1. Introduction
Disasters cause hardship and adversity for people [
1], badly disrupt the functioning of a locality, and lead to human, economic, material and environmental losses that are beyond the control of a population’s ability by applying its own resources [
2,
3]. In the past few decades in developing countries, more than 2 billion people have suffered due to climate-related hazards. Alone in 2010, almost 385 natural disasters worldwide killed more than 297,000 people, affected over 217 million people, and around 123.9 billion USD worth of assets were damaged [
4]. Similarly, in the four decades from 1970 to 2010, in South Asian countries alone, 980,000 people died, and another 2.4 million people were seriously affected. Assets worth 105 billion USD were damaged and around 1333 major disasters struck in South Asia [
5]. There are hundreds more catastrophes that do not attract as much attention but nevertheless have equally devastating impact. A major threat to South Asian countries is global warming. Pakistan is ranked in the top 10 among the most vulnerable countries to climate-induced disasters. Major natural disasters since independence have caused economic losses worth
$29 billion and killed approximately 113,000 people. As estimated, the country requires nearly
$40 billion to cope with the adaptation of climate change [
6]. Unfortunately, disasters will increase five-fold over the coming 50 years in Pakistan [
7,
8]. Disasters cause causalities, disabilities and losses of assets that create not merely financial problems for those affected, but also impact them psychologically.
In all stages of a disaster, logistics play a very important role in the success of humanitarian relief. Holguín-Veras et al. [
9] stated that humanitarian logistics (HL) is a very extensive field, and therefore it is impossible to fit it into single definition. Rabta et al. [
10] reported that HL, the technical term, includes procurement, transportation and relief materials’ warehousing from the origin point to the beneficiaries’ location. For a mixed array of disaster operations, HL is an umbrella term, which covers both response and developmental phases of disasters [
8]. HL is one of the central activities in a catastrophe. However, HOs have not yet recognized and defined this fact. It is also noted that particularly relief agencies do not keep in their team a sufficient number of logisticians and also do not provide a proper training to make them effective humanitarian logisticians [
1]. This indicates that HL always has a lower priority within humanitarian organizations (HOs), despite being a factor that can determine the success or failure of disaster relief operation (DRO). Even though, the participation and cost of logistics account for almost 80% of relief operation [
11]. Hence, efficient disaster relief supply chain (SC) is imperative because logistics serve as a bridge between disaster preparedness and response, between distribution and procurement and between field and headquarters.
The resources shortage and competition for funding raise the significance of transparent HL [
12]. Information sharing in logistics leads to an increase of organizational capital and effectiveness and efficiency of DRO [
13]. Globally, both profit and nonprofit organizations and firms are under increasing pressure to be more transparent. Donors are the most important stakeholders with the greatest power in HL [
14]. They are motivated by the specific purpose of providing funds to the HOs to reduce disaster risk. If the utilization and performance of resources are poor in any organization, the donors can discontinue funding. The donors want to have greater transparency, visibility and accountability [
11]. Fair distribution of relief items is a sign of effective HL [
15,
16]. Effective HL can not only decrease risk, cost and timelines, but can also save lives and reduce suffering. Hence, HL must be fair, fast and safe.
When relief help is a matter of life or death for those afflicted, some people are merely interested in money and are not interested in helping the victims. Furthermore, all HOs want to help those affected by disaster. But unwillingness appears due to a number of reasons, such as corruption and noninterest of the government. Even, some governments hamper international humanitarian organizations (IHOs) from work in order to receive bribes [
17]. The involvement of local people in the HL process is also a hurdle in the way of fair distribution. Local influential people influence the humanitarian logistics service providers (HLSP) to control the list of beneficiaries and favor some specific groups [
18] in the houses’ allocation [
19] and add the name of their own well-wishers to the recipient lists during cash or relief distribution [
20]. The elite’s homes are used as a distribution center. Therefore, logisticians are distributing aid items according to the elite’s will instead of the needs of the victims [
18]. On the other hand, due to financial shortage [
19], and strong competition for funding, some HOs mostly focus on fundraising but not on spending funds efficiently [
14]. In addition, HLSPs also offer bribes to the local influential people to remain quiet regarding poor quality of construction and non-distribution of relief items. Moreover, in DRO, distribution of unfair and low-quality products is a common phenomenon. HOs sometimes unload trucks at night so that the public cannot notice the warehouse [
19].
The case study of the Philippines Super-Typhoon Haiyan (Yolanda) in November 2013 shows a lack of transparency. As a good example of a lack of transparency and high-profile corruption, in the Haiti earthquake the American Red Cross received half a billion US dollars in donations but built only six houses and falsely claimed to have built houses for 130,000 victims [
21]. Furthermore, the flood of 2010 in Pakistan where only 43% eligible households truly got Watan cards [
22,
23] indicates unfair distribution. Further, the 2008 Wenchuan earthquake in China, the 2015 Nepal earthquake, and the Indian Ocean Tsunami in 2004 demonstrate a lack of transparency. The sex-for-food scandal in 2002 in West Africa is a sign of corruption beyond financial corruption. Hurricane Katrina, and wars in Afghanistan, Iraq [
19] and Nepal are all examples of high-profile corruption and a lack of transparency. The range of claims exhibit the risk of increased corruption and a lack of transparency, not only in developing but also in developed countries.
The performance, efficiency and effectiveness of HL cannot be increased as a whole because multiple situations arise depending on the intensity, location and type etc., of the disaster. It is therefore vital that the HLSPs adjust, modify and reconfigure their HL by enhancing their performance, efficiency and effectiveness to the situation arising from these calamitous events. All these aspects lead scholars to think about the problem from various angles with the intention of making small contributions to raise the effectiveness of HL. As noted, other factors that affect the human suffering of survivors in the aftermath of disasters are the unfair distribution of resources due to a lack of transparency. Therefore, the role of incorporating transparency in HL is being realized. Research papers that have focused on transparency in other fields have mainly concentrated on the combination of transparency and trust of stakeholders. Such models proposed by references [
24,
25,
26,
27] are formulated to build trust and increase performance. The potential of transparency in HL and their positive impact on HL effectiveness have therefore remained relatively unexplored. Hence, the key objective of this research is to present a full picture of the need for HL transparency and how this can be achieved. More specifically, the aim of the study is to address this question: “How can the performance, efficiency and effectiveness of HL be improved through transparency?” In addition, the state of the existing literature on transparency does not precisely specify how the construct should be conceptualized, how it relates to managing public trust in the organization, or how organizations manage transparency in terms of HL. Therefore, this study has three objectives. First, the literature on transparency is incorporated across academic disciplines to extend a complete understanding of transparency in structural dimensions and components. Second, the actual uses of transparency dimensions and the components mediated by public trust are analyzed. Third, the importance of those determinants in influencing the performance, efficiency and effectiveness of HL is examined. To fulfil these objectives, this research adopts a covariance-based structure equation model (CB-SEM) based on confirmatory factor analysis (CFA) with SmartPLS software was used.
This study argues that effective HL is determined by perceived public trust, whereas public trust occurs through the proposed dimensions and components of transparency. The study findings reveal that transparency enhances performance, efficiency and effectiveness through public trust in the context of HL. Furthermore, the findings contribute to the existing literature in HL and pave the way for further development in DRO. Research gaps are explored, and suggestions are made for future research studies to advance more effective HL operations.
The rest of this article is organized as follows.
Section 2 lays out the research theoretical model and hypotheses.
Section 3 examines the research methodology.
Section 4 details the study analysis and research findings.
Section 5 discusses the contributions and scope for future research. Finally,
Section 6 presents the study conclusions.
3. Research Design and Methodology
For this study, survey methodology has been used to empirically investigate the aforementioned relationships of the proposed model. More specifically, the survey methodology is applied to structure and describe the role of transparency in the effectiveness of HL. Based on experiences from previously published works, the survey strategy is an appropriate method. (Saunders, Lewis, et al. 2009) stated that the survey strategy is popular and common in business and management research. It is commonly used to economically collect a large amount of information from a sizeable population [
83].
For this study, three types of organizations were selected from Pakistan: HOs working under the umbrella of UN, IHOs and local HOs. quotative data were collected via survey technique using an online questionnaire. An initial approach was made to 281 NGOs found at
https://pakngos.com.pk/ngos and
https://reliefweb.int/organizations. A cover letter was accompanied with an online questionnaire (link of Google form) and contained a short introduction to the survey purpose. It was sent to the respondents via their email collected from the relevant website of the organization. Also, some of the respondents were contacted through Facebook messenger. To ensure the reliability of the questionnaire, it was reviewed by experts (professors and researchers) in the supply chain management area. The questionnaire was pre-tested several times to ensure that the format, wording, length and sequencing were appropriate based on expert opinion. During each successive pre-test, feedback was obtained from approximately 38 respondents. It helped in refining the enhancement of HL performance through transparency. In each subsequent test, the results reflected the reliability and validity of the construct. Finally, it confirmed that the instrument was ready to be applied in the main survey.
Purposive sampling was deployed to make sure that the targeted respondents were practicing expatriate logisticians for getting eloquent data for analysis. Patton [
84] stated that a purposive sampling method was applied as selections were made on the basis of the subjects having particular characteristics. Therefore, in the HL context a single data collection phase was used. The population considered in this research was comprised entirely of personnel engaged in logistics, procurement, storage, distribution, SC activities, or humanitarian work. Moreover, the organizations were selected based on their presence in any DRO. However, their participation in the DRO was further ensured by the introduction section in the questionnaire. The questionnaire (demographic section) confirmed their presence in any DRO. If they were not participating in any DRO, or if the qualification of the respondent was less than secondary school certificate, then their responses were excluded from the study. This was done to ensure the widest possible range of responses and to support the generalizability of the study results.
There is a little consensus on the suggested sample size for the structure equation model (SEM). A “critical sample size” is of 200. Furthermore, any number above 200 is recognized to provide appropriate statistical power for data analysis [
85,
86,
87]. Out of 344 questionnaires sent out, 231 responded to the e-survey. After excluding inappropriate questionnaires, 210 remained as a valid sample for analysis. This low response rate might be due to the target population nature. Those who participated in DRO are mostly mobile and perhaps were not able to respond. Furthermore, some participants probably felt that the information concerning this topic was very sensitive and hence declined to respond. Based on the topic sensitivity, the researcher guaranteed the organizations regarding the confidentiality of the information. Consequently, the names of the organizations and participants will not be revealed. A five-point Likert scale was used. The scale differs from prior studies. Because using coarser scale points (with fewer scale points) is easy for the respondent to read out the scale list completely and to answer on a particular issue as compare to finer scale (those with many scale points) ones [
88,
89,
90]. Furthermore, five- to seven-point scales also increase reliability and validity as compared to coarser ones. However, using further finely point scales will not bring any changes in reliability and validity. On the other hand, data collected with the five-point scale may be “bunched up” at the positive end of the scale due to providing limited options of scale points. In contrast, 10-point scale can decrease this negative skew by permitting for many degrees of positive response. In addition, 10-point scale may also reduce the total mean score rather than five- to seven- points scale [
91]. Furthermore, data collected with the 10- point scale rather than the five-point scale helps to minimize the problem of leniency and central tendency [
92]. Moreover, Smith et al. [
93] reported that using the five-point scale has less stability and consistency as compared to 10-point scale. In short, every scale point has pros and cons, but this is outside the scope of this research.
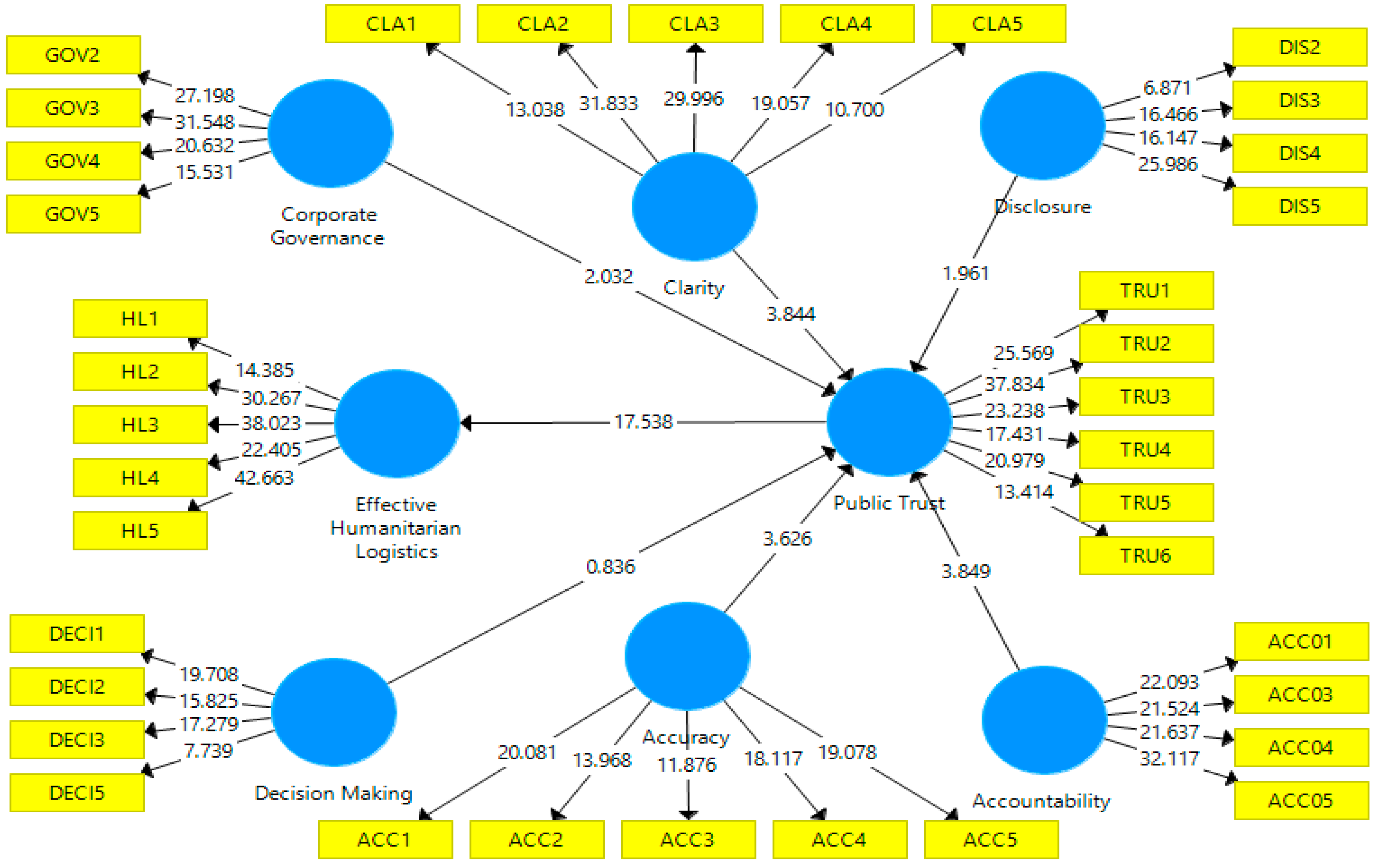
The CFA measurement model assessment is the first step of SEM. The main purpose of the measurement model evaluation is to state the pattern by which each indicator (measure) loads on a specific dimension and to assure the reliability and validity of the measures and constructs. In this research, different measures were used to test the items’ reliability, discriminate validity and goodness of fit (GoF). R square and adjusted R square were used to estimate Pearson’s coefficients. Cronbach’s alpha and the composite reliability (CR) were applied for convention measures of model reliability. Convergent validity is measured by using average variance extracted (AVE). Discriminant validity was measured through the Fornell–Larcker discriminant validity criterion and Heterotrait-Monotrait Ratio (HTMT). GoF was measured by using SRMR, NFI and RMS_theta. The predictive validity was measured using (Q2) r Stone–Geisser indicator. The variance inflation factor (VIF) was used to estimate multicollinearity. Finally, the psychometrical soundness of the hypothesized model was measured by using T-Test. The proposed measurement model of this study has eight constructs represented by 41 reflective measured parameters (indicators) using the covariance-based SEM (CB-SEM) method. Hence the selection of measurement items was based on a thorough review of the existing literature and evaluated by experts.
4. Analysis and Results
After formulating a conceptual model and constructing applicable indicators based on previous studies, the indicators were revolved into measurable variables. The study investigates how the different aspects of the transparency lead to an assessment of public trust, which in turn leads to effective HL. Based on the collected indicators in the research, the measurement model was formulated by incorporating the indicators into a questionnaire. The qualitative design of research gave information regarding how to construct these indicators. It was essential that the indicators were correctly used with exactly the same meaning by all respondents and that the measures precisely correspond with the research aims (validity). Therefore, each latent variable was illustrated in the questionnaire. For the purpose of research, it was decided to include questions regarding both variables and importance in the questionnaire.
Public trust in HOs for effective HL was found to have an association with demographic characteristics of HLSPs as also found by [
1,
94,
95]. In this study gender, age, qualification, experience and position in the organization and type and function of the organization were used. The data were measured after screening for normality. Likewise, missing and inappropriate data were removed from the dataset as discussed in the sample selection section. The remaining 210 respondents represented 41 measured parameters (indicators) for structural equation modeling.
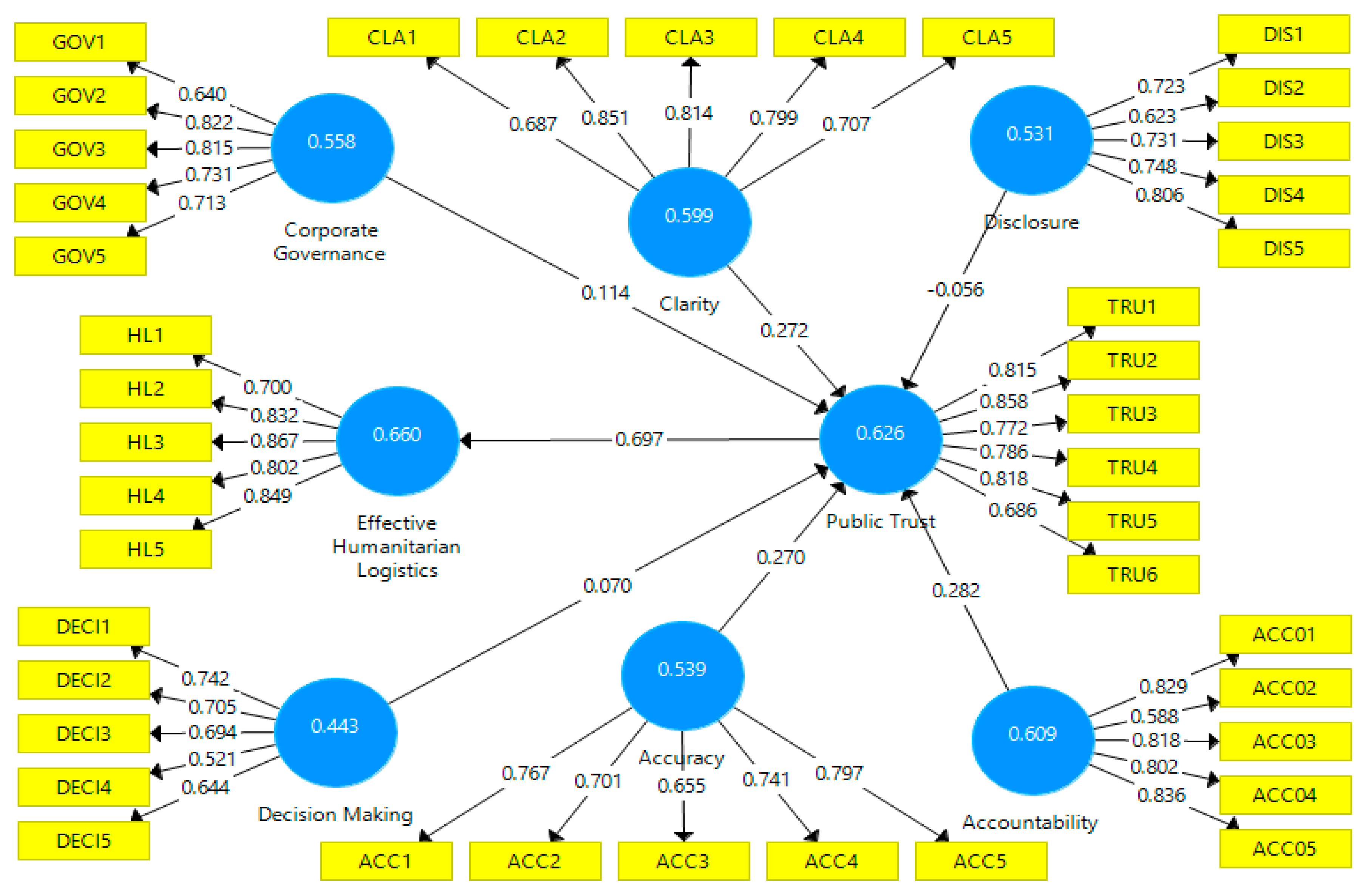
A two-step approach was used by the SEM. Firstly, CFA was used to construct reliability and validity, as seen in
Table 1. Second, after confirming through CFA, multiple fit indexes were used to evaluate SEM. Historically formative models have been the norm in partial least squares (PLS) modeling and reflective models have been the norm in CB-SEM [
96]. A path model is reflective if causal arrows in the path diagram go from the latent variable (factor) to the indicator measured variables. A path model is formative if the causal arrows go from the observed indicator measures to the latent variables. CB-SEM/(traditional SEM) has superior statistical technique for reflective models. PLS-SEM is an alternative to CB-SEM, where SEM is based on CFA and PLS regression on principal component analysis (PCA). De Winter & Dodou [
97] described that results obtained from CFA and PCA were usually comparable and that there is no basis to propose that either method is more perfect. Importantly, CB-SEM is preferred when the research purpose is confirmatory modeling. This specific research model is reflective. Therefore, traditional SEM/CB-SEM based on CFA with SmartPLS 3 software was used for this study.
The analysis of
Table 1, indicates the aspect investigated in the measuring models. Outer model loadings are the focal point in reflective models, denoting the paths from a latent variable to its representative indicator variables. Outer loadings denote the total contribution of the indicator to the description of its latent variable. Each these results are discussed next in detail.
4.1. R Square and R Square Adjusted
The first analysis is the estimation of Pearson’s coefficients R Square (R
2). The R
2 value evaluates the portion of the variance of the endogenous variables, is explained by the structural model and indicates the adjusted model quality. For the area of the social sciences, (Cohen [
98] classified R
2 = 2% as having a small effect, R
2 = 13% as a medium effect, and R
2 = 26% as a large effect [
99].
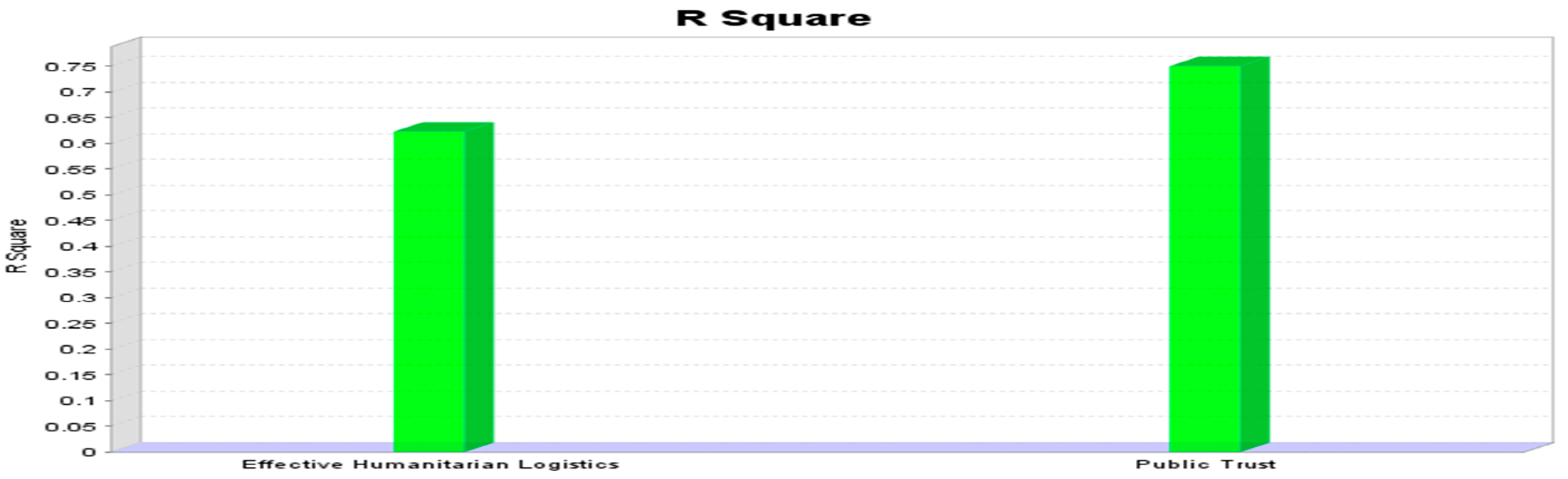
Table 1, reveals that adjusted R square is very close to unadjusted. The R
2 and adjusted R
2 values are shown for (factors) endogenous latent variables. In the path model this is the most common effect size measure and gives an interpretation similar to that in multiple regressions. In this research, the only endogenous variables were effective HL and public trust. For the endogenous variable effective HL, the R
2 and R
2 adjusted values are 0.627 and 0.626, respectively (see
Figure 2). For public trust, the R
2 and R
2 adjusted values were 0.749 and 0.742, respectively, indicating that about 63% of the variance in effective HL was explained by the model. Likewise, almost 74% the variance in public trust was explained by the model in the presence of the control variable. The values of R
2 and adjusted R
2 were higher. Therefore, the values represent a perfect fit of the study model. Furthermore, in this study, there are direct effects on public trust and indirect effects on effective HL mediated by public trust.
4.2. Reliability of the Measurement Model
4.2.1. Cronbach’s Alpha
Cronbach’s alpha is a conventional measure of model reliability, measuring the internal consistency reliability of a construct. However, CR on is recommended as more appropriate because it considers the indicators’ differential weights [
100,
101], whereas Cronbach’s alpha equally weights the indicators [
102]. By rule of thumb commonly, a reliability of 0.60 or higher is suitable for exploratory purposes, 0.70 or higher is suitable and 0.80 or higher is good for confirmatory purposes. Cronbach’s alpha below 0.60 indicates that the indicators construct does not fit well together. Cronbach’s alpha addresses the question of whether the constructs for latent variables show convergent validity and henceforth display reliability [
103].
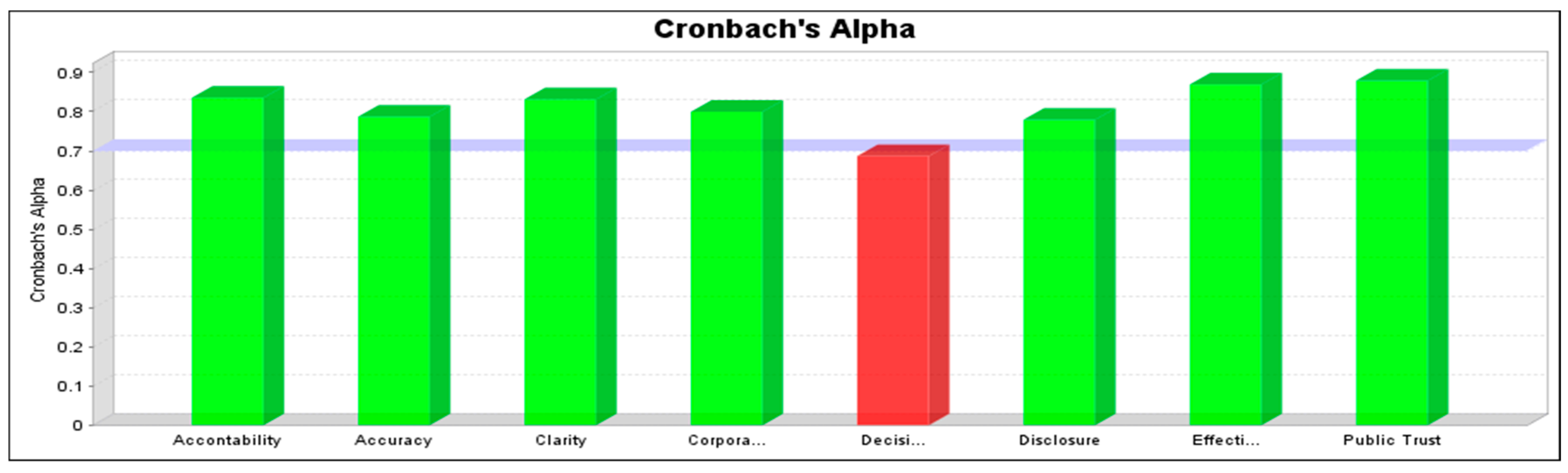
In this study, as shown in
Table 1, and
Figure 3, the Cronbach’s alpha coefficient for all constructs is higher than 0.70 except for decision making which is 0.69. The model demonstrates a high reliability. The decision-making latent factor falls short of this cut-off. The items used in this research have content validity since the measurement items selection was based on a thorough review of the existing literature and evaluation by experts.
4.2.2. Composite Reliability (CR)
CR is a slightly more lenient internal consistency model reliability criterion. It uses similar cutoffs as for Cronbach’s alpha [
102]. In a reflective model, CR is a preferred alternative to Cronbach’s alpha as a test of convergent validity because Cronbach’s alpha can over or, more usually, underestimate scale reliability. CR ranges from zero to one, with one being higher estimated reliability. In an adequate model for exploratory purposes, CR should be equal to or greater than 0.60 [
101], 0.07 or higher for an adequate model for confirmatory purpose [
96]; and 0.80 or higher is good for confirmatory model [
104]. Greater than 0.90 CR shows that the multiple indicators are minor wording differences of each other rather than being representative measures truly of the construct.
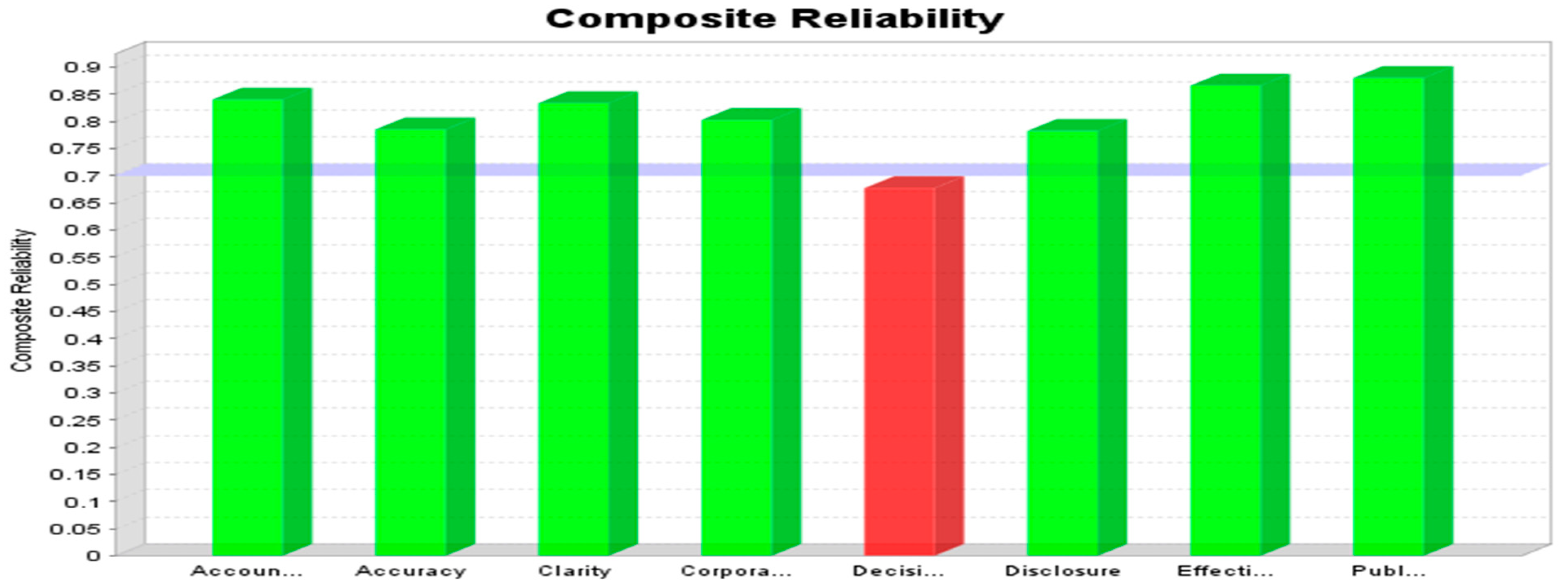
As seen in
Table 1 and
Figure 4, the reliability measure shows good reliability for both the dependent and independent constructs, except for decision making, which shows poor reliability.
CR is also shown by a higher loading of factor of a measurement item on its latent construct. The model had a high CR score as it exceeded the recommended value of 0.7, except for decision making, which was 0.68 and which does not exhibit internal consistency model reliability. Furthermore, there was no very high CR (>0.90), which may indicate that the multiple indicators have no wording similarity. Likewise, the model does not reflect a design problem but is a truly representative measure of the construct.
4.3. Validity of the Measurement Model
Neuman [
105] stated that a measure can be reliable but not valid. Nevertheless, it cannot be valid without being reliability. Cronbach’s alpha and CR do not guarantee construct validity. Therefore, convergent and discriminant validity should be considered.
4.3.1. Average Variance Extracted (AVE)
Convergent validity measures the degree to which the scales of the same construct positively correlate with other measures. High factor loadings on the same construct reflect that the observed variables converge. At least all factor loadings must be significant statistically and higher than 0.70. A loading of 0.70 highlights that the construct explains approximately 50%. AVE indicates the average communality for each latent variable in a reflective model. In an adequate model, AVE needs to be greater than 0.5 [
101], as well as greater than the cross-loadings. This means that the factors must explain at least half the variance of their respective constructs, and hence that AVE below 0.50 means error variance.
AVE may also be used to form discriminant validity by the Fornell–Larcker criterion. For any latent variable, the AVE square root should be more than its correlation with any other latent variable [
106]. For each item, the standardized factor loadings applied in this study on their respective constructs ranged from 0.521 to 0.836. Likewise, the AVE for each construct was greater than 0.50 except for decision making, demonstrating convergent validity.
Table 1 and
Figure 5, show that the construct elucidates greater than half of the variance of its indicators.
4.3.2. The Fornell–Larcker Discriminant Validity Criterion
The Fornell–Larcker criterion is the most widely applied discriminant validity approach with CB-SEM, whereas Voorhees et al. [
107] recommend HTMT.
Discriminant validity assessment by means of the Fornell–Larcker criterion produces divergent results for CB-SEM. In contrast, with values below 0.90, the HTMT criterion indicated that discriminant validity had been met [
100]. CB-SEM as the HTMT criterion solely rests on indicator correlations, whose values are independent of the SEM method used [
102]. In
Table 2, the Fornell–Larcker criterion reveals the useful discriminant validity of the present study data.
4.3.3. Heterotrait-Monotrait Ratio (HTMT)
As noted in SmartPLS documentation, use of the Fornell-Larcker criterion is a conventional method for measuring the discriminant validity of a SEM. This technique has shortcomings. Henseler et al. [
100] used simulation studies to reveal that a lack of discriminant validity is better detected by the HTMT ratio they developed.
The HTMT ratio is the geometric mean of the correlations of heterotrait-heteromethod (such as across constructs the correlations of indicators measuring different phenomena) divided by the monotrait-heteromethod correlations average [
102]. In a best-fitting model, heterotrait correlations must be smaller than monotrait correlations, i.e., the HTMT ratio must be below 1.0. Henseler et al. [
100] (p. 121) argue that if the value of HTMT is below 0.90 between a specified pair of reflective constructs, then discriminant validity has been established. Also, Gold et al. [
108] and Teo et al. [
109] use the 0.90 cutoff. In contrast Clark [
110] and Kline [
111] use the more stringent cutoff of 0.85.
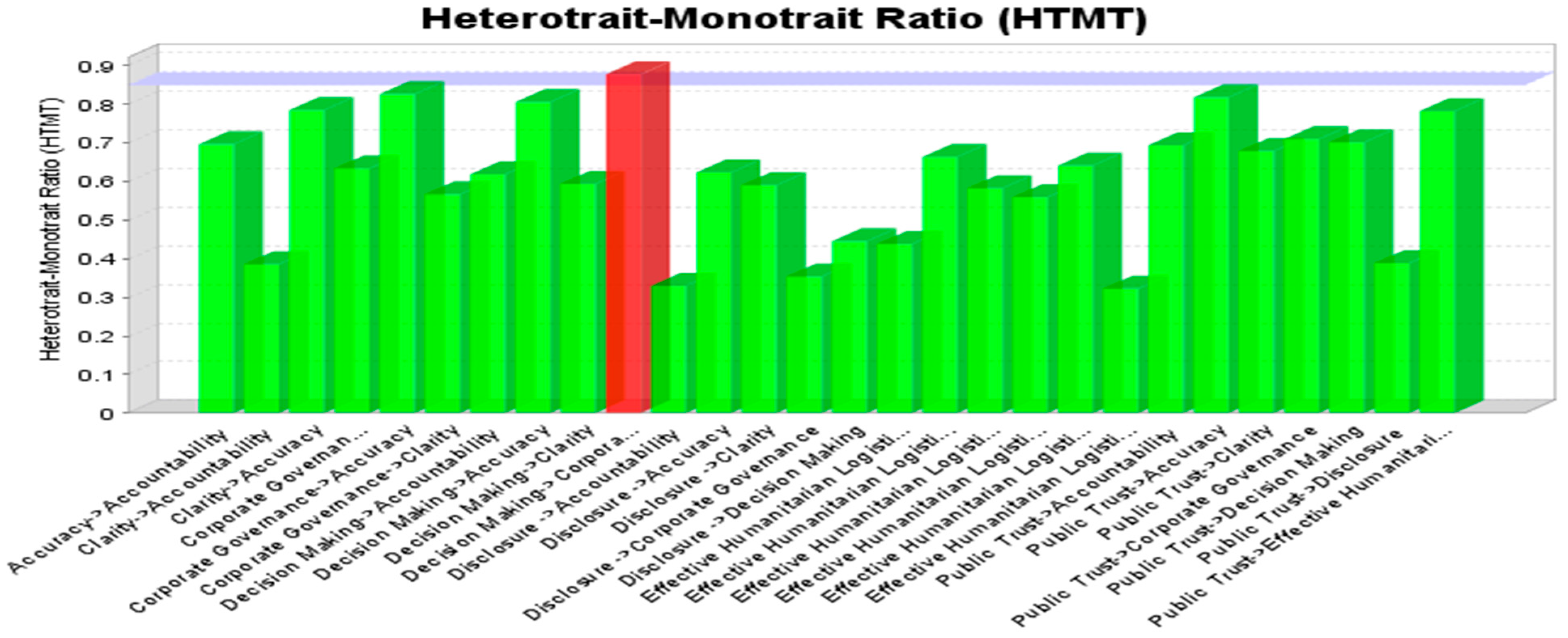
As per the above
Figure 6, the values of the latent variables were less than 0.85, except for that of decision making, where all the values were less than 0.90 and, therefore, the model has great discriminant validity.
4.4. Goodness of Fit (GoF) of Measurement Model
The next step was to assess the model fit of the SEM. The GoF was also measured for the hypothesized model to estimate its applicability for the prediction [
112]. There is no global GoF measure existing in PLS-SEM, unlike CB-SEM, and therefore CB-SEM is perfect for causal models and testing hypotheses. Model GoF reflects how well the specified model among the measured parameters reproduces the covariance matrix.
The model GoF was assessed to compare the proposed model with the observed or actual data. If the relationships are constant with each other, then the model fits may be considered a reliable justification for the hypothesized relationships. Over the past few decades, a minimum of 24 fit indexes have been recommended [
113]. For model fit there is presently no universal agreement on which measures should be preferred. Therefore, researchers recommend the use of multiple fit criteria. The various indicators designed for evaluating the model’s GoF of a model are Parsimony Fit Indices, Absolute Fit Indices and Incremental Fit Indices. Parsimony Fit Indices are primarily meant to evaluate fitness in relation to the complexity of a model and are useful in measuring competing models. Parsimony fit indices have not been considered for this study because there is no competing model. For this specific reflective model, the SmartPLS report displays various model fit related to the model quality as shown below.
4.4.1. Standardized Root Mean Square Residual (SRMR)
Absolute fit indices can measure either goodness or badness of fit of the proposed model. SRMR is a measure of the approximate model fit of the research and of the variation between the model-implied correlation matrix and the observed correlation matrix. The SRMR reflects the average magnitude of such variances, with lower SRMR being well fit. Traditionally, a model has good fit when SRMR is below 0.08 [
114]. Some scholars use the more lenient cutoff of below 0.10. As seen in the above
Table 3, for this study the analysis generated SRMR values of 0.07, which is well within the acceptable value. Therefore, on the Absolute Fit Indices’ parameter the model appeared to give a good fit.
4.4.2. Normed Fit Index (NFI)
One of the first fit measures suggested in the SEM literature is the NFI by Bentler et al. [
115]. The NFI values must be between zero and one. The closer the NFI value to one, the better the model fit. NFI values of 0.9 or above mostly represent best fit. The NFI denotes an incremental fit measure. A major disadvantage is that it does not penalize model complexity. The more parameters in the model, the better the NFI result. Due to this disadvantage the value is not expected to be very high. The data set for this study generated an NFI value of 0.68, which is not very high but is well above the threshold level. Therefore, on the Incremental Fit Indices’ perimeter also, the model was presented to be a good fit model.
4.4.3. RMS_theta
The RMS_theta is the root mean squared residual covariance matrix of the outer model residuals [
116]. This fit measure is useful merely to evaluate purely reflective models. The RMS_theta assesses the level of correlation with the outer model residuals. It builds on the outer model residuals and denotes the differences between the values of predicted indicator and the observed indicator. The measure must be close to zero to reflect good model fit, because it may imply that correlations are too small (close to zero) between the outer model residuals. RMS_theta with values of 0.12 or below reflect a well-fitting model, and higher values indicating a lack of fit [
100].
As shown in
Table 4, the value of 0.12 shows a well-fitting model. The fit statistics show that the theoretical model is adequate to fit the data. The overall fit confirms that the relationships among independent variables mediate the variable and that the dependent variable is significant.
The fit statistics show that the theoretical model is acceptable to fit the data. The total fit confirms that the relationships among independent variables mediate the variable and that the dependent variable is significant. CB-SEM performs factor analysis during its execution. The results of CFA are shown in
Table 1.
Finally, most GoF measures resulting from the model assessment using CB-SEM meet the recommended guidelines, but only after indicator deletion. For this specific study for measuring GoF, the result was good even though no item was deleted. Specifically, the analysis result in an rms-theta of 0.12 meets the recommended guidelines. Likewise, the SEM is the SRMR at <0.08 and also meets the suggested guidelines. Due to these disadvantages, the NFI was not expected to be very high. The dataset for this study generated an NFI value of 0.68, which is well above the threshold level. Therefore, on the Incremental Fit Indices’ perimeter also, the model presented as a good fit model.
4.5. Multicollinearity in Reflective Models
A rule of thumb is that problematic multicollinearity can be observed when the variance inflation factor (VIF) coefficient is above 4.0 whereas some researchers use 5.0 as a more lenient cut-off. Even reference [
117] argued that VIF values <10 indicate an absence of multicollinearity [
118]. VIF is the contrary of the tolerance coefficient, for which multicollinearity is marked when tolerance is less than 0.25. This research performed VIF in SmartPLS to check for multicollinearity. The results shown that each indicator has a VIF value <3, which confirms the absence of any multicollinearity issue in the study. There were no issues of multicollinearity between the variables (dependent and independent) which can cause problems in interpreting CFA results. VIF of the indicators are presented in
Table 5.
4.6. “Predictive Accuracy” Criteria (Estimation with Blindfolding)
The blindfolding procedure should be used for reflective models. Blindfolding utilizes a cross-validation strategy. It reports cross validated redundancy and communality for constructs as well as indicators calls criteria of “predictive accuracy”. For a reflectively modeled endogenous factor Q
2, the cross-validated redundancy is also known as Stone-Geisser Q
2, a model fit measure. The Stone–Geisser Indicator (Q
2) assesses how closely the model approaches its anticipated position. Values greater than zero must be obtained in this assessment (See
Table 6). A perfect model must have Q
2 = 1 (which indicates that the model replicates reality—without errors) [
99]. There is a Q
2 value in the model for each reflectively-modeled endogenous factor. A Q
2 value higher than 0 indicates that the model is suitable to predict that factor, a value with a negative or 0 value indicates that the model is irrelevant to the prediction of the given endogenous factor. Cohen [
98] reported that 0.02, 0.15 and 0.35 represent a “small” “medium” and “high” effect size, respectively.
For this study, Q2 is 0.30 and 0.35. Therefore, this reflective model has a high degree of predictive relevance with regard to the endogenous factors of public trust and effective HL. The values of Q2 indicate that the model is accurate and that the constructs are important for the general adjustment of the model.
4.7. Psychometrical Soundness of the Measurement Model
CB-SEM performs both CFA and path analysis during its implementation. The results of CFA are shown in
Table 1. Although the 41 retained items comprising 8 variables met the reliability and validity requirements, the measurement model parameter estimates must be statistically significant in order to prove the psychometrical soundness. The two popular parameter estimates are T-Statistics (item standardized factor loadings) and squared multiple correlations. For this study T-statistic will be considered using SmartPLS software.
The statistical significance was set at the level of 0.05 alpha (two tailed), and parameters (e.g., item factor loadings) related with t values of ±1.96 or above are statistically significant. Factor loadings of items with t values less than ±1.96 are non-significant statistically.
For this study, in order to test the significance of cited relations, the bootstrapping module was used. Eliminating the four observed variables (indicators) from the proposed model resulted in t test values that were significant for all the assumptions except for one.
Table 7, and
Figure 7, reveal that all the 37 retained items were loaded significantly on their corresponding constructs in the revised measurement model. As seen in
Figure 7, all the values are 1.96 or above except for hypothesis 5 which is non-significant. In all the cases except one the HO was accepted.
4.8. Summary
A two-step approach was used by the SEM. Firstly, CFA was used to construct reliability and validity, as seen in
Table 1. Second, after CFA confirmation, multiple fit indexes were used to evaluate SEM. All constructs in the measurement model showed greater reliability and validity except for decision making. After confirming through CFA and SEM, the psychometrical soundness of the measurement model was tested. Student T test was applied to test the seven study hypotheses. The 37 measured variables with eight constructs were taken in combination to develop the structural model. In the initial structural model all factor loadings were significant at
p < 0.05, except the relationships between decision making and public trust. Hence a model without the above relationship was found to have a better model fit. The implications of these findings are discussed in the next section in detail.
5. Discussion, Contributions, Practical Implications and Scope for Future Research
HL is growing in maturity and is being progressively investigated. This research has attempted to construct a model for measuring transparency sets of variables with HL. The model, based on previous studies, was verified to be a good fit for measuring the perceptions of multiple dimensions and factors of transparency towards HL. However, some recommendations and considerations can be formulated. One study result is the confirmation that transparency enhances performance, efficiency and effectiveness through public trust in the context of HL. This is an essential finding as it validates the transparency multidimensional view in a manner more rigorously than that of previous studies. The study findings will also enable scholars and practitioners to take a broader view of transparency and public trust in the HL context.
The hypotheses relationships proposed in the structural model between the latent variables were tested through student T test association with P. value. As seen in
Figure 7 and
Table 7, six of the seven hypothesized relationships between endogenous constructs were accepted. The result demonstrated that the dimensions of transparency, namely disclosure, clarity and accuracy are associated positively with public trust, which in turn is associated with the effective HL. This supports hypotheses H1, H2 and H3. The result shows that corporate governance is positively related to public trust in organization, supporting hypothesis H4. The results suggest that the accountability of an organization positively impacts on the public trust in an organization in the HL context, thus supporting H6. Similarly, the mediating variable (public trust) is positively related to the response variable (effective HL), supporting H7. Finally, the impact of decision making was not found to be significant. Decision making has poor association with public trust in the HL context; hence H5 was not supported.
The study results agree with the previous studies recommendations [
24,
25,
26,
29]. Furthermore, the proposed reflective model has a high degree of predictive relevance with regard to the endogenous factors of public trust and effective HL. There were no issues of multicollinearity between the variables, which can cause problems when interpreting CFA results. Overall, decision making is the weakest component to explain public trust. Cronbach’s Alpha and CR showed moderately strong relationships. However, the T-statistic test was not found to be a significant or strong explanatory component for public trust with decision making, possibly due to the indicators of the component. Nevertheless, deleting the four very weak indicators did not enhance the squared multiple correlations of decision making in the SEM model.
5.1. Theoretical Contributions
The study results may contribute in several important ways to the literature. First, the applicability of the proposed theoretical model to the HL field was confirmed. Second, the study findings will help scholars further expand the literature and develop further theories in the field of HL. Third, the literature dimensions of transparency, such as disclosure, clarity and accuracy, and the components of transparency, namely corporate governance, decision making and accountability, have only been, to the best of our knowledge, examined in the literature separately. In contrast, this is the first integrated theoretical model incorporating all these constructs that has been developed and validated empirically. Fourth, transparency should serve as a key tool for considering stakeholder distrust by disclosing the issues that are generally left hidden, thus improving the organization’s responsible management practices, decreasing corruption and creating a sense of accountability and building trust [
31]. This study extends these lines and identifies that corporate governance and accountability are imperative components of transparency. A key characteristic of a transparent organization is the fair distribution of resources, which in turn builds public trust and enhances the effectiveness of HL. Together, these dimensions and components of transparency with public trust and effective HL relations could significantly enrich this study approach to both organizational transparency theory and practice and also allow scholars to extend the HL literature by providing a broader view on the value of accountability in managing logistics. Finally, with insights obtained from stakeholder theory or principal agent theory, this study identifies transparency as a key to gain public trust. In contrast, public trust is undermined by corruption reports launched against HOs. They are very sensitive because most organizations get funds from public appeals through donors.
5.2. Practical Implications
This research has four valuable implications. First, the key purpose of this study is to identify the interrelationship between transparency dimensions and components with public trust, which in turn increase HL effectiveness. This mentioned issue is important because transparency in the HL context has a strong impact not only on the well-being of disasters survivors but also on other stakeholders. Second the findings are beneficial for all stakeholders in the management of disaster risk. They might be dealing with similar challenges while constantly seeking strategies to facilitate victims. They can evaluate their competitiveness better based on the factors presented in this study. Third, the research opens new insight into the topic. In short, during relief operations, transparency all the way from the supply funds by donors to the last-mile distribution by logisticians is the basis for fast (considering physical flow of relief items, excluding involved documentations) fair and safe HL. This can boost public trust and enhance the organization’s image. Similarly, Khan [
119] reported that foreign direct investment inflow to host countries is prevented by high corruption. Transparency enhances the image of the affected country, by reducing corruption and increasing the speed and fairness of HL. This is the key method for saving more lives. Lastly, nowadays transparency is a key to operate HL and it ranks high on the agenda owing to its huge impacts. Therefore, this study reveals the different aspects of transparency in HL. The planned methodology will serve as a road map to the HSCM to understand the variables that have to be managed to enhance transparency across HL.
5.3. Limitations and Future Research
Although this study has made significant contributions to the literature, the following four potential limitations of this research should be taken into consideration when analyzing the impact of the study findings.
First, since the transparency topic in HL is a comparatively new topic, researchers can benefit from the study findings and may apply them in their future observations. Second, decision making did not show a positive impact on public trust in terms of HL. Although existing theory supports the positive relationship of decision making with trust, future research needs to use a longitudinal design between decision making and public trust in terms of effective HL. It can utilize further variables in order to more completely establish the causal relationship between decision making, intermediate variables and effective HL. Furthermore, future study should also use a larger sample size in order to address the weak relationship of decision making with public trust. Third, the study results are limited to employee perceptions. The generalizability of the results needs to be cross-validated by larger sample size and various organizational/stakeholders’ settings such as donors, government, and victims. Benefits will be obtained by future research exploring other areas affected by similar problems and comparing the steps taken in these situations. Finally, the present study outlines a path for future researchers to investigate empirically the impact of increasing levels of public trust on HL performance more systematically, by treating public trust as a continuous (instead of dichotomous) variable. In addition, this study was based on the results of a questionnaire survey. Further mixed methods will enrich the findings.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}