
Some Critical Reflections on the Measurement of Social Sustainability and Well-Being in Complex Societies




Abstract
:1. Introduction
2. The Subtle and Problematic Nature of Social Measurement
3. The Complexity of Modern Societies
4. A Structural Point of View on the Measurement of Social Sustainability and Well-Being
- It must be acknowledged that not all of the dimensions involved in the description of society can be actually and meaningfully quantified in order to get neat and unambiguous pictures of them. This is clearly expressed by Amartya Sen, with reference to well-being and inequality measurement [19]: “Indeed, the nature of interpersonal comparisons of well-being as well as the task of inequality evaluation as a discipline may admit incompleteness as a regular part of the respective exercises. Both well-being and inequality are broad and partly opaque concepts. Trying to reflect them in the form of totally complete and clear-cut orderings can do less than justice to the nature of these concepts. There is a real danger of overprecision here.” Indeed, the general tendency to quantification, somehow imitating natural sciences, puts aside that in the social sciences numerical precision is often just a computational artifact and that elementary indicators are often expressed in different metrics and refer to non-homogeneous concepts, making final aggregated scores hardly interpretable, due to the absence of a common reference scale;
- The definitional uncertainty and the doubtful validity of many social measurement processes unveil that the attempt to monitor social sustainability, by precisely measuring social processes, is definitely fragile. In the vagueness of the correspondence between social measures and the corresponding social traits, divergent and unpredictable evolutions of the social system are hidden, making it risky to founding policy-making on precise quantification and making it preferable to rely on more robust views;
- Given the deep interdependence of social life domains, it is dangerous to focus on single aspects of well-being and sustainability, as if they could be isolated from the others; indeed, optimizing “locally” may well be “globally” inefficient, leading to unwanted and unexpected consequences, on the system as a whole.
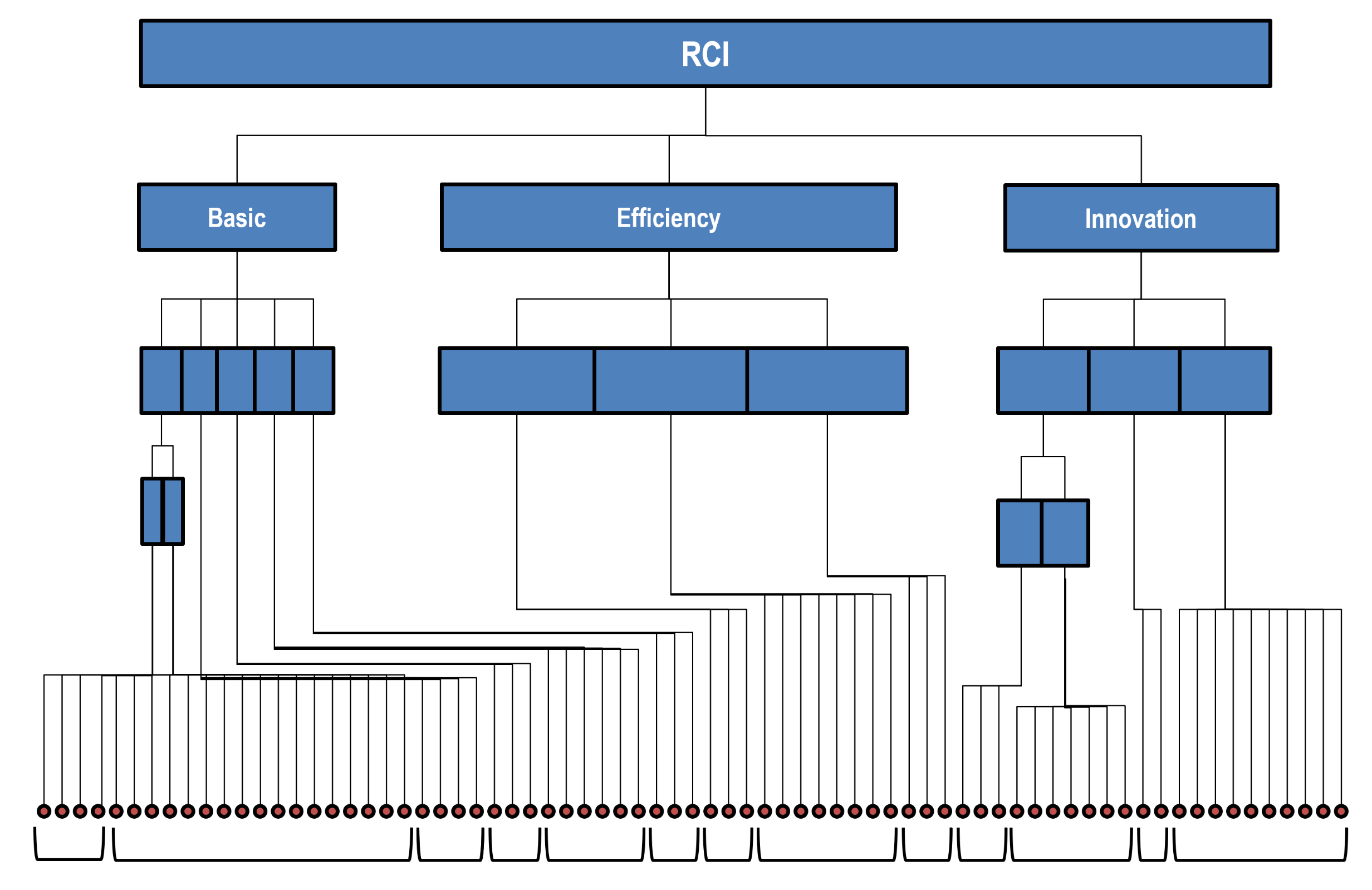
5. Structural Approach to Synthesis: A Few Examples on Well-Being Data
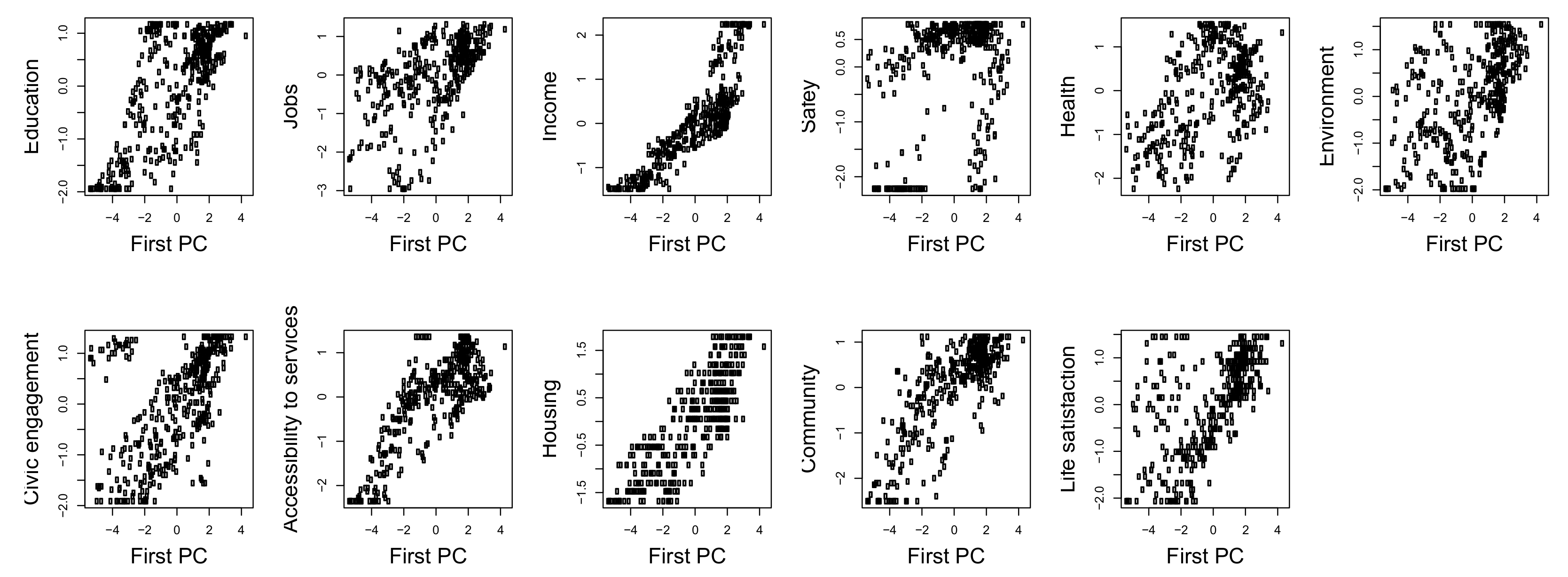
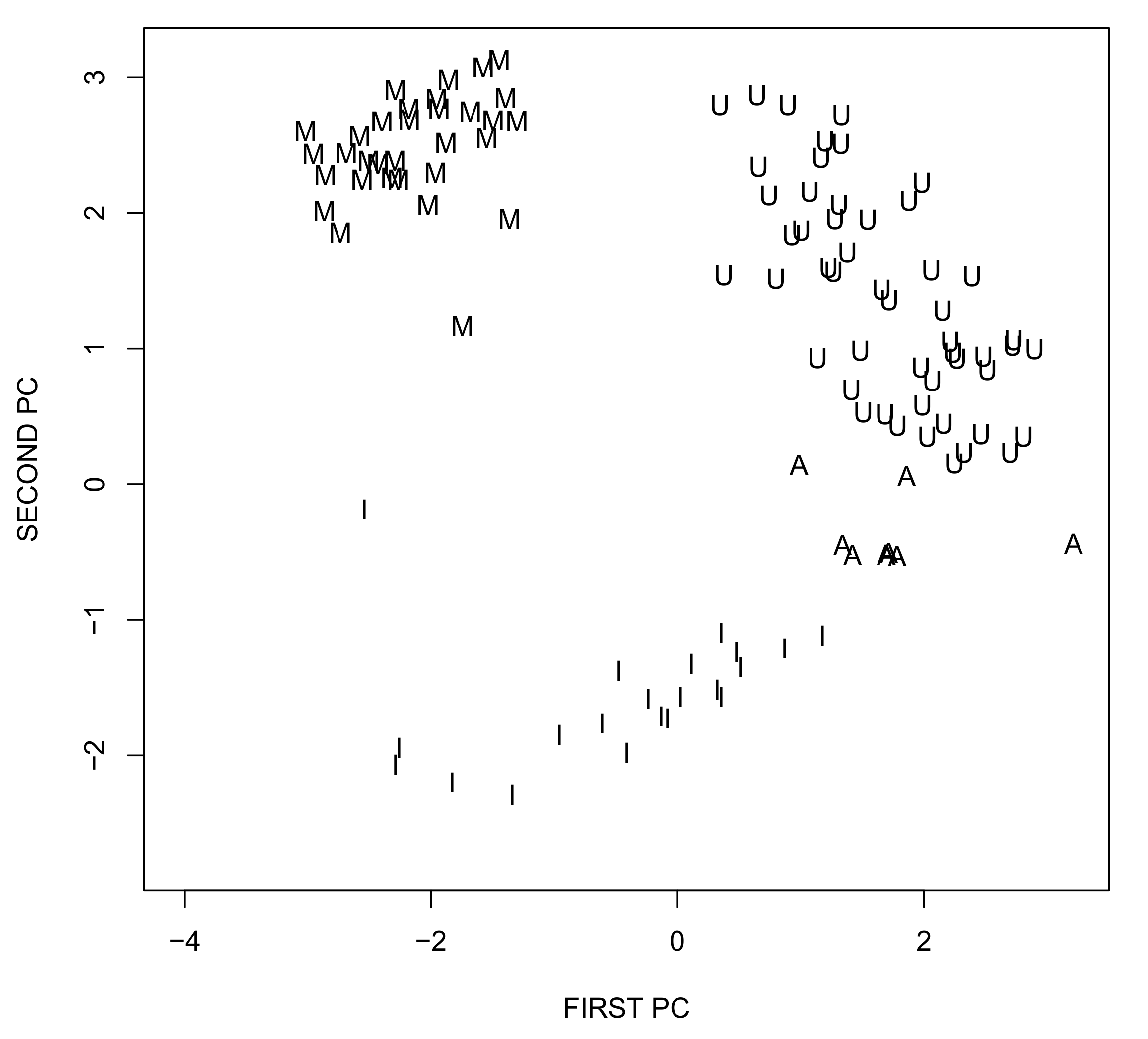
5.1. Principal Component Aggregation
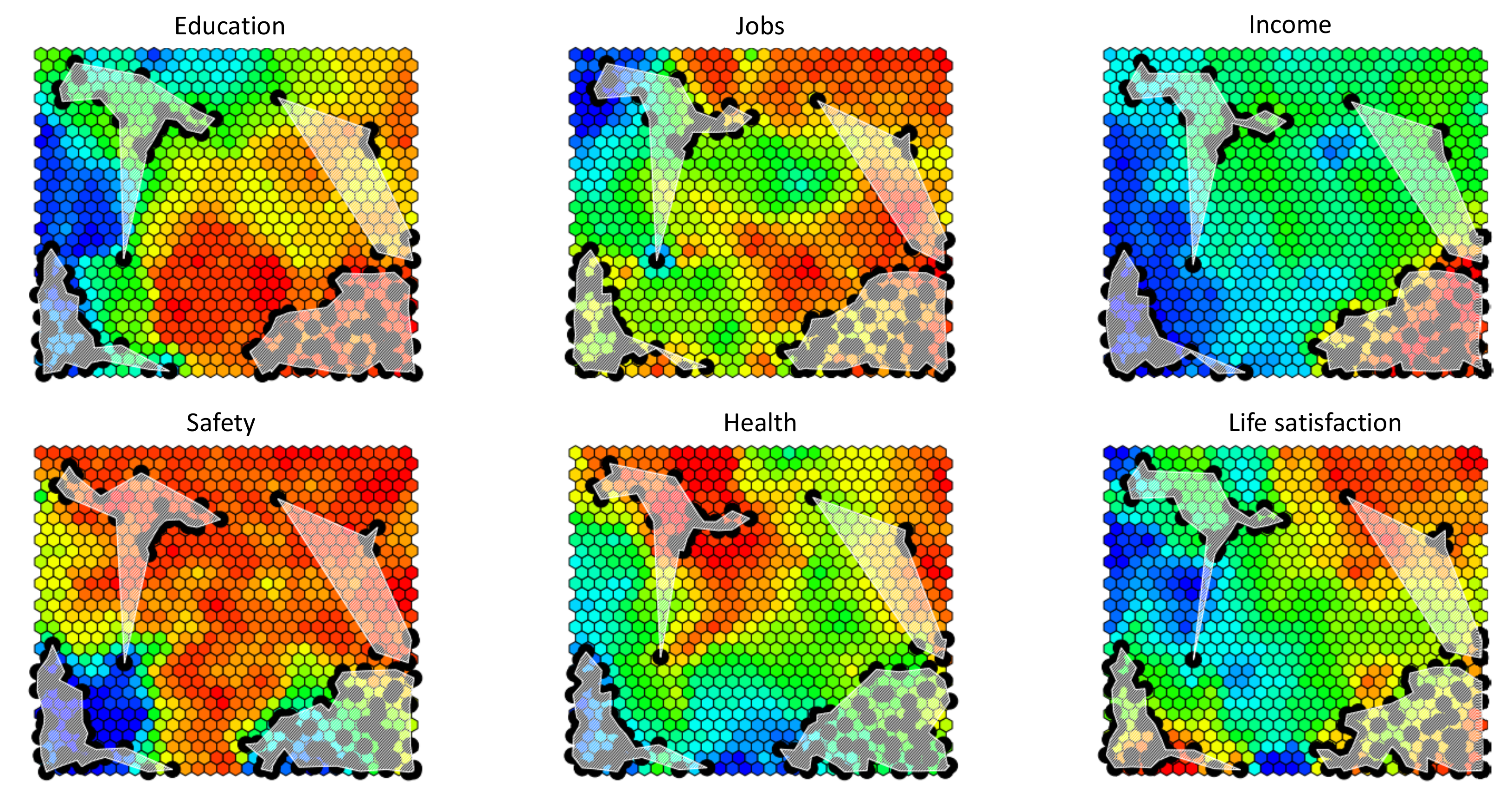
5.2. Semantic Maps of Well-Being
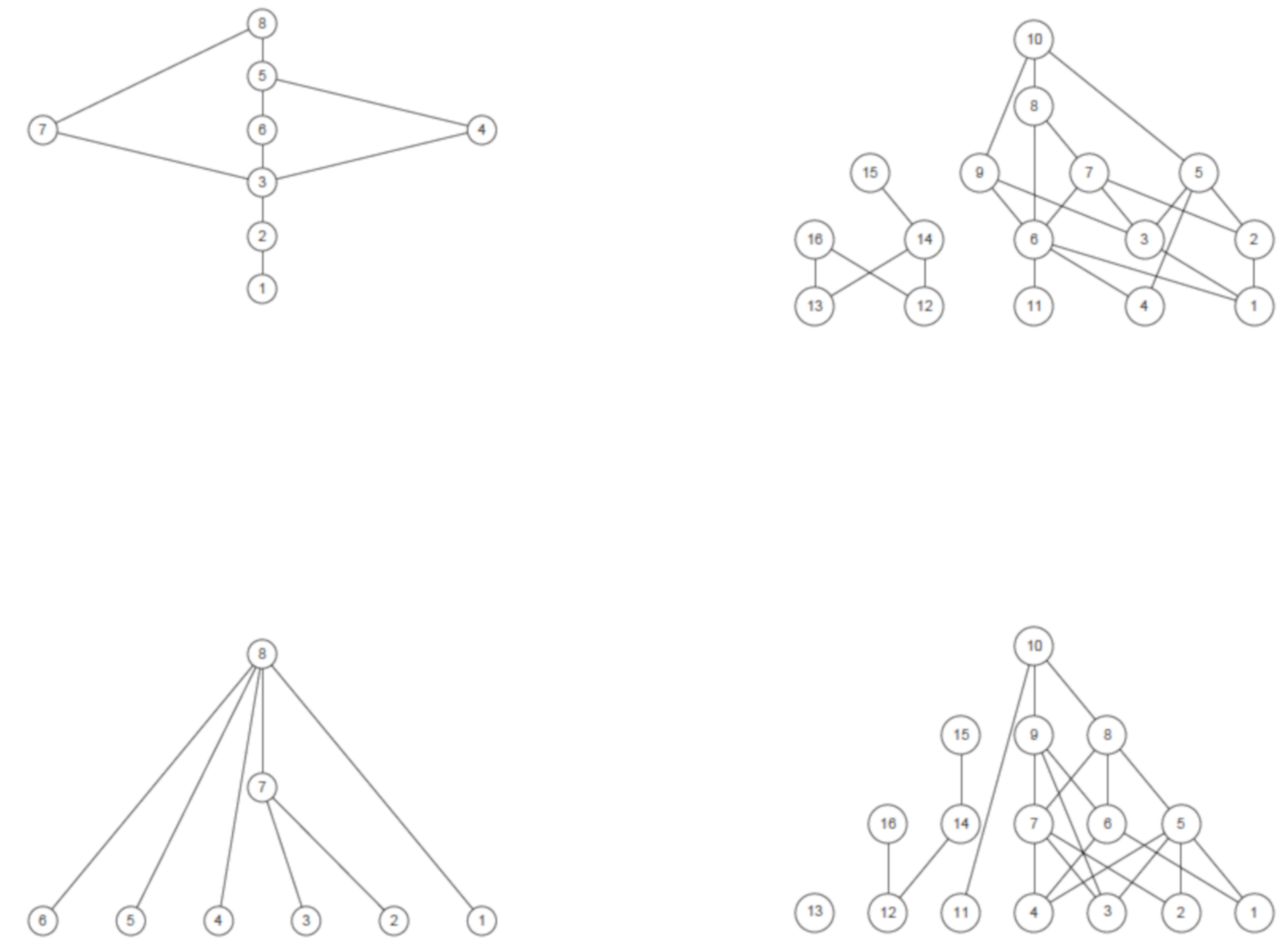
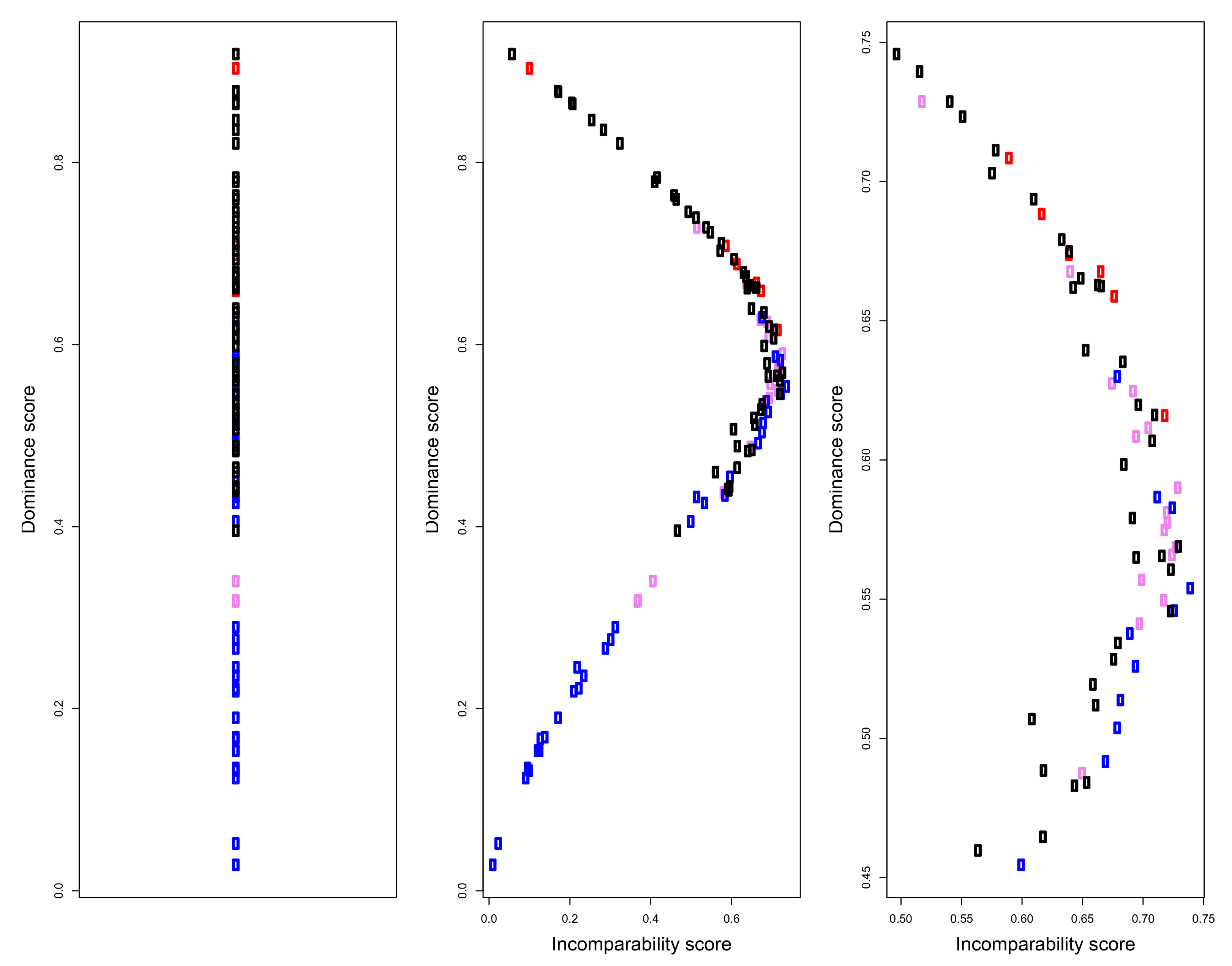
5.3. Well-Being and Partial Orders
5.4. Final Remark
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ravallion, M. Mashup indices of development. World Bank Res. Obs. 2012, 27, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Shek, D.T.; Wu, F.K. The social indicators movement: Progress, paradigms, puzzles, promise and potential research directions. Soc. Indic. Res. 2018, 135, 975–990. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cobb, C.W.; Rixford, C. Lessons Learned from the History of Social Indicators; Redefining Progress: San Francisco, CA, USA, 1998; Volume 1. [Google Scholar]
- Michell, J. Measurement theory: History and philosophy. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; Volume 14. [Google Scholar]
- Stanford Encyclopedia of Philosophy; Measurement in Sciences; Department of Philosophy, Stanford University Library of Congress Catalog Data: 2021. Available online: https://plato.stanford.edu/entries/measurement-science/ (accessed on 20 September 2021).
- Suck, R. Measurement, Representational Theory. In International Encyclopedia of the Social & Behavioral Sciences, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2015; Volume 14. [Google Scholar]
- Alexandrova, A. First-Person Reports and the Measurement of Happiness. Philos. Psychol. 2008, 21, 571–583. [Google Scholar] [CrossRef]
- Schönemann, P.H.; Steiger, J.H. On the validity of indeterminate factor scores. Bull. Psychon. Soc. 1978, 12, 287–290. [Google Scholar] [CrossRef]
- Moro, M.; Brereton, F.; Ferreira, S.; Clinch, J.P. Ranking quality of life using subjective well-being data. Ecol. Econ. 2008, 65, 448–460. [Google Scholar] [CrossRef]
- Giordani, A.; Mari, L. Modeling measurement: Error and uncertainty. In Error and Uncertainty in Scientific Practice; Boumans, M., Hon, G., Petersen, A., Eds.; University of Amsterdam: Amsterdam, The Netherlands; University of Haifa: Haifa, Israel; VU University Amsterdam: Amsterdam, The Netherlands, 2014; Chapter 4. [Google Scholar]
- Grégis, F. Can we dispense with the notion of ‘true value’in metrology? In Standardization in Measurement; Schlaudt, H., Ed.; Routledge: Oxfordshire, UK, 2015; pp. 95–108. [Google Scholar]
- Bridgman, P.W.; Williams, P. Operational Analysis. Philos. Sci. 1938, 5, 114–131. [Google Scholar] [CrossRef]
- Bridgman, P.W. Some general principles of operational analysis. In Psychological Review; Boring: Hawthorne, CA, USA, 1945; Volume 52, pp. 246–249. [Google Scholar] [CrossRef]
- Bridgman, P.W. The Present State of Operationalism. In The Validation of Scientific Theories; Frank: New York, NY, USA, 1956; pp. 74–79. [Google Scholar]
- Lighthill, M.J. The recently recognized failure of predictability in Newtonian dynamics. Proc. R. Soc. Lond. A Math. Phys. Sci. 1986, 407, 35–50. [Google Scholar]
- Annoni, P.; Dijkstra, L. EU Regional Competitiveness Index; Technical and Scientific Reports of JRC European Commission JRC-IPSC: Brussels, Belgium, 2013. [Google Scholar]
- Italian National Institute of Statistics (ISTAT). Bes Report 2021 Equitable and Sustainable Well-Being in Italy. 2021. Available online: https://www.istat.it/en/well-being-and-sustainability (accessed on 20 September 2021).
- Department of Economic and Social Affairs. Transforming Our World: The 2030 Agenda for Sustainable Development; Technical Report; Unated Nations: San Francisco, CA, USA, 2015; Available online: https://sdgs.un.org/goals (accessed on 20 September 2021).
- Sen, A. Inequality Reexamined; Volume First Hardcove; Oxford University Press: Oxford, UK, 1992. [Google Scholar]
- Rimoldi, S.M.L.; Arcagni, A.; Fattore, M.; Barbiano di Belgiojoso, E. Targeting Policies for Multidimensional Poverty and Social Fragility Relief Among Migrants in Italy, Using F-FOD Analysis. Soc. Indic. Res. 2020, 157, 57–75. [Google Scholar] [CrossRef]
- OECD. Regional Well-Being User Guide. 2018. Available online: https://www.oecdregionalwellbeing.org/assets/downloads/Regional-Well-Being-User-Guide.pdf (accessed on 20 September 2021).
- Kohonen, T. Essentials of the self-organizing map. Neural Netw. 2013, 37, 52–65. [Google Scholar] [CrossRef] [PubMed]
- Davey, B.A.; Priestley, H.A. Introduction to Lattices; Cambridge University Press: Cambridge, UK, 2002. [Google Scholar]
- Rimoldi, S.M.L.; Arcagni, A.; Fattore, M.; Terzera, L. Social and Material Vulnerability of the Italian Municipalities: Comparing Alternative Approaches. Soc. Indic. Res. 2020, 1–18. [Google Scholar] [CrossRef]
- Brüggemann, R.; Patil, G.P. Ranking and Prioritization for Multi-Indicator Systems: Introduction to Partial Order Applications; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Comim, F. A Poset-Generalizability Method for Human Development Indicators. Soc. Indic. Res. 2021, 1–20. [Google Scholar] [CrossRef]
- Fattore, M.; Arcagni, A. Posetic tools in the social sciences: A tutorial exposition. In Measuring and Understanding Complex Phenomena: Indicators and Their Analysis in Different Scientific Fields, Springer Nature, 2nd ed.; Brüggemann, R., Ed.; Elsevier: Amsterdam, The Netherlands, 2021; pp. 219–241. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input Variable | Reproduced Variance |
|---|---|
| Education | 52% |
| Jobs | 34% |
| Income | 72% |
| Safety | 15% |
| Health | 23% |
| Environment | 26% |
| Civic engagement | 28% |
| Accessibility to services | 63% |
| Housing | 66% |
| Community | 63% |
| Life satisfaction | 37% |
| Input Variable | First PC | Second PC | Sign |
|---|---|---|---|
| Education | 64% | 0% | + |
| Jobs | 52% | 13% | - |
| Income | 70% | 0% | - |
| Safety | 9% | 73% | + |
| Health | 18% | 55% | + |
| Life satisfaction | 43% | 20% | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arcagni, A.; Fattore, M.; Maggino, F.; Vittadini, G. Some Critical Reflections on the Measurement of Social Sustainability and Well-Being in Complex Societies. Sustainability 2021, 13, 12679. https://doi.org/10.3390/su132212679
Arcagni A, Fattore M, Maggino F, Vittadini G. Some Critical Reflections on the Measurement of Social Sustainability and Well-Being in Complex Societies. Sustainability. 2021; 13(22):12679. https://doi.org/10.3390/su132212679
Chicago/Turabian StyleArcagni, Alberto, Marco Fattore, Filomena Maggino, and Giorgio Vittadini. 2021. "Some Critical Reflections on the Measurement of Social Sustainability and Well-Being in Complex Societies" Sustainability 13, no. 22: 12679. https://doi.org/10.3390/su132212679
APA StyleArcagni, A., Fattore, M., Maggino, F., & Vittadini, G. (2021). Some Critical Reflections on the Measurement of Social Sustainability and Well-Being in Complex Societies. Sustainability, 13(22), 12679. https://doi.org/10.3390/su132212679