2. A Motivating Scenario
This section illustrates the features of a sustainable Mashup and the details in the actual construction through an example of investigating a criminal case [
13], in which the policemen need to obtain the data related to the case from different business departments when they investigate a criminal case. If each business department provides data access interfaces using Web services, the policemen can implement data integration through composing available Web services. Thus, they can obtain the required data.
Figure 1 shows the process of the investigation.
For example, there is a murder case somewhere. The time range of the crime and the height, gender, and approximate age of the victim can be determined through on-the-spot investigation. At the same time, there are tire marks around the scene and surveillance cameras around the junction. So, how to get the potential suspects? How to get relevant clues from a large number of available data sources? The policemen first try to determine the victim’s identity by the Web service getLostPersons, provided by the public security department according to the obtained height, gender, and age of the victim. Assuming that the identity of the victim is obtained in the example, which services should be used to obtain the required data in the next step? The policemen try to use the victim’s recent telephone contacts as candidate suspects. According to the obtained ID number of the victim, they use the service getTelecomUser provided by the telecom department to obtain the names and mobile phone numbers of the victim’s recent contact persons in the 2nd step. Next, how to determine whether these persons are suspects? The policemen try to obtain the vehicles registered under the names of these persons, and then judge whether these vehicles appear at the designated junction within the time period of the murder. If so, they may be suspects. Therefore, the ID numbers of these contact persons can be obtained through the service getContact in the 3rd step, and the license plate numbers owned by them can be obtained through the service getVehicleRegistration in the 4th step. Then, the license plates of all vehicles that pass through the scene junction during the time period of the murder are obtained by the service getTrafficMonitoring. Through the service composition operation Intersection, the license plates are compared with those of the vehicles owned by the recent contacts obtained previously in the 4th step. If there are outputs, the persons in the output can be determined as the candidate suspects. If there are no outputs, the policemen have to choose other Web services to get new clues. On the basis of the obtained data, the policemen may try to take the victim’s relatives as candidate suspects and obtain the information of the victim’s relatives through the service getRelatives in the 6th step. Next, they can obtain the license plates of their vehicles and reuse the Intersection operation. Finally, they can decide whether candidate suspects are contained in the comparison results.
In this example, the data requirement of the policemen cannot be accurately expressed before the service Mashup is constructed. Furthermore, the data requirement may change based on obtained data during the construction process. From the perspective of the overall process of a service Mashup, it is impossible to determine exactly what services are required and how to compose these services in advance. The policemen need to select and compose services manually, determine the subsequent services according to the composition results. Based on the obtained composition results, they can continue to select services for composition and obtain more data continuously. Therefore, this is a typical sustainable service Mashup. Instant service recommendation can help the policemen to select services at each step efficiently. Thus, the overall efficiency of building a service Mashup is improved.
3. The Overall Framework of the Proposed Approach
From the example in
Figure 1, we can see that the services that have been selected in the constructing process of a sustainable service Mashup imply the requirement of a user. Therefore, the services that may be used next step can be recommended according to the services currently used by the user. So, how to discover these services according to the services already used? Through the analysis of existing service Mashups, it can be seen that service Mashups that meet the similar requirements of users may use similar services. Therefore, in the construction process of a sustainable service Mashup, existing Mashups that are similar to the currently constructed Mashup can be queried using the used services, and services that are used in these similar Mashups can be used as recommended services. Moreover, from the perspective of the actual operation of composing Web services, the composition strategy of services should be determined according to the input and output parameters of the chosen services. For example, in
Figure 1, the values of the attribute ID NO in the output of the service getLostPersons can be used as the input of the service getTelecomUser. Therefore, the correlations between the input and output parameters of Web services are also a basis for determining candidate services.
The effectiveness of services recommendation using similar Mashups is affected by the number of existing Mashups. Therefore, when recommended services cannot be obtained through existing similar Mashups, the services can be further selected through the parameter correlations of the used services. In this paper, service recommendation based on similar Mashups is combined with the recommendation based on parameter correlations of Web services to provide instant service recommendation for sustainable service Mashups. Using this approach, the following N services can be recommended to the user according to the used services. Specifically, assume that N Web services need to be recommended, and M services are chosen by similar Mashups first. If M is less that N, other N-M services are chosen based on the parameter correlations of the used services.
4. Similar Mashups-Based Service Recommendation
For the similarity measure between the constructing Mashup and an existing Mashup, a fundamental hypothesis is that, the more the same services are contained in these two Mashups, the more similar they are. Moreover, the way that the same services are used should also be taken into account when computing their similarity. Specifically, first, during the construction of a service Mashup, a user needs to assign values to some input parameters of the used services. Second, after a service is invoked, the user may need only a part of its output. For example, the user may delete some parameters of the output to retain what he/she needs. Therefore, both input parameters that are assigned values by a user and output parameters that are retained in a service Mashup imply the data requirement of this Mashup more accurately.
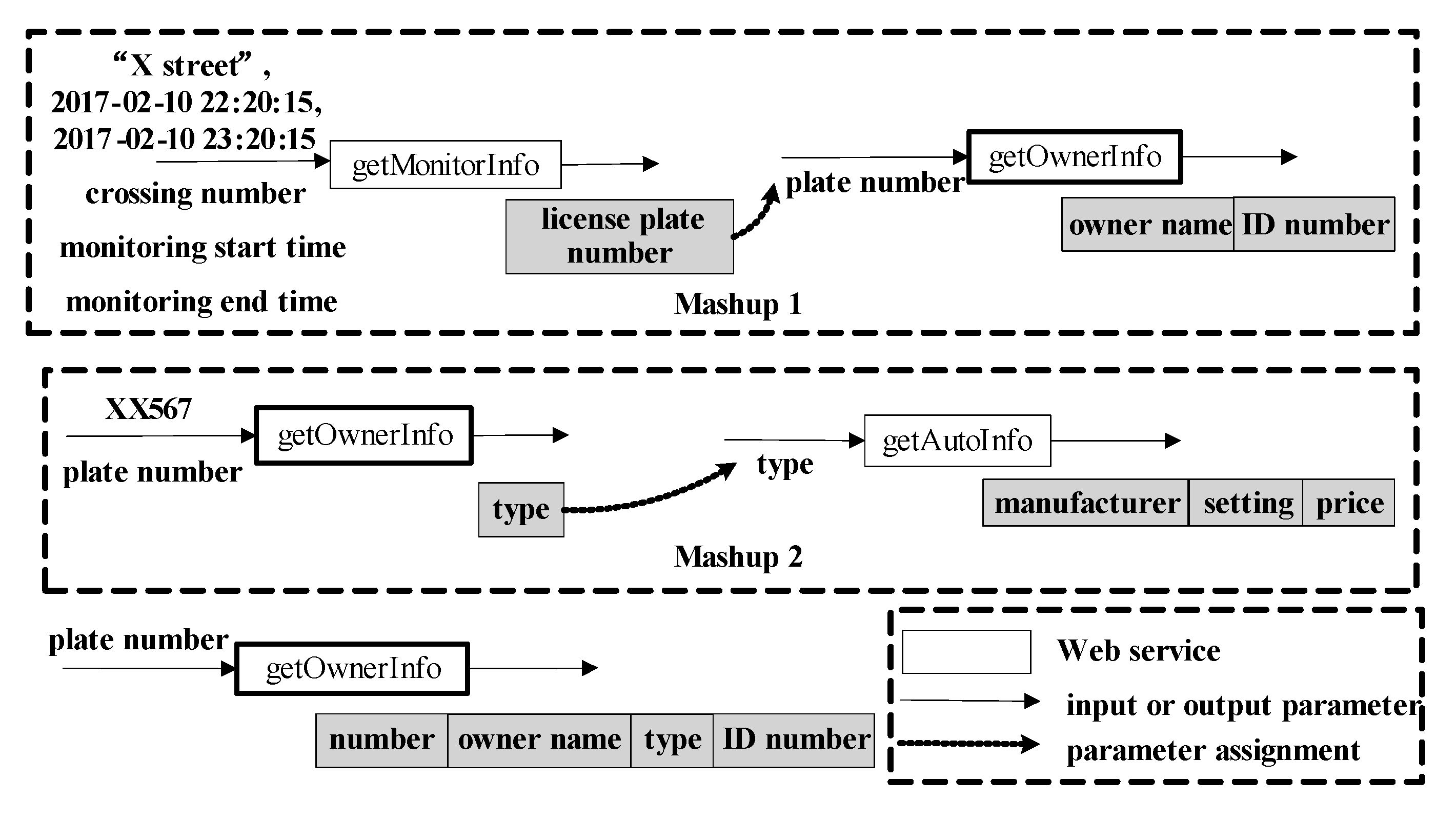
Take the two service Mashups in
Figure 2 for example. These two Mashups contain the service getOwnerInfo that receives the plate number of a car and outputs the information of the car’s owner. In the first Mashup, the user assigns values to the input parameters crossing number, monitoring start time, and monitoring end time. Then, the user gets the output describing the cars passing
X street between the start and end time. After editing the output, the user only retains the car’s license plate number. Next, the user takes the obtained plate number as the input of the service getOwnerInfo and invokes this service. Finally, the user only retains the owner name and ID number of the output. In this Mashup, the user aims to get the information of the owners whose cars pass the
X street in the specified period of time. In the second Mashup, the user first assigns the value for the input parameter plate number for the service getOwnerInfo and gets the data about the car with the number XX567. The user only retains the attribute type of the output. Then, the user uses the obtained type value as the input and invokes the service getAutoInfo. Finally, the user gets the manufacturer, setting, and price of the output. In this Mashup, the user aims to search for the specific information of a car through its plate number. Both Mashups use the service getOwnerInfo. If their similarity is computed only by the same services using the Jaccard formula, their similarity is 1/3. However, from the actual requirements of these two Mashups, their similarity is much lower than 1/3. This is because the same service is used in completely different ways. For the service getOwnerInfo, the retained parameters of the output are different in two service Mashups, which reflects the difference of the user’s required data. Meanwhile, the input parameters assigned by the user are also different, which indicates the different initial states of these two Mashups. Therefore, if two service Mashups contain the same services, input parameters assigned and output parameters retained by the user should all be taken into account for their similarity measure.
Let
s be a Web service contained in service Mashups
u and
v. The input and output parameters of
s are denoted as
s.input = (
i1,
i2…
in) and
s.output = (
o1,
o2…
om), respectively. Then,
s.io = (
i1,
i2…
in,
o1,
o2…
om) is an
n + m dimension vector. In addition, s
u.io and s
v.io are both
n + m dimension vectors that describe the input parameters assigned by the user and output parameters retained in the final result, respectively. For s
u.io, let its
xth (1 ≤
x ≤
n) input parameter be
ix, and the value of the dimension that
ix stands for is: If
s.
ix in
u is assigned by the user, s
u.io[
ix] = 1, otherwise s
u.io[
ix] = 0. Similarly, for s
u.io, the value of the dimension that the
yth (1 ≤
y ≤
m) output parameter o
y stands for is: If s.
oy in
u is retained by the user, s
u.io[
oy] = 1, otherwise s
u.io[
oy] = 0. Let
Simu,v(
s) be the similarity that
s is used in
u and
v. Based on the way that
s is used in
u and
v,
Simu,v(
s) can be computed by the cosine similarity in Equation (1). We denote the set of services contained in
u and
v as
N(
u) and
N(
v), respectively. Then, the similarity between
u and
v that is denoted as
Similarity(
u,
v) can be measured by Equation (2).
The left part of Equation (2) is used to compute the similarity of
u and
v through the same services in them, and the right part is used to compute the average similarity of all the same services. After the same part of the numerator and denominator is divided out, the final formula for measuring
Similarity(
u,
v) is shown as Equation (3).
Go back to the example in
Figure 2. The first and second Mashup are noted as
u and
v, respectively. For the service getOwnerInfo, its input parameter is assigned by the output of the former service in
u. While in
v, this input parameter is assigned by the user. Therefore, there is no same input parameter assigned by the user in
u and
v. Meanwhile, the output parameters of getOwnerInfo retained in
u and
v are different. By Equation (1),
Simu,v(
getOwnerInfo) = 0. Therefore,
Similarity(
u,
v) = 0 according to Equation (3). The reason for this result is that the way that getOwnerInfo is used in
u and
v is completely different, which is in accordance with the actual situation of the example in
Figure 2.
Through the similarity of the constructing Mashup and existing Mashups, each candidate service can be assigned a score called a Mashup relevancy. Through Equation (3), we can obtain a group of Mashups, in which each Mashup’s similarity with the constructing one is higher than a threshold
λ. Then, for each service that is used in these Mashups, but not in the constructing one, we compute its total Mashup relevancy. Let the constructing Mashup be
c, and services in
c be
Sc. The Mashups whose similarity with
c are higher than
λ is
c1,
…ci…cn(1 ≤
i ≤
n), and the similarity between
ci and
c is
Similarity(
ci,
c). For
ci, the services in
ci are denoted as S
ci. For any service
s Sci–Sc, the Mashup relevancy obtained through
ci is
MReli(s) = Similarity(ci, c). Since
s may be used in multiple Mashups, the Mashup relevancy of
s (denoted as
MRel(s)) that is obtained through
c1, c2, …ci…cn, can be measured by Equation (4).
The algorithm getWSFromMashups (
m, M, λ, N) to recommend
N services for the constructing Mashup
m is shown in Algorithm 1. In this algorithm, the function getSimMashups
(m, λ) is used to obtain existing Mashups whose similarity with
m is higher than
λ. For a candidate service
cs, the function
getMRel (cs, mu) returns the Mashup relevancy of
cs in a Mashup
mu. The function
add (R, cs, MRel (cs)) is used to add
cs and its relevancy into
R. If
R contains
cs, its Mashup relevancy is added with the existing value in
R. Finally, the function getTop
(R, N) returns
N services that own the top Mashup relevancy in
R. If the number of services in
R is less than
N, R is returned directly.
| Algorithm 1 getWSFromMashups(m, M, λ, N) |
Input: The constructing Mashup (m), services in m (m.S), the set of existing Mashups (M), Mashup similarity threshold (λ), the number of recommended services (N)
Output: The set of services recommended (R) |
R = candiWSs = Φ simMashups = getSimMashups(m, λ)//obtain Mashups whose similarity with m is higher than λ for each mu in simMashups candiWSs = mu.S − m.S for each cs in candiWSs MRel(cs) = getMRel(cs, mu)//get the Mashup relevancy of cs in the Mashup mu add (R, cs, MRel(cs)) Endfor Endfor return getTop(R, N)//get N services that own the top Mashup relevancy in R
|
6. Instant Service Recommendation for Sustainable Service Mashup
According to the overall framework of the proposed approach in
Section 3, Algorithm 3 presents the complete process to recommend
N services for a constructing service Mashup using the above two approaches.
| Algorithm 3 recommendWS (m, M, SN, λ, N) |
Input: The constructing Mashup (m), the set of existing Mashups (M), the service network (SN), Mashup similarity threshold (λ), the number of recommended services (N)
Output: The set of N services recommended (R) |
R = getWSFromMashups(m, M, λ, N) If (size(R) = = N) return R Else n = N − size(R) add (R, getWSFromWSN(m, SN, n)) EndIf
|
In the constructing process of a sustainable service Mashup, services are recommended again by Algorithm 3 if services in the constructing Mashup are changed. In this way, the instant recommendation is implemented.
Algorithm 3 first uses getWSFromMashups to recommend N services. When the number of services returned by getWSFromMashups is less than N, the remaining services are recommended by getWSFromWSN. Therefore, the time complexity of Algorithm 3 can be obtained by the complexity of getWSFromMashups and getWSFromWSN. The time complexity of getWSFromMashups is mainly related to the number of Mashups (denoted as |M|) in the existing Mashup library and the average number of services contained in each Mashup (denoted as |S|). As a result, its complexity is O(|M|*|S|). As for getWSFromWSN, when the correlation between services in SN is calculated offline, its time complexity is only related to the number of recommended services N, so its complexity is O(N). As N is usually much less than |M|*|S|, the time complexity of Algorithm 3 is O(|M|*|S|).
We take the sustainable service Mashup in
Figure 1 as an example to introduce the process of Web services recommendation in Algorithm 3. Suppose that
N Web services need to be recommended each time by Algorithm 3 when the user selects a Web service. After the user selects the service getLostPersons to identify the victim, the algorithm finds a group of Mashups from the existing Mashup library that have a similarity value greater than the threshold through the used service getLostPersons, as well as its input parameters assigned by the user and retained output parameters. Thus, the relevancy values of each service except getLostPersons in these similar Mashups are calculated by Equation (4). If the number of obtained services is greater than
N, the top
N services are regarded as recommended services. On the contrary, if the number of services obtained is less than
N (assuming
M), the
N-M services with the highest correlation degree values with getLostPersons can be obtained from
SN by Equation (6), and they are regarded as another part of the recommended services. In special cases, if the number of candidate services based on similar Mashups and
SN is still less than
N, only the services obtained according to Algorithm 3 are recommended. Repeating the process, this algorithm automatically recommends
N services to the user after the user selects a new service to the current Mashup. In this way, the instant service recommendation for a sustainable service Mashup is provided.
The proposed approach can cope with the problems of the existing two kinds of instant service recommendation approaches in
Table 1. First, this approach makes use of existing Mashups to find candidate services through similar Mashups. The idea is similar to the service recommendation approaches based on composition history listed in
Table 1. The difference is that the approach in this paper takes the same services used and the usage of the same services into account to measure the similarity of Mashups. Thus, the implicit requirements of users can be described more accurately. In addition, the complexity of searching similar Mashups is lower than those based on Mashup graph matching [
25,
26], making this approach more suitable for the instant recommendation of sustainable service Mashups. Although service recommendation based on composition history is limited by the scale of existing Mashups, the proposed approach can find other services further based on
SN when services cannot be obtained as required by existing similar Mashups. Because the service hyperlinks can be obtained in many ways [
33,
36], it is not limited by the scale of existing service compositions or Mashups. As a result, our approach can solve the problem that the approaches based on composition history exist. Second, for the approaches that only consider service parameter correlations, too many correlations may be built because of different semantic granularity of service parameters, leading to poor effectiveness in recommending services. As is shown in the two examples of
Section 5.2, the service that provides search function has the input parameter keyword may have hyperlinks with a large number of other services in
SN because the input and output parameters of most services can be correlated with its input. However, most of these linked services may have nothing to do with the actual requirements of the user when the service is used in a sustainable service Mashup. As a result, the effectiveness of recommendation may be lowered. The proposed approach first leverages similar Mashups to discover the user’s implicit requirements based on the used services. Thus, services can be recommended more accurately compared with the approaches that only consider the directly linked services by parameter correlations of services.
7. Experimental Evaluation
In this section, we present the experiments to evaluate the effectiveness of the proposed instant service recommendation approach.
7.1. Data Set and Evaluation Metrics
We get a group of available Web services and Mashups from ProgrammableWeb.com, as well as existing services and Mashups in our service composition platform. We get 1180 Web services (including REST and SOAP services) and 638 Mashups in total. By our service composition platform, these services can be encapsulated into the uniform services and composed to build these Mashups. Service hyperlinks can be obtained through the hyperlink modeling approach proposed in [
33]. Meanwhile, we divide the obtained Mashups into two groups. One is the test data set
T, containing 100 Mashups, in which each Mashup contains at least three services and fit the demands of a sustainable service Mashup. Another group that contains 500 Mashups is randomly selected from the remaining Mashups, and it is regarded as the Mashups library. We select the test data set and Mashup library randomly three times to conduct the experiments and take the average values of three times as the final result.
The approach proposed in this paper belongs to TopN recommendation. Therefore, the precision and recall are used as the evaluation metrics. Furthermore, coverage is used as another metric to verify the effectiveness of the approach in recommending infrequently used services and newly added services. Specifically, for each Mashup in the test data set,
N services (the set is denoted as S
R) are recommended according to the 1/3 front services by the proposed algorithm. The service set made up of the back 2/3 services in this Mashup is denoted as S
U. The precision, recall, and coverage can be measured by Equation (7). First, S
R is all the recommended services using Algorithm 3, and S
U is all the services that should be recommended. Therefore, S
R ∩ S
U indicates the correctly recommended services. Thus, we can get the Precision and Recall in Equation (7). Second, in the formula of coverage, the numerator is the number of total services recommended for the 100 Mashups in the test data set
T, and the denominator is the number of all the services (denoted as
S). Through dividing the number of all recommended services by the number of all services, the coverage of the recommendation approach can be obtained.
In order to evaluate the effectiveness of our approach, we first analyze some features of our algorithm. Specifically, we examine the effect of a few parameters on the algorithm, including the number of existing Mashups, the scale of SN, the number of services to be recommended, and the Mashup similarity threshold λ. Second, we compare the algorithm with other related approaches to observe the effect on the precision and recall. Finally, we observe the coverage value of the proposed approach and compare it with related approaches to analyze the effect on newly added and less frequently used services.
7.2. Evaluation Approach
First, we observe the influence of the number of existing Mashups and the scale of SN on the recommendation algorithm. We divide the existing Mashups library into five groups which contain 50, 100, 200, 300, and 500 Mashups, respectively. Meanwhile, we adjust service hyperlinks according to the number of existing Mashups. For example, for the case of 200 Mashups, we randomly delete the service hyperlinks in SN, and keep 2/5 (200/500) hyperlinks. In this way, the remaining SN is regarded as the corresponding network. Through five groups of different Mashups libraries and SNs, we obtain the precision, recall, and coverage of the algorithm.
Second, we compare our approach with the following related approaches. (1) The approach only uses parameter correlations to recommend services. In this approach, correlations or hyperlinks among services are built according to the input and output parameters of the services. Then, services having correlations or hyperlinks with those used services are recommended [
26]. In our experiments, we get services linked by the hyperlinks of the front 1/3 services used in the constructing Mashup, and select
N services randomly as the recommendation. (2) The approach counts the co-existence of services in existing Mashups and gets the similarity of services. In this approach, services similar to the used services are recommended [
38]. In our experiments, we use these two approaches to recommend services and compare their results with ours. Because these three approaches are all affected by the number of existing Mashups and the scale of
SN, we divide existing Mashups into five groups and deal with the
SN as above. We observe the precision, recall, and coverage of these three approaches in these five cases. In this experiment, the Mashup similarity threshold
λ is 0.4, and the number of recommended services is 5. In addition, we compare the running time of these three approaches to evaluate the efficiency and availability of these approaches.
Third, we observe the influence of the number of recommended services (N) and the Mashup similarity threshold (λ). We set fixed Mashups and the scale of SN to observe the influence of these two parameters on the algorithm’s precision and recall.
7.3. Results
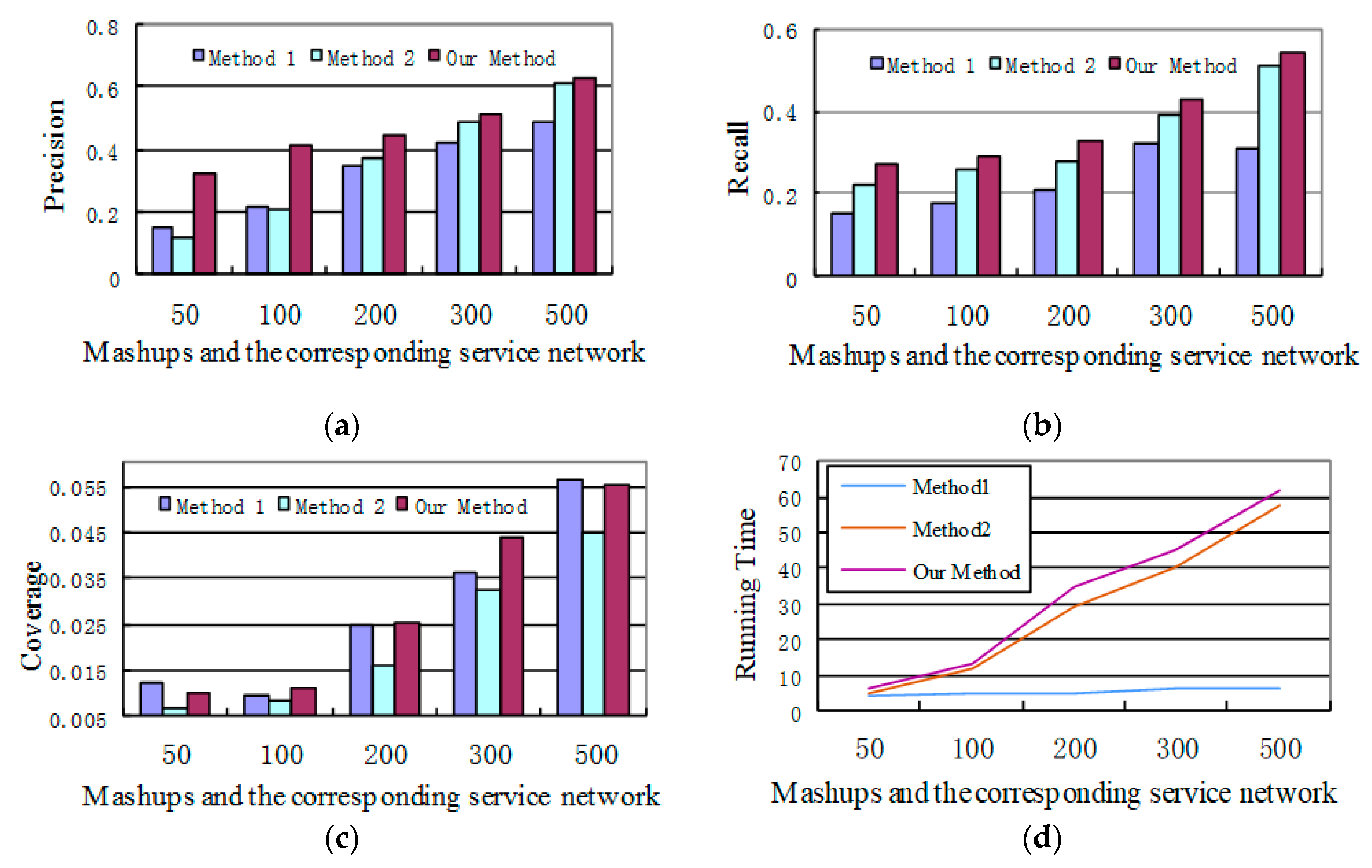
Figure 4 shows the experimental results, based on which we can get the following conclusions.
First, the proposed approach is influenced by the number of existing Mashups and the scale of SN. If the scale of the existing Mashups, SN, and the number of recommended services are all small, the precision, recall, and coverage are not high. As the scale of existing Mashups and SN increases, the approach can find more similar Mashups and more services with higher correlation degree. As a result, the values of the above three metrics are all increased.
Second, compared with the first approach, the precision and recall of our approach are higher. In addition, the coverage of the first approach is comparable to our approach. If the scale of SN is small, services are selected randomly in this approach. Thus, the less frequently used services can be recommended. Therefore, the number of recommended services is comparable to our approach, making its coverage comparable to our approach. However, recommended services are not selected from the point of user requirement in the first approach. The services having parameter correlations with a service in the constructing Mashup may belong to multiple domains, and some of them may have little relation with the requirement of the constructing Mashup. In our approach, both services with more comprehensive parameter correlations and those in the similar Mashups are all considered. Therefore, our approach has higher precision and recall than the first approach.
Compared with the second approach, the precision, recall, and coverage of our approach are all higher when the number of existing Mashups is small. Meanwhile, if the existing Mashups reach a certain scale, three metrics of the second approach are comparable to our approach. This is because the specified number of services cannot be recommended only depending on the existing Mashups using the second approach under the condition that the scale of the existing Mashups and SN is small. However, candidate services can be selected through the SN when services cannot be recommended only using existing Mashups in our approach. Specifically, for services that are not popular or less frequently used in the constructing Mashup, services can also be recommended based on SN. Hence, the coverage of our approach is higher. Through the experiment, we find that if existing Mashups reach a certain scale, services can be recommended only using existing Mashups in our approach. In this case, SN is not needed for service recommendation. That is, services that are recommended through existing Mashups typically have parameter correlations.
In addition, in terms of the time complexity, the complexity of the proposed approach is higher than the other two methods according to
Figure 4d. This is because the proposed approach leverages both service parameter correlations and existing similar Mashups. However, the experimental results show that compared with method 1 and method 2, the proposed algorithm can return results in less than 100 ms under different Mashups libraries and scales of
SN. Therefore, the requirements of instant service recommendation in sustainable service Mashups can be met using our approach.
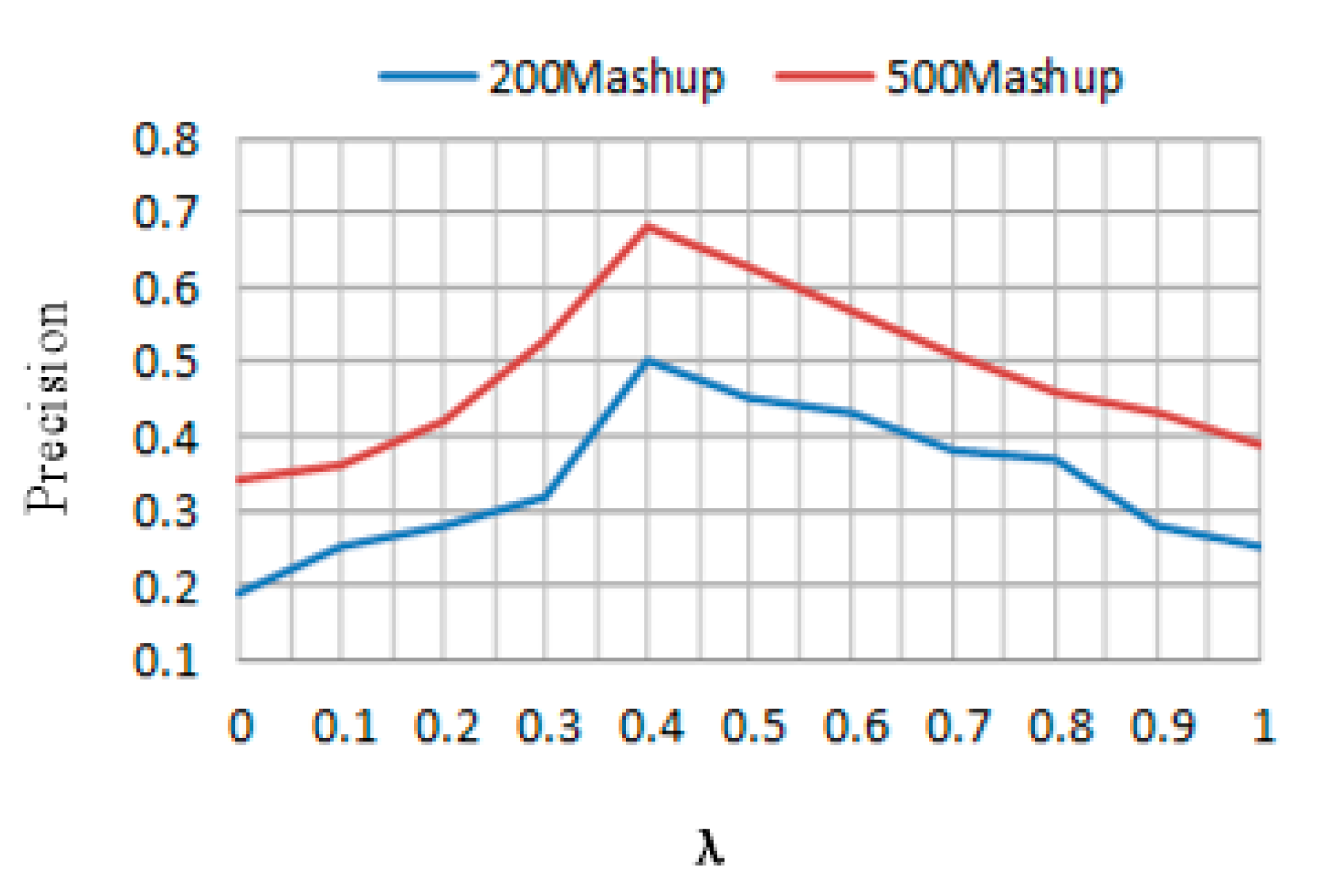
To observe the influence of
λ, three services are recommended for each Mashup in the test data set. The numbers of existing Mashups are set to 200 and 500, respectively, and
SN is processed as above. The value of
λ ranges from 0 to 1 with 0.1 increasement each time.
Figure 5 shows the values of the precision as
λ changes under the conditions that the numbers of existing Mashups are 200 and 500, respectively. Based on the obtained results, we can see that the precision is the best when
λ = 0.4.
In order to observe how the number of recommended services (
N) influences the effectiveness of the recommendation, we set different values for
N to get the precision and recall. The experiment is conducted under the conditions that the number of existing Mashups is 500, and
SN is in the corresponding scale. Because the proposed approach does not need to recommend many services,
N is set to 1, 3, 5, 7, and 9, respectively. The obtained results are shown in
Figure 6, based on which we can see that the precision and recall are the highest when
N = 5 and the number of existing Mashups is 500.
Based on the experimental results, we can draw the final conclusions. For sustainable service Mashups, the effectiveness of our approach is improved as the scale of existing Mashups and SN increases. If the scale of existing Mashups and SN reaches a certain scale, the precision, recall, and coverage of our approach are higher than existing approaches.
To sum up, we can see from the experimental results that when the number of existing composition history or Mashups reaches a certain scale, the proposed approach has the similar precision and recall with the existing service recommendation approaches based on composition history. Differently, the proposed approach has better coverage. While the number of existing compositions or Mashups is small, the precision and recall of the proposed approach are better than existing composition history-based service recommendation approaches because it can find other suitable services through SN. Compared with approaches that only consider the parameter correlation, our approach has better precision and recall. In addition, the time complexity of our approach is suitable for instant service recommendation in the building process of a sustainable service Mashup.
8. Conclusions
In this paper, we propose an instant Web service recommendation approach for sustainable service Mashups that considers services used in similar Mashups and parameter correlations among the input and output parameters of Web services. First, services are selected from existing Mashups that are similar to the constructing Mashup. The similarity between two Mashups is computed based on the same services used and the way they are used. Second, services are selected through the service network that is built based on the services and their hyperlinks from the perspective of actual operations of Web service composition. We propose to compute the service correlation degree based on parameter correlations. According to the experimental results, the shortcomings of existing approaches in Web services instant recommendation for sustainable service Mashups are properly tackled by combining two recommendation approaches. Meanwhile, the proposed approach has better precision, recall, and coverage on the whole, and can recommend Web services instantly to a user during the construction of a sustainable service Mashup. In conclusion, the proposed approach is more suitable for instant service recommendation of sustainable service Mashups.
With the wider application of Web services, more and more service compositions or Mashups will be accumulated on the Internet, and more parameter correlations between services will be found, which help to gradually form service big data. How to combine the machine learning techniques, especially the deep learning techniques, to achieve more accurate and efficient service recommendation, is an important issue of the future work. In addition, the execution of composed services can be regarded as a business process, advanced process modeling and analysis techniques, e.g., [
39,
40,
41], can be applied for service behavior analysis.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}