3.1. Data Description
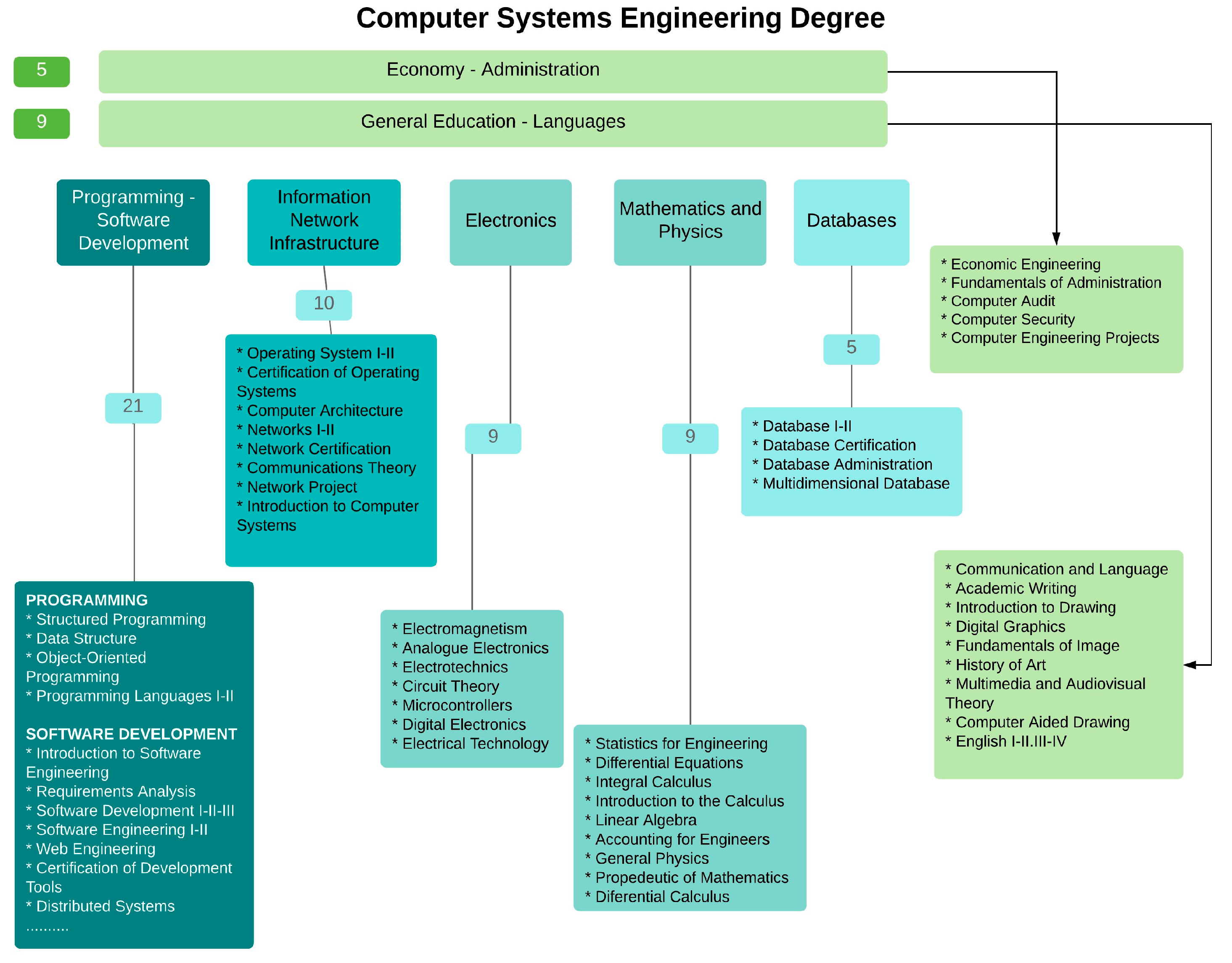
The dataset used for the present work is composed of the academic records of 335 students. The total number of historical records of students’ grades was 6358, which corresponds to all the subjects taken by this group of students. The periods analyzed were from the semester 2016-1 to the semester 2018-2 in the Computer Systems Engineering Degree of a university in Ecuador. In addition, the dataset comprises a total of 68 subjects organized into seven knowledge areas (Programming and Software Development, Mathematics and Physics, Information Network Infrastructure, Electronics, Databases, Economy—Administration, General Education—Languages), as can be seen in
Figure 2. In addition,
Figure 2 shows the number of subjects by areas of knowledge. According to the educational model used by the university, curricular coherence is vertically aligned in each of the seven areas of knowledge, that is, what students learn in the course or module is used as the basis for the next academic course. However, it is important to point out an exception, since the transversal knowledge areas, such as Economics—Administration and General Education are more aligned horizontally, where there are no such strong dependencies in different subjects and academic years.
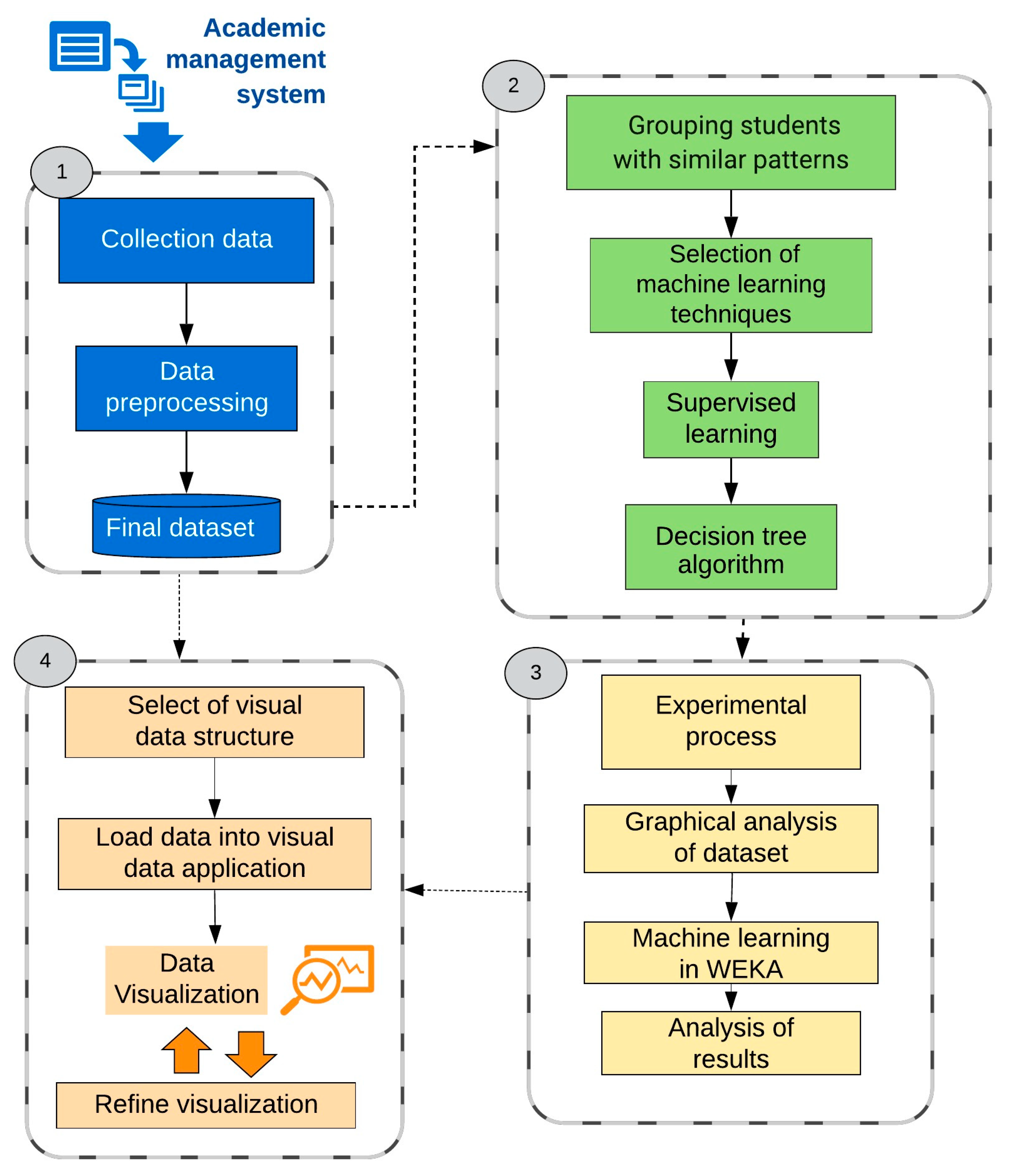
The data were extracted from the institution’s academic management system and stored in CSV format file. This information was periodically retrieved from the university’s grades system and stored in an integrated data repository. From this repository, some dashboards useful for the stakeholders were built.
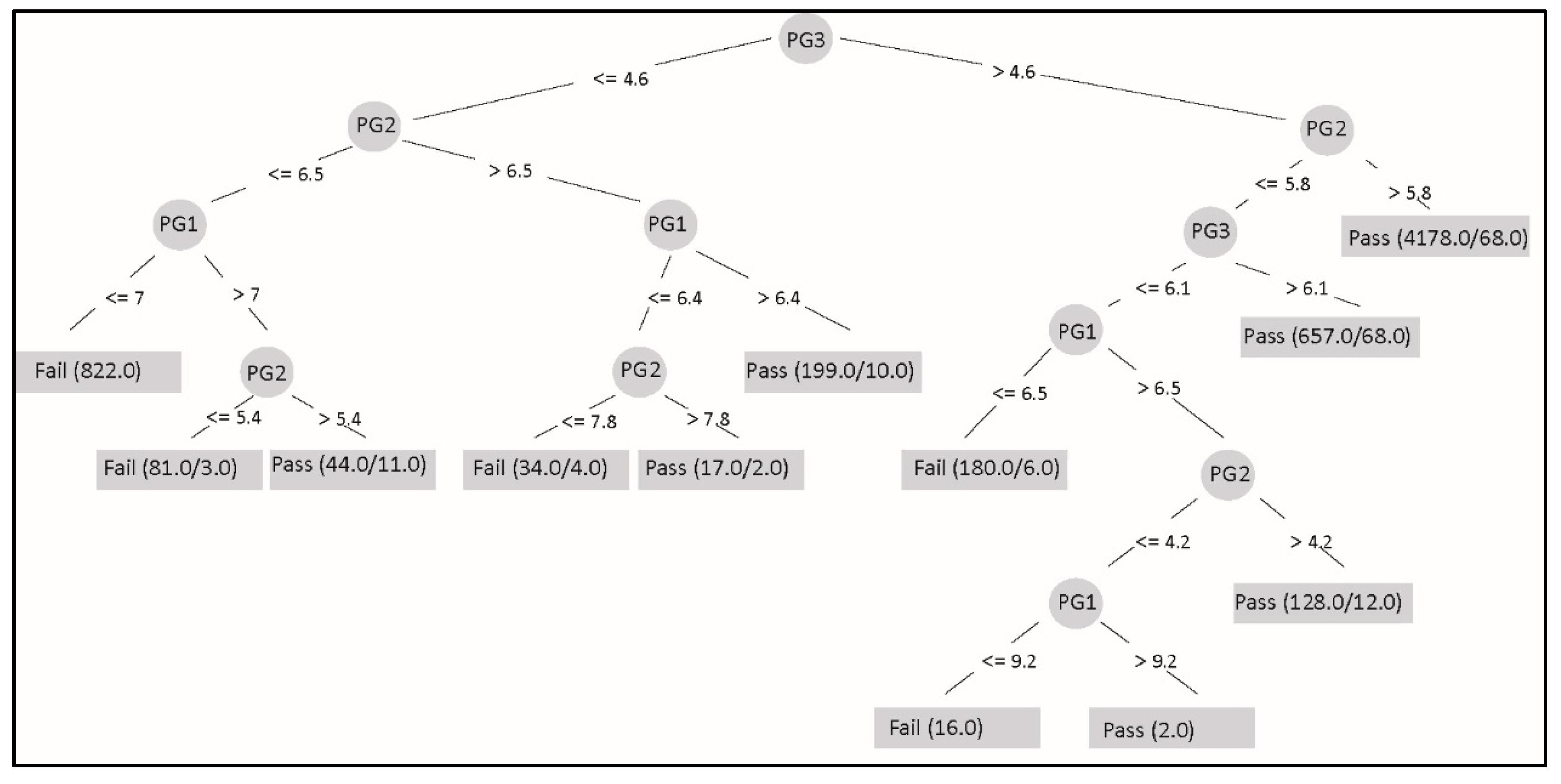
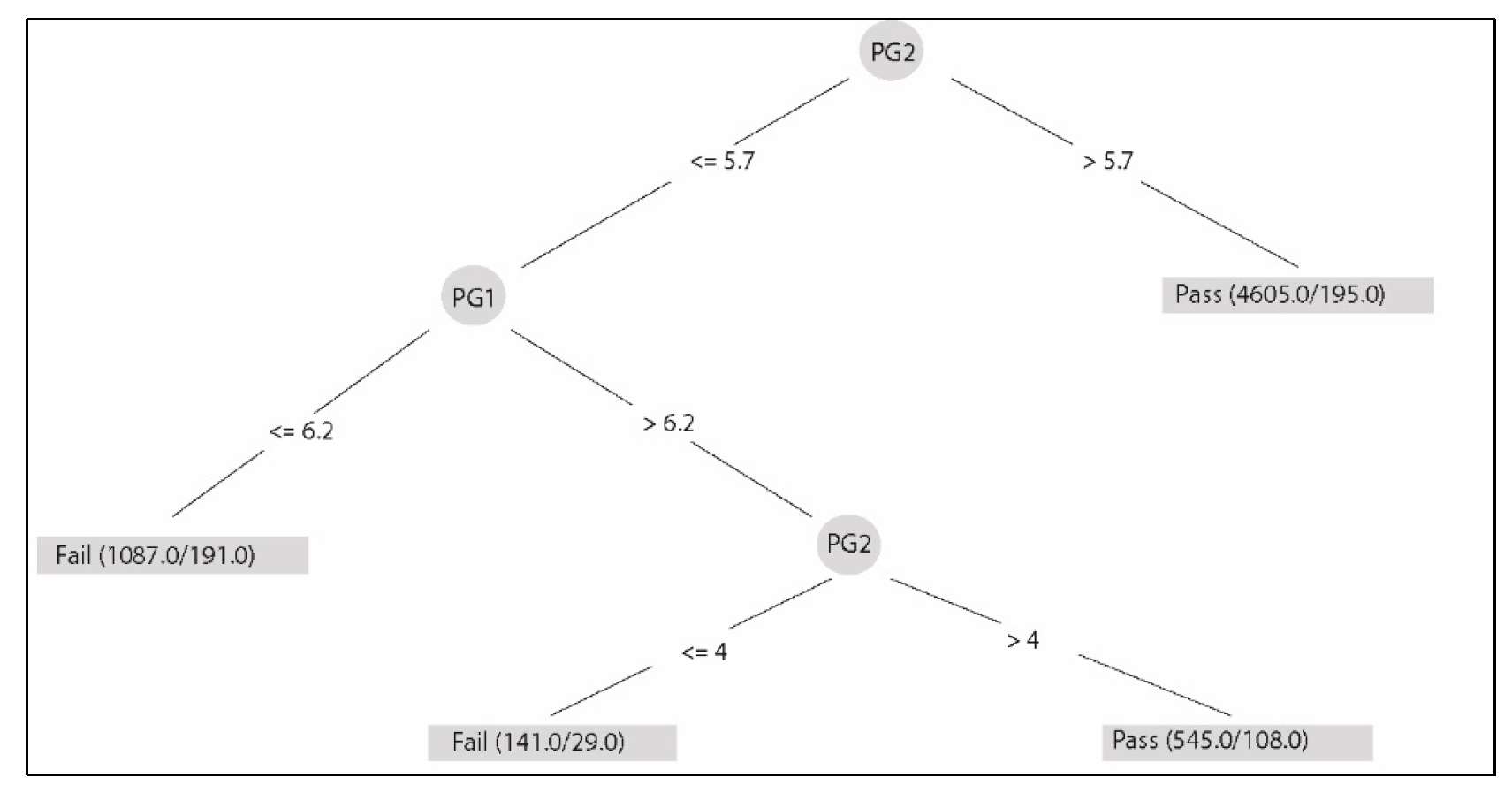
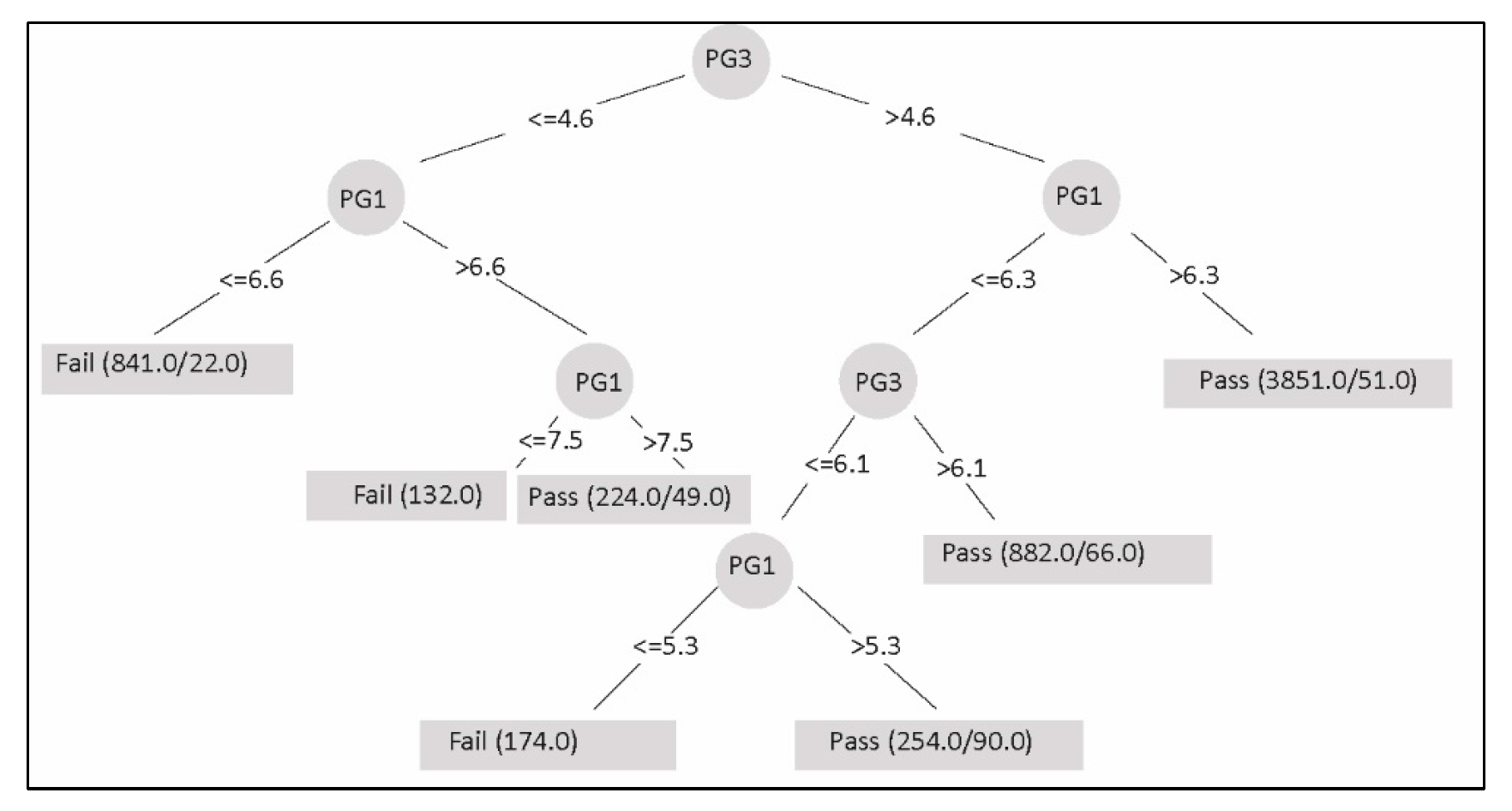
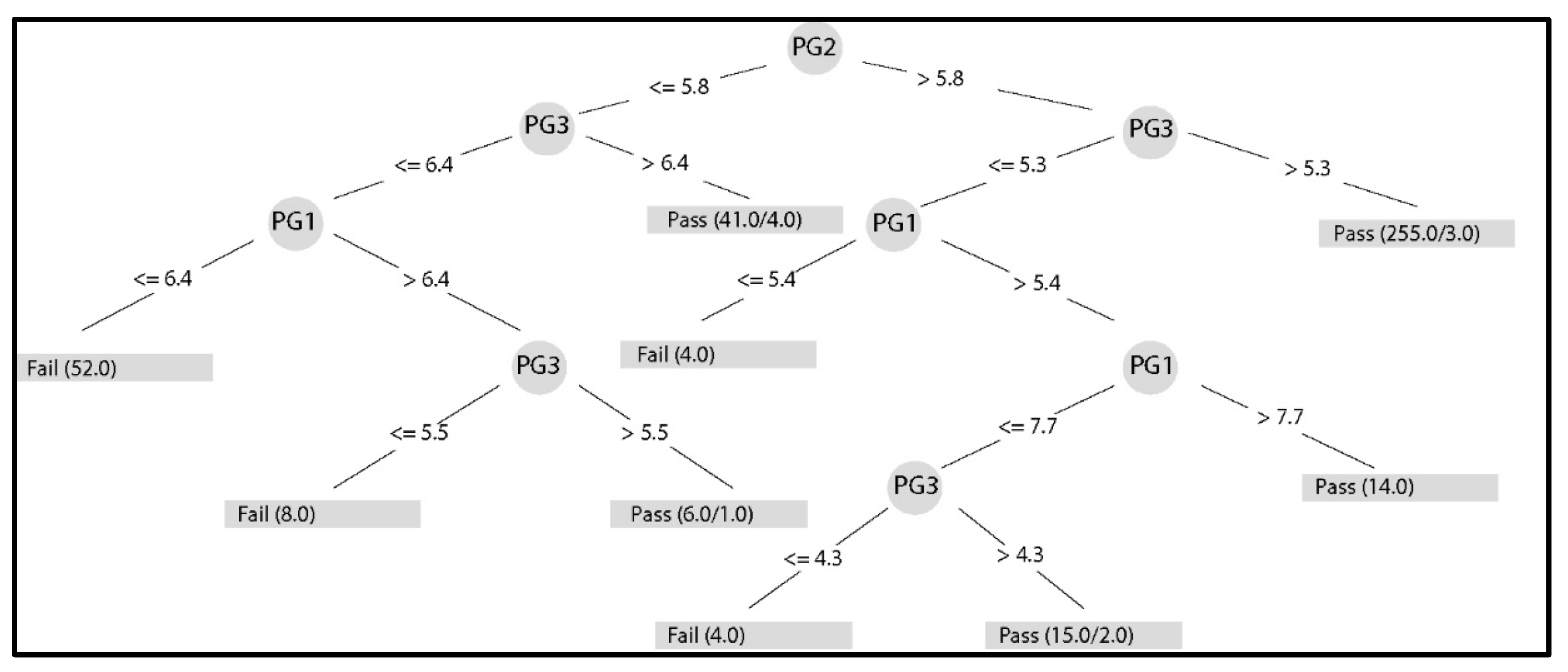
Table 1 shows a sample of the dataset. In order to pass a subject, the student must obtain a FG (FG) equal to or higher than 6. The FG is composed of three partial components (i.e., PG) weighted differently: PG1 is 35%; PG2 is 35%; and PG3 is 30%. This formula applies equally to all subjects and is a curricular definition for the entire university.
In the data preprocessing phase, duplicate records and null value records in components PG1, PG2, and PG3 were eliminated. In addition, in this phase the subjects of the knowledge areas Economy—Administration and General Education—Languages were eliminated. Another important task was executing a process to anonymizing the data that was carried out to comply with international data protection standards. This process consisted of eliminating or substituting the personal data fields (identification number, names, and surnames) of both students and teachers.
Before the dataset was loaded into the WEKA (
https://www.cs.waikato.ac.nz/ml/weka/) (Waikato Environment for Knowledge Analysis) machine learning software to carry out a series of experiments, it was of interest to observe and study the dataset in terms of visual graphs.
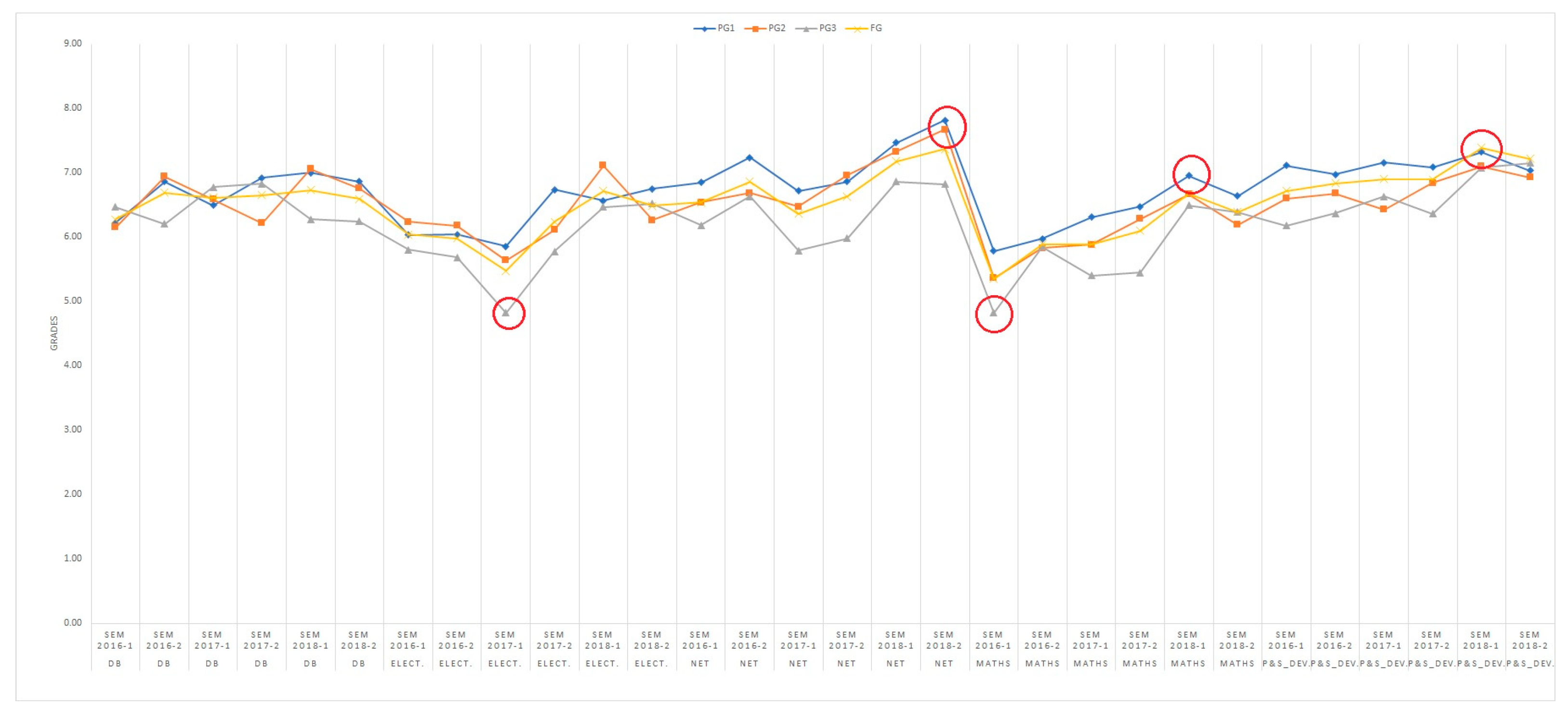
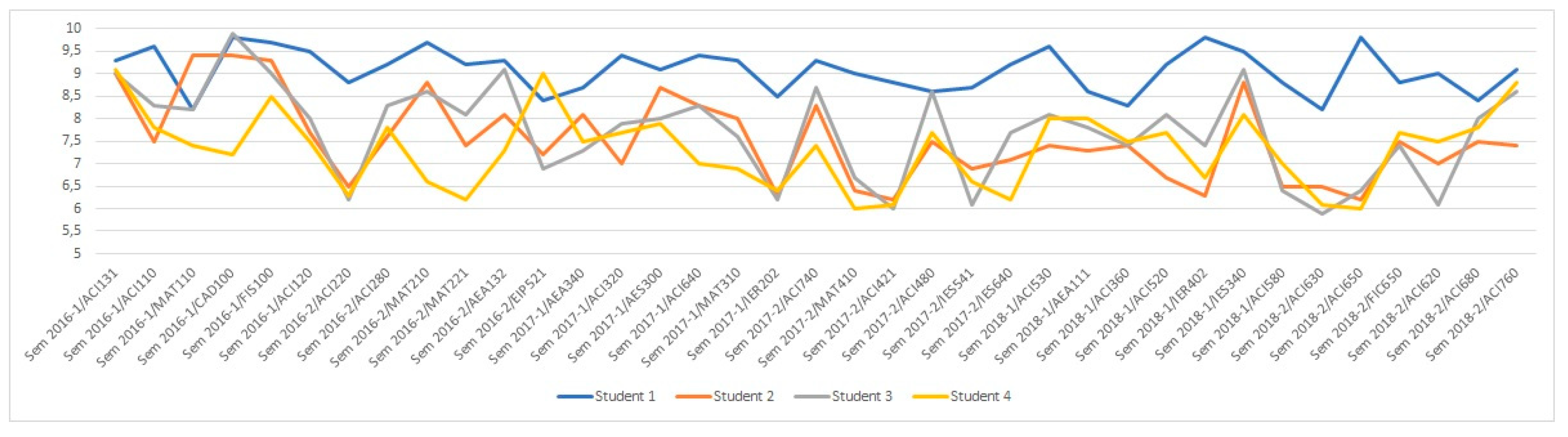
Figure 3 shows the evolution of student grades from the first semester of 2016 to the last semester of 2018, showing the four-color lines for every grade PG1, PG2, PG3, and FG.
It is striking to verify that in general, there is a trend of similar grades by area. Inclusive, as can be seen in some interesting deviations that have been highlighted with a red circle. These peaks represent ascending and descending trends in grades by area of knowledge. It is possible to think that this could be due to virtual groupings (similar grades are obtained in the same area) by professors of subjects within the same area. Or, it could even be due to similar criteria in the evaluation of these professors who belong to the same area.
It is interesting to deepen the analysis, since, after consulting the course coordinators of the knowledge area, at first glance, it seems that these similar peaks of grades graphed in
Figure 3 respond to a coincidence. For the analysis, it must be taken into account that a subject, in a certain area of knowledge, can be taught by different professors. In addition, in spite of the fact that the evaluation criteria are uniformly managed in the university, each teacher applies the academic freedom in their evaluation methods.
In
Figure 3, some interesting deviations are highlighted with a red circle, with first highly descending peaks and then two others as highly ascending. It is worthwhile studying what these situations might be due to. At first, it seems the explanations could have to do with students attaining good grades in their first tests and then their grades deteriorating as the course advances. That might be the reason why PG3 decreased and vice versa with the last two red circles that show that the students at the end studied harder to get a better FG. In addition, there is an important factor that, since the semester 2018-1, the percentage weightings of each PG changed:
From 2016-1 to 2017-2, the FG was calculated as follows:
In these periods, students put their greatest interest (and effort) at the beginning of the course, PG1 and PG2. In many cases, just with these two PGs, they were able to pass the subject (although with the minimum mark required) and, therefore, neglected their academic performance in the PG3. For this reason, as of semester 2018-1, the FG is calculated as follows:
From this semester, it was observed that students improved their grades in PG3.
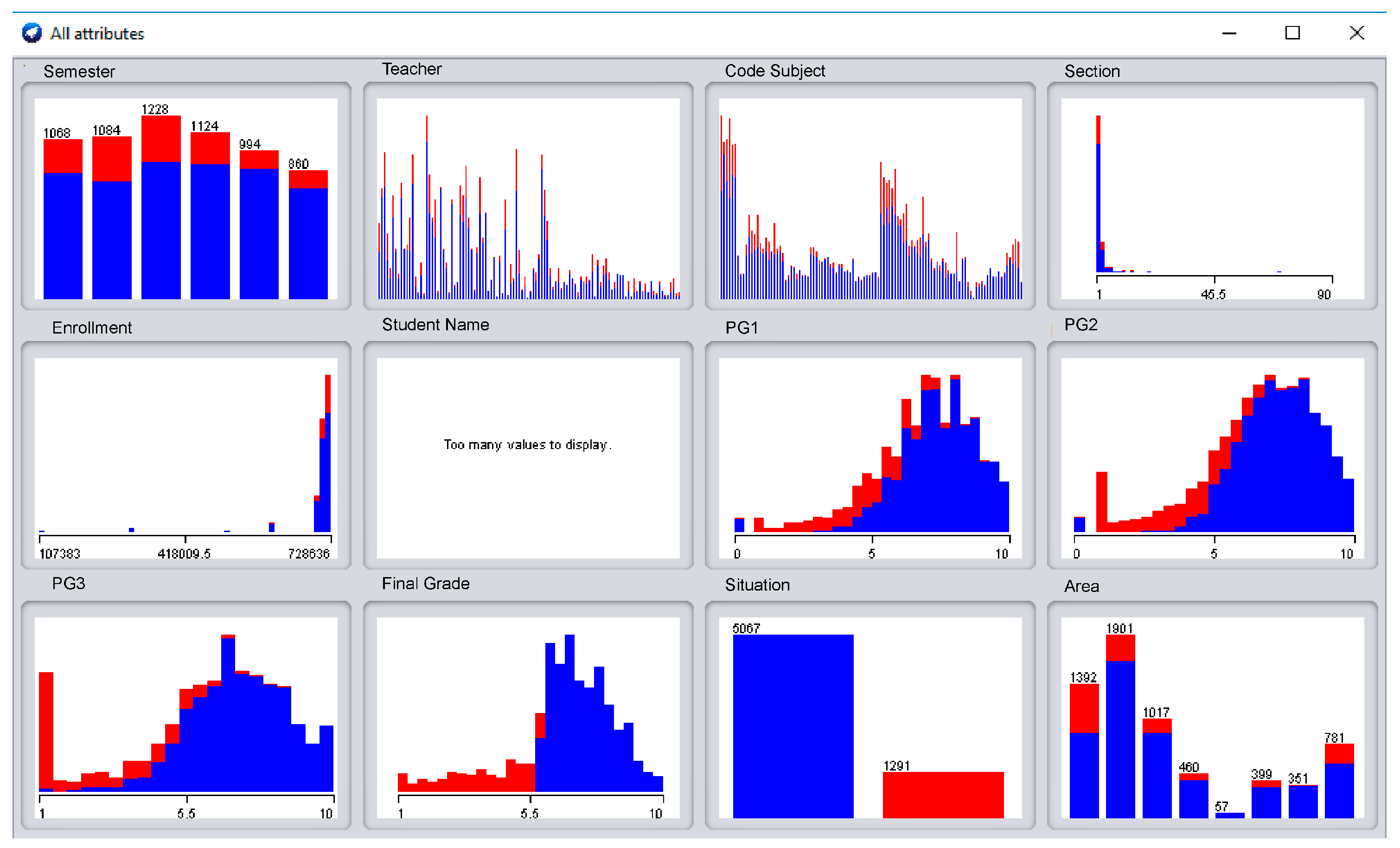
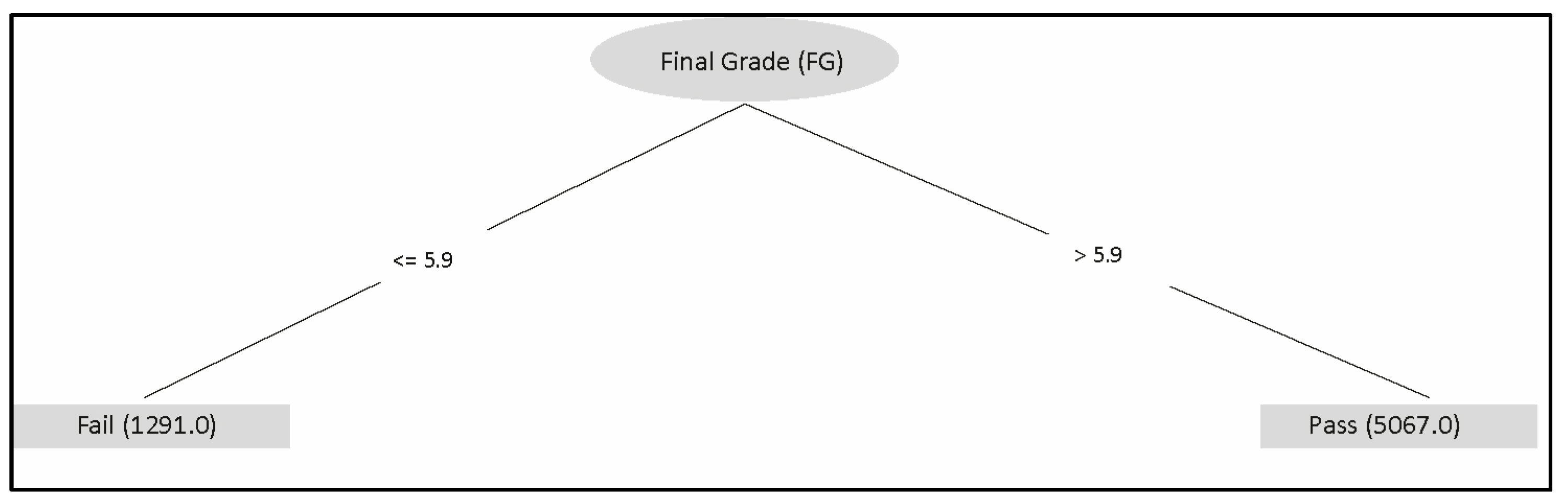
Figure 4 shows all the data loaded graphically to more easily appreciate the correlation between all the columns with respect to the final result (pass or fail the course, column “Situation”; red = “fail”, blue = “pass”). The aim of this figure is to show dashboards where it is possible to measure the influence of and relationship between every particular feature regarding the FG (Situation). Evidently, there are cases where that correlation is clearly identifiable. This FG, named “Situation”, shown in
Figure 4, clearly identifies (almost with a perfect line) that up to 5.6, the FG will be “fail”, whereas over this value, the FG will be “pass”.
Most of the remaining dashboards are not as straightforward to interpret. They often show mixes of “red & blue” to confuse the correlation. Of course, there are general signs of these indicators, like the PGs (PG1–PG3), which indicate a trend to blue when the value increases, and they are red when the value is low. In fact, this is the clear objective of an indicator, obvious and concise.
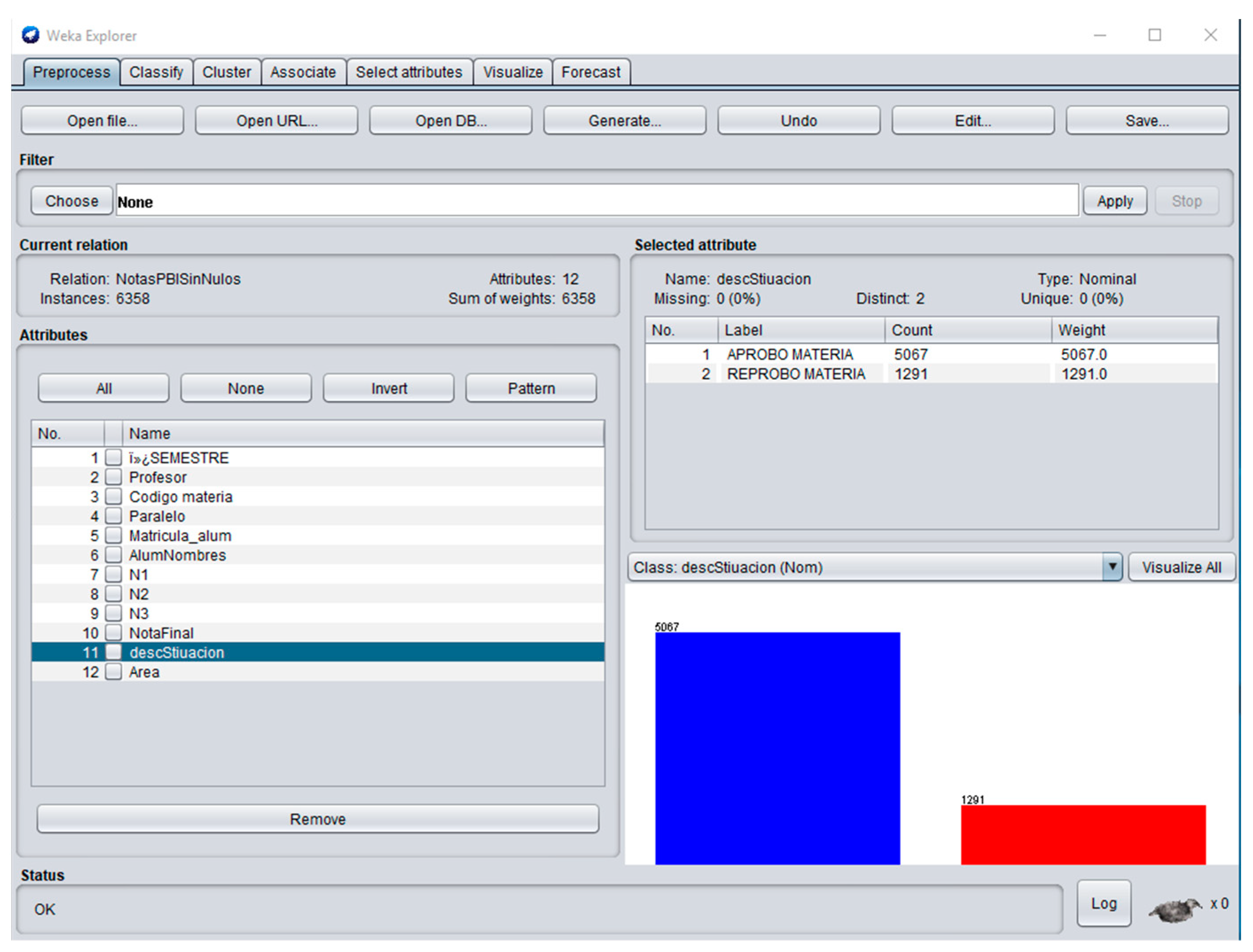
It is also worthwhile mentioning the variables “Area” and “Code Subject”, as it is widely believed that a particular area, as well as a specific subject, have a direct connection with the FG. The dashboard of “Code Subject” is harder to explain due to the high number of subjects. We could appreciate higher concentration of red in the central area, whereas at the beginning and just after the middle, there is a good proportion of blue. Nevertheless, there will be always a majority of blue as the classes (pass and fail) are totally unbalanced (5067 vs. 1291, respectively), as can be seen in
Figure 5.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}