1. Introduction
Research has been extensively conducted to accurately estimate actual housing transaction prices while the importance of accurate valuation has become apparent in recent years. As previous research has found [
1], the housing prices perform a role of an early warning signal for financial crisis. In addition, due to the significant effect of volatility in real estate value on the national economy [
2], correctly assessing the value of real estate based on the actual housing transaction price is crucial. Prior studies [
3,
4] warned that insufficient data and analysis would lead to the banks’ underestimating the financial market loan risk, fostering a false sense of prosperity and a consequent economic collapse. Thus, the inaccurate valuation of real estate can trigger a collective panic by the investors, causing losses in financial institutions and increasing economic danger [
5].
A widely known example of a financial crisis caused by an inaccurate real estate valuation is the subprime mortgage crisis [
6] that occurred in 2008. The subprime mortgage crisis started with the United States’ policy to boost the stagnant economy in an economic downturn that incentivized mortgage loans with low interests, which led to an increase in housing prices. The trend of rising housing prices, combined with the low mortgage interest, guaranteed the financial institutions a safety net even when a borrower filed for bankruptcy. This allowed for more lenient loan regulations and valuations of real estate. These securitized subprime mortgage loans were given investment-grade ratings, guaranteeing a higher return, and amplifying the volume of transactions. However, as the housing bubble started to burst in 2004 when the low-interest policy ended, low-income borrowers were unable to make payments as the subprime mortgage loan interest rose. Consequently, numerous financial institutions that had purchased securitized subprime mortgage loans could not recover their loans and suffered massive losses. This process resulted in the insolvency of many companies, which led to a series of bankruptcies of large U.S. financial and security firms.
As aforementioned, an accurate estimation of the housing transaction price is crucial to preventing an economic crisis on national and societal levels and providing an effective investment opportunity on a personal level. Moreover, from the perspective of long-term urban planning, appropriate tax estimation achieved through accurate valuation of massive real estate properties can invoke balanced and sustainable urban development [
7]. For accurate valuation, many applications have been developed and utilized [
8,
9]; among them, the key element is the Hedonic Pricing Method (HPM) [
10]. The HPM, a commonly used method to estimate the value of real estate properties, parametrizes the internal characteristics (structural or physical characteristics) and external characteristics (neighborhood or environmental characteristics) of a house to assess its value. This method considers those characteristics as independent variables and the housing transaction price as the dependent variable. The relationship, or the degree of influence, between these variables is assumed to be linear to determine the housing transaction price intuitively.
Given that the purpose of a house is not limited to residence and that it can be used as an investment asset for profits, the housing price can be affected by many external forces such as economic fluctuations, government regulations, and future development plans. Further, the housing transaction price is determined by considering not only internal and external characteristics of a house but also many other elements of changes in the real estate market such as the price changes of comparable houses in the neighborhood and current mortgage terms. In addition, house price changes are different from other financial assets (e.g., stock, gold, oil, bitcoin), and they are different from one area to another. Despite its popularity, however, the HPM lacks the mechanism that directly reflects the target property’s price fluctuation and the real estate market’s volatility over time. To overcome these limitations, Kim et al. [
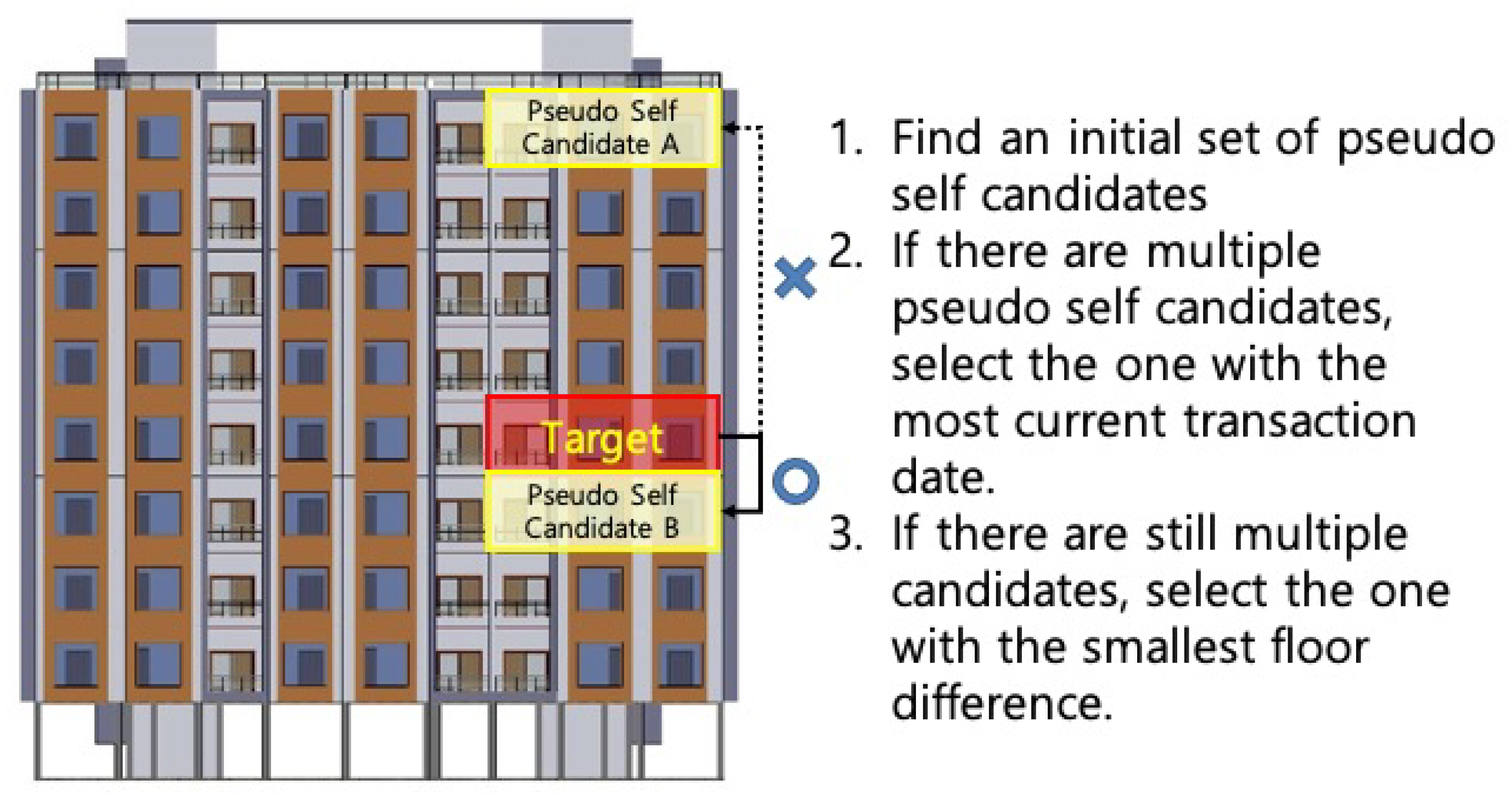
11] proposed a new method based on the Sales Comparison Approach (SCA), which estimates the housing price from the selected comparable sales. Their method automatically selects comparable sales based on a set of predefined criteria and estimates the values of real estate properties on a mass scale. Going further, in this study, we propose Pseudo Self Comparison Method (PSCM), which reduces the real estate valuation problem to finding a pseudo-self, which is defined as a housing property that can most closely approximate the characteristics of the target housing property, and adjusting its previous transaction price to be in sync with the real estate market change. The method is more efficient than the Kim et al.’s approach, with comparable results (slight performance differences are due to the methodological artifacts of regression vs. machine learniang).
6. Discussion
Modeling the values of real estate properties is a long-established research stream. This study identifies the limitations of the HPM, a methodology that has been commonly employed to estimate a real estate property’s transaction price. The HPM is based on the theory that the internal (e.g., number of rooms, bathrooms, floorspace) and external (e.g., number of households in the neighborhood, distance to amenities) characteristics of a house determine its real estate value. This theory was often utilized for the interpretation of the relationships between the characteristics and the real estate value but is limited in reflecting the volatility of the real estate market. Real estate agents and appraisers often use more intuitive methods such as the Sales Comparison Approach (SCA) to estimate the transaction price. This method typically selects at least three comparable sales in the neighborhood, and the information of those sales transactions is referenced and adjusted for an estimation. However, this method is limited in that it relies on subjective judgments made by real estate agents. To overcome this limitation, a new method, Pseudo Self Comparison Method (PSCM), is proposed in this study. Instead of the subjective selection of the comparable sales, the PSCM automatically identifies a property’s pseudo self, which is the most similar real estate property that have been sold most recently. Unlike the SCA, the PSCM utilizes only one closest previous transaction among a myriad of previous transactions. Furthermore, the PSCM adjusts the past transaction price of the pseudo self by utilizing new variables that reflect the change of the real estate market so that the past transaction price can be properly updated.
Our comparative analysis of the HPM vs. PSCM models, performed by extensively utilizing simple linear regressions and regularized regressions, show that the proposed PSCM models produces much more accurate predictions of real estate prices, with almost five times lower estimation errors, compared to the HPM models. Furthermore, the PSCM models show more robust estimations even during highly volatile market periods. The regularized linear regression methods are also used to construct valuation models, and significant improvements are observed for Lasso due to the method’s ability to focus on a specific feature using various market change signals based on the PSCM features.
We acknowledge that the findings from this study cannot be easily generalized because the scope of the study was limited to a densely populated city and its surrounding region in one country. Because our proposed method utilizes pseudo self’s information, its applicability to cities with low population density and relatively infrequent real estate transactions might be limited. However, the 2018 Revision of World Urbanization Prospects in UN [
41] shows that over half of the population in the world live in urban areas, and the ratio of living urban settings is expected to be increasing. Therefore, we can expect that the proposed method can become increasingly more applicable. Moreover, the proposed modeling approach does not rely on the typical approach of utilizing the physical and external properties of the target house, but only uses the previous transaction information and the real estate market information. Therefore, reliable estimation results can be efficiently obtained using the proposed method when mass valuations need to be done for urban planning. Additionally, we utilized the indexes provided by Kookmin Bank in South Korea to produce the market change features. Globally, local governments and real estate development companies are producing similar indicators in their efforts to trace and manage the volatility of the real estate market. Typical examples are the house price index by Federal Housing Finance Agency (FHFA) [
42], the Case-Shiller Home Price Indices by Standard&Poors (S&P) [
43], and the Zillow Home Value Index (ZHVI) by Zillow [
44]. Using these indices, we expect that our method can be extended and generalized to other cities and regions globally.
As opportunities for immigration abroad have expanded, cross-border housing purchase activities have greatly affected the international real estate market [
45]. Various methods have been proposed to identify the real estate markets that affect each other at the national level, including a dynamic model averaging framework [
46] and a hierarchical clustering [
47]. These methods are easy to use for analyzing the factors that influence real estate prices at the macro (or national) level, but they are difficult to use for estimating individual housing prices. In addition, due to the differences in housing construction regulations and standards between countries, using the HPM as a general application for housing price estimation might trigger inappropriate price estimation. In contrast, the proposed PSCM is an appropriate tool for the valuation of real estate properties in the international housing markets.
Furthermore, this method can be applied to analyze and avert financial crises, such as the subprime mortgage crisis, resulting from inaccurate and improper market evaluations. At the individual level, this model can be used to appropriately value and make safer financial investments. In the future, we expect to further improve the estimation of transaction prices by investigating new signals that more aptly and more swiftly reflect the market change and enhance the generalizability of the proposed method by incorporating the concept of generalized pseudo self.
7. Conclusions
This study suggests the pseudo self comparison method as an alternative to the hedonic price method, a standard method for estimating real estate transaction prices, which does not appropriately adjust them for market volatility. Our proposed method reduces the real estate valuation problem to finding a single pseudo-self, which is defined as a housing property that can most closely approximate the characteristics of the target housing property, and adjusting its previous transaction price to be in line with the real estate market change.
In this study, the proposed method is tested for two scenarios in which the volatility of the real estate market varies greatly, using the transaction data collected from Seoul, the capital city of South Korea, and its surrounding province, Gyeonggi. The study results showed almost five times smaller estimation errors in terms of MAPE in predicting the transaction prices of apartments using the Pseudo Self Comparison Method, when compared with the Hedonic Pricing Method. Furthermore, even in highly volatile market periods, the proposed method identified and focused on specific useful features to derive robust estimation results. Our proposed method shows novel usage of publicly available indexes to capture and trace the real estate market changes. Although the proposed method needs to be tested in various market conditions involving diverse housing types to secure its generalizability, it can be used as a useful mass valuation tool first applied to periodic monitoring of the city area’s market fluctuation for intelligent urban planning.





{kind=link}
{kind=link}
{kind=link}


