1. Introduction
The consumption of natural gas has seen a substantial increase during recent years, as it presents a reliable and economical energy and heating solution for businesses as well as households. Its wide acceptance from large-scale infrastructures to small houses has created diverse consumption patterns, especially during high-demand occasions. Inevitably, this has perplexed any attempt of forecasting its demand, especially when one considers the diversity of the consumers and the finite restrictions of the natural gas infrastructure, i.e., low accumulation ability within the grid.
Analytical modelling of such complicated systems would require substantial effort in order to design the grid architecture and each of its consumers, apply correct heat losses throughout the pipes, and in general, include a variety of intricate parameters into the whole system before running the simulation computations. On the other hand, data-driven models are invariant of such parameter tuning and can properly model a system by learning valuable patterns from its collected data. Machine learning algorithms create models by recurrently learning from data, until they can model a process in the best way possible. Being dependent on data alone, alternative scenarios based on different energy resources like fossil fuels, oil, or electricity may as well utilize these methods for their own forecasting purposes.
State-of-the-art published studies which focus on natural gas forecasting of production, consumption, demand, market volatility and fluctuation in prices, and income elasticity have been surveyed and are presented in [
1]. Efficient energy supply planning is essential for any country’s socio-economic state since it is crucial, especially for building successful development plans [
2]. There is a large number of papers found in the relevant literature that tackle the problem of accurate forecasting of natural gas consumption, mostly focusing in hourly intervals [
3]. Short-term forecasting is based on the pattern analysis of time series in order to predict accurate values of consumption or demand [
4]. Artificial intelligence, machine learning, and other statistical methods are typically used in short-, medium-, and long-term forecasts of energy demand [
5]. Based on research studies from the literature, there are notable findings that utilized artificial neural network (ANN) algorithms on forecasting natural gas demand, and whose day-ahead predictions had high accuracy [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Multiple variants of neural networks, especially deep neural networks, have been extensively used to tackle the problem of short-term demand forecasting of natural gas. Deep learning was firstly used by Merkel et al. for forecasting short-term load of natural gas [
16,
17], and then to be compared to traditional ANN and linear regression models on 62 different areas with at least 10 years of data [
18].
Other data-driven approaches, such as neuro-fuzzy methods or genetic algorithms, have tackled the problem of natural gas demand [
19,
20,
21]. Hybrid approaches including Wavelet Transform (WT), Genetic Algorithm (GA), Adaptive Neuro-Fuzzy Inference System (ANFIS), and Feed-Forward Neural Network (FFNN) have been used by Panapakidis and Dagoumas in order to forecast natural gas demand in the Greek natural gas grid [
22]. Moreover, other soft computing techniques, like fuzzy cognitive maps (FCMs), enhanced by evolutionary algorithms, have been applied for modeling time series problems [
23,
24,
25,
26,
27,
28]. In [
29], Poczeta and Papageorgiou conducted a preliminary study on implementing FCMs with ANNs for natural gas prediction, showing for first time the capabilities of evolutionary FCMs in this domain. Furthermore, the research team in [
30] recently conducted a study for time series analysis devoted to natural gas demand prediction in three Greek cities, implementing an efficient ensemble forecasting approach through combining ANN, RCGAFCM, SOGA-FCM, and hybrid FCM-ANN. In this research study, the advantageous features of intelligent methods, through an ensemble to multivariate time series prediction, have emerged.
Many works can be found in the literature that address the accurate forecasting of natural gas demand with a methodology that was based solely on an artificial neural network, or was used in combination with other methods in hybrid forecasting systems; however, in the present work, an innovative approach that includes vital social factors in deep neural network (DNN) models was studied exclusively, contributing to the novelty of the current study. The main aim of this study is the development of a non-linear time series model that can accurately predict future energy demand and estimate how the introduction of important social factors can improve the accuracy of its predictions. As a case study for the demonstration of the approach’s applicability, natural gas energy data from various cities in Greece, which present socio-economic aspects and thus different consumption attributes, have been implemented.
Contrary to most studies that focus on quantitative-only inputs, there are some studies that take into consideration the impact of social or socio-economic factors with machine learning based approaches [
31]. The behavioral habits and characteristics of consumers are strong indicators in forecasting electricity load in households [
32,
33,
34]. Social factors were taken into consideration in the prediction of total energy demand in several cases such as Spain [
35], China [
36], and Turkey [
37,
38]. The application of social components alongside meteorological and past consumption data was also studied in district heating networks [
39,
40]. In all relevant studies, the results showed that the inclusion of social parameters in the modelling can increase the model’s overall accuracy [
41,
42].
Our effort focuses on investigating three types of approaches. The first approach relies on a simple Artificial Neural Network (ANN), namely a single-layer perceptron, that takes into account only quantitative variables. The second approach is based on the state-of-the-art recurrent neural network (RNN), namely Long Short-Term Memory (LSTM) network, which uses single-variable time series and can predict a variable’s value for the next point in time by “memorizing” past variations. The third approach is the proposed Deep Neural Network (DNN) that takes as input not only quantitative, but also qualitative variables. The DNN consists of more nodes and layers than the ANN since it needs to process a larger and more diverse amount of inputs, both numerical and categorical, in a more appropriate fashion. The qualitative variables that are being used in the proposed DNN approach are social factors that fit the characteristics of the country of Greece and will be described in detail in paragraph 2.2. For the case of natural gas demand forecasting, the consumption of energy is bound to the behavior of the human population, which is dependent on social habits, a factor whose impact is investigated extensively in this study.
In the present study, the aim is to build a robust forecasting model based on a proposed deep neural network (DNN) and compare it with an artificial neural network (ANN) and a recurrent neural network (RNN), both of which are able to accurately forecast energy demand [
43]. This comparative analysis aims to investigate whether the factors that dictate human behavior can offer crucial information and increase the accuracy of our forecasts. The results clearly demonstrate that the proposed DNN approach, with the inclusion of social factors, has attained better accuracies than other state of the art intelligent models for natural gas consumption forecasting.
2. Materials and Methods
The Hellenic Gas Transmission System Operator S.A. (DESFA) (
www.desfa.gr) is the operator that manages and develops the Greek natural gas infrastructure. DESFA handles all natural gas off-takes, deliveries, and general distribution, as well as the collection of useful data. They have provided with the dataset that was used in this study. Details on the dataset and its features are provided below.
2.1. Dataset
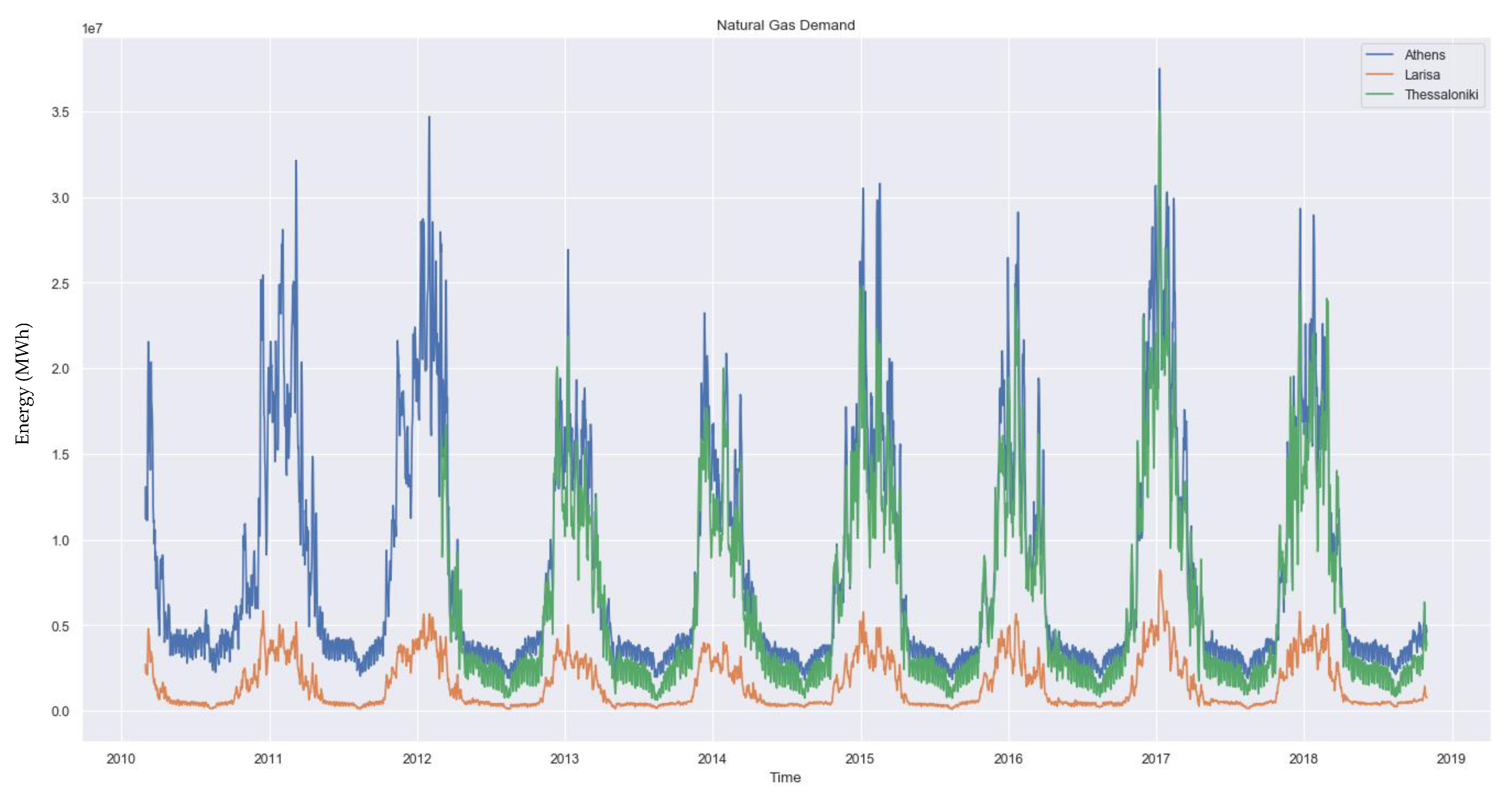
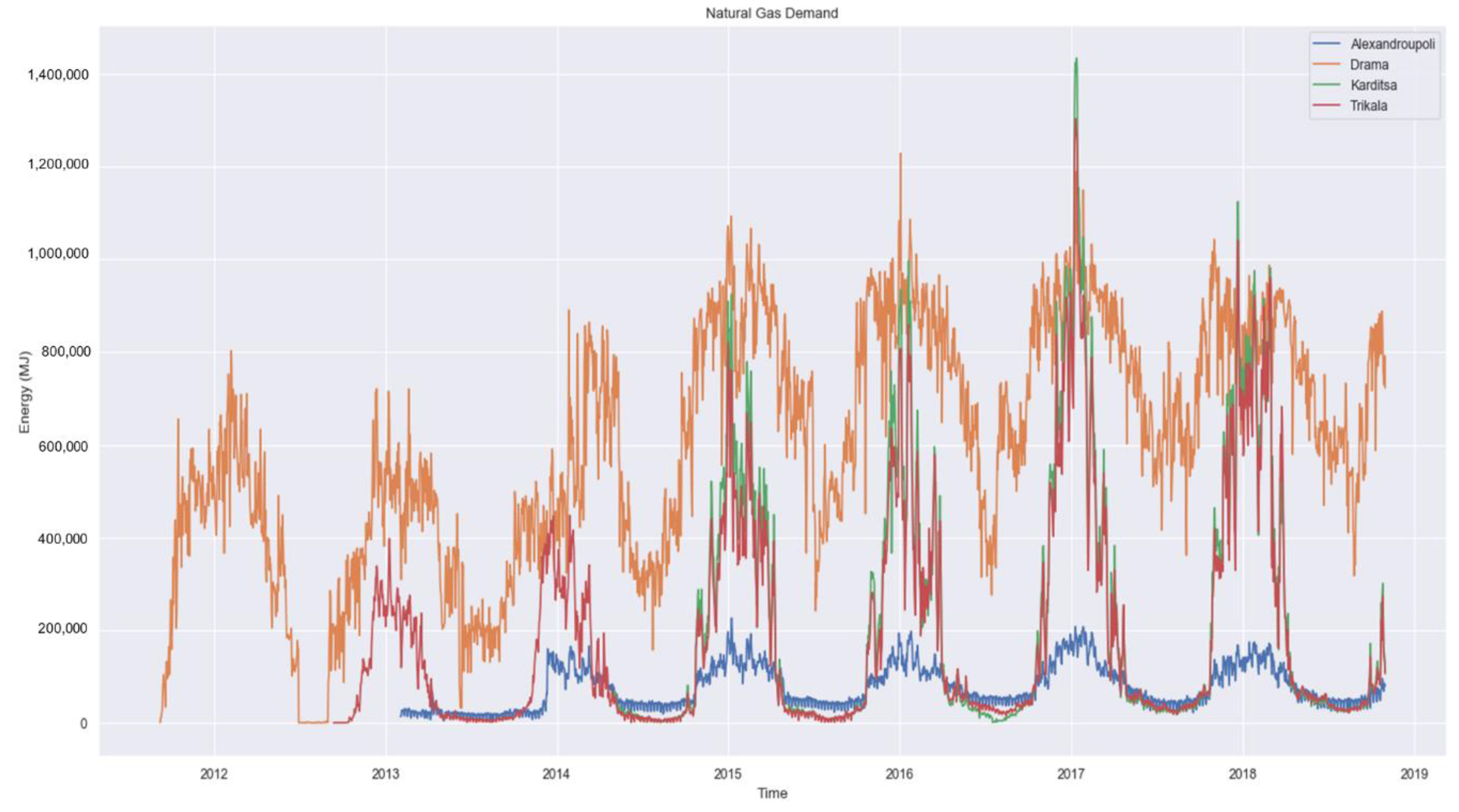
The dataset contains historical data of time series from the natural gas consumption of multiple cities all over Greece, as well as the average daily temperature of each city’s surrounding area. The data spans from 1 March 2010, or later on for some cities, until 31 October 2018. Specifically for some centralized larger cities of Greece such as Athens and Larissa, where the natural gas distribution system was installed early on, there is data since 1 March 2010, as seen in
Figure 1, while in some other large cities, like Thessaloniki, also seen in
Figure 1, or smaller ones, like Alexandroupoli, seen in
Figure 2, data collection started later on. The exact starting dates of data collection for each city are given later on in
Section 3.
As provided, the dataset contained time and dates, natural gas consumption of each city’s distribution point, and the daily average temperature of the area in Celsius degrees. On top of the existing data, social indicators have been added to the dataset such as a month indicator, a day indicator, a weekday/weekend indicator, and a bank holiday indicator. The proper addition of social variables is a key factor to the study since the aim is to see if qualitative social traits can improve the performance of a forecasting model, and by how much compared to other methods.
2.2. Feature Engineering
A certain amount of feature engineering is required for the qualitative data to take proper form, in order to be readable by the machine learning algorithms. This takes place during the preprocessing phase and is conducted in the following way: Months and days are described by a name, e.g., September, Tuesday, etc., and need to be transformed into categorical values, e.g., 9, 2, etc., in a serial way. Therefore, the following association is considered: January-1, February-2, etc., and Monday-1, Tuesday-2, etc. Each of these values are then transformed into vectors with the size of the value range of the variable. In detail, the “month” variable contains 12 different values, one for each month, therefore the size of the vector is 1 × 12. Respectively, the “day” variable contains 7 values, one for each day, therefore the size for this vector is 1 × 7. Consecutively, the “month” variable is transformed into 12 variables, one for each month, and the “day” variable is transformed into 7 variables, one for each day of the week. The “bank holiday” variable denotes a public or religious holiday that affects social behavior (businesses are closed, people are out celebrating, etc.) and is binary, therefore there is no need for any kind of further transformation.
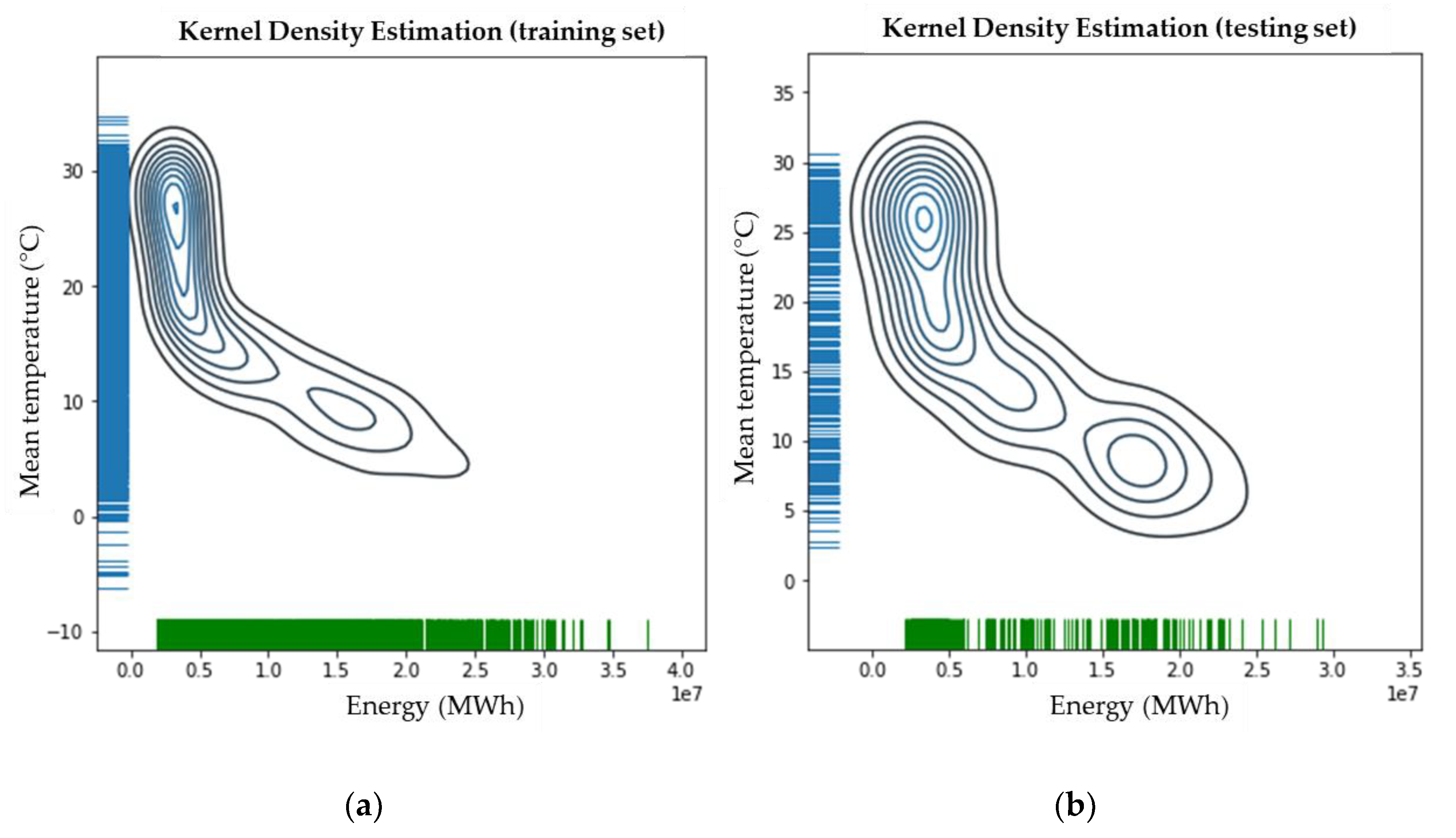
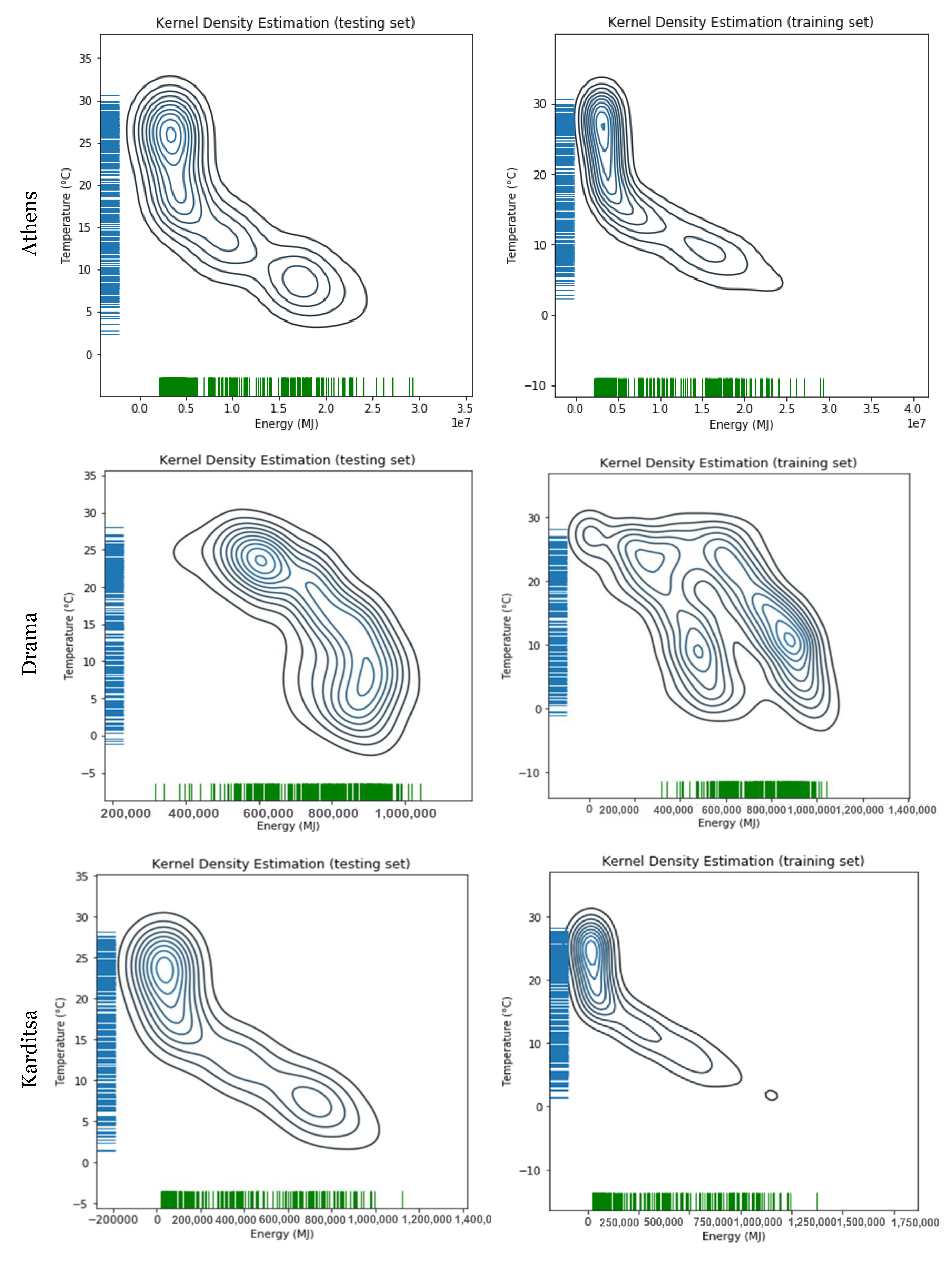
Time and date data are transformed into a single timedate variable which is then used as an index, thus leading to the total amount of 22 variables that are being taken as inputs for the modeling of the energy forecast of the proposed methodology. The desirable variable for the forecast is the natural gas energy consumption from the specific distribution point, which is used as output. The correlation of the consumption energy with the mean daily temperature for the city of Athens is shown in
Figure 3.
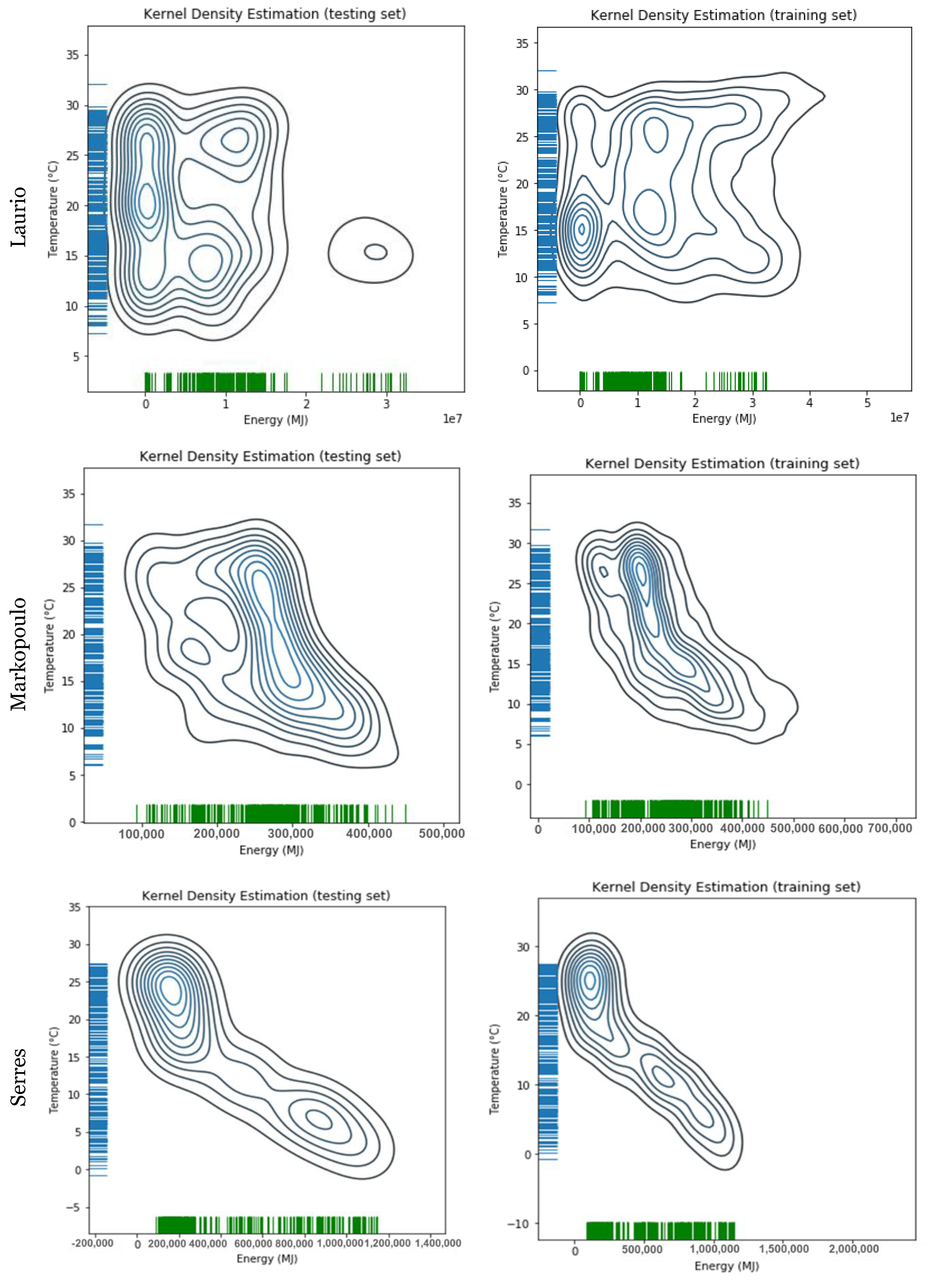
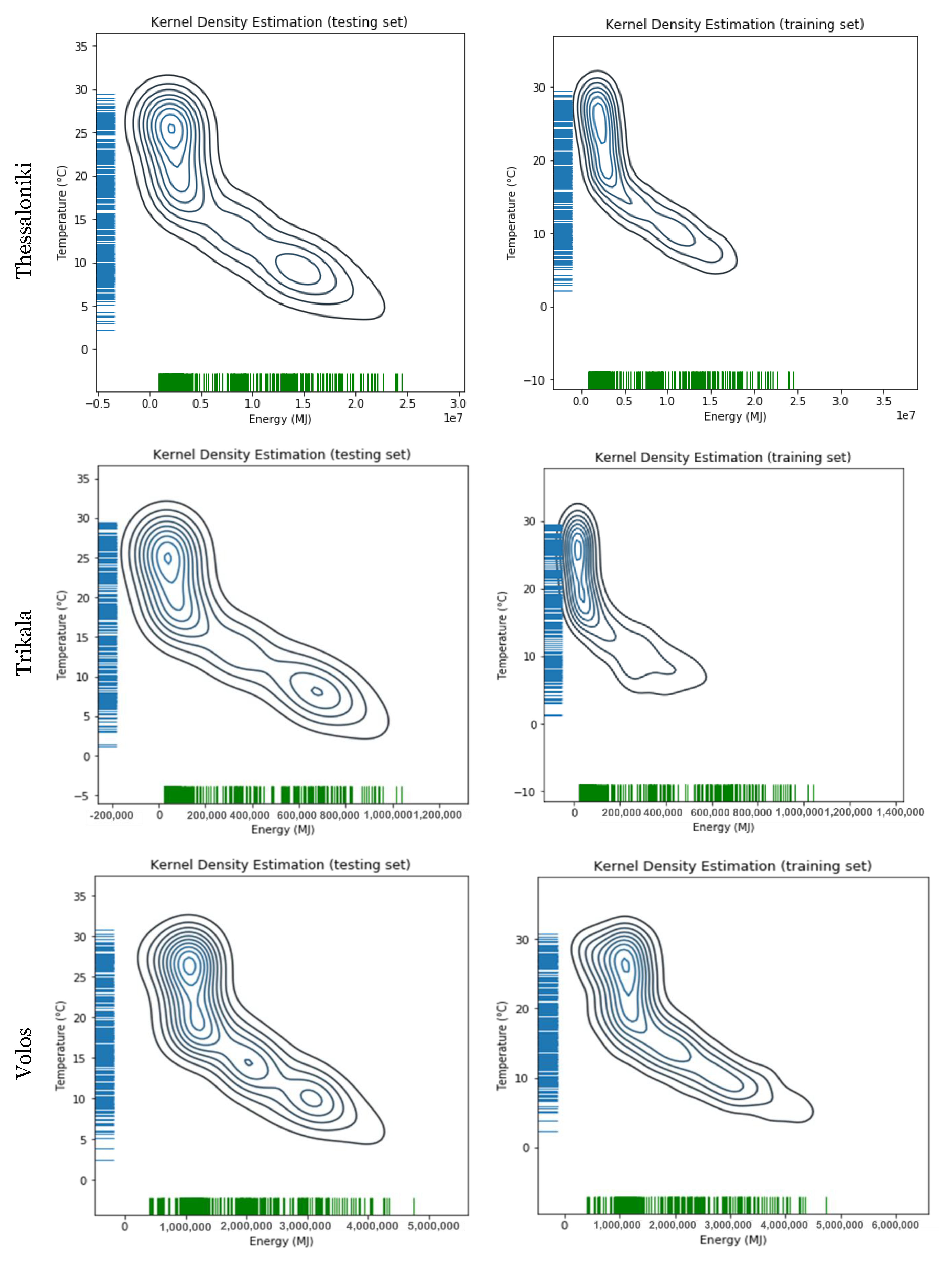
The correlation plots of consumption energy and mean temperature for all the investigated cities are given in the
Appendix, where it is obvious that not all cities have the same pattern of correlation between the mean temperature and the consumption of natural gas. This variation in patterns is one of the reasons that the implemented models achieve different accuracies for each different city, as will be shown later.
3. Methodology
Three types of neural network variants were modeled and tested for accurately forecasting natural gas energy demand. Their implementations differ even though they all belong to the neural network family of algorithms. Each approach has different input variables, however, the general approach remains the same; historical data train a model that is able to produce accurate forecasts of natural gas energy consumption. The approaches, as well as the general process flow, are described in the following sections.
3.1. Artificial Neural Networks (ANN)
Artificial Neural Networks (ANN) [
44] were hypothesized as a method to imitate the human brain and its functions while it performs cognitive tasks, or when it learns. For the mathematical structure of such networks, nodes are used to represent the neurons, and layers are used to represent their interactive synapses in the same fashion as it is within the brain. They received wide acceptance ever since they were conceptualized, however, they started gaining more and more fame ever since the computational power, especially in graphic processing units, has become cheaper and thus easily attainable. Another important reason for their wide acceptance is the vast availability of immense amounts of data that have been collected throughout the past years. This adoption has enhanced the scientific progress of the ANN algorithms, which started from the single-layer perceptron [
45], moved to multi-layer perceptron [
46], introduced the back-propagation algorithm [
47], and led to many new derivatives of ANNs, the most well-known being the deep neural networks that are described in the next paragraph.
3.2. Long Short-Term Memory Networks (LSTM)
Long Short-Term Memory are also neural networks which are built upon a recurrent fashion by introducing memory cells and their in-between connections, in order to construct a graph directed over a sequence. In general, recurrent networks process sequences by using said memory cells in a fashion that is different than that of the simple ANNs, and even though they are well suited for problems with time dependency, they often face the problem of vanishing gradients, or not being able to “memorize” large portions of data. LSTMs [
48] solved this problem because of the specific cell structure they have, which allows the network the ability to variate the amount of retained information. These cell structures are called gates, and they control which information is stored in the long memory and which is discarded, thus optimizing the memorizing process. Dynamic temporal behavior problems, i.e., time sequences, were suited for such approaches.
3.3. Deep Neural Networks (DNN)
Deep neural networks [
49] are the basis of deep learning, one of the most influential areas of the artificial intelligence for the past decade. Based on the ANN, the DNN is comprised by more layers and nodes in the same sequential fashion. For very deep implementations, the problem of “vanishing” or “exploding” gradients would not allow the network to learn properly, therefore new techniques were introduced, such as “identity shortcut connections” as seen in Resnet [
50], as well as others, in order to solve these obstacles. The “deep” approach has been used in all derivatives of neural networks. Deep convolutional neural networks (CNN) have been used for image classification and object detection [
51,
52], and deep recurrent neural networks (RNN) have been used for word prediction [
53] and time series forecasting [
54].
3.4. Process Flow
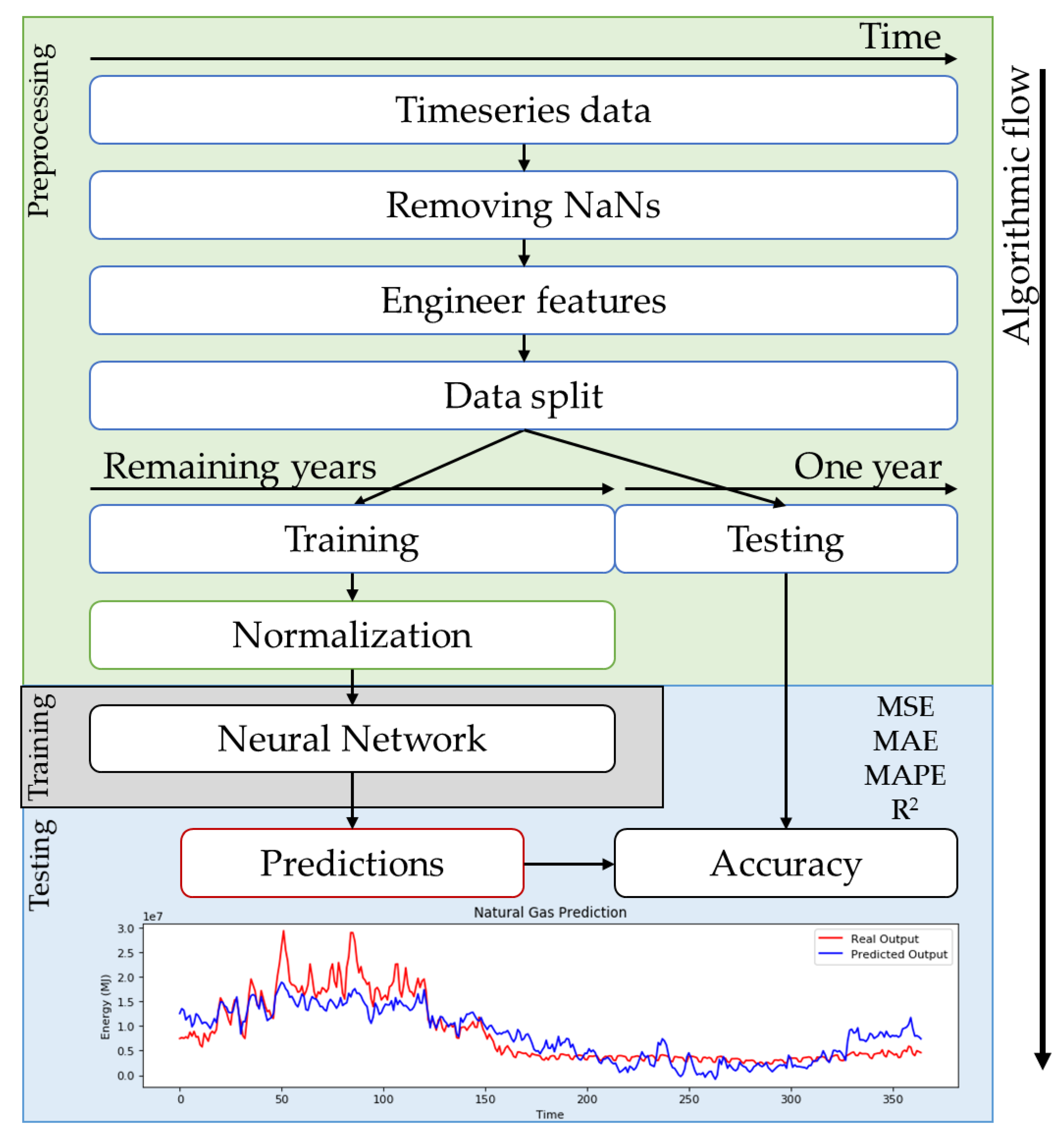
In order to accurately model the natural gas energy forecast, a specific process flow has been designed. The steps that have been followed, are described below.
3.4.1. Preprocessing
The initial preprocessing is focused on the organization of the original unstructured data. Same-variable columns have been aligned and set in correct time and date order, and columns that were empty or contained plenty of NaN (Not a Number) values were removed completely. The columns “date” and “time” were merged into a TIMEDATE column, which was consecutively used as index. The MONTH and DAY variables were manually added and later transformed into multiple categorical variables as described in
Section 2.
For the ANN implementation, only the daily mean temperature is considered as input, for the LSTM, only the energy consumption is used as both input and output (past and present values respectively), and for the DNN implementation, all the aforementioned variables are used with the addition of vectorial representations of qualitative variables. The inputs that are used in each neural network variant, as well as the output variable, that are being used in this study, are shown in
Table 1.
3.4.2. Data Split
The data was split in the following way: The last year, ranging from 1 November 2017 till 31 October 2018, was used as the testing period for all models, approaches, and for all cities. The starting date of data collection for each city, as well as the ratio of training/testing portions of each dataset, is shown in
Table 2.
During the training phase, 20% of the training dataset is used as a validation set, in order to identify whether our model tends to under- or overfit, and to be able to measure its loss and accuracy.
For the ANN implementation, only the numerical variables were used as input, i.e., the energy consumption of 2 prior days and the mean temperature. For the LSTM implementation, the natural gas energy consumption is used both as input and output, so the previous 365 values are used to find the future trend, i.e., the energy demand. For the DNN implementation, all the variables described in paragraph 2.2 are used as inputs, and the natural gas energy consumption is used as output, as it is with all implementations.
3.4.3. Standardization
All data was normalized with Python’s SciKit Learn MinMaxScaler, between 0 and 1 values [
55]. This way, the performance metrics are common for all cities, therefore direct comparisons can be conducted, but more importantly because during training it allows the non-convex cost function to converge to the global minimum faster and in a more appropriate fashion.
3.4.4. Processing
In all ANN, LSTM, and DNN approaches, we used the “ReLU” activation function, the “adam” optimizer for the cost function, mean squared error for measuring the loss of training and validation, and an early stopping function (EarlyStopping callback in Keras [
56] with 5 epochs patience) in order to avoid overfitting [
57]. For the LSTM approach, the previous 365 energy values were used as input, and the consumption for the next 365 days was forecasted. After the model training, all models are being evaluated on the testing portion of the dataset. Their performance is measured based on certain metrics that are described in the following section.
4. Evaluation metrics
The performance and robustness of each studied natural gas forecasting model is based on four of the most common evaluation metrics. Mean square error (MSE), absolute error (MAE), mean absolute percentage error (MAPE), and coefficient of determination (R
2) are all being used in order to determine the best performing model [
5,
7,
43].
All the modelling, tests, and evaluations were performed with the use of Python 3.7 and the Tensorflow 1.14, Keras 2.3, SciKit Learn 0.21, Pandas 0.25, Numpy 1.17, Matplotlib 3.1, Seaborn 0.9 libraries. The mathematical equations of these evaluation metrics are described below:
Mean Absolute Percentage Error:
Coefficient of Correlation:
where
is the predicted value,
is the real value,
is the iteration at each point (
), and
is the number of testing records.
Low MSE, MAE, and MAPE values signify small error, therefore higher accuracy. On the contrary, R2 value close to 1 is preferred, signifying better performance for the model and that the regression curve is well fit on the data. A coefficient of determination value of 1 would signify that the regression line fits the data perfectly; however, this could also denote overfitting on the data.
To summarize, the whole process so far can be visually represented into an algorithmic flowchart. Starting from the data preprocessing, to the training of the algorithm and the prediction of the results, all the consecutive steps are shown in
Figure 4.
5. Results
Athens was chosen as a reference point for searching the best fitting parameters of each method. The outcomes of each parameter selection for the ANN, the LSTM, and the DNN architectures are presented in paragraphs 5.1, 5.2, and 5.3. The parameters that resulted to the best performing model for all 15 cities are presented in paragraph 5.4. For the evaluation of all tests, MSE, MAE, MAPE, and R2 were used.
5.1. Results from ANN
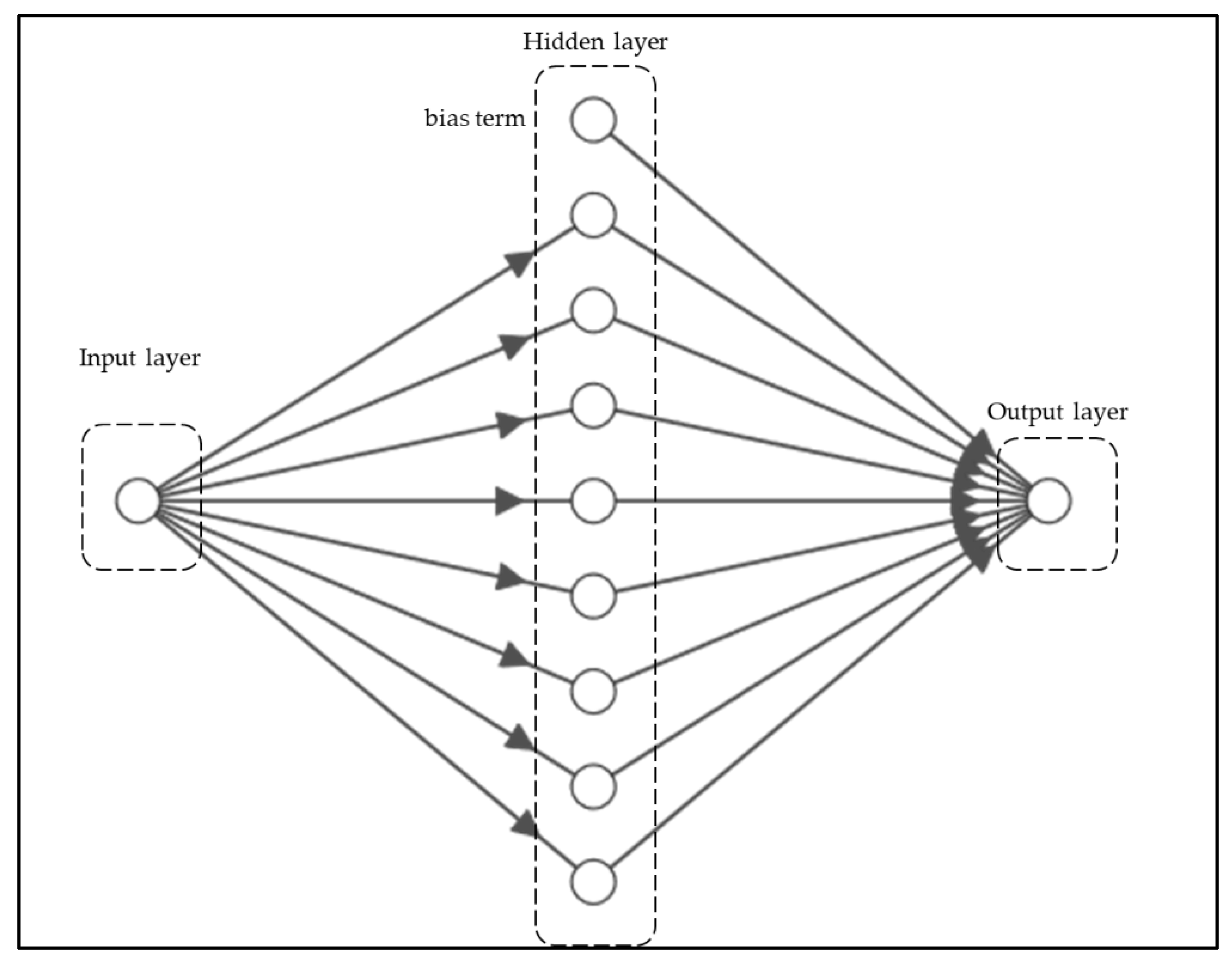
For the ANN implementation, an architecture of a single-layer perceptron with 8 nodes in the hidden layer was selected, after a concise exploratory analysis. The simple ANN was selected for benchmarking purposes. Having a simplistic model as a baseline, we can investigate the performance improvement of the other approaches. The initial architecture, seen in
Figure 5, was tested and evaluated without any dropout function, and the performance metrics are shown in
Table 3.
Next, the effect of the dropout rate is investigated, and in order to understand how it affects the model’s performance, four distinct percentages have been tested. The results are presented in
Table 4.
The ability of forecasting the energy demand in yearly intervals was also investigated. Even though this study is focused in one-year ahead forecasts, a timeframe of yearly depths up to four years ahead was investigated. This investigation was conducted in order to see the magnitude of the forecasts’ accuracy through time, and the results are presented in
Table 5.
The ANN approach is able to capture the general trend, however, it deviates significantly from the real consumption values, something that could signify that the model cannot give better forecasts for longer time ahead.
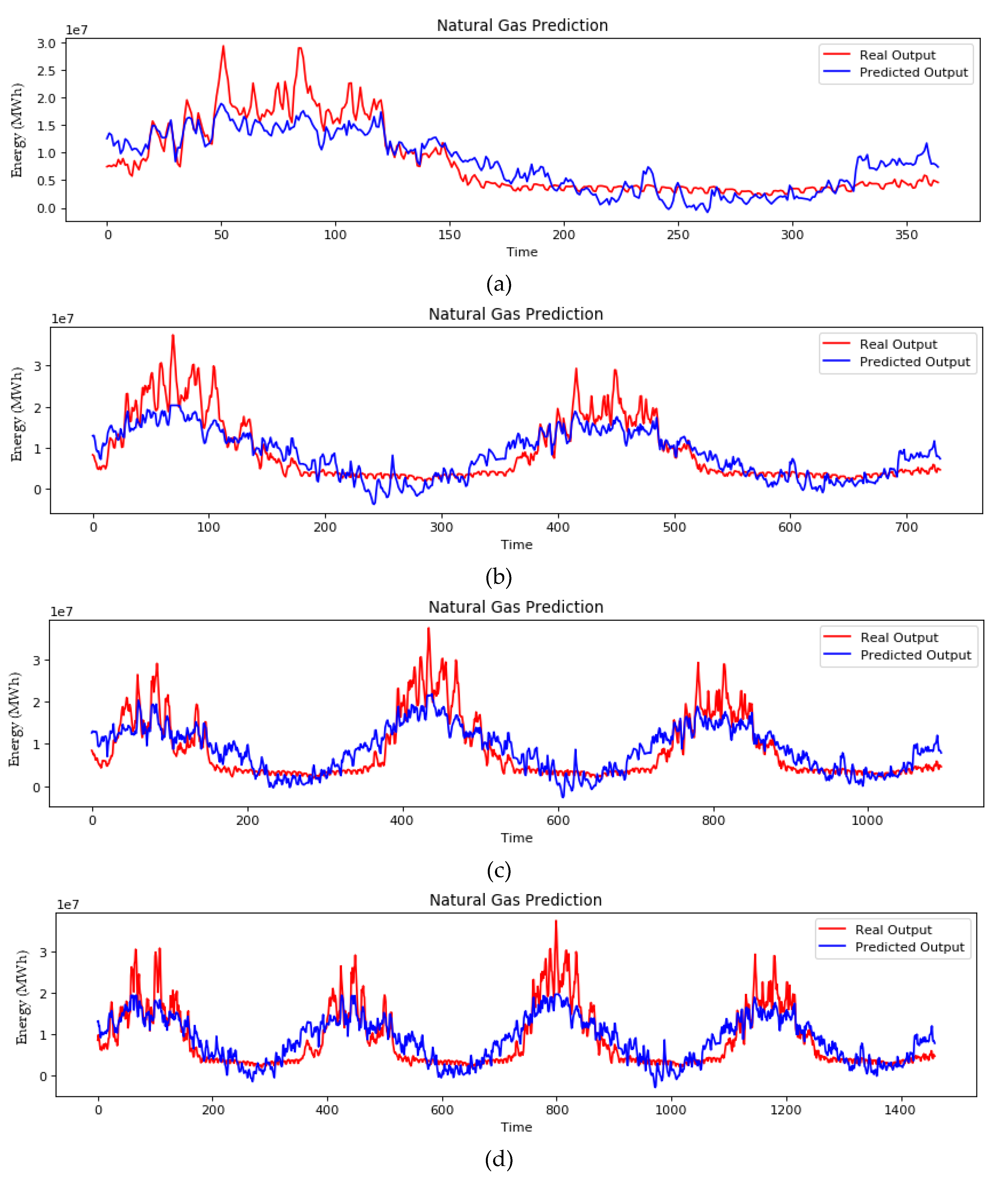
Figure 6 shows the plots of the ANN implementation for (a) one-, (b) two-, (c) three-, and (d) four-year ahead forecasting. The prediction of the energy demand in MWh is depicted in blue, and the real output is depicted in red.
It is evident that the ANN model, even though it can follow the trend of the fluctuation, fails to forecast accurately the consumption of the natural gas. Furthermore, the more the forecasting time increases, the greater this deviation gets. Even though ANNs are powerful algorithms for forecasting, in this particular problem, the single-layer perceptron is not enough to model the problem accurately.
5.2. Results from LSTM
An investigatory analysis was conducted also for the LSTM implementation. The number of layers and memory units were explored in order to find the best combination, which was comprised of one LSTM layer with 200 memory units. The architecture of this implementation is seen in
Figure 7, and its performance is shown in
Table 6.
The dropout’s effect on the LSTM implementation was also investigated, and its effect on the performance of the model is seen in
Table 7.
Dropout application seems to increase performance over a non-dropout approach, and in fact the highest rate selected has given the best results.
Again, forecasts of up to four years ahead were evaluated in order to investigate how the predictions are affected. The results are presented in
Table 8.
The plots of the LSTM setup are shown in
Figure 8 for (a) one-, (b) two-, (c) three-, and (d) four-year ahead forecasting. The prediction of the energy demand in MWh is depicted in blue, and the real output is depicted in red.
In the case of LSTM implementation, it is clear that the forecasts for the one- and two-year ahead demands are more accurate than that of the ANN implementation. However, it is evident that anything beyond the two-year ahead forecast is tremendously inaccurate, resulting even in negative R2 values. LSTMs can offer excellent accuracy for single-variable time series; however, it is evident that they are highly susceptible to the depth of the forecasting period, as well as to the data that are required for proper training.
5.3. Results from DNN
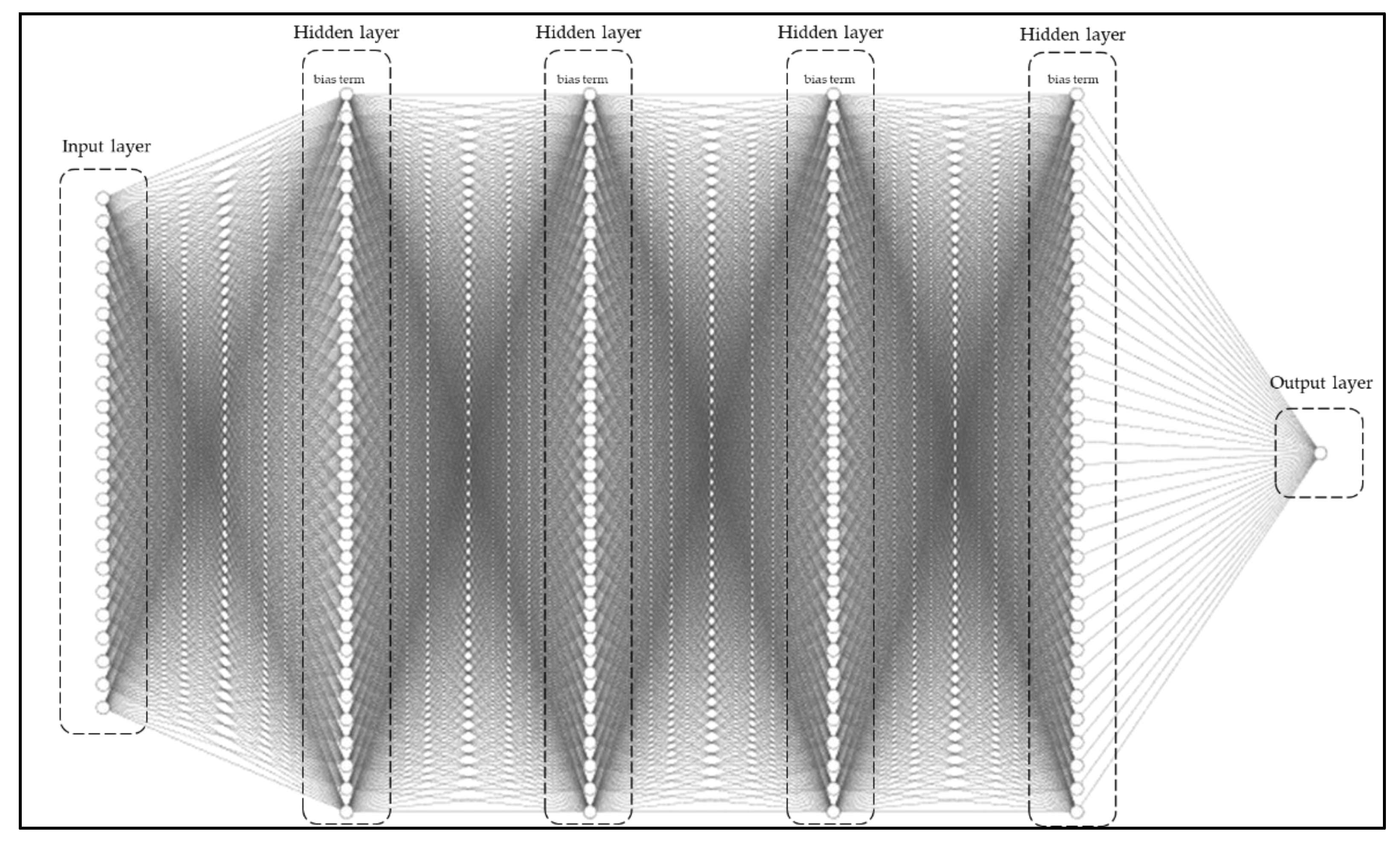
For the DNN implementation, a deeper, more complex network was constructed that is comprised of 4 hidden layers with 32 nodes in each layer. The proposed architecture is structured in such way so that it can take as input the vectorial representations of categorical values, the ones mentioned above, the quantitative values from the current time (in each step), as well as the energy values from past inputs. The architecture of the ANN approach is seen in
Figure 9. No dropout was initially set for the exploratory analysis, and the performance metrics for the selected setup is shown in
Table 9.
The effect of the dropout rate is investigated once again, and the same four percentages have been tested and evaluated, the results of which are presented in
Table 10.
It is evident that the proposed DNN model performs better than the ANN and the LSTM. Testing its forecasting capabilities for up to four years ahead will show its ability to generalize well and properly model the consumption pattern. The results are presented in
Table 11.
At this point, it is interesting to mention that the accuracy of the predictions is hardly affected for up to four years ahead. This is due to the yearly periodicity of the energy demand that is caused not only by the general temperature trends, but also by the social aspects that govern human behavior in certain periods of time.
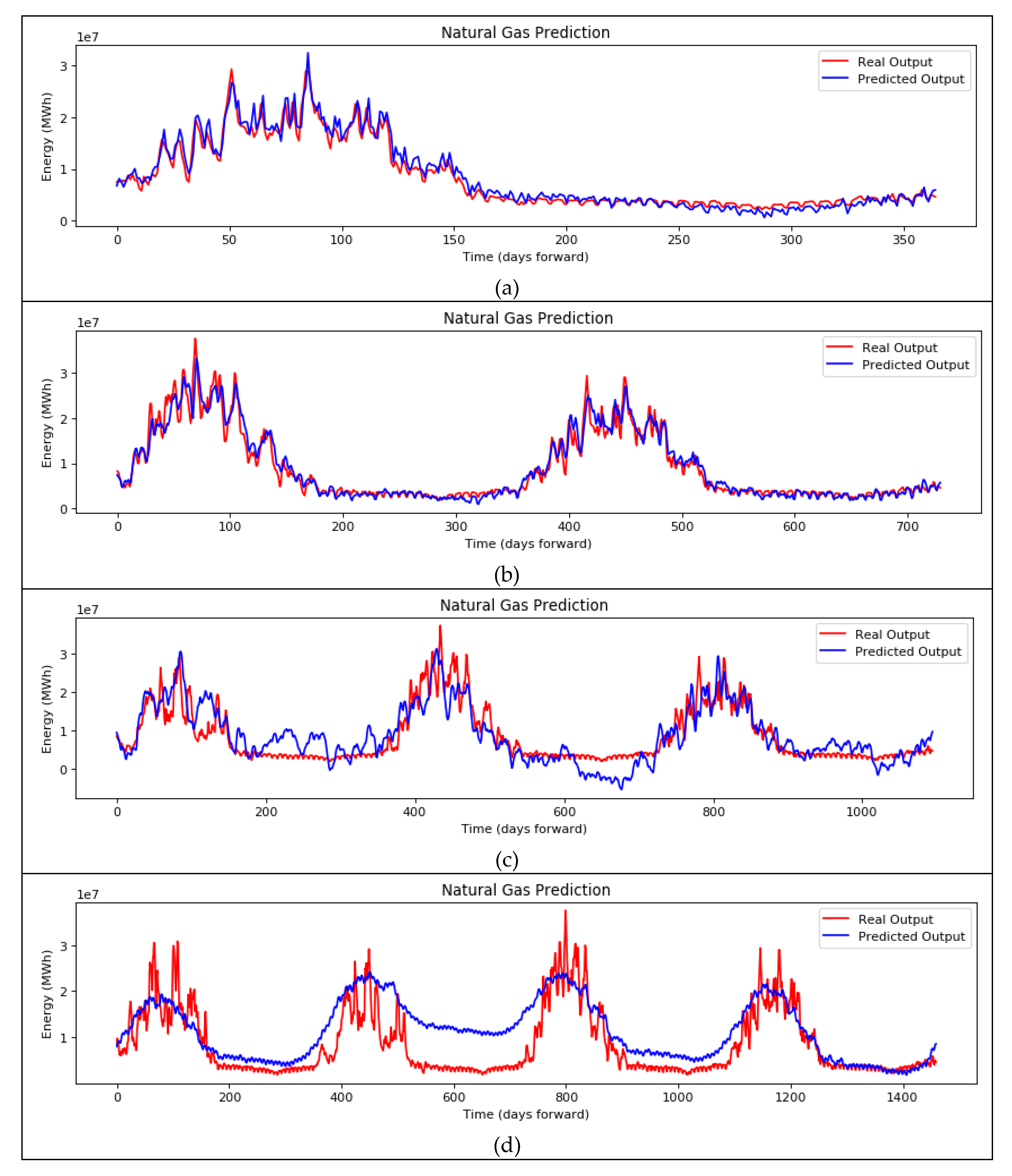
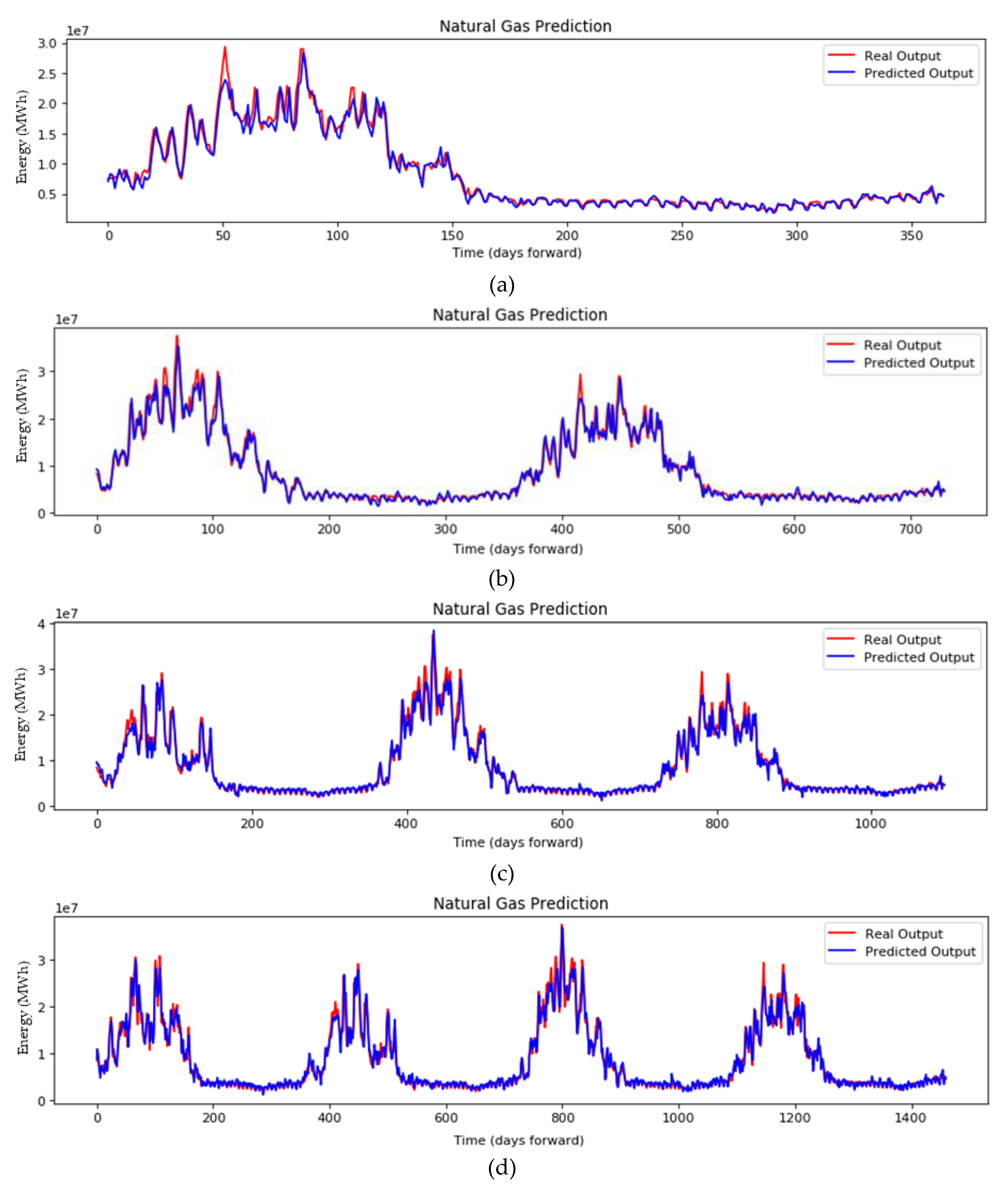
Figure 10 shows the plots of the best performing setup for the DNN implementation for (a) one-, (b) two-, (c) three-, and (d) four-year ahead forecasting. The prediction of the energy demand in MWh is depicted in blue, and the real output is depicted in red.
For the proposed DNN, it is clear that its forecasting capabilities surpass by far the ANN and the state-of-the-art LSTM models. The inclusion of qualitative social variables alongside measurable quantities has improved not only the accuracy of the forecasts, but also the depth of forecasting time into the future. This is an indicator that the deeper network, alongside with behavioral knowledge, has offered a generalized understanding of the energy consumption trend.
5.4. Comparison (Cities)
The trained models of all approaches were applied on a range of fifteen cities all around Greece for the sake of comparison. Each city had different energy distributions during the documented years depending on its size, population, and specific natural gas network characteristics. Testing all implementations on different cities, offers insight on whether each model can provide accurate one-year ahead forecasts in cities that are in different geographical locations, but also with different behavioral patterns. The confidence interval (CI) [
58] is also included in the following analysis, to demonstrate the range of energy values, in which 95% of the predictions fall within, for each city. The performance metrics for all cities are shown in
Table 12 for the ANN,
Table 13 for the LSTM, and
Table 14 for the proposed DNN.
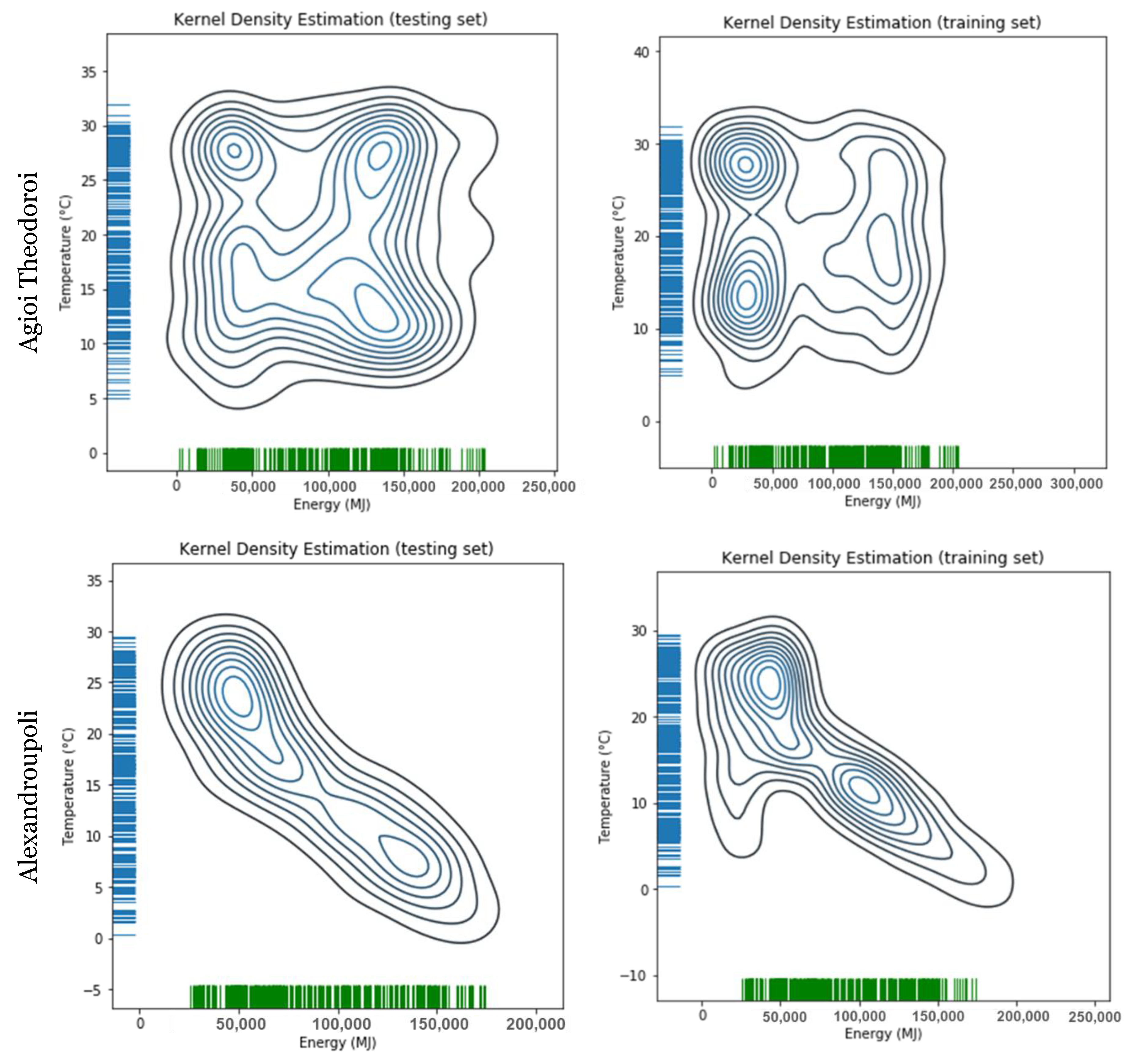
For the ANN implementation, the performance of the model ranges from ~14% for Agioi Theodoroi till ~97% for Trikala considering R2. Seven out of fourteen cities achieved an accuracy of >90%, however, for the other seven cities, the performance of the model is disappointing.
For the LSTM implementation, the prediction accuracies are better than the ANN, ranging from ~39% for Agioi Theodoroi to ~96% for Athens, using R2 as the primary metric. Here, six cities achieved an accuracy of >94%, with the rest achieving higher accuracy when compared to the ANN.
For the proposed DNN implementation, the performance of the model ranges from ~58% for Agioi Theodoroi till ~99% for Larissa considering R2. For seven out of fourteen cities, the proposed methodology achieved an accuracy of >94%, which is considered very satisfactory for prediction, considering that the MSE of these models is also very low.
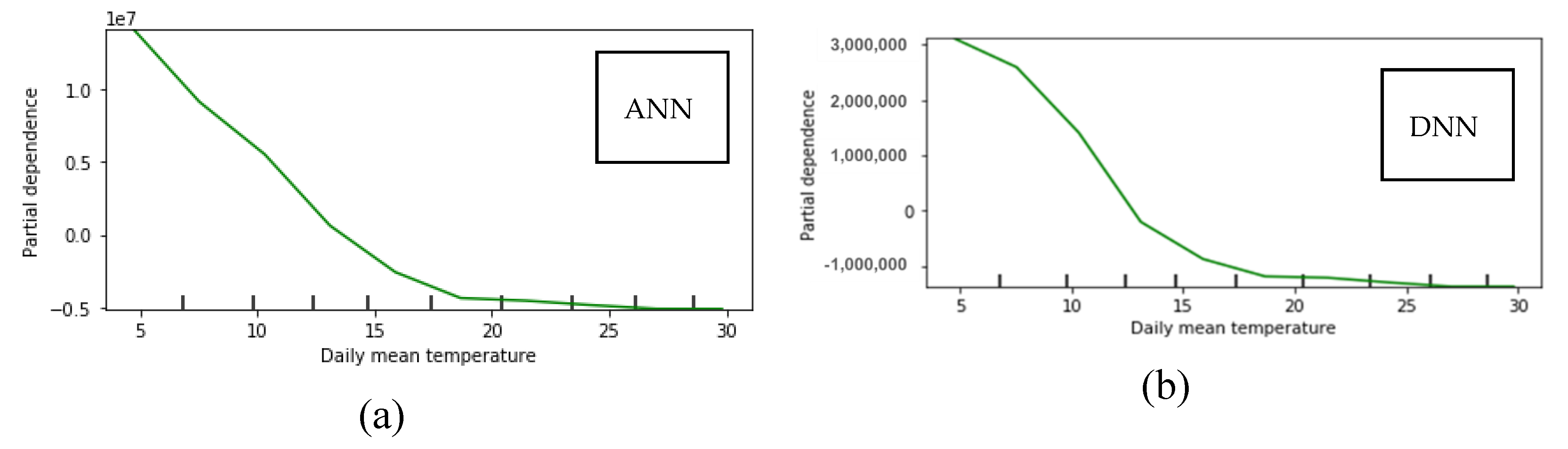
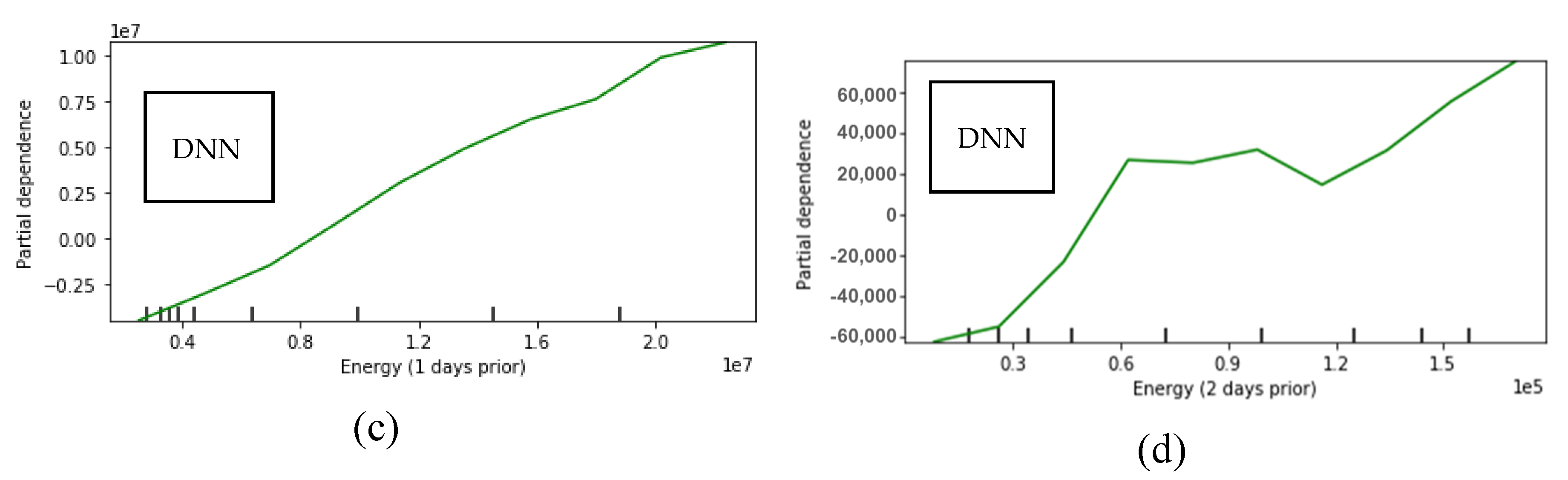
5.5. Sensitivity Analysis
A sensitivity analysis is conducted on the dataset of Athens. The selected method for the sensitivity analysis is the Partial Dependence Plots (PDP) [
59,
60], where target variables (features) of the dataset are investigated through their range of values in order to visualize their dependence to the target outcome. The numerical variables used in the datasets, i.e., daily mean temperature, 1-day and 2-days prior consumption energy are used as the target features and the dependence of the target outcome, i.e., the present-day consumption energy, is shown in
Figure 11.
Both for the ANN and the DNN, the mean daily temperature is inversely proportional to the daily energy consumption, which is expected since heating needs are lower when the external temperature is high. For the DNN, the 1-day prior consumption is directly proportional to the target outcome, the same applying for the 2-days prior consumption as well. We notice that for the 2-days prior, the scale is two orders of magnitude less than for the 1-day prior and one order less than the mean daily temperature. This signifies that the model interprets a weaker relationship with this variable and the outcome, meaning that the dependence of the target outcome from this feature is less significant than the others.
Qualitative values cannot be included in the sensitivity analysis because they don’t span over a range of values. Also, for the LSTM model, there can be no sensitivity analysis because only one variable is used as time series, therefore only past values of energy consumption are used for future predictions.
6. Discussion
Three methods, focused on tackling the problem of accurate forecasting of natural gas energy consumption in fifteen cities all over Greece, were investigated and applied in this study. The first method is an ANN that takes into consideration quantitative variables only, like the energy consumption and the external daily temperature. The second method is a LSTM that takes into consideration 365 previous values of only energy consumption of each city. The third method is a DNN that takes into consideration not only the quantitative variables used in the ANN, but also qualitative variables that govern human behavior such as weekdays, weekends, and bank holidays. Comparison analyses were conducted for each method in order to find the optimal architecture for each one.
All models perform adequately in most cases. The value of artificial neural networks and their derivatives is well known, however, the purpose of this study is to increase the accuracy and the time-depth of the forecasting capabilities. For the larger cities, high accuracies in forecasting energy consumption is achieved. The proposed DNN implementation achieved the highest R2 for the city of Larissa (0.9846) while the LSTM implementation for the city of Athens (0.9644) and the ANN for the city of Trikala (0.699). For the worst-case scenario, the city of Agioi Theodoroi, has consistently obtained the worst accuracies, with the DNN (0.5748) achieving significant higher accuracy, even though still not so good, compared to the LSTM (0.3848) and ANN (0.1440) implementation. The dataset of Agioi Theodoroi is the smallest compared to the rest, being one reason for achieving these low accuracies. It ca be argued that the size of the city (<5000 habitants) is another important reason, since the consumption trends are sparser due its low population.
For the city of Agioi Theodoroi, the DNN increased the accuracy of its forecasts by 49.362% compared to the LSTM, and 299.195% compared to the ANN. Regarding the city of Athens, the DNN increased the accuracy of its forecasts by 0.682% compared to the LSTM, and 1.292% compared to the ANN. The proposed DNN increased the accuracy of the forecasts in almost all cases, however, its main impact was on small-scale cities such as Kilkis (+94.698%), Lamia (+259.457%), Markopoulo (+207.667%), and Xanthi (+330.273%), which have small populations, energy consumption, and less amount of gathered data. In a previous study [
43] where only the ANN and LSTM approaches were applied on quantitative-only datasets, the LSTM approach offered the best results. The particular problem of forecasting energy values, is time-dependent, thus allowing the LSTM approach to excel. However, since there are other factors that affect the behavior of the consumers, and consequently the consumption of energy, the DNN was considered as an approach that could improve the accuracy of the forecasts.
For the implementation of the LSTM, the application of dropout has improved performance for the one-year-ahead forecast. By selecting 200 units in the layer of the selected implementation, the LSTM is able to capture a measurable part of the input (365 days); however, in order to generalize well, the model should randomly drop a percentage of the weights it has “learned”. This way it has the ability to “memorize” large inputs, however, these inputs are generalized and do not overfit on the past data. This conflicts with the other implementations of ANN and DNN; however, LSTM utilizes information in a different way than the ANN and DNN. The reason why the LSTM performs better with a high dropout rate is because it tends to overfit soon during training, and even if it could reach high training accuracy, its validation (and therefore testing) accuracy would be weak. In this study, there is a trend based on seasonality, and in order to have an LSTM model that is not overly simplistic (therefore needing at least 200 units), and to train as long as possible, generalization was achieved via high dropout [
61].
For the long-term predictions, the ANN and LSTM models fail to produce accurate predictions, resulting in negative R
2 values. This can be derived from several facts. The more important is that since the dataset is finite, the further ahead in time the prediction is, the less training data the model is left with to “learn” from. Machine learning models are highly dependent on data, and their performance is highly correlated to the data quality and quantity. Particularly for the ANN approach, it’s simplistic implementation cannot capture the complexity that is required for the long-term forecasting, even if in general ANNs are powerful. Another reason is that the scale of the energy prediction units is large (in absolute numbers), thus the worse the prediction is, the larger is the penalty for it. Additionally, since the forecasting timescale increases for additionally 1, 2, and 3 years, the ill-fitted models produce large errors in predictions which are accumulated, because the forecasting time is 1, 2, and 3 times larger, respectively. The R
2 metric is based on the MSE, and is scale-dependent, while MAPE is not, therefore it is useful for understanding the performance of the models. It is considered that R
2 is still probably the best metric for forecasts [
62], however, MAPE can still be used because the percentage of error makes sense and there are no zero values in our dataset.
In our proposed architecture, social behavior variables were added as inputs and the number of layers and nodes in our neural network was increased, in order to investigate the effect of these additions on the forecasting accuracy. These variables are strong indicators of social behavior and habits of the majority of the Greek population, which can affect the energy consumption in specific days/occasions. Overfitting was avoided by monitoring loss and accuracy throughout the training phase.
Furthermore, in order to show the effectiveness of the proposed DNN forecasting methodology, a comparative analysis was conducted with a SOGA-FCM, which was applied in one year ahead of natural gas consumption predictions concerning the same dataset of the three Greek cities (Athens, Thessaloniki, and Larissa) in [
29], and a recent soft computing technique for time series forecasting using evolutionary fuzzy cognitive maps and their ensemble combination [
30]. This comparison is shown in
Table 15, where the MSE and MAE are used as performance metrics.
It is evident that all methods achieve high accuracy in the predictions of the energy consumption patterns in their relative timescales. The ensemble and hybrid methods achieve the same accuracy as the ANN, with the LSTM performing slightly better. The proposed DNN, by utilizing inputs of social variables into its learning patterns and having a deeper architecture, outperforms all other methods with significant difference. The significance of this outcome lies on the fact that qualitative variables that dictate human behavior can be learned by computational algorithms and be utilized to improve forecasting accuracy furthermore.
The case of Greece has some sensitive aspects, since multiple dynamics in natural gas consumption were introduced due to the financial crisis of the previous years. This instability created an additional obstacle to the accurate forecasting of energy demand, thus increasing the need for efficient forecasting models that can accurately offer in-depth insight on the demand trends of each city and adapt to their different conditions. Since the proposed method offers high accuracy and long forecasting capabilities, it can be used by any utilities and distribution operators, as a solution to upgrade operational long-term planning, as well as to provide insight on policy making from the side of the state.
7. Conclusions
Summing up, three different forecasting approaches have been implemented in order to develop models for predicting energy demand of natural gas. Investigative analysis took place for an ANN, a LSTM, and the proposed DNN implementations in order to find a desired architecture for each method. Fifteen cities all around Greece were tested, each one with a dataset of measurements that spanned from 3 to 7 years. The investigated cities differ both in size as well as in geographical location, amplifying as much as possible the variability of each use case examined. Despite the fact that this study is focused on cities that are only in Greece, the proposed methodology is highly generalizable for any other city that can provide sufficient amount of data, both measurable and behavioral.
The goal of this study was to propose an efficient neural network implementation that utilizes a variety of quantitative and qualitative inputs, as well as a deep architecture with many layers and nodes, to demonstrate how social factors can improve the performance of the model and increase the accuracy of its forecasts. The proposed methodology has outperformed both the simple ANN approach as well as the state-of-the-art LSTM approach even though both still offer good accuracy in most cases. The inclusion of social factors in the proposed DNN approach offered consistently more generalized, high-accuracy results. This derives from the fact that by exploring longer forecasts, the four-year ahead forecast was achieved only with the proposed DNN implementation, while the LSTM could only provide accurate results up to two years ahead, and the ANN was deviating systematically.
Applying a combination of multi-parametric social factors, by also taking advantage of the memory cells structure of the LSTM implementation will be the base of the future work that will aim to outperform the DNN implementation. Additional Fuzzy Cognitive Maps structures will be also considered for increasing the interpretability of the models and how the inputs affect the performance.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}