1. Introduction
Transport experience varies from different groups within a population [
1]. Men and women have different travel characteristics [
2,
3,
4], place different degrees of importance on mobility-decision factors (e.g., time, cost, accessibility, frequency, safety), and move differently across the city depending on their daily activities [
5,
6,
7,
8]. This difference is critical for the sustainability of cities, as stated in one of the Sustainable Development Goals by the United Nations, which aims to “provide access to safe, affordable, accessible, and sustainable transport systems for
all, […] with special attention to the needs of those in vulnerable situations,
women […]” (emphasis ours). (
https://www.undp.org/content/undp/en/home/sustainable-development-goals/goal-11-sustainable-cities-and-communities.html).
Advancing toward reaching this goal is not an easy task. One of the main difficulties is quantifying the differences in population groups. It is vital for transport planners to take into consideration the trends and behaviors of different segments of the population and understand their context (conditions, opportunities, and constraints) [
9]. Traditional methods to gather information on travel experience often observe users as one “average user” group, without considering the heterogeneity among groups of people. For instance, surveys are the most common tool to measure the travel experience [
10,
11]. Typically, their design is targeted to optimize quantitative characteristics such as costs for the system, while maintaining or improving quality of service, mainly, time and frequency. Even though they offer rich information, surveys have limitations. Surveys are not created to consider the multi-dimensional aspects of perception when people travel [
12], leading to conclusions assuming that the travel experience is the same for both genders [
13]. Reportedly, that is not the case. For instance, women experience higher levels of violence and harassment in transportation, which leads them to respond in ways that affect their travel experience and quality of life [
14]. Many of these incidents are under-reported to the authorities, thus lowering the probability of this problem being accurately reflected in urban and transport planning [
15]. The reasons include entrenched gendered power hierarchies and the lack of robust information about women’s needs.
The ubiquity of mobile phones has allowed people to express their opinions and daily experiences on social media platforms, creating a vast source of unstructured data on implicit user satisfaction. We propose that social media data may complement surveys and other methods. In particular, in this study, we analyze gender differences in transport perception through the analysis of posts on Twitter. We hypothesize that, if gender influences travel experience in any way, this should be reflected by a difference in the linguistic components of the texts published in social media. Measuring the perception and its potential gender differences is a challenging task due to the unstructured data and the informal nature of social media.
The research question that drives our study is: How can we measure the gender differences in transport perception presented in social media? To answer this question, we develop a three-step process to analyze transport-related opinions expressed on social media platforms. First, we infer gender for user profiles, which is not directly available on micro-blogging sites. Second, we extract the latent structure from the discussion using a topic modeling approach [
16,
17], which allows to separate the personal experience (e.g., feelings about a specific trip by bus) from the general discussion (e.g., opinions on public transport policy). Finally, we quantify perception and its differences with respect to gender with an analysis grounded on psycho-linguistic theory, which allows us to study the affective and relative aspects of transportation revealed by users.
With this methodology, we study the Twitter transport perception in Santiago (Chile) during 2017–2018. We chose Chile as it has been the most connected country in Latin America since 2017 [
18], and Santiago as it is the largest city in Chile, with a population of 7 million people. Santiago also poses a wide offer of transportation modes, including metro, bus, taxi, shared taxi, public bikes, and several ride-share apps for cars, scooters, and bikes. We chose Twitter as it is one of the most accessed applications from mobile phones in Santiago [
19].
The main contributions of this work are two-fold. The first contribution is a methodology to analyze the discussion about transportation in social media, with a focus on gender differences. This contribution could help data scientists to extract new applied insights from already available data. The second contribution is a case study of measured gender differences, using Twitter data from a big city. These contributions could help urban planners to widen their understanding of how different groups of people experience one of the most recurrent daily activities, transportation, using a promising data source in planning for sustainability: social media [
20].
This paper is structured as follows.
Section 2 presents the related work about social media analysis and transportation experience measurement.
Section 3 introduces the data and the proposed methodology for measuring gender differences in transport perception using social media data.
Section 4 shows the results for a case study in Santiago, Chile.
Section 5 presents the implications and main limitations of this work, as well as future work. The conclusions are given in
Section 6.
3. Data and Methodology
In this section, we describe the dataset and methodology used to answer our research question. The context is the discussion about transportation from the city of Santiago, Chile. This discussion is contained in a collection of messages from the micro-blogging platform Twitter.
3.1. Social Media Dataset
Twitter is a micro-blogging platform that allows people to publish and exchange posts up to 280 characters, called tweets. Tweets may contain mentions to other users, hashtags to indicate topics of the post, website addresses, emoji, etc. Given that it is one of the most accessed applications from mobile phones in Santiago [
19], we expect that people will frequently report their daily experiences, including transportation. We collected tweets related to transportation from the years 2017 and 2018. We used a manually crafted dictionary of keywords to query the Twitter streaming Application Programming Interface (API). The list contained transportation-related words, hashtags, mentions of transportation accounts, URLs, and transportation emojis. Samples of these query terms can be found in
Table 1.
In total, we collected 443,000 tweets from 112,000 users living in the Santiago Metropolitan area. A manual inspection of these tweets showed several themes within transportation, e.g., complaints mentioning the subway service provider, announcements of new bicycle paths, and general complaints about the size of the children safety chairs in cars (see
Table 2 for example tweets).
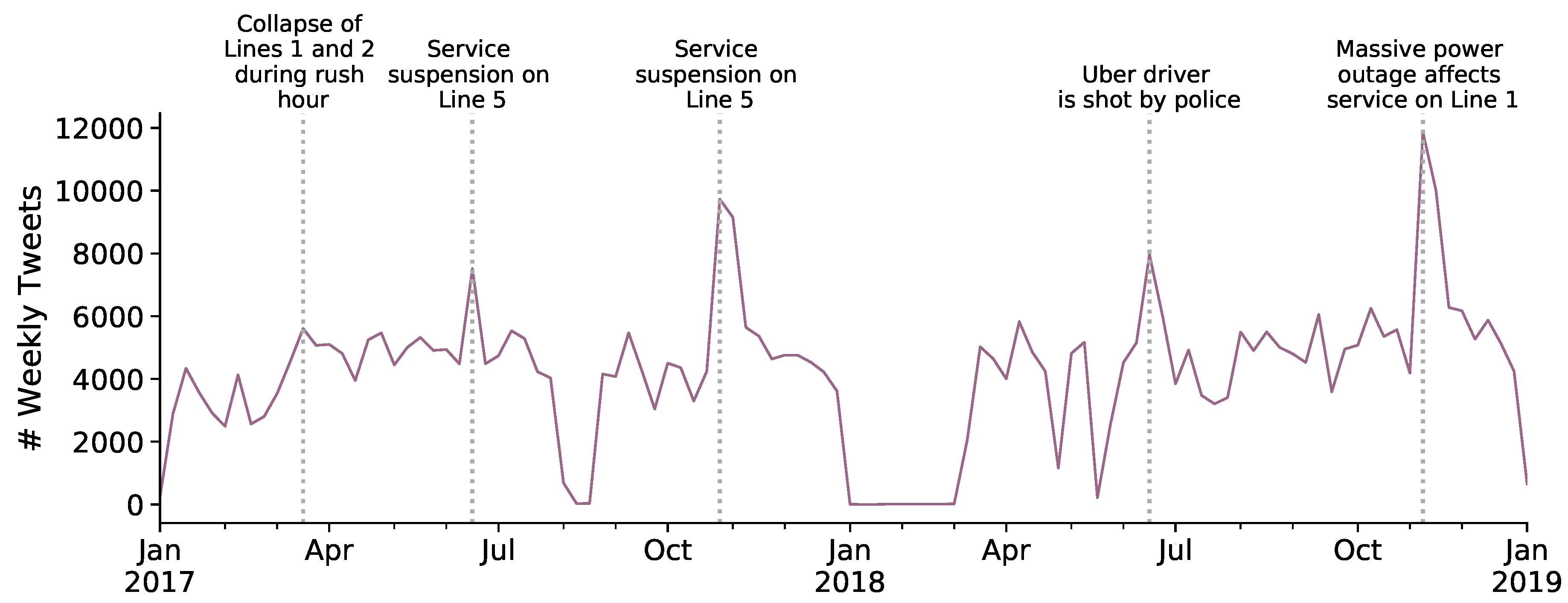
The weekly publishing rate of those tweets is not uniform in time; on the contrary, people react to certain events. The periods with most volume have identifiable events related to transportation, but not necessarily to the transportation experience. Topics include public transport service shutdowns, malfunctions, and massive power outages, among others (see
Figure 1). The daily frequency also changes from day to day, as more tweets are published during business days than on weekends (see
Figure 2).
The hourly frequency distribution exhibits morning and evening peaks related to commuting times in Santiago (see
Figure 3). It does not resemble the general usage of the application in the city [
19]. For instance, during lunch hours, people tweet less about transportation.
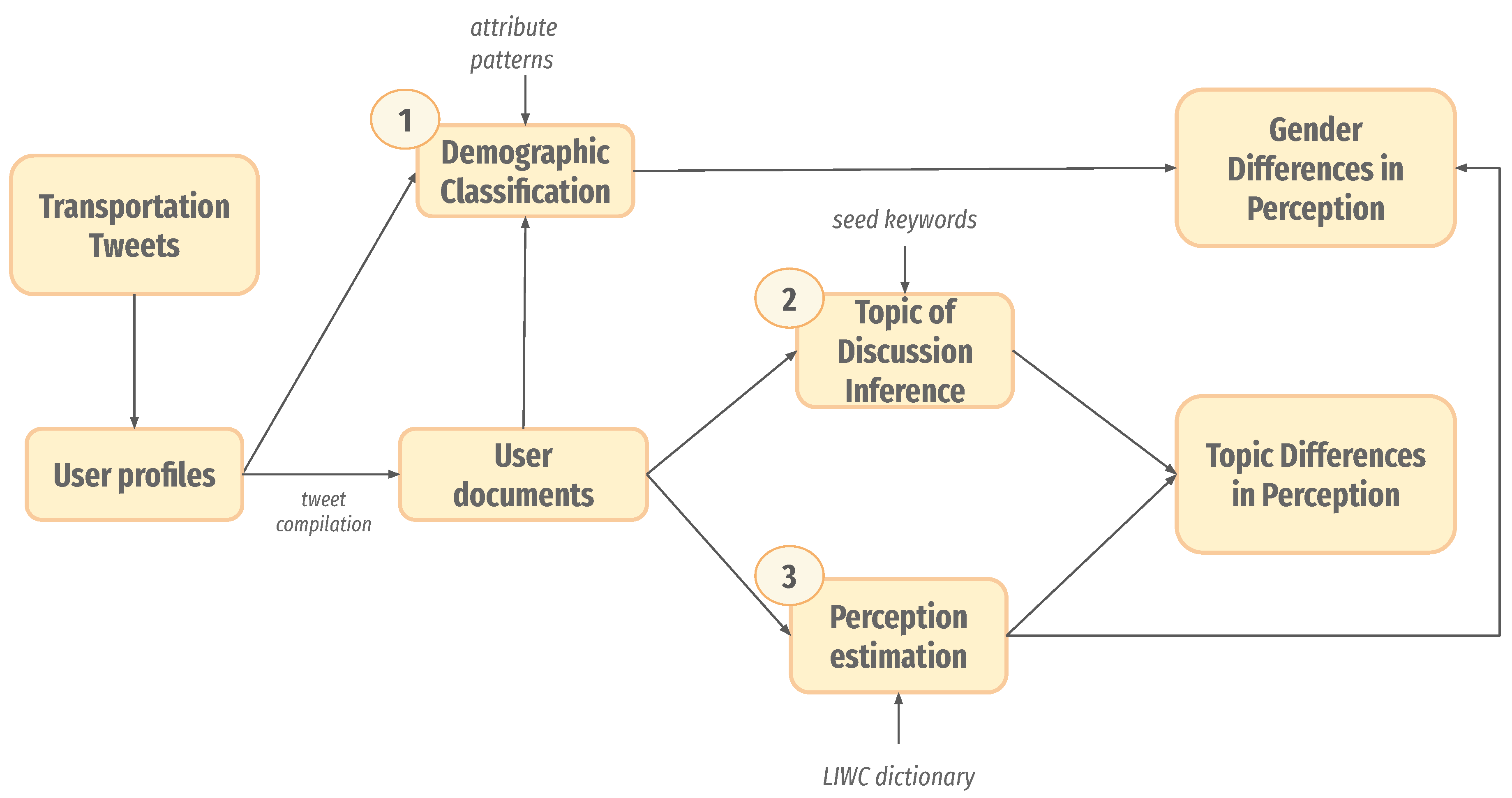
With this data set, we sought to answer our research question on understanding gender differences in transport perception. Next, we explain our methodology. It is composed of three main steps (see
Figure 4 for a schematic diagram): (1) user profiling used to infer gender, (2) inference of transportation topics in the discussion, and (3) measurement of perception with gender differences.
3.2. User Profiling
In Twitter, user profiles contain the following attributes used in our study: an id (a unique number for each user), a full name (freely reported), a description (usually used as biography), a location (freely reported), and the number of tweets. Although Twitter requests such information, these fields are not mandatory, and can be filled with fictional data. For instance, a user could decide to write a fictional place (e.g., Wonderland) as their profile location [
71], use a fantasy name, or no name at all. In this step of the methodology, we inferred gender (binary) using the available user attributes and published content by using information provided by some users—whom we could identify as residents of Santiago, with a specific gender—to predict the attributes of others.
To predict these attributes we used XGBoost [
72], a gradient boosting classifier based on decision trees. Our approach was based on the idea of using profiles that self-report their attributes to train a classifier, and then to propagate attribute labels to the rest of the data set [
23]. In order to classify these attributes, we characterized each user through a set of features, which included:
The content published in his/her/their tweets, separated into terms, where a term may be a word, a hashtag, an emoji, an URL, or an n-gram (i.e., n single terms that appear consecutively). Not all terms appear on the feature matrix, as there were many terms that were not relevant for the task at hand, such as lexical errors. Hence, we discarded terms that were used by fewer than 50 users (determined through manual exploration).
The content published in his/her/their biographies, separated into terms (in the same way as tweet content). Here, we use a minimum threshold of five users for each term (determined through manual exploration).
The profile information, which includes time-zone, the home page link, and the use of specific words related to commonly discussed topics (sports, religion, TV, etc.).
The interactions with other profiles through replies, retweets, and quoting other tweets.
Using these features for users, a classifier may learn that specific language cues, interactions, words in profile description, among other characteristics, have predictive power.
Next, we identified which users self-reported demographic attributes in their profiles. Gender may be revealed by displaying a typically gendered name in the profile [
73], and location may be disclosed by mentioning where a user lives in the profile [
71]. The set of users that we could label though these simple measures were the training sets for the XGBoost classifiers, one for gender and one for location. Note that we used the location classifier just to discard users from the data set that belonged to non-relevant locations in the study.
Once a classifier was trained with profiles that self-disclosed their attributes, we proceeded to predict those attributes for the rest of the dataset, enabling us to have demographic attributes for all users. Note that XGBoost included prediction confidence (where 1 is maximum confidence), and thus, we only kept users with a minimum confidence of 0.7 (determined by manual exploration). Technical details about this classification process can be found in Ref. [
74].
3.3. Topics in Transport Modeling
Some users may comment on their daily experiences, positive or negative. Other users participate in the political discussion of transport, giving their opinion on the subject. This work will focus on classifying transport discussion into two main topics: personal experience and general discussion.
Given that the text from Twitter is unstructured, the task at hand required a method to infer the latent structure that separates both aspects of content. We resort to topic modeling methods to achieve that aim. Particularly, we used Topic-Supervised Non-Negative Matrix Factorization (TS-NMF) [
16], which has been used successfully in our previous work to infer the main mode of transportation of Twitter users [
41], as well as mobile phone users [
17].
Topic modeling techniques require a parameter with the number of topics, i.e., the number of latent dimensions in the structure inferred by the model. In general, because these topics are latent, they do not always align with human interpretation. The TS-NMF method is semi-supervised, which means that each latent dimension can be guided toward a specific meaning. A set of terms can be pre-labeled with their association to one or more topics, two in our case study. Then, the model guides the topic extraction process by aligning the obtained latent topics with the input information.
TS-NMF works by decomposing a known matrix
D into the multiplication of two lower-rank matrices
W and
H of rank
k. The supervision matrix
L contains the available labels for user-documents (i.e., rows of
X). The
W and
H matrices are found by solving the following optimization problem:
where
is the Frobenius norm, ∘ is the Haddamard product operator,
k represents the number of topics,
W represents the relevance of each topic in each document, and
H represents the relevance of each term in each topic. The matrix
L contains the subset of terms categorized into a topic, where each row is a term, and each column is a topic, and a cell value of 1 indicates association to the topic. (An efficient Python implementation of the TS-NMF method is available at
https://github.com/Vokturz/tsnmf-sparse).
In our context,
, and
D is a term-user matrix, where each cell contains the weighted number of times the corresponding user published a tweet with the corresponding term. The weight is estimated using Term-Frequency–Inverse-Document-Frequency (TFIDF) [
75], which measures how important a word is to a document in a collection or corpus. We apply TFIDF to
D to give more weight to words that are less frequent in the data set, but that may be relevant for each discussion topic. The matrix
L contains the subset of terms categorized into personal experience and general discussion. See
Figure 5 for an overview of this approach.
After applying the TS-NMF method, we obtained two matrices, one with the association of users with the topics of discussion, and one with the association of terms with the topics of discussion. We assigned each user to a specific discussion group by estimating the maximum topic association. Users with a max topic score lower than 0.8 were discarded from the analysis due to being hard to classify (the threshold was determined via manual exploration).
At this stage of the methodology, for each user we knew his/her/their gender and main topic of discussion.
3.4. Transport Perception Metric
Once users had demographic attributes and the discussion was divided in two topics, the next step was to measure perception in each discussion. To do so, we followed a lexical approach, because language style can be an indicator of the subjective way in which people understand themselves and the different situations they take part in. Particularly, we used a well-known dictionary approach based on the psycho-linguistic dictionary named Linguistic Inquiry and Word Count (LIWC) [
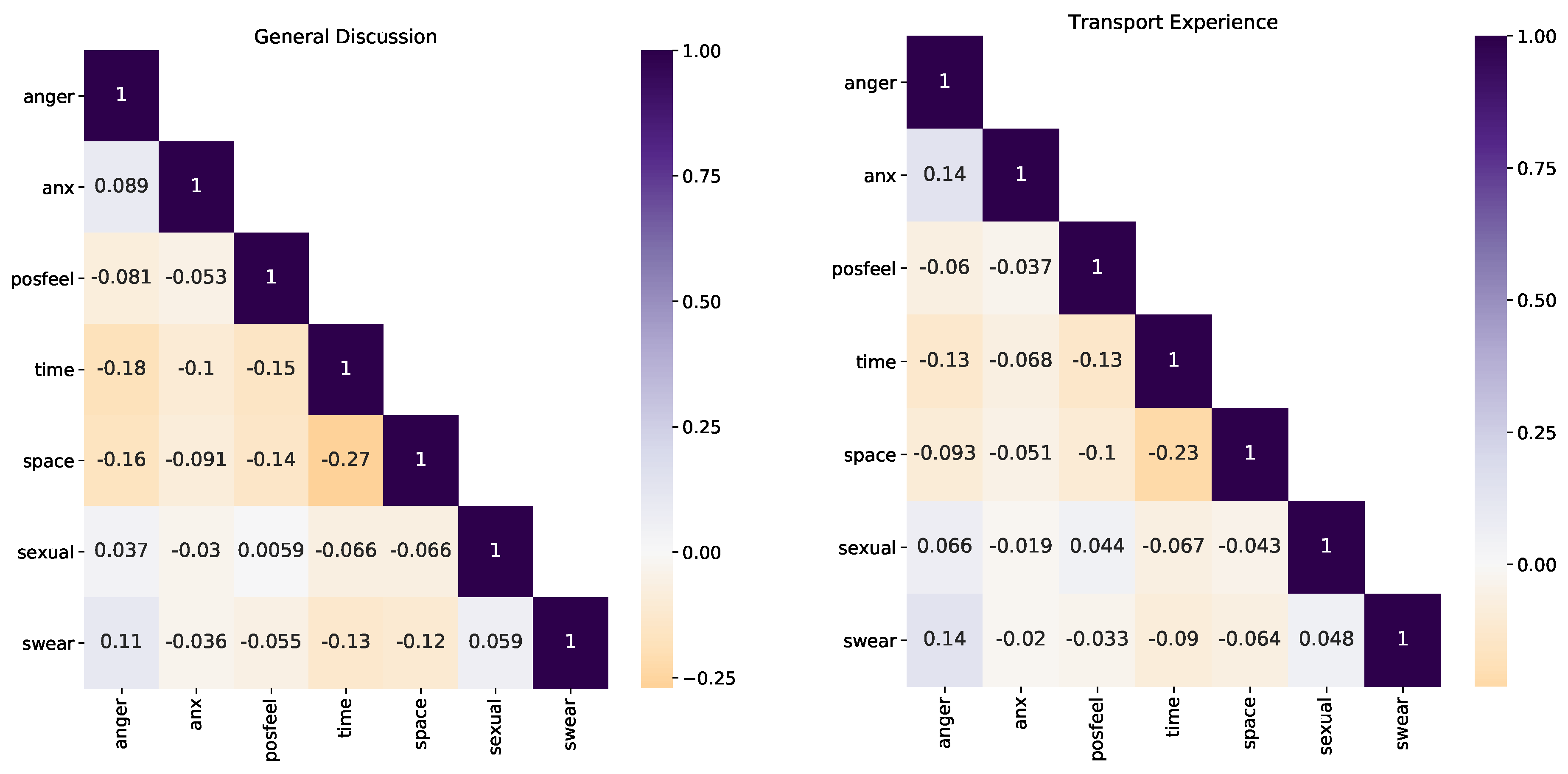
27], which is designed to capture emotional, cognitive, and structural components present in speech. LIWC defines several categories and words belonging to these categories. The frequency of word usage is assumed to be a proxy of how these categories are related to who is performing the speech. As relevant categories for our study, we considered affective processes such as anxiety, anger, and positive feelings; relativity notions of time and space; and usage of certain words such as cursing, or sexual language (see
Table 3 for examples of words from these categories). For this project, we updated the original dictionary to include Chilean slang, e.g., weón (dude, in swearing), agarrón (grab, in sexual language), and taco (traffic jam, in space).
We refer to our selected categories as perception categories, because they are proxies of how people perceive the transportation experience and the general discussion. The perception of users is represented in a Perception Matrix
P using the LIWC dictionary, such that:
where
c is the perception category of interest,
i is a user id. In this way,
P contains emotional and contextual cues of how users feel regarding transportation, according to the frequency of words in perception categories. This matrix is divided into subgroups for the next step. For instance, two sub-matrices can be defined according to the most associated topic of users,
(subset of
P with users associated with personal experience) and
(subset of
P with users associated to general discussion). Four sub-matrices can be defined according to that definition, this time separating each group by gender.
Following previous work on perception in Twitter [
76], we define the Transport Perception Metric (
) of user
i in sub-group
S (e.g.,
S is one of
or
) for category
c as:
where
is the mean of column vector
, and
is the standard deviation of column vector
. In summary,
is a standardized measure of how each user in a subgroup expresses each category in relation to the rest of users in the same group.
Considering the previous definition of
, we define the gender gap in perception as the difference in
in a category
c for a given discussion group
S as:
where
is the group of women users in
S, and
is the group of men users in
S. As result, GAP tells us if the tendency of using a specific perception category in a group is more skewed towards women (GAP
) or men (GAP
). The GAP metric allows us to calculate the gender differences in each perception category, it provides answer to our research question.
In summary, by following this methodology, it was possible to infer users’ attributes, identify topics of discussion in transportation, estimate their perception in the discussion, and measure the gender differences of these perceptions. In the next section, we applied this methodology to tweets describing transportation in Santiago.
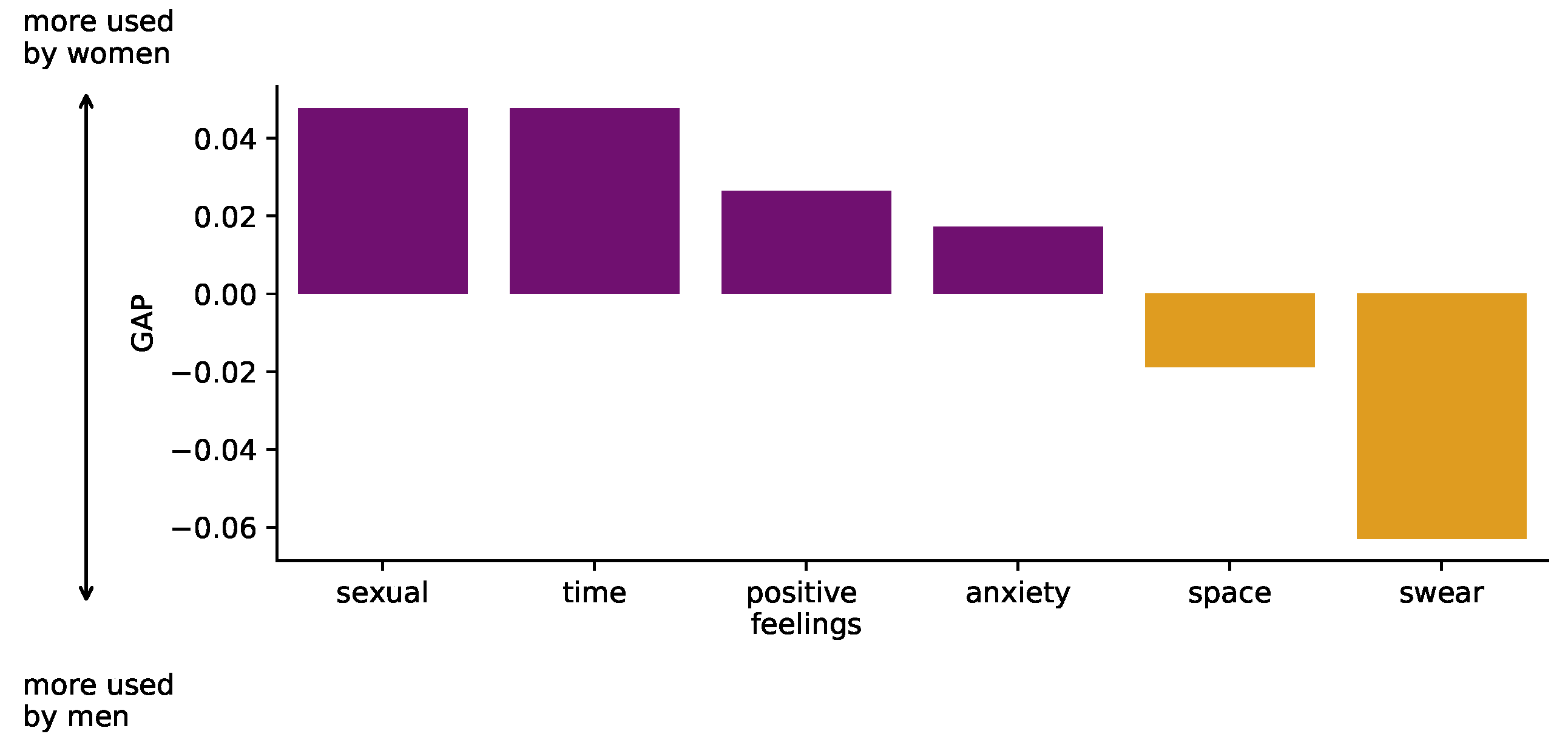
5. Discussion
The main aim of this paper was to design a methodology to measure the gender differences in transport perception as seen on social media platforms. We measured the gender differences across seven perception categories: affective processes (anxiety, anger, and positive feelings), relativity notions (such as time and space), and the use of words associated with cursing or sexual issues. In particular, we conducted a case study of gender differences in perception in micro-blogging messages from Santiago, Chile. Here we showed that both genders express differently. On the one hand, female users write about their emotions regarding travel (both positive and negative feelings). On the other hand, male users use more slang, making it difficult to interpret emotion. The most notable difference is related to female sexual-related harassment, not only on transportation, but also on the public space. This may indicate that women are more exposed to sexual harassment in transportation, a situation reported in other big cities in Latin America [
14].
Overall, we believe that data obtained from social media can complement traditional information gathering methods, overcoming restrictions such as time and cost, while also allowing for previously unseen granularity of data. In this context, here we discuss the implications, limitations, and future work derived from this paper.
5.1. Comparison with Previous Works
A previous study on gender differences in language use has shown that women often tend to express anxiety or positive feelings more frequently, with no differences in anger word usage [
81]. However, for the personal experience discussion, women showed significantly more anger in their publications, proving their dissatisfaction with their journey experience. At the same time, women also referred more to time while talking about their personal experiences, which is consistent with previous studies on the perception of quality factors in which women place a high emphasis on punctuality in transportation systems [
59]. The most significant gender difference is related to harassment to women, not only on transportation but also on the public space. Both issues are consistent with recent studies in Latin American cities [
82].
Our results contradict previous assessments of sentiment toward public transport in Santiago de Chile, where it was found that most messages regarding transport experience were negative [
69]. From a dataset point of view, both approaches are not directly comparable, as the referenced study focused on tweets about bus stops and bus routes, which may prompt adverse reactions when published on the go. From a methodological point of view, the study did not consider differences concerning gender, which may influence results considering the over-representation of men in Twitter [
21,
80]. Addressing this disagreement could be done by defining more specific topics in future work.
5.2. Implications
Social media analysis enables the identification of significant gender differences in the transport experience. Historically, these differences have been hidden due to the consideration of the “average user” in transportation. This identification of differences may be helpful for service providers and policymakers, not only in terms of management and planning, but also to improve accessibility of the public transportation with a gender perspective, in line with the Sustainable Development Goals by the UN, which aim to make cities more inclusive for all.
Service providers could track the most used terms to refer to transportation on their social networks, and study their occurrence based on events, time or characteristics of their users. Our method would allow them to highlight particularities that a survey or a traditional method fails to show.
Another benefit of having gender indicators is that it makes it possible to monitor the situation of women in transport. It allows evidence-based decisions to be made by policymakers to design, formulate, monitor, and evaluate interventions effectively. We focused our analysis on Santiago, Chile, however, harassment in the public space and transportation is a common problem in Latin America, thus, our work could be generalized and applied to other cities such as Quito, Buenos Aires, among others [
82].
5.3. Scope and Limitations
Critics may point out three aspects that scope the reach of this work: representativeness, geographical coverage, and methodological points of improvement.
First, we measured and compared transportation discussion with respect to gender, however, there are also other population groups with special needs, such as children and the elderly. Including them in this kind of study is not just a matter of adding categories to the demographic classifier, as these groups are also under-represented in social media in general. This aspect does not hinder the insights obtained: as long as it is made clear who is represented by the study, then insights are valuable and actionable.
Second, the lack of geographic information prevents us from comparing different sectors of the city, which may be crucial for transportation discussion. For instance, comparing the wealthier part of the city with deprived sectors may reveal different emotional patterns with respect to the transportation experience.
Third, our methodology can be deepened in several steps. For instance, users are assigned to their most associated topic, whereas a more advanced alternative would be to assign weights to topics. The consideration of the temporal aspect of discussions is also needed, as it would allow answering questions such as “what is the time of the day perceived as more safe/dangerous for women?” Still, our work has proven that it is possible to move in this direction. We leave these advancements to future work.
5.4. Future Work
In addition to address the limitations of this work, we devised two main lines of research: visualization and bias mitigation. Our current results provide insights regarding the transportation discussion, with identified implications for two types of stakeholders. However, it is not clear how to actually transfer those insights to these stakeholders in a meaningful way. Visualization has been a successful medium to communicate between data scientists and transportation experts, particularly in scenarios of solving transportation problems with non-traditional data sources and methods [
83]. Finally, social media data is not considered a representative source of population information [
21]. Several access gaps to technology, plus the different algorithmic and systemic biases in operation in these scenarios, imply that designing and implementing bias mitigation strategies are needed, especially if the insights derived are planned to be used in decision making and policy design.
6. Conclusions
In this paper we quantified the gender differences in perception of transportation from a two-fold perspective: the personal experience of transport, and the general discussion around it. The usage of social media data, particularly from Twitter, which is not used traditionally for these issues, analyzed with methods from machine learning and psycho-linguistics, proved fruitful in finding topic- and gender-specific insights.
If these differences are taken into account by relevant stakeholders in city planning and management, policies could be implemented that help eliminates gender gaps in terms of access to work, education, opportunities, and above all, equal access to the opportunities a city has to offer, in line with the Sustainable Development Goals. Future work should address methodological aspects of our proposal, but also communication and transfer strategies to ensure its adoption in planning, complementing survey-based information, making visible critical problems that are hidden in these traditional instruments.














{kind=link}
{kind=link}
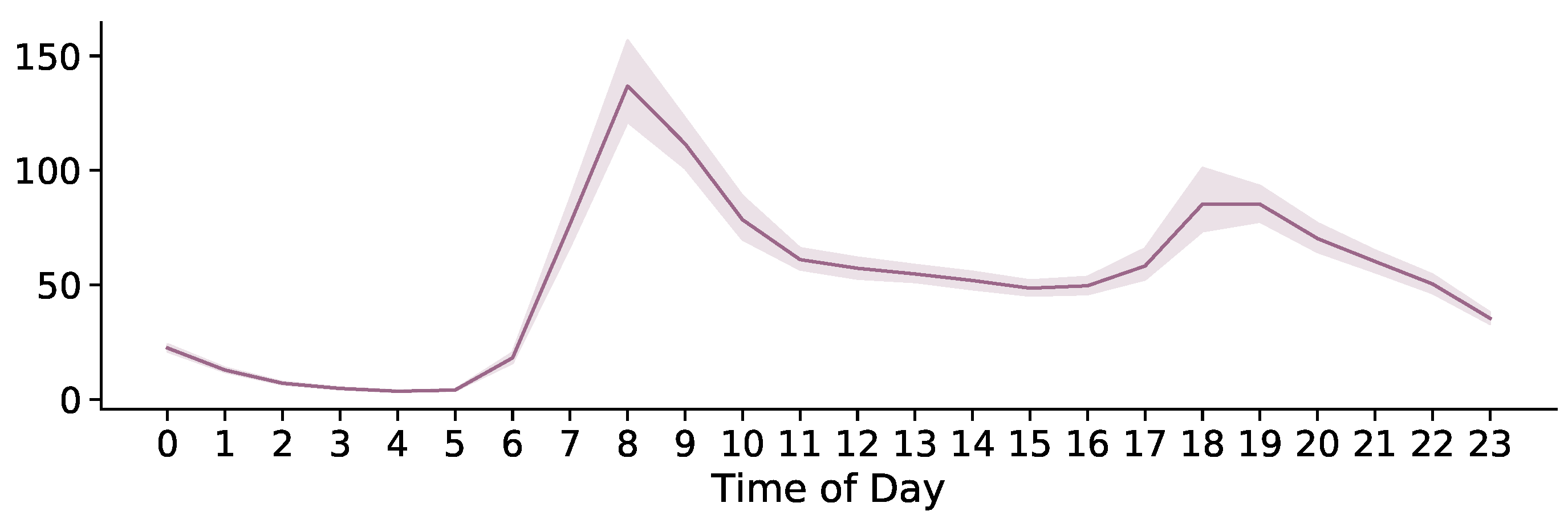{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











 this always happens in the evenings! terrible
this always happens in the evenings! terrible
 , @metbus, bicycle, @bikesantiago, #ipedal,
, @metbus, bicycle, @bikesantiago, #ipedal,  , highway (autopista), taxi, wazers (community of Waze users), #vespuciosur (a highway in Santiago), cabify (a ride-hailing application)
, highway (autopista), taxi, wazers (community of Waze users), #vespuciosur (a highway in Santiago), cabify (a ride-hailing application)