend preserving statistical downscaling methods to the CMIP5 ensemble. Int. J. Climatol. 2017, 37, 3381–3397. [Google Scholar] [CrossRef]
- Lee, S.H.; Kang, S.U. A parameter regionalization study of a modified Tank model using characteristic factors of watersheds. J. Korean Soc. Civ. Eng. 2007, 27, 379–385. [Google Scholar]
- Hawkins, E.; Sutton, R. The potential to narrow uncertainty in regional climate predictions. Bull. Am. Meteorol. Soc. 2009, 90, 1095–1107. [Google Scholar] [CrossRef]
- Seo, S.B.; Sinha, T.; Mahinthakumar, G.; Sankarasubramanian, A.; Kumar, M. Identification of dominant source of errors in developing streamflow and groundwater projections under near-term climate change. J. Geophys. Res. Atmos. 2016, 121, 7652–7672. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Index | Description | Change |
|---|---|---|---|
| mean flow | PRCPTOT | Annual total precipitation in wet days | % |
| MEANTEMP | Annual mean temperature (°C) | ||
| high flow | Rx5day PRCP | Annual maximum consecutive 5-day precipitation (mm) | % |
| Rx3day PRCP | Annual maximum consecutive 3-day precipitation (mm) | % | |
| low flow | DTR | Annual mean difference between daily max temperature and min temperature (°C) | |
| Rn30day PRCP | Annual minimum consecutive 30-day precipitation (mm) | % |
| No. | Model | Resolution [Degrees] | Reference |
|---|---|---|---|
| 1 | BCC-CSM1-1 | 2.813 × 2.791 | Wu [25] |
| 2 | BCC-CSM1-1-M | 1.125 × 1.122 | Wu [25] |
| 3 | CanESM2 | 2.813 × 2.791 | Chylek et al. [26] |
| 4 | CCSM4 | 1.250 × 0.942 | Gent et al. [27] |
| 5 | CESM1-BGC | 1.250 × 0.942 | Moore et al. [28] |
| 6 | CESM1-CAM5 | 1.250 × 0.942 | Meehl et al. [29] |
| 7 | CMCC-CM | 0.750 × 0.748 | Scoccimarro et al. [30] |
| 8 | CMCC-CMS | 1.875 × 1.865 | Davini et al. [31] |
| 9 | CNRM-CM5 | 1.406 × 1.401 | Voldoire et al. [32] |
| 10 | FGOALS-s2 | 2.813 × 1.659 | Bao et al. [33] |
| 11 | GFDL-ESM2G | 2.500 × 2.023 | Dunne et al. [34] |
| 12 | GFDL-ESM2M | 2.500 × 2.023 | Dunne et al. [34] |
| 13 | GISS-E2-R | 2.000 × 2.500 | Schmidt et al. [35] |
| 14 | HadGEM2-AO | 1.875 × 1.250 | Collins et al. [36] |
| 15 | HadGEM2-CC | 1.875 × 1.250 | Collins et al. [36] |
| 16 | HadGEM2-ES | 1.875 × 1.250 | Collins et al. [36] |
| 17 | INM-CM4 | 2.000 × 1.500 | Volodin et al. [37] |
| 18 | IPSL-CM5A-LR | 3.750 × 1.895 | Dufresne et al. [38] |
| 19 | IPSL-CM5A-MR | 1.875 × 1.865 | Dufresne et al. [38] |
| 20 | IPSL-CM5B-LR | 3.750 × 1.895 | Dufresne et al. [38] |
| 21 | MIROC5 | 1.406 × 1.401 | Tatebe et al. [39] |
| 22 | MIROC-ESM | 2.813 × 2.791 | Watanabe et al. [40] |
| 23 | MIROC-ESM-CHEM | 2.813 × 2.791 | Watanabe et al. [40] |
| 24 | MPI-ESM-LR | 1.875 × 1.865 | Giorgetta et al. [41] |
| 25 | MPI-ESM-MR | 1.875 × 1.865 | Giorgetta et al. [41] |
| 26 | MRI-CGCM3 | 1.125 × 1.122 | Yukimoto et al. [42] |
| 27 | NorESM1-M | 2.500 × 1.895 | Bentsen et al. [43] |
| 2030s | 2060s | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| National Level | River Region Level | National Level | River Region Level | |||||||||||
| Rank | Korea | Han | Nak Dong | Geum | Seom jin | Yeong San | Korea | Han | Nak Dong | Geum | Seom Jin | Yeong San | ||
| Mean flow | 1 | 5 | 20 | 2 | 5 | 5 | 5 | 10 | 12 | 9 | 10 | 27 | 27 | |
| 2 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 24 | ||
| 3 | 16 | 16 | 16 | 16 | 16 | 16 | 23 | 17 | 23 | 23 | 24 | 8 | ||
| 4 | 23 | 23 | 17 | 23 | 23 | 23 | 16 | 23 | 17 | 17 | 22 | 13 | ||
| 5 | 17 | 17 | 23 | 26 | 14 | 26 | 17 | 16 | 22 | 24 | 13 | 22 | ||
| High flow | 1 | 13 | 2 | 24 | 24 | 17 | 9 | 5 | 11 | 6 | 14 | 7 | 5 | |
| 2 | 8 | 8 | 8 | 8 | 23 | 16 | 8 | 8 | 8 | 8 | 4 | 4 | ||
| 3 | 16 | 16 | 23 | 21 | 8 | 8 | 4 | 21 | 4 | 4 | 8 | 8 | ||
| 4 | 10 | 10 | 1 | 23 | 16 | 23 | 13 | 9 | 19 | 23 | 24 | 24 | ||
| 5 | 23 | 21 | 16 | 10 | 5 | 5 | 23 | 2 | 23 | 6 | 13 | 26 | ||
| Low flow | 1 | 9 | 13 | 9 | 1 | 9 | 17 | 5 | 12 | 7 | 10 | 21 | 15 | |
| 2 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 8 | 24 | 8 | 8 | 24 | ||
| 3 | 16 | 16 | 25 | 16 | 23 | 16 | 24 | 16 | 8 | 24 | 24 | 8 | ||
| 4 | 24 | 20 | 16 | 19 | 16 | 6 | 16 | 21 | 17 | 19 | 17 | 27 | ||
| 5 | 19 | 19 | 24 | 23 | 19 | 19 | 25 | 18 | 25 | 6 | 27 | 19 | ||
| 2030s | 2060s | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| National Level | River Region Level | National Level | River Region Level | ||||||||||
| Rank | Korea | Han | Nak Dong | Geum | Seom Jin | Yeong San | Korea | Han | Nak Dong | Geum | Seom Jin | Yeong San | |
| Mean Flow | 1 | 12 | 12 | 7 | 21 | 9 | 9 | 6 | 10 | 27 | 6 | 20 | 20 |
| 2 | 23 | 23 | 6 | 10 | 15 | 15 | 17 | 17 | 17 | 15 | 13 | 13 | |
| 3 | 6 | 26 | 10 | 24 | 24 | 24 | 23 | 23 | 23 | 23 | 23 | 15 | |
| 4 | 10 | 16 | 23 | 23 | 10 | 10 | 13 | 13 | 13 | 13 | 15 | 23 | |
| 5 | 26 | 10 | 26 | 15 | 14 | 19 | 15 | 15 | 3 | 3 | 17 | 17 | |
| High Flow | 1 | 5 | 25 | 5 | 6 | 7 | 18 | 3 | 12 | 4 | 14 | 12 | 19 |
| 2 | 23 | 23 | 23 | 21 | 14 | 23 | 17 | 27 | 23 | 23 | 23 | 23 | |
| 3 | 10 | 14 | 19 | 10 | 10 | 10 | 23 | 17 | 17 | 17 | 17 | 17 | |
| 4 | 16 | 16 | 24 | 24 | 24 | 24 | 13 | 7 | 9 | 9 | 13 | 21 | |
| 5 | 15 | 10 | 10 | 15 | 26 | 19 | 9 | 26 | 13 | 13 | 21 | 11 | |
| Low Flow | 1 | 8 | 4 | 15 | 27 | 4 | 15 | 12 | 7 | 12 | 12 | 5 | 5 |
| 2 | 24 | 20 | 24 | 24 | 24 | 24 | 19 | 17 | 17 | 17 | 19 | 19 | |
| 3 | 10 | 16 | 19 | 20 | 19 | 19 | 3 | 21 | 3 | 10 | 15 | 27 | |
| 4 | 6 | 24 | 6 | 10 | 6 | 6 | 17 | 18 | 19 | 19 | 17 | 23 | |
| 5 | 19 | 10 | 10 | 11 | 10 | 10 | 23 | 19 | 6 | 15 | 3 | 7 | |
| Hydrologic Variable | Spatial Scale | Representative Climate Scenarios (GCMs) | Number of Subbasins | ||||
|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | |||
| mean flow | South Korea | CESM1-BGC | CMCC-CMS | HadGEM-ES | MIROC-ESM-CHEM | INM-CM4 | 113 |
| high flow | South Korea | GISS-E2-R | CMCC-CMS | HadGEM-ES | FGOALS-s2 | MIROC-ESM-CHEM | 113 |
| low flow | Han River | GISS-E2-R | CMCC-CMS | HadGEM-ES | IPSL-CM5B-LR | IPSL-CM5A-MR | 30 |
| Nakdong River | CNRM-CM5 | CMCC-CMS | MPI-ESM-MR | HadGEM-ES | MPI-ESM-LR | 33 | |
| Geum River | BCC-CSM1-1 | CMCC-CMS | HadGEM-ES | IPSL-CM5B-MR | MIROC-ESM-CHEM | 21 | |
| Seomjin River | CNRM-CM5 | CMCC-CMS | MIROC-ESM-CHEM | HadGEM-ES | IPSL-CM5A-MR | 15 | |
| Yeongsan River | INM-CM4 | CMCC-CMS | HadGEM-ES | CESM1-CAM5 | IPSL-CM5A-MR | 14 | |
| Hydrologic Variable | Spatial Scale | Representative Climate Scenarios (GCMs) | Number of Subbasins | ||||
|---|---|---|---|---|---|---|---|
| 1st | 2nd | 3rd | 4th | 5th | |||
| mean flow | South Korea | FGOALS-s2 | CMCC-CMS | MIROC-ESM-CHEM | HadGEM-ES | INM-CM4 | 113 |
| high flow | South Korea | CESM1-BGC | CMCC-CMS | CCSM4 | GISS-E2-R | MIROC-ESM-CHEM | 113 |
| low flow | Han River | GFDL-ESM2M | CMCC-CMS | HadGEM-ES | MIROC5 | IPSL-CM5A-LR | 30 |
| Nakdong River | CMCC-CM | MPI-ESM-LR | CMCC-CMS | INM-CM4 | MPI-ESM-MR | 33 | |
| Geum River | FGOALS-s2 | CMCC-CMS | MPI-ESM-LR | IPSL-CM5A-MR | CESM1-CAM5 | 21 | |
| Seomjin River | MIROC5 | CMCC-CMS | MPI-ESM-LR | INM-CM4 | NorESM1-M | 15 | |
| Yeongsan River | HadGEM2-CC | MPI-ESM-LR | CMCC-CMS | NorESM1-M | IPSL-CM5A-MR | 14 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Seo, S.B.; Kim, Y.-O. Impact of Spatial Aggregation Level of Climate Indicators on a National-Level Selection for Representative Climate Change Scenarios. Sustainability 2018, 10, 2409. https://doi.org/10.3390/su10072409
Seo SB, Kim Y-O. Impact of Spatial Aggregation Level of Climate Indicators on a National-Level Selection for Representative Climate Change Scenarios. Sustainability. 2018; 10(7):2409. https://doi.org/10.3390/su10072409
Chicago/Turabian StyleSeo, Seung Beom, and Young-Oh Kim. 2018. "Impact of Spatial Aggregation Level of Climate Indicators on a National-Level Selection for Representative Climate Change Scenarios" Sustainability 10, no. 7: 2409. https://doi.org/10.3390/su10072409
APA StyleSeo, S. B., & Kim, Y. -O. (2018). Impact of Spatial Aggregation Level of Climate Indicators on a National-Level Selection for Representative Climate Change Scenarios. Sustainability, 10(7), 2409. https://doi.org/10.3390/su10072409