MultiDefectNet: Multi-Class Defect Detection of Building Façade Based on Deep Convolutional Neural Network




Abstract
:1. Introduction
2. Literature Review
3. Research Methodology
3.1. Overall Architecture
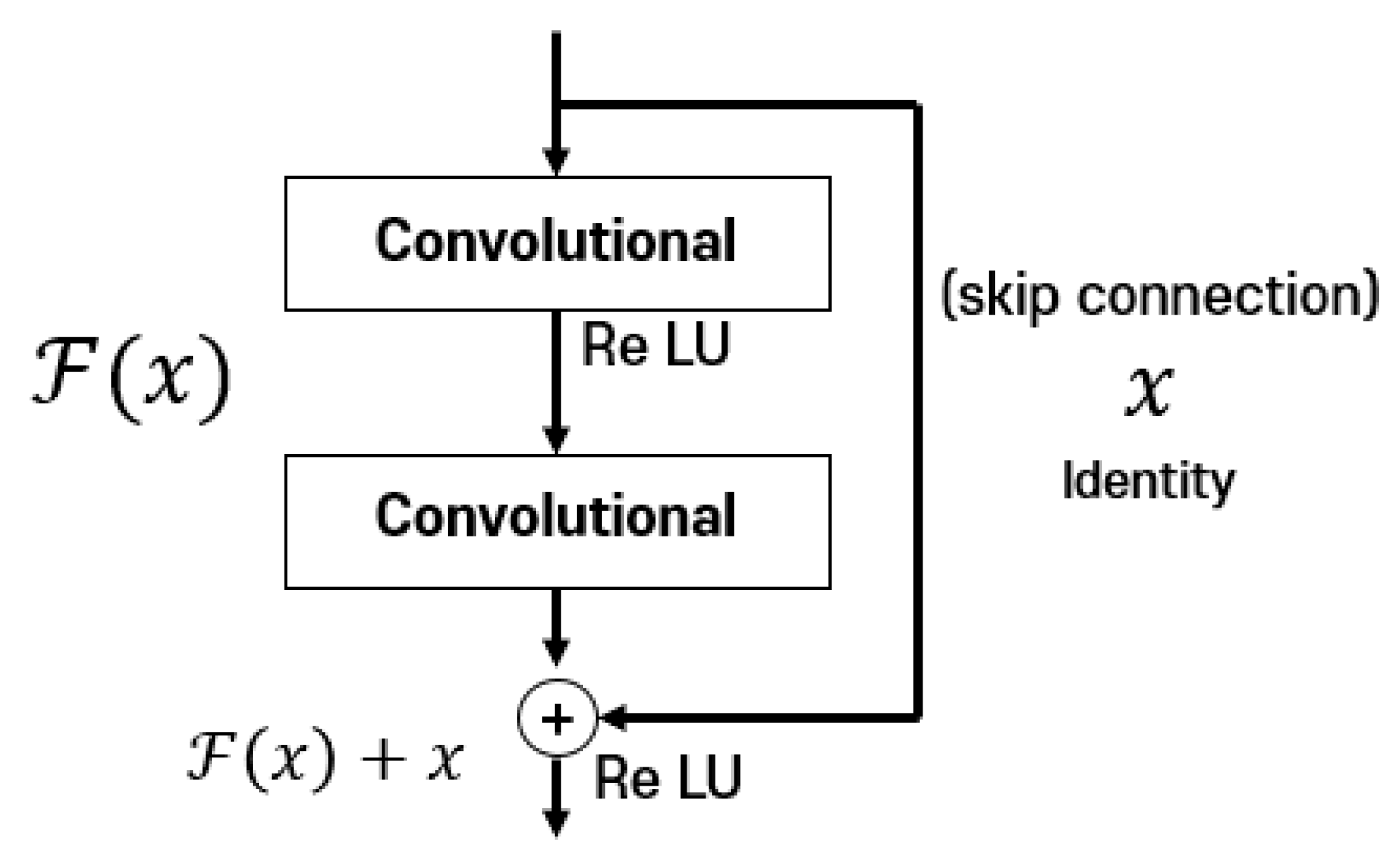
3.2. Shared Convolutional Neural Network
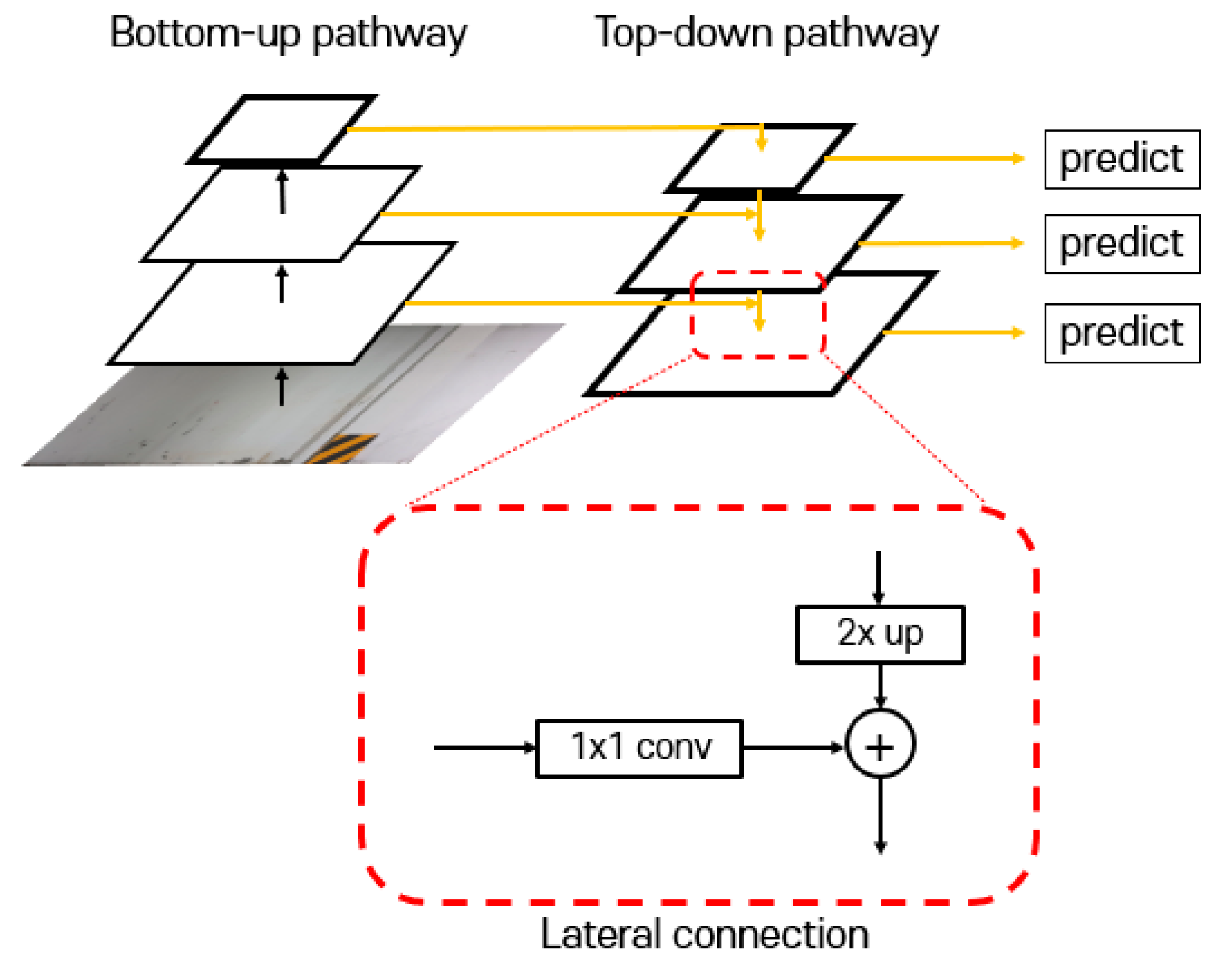
3.3. Feature Pyramidal Network
3.4. Region Proposal Network
3.5. Fast R-CNN Detector (RoI Pooler)
4. Experiments and Results
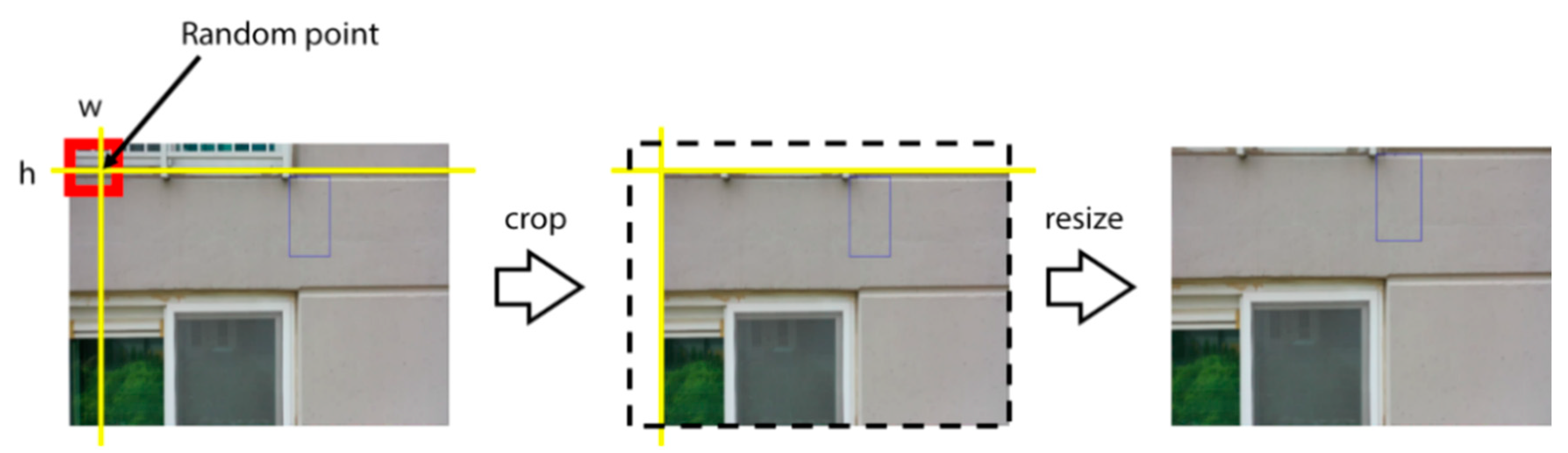
4.1. Dataset
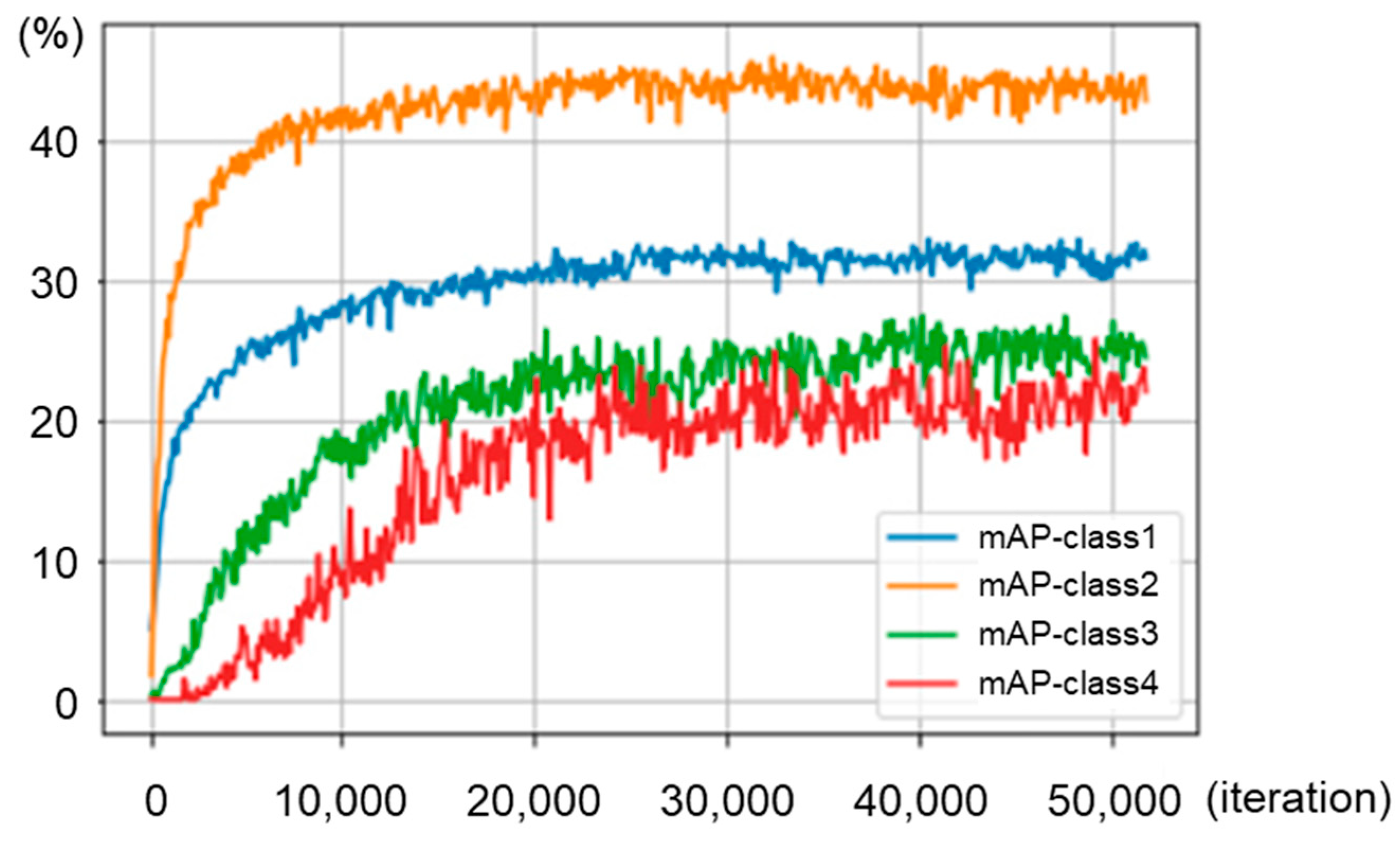
4.2. Results
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kim, S.-S.; Yang, I.-H.; Yeo, M.-S.; Kim, K.-W. Development of a housing performance evaluation model for multi-family residential buildings in Korea. Build. Environ. 2005, 40, 1103–1116. [Google Scholar] [CrossRef]
- Meier, J.R.; Russell, J.S. Model process for implementing maintainability. J. Constr. Eng. Manag. 2000, 126, 440–450. [Google Scholar] [CrossRef]
- Ikpo, I.J. Maintainability indices for public building design. J. Build. Apprais. 2009, 4, 321–327. [Google Scholar] [CrossRef] [Green Version]
- Chew, M.Y.L. Maintainability of Facilities: For Building Professionals; World Scientific: Hackensack, NJ, USA, 2010. [Google Scholar]
- Lee, J.-S. Value engineering for defect prevention on building façade. J. Constr. Eng. Manag. 2018, 144, 04018069. [Google Scholar] [CrossRef]
- Das, S.; Chew, M.Y.L. Generic method of grading building defects using FMECA to improve maintainability decisions. J. Perform. Constr. Facil. 2011, 25, 522–533. [Google Scholar] [CrossRef]
- Guo, J.; Wang, Q.; Li, Y.; Liu, P. Façade defects classification from imbalanced dataset using meta learning-based convolutional neural network. Comput. Aided Civ. Infrastruct. Eng. 2020, 35, 1–16. [Google Scholar] [CrossRef]
- Kim, S.; Frangopol, D.M.; Zhu, B. Probabilistic optimum inspection/repair planning to extend lifetime of deteriorating structures. J. Perform. Constr. Facil. 2010, 25, 534–544. [Google Scholar] [CrossRef]
- Love, P.E.D.; Smith, J. Toward error management in construction: Moving beyond a zero vision. J. Constr. Eng. Manag. 2016, 142, 04016058. [Google Scholar] [CrossRef]
- Liu, Z.; Cao, Y.; Wang, Y.; Wang, W. Computer vision-based concrete crack detection using U-net fully convolutional networks. Autom. Constr. 2019, 104, 129–139. [Google Scholar] [CrossRef]
- Yang, Y.-S.; Yang, C.-M.; Huang, C.-W. Thin crack observation in a reinforced concrete bridge pier test using image processing and analysis. Adv. Eng. Softw. 2015, 83, 99–108. [Google Scholar] [CrossRef]
- Abudayyeh, O.; Al Bataineh, M.; Abdel-Qader, I. An imaging data model for concrete bridge inspection. Adv. Eng. Softw. 2004, 35, 473–480. [Google Scholar] [CrossRef]
- Abdel-Qader, I.; Pashaie-Rad, S.; Abudayyeh, O.; Yehia, S. PCA-based algorithm for unsupervised bridge crack detection. Adv. Eng. Softw. 2006, 37, 771–778. [Google Scholar] [CrossRef]
- Macarulla, M.; Forcada, N.; Casals, M.; Gangolells, M.; Fuertes, A.; Roca, X. Standardizing housing defects: Classification, validation, and benefits. J. Constr. Eng. Manag. 2013, 139, 968–976. [Google Scholar] [CrossRef]
- Pan, W.; Thomas, R. Defects and their influencing factors of posthandover new-build homes. J. Perform. Constr. Facil. 2015, 29, 04014119. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Choi, W.; Büyüköztürk, O. Deep learning-based crack damage detection using convolutional neural networks. Comput. Aided Civ. Infrastruct. Eng. 2017, 32, 361–378. [Google Scholar] [CrossRef]
- Pan, Y.; Zhang, G.; Zhang, L. A spatial-channel hierarchical deep learning network for pixel-level automated crack detection. Autom. Constr. 2020, 119, 103357. [Google Scholar] [CrossRef]
- Li, D.; Cong, A.; Guo, S. Sewer damage detection from imbalanced CCTV inspection data using deep convolutional neural networks with hierarchical classification. Autom. Constr. 2019, 101, 199–208. [Google Scholar] [CrossRef]
- Dung, C.V.; Anh, L.D. Autonomous concrete crack detection using deep fully convolutional neural network. Autom. Constr. 2019, 99, 52–58. [Google Scholar] [CrossRef]
- Yang, Q.; Shi, W.; Chen, J.; Lin, W. Deep convolution neural network-based transfer learning method for civil infrastructure crack detection. Autom. Constr. 2020, 116, 103199. [Google Scholar] [CrossRef]
- Yin, X.; Chen, Y.; Bouferguene, A.; Zaman, H.; Al-Hussein, M.; Kurach, L. A deep learning-based framework for an automated defect detection system for sewer pipes. Autom. Constr. 2020, 109, 102967. [Google Scholar] [CrossRef]
- Liao, C.-W. Optimal Inspection Strategies for Labor Inspection in the Construction Industry. J. Constr. Eng. Manag. 2015, 141, 04014073. [Google Scholar] [CrossRef]
- Pires, R.; de Brito, J.; Amaro, B. Inspection, diagnosis, and rehabilitation system of painted rendered façades. J. Perform. Constr. Facil. 2015, 29, 04014062. [Google Scholar] [CrossRef]
- Bortolini, R.; Forcada, N. Building inspection system for evaluating the technical performance of existing buildings. J. Perform. Constr. Facil. 2018, 32, 04018073. [Google Scholar] [CrossRef]
- Rabinovich, D.; Givoli, D.; Vigdergauz, S. XFEM-based crack detection scheme using a genetic algorithm. Int. J. Numer. Methods Eng. 2007, 71, 1051–1080. [Google Scholar] [CrossRef]
- Chatzi, E.N.; Hiriyur, B.; Waisman, H.; Smyth, A.W. Experimental application and enhancement of the XFEM-GA algorithm for the detection of flaws in structures. Comput. Struct. 2011, 89, 556–570. [Google Scholar] [CrossRef]
- Cha, Y.-J.; Buyukozturk, O. Structural Damage Detection Using Modal Strain Energy and Hybrid Multiobjective Optimization. Comput. Aided Civ. Infrastruct. Eng. 2015, 30, 347–358. [Google Scholar] [CrossRef]
- Laofor, C.; Peansupap, V. Defect detection and quantification system to support subjective visual qualityinspection via a digital image processing: A tiling work case study. Autom. Constr. 2012, 24, 160–174. [Google Scholar] [CrossRef]
- Liao, K.-W.; Lee, Y.-T. Detection of rust defects on steel bridge coatings via digital image recognition. Autom. Constr. 2016, 71, 294–306. [Google Scholar] [CrossRef]
- Shen, H.-K.; Chen, P.-H.; Chang, L.-M. Automated steel bridge coating rust defect recognition method based on color and texture feature. Autom. Constr. 2013, 31, 338–356. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 27th IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28, Proceedings of the 29th Annual Conference on Neural Information processing Systems, Montreal, QC, Canada, 7–12 December 2015; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnet, R., Eds.; Neural Information Processing Systems Foundation Inc.: San Diego, CA, USA, 2015. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 29th IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated residual transformations for deep neural networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, San Diego, CA, USA, 20–26 June 2005. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S. SSD: Single shot multibox detector. In Proceedings of the ECCV, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Before Crop Augmentation | After Crop Augmentation | Validation Set | Test Set | |
|---|---|---|---|---|---|
| images | 7635 | 157,584 | 1091 | 2181 | |
| objects | Class 1: delamination | 5201 | 104,073 | 659 | 1430 |
| Class 2: crack | 5668 | 114,852 | 834 | 1717 | |
| Class 3: peeled paint | 1234 | 25,267 | 165 | 348 | |
| Class 4: leakage of water | 222 | 3773 | 38 | 47 | |
| Category | AP (IoU = 0.5) (%) | AP (IoU = 0.5:0.05:0.95) (%) |
|---|---|---|
| All Classes | 62.717 | 31.487 |
| Class 1 | 49.765 | 27.289 |
| Class 2 | 69.732 | 42.201 |
| Class 3 | 50.140 | 26.829 |
| Class 4 | 67.260 | 29.629 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, K.; Hong, G.; Sael, L.; Lee, S.; Kim, H.Y. MultiDefectNet: Multi-Class Defect Detection of Building Façade Based on Deep Convolutional Neural Network. Sustainability 2020, 12, 9785. https://doi.org/10.3390/su12229785
Lee K, Hong G, Sael L, Lee S, Kim HY. MultiDefectNet: Multi-Class Defect Detection of Building Façade Based on Deep Convolutional Neural Network. Sustainability. 2020; 12(22):9785. https://doi.org/10.3390/su12229785
Chicago/Turabian StyleLee, Kisu, Goopyo Hong, Lee Sael, Sanghyo Lee, and Ha Young Kim. 2020. "MultiDefectNet: Multi-Class Defect Detection of Building Façade Based on Deep Convolutional Neural Network" Sustainability 12, no. 22: 9785. https://doi.org/10.3390/su12229785
APA StyleLee, K., Hong, G., Sael, L., Lee, S., & Kim, H. Y. (2020). MultiDefectNet: Multi-Class Defect Detection of Building Façade Based on Deep Convolutional Neural Network. Sustainability, 12(22), 9785. https://doi.org/10.3390/su12229785