Spatially Explicit Mapping of Historical Population Density with Random Forest Regression: A Case Study of Gansu Province, China, in 1820 and 2000



Abstract
:1. Introduction
2. Materials and Methods
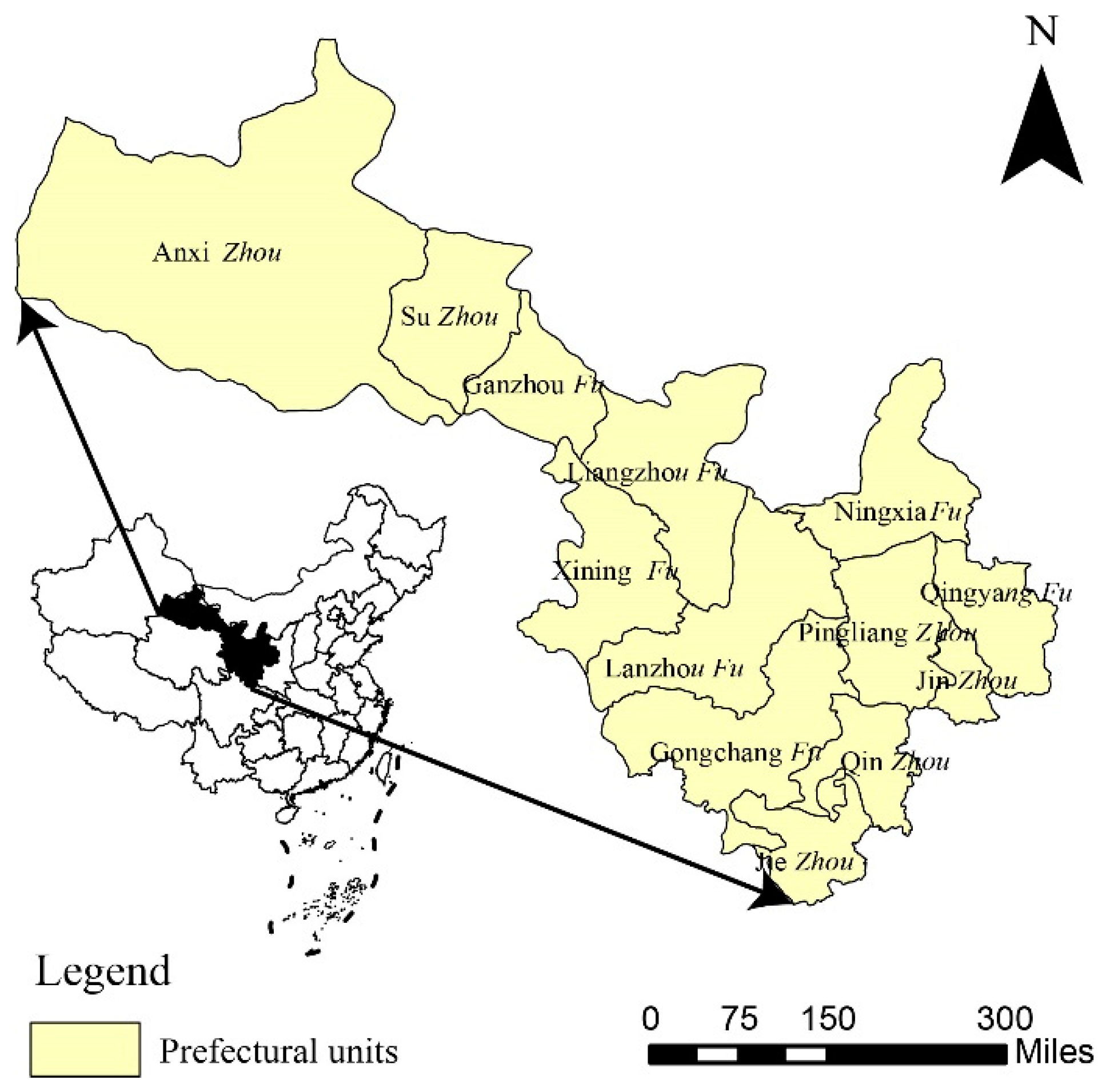
2.1. Study Area
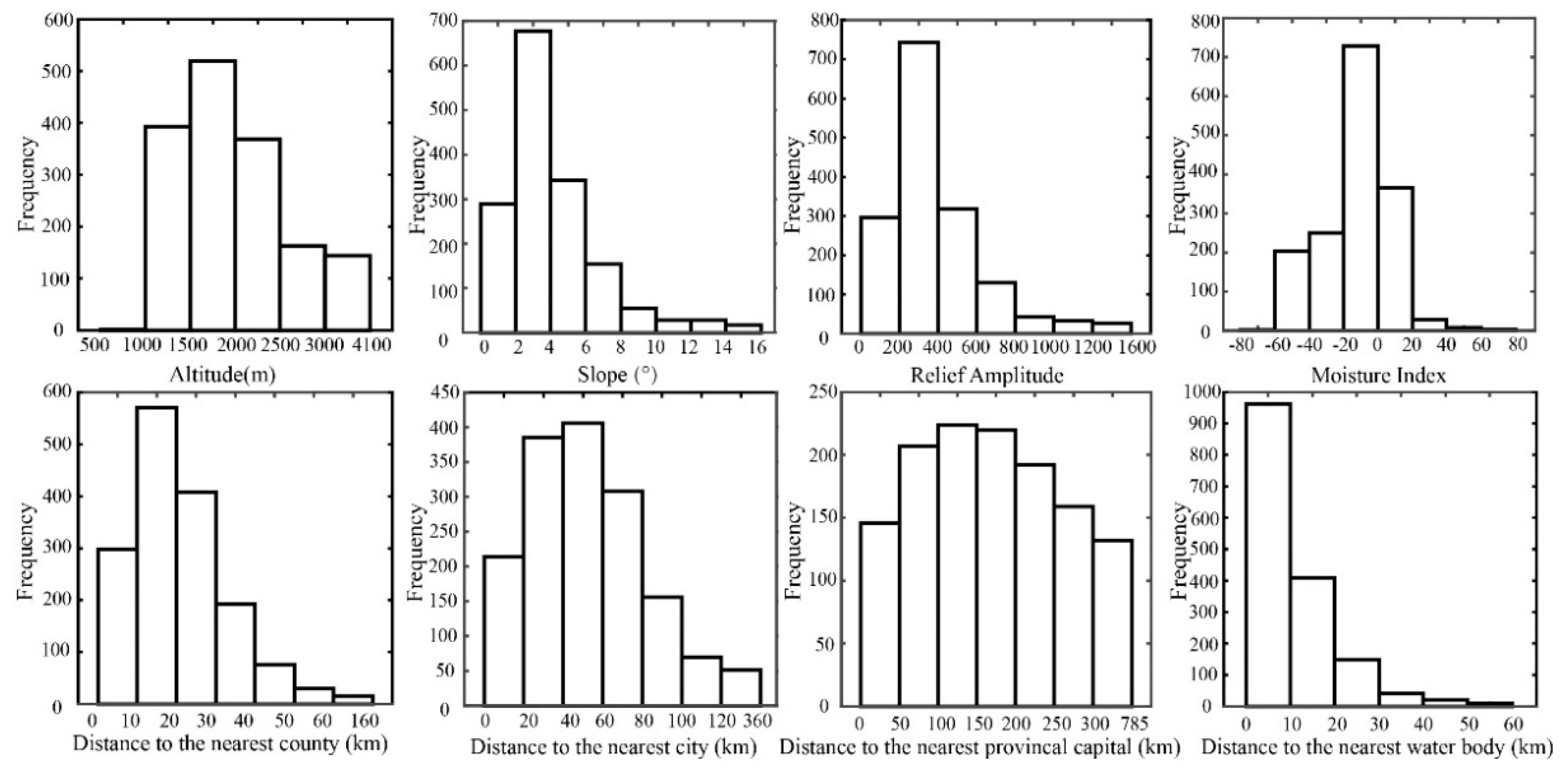
2.2. Environment Factors and Data Resources
2.3. Method
2.3.1. Random Forest Regression Model
2.3.2. Calibration and Verification of RFRM
- The training subsets were randomly extracted from the original dataset with replacement by using the bootstrap method, in which sizes were equal to the original dataset.
- When constructing the regression trees, the optimal split at each node was chosen from all the environmental factors or a random subset of them according to the lowest Gini Impurity Index. It can be calculated as Equation (1).where IG donates the Gini Impurity Index, f(tx(xi), j) donates the proportion of samples with the value xi belonging to leave j as node t [46].
- Each regression tree grew recursively from top to bottom without pruning until a specified termination condition was reached [47].
- The final prediction result of the RFRM was determined by averaging the prediction results of all the individual decision trees.
2.3.3. Application of RFRM
3. Results
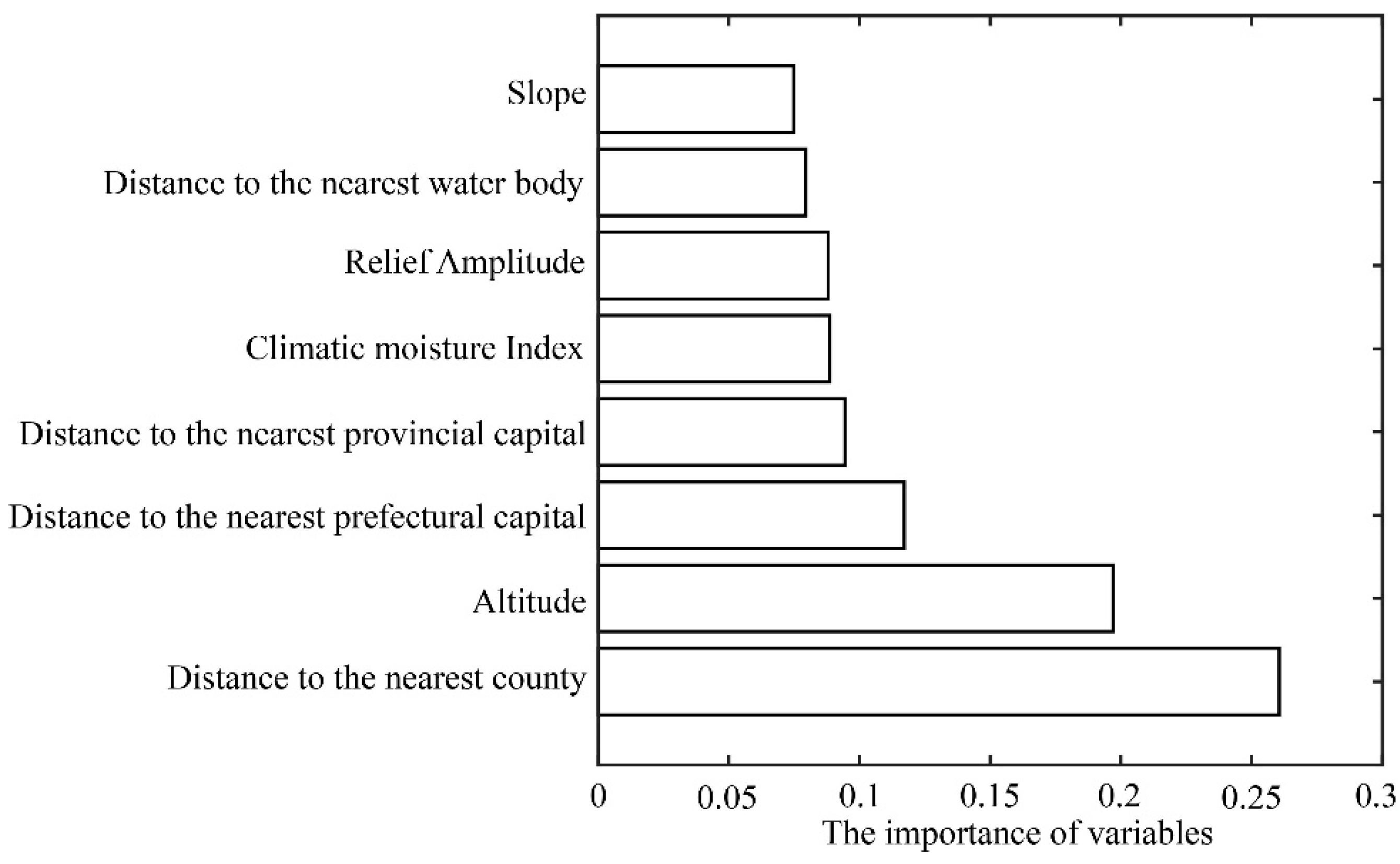
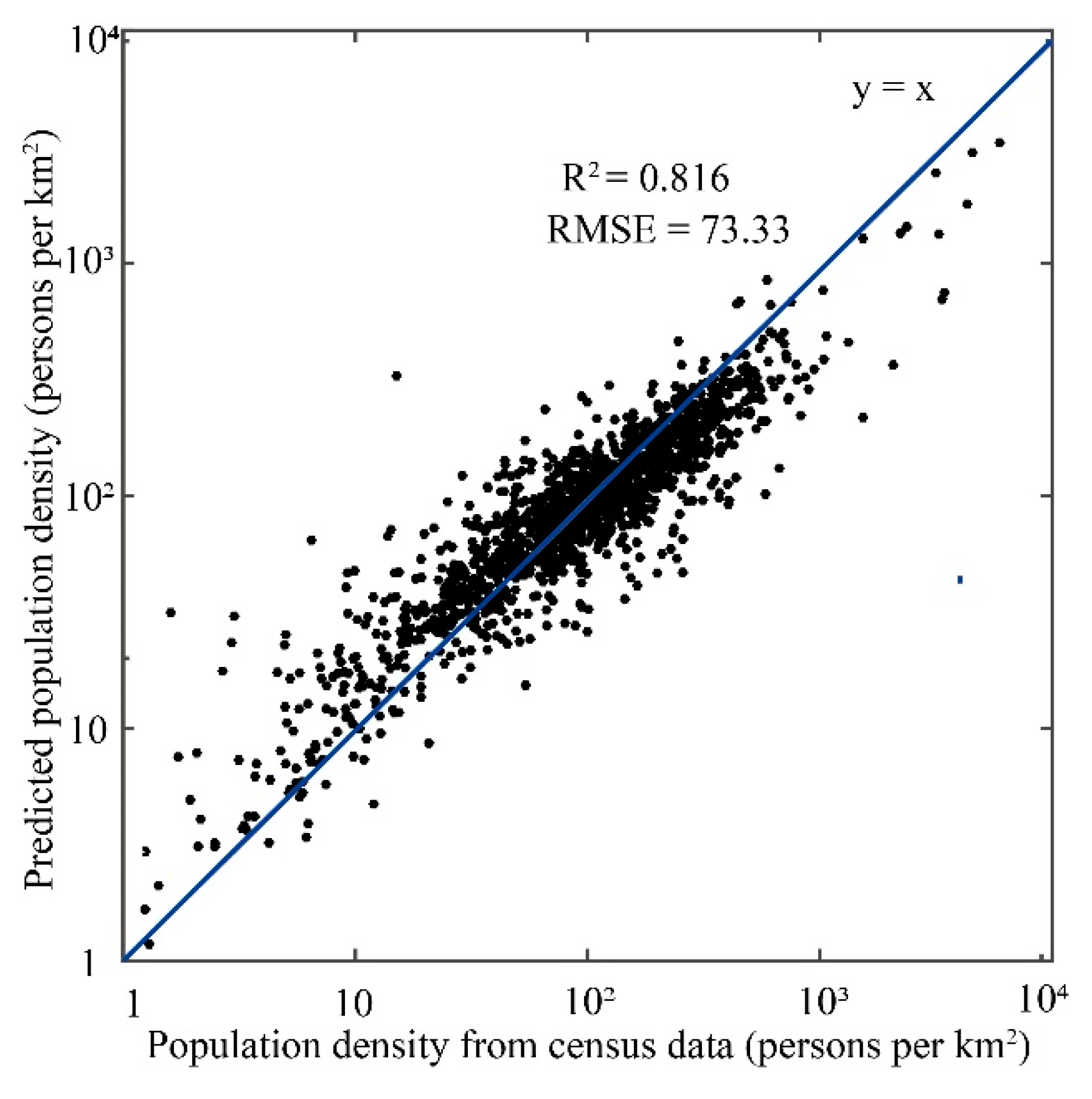
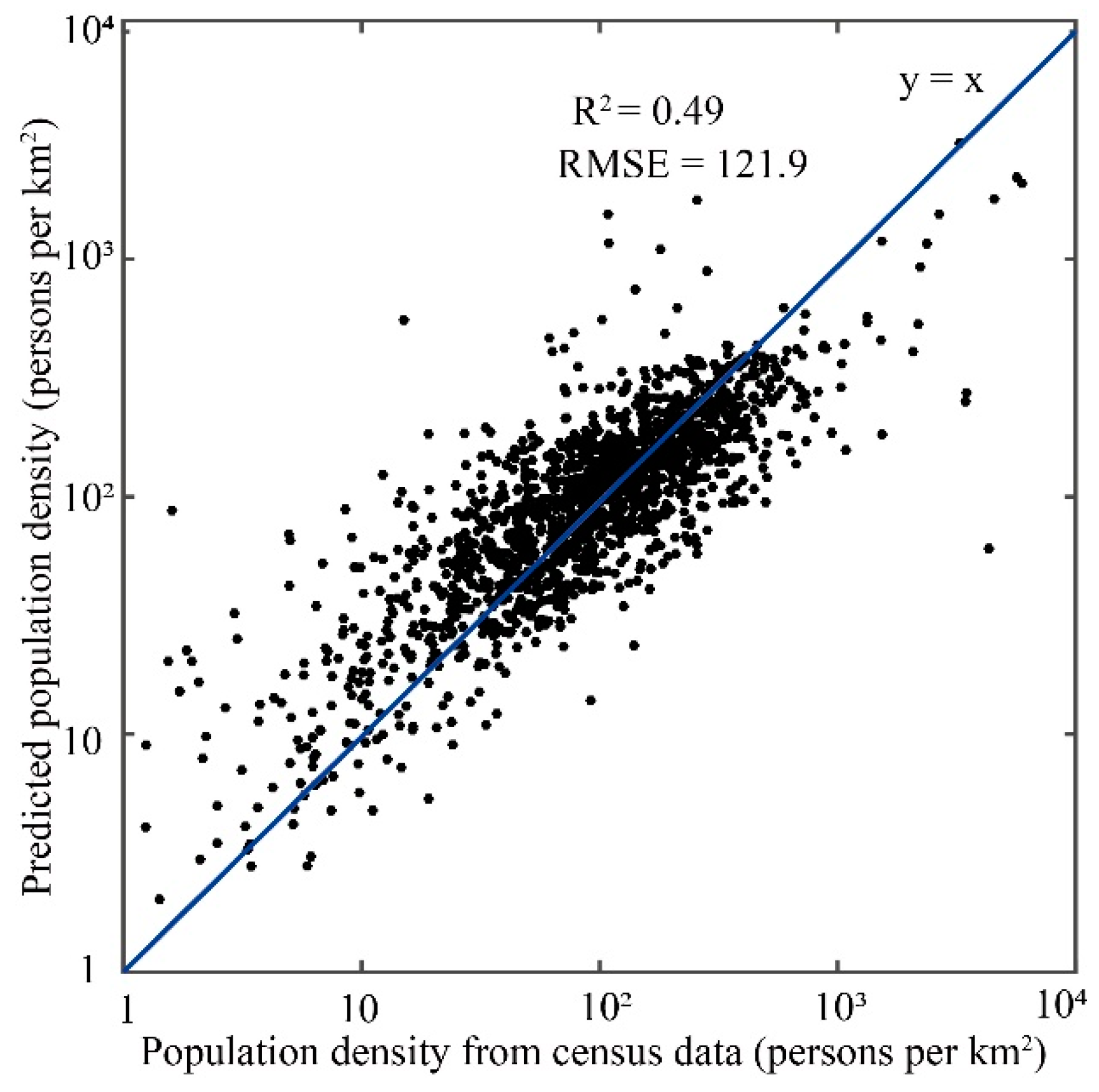
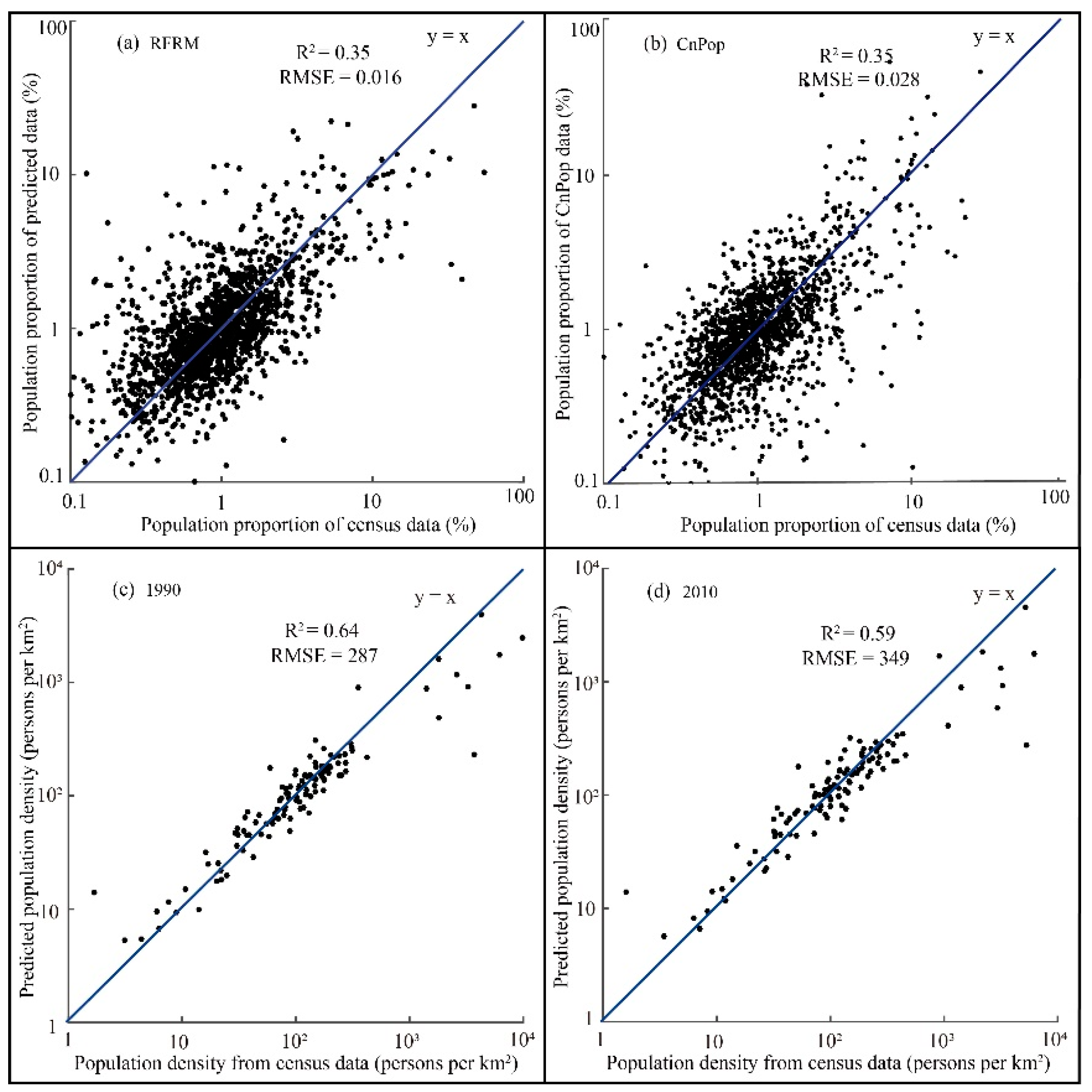
3.1. Evaluation of Model Performance
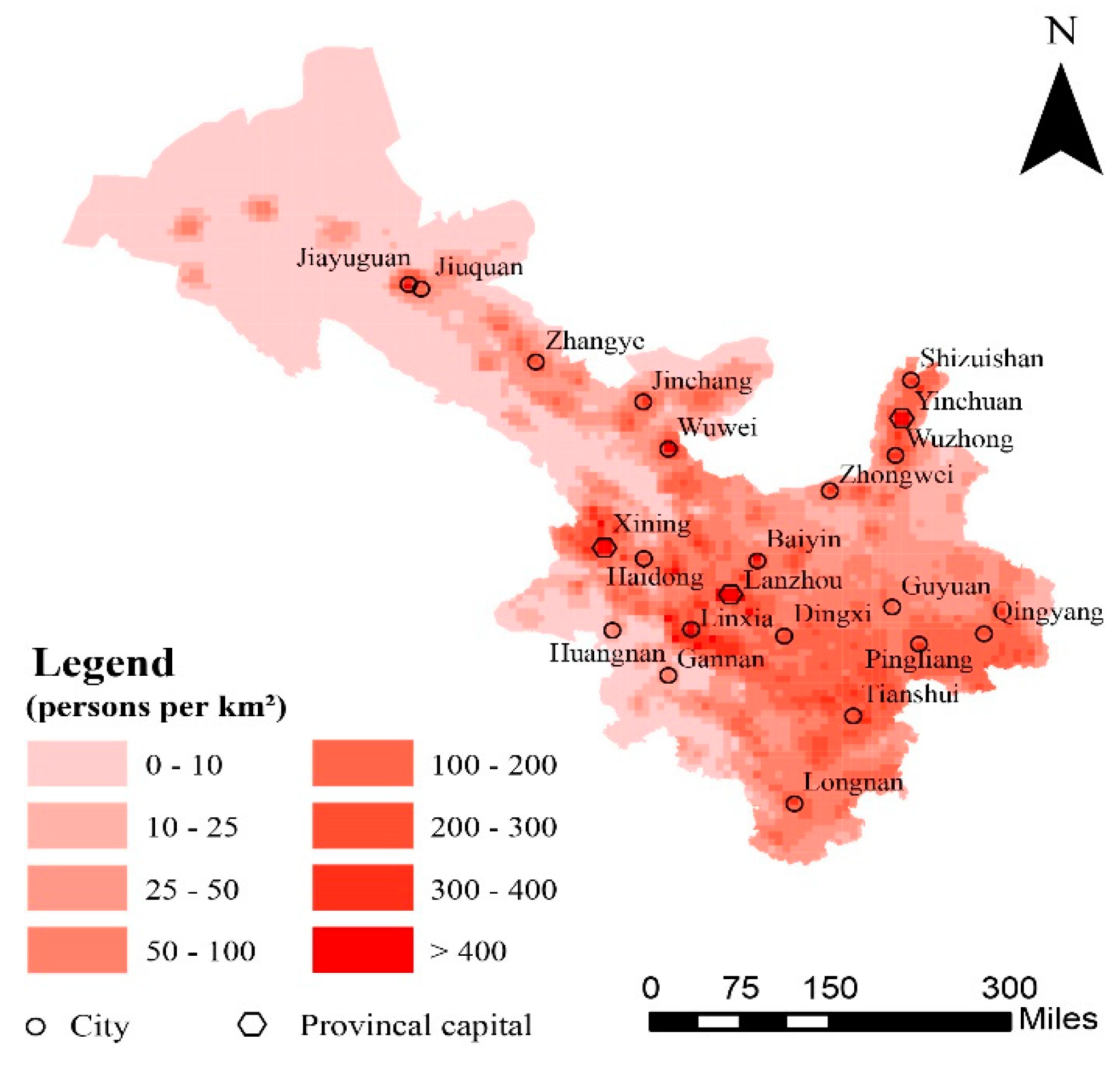
3.2. Modeling the Population Density in the 2000
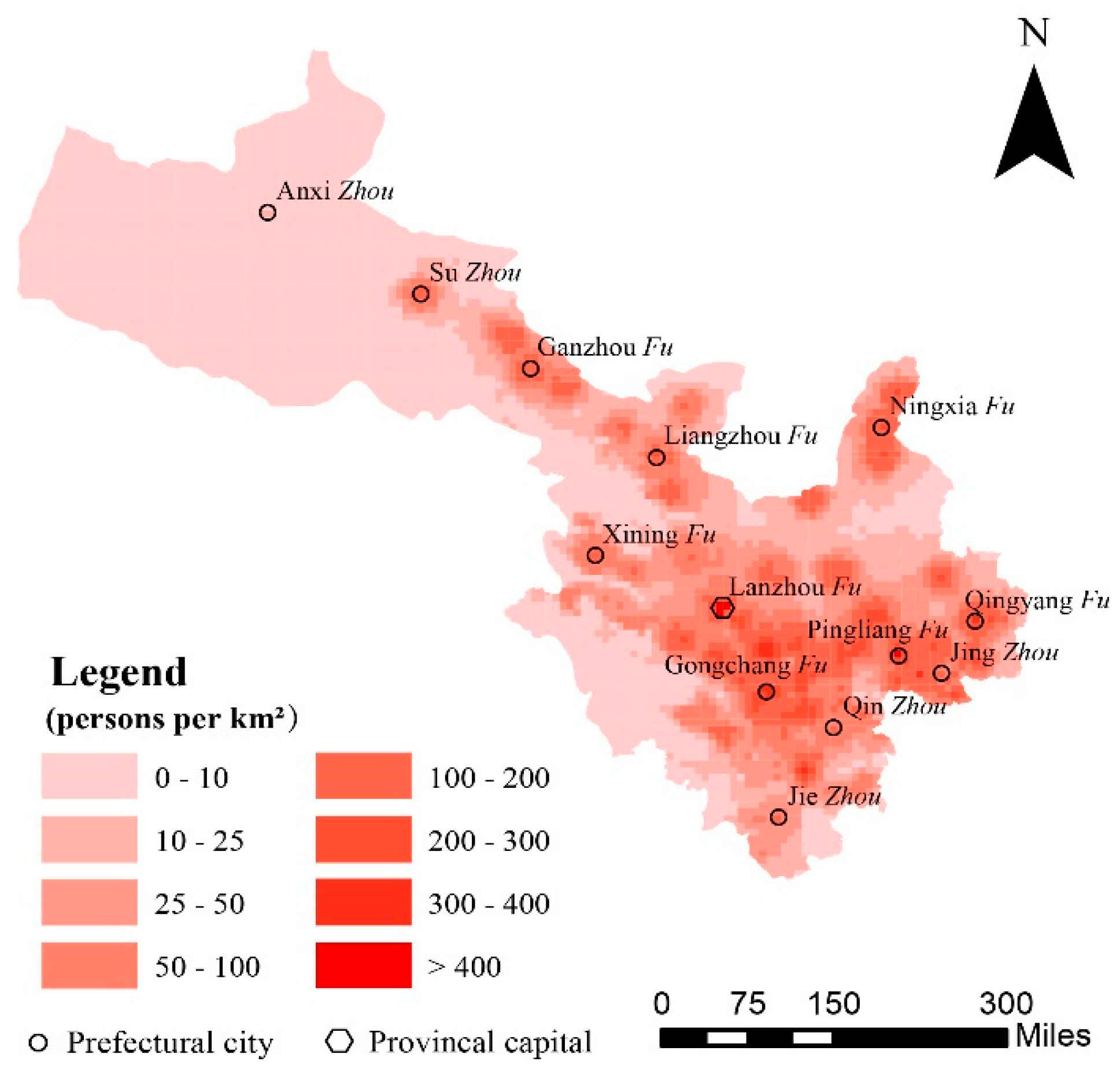
3.3. Modeling the Population Density in the 1820
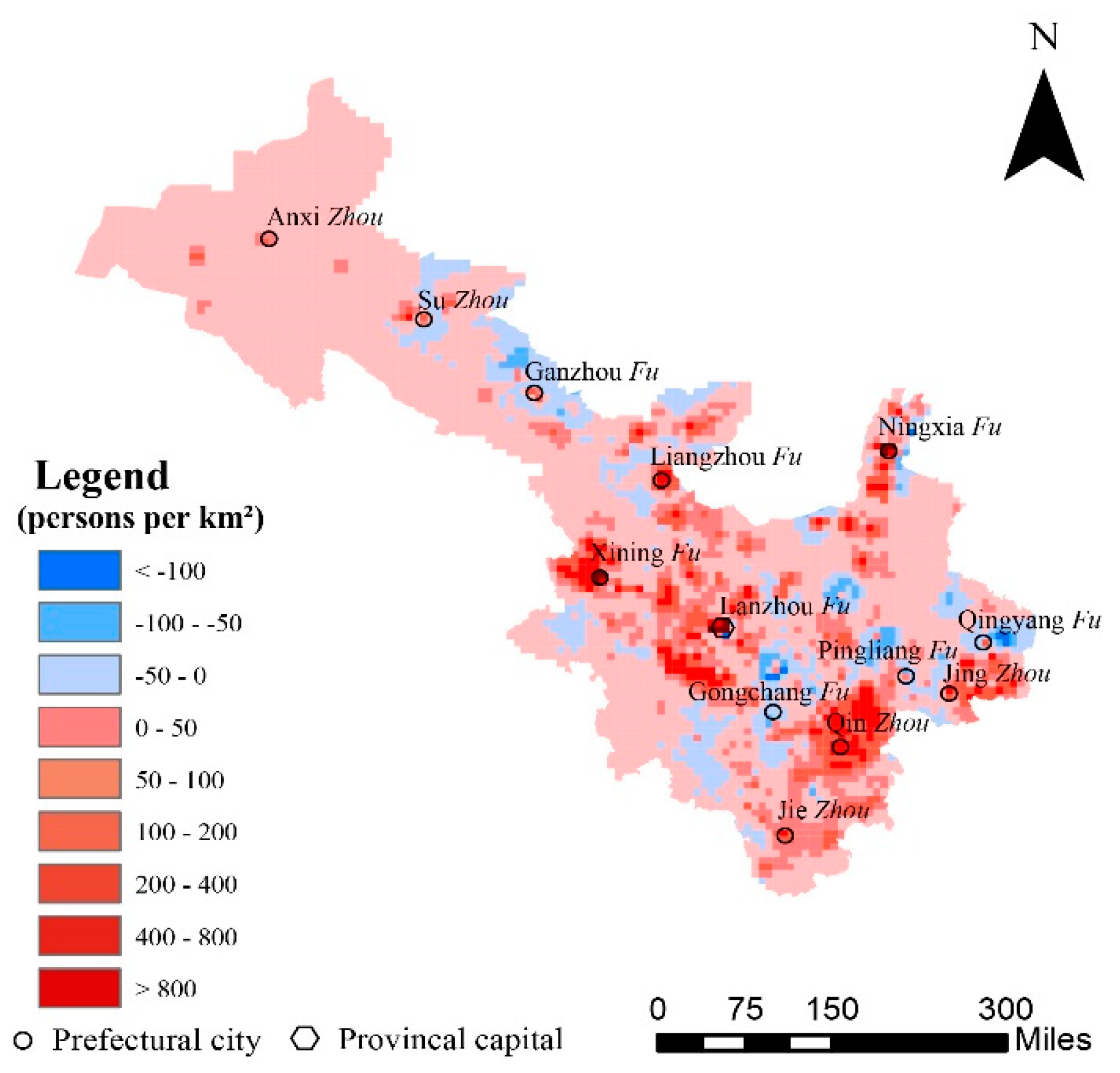
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fuguitt, G.V.; Zuiches, J.J. Residential Preferences and Population Distribution. Demography 1975, 12, 491. [Google Scholar] [CrossRef] [PubMed]
- Yue, T.X.; Wang, Y.A.; Liu, J.Y.; Chen, S.P.; Qiu, D.S.; Deng, X.Z.; Liu, M.L.; Tian, Y.Z.; Su, B.P. Surface modelling of human population distribution in China. Ecol. Model. 2005, 181, 461–478. [Google Scholar] [CrossRef]
- Balk, D.L.; Deichmann, U.; Yetman, G.; Pozzi, F.; Hay, S.I.; Nelson, A. Determining global population distribution: Methods, applications and data. Adv. Parasitol. 2006, 62, 119–156. [Google Scholar] [PubMed] [Green Version]
- Tobler, W.; Deichmann, U.; Gottsegen, J.; Maloy, K. World population in a grid of spherical quadrilaterals. Int. J. Popul. Geogr. 1997, 3, 203–225. [Google Scholar] [CrossRef]
- Wu, J.; Mohamed, R.; Wang, Z. Agent-based simulation of the spatial evolution of the historical population in China. J. Hist. Geogr. 2011, 37, 12–21. [Google Scholar] [CrossRef]
- Klein Goldewijk, K.; Beusen, A.; Van Drecht, G.; De Vos, M. The HYDE 3.1 spatially explicit database of human-induced global land-use change over the past 12,000 years. Glob. Ecol. Biogeogr. 2011, 20, 73–86. [Google Scholar] [CrossRef]
- Lin, S.; Zheng, J.; He, F. Gridding cropland data reconstruction over the agricultural region of China in 1820. J. Geogr. Sci. 2009, 19, 36–48. [Google Scholar] [CrossRef]
- Arneth, A.; Sitch, S.; Pongratz, J.; Stocker, B.D.; Ciais, P.; Poulter, B.; Bayer, A.D.; Bondeau, A.; Calle, L.; Calle, L.; et al. Historical carbon dioxide emissions caused by land-use changes are possibly larger than assumed. Nat. Geosci. 2017, 10, 79. [Google Scholar] [CrossRef]
- Leyk, S.; Gaughan, A.E.; Adamo, S.B.; de Sherbinin, A.; Balk, D.; Freire, S.; Rose, A.; Stevens, F.R.; Blankespoor, B.; Frye, C.; et al. The spatial allocation of population: A review of large-scale gridded population data products and their fitness for use. Earth Syst. Sci. Data 2019, 11, 1385–1409. [Google Scholar] [CrossRef] [Green Version]
- Islam, M.S.; Oki, T.; Kanae, S.; Hanasaki, N.; Agata, Y.; Yoshimura, K. A grid-based assessment of global water scarcity including virtual water trading. Water Resour. Manag. 2007, 21, 19. [Google Scholar] [CrossRef]
- Dasgupta, S.; Laplante, B.; Murray, S.; Wheeler, D. Exposure of developing countries to sea-level rise and storm surges. Clim. Chang. 2011, 106, 567–579. [Google Scholar] [CrossRef]
- Mondal, P.; Tatem, A.J. Uncertainties in Measuring Populations Potentially Impacted by Sea Level Rise and Coastal Flooding. PLoS ONE 2012, 7, e48191. [Google Scholar] [CrossRef] [PubMed]
- Hay, S.I.; Noor, A.M.; Nelson, A.; Tatem, A.J. The accuracy of human population maps for public health application. Trop. Med. Int. Health 2005, 10, 1073–1086. [Google Scholar] [CrossRef]
- Lam, N.S.N. Spatial interpolation methods: A review. Am. Cartogr. 1983, 10, 129–150. [Google Scholar] [CrossRef]
- De Amorim Borges, P.; Franke, J.; da Anunciação, Y.M.T.; Weiss, H.; Bernhofer, C. Comparison of spatial interpolation methods for the estimation of precipitation distribution in Distrito Federal, Brazil. Theor. Appl. Climatol. 2016, 123, 335–348. [Google Scholar] [CrossRef]
- Azar, D.; Engstrom, R.; Graesser, J.; Comenetz, J. Generation of fine-scale population layers using multi-resolution satellite imagery and geospatial data. Remote Sens. Environ. 2013, 130, 219–232. [Google Scholar] [CrossRef]
- Zeng, C.; Zhou, Y.; Wang, S.; Yan, F.; Zhao, Q. Population spatialization in China based on night-time imagery and land use data. Int. J. Remote Sens. 2011, 32, 9599–9620. [Google Scholar] [CrossRef]
- Hu, L.; He, Z.; Liu, J. Adaptive Multi-Scale Population Spatialization Model Constrained by Multiple Factors: A Case Study of Russia. Cartogr. J. 2011, 54, 265–282. [Google Scholar] [CrossRef]
- Zhuo, L.; Ichinose, T.; Zheng, J.; Chen, J.; Shi, P.J.; Li, X. Modelling the population density of China at the pixel level based on DMSP/OLS non-radiance-calibrated night-time light images. Int. J. Remote Sens. 2009, 30, 1003–1018. [Google Scholar] [CrossRef]
- Tan, M.; Li, X.; Li, S.; Xin, L.; Wang, X.; Li, Q.; Li, W.; Li, Y.; Xiang, W. Modeling population density based on nighttime light images and land use data in China. Appl. Geogr. 2018, 90, 239–247. [Google Scholar] [CrossRef]
- Calka, B.; Nowak Da Costa, J.; Bielecka, E. Fine scale population density data and its application in risk assessment. Geomatics. Nat. Hazards Risk 2017, 8, 1440–1455. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating census data for population mapping using random forests with remotely-sensed and ancillary data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Youssef, A.M.; Pourghasemi, H.R.; Pourtaghi, Z.S.; Al-Katheeri, M.M. Landslide susceptibility mapping using random forest, boosted regression tree, classification and regression tree, and general linear models and comparison of their performance at Wadi Tayyah Basin, Asir Region, Saudi Arabia. Landslides 2016, 13, 839–856. [Google Scholar] [CrossRef]
- Zhang, H.; Wu, P.; Yin, A.; Yang, X.; Zhang, M.; Gao, C. Prediction of soil organic carbon in an intensively managed reclamation zone of eastern China: A comparison of multiple linear regressions and the random forest model. Sci. Total Environ. 2017, 592, 704–713. [Google Scholar] [CrossRef]
- Forkuor, G.; Hounkpatin, O.K.; Welp, G.; Thiel, M. High resolution mapping of soil properties using remote sensing variables in south-western Burkina Faso: A comparison of machine learning and multiple linear regression models. PLoS ONE 2017, 12, e0170478. [Google Scholar] [CrossRef]
- Ye, T.; Zhao, N.; Yang, X.; Ouyang, Z.; Liu, X.; Chen, Q.; Hu, K.; Yue, W.; Qi, J.; Li, Z.; et al. Improved population mapping for China using remotely sensed and points-of-interest data within a random forests model. Sci. Total Environ. 2019, 658, 936–946. [Google Scholar] [CrossRef]
- Li, H.; Liu, F.; Cui, Y.; Ren, L.; Storozum, M.J.; Qin, Z.; Wang, J.; Dong, G. Human settlement and its influencing factors during the historical period in an oasis-desert transition zone of Dunhuang, Hexi Corridor, northwest China. Quat. Int. 2017, 458, 113–122. [Google Scholar] [CrossRef]
- Zinyama, L.; Whitlow, R. Changing patterns of population distribution in Zimbabwe. GeoJournal 1986, 13, 365–384. [Google Scholar] [CrossRef]
- Wang, P.; Wang, Z.W.; Zhang, X.T.; Wang, X.; Feng, Q.S.; Chen, Q.G. The Spatial Patterns of China’s Population and Their Cause of Format ion in Western Han Dynasty. Northwest Popul. J. 2010, 5, 88–90. [Google Scholar]
- Dong, G.; Yang, Y.; Zhao, Y.; Zhou, A.; Zhang, X.; Li, X.; Chen, F. Human settlement and human-environment interactions during the historical period in Zhuanglang County, western Loess Plateau, China. Quat. Int. 2012, 281, 78–83. [Google Scholar] [CrossRef]
- Small, C.; Cohen, J. Continental physiography, climate, and the global distribution of human population. Curr. Anthropol. 2004, 45, 269–277. [Google Scholar] [CrossRef]
- Kummu, M.; De Moel, H.; Salvucci, G.; Viviroli, D.; Ward, P.J.; Varis, O. Over the hills and further away from coast: Global geospatial patterns of human and environment over the 20th–21st centuries. Environ. Res. Lett. 2016, 11, 034010. [Google Scholar] [CrossRef]
- Cohen, J.E.; Small, C. Hypsographic demography: The distribution of human population by altitude. Proc. Natl. Acad. Sci. USA 1998, 95, 14009–14014. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Feng, Z.; Tang, Y.; Yang, Y.; Zhang, D. Relief degree of land surface and its influence on population distribution in China. J. Geogr. Sci. 2008, 18, 237–246. [Google Scholar] [CrossRef]
- Dong, N.; Yang, X.; Cai, H. Research progress and perspective on the spatialization of population data. J. Geo-Inf. Sci. 2016, 18, 1295–1304. [Google Scholar]
- Liu, Y.; Deng, W.; Song, X. Relief degree of land surface and population distribution of mountainous areas in China. J. Mt. Sci. 2015, 12, 518–532. [Google Scholar] [CrossRef]
- Xu, X.; Zhang, Y. Chinese meteorological background dataset. Resources and Environmental Scientific Data Center (RESDC). Chin. Acad. Sci. CAS 2017. [Google Scholar] [CrossRef]
- Cao, S.J. Population History of China (Vol. 5, Qing Dynasty Period); Fudan University Press: Shanghai, China, 2007; pp. 690–720. [Google Scholar]
- Lu, W.D. Fifty Years of Population in Northwest China (1861–1911); Fudan University Press: Shanghai, China, 2017; pp. 135–136. [Google Scholar]
- Department of Population Social Science and Technology Statistics National Bureau of Statistics of China. China Population by Township; China Statistics Press: Beijing, China, 2002.
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Biau, G. Analysis of a random forests model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar]
- Rodriguez-Galiano, V.; Mendes, M.P.; Garcia-Soldado, M.J.; Chica-Olmo, M.; Ribeiro, L. Predictive modeling of groundwater nitrate pollution using Random Forest and multisource variables related to intrinsic and specific vulnerability: A case study in an agricultural setting (Southern Spain). Sci. Total Environ. 2014, 476, 189–206. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Strobl, C.; Boulesteix, A.L.; Kneib, T.; Augustin, T.; Zeileis, A. Conditional variable importance for random forests. BMC Bioinform. 2008, 9, 307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, L.A.; Zhou, X.; Zhu, X.; Dong, Z.; Guo, W. Estimation of biomass in wheat using random forest regression algorithm and remote sensing data. Crop J. 2016, 4, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Chen, Y.; Li, Y. The Random Forest-Based Method of Fine-Resolution Population Spatialization by Using the International Space Station Nighttime Photography and Social Sensing Data. Remote Sens. 2018, 10, 1650. [Google Scholar] [CrossRef] [Green Version]
- Tan, M.; Liu, K.; Lin, L.; Zhu, Y.; Wang, D. Spatialization of population in the Pearl River Delta in 30 m grids using random forest model. Prog. Geogr. 2017, 36, 1304–1312. [Google Scholar]
- Michaelsen, J. Cross-validation in statistical climate forecast models. J. Clim. Appl. Meteorol. 1987, 26, 1589–1600. [Google Scholar] [CrossRef] [Green Version]
- Gou, X.; Gao, L.; Deng, Y.; Chen, F.; Yang, M.; Still, C. An 850-year tree-ring-based reconstruction of drought history in the western Qilian Mountains of northwestern China. Int. J. Climatol. 2015, 35, 3308–3319. [Google Scholar] [CrossRef]
- Bai, Z.; Wang, J.; Wang, M.; Gao, M.; Sun, J. Accuracy assessment of multi-source gridded population distribution datasets in China. Sustainability 2018, 10, 1363. [Google Scholar] [CrossRef] [Green Version]
- Gou, X.; Deng, Y.; Gao, L.; Chen, F.; Cook, E.; Yang, M.; Zhang, F. Millennium tree-ring reconstruction of drought variability in the eastern Qilian Mountains, northwest China. Clim. Dyn. 2015, 45, 1761–1770. [Google Scholar] [CrossRef] [Green Version]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Altitude (Meters) | Population in 1820 (104 Persons) | Population in 2000 (104 Persons) | Change (104 Persons) | Proportion of Population Growth (%) |
|---|---|---|---|---|
| <1500 | 520.11 | 906.74 | 386.63 | 23.60 |
| 1500–2000 | 684.54 | 1196.88 | 512.34 | 31.27 |
| 2000–2500 | 416.87 | 827.44 | 410.57 | 25.06 |
| 2500–3000 | 126.90 | 329.82 | 202.92 | 12.38 |
| 3000–3500 | 28.99 | 126.12 | 97.13 | 5.93 |
| >3500 | 7.15 | 36.07 | 28.92 | 1.76 |
| Total | 1784.56 | 3423.06 | 1638.51 | 100 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, F.; Lu, W.; Zheng, J.; Li, S.; Zhang, X. Spatially Explicit Mapping of Historical Population Density with Random Forest Regression: A Case Study of Gansu Province, China, in 1820 and 2000. Sustainability 2020, 12, 1231. https://doi.org/10.3390/su12031231
Wang F, Lu W, Zheng J, Li S, Zhang X. Spatially Explicit Mapping of Historical Population Density with Random Forest Regression: A Case Study of Gansu Province, China, in 1820 and 2000. Sustainability. 2020; 12(3):1231. https://doi.org/10.3390/su12031231
Chicago/Turabian StyleWang, Fahao, Weidong Lu, Jingyun Zheng, Shicheng Li, and Xuezhen Zhang. 2020. "Spatially Explicit Mapping of Historical Population Density with Random Forest Regression: A Case Study of Gansu Province, China, in 1820 and 2000" Sustainability 12, no. 3: 1231. https://doi.org/10.3390/su12031231
APA StyleWang, F., Lu, W., Zheng, J., Li, S., & Zhang, X. (2020). Spatially Explicit Mapping of Historical Population Density with Random Forest Regression: A Case Study of Gansu Province, China, in 1820 and 2000. Sustainability, 12(3), 1231. https://doi.org/10.3390/su12031231