3.1. The Relationships Matrix
Defining relationships between all possible attributes is not straight-forward and not practical because: (a) 175 attributes have been defined leading to 15,225 relationship pairs ((1752–175)/2) and, (b) each FWMS will present distinctive relationships that should be considered on a case-by-case basis. In addition, it is necessary to define different types of relationships between two paired attributes:
No relationship: both attributes assessed lack of any dependency to each other. For example, the ‘density’ of FW and the ‘job creation’ social indicator are not related, i.e., in order to calculate the value of one attribute the other one is not needed.
Indirect relationship: there is no mathematical connection between both attributes, although one attribute indirectly affects the possible values of the other attribute. This occurs when, for instance, the value of one variable limits the use of a FWMS, and therefore the value of the second attribute is affected. For example, ‘energy/nutrient value’ is only needed for animal feeding, and the use of animal feeding can be restricted by the ‘edibility’ and ‘state’ of FW. Although neither ‘edibility’ nor ‘state’ are needed to calculate the ‘energy/nutrient value’ of FW, their values can restrict the use of FW for animal feeding and therefore the need to assess ‘energy/nutrient value’.
Direct relationship: both attributes assessed are related, i.e., in order to calculate the value of one attribute the value of the other one is needed. For example, ‘carbohydrate content’ of FW is needed to estimate the ‘chemical oxygen demand’ of the wastewater generated from FWM.
Clearly, instances of no relationship can be disregarded and due to the impracticality of assessing indirect relationships, only direct relationships are identified and presented in this paper. The presence or absence of relationships between attributes has been represented in a 175 × 175 matrix with 30,450 relationships. Relationships ‘attribute A’ → ‘attribute B’ and ‘attribute B’ → ‘attribute A’ needed to be considered separately as they represent different dependencies. These relationships were identified based on the authors’ knowledge about the FWMSs studied. The complete relationships matrix can be found in
Supplementary Materials with the name
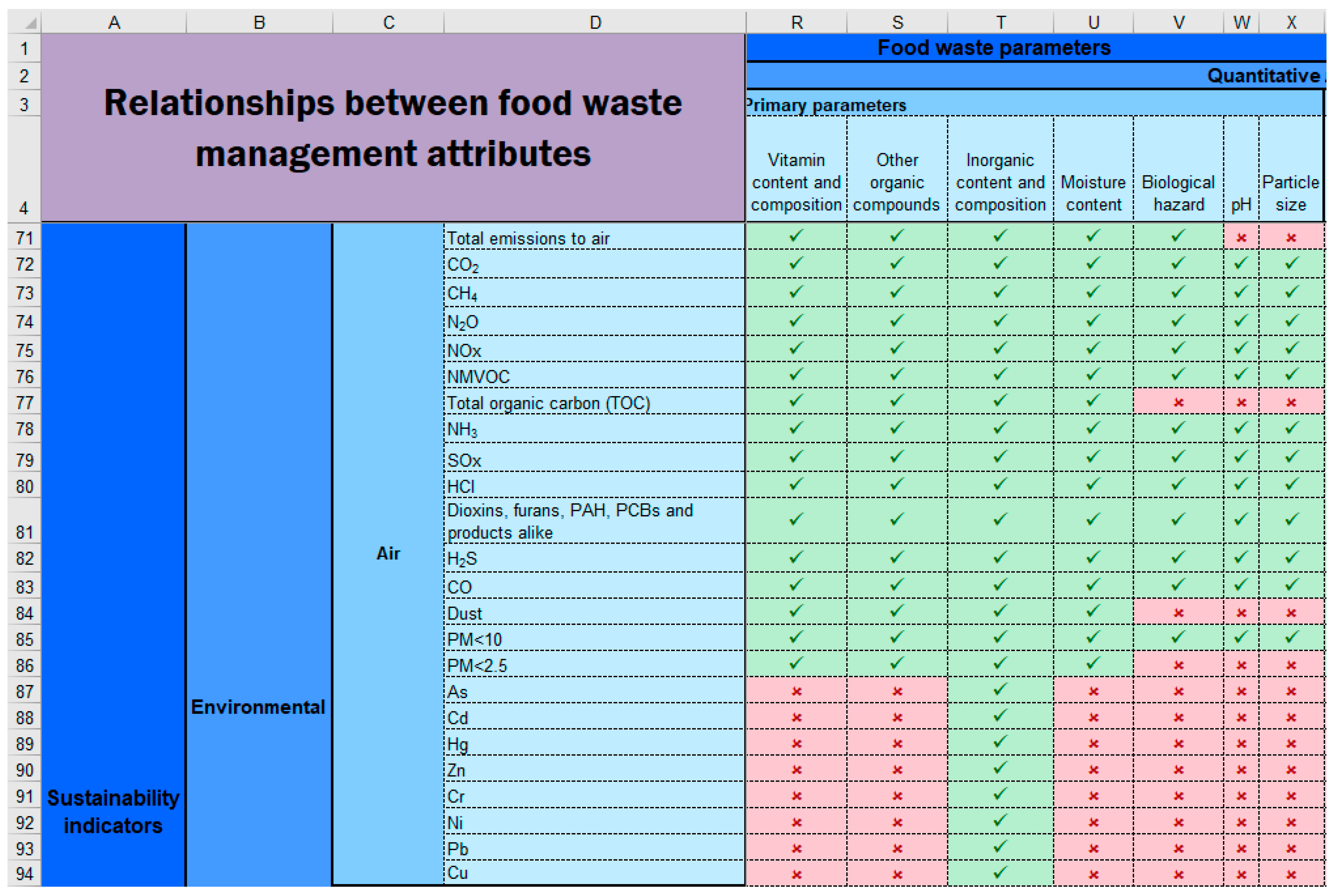
Supplementary Material—2. Relationships Matrices. Below, screenshots of two sections of the relationships matrix (
Figure 2 and
Figure 3) are provided as small examples of the full matrix. A green tick denotes presence of direct relationship and a red cross absence of a direct relationship.
In
Figure 2, it can be observed that ‘inorganic content and composition’ affects all environmental impact to air indicators listed in this example, since presence of different inorganic compounds can largely affect the composition of gases obtained from a FWMS. However, ‘other organic compounds’ have an effect in most compounds that can be created during treatment of FW, but not on the release to the atmosphere of inorganic substances such as As, Cd, and Hg, since their presence in the gases generated as suspended particles must be explained due to their original presence in FW.
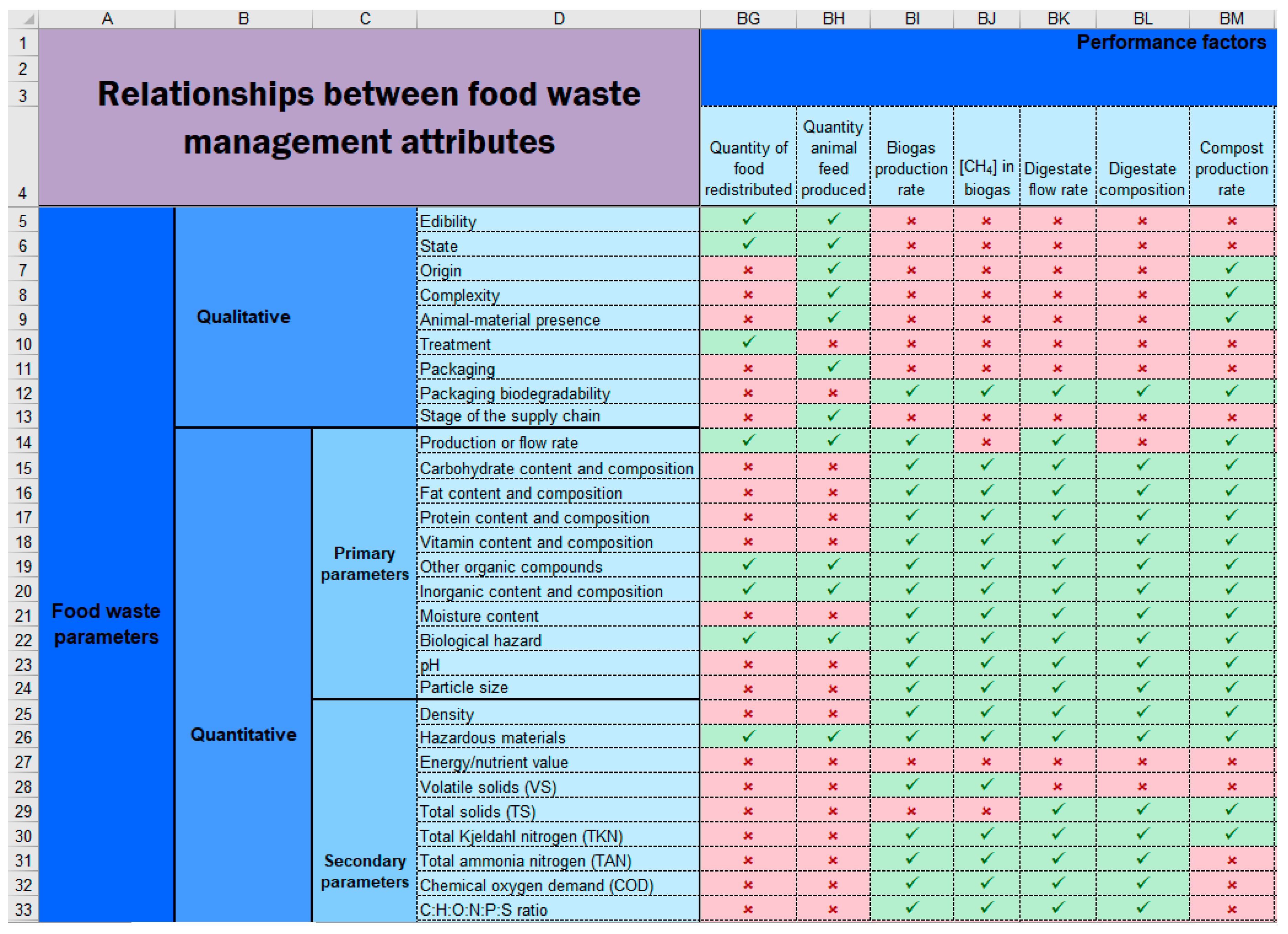
In
Figure 3, the attributes that affect ‘quantity of food redistributed’ and ‘quantity of animal feed produced’ are nearly the same, since both factors mainly depend on ‘production or flow rate’, ‘edibility’, and ‘state’, and the attributes which depend on ‘edibility’ and ‘state’. However, ‘quantity of food redistributed’ is also affected by ‘treatment’ and ‘quantity of animal feed produced’ by ‘packaging’ and ‘stage of the supply chain’.
A relationship between two attributes is considered to exist even if it only exists for some FWMSs and not for others. For instance, ‘biological hazard’ and ‘economic value of solid material’ are related for anaerobic digestion and composting, since biologically contaminated digestate or compost may not be spread on land. However, for thermal treatment with energy recovery, this is not relevant when the char obtained is used as fuel. Since there are some situations in which this relationship exists, it was considered that both attributes were related in the relationships matrix.
Possible chemical reactions are considered in this analysis. For instance, nitrogen present in a particular FW (and measured with ‘total Kjeldahl nitrogen’ and/or ‘total ammonia nitrogen’) may react and create substances such as N2O, NOX, NH3, and NO3−, which can pollute air, water, or soil. Therefore, when assessing chemical compounds that can be formed during the process (e.g., NH3), the precise initial composition of a FW is needed (i.e., content of carbohydrate, fat, protein, and other molecules and elements) since this will have a bearing on the generation of new substances. On the other hand, if it can be assumed that the substances were present in the initial FW sample and they have not been altered, only the relevant primary quantitative FW parameters must be assessed. For instance, in order to assess impact of nickel in soil, only the ‘inorganic content and composition’ must be assessed as a primary quantitative FW parameter, since nickel was not created during the FWM process.
Specific considerations that affect individual attributes can be found in the
Supplementary Material—2. Relationships Matrices, in the sheet “Notes on specific relationships”.
In its basic form the considerable size of the relationships matrix makes it cumbersome for use. Therefore, a number of actions have been taken to reduce its size and improve its usability. In all cases where a group of attributes are related to the same attributes, they have been combined. For instance, ‘CO
2’, ‘CH
4’, ‘NMVOC’, and ‘PM < 10’ are related to the same attributes: ‘density’, ‘hazardous materials’, and ‘volatile solids’ (in fact, that similarity is extended to the rest of the relationships matrix). Consequently, these attributes have been combined into one single attribute, namely ‘CO
2, CH
4, NMVOC and PM < 10’. Doing this for all relevant cases, the combination of attributes allows a reduction in the size of the relationships matrix from a 175 × 175 matrix with 30,450 relationships to a 136 × 136 matrix with 18,360 relationships. This version of the relationships matrix can be found in the
Supplementary Material—2. Relationships Matrices, in the sheet “Relationships Matrix (grouped)”.
Additionally, an alternative version of the matrix has been developed to further reduce the size of the relationships matrix: the streamlined relationships matrix. Since the stage of the FWMMP with more attributes correspond to environmental indicators, this list has been reduced to include only the most relevant indicators: ‘total emissions to air’, ‘CO
2’, and ‘CH
4’ for environmental impacts to air; ‘wastewater flow’, ‘chemical oxygen demand’, and ‘total suspended solids’ for environmental impacts to water; and ‘solid residue flow rate’, ‘nutrient content: N’, ‘nutrient content: P’, and ‘nutrient content: K’ for environmental impacts to soil. The selection of these indicators was undertaken considering the most commonly-used indicators to assess environmental impacts of FWM in the literature. This version of the relationships matrix can be found in the
Supplementary Material—2. Relationships Matrices, in the sheet “Relationships Matrix (strml.)”.
Similarly, the list of process and company variables has been reduced to include only the most relevant attributes. Accordingly, only the following company and process variables have been included in the streamlined relationships matrix: ‘distance to transport food waste’, ‘volume of equipment available’, ‘temperature’, ‘process time’, ‘pH’, ‘organic loading rate (OLR)’, ‘oxygen concentration/air ratio’, and ‘pressure’. This version of the relationships matrix, with the reduced environmental indicators and process and company variables, can be found in the
Supplementary Material—2. Relationships Matrices, in the sheet “Relationships Matrix (strml.2)”.
The dimension of the “Streamlined 2” relationships matrix is 73 × 73 and contains 5256 relationships.
3.2. Dependencies Lists
Once all relationships between attributes have been found, there is a need to assess the dependencies between attributes. For instance, for animal feeding, the relationships matrix shows that ‘energy/nutrient value’ and ‘economic value of solid material’ are related, but not which attribute depends on the other. In this example, ‘economic value of solid material’ depend on ‘energy/nutrient value’, since the value of ‘energy/nutrient value’ is needed to quantify the value of ‘economic value of solid material’, and not the other way around. All dependencies for each relationship have been assessed and listed in the
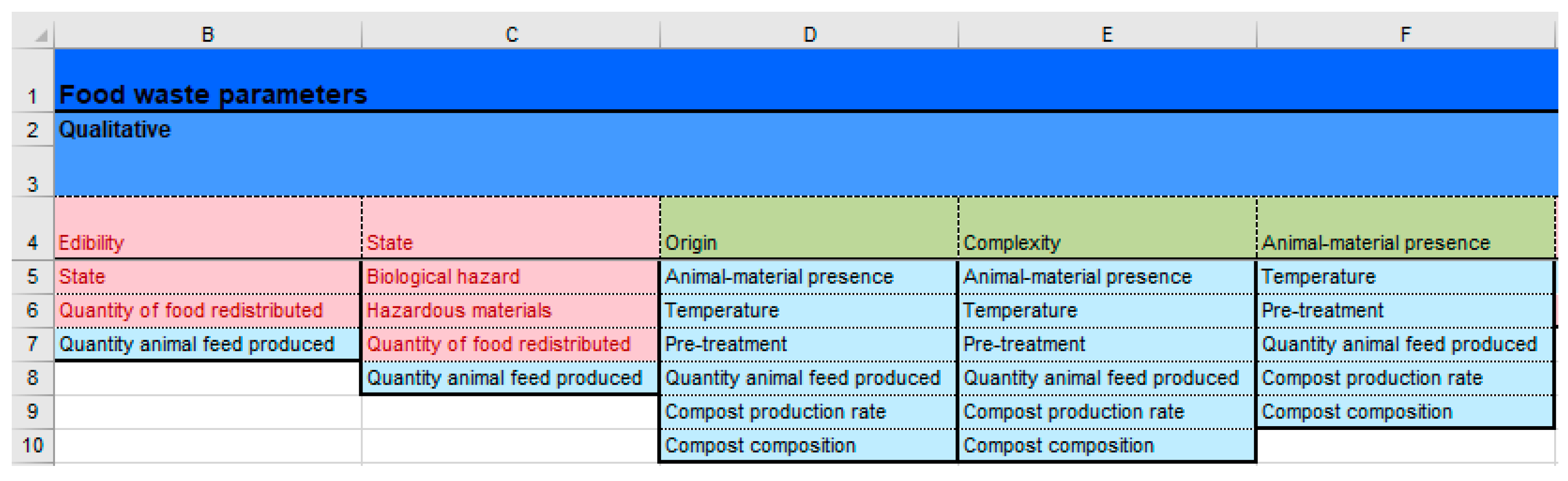
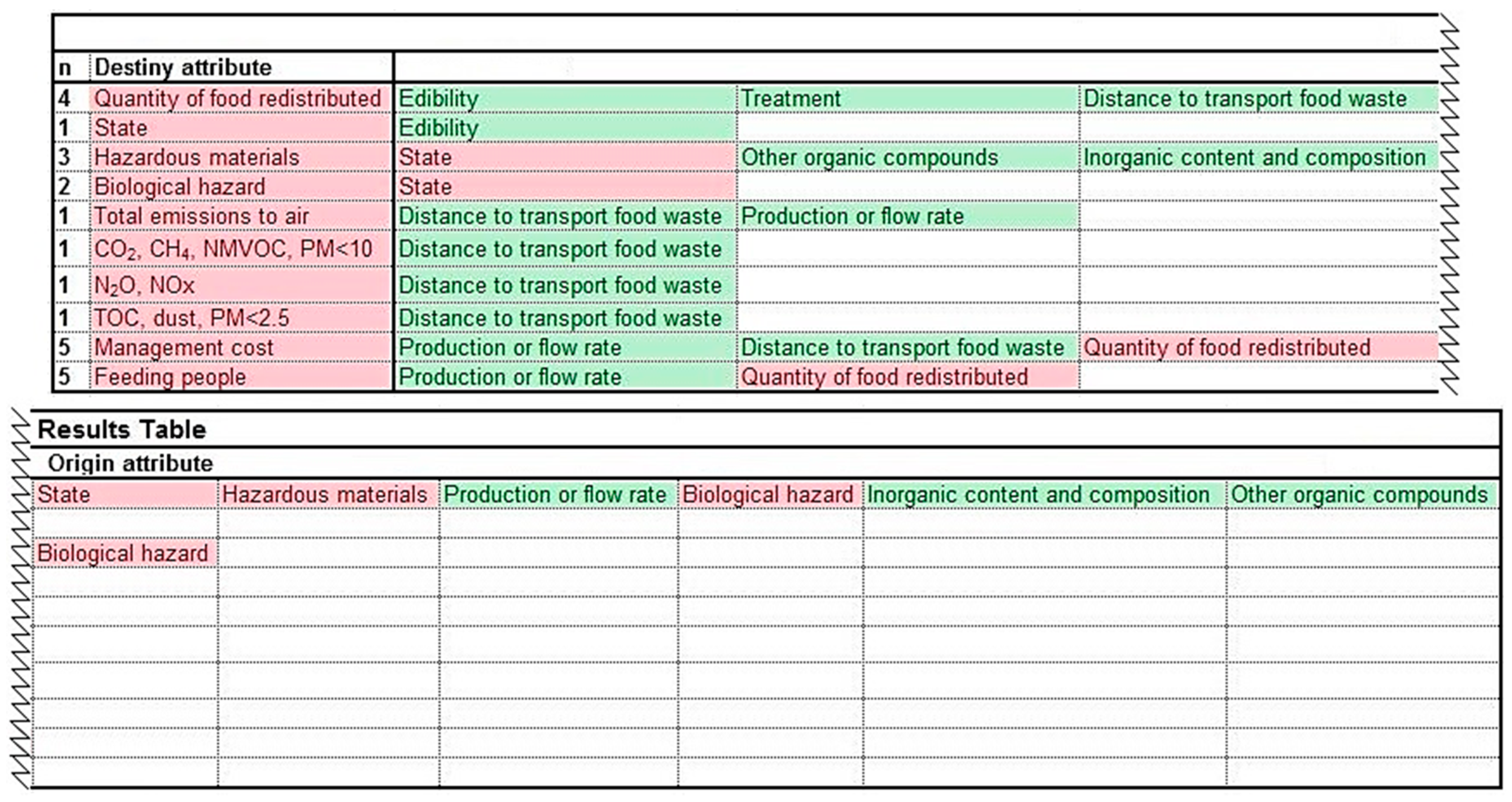
Supplementary Material—3. Dependencies List, in which each attribute is listed at the top of each column, and the attributes which depend on it are underneath. This procedure has been completed for all 136 attributes which were obtained after combining attributes (“Relationships Matrix (strml.)”). An example of a section of a dependencies list can be seen in
Figure 4.
Five dependencies lists have been created, one for each FWMS under consideration: redistribution for human consumption, animal feeding, anaerobic digestion, composting, and thermal treatment with energy recovery, and are provided in
Supplementary Material—3. Dependencies List, in their pertinent sheet. In each dependencies list, the attributes relevant to the FWMS assessed have been highlighted in red (as in
Figure 4), because only those attributes are needed to model that FWMS. For instance, ‘quantity of animal feed produced’ is not needed to assess redistribution for human consumption and therefore is not highlighted in
Figure 4.
Even with the specific list of attributes for each FWMS it is not always necessary to consider all relationships: some may be discarded for that particular analysis. For instance, ‘other compounds of interest’ were considered relevant for redistribution for human consumption, since they may include hazardous materials. However, for anaerobic digestion, composting and thermal treatment with energy recovery ‘other compounds of interest’ is also needed for attributes such as ‘total emissions to air’, since FW composition affects the gases generated from the processes. Hence, each dependency from each FWMS has been assessed independently to discard non-necessary dependencies. The discarded dependencies can be found in
Supplementary Material—3. Dependencies List, in the sheet “List of exceptions”.
3.4. Table of Assessment
It is important to be able to determine the attributes needed to assess a FWMS and also the attributes needed to assess unknown values of other attributes. This section describes a methodology for this purpose that has been designed in a way such that it can be used by any company or suitably knowledgeable person who manages FW, henceforth referred to as the ‘user’. The methodology is intended to be applied each time a new FW is identified, or the user becomes aware of a change in the known/unknown attributes.
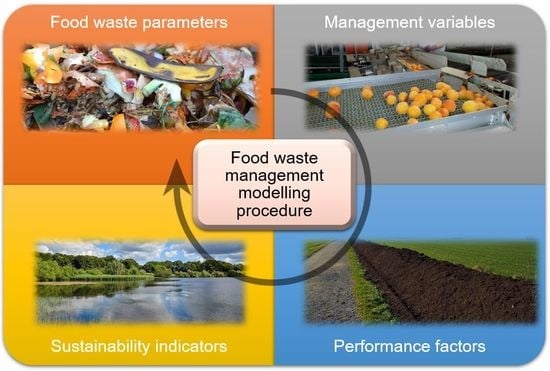
The main tool for this part of the FWMMP is the Table of Assessment. The Table of Assessment is built from the dependencies list, and it can used to obtain the results table, which in turn can be used to draw information flow diagrams, as shown in
Figure 1.
The user starts the analysis using the Table of Assessment, which is a spreadsheet that contains one sheet for each FWMS. The Table of Assessment can be found in
Supplementary Material—5. Table of Assessment. In each of the sheets, all attributes needed to model FWM for that particular FWMS are listed, which have been identified using the tables in
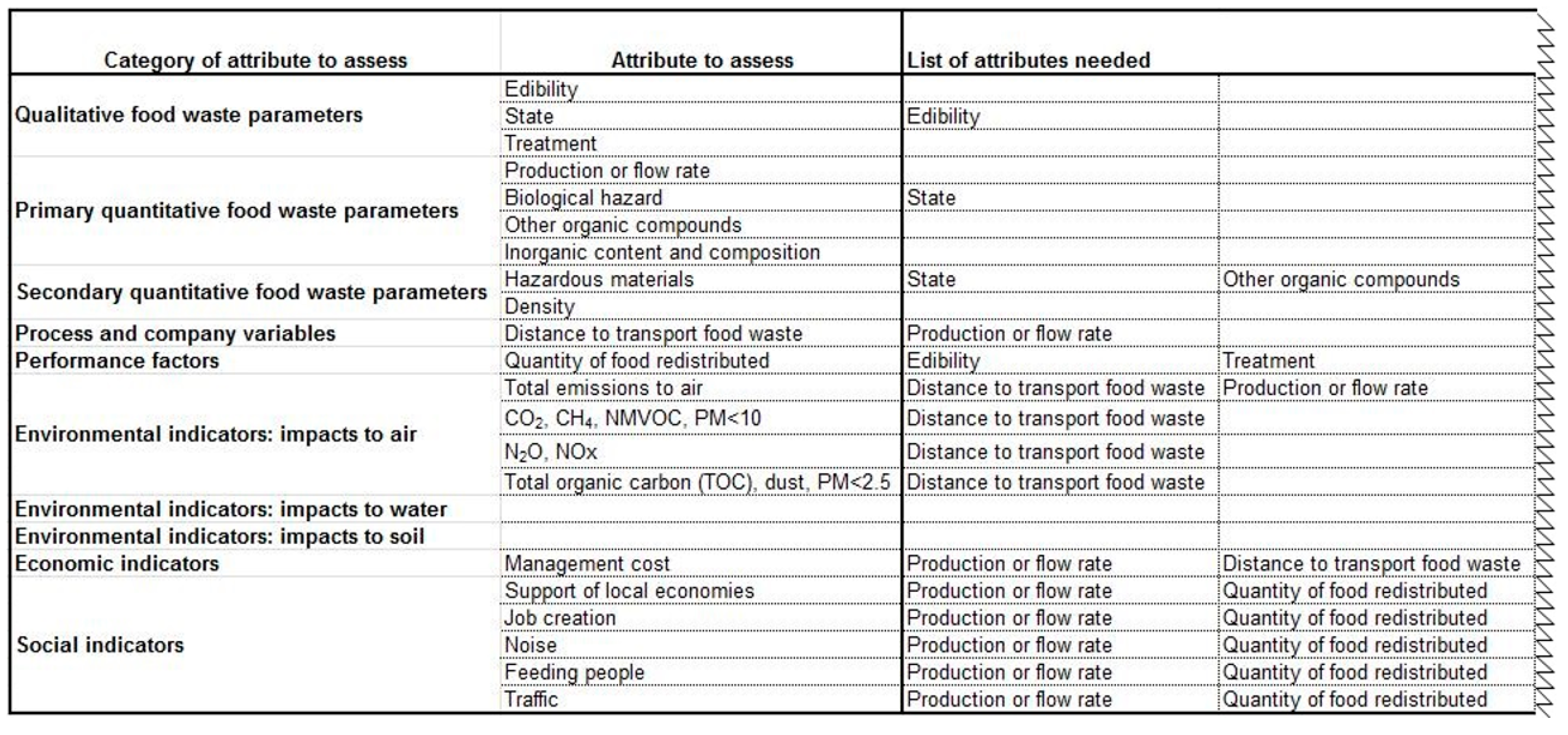
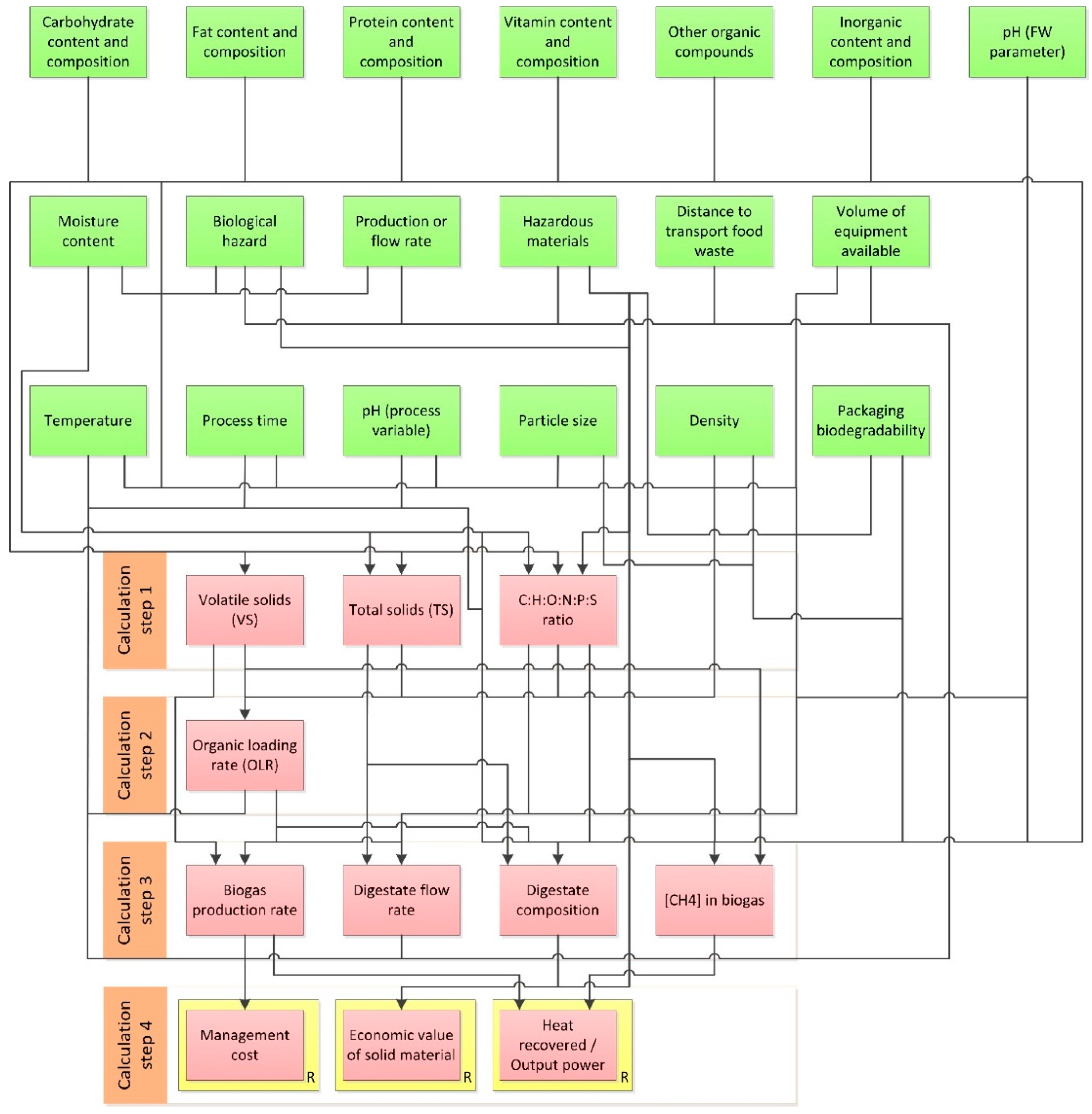
Supplementary Material—1. List of Attributes. Additionally, for each attribute identified the attributes on which it depends were determined, which were added to a ‘list of attributes needed’ in the spreadsheet, as explained below. An example of a section of the Table of Assessment can be seen in
Figure 5.
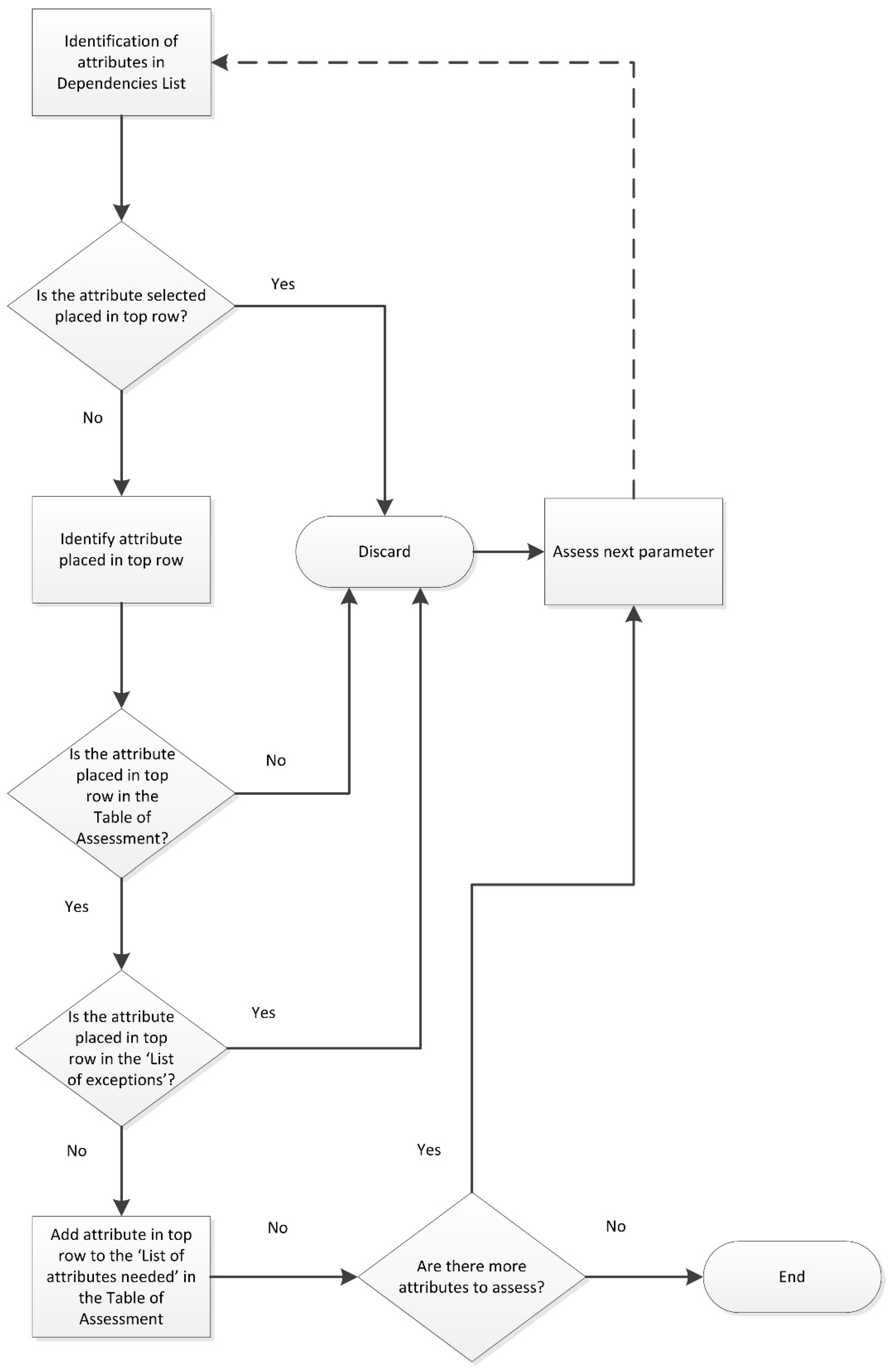
The dependencies lists and the dependencies flowcharts were both used to populate the ‘list of attributes needed’. The specific methodology used to build the ‘list of attributes needed’ is depicted in
Figure 6. Firstly, each attribute relevant to the FWMS under consideration must be found in the dependencies list. If the attribute found is in the top row, it must not be assessed, because its position indicates that it does not depend on the value of other attributes. It must be noted that all attributes appear once in the top row, since all attributes and relationships have been assessed, but for this process only the attributes that depend on other attributes are needed. Secondly, for each time an attribute is found, the attribute in the top row must be identified. However, only those attributes which appear in the Table of Assessment are needed, since this means that the attribute is necessary to model the FWMS under consideration. Additionally, the attribute must be added to the ‘list of attributes needed’ only if the relationship found is not included in the ‘list of exceptions’ (the sheet of list of exceptions is in
Supplementary Material—3. Dependencies List). This process should be repeated until all attributes relevant to the FWMS under consideration have been assessed, completing the ‘list of attributes needed’.
Once the ‘list of attributes needed’ has been built for each FWMS, an analysis must be carried out to define the order of calculation for the different attributes, and which attributes should be used to calculate unknown attributes. The entire process, integrating all research presented in this paper, is explained below.
The process is initiated when the user identifies the FW to be analysed and chooses a potential FWMS to be used. The methodology presented by Garcia-Garcia et al. (2017) [
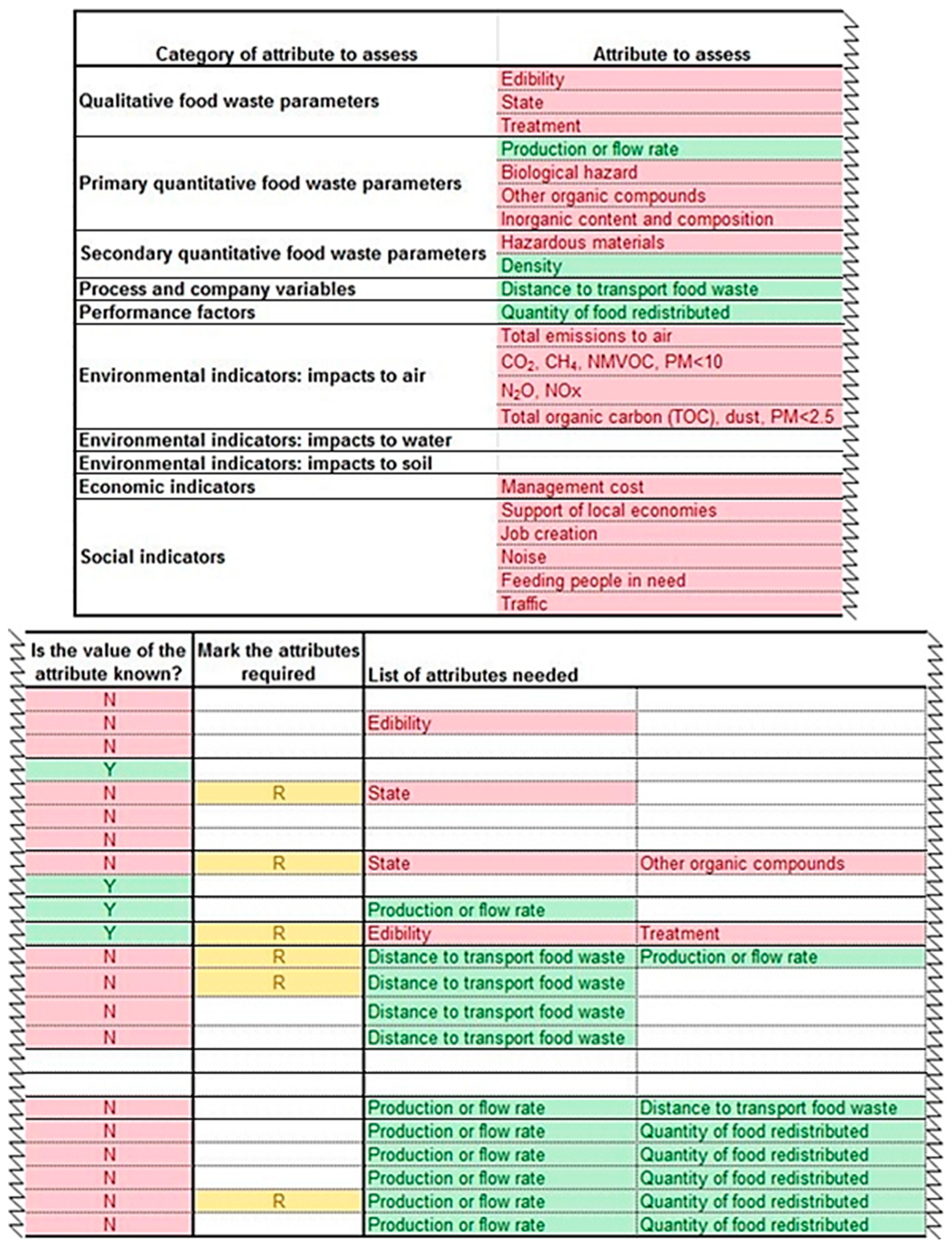
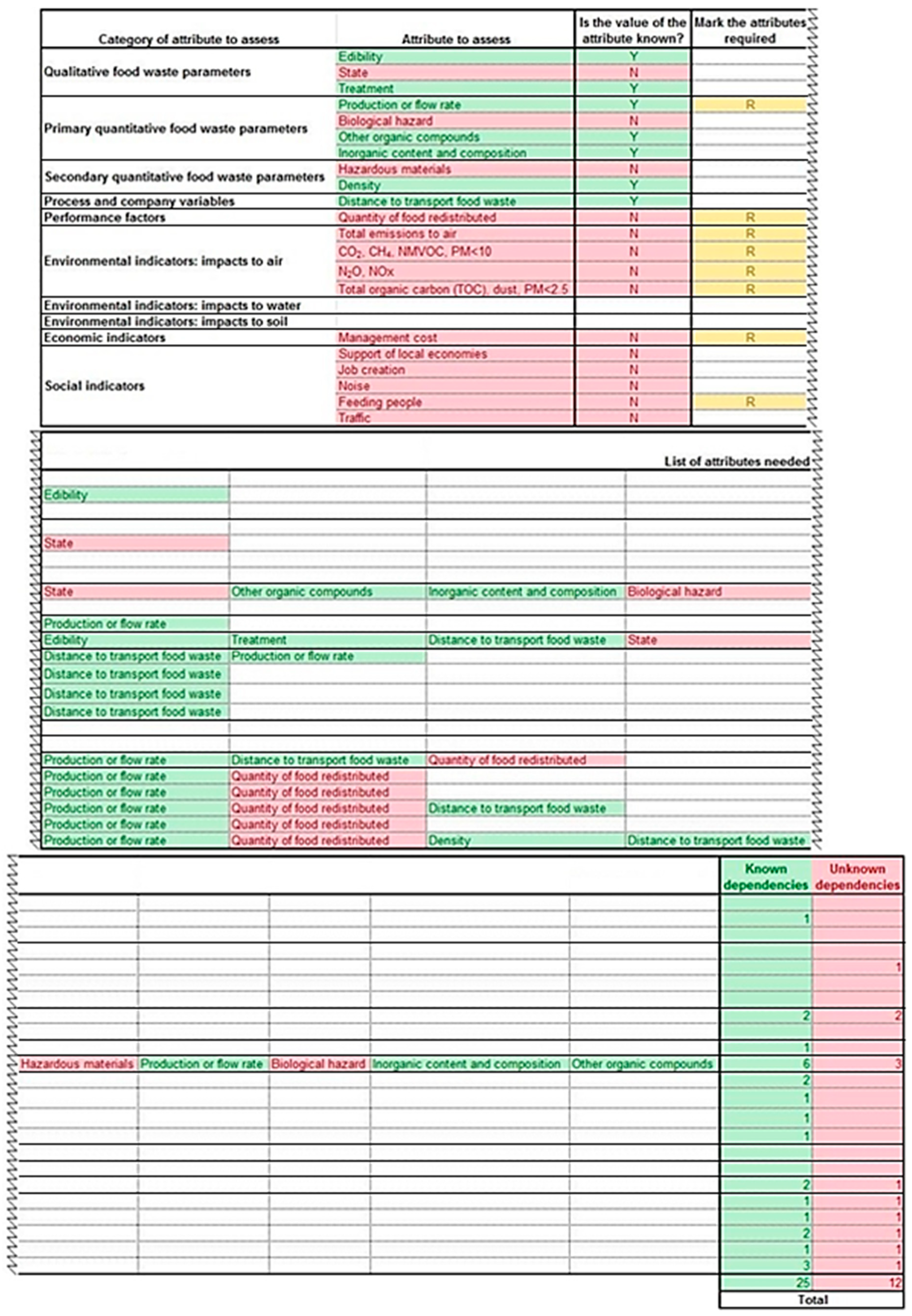
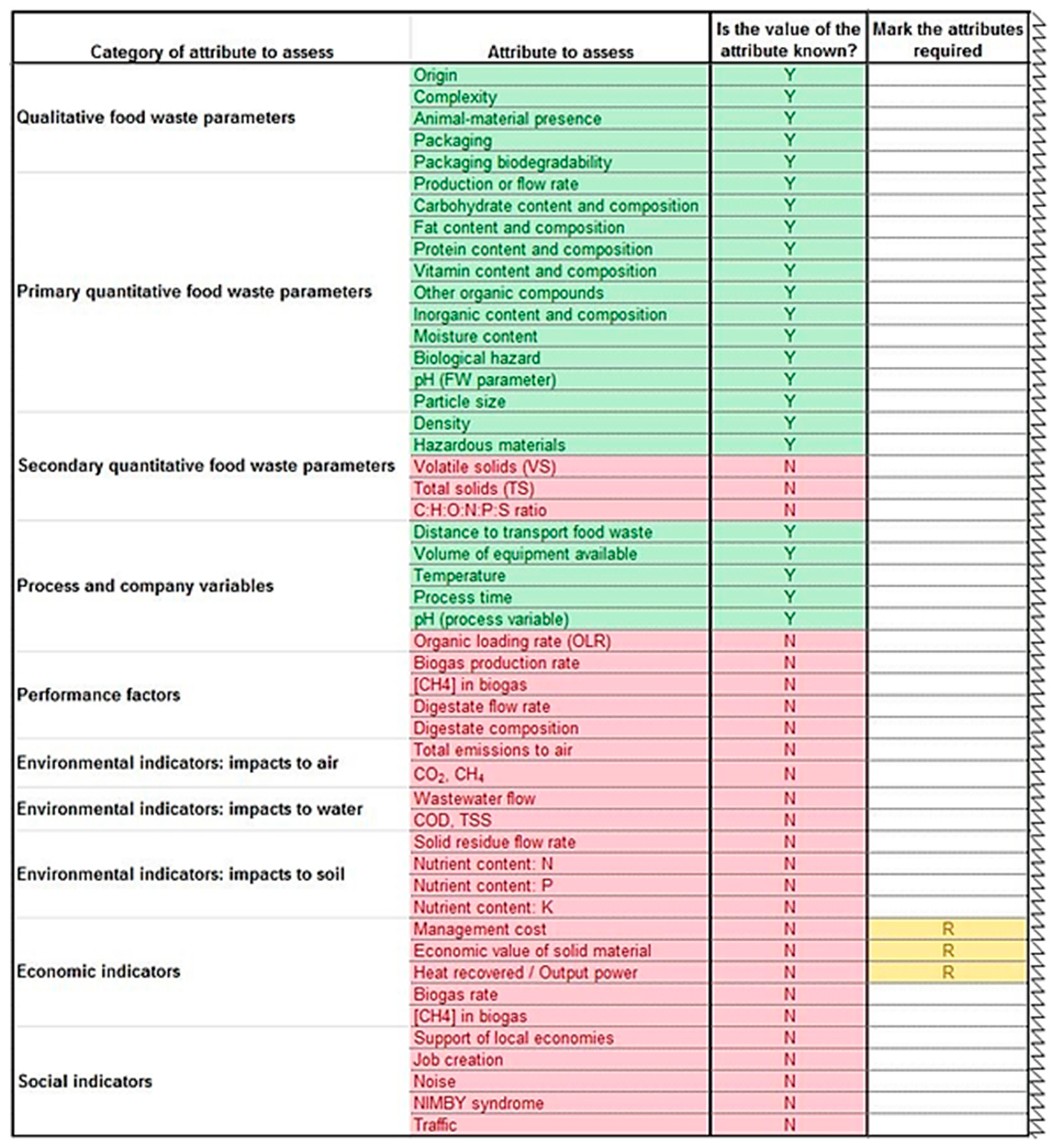
17] can be used to guide this stage. After that, the user should open the Table of Assessment and select the correct sheet, according to the FWMS chosen. The user would see a list of attributes to be assessed, the category to which they belong, and the ‘list of attributes needed’ in order to assess each attribute. Then, the user has to identify which values of attributes are known (‘Y’), unknown (‘N’) and required (‘R’), since not all attributes may be required for assessment by the user. An example of a section of the Table of Assessment, with the required information completed, can be seen in
Figure 7. In this example, the ‘production or flow rate’, ‘density of FW’, ‘distance to transport FW’, and ‘quantity of food redistributed’ are the only values known by the user. ‘Biological hazard’, ‘hazardous materials’, ‘total emissions to air’, ‘CO
2’, ‘CH
4’, ‘NMVOC’, ‘PM < 10’, and ‘feeding people in need’ are the unknown variables required by the user. The ‘quantity of food redistributed’ is also required, but its value is already known by the user as mentioned above.
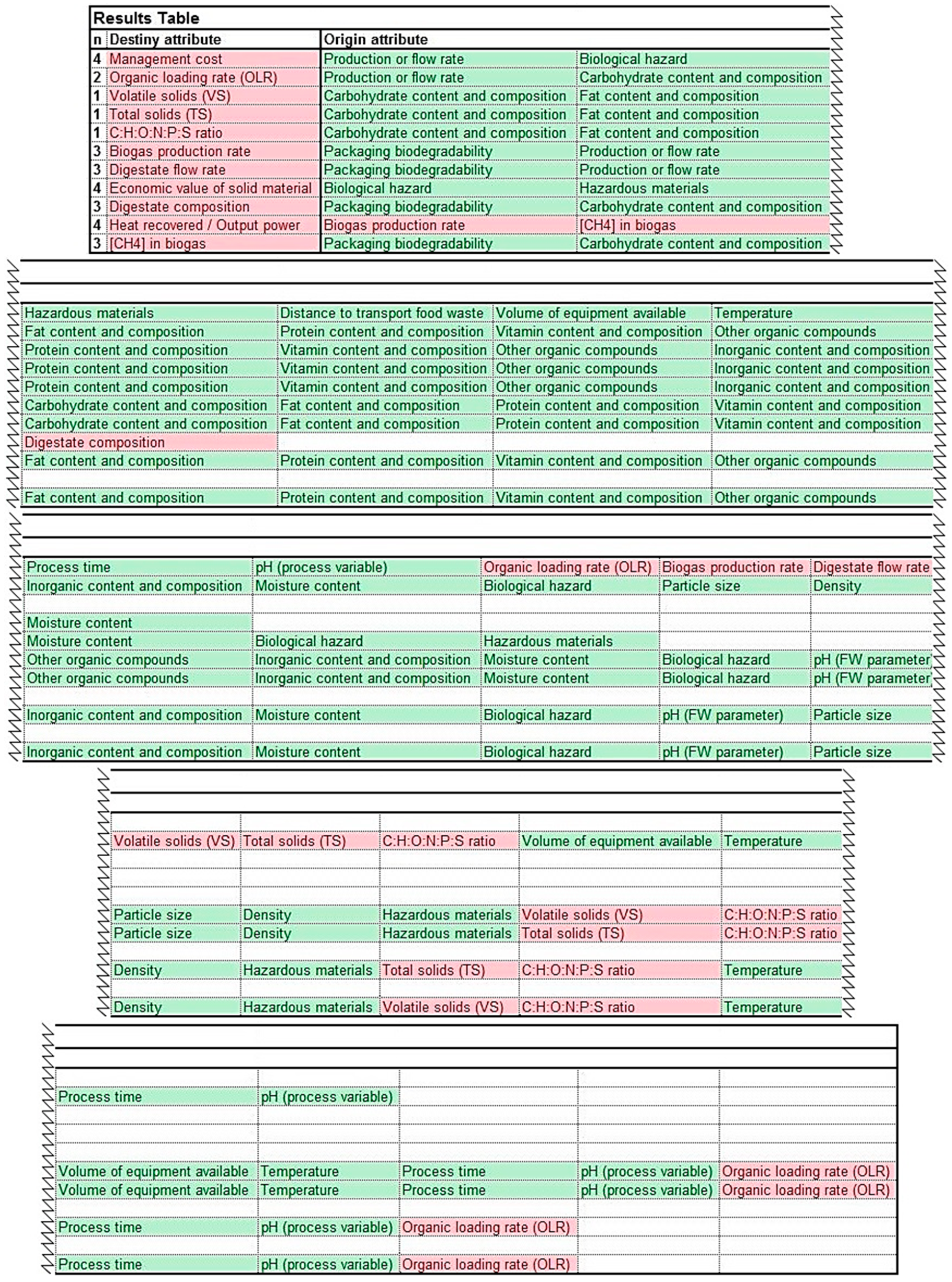
Once the two columns of the Table of Assessment have been completed, the results table should be filled (“Results Table” sheet in
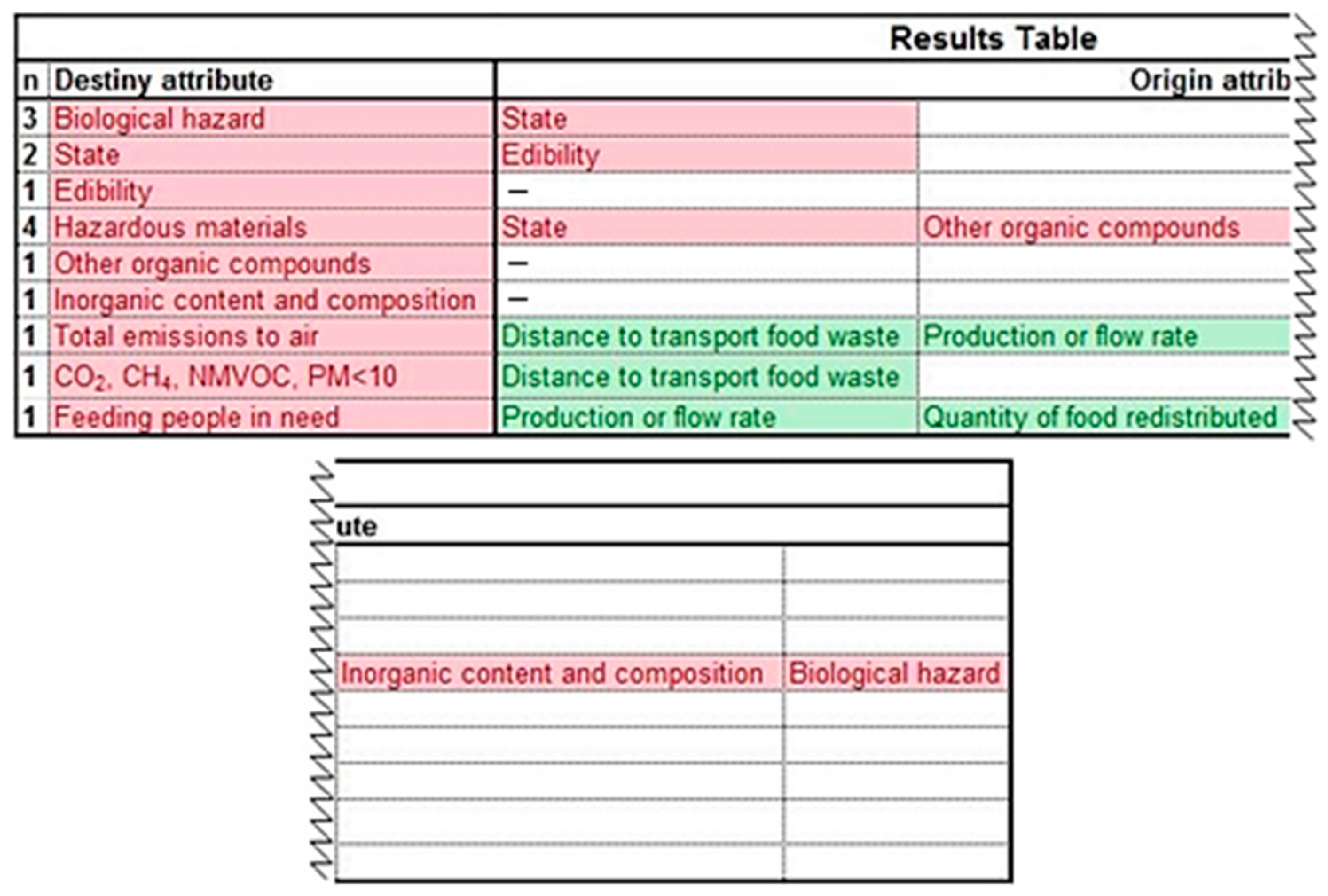
Supplementary Material—5. Table of Assessment). An example of a results table for the example presented above can be seen in
Figure 8. The user must identify all attributes which are both unknown and required, and copy them into the column ‘destiny attribute’ in the results table. Additionally, the attributes from ‘list of attributes needed’ are copied to ‘origin attribute’ for each ‘attribute to assess’ copied to ‘destiny attribute’.
Next, the row ‘origin attribute’ for each ‘destiny attribute’ is assessed to find unknown attributes. If only known attributes, or no attributes are found in ‘origin attribute’, ‘destiny attribute’ receives a value
n = 1, which means that the attribute must be assessed in the first place. For instance, in
Figure 8 ‘edibility’, ‘other organic compounds’, ‘inorganic content and composition’, ‘total emissions to air’, ‘CO
2, CH
4, NMVOC, PM < 10’, and ‘feeding people’ receive a value
n = 1.
Each unknown attribute found in ‘origin attribute’ must be assessed and added to the results table as a new ‘destiny attribute’ (along with its correspondent attributes to ‘origin attribute’) if they had not been placed there before. For instance, in the example presented in
Figure 7, the first ‘attribute to assess’ is ‘biological hazard’, since it is unknown and required. ‘Biological hazard’ and ‘state’ (from the ‘list of attributes needed’) are copied to ‘destiny attribute’ and ‘origin attribute’, respectively. Since ‘state’ is unknown, ‘state’ is also copied to ‘destiny attribute’, and consequently ‘edibility’ to ‘origin attribute’. The process is repeated for ‘edibility’, which does not depend on any other attribute, and therefore receives a value
n = 1.
Each time the process is repeated, the value of
n increases by one unit. Each attribute from ‘destiny attribute’ receives an increasing
n value, starting from the last attribute assessed. In the example presented,
n(
edibility) = 1,
n(
state) = 2 and
n(
biological hazard) = 3. When there is more than one attribute in ‘origin attribute’, the
n value of ‘destiny attribute’ is the highest from all possible of ‘origin attribute’ + 1. For instance, it can be seen in
Figure 8 that ‘hazardous materials’ has an
n = 4. The values of
n for each of its ‘origin attribute’ is
n(
state) = 2,
n(
other organic compounds) = 1,
n(
inorganic content and composition) = 1 and
n(
biological hazard) = 3. Therefore, highest
n is
n(
biological hazard) = 3 and consequently
n(
hazardous materials) =
n(biological hazard) + 1 = 3 + 1 = 4.
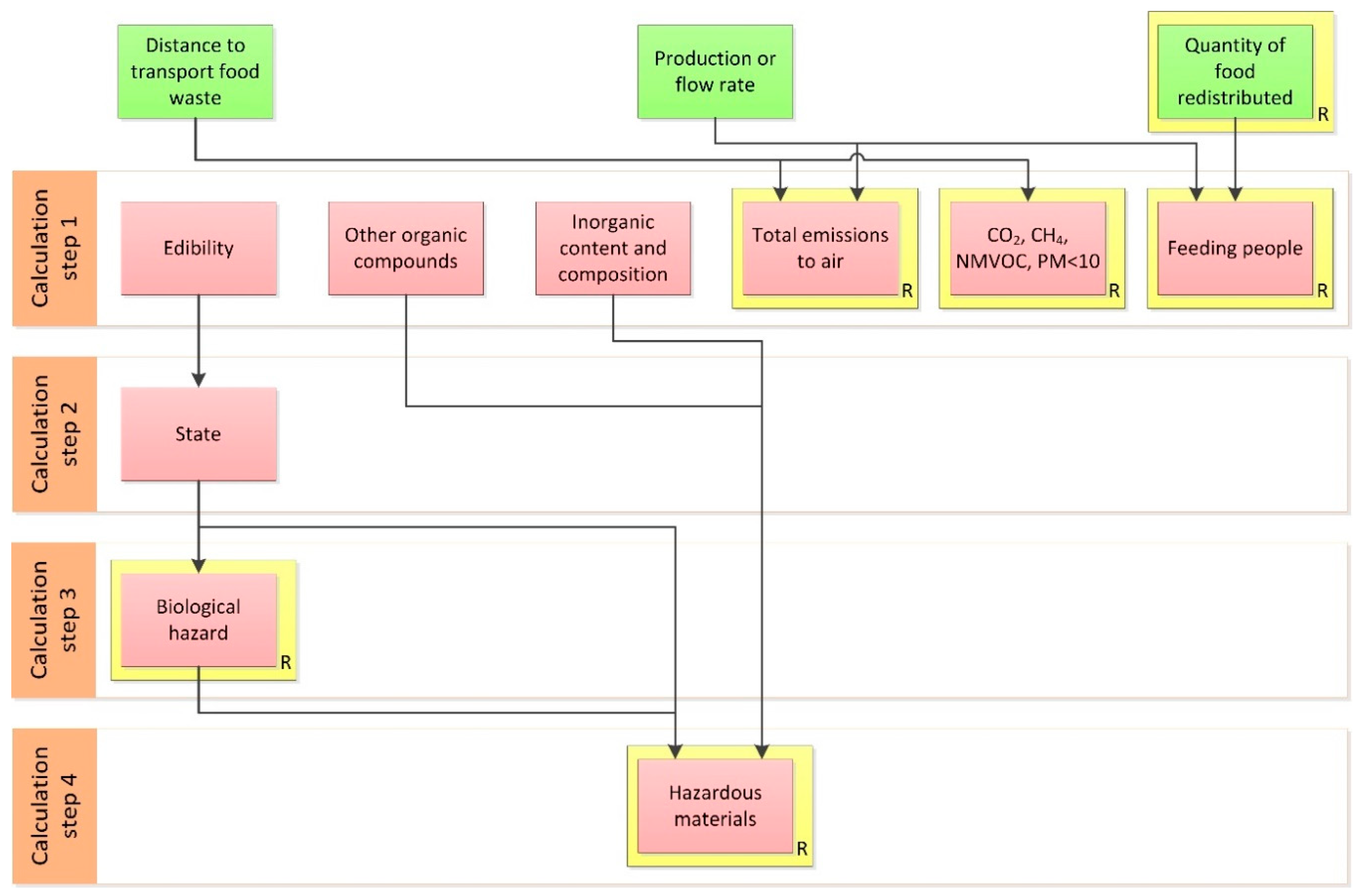
The user can use the results obtained in
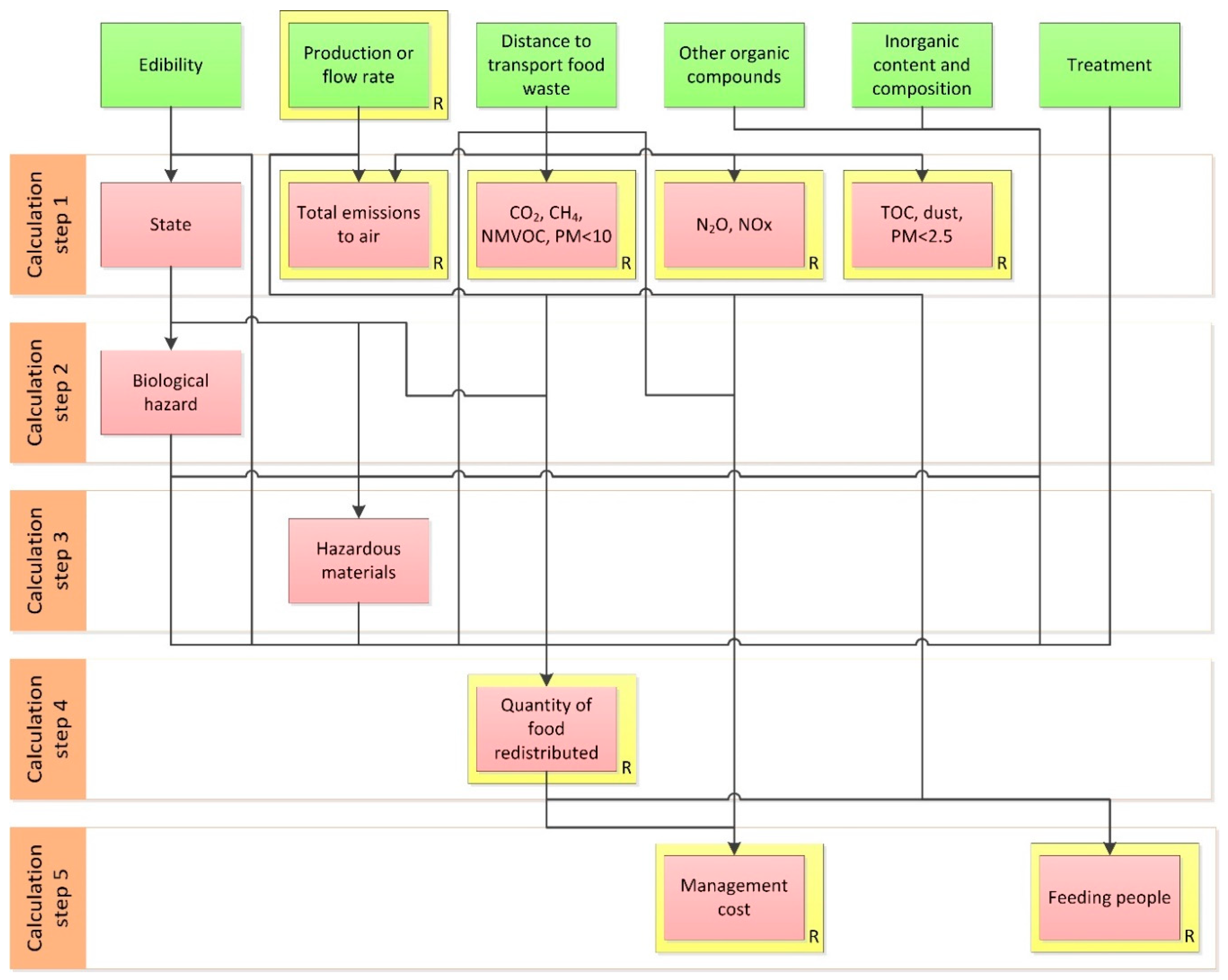
Figure 8 to determine the attributes needed to assess unknown attributes and the required order of the assessment. This is represented in
Figure 9, which shows known, unknown, and required attributes in the different calculation steps according to their
n value, and arrows representing information flows. The arrows must be read from top to bottom, and considering all existing intersections. The origin of the arrow represents the ‘origin attribute’ and the arrowhead the ‘destiny attribute’. The use can draw information flow diagrams to more easily identify the attributes that must be defined and assessed to obtain the information pursued, and also support their evaluation by providing a structure for calculation steps, i.e., the order of the assessment. For instance, in
Figure 9 there are four calculation steps needed to calculate values of all unknown required attributes, and the attributes that must be calculated in each of these steps are also shown in the information flow diagram. In summary, the user can utilise information flow diagrams to identify the specific information needed to model FWMSs and break down complex calculation processes into a step-by-step approach, gaining accurate and appropriate guidance to assess different FWM scenarios. The use of the information flow diagrams is the last step of the FWMMP as shown in
Figure 1. After using the information flow diagrams to identify calculation steps and the order of the assessment, and the values of unknown required attributes are calculated, the data obtained can be used in an LCA study and/or to undertake socio-economic assessments of FWM.




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}