Introducing Patents with Indirect Connection (PIC) for Establishing Patent Strategies


Abstract
:1. Introduction
- What patents may pose a potential threat to my organization?
- Which of our technologies could be involved in lawsuits?
- What are the prior technologies that can serve as a driving force for competitive advantage when converged with our technology?
2. Related Works
2.1. Studies on Finding Core Patents and Prior Art
2.2. Development of Counter Strategies
- Developing non-infringement logic: Discovering loopholes in existing patents’ claims.
- Developing invalidation logic: Prior art searches that could deny the novelty or progressiveness of the claims included in existing patents.
- Design of circumvention: Alternative technology design to avoid infringing on the rights of existing patents.
- Cross license: Negotiation through contracts with patent owners where there is potential for patent rights conflict.
3. Backgrounds
4. Proposed Methodology
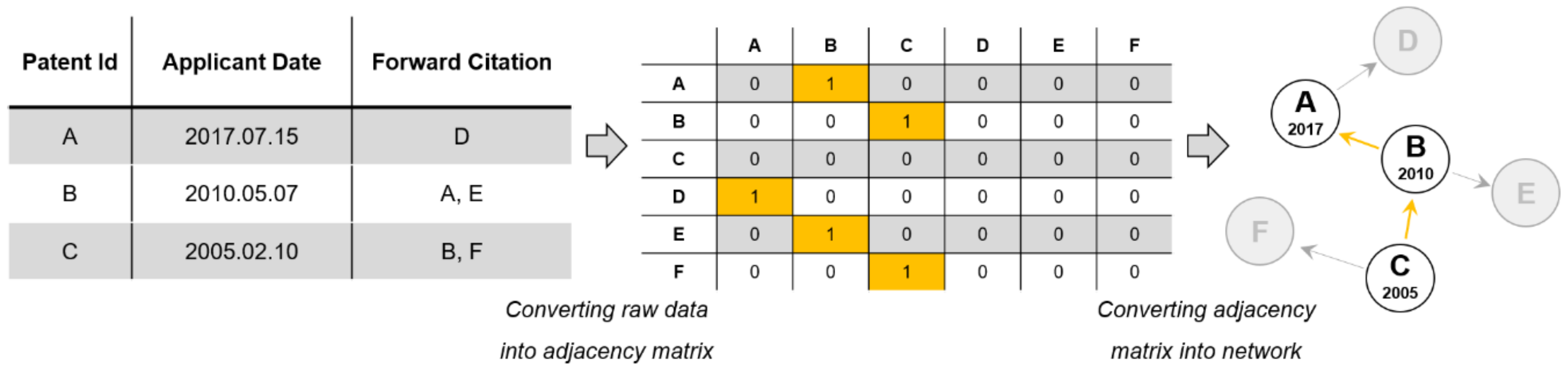
4.1. PIC: A Pair of Patents that Can Be Found by Similarity and Citation Information between Technologies
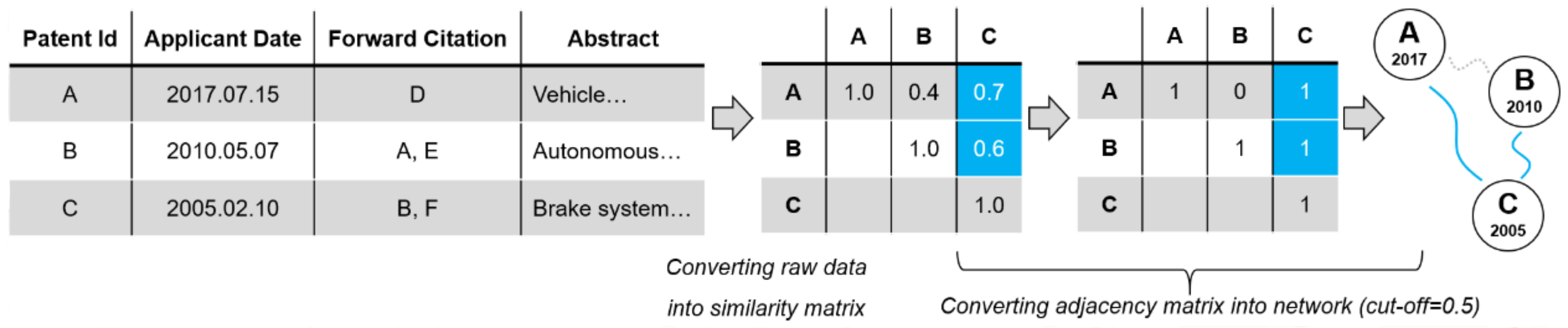
4.2. CS-Net: A Method of Merging the Citation Network and the Similarity Network
4.3. PIC-E: A Method of Exploring PIC from CS-Net
5. Experimental Study
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PIC | Sim | Year | Title of Patent Document |
|---|---|---|---|
| 1 | 0.913 | 2011 | The apparatus and method of multi-lane car plate detection and recognition |
| 2013 | The One shot camera for artificial intelligence function by using neuromorphic chip | ||
| 2 | 0.818 | 2006 | Real time predicting system for energy management system using machine learning |
| 2017 | Predicting system for energy management system | ||
| 3 | 0.781 | 2016 | The intelligent disclosure of public records management system based machine learning |
| 2016 | System for classifying and opening information based on natural language | ||
| 4 | 0.702 | 2010 | Apparatus for analysis of mobile big data |
| 2017 | Device for analyzing mobile data using data mining and method thereof | ||
| 5 | 0.677 | 2007 | Lotto lottery numbers mixing system for using data mining and service method thereof |
| 2009 | System and method of recommendation number of lotto lottery number for providing lotto lottery for increasing winning ration using data mining | ||
| 6 | 0.675 | 2007 | Grid-based hybrid data mining device and method thereof |
| 2015 | Simulation-based computational grid resource management device using ontology and method thereof | ||
| 7 | 0.655 | 2009 | Semantic information based grid management system and method for grid computing |
| 2015 | Simulation-based computational grid resource management device using ontology and method thereof | ||
| 8 | 0.650 | 2012 | Storeroom environment state management system and method of base ontology |
| 2018 | System and method for smart refrigerator management based on situation-awareness | ||
| 9 | 0.613 | 2016 | Method for mining weighted erasable by using underestimated constraint-based pruning technique |
| 2017 | Method of miming top-k important patterns | ||
| 10 | 0.597 | 2014 | System and method for searching contents using ontology |
| 2016 | Apparatus and method for frequent sub-graph component mining in graph data | ||
| 11 | 0.568 | 2009 | Apparatus and method for generating a reconstituted ontology based on the conceptual structure |
| 2012 | Browsing system and method of information using ontology | ||
| 12 | 0.566 | 2010 | Method for mining maximal weighted frequent patterns |
| 2016 | Method for mining weighted erasable by using underestimated constraint-based pruning technique | ||
| 13 | 0.563 | 2007 | System and method for providing context cognition to control home network service |
| 2015 | Personalized home automation service providing method based on ontology and service providing system using ontology based on context awareness | ||
| 14 | 0.549 | 2016 | Intelligent video surveillance system for school zone |
| 2017 | Method for counting vehicles based on image recognition and apparatus using the same | ||
| 15 | 0.549 | 2014 | Method and apparatus for usability test based on big data |
| 2018 | Automatic task classification based upon machine learning | ||
| 16 | 0.518 | 2007 | Modeling method and apparatus for multi-ontology |
| 2010 | System and method for retrieving/classifying web ontology | ||
| 17 | 0.515 | 2012 | System and method for processing ontology models, and its program recorded recording medium |
| 2014 | Apparatus and method for converting English ontology to Korean ontology | ||
| 18 | 0.494 | 2013 | Pattern mining method for searching tree on top-down traversal for considering weight in a data stream |
| 2016 | Method for mining weighted erasable by using an underestimated constraint-based pruning technique | ||
| 19 | 0.456 | 2000 | Study system and method for foreign language |
| 2013 | System for assessing improvement of basic skills in education | ||
| 20 | 0.434 | 2008 | English learning method and apparatus thereof |
| 2010 | Method and system for learning English using word order map | ||
| 21 | 0.431 | 2003 | Single-pass mining of frequent simultaneous event groups for stream data, an apparatus for single-pass mining of frequent simultaneous event groups for stream data |
| 2007 | System and mechanism for discovering temporal relation rules from interval data | ||
| 22 | 0.423 | 2009 | Apparatus and method for generating a reconstituted ontology based on the conceptual structure |
| 2011 | Web ontology editing and operating system | ||
| 23 | 0.413 | 2006 | Clustering system and method using search result documents |
| 2015 | Analysis system for environment research using environmental geographical information and textmining among big data | ||
| 24 | 0.406 | 2007 | System for recommending personalized meaning-based web-document and its method |
| 2010 | Method for calculating similarity between document elements |
References
- Brent, A.; Pretorius, M. Sustainable development: A conceptual framework for the management of knowledge and a departure for further research. S. Afr. J. Ind. Eng. 2008, 19, 31–52. [Google Scholar] [CrossRef] [Green Version]
- Park, S. Development of a Categorized Checklist for Valuation of Patent Technology. J. Intellect. Prop. 2007, 2, 30–56. [Google Scholar] [CrossRef] [Green Version]
- Betz, F. Managing Technological Innovation: Competitive Advantage from Change, 3rd ed.; Wiley–Interscience: Hoboken, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Choi, J.; Jun, S.; Park, S. A patent analysis for sustainable technology management. Sustainability 2016, 8, 688. [Google Scholar] [CrossRef] [Green Version]
- Schilling, M. Strategic Management of Technological Innovation, 5th ed.; McGraw-Hill Education: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Storey, C.; Easingwood, C. Types of new product performance: Evidence from the consumer financial sector. J. Bus. Res. 1999, 85, 275–287. [Google Scholar] [CrossRef]
- Roberts, J. Developing new rules for new markets. J. Acad. Mark. Sci. 2000, 28, 31–44. [Google Scholar] [CrossRef]
- Menor, L.; Tatikonda, M.; Sampson, S. New service development: Areas for exploitation and exploration. J. Acad. Mark. Sci. 2002, 20, 135–157. [Google Scholar] [CrossRef]
- Tseng, C. Technology development and knowledge spillover in Africa: Evidence using patent and citation data. Int. J. Technol. Manag. 2009, 45, 50–61. [Google Scholar] [CrossRef]
- Kim, C.; Lee, H. A database–centred approach to the development of new mobile service concepts. Int. J. Mob. Commun. 2012, 10, 248–264. [Google Scholar] [CrossRef]
- Lee, S.; Park, S.; Jung, E. A Study on the Analysis of Competitiveness of Corporations by Comparing of Patent Citations Based on Data Mining. J. Korean Inst. Intell. Syst. 2019, 29, 452–457. [Google Scholar] [CrossRef]
- Lai, K.; Wu, S. Using the patent co–citation approach to establish a new patent classification system. Inf. Process. Manag. 2005, 41, 313–330. [Google Scholar] [CrossRef]
- Gipp, B.; Beel, J. Citation Proximity Analysis (CPA)–A New Approach for Identifying Related Work Based on Co–Citation Analysis. 2009. Available online: http://nbn-resolving.de/urn:nbn:de:bsz:352-0-285851 (accessed on 13 January 2021).
- Ritchie, A. Citation Context Analysis for Information Retrieval. 2009. Available online: https://www.cl.cam.ac.uk/techreports/UCAM-CL-TR-744.pdf (accessed on 13 January 2021).
- Gurulingappa, H.; Mueller, B.; Klinger, R.; Mevissen, H.; Hofmann–Apitus, M.; Fluck, J.; Friedrich, C. Prior Art Search in Chemistry Patents on Semantic Concepts and Cocitation Analysis. 2010. Available online: https://trec.nist.gov/pubs/trec19/papers/fraunhofer-scai.chem.rev.pdf (accessed on 13 January 2021).
- Zhao, H. Sharding for literature search via cutting citation graphs. In Proceedings of the IEEE International Conference on Big Data, Washington, DC, USA, 27–30 October 2014; pp. 77–79. [Google Scholar] [CrossRef]
- Rodriguez, A.; Kim, B.; Turkoz, M.; Lee, J.M.; Coh, B.Y.; Jeong, M.K. New multi-stage similarity measure for calculation of pairwise patent similarity in a patent citation network. Scientometrics 2015, 103, 565–581. [Google Scholar] [CrossRef]
- No, H.; An, Y.; Park, Y. A structured approach to explore knowledge flows through technology–based business methods by integrating patent citation analysis and text mining. Technol. Forecast. Soc. Chang. 2015, 97, 181–192. [Google Scholar] [CrossRef]
- Nakamura, H.; Suzuki, S.; Sakata, I.; Kajikawa, Y. Knowledge combination modeling: The measurement of knowledge similarity between different technological domains. Technol. Forecast. Soc. Chang. 2015, 94, 187–201. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Park, S. A method of Establishing Patent Strategy using Self–Organizing Map. J. Korean Inst. Intell. Syst. 2018, 28, 422–427. [Google Scholar] [CrossRef]
- Zhu, D. Bibliometric analysis of patent infringement retrieval model based on self–organizing map neural network algorithm. Libr. Hi Tech. 2019, 38, 479–491. [Google Scholar] [CrossRef]
- Korean Intellectual Property Office. Studies on the effect of IP strategies on the Survival and Performance of firms. In Korean Institute of Intellectual Property; Korean Intellectual Property Office: Seoul, Korea, 2015. [Google Scholar]
- Su, F.; Yang, W.; Lai, K. A heuristic procedure to identify the most valuable chain of patent priority network. Technol. Forecast. Soc. Chang. 2011, 78, 319–331. [Google Scholar] [CrossRef]
- Kim, H.; Kim, J.; Lee, J.; Park, S.; Jang, D. A Novel Methodology for Extracting Core Technology and Patents by IP Mining. J. Intell. Syst. 2015, 25, 392–397. [Google Scholar] [CrossRef] [Green Version]
- Yoon, J.; Choi, S. Planning Future Technology Strategies Using Patent Information Analysis and Scenario Planning: The Case of Fuel Cells. J. Inf. Sci. Theory Pract. 2012, 43, 169–197. [Google Scholar] [CrossRef]
- Kwon, W.; Lee, J.; Kang, J.; Park, S.; Jang, D. Patent Information Analysis Using Quantitative Patent Index. In Proceedings of the Korean Institute of Intelligent Systems, Seoul, Korea, 19–21 April 2018; pp. 9–10. [Google Scholar]
- Kang, J.; Kim, J.; Lee, J.; Park, S.; Jang, D. Methodology of Prior Art Search Based on Hierarchical Citation Analysis. J. Korean Inst. Intell. Syst. 2017, 28, 72–78. [Google Scholar] [CrossRef]
- Shibata, N.; Kajikawa, Y.; Takeda, Y.; Matsushima, K. Detecting emerging research fronts based on topological measures in citation networks of scientific publications. Technovation 2008, 28, 758–775. [Google Scholar] [CrossRef]
- Yaghtin, M.; Sotudeh, H.; Mohammadi, M.; Mirzabeigi, M.; Fakhrahmad, S. A Correlation Study of Co–Opinion and Co–Citation Similarity Measures. 2019. Available online: https://ijism.ricest.ac.ir/index.php/ijism/article/view/1517/366 (accessed on 13 January 2021).
- Jui, C.; Trappey, A.; Fu, C. Method of Claim–Based Technology Analysis for Strategic Innovation Management–Using TPP–Relates as Case Examples. 2016. Available online: http://nopr.niscair.res.in/handle/123456789/35372 (accessed on 13 January 2021).
- Chen, C.; Chen, R.; Wang, D.; Dai, T. GA–based Dissimilarity Visualization Engine for Design Patent Map Systems. In Proceedings of the IEEE International Conference on Hybrid Intelligent Systems, Melacca, Malaysia, 5–8 December 2011; pp. 595–600. [Google Scholar] [CrossRef]
- Dejean, S.; Faessel, N.; Marty, L.; Mothe, J.; Sadala, S.; Thiam, S. Analysis of Patents for Prior Art Candidate Search. 2013. Available online: ftp://ftp.irit.fr/IRIT/SIG/2013_IMMM_DFMMST.pdf (accessed on 13 January 2021).
- Jeong, B.; Ko, N.; Kyung, J.; Choi, D.; Yoon, J. Development of a Patent Prior Art Search System for Invalidation Analysis of Barrier Patents. 2017. Available online: https://scienceon.kisti.re.kr/srch/selectPORSrchArticle.do?cn=ART002249787 (accessed on 13 January 2021).
- Korean Intellectual Property Office. Patent–oriented R&D innovation strategy. In R&D Patent Center; Korean Intellectual Property Office: Seoul, Korea, 2012. [Google Scholar]
- Grindley, P.; Teece, D. Managing Intellectual Capital: Licensing and Cross–Licensing in Semiconductors and Electronics. 1997. Available online: https://journals.sagepub.com/doi/pdf/10.2307/41165885?casa_token=AHfMaSfSAZUAAAAA:hvc2RUlk4NsgNmpZ5ylCQn1ad_T4QvxpSZCUINwghmAxzo-dg42blzt8lUt6GrNeUXOeW_lpxDJnGw (accessed on 13 January 2021).
- Lippman, S.; Rumelt, R. Uncertain imitability: An analysis of interfirm differences in efficiency under competition. Bell J. Econ. 1982, 13, 418–438. [Google Scholar] [CrossRef]
- Arora, A.; Fosfuri, A. Licensing the market for technology. J. Econ. Behav. Organ. 2003, 52, 277–295. [Google Scholar] [CrossRef] [Green Version]
- Rherrad, I.; Gallaud, D. Exploring appropriation strategies: Evidence from French high–tech firms. Int. J. Technol. Transf. Commercialis. 2009, 8, 316–339. [Google Scholar] [CrossRef]
- Davis, L.; Kjær, K. Patent Strategies of Small Danish High–Tech Firms. 2003. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.195.5905&rep=rep1&type=pdf (accessed on 13 January 2021).
- Choi, J.; Kim, H.; Im, N. Keyword Network Analysis for Technology Forecasting. J. Intell. Inf. Syst. 2011, 17, 227–240. [Google Scholar] [CrossRef]
- Gui, B.; Ju, Y.; Liu, Y. Mapping technological development using patent citation trees: An analysis of bogie technology. Technol. Anal. Strateg. Manag. 2019, 31, 213–226. [Google Scholar] [CrossRef]
- Park, S. A Study on Patent Big Data Visualization Using Inference model–based Performance Indicator Network. J. Korean Inst. Intell. Syst. 2020, 30, 74–79. [Google Scholar] [CrossRef]
- McGill, M.; Koll, M.; Noreault, T. An Evaluation of Factors Affecting Document Ranking by Information Retrieval Systems. In School of Information Studies; 1978. Available online: https://files.eric.ed.gov/fulltext/ED188587.pdf (accessed on 13 January 2021).
- Salton, G.; McGill, M. Introduction to Modern Information Retrieval. 1986. Available online: https://sigir.org/files/museum/introduction_to_modern_information_retrieval/frontmatter.pdf (accessed on 13 January 2021).
- Zhang, J.; Korfhage, R. A distance and angle similarity measure. J. Am. Soc. Inf. Sci. 1990, 50, 772–778. [Google Scholar] [CrossRef]
- Khaiii. Github. 2018. Available online: https://github.com/kakao/khaiii (accessed on 3 November 2020).
- Han, G.; Baek, S.; Lim, J. Open Sourced and Collaborative Method to Fix Errors of Sejong Morphologically Annotated Corpora. 2017. Available online: https://www.koreascience.or.kr/article/CFKO201731951960133.pdf (accessed on 13 January 2021).
- Lee, Y.; Kim, S.; Hong, H.; Kim, J. Comparison and Evaluation of Morphological Analyzer for Patent Documents. In Proceedings of the Korean Institute of Information Technology, Daejeon, Korea, 13–15 June 2019; pp. 264–265. [Google Scholar]
- Hong, J.; Cha, J. Error Correction of Sejong Morphological Annotation Corpora using Part–of–Speech Tagger and Frequency Information. 2013. Available online: https://www.kci.go.kr/kciportal/ci/sereArticleSearch/ciSereArtiView.kci?sereArticleSearchBean.artiId=ART001789163 (accessed on 13 January 2021).
- Shim, K. Morpheme Restoration for Syllable–based Korean POS Tagging. 2013. Available online: https://www.dbpia.co.kr/Journal/articleDetail?nodeId=NODE02112476 (accessed on 13 January 2021).
- Aizawa, A. An information–theoretic perspective of tf–idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Wu, H.; Luk, R.; Wong, K.; Kwok, K. Interpreting tf–idf term weights as making relevance decisions. ACM Trans. Inf. Syst. 2008, 26, 1–37. [Google Scholar] [CrossRef]






| Input | : CAM = citation adjacency matrix (m × m), m = n + k | ||
| SAM = similarity adjacency matrix (n × n), m ≥ n | |||
| Output | : CS = adjacency matrix (m × m) | ||
| Initialize | : CS = zero matrix (m × m) | ||
| FOR all the elements in the CAM | |||
| IF the order of elements ≤ n then | |||
| Summation each element of CAM and SAM | |||
| ELSE the value of CAM is used as it is | |||
| END | |||
| Input | : CS = CS-Net (CAM, SAM) (m × m) | |||||||
| Datei = Application date of ith patent Pi | ||||||||
| Output | : PIC | |||||||
| Initialize | : PIC as a list | |||||||
| FOR xij is the element in the CS (i,j = 1, 2, …, m and i ≠ j) do | ||||||||
| IF xij ≥ 1 then | ||||||||
| DEFINE Diff = Datei–Datej | ||||||||
| IF Diff ≤ 0 then | ||||||||
| the prior patent Pi is PE and the later patent Pj is PL (means that Pi was filed earlier than Pj) | ||||||||
| ELSE Pi is PL, Pj is PE | ||||||||
| DEFINE | F1 = set of forward citations of PE | |||||||
| F2 = set of forward citations of PE’, one of F1 | ||||||||
| IF PL exists in F2 then | ||||||||
| SAVE (Pi, Pj) to PIC | ||||||||
| ELSE Pass | ||||||||
| ELSE Pass | ||||||||
| END | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Park, S.; Kang, J. Introducing Patents with Indirect Connection (PIC) for Establishing Patent Strategies. Sustainability 2021, 13, 820. https://doi.org/10.3390/su13020820
Lee J, Park S, Kang J. Introducing Patents with Indirect Connection (PIC) for Establishing Patent Strategies. Sustainability. 2021; 13(2):820. https://doi.org/10.3390/su13020820
Chicago/Turabian StyleLee, Juhyun, Sangsung Park, and Jiho Kang. 2021. "Introducing Patents with Indirect Connection (PIC) for Establishing Patent Strategies" Sustainability 13, no. 2: 820. https://doi.org/10.3390/su13020820
APA StyleLee, J., Park, S., & Kang, J. (2021). Introducing Patents with Indirect Connection (PIC) for Establishing Patent Strategies. Sustainability, 13(2), 820. https://doi.org/10.3390/su13020820