1. Introduction
Education for Sustainable Development (ESD) aims at promoting and improving the quality of lifelong learning aimed at acquiring sustainability knowledge, skills and values and reorienting academic curricula (rethinking, integrating, reforming, and greening education towards sustainability), thus raising public awareness through a better understanding of the concept of Sustainable Development (SD) [
1,
2,
3,
4]. ESD has the potential to develop individuals’ potential by improving their awareness, skills, and ability to act more sustainably [
5,
6,
7]. Educational institutions deliver massive online courses as a recent trend in online education, and it seems a successful learning experience for students. Ubiquitous learning, unlike any location, is easily accessible to the students anywhere [
8].
The demand for online courses is speedily growing and becoming a viable feature of the educational system. It is revealed that almost every third student takes the course online while attending their college or university, and this figure has surprisingly increased over the past decades [
9].
Notably, the online learning environment needs a higher gradation of self-regulation than the physical classroom environment [
10]. It is different from face-to-face learning, where students and teachers collaborate and interact [
11]. A time- and place-independent e-learning system [
12,
13], a self-regulated learning process [
14], and an inter-disciplinary approach to teaching and learning are vital factors in ESD [
15]. In a virtual learning environment, e-learning depends on the synchronous and asynchronous correspondence and teamwork [
16].
While taking an online course, students must track and manage the learning time effectively and keep an eye on progress and learning skills to meet critical deadlines. However, it appears somehow that students can lack mastery of the abilities. For example, when using the Learning Management System (LMS), students use it from home or elsewhere through their laptops, desktop PCs, tablets, or mobile phones [
17]. They do all of the things on LMS, including assignments, quizzes, and graded discussion boards (GDBs). LMS can cause students to deviate and disconnect more from the course than they would in a face-to-face setting, or grasp the ability. All this uncertainty can result in procrastination as students refrain from fulfilling their responsibilities on time and wait until the last moment before the given deadline. Identifying students’ learning habits related to time management, and in particular, procrastination, is one of the critical factors for enhancing online learning [
18].
Higher education institutions should emphasize the promotion of interdisciplinary thinking and analysis, which is the basis of SD, by teaching the more multifaceted interrelationships between economic, social, and environmental concepts. It is done at the tertiary or university level in many countries, in terms of the principle of SD (development of course curricula within different academic disciplines), but also in terms of the daily routine operations of the institutions (as in the whole school approach) [
19]. Curricular development should also be achieved by research on pedagogical methods and their effectiveness in delivering sustainability education and training programs for educators [
20].
Procrastination is the propensity to delay the initiation or completion of duties, tasks, or works. To assure the fulfillment of assignments, the learners must resolve that weakness. Therefore, it is most important to identify or predict which learners are at risk of procrastination and the processes by which online learning will affect performance [
21].
Schraw and colleagues explain that academic procrastination is the intentional nature of the learner to defer or postpone work that must be completed before time [
22]. In the study of Michinov and colleagues, they used the e-learning framework, Modular Object-Oriented Dynamic Learning Environment (Moodle), to calculate the rate of procrastination at the beginning and end of the course. They implemented a web-based questionnaire for all participants, who were asked to fill in the questionnaire after the final evaluation, which explores learners’ changing behaviors. The questionnaire also documented the different details, such as times (when learners had to start or resume working), feeling like giving up or leaving, and feeling motivated or excited about completing their course. This research further found that learners who perform poorly or have less than average results are more likely to procrastinate [
21].
In the online course or education, procrastination may also be assessed by evaluating students or learners’ acts or behaviors, such as clicking on lecture videos, attempting GDBs, submitting assignments and quizzes on time, visiting and reading web pages, and constructively looking for and answering questions in discussion forums. A standard method of calculating procrastination is to measure the total time a student is engaging with or communicating with the LMS before a course term. Additionally, studies that take these kinds of measures as a sign of procrastination show that the symbols have a negative association with course results [
23,
24,
25].
The research of Kazerouni and colleagues explains that the assessment of learner habits, such as additional growth and procrastination, has a direct relationship with the accuracy of solutions, the completion time of the given work, or the overall amount of time spent working on a solution. They also found that procrastination contributes to lower scores [
24].
The author You discussed that the learners who fail to study consistently and in time are characterized by poor academic results, procrastination, and abandonment. These triggers have proven to be persistent problems in online learning, and some approaches need to be developed and explored to keep learners motivated, enthusiastic, supervised, and active in their courses to fulfill the task [
25].
LMS mechanically records all the learning activities when the student logs in and traces the self-regulated learning as well. The usage of LMS in institutions is widespread, as it is considered to be the best source for identifying the learners’ presence and academic performance [
26]. Moreover, LMS also assists teachers in determining essential insights [
27]. It provides instant feedback for the students who are at risk of failure, procrastination, and withdrawal from the course and allows regulating the instructional policies and procedures [
28].
Self-supervision deficiency is one of the causes to provoke procrastination in education, and indeed has a higher negative impact on success, usually resulting in backing off or abandonment [
29]. Many studies also elaborate on the importance of formal and appropriate learning behaviors in online education [
30].
Using two found behaviors linked to academic procrastination in LMS data, the author You examined the damaging impact of procrastination on academic achievement. The study identified the students who failed to stick to the weekly scheduled assignment submission or their delays in the timely submission of the assignment, which are considered the vital signs of academic procrastination. The results of this study showed that chronic and repetitive learning behaviors related to time management and preparation must be taken into account in order to prevent erroneously expected success and achievement of the course [
26].
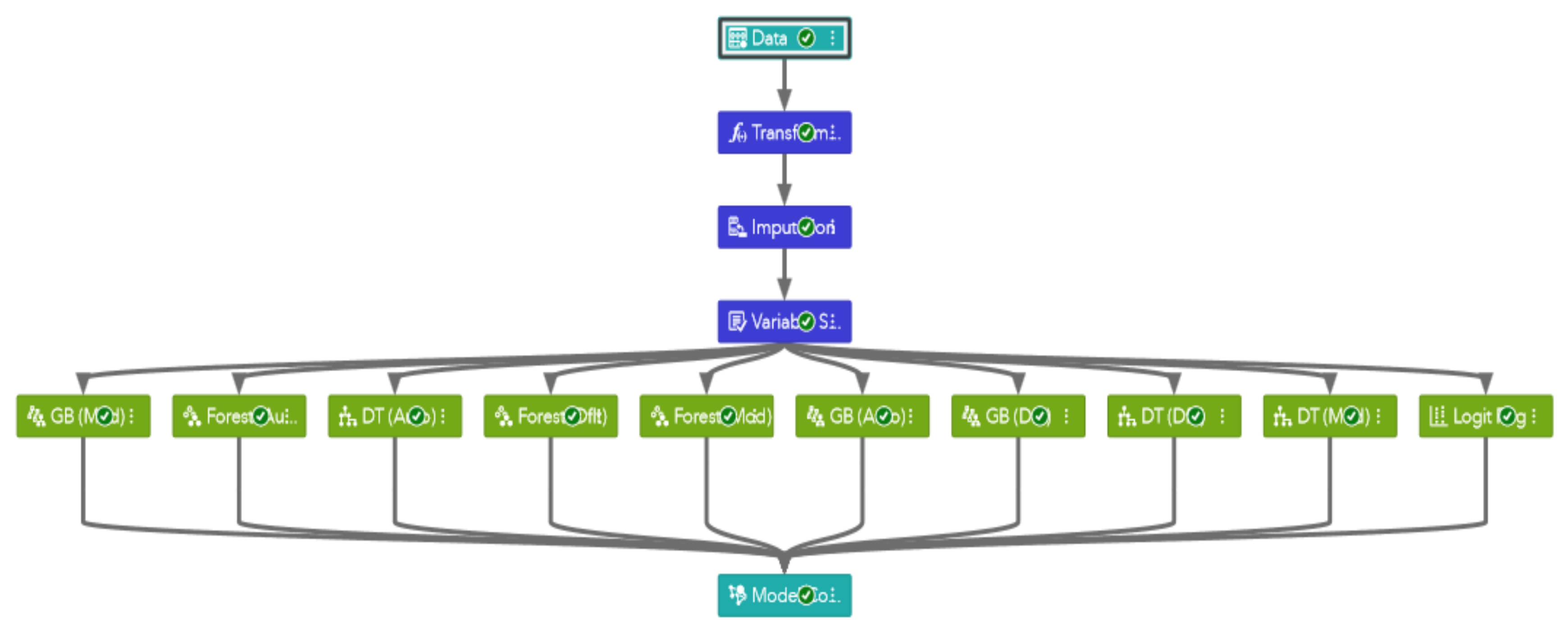
Motivated by the previous studies, we used a data-driven approach and an intelligent tutoring system (ITS), i.e., ASSISTments, to recognize academic procrastination using skill-building data from the highest number of responses to 111 skills from students. In this paper, we discuss the use of machine learning ensemble models for evaluating and predicting students who are procrastinating. To the best of our knowledge, a limited amount of research was performed on a quantitative approach to demystifying procrastinate behavior. Our ensemble models describe the hidden patterns of learning activity in the results, where the trends among the learners are recognized as matching academic procrastinating and non-procrastinating behaviors. Additionally, we detect that students who regularly procrastinate may often show a mixture of mind planning and procrastinating actions during learning. We devise a composite score addressing these subtleties, which incorporates the overall estimate of being considered a procrastinate learner. The approach we build through machine learning allows for a fine-grained study of procrastination and its connection with learning outcomes that can help understand more successful rearrangements of online learning and sustainable reforms in education.
The rest of this article is arranged as follows:
Section 2 explains the evaluation of past studies on identifying procrastination among students. In
Section 3, relationship explorations and procedures used in this paper are presented. In
Section 4, we introduce the experiment and results, along with the proposed methods and modeling to evaluate and analyze the predictive performance through prediction models built. In
Section 5, limitations of the study are discussed, and then finally, we leave the reader with discussion, concluding thoughts, and future perspectives in
Section 6.
2. Related Works
The research of [
25,
31] apprises the significant indicators of course success in online learning, such as scheduled planning and management of time. These behaviors exhibit the learners’ interests and attitudes toward online learning. On the other hand, learners who are weak in managing the time and postpone finishing the work until the final deadline reveal substantial evidence of procrastination behaviors, which can indeed lead to poor performance and success [
18].
Artino and Jones explored the relationship between emotions and self-regulated learning behavior in the undergraduate online learning course. In this study, the authors highlighted features, such as boredom, dissatisfaction, and enjoyment related to achievement emotions, and considered elaboration and metacognition as self-regulated behavior [
11].
Many past studies have focused on identifying the behavior of procrastination, which hampers students from mastering online courses [
18,
26,
31]. The study of Dvorak and Jia compared two groups of students using online analytics data and observed their respective working habits. They found that the group which completed their assignments on time had earned better grades as compared to those who do not complete the work before deadlines [
32].
Further, other studies have found similar outcomes; when learners defer their assigned coursework, they are probably performing poorly [
25,
26]. These findings verify the unsatisfactory description of procrastination as well as highlight the ordinary learning behaviors [
18].
Another comprehensive work of Chen and colleagues has shown that students from depreciated backgrounds, such as those who come from below-average income households, or who are attending college or universities for the first time, are most likely to leave or surrender Science, Technology, Engineering, and Mathematics (STEM) degrees or majors [
33].
Styck highlighted the problems which are intensifying in online learning. Many essential aspects that describe the matters related to students who are coming from diminished environments or cultures hinder the students’ achievement and success. Such negative factors include monetary matters, shortage of counseling, and a sense of segregation [
34]. Prior work has also shown the rapidly increasing trend that underrepresented groups are more likely to engage in procrastination than their counterparts. They determined the characteristics of habitual procrastinators from a global sample based on various demographic variables [
35].
Park and colleagues in their study measured the procrastination by using interviews and questionnaires. Their ultimate aim was to explore the association and connection of students’ cultural upbringing and different states of procrastination on an individual basis. They looked at time management attitudes, particularly for those students who enroll in online learning courses [
18].
In an online learning environment, measuring the procrastination is very candid and identical. Most commonly, researchers calculate the finishing time of a task and determine the differences between the free time [
36] and the deadline of the particular task [
23,
24].
Table 1 represents the past research in chronological order and highlights the methods used to demystify self-regulating learning behavior and procrastination among the learners in online courses.
5. Limitations of the Study
Like many studies, the present research has some deficiencies related to theory and methodology, which may reduce its scope. The first shortcoming is that we have focused on the limited number of features, as there are so many attributes available (such as postponement of a task, level of interaction and participation, and time spent viewing practice videos), which could be taken into consideration. The second limitation is that by taking the autotuned model, which involves building models based on the selected hyperparameter values. Nevertheless, there is no surety that the autotuned model will arrive at the best model. However, it provides the right starting place to use further domain knowledge and expertise in improving the model.
Furthermore, in this research, we did not track the mental and physical health problems among the students that may be one of the reasons for procrastination of the assigned work. Nevertheless, it is a complete study, since in case of learning and attempting to solve the assigned task through a web-based tutoring system, the past medical record can also be considered as one of the predictors to evaluate and quantify the procrastinator students. Accumulation of these features in the data may enhance the correctness and accuracy of the prediction.
6. Discussion, Conclusions, and Perspectives
As far as the ESD perspective is concerned, the method used in this study assists teachers to pinpoint which student has procrastination behavior or has a risk of being a procrastinator. Teachers can provide attention to particular skills and counseling to those students in class the next day to avoid procrastination. Thus, the early prediction of procrastinating behavior could aid in preserving educational sustainability, as sustainable green education prioritizes the present needs rather than future needs. Online education using Massive Open Online Courses (MOOCs), and Intelligent Tutoring System (ITS) all devote to sustainable educational development. Advancement is based on the fulfillment of present-day prerequisites without negotiating future desires. Moreover, the prime objective of ESD is to balance the environmental, economic, and societal demands [
40,
46].
The evolution of ESD in higher education could be seen in numerous dimensions: (1) Sustainability in policy, planning, administration, and control, (2) courses and curricula, (3) research, (4) campus operation, (5) evaluation and reporting [
15,
47]. Several universities are already actively motivated to incorporate ESD into their educational activities. Such programs are directed towards: (i) Positive student learning outcomes; (ii) curricula and evaluation methods; (iii) elimination of barriers; (iv) changing teaching paradigms; (v) improvement of social skills; (vi) communication skills and community relations; and (viii) expansion of their participation in local and national projects (see this section for several examples of such projects) [
48]. “One reason behind the latest initiatives is the UN Decade on Sustainable Development Education (DESD, 2005e2014),” undertaken by UNESCO, which aims to combine concepts, values, and practices for sustainability [
49].
Sustainability competencies are, therefore, linked to the acquisition of knowledge, skills, and attitudes that allow excellent task performance and problem-solving concerning real-world sustainability issues, challenges, and opportunities [
50,
51,
52]. ESD must, therefore, translate these competencies into an educational perspective, so that they can contribute fully to SD and sustainability [
52,
53,
54,
55].
According to the ‘The Brundtland Commission Report’, sustainable development (SD) in education is an integrative approach that covers the connected environmental, societal, and economic facet of the formal and informal educational curriculum. Thus, this educational approach can help students to grow their tendency, knowledge, know-how, and practical understanding to show a compelling role in eco-friendly SD for education and become a liable representative of society. Further, sharing teaching and learning approaches are also required to boost and strengthen learners to revamp their performances and take remedial actions for a sustainable educational environment. Analytical and lateral thinking, visualizing the future, and the respective decision making are the capabilities that ESD promotes [
56].
Although limited in scope, the present research can lead to many meaningful educational, methodological, and practical inferences. Firstly, to the best of our knowledge and information, our research, amongst the previous studies for investigating procrastination and its behavior by using machine learning techniques for educational sustainability or ESD, is one of the rare studies that has focused on these perspectives.
6.1. Conclusions
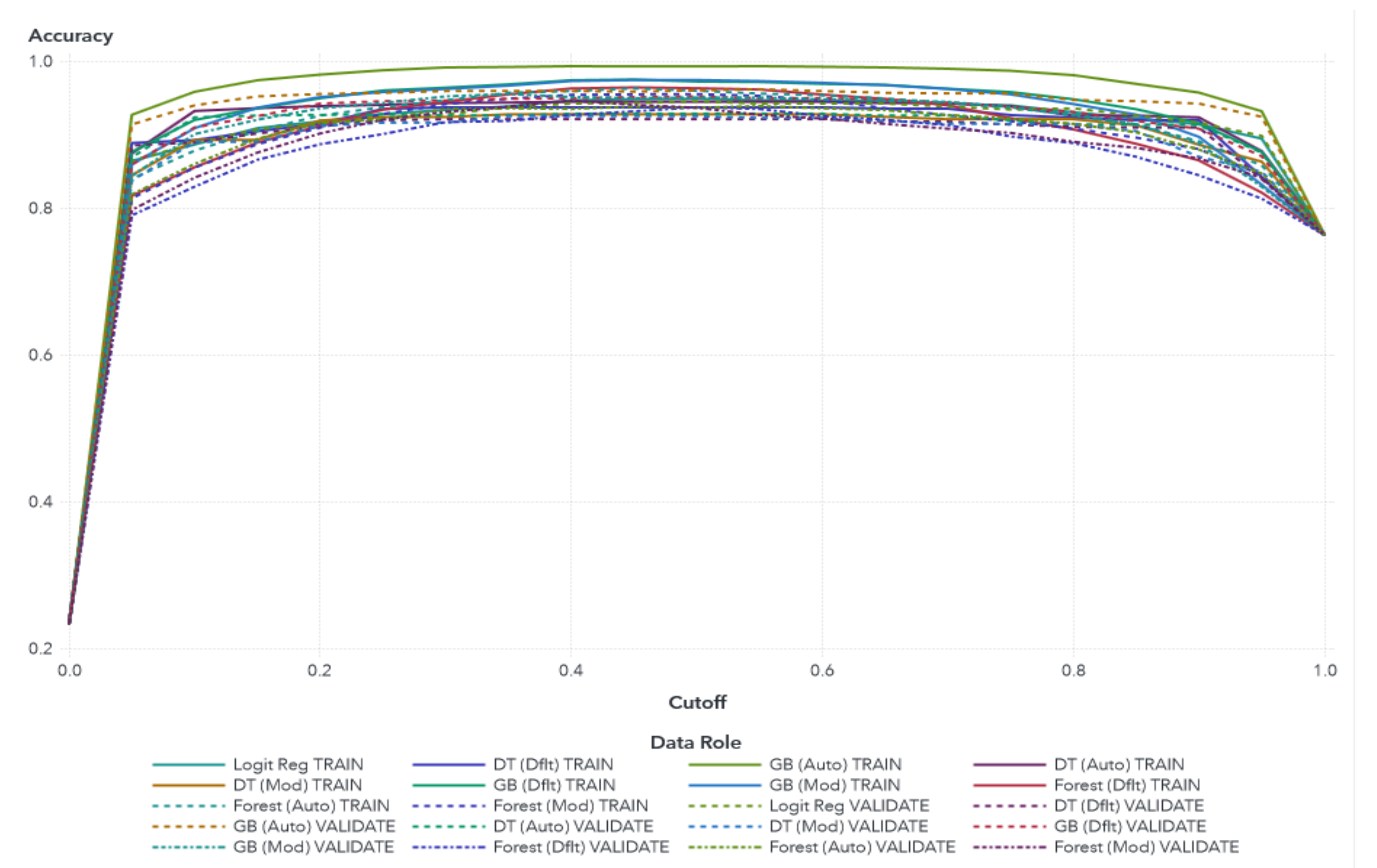
This study introduces a data-driven methodology for predicting student procrastination in web-based online homework using an Intelligent Tutoring System (i.e., ASSISTments). The study identifies some unique patterns inside the big data, as well as makes some essential findings for academia. We suggest that (1) by attempting homework activity on ITS, students undertake various actions that could be further employed to measure procrastination. (2) Early prediction of student procrastination can help the development of an environmentally friendly and sustainable educational context while fulfilling social responsibility. By using machine learning models, we have quantified the procrastinator students. We have used the Kolmogorov–Smirnov (KS) statistic property as our selection criteria class and recorded the KS value.
Additionally, we considered the other measurement metric, such as Average Squared Error (ASE), along with KS statistics. The result suggests that based on the KS and ASE values (i.e., 91.77%, and 2.79%), respectively, GB autotuned model is considered to be the best and most ideal model for deployment that significantly outperformed as compared to the other classifiers in the pipeline due to the increasing KS and decreasing ASE values; the higher value of KS is considered excellent. We have also tested the ensemble classifiers without using the autotuned model, and we found that the GB default model is considered best to classify procrastinator students. It gives KS value 90.74% and ASE of 3.66%, which is slightly higher than the GB modified classifier.
6.2. Future Perspectives
We will focus future research on comprehensive health problems such as (smoking addiction, Influenza, congenital cataract, emotions (frustration and boredom), and behavior) and determining the well-being of students who engage in the online tutoring system to complete their homework or assignments. Poor health in teenagers and adolescents may be one of the reasons for procrastinating the assigned job. In Vietnam [
57], a cross-sectional study gathering the participants from ten groups from high schools and universities also revealed the potential adverse impacts of risky online interactions and the harmful effects of Shisha smoking.

 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




