Predicting Corporate Financial Sustainability Using Novel Business Analytics




Abstract
:1. Introduction
2. Literature Review
2.1. Prior Studies on Financial Distress Prediction
2.2. SVM and its Application to Financial Forecasting
2.3. Genetic Algorithm (GA)
2.4. Optimization of SVM Using GA
3. Global Optimization Model of SVM using GA
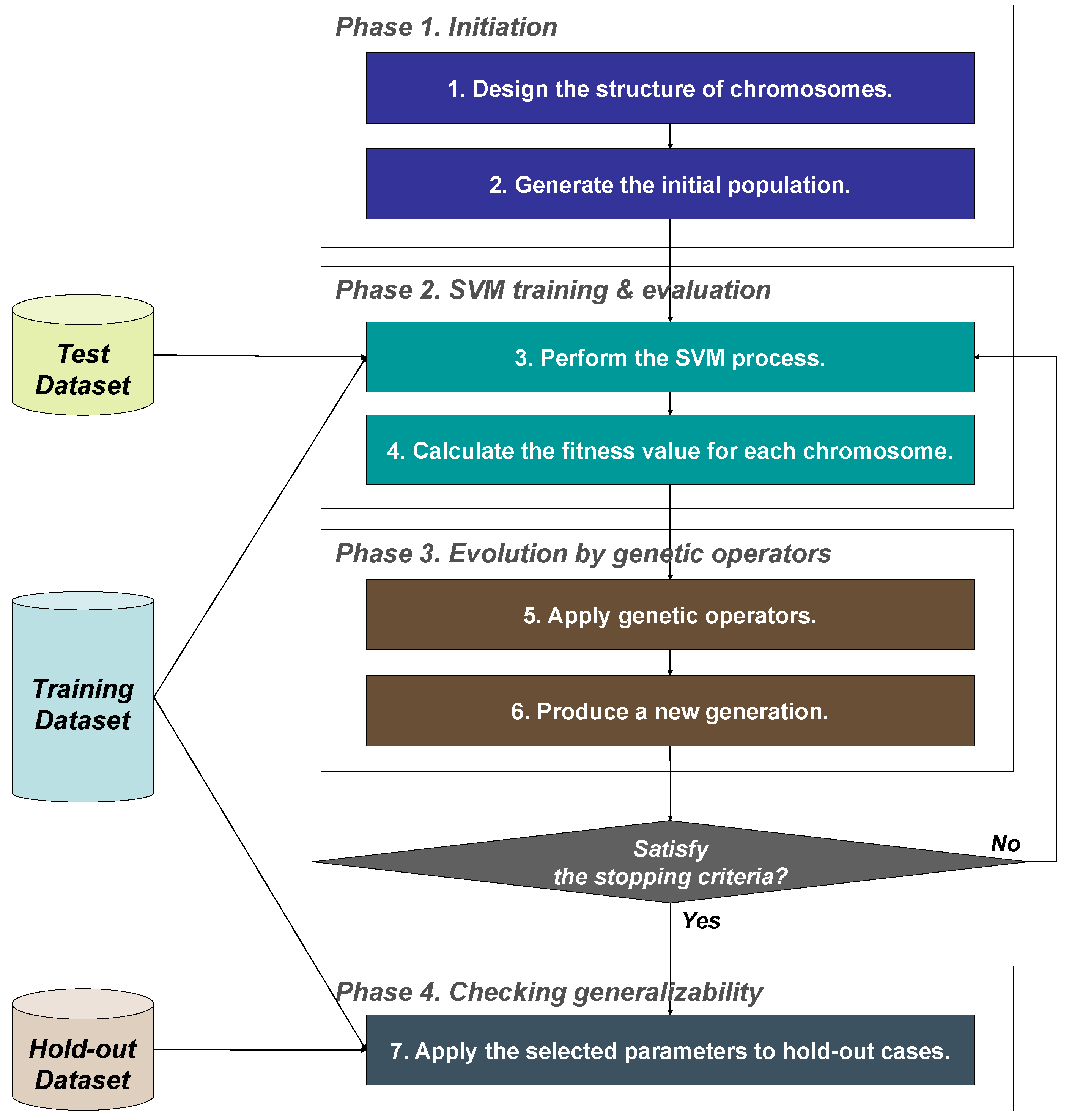
3.1. Phase 1. Initiation
3.2. Phase 2. SVM Training and Evaluation
3.3. Phase 3. Evolution by Genetic Operators
3.4. Phase 4. Checking for Generalization
4. The Research Design and Experiments
4.1. Application Data
4.2. Comparative Models
4.3. Experimental Settings and System Development
5. Experimental Results
6. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Appendix A. Detailed Experimental Results
| k of k-NN | 1 | 2 | 3 | 4 | 5 | 6 | 7 * | 8 | 9 | 10 |
| Prediction accuracy (%) for hold-out data | 60.6 | 56.8 | 63.5 | 62.6 | 67.1 | 66.8 | 68.4 * | 64.5 | 66.8 | 65.2 |
| * The best prediction accuracy. | ||||||||||
| The number of nodes in the hidden layer | 21 | 42 * | 63 | 84 | |
| Prediction Accuracy | Training data | 72.0% | 72.8% | 71.4% | 72.7% |
| Test data | 71.6% | 71.9% | 70.6% | 71.3% | |
| Hold-out data | 69.7% | 70.3% * | 69.0% | 68.4% | |
| * The best prediction accuracy. | |||||
| Kernel function and its parameters | Train data | Hold-out data | ||
| Linear function | C = 1 | 75.9% | 74.5% | |
| C = 10 | 77.6% | 73.2% | ||
| C = 33 | 78.2% | 72.3% | ||
| C = 55 | 78.7% | 73.2% | ||
| C = 78 | 78.6% | 72.9% | ||
| C = 100 | 78.8% | 73.5% | ||
| Polynomial function | C = 1 | d = 1 | 69.7% | 69.7% |
| d = 2 | 69.1% | 69.7% | ||
| d = 3 | 65.8% | 66.1% | ||
| d = 4 | 50.0% | 50.0% | ||
| d = 5 | 50.0% | 50.0% | ||
| C = 10 | d = 1 | 74.2% | 74.5% | |
| d = 2 | 73.3% | 71.3% | ||
| d = 3 | 70.3% | 71.3% | ||
| d = 4 | 68.9% | 70.0% | ||
| d = 5 | 53.2% | 54.8% | ||
| C = 33 | d = 1 | 75.1% | 74.5% | |
| d = 2 | 74.9% | 73.5% | ||
| d = 3 | 72.7% | 72.3% | ||
| d = 4 | 70.6% | 71.0% | ||
| d = 5 | 65.5% | 66.5% | ||
| C = 55 | d = 1 | 76.3% | 74.2% | |
| d = 2 | 75.5% | 72.9% | ||
| d = 3 | 73.9% | 71.3% | ||
| d = 4 | 71.3% | 71.0% | ||
| d = 5 | 68.9% | 70.6% | ||
| C = 78 | d = 1 | 76.6% | 74.5% | |
| d = 2 | 76.9% | 72.6% | ||
| d = 3 | 75.4% | 72.6% | ||
| d = 4 | 71.9% | 70.6% | ||
| d = 5 | 70.3% | 70.6% | ||
| C = 100 | d = 1 | 76.7% | 74.2% | |
| d = 2 | 77.3% | 72.3% | ||
| d = 3 | 75.6% | 71.9% | ||
| d = 4 | 72.4% | 70.3% | ||
| d = 5 | 70.4% | 70.6% | ||
| Gaussian Radial Basis Function * | C = 1 | σ2 = 1 | 87.2% | 72.9% |
| σ2 = 25 | 72.8% | 71.6% | ||
| σ2 = 50 | 71.0% | 69.4% | ||
| σ2 = 75 | 70.0% | 70.0% | ||
| σ2 = 100 | 69.6% | 70.3% | ||
| C = 10 | σ2 = 1 | 97.8% | 71.3% | |
| σ2 = 25 | 77.0% | 73.5% | ||
| σ2 = 50 | 75.4% | 74.2% | ||
| σ2 = 75 | 74.7% | 74.5% | ||
| σ2 = 100 | 74.2% | 73.5% | ||
| C = 33 | σ2 = 1 | 99.7% | 69.0% | |
| σ2 = 25 | 79.4% | 73.9% | ||
| σ2 = 50 | 77.3% | 74.2% | ||
| σ2 = 75 | 75.9% | 74.2% | ||
| σ2 = 100 | 75.8% | 73.9% | ||
| C = 55 | σ2 = 1 | 99.9% | 68.1% | |
| σ2 = 25 | 81.7% | 74.5% | ||
| σ2 = 50 | 78.0% | 73.9% | ||
| σ2 = 75 | 77.5% | 73.9% | ||
| σ2 = 100 | 76.4% | 73.9% | ||
| C = 78 | σ2 = 1 | 99.9% | 68.4% | |
| σ2 = 25 | 82.9% | 73.9% | ||
| σ2 = 50 | 79.5% | 73.9% | ||
| σ2 = 75 | 77.5% | 73.9% | ||
| σ2 = 100 | 77.0% | 73.5% | ||
| C = 100 * | σ2 = 1 | 100.0% | 67.4% | |
| σ2 = 25 * | 82.7% * | 74.5% * | ||
| σ2 = 50 | 80.1% | 74.5% | ||
| σ2 = 75 | 77.8% | 73.9% | ||
| σ2 = 100 | 77.5% | 74.2% | ||
| * The best prediction accuracy. | ||||
References
- Hu, H.; Sathye, M. Predicting Financial Distress in the Hong Kong Growth Enterprises Market from the Perspective of Financial Sustainability. Sustainability 2015, 7, 1186–1200. [Google Scholar] [CrossRef] [Green Version]
- Valaskova, K.; Kliestik, T.; Svabova, L.; Adamko, P. Financial risk measurement and prediction modelling for sustainable development of business entities using regression analysis. Sustainability 2018, 10, 2144. [Google Scholar] [CrossRef]
- Altman, E.I. Financial ratios, discriminant analysis and the prediction of corporate bankruptcy. J. Financ. 1968, 23, 589–609. [Google Scholar] [CrossRef]
- Ohlson, J. Financial ratios and the probabilistic prediction of bankruptcy. J. Account. Res. 1980, 18, 109–131. [Google Scholar] [CrossRef]
- Odom, M.; Sharda, R. A neural network model for bankruptcy prediction. In Proceedings of the International Joint Conference on Neural Networks, San Diego, CA, USA, 17–21 June 1990; pp. 163–168. [Google Scholar]
- Tam, K.Y.; Kiang, M.Y. Managerial applications of the neural networks: The case of bank failure predictions. Manag. Sci. 1992, 38, 926–947. [Google Scholar] [CrossRef]
- Jo, H.; Han, I. Integration of case-based forecasting, neural network and discriminant analysis for bankruptcy prediction. Expert Syst. Appl. 1996, 11, 415–422. [Google Scholar] [CrossRef]
- Ahn, H.; Kim, K.-J. Bankruptcy prediction modeling with hybrid case-based reasoning and genetic algorithms approach. Appl. Soft Comput. 2009, 9, 599–607. [Google Scholar] [CrossRef]
- Fan, A.; Palaniswami, M. Selecting bankruptcy predictors using a support vector machine approach. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks, Como, Italy, 27–27 July 2000; pp. 354–359. [Google Scholar]
- Shin, K.-S.; Lee, T.S.; Kim, H.-J. An application of support vector machines in bankruptcy prediction model. Expert Syst. Appl. 2005, 28, 127–135. [Google Scholar] [CrossRef]
- Min, J.H.; Lee, Y.-C. Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters. Expert Syst. Appl. 2005, 28, 603–614. [Google Scholar] [CrossRef]
- Min, S.-H.; Lee, J.; Han, I. Hybrid genetic algorithms and support vector machines for bankruptcy prediction. Expert Syst. Appl. 2006, 31, 652–660. [Google Scholar] [CrossRef]
- Hua, Z.; Wang, Y.; Xu, X.; Zhang, B.; Liang, L. Predicting corporate financial distress based on integration of support vector machine and logistic regression. Expert Syst. Appl. 2007, 33, 434–440. [Google Scholar] [CrossRef]
- Ding, Y.; Song, X.; Zen, Y. Forecasting financial condition of Chinese listed companies based on support vector machine. Expert Syst. Appl. 2008, 34, 3081–3089. [Google Scholar] [CrossRef]
- Chaudhuri, A.; De, K. Fuzzy Support Vector Machine for bankruptcy prediction. Appl. Soft Comput. 2011, 11, 2472–2486. [Google Scholar] [CrossRef]
- Li, H.; Sun, J. Predicting business failure using support vector machines with straightforward wrapper: A re-sampling study. Expert Syst. Appl. 2011, 38, 12747–12756. [Google Scholar] [CrossRef]
- Lin, F.; Yeh, C.C.; Lee, M.Y. The use of hybrid manifold learning and support vector machines in the prediction of business failure. Knowl.-Based Syst. 2011, 24, 95–101. [Google Scholar] [CrossRef]
- Yang, Z.; You, W.; Ji, G. Using partial least squares and support vector machines for bankruptcy prediction. Expert Syst. Appl. 2011, 38, 8336–8342. [Google Scholar] [CrossRef]
- Tsai, C.-F.; Cheng, K.-C. Simple instance selection for bankruptcy prediction. Knowl.-Based Syst. 2012, 27, 333–342. [Google Scholar] [CrossRef]
- Huang, C.L.; Wang, C.J. A GA-based feature selection and parameters optimization for support vector machines. Expert Syst. Appl. 2006, 31, 231–240. [Google Scholar] [CrossRef]
- Chen, L.H.; Hsiao, H.D. Feature selection to diagnose a business crisis by using a real GA-based support vector machine: An empirical study. Expert Syst. Appl. 2008, 35, 1145–1155. [Google Scholar] [CrossRef]
- Kim, K.-J.; Ahn, H. Simultaneous optimization of artificial neural networks for financial forecasting. Appl. Intel. 2012, 36, 887–898. [Google Scholar] [CrossRef]
- Li, L.; Tang, H.; Wu, Z.; Gong, J.; Gruidl, M.; Zou, J.; Tockman, M.; Clark, R.A. Data mining techniques for cancer detection using serum proteomic profiling. Artif. Intel. Med. 2004, 32, 71–83. [Google Scholar] [CrossRef] [PubMed]
- Ahn, H.; Lee, K.; Kim, K.-J. Global optimization of support vector machines using genetic algorithms for bankruptcy prediction. In Neural Information Processing; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2006; Volume 4234, pp. 420–429. [Google Scholar]
- Falbo, P. Credit-scoring by enlarged discriminant models. Omega 1991, 19, 275–289. [Google Scholar] [CrossRef]
- Tam, K.Y. Neural network models and the prediction of bank bankruptcy. Omega 1991, 19, 429–445. [Google Scholar] [CrossRef]
- Malhotra, R.; Malhotra, D.K. Evaluating consumer loans using neural networks. Omega 2003, 31, 83–96. [Google Scholar] [CrossRef]
- Vapnik, V.N. Statistical Learning Theory; Wiley: Hoboken, NJ, USA, 1998. [Google Scholar]
- Pai, P.-F.; Hong, W.-C. Forecasting regional electricity load based on recurrent support vector machines with genetic algorithms. Electr. Power Syst. Res. 2005, 74, 417–425. [Google Scholar] [CrossRef]
- Smola, A.J. Learning with Kernels. Ph.D. Thesis, Department of Computer Science, Technical University Berlin, Germany, 1998. [Google Scholar]
- Gunn, S.R. Support Vector Machines for Classification and Regression; Technical Report; University of Southampton: Southampton, UK, 1998. [Google Scholar]
- Drucker, H.; Wu, D.; Vapnik, V.N. Support vector machines for spam categorization. IEEE Trans. Neural Netw. 1999, 10, 1048–1054. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations; Morgan Kaufmann Publishers: Burlington, MA, USA, 2000. [Google Scholar]
- Mukherjee, S.; Osuna, E.; Girosi, F. Nonlinear prediction of chaotic time series using support vector machines. In Proceedings of the IEEE Workshop on Neural Networks for Signal Processing, Amelia Island, FL, USA, 24–26 September 1997; pp. 511–520. [Google Scholar] [Green Version]
- Tay, F.E.H.; Cao, L. Application of support vector machines in financial time series forecasting. Omega 2001, 29, 309–317. [Google Scholar] [CrossRef]
- Kim, K.-J. Financial forecasting using support vector machines. Neurocomputing 2003, 55, 307–319. [Google Scholar] [CrossRef]
- Huang, C.L.; Chen, M.C.; Wang, C.J. Credit scoring with a data mining approach based on support vector machines. Expert Syst. Appl. 2007, 33, 847–856. [Google Scholar] [CrossRef] [Green Version]
- Wu, C.H.; Tzeng, G.H.; Goo, Y.J.; Fang, W.C. A real-valued genetic algorithm to optimize the parameters of support vector machine for prediction bankruptcy. Expert Syst. Appl. 2007, 32, 397–408. [Google Scholar] [CrossRef]
- Zhou, L.; Lai, K.K.; Yu, L. Credit scoring using support vector machines with direct search for parameters selection. Soft Comput. 2009, 13, 149–155. [Google Scholar] [CrossRef]
- Chung, H.; Shin, K.-S. Genetic algorithm-optimized long short-term memory network for stock market prediction. Sustainability 2018, 10, 3765. [Google Scholar] [CrossRef]
- Fu, Y.; Shen, R. GA based CBR approach in Q&A system. Expert Syst. Appl. 2004, 26, 167–170. [Google Scholar]
- Han, J.; Kamber, M. Datamining: Concepts and Techniques; Morgan Kaufmann Publishers: Burlington, MA, USA, 2001. [Google Scholar]
- Gu, J.; Zhu, M.; Jiang, L. Housing price forecasting based on genetic algorithm and support vector machine. Expert Syst. Appl. 2011, 38, 3383–3386. [Google Scholar] [CrossRef]
- Howley, T.; Madden, M.G. The Genetic Kernel Support Vector Machine: Description and Evaluation. Artif. Intel. Rev. 2005, 24, 379–395. [Google Scholar] [CrossRef] [Green Version]
- Pai, P.-F.; Hsu, M.-F.; Wang, M.-C. A support vector machine-based model for detecting top management fraud. Knowl.-Based Syst. 2011, 24, 314–321. [Google Scholar] [CrossRef]
- Lee, K.; Byun, H. A new face authentication system for memory-constrained devices. IEEE Trans. Consum. Electron. 2003, 49, 1214–1222. [Google Scholar]
- Sun, Z.; Bebis, G.; Miller, R. Object detection using feature subset selection. Pattern Recognit. 2004, 37, 2165–2176. [Google Scholar] [CrossRef] [Green Version]
- Samanta, B. Gear fault detection using artificial neural networks and support vector machines with genetic algorithms. Mech. Syst. Signal Process. 2004, 18, 625–644. [Google Scholar] [CrossRef]
- Yu, E.; Cho, S. Keystroke dynamics identity verification: Its problems and practical solutions. Comput. Secur. 2004, 23, 428–440. [Google Scholar] [CrossRef]
- Yu, E.; Cho, S. Constructing response model using ensemble based on feature subset selection. Expert Syst. Appl. 2006, 30, 352–360. [Google Scholar] [CrossRef]
- Yu, L.; Wang, S.; Lai, K.K. Mining stock market tendency using GA-based support vector machines. In International Workshop on Internet and Network Economics; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3828, pp. 336–345. [Google Scholar]
- Jack, L.B.; Nandi, A.K. Fault detection using support vector machines and artificial neural networks, augmented by genetic algorithms. Mech. Syst. Signal Process. 2002, 16, 373–390. [Google Scholar] [CrossRef]
- Zhao, X.-M.; Cheung, Y.-M.; Huang, D.-S. A novel approach to extracting features from motif content and protein composition for protein sequence classification. Neural Netw. 2005, 18, 1019–1028. [Google Scholar] [CrossRef] [PubMed]
- Reeves, C.R.; Taylor, S.J. Selection of training sets for neural networks by a genetic algorithm. In Parallel Problem-Solving from Nature; Eiden, A.E., Back, T., Schoenauer, M., Schwefel, H.-P., Eds.; Springer: Berlin/Heidelberg, Germany, 1998. [Google Scholar]
- Babu, T.R.; Murty, M.N. Comparison of genetic algorithm based prototype selection schemes. Pattern Recognit. 2001, 34, 523–525. [Google Scholar] [CrossRef]
- Tahayna, B.; Belkhatir, M.; Alhashmi, S.M.; O’Daniel, T. Optimizing support vector machine based classification and retrieval of semantic video events with genetic algorithms. In Proceedings of the 2010 IEEE seventeenth International Conference on Image Processing (ICIP 2010), Hong Kong, China, 26–29 September 2010; pp. 1485–1488. [Google Scholar]
- Tahayna, B.; Belkhatir, M.; Alhashmi, S.M.; O’Daniel, T. Human action detection and classification using optimal bag-of-words representation. In Proceedings of the 2010 IEEE Sixth International Conference on Digital Content, Multimedia Technology and its Applications (IDC 2010), Seoul, Korea, 16–18 August 2010; pp. 75–80. [Google Scholar]
- Kim, K.-J. Toward global optimization of case-based reasoning systems for financial forecasting. Appl. Intel. 2004, 21, 239–249. [Google Scholar] [CrossRef]
- Kim, K.-J. Artificial neural networks with evolutionary instance selection for financial forecasting. Expert Syst. Appl. 2006, 30, 519–526. [Google Scholar] [CrossRef]
- Kim, D.S.; Nguyen, H.-N.; Park, J.S. Genetic algorithm to improve SVM based network intrusion detection system. In Proceedings of the 19th International Conference on Advanced Information Networking and Applications, Taipei, Taiwan, 28–30 March 2005; pp. 155–158. [Google Scholar]
- Chang, C.-C.; Lin, C.-J. LIBSVM: A library for support vector machines. ACM Trans. Intel. Syst. Technol. 2011, 2, 27:1–27:27. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 7 November 2018). [CrossRef]
- Harnett, D.L.; Soni, A.K. Statistical Methods for Business and Economics; Addison-Wesley: Boston, MA, USA, 1991. [Google Scholar]
- Diebold, F.X.; Mariano, R.S. Comparing predictive accuracy. J. Bus. Econom. Stat. 1995, 13, 134–144. [Google Scholar]
- Derrac, J.; García, S.; Molina, D.; Herrera, F. A practical tutorial on the use of nonparametric statistical tests as a methodology for comparing evolutionary and swarm intelligence algorithms. Swarm Evolut. Comput. 2011, 1, 3–18. [Google Scholar] [CrossRef]
- Fan, G.F.; Peng, L.L.; Hong, W.C. Short term load forecasting based on phase space reconstruction algorithm and bi-square kernel regression model. Appl. Energy 2018, 224, 13–33. [Google Scholar] [CrossRef]
- Iotti, M.; Bonazzi, G. Analysis of the Risk of Bankruptcy of Tomato Processing Companies Operating in the Inter-Regional Interprofessional Organization “OI Pomodoro da Industria Nord Italia”. Sustainability 2018, 10, 947. [Google Scholar] [CrossRef]


{kind=link}
| Model | Train | Test | Hold-out | Optimal | Portion of the Selected | ||
|---|---|---|---|---|---|---|---|
| σ2 | C | Features | Instances | ||||
| COSVM | 82.7% | - | 74.5% | 25 | 100 | 100% | 100% |
| GSSVM | 80.2% | - | 74.2% | 22.6 | 32 | 100% | 100% |
| KPSVM | 84.8% | 77.4% | 76.5% | 13.0 | 55.9 | 100% | 100% |
| FSSVM | 82.6% | 77.8% | 77.4% | 8.8 | 93.3 | 61% | 100% |
| ISSVM | 84.6% | 80.0% | 79.4% | 12.7 | 36.8 | 100% | 53% |
| GOSVM | 84.6% | 80.3% | 80.3% | 18.3 | 90 | 80% | 62% |
| Model | Train | Test | Hold-out | Remarks for Finally Selected Model |
|---|---|---|---|---|
| LOGIT | 78.6% | - | 74.8% | Backward conditional, The number of the selected features = 37 |
| DA | 75.0% | - | 72.6% | Stepwise, The number of the selected features = 16 |
| CBR | - | - | 68.4% | k of k-NN = 7 |
| ANN | 72.8% | 71.9% | 70.3% | The number of the nodes in the hidden layer = 42 |
| GOSVM | 84.6% | 80.3% | 80.3% | Gaussian RBF kernel, = 18.3, = 90 |
| DA | CBR | ANN | COSVM | GSSVM | KPSVM | FSSVM | ISSVM | GOSVM | |
|---|---|---|---|---|---|---|---|---|---|
| LOGIT | −0.639 | −1.781 ** | −1.260 * | −0.092 | −0.184 | 0.468 | 0.754 | 1.338 ** | 1.637 ** |
| DA | −1.145 * | −0.622 | 0.546 | 0.454 | 1.106 * | 1.391 ** | 1.974 ** | 2.272 *** | |
| CBR | −0.523 | 1.690 ** | 1.598 ** | 2.247 *** | 2.530 *** | 3.108 *** | 3.403 *** | ||
| ANN | 1.168 * | 1.076 * | 1.727 ** | 2.011 ** | 2.591 *** | 2.888 *** | |||
| COSVM | −0.092 | 0.560 | 0.846 * | 1.430 ** | 1.729 ** | ||||
| GSSVM | 0.652 | 0.938 * | 1.522 ** | 1.820 ** | |||||
| KPSVM | 0.286 | 0.871 * | 1.171 * | ||||||
| FSSVM | 0.585 | 0.885 * | |||||||
| ISSVM | 0.300 |
| DA | CBR | ANN | COSVM | GSSVM | KPSVM | FSSVM | ISSVM | GOSVM | |
|---|---|---|---|---|---|---|---|---|---|
| LOGIT | 1.091 | 2.347 | 3.924 ** | 0.000 | 0.036 | 0.516 | 1.361 | 4.024 ** | 5.020 ** |
| DA | 0.554 | 1.618 | 0.694 | 0.485 | 3.184 * | 4.780 ** | 8.889 *** | 9.121 *** | |
| CBR | 0.347 | 2.215 | 1.891 | 4.836 ** | 7.603 *** | 9.851 *** | 31.858 *** | ||
| ANN | 3.904 ** | 15.858 *** | 7.291 *** | 8.890 *** | 12.375 *** | 13.935 *** | |||
| COSVM | 3.440 * | - | 2.370 | 6.759 *** | 7.605 *** | ||||
| GSSVM | - | - * | 7.031 *** | 7.200 *** | |||||
| KPSVM | 0.148 | 2.370 | 3.184 * | ||||||
| FSSVM | 0.625 | 1.362 | |||||||
| ISSVM | 0.093 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, K.-j.; Lee, K.; Ahn, H. Predicting Corporate Financial Sustainability Using Novel Business Analytics. Sustainability 2019, 11, 64. https://doi.org/10.3390/su11010064
Kim K-j, Lee K, Ahn H. Predicting Corporate Financial Sustainability Using Novel Business Analytics. Sustainability. 2019; 11(1):64. https://doi.org/10.3390/su11010064
Chicago/Turabian StyleKim, Kyoung-jae, Kichun Lee, and Hyunchul Ahn. 2019. "Predicting Corporate Financial Sustainability Using Novel Business Analytics" Sustainability 11, no. 1: 64. https://doi.org/10.3390/su11010064
APA StyleKim, K. -j., Lee, K., & Ahn, H. (2019). Predicting Corporate Financial Sustainability Using Novel Business Analytics. Sustainability, 11(1), 64. https://doi.org/10.3390/su11010064