
Assessing the Performance of Deep Learning Algorithms for Short-Term Surface Water Quality Prediction


Abstract
:1. Introduction
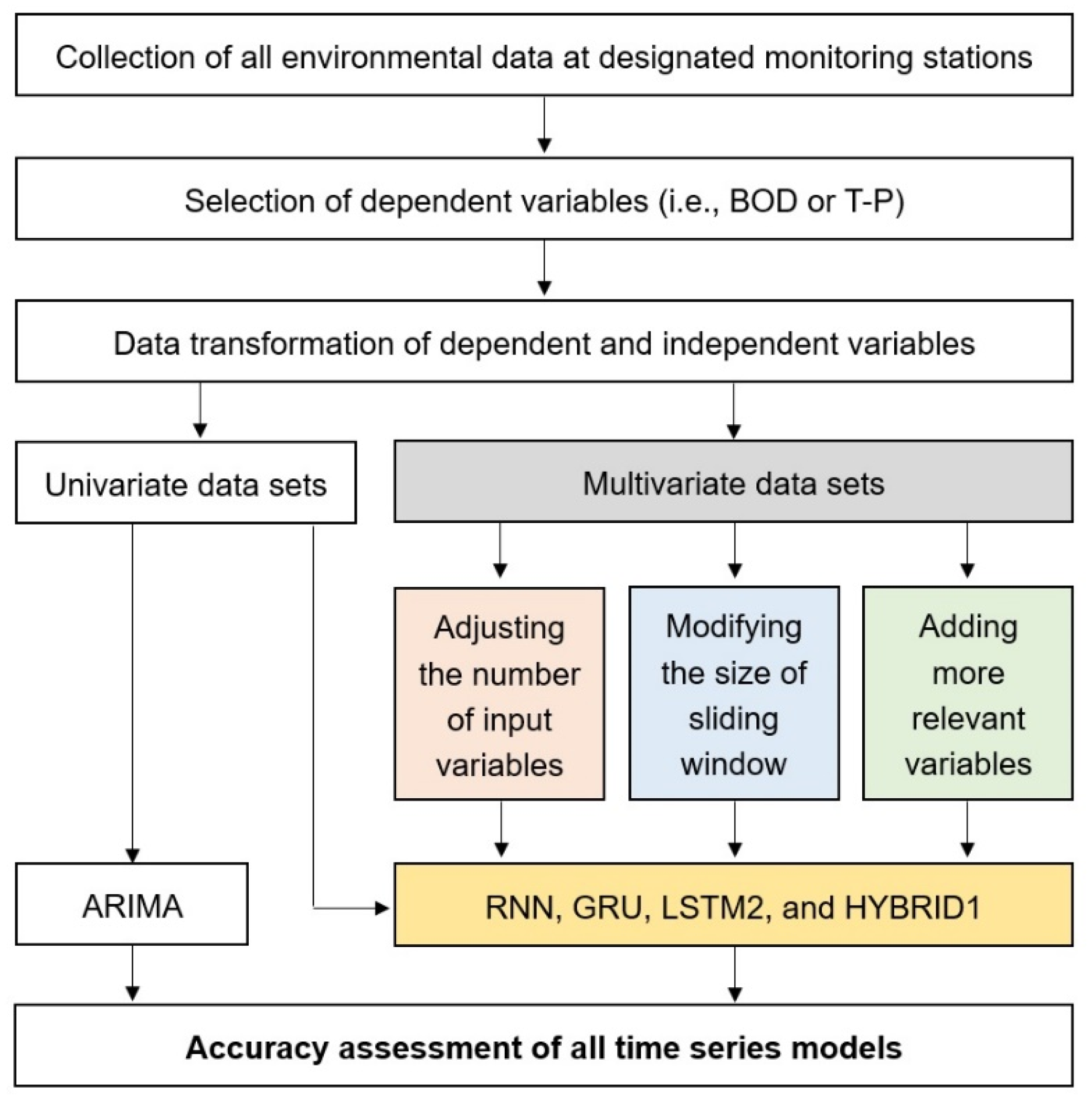
2. Materials and Methods
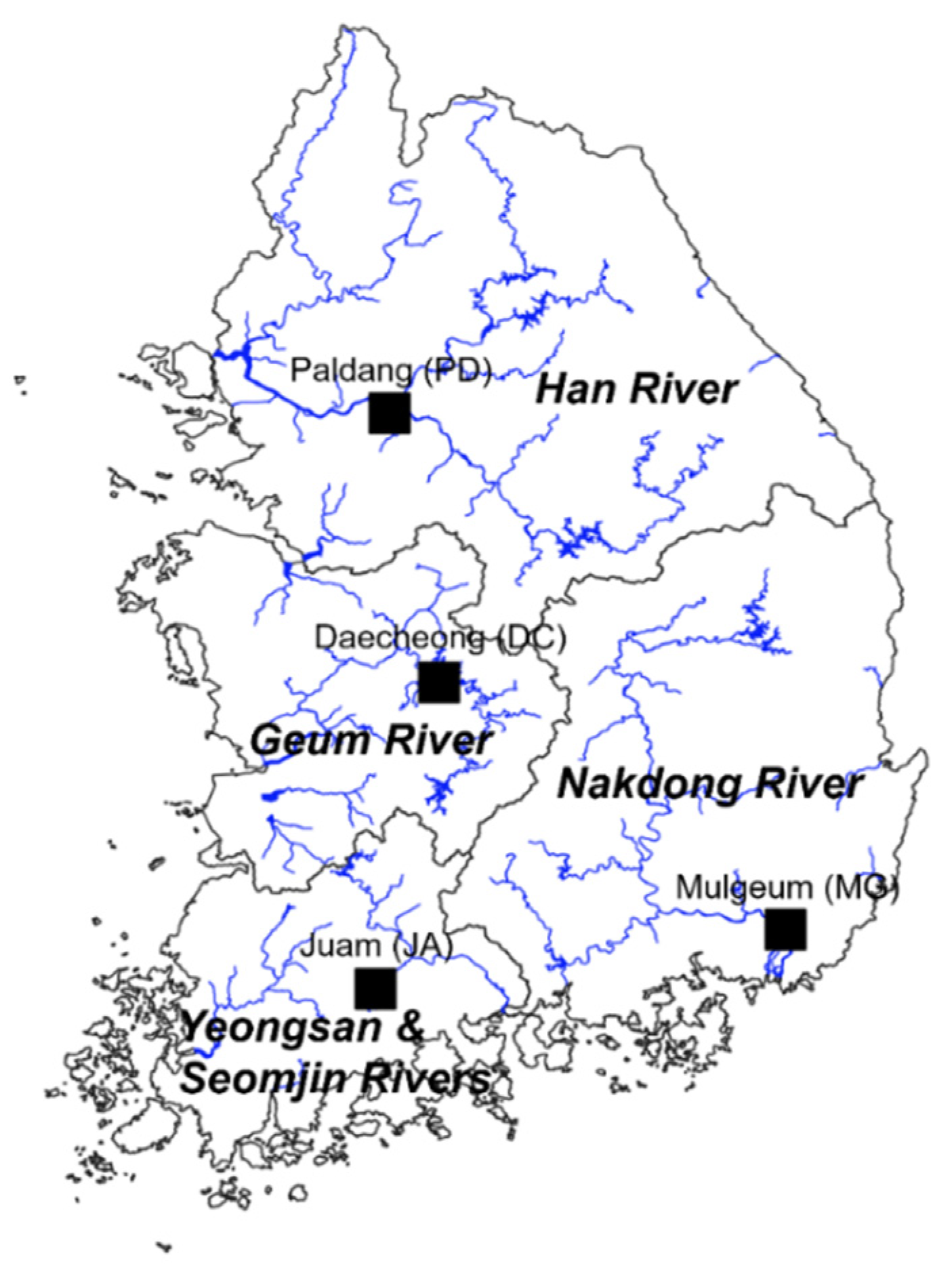
2.1. Monitoring Stations and Data Collection
2.2. Input Data Preparation
2.3. Applied Prediction Algorithms
2.4. Variable Selection
3. Results and Discussion
3.1. Performance Assessment on Univariate Data Sets
3.2. Performance Assessment on Multivariate Data Sets
3.3. Influence of Other Factors on Performance
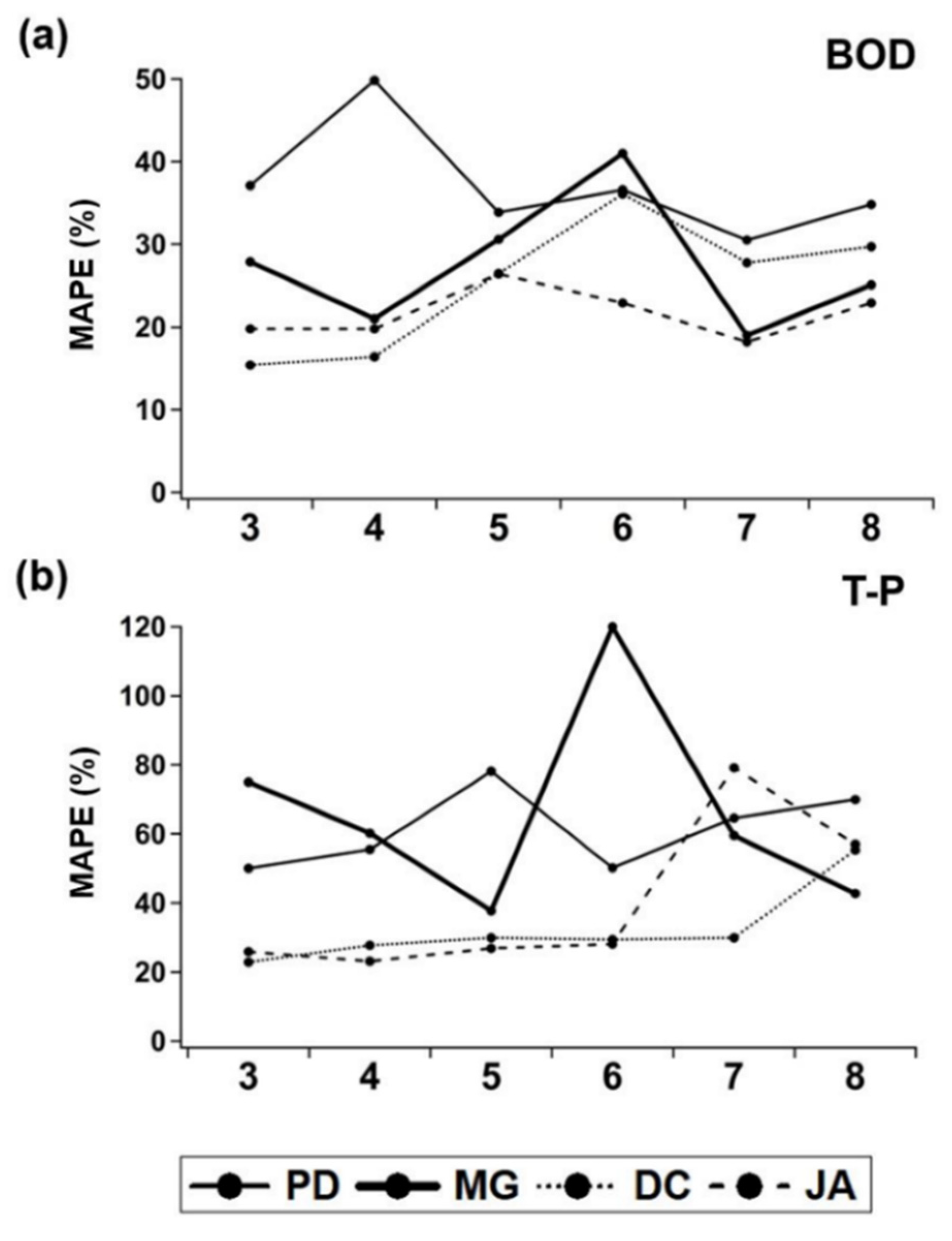
3.3.1. The Number of Input Variables
3.3.2. Sliding Window Size
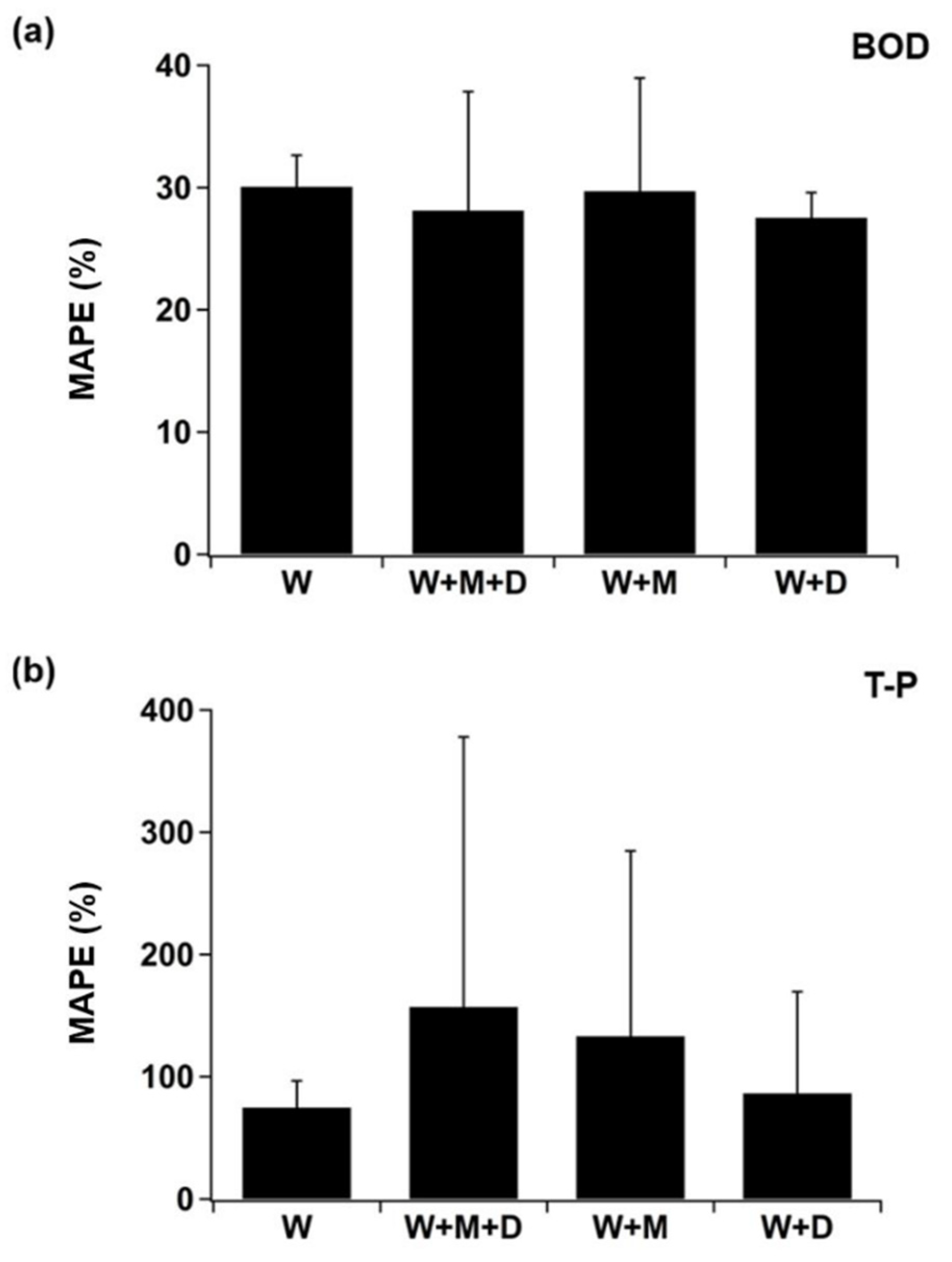
3.3.3. Relevant Variables
4. Conclusions
- All deep learning algorithms applied to univariate data sets achieved more reliable forecasts than the ARIMA model whatever the dependent variables BOD and T-P. However, the performance of all prediction models, including ARIMA, was heavily dependent on monitoring stations.
- Using multivariate data sets, we observed noticeable improvement in the predictive accuracy of deep learning models for BOD rather than for T-P (in contrast to that of the ARIMA model derived from each dependent variable). This implied that additional water quality variables did not always enhance the accuracy of prediction for all target variables.
- The number of input variables and sliding window size (input and output steps in the models) were responsible for changes in the performance of deep learning models. The highest prediction accuracy of deep learning models was achieved with the addition of discharge variable (to existing multivariate data sets), instead of using other data sets merging water quality and relevant parameters such as meteorological variables or both meteorological and discharge variables. In our case, this assumption is, however, only valid for prediction of BOD (time series).
- As a preliminary study, this study did not examine the effectiveness of other advanced variants such as encoder-decoder model and attention mechanism, which evolved from traditional deep learning approaches proposed for time series forecasting. More research is, therefore, needed to verify the superiority of those single algorithms, in addition to ensemble learning which combine predictions from multiple (deep learning) models to improve its prediction accuracy over a standalone model. Moreover, as the performance of deep learning algorithms was noticeably affected by the amount of data, model architectures, and dependent variables, these issues should be carefully addressed when developing short-term surface water quality prediction models, specifically using data sets updated monthly or weekly.
Author Contributions
Funding
Conflicts of Interest
References
- Than, N.H.; Ly, C.D.; Van Tat, P. The Performance of Classification and Forecasting Dong Nai River Water Quality for Sustainable Water Resources Management Using Neural Network Techniques. J. Hydrol. 2021, 596, 126099. [Google Scholar] [CrossRef]
- Liu, P.; Wang, J.; Sangaiah, A.K.; Xie, Y.; Yin, X. Analysis and Prediction of Water Quality Using LSTM Deep Neural Networks in IoT Environment. Sustainability 2019, 11, 2058. [Google Scholar] [CrossRef] [Green Version]
- Zhi, W.; Feng, D.; Tsai, W.P.; Sterle, G.; Harpold, A.; Shen, C.; Li, L. From Hydrometeorology to River Water Quality: Can a Deep Learning Model Predict Dissolved Oxygen at the Continental Scale? Environ. Sci. Technol. 2021, 55, 2357–2368. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.; Lee, D. Improved Prediction of Harmful Algal Blooms in Four Major South Korea’s Rivers Using Deep Learning Models. Int. J. Environ. Res. Public Health 2018, 15, 1322. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peterson, K.T.; Sagan, V.; Sloan, J.J. Deep Learning-Based Water Quality Estimation and Anomaly Detection Using Landsat-8/Sentinel-2 Virtual Constellation and Cloud Computing. GIScience Remote Sens. 2020, 57, 510–525. [Google Scholar] [CrossRef]
- Li, Z.; Ling, K.; Zhou, L.; Zhu, M. Deep Learning Framework with Time Series Analysis Methods for Runoff Prediction. Water 2021, 13, 575. [Google Scholar]
- Udayakumar, K.; Subiramaniyam, N.P. Deep Learning-Based Production Assists Water Quality Warning System for Reverse Osmosis Plants. H2Open J. 2020, 3, 538–553. [Google Scholar]
- Barzegar, R.; Aalami, M.T.; Adamowski, J. Short-Term Water Quality Variable Prediction Using a Hybrid CNN–LSTM Deep Learning Model. Stoch. Environ. Res. Risk Assess. 2020, 34, 415–433. [Google Scholar] [CrossRef]
- Yan, J.; Liu, J.; Yu, Y.; Xu, H. Water Quality Prediction in the Luan River Based on 1-Drcnn and Bigru Hybrid Neural Network Model. Water 2021, 13, 1273. [Google Scholar]
- Thai-Nghe, N.; Thanh-Hai, N.; Ngon, N.C. Deep Learning Approach for Forecasting Water Quality in IoT Systems. Int. J. Adv. Comput. Sci. Appl. 2020, 11, 686–693. [Google Scholar]
- Wang, X.; Zhang, C. Water Quality Prediction of San Francisco Bay Based on Deep Learning. J. Jilin Univ. (Earth Sci. Ed.) 2021, 51, 222–230. [Google Scholar]
- Chandra, R.; Goyal, S.; Gupta, R. Evaluation of Deep Learning Models for Multi-Step Ahead Time Series Prediction. IEEE Access 2021, 9, 83105–83123. [Google Scholar]
- Sha, J.; Li, X.; Zhang, M.; Wang, Z.L. Comparison of Forecasting Models for Real-time Monitoring of Water Quality Parameters Based on Hybrid Deep Learning Neural Networks. Water 2021, 13, 1547. [Google Scholar] [CrossRef]
- Baek, S.S.; Pyo, J.; Chun, J.A. Prediction of Water Level and Water Quality Using a CNN-LSTM Combined Deep Learning Approach. Water 2020, 12, 3399. [Google Scholar] [CrossRef]
- Yan, J.; Gao, Y.; Yu, Y.; Xu, H.; Xu, Z. A Prediction Model Based on Deep Belief Network and Least Squares SVR Applied to Cross-Section Water Quality. Water 2020, 12, 1929. [Google Scholar]
- Hu, Z.; Zhang, Y.; Zhao, Y.; Xie, M.; Zhong, J.; Tu, Z.; Liu, J. A water quality prediction method based on the deep LSTM network considering correlation in smart mariculture. Sensors 2019, 19, 1420. [Google Scholar] [CrossRef] [Green Version]
- Faruk, D.Ö. A Hybrid Neural Network and ARIMA Model for Water Quality Time Series Prediction. Eng. Appl. Artif. Intell. 2010, 23, 586–594. [Google Scholar]
- Li, Z.; Peng, F.; Niu, B.; Li, G.; Wu, J.; Miao, Z. Water quality prediction model combining sparse auto-encoder and LSTM network. IFAC-Pap. 2018, 51, 831–836. [Google Scholar] [CrossRef]
- Zhou, Y. Real-Time Probabilistic Forecasting of River Water Quality under Data Missing Situation: Deep Learning plus Post-Processing Techniques. J. Hydrol. 2020, 589, 125164. [Google Scholar]
- Loc, H.H.; Do, Q.H.; Cokro, A.A.; Irvine, K.N. Deep Neural Network Analyses of Water Quality Time Series Associated with Water Sensitive Urban Design (WSUD) Features. J. Appl. Water Eng. Res. 2020, 8, 313–332. [Google Scholar]
- Najafzadeh, M. Evaluation of conjugate depths of hydraulic jump in circular pipes using evolutionary computing. Soft Comput. 2019, 23, 13375–13391. [Google Scholar] [CrossRef]
- Saberi-Movahed, F.; Najafzadeh, M.; Mehrpooya, A. Receiving more accurate predictions for longitudinal dispersion coefficients in water pipelines: Training group method of data handling using extreme learning machine conceptions. Water Resour. Manag. 2020, 34, 529–561. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Ghaemi, A.; Emamgholizadeh, S. Prediction of water quality parameters using evolutionary computing-based formulations. Int. J. Environ. Sci. Technol. 2019, 16, 6377–6396. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Homaei, F.; Farhadi, H. Reliability assessment of water quality index based on guidelines of national sanitation foundation in natural streams: Integration of remote sensing and data-driven models. Artif. Intell. Rev. 2021, 54, 4619–4651. [Google Scholar] [CrossRef]
- Heddam, S.; Kisi, O. Modelling daily dissolved oxygen concentration using least square support vector machine, multivariate adaptive regression splines and M5 model tree. J. Hydrol. 2018, 559, 499–509. [Google Scholar] [CrossRef]
- Najafzadeh, M.; Niazmardi, S. A Novel Multiple-Kernel Support Vector Regression Algorithm for Estimation of Water Quality Parameters. Nat. Resour. Res. 2021, 30, 3761–3775. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, Y.; Xiao, F.; Wang, Y.; Sun, L. Water quality prediction method based on IGRA and LSTM. Water 2018, 10, 1148. [Google Scholar] [CrossRef] [Green Version]
- Khullar, S.; Singh, N. Water quality assessment of a river using deep learning Bi-LSTM methodology: Forecasting and validation. Environ. Sci. Pollut. Res. 2021. [Google Scholar] [CrossRef]
- Korea Water Resources Association. A Study on Water Quality Assessment with Data-Driven Models and Its Short-Term Prediction Methods; National Institute of Environmental Research: Incheon, Korea, 2021. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variables | Units | n | PD | MG | DC | JA | ||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | CV | Mean | CV | Mean | CV | Mean | CV | |||
| Water temperature | °C | 120 | 13.08 | 0.60 | 16.64 | 0.51 | 15.09 | 0.51 | 11.81 | 0.40 |
| pH | – | 120 | 7.77 | 0.10 | 8.03 | 0.05 | 7.85 | 0.05 | 6.93 | 0.05 |
| Dissolved oxygen | mg/L | 120 | 10.41 | 0.24 | 10.63 | 0.23 | 9.75 | 0.27 | 7.57 | 0.37 |
| Biochemical oxygen demand | mg/L | 120 | 1.16 | 0.31 | 2.17 | 0.36 | 0.95 | 0.25 | 0.84 | 0.24 |
| Chemical oxygen demand | mg/L | 120 | 3.69 | 0.16 | 6.33 | 0.19 | 4.12 | 0.17 | 2.97 | 0.12 |
| Suspended solids | mg/L | 120 | 6.42 | 1.20 | 16.35 | 1.12 | 2.70 | 0.56 | 1.99 | 0.54 |
| Electrical conductivity | µS/cm | 120 | 168.93 | 0.23 | 314.37 | 0.33 | 146.05 | 0.13 | 74.81 | 0.12 |
| Total nitrogen | mg/L | 120 | 2.08 | 0.18 | 2.81 | 0.24 | 1.45 | 0.23 | 0.75 | 0.14 |
| Total phosphorus | mg/L | 120 | 0.03 | 0.59 | 0.07 | 0.60 | 0.02 | 0.56 | 0.01 | 0.40 |
| Total coliforms | cfu/100 mL | 120 | 706.90 | 2.85 | 17,694 | 9.25 | 28.56 | 2.03 | 76.18 | 3.30 |
| Prediction Algorithms | BOD | T-P | ||||||
|---|---|---|---|---|---|---|---|---|
| PD | MG | DC | JA | PD | MG | DC | JA | |
| ARIMA | 109.64 | 404.54 | 27.32 | 43.97 | 27.61 | 69.14 | 40.70 | 36.16 |
| RNN | 7.91 | 18.78 | 6.51 | 10.90 | 13.06 | 8.82 | 11.32 | 8.08 |
| GRU | 9.50 | 18.54 | 8.84 | 10.37 | 17.47 | 9.63 | 18.26 | 7.98 |
| LSTM2 | 7.46 | 15.60 | 11.14 | 10.59 | 13.54 | 9.96 | 13.91 | 9.65 |
| HYBRID1 | 7.46 | 15.61 | 7.73 | 10.27 | 18.66 | 10.17 | 11.21 | 8.24 |
| Prediction Algorithms | BOD | T-P | ||||||
|---|---|---|---|---|---|---|---|---|
| PD | MG | DC | JA | PD | MG | DC | JA | |
| ARIMA | 109.64 | 404.54 | 27.32 | 43.97 | 27.61 | 69.14 | 40.70 | 36.16 |
| RNN | 40.40 | 48.91 | 27.10 | 27.69 | 57.68 | 368.80 | 40.76 | 22.22 |
| GRU | 36.06 | 29.03 | 25.20 | 26.16 | 96.20 | 183.00 | 121.80 | 243.60 |
| LSTM2 | 39.08 | 32.91 | 24.54 | 25.02 | 54.84 | 71.91 | 54.33 | 42.26 |
| HYBRID1 | 64.75 | 39.99 | 21.98 | 17.61 | 108.30 | 81.54 | 31.32 | 37.06 |
| Input and Output Steps | BOD | T-P | ||||
|---|---|---|---|---|---|---|
| MG | DC | JA | MG | DC | JA | |
| 9 + 1 | 24.69 | 22.9 | 22.90 | 15.17 | 24.58 | 21.63 |
| 9 + 2 | 33.70 | 22.55 | 22.55 | 18.36 | 24.11 | 39.17 |
| 9 + 3 | 27.56 | 26.16 | 26.16 | 19.34 | 24.71 | 22.12 |
| 12 + 1 | 29.55 | 23.90 | 23.90 | 15.48 | 39.64 | 20.70 |
| 12 + 2 | 37.43 | 27.16 | 27.16 | 18.70 | 26.53 | 22.69 |
| 12 + 3 | 33.12 | 26.69 | 26.69 | 19.91 | 25.00 | 23.33 |
| 15 + 1 | 26.21 | 24.50 | 24.50 | 14.99 | 24.41 | 24.29 |
| 15 + 2 | 32.91 | 24.33 | 24.33 | 21.18 | 25.50 | 24.58 |
| 15 + 3 | 34.81 | 25.14 | 25.14 | 19.27 | 26.85 | 24.57 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.; Suh, S.-I.; Kim, S.-H.; Han, E.J.; Ki, S.J. Assessing the Performance of Deep Learning Algorithms for Short-Term Surface Water Quality Prediction. Sustainability 2021, 13, 10690. https://doi.org/10.3390/su131910690
Choi H, Suh S-I, Kim S-H, Han EJ, Ki SJ. Assessing the Performance of Deep Learning Algorithms for Short-Term Surface Water Quality Prediction. Sustainability. 2021; 13(19):10690. https://doi.org/10.3390/su131910690
Chicago/Turabian StyleChoi, Heelak, Sang-Ik Suh, Su-Hee Kim, Eun Jin Han, and Seo Jin Ki. 2021. "Assessing the Performance of Deep Learning Algorithms for Short-Term Surface Water Quality Prediction" Sustainability 13, no. 19: 10690. https://doi.org/10.3390/su131910690
APA StyleChoi, H., Suh, S. -I., Kim, S. -H., Han, E. J., & Ki, S. J. (2021). Assessing the Performance of Deep Learning Algorithms for Short-Term Surface Water Quality Prediction. Sustainability, 13(19), 10690. https://doi.org/10.3390/su131910690