1. Introduction
In 2015, the United Nations set forth 17 Sustainable Development Goals (SDGs) and Education for Sustainable Development (ESD) is recognized as a part of SDG No. 4 to empower learners to take informed decisions, accept responsibilities, and devise solutions to achieve environment integrity, economic viability, and social justice [
1]. Based on the concept of integrating sustainable development into education, relevant studies have concentrated on two basic elements of quality education, i.e., educational content and learning environment. The former covers locally and globally critical topics regarding nature conservation, biodiversity, challenges faced by culturally diverse communities, etc. [
2], and the latter encompasses ecological, economic, social, and cultural aspects to predict and solve social environmental problems which affect learners’ understanding of the modern, diverse world’s interests and needs [
3]. However, few studies have paid attention to (foreign) language education for sustainable development in comparison to other learning-related issues. Language, as a tool which helps build human relationships via education, is an essential instrument when people face global challenges of sustainable development.
In addition to its role in traditional pedagogy, higher education institutions play a major role in the establishment and demonstration of ESD in which a foreign language competence is a key prerequisite for acquiring desired results for sustainable development in the 21st century. In response to the changes in the education environment in Taiwan and to the development of information education, students should be trained to master multiple languages in future curricula. Hence, besides English, it is also necessary to encourage students to learn a second foreign language to help them develop professional competence and enhance competitiveness. In recent years, Taiwan has witnessed a growing trend of internationalization and Japanese culture influence. According to the statistics of Japanese-Language Proficiency Test (JLPT), the number of global test takers was as high as 1.02 million in 2017, proving the increasing learning interest in Japanese.
In the light of the evaluation and certificate of Japanese language proficiency of non-native speakers, the JLPT has five levels: N1 (the most difficult), N2, N3, N4, and N5 (the easiest), and measures comprehensive Japanese-language communicative competence. The number of test takers in Taiwan has also set a record high with more than 86,000 test takers, ranking third among all countries other than Japan. Judging from the number of Japanese learners, when students face global competitions and challenges, learning Japanese as a second foreign language has become a prominent choice for the present and future generations in Taiwan.
Language is a fundamental expression of culture and a primary resource for social interaction. That is, language and culture are inseparable. To learn a language well, one must first understand the particular culture. In the context of Japanese culture, “Mimicry and Onomatopoeia, MIO” (the term “MIO” is quoted from [
4]) is a form of Japanese expression acquired innately by the Japanese, frequently used in daily conversations and literary works by the Japanese people [
5]. The abundant amount of “mimicry and onomatopoeia” (hereafter jointly referred to as “onomatopoeia”) makes Japanese expressions more vivid. In addition, onomatopoeia also plays a critical part in the text of news, advertisements, animations, and games. By definition, onomatopoeia (
giongo in Japanese) refers to a word used to imitate sounds made by things in nature (e.g.,
woof woof for dog barks). The sound heard by the ear is expressed in the form of onomatopoeia. On the other hand, mimicry (
gitaigo in Japanese) is a word that describes the movement, appearance, shape, or state of objects or living beings (e.g.,
kira-kira for the twinkling stars). In other words, mimicry symbolizes what is seen by the eye (i.e., form, action, or appearance) by describing how it should sound. However, for non-native Japanese learners, onomatopoeia is extremely difficult, mainly because the abstract meaning of onomatopoeia must be mastered before it can be used adeptly in communication. Besides, for Chinese native L2 learners, onomatopoeia is especially difficult, since they often rely too much on Kanji, i.e., the adopted logographic Chinese characters used in the Japanese writing system.
When learning onomatopoeia in the past, Japanese learners often tried to simply memorize the words. Then, supplementary materials with vivid pictures came into the pedagogy. By describing vivid actions and expressions, these materials allow learners to go beyond words and immediately understand the meaning of onomatopoeia words, so that they can learn Japanese onomatopoeia in a more effortless way. Since onomatopoeia words “simulate” sounds and states of objects, it requires a cultural tacit understanding and a common background to use onomatopoeia words in a natural way. Ref. [
6] pointed out that understanding and imagining the meaning of onomatopoeia only through vivid pictures can help learners relate to the usage of onomatopoeia, but since the teaching is not conducted verbally, it still cannot effectively improve the learning outcome. Ref. [
7] also mentioned that Japanese onomatopoeia must be expressed correctly through various senses, and it includes many synonyms, reduplications, and assonances. Hence, it is considerably difficult to use onomatopoeia properly in Japanese conversations.
To tackle this issue, ref. [
6,
7] both used information technology to develop a context-aware Japanese onomatopoeia learning assistant system called JAMIOLAS (Japanese Mimicry and Onomatopoeia Learning Assistant System). JAMIOLAS versions 1.0 and 2.0 used, respectively, wearable sensors and a sensor network to automatically detect the participants’ environment in order to achieve accurate learning results [
7]. A later version, JAMIOLAS 3.0, used a web-based system which allows teachers to create an onomatopoeia database and contextual scenarios, and can facilitate the context-aware learning of onomatopoeia by using the sensor data collected via the Internet [
6]. However, most JAMIOLAS participants are Japanese students accustomed to using onomatopoeia in daily conversations. Hence, for L learners of Japanese, no empirical evidence can confirm whether the JAMIOLAS system can help them learn onomatopoeia in a more effective way. In this regard, ref. [
8] adopted a semantic differential (SD) method to predict the meaning of onomatopoeia for non-native Japanese learners. The research concludes that only sounds and contextual clues do not suffice to help predict and understand onomatopoeia without the implementation of onomatopoeia teaching. To deal with this issue, ref. [
9] proposed a learning system to help international students with onomatopoeia based on a previously-constructed system: SCROLL (System for Capturing and Reminding of Learning Logs). SCROLL is the result of a pilot study, and there is the problem of insufficient test functionality. That is, due to the relatively small number of participants, it can only be evaluated as a conducive system which meets the needs of students surveyed, and there is still much room for improvement.
According to the cognitive theory of multimedia learning issued by [
10] constructed based on the dual code theory [
11], the brain does not interpret a multimedia presentation of words, pictures, and auditory information in a mutually exclusive fashion. That is, words and pictures complement, but cannot replace each other. When words and images are presented together, it helps students to produce mental constructs of language and images and build the relationship between the two mental constructs. Studies also found that combinations of text, imagery, and pictures in instruction facilitated conceptual understanding in multimedia learning [
12,
13,
14]. Ref. [
15] further contends that meaningful learning in multimedia environments occurs when learners choose relevant information, conduct the information to form coherent mental representations, and integrate new and existing representations. As a result, to adequately use adjective expressions becomes an important element in the context of multimedia learning while learning Japanese MIO words. Using the rhetorical way of speaking, especially in Japanese onomatopoeia, overseas students would have the solid understanding of the onomatopoeia situations not only to rich communication with Japanese native speakers, but also to properly express the usage of Japanese onomatopoeia depending on the situation where the participants are. Therefore, this study aimed to propose a VR scenario to improve the immersive learning environment and support the effectiveness of learning MIO words.
Compared with traditional teaching materials, VR materials can offer richer experiences. VR technology mainly presents real-time, dynamic, and interactive scenes, which can simulate phenomena that cannot be operated or observed in a real-life teaching setting in a two-way communication of information, known as human-computer interface (HCI). This feature bridges the cognitive difference and allows users to interact with the virtual environment with appropriate software and/or hardware HCI. In this way, users can acquire a more concrete learning experience, which in turn enhances the users’ learning interests and outcomes. For example, ref. [
16] integrated VR technology into high school biomolecular education by developing a system called MolecularStudio and concluded that three-dimensional visual design stimulated students’ engagement and motivation when they were learning about protein structures. Another instance can be seen in [
17], in which VR technology was adopted to create a learning system which teaches canine bone anatomy and related knowledge [
18], on the other hand, provided insight into the learning process and outcomes of using 3D virtual learning environment in computer engineering education. All these examples illustrate that various applications are being derived from VR technology, in fields including medicine, education, etc.
However, with the development of information technology, users now have higher expectations for VR. If VR only realizes the interactive change of view anglevia the gyroscope or head rotation, it can no longer satisfy users. In this sense, innovations in VR must be made, and eye tracking technology is a possible answer as it can identify the true focal point of the eyes. Eye tracking technology has now become the largest application market for VR, as it can solve demands regarding VR experience. Through the acquisition, modeling, and simulation of eye movement data, VR devices can better interact with users and thus enhance immersion and interaction. Thus, in the near future, the integration of VR and eye tracking technologies will very likely be one of the most important applications in teaching settings.
Eye movement is a process in which a person’s gazes would center on interesting or informative areas of the image, leaving blank or uniform regions uninspected. This process involves continuous movements of the eyes, and eye tracking technology is the detection technology to observe such eye movement. The technology enables unobtrusive data collection of eye movement with certain software. In [
19], eye tracking applications were surveyed in a variety of domains (such as neuroscience, psychology, industrial engineering, and computer science) and human factors (such as marketing/advertising). Ref. [
19] also reported that “Perhaps the first well-known use of eye trackers in the study of human (overt) visual attention occurred during reading experiments” ([
19], p. 456). In addition, ref. [
20] pointed out that eye tracking technology is an important tool for natural and real-time exploration of cognitive thinking. The information receiving process reflects the correlation between eye movement and psychological change(s) of the reader. Hence, this technology is widely used to understand the reading process and other related topics (e.g., eye movement characteristics, perceptual breadth, information integration, etc.), and to test the cognitive process during different tasks [
21].
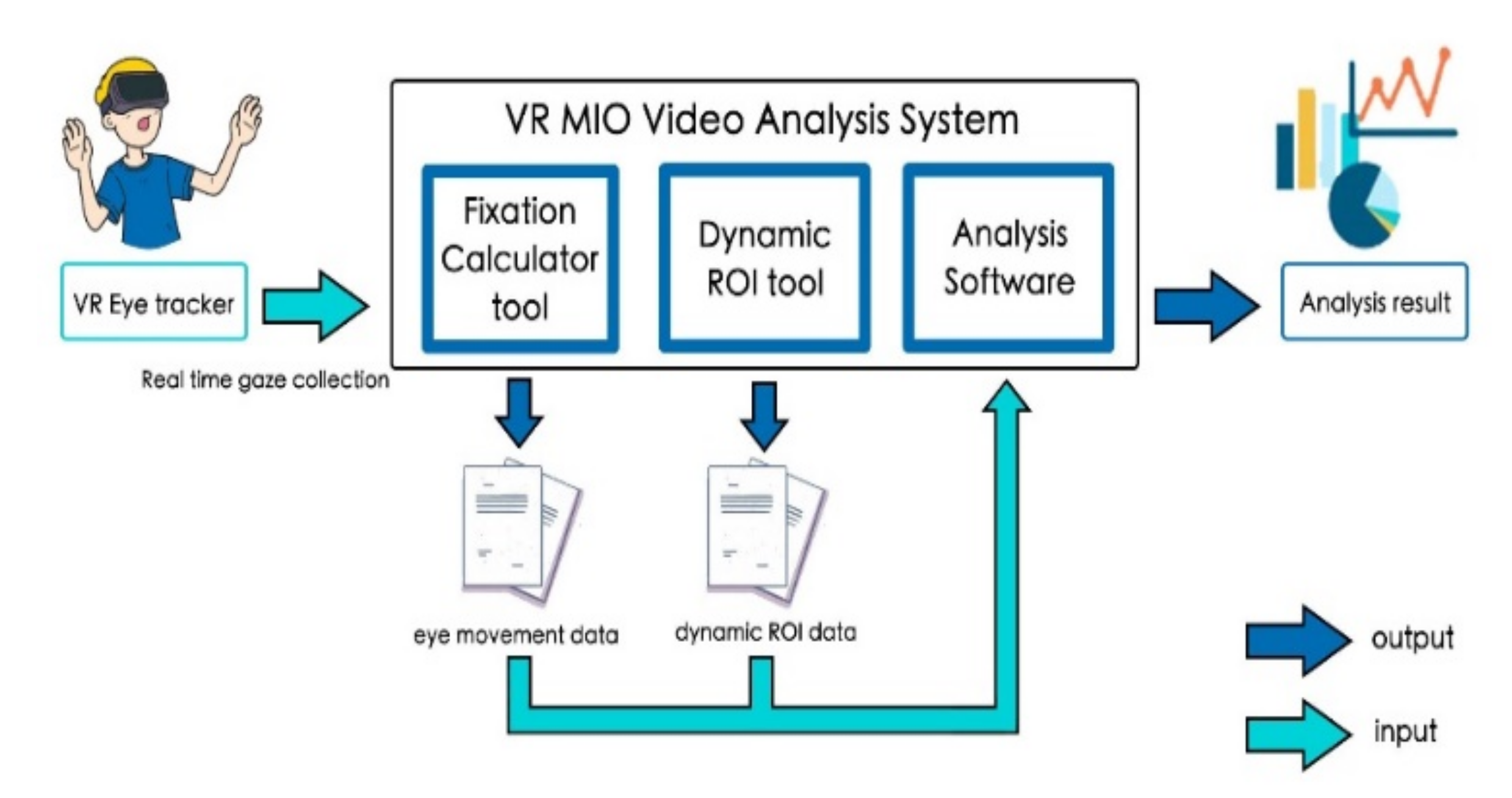
In recent years, the innovation of hardware and software technology has made the collection and analysis of eye movement data easier [
22], which allows researchers to record individual fixation, saccade, and blink events in real time. The first two, i.e., fixation and saccade events, are the two most used parameters in the field of image cognition in a region of interest (ROI), i.e., an area of an object labeled based on a particular purpose and often defined according to research questions.
In relevant research, “fixation” is usually defined as visual attention in a ROI which lasts for 200–300 milliseconds (ms) or longer; on the other hand, “saccade” is defined as rapid movements between fixations that help the eyes land on a specific visual target. During such eye movement, although some peripheral information can be obtained, information processing is constrained [
20]. Moreover, the reading process includes a series of saccades and fixations, and the sequence is called a scan path [
23,
24]. Through eye tracking analysis, it is possible to explore the spots and trajectory of visual attention when a learner is focusing on a certain task, which can serve as supplementary evidence for scientific research.
From the two basic eye movement behaviors, i.e., fixation and saccade, a number of commonly used eye movement indicators are applied in empirical research to analyze the reading of scientific graphs and texts. These indicators include total fixation duration, fixation count, number of saccades, sequence of fixation, ratio of total fixation, times of regression in a text zone, and saccade amplitude [
14]. Till now, few studies have accurately discussed the use of eye tracking technology to acquire and process visual attention when learners are watching or reading onomatopoeia-related materials. In addition, in terms of experiment materials, most eye tracking research (e.g., [
25,
26,
27,
28]) focuses on reading materials in Chinese or English, with few studies using Japanese texts as the reading material.
What is more, results of recent studies related to learning have consistently illustrated that fixation duration is affected by both signal cues and prior knowledge. With the increase in prior knowledge, participants tend to have more and faster fixation regarding task-related information [
29,
30,
31,
32]. Moreover, ref. [
33] proposed that eye tracking technology provides a unique opportunity to understand learners’ perceptual processing in learning and helps to examine the influence of specific teaching methods on learning, which can serve as a reference for teaching material design.
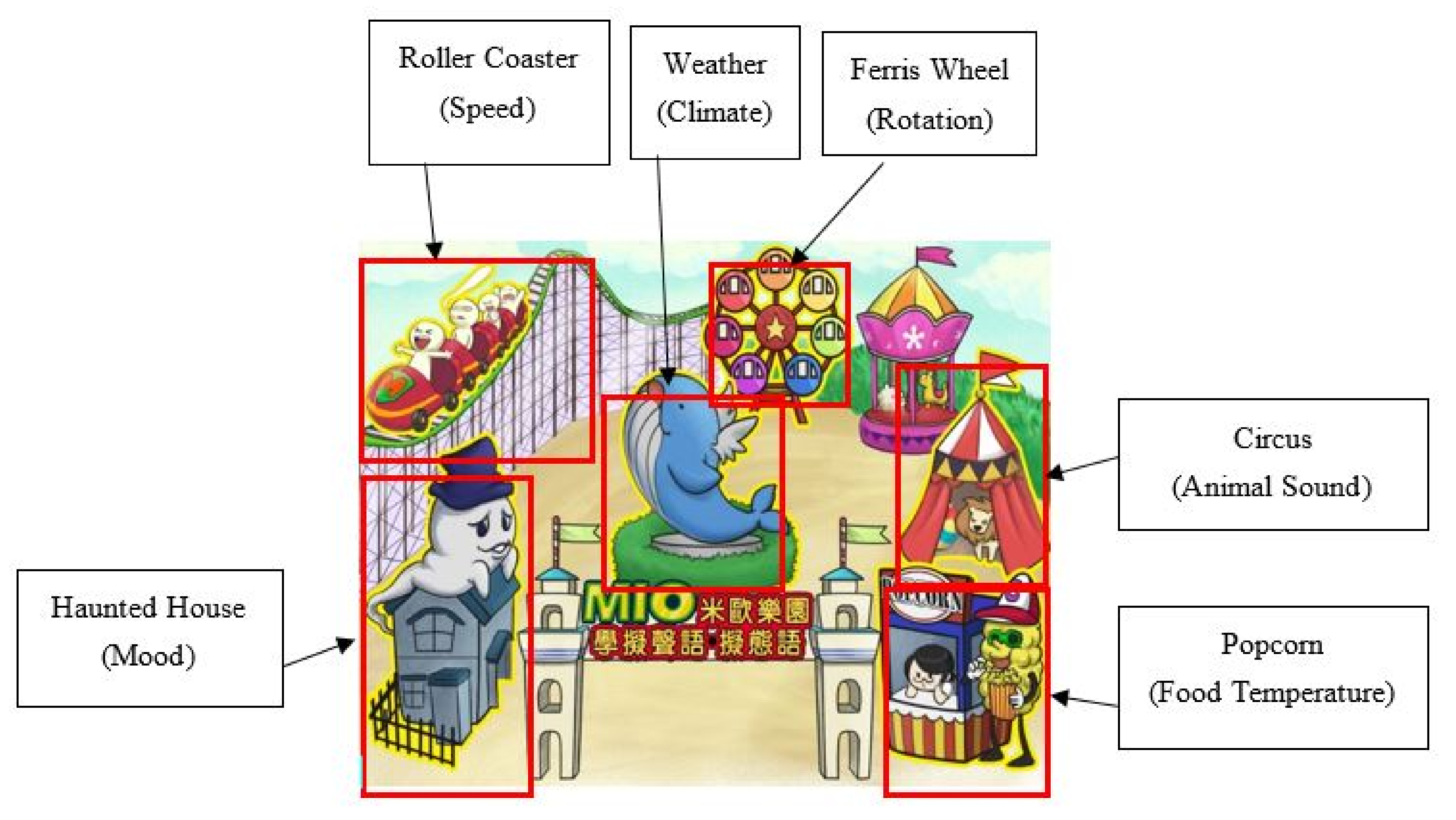
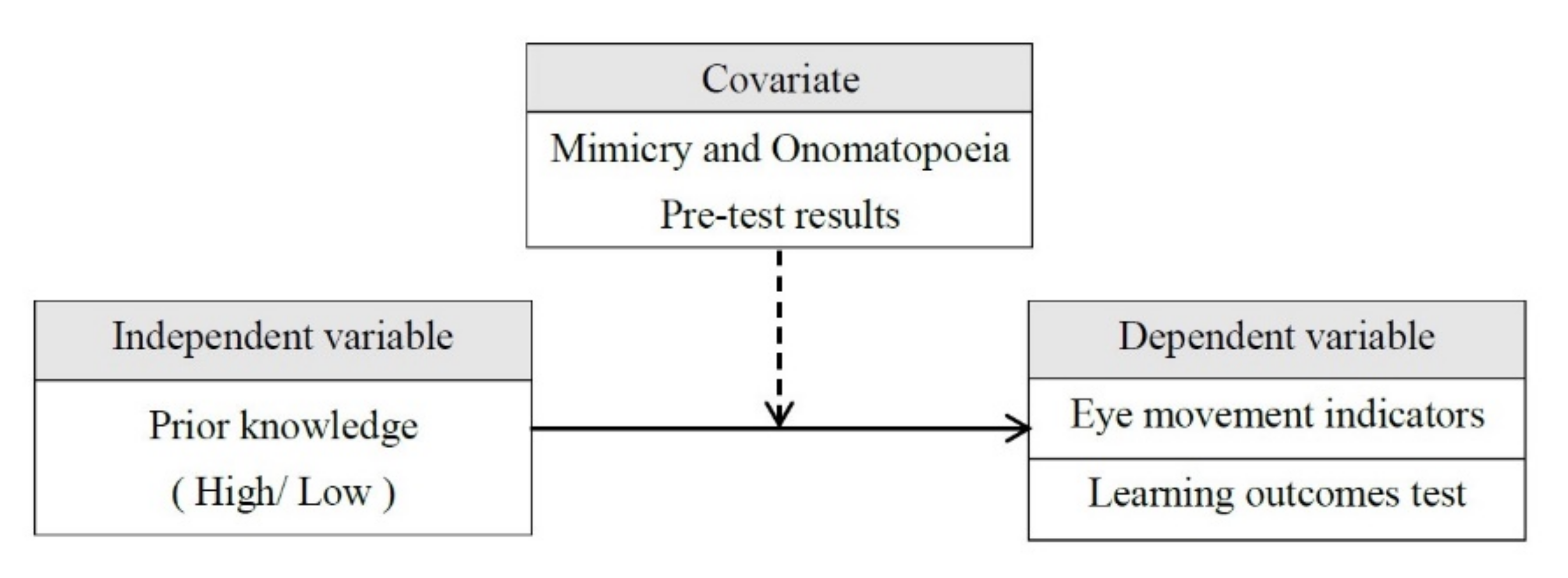
To bridge this gap, the present study aims to explore the eye movements and learning outcome of students with different levels of prior knowledge when they try to understand Japanese onomatopoeia, using eye tracker with contextual teaching content of onomatopoeia enabled by VR. When each participant entered the virtual environment for onomatopoeia learning experience, their eye movements were observed, tracked, and recorded. By analyzing the total fixation durations, total fixation count, total viewing duration, and number of saccades, the study seeks to evaluate whether visual attention distribution differs in the ROIs, and to further compare the differences, if any, in the learning outcomes in a VR setting. The results can serve as reference for teaching strategies and the design of teaching materials, so that Japanese onomatopoeia teaching can be improved, and the practical value of attention-related research in a VR setting can be better demonstrated.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}