1. Introduction
Meteorological conditions are key factors in many areas of human activity such as agriculture, transport, power engineering, insurance and risk assessment [
1], industrial and marketing planning [
2], tourism, sport, mass events [
3,
4], national security, and many more where atmospheric conditions may have a direct or indirect impact [
5,
6,
7,
8]. Besides the financial and safety relevance of meteorological and hydrological datasets [
9], this kind of information is very often crucial to reliably answer a scientific problem [
10], which heavily relies on the quality of meteorological dataset used in this kind of research.
National meteorological agencies collect in-situ measurements of the highest quality according to the standards of the World Meteorological Organization (WMO). They are simultaneously responsible for maintaining and sharing their archived databases. A significant part of the meteorological data is available for free from the global exchange of the surface synoptic observations (SYNOP), meteorological information used by aircraft pilots (METAR), or upper air soundings (TEMP) reports. Even if most of this information is limited only to the main synoptic stations and covers only basic meteorological parameters, the data itself usually provides better accuracy compared to commonly applied coarse gridded reanalysis products [
11,
12].
The availability of meteorological archive databases varies among countries. In most cases, access to such databases is usually not free of charge. However, the near-surface meteorological information from synoptic stations all around the world is publicly available free of charge due to the exchange of meteorological reports (e.g., FM-12 code established by the WMO) and is stored online. The
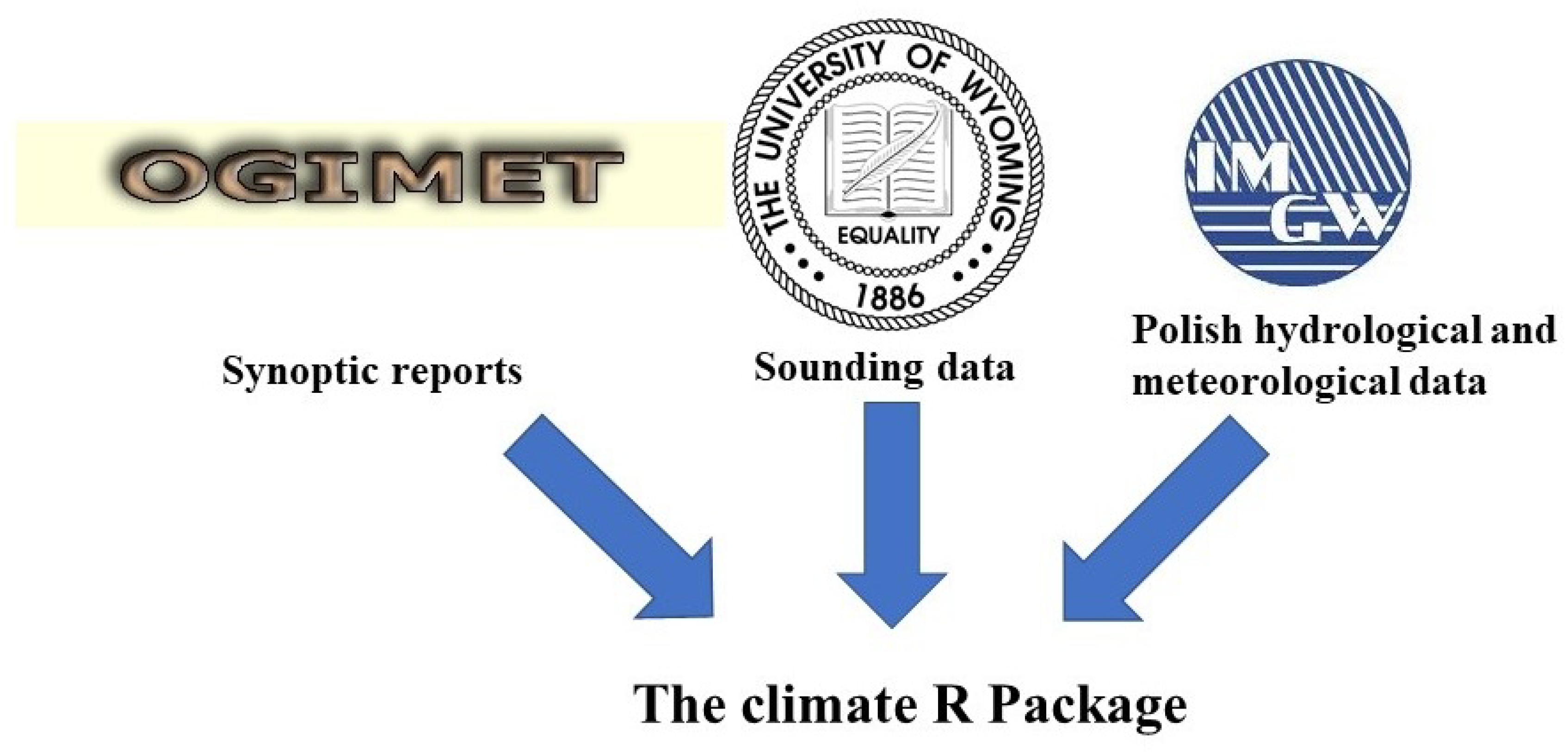
ogimet.com web service is one of the most popular repositories of meteorological data that is heavily based on freely available data sources from the National Oceanic and Atmospheric Administration (NOAA) archives processed in a raw and human-readable format. Most of the archive dataset starts around the second part of 1999 and is being updated immediately after new reports are available.
The dataset representing atmospheric upper layers are also collected on the NOAA’s as well as an independent data repositories. In this study, a publicly available repository of the University of Wyoming (
http://weather.uwyo.edu/upperair/sounding.html) was used, as it allows for downloading atmospheric data representing vertical profiles of the atmosphere on any of the global sounding stations dated back even up to 1960s. Moreover, this repository provides a quick summary of thermodynamic atmospheric indices, which also can be a useful source of information for interested groups of end-users.
Other data sources exist that can be more suited for locally targeted problems. Such an example is a data source provided by the Polish Institute of Meteorology and Water Management—National Research Institute (IMGW-PIB) that distributes their resources through an HTTP file server (
https://dane.imgw.pl/). Thanks to the actions of the Polish atmospheric-related communities against limited access to collected data, the legislative changes were possible [
13,
14]. It ensured free access to meteorological and hydrological data for most commonly applied non-commercial use cases since January 2017. Nowadays, the way of the distribution of this operational data is one of the most liberal among European meteorological services.
A typical workflow of downloading meteorological data from a repository (e.g., Ogimet) conventionally using a web browser is to (1) select a country or station (2) for the given time range, and (3) measurement interval (i.e., hourly/daily). As a single query is limited to a few tens of rows per one search, thus creating a proper dataset requires manual and tedious routines. However, this approach is not a standard for all repositories. For example, the Polish hydro-meteorological repository requires a user to select the type of data, interval, and station of interest. Depending on the period and interval, a single (ZIP archive) file contains one- or five-years of observations with one or two files in every archive. Once the user selects the year (or five-year period), depending on the choices made earlier, they may encounter one set of files in the case of monthly synoptic data, three sets of files for the annual hydrological data, 13 sets for daily hydrological data, or about 60 sets in the case of hourly synoptic data. Each case has a separate data structure and different documentation. Overall, 23 possible cases for the meteorological and hydrological data exist, each requiring an individual approach for downloading and processing of the files. Since the beginning of 2017, the structure of these data has undergone numerous changes, which have confused some users, thereby discouraging them from using the repository.
The created package aims to supply access to the observational datasets which were missing so far among the R atmospheric community that had used mostly tools for downloading gridded or built-in datasets (e.g., ESD [
15], rNOMADS [
16], knmiR [
17]). Partly this gap was covered by the
rdwd package [
18], however, its functionality is restricted to the products of the German Meteorological Service only. Keeping the aforementioned in mind, the main goal of the
climate R package is to deliver a convenient way of accessing global and regional repositories containing meteorological and hydrological data. The choice of R [
19] is related to the fact that this is currently one of the most popular programming languages among environmental researchers and data scientists, and simultaneously, it is free of charge. The created package aims at processing all formats of meteorological data independently of its origin in a tidy tabular form [
20] that is suitable for various visualization and processing applications. Abbreviations of the variables are specified according to the WMO standards and were added to the package documentation. Relevant dictionaries attached to the
climate package can be read by
imgw_meteo_abbrev or
imgw_hydro_abbrev commands. The created package also contains a database that clarifies the variables’ metadata and geographical coordinates of each stations’ location. Thanks to this feature, users can directly use the output data in geospatial analysis using R [
21] programming language or external GIS software.
2. Methods and Materials
The
climate package is distributed under the MIT license. However, users are obliged to follow the regulations provided on the respective webpages, as the package only provides an interface to the official repositories. The most stable version of the climate package is available at the Comprehensive R Archive Network (CRAN), while its developer version is hosted on the GitHub platform at
http://rclimate.ml (mirrored to:
https://github.com/bczernecki/climate), where third-party users can contribute to its further development.
2.1. Installation and User Guide
The
climate package can be installed and run on any modern computer with the R environment version 3.1 or higher. The package was tested on a wide span of Windows instances and several Linux and Mac OS X distributions, and has positively undergone numerous tests before being published in the CRAN repository. The authors also deliberately avoided using external libraries in order to reduce possible dependencies or installation issues. The stable version of the
climate package hosted on the official CRAN repository can be installed with the R’s
install.packages("climate") and activated using the
library(climate) commands respectively. The development version is hosted on the GitHub platform at (
https://github.com/bczernecki/climate), where all instructions for installing and using the package are provided. Additionally, users are encouraged to contribute, leave feedback, or suggest their own ideas for further improvements that may be added in future releases.
2.2. Datasets
The synoptic reports available in the Ogimet web service are dated back to the year 1999. This global repository shares up to 17 variables (columns) representing instantaneous measurement for an individual station in a given date and time. Data is divided into daily and hourly time intervals. It contains information for the following: 2 meters air temperature (min., max., avg.) and dew point temperature [C], atmospheric and sea level pressure [hPa], geographical coordinates [°], altitude [m], relative humidity [%], wind speed and wind gust [km · h], wind direction [direction], cloudiness [octants] and height of cloud base [km], visibility [km], sunshine duration and height of snow cover [cm].
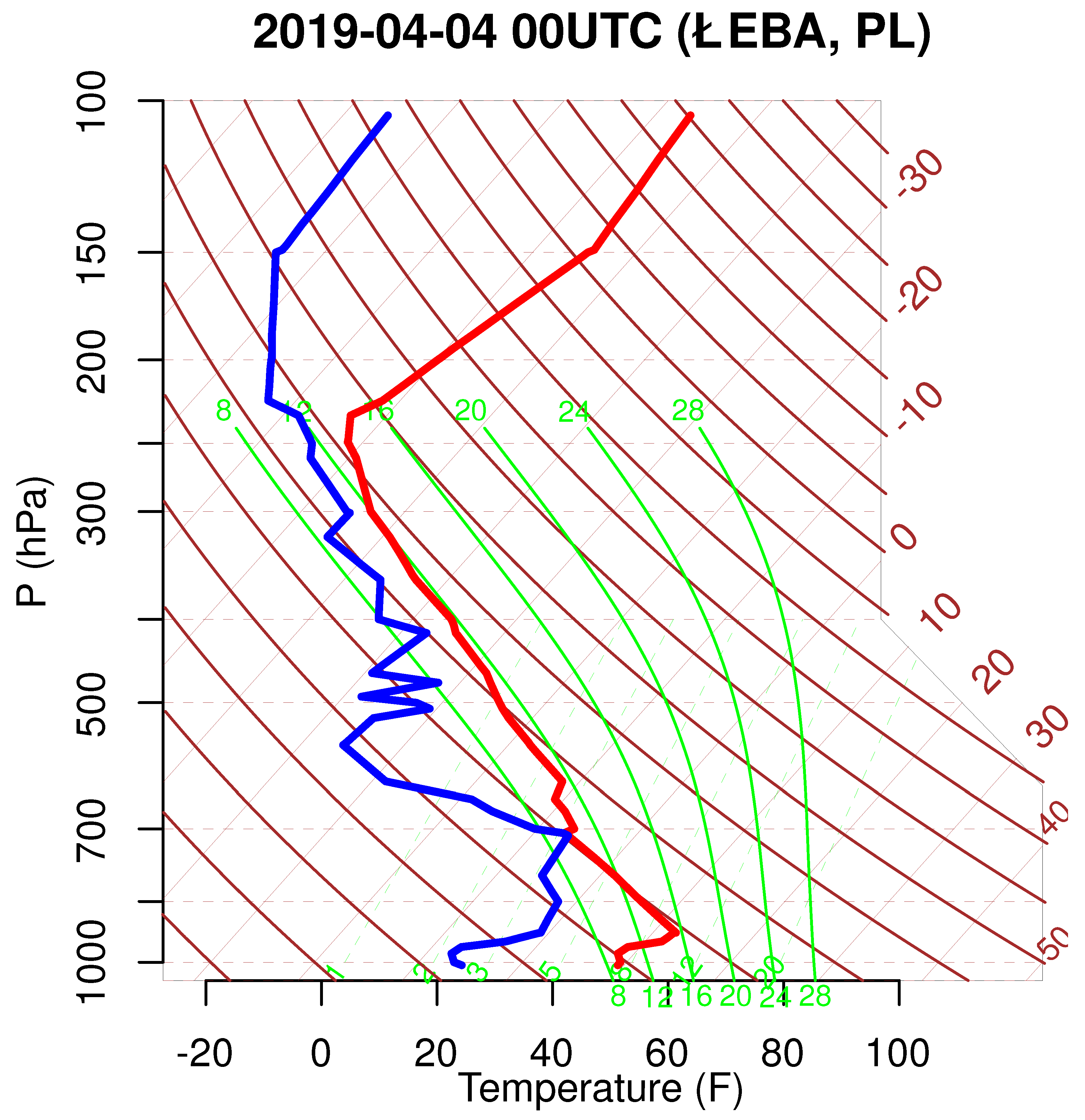
The historical sounding (i.e., upper air from the University of Wyoming’s repository) observations are not available on the Ogimet website. Therefore, this capability was added to the climate package due to the high demand for this kind of information among severe weather community, where it is commonly used for analyzing thermodynamic and kinematic atmospheric parameters [
22,
23]. This is also crucial information for identifying the atmospheric processes responsible for air quality problems [
24]. The measurement interval is in most cases 12 hours (i.e., at 00 and 12 UTC, occasionally on some stations at 06 UTC and 18 UTC) and the data are usually available a few hours after beginning of the measurements. The sounding (also known as “rawinsonde”) data has 11 columns representing the instantaneous measurement of the atmospheric vertical profile for a single station and time. It contains information for the following parameters: atmospheric pressure [hPa], altitude [m], air temperature and dew point [
C], relative humidity [%] and mixing ratio [g · kg
], wind speed [knots] and wind direction [°], and thermodynamic properties along with measurement metadata.
The IMGW-PIB (i.e., Polish hydro-meteorological) dataset contains measurements back to the 1950s, and the database is continually being updated, usually on a monthly basis. The meteorological data in the repository is divided, according to the hierarchy of stations, into (1) synoptic, (2) climatological, and (3) precipitation data. The synoptic and climatological stations consist of (1) hourly, (2) daily, and (3) monthly time intervals. The precipitation stations have no measurements at an hourly interval. The synoptic data are the most extensive and contain over 100 meteorological parameters. The climate data describes four essential meteorological components: air temperature [C], wind speed [m · s], relative humidity [%], and cloudiness [octants]. The precipitation data consist of the amount of precipitation with a description of the phenomena or surface precipitation type (i.e., rain, snow, snow cover height). Due to a relatively broad range of parameters obtainable for the meteorological data, the authors have thus decided to include a “vocabulary” that contains column names (i.e., meteorological parameters) in a (1) short, (2) more descriptive, or (3) original (Polish) forms. The hydrological data in the IMGW-PIB repository contains (1) daily, (2) monthly, and (3) semi-annual/annual measurements. All hydrological data uses the hydrological year, which begins on November 1st and ends on October 31st. Regardless of the temporal resolution, the hydrological data contains measurements of the maximum, mean, and minimum for the following: water flow [m· s], water temperature [C], and water level [cm]. Additionally, the daily dataset includes characteristics of the ice and overgrowth phenomena observed at the station. Similar to the meteorological dataset, a user can decide whether to add an extra description to the column names.
2.3. Core Functionality of the Climate R Package
The climate package currently consists of 21 functions with ten of them visible for the end-user (
Table 1). Three of them are intended for downloading meteorological data, one for hydrological data, and four are auxiliary functions to improve the legibility and improve data exploration capabilities. Despite a relatively large number of functions that might be potentially used, there are four main functions called
meteo_ogimet, sounding_wyoming, meteo_imgw and
hydro_imgw that are generic wrappers for other functions. They allow for simplified downloading of any requested data in a convenient way. All available functions are documented on the package website and inside the built-in R help system where the exemplary code is also provided.
2.4. Ogimet Meteorological Data
The generic function for downloading decoded SYNOP reports from the Ogimet repository requires defining a set of arguments according to the schema provided below for the most generic
meteo_ogimet function.
where:
interval - temporal resolution of the data ("hourly", "daily") (argument not valid for: ogimet_hourly and ogimet_daily functions)
date - start and finish dates (e.g., date = c("2018-05-01", "2018-07-01") )—character or Date class object
coords—logical argument (TRUE or FALSE); if TRUE coordinates are added
station—WMO ID of meteorological station(s). Character or numeric vector
precip_split—whether to split precipitation fields into 6/12/24 h, numeric fields (logical value = TRUE (default) or FALSE); valid only for an hourly time step
2.5. Sounding Data
The proposed solution is based on the decoded TEMP sounding (radiosonde) reports hosted on the University of Wyoming (
http://weather.uwyo.edu) server. It contains archived data for all upper air profiling stations working globally in the WMO network. The syntax for downloading the single sounding is as follows:
This function requires a few numeric arguments:
The returned object contains a list of two data frames. The first consists of measurements in a tabular form for 11 meteorological elements, while the second consists of metadata and the most fundamental thermodynamic and atmospheric instability indices.
2.6. IMGW-PIB Meteorological Data
The extended range of meteorological near-surface measurements can be achieved, usually from the regional met offices’ repositories. The publicly available Polish historical meteorological dataset comprises of two sections: meteorological and actinometrical data. Each of these sections is divided into subsections depending on the observational interval. The actinometric data was not implemented in the climate package due to ongoing changes to the data storage, and it will be added after the final format is determined.
The
climate package contains an interface to the Polish IMGW-PIB dataset, which can be downloaded with a very similar syntax to the global dataset described previously in a simplified way. The schema shown below describes the use of the most generic
meteo_imgw function and contains all arguments that can be used to define requested data.
where:
interval—temporal resolution of the data ("hourly", "daily", "monthly")
rank—type of the stations to be downloaded ("synop", "climate", or "precip")
year—vector of years (e.g., 1966:2000)
status—logical argument (TRUE or FALSE); for removing status of the measurements
coords—logical argument (TRUE or FALSE); if TRUE coordinates are added
station—vector of stations; it can be an ID of a station (numeric) or a name of a stations (capital letters)
col_names—three types of column names possible: “short”—default, values with shortened names, “full”—full English description, “Polish”—original names in the dataset
It is also worth noting that most of the arguments have predefined default values to support less experienced users. For example, if the station argument is not given, then all available datasets (here: data for all stations) are automatically downloaded. Only the interval, rank and year arguments are mandatory. In case any of them is not defined, the user is given a hint on the correct syntax.
2.7. IMGW-PIB Hydrological Data
The hydrological data is available in daily, monthly, and semiannual/annual temporal resolutions. The definition of the arguments in
hydro_imgw is an analogue to the previously described for the meteorological data, with the syntax described below:
where:
interval—temporal resolution of the data (“daily”, "monthly", "semiannual_and_annual")
year—vector of years (e.g., 1966:2000)
coords—logical argument TRUE or FALSE; if TRUE coordinates are added
value—type of data (can be: state—"H", flow—“Q”, or temperature—“T”).
station—vector of stations; it can be an ID of a station (numeric) or a name of a stations (capital letters)
col_names—three types of column names possible: “short”—default, values with shortened names, “full”—full English description, “polish”—original names in the dataset
4. Conclusions
The
climate R package allows users to obtain historical and most up-to-date meteorological information from both: ground and upper parts of the atmosphere. Data downloaded by
climate gives possibilities for applying atmospheric data collected according to the WMO standards in an intuitive and fully automated way. The package is designed to be user-friendly and envisages, for the most part, environmental scientists wanting to obtain hydrological or meteorological data for research purposes in an convenient and programmable way within the R programming language. The usefulness and simplicity of the proposed solution can be especially valuable for many non-atmospheric scientists struggling with typically sophisticated and time-consuming mechanisms for accessing in-situ atmospheric data in a ready-to-use structure. The proposed solution with the
climate package lets to save time for typical data flow in data science projects where a significant amount of time is spent on data preparation, while a core part of the computation is usually a magnitude shorter when compared to data cleaning and preprocessing [
29].
Therefore for future improvements, it is planned to enlarge the climate R package with new local repositories so that more countries can conduct interdisciplinary research on meteorological data using a single tool, which can be targeted on a local scale in combination with global meteorological information. Also, new products (e.g., actinometric data in Poland) will be included once the IMGW-PIB repository has a mature form.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




