1. Introduction
Cleanliness of the indoor environment is an important issue as a lot of people spend most of the day indoors, without realizing the impact of indoor pollution on their health and well-being. When a healthy lifestyle is becoming more common and people play sports and consume food without pesticides, there is a need to also pay attention to the air we breathe [
1]. The condition of the indoor environment depends mainly on the quality of the indoor air. Some people in the world spend most of the time indoor—due to working mode or air temperature in a given climate zone. Therefore, the internal microclimate has a strong impact on human health, well-being, and productivity [
2,
3].
There are many harmful chemical and mineral compounds present in indoor air, both in the form of solid particles and in the gaseous state, so it is difficult to determine their exact amount and concentration. Indoor air pollution can come from outside air that penetrates inside as well as from indoor sources [
4,
5]. The most common pollutants that have the greatest impact on reducing air quality are: solid particles (especially PM2.5 and PM10) and gaseous pollutants such as carbon dioxide and oxide, nitrogen oxides, ozone, and volatile organic compounds (VOCs) [
3,
6,
7].
Long-term exposure to high concentration of air pollutants causes illness and affects comfort of work and use of premises. Therefore, to ensure human safety and health, the air exchange rate should be adjusted, providing that the outside air is less polluted than indoor air [
8,
9]. According to research, particulate matters PM2.5 and PM10 are the pollutants responsible for the largest proportion of diseases caused by poor indoor air quality in the EU (European Union)—around 78%. Low air quality is associated with the occurrence of illnesses such as asthma, lung cancer, allergies, and skin irritation. Particulate with a diameter smaller than 2.5 μm has been harmfully affecting urban societies around the world for decades [
10,
11,
12,
13,
14].
In Poland, the problem of smog and increased concentrations of particulate matters PM10 and PM2.5 is still present. According to EEA (European Environment Agency), the average annual dust concentration with a diameter less than 10 µm should not exceed 40 µg/m
3, while the 24-h concentration should be lower than 50 µg/m
3. The average annual concentration standard for PM2.5 particulate is 25 µg/m
3 [
15]. Annual and daily concentrations of particulate matter measured in urban and suburban areas often exceed World Health Organization (WHO), European Union (EU), and national levels [
16,
17,
18]. Therefore, it is necessary to monitor particulate concentrations in order to identify sources and improve air quality in terms of reducing the concentration of pollutants from anthropic sources [
19,
20,
21,
22,
23,
24,
25]. Monitoring of air pollution concentrations is also necessary to analyze the occurrence of related illnesses in a given area and implement appropriate preventive measures in the field of health protection [
26].
Air monitoring tasks are performed not only by measuring devices, but also by using prognostic tools such as neural networks and numerical models [
27,
28,
29,
30]. Mathematical models are widely used to describe the relationships between various types of factors. In the case of the environment component, which is air, the modeling can be helpful in determining the concentration of pollutants or as a tool supporting the selection of the best method to improve the air quality in a building [
31]. Statistical and mathematical methods are also used to analyze the impact of some meteorological factors on concentrations of air pollutants [
32,
33,
34,
35,
36,
37,
38].
The concentration of suspended dust in a given place and time may depend on a number of factors. The first group are meteorological factors, which include: air temperature, relative humidity, and wind strength. The second group is related to the environment, i.e., the proximity of dust emission sources (industrial plants, roads), soil type, and vegetation covering the area [
38].
The aim of this article is to propose a mathematical testing model that will allows the correlation between the concentration level of the PM2.5 suspended particle in the indoor air depending on the influence of factors present in the external environment: PM10 and PM2.5 concentration, relative humidity and temperature. Factors that could be measured by devices were selected for analysis, therefore the proposed model could represent a simplified model for further research in the area of suspended dust modeling.
2. Materials and Methods
The basis for further considerations in this paper is the analysis of PM10 and PM2.5 concentrations and the frequency of exceedances throughout the city. There are two measuring stations of the State Environmental Monitoring in Białystok. The highest annual average for PM10 was 26 µg/m
3, so the annual average was not exceeded. The recorded number of days with exceeding the daily average value is 17 days. In the Białystok Agglomeration, the permissible average annual PM2.5 concentration was not exceeded at both measuring stations, and the maximum average annual value was 19 µg/m
3. It should be noted that daily dust concentrations exceeding the permissible level show a significant seasonal variation in concentrations—higher values characterize the heating period. This indicates the origin of PM10 and PM2.5 from low emission sources [
39].
The measurements in the house were carried out with the Aeroqual Series 500 Portable Indoor Air Quality Monitor with a sensor dedicated to particulate matter measurements with a relative humidity correction. The Aeroqual portable monitor is equipped with a laser particle counter (LPC) which is very convenient due to a small size and portability. The sensor uses optimized signal processing and algorithms to correct for disruptions, e.g., humidity. According to the producer, it is accurate for indoor tests and it is working automatically. The measuring range is between 0 and 1.000 mg/m
3. The concentration of PM10 and PM2.5 is measured in mg/m
3 and stored in the device’s internal memory, and then exported using the Aeroqual S500 V6.1 program to read and present data tabular or graphically [
35].
The measurements of particulate matter concentration were made between 2 October 2019 and 1 November 2019 in a single-family house located at Zwycięstwa Street in Białystok, Poland (
Figure 1).
The house is located in a district where single-family and service buildings predominate. It has a central heating system powered by a wood-burning boiler. The research period coincides with the beginning of the heating season in the city. In the immediate neighborhood, the buildings are heated by home boiler rooms or are connected to the municipal heating network.
The house was made in wooden technology, has two entrances and three separate apartments. The building is insulated with mineral wool, covered with facade siding. The house has no basement, the floor is made of concrete, covered with wooden panels. The windows in the building are double glazed, made of PVC (poly(vinyl chloride). The study was conducted in an upstairs flat, which is uninhabited. This allowed to eliminate additional sources of indoor air pollution, which are associated with the use of rooms by people. The measuring portable monitor was programmed for continuous measurement with a recording frequency of 1 h. Measuring position was located near the window, on the stool (see
Figure 2). All windows were closed during the survey.
The concentration of PM10 and PM2.5 in the external air was simultaneously examined to the indoor air. In addition, relative humidity, outside air temperature, and atmospheric pressure were measured. Measurements were also made between 2 October 2019 and 1 November 2019 and were registered by the Airly air quality sensor (
Figure 3 and
Figure 4).
The sensor’s operation principle is based on a laser method, the measurements are processed into information, which is then sent to a data cloud via GSM (Global System for Mobile Communications) or WiFi. Data from the sensor can be read in the analytical panel, on an interactive map, and through the Airly mobile application. The sensor was installed on the eastern wall of the building (
Figure 2), at a height of about 4 m above ground level. The device is located directly at the window of the room where the Aeroqual sensor was placed for measuring particles suspended in the internal air (
Figure 3 and
Figure 4).
The results from both devices were tabulated in Excel, units were converted, and then subjected to statistical analysis. The measurements were averaged over 24 h to compare to the WHO daily norms [
33,
34].
The purpose of this dissertation is to determine the effect of PM10 and PM2.5 concentration in atmospheric air and atmospheric factors (temperature, pressure and relative humidity) outside the building on the concentration of PM2.5 particulate inside the room. In order to achieve it, an attempt was made to create a linear regression model that describes the relationship between the concentration of PM2.5 (response variable) in a building and external factors (independent variables). The linear econometric model with many explanatory variables can be presented as (1) [
37]:
where:
Yt—response variable in period t,
Xti—nth independent variable in period t,
ai—model structural parameter referring to the nth independent variable,
t—unobserved accomplishment of random element in period t.
Matrix-vector representation (2):
2.1. The Individual Stages of Developing a Regression Model
2.1.1. STAGE I—Examination of Independent Variables Fluctuation
The initial stage is to prepare a set of potential independent variables (X
1, X
2, …, X
m), depending of the availability of the results from the device used for research. Statistical data are collected, which are implementations of the response variable and potential independent variables. As a result, vector Y and the matrix X are obtained (equation number). Having the basic descriptive statistics of variables: arithmetic mean (
and standard deviation (
the coefficient of variation
(3) can be calculated [
36]:
If the variation coefficient
is greater than 10%, potential independent variables show too high differential and shall be discarded and not used in further analysis [
36].
2.1.2. STAGE II—Hellwig’s Variables Choice Method
The second stage is the selection of variables for the model using the Hellwig method. The idea of the method is that among the possible independent variables, all possible combinations of these variables are created, and then the so-called integral capacity of information resulting from the use of each of the possible combinations of these variables is tested.
The procedure for selecting independent variables for the model according to the Hellwig method can be presented as follows [
37]:
All possible combinations of potential independent variables are developed that can be created from m variables. Their number is equal to the number of all possible subsets of the m-element set, i.e., L = 2m − 1.
Then, for each n-th potential independent variable, in each l-th combination, the individual information capacity hsj -th of this variable in the combination is calculated according to the formula (4):
s—combination number,
j—number of variable in combination,
Cs—a set of variable numbers consisting in the s-th combination, s = 1, 2, …, 2m − 1.
The best combination is the subset of “candidates” for the independent variables for which the integral capacity (6) is the largest, i.e.,:
The Hs parameter adopts the value from the integral <0,1>. The larger it is, the better the selected combination of variables describes the modeled phenomenon.
2.1.3. STAGE III—Evaluation of Parameters By The Classical Least Square Method (CLS)
The third stage involves evaluation of model parameters. The combinations obtained as a result of the Hellwig method are subjected to regression statistics and analysis of variance. Analysis of variance in Excel returns the value of p, which is a factor that indicates the statistical significance of the independent variable. The critical level of significance was assumed at α = 0.05. If the
p value is <0.05, then the independent variable is statistically significant and should be included in the model. A
p-value higher than the significance level (
p > 0.05) is informative—it does not provide either for or against the null hypothesis, which may mean that the study had too low statistical power [
40].
Regression statistics carry important information on how to fit the model to the data. The determination coefficient R
2 (7) informs to what extent the variability of the response variable has been estimated by the model. The value of the coefficient of determination is a number from the range (0, 1). If the matching of the model to the data were perfect, then R
2 = 1, so the closer to 1, the more matching the model [
37]:
where:
—arithmetic mean from a series of empirical data of the response variable,
—square of model residuals.
Analysis of variance allows estimation of directional coefficients α.
2.1.4. STAGE IV—Substantive Verification—Sensibility of The Model
The substantive verification of the model is aimed at checking the sense of the α coefficients obtained in relation to the data. In addition, the coincidence property is examined, which checks whether an increase in the value of dependent variables causes an increase in the value of the response variable. The model is coincidental if, for each independent variable, the sign of the coefficient standing next to the variable in the model is equal to the correlation coefficient with the response variable. This means that for each i = 1, … m, where m is the number of variables in the model, the condition (8) is met [
37]:
2.1.5. STAGE V—Statistical Verification—Testing The Degree of Compliance of The Model With Empirical Data
The analysis of matching of the model to real data consists in comparing the observed values of y
t, t = 1, 2, …, n with theoretical values determined on the basis of the y
t model. Measures determining the degree of compliance of the model with empirical data (stochastic parameters of the model) are calculated based on the value of residuals e
t [
36,
37].
the residual variance and the standard deviation of the residuals —inform how much the average actual values of the response variable differ from its theoretical values determined on the basis of an econometric model.
determination coefficient R2—informs to what extent the variability of the response variable has been determined by the model. In order for the model to be positively assessed, the R2 value should be at least 80%.
convergence factor φ2 = 1 − R2—informs to what extent the variability of the response variable has not been explained by the model when its value is below 20%, the model is verified positively.
multiple correlation coefficient (significance) R—informs to what extent the empirical (Y) and theoretical () values of the response variable are correlated. The hypothesis on the significance of the multiple correlation coefficient R should be verified using the F statistics. The F* value is calculated using Fisher–Snedecor tables. If F > F*, then the null H0 hypothesis should be rejected in favor of the alternative HA hypothesis. This means that the multiple correlation coefficient is significant and matching of the econometric model with the data is sufficiently high.
2.1.6. STAGE VI—Statistical Verification—Analysis of The Error Size of Standard Parameter Assessments
Standard errors of estimation of structural parameters S(ai) and relative average errors of estimation of parameters V(ai) are evaluated. If all V(ai) ≤ 50%, then the model shall be assessed positively.
2.1.7. STAGE VII—Statistical Verification—Examination of Significance of Independent Variables
The significance of a single response variable is tested by using the t test. The hypothesis about the statistical significance of the Xj variable is verified using t-statistics. The t* value is calculated using t-tables. If t > t*, the null hypothesis H
0 should be rejected in favor of the alternative H
A hypothesis. This means that the variable Xj has a statistically significant effect on the response variable Y. If all variables are statistically significant (they have a significant effect on the response variable Y), then the model is assessed positively [
37].
2.1.8. STAGE VIII—Statistical Verification—Study of The Distribution of Random Deviations
To study the distribution of random deviations, the GRETL program was used, which can be applied to quickly perform the following tests [
37]:
linearity test—White’s test (nonlinearity–squares),
random component autocorrelation study—Durbin–Watson test,
testing the normality of the random deviation distribution—Doornik–Hansen test.
3. Results and Discussion
The table below (
Table 1) presents the average daily concentrations of PM2.5 particle in indoor air and factors potentially affecting PM2.5. Suspended particulate matter concentrations and atmospheric factors were classified as the following variables that will be used to develop the model:
the average daily concentrations of PM2.5 particle in indoor air [µg/m3](PM2.5 INDOOR)—response variable (Y),
the average daily concentrations of PM10 in indoor air [µg/m3] (PM10 OUTDOOR)—independent variable (X1),
the average daily concentrations of PM2.5 w outdoor air [µg/m3] (PM2.5 OUTDOOR—independent variable (X2),
the average daily temperature of outdoor air [°C] (Temperature OUTDOOR)—independent variable (X3),
the average daily humidity of outdoor air [%] (Relative Humidity OUTDOOR)—independent variable (X4).
3.1. STAGE I—Study of Changeability of Independent Variables
Development of the model commenced with testing the variability of independent variables (X). Below are the basic statistical parameters, a standard confidence level of 95% is assumed (
Table 2).
For the independent variables to be statistically significant, the coefficient of variation should be at least 10%. Variables X1, X2, X3 will be further analyzed, while variable X4 will be rejected.
3.2. STAGE II—Selection of Variables—Hellwig Method
The next stage is the selection of independent variables using the Hellwig method (
Table 3). For three independent variables, L = 2
3 − 1 = 7 combinations are arranged (C1 ÷ C7).
Then, a variable correlation matrix (
Table 4) was created.
The information capacity (H) of each combination of variables (
Table 5) was calculated (based on formula (5).
3.3. STAGE III—Estimation of Parameters Using The Classical Least Squares Method (CLS)
An analysis of variance was performed for all C1–C7 combinations to determine the p parameter, which indicates the statistical significance of the variables. Combinations of C4–C7 with two or three variables were rejected because of a p-value >0.05. Combinations C1 and C2 had a p value of <0.05. The C1 combination was chosen because of the largest information capacity H and the lowest possible coefficient p = 7.197 × 10−15.
The estimated model:
received regression statistics and analysis of variance (
Table 6,
Table 7 and
Table 8) (calculated in Excel).
The analysis of variance allowed to estimate the model’s directional coefficients:
The estimated model is as follows:
3.4. STAGE IV—Substantial Verification—Sensibility of Model
After estimating the model, its substantive verification was initiated.
checking the sense of parameter estimates—factor a1 = 0.301682, so it means that if the concentration of PM10 OUTDOOR increases by 1 µg/m3, then the concentration of PM2.5 INDOOR will increase by 0.302 µg/m3, with other factors unchanged. Verification is positive—meaningful parameter assessment:
The model is coincidental because the condition is met with independent variable of the model: sgn ri = sgn ai.
3.5. STAGE V—Statistical Verification—Examining The Degree of Compliance of the Model With Empirical Data
standard deviation of the residuals of the model Se = 1.28703, which means that the observed values of the response variable (concentration of PM2.5 INDOOR) deviate from the theoretical values calculated from the model by an average of 1.287 µg/m3,
coefficient of determination R2 = 0.87969—changeability of the response variable was explained by the model in 87.97%, thus the model is verified positively,
convergence coefficient φ2 = 1 − R2 = 0.12031—the changeability of the response variable was not explained by the model in 12.03%, thus the model is verified positively,
multiple correlation coefficient (significance) R:
where F > F*, then H
0 is rejected for the benefit of H
A. The probability of making a mistake is 0.05. The multiple correlation coefficient R is significant and the degree of matching of the model to the data is high enough, so the model is verified as positive.
3.6. STAGE VI—Statistical Verification —Analysis of The Error Size of Standard Parameter Evaluations
Parameters a0 and a1 were precisely assessed, because coefficient V(a) < 50%. The cognitive value of the estimated parameter is good, therefore the model is assessed positively.
3.7. STAGE VII—Statistical Verification—Assessment of Significance Of Independent Variables
The significance of independent variables is conducted using the
t-test:
where t
1 > t*, therefore H
0 is rejected for the benefit of H
A, which means that the variable X
1 has a statistically significant effect on the response variable Y. The probability of making an error is 0.05.
3.8. STAGE VIII—Statistical Verification—Assessment of The Distribution of Random Deviations
examination of linearity—White test (nonlinearity–squares)
where
p > α, hence there is no reason to reject H
0, which means that the relationship is linear. The model is verified positively.
random component autocorrelation study—Durbin–Watson test
where
p > α, hence there is no reason to reject H
0, which means that the model does not show autocorrelation of random component. The model is verified positively.
assessing the normality of the random deviation distribution—Doornik–Hansen test
where
p > α, hence there is no reason to reject H
0. The distribution of random deviations of the model is normal. The model is verified positively.
The final model is shown below:
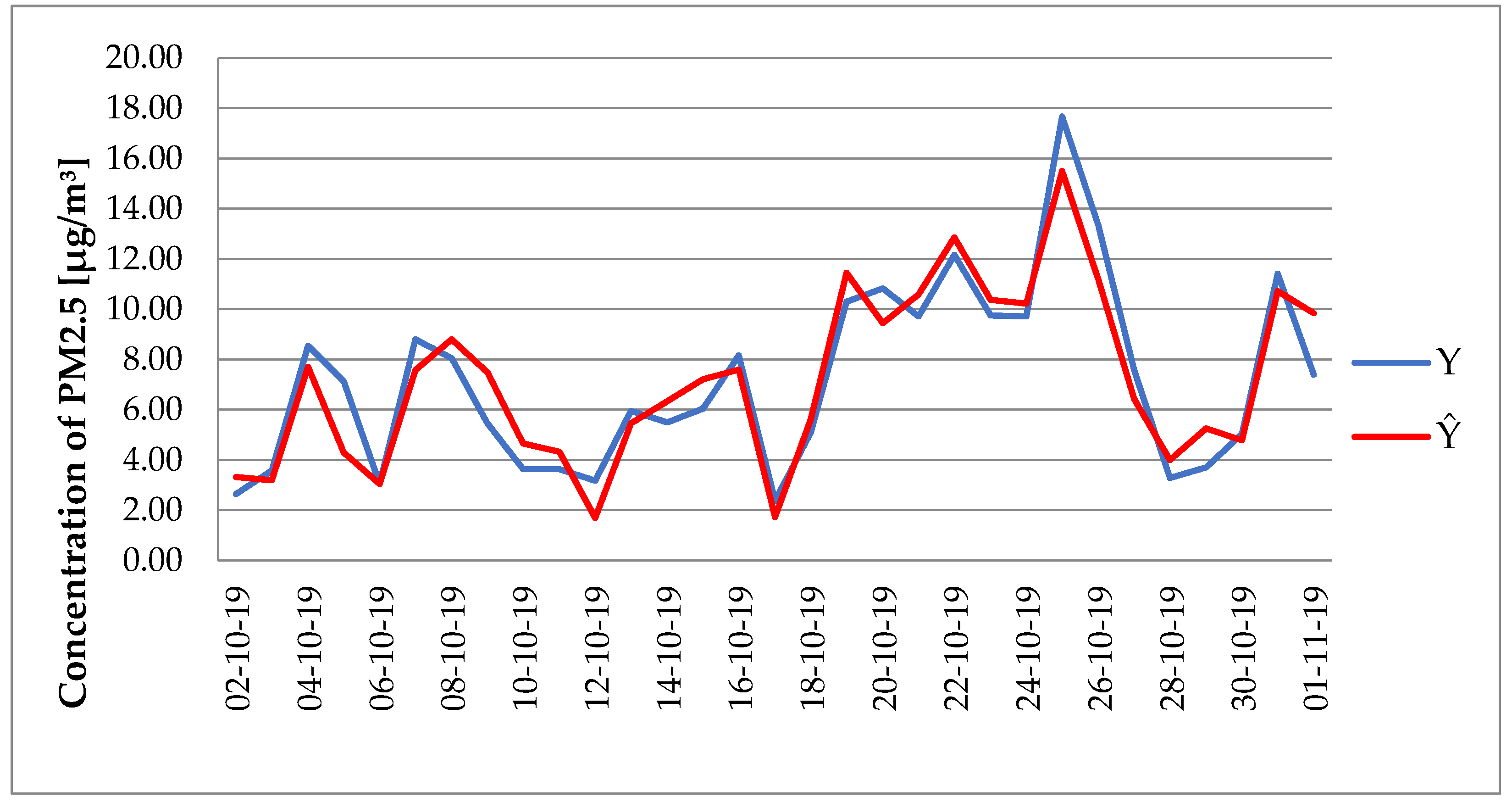
The graph representation of the actual concentration of PM2.5 in the room (Y) with the concentration calculated using the model (
) (
Figure 5) illustrates the matching of the model with the real data. It can be stated that the degree of matching of the model with real data is high.
4. Conclusions
According to WHO Air Quality Guidelines recommendations, the concentration of PM10 should be below 50 μg/m
3 per day and for PM2.5 below 25 μg/m
3 per day in the outdoor and indoor environment [
33]. The PM10 daily average concentration in the outdoor air was exceeded once during the period tested, while the PM2.5 daily outdoor average concentration exceeded the WHO recommended level for nine days. Increased levels of PM10 and PM2.5 particulates will without doubt adversely affect the air quality in the room. A linear regression model was built that allows estimation of PM2.5 concentration inside the building on the basis of data on atmospheric dust concentration. Statistical and substantive verification of the model indicates that the concentration of PM10 in outdoor air is the variable most strongly affecting the concentration of harmful PM2.5 in indoor air. The model therefore allows estimating the concentration of PM2.5 in the building on the basis of data on the concentration of PM10 outside the tested object, which can be useful for assessing indoor air quality without using a measuring tool inside the building.
Further research should consider including additional variables in the analysis, such as wind strength or vegetation covering the area. There is also a need to test the regression model in various environments, e.g., in a non-wooden building, in a multi-family building, in an office building. A tested and improved model can be a useful tool for determining indoor air quality in terms of PM2.5 concentration.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}