Identifying Vulnerable Households Using Machine Learning


Abstract
:1. Introduction
2. Literature Review
3. Methodology
4. Data Description
4.1. Handling Sample Weights
4.2. Construction of FI indicator
4.3. Constructing a Household Income Measure
4.4. Resultant Statistics
5. Model Validation
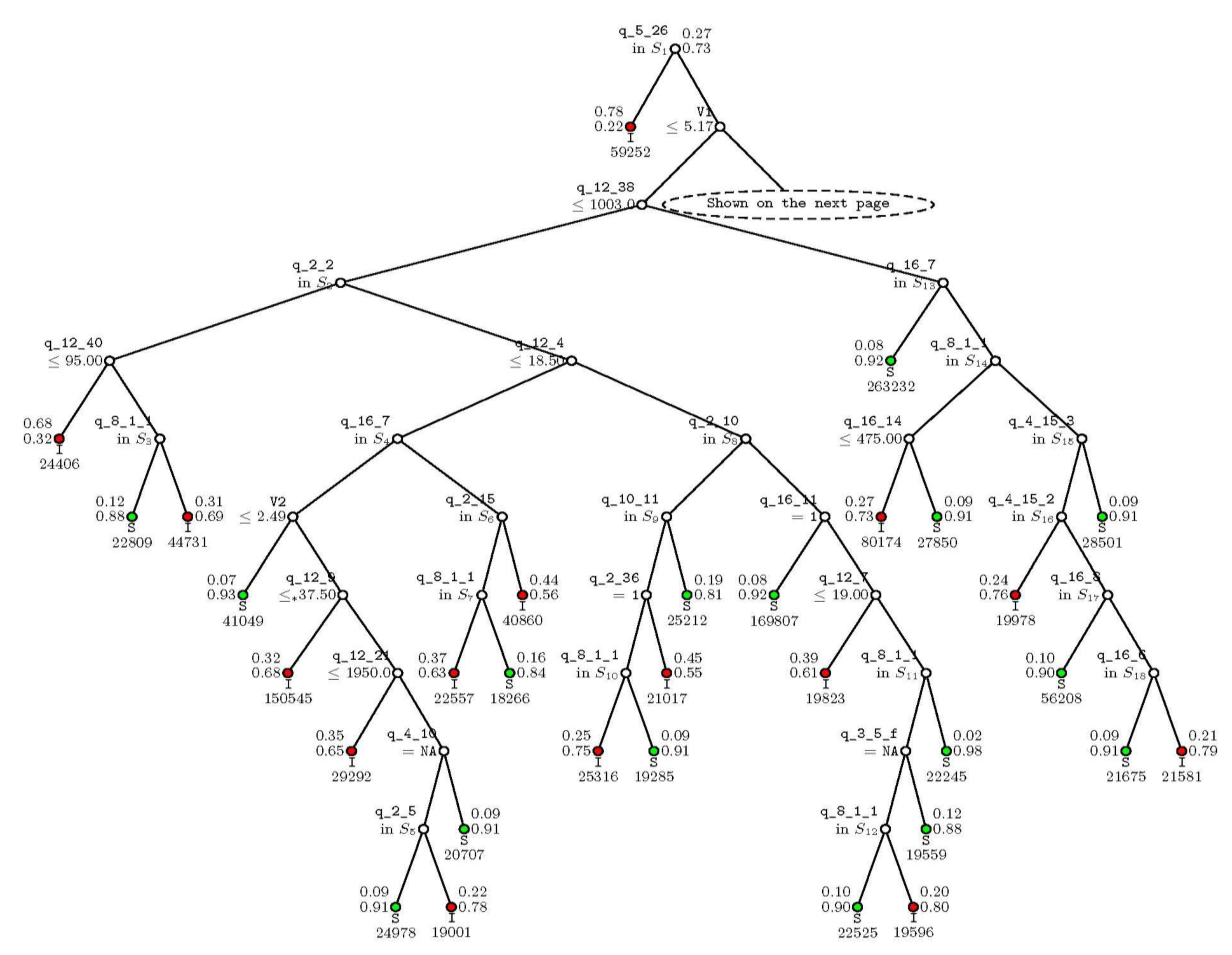
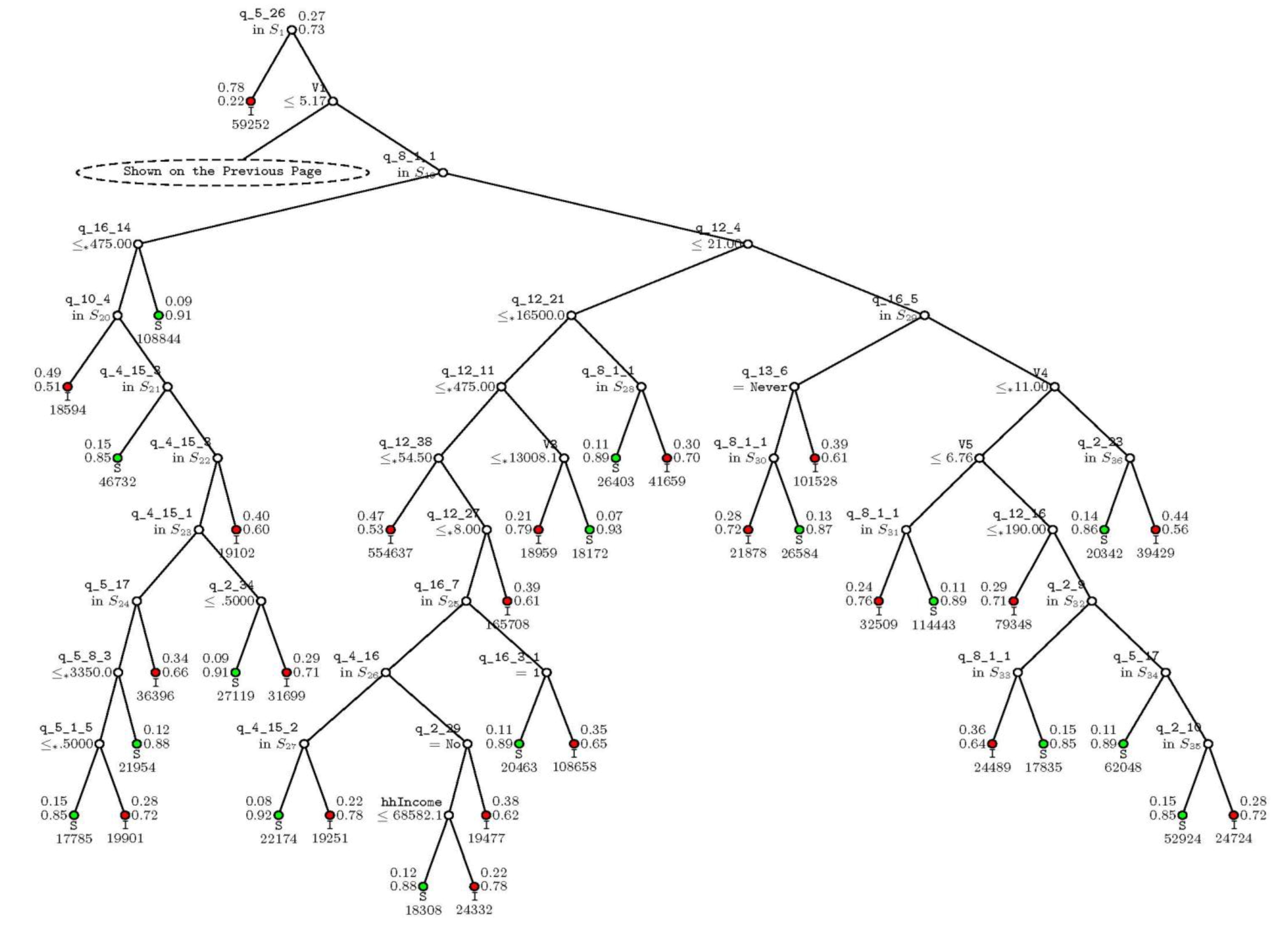
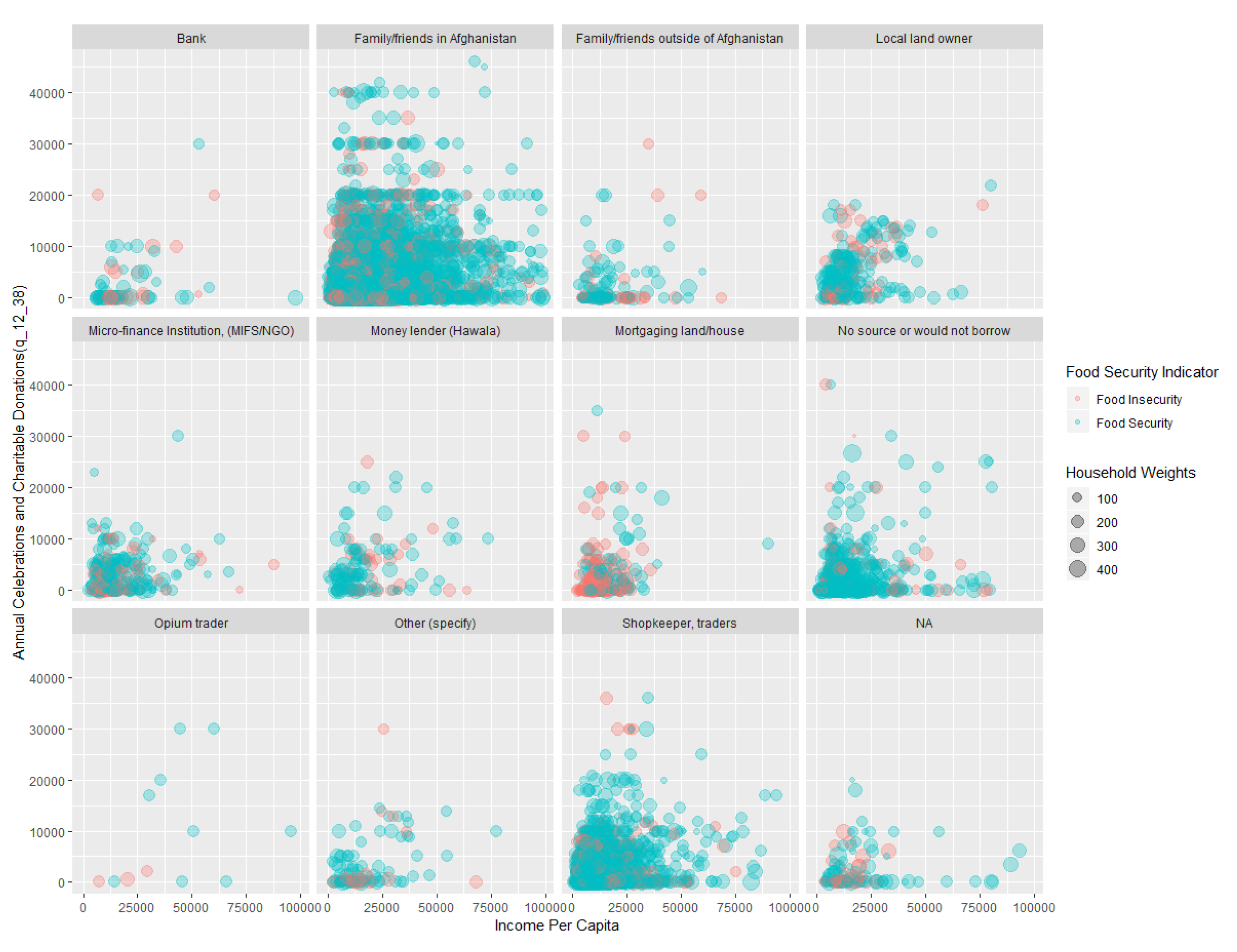
6. Results and Discussion
- Income and expenditure patterns such as expenditures on medicines (q_12_21), transportation fare (q_12_16), laundry charges (q_12_11), income per capita (V4), and annual celebrations and charitable donations (q_12_38).
- Household size (V1).
- Farm-related measures, such as the three most important crops harvested in the last cultivation season—e.g., wheat, maize, barley, etc.—and the area of the land that was rented out in the last summer cultivation season (q_4_10, q_4_15_1, q_4_15_2, and q_4_15_3).
- Realized stresses, such as “How would you compare the overall economic situation of the household with 1 year ago?” (q_16_7) and “ How often in the last year did you have problems satisfying the food needs of the household?” (q_16_8).
- Long-term household characteristics representative of accumulated wealth, such as the construction material used in the exterior walls of dwellings (q_2_2), the type of kitchen/cooking facility in the dwelling (q_2_15), and the ownership of the dwelling (q_2_10).
- Access to resources, such as the connection to sewage (q_2_29), the distance to the main source of water (q_2_34), the ability to access the main water source at any time (q_2_36), the main source of irrigation water (q_4_16), the knowledge of iodized salt (q_16_3_1), and the purchase of iodized salt (q_16_5 and q_16_6)
7. Robustness Tests
8. Conclusions and Policy Implications
Author Contributions
Funding
Conflicts of Interest
Appendix A. Survey Questions
Appendix B. Reference of Food Security Indicator Construction

{kind=link}
{kind=link}
{kind=link}
| Age | Calories (kCal) | Protein (g) | Calories Index | |
|---|---|---|---|---|
| Infants | 0.0–0.5 | 650 | 13 | 0.255 |
| 0.5–1.0 | 850 | 14 | 0.333 | |
| Children | 1–3 | 1300 | 16 | 0.510 |
| 4–6 | 1800 | 24 | 0.706 | |
| 7–10 | 2000 | 28 | 0.784 | |
| Males | 11–14 | 2500 | 45 | 0.980 |
| 15–18 | 3000 | 59 | 1.176 | |
| 19–24 | 2900 | 58 | 1.137 | |
| 25–50 | 2900 | 63 | 1.137 | |
| 51+ | 2300 | 63 | 0.902 | |
| Females | 11–14 | 2200 | 46 | 0.863 |
| 15–18 | 2200 | 44 | 0.863 | |
| 19–24 | 2200 | 46 | 0.863 | |
| 25–50 | 2200 | 50 | 0.863 | |
| 51+ | 1900 | 50 | 0.745 |
Appendix C. Questions and Responses to Categorical Variables to Split the Nodes in the Decision Tree
- Questions:
- Responses of categorical variables to split the nodes:
References
- von Grebmer, K.; Ruel, M.T.; Menon, P.; Nestorova, B.; Olofinbiyi, T.; Fritschel, H.; Yohannes, Y.; von Oppeln, C.; Towey, O.; Golden, K.; et al. Global Hunger Index 2010. In The Challenge of Hunger, Focus on the Crisis of Child Undernutrition; CABI: Wallingford, UK, 2010. [Google Scholar]
- Von Grebmer, K.; Bernstein, J.; de Waal, A.; Prasai, N.; Yin, S.; Yohannes, Y. 2015 Global Hunger Index: Armed Conflict and the Challenge of Hunger; International Food Policy Research Institute: Washington, DC, USA, 2015. [Google Scholar]
- Jain, R. Afghanistan’s Poverty Rate Rises as Economy Suffers. 2018. Available online: https://www.reuters.com/article/us-afghanistan-economy-idUSKBN1I818X (accessed on 12 August 2018).
- Hossain, M.; Mullally, C.; Asadullah, M.N. Alternatives to calorie-based indicators of food security: An application of machine learning methods. Food Policy 2019, 84, 77–91. [Google Scholar] [CrossRef]
- Lobell, D.B.; Burke, M.B.; Tebaldi, C.; Mastrandrea, M.D.; Falcon, W.P.; Naylor, R.L. Prioritizing Climate Change Adaptation Needs for Food Security in 2030. Science 2008, 319, 607–610. [Google Scholar] [CrossRef] [PubMed]
- D’Souza, A.; Jolliffe, D. Rising Food Prices and Coping Strategies: Household-Level Evidence from Afghanistan; The World Bank: Washington, DC, USA, 2010. [Google Scholar]
- Ye, L.; Xiong, W.; Li, Z.; Yang, P.; Wu, W.; Yang, G.; Fu, Y.; Zou, J.; Chen, Z.; Van Ranst, E.; et al. Climate change impact on China food security in 2050. Agron. Sustain. Dev. 2013, 33, 363–374. [Google Scholar] [CrossRef] [Green Version]
- D’Souza, A.; Jolliffe, D. Food Insecurity in Vulnerable Populations: Coping with Food Price Shocks in Afghanistan. Am. J. Agric. Econ. 2014, 96, 790–812. [Google Scholar] [CrossRef] [Green Version]
- Porter, J.R.; Xie, L.; Challinor, A.J.; Cochrane, K.; Howden, S.M.; Iqbal, M.M.; Lobell, D.B.; Travasso, M.I. Chapter 7: Food Security and Food Production Systems. In Climate Change 2014: Impacts, Adaptation, and Vulnerability. Part A: Global and Sectoral Aspects. Contribution of Working Group II to the Fifth Assessment Report of the Intergovernmental Panel on Climate Change; Cambridge University Press: Cambridge, UK, 2014; pp. 485–533. [Google Scholar]
- Altman, M.; Hart, T.; Jacobs, P. Food security in South Africa; Centre for Poverty, Employment and Growth: Cape Town, South Africa, 2010. [Google Scholar]
- Mwebaze, E.; Okori, W.; Quinn, J.A. Causal Structure Learning for Famine Prediction. In Proceedings of the AAAI Spring Symposium: Artificial Intelligence for Development, Stanford, CA, USA, 22–24 March 2010. [Google Scholar]
- Weiser, S.D.; Young, S.L.; Cohen, C.R.; Kushel, M.B.; Tsai, A.C.; Tien, P.C.; Hatcher, A.M.; Frongillo, E.A.; Bangsberg, D.R. Conceptual framework for understanding the bidirectional links between food insecurity and HIV/AIDS. Am. J. Clin. Nutr. 2011, 94, 1729S–1739S. [Google Scholar] [CrossRef]
- Lokosang, L.B.; Ramroop, S.; Hendriks, S.L. Establishing a robust technique for monitoring and early warning of food insecurity in post-conflict South Sudan using ordinal logistic regression. Agrekon 2011, 50, 101–130. [Google Scholar] [CrossRef] [Green Version]
- Hoddinott, J. Choosing Outcome Indicators of Household Food Security; Citeseer: Princeton, NJ, USA, 1999. [Google Scholar]
- Arene, C.J.; Anyaeji, R.C. Determinants of food security among households in Nsukka Metropolis of Enugu State, Nigeria. Pak. J. Soc. Sci. 2010, 30, 9–16. [Google Scholar]
- Maharjan, K.L.; Joshi, N.P. Determinants of household food security in Nepal: A binary logistic regression analysis. J. Mt. Sci. 2011, 8, 403–413. [Google Scholar] [CrossRef] [Green Version]
- Aidoo, R.; Mensah, J.O.; Tuffour, T. Determinants of household food security in the Sekyere-Afram plains district of Ghana. Eur. Sci. J. 2013, 9, 514–521. [Google Scholar]
- Ifeoma, I.; Agwu, A. Assessment of food security situation among farming households in rural areas of Kano state, Nigeria. J. Cent. Eur. Agric. 2014, 15, 94–107. [Google Scholar] [CrossRef]
- Zhou, D.; Shah, T.; Ali, S.; Ahmad, W.; Din, I.U.; Ilyas, A. Factors affecting household food security in rural northern hinterland of Pakistan. J. Saudi Soc. Agric. Sci. 2019, 18, 201–210. [Google Scholar]
- Wooldridge, J.M. Introductory Econometrics: A Modern Approach; Nelson Education: Toronto, ON, Canada, 2016. [Google Scholar]
- Magombeyi, M.T.; Odhiambo, N.M. Causal relationship between FDI and poverty reduction in South Africa. Cogent Econ. Financ. 2017, 5, 1357901. [Google Scholar] [CrossRef]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tan, A.C.; Gilbert, D. Ensemble machine learning on gene expression data for cancer classification. Appl. Bioinform. 2003, 2, S75–S83. [Google Scholar]
- Brown, I.; Mues, C. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Syst. Appl. 2012, 39, 3446–3453. [Google Scholar] [CrossRef] [Green Version]
- Khandani, A.E.; Kim, A.J.; Lo, A.W. Consumer credit-risk models via machine-learning algorithms. J. Bank. Financ. 2010, 34, 2767–2787. [Google Scholar] [CrossRef] [Green Version]
- Loh, W.-Y. Classification and regression trees. Wires Data Min. Knowl. Discov. 2011, 1, 14–23. [Google Scholar] [CrossRef]
- Loh, W.-Y. Variable Selection for Classification and Regression in Large p, Small n Problems. In Probability Approximations and Beyond; Barbour, A., Chan, H.P., Siegmund, D., Eds.; Springer: New York, NY, USA, 2012; pp. 135–159. [Google Scholar]
- Barbosa, R.M.; Nelson, D.R. The Use of Support Vector Machine to Analyze Food Security in a Region of Brazil. Appl. Artif. Intell. 2016, 30, 318–330. [Google Scholar] [CrossRef]
- Loh, W.-Y. Regression tress with unbiased variable selection and interaction detection. Stat. Sin. 2002, 12, 361–386. [Google Scholar]
- Loh, W.-Y. Improving the precision of classification trees. Ann. Appl. Stat. 2009, 3, 1710–1737. [Google Scholar] [CrossRef] [Green Version]
- Loh, W.-Y. Classification and Regression Tree Methods. In Wiley StatsRef: Statistics Reference Online; American Cancer Society: New York, NY, USA, 2014. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2001. [Google Scholar]
- Padmaja, T.M.; Dhulipalla, N.; Bapi, R.S.; Krishna, P.R. Unbalanced data classification using extreme outlier elimination and sampling techniques for fraud detection. In Proceedings of the 15th International Conference on Advanced Computing and Communications (ADCOM 2007), Guwahati, India, 18–21 December 2007; pp. 511–516. [Google Scholar]
- Bhowan, U.; Johnston, M.; Zhang, M.; Yao, X. Evolving Diverse Ensembles Using Genetic Programming for Classification With Unbalanced Data. Ieee Trans. Evol. Comput. 2013, 17, 368–386. [Google Scholar] [CrossRef] [Green Version]
- Central Statistics Organization (Afghanistan). National Risk and Vulnerability Assessment 2007–2008; Central Statistics Organization: Kabul, Afghanistan, 2008. [Google Scholar]
- US Department of Agriculture Agricultural Research Service: Food Composition Databases. Available online: https://ndb.nal.usda.gov/ndb/search/list (accessed on 12 August 2018).
- National Research Council (US). Recommended Dietary Allowances, 10th ed.; National Academies Press (US): Washington, DC, USA, 1989. [Google Scholar]
- Abdula, R.D. Computable General Equilibrium Analysis of the Economic and Land-use Interfaces of Bio-energy Development. Presented at the 2006 Annual Meeting of the International Association of Agricultural Economists, Queensland, Australia, 12 August 2006. [Google Scholar]
- Carter, P.M.R.; Barrett, C.B. The economics of poverty traps and persistent poverty: An asset-based approach. J. Dev. Stud. 2006, 42, 178–199. [Google Scholar] [CrossRef] [Green Version]
- Mammen, S.; Bauer, J.W.; Richards, L. Understanding Persistent Food Insecurity: A Paradox of Place and Circumstance. Soc. Indic. Res. 2008, 92, 151. [Google Scholar] [CrossRef] [Green Version]
- Loh, W.-Y.; He, X.; Man, M. A regression tree approach to identifying subgroups with differential treatment effects. Stat. Med. 2015, 34, 1818–1833. [Google Scholar] [CrossRef] [Green Version]



| ---------------Food Insecure Households ----------- | ------------Food Secure Households------------- | |||||||
|---|---|---|---|---|---|---|---|---|
| Mean | Standard Deviation | Minimum | Maximum | Mean | Standard Deviation | Minimum | Maximum | |
| Number of observations | 913,470 | 2,512,975 | ||||||
| Celebration/Donation Expenditures | 2045 | 5307 | 0 | 100,000 | 290 | 6374 | 0 | 200,000 |
| Income per Capita | 12,928 | 11,740 | 125 | 215,517 | 16,977 | 18,427 | 0.86 | 600,000 |
| Matches Expenditure | 21 | 16 | 0 | 200 | 24 | 19 | 0 | 900 |
| Effective Household Size | 7 | 3 | 1 | 22 | 6 | 3 | 1 | 28 |
| Fuel Oil Expenditure | 152 | 211 | 0 | 8600 | 193 | 269 | 0 | 9999 |
| Doctor Expenditure | 648 | 1791 | 0 | 90,000 | 814 | 1722 | 0 | 100,000 |
| Medicines Expenditure | 4813 | 8632 | 0 | 320,000 | 6185 | 15,404 | 0 | 999,999 |
| UREA Fertilizer Usage | 139 | 168 | 0 | 999 | 206 | 225 | 0 | 999 |
| DAP Fertilizer Usage | 87 | 116 | 0 | 999 | 130 | 163 | 0 | 999 |
| Shampoo Expenditure | 57 | 65 | 0 | 900 | 68 | 76 | 0 | 1800 |
| Other Misc Expenditure | 636 | 1189 | 0 | 12,000 | 921 | 1710 | 0 | 60,000 |
| Expense on Talismans | 125 | 534 | 0 | 20,000 | 304 | 1294 | 0 | 60,000 |
| School Supplies Expenditure | 180 | 332 | 0 | 5000 | 170 | 427 | 0 | 9000 |
| Soap Expenditure | 35 | 41 | 0 | 700 | 41 | 60 | 0 | 3000 |
| Distance to 2nd Water Source | 12 | 17 | 0 | 240 | 15 | 29 | 0 | 480 |
| Decision Tree | Decision Tree (with 100 Variables) | Random Forest | |
|---|---|---|---|
| Training Sample Recall Rate | 80% | 81% | 82% |
| Testing Sample Recall Rate | 79% | 79% | 80% |
| Variable | Question Number | Example of Answers | Rank | Importance Score |
|---|---|---|---|---|
| Primary Income Source for the Household | Q_8_1_1 | Crop production, Skilled Labor, Salary, Sale of Food Aid | 1 | 15,087 |
| Spending on Annual Celebrations and Charitable Donations | Q_12_38 | Amount in Afghanis | 2 | 14,841 |
| Income per Capita | Income_per_cap | Amount in Afghanis | 3 | 13,623 |
| Spending on Matches in Last 30 Days | Q_12_4 | Amount in Afghanis | 4 | 12,845 |
| Effective Household Size | EffecHHsize | Standard Index | 5 | 12,273 |
| Fuel Oil spending in Last 30 Days | Q_2_25_c | Amount in Afghanis | 6 | 10,283 |
| Shocks Not Specifically Listed | Q_13_1_32 | Yes (specify), No | 7 | 10,210 |
| Annual Expenditures on Doctors | Q_12_22 | Amount in Afghanis | 8 | 9779 |
| Material of the Exterior of Dwelling | Q_2_2 | Concrete, Wood, Mud | 9 | 9496 |
| Availability of Main Water Source | Q_2_36 | Always available, Usually available, Cannot access | 10 | 9175 |
| Was there a Food Problem Last Year (Female Questionnaire) | Q_16_8 | Never, Often, Mostly | 11 | 9028 |
| Times you had Food Problem Last Year (Male Questionnaire) | Q_13_6 | Rarely, Sometimes, Often | 12 | 8803 |
| First Source of Borrowed Money | Q_5_26 | Family, Landlord, Mortgaging house | 13 | 8672 |
| Reason why NOT in Food Aid Program | Q_10_11 | No program, Not aware, Not selected | 14 | 8482 |
| Annual Medicine Expenses | Q_12_21 | Amount in Afghanis | 15 | 8456 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, C.; Fei, C.J.; McCarl, B.A.; Leatham, D.J. Identifying Vulnerable Households Using Machine Learning. Sustainability 2020, 12, 6002. https://doi.org/10.3390/su12156002
Gao C, Fei CJ, McCarl BA, Leatham DJ. Identifying Vulnerable Households Using Machine Learning. Sustainability. 2020; 12(15):6002. https://doi.org/10.3390/su12156002
Chicago/Turabian StyleGao, Chen, Chengcheng J. Fei, Bruce A. McCarl, and David J. Leatham. 2020. "Identifying Vulnerable Households Using Machine Learning" Sustainability 12, no. 15: 6002. https://doi.org/10.3390/su12156002
APA StyleGao, C., Fei, C. J., McCarl, B. A., & Leatham, D. J. (2020). Identifying Vulnerable Households Using Machine Learning. Sustainability, 12(15), 6002. https://doi.org/10.3390/su12156002