
Map-Matching Using Hidden Markov Model and Path Choice Preferences under Sparse Trajectory

Abstract
:1. Introduction
2. Literature Review
3. Methods and Techniques
3.1. Notations and Definitions
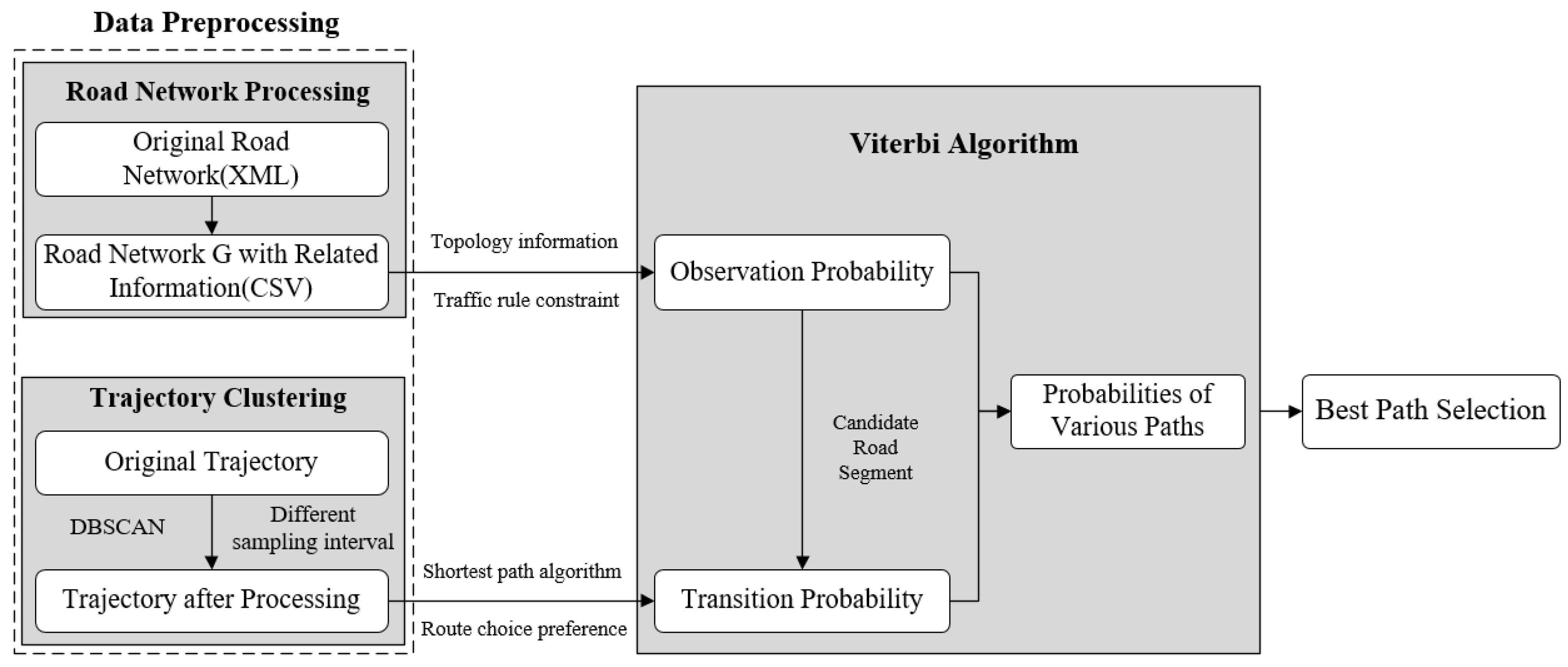
3.2. Algorithm Overview
- Part 1: data processing
- Part 2: Hidden Markov Model
- In summary, the overall flow of the proposed algorithm is as follows.
- (1)
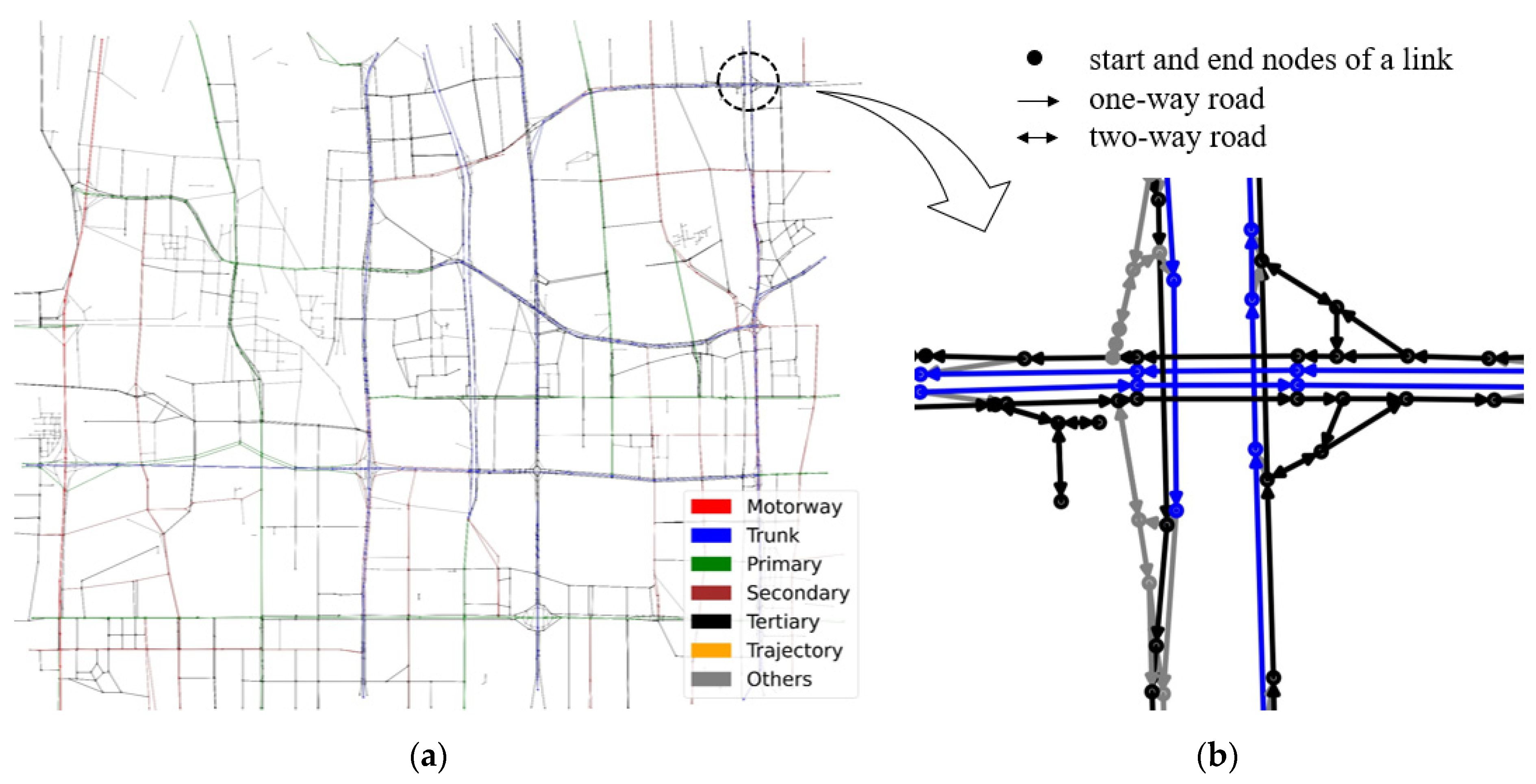
- Input: Road network , each road segment is associated with a list of properties, such as road ID, name, the start and end node, grade, speed limit, azimuth and a sequence of N observations ;
- (2)
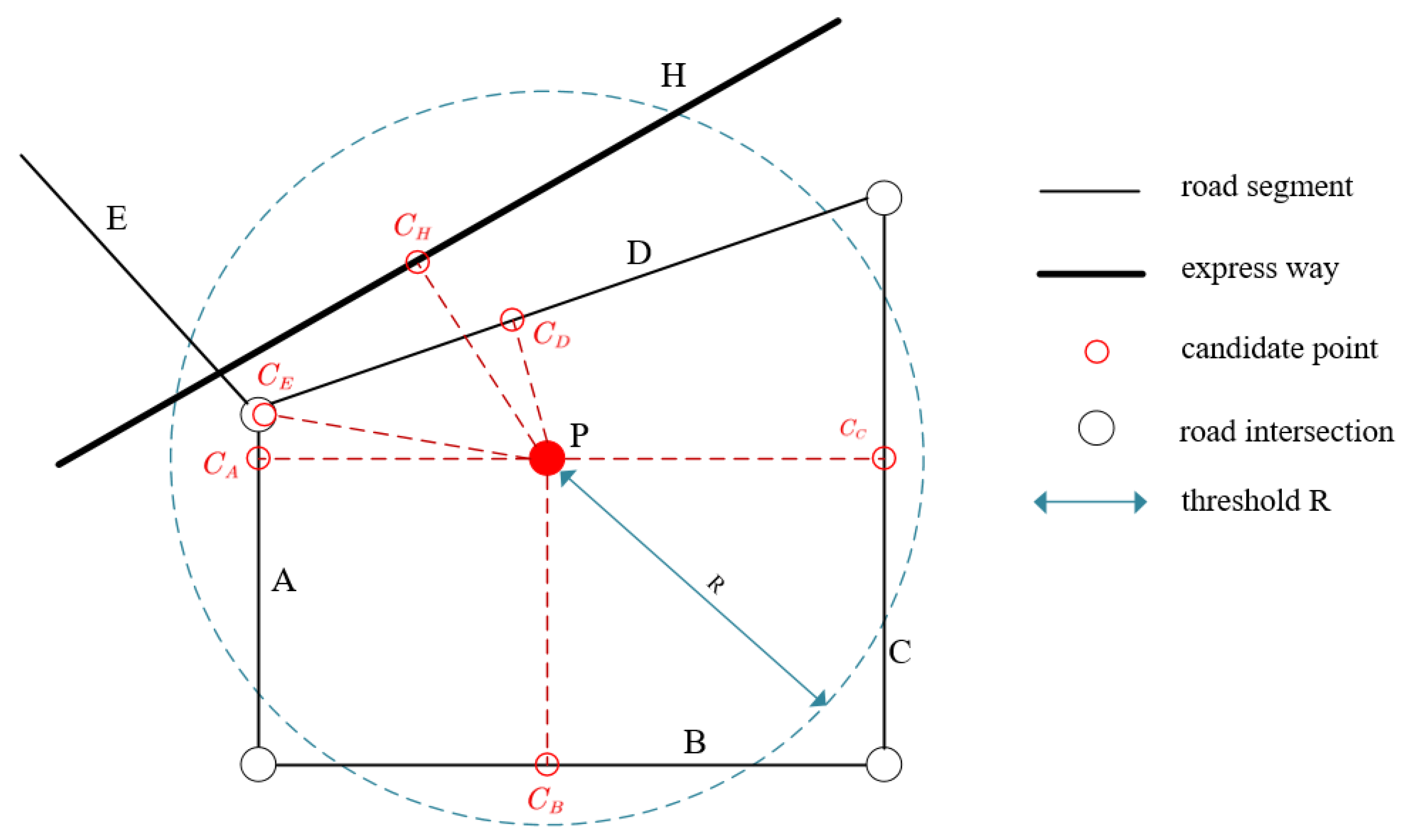
- For a threshold value , set the road segments within the proximity of observation as the candidate links, as shown in Figure 2. Then, the observation probability for each candidate link is calculated;
- (3)
- When , is treated as the initial state;
- (4)
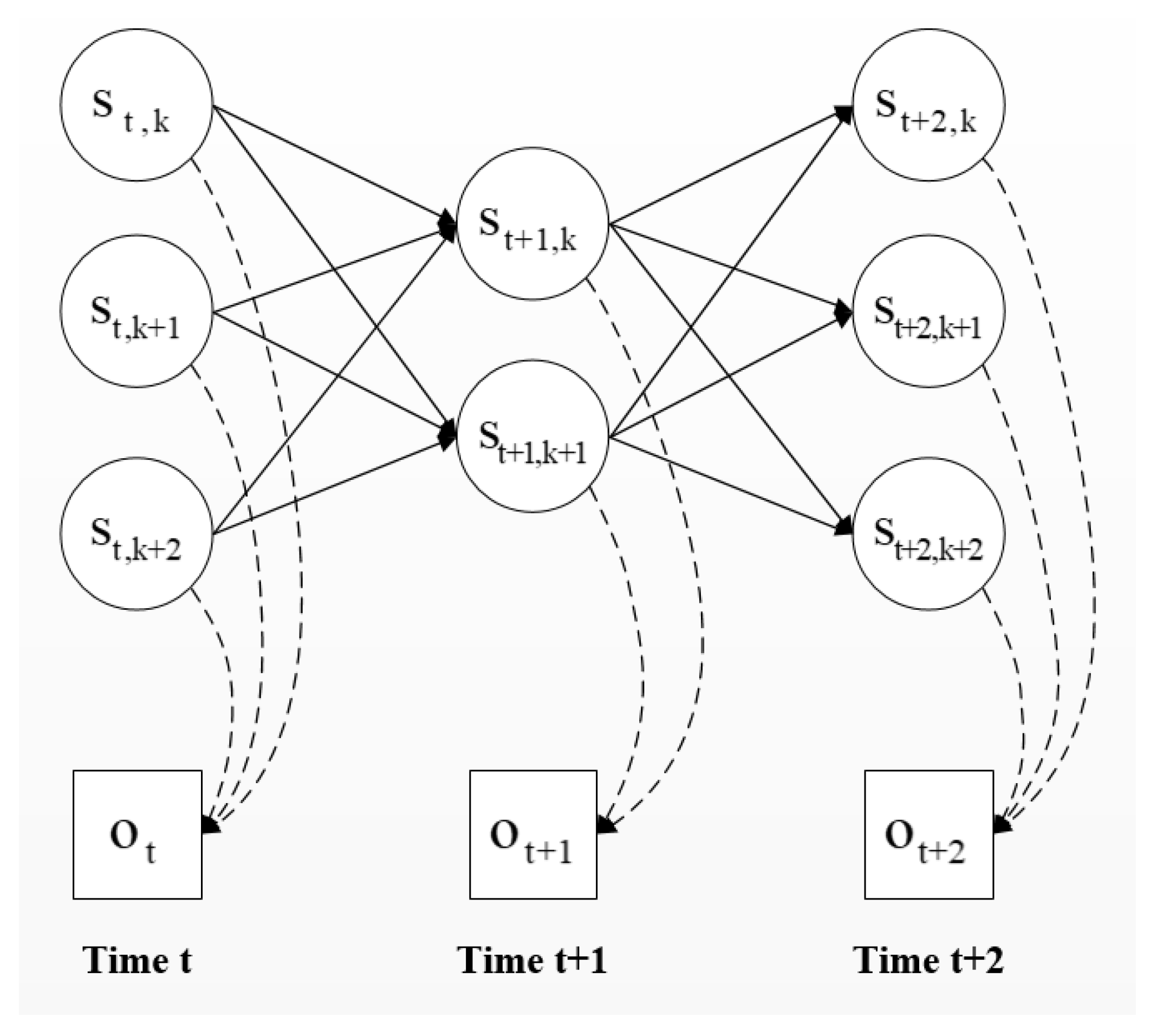
- When , the Viterbi algorithm is used to compute the state at time step ;
- (5)
- At the last time step , the path with the highest probability is taken as the optimal path.
3.3. Data Processing and Description
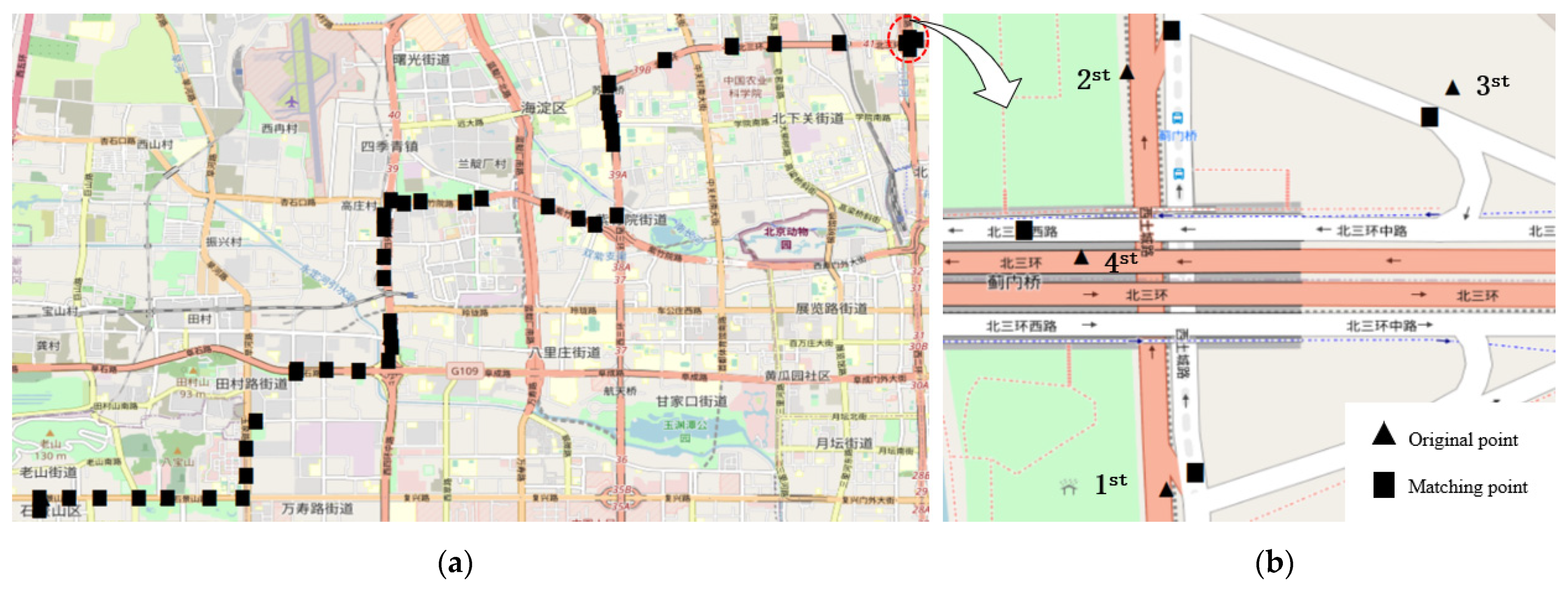
3.3.1. GPS Trajectory Data
3.3.2. Road Network Data
3.4. HMM in Map Matching
- Markov Assumption: The probability of a particular state is dependent only on the immediate previous state:
- Independent Assumption: The probability of an observation is dependent only on the state that produced the observation and not on any other state or any other observations:
3.4.1. Transition Probability
3.4.2. Observation Probability
3.4.3. Viterbi Algorithm
4. Experiments and Results
4.1. Parameter Setting
4.1.1. Maximum Distance
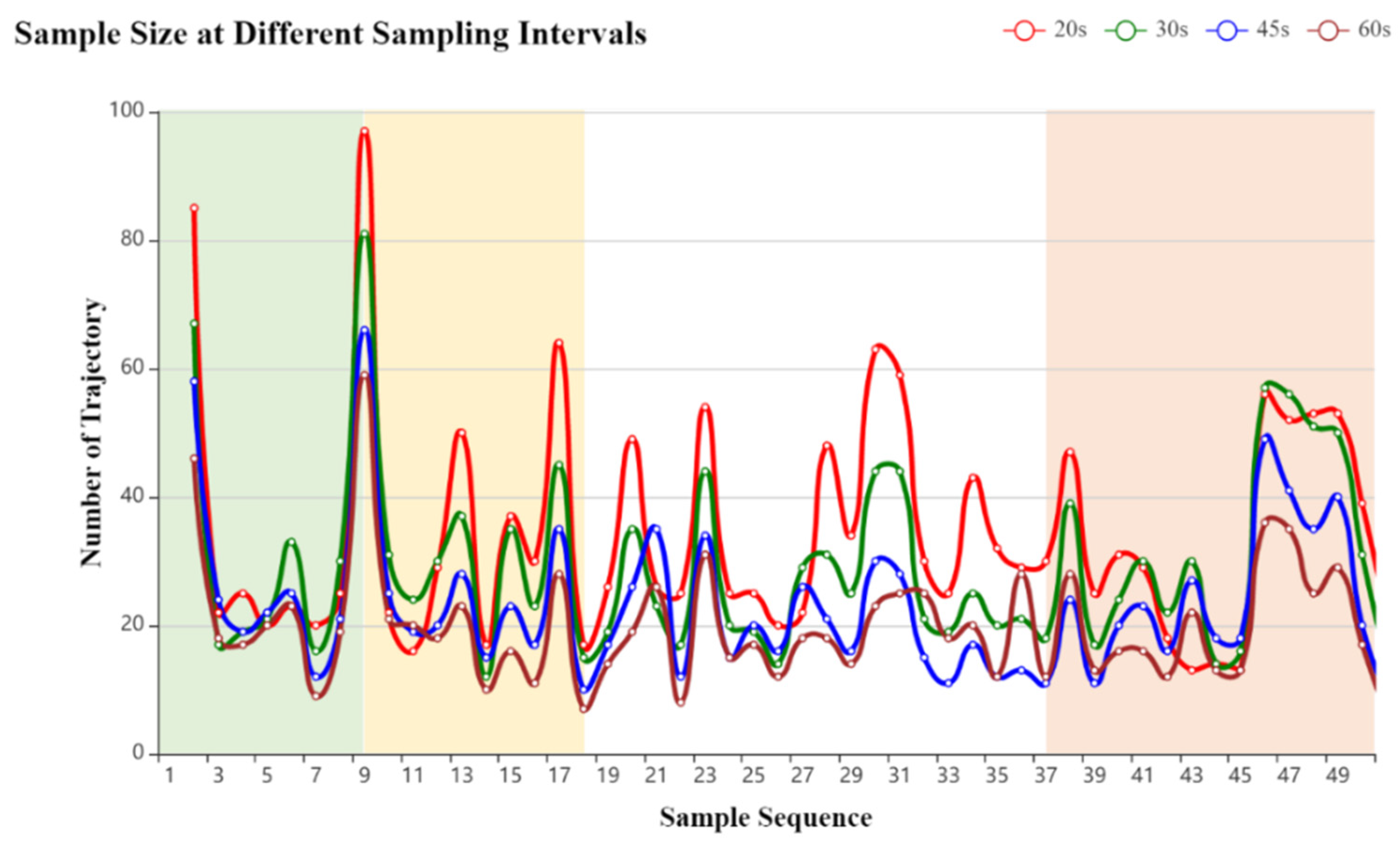
4.1.2. Parameters of the DBSCAN
4.2. Assessment Criteria
4.3. Results
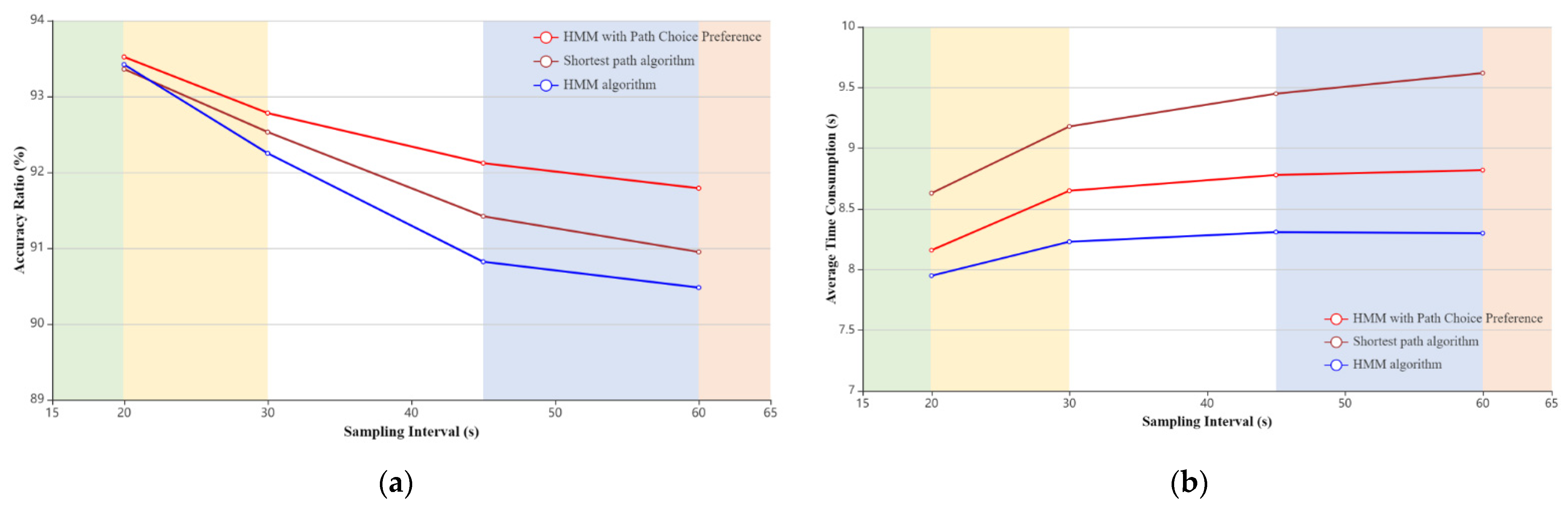
- As shown in Table 2, the accuracy ratio of matching decreases rapidly, and the average time consumption increases slowly when the sampling interval is increased. For the measurement of AT, when a larger sampling interval is selected, the amount of map data used to calculate the shortest path between adjacent trajectory points does not change much, resulting in constant average time consumption. Furthermore, when examining the mismatched points, we found that most of the mismatches occurred because the traveler did not choose the shortest path, which was inconsistent with our hypothesis and resulted in lower matching accuracy at larger sampling intervals.
- Figure 8a shows the matching accuracy of the three algorithms for four different sampling intervals, the horizontal axis represents the sampling frequency and the vertical axis represents the percentage of accuracy. The AR values of all three methods are higher than 0.9, while the proposed algorithm has higher matching accuracy than the other two. We also note that all three algorithms can achieve good matching precision at high frequency sampling, and the shortest path-based HMM performs better than the HMM and shortest path algorithms when the sampling frequency is low.
- In Figure 8b, the HMM algorithm has the smallest ATC for all four sampling intervals and the longest average time consumed by the SPM algorithm. On the other hand, when the sampling interval is greater than 30 s, the proposed algorithm and the HMM algorithm generate relatively stable ATC, while the ATC of the SPM algorithm gradually increases.
5. Conclusions and Discussions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bernstein, D.; Kornhauser, A. An Introduction to Map Matching for Personal Navigation Assistants. 1998. Available online: https://rosap.ntl.bts.gov/view/dot/38257 (accessed on 16 November 2021).
- Militino, A.F.; Ugarte, M.D.; Iribas, J.; Lizarraga-Garcia, E. Mapping GPS positional errors using spatial linear mixed models. J. Geod. 2013, 87, 675–685. [Google Scholar] [CrossRef]
- Rahmani, M.; Koutsopoulos, H.N. Path inference from sparse floating car data for urban networks. Transp. Res. Part C Emerg. Technol. 2013, 30, 41–54. [Google Scholar] [CrossRef]
- Quddus, M.; Washington, S. Shortest path and vehicle trajectory aided map-matching for low frequency GPS data. Transp. Res. Part C Emerg. Technol. 2015, 55, 328–339. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.Y.; Yuan, H.; Li, Q.; Lam, W.H.K.; Shaw, S.-L.; Yan, K. Map-matching algorithm for large-scale low-frequency floating car data. Int. J. Geogr. Inf. Sci. 2013, 28, 22–38. [Google Scholar] [CrossRef]
- Newson, P.; Krumm, J. Hidden Markov map matching through noise and sparseness. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4 November 2009; pp. 336–343. [Google Scholar]
- White, C.E.; Bernstein, D.; Kornhauser, A.L. Some map matching algorithms for personal navigation assistants. Transp. Res. Part C Emerg. Technol. 2000, 8, 91–108. [Google Scholar] [CrossRef]
- Pyo, J.S.; Shin, D.H.; Sung, T.K. Development of a map matching method using the multiple hypothesis technique. In Proceedings of the ITSC 2001, 2001 IEEE Intelligent Transportation Systems, (Cat. No.01TH8585), Oakland, CA, USA, 25–29 August 2001; pp. 23–27. [Google Scholar]
- Bierlaire, M.; Chen, J.; Newman, J. A probabilistic map matching method for smartphone GPS data. Transp. Res. Part C Emerg. Technol. 2013, 26, 78–98. [Google Scholar] [CrossRef]
- Luo, A.; Chen, S.; Xv, B. Enhanced Map-Matching Algorithm with a Hidden Markov Model for Mobile Phone Positioning. ISPRS Int. J. Geo-Inf. 2017, 6, 327. [Google Scholar] [CrossRef] [Green Version]
- Lou, Y.; Zhang, C.; Zheng, Y.; Xie, X.; Wang, W.; Huang, Y. Map-matching for low-sampling-rate GPS trajectories. In Proceedings of the 17th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 4 November 2009; pp. 352–361. [Google Scholar]
- Hsueh, Y.-L.; Chen, H.-C. Map matching for low-sampling-rate GPS trajectories by exploring real-time moving directions. Inf. Sci. 2018, 433–434, 55–69. [Google Scholar] [CrossRef]
- Zheng, Y. Trajectory Data Mining. ACM Trans. Intell. Syst. Technol. 2015, 6, 1–41. [Google Scholar] [CrossRef]
- OpenStreetMap. Available online: https://wiki.osmfoundation.org/wiki/Main_Page (accessed on 15 September 2021).
- Dogramadzi, M.; Khan, A. Accelerated Map Matching for GPS Trajectories. IEEE Trans. Intell. Transp. Syst. 2021, 1–10. [Google Scholar] [CrossRef]
- Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition. Proc. IEEE 1989, 77, 257–286. [Google Scholar] [CrossRef]
- Yu, S.-Z. Hidden semi-Markov models. Artif. Intell. 2010, 174, 215–243. [Google Scholar] [CrossRef] [Green Version]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE ASSP Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Luo, L.; Hou, X.; Cai, W.; Guo, B. Incremental route inference from low-sampling GPS data: An opportunistic approach to online map matching. Inf. Sci. 2020, 512, 1407–1423. [Google Scholar] [CrossRef]
- Jagadeesh, G.R.; Srikanthan, T. Online Map-Matching of Noisy and Sparse Location Data With Hidden Markov and Route Choice Models. IEEE Trans. Intell. Transp. Syst. 2017, 18, 2423–2434. [Google Scholar] [CrossRef]
- Sinnott, R. Virtues of the Haversine. Sky Telesc. 1984, 68, 158. [Google Scholar]
- Dijkstra, E.W. A note on two problems in connexion with graphs. Numer. Math. 1959, 1, 269–271. [Google Scholar] [CrossRef] [Green Version]
- Chambers, E.; Fasy, B.T.; Wang, Y.; Wenk, C. Map-Matching Using Shortest Paths. ACM Trans. Spat. Algorithms Syst. 2020, 6, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Liu, M.; Zhang, L.; Ge, J.; Long, Y.; Che, W. Map Matching for Urban High-Sampling-Frequency GPS Trajectories. ISPRS Int. J. Geo-Inf. 2020, 9, 31. [Google Scholar] [CrossRef] [Green Version]
- Hunter, T.; Abbeel, P.; Bayen, A. The Path Inference Filter: Model-Based Low-Latency Map Matching of Probe Vehicle Data. IEEE Trans. Intell. Transp. Syst. 2014, 15, 507–529. [Google Scholar] [CrossRef] [Green Version]
- Qi, H.; Di, X.; Li, J. Map-matching algorithm based on the junction decision domain and the hidden Markov model. PLoS ONE 2019, 14, e0216476. [Google Scholar] [CrossRef] [PubMed]
- Wikipedia. Error Analysis for the Global Positioning System. Available online: https://en.wikipedia.org/wiki (accessed on 21 September 2021).
- Sander, J.; Ester, M.; Kriegel, H.-P.; Xu, X. Density-Based Clustering in Spatial Databases: The Algorithm GDBSCAN and Its Applications. Data Min. Knowl. Discov. 1998, 2, 169–194. [Google Scholar] [CrossRef]
- Wu, Z.; Xie, J.; Wang, Y.; Nie, Y. Map matching based on multi-layer road index. Transp. Res. Part C Emerg. Technol. 2020, 118. [Google Scholar] [CrossRef]
- Miwa, T.; Kiuchi, D.; Yamamoto, T.; Morikawa, T. Development of map matching algorithm for low frequency probe data. Transp. Res. Part C Emerg. Technol. 2012, 22, 132–145. [Google Scholar] [CrossRef]
- Hu, Y.; Lu, B. A Hidden Markov Model-Based Map Matching Algorithm for Low Sampling Rate Trajectory Data. IEEE Access 2019, 7, 178235–178245. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Volunteer ID | Time | Longitude | Latitude | Speed |
|---|---|---|---|---|
| 1 | 25 February 2019 17:12:42 | 116.348533844 | 39.9656527041 | 10.73298 |
| 1 | 25 February 2019 17:12:49 | 116.348587135 | 39.9658000376 | 12.62736 |
| 1 | 25 February 2019 17:12:53 | 116.34855805 | 39.9659548095 | 15.11853 |
| 1 | 25 February 2019 17:12:58 | 116.348499544 | 39.9658969324 | 16.44845 |
| 1 | 25 February 2019 17:13:03 | 116.348489402 | 39.9658808811 | 14.98515 |
| 1 | 25 February 2019 17:13:08 | 116.348543298 | 39.9659085414 | 13.42683 |
| Variables | Sampling Interval (s) | |||
|---|---|---|---|---|
| 20 | 30 | 45 | 60 | |
| Sample size | 8332 | 6748 | 5612 | 4825 |
| AR (%) | 93.52 | 92.78 | 92.12 | 91.79 |
| AT (s) | 8.16 | 8.65 | 8.78 | 8.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiong, Z.; Li, B.; Liu, D. Map-Matching Using Hidden Markov Model and Path Choice Preferences under Sparse Trajectory. Sustainability 2021, 13, 12820. https://doi.org/10.3390/su132212820
Xiong Z, Li B, Liu D. Map-Matching Using Hidden Markov Model and Path Choice Preferences under Sparse Trajectory. Sustainability. 2021; 13(22):12820. https://doi.org/10.3390/su132212820
Chicago/Turabian StyleXiong, Zhengang, Bin Li, and Dongmei Liu. 2021. "Map-Matching Using Hidden Markov Model and Path Choice Preferences under Sparse Trajectory" Sustainability 13, no. 22: 12820. https://doi.org/10.3390/su132212820
APA StyleXiong, Z., Li, B., & Liu, D. (2021). Map-Matching Using Hidden Markov Model and Path Choice Preferences under Sparse Trajectory. Sustainability, 13(22), 12820. https://doi.org/10.3390/su132212820