On the Operational Flood Forecasting Practices Using Low-Quality Data Input of a Distributed Hydrological Model

 ,
, 
Abstract
:1. Introduction
2. Materials and Methods
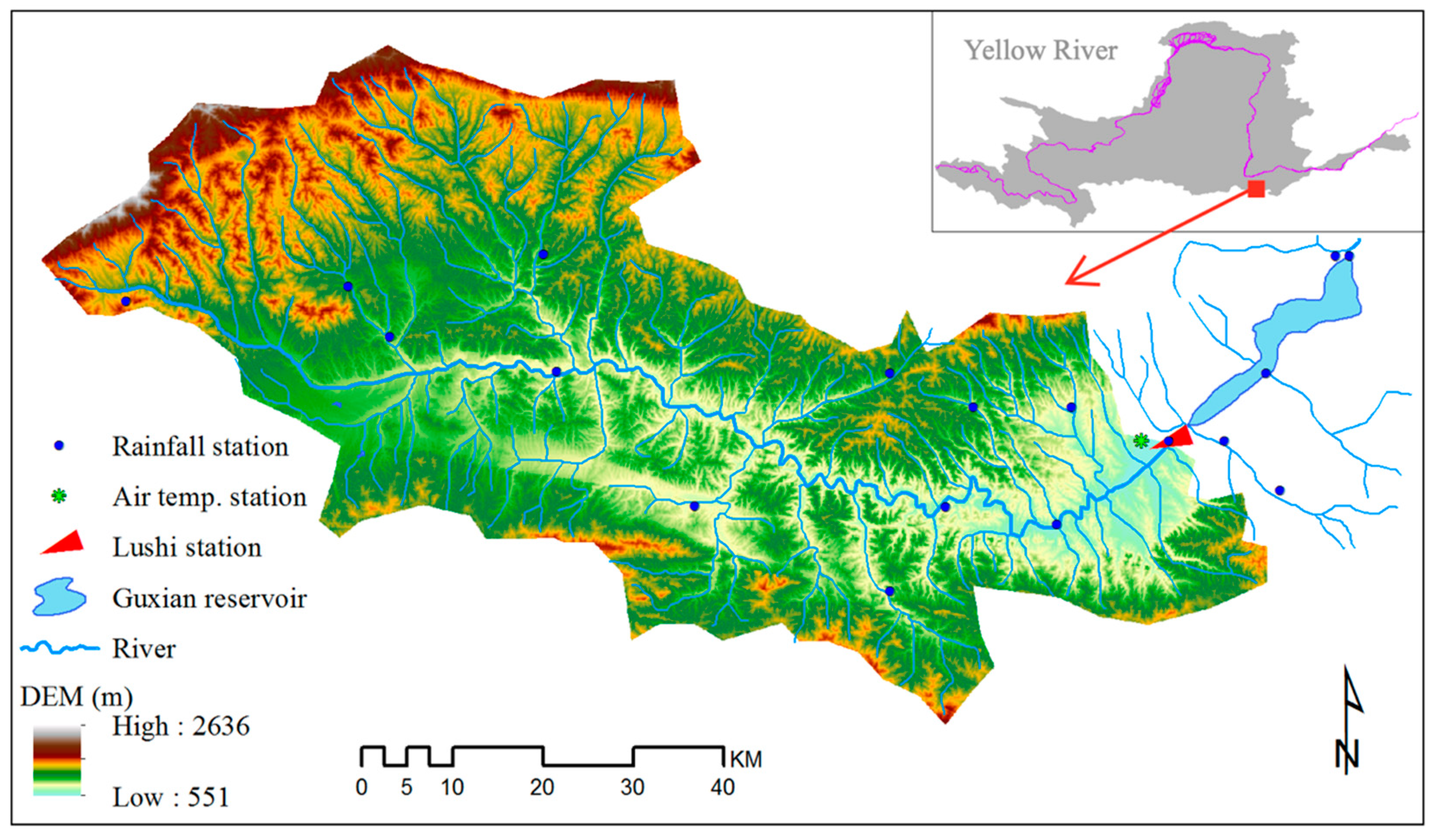
2.1. Study Basin
2.2. Data
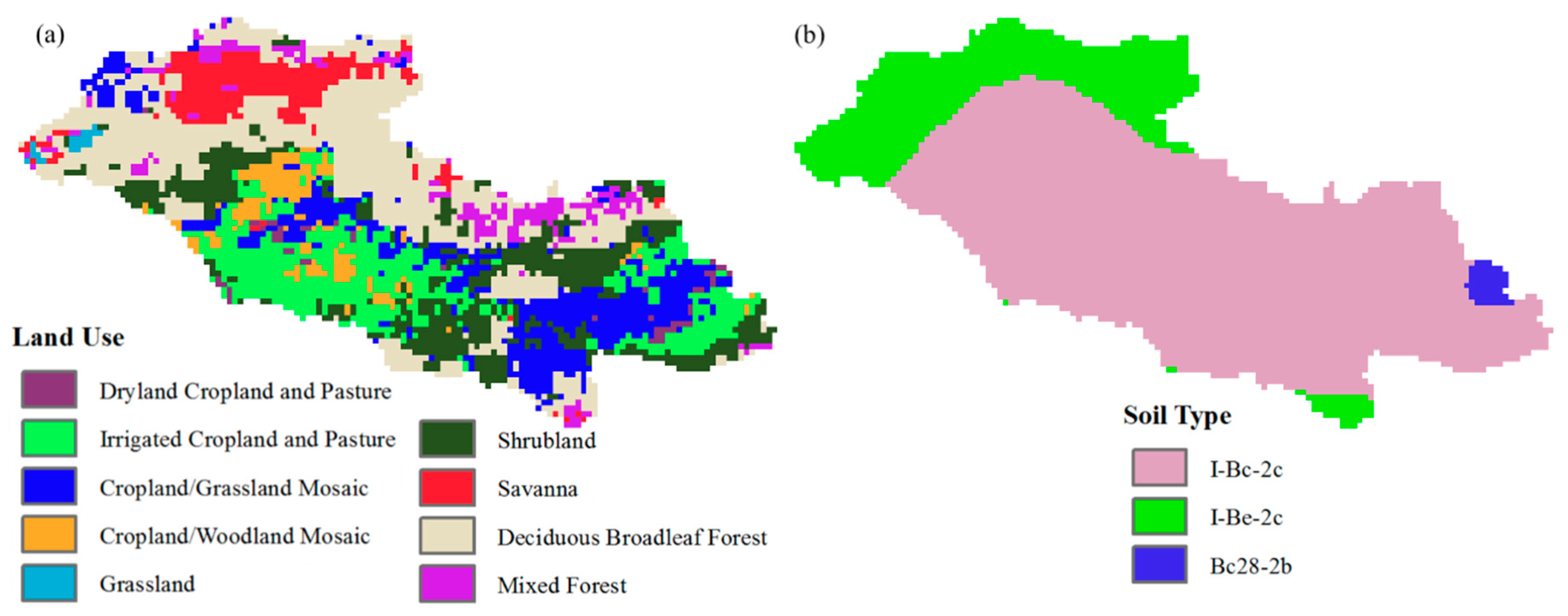
2.2.1. Thematic Maps
2.2.2. Hydrometeorological Data
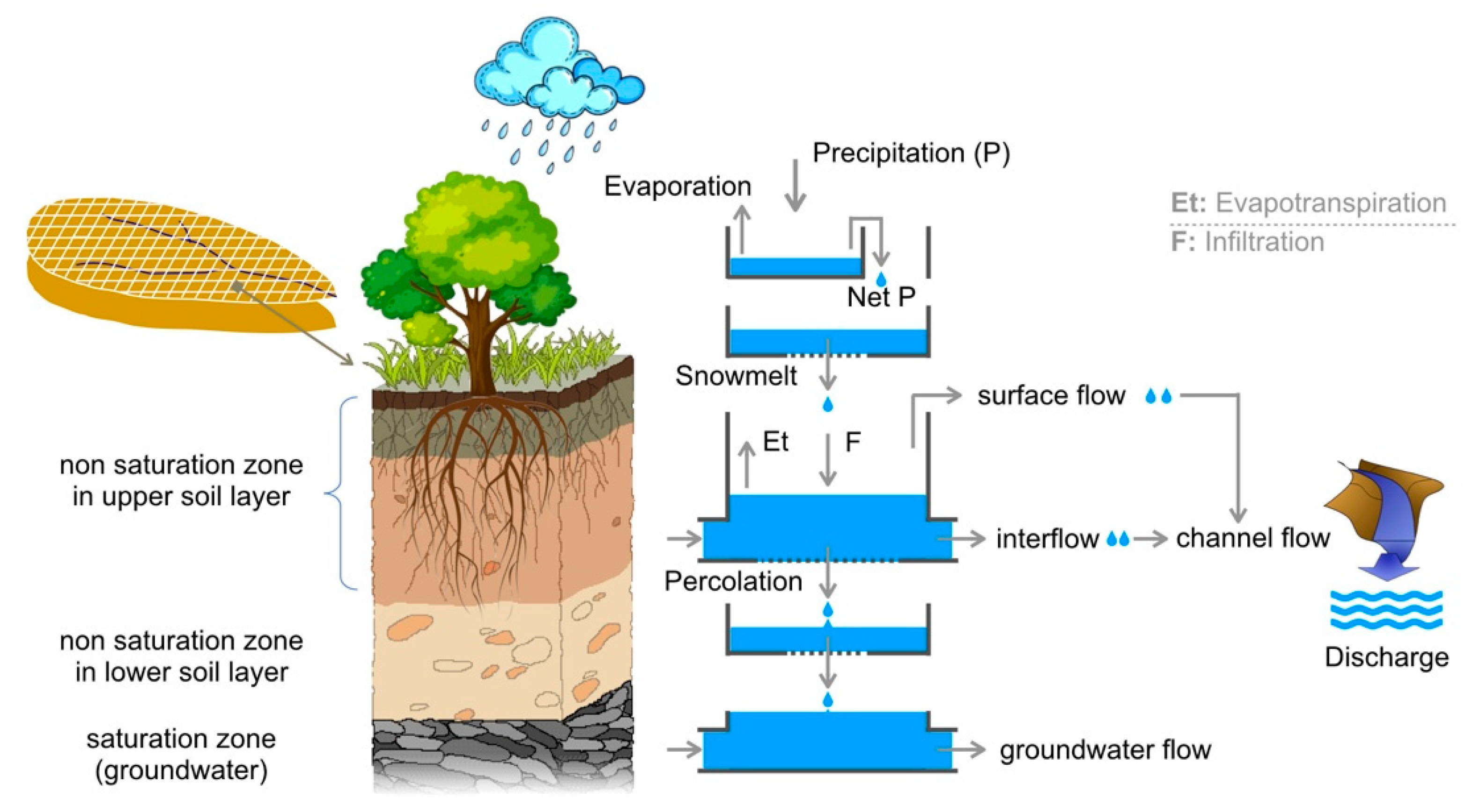
2.3. The Distributed Hydrological Model
2.4. Hydrologic Uncertainty Processor
2.5. Model Coupling
2.5.1. Model Combination of TOPKAPI and HUP
2.5.2. Performance Metrics
- Correlation Coefficient (CC)
- Mean Absolute Error (MAE)
- Nash–Sutcliffe Coefficient Efficiency (NSCE)
- Index of Agreement (IOA)
3. Results and Discussion
3.1. Model Calibration and Validation
3.1.1. Parameters of the TOPKAPI Model
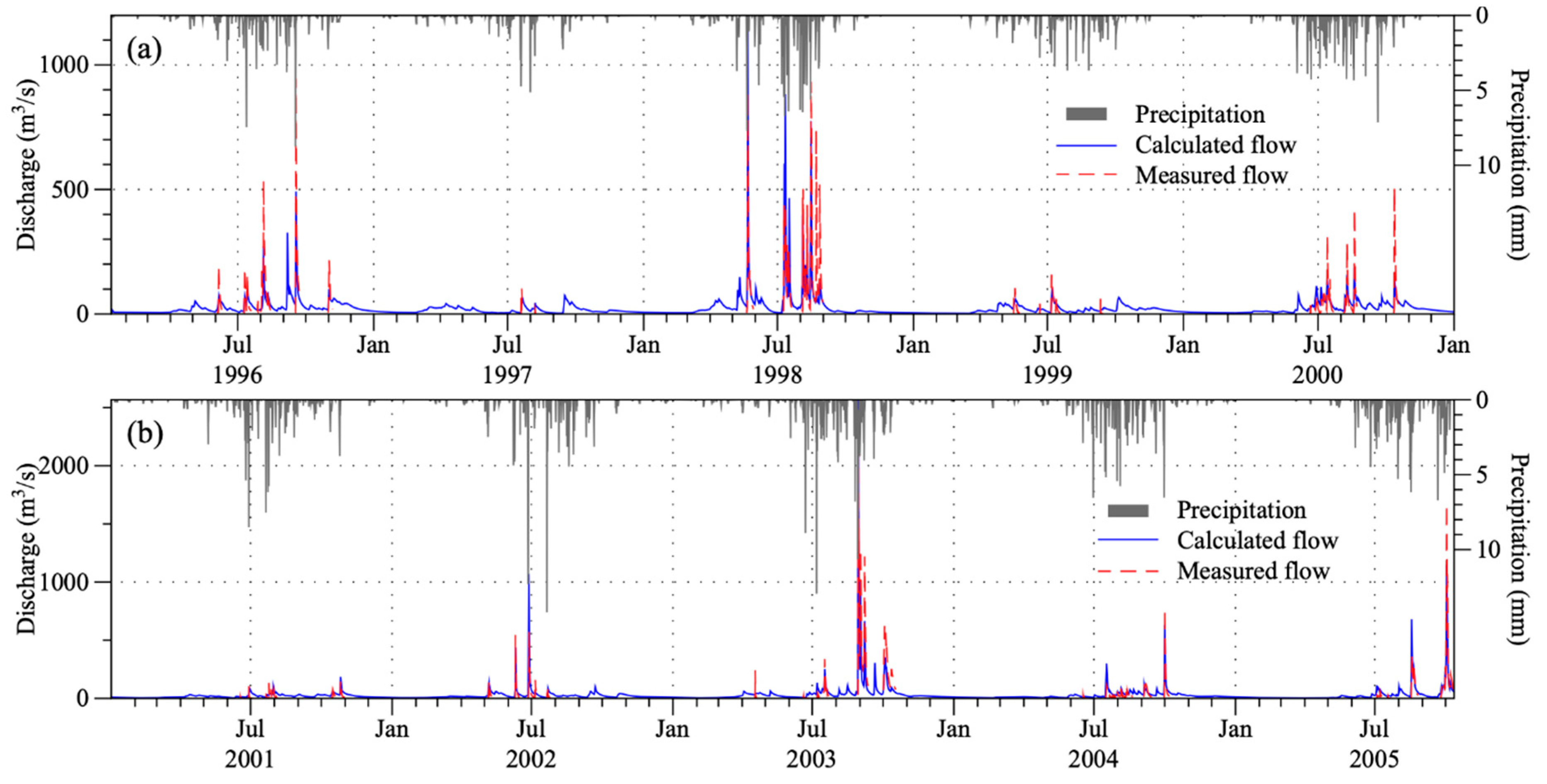
3.1.2. Model Test
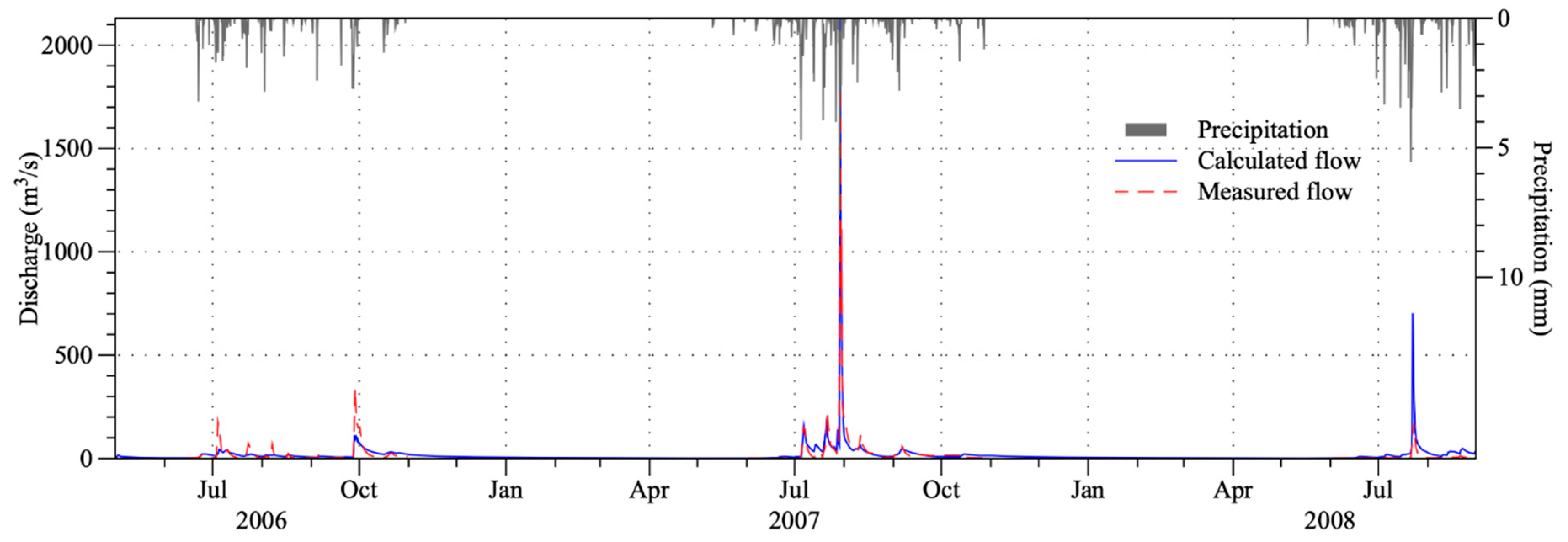
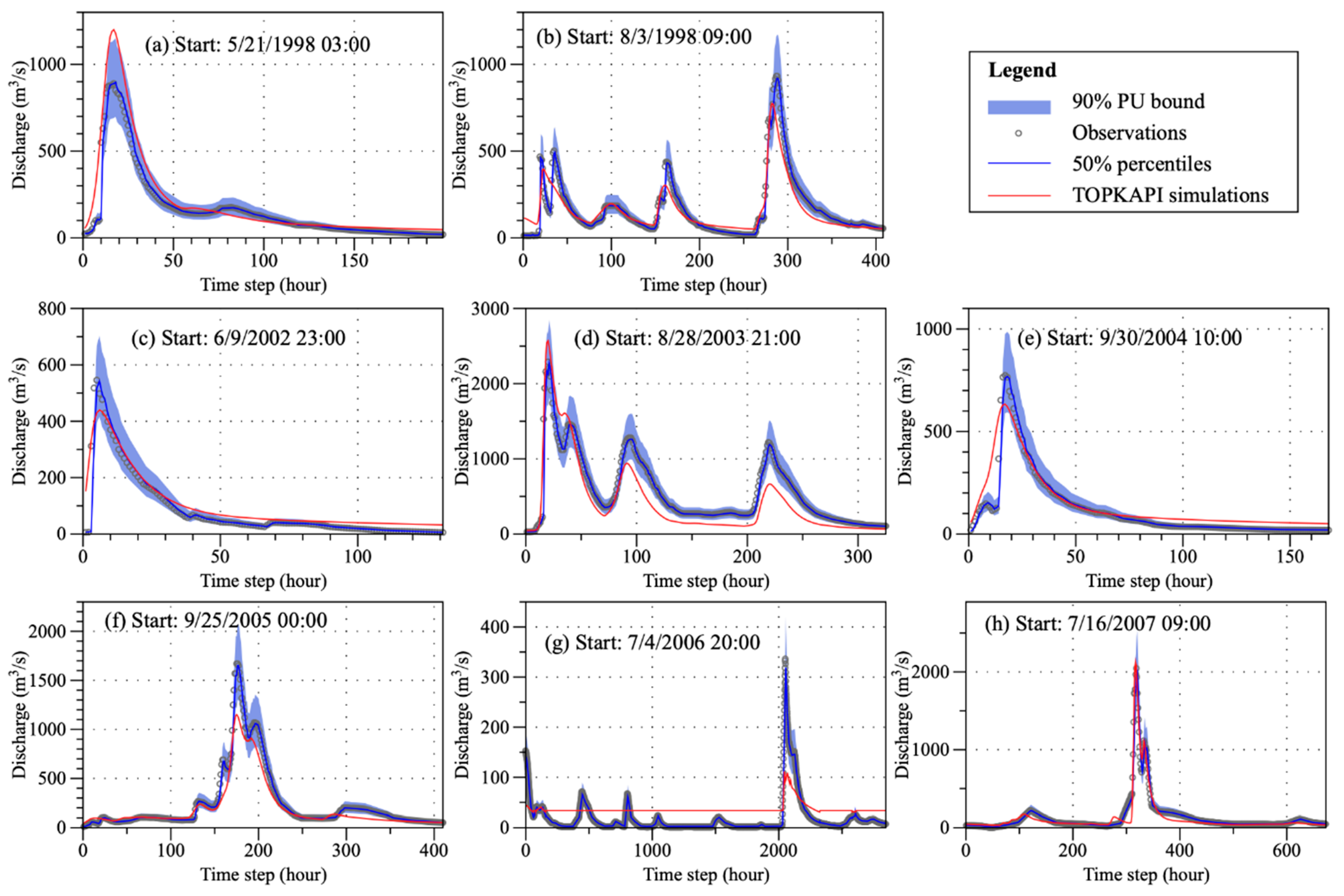
3.2. Flood Event Simulations
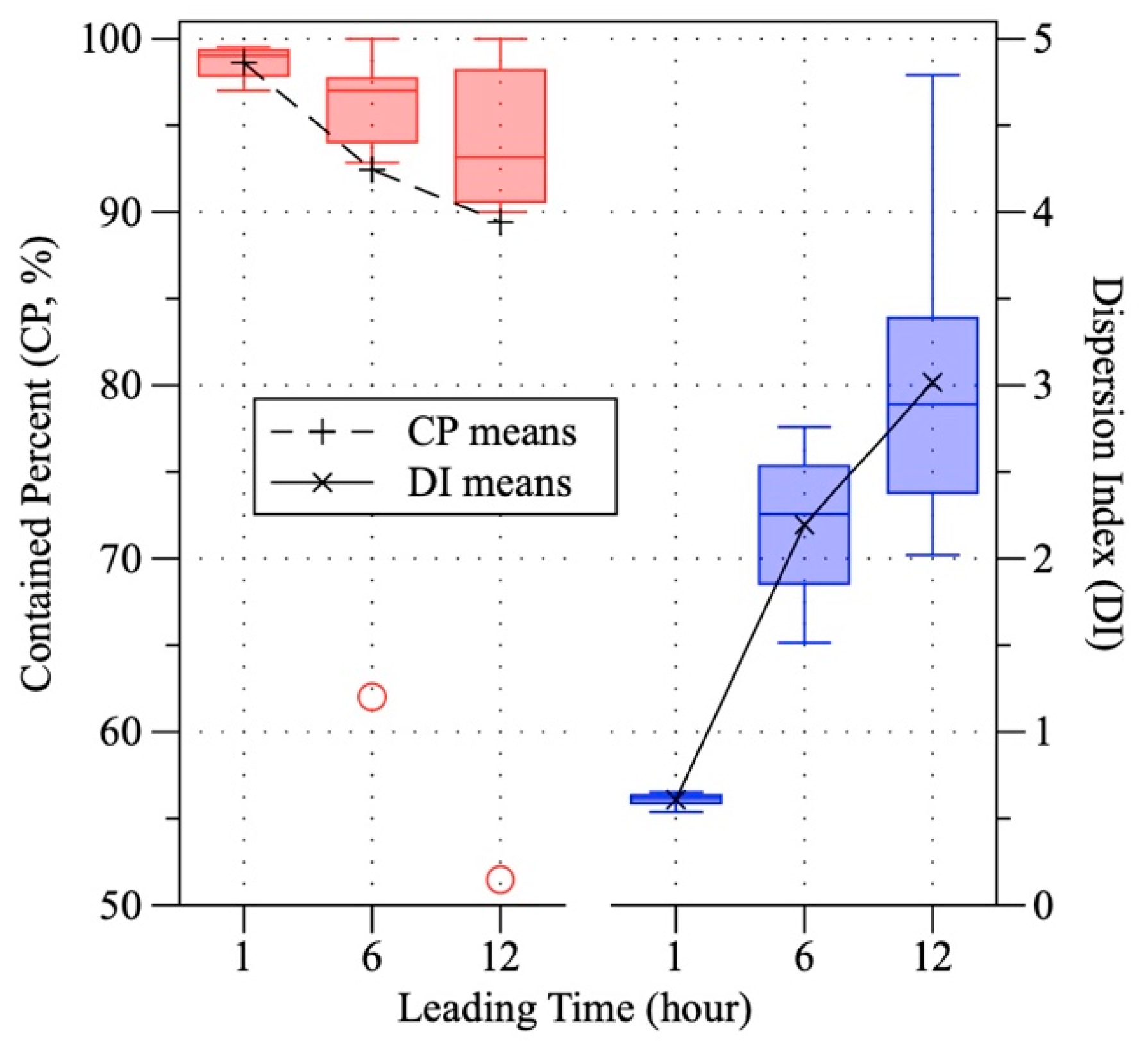
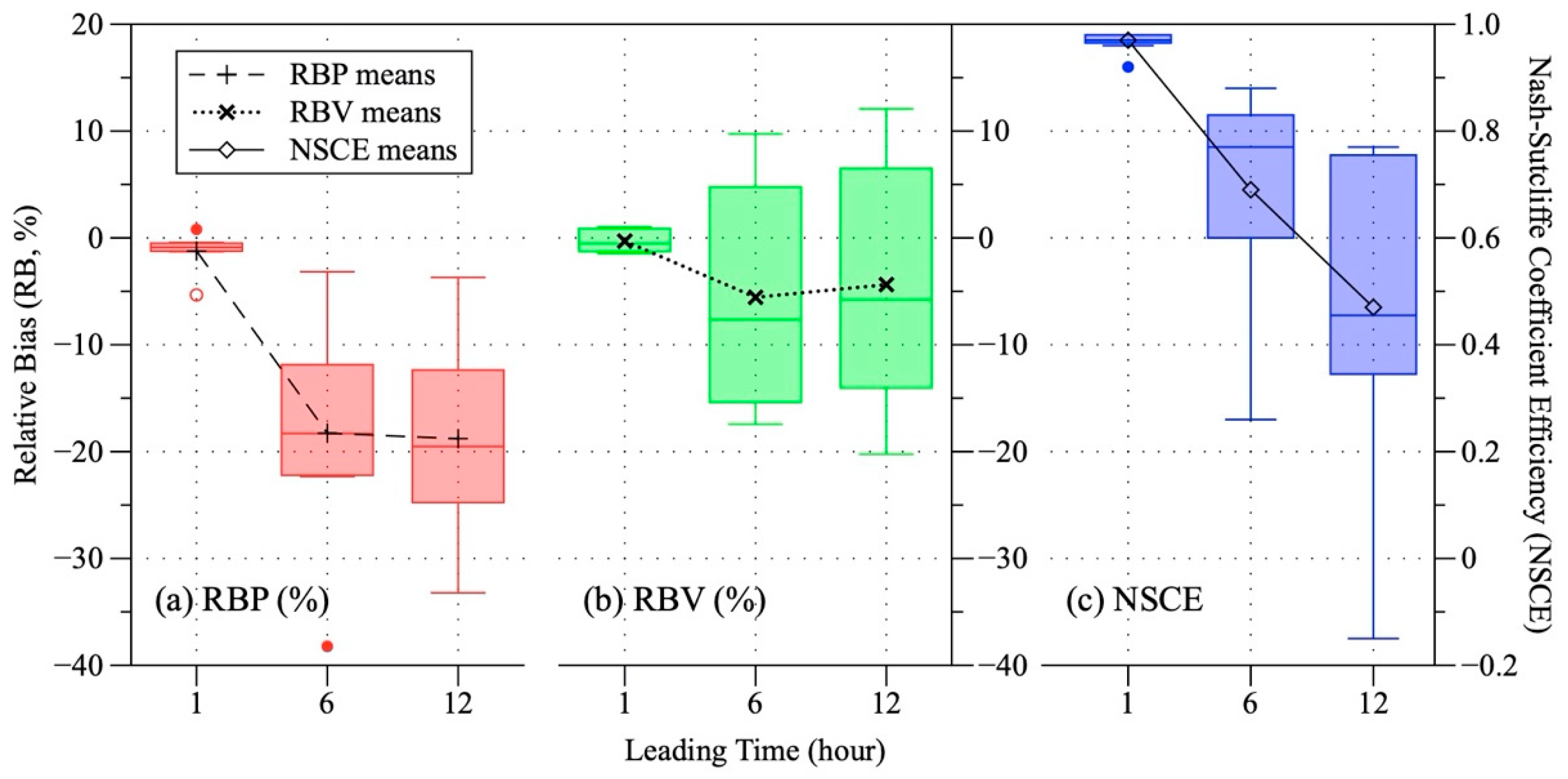
3.3. Model Accuracy Changes with Leading Time Increasing
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- McKinnon, S. Remembering and forgetting 1974: The 2011 Brisbane floods and memories of an earlier disaster. Geogr. Res. 2019, 57, 204–214. [Google Scholar] [CrossRef]
- Aerts, J.C.J.H.; Botzen, W.J.; Clarke, K.C.; Cutter, S.L.; Hall, J.W.; Merz, B.; Michel-Kerjan, E.; Mysiak, J.; Surminski, S.; Kunreuther, H. Integrating human behaviour dynamics into flood disaster risk assessment. Nat. Clim. Chang. 2018, 8, 193–199. [Google Scholar] [CrossRef] [Green Version]
- Jongman, B.; Hochrainer-Stigler, S.; Feyen, L.; Aerts, J.C.J.H.; Mechler, R.; Botzen, W.J.W.; Bouwer, L.M.; Pflug, G.; Rojas, R.; Ward, P.J. Increasing stress on disaster-risk finance due to large floods. Nat. Clim. Chang. 2014, 4, 264–268. [Google Scholar] [CrossRef]
- Vercruysse, K.; Dawson, D.A.; Glenis, V.; Bertsch, R.; Wright, N.; Kilsby, C. Developing spatial prioritization criteria for integrated urban flood management based on a source-to-impact flood analysis. J. Hydrol. 2019, 578, 124038. [Google Scholar] [CrossRef]
- Li, B.; Yu, Z.; Liang, Z.; Acharya, K. Hydrologic response of a high altitude glacierized basin in the central Tibetan Plateau. Glob. Planet. Chang. 2014, 118, 69–84. [Google Scholar] [CrossRef]
- Yu, M.; Li, Q.; Liu, X.; Zhang, J. Quantifying the effect on flood regime of land use pattern changes via hydrological simulation in the upper Huaihe River Basin, China. Nat. Hazards 2016, 84, 2279–2297. [Google Scholar] [CrossRef]
- Liang, Z.; Tang, T.; Li, B.; Liu, T.; Wang, J.; Hu, Y. Long-term streamflow forecasting using SWAT through the integration of the random forests precipitation generator: Case study of Danjiangkou Reservoir. Hydrol. Res. 2018, 49, 1513–1527. [Google Scholar] [CrossRef] [Green Version]
- Cloke, H.L.; Pappenberger, F. Ensemble flood forecasting: A review. J. Hydrol. 2009, 375, 613–626. [Google Scholar] [CrossRef]
- Xiao, Z.; Liang, Z.; Li, B.; Hou, B.; Hu, Y.; Wang, J. New flood early warning and forecasting method based on similarity theory. J. Hydrol. Eng. 2019, 24, 04019023. [Google Scholar] [CrossRef] [Green Version]
- Adnan, R.M.; Liang, Z.; Heddam, S.; Zounemat-Kermani, M.; Kisi, O.; Li, B. Least square support vector machine and multivariate adaptive regression splines for streamflow prediction in mountainous basin using hydro-meteorological data as inputs. J. Hydrol. 2020, 124371. [Google Scholar] [CrossRef]
- Liang, Z.; Xiao, Z.; Wang, J.; Sun, L.; Li, B.; Hu, Y.; Wu, Y. An improved chaos similarity model for hydrological forecasting. J. Hydrol. 2019, 577, 123953. [Google Scholar] [CrossRef]
- Belabid, N.; Zhao, F.; Brocca, L.; Huang, Y.; Tan, Y. Near-real-time flood forecasting based on satellite precipitation products. Remote Sens. 2019, 11, 252. [Google Scholar] [CrossRef] [Green Version]
- Jiang, X.; Gupta, H.V.; Liang, Z.; Li, B. Toward improved probabilistic predictions for flood forecasts generated using deterministic models. Water Resour. Res. 2019, 55, 9519–9543. [Google Scholar] [CrossRef]
- Todini, E. Hydrological catchment modelling: Past, present and future. Hydrol. Earth Syst. Sci. 2007, 11, 468–482. [Google Scholar] [CrossRef] [Green Version]
- Bloschl, G.; Reszler, C.; Komma, J. A spatially distributed flash flood forecasting model. Environ. Model. Softw. 2008, 23, 464–478. [Google Scholar] [CrossRef]
- Shafizadeh-Moghadam, H.; Valavi, R.; Shahabi, H.; Chapi, K.; Shirzadi, A. Novel forecasting approaches using combination of machine learning and statistical models for flood susceptibility mapping. J. Environ. Manag. 2018, 217, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Ritter, A.; Munoz-Carpena, R. Performance evaluation of hydrological models: Statistical significance for reducing subjectivity in goodness-of-fit assessments. J. Hydrol. 2013, 480, 33–45. [Google Scholar] [CrossRef]
- Li, B.; Liang, Z.; He, Y.; Hu, L.; Zhao, W.; Acharya, K. Comparison of parameter uncertainty analysis techniques for a TOPMODEL application. Stoch. Environ. Res. Risk Assess. 2017, 31, 1045–1059. [Google Scholar] [CrossRef]
- Li, B.; He, Y.; Ren, L. Multisource hydrologic modeling uncertainty analysis using the IBUNE framework in a humid catchment. Stoch. Environ. Res. Risk Assess. 2018, 32, 37–50. [Google Scholar] [CrossRef]
- Huang, H.; Liang, Z.; Li, B.; Wang, D.; Hu, Y.; Li, Y. Combination of multiple data-driven models for the long-term monthly runoff predictions based on Bayesian Model Averaging. Water Resour. Manag. 2019, 33, 3321–3338. [Google Scholar] [CrossRef]
- Liu, Z.; Martina, M.L.V.; Todini, E. Flood forecasting using a fully distributed model: Application of the TOPKAPI model to the Upper Xixian Catchment. Hydrol. Earth Syst. Sci. 2005, 9, 347–364. [Google Scholar] [CrossRef] [Green Version]
- Li, D.; Liang, Z.; Li, B.; Lei, X.; Zhou, Y. Multi-objective calibration of MIKE SHE with SMAP soil moisture datasets. Hydrol. Res. 2019, 50, 644–654. [Google Scholar] [CrossRef] [Green Version]
- Sun, W.; Wang, Y.; Wang, G.; Cui, X.; Yu, J.; Zuo, D.; Xu, Z. Physically based distributed hydrological model calibration based on a short period of streamflow data: Case studies in four Chinese basins. Hydrol. Earth Syst. Sci. 2017, 21, 251–265. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Jin, X.; He, C.; Zhang, B.; Zhang, X.; Li, J.; Zhao, C.; Tian, J.; DeMarchi, C. Comparison of SWAT and DLBRM for hydrological modeling of a mountainous watershed in arid northwest China. J. Hydrol. Eng. 2016, 21, 04016007. [Google Scholar] [CrossRef]
- Xu, H.; Xu, C.Y.; Chen, S.; Chen, H. Similarity and difference of global reanalysis datasets (WFD and APHRODITE) in driving lumped and distributed hydrological models in a humid region of China. J. Hydrol. 2016, 542, 343–356. [Google Scholar] [CrossRef]
- Xu, B.; Boyce, S.E.; Zhang, Y.; Liu, Q.; Guo, L.; Zhong, P.-A. Stochastic programming with a joint chance constraint model for reservoir refill operation considering flood risk. J. Water Resour. Plan. Manag. 2017, 143, 04016067. [Google Scholar] [CrossRef]
- Xu, B.; Zhu, F.; Zhong, P.-A.; Chen, J.; Liu, W.; Ma, Y.; Guo, L.; Deng, X. Identifying long-term effects of using hydropower to complement wind power uncertainty through stochastic programming. Appl. Energy 2019, 253, 113535. [Google Scholar] [CrossRef]
- Chen, T.; Ren, L.; Yuan, F.; Yang, X.; Jiang, S.; Tang, T.; Liu, Y.; Zhao, C.; Zhang, L. Comparison of spatial interpolation schemes for rainfall data and application in hydrological modeling. Water 2017, 9, 342. [Google Scholar] [CrossRef] [Green Version]
- Xu, W.; Zou, Y.; Zhang, G.; Linderman, M. A comparison among spatial interpolation techniques for daily rainfall data in Sichuan Province, China. Int. J. Climatol. 2015, 35, 898–2907. [Google Scholar] [CrossRef]
- Wagner, P.D.; Fiener, P.; Wilken, F.; Kumar, S.; Schneider, K. Comparison and evaluation of spatial interpolation schemes for daily rainfall in data scarce regions. J. Hydrol. 2012, 464, 388–400. [Google Scholar] [CrossRef]
- Huang, H.; Liang, Z.; Li, B.; Wang, D. A new spatial precipitation interpolation method based on the information diffusion principle. Stoch. Environ. Res. Risk Assess. 2019, 33, 765–777. [Google Scholar] [CrossRef]
- De Amorim Borges, P.; Franke, J.; da Anunciação, Y.M.T.; Weiss, H.; Bernhofer, C. Comparison of spatial interpolation methods for the estimation of precipitation distribution in Distrito Federal, Brazil. Theor. Appl. Climatol. 2016, 123, 335–348. [Google Scholar] [CrossRef]
- Li, B.; Liang, Z.; Bao, Z.; Wang, J.; Hu, Y. Changes in streamflow and sediment for a planned large reservoir in the middle Yellow River. Land Degrad. Dev. 2019, 30, 878–893. [Google Scholar] [CrossRef] [Green Version]
- Ciarrapica, L. Topkapi: A New Approach to Rainfall-Runoff Modelling. Ph.D. Thesis, University of Bologna, Bologna, Italy, 1995. [Google Scholar]
- Liu, Z. Toward a Comprehensive Distributed/Lumped Rainfall-Runoff Model: Analysis of Available Physically-Based Models and Proposal of a New TOPKAPI Model. Ph.D. Thesis, University of Bologna, Bologna, Italy, 2002. [Google Scholar]
- Abbott, M.B.; Bathurst, J.C.; Cunge, J.A.; O’Connell, P.E.; Rasmussen, J. An introduction to the European hydrological system—Systeme hydrologique Europeen, “SHE”, 1: History and philosophy of a physically-based, distributed modelling system. J. Hydrol. 1986, 87, 45–59. [Google Scholar] [CrossRef]
- Abbott, M.B.; Bathurst, J.C.; Cunge, J.A.; O’Connell, P.E.; Rasmussen, J. An introduction to the European hydrological system—Systeme hydrologique Europeen, “SHE”, 2: Structure of a physically-based, distributed modelling system. J. Hydrol. 1986, 87, 61–77. [Google Scholar] [CrossRef]
- Thornthwaite, C.W. An approach toward a rational classification of climate. Geogr. Rev. 1948, 38, 55–94. [Google Scholar] [CrossRef]
- Krzysztofowicz, R. Bayesian theory of probabilistic forecasting via deterministic hydrological model. Water Resour. Res. 1999, 35, 2739–2750. [Google Scholar] [CrossRef] [Green Version]
- Biondi, D.; De Luca, D.L. Performance assessment of a Bayesian forecasting system (BFS) for real-time flood forecasting. J. Hydrol. 2013, 479, 51–63. [Google Scholar] [CrossRef]
- Li, B.; Liang, Z.; Zhang, J.; Chen, X.; Jiang, X.; Wang, J.; Hu, Y. Risk analysis of reservoir flood routing calculation based on inflow forecast uncertainty. Water 2016, 8, 486. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, S.; Xiong, L.; Xu, C.Y. Hydrologic uncertainty processor based on a copula function. Hydrol. Sci. J. 2017, 63, 74–86. [Google Scholar] [CrossRef]
- Han, S.; Coulibaly, P. Probabilistic flood forecasting using hydrologic uncertainty processor with ensemble weather forecasts. J. Hydrometeorol. 2019, 20, 1379–1398. [Google Scholar] [CrossRef]
- Yao, Y.; Liang, Z.; Zhao, W.; Jiang, X.; Li, B. Performance assessment of hydrologic uncertainty processor through the integration of the principal components analysis. J. Water Clim. Chang. 2019, 10, 379–390. [Google Scholar] [CrossRef]
- Feng, K.; Zhou, J.; Liu, Y.; Lu, C.; He, Z. Hydrologic uncertainty processor (HUP) with estimation of the marginal distribution by a Gaussian mixture model. Water Resour. Manag. 2019, 33, 2975–2990. [Google Scholar] [CrossRef]
- Krzysztofowicz, R.; Kelly, K.S. Hydrologic uncertainty processor for probabilistic river stage forecasting. Water Resour. Res. 2000, 36, 3265–3277. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FAO Soil Type | Horizontal Permeability at Saturation (m/s) | Saturated Water Content | Residual Water Content | Soil Depth (m) | Horizontal Non-Linear Reservoir Exponent | Vertical Permeability at Saturation (m/s) | Vertical Non-Linear Reservoir Exponent |
|---|---|---|---|---|---|---|---|
| I-Bc–2c | 2.19 × 10−3 | 0.423 | 0.303 | 0.85 | 2.5 | 2.19 × 10−7 | 23.8 |
| I-Be–2c | 9.27 × 10−4 | 0.39 | 0.27 | 0.55 | 2.5 | 3.27 × 10−7 | 18.5 |
| Bc28–2b | 7.67 × 10−4 | 0.33 | 0.21 | 1.35 | 2.5 | 7.67 × 10−8 | 17.2 |
| Land Use Type | Manning Coefficient (s/m^(1/3)) |
|---|---|
| Dryland cropland and pasture | 0.08 |
| Irrigated cropland and pasture | 0.10 |
| Cropland/grassland mosaic | 0.12 |
| Cropland/woodland mosaic | 0.14 |
| Grassland | 0.12 |
| Shrubland | 0.13 |
| Savanna | 0.13 |
| Deciduous broadleaf forest | 0.19 |
| Mixed forest | 0.19 |
| Land Use Type | Crop Factors | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Jan | Feb | Mar | Apr | May | Jun | Jul | Aug | Sep | Oct | Nov | Dec | |
| Dryland cropland and pasture | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 1.1 | 1.15 | 1 | 1 | 0.9 | 0.8 | 0.8 |
| Irrigated cropland and pasture | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 1.1 | 1.15 | 1 | 1 | 0.9 | 0.8 | 0.8 |
| Cropland/ grassland mosaic | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 1.1 | 1.15 | 1 | 1 | 0.9 | 0.8 | 0.8 |
| Cropland/ woodland mosaic | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 1.1 | 1.15 | 1 | 1 | 0.9 | 0.8 | 0.8 |
| Grassland | 0.7 | 0.7 | 0.8 | 0.8 | 0.9 | 1.1 | 1.2 | 1 | 1 | 0.9 | 0.8 | 0.8 |
| Shrubland | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 | 0.5 |
| Savanna | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 |
| Deciduous broadleaf forest | 0.63 | 0.63 | 0.72 | 0.72 | 0.81 | 0.81 | 0.99 | 0.9 | 0.9 | 0.81 | 0.72 | 0.72 |
| Mixed forest | 0.66 | 0.66 | 0.76 | 0.76 | 0.85 | 0.85 | 1.04 | 0.95 | 0.95 | 0.85 | 0.76 | 0.76 |
| Period | Sample Size | Correlation Coefficient | Mean Absolute Error (m3/s) | Nash–Sutcliffe Coefficient Efficiency | Index of Agreement |
|---|---|---|---|---|---|
| 1996 | 1204 | 0.89 | 39.93 | 0.65 | 0.86 |
| 1997 | 150 | 0.43 | 28.44 | −0.81 | 0.55 |
| 1998 | 1170 | 0.75 | 72.75 | 0.44 | 0.86 |
| 1999 | 672 | 0.81 | 19.61 | 0.51 | 0.81 |
| 2000 | 1450 | 0.85 | 32.34 | 0.52 | 0.75 |
| 2001 | 980 | 0.66 | 32.01 | −1.58 | 0.63 |
| 2002 | 678 | 0.89 | 44.11 | 0.12 | 0.87 |
| 2003 | 1342 | 0.92 | 94.03 | 0.82 | 0.95 |
| 2004 | 1424 | 0.85 | 28.42 | 0.60 | 0.90 |
| 2005 | 948 | 0.94 | 51.19 | 0.86 | 0.96 |
| 2006 | 3314 | 0.82 | 13.11 | 0.53 | 0.76 |
| 2007 | 3674 | 0.97 | 13.35 | 0.95 | 0.99 |
| 2008 | 2154 | 0.85 | 19.84 | −5.60 | 0.63 |
| 1996–2005 | 10,018 | 0.88 | 47.31 | 0.78 | 0.93 |
| 2006–2008 | 9142 | 0.92 | 14.79 | 0.82 | 0.95 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, B.; Liang, Z.; Chang, Q.; Zhou, W.; Wang, H.; Wang, J.; Hu, Y. On the Operational Flood Forecasting Practices Using Low-Quality Data Input of a Distributed Hydrological Model. Sustainability 2020, 12, 8268. https://doi.org/10.3390/su12198268
Li B, Liang Z, Chang Q, Zhou W, Wang H, Wang J, Hu Y. On the Operational Flood Forecasting Practices Using Low-Quality Data Input of a Distributed Hydrological Model. Sustainability. 2020; 12(19):8268. https://doi.org/10.3390/su12198268
Chicago/Turabian StyleLi, Binquan, Zhongmin Liang, Qingrui Chang, Wei Zhou, Huan Wang, Jun Wang, and Yiming Hu. 2020. "On the Operational Flood Forecasting Practices Using Low-Quality Data Input of a Distributed Hydrological Model" Sustainability 12, no. 19: 8268. https://doi.org/10.3390/su12198268
APA StyleLi, B., Liang, Z., Chang, Q., Zhou, W., Wang, H., Wang, J., & Hu, Y. (2020). On the Operational Flood Forecasting Practices Using Low-Quality Data Input of a Distributed Hydrological Model. Sustainability, 12(19), 8268. https://doi.org/10.3390/su12198268