Research on User Influence Model Integrating Personality Traits under Strong Connection

Abstract
:1. Introduction
- In the literature review, we combed the relevant literature on the measurement of personality traits and related literature on influence measurement, providing a solid foundation for the experiment.
- We have integrated three methods of influence measurement to obtain effective basic influences, including information perspective, structural perspective, and behavioral perspective.
- Taking into account the personality differences of the influencers and the audience can improve the accuracy of the influence measurement, which helps obtain the opinion leaders of different traits audiences more accurately. These results will be demonstrated in Section 5.
2. Related Works
2.1. Personality Traits Theory
2.2. Influence Theory
3. User Influence Model Integrating Personality Traits (IPUIM)
3.1. Definition
3.2. Establishing Model
4. Method of User Influence Measurement
4.1. Personality Traits Assessment
4.2. User Influence Integrating Personality Traits Measurement
5. Experiments
5.1. Data Acquisition
5.2. Personality Report Of User Group
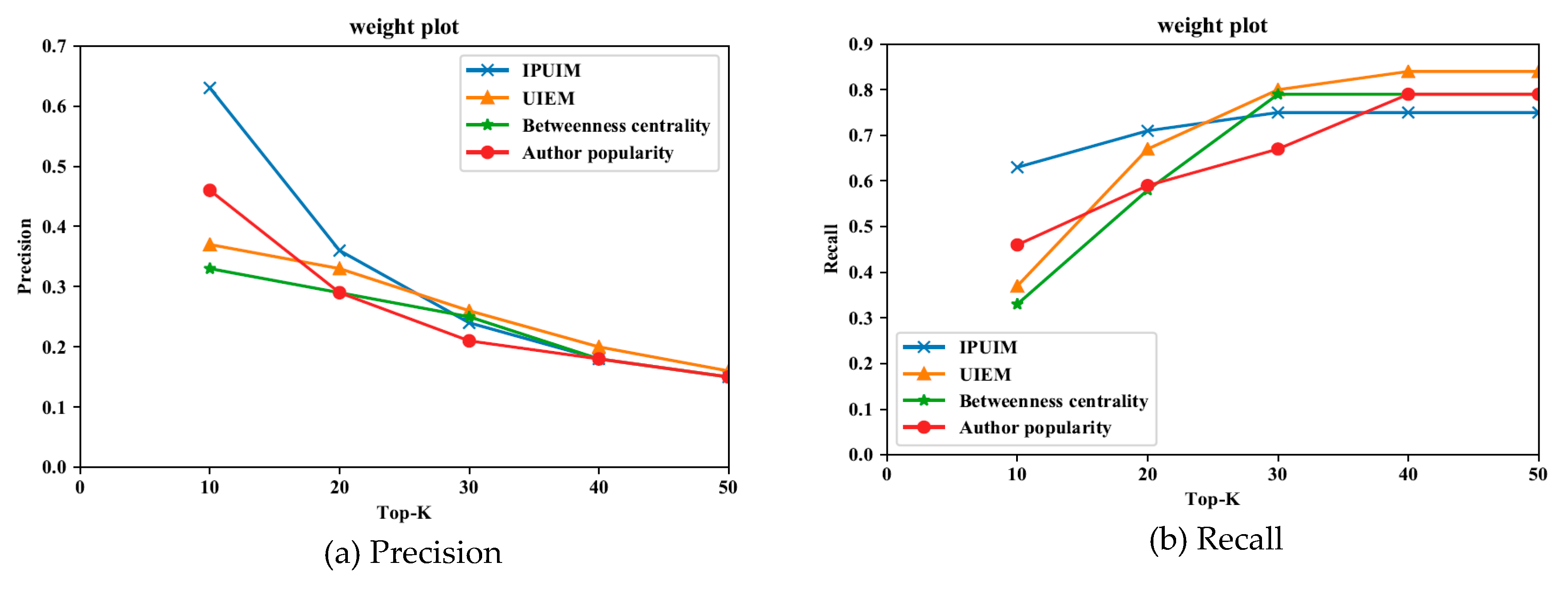
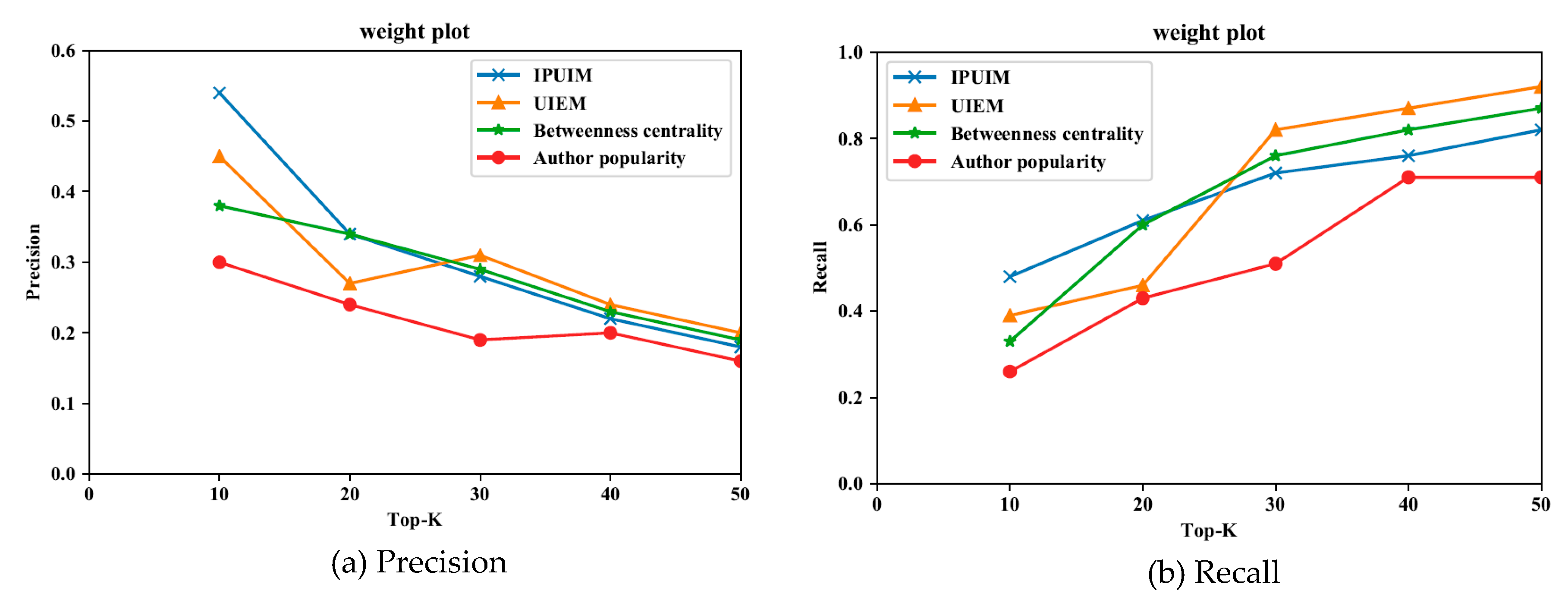
5.3. Experimental Verification Analysis on IPUIM
5.3.1. Contrast Model and Index Selection
5.3.2. Comparison Based on Traits Cluster
6. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Granovetter, M.S. The strength of weak ties. In Social Netwks; Elsevier: Amsterdam, The Netherlands, 1973; pp. 347–367. [Google Scholar]
- Granovetter, M. Getting A Job: A Study of Contacts and Careers, 2nd ed.; University of Chicago Press: Chicago, IL, USA, 1994. [Google Scholar]
- Frenzen, J.; Nakamoto, K. Structure, cooperation, and the flow of market information. J. Cons. Res. 1993, 20, 360–375. [Google Scholar] [CrossRef]
- Wellman, B.; Wortley, S. Different strokes from different folks: Community ties and social support. Am. J. Sociol. 1990, 96, 558–588. [Google Scholar] [CrossRef] [Green Version]
- Roshwalb, I. Personal influence: The part played by people in the flow of mass communications. J. Mark. pre-1986 1956, 21, 129. [Google Scholar] [CrossRef]
- Romero, D.M.; Galuba, W.; Asur, S.; Huberman, B.A. Influence and passivity in social media. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Hyderabad, India, 28 March–1 April 2011; pp. 18–33. [Google Scholar]
- Aiello, L.M.; Barrat, A.; Schifanella, R.; Cattuto, C.; Markines, B.; Menczer, F. Friendship prediction and homophily in social media. ACM Trans. Web TWEB 2012, 6, 1–33. [Google Scholar] [CrossRef]
- Tang, J.; Sun, J.; Wang, C.; Yang, Z. Social influence analysis in large-scale networks. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 807–816. [Google Scholar]
- Bakshy, E.; Eckles, D.; Yan, R.; Rosenn, I. Social influence in social advertising: Evidence from field experiments. In Proceedings of the 13th ACM Conference on Electronic Commerce, Valencia, Spain, 4–8 June 2012; pp. 146–161. [Google Scholar]
- Yu, G.; Xiwei, W.; Shimeng, L.; Nan’axue, W. Research on the Influence Model of Social Network Users Based on Emotional Analysis. J. China Soc. Sci. Tech. Inf. 2017, 1139–1147. [Google Scholar]
- Chengcheng, G.; Du Pan, H.M.; Yue, L.; Xueqi, C. Tsk-shell: An algorithm for finding topic-sensitive influential spreaders. J. Comput. Res. Dev. 2017, 54, 361. [Google Scholar]
- McCrae, R.R.; Costa, P.T. The structure of interpersonal traits: Wiggins’s circumplex and the five-factor model. JPSP 1989, 56, 586. [Google Scholar] [CrossRef]
- Freeman, L.C. Centrality in social networks conceptual clarification. Soc. Netw. 1978, 1, 215–239. [Google Scholar] [CrossRef] [Green Version]
- Newman, M.E. A measure of betweenness centrality based on random walks. Soc. Netw. 2005, 27, 39–54. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Leskovec, J. Modeling information diffusion in implicit networks. In Proceedings of the 2010 IEEE International Conference on Data Mining, Sydney, Australia, 13–17 December 2010; pp. 599–608. [Google Scholar]
- Cui, P.; Wang, F.; Liu, S.; Ou, M.; Yang, S.; Sun, L. Who should share what? Item-level social influence prediction for users and posts ranking. In Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval, Beijing, China, 24–28 July 2011; pp. 185–194. [Google Scholar]
- Cano, A.E.; Mazumdar, S.; Ciravegna, F. Social influence analysis in microblogging platforms–a topic-sensitive based approach. Semant. Web 2014, 5, 357–372. [Google Scholar] [CrossRef] [Green Version]
- Yarkoni, T. Personality in 100,000 words: A large-scale analysis of personality and word use among bloggers. J. Res. Personal. 2010, 44, 363–373. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tandera, T.; Suhartono, D.; Wongso, R.; Prasetio, Y.L. Personality prediction system from facebook users. Procedia Comput. Sci. 2017, 116, 604–611. [Google Scholar] [CrossRef]
- Guo, X. The Research of Wechat Moments on Interpersonal Communication. Master‘s Thesis, Shandong University, Jinan, China, 2015. [Google Scholar]
- Newman, M.E. The structure and function of complex networks. SIAMR Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.-M.; Lai, C.-Y.; Chen, C.-W. Discovering influencers for marketing in the blogosphere. Inf. Sci. 2011, 181, 5143–5157. [Google Scholar] [CrossRef]
- Vexliard, A. The Peoples Choice. In How the Voter makes up his Mind in a Presidential Campaign; Presses Universitaires de France: Paris, France, 1949; pp. 237–238. [Google Scholar]
- Cha, M.; Haddadi, H.; Benevenuto, F.; Gummadi, K.P. Measuring user influence in twitter: The million follower fallacy. In Proceedings of the Fourth International AAAI Conference on Weblogs and Social Media, Washington, DC, USA, 23–26 May 2010. [Google Scholar]
- Li, Z.; Zhuang, Y. Multidimensional user influence measurement model based on spammer trust punishment. Syst. Eng. Theory Pract. 2017, 37, 1820–1832. [Google Scholar]
- Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Dziurzynski, L.; Ramones, S.M.; Agrawal, M.; Shah, A.; Kosinski, M.; Stillwell, D.; Seligman, M.E. Personality, gender, and age in the language of social media: The open-vocabulary approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Chen, Z.X.; Yang, B. Personality analysis and prediction of social network users. Chin. J. Comput. 2014, 37, 1877–1894. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, M.; Niu, G.; Liu, Y. Weibo user influence evaluation method based on topic and node attributes. In Proceedings of the International Conference on Web Information Systems and Applications, Taiyuan, China, 14–15 September 2018; pp. 382–391. [Google Scholar]
- Mayzlin, D. Promotional chat on the Internet. Mark. Sci. 2006, 25, 155–163. [Google Scholar] [CrossRef] [Green Version]
- Watts, D.J.; Dodds, P.S. Influentials, networks, and public opinion formation. J. Cons. Res. 2007, 34, 441–458. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Key | Value | ||
|---|---|---|---|
| Author ID | wxid***hiu11 | ||
| Author Name | In***nd | ||
| Content | Mom, This is Jerry, not rabbit! | ||
| Likes | wxid***zc22, l***bao, wxid***5j21 | ||
| Comments | Id: wxid***5j21 | Name: ***ter | Content: Its ears are so big |
| Id: wxid ***hiu11 | Name: In***nd | Content: Maybe[facepalm] | |
| Id: wxid ***yad22 | Name: 777 | Content:… [Frown] | |
| Timestap | 1531450752 | ||
| Model | IPUIM | UIEM | Betweenness Centrality | Author Popularity |
|---|---|---|---|---|
| Repetition Rate | 1.42% | 29.88% | 41.64% | 68.51% |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ju, C.; Gu, Q.; Fang, Y.; Bao, F. Research on User Influence Model Integrating Personality Traits under Strong Connection. Sustainability 2020, 12, 2217. https://doi.org/10.3390/su12062217
Ju C, Gu Q, Fang Y, Bao F. Research on User Influence Model Integrating Personality Traits under Strong Connection. Sustainability. 2020; 12(6):2217. https://doi.org/10.3390/su12062217
Chicago/Turabian StyleJu, Chunhua, Qiuyang Gu, Yi Fang, and Fuguang Bao. 2020. "Research on User Influence Model Integrating Personality Traits under Strong Connection" Sustainability 12, no. 6: 2217. https://doi.org/10.3390/su12062217
APA StyleJu, C., Gu, Q., Fang, Y., & Bao, F. (2020). Research on User Influence Model Integrating Personality Traits under Strong Connection. Sustainability, 12(6), 2217. https://doi.org/10.3390/su12062217